mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
25 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 7755971d11 | |||
| 7634be5446 | |||
| 5e17ad88f6 | |||
| 24d0f65116 | |||
| a326046733 | |||
| 9bab00fd8b | |||
| b4a13a48b9 | |||
| 21601f9688 | |||
| 4c3ec87341 | |||
| b149d7fc87 | |||
| 52e6107c6e | |||
| b340637331 | |||
| 044867449a | |||
| 9e3f438823 | |||
| 887d55c3f3 | |||
| 19d54f3310 | |||
| 514a8762eb | |||
| 957c74d226 | |||
| 7b0432d6ff | |||
| 09754849be | |||
| 25ad48a97a | |||
| 3b2520afa9 | |||
| 77c2041ad3 | |||
| 8af3b53937 | |||
| 5ef2e6954e |
75
HISTORY.rst
75
HISTORY.rst
@ -3,6 +3,81 @@ History
|
||||
-------
|
||||
|
||||
|
||||
7.0.11 (2016-09-23)
|
||||
++++++++++++++++++
|
||||
|
||||
- Handle UnicodeDecodeError when when logging. Related to #68.
|
||||
|
||||
|
||||
7.0.10 (2016-09-22)
|
||||
++++++++++++++++++
|
||||
|
||||
- Handle UnicodeDecodeError when looking for python. Fixes #68.
|
||||
- Upgrade wakatime-cli to v6.0.9.
|
||||
|
||||
|
||||
7.0.9 (2016-09-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.8.
|
||||
|
||||
|
||||
7.0.8 (2016-07-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to master version to fix debug logging encoding bug.
|
||||
|
||||
|
||||
7.0.7 (2016-07-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.7.
|
||||
- Handle unknown exceptions from requests library by deleting cached session
|
||||
object because it could be from a previous conflicting version.
|
||||
- New hostname setting in config file to set machine hostname. Hostname
|
||||
argument takes priority over hostname from config file.
|
||||
- Prevent logging unrelated exception when logging tracebacks.
|
||||
- Use correct namespace for pygments.lexers.ClassNotFound exception so it is
|
||||
caught when dependency detection not available for a language.
|
||||
|
||||
|
||||
7.0.6 (2016-06-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.5.
|
||||
- Upgrade pygments to v2.1.3 for better language coverage.
|
||||
|
||||
|
||||
7.0.5 (2016-06-08)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to master version to fix bug in urllib3 package causing
|
||||
unhandled retry exceptions.
|
||||
- Prevent tracking git branch with detached head.
|
||||
|
||||
|
||||
7.0.4 (2016-05-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.3.
|
||||
- Upgrade requests dependency to v2.10.0.
|
||||
- Support for SOCKS proxies.
|
||||
|
||||
|
||||
7.0.3 (2016-05-16)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.2.
|
||||
- Prevent popup on Mac when xcode-tools is not installed.
|
||||
|
||||
|
||||
7.0.2 (2016-04-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- Prevent implicit unicode decoding from string format when logging output
|
||||
from Python version check.
|
||||
|
||||
|
||||
7.0.1 (2016-04-28)
|
||||
++++++++++++++++++
|
||||
|
||||
|
||||
@ -47,7 +47,7 @@ Troubleshooting
|
||||
|
||||
First, turn on debug mode in your `WakaTime.sublime-settings` file.
|
||||
|
||||
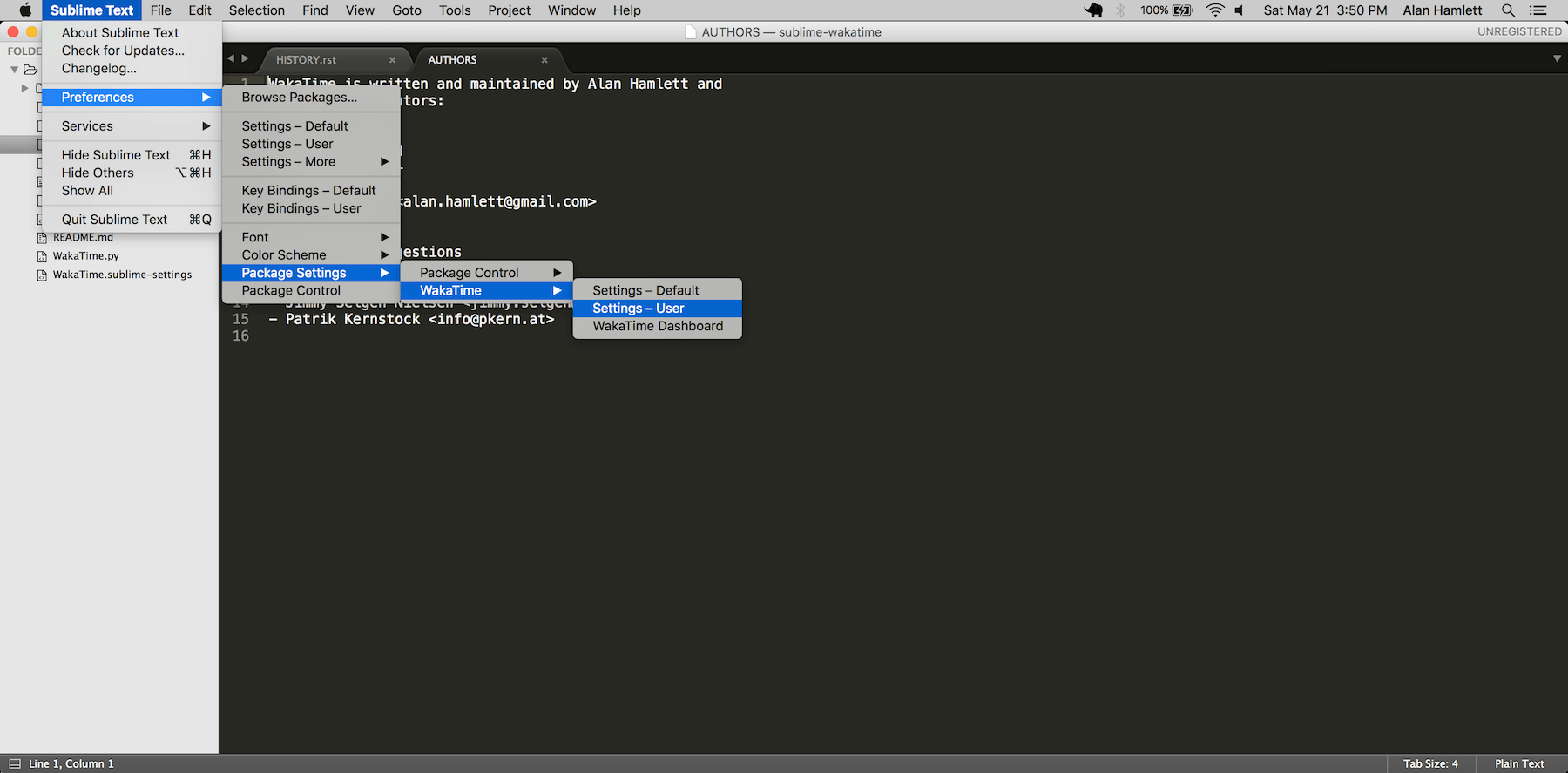
|
||||
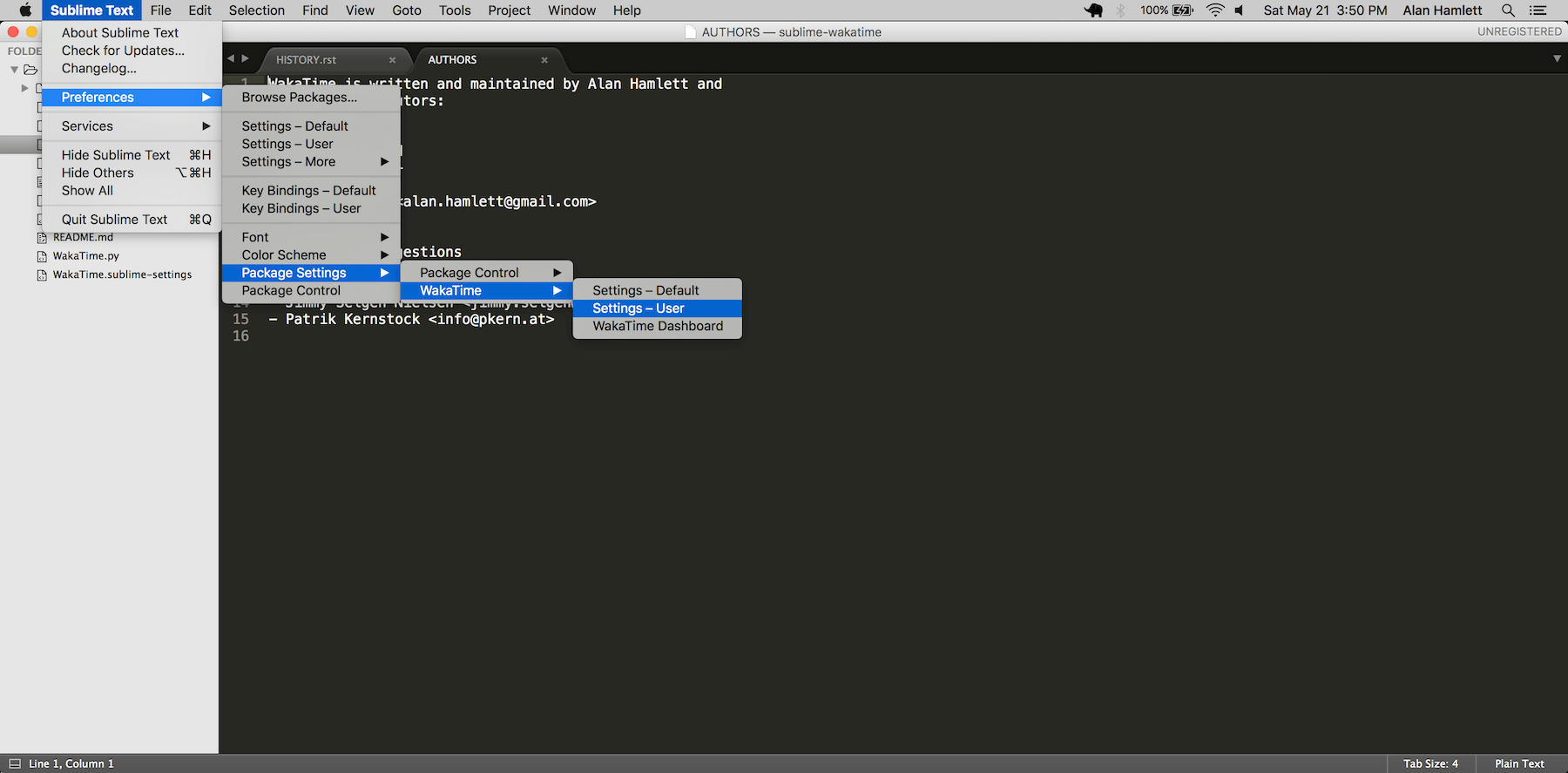
|
||||
|
||||
Add the line: `"debug": true`
|
||||
|
||||
|
||||
45
WakaTime.py
45
WakaTime.py
@ -7,7 +7,7 @@ Website: https://wakatime.com/
|
||||
==========================================================="""
|
||||
|
||||
|
||||
__version__ = '7.0.1'
|
||||
__version__ = '7.0.11'
|
||||
|
||||
|
||||
import sublime
|
||||
@ -46,7 +46,6 @@ if is_py2:
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
text = str(text)
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
@ -55,7 +54,7 @@ if is_py2:
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
return text.decode('utf-8', 'replace')
|
||||
|
||||
elif is_py3:
|
||||
def u(text):
|
||||
@ -72,7 +71,7 @@ elif is_py3:
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
return text.decode('utf-8', 'replace')
|
||||
|
||||
else:
|
||||
raise Exception('Unsupported Python version: {0}.{1}.{2}'.format(
|
||||
@ -136,11 +135,21 @@ def log(lvl, message, *args, **kwargs):
|
||||
msg = message.format(*args)
|
||||
elif len(kwargs) > 0:
|
||||
msg = message.format(**kwargs)
|
||||
print('[WakaTime] [{lvl}] {msg}'.format(lvl=lvl, msg=msg))
|
||||
try:
|
||||
print('[WakaTime] [{lvl}] {msg}'.format(lvl=lvl, msg=msg))
|
||||
except UnicodeDecodeError:
|
||||
print(u('[WakaTime] [{lvl}] {msg}').format(lvl=lvl, msg=u(msg)))
|
||||
except RuntimeError:
|
||||
set_timeout(lambda: log(lvl, message, *args, **kwargs), 0)
|
||||
|
||||
|
||||
def resources_folder():
|
||||
if platform.system() == 'Windows':
|
||||
return os.path.join(os.getenv('APPDATA'), 'WakaTime')
|
||||
else:
|
||||
return os.path.join(os.path.expanduser('~'), '.wakatime')
|
||||
|
||||
|
||||
def update_status_bar(status):
|
||||
"""Updates the status bar."""
|
||||
|
||||
@ -158,7 +167,7 @@ def update_status_bar(status):
|
||||
set_timeout(lambda: update_status_bar(status), 0)
|
||||
|
||||
|
||||
def createConfigFile():
|
||||
def create_config_file():
|
||||
"""Creates the .wakatime.cfg INI file in $HOME directory, if it does
|
||||
not already exist.
|
||||
"""
|
||||
@ -179,7 +188,7 @@ def createConfigFile():
|
||||
def prompt_api_key():
|
||||
global SETTINGS
|
||||
|
||||
createConfigFile()
|
||||
create_config_file()
|
||||
|
||||
default_key = ''
|
||||
try:
|
||||
@ -212,7 +221,7 @@ def python_binary():
|
||||
|
||||
# look for python in PATH and common install locations
|
||||
paths = [
|
||||
os.path.join(os.path.expanduser('~'), '.wakatime', 'python'),
|
||||
os.path.join(resources_folder(), 'python'),
|
||||
None,
|
||||
'/',
|
||||
'/usr/local/bin/',
|
||||
@ -308,7 +317,7 @@ def find_python_in_folder(folder, headless=True):
|
||||
path = os.path.realpath(os.path.join(folder, 'python'))
|
||||
if headless:
|
||||
path = u(path) + u('w')
|
||||
log(DEBUG, u('Looking for Python at: {0}').format(path))
|
||||
log(DEBUG, u('Looking for Python at: {0}').format(u(path)))
|
||||
try:
|
||||
process = Popen([path, '--version'], stdout=PIPE, stderr=STDOUT)
|
||||
output, err = process.communicate()
|
||||
@ -318,7 +327,7 @@ def find_python_in_folder(folder, headless=True):
|
||||
if not retcode and pattern.search(output):
|
||||
return path
|
||||
except:
|
||||
log(DEBUG, u('Python Version Output: {0}').format(u(sys.exc_info()[1])))
|
||||
log(DEBUG, u(sys.exc_info()[1]))
|
||||
|
||||
if headless:
|
||||
path = find_python_in_folder(folder, headless=False)
|
||||
@ -387,7 +396,7 @@ def is_view_active(view):
|
||||
return False
|
||||
|
||||
|
||||
def handle_heartbeat(view, is_write=False):
|
||||
def handle_activity(view, is_write=False):
|
||||
window = view.window()
|
||||
if window is not None:
|
||||
entity = view.file_name()
|
||||
@ -573,10 +582,10 @@ class DownloadPython(threading.Thread):
|
||||
arch=arch,
|
||||
)
|
||||
|
||||
if not os.path.exists(os.path.join(os.path.expanduser('~'), '.wakatime')):
|
||||
os.makedirs(os.path.join(os.path.expanduser('~'), '.wakatime'))
|
||||
if not os.path.exists(resources_folder()):
|
||||
os.makedirs(resources_folder())
|
||||
|
||||
zip_file = os.path.join(os.path.expanduser('~'), '.wakatime', 'python.zip')
|
||||
zip_file = os.path.join(resources_folder(), 'python.zip')
|
||||
try:
|
||||
urllib.urlretrieve(url, zip_file)
|
||||
except AttributeError:
|
||||
@ -584,7 +593,7 @@ class DownloadPython(threading.Thread):
|
||||
|
||||
log(INFO, 'Extracting Python...')
|
||||
with ZipFile(zip_file) as zf:
|
||||
path = os.path.join(os.path.expanduser('~'), '.wakatime', 'python')
|
||||
path = os.path.join(resources_folder(), 'python')
|
||||
zf.extractall(path)
|
||||
|
||||
try:
|
||||
@ -626,15 +635,15 @@ if ST_VERSION < 3000:
|
||||
class WakatimeListener(sublime_plugin.EventListener):
|
||||
|
||||
def on_post_save(self, view):
|
||||
handle_heartbeat(view, is_write=True)
|
||||
handle_activity(view, is_write=True)
|
||||
|
||||
def on_selection_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
handle_activity(view)
|
||||
|
||||
def on_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
handle_activity(view)
|
||||
|
||||
|
||||
class WakatimeDashboardCommand(sublime_plugin.ApplicationCommand):
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
__title__ = 'wakatime'
|
||||
__description__ = 'Common interface to the WakaTime api.'
|
||||
__url__ = 'https://github.com/wakatime/wakatime'
|
||||
__version_info__ = ('6', '0', '1')
|
||||
__version_info__ = ('6', '0', '9')
|
||||
__version__ = '.'.join(__version_info__)
|
||||
__author__ = 'Alan Hamlett'
|
||||
__author_email__ = 'alan@wakatime.com'
|
||||
|
||||
@ -31,7 +31,7 @@ if is_py2: # pragma: nocover
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
return text.decode('utf-8', 'replace')
|
||||
open = codecs.open
|
||||
basestring = basestring
|
||||
|
||||
@ -52,7 +52,7 @@ elif is_py3: # pragma: nocover
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
return text.decode('utf-8', 'replace')
|
||||
open = open
|
||||
basestring = (str, bytes)
|
||||
|
||||
|
||||
@ -9,10 +9,32 @@
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
""" Success
|
||||
Exit code used when a heartbeat was sent successfully.
|
||||
"""
|
||||
SUCCESS = 0
|
||||
|
||||
""" Api Error
|
||||
Exit code used when the WakaTime API returned an error.
|
||||
"""
|
||||
API_ERROR = 102
|
||||
|
||||
""" Config File Parse Error
|
||||
Exit code used when the ~/.wakatime.cfg config file could not be parsed.
|
||||
"""
|
||||
CONFIG_FILE_PARSE_ERROR = 103
|
||||
|
||||
""" Auth Error
|
||||
Exit code used when our api key is invalid.
|
||||
"""
|
||||
AUTH_ERROR = 104
|
||||
|
||||
""" Unknown Error
|
||||
Exit code used when there was an unhandled exception.
|
||||
"""
|
||||
UNKNOWN_ERROR = 105
|
||||
|
||||
""" Malformed Heartbeat Error
|
||||
Exit code used when the JSON input from `--extra-heartbeats` is malformed.
|
||||
"""
|
||||
MALFORMED_HEARTBEAT_ERROR = 106
|
||||
|
||||
@ -12,7 +12,6 @@
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from ..compat import u, open, import_module
|
||||
from ..exceptions import NotYetImplemented
|
||||
@ -68,7 +67,7 @@ class TokenParser(object):
|
||||
pass
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000)) # pragma: nocover
|
||||
except:
|
||||
pass
|
||||
return []
|
||||
@ -120,7 +119,7 @@ class DependencyParser(object):
|
||||
except AttributeError:
|
||||
log.debug('Module {0} is missing class {1}'.format(module.__name__, class_name))
|
||||
except ImportError:
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback(logging.DEBUG)
|
||||
|
||||
def parse(self):
|
||||
if self.parser:
|
||||
|
||||
@ -12,34 +12,6 @@
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
|
||||
class CParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
@ -47,6 +19,7 @@ class CParser(TokenParser):
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
state = None
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
@ -54,15 +27,25 @@ class CParser(TokenParser):
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc':
|
||||
if self.partial(token) == 'Preproc' or self.partial(token) == 'PreprocFile':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content)
|
||||
if self.state == 'include':
|
||||
if content != '\n' and content != '#':
|
||||
content = content.strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content, truncate=True, separator='/')
|
||||
self.state = None
|
||||
elif content.strip().startswith('include'):
|
||||
self.state = 'include'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
|
||||
class CppParser(CParser):
|
||||
pass
|
||||
|
||||
@ -18,7 +18,9 @@ class PythonParser(TokenParser):
|
||||
nonpackage = False
|
||||
exclude = [
|
||||
r'^os$',
|
||||
r'^sys$',
|
||||
r'^sys\.',
|
||||
r'^__future__$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
@ -48,9 +50,7 @@ class PythonParser(TokenParser):
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == '.':
|
||||
self.nonpackage = True
|
||||
pass
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
@ -73,8 +73,6 @@ class PythonParser(TokenParser):
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'import-2'
|
||||
|
||||
@ -69,30 +69,9 @@ KEYWORDS = [
|
||||
]
|
||||
|
||||
|
||||
class LassoJavascriptParser(TokenParser):
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Other':
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if content.lower() in KEYWORDS:
|
||||
self.append(content.lower())
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if 'famous/core/' in content.strip('"').strip("'"):
|
||||
self.append('famous')
|
||||
|
||||
|
||||
class HtmlDjangoParser(TokenParser):
|
||||
tags = []
|
||||
opening_tag = False
|
||||
getting_attrs = False
|
||||
current_attr = None
|
||||
current_attr_value = None
|
||||
@ -103,7 +82,9 @@ class HtmlDjangoParser(TokenParser):
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Tag':
|
||||
if u(token) == 'Token.Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token) == 'Token.Name.Tag':
|
||||
self._process_tag(token, content)
|
||||
elif u(token) == 'Token.Literal.String':
|
||||
self._process_string(token, content)
|
||||
@ -114,26 +95,30 @@ class HtmlDjangoParser(TokenParser):
|
||||
def current_tag(self):
|
||||
return None if len(self.tags) == 0 else self.tags[0]
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
def _process_punctuation(self, token, content):
|
||||
if content.startswith('</') or content.startswith('/'):
|
||||
try:
|
||||
self.tags.pop(0)
|
||||
except IndexError:
|
||||
# ignore errors from malformed markup
|
||||
pass
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
elif content.startswith('<'):
|
||||
self.opening_tag = True
|
||||
elif content.startswith('>'):
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
if self.opening_tag:
|
||||
self.tags.insert(0, content.replace('<', '', 1).strip().lower())
|
||||
self.getting_attrs = True
|
||||
elif content.startswith('>'):
|
||||
self.getting_attrs = False
|
||||
self.current_attr = None
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.getting_attrs:
|
||||
self.current_attr = content.lower().strip('=')
|
||||
else:
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
|
||||
def _process_string(self, token, content):
|
||||
@ -156,8 +141,6 @@ class HtmlDjangoParser(TokenParser):
|
||||
elif content.startswith('"') or content.startswith("'"):
|
||||
if self.current_attr_value is None:
|
||||
self.current_attr_value = content
|
||||
else:
|
||||
self.current_attr_value += content
|
||||
|
||||
|
||||
class VelocityHtmlParser(HtmlDjangoParser):
|
||||
|
||||
@ -25,20 +25,6 @@ except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes): # pragma: nocover
|
||||
obj = u(obj)
|
||||
return json.dumps(obj)
|
||||
try: # pragma: nocover
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, is_write, entity, version, plugin, verbose,
|
||||
@ -55,32 +41,25 @@ class JsonFormatter(logging.Formatter):
|
||||
data = OrderedDict([
|
||||
('now', self.formatTime(record, self.datefmt)),
|
||||
])
|
||||
data['version'] = self.version
|
||||
data['plugin'] = self.plugin
|
||||
data['version'] = u(self.version)
|
||||
if self.plugin:
|
||||
data['plugin'] = u(self.plugin)
|
||||
data['time'] = self.timestamp
|
||||
if self.verbose:
|
||||
data['caller'] = record.pathname
|
||||
data['caller'] = u(record.pathname)
|
||||
data['lineno'] = record.lineno
|
||||
data['is_write'] = self.is_write
|
||||
data['file'] = self.entity
|
||||
if not self.is_write:
|
||||
del data['is_write']
|
||||
if self.is_write:
|
||||
data['is_write'] = self.is_write
|
||||
data['file'] = u(self.entity)
|
||||
data['level'] = record.levelname
|
||||
data['message'] = record.getMessage() if self.warnings else record.msg
|
||||
if not self.plugin:
|
||||
del data['plugin']
|
||||
return CustomEncoder().encode(data)
|
||||
data['message'] = u(record.getMessage() if self.warnings else record.msg)
|
||||
return json.dumps(data)
|
||||
|
||||
|
||||
def traceback_formatter(*args, **kwargs):
|
||||
if 'level' in kwargs and (kwargs['level'].lower() == 'warn' or kwargs['level'].lower() == 'warning'):
|
||||
logging.getLogger('WakaTime').warning(traceback.format_exc())
|
||||
elif 'level' in kwargs and kwargs['level'].lower() == 'info':
|
||||
logging.getLogger('WakaTime').info(traceback.format_exc())
|
||||
elif 'level' in kwargs and kwargs['level'].lower() == 'debug':
|
||||
logging.getLogger('WakaTime').debug(traceback.format_exc())
|
||||
else:
|
||||
logging.getLogger('WakaTime').error(traceback.format_exc())
|
||||
def traceback(self, lvl=None):
|
||||
logger = logging.getLogger('WakaTime')
|
||||
if not lvl:
|
||||
lvl = logger.getEffectiveLevel()
|
||||
logger.log(lvl, traceback.format_exc())
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
@ -113,7 +92,7 @@ def setup_logging(args, version):
|
||||
logger.addHandler(handler)
|
||||
|
||||
# add custom traceback logging method
|
||||
logger.traceback = traceback_formatter
|
||||
logger.traceback = formatter.traceback
|
||||
|
||||
warnings_formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
warnings_formatter.setup(
|
||||
|
||||
@ -127,8 +127,10 @@ def parseArguments():
|
||||
help='entity type for this heartbeat. can be one of "file", '+
|
||||
'"domain", or "app"; defaults to file.')
|
||||
parser.add_argument('--proxy', dest='proxy',
|
||||
help='optional https proxy url; for example: '+
|
||||
'https://user:pass@localhost:8080')
|
||||
help='optional proxy configuration. Supports HTTPS '+
|
||||
'and SOCKS proxies. For example: '+
|
||||
'https://user:pass@host:port or '+
|
||||
'socks5://user:pass@host:port')
|
||||
parser.add_argument('--project', dest='project',
|
||||
help='optional project name')
|
||||
parser.add_argument('--alternate-project', dest='alternate_project',
|
||||
@ -183,6 +185,9 @@ def parseArguments():
|
||||
return args, configs
|
||||
|
||||
# update args from configs
|
||||
if not args.hostname:
|
||||
if configs.has_option('settings', 'hostname'):
|
||||
args.hostname = configs.get('settings', 'hostname')
|
||||
if not args.key:
|
||||
default_key = None
|
||||
if configs.has_option('settings', 'api_key'):
|
||||
@ -383,6 +388,18 @@ def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
log.warn(exception_data)
|
||||
else:
|
||||
log.error(exception_data)
|
||||
|
||||
except: # delete cached session when requests raises unknown exception
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
'traceback': traceback.format_exc(),
|
||||
}
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
log.warn(exception_data)
|
||||
session_cache.delete()
|
||||
|
||||
else:
|
||||
code = response.status_code if response is not None else None
|
||||
content = response.text if response is not None else None
|
||||
@ -454,6 +471,17 @@ def sync_offline_heartbeats(args, hostname):
|
||||
return SUCCESS
|
||||
|
||||
|
||||
def format_file_path(filepath):
|
||||
"""Formats a path as absolute and with the correct platform separator."""
|
||||
|
||||
try:
|
||||
filepath = os.path.realpath(os.path.abspath(filepath))
|
||||
filepath = re.sub(r'[/\\]', os.path.sep, filepath)
|
||||
except:
|
||||
pass # pragma: nocover
|
||||
return filepath
|
||||
|
||||
|
||||
def process_heartbeat(args, configs, hostname, heartbeat):
|
||||
exclude = should_exclude(heartbeat['entity'], args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
@ -465,6 +493,9 @@ def process_heartbeat(args, configs, hostname, heartbeat):
|
||||
if heartbeat.get('entity_type') not in ['file', 'domain', 'app']:
|
||||
heartbeat['entity_type'] = 'file'
|
||||
|
||||
if heartbeat['entity_type'] == 'file':
|
||||
heartbeat['entity'] = format_file_path(heartbeat['entity'])
|
||||
|
||||
if heartbeat['entity_type'] != 'file' or os.path.isfile(heartbeat['entity']):
|
||||
|
||||
stats = get_file_stats(heartbeat['entity'],
|
||||
@ -528,6 +559,6 @@ def execute(argv=None):
|
||||
return retval
|
||||
|
||||
except:
|
||||
log.traceback()
|
||||
log.traceback(logging.ERROR)
|
||||
print(traceback.format_exc())
|
||||
return UNKNOWN_ERROR
|
||||
|
||||
@ -12,7 +12,6 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import traceback
|
||||
from time import sleep
|
||||
|
||||
try:
|
||||
@ -70,7 +69,7 @@ class Queue(object):
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.error(traceback.format_exc())
|
||||
log.traceback()
|
||||
|
||||
def pop(self):
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
@ -81,7 +80,7 @@ class Queue(object):
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback(logging.DEBUG)
|
||||
return None
|
||||
loop = True
|
||||
while loop and tries > -1:
|
||||
@ -119,11 +118,11 @@ class Queue(object):
|
||||
}
|
||||
loop = False
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback(logging.DEBUG)
|
||||
sleep(wait)
|
||||
tries -= 1
|
||||
try:
|
||||
conn.close()
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback(logging.DEBUG)
|
||||
return heartbeat
|
||||
|
||||
@ -1,13 +1,3 @@
|
||||
import os
|
||||
import sys
|
||||
|
||||
from ..compat import is_py2
|
||||
|
||||
if is_py2:
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'py2'))
|
||||
else:
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'py3'))
|
||||
|
||||
import tzlocal
|
||||
from pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.console
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
Format colored console output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
esc = "\x1b["
|
||||
|
||||
codes = {}
|
||||
codes[""] = ""
|
||||
codes["reset"] = esc + "39;49;00m"
|
||||
|
||||
codes["bold"] = esc + "01m"
|
||||
codes["faint"] = esc + "02m"
|
||||
codes["standout"] = esc + "03m"
|
||||
codes["underline"] = esc + "04m"
|
||||
codes["blink"] = esc + "05m"
|
||||
codes["overline"] = esc + "06m"
|
||||
|
||||
dark_colors = ["black", "darkred", "darkgreen", "brown", "darkblue",
|
||||
"purple", "teal", "lightgray"]
|
||||
light_colors = ["darkgray", "red", "green", "yellow", "blue",
|
||||
"fuchsia", "turquoise", "white"]
|
||||
|
||||
x = 30
|
||||
for d, l in zip(dark_colors, light_colors):
|
||||
codes[d] = esc + "%im" % x
|
||||
codes[l] = esc + "%i;01m" % x
|
||||
x += 1
|
||||
|
||||
del d, l, x
|
||||
|
||||
codes["darkteal"] = codes["turquoise"]
|
||||
codes["darkyellow"] = codes["brown"]
|
||||
codes["fuscia"] = codes["fuchsia"]
|
||||
codes["white"] = codes["bold"]
|
||||
|
||||
|
||||
def reset_color():
|
||||
return codes["reset"]
|
||||
|
||||
|
||||
def colorize(color_key, text):
|
||||
return codes[color_key] + text + codes["reset"]
|
||||
|
||||
|
||||
def ansiformat(attr, text):
|
||||
"""
|
||||
Format ``text`` with a color and/or some attributes::
|
||||
|
||||
color normal color
|
||||
*color* bold color
|
||||
_color_ underlined color
|
||||
+color+ blinking color
|
||||
"""
|
||||
result = []
|
||||
if attr[:1] == attr[-1:] == '+':
|
||||
result.append(codes['blink'])
|
||||
attr = attr[1:-1]
|
||||
if attr[:1] == attr[-1:] == '*':
|
||||
result.append(codes['bold'])
|
||||
attr = attr[1:-1]
|
||||
if attr[:1] == attr[-1:] == '_':
|
||||
result.append(codes['underline'])
|
||||
attr = attr[1:-1]
|
||||
result.append(codes[attr])
|
||||
result.append(text)
|
||||
result.append(codes['reset'])
|
||||
return ''.join(result)
|
||||
@ -1,74 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.filter
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
Module that implements the default filter.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
|
||||
def apply_filters(stream, filters, lexer=None):
|
||||
"""
|
||||
Use this method to apply an iterable of filters to
|
||||
a stream. If lexer is given it's forwarded to the
|
||||
filter, otherwise the filter receives `None`.
|
||||
"""
|
||||
def _apply(filter_, stream):
|
||||
for token in filter_.filter(lexer, stream):
|
||||
yield token
|
||||
for filter_ in filters:
|
||||
stream = _apply(filter_, stream)
|
||||
return stream
|
||||
|
||||
|
||||
def simplefilter(f):
|
||||
"""
|
||||
Decorator that converts a function into a filter::
|
||||
|
||||
@simplefilter
|
||||
def lowercase(lexer, stream, options):
|
||||
for ttype, value in stream:
|
||||
yield ttype, value.lower()
|
||||
"""
|
||||
return type(f.__name__, (FunctionFilter,), {
|
||||
'function': f,
|
||||
'__module__': getattr(f, '__module__'),
|
||||
'__doc__': f.__doc__
|
||||
})
|
||||
|
||||
|
||||
class Filter(object):
|
||||
"""
|
||||
Default filter. Subclass this class or use the `simplefilter`
|
||||
decorator to create own filters.
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
self.options = options
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
raise NotImplementedError()
|
||||
|
||||
|
||||
class FunctionFilter(Filter):
|
||||
"""
|
||||
Abstract class used by `simplefilter` to create simple
|
||||
function filters on the fly. The `simplefilter` decorator
|
||||
automatically creates subclasses of this class for
|
||||
functions passed to it.
|
||||
"""
|
||||
function = None
|
||||
|
||||
def __init__(self, **options):
|
||||
if not hasattr(self, 'function'):
|
||||
raise TypeError('%r used without bound function' %
|
||||
self.__class__.__name__)
|
||||
Filter.__init__(self, **options)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
# pylint: disable-msg=E1102
|
||||
for ttype, value in self.function(lexer, stream, self.options):
|
||||
yield ttype, value
|
||||
@ -1,350 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.filters
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
Module containing filter lookup functions and default
|
||||
filters.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.token import String, Comment, Keyword, Name, Error, Whitespace, \
|
||||
string_to_tokentype
|
||||
from pygments.filter import Filter
|
||||
from pygments.util import get_list_opt, get_int_opt, get_bool_opt, \
|
||||
get_choice_opt, ClassNotFound, OptionError, text_type, string_types
|
||||
from pygments.plugin import find_plugin_filters
|
||||
|
||||
|
||||
def find_filter_class(filtername):
|
||||
"""Lookup a filter by name. Return None if not found."""
|
||||
if filtername in FILTERS:
|
||||
return FILTERS[filtername]
|
||||
for name, cls in find_plugin_filters():
|
||||
if name == filtername:
|
||||
return cls
|
||||
return None
|
||||
|
||||
|
||||
def get_filter_by_name(filtername, **options):
|
||||
"""Return an instantiated filter.
|
||||
|
||||
Options are passed to the filter initializer if wanted.
|
||||
Raise a ClassNotFound if not found.
|
||||
"""
|
||||
cls = find_filter_class(filtername)
|
||||
if cls:
|
||||
return cls(**options)
|
||||
else:
|
||||
raise ClassNotFound('filter %r not found' % filtername)
|
||||
|
||||
|
||||
def get_all_filters():
|
||||
"""Return a generator of all filter names."""
|
||||
for name in FILTERS:
|
||||
yield name
|
||||
for name, _ in find_plugin_filters():
|
||||
yield name
|
||||
|
||||
|
||||
def _replace_special(ttype, value, regex, specialttype,
|
||||
replacefunc=lambda x: x):
|
||||
last = 0
|
||||
for match in regex.finditer(value):
|
||||
start, end = match.start(), match.end()
|
||||
if start != last:
|
||||
yield ttype, value[last:start]
|
||||
yield specialttype, replacefunc(value[start:end])
|
||||
last = end
|
||||
if last != len(value):
|
||||
yield ttype, value[last:]
|
||||
|
||||
|
||||
class CodeTagFilter(Filter):
|
||||
"""Highlight special code tags in comments and docstrings.
|
||||
|
||||
Options accepted:
|
||||
|
||||
`codetags` : list of strings
|
||||
A list of strings that are flagged as code tags. The default is to
|
||||
highlight ``XXX``, ``TODO``, ``BUG`` and ``NOTE``.
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
tags = get_list_opt(options, 'codetags',
|
||||
['XXX', 'TODO', 'BUG', 'NOTE'])
|
||||
self.tag_re = re.compile(r'\b(%s)\b' % '|'.join([
|
||||
re.escape(tag) for tag in tags if tag
|
||||
]))
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
regex = self.tag_re
|
||||
for ttype, value in stream:
|
||||
if ttype in String.Doc or \
|
||||
ttype in Comment and \
|
||||
ttype not in Comment.Preproc:
|
||||
for sttype, svalue in _replace_special(ttype, value, regex,
|
||||
Comment.Special):
|
||||
yield sttype, svalue
|
||||
else:
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class KeywordCaseFilter(Filter):
|
||||
"""Convert keywords to lowercase or uppercase or capitalize them, which
|
||||
means first letter uppercase, rest lowercase.
|
||||
|
||||
This can be useful e.g. if you highlight Pascal code and want to adapt the
|
||||
code to your styleguide.
|
||||
|
||||
Options accepted:
|
||||
|
||||
`case` : string
|
||||
The casing to convert keywords to. Must be one of ``'lower'``,
|
||||
``'upper'`` or ``'capitalize'``. The default is ``'lower'``.
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
case = get_choice_opt(options, 'case',
|
||||
['lower', 'upper', 'capitalize'], 'lower')
|
||||
self.convert = getattr(text_type, case)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
for ttype, value in stream:
|
||||
if ttype in Keyword:
|
||||
yield ttype, self.convert(value)
|
||||
else:
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class NameHighlightFilter(Filter):
|
||||
"""Highlight a normal Name (and Name.*) token with a different token type.
|
||||
|
||||
Example::
|
||||
|
||||
filter = NameHighlightFilter(
|
||||
names=['foo', 'bar', 'baz'],
|
||||
tokentype=Name.Function,
|
||||
)
|
||||
|
||||
This would highlight the names "foo", "bar" and "baz"
|
||||
as functions. `Name.Function` is the default token type.
|
||||
|
||||
Options accepted:
|
||||
|
||||
`names` : list of strings
|
||||
A list of names that should be given the different token type.
|
||||
There is no default.
|
||||
`tokentype` : TokenType or string
|
||||
A token type or a string containing a token type name that is
|
||||
used for highlighting the strings in `names`. The default is
|
||||
`Name.Function`.
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
self.names = set(get_list_opt(options, 'names', []))
|
||||
tokentype = options.get('tokentype')
|
||||
if tokentype:
|
||||
self.tokentype = string_to_tokentype(tokentype)
|
||||
else:
|
||||
self.tokentype = Name.Function
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
for ttype, value in stream:
|
||||
if ttype in Name and value in self.names:
|
||||
yield self.tokentype, value
|
||||
else:
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class ErrorToken(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class RaiseOnErrorTokenFilter(Filter):
|
||||
"""Raise an exception when the lexer generates an error token.
|
||||
|
||||
Options accepted:
|
||||
|
||||
`excclass` : Exception class
|
||||
The exception class to raise.
|
||||
The default is `pygments.filters.ErrorToken`.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
self.exception = options.get('excclass', ErrorToken)
|
||||
try:
|
||||
# issubclass() will raise TypeError if first argument is not a class
|
||||
if not issubclass(self.exception, Exception):
|
||||
raise TypeError
|
||||
except TypeError:
|
||||
raise OptionError('excclass option is not an exception class')
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
for ttype, value in stream:
|
||||
if ttype is Error:
|
||||
raise self.exception(value)
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class VisibleWhitespaceFilter(Filter):
|
||||
"""Convert tabs, newlines and/or spaces to visible characters.
|
||||
|
||||
Options accepted:
|
||||
|
||||
`spaces` : string or bool
|
||||
If this is a one-character string, spaces will be replaces by this string.
|
||||
If it is another true value, spaces will be replaced by ``·`` (unicode
|
||||
MIDDLE DOT). If it is a false value, spaces will not be replaced. The
|
||||
default is ``False``.
|
||||
`tabs` : string or bool
|
||||
The same as for `spaces`, but the default replacement character is ``»``
|
||||
(unicode RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK). The default value
|
||||
is ``False``. Note: this will not work if the `tabsize` option for the
|
||||
lexer is nonzero, as tabs will already have been expanded then.
|
||||
`tabsize` : int
|
||||
If tabs are to be replaced by this filter (see the `tabs` option), this
|
||||
is the total number of characters that a tab should be expanded to.
|
||||
The default is ``8``.
|
||||
`newlines` : string or bool
|
||||
The same as for `spaces`, but the default replacement character is ``¶``
|
||||
(unicode PILCROW SIGN). The default value is ``False``.
|
||||
`wstokentype` : bool
|
||||
If true, give whitespace the special `Whitespace` token type. This allows
|
||||
styling the visible whitespace differently (e.g. greyed out), but it can
|
||||
disrupt background colors. The default is ``True``.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
for name, default in [('spaces', u'·'),
|
||||
('tabs', u'»'),
|
||||
('newlines', u'¶')]:
|
||||
opt = options.get(name, False)
|
||||
if isinstance(opt, string_types) and len(opt) == 1:
|
||||
setattr(self, name, opt)
|
||||
else:
|
||||
setattr(self, name, (opt and default or ''))
|
||||
tabsize = get_int_opt(options, 'tabsize', 8)
|
||||
if self.tabs:
|
||||
self.tabs += ' ' * (tabsize - 1)
|
||||
if self.newlines:
|
||||
self.newlines += '\n'
|
||||
self.wstt = get_bool_opt(options, 'wstokentype', True)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
if self.wstt:
|
||||
spaces = self.spaces or u' '
|
||||
tabs = self.tabs or u'\t'
|
||||
newlines = self.newlines or u'\n'
|
||||
regex = re.compile(r'\s')
|
||||
def replacefunc(wschar):
|
||||
if wschar == ' ':
|
||||
return spaces
|
||||
elif wschar == '\t':
|
||||
return tabs
|
||||
elif wschar == '\n':
|
||||
return newlines
|
||||
return wschar
|
||||
|
||||
for ttype, value in stream:
|
||||
for sttype, svalue in _replace_special(ttype, value, regex,
|
||||
Whitespace, replacefunc):
|
||||
yield sttype, svalue
|
||||
else:
|
||||
spaces, tabs, newlines = self.spaces, self.tabs, self.newlines
|
||||
# simpler processing
|
||||
for ttype, value in stream:
|
||||
if spaces:
|
||||
value = value.replace(' ', spaces)
|
||||
if tabs:
|
||||
value = value.replace('\t', tabs)
|
||||
if newlines:
|
||||
value = value.replace('\n', newlines)
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class GobbleFilter(Filter):
|
||||
"""Gobbles source code lines (eats initial characters).
|
||||
|
||||
This filter drops the first ``n`` characters off every line of code. This
|
||||
may be useful when the source code fed to the lexer is indented by a fixed
|
||||
amount of space that isn't desired in the output.
|
||||
|
||||
Options accepted:
|
||||
|
||||
`n` : int
|
||||
The number of characters to gobble.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
self.n = get_int_opt(options, 'n', 0)
|
||||
|
||||
def gobble(self, value, left):
|
||||
if left < len(value):
|
||||
return value[left:], 0
|
||||
else:
|
||||
return u'', left - len(value)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
n = self.n
|
||||
left = n # How many characters left to gobble.
|
||||
for ttype, value in stream:
|
||||
# Remove ``left`` tokens from first line, ``n`` from all others.
|
||||
parts = value.split('\n')
|
||||
(parts[0], left) = self.gobble(parts[0], left)
|
||||
for i in range(1, len(parts)):
|
||||
(parts[i], left) = self.gobble(parts[i], n)
|
||||
value = u'\n'.join(parts)
|
||||
|
||||
if value != '':
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class TokenMergeFilter(Filter):
|
||||
"""Merges consecutive tokens with the same token type in the output
|
||||
stream of a lexer.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
current_type = None
|
||||
current_value = None
|
||||
for ttype, value in stream:
|
||||
if ttype is current_type:
|
||||
current_value += value
|
||||
else:
|
||||
if current_type is not None:
|
||||
yield current_type, current_value
|
||||
current_type = ttype
|
||||
current_value = value
|
||||
if current_type is not None:
|
||||
yield current_type, current_value
|
||||
|
||||
|
||||
FILTERS = {
|
||||
'codetagify': CodeTagFilter,
|
||||
'keywordcase': KeywordCaseFilter,
|
||||
'highlight': NameHighlightFilter,
|
||||
'raiseonerror': RaiseOnErrorTokenFilter,
|
||||
'whitespace': VisibleWhitespaceFilter,
|
||||
'gobble': GobbleFilter,
|
||||
'tokenmerge': TokenMergeFilter,
|
||||
}
|
||||
@ -1,95 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatter
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Base formatter class.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import codecs
|
||||
|
||||
from pygments.util import get_bool_opt, string_types
|
||||
from pygments.styles import get_style_by_name
|
||||
|
||||
__all__ = ['Formatter']
|
||||
|
||||
|
||||
def _lookup_style(style):
|
||||
if isinstance(style, string_types):
|
||||
return get_style_by_name(style)
|
||||
return style
|
||||
|
||||
|
||||
class Formatter(object):
|
||||
"""
|
||||
Converts a token stream to text.
|
||||
|
||||
Options accepted:
|
||||
|
||||
``style``
|
||||
The style to use, can be a string or a Style subclass
|
||||
(default: "default"). Not used by e.g. the
|
||||
TerminalFormatter.
|
||||
``full``
|
||||
Tells the formatter to output a "full" document, i.e.
|
||||
a complete self-contained document. This doesn't have
|
||||
any effect for some formatters (default: false).
|
||||
``title``
|
||||
If ``full`` is true, the title that should be used to
|
||||
caption the document (default: '').
|
||||
``encoding``
|
||||
If given, must be an encoding name. This will be used to
|
||||
convert the Unicode token strings to byte strings in the
|
||||
output. If it is "" or None, Unicode strings will be written
|
||||
to the output file, which most file-like objects do not
|
||||
support (default: None).
|
||||
``outencoding``
|
||||
Overrides ``encoding`` if given.
|
||||
"""
|
||||
|
||||
#: Name of the formatter
|
||||
name = None
|
||||
|
||||
#: Shortcuts for the formatter
|
||||
aliases = []
|
||||
|
||||
#: fn match rules
|
||||
filenames = []
|
||||
|
||||
#: If True, this formatter outputs Unicode strings when no encoding
|
||||
#: option is given.
|
||||
unicodeoutput = True
|
||||
|
||||
def __init__(self, **options):
|
||||
self.style = _lookup_style(options.get('style', 'default'))
|
||||
self.full = get_bool_opt(options, 'full', False)
|
||||
self.title = options.get('title', '')
|
||||
self.encoding = options.get('encoding', None) or None
|
||||
if self.encoding in ('guess', 'chardet'):
|
||||
# can happen for e.g. pygmentize -O encoding=guess
|
||||
self.encoding = 'utf-8'
|
||||
self.encoding = options.get('outencoding') or self.encoding
|
||||
self.options = options
|
||||
|
||||
def get_style_defs(self, arg=''):
|
||||
"""
|
||||
Return the style definitions for the current style as a string.
|
||||
|
||||
``arg`` is an additional argument whose meaning depends on the
|
||||
formatter used. Note that ``arg`` can also be a list or tuple
|
||||
for some formatters like the html formatter.
|
||||
"""
|
||||
return ''
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
"""
|
||||
Format ``tokensource``, an iterable of ``(tokentype, tokenstring)``
|
||||
tuples and write it into ``outfile``.
|
||||
"""
|
||||
if self.encoding:
|
||||
# wrap the outfile in a StreamWriter
|
||||
outfile = codecs.lookup(self.encoding)[3](outfile)
|
||||
return self.format_unencoded(tokensource, outfile)
|
||||
@ -1,118 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Pygments formatters.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import sys
|
||||
import types
|
||||
import fnmatch
|
||||
from os.path import basename
|
||||
|
||||
from pygments.formatters._mapping import FORMATTERS
|
||||
from pygments.plugin import find_plugin_formatters
|
||||
from pygments.util import ClassNotFound, itervalues
|
||||
|
||||
__all__ = ['get_formatter_by_name', 'get_formatter_for_filename',
|
||||
'get_all_formatters'] + list(FORMATTERS)
|
||||
|
||||
_formatter_cache = {} # classes by name
|
||||
_pattern_cache = {}
|
||||
|
||||
|
||||
def _fn_matches(fn, glob):
|
||||
"""Return whether the supplied file name fn matches pattern filename."""
|
||||
if glob not in _pattern_cache:
|
||||
pattern = _pattern_cache[glob] = re.compile(fnmatch.translate(glob))
|
||||
return pattern.match(fn)
|
||||
return _pattern_cache[glob].match(fn)
|
||||
|
||||
|
||||
def _load_formatters(module_name):
|
||||
"""Load a formatter (and all others in the module too)."""
|
||||
mod = __import__(module_name, None, None, ['__all__'])
|
||||
for formatter_name in mod.__all__:
|
||||
cls = getattr(mod, formatter_name)
|
||||
_formatter_cache[cls.name] = cls
|
||||
|
||||
|
||||
def get_all_formatters():
|
||||
"""Return a generator for all formatter classes."""
|
||||
# NB: this returns formatter classes, not info like get_all_lexers().
|
||||
for info in itervalues(FORMATTERS):
|
||||
if info[1] not in _formatter_cache:
|
||||
_load_formatters(info[0])
|
||||
yield _formatter_cache[info[1]]
|
||||
for _, formatter in find_plugin_formatters():
|
||||
yield formatter
|
||||
|
||||
|
||||
def find_formatter_class(alias):
|
||||
"""Lookup a formatter by alias.
|
||||
|
||||
Returns None if not found.
|
||||
"""
|
||||
for module_name, name, aliases, _, _ in itervalues(FORMATTERS):
|
||||
if alias in aliases:
|
||||
if name not in _formatter_cache:
|
||||
_load_formatters(module_name)
|
||||
return _formatter_cache[name]
|
||||
for _, cls in find_plugin_formatters():
|
||||
if alias in cls.aliases:
|
||||
return cls
|
||||
|
||||
|
||||
def get_formatter_by_name(_alias, **options):
|
||||
"""Lookup and instantiate a formatter by alias.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
cls = find_formatter_class(_alias)
|
||||
if cls is None:
|
||||
raise ClassNotFound("No formatter found for name %r" % _alias)
|
||||
return cls(**options)
|
||||
|
||||
|
||||
def get_formatter_for_filename(fn, **options):
|
||||
"""Lookup and instantiate a formatter by filename pattern.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
fn = basename(fn)
|
||||
for modname, name, _, filenames, _ in itervalues(FORMATTERS):
|
||||
for filename in filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
if name not in _formatter_cache:
|
||||
_load_formatters(modname)
|
||||
return _formatter_cache[name](**options)
|
||||
for cls in find_plugin_formatters():
|
||||
for filename in cls.filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
return cls(**options)
|
||||
raise ClassNotFound("No formatter found for file name %r" % fn)
|
||||
|
||||
|
||||
class _automodule(types.ModuleType):
|
||||
"""Automatically import formatters."""
|
||||
|
||||
def __getattr__(self, name):
|
||||
info = FORMATTERS.get(name)
|
||||
if info:
|
||||
_load_formatters(info[0])
|
||||
cls = _formatter_cache[info[1]]
|
||||
setattr(self, name, cls)
|
||||
return cls
|
||||
raise AttributeError(name)
|
||||
|
||||
|
||||
oldmod = sys.modules[__name__]
|
||||
newmod = _automodule(__name__)
|
||||
newmod.__dict__.update(oldmod.__dict__)
|
||||
sys.modules[__name__] = newmod
|
||||
del newmod.newmod, newmod.oldmod, newmod.sys, newmod.types
|
||||
@ -1,76 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter mapping definitions. This file is generated by itself. Everytime
|
||||
you change something on a builtin formatter definition, run this script from
|
||||
the formatters folder to update it.
|
||||
|
||||
Do not alter the FORMATTERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
FORMATTERS = {
|
||||
'BBCodeFormatter': ('pygments.formatters.bbcode', 'BBCode', ('bbcode', 'bb'), (), 'Format tokens with BBcodes. These formatting codes are used by many bulletin boards, so you can highlight your sourcecode with pygments before posting it there.'),
|
||||
'BmpImageFormatter': ('pygments.formatters.img', 'img_bmp', ('bmp', 'bitmap'), ('*.bmp',), 'Create a bitmap image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'GifImageFormatter': ('pygments.formatters.img', 'img_gif', ('gif',), ('*.gif',), 'Create a GIF image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'HtmlFormatter': ('pygments.formatters.html', 'HTML', ('html',), ('*.html', '*.htm'), "Format tokens as HTML 4 ``<span>`` tags within a ``<pre>`` tag, wrapped in a ``<div>`` tag. The ``<div>``'s CSS class can be set by the `cssclass` option."),
|
||||
'ImageFormatter': ('pygments.formatters.img', 'img', ('img', 'IMG', 'png'), ('*.png',), 'Create a PNG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'JpgImageFormatter': ('pygments.formatters.img', 'img_jpg', ('jpg', 'jpeg'), ('*.jpg',), 'Create a JPEG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'LatexFormatter': ('pygments.formatters.latex', 'LaTeX', ('latex', 'tex'), ('*.tex',), 'Format tokens as LaTeX code. This needs the `fancyvrb` and `color` standard packages.'),
|
||||
'NullFormatter': ('pygments.formatters.other', 'Text only', ('text', 'null'), ('*.txt',), 'Output the text unchanged without any formatting.'),
|
||||
'RawTokenFormatter': ('pygments.formatters.other', 'Raw tokens', ('raw', 'tokens'), ('*.raw',), 'Format tokens as a raw representation for storing token streams.'),
|
||||
'RtfFormatter': ('pygments.formatters.rtf', 'RTF', ('rtf',), ('*.rtf',), 'Format tokens as RTF markup. This formatter automatically outputs full RTF documents with color information and other useful stuff. Perfect for Copy and Paste into Microsoft(R) Word(R) documents.'),
|
||||
'SvgFormatter': ('pygments.formatters.svg', 'SVG', ('svg',), ('*.svg',), 'Format tokens as an SVG graphics file. This formatter is still experimental. Each line of code is a ``<text>`` element with explicit ``x`` and ``y`` coordinates containing ``<tspan>`` elements with the individual token styles.'),
|
||||
'Terminal256Formatter': ('pygments.formatters.terminal256', 'Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TerminalFormatter': ('pygments.formatters.terminal', 'Terminal', ('terminal', 'console'), (), 'Format tokens with ANSI color sequences, for output in a text console. Color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TestcaseFormatter': ('pygments.formatters.other', 'Testcase', ('testcase',), (), 'Format tokens as appropriate for a new testcase.')
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup formatters
|
||||
found_formatters = []
|
||||
imports = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
from pygments.util import docstring_headline
|
||||
|
||||
for root, dirs, files in os.walk('.'):
|
||||
for filename in files:
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.formatters%s.%s' % (
|
||||
root[1:].replace('/', '.'), filename[:-3])
|
||||
print(module_name)
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for formatter_name in module.__all__:
|
||||
formatter = getattr(module, formatter_name)
|
||||
found_formatters.append(
|
||||
'%r: %r' % (formatter_name,
|
||||
(module_name,
|
||||
formatter.name,
|
||||
tuple(formatter.aliases),
|
||||
tuple(formatter.filenames),
|
||||
docstring_headline(formatter))))
|
||||
# sort them to make the diff minimal
|
||||
found_formatters.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
with open(__file__) as fp:
|
||||
content = fp.read()
|
||||
header = content[:content.find('FORMATTERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
with open(__file__, 'w') as fp:
|
||||
fp.write(header)
|
||||
fp.write('FORMATTERS = {\n %s\n}\n\n' % ',\n '.join(found_formatters))
|
||||
fp.write(footer)
|
||||
|
||||
print ('=== %d formatters processed.' % len(found_formatters))
|
||||
@ -1,560 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters.img
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter for Pixmap output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import sys
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
|
||||
get_choice_opt, xrange
|
||||
|
||||
# Import this carefully
|
||||
try:
|
||||
from PIL import Image, ImageDraw, ImageFont
|
||||
pil_available = True
|
||||
except ImportError:
|
||||
pil_available = False
|
||||
|
||||
try:
|
||||
import _winreg
|
||||
except ImportError:
|
||||
try:
|
||||
import winreg as _winreg
|
||||
except ImportError:
|
||||
_winreg = None
|
||||
|
||||
__all__ = ['ImageFormatter', 'GifImageFormatter', 'JpgImageFormatter',
|
||||
'BmpImageFormatter']
|
||||
|
||||
|
||||
# For some unknown reason every font calls it something different
|
||||
STYLES = {
|
||||
'NORMAL': ['', 'Roman', 'Book', 'Normal', 'Regular', 'Medium'],
|
||||
'ITALIC': ['Oblique', 'Italic'],
|
||||
'BOLD': ['Bold'],
|
||||
'BOLDITALIC': ['Bold Oblique', 'Bold Italic'],
|
||||
}
|
||||
|
||||
# A sane default for modern systems
|
||||
DEFAULT_FONT_NAME_NIX = 'Bitstream Vera Sans Mono'
|
||||
DEFAULT_FONT_NAME_WIN = 'Courier New'
|
||||
|
||||
|
||||
class PilNotAvailable(ImportError):
|
||||
"""When Python imaging library is not available"""
|
||||
|
||||
|
||||
class FontNotFound(Exception):
|
||||
"""When there are no usable fonts specified"""
|
||||
|
||||
|
||||
class FontManager(object):
|
||||
"""
|
||||
Manages a set of fonts: normal, italic, bold, etc...
|
||||
"""
|
||||
|
||||
def __init__(self, font_name, font_size=14):
|
||||
self.font_name = font_name
|
||||
self.font_size = font_size
|
||||
self.fonts = {}
|
||||
self.encoding = None
|
||||
if sys.platform.startswith('win'):
|
||||
if not font_name:
|
||||
self.font_name = DEFAULT_FONT_NAME_WIN
|
||||
self._create_win()
|
||||
else:
|
||||
if not font_name:
|
||||
self.font_name = DEFAULT_FONT_NAME_NIX
|
||||
self._create_nix()
|
||||
|
||||
def _get_nix_font_path(self, name, style):
|
||||
try:
|
||||
from commands import getstatusoutput
|
||||
except ImportError:
|
||||
from subprocess import getstatusoutput
|
||||
exit, out = getstatusoutput('fc-list "%s:style=%s" file' %
|
||||
(name, style))
|
||||
if not exit:
|
||||
lines = out.splitlines()
|
||||
if lines:
|
||||
path = lines[0].strip().strip(':')
|
||||
return path
|
||||
|
||||
def _create_nix(self):
|
||||
for name in STYLES['NORMAL']:
|
||||
path = self._get_nix_font_path(self.font_name, name)
|
||||
if path is not None:
|
||||
self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
|
||||
break
|
||||
else:
|
||||
raise FontNotFound('No usable fonts named: "%s"' %
|
||||
self.font_name)
|
||||
for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
|
||||
for stylename in STYLES[style]:
|
||||
path = self._get_nix_font_path(self.font_name, stylename)
|
||||
if path is not None:
|
||||
self.fonts[style] = ImageFont.truetype(path, self.font_size)
|
||||
break
|
||||
else:
|
||||
if style == 'BOLDITALIC':
|
||||
self.fonts[style] = self.fonts['BOLD']
|
||||
else:
|
||||
self.fonts[style] = self.fonts['NORMAL']
|
||||
|
||||
def _lookup_win(self, key, basename, styles, fail=False):
|
||||
for suffix in ('', ' (TrueType)'):
|
||||
for style in styles:
|
||||
try:
|
||||
valname = '%s%s%s' % (basename, style and ' '+style, suffix)
|
||||
val, _ = _winreg.QueryValueEx(key, valname)
|
||||
return val
|
||||
except EnvironmentError:
|
||||
continue
|
||||
else:
|
||||
if fail:
|
||||
raise FontNotFound('Font %s (%s) not found in registry' %
|
||||
(basename, styles[0]))
|
||||
return None
|
||||
|
||||
def _create_win(self):
|
||||
try:
|
||||
key = _winreg.OpenKey(
|
||||
_winreg.HKEY_LOCAL_MACHINE,
|
||||
r'Software\Microsoft\Windows NT\CurrentVersion\Fonts')
|
||||
except EnvironmentError:
|
||||
try:
|
||||
key = _winreg.OpenKey(
|
||||
_winreg.HKEY_LOCAL_MACHINE,
|
||||
r'Software\Microsoft\Windows\CurrentVersion\Fonts')
|
||||
except EnvironmentError:
|
||||
raise FontNotFound('Can\'t open Windows font registry key')
|
||||
try:
|
||||
path = self._lookup_win(key, self.font_name, STYLES['NORMAL'], True)
|
||||
self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
|
||||
for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
|
||||
path = self._lookup_win(key, self.font_name, STYLES[style])
|
||||
if path:
|
||||
self.fonts[style] = ImageFont.truetype(path, self.font_size)
|
||||
else:
|
||||
if style == 'BOLDITALIC':
|
||||
self.fonts[style] = self.fonts['BOLD']
|
||||
else:
|
||||
self.fonts[style] = self.fonts['NORMAL']
|
||||
finally:
|
||||
_winreg.CloseKey(key)
|
||||
|
||||
def get_char_size(self):
|
||||
"""
|
||||
Get the character size.
|
||||
"""
|
||||
return self.fonts['NORMAL'].getsize('M')
|
||||
|
||||
def get_font(self, bold, oblique):
|
||||
"""
|
||||
Get the font based on bold and italic flags.
|
||||
"""
|
||||
if bold and oblique:
|
||||
return self.fonts['BOLDITALIC']
|
||||
elif bold:
|
||||
return self.fonts['BOLD']
|
||||
elif oblique:
|
||||
return self.fonts['ITALIC']
|
||||
else:
|
||||
return self.fonts['NORMAL']
|
||||
|
||||
|
||||
class ImageFormatter(Formatter):
|
||||
"""
|
||||
Create a PNG image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
`image_format`
|
||||
An image format to output to that is recognised by PIL, these include:
|
||||
|
||||
* "PNG" (default)
|
||||
* "JPEG"
|
||||
* "BMP"
|
||||
* "GIF"
|
||||
|
||||
`line_pad`
|
||||
The extra spacing (in pixels) between each line of text.
|
||||
|
||||
Default: 2
|
||||
|
||||
`font_name`
|
||||
The font name to be used as the base font from which others, such as
|
||||
bold and italic fonts will be generated. This really should be a
|
||||
monospace font to look sane.
|
||||
|
||||
Default: "Bitstream Vera Sans Mono"
|
||||
|
||||
`font_size`
|
||||
The font size in points to be used.
|
||||
|
||||
Default: 14
|
||||
|
||||
`image_pad`
|
||||
The padding, in pixels to be used at each edge of the resulting image.
|
||||
|
||||
Default: 10
|
||||
|
||||
`line_numbers`
|
||||
Whether line numbers should be shown: True/False
|
||||
|
||||
Default: True
|
||||
|
||||
`line_number_start`
|
||||
The line number of the first line.
|
||||
|
||||
Default: 1
|
||||
|
||||
`line_number_step`
|
||||
The step used when printing line numbers.
|
||||
|
||||
Default: 1
|
||||
|
||||
`line_number_bg`
|
||||
The background colour (in "#123456" format) of the line number bar, or
|
||||
None to use the style background color.
|
||||
|
||||
Default: "#eed"
|
||||
|
||||
`line_number_fg`
|
||||
The text color of the line numbers (in "#123456"-like format).
|
||||
|
||||
Default: "#886"
|
||||
|
||||
`line_number_chars`
|
||||
The number of columns of line numbers allowable in the line number
|
||||
margin.
|
||||
|
||||
Default: 2
|
||||
|
||||
`line_number_bold`
|
||||
Whether line numbers will be bold: True/False
|
||||
|
||||
Default: False
|
||||
|
||||
`line_number_italic`
|
||||
Whether line numbers will be italicized: True/False
|
||||
|
||||
Default: False
|
||||
|
||||
`line_number_separator`
|
||||
Whether a line will be drawn between the line number area and the
|
||||
source code area: True/False
|
||||
|
||||
Default: True
|
||||
|
||||
`line_number_pad`
|
||||
The horizontal padding (in pixels) between the line number margin, and
|
||||
the source code area.
|
||||
|
||||
Default: 6
|
||||
|
||||
`hl_lines`
|
||||
Specify a list of lines to be highlighted.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
|
||||
Default: empty list
|
||||
|
||||
`hl_color`
|
||||
Specify the color for highlighting lines.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
|
||||
Default: highlight color of the selected style
|
||||
"""
|
||||
|
||||
# Required by the pygments mapper
|
||||
name = 'img'
|
||||
aliases = ['img', 'IMG', 'png']
|
||||
filenames = ['*.png']
|
||||
|
||||
unicodeoutput = False
|
||||
|
||||
default_image_format = 'png'
|
||||
|
||||
def __init__(self, **options):
|
||||
"""
|
||||
See the class docstring for explanation of options.
|
||||
"""
|
||||
if not pil_available:
|
||||
raise PilNotAvailable(
|
||||
'Python Imaging Library is required for this formatter')
|
||||
Formatter.__init__(self, **options)
|
||||
self.encoding = 'latin1' # let pygments.format() do the right thing
|
||||
# Read the style
|
||||
self.styles = dict(self.style)
|
||||
if self.style.background_color is None:
|
||||
self.background_color = '#fff'
|
||||
else:
|
||||
self.background_color = self.style.background_color
|
||||
# Image options
|
||||
self.image_format = get_choice_opt(
|
||||
options, 'image_format', ['png', 'jpeg', 'gif', 'bmp'],
|
||||
self.default_image_format, normcase=True)
|
||||
self.image_pad = get_int_opt(options, 'image_pad', 10)
|
||||
self.line_pad = get_int_opt(options, 'line_pad', 2)
|
||||
# The fonts
|
||||
fontsize = get_int_opt(options, 'font_size', 14)
|
||||
self.fonts = FontManager(options.get('font_name', ''), fontsize)
|
||||
self.fontw, self.fonth = self.fonts.get_char_size()
|
||||
# Line number options
|
||||
self.line_number_fg = options.get('line_number_fg', '#886')
|
||||
self.line_number_bg = options.get('line_number_bg', '#eed')
|
||||
self.line_number_chars = get_int_opt(options,
|
||||
'line_number_chars', 2)
|
||||
self.line_number_bold = get_bool_opt(options,
|
||||
'line_number_bold', False)
|
||||
self.line_number_italic = get_bool_opt(options,
|
||||
'line_number_italic', False)
|
||||
self.line_number_pad = get_int_opt(options, 'line_number_pad', 6)
|
||||
self.line_numbers = get_bool_opt(options, 'line_numbers', True)
|
||||
self.line_number_separator = get_bool_opt(options,
|
||||
'line_number_separator', True)
|
||||
self.line_number_step = get_int_opt(options, 'line_number_step', 1)
|
||||
self.line_number_start = get_int_opt(options, 'line_number_start', 1)
|
||||
if self.line_numbers:
|
||||
self.line_number_width = (self.fontw * self.line_number_chars +
|
||||
self.line_number_pad * 2)
|
||||
else:
|
||||
self.line_number_width = 0
|
||||
self.hl_lines = []
|
||||
hl_lines_str = get_list_opt(options, 'hl_lines', [])
|
||||
for line in hl_lines_str:
|
||||
try:
|
||||
self.hl_lines.append(int(line))
|
||||
except ValueError:
|
||||
pass
|
||||
self.hl_color = options.get('hl_color',
|
||||
self.style.highlight_color) or '#f90'
|
||||
self.drawables = []
|
||||
|
||||
def get_style_defs(self, arg=''):
|
||||
raise NotImplementedError('The -S option is meaningless for the image '
|
||||
'formatter. Use -O style=<stylename> instead.')
|
||||
|
||||
def _get_line_height(self):
|
||||
"""
|
||||
Get the height of a line.
|
||||
"""
|
||||
return self.fonth + self.line_pad
|
||||
|
||||
def _get_line_y(self, lineno):
|
||||
"""
|
||||
Get the Y coordinate of a line number.
|
||||
"""
|
||||
return lineno * self._get_line_height() + self.image_pad
|
||||
|
||||
def _get_char_width(self):
|
||||
"""
|
||||
Get the width of a character.
|
||||
"""
|
||||
return self.fontw
|
||||
|
||||
def _get_char_x(self, charno):
|
||||
"""
|
||||
Get the X coordinate of a character position.
|
||||
"""
|
||||
return charno * self.fontw + self.image_pad + self.line_number_width
|
||||
|
||||
def _get_text_pos(self, charno, lineno):
|
||||
"""
|
||||
Get the actual position for a character and line position.
|
||||
"""
|
||||
return self._get_char_x(charno), self._get_line_y(lineno)
|
||||
|
||||
def _get_linenumber_pos(self, lineno):
|
||||
"""
|
||||
Get the actual position for the start of a line number.
|
||||
"""
|
||||
return (self.image_pad, self._get_line_y(lineno))
|
||||
|
||||
def _get_text_color(self, style):
|
||||
"""
|
||||
Get the correct color for the token from the style.
|
||||
"""
|
||||
if style['color'] is not None:
|
||||
fill = '#' + style['color']
|
||||
else:
|
||||
fill = '#000'
|
||||
return fill
|
||||
|
||||
def _get_style_font(self, style):
|
||||
"""
|
||||
Get the correct font for the style.
|
||||
"""
|
||||
return self.fonts.get_font(style['bold'], style['italic'])
|
||||
|
||||
def _get_image_size(self, maxcharno, maxlineno):
|
||||
"""
|
||||
Get the required image size.
|
||||
"""
|
||||
return (self._get_char_x(maxcharno) + self.image_pad,
|
||||
self._get_line_y(maxlineno + 0) + self.image_pad)
|
||||
|
||||
def _draw_linenumber(self, posno, lineno):
|
||||
"""
|
||||
Remember a line number drawable to paint later.
|
||||
"""
|
||||
self._draw_text(
|
||||
self._get_linenumber_pos(posno),
|
||||
str(lineno).rjust(self.line_number_chars),
|
||||
font=self.fonts.get_font(self.line_number_bold,
|
||||
self.line_number_italic),
|
||||
fill=self.line_number_fg,
|
||||
)
|
||||
|
||||
def _draw_text(self, pos, text, font, **kw):
|
||||
"""
|
||||
Remember a single drawable tuple to paint later.
|
||||
"""
|
||||
self.drawables.append((pos, text, font, kw))
|
||||
|
||||
def _create_drawables(self, tokensource):
|
||||
"""
|
||||
Create drawables for the token content.
|
||||
"""
|
||||
lineno = charno = maxcharno = 0
|
||||
for ttype, value in tokensource:
|
||||
while ttype not in self.styles:
|
||||
ttype = ttype.parent
|
||||
style = self.styles[ttype]
|
||||
# TODO: make sure tab expansion happens earlier in the chain. It
|
||||
# really ought to be done on the input, as to do it right here is
|
||||
# quite complex.
|
||||
value = value.expandtabs(4)
|
||||
lines = value.splitlines(True)
|
||||
# print lines
|
||||
for i, line in enumerate(lines):
|
||||
temp = line.rstrip('\n')
|
||||
if temp:
|
||||
self._draw_text(
|
||||
self._get_text_pos(charno, lineno),
|
||||
temp,
|
||||
font = self._get_style_font(style),
|
||||
fill = self._get_text_color(style)
|
||||
)
|
||||
charno += len(temp)
|
||||
maxcharno = max(maxcharno, charno)
|
||||
if line.endswith('\n'):
|
||||
# add a line for each extra line in the value
|
||||
charno = 0
|
||||
lineno += 1
|
||||
self.maxcharno = maxcharno
|
||||
self.maxlineno = lineno
|
||||
|
||||
def _draw_line_numbers(self):
|
||||
"""
|
||||
Create drawables for the line numbers.
|
||||
"""
|
||||
if not self.line_numbers:
|
||||
return
|
||||
for p in xrange(self.maxlineno):
|
||||
n = p + self.line_number_start
|
||||
if (n % self.line_number_step) == 0:
|
||||
self._draw_linenumber(p, n)
|
||||
|
||||
def _paint_line_number_bg(self, im):
|
||||
"""
|
||||
Paint the line number background on the image.
|
||||
"""
|
||||
if not self.line_numbers:
|
||||
return
|
||||
if self.line_number_fg is None:
|
||||
return
|
||||
draw = ImageDraw.Draw(im)
|
||||
recth = im.size[-1]
|
||||
rectw = self.image_pad + self.line_number_width - self.line_number_pad
|
||||
draw.rectangle([(0, 0), (rectw, recth)],
|
||||
fill=self.line_number_bg)
|
||||
draw.line([(rectw, 0), (rectw, recth)], fill=self.line_number_fg)
|
||||
del draw
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
"""
|
||||
Format ``tokensource``, an iterable of ``(tokentype, tokenstring)``
|
||||
tuples and write it into ``outfile``.
|
||||
|
||||
This implementation calculates where it should draw each token on the
|
||||
pixmap, then calculates the required pixmap size and draws the items.
|
||||
"""
|
||||
self._create_drawables(tokensource)
|
||||
self._draw_line_numbers()
|
||||
im = Image.new(
|
||||
'RGB',
|
||||
self._get_image_size(self.maxcharno, self.maxlineno),
|
||||
self.background_color
|
||||
)
|
||||
self._paint_line_number_bg(im)
|
||||
draw = ImageDraw.Draw(im)
|
||||
# Highlight
|
||||
if self.hl_lines:
|
||||
x = self.image_pad + self.line_number_width - self.line_number_pad + 1
|
||||
recth = self._get_line_height()
|
||||
rectw = im.size[0] - x
|
||||
for linenumber in self.hl_lines:
|
||||
y = self._get_line_y(linenumber - 1)
|
||||
draw.rectangle([(x, y), (x + rectw, y + recth)],
|
||||
fill=self.hl_color)
|
||||
for pos, value, font, kw in self.drawables:
|
||||
draw.text(pos, value, font=font, **kw)
|
||||
im.save(outfile, self.image_format.upper())
|
||||
|
||||
|
||||
# Add one formatter per format, so that the "-f gif" option gives the correct result
|
||||
# when used in pygmentize.
|
||||
|
||||
class GifImageFormatter(ImageFormatter):
|
||||
"""
|
||||
Create a GIF image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'img_gif'
|
||||
aliases = ['gif']
|
||||
filenames = ['*.gif']
|
||||
default_image_format = 'gif'
|
||||
|
||||
|
||||
class JpgImageFormatter(ImageFormatter):
|
||||
"""
|
||||
Create a JPEG image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'img_jpg'
|
||||
aliases = ['jpg', 'jpeg']
|
||||
filenames = ['*.jpg']
|
||||
default_image_format = 'jpeg'
|
||||
|
||||
|
||||
class BmpImageFormatter(ImageFormatter):
|
||||
"""
|
||||
Create a bitmap image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'img_bmp'
|
||||
aliases = ['bmp', 'bitmap']
|
||||
filenames = ['*.bmp']
|
||||
default_image_format = 'bmp'
|
||||
@ -1,160 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters.other
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Other formatters: NullFormatter, RawTokenFormatter.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.util import OptionError, get_choice_opt
|
||||
from pygments.token import Token
|
||||
from pygments.console import colorize
|
||||
|
||||
__all__ = ['NullFormatter', 'RawTokenFormatter', 'TestcaseFormatter']
|
||||
|
||||
|
||||
class NullFormatter(Formatter):
|
||||
"""
|
||||
Output the text unchanged without any formatting.
|
||||
"""
|
||||
name = 'Text only'
|
||||
aliases = ['text', 'null']
|
||||
filenames = ['*.txt']
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
enc = self.encoding
|
||||
for ttype, value in tokensource:
|
||||
if enc:
|
||||
outfile.write(value.encode(enc))
|
||||
else:
|
||||
outfile.write(value)
|
||||
|
||||
|
||||
class RawTokenFormatter(Formatter):
|
||||
r"""
|
||||
Format tokens as a raw representation for storing token streams.
|
||||
|
||||
The format is ``tokentype<TAB>repr(tokenstring)\n``. The output can later
|
||||
be converted to a token stream with the `RawTokenLexer`, described in the
|
||||
:doc:`lexer list <lexers>`.
|
||||
|
||||
Only two options are accepted:
|
||||
|
||||
`compress`
|
||||
If set to ``'gz'`` or ``'bz2'``, compress the output with the given
|
||||
compression algorithm after encoding (default: ``''``).
|
||||
`error_color`
|
||||
If set to a color name, highlight error tokens using that color. If
|
||||
set but with no value, defaults to ``'red'``.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
|
||||
"""
|
||||
name = 'Raw tokens'
|
||||
aliases = ['raw', 'tokens']
|
||||
filenames = ['*.raw']
|
||||
|
||||
unicodeoutput = False
|
||||
|
||||
def __init__(self, **options):
|
||||
Formatter.__init__(self, **options)
|
||||
# We ignore self.encoding if it is set, since it gets set for lexer
|
||||
# and formatter if given with -Oencoding on the command line.
|
||||
# The RawTokenFormatter outputs only ASCII. Override here.
|
||||
self.encoding = 'ascii' # let pygments.format() do the right thing
|
||||
self.compress = get_choice_opt(options, 'compress',
|
||||
['', 'none', 'gz', 'bz2'], '')
|
||||
self.error_color = options.get('error_color', None)
|
||||
if self.error_color is True:
|
||||
self.error_color = 'red'
|
||||
if self.error_color is not None:
|
||||
try:
|
||||
colorize(self.error_color, '')
|
||||
except KeyError:
|
||||
raise ValueError("Invalid color %r specified" %
|
||||
self.error_color)
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
try:
|
||||
outfile.write(b'')
|
||||
except TypeError:
|
||||
raise TypeError('The raw tokens formatter needs a binary '
|
||||
'output file')
|
||||
if self.compress == 'gz':
|
||||
import gzip
|
||||
outfile = gzip.GzipFile('', 'wb', 9, outfile)
|
||||
def write(text):
|
||||
outfile.write(text.encode())
|
||||
flush = outfile.flush
|
||||
elif self.compress == 'bz2':
|
||||
import bz2
|
||||
compressor = bz2.BZ2Compressor(9)
|
||||
def write(text):
|
||||
outfile.write(compressor.compress(text.encode()))
|
||||
def flush():
|
||||
outfile.write(compressor.flush())
|
||||
outfile.flush()
|
||||
else:
|
||||
def write(text):
|
||||
outfile.write(text.encode())
|
||||
flush = outfile.flush
|
||||
|
||||
if self.error_color:
|
||||
for ttype, value in tokensource:
|
||||
line = "%s\t%r\n" % (ttype, value)
|
||||
if ttype is Token.Error:
|
||||
write(colorize(self.error_color, line))
|
||||
else:
|
||||
write(line)
|
||||
else:
|
||||
for ttype, value in tokensource:
|
||||
write("%s\t%r\n" % (ttype, value))
|
||||
flush()
|
||||
|
||||
TESTCASE_BEFORE = u'''\
|
||||
def testNeedsName(self):
|
||||
fragment = %r
|
||||
tokens = [
|
||||
'''
|
||||
TESTCASE_AFTER = u'''\
|
||||
]
|
||||
self.assertEqual(tokens, list(self.lexer.get_tokens(fragment)))
|
||||
'''
|
||||
|
||||
|
||||
class TestcaseFormatter(Formatter):
|
||||
"""
|
||||
Format tokens as appropriate for a new testcase.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Testcase'
|
||||
aliases = ['testcase']
|
||||
|
||||
def __init__(self, **options):
|
||||
Formatter.__init__(self, **options)
|
||||
if self.encoding is not None and self.encoding != 'utf-8':
|
||||
raise ValueError("Only None and utf-8 are allowed encodings.")
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
indentation = ' ' * 12
|
||||
rawbuf = []
|
||||
outbuf = []
|
||||
for ttype, value in tokensource:
|
||||
rawbuf.append(value)
|
||||
outbuf.append('%s(%s, %r),\n' % (indentation, ttype, value))
|
||||
|
||||
before = TESTCASE_BEFORE % (u''.join(rawbuf),)
|
||||
during = u''.join(outbuf)
|
||||
after = TESTCASE_AFTER
|
||||
if self.encoding is None:
|
||||
outfile.write(before + during + after)
|
||||
else:
|
||||
outfile.write(before.encode('utf-8'))
|
||||
outfile.write(during.encode('utf-8'))
|
||||
outfile.write(after.encode('utf-8'))
|
||||
outfile.flush()
|
||||
@ -1,147 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters.rtf
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
A formatter that generates RTF files.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.util import get_int_opt, _surrogatepair
|
||||
|
||||
|
||||
__all__ = ['RtfFormatter']
|
||||
|
||||
|
||||
class RtfFormatter(Formatter):
|
||||
"""
|
||||
Format tokens as RTF markup. This formatter automatically outputs full RTF
|
||||
documents with color information and other useful stuff. Perfect for Copy and
|
||||
Paste into Microsoft(R) Word(R) documents.
|
||||
|
||||
Please note that ``encoding`` and ``outencoding`` options are ignored.
|
||||
The RTF format is ASCII natively, but handles unicode characters correctly
|
||||
thanks to escape sequences.
|
||||
|
||||
.. versionadded:: 0.6
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
`style`
|
||||
The style to use, can be a string or a Style subclass (default:
|
||||
``'default'``).
|
||||
|
||||
`fontface`
|
||||
The used font famliy, for example ``Bitstream Vera Sans``. Defaults to
|
||||
some generic font which is supposed to have fixed width.
|
||||
|
||||
`fontsize`
|
||||
Size of the font used. Size is specified in half points. The
|
||||
default is 24 half-points, giving a size 12 font.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'RTF'
|
||||
aliases = ['rtf']
|
||||
filenames = ['*.rtf']
|
||||
|
||||
def __init__(self, **options):
|
||||
r"""
|
||||
Additional options accepted:
|
||||
|
||||
``fontface``
|
||||
Name of the font used. Could for example be ``'Courier New'``
|
||||
to further specify the default which is ``'\fmodern'``. The RTF
|
||||
specification claims that ``\fmodern`` are "Fixed-pitch serif
|
||||
and sans serif fonts". Hope every RTF implementation thinks
|
||||
the same about modern...
|
||||
|
||||
"""
|
||||
Formatter.__init__(self, **options)
|
||||
self.fontface = options.get('fontface') or ''
|
||||
self.fontsize = get_int_opt(options, 'fontsize', 0)
|
||||
|
||||
def _escape(self, text):
|
||||
return text.replace(u'\\', u'\\\\') \
|
||||
.replace(u'{', u'\\{') \
|
||||
.replace(u'}', u'\\}')
|
||||
|
||||
def _escape_text(self, text):
|
||||
# empty strings, should give a small performance improvment
|
||||
if not text:
|
||||
return u''
|
||||
|
||||
# escape text
|
||||
text = self._escape(text)
|
||||
|
||||
buf = []
|
||||
for c in text:
|
||||
cn = ord(c)
|
||||
if cn < (2**7):
|
||||
# ASCII character
|
||||
buf.append(str(c))
|
||||
elif (2**7) <= cn < (2**16):
|
||||
# single unicode escape sequence
|
||||
buf.append(u'{\\u%d}' % cn)
|
||||
elif (2**16) <= cn:
|
||||
# RTF limits unicode to 16 bits.
|
||||
# Force surrogate pairs
|
||||
buf.append(u'{\\u%d}{\\u%d}' % _surrogatepair(cn))
|
||||
|
||||
return u''.join(buf).replace(u'\n', u'\\par\n')
|
||||
|
||||
def format_unencoded(self, tokensource, outfile):
|
||||
# rtf 1.8 header
|
||||
outfile.write(u'{\\rtf1\\ansi\\uc0\\deff0'
|
||||
u'{\\fonttbl{\\f0\\fmodern\\fprq1\\fcharset0%s;}}'
|
||||
u'{\\colortbl;' % (self.fontface and
|
||||
u' ' + self._escape(self.fontface) or
|
||||
u''))
|
||||
|
||||
# convert colors and save them in a mapping to access them later.
|
||||
color_mapping = {}
|
||||
offset = 1
|
||||
for _, style in self.style:
|
||||
for color in style['color'], style['bgcolor'], style['border']:
|
||||
if color and color not in color_mapping:
|
||||
color_mapping[color] = offset
|
||||
outfile.write(u'\\red%d\\green%d\\blue%d;' % (
|
||||
int(color[0:2], 16),
|
||||
int(color[2:4], 16),
|
||||
int(color[4:6], 16)
|
||||
))
|
||||
offset += 1
|
||||
outfile.write(u'}\\f0 ')
|
||||
if self.fontsize:
|
||||
outfile.write(u'\\fs%d' % (self.fontsize))
|
||||
|
||||
# highlight stream
|
||||
for ttype, value in tokensource:
|
||||
while not self.style.styles_token(ttype) and ttype.parent:
|
||||
ttype = ttype.parent
|
||||
style = self.style.style_for_token(ttype)
|
||||
buf = []
|
||||
if style['bgcolor']:
|
||||
buf.append(u'\\cb%d' % color_mapping[style['bgcolor']])
|
||||
if style['color']:
|
||||
buf.append(u'\\cf%d' % color_mapping[style['color']])
|
||||
if style['bold']:
|
||||
buf.append(u'\\b')
|
||||
if style['italic']:
|
||||
buf.append(u'\\i')
|
||||
if style['underline']:
|
||||
buf.append(u'\\ul')
|
||||
if style['border']:
|
||||
buf.append(u'\\chbrdr\\chcfpat%d' %
|
||||
color_mapping[style['border']])
|
||||
start = u''.join(buf)
|
||||
if start:
|
||||
outfile.write(u'{%s ' % start)
|
||||
outfile.write(self._escape_text(value))
|
||||
if start:
|
||||
outfile.write(u'}')
|
||||
|
||||
outfile.write(u'}')
|
||||
@ -1,223 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters.terminal256
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter for 256-color terminal output with ANSI sequences.
|
||||
|
||||
RGB-to-XTERM color conversion routines adapted from xterm256-conv
|
||||
tool (http://frexx.de/xterm-256-notes/data/xterm256-conv2.tar.bz2)
|
||||
by Wolfgang Frisch.
|
||||
|
||||
Formatter version 1.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
# TODO:
|
||||
# - Options to map style's bold/underline/italic/border attributes
|
||||
# to some ANSI attrbutes (something like 'italic=underline')
|
||||
# - An option to output "style RGB to xterm RGB/index" conversion table
|
||||
# - An option to indicate that we are running in "reverse background"
|
||||
# xterm. This means that default colors are white-on-black, not
|
||||
# black-on-while, so colors like "white background" need to be converted
|
||||
# to "white background, black foreground", etc...
|
||||
|
||||
import sys
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
|
||||
|
||||
__all__ = ['Terminal256Formatter']
|
||||
|
||||
|
||||
class EscapeSequence:
|
||||
def __init__(self, fg=None, bg=None, bold=False, underline=False):
|
||||
self.fg = fg
|
||||
self.bg = bg
|
||||
self.bold = bold
|
||||
self.underline = underline
|
||||
|
||||
def escape(self, attrs):
|
||||
if len(attrs):
|
||||
return "\x1b[" + ";".join(attrs) + "m"
|
||||
return ""
|
||||
|
||||
def color_string(self):
|
||||
attrs = []
|
||||
if self.fg is not None:
|
||||
attrs.extend(("38", "5", "%i" % self.fg))
|
||||
if self.bg is not None:
|
||||
attrs.extend(("48", "5", "%i" % self.bg))
|
||||
if self.bold:
|
||||
attrs.append("01")
|
||||
if self.underline:
|
||||
attrs.append("04")
|
||||
return self.escape(attrs)
|
||||
|
||||
def reset_string(self):
|
||||
attrs = []
|
||||
if self.fg is not None:
|
||||
attrs.append("39")
|
||||
if self.bg is not None:
|
||||
attrs.append("49")
|
||||
if self.bold or self.underline:
|
||||
attrs.append("00")
|
||||
return self.escape(attrs)
|
||||
|
||||
|
||||
class Terminal256Formatter(Formatter):
|
||||
r"""
|
||||
Format tokens with ANSI color sequences, for output in a 256-color
|
||||
terminal or console. Like in `TerminalFormatter` color sequences
|
||||
are terminated at newlines, so that paging the output works correctly.
|
||||
|
||||
The formatter takes colors from a style defined by the `style` option
|
||||
and converts them to nearest ANSI 256-color escape sequences. Bold and
|
||||
underline attributes from the style are preserved (and displayed).
|
||||
|
||||
.. versionadded:: 0.9
|
||||
|
||||
Options accepted:
|
||||
|
||||
`style`
|
||||
The style to use, can be a string or a Style subclass (default:
|
||||
``'default'``).
|
||||
"""
|
||||
name = 'Terminal256'
|
||||
aliases = ['terminal256', 'console256', '256']
|
||||
filenames = []
|
||||
|
||||
def __init__(self, **options):
|
||||
Formatter.__init__(self, **options)
|
||||
|
||||
self.xterm_colors = []
|
||||
self.best_match = {}
|
||||
self.style_string = {}
|
||||
|
||||
self.usebold = 'nobold' not in options
|
||||
self.useunderline = 'nounderline' not in options
|
||||
|
||||
self._build_color_table() # build an RGB-to-256 color conversion table
|
||||
self._setup_styles() # convert selected style's colors to term. colors
|
||||
|
||||
def _build_color_table(self):
|
||||
# colors 0..15: 16 basic colors
|
||||
|
||||
self.xterm_colors.append((0x00, 0x00, 0x00)) # 0
|
||||
self.xterm_colors.append((0xcd, 0x00, 0x00)) # 1
|
||||
self.xterm_colors.append((0x00, 0xcd, 0x00)) # 2
|
||||
self.xterm_colors.append((0xcd, 0xcd, 0x00)) # 3
|
||||
self.xterm_colors.append((0x00, 0x00, 0xee)) # 4
|
||||
self.xterm_colors.append((0xcd, 0x00, 0xcd)) # 5
|
||||
self.xterm_colors.append((0x00, 0xcd, 0xcd)) # 6
|
||||
self.xterm_colors.append((0xe5, 0xe5, 0xe5)) # 7
|
||||
self.xterm_colors.append((0x7f, 0x7f, 0x7f)) # 8
|
||||
self.xterm_colors.append((0xff, 0x00, 0x00)) # 9
|
||||
self.xterm_colors.append((0x00, 0xff, 0x00)) # 10
|
||||
self.xterm_colors.append((0xff, 0xff, 0x00)) # 11
|
||||
self.xterm_colors.append((0x5c, 0x5c, 0xff)) # 12
|
||||
self.xterm_colors.append((0xff, 0x00, 0xff)) # 13
|
||||
self.xterm_colors.append((0x00, 0xff, 0xff)) # 14
|
||||
self.xterm_colors.append((0xff, 0xff, 0xff)) # 15
|
||||
|
||||
# colors 16..232: the 6x6x6 color cube
|
||||
|
||||
valuerange = (0x00, 0x5f, 0x87, 0xaf, 0xd7, 0xff)
|
||||
|
||||
for i in range(217):
|
||||
r = valuerange[(i // 36) % 6]
|
||||
g = valuerange[(i // 6) % 6]
|
||||
b = valuerange[i % 6]
|
||||
self.xterm_colors.append((r, g, b))
|
||||
|
||||
# colors 233..253: grayscale
|
||||
|
||||
for i in range(1, 22):
|
||||
v = 8 + i * 10
|
||||
self.xterm_colors.append((v, v, v))
|
||||
|
||||
def _closest_color(self, r, g, b):
|
||||
distance = 257*257*3 # "infinity" (>distance from #000000 to #ffffff)
|
||||
match = 0
|
||||
|
||||
for i in range(0, 254):
|
||||
values = self.xterm_colors[i]
|
||||
|
||||
rd = r - values[0]
|
||||
gd = g - values[1]
|
||||
bd = b - values[2]
|
||||
d = rd*rd + gd*gd + bd*bd
|
||||
|
||||
if d < distance:
|
||||
match = i
|
||||
distance = d
|
||||
return match
|
||||
|
||||
def _color_index(self, color):
|
||||
index = self.best_match.get(color, None)
|
||||
if index is None:
|
||||
try:
|
||||
rgb = int(str(color), 16)
|
||||
except ValueError:
|
||||
rgb = 0
|
||||
|
||||
r = (rgb >> 16) & 0xff
|
||||
g = (rgb >> 8) & 0xff
|
||||
b = rgb & 0xff
|
||||
index = self._closest_color(r, g, b)
|
||||
self.best_match[color] = index
|
||||
return index
|
||||
|
||||
def _setup_styles(self):
|
||||
for ttype, ndef in self.style:
|
||||
escape = EscapeSequence()
|
||||
if ndef['color']:
|
||||
escape.fg = self._color_index(ndef['color'])
|
||||
if ndef['bgcolor']:
|
||||
escape.bg = self._color_index(ndef['bgcolor'])
|
||||
if self.usebold and ndef['bold']:
|
||||
escape.bold = True
|
||||
if self.useunderline and ndef['underline']:
|
||||
escape.underline = True
|
||||
self.style_string[str(ttype)] = (escape.color_string(),
|
||||
escape.reset_string())
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
# hack: if the output is a terminal and has an encoding set,
|
||||
# use that to avoid unicode encode problems
|
||||
if not self.encoding and hasattr(outfile, "encoding") and \
|
||||
hasattr(outfile, "isatty") and outfile.isatty() and \
|
||||
sys.version_info < (3,):
|
||||
self.encoding = outfile.encoding
|
||||
return Formatter.format(self, tokensource, outfile)
|
||||
|
||||
def format_unencoded(self, tokensource, outfile):
|
||||
for ttype, value in tokensource:
|
||||
not_found = True
|
||||
while ttype and not_found:
|
||||
try:
|
||||
# outfile.write( "<" + str(ttype) + ">" )
|
||||
on, off = self.style_string[str(ttype)]
|
||||
|
||||
# Like TerminalFormatter, add "reset colors" escape sequence
|
||||
# on newline.
|
||||
spl = value.split('\n')
|
||||
for line in spl[:-1]:
|
||||
if line:
|
||||
outfile.write(on + line + off)
|
||||
outfile.write('\n')
|
||||
if spl[-1]:
|
||||
outfile.write(on + spl[-1] + off)
|
||||
|
||||
not_found = False
|
||||
# outfile.write( '#' + str(ttype) + '#' )
|
||||
|
||||
except KeyError:
|
||||
# ottype = ttype
|
||||
ttype = ttype[:-1]
|
||||
# outfile.write( '!' + str(ottype) + '->' + str(ttype) + '!' )
|
||||
|
||||
if not_found:
|
||||
outfile.write(value)
|
||||
@ -1,273 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
Pygments lexers.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import sys
|
||||
import types
|
||||
import fnmatch
|
||||
from os.path import basename
|
||||
|
||||
from pygments.lexers._mapping import LEXERS
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
from pygments.plugin import find_plugin_lexers
|
||||
from pygments.util import ClassNotFound, itervalues, guess_decode
|
||||
|
||||
|
||||
__all__ = ['get_lexer_by_name', 'get_lexer_for_filename', 'find_lexer_class',
|
||||
'guess_lexer'] + list(LEXERS)
|
||||
|
||||
_lexer_cache = {}
|
||||
_pattern_cache = {}
|
||||
|
||||
|
||||
def _fn_matches(fn, glob):
|
||||
"""Return whether the supplied file name fn matches pattern filename."""
|
||||
if glob not in _pattern_cache:
|
||||
pattern = _pattern_cache[glob] = re.compile(fnmatch.translate(glob))
|
||||
return pattern.match(fn)
|
||||
return _pattern_cache[glob].match(fn)
|
||||
|
||||
|
||||
def _load_lexers(module_name):
|
||||
"""Load a lexer (and all others in the module too)."""
|
||||
mod = __import__(module_name, None, None, ['__all__'])
|
||||
for lexer_name in mod.__all__:
|
||||
cls = getattr(mod, lexer_name)
|
||||
_lexer_cache[cls.name] = cls
|
||||
|
||||
|
||||
def get_all_lexers():
|
||||
"""Return a generator of tuples in the form ``(name, aliases,
|
||||
filenames, mimetypes)`` of all know lexers.
|
||||
"""
|
||||
for item in itervalues(LEXERS):
|
||||
yield item[1:]
|
||||
for lexer in find_plugin_lexers():
|
||||
yield lexer.name, lexer.aliases, lexer.filenames, lexer.mimetypes
|
||||
|
||||
|
||||
def find_lexer_class(name):
|
||||
"""Lookup a lexer class by name.
|
||||
|
||||
Return None if not found.
|
||||
"""
|
||||
if name in _lexer_cache:
|
||||
return _lexer_cache[name]
|
||||
# lookup builtin lexers
|
||||
for module_name, lname, aliases, _, _ in itervalues(LEXERS):
|
||||
if name == lname:
|
||||
_load_lexers(module_name)
|
||||
return _lexer_cache[name]
|
||||
# continue with lexers from setuptools entrypoints
|
||||
for cls in find_plugin_lexers():
|
||||
if cls.name == name:
|
||||
return cls
|
||||
|
||||
|
||||
def get_lexer_by_name(_alias, **options):
|
||||
"""Get a lexer by an alias.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
if not _alias:
|
||||
raise ClassNotFound('no lexer for alias %r found' % _alias)
|
||||
|
||||
# lookup builtin lexers
|
||||
for module_name, name, aliases, _, _ in itervalues(LEXERS):
|
||||
if _alias.lower() in aliases:
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(module_name)
|
||||
return _lexer_cache[name](**options)
|
||||
# continue with lexers from setuptools entrypoints
|
||||
for cls in find_plugin_lexers():
|
||||
if _alias in cls.aliases:
|
||||
return cls(**options)
|
||||
raise ClassNotFound('no lexer for alias %r found' % _alias)
|
||||
|
||||
|
||||
def find_lexer_class_for_filename(_fn, code=None):
|
||||
"""Get a lexer for a filename.
|
||||
|
||||
If multiple lexers match the filename pattern, use ``analyse_text()`` to
|
||||
figure out which one is more appropriate.
|
||||
|
||||
Returns None if not found.
|
||||
"""
|
||||
matches = []
|
||||
fn = basename(_fn)
|
||||
for modname, name, _, filenames, _ in itervalues(LEXERS):
|
||||
for filename in filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(modname)
|
||||
matches.append((_lexer_cache[name], filename))
|
||||
for cls in find_plugin_lexers():
|
||||
for filename in cls.filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
matches.append((cls, filename))
|
||||
|
||||
if sys.version_info > (3,) and isinstance(code, bytes):
|
||||
# decode it, since all analyse_text functions expect unicode
|
||||
code = guess_decode(code)
|
||||
|
||||
def get_rating(info):
|
||||
cls, filename = info
|
||||
# explicit patterns get a bonus
|
||||
bonus = '*' not in filename and 0.5 or 0
|
||||
# The class _always_ defines analyse_text because it's included in
|
||||
# the Lexer class. The default implementation returns None which
|
||||
# gets turned into 0.0. Run scripts/detect_missing_analyse_text.py
|
||||
# to find lexers which need it overridden.
|
||||
if code:
|
||||
return cls.analyse_text(code) + bonus
|
||||
return cls.priority + bonus
|
||||
|
||||
if matches:
|
||||
matches.sort(key=get_rating)
|
||||
# print "Possible lexers, after sort:", matches
|
||||
return matches[-1][0]
|
||||
|
||||
|
||||
def get_lexer_for_filename(_fn, code=None, **options):
|
||||
"""Get a lexer for a filename.
|
||||
|
||||
If multiple lexers match the filename pattern, use ``analyse_text()`` to
|
||||
figure out which one is more appropriate.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
res = find_lexer_class_for_filename(_fn, code)
|
||||
if not res:
|
||||
raise ClassNotFound('no lexer for filename %r found' % _fn)
|
||||
return res(**options)
|
||||
|
||||
|
||||
def get_lexer_for_mimetype(_mime, **options):
|
||||
"""Get a lexer for a mimetype.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
for modname, name, _, _, mimetypes in itervalues(LEXERS):
|
||||
if _mime in mimetypes:
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(modname)
|
||||
return _lexer_cache[name](**options)
|
||||
for cls in find_plugin_lexers():
|
||||
if _mime in cls.mimetypes:
|
||||
return cls(**options)
|
||||
raise ClassNotFound('no lexer for mimetype %r found' % _mime)
|
||||
|
||||
|
||||
def _iter_lexerclasses(plugins=True):
|
||||
"""Return an iterator over all lexer classes."""
|
||||
for key in sorted(LEXERS):
|
||||
module_name, name = LEXERS[key][:2]
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(module_name)
|
||||
yield _lexer_cache[name]
|
||||
if plugins:
|
||||
for lexer in find_plugin_lexers():
|
||||
yield lexer
|
||||
|
||||
|
||||
def guess_lexer_for_filename(_fn, _text, **options):
|
||||
"""
|
||||
Lookup all lexers that handle those filenames primary (``filenames``)
|
||||
or secondary (``alias_filenames``). Then run a text analysis for those
|
||||
lexers and choose the best result.
|
||||
|
||||
usage::
|
||||
|
||||
>>> from pygments.lexers import guess_lexer_for_filename
|
||||
>>> guess_lexer_for_filename('hello.html', '<%= @foo %>')
|
||||
<pygments.lexers.templates.RhtmlLexer object at 0xb7d2f32c>
|
||||
>>> guess_lexer_for_filename('hello.html', '<h1>{{ title|e }}</h1>')
|
||||
<pygments.lexers.templates.HtmlDjangoLexer object at 0xb7d2f2ac>
|
||||
>>> guess_lexer_for_filename('style.css', 'a { color: <?= $link ?> }')
|
||||
<pygments.lexers.templates.CssPhpLexer object at 0xb7ba518c>
|
||||
"""
|
||||
fn = basename(_fn)
|
||||
primary = {}
|
||||
matching_lexers = set()
|
||||
for lexer in _iter_lexerclasses():
|
||||
for filename in lexer.filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
matching_lexers.add(lexer)
|
||||
primary[lexer] = True
|
||||
for filename in lexer.alias_filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
matching_lexers.add(lexer)
|
||||
primary[lexer] = False
|
||||
if not matching_lexers:
|
||||
raise ClassNotFound('no lexer for filename %r found' % fn)
|
||||
if len(matching_lexers) == 1:
|
||||
return matching_lexers.pop()(**options)
|
||||
result = []
|
||||
for lexer in matching_lexers:
|
||||
rv = lexer.analyse_text(_text)
|
||||
if rv == 1.0:
|
||||
return lexer(**options)
|
||||
result.append((rv, lexer))
|
||||
|
||||
def type_sort(t):
|
||||
# sort by:
|
||||
# - analyse score
|
||||
# - is primary filename pattern?
|
||||
# - priority
|
||||
# - last resort: class name
|
||||
return (t[0], primary[t[1]], t[1].priority, t[1].__name__)
|
||||
result.sort(key=type_sort)
|
||||
|
||||
return result[-1][1](**options)
|
||||
|
||||
|
||||
def guess_lexer(_text, **options):
|
||||
"""Guess a lexer by strong distinctions in the text (eg, shebang)."""
|
||||
|
||||
# try to get a vim modeline first
|
||||
ft = get_filetype_from_buffer(_text)
|
||||
|
||||
if ft is not None:
|
||||
try:
|
||||
return get_lexer_by_name(ft, **options)
|
||||
except ClassNotFound:
|
||||
pass
|
||||
|
||||
best_lexer = [0.0, None]
|
||||
for lexer in _iter_lexerclasses():
|
||||
rv = lexer.analyse_text(_text)
|
||||
if rv == 1.0:
|
||||
return lexer(**options)
|
||||
if rv > best_lexer[0]:
|
||||
best_lexer[:] = (rv, lexer)
|
||||
if not best_lexer[0] or best_lexer[1] is None:
|
||||
raise ClassNotFound('no lexer matching the text found')
|
||||
return best_lexer[1](**options)
|
||||
|
||||
|
||||
class _automodule(types.ModuleType):
|
||||
"""Automatically import lexers."""
|
||||
|
||||
def __getattr__(self, name):
|
||||
info = LEXERS.get(name)
|
||||
if info:
|
||||
_load_lexers(info[0])
|
||||
cls = _lexer_cache[info[1]]
|
||||
setattr(self, name, cls)
|
||||
return cls
|
||||
raise AttributeError(name)
|
||||
|
||||
|
||||
oldmod = sys.modules[__name__]
|
||||
newmod = _automodule(__name__)
|
||||
newmod.__dict__.update(oldmod.__dict__)
|
||||
sys.modules[__name__] = newmod
|
||||
del newmod.newmod, newmod.oldmod, newmod.sys, newmod.types
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because one or more lines are too long
@ -1,250 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._lua_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This file contains the names and modules of lua functions
|
||||
It is able to re-generate itself, but for adding new functions you
|
||||
probably have to add some callbacks (see function module_callbacks).
|
||||
|
||||
Do not edit the MODULES dict by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
|
||||
MODULES = {'basic': ('_G',
|
||||
'_VERSION',
|
||||
'assert',
|
||||
'collectgarbage',
|
||||
'dofile',
|
||||
'error',
|
||||
'getfenv',
|
||||
'getmetatable',
|
||||
'ipairs',
|
||||
'load',
|
||||
'loadfile',
|
||||
'loadstring',
|
||||
'next',
|
||||
'pairs',
|
||||
'pcall',
|
||||
'print',
|
||||
'rawequal',
|
||||
'rawget',
|
||||
'rawset',
|
||||
'select',
|
||||
'setfenv',
|
||||
'setmetatable',
|
||||
'tonumber',
|
||||
'tostring',
|
||||
'type',
|
||||
'unpack',
|
||||
'xpcall'),
|
||||
'coroutine': ('coroutine.create',
|
||||
'coroutine.resume',
|
||||
'coroutine.running',
|
||||
'coroutine.status',
|
||||
'coroutine.wrap',
|
||||
'coroutine.yield'),
|
||||
'debug': ('debug.debug',
|
||||
'debug.getfenv',
|
||||
'debug.gethook',
|
||||
'debug.getinfo',
|
||||
'debug.getlocal',
|
||||
'debug.getmetatable',
|
||||
'debug.getregistry',
|
||||
'debug.getupvalue',
|
||||
'debug.setfenv',
|
||||
'debug.sethook',
|
||||
'debug.setlocal',
|
||||
'debug.setmetatable',
|
||||
'debug.setupvalue',
|
||||
'debug.traceback'),
|
||||
'io': ('io.close',
|
||||
'io.flush',
|
||||
'io.input',
|
||||
'io.lines',
|
||||
'io.open',
|
||||
'io.output',
|
||||
'io.popen',
|
||||
'io.read',
|
||||
'io.tmpfile',
|
||||
'io.type',
|
||||
'io.write'),
|
||||
'math': ('math.abs',
|
||||
'math.acos',
|
||||
'math.asin',
|
||||
'math.atan2',
|
||||
'math.atan',
|
||||
'math.ceil',
|
||||
'math.cosh',
|
||||
'math.cos',
|
||||
'math.deg',
|
||||
'math.exp',
|
||||
'math.floor',
|
||||
'math.fmod',
|
||||
'math.frexp',
|
||||
'math.huge',
|
||||
'math.ldexp',
|
||||
'math.log10',
|
||||
'math.log',
|
||||
'math.max',
|
||||
'math.min',
|
||||
'math.modf',
|
||||
'math.pi',
|
||||
'math.pow',
|
||||
'math.rad',
|
||||
'math.random',
|
||||
'math.randomseed',
|
||||
'math.sinh',
|
||||
'math.sin',
|
||||
'math.sqrt',
|
||||
'math.tanh',
|
||||
'math.tan'),
|
||||
'modules': ('module',
|
||||
'require',
|
||||
'package.cpath',
|
||||
'package.loaded',
|
||||
'package.loadlib',
|
||||
'package.path',
|
||||
'package.preload',
|
||||
'package.seeall'),
|
||||
'os': ('os.clock',
|
||||
'os.date',
|
||||
'os.difftime',
|
||||
'os.execute',
|
||||
'os.exit',
|
||||
'os.getenv',
|
||||
'os.remove',
|
||||
'os.rename',
|
||||
'os.setlocale',
|
||||
'os.time',
|
||||
'os.tmpname'),
|
||||
'string': ('string.byte',
|
||||
'string.char',
|
||||
'string.dump',
|
||||
'string.find',
|
||||
'string.format',
|
||||
'string.gmatch',
|
||||
'string.gsub',
|
||||
'string.len',
|
||||
'string.lower',
|
||||
'string.match',
|
||||
'string.rep',
|
||||
'string.reverse',
|
||||
'string.sub',
|
||||
'string.upper'),
|
||||
'table': ('table.concat',
|
||||
'table.insert',
|
||||
'table.maxn',
|
||||
'table.remove',
|
||||
'table.sort')}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import re
|
||||
try:
|
||||
from urllib import urlopen
|
||||
except ImportError:
|
||||
from urllib.request import urlopen
|
||||
import pprint
|
||||
|
||||
# you can't generally find out what module a function belongs to if you
|
||||
# have only its name. Because of this, here are some callback functions
|
||||
# that recognize if a gioven function belongs to a specific module
|
||||
def module_callbacks():
|
||||
def is_in_coroutine_module(name):
|
||||
return name.startswith('coroutine.')
|
||||
|
||||
def is_in_modules_module(name):
|
||||
if name in ['require', 'module'] or name.startswith('package'):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
def is_in_string_module(name):
|
||||
return name.startswith('string.')
|
||||
|
||||
def is_in_table_module(name):
|
||||
return name.startswith('table.')
|
||||
|
||||
def is_in_math_module(name):
|
||||
return name.startswith('math')
|
||||
|
||||
def is_in_io_module(name):
|
||||
return name.startswith('io.')
|
||||
|
||||
def is_in_os_module(name):
|
||||
return name.startswith('os.')
|
||||
|
||||
def is_in_debug_module(name):
|
||||
return name.startswith('debug.')
|
||||
|
||||
return {'coroutine': is_in_coroutine_module,
|
||||
'modules': is_in_modules_module,
|
||||
'string': is_in_string_module,
|
||||
'table': is_in_table_module,
|
||||
'math': is_in_math_module,
|
||||
'io': is_in_io_module,
|
||||
'os': is_in_os_module,
|
||||
'debug': is_in_debug_module}
|
||||
|
||||
|
||||
|
||||
def get_newest_version():
|
||||
f = urlopen('http://www.lua.org/manual/')
|
||||
r = re.compile(r'^<A HREF="(\d\.\d)/">Lua \1</A>')
|
||||
for line in f:
|
||||
m = r.match(line)
|
||||
if m is not None:
|
||||
return m.groups()[0]
|
||||
|
||||
def get_lua_functions(version):
|
||||
f = urlopen('http://www.lua.org/manual/%s/' % version)
|
||||
r = re.compile(r'^<A HREF="manual.html#pdf-(.+)">\1</A>')
|
||||
functions = []
|
||||
for line in f:
|
||||
m = r.match(line)
|
||||
if m is not None:
|
||||
functions.append(m.groups()[0])
|
||||
return functions
|
||||
|
||||
def get_function_module(name):
|
||||
for mod, cb in module_callbacks().items():
|
||||
if cb(name):
|
||||
return mod
|
||||
if '.' in name:
|
||||
return name.split('.')[0]
|
||||
else:
|
||||
return 'basic'
|
||||
|
||||
def regenerate(filename, modules):
|
||||
with open(filename) as fp:
|
||||
content = fp.read()
|
||||
|
||||
header = content[:content.find('MODULES = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
|
||||
with open(filename, 'w') as fp:
|
||||
fp.write(header)
|
||||
fp.write('MODULES = %s\n\n' % pprint.pformat(modules))
|
||||
fp.write(footer)
|
||||
|
||||
def run():
|
||||
version = get_newest_version()
|
||||
print('> Downloading function index for Lua %s' % version)
|
||||
functions = get_lua_functions(version)
|
||||
print('> %d functions found:' % len(functions))
|
||||
|
||||
modules = {}
|
||||
for full_function_name in functions:
|
||||
print('>> %s' % full_function_name)
|
||||
m = get_function_module(full_function_name)
|
||||
modules.setdefault(m, []).append(full_function_name)
|
||||
|
||||
regenerate(__file__, modules)
|
||||
|
||||
run()
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,240 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.actionscript
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for ActionScript and MXML.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, using, this, words, default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['ActionScriptLexer', 'ActionScript3Lexer', 'MxmlLexer']
|
||||
|
||||
|
||||
class ActionScriptLexer(RegexLexer):
|
||||
"""
|
||||
For ActionScript source code.
|
||||
|
||||
.. versionadded:: 0.9
|
||||
"""
|
||||
|
||||
name = 'ActionScript'
|
||||
aliases = ['as', 'actionscript']
|
||||
filenames = ['*.as']
|
||||
mimetypes = ['application/x-actionscript', 'text/x-actionscript',
|
||||
'text/actionscript']
|
||||
|
||||
flags = re.DOTALL
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'/(\\\\|\\/|[^/\n])*/[gim]*', String.Regex),
|
||||
(r'[~^*!%&<>|+=:;,/?\\-]+', Operator),
|
||||
(r'[{}\[\]();.]+', Punctuation),
|
||||
(words((
|
||||
'case', 'default', 'for', 'each', 'in', 'while', 'do', 'break',
|
||||
'return', 'continue', 'if', 'else', 'throw', 'try', 'catch',
|
||||
'var', 'with', 'new', 'typeof', 'arguments', 'instanceof', 'this',
|
||||
'switch'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'class', 'public', 'final', 'internal', 'native', 'override', 'private',
|
||||
'protected', 'static', 'import', 'extends', 'implements', 'interface',
|
||||
'intrinsic', 'return', 'super', 'dynamic', 'function', 'const', 'get',
|
||||
'namespace', 'package', 'set'), suffix=r'\b'),
|
||||
Keyword.Declaration),
|
||||
(r'(true|false|null|NaN|Infinity|-Infinity|undefined|Void)\b',
|
||||
Keyword.Constant),
|
||||
(words((
|
||||
'Accessibility', 'AccessibilityProperties', 'ActionScriptVersion',
|
||||
'ActivityEvent', 'AntiAliasType', 'ApplicationDomain', 'AsBroadcaster', 'Array',
|
||||
'AsyncErrorEvent', 'AVM1Movie', 'BevelFilter', 'Bitmap', 'BitmapData',
|
||||
'BitmapDataChannel', 'BitmapFilter', 'BitmapFilterQuality', 'BitmapFilterType',
|
||||
'BlendMode', 'BlurFilter', 'Boolean', 'ByteArray', 'Camera', 'Capabilities', 'CapsStyle',
|
||||
'Class', 'Color', 'ColorMatrixFilter', 'ColorTransform', 'ContextMenu',
|
||||
'ContextMenuBuiltInItems', 'ContextMenuEvent', 'ContextMenuItem',
|
||||
'ConvultionFilter', 'CSMSettings', 'DataEvent', 'Date', 'DefinitionError',
|
||||
'DeleteObjectSample', 'Dictionary', 'DisplacmentMapFilter', 'DisplayObject',
|
||||
'DisplacmentMapFilterMode', 'DisplayObjectContainer', 'DropShadowFilter',
|
||||
'Endian', 'EOFError', 'Error', 'ErrorEvent', 'EvalError', 'Event', 'EventDispatcher',
|
||||
'EventPhase', 'ExternalInterface', 'FileFilter', 'FileReference',
|
||||
'FileReferenceList', 'FocusDirection', 'FocusEvent', 'Font', 'FontStyle', 'FontType',
|
||||
'FrameLabel', 'FullScreenEvent', 'Function', 'GlowFilter', 'GradientBevelFilter',
|
||||
'GradientGlowFilter', 'GradientType', 'Graphics', 'GridFitType', 'HTTPStatusEvent',
|
||||
'IBitmapDrawable', 'ID3Info', 'IDataInput', 'IDataOutput', 'IDynamicPropertyOutput'
|
||||
'IDynamicPropertyWriter', 'IEventDispatcher', 'IExternalizable',
|
||||
'IllegalOperationError', 'IME', 'IMEConversionMode', 'IMEEvent', 'int',
|
||||
'InteractiveObject', 'InterpolationMethod', 'InvalidSWFError', 'InvokeEvent',
|
||||
'IOError', 'IOErrorEvent', 'JointStyle', 'Key', 'Keyboard', 'KeyboardEvent', 'KeyLocation',
|
||||
'LineScaleMode', 'Loader', 'LoaderContext', 'LoaderInfo', 'LoadVars', 'LocalConnection',
|
||||
'Locale', 'Math', 'Matrix', 'MemoryError', 'Microphone', 'MorphShape', 'Mouse', 'MouseEvent',
|
||||
'MovieClip', 'MovieClipLoader', 'Namespace', 'NetConnection', 'NetStatusEvent',
|
||||
'NetStream', 'NewObjectSample', 'Number', 'Object', 'ObjectEncoding', 'PixelSnapping',
|
||||
'Point', 'PrintJob', 'PrintJobOptions', 'PrintJobOrientation', 'ProgressEvent', 'Proxy',
|
||||
'QName', 'RangeError', 'Rectangle', 'ReferenceError', 'RegExp', 'Responder', 'Sample',
|
||||
'Scene', 'ScriptTimeoutError', 'Security', 'SecurityDomain', 'SecurityError',
|
||||
'SecurityErrorEvent', 'SecurityPanel', 'Selection', 'Shape', 'SharedObject',
|
||||
'SharedObjectFlushStatus', 'SimpleButton', 'Socket', 'Sound', 'SoundChannel',
|
||||
'SoundLoaderContext', 'SoundMixer', 'SoundTransform', 'SpreadMethod', 'Sprite',
|
||||
'StackFrame', 'StackOverflowError', 'Stage', 'StageAlign', 'StageDisplayState',
|
||||
'StageQuality', 'StageScaleMode', 'StaticText', 'StatusEvent', 'String', 'StyleSheet',
|
||||
'SWFVersion', 'SyncEvent', 'SyntaxError', 'System', 'TextColorType', 'TextField',
|
||||
'TextFieldAutoSize', 'TextFieldType', 'TextFormat', 'TextFormatAlign',
|
||||
'TextLineMetrics', 'TextRenderer', 'TextSnapshot', 'Timer', 'TimerEvent', 'Transform',
|
||||
'TypeError', 'uint', 'URIError', 'URLLoader', 'URLLoaderDataFormat', 'URLRequest',
|
||||
'URLRequestHeader', 'URLRequestMethod', 'URLStream', 'URLVariabeles', 'VerifyError',
|
||||
'Video', 'XML', 'XMLDocument', 'XMLList', 'XMLNode', 'XMLNodeType', 'XMLSocket',
|
||||
'XMLUI'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(words((
|
||||
'decodeURI', 'decodeURIComponent', 'encodeURI', 'escape', 'eval', 'isFinite', 'isNaN',
|
||||
'isXMLName', 'clearInterval', 'fscommand', 'getTimer', 'getURL', 'getVersion',
|
||||
'parseFloat', 'parseInt', 'setInterval', 'trace', 'updateAfterEvent',
|
||||
'unescape'), suffix=r'\b'),
|
||||
Name.Function),
|
||||
(r'[$a-zA-Z_]\w*', Name.Other),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-f]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class ActionScript3Lexer(RegexLexer):
|
||||
"""
|
||||
For ActionScript 3 source code.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
|
||||
name = 'ActionScript 3'
|
||||
aliases = ['as3', 'actionscript3']
|
||||
filenames = ['*.as']
|
||||
mimetypes = ['application/x-actionscript3', 'text/x-actionscript3',
|
||||
'text/actionscript3']
|
||||
|
||||
identifier = r'[$a-zA-Z_]\w*'
|
||||
typeidentifier = identifier + '(?:\.<\w+>)?'
|
||||
|
||||
flags = re.DOTALL | re.MULTILINE
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'(function\s+)(' + identifier + r')(\s*)(\()',
|
||||
bygroups(Keyword.Declaration, Name.Function, Text, Operator),
|
||||
'funcparams'),
|
||||
(r'(var|const)(\s+)(' + identifier + r')(\s*)(:)(\s*)(' +
|
||||
typeidentifier + r')',
|
||||
bygroups(Keyword.Declaration, Text, Name, Text, Punctuation, Text,
|
||||
Keyword.Type)),
|
||||
(r'(import|package)(\s+)((?:' + identifier + r'|\.)+)(\s*)',
|
||||
bygroups(Keyword, Text, Name.Namespace, Text)),
|
||||
(r'(new)(\s+)(' + typeidentifier + r')(\s*)(\()',
|
||||
bygroups(Keyword, Text, Keyword.Type, Text, Operator)),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'/(\\\\|\\/|[^\n])*/[gisx]*', String.Regex),
|
||||
(r'(\.)(' + identifier + r')', bygroups(Operator, Name.Attribute)),
|
||||
(r'(case|default|for|each|in|while|do|break|return|continue|if|else|'
|
||||
r'throw|try|catch|with|new|typeof|arguments|instanceof|this|'
|
||||
r'switch|import|include|as|is)\b',
|
||||
Keyword),
|
||||
(r'(class|public|final|internal|native|override|private|protected|'
|
||||
r'static|import|extends|implements|interface|intrinsic|return|super|'
|
||||
r'dynamic|function|const|get|namespace|package|set)\b',
|
||||
Keyword.Declaration),
|
||||
(r'(true|false|null|NaN|Infinity|-Infinity|undefined|void)\b',
|
||||
Keyword.Constant),
|
||||
(r'(decodeURI|decodeURIComponent|encodeURI|escape|eval|isFinite|isNaN|'
|
||||
r'isXMLName|clearInterval|fscommand|getTimer|getURL|getVersion|'
|
||||
r'isFinite|parseFloat|parseInt|setInterval|trace|updateAfterEvent|'
|
||||
r'unescape)\b', Name.Function),
|
||||
(identifier, Name),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-f]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'[~^*!%&<>|+=:;,/?\\{}\[\]().-]+', Operator),
|
||||
],
|
||||
'funcparams': [
|
||||
(r'\s+', Text),
|
||||
(r'(\s*)(\.\.\.)?(' + identifier + r')(\s*)(:)(\s*)(' +
|
||||
typeidentifier + r'|\*)(\s*)',
|
||||
bygroups(Text, Punctuation, Name, Text, Operator, Text,
|
||||
Keyword.Type, Text), 'defval'),
|
||||
(r'\)', Operator, 'type')
|
||||
],
|
||||
'type': [
|
||||
(r'(\s*)(:)(\s*)(' + typeidentifier + r'|\*)',
|
||||
bygroups(Text, Operator, Text, Keyword.Type), '#pop:2'),
|
||||
(r'\s+', Text, '#pop:2'),
|
||||
default('#pop:2')
|
||||
],
|
||||
'defval': [
|
||||
(r'(=)(\s*)([^(),]+)(\s*)(,?)',
|
||||
bygroups(Operator, Text, using(this), Text, Operator), '#pop'),
|
||||
(r',', Operator, '#pop'),
|
||||
default('#pop')
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if re.match(r'\w+\s*:\s*\w', text):
|
||||
return 0.3
|
||||
return 0
|
||||
|
||||
|
||||
class MxmlLexer(RegexLexer):
|
||||
"""
|
||||
For MXML markup.
|
||||
Nested AS3 in <script> tags is highlighted by the appropriate lexer.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
flags = re.MULTILINE | re.DOTALL
|
||||
name = 'MXML'
|
||||
aliases = ['mxml']
|
||||
filenames = ['*.mxml']
|
||||
mimetimes = ['text/xml', 'application/xml']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
('[^<&]+', Text),
|
||||
(r'&\S*?;', Name.Entity),
|
||||
(r'(\<\!\[CDATA\[)(.*?)(\]\]\>)',
|
||||
bygroups(String, using(ActionScript3Lexer), String)),
|
||||
('<!--', Comment, 'comment'),
|
||||
(r'<\?.*?\?>', Comment.Preproc),
|
||||
('<![^>]*>', Comment.Preproc),
|
||||
(r'<\s*[\w:.-]+', Name.Tag, 'tag'),
|
||||
(r'<\s*/\s*[\w:.-]+\s*>', Name.Tag),
|
||||
],
|
||||
'comment': [
|
||||
('[^-]+', Comment),
|
||||
('-->', Comment, '#pop'),
|
||||
('-', Comment),
|
||||
],
|
||||
'tag': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w.:-]+\s*=', Name.Attribute, 'attr'),
|
||||
(r'/?\s*>', Name.Tag, '#pop'),
|
||||
],
|
||||
'attr': [
|
||||
('\s+', Text),
|
||||
('".*?"', String, '#pop'),
|
||||
("'.*?'", String, '#pop'),
|
||||
(r'[^\s>]+', String, '#pop'),
|
||||
],
|
||||
}
|
||||
@ -1,187 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.algebra
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for computer algebra systems.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['GAPLexer', 'MathematicaLexer', 'MuPADLexer']
|
||||
|
||||
|
||||
class GAPLexer(RegexLexer):
|
||||
"""
|
||||
For `GAP <http://www.gap-system.org>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'GAP'
|
||||
aliases = ['gap']
|
||||
filenames = ['*.g', '*.gd', '*.gi', '*.gap']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'#.*$', Comment.Single),
|
||||
(r'"(?:[^"\\]|\\.)*"', String),
|
||||
(r'\(|\)|\[|\]|\{|\}', Punctuation),
|
||||
(r'''(?x)\b(?:
|
||||
if|then|elif|else|fi|
|
||||
for|while|do|od|
|
||||
repeat|until|
|
||||
break|continue|
|
||||
function|local|return|end|
|
||||
rec|
|
||||
quit|QUIT|
|
||||
IsBound|Unbind|
|
||||
TryNextMethod|
|
||||
Info|Assert
|
||||
)\b''', Keyword),
|
||||
(r'''(?x)\b(?:
|
||||
true|false|fail|infinity
|
||||
)\b''',
|
||||
Name.Constant),
|
||||
(r'''(?x)\b(?:
|
||||
(Declare|Install)([A-Z][A-Za-z]+)|
|
||||
BindGlobal|BIND_GLOBAL
|
||||
)\b''',
|
||||
Name.Builtin),
|
||||
(r'\.|,|:=|;|=|\+|-|\*|/|\^|>|<', Operator),
|
||||
(r'''(?x)\b(?:
|
||||
and|or|not|mod|in
|
||||
)\b''',
|
||||
Operator.Word),
|
||||
(r'''(?x)
|
||||
(?:\w+|`[^`]*`)
|
||||
(?:::\w+|`[^`]*`)*''', Name.Variable),
|
||||
(r'[0-9]+(?:\.[0-9]*)?(?:e[0-9]+)?', Number),
|
||||
(r'\.[0-9]+(?:e[0-9]+)?', Number),
|
||||
(r'.', Text)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class MathematicaLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Mathematica <http://www.wolfram.com/mathematica/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Mathematica'
|
||||
aliases = ['mathematica', 'mma', 'nb']
|
||||
filenames = ['*.nb', '*.cdf', '*.nbp', '*.ma']
|
||||
mimetypes = ['application/mathematica',
|
||||
'application/vnd.wolfram.mathematica',
|
||||
'application/vnd.wolfram.mathematica.package',
|
||||
'application/vnd.wolfram.cdf']
|
||||
|
||||
# http://reference.wolfram.com/mathematica/guide/Syntax.html
|
||||
operators = (
|
||||
";;", "=", "=.", "!=" "==", ":=", "->", ":>", "/.", "+", "-", "*", "/",
|
||||
"^", "&&", "||", "!", "<>", "|", "/;", "?", "@", "//", "/@", "@@",
|
||||
"@@@", "~~", "===", "&", "<", ">", "<=", ">=",
|
||||
)
|
||||
|
||||
punctuation = (",", ";", "(", ")", "[", "]", "{", "}")
|
||||
|
||||
def _multi_escape(entries):
|
||||
return '(%s)' % ('|'.join(re.escape(entry) for entry in entries))
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'(?s)\(\*.*?\*\)', Comment),
|
||||
|
||||
(r'([a-zA-Z]+[A-Za-z0-9]*`)', Name.Namespace),
|
||||
(r'([A-Za-z0-9]*_+[A-Za-z0-9]*)', Name.Variable),
|
||||
(r'#\d*', Name.Variable),
|
||||
(r'([a-zA-Z]+[a-zA-Z0-9]*)', Name),
|
||||
|
||||
(r'-?[0-9]+\.[0-9]*', Number.Float),
|
||||
(r'-?[0-9]*\.[0-9]+', Number.Float),
|
||||
(r'-?[0-9]+', Number.Integer),
|
||||
|
||||
(words(operators), Operator),
|
||||
(words(punctuation), Punctuation),
|
||||
(r'".*?"', String),
|
||||
(r'\s+', Text.Whitespace),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class MuPADLexer(RegexLexer):
|
||||
"""
|
||||
A `MuPAD <http://www.mupad.com>`_ lexer.
|
||||
Contributed by Christopher Creutzig <christopher@creutzig.de>.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
name = 'MuPAD'
|
||||
aliases = ['mupad']
|
||||
filenames = ['*.mu']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'//.*?$', Comment.Single),
|
||||
(r'/\*', Comment.Multiline, 'comment'),
|
||||
(r'"(?:[^"\\]|\\.)*"', String),
|
||||
(r'\(|\)|\[|\]|\{|\}', Punctuation),
|
||||
(r'''(?x)\b(?:
|
||||
next|break|end|
|
||||
axiom|end_axiom|category|end_category|domain|end_domain|inherits|
|
||||
if|%if|then|elif|else|end_if|
|
||||
case|of|do|otherwise|end_case|
|
||||
while|end_while|
|
||||
repeat|until|end_repeat|
|
||||
for|from|to|downto|step|end_for|
|
||||
proc|local|option|save|begin|end_proc|
|
||||
delete|frame
|
||||
)\b''', Keyword),
|
||||
(r'''(?x)\b(?:
|
||||
DOM_ARRAY|DOM_BOOL|DOM_COMPLEX|DOM_DOMAIN|DOM_EXEC|DOM_EXPR|
|
||||
DOM_FAIL|DOM_FLOAT|DOM_FRAME|DOM_FUNC_ENV|DOM_HFARRAY|DOM_IDENT|
|
||||
DOM_INT|DOM_INTERVAL|DOM_LIST|DOM_NIL|DOM_NULL|DOM_POLY|DOM_PROC|
|
||||
DOM_PROC_ENV|DOM_RAT|DOM_SET|DOM_STRING|DOM_TABLE|DOM_VAR
|
||||
)\b''', Name.Class),
|
||||
(r'''(?x)\b(?:
|
||||
PI|EULER|E|CATALAN|
|
||||
NIL|FAIL|undefined|infinity|
|
||||
TRUE|FALSE|UNKNOWN
|
||||
)\b''',
|
||||
Name.Constant),
|
||||
(r'\b(?:dom|procname)\b', Name.Builtin.Pseudo),
|
||||
(r'\.|,|:|;|=|\+|-|\*|/|\^|@|>|<|\$|\||!|\'|%|~=', Operator),
|
||||
(r'''(?x)\b(?:
|
||||
and|or|not|xor|
|
||||
assuming|
|
||||
div|mod|
|
||||
union|minus|intersect|in|subset
|
||||
)\b''',
|
||||
Operator.Word),
|
||||
(r'\b(?:I|RDN_INF|RD_NINF|RD_NAN)\b', Number),
|
||||
# (r'\b(?:adt|linalg|newDomain|hold)\b', Name.Builtin),
|
||||
(r'''(?x)
|
||||
((?:[a-zA-Z_#][\w#]*|`[^`]*`)
|
||||
(?:::[a-zA-Z_#][\w#]*|`[^`]*`)*)(\s*)([(])''',
|
||||
bygroups(Name.Function, Text, Punctuation)),
|
||||
(r'''(?x)
|
||||
(?:[a-zA-Z_#][\w#]*|`[^`]*`)
|
||||
(?:::[a-zA-Z_#][\w#]*|`[^`]*`)*''', Name.Variable),
|
||||
(r'[0-9]+(?:\.[0-9]*)?(?:e[0-9]+)?', Number),
|
||||
(r'\.[0-9]+(?:e[0-9]+)?', Number),
|
||||
(r'.', Text)
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
]
|
||||
}
|
||||
@ -1,101 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.apl
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for APL.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['APLLexer']
|
||||
|
||||
|
||||
class APLLexer(RegexLexer):
|
||||
"""
|
||||
A simple APL lexer.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'APL'
|
||||
aliases = ['apl']
|
||||
filenames = ['*.apl']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Whitespace
|
||||
# ==========
|
||||
(r'\s+', Text),
|
||||
#
|
||||
# Comment
|
||||
# =======
|
||||
# '⍝' is traditional; '#' is supported by GNU APL and NGN (but not Dyalog)
|
||||
(u'[⍝#].*$', Comment.Single),
|
||||
#
|
||||
# Strings
|
||||
# =======
|
||||
(r'\'((\'\')|[^\'])*\'', String.Single),
|
||||
(r'"(("")|[^"])*"', String.Double), # supported by NGN APL
|
||||
#
|
||||
# Punctuation
|
||||
# ===========
|
||||
# This token type is used for diamond and parenthesis
|
||||
# but not for bracket and ; (see below)
|
||||
(u'[⋄◇()]', Punctuation),
|
||||
#
|
||||
# Array indexing
|
||||
# ==============
|
||||
# Since this token type is very important in APL, it is not included in
|
||||
# the punctuation token type but rather in the following one
|
||||
(r'[\[\];]', String.Regex),
|
||||
#
|
||||
# Distinguished names
|
||||
# ===================
|
||||
# following IBM APL2 standard
|
||||
(u'⎕[A-Za-zΔ∆⍙][A-Za-zΔ∆⍙_¯0-9]*', Name.Function),
|
||||
#
|
||||
# Labels
|
||||
# ======
|
||||
# following IBM APL2 standard
|
||||
# (u'[A-Za-zΔ∆⍙][A-Za-zΔ∆⍙_¯0-9]*:', Name.Label),
|
||||
#
|
||||
# Variables
|
||||
# =========
|
||||
# following IBM APL2 standard
|
||||
(u'[A-Za-zΔ∆⍙][A-Za-zΔ∆⍙_¯0-9]*', Name.Variable),
|
||||
#
|
||||
# Numbers
|
||||
# =======
|
||||
(u'¯?(0[Xx][0-9A-Fa-f]+|[0-9]*\.?[0-9]+([Ee][+¯]?[0-9]+)?|¯|∞)'
|
||||
u'([Jj]¯?(0[Xx][0-9A-Fa-f]+|[0-9]*\.?[0-9]+([Ee][+¯]?[0-9]+)?|¯|∞))?',
|
||||
Number),
|
||||
#
|
||||
# Operators
|
||||
# ==========
|
||||
(u'[\.\\\/⌿⍀¨⍣⍨⍠⍤∘]', Name.Attribute), # closest token type
|
||||
(u'[+\-×÷⌈⌊∣|⍳?*⍟○!⌹<≤=>≥≠≡≢∊⍷∪∩~∨∧⍱⍲⍴,⍪⌽⊖⍉↑↓⊂⊃⌷⍋⍒⊤⊥⍕⍎⊣⊢⍁⍂≈⌸⍯↗]',
|
||||
Operator),
|
||||
#
|
||||
# Constant
|
||||
# ========
|
||||
(u'⍬', Name.Constant),
|
||||
#
|
||||
# Quad symbol
|
||||
# ===========
|
||||
(u'[⎕⍞]', Name.Variable.Global),
|
||||
#
|
||||
# Arrows left/right
|
||||
# =================
|
||||
(u'[←→]', Keyword.Declaration),
|
||||
#
|
||||
# D-Fn
|
||||
# ====
|
||||
(u'[⍺⍵⍶⍹∇:]', Name.Builtin.Pseudo),
|
||||
(r'[{}]', Keyword.Type),
|
||||
],
|
||||
}
|
||||
@ -1,435 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.asm
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for assembly languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, DelegatingLexer
|
||||
from pygments.lexers.c_cpp import CppLexer, CLexer
|
||||
from pygments.lexers.d import DLexer
|
||||
from pygments.token import Text, Name, Number, String, Comment, Punctuation, \
|
||||
Other, Keyword, Operator
|
||||
|
||||
__all__ = ['GasLexer', 'ObjdumpLexer', 'DObjdumpLexer', 'CppObjdumpLexer',
|
||||
'CObjdumpLexer', 'LlvmLexer', 'NasmLexer', 'NasmObjdumpLexer',
|
||||
'Ca65Lexer']
|
||||
|
||||
|
||||
class GasLexer(RegexLexer):
|
||||
"""
|
||||
For Gas (AT&T) assembly code.
|
||||
"""
|
||||
name = 'GAS'
|
||||
aliases = ['gas', 'asm']
|
||||
filenames = ['*.s', '*.S']
|
||||
mimetypes = ['text/x-gas']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
string = r'"(\\"|[^"])*"'
|
||||
char = r'[\w$.@-]'
|
||||
identifier = r'(?:[a-zA-Z$_]' + char + '*|\.' + char + '+)'
|
||||
number = r'(?:0[xX][a-zA-Z0-9]+|\d+)'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
(identifier + ':', Name.Label),
|
||||
(r'\.' + identifier, Name.Attribute, 'directive-args'),
|
||||
(r'lock|rep(n?z)?|data\d+', Name.Attribute),
|
||||
(identifier, Name.Function, 'instruction-args'),
|
||||
(r'[\r\n]+', Text)
|
||||
],
|
||||
'directive-args': [
|
||||
(identifier, Name.Constant),
|
||||
(string, String),
|
||||
('@' + identifier, Name.Attribute),
|
||||
(number, Number.Integer),
|
||||
(r'[\r\n]+', Text, '#pop'),
|
||||
|
||||
(r'#.*?$', Comment, '#pop'),
|
||||
|
||||
include('punctuation'),
|
||||
include('whitespace')
|
||||
],
|
||||
'instruction-args': [
|
||||
# For objdump-disassembled code, shouldn't occur in
|
||||
# actual assembler input
|
||||
('([a-z0-9]+)( )(<)('+identifier+')(>)',
|
||||
bygroups(Number.Hex, Text, Punctuation, Name.Constant,
|
||||
Punctuation)),
|
||||
('([a-z0-9]+)( )(<)('+identifier+')([-+])('+number+')(>)',
|
||||
bygroups(Number.Hex, Text, Punctuation, Name.Constant,
|
||||
Punctuation, Number.Integer, Punctuation)),
|
||||
|
||||
# Address constants
|
||||
(identifier, Name.Constant),
|
||||
(number, Number.Integer),
|
||||
# Registers
|
||||
('%' + identifier, Name.Variable),
|
||||
# Numeric constants
|
||||
('$'+number, Number.Integer),
|
||||
(r"$'(.|\\')'", String.Char),
|
||||
(r'[\r\n]+', Text, '#pop'),
|
||||
(r'#.*?$', Comment, '#pop'),
|
||||
include('punctuation'),
|
||||
include('whitespace')
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'#.*?\n', Comment)
|
||||
],
|
||||
'punctuation': [
|
||||
(r'[-*,.():]+', Punctuation)
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if re.match(r'^\.(text|data|section)', text, re.M):
|
||||
return True
|
||||
elif re.match(r'^\.\w+', text, re.M):
|
||||
return 0.1
|
||||
|
||||
|
||||
def _objdump_lexer_tokens(asm_lexer):
|
||||
"""
|
||||
Common objdump lexer tokens to wrap an ASM lexer.
|
||||
"""
|
||||
hex_re = r'[0-9A-Za-z]'
|
||||
return {
|
||||
'root': [
|
||||
# File name & format:
|
||||
('(.*?)(:)( +file format )(.*?)$',
|
||||
bygroups(Name.Label, Punctuation, Text, String)),
|
||||
# Section header
|
||||
('(Disassembly of section )(.*?)(:)$',
|
||||
bygroups(Text, Name.Label, Punctuation)),
|
||||
# Function labels
|
||||
# (With offset)
|
||||
('('+hex_re+'+)( )(<)(.*?)([-+])(0[xX][A-Za-z0-9]+)(>:)$',
|
||||
bygroups(Number.Hex, Text, Punctuation, Name.Function,
|
||||
Punctuation, Number.Hex, Punctuation)),
|
||||
# (Without offset)
|
||||
('('+hex_re+'+)( )(<)(.*?)(>:)$',
|
||||
bygroups(Number.Hex, Text, Punctuation, Name.Function,
|
||||
Punctuation)),
|
||||
# Code line with disassembled instructions
|
||||
('( *)('+hex_re+r'+:)(\t)((?:'+hex_re+hex_re+' )+)( *\t)([a-zA-Z].*?)$',
|
||||
bygroups(Text, Name.Label, Text, Number.Hex, Text,
|
||||
using(asm_lexer))),
|
||||
# Code line with ascii
|
||||
('( *)('+hex_re+r'+:)(\t)((?:'+hex_re+hex_re+' )+)( *)(.*?)$',
|
||||
bygroups(Text, Name.Label, Text, Number.Hex, Text, String)),
|
||||
# Continued code line, only raw opcodes without disassembled
|
||||
# instruction
|
||||
('( *)('+hex_re+r'+:)(\t)((?:'+hex_re+hex_re+' )+)$',
|
||||
bygroups(Text, Name.Label, Text, Number.Hex)),
|
||||
# Skipped a few bytes
|
||||
(r'\t\.\.\.$', Text),
|
||||
# Relocation line
|
||||
# (With offset)
|
||||
(r'(\t\t\t)('+hex_re+r'+:)( )([^\t]+)(\t)(.*?)([-+])(0x'+hex_re+'+)$',
|
||||
bygroups(Text, Name.Label, Text, Name.Property, Text,
|
||||
Name.Constant, Punctuation, Number.Hex)),
|
||||
# (Without offset)
|
||||
(r'(\t\t\t)('+hex_re+r'+:)( )([^\t]+)(\t)(.*?)$',
|
||||
bygroups(Text, Name.Label, Text, Name.Property, Text,
|
||||
Name.Constant)),
|
||||
(r'[^\n]+\n', Other)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class ObjdumpLexer(RegexLexer):
|
||||
"""
|
||||
For the output of 'objdump -dr'
|
||||
"""
|
||||
name = 'objdump'
|
||||
aliases = ['objdump']
|
||||
filenames = ['*.objdump']
|
||||
mimetypes = ['text/x-objdump']
|
||||
|
||||
tokens = _objdump_lexer_tokens(GasLexer)
|
||||
|
||||
|
||||
class DObjdumpLexer(DelegatingLexer):
|
||||
"""
|
||||
For the output of 'objdump -Sr on compiled D files'
|
||||
"""
|
||||
name = 'd-objdump'
|
||||
aliases = ['d-objdump']
|
||||
filenames = ['*.d-objdump']
|
||||
mimetypes = ['text/x-d-objdump']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(DObjdumpLexer, self).__init__(DLexer, ObjdumpLexer, **options)
|
||||
|
||||
|
||||
class CppObjdumpLexer(DelegatingLexer):
|
||||
"""
|
||||
For the output of 'objdump -Sr on compiled C++ files'
|
||||
"""
|
||||
name = 'cpp-objdump'
|
||||
aliases = ['cpp-objdump', 'c++-objdumb', 'cxx-objdump']
|
||||
filenames = ['*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump']
|
||||
mimetypes = ['text/x-cpp-objdump']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(CppObjdumpLexer, self).__init__(CppLexer, ObjdumpLexer, **options)
|
||||
|
||||
|
||||
class CObjdumpLexer(DelegatingLexer):
|
||||
"""
|
||||
For the output of 'objdump -Sr on compiled C files'
|
||||
"""
|
||||
name = 'c-objdump'
|
||||
aliases = ['c-objdump']
|
||||
filenames = ['*.c-objdump']
|
||||
mimetypes = ['text/x-c-objdump']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(CObjdumpLexer, self).__init__(CLexer, ObjdumpLexer, **options)
|
||||
|
||||
|
||||
class LlvmLexer(RegexLexer):
|
||||
"""
|
||||
For LLVM assembly code.
|
||||
"""
|
||||
name = 'LLVM'
|
||||
aliases = ['llvm']
|
||||
filenames = ['*.ll']
|
||||
mimetypes = ['text/x-llvm']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
string = r'"[^"]*?"'
|
||||
identifier = r'([-a-zA-Z$._][\w\-$.]*|' + string + ')'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
|
||||
# Before keywords, because keywords are valid label names :(...
|
||||
(identifier + '\s*:', Name.Label),
|
||||
|
||||
include('keyword'),
|
||||
|
||||
(r'%' + identifier, Name.Variable),
|
||||
(r'@' + identifier, Name.Variable.Global),
|
||||
(r'%\d+', Name.Variable.Anonymous),
|
||||
(r'@\d+', Name.Variable.Global),
|
||||
(r'#\d+', Name.Variable.Global),
|
||||
(r'!' + identifier, Name.Variable),
|
||||
(r'!\d+', Name.Variable.Anonymous),
|
||||
(r'c?' + string, String),
|
||||
|
||||
(r'0[xX][a-fA-F0-9]+', Number),
|
||||
(r'-?\d+(?:[.]\d+)?(?:[eE][-+]?\d+(?:[.]\d+)?)?', Number),
|
||||
|
||||
(r'[=<>{}\[\]()*.,!]|x\b', Punctuation)
|
||||
],
|
||||
'whitespace': [
|
||||
(r'(\n|\s)+', Text),
|
||||
(r';.*?\n', Comment)
|
||||
],
|
||||
'keyword': [
|
||||
# Regular keywords
|
||||
(r'(begin|end'
|
||||
r'|true|false'
|
||||
r'|declare|define'
|
||||
r'|global|constant'
|
||||
|
||||
r'|private|linker_private|internal|available_externally|linkonce'
|
||||
r'|linkonce_odr|weak|weak_odr|appending|dllimport|dllexport'
|
||||
r'|common|default|hidden|protected|extern_weak|external'
|
||||
r'|thread_local|zeroinitializer|undef|null|to|tail|target|triple'
|
||||
r'|datalayout|volatile|nuw|nsw|nnan|ninf|nsz|arcp|fast|exact|inbounds'
|
||||
r'|align|addrspace|section|alias|module|asm|sideeffect|gc|dbg'
|
||||
r'|linker_private_weak'
|
||||
r'|attributes|blockaddress|initialexec|localdynamic|localexec'
|
||||
r'|prefix|unnamed_addr'
|
||||
|
||||
r'|ccc|fastcc|coldcc|x86_stdcallcc|x86_fastcallcc|arm_apcscc'
|
||||
r'|arm_aapcscc|arm_aapcs_vfpcc|ptx_device|ptx_kernel'
|
||||
r'|intel_ocl_bicc|msp430_intrcc|spir_func|spir_kernel'
|
||||
r'|x86_64_sysvcc|x86_64_win64cc|x86_thiscallcc'
|
||||
|
||||
r'|cc|c'
|
||||
|
||||
r'|signext|zeroext|inreg|sret|nounwind|noreturn|noalias|nocapture'
|
||||
r'|byval|nest|readnone|readonly'
|
||||
r'|inlinehint|noinline|alwaysinline|optsize|ssp|sspreq|noredzone'
|
||||
r'|noimplicitfloat|naked'
|
||||
r'|builtin|cold|nobuiltin|noduplicate|nonlazybind|optnone'
|
||||
r'|returns_twice|sanitize_address|sanitize_memory|sanitize_thread'
|
||||
r'|sspstrong|uwtable|returned'
|
||||
|
||||
r'|type|opaque'
|
||||
|
||||
r'|eq|ne|slt|sgt|sle'
|
||||
r'|sge|ult|ugt|ule|uge'
|
||||
r'|oeq|one|olt|ogt|ole'
|
||||
r'|oge|ord|uno|ueq|une'
|
||||
r'|x'
|
||||
r'|acq_rel|acquire|alignstack|atomic|catch|cleanup|filter'
|
||||
r'|inteldialect|max|min|monotonic|nand|personality|release'
|
||||
r'|seq_cst|singlethread|umax|umin|unordered|xchg'
|
||||
|
||||
# instructions
|
||||
r'|add|fadd|sub|fsub|mul|fmul|udiv|sdiv|fdiv|urem|srem|frem|shl'
|
||||
r'|lshr|ashr|and|or|xor|icmp|fcmp'
|
||||
|
||||
r'|phi|call|trunc|zext|sext|fptrunc|fpext|uitofp|sitofp|fptoui'
|
||||
r'|fptosi|inttoptr|ptrtoint|bitcast|select|va_arg|ret|br|switch'
|
||||
r'|invoke|unwind|unreachable'
|
||||
r'|indirectbr|landingpad|resume'
|
||||
|
||||
r'|malloc|alloca|free|load|store|getelementptr'
|
||||
|
||||
r'|extractelement|insertelement|shufflevector|getresult'
|
||||
r'|extractvalue|insertvalue'
|
||||
|
||||
r'|atomicrmw|cmpxchg|fence'
|
||||
|
||||
r')\b', Keyword),
|
||||
|
||||
# Types
|
||||
(r'void|half|float|double|x86_fp80|fp128|ppc_fp128|label|metadata',
|
||||
Keyword.Type),
|
||||
|
||||
# Integer types
|
||||
(r'i[1-9]\d*', Keyword)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class NasmLexer(RegexLexer):
|
||||
"""
|
||||
For Nasm (Intel) assembly code.
|
||||
"""
|
||||
name = 'NASM'
|
||||
aliases = ['nasm']
|
||||
filenames = ['*.asm', '*.ASM']
|
||||
mimetypes = ['text/x-nasm']
|
||||
|
||||
identifier = r'[a-z$._?][\w$.?#@~]*'
|
||||
hexn = r'(?:0x[0-9a-f]+|$0[0-9a-f]*|[0-9]+[0-9a-f]*h)'
|
||||
octn = r'[0-7]+q'
|
||||
binn = r'[01]+b'
|
||||
decn = r'[0-9]+'
|
||||
floatn = decn + r'\.e?' + decn
|
||||
string = r'"(\\"|[^"\n])*"|' + r"'(\\'|[^'\n])*'|" + r"`(\\`|[^`\n])*`"
|
||||
declkw = r'(?:res|d)[bwdqt]|times'
|
||||
register = (r'r[0-9][0-5]?[bwd]|'
|
||||
r'[a-d][lh]|[er]?[a-d]x|[er]?[sb]p|[er]?[sd]i|[c-gs]s|st[0-7]|'
|
||||
r'mm[0-7]|cr[0-4]|dr[0-367]|tr[3-7]')
|
||||
wordop = r'seg|wrt|strict'
|
||||
type = r'byte|[dq]?word'
|
||||
directives = (r'BITS|USE16|USE32|SECTION|SEGMENT|ABSOLUTE|EXTERN|GLOBAL|'
|
||||
r'ORG|ALIGN|STRUC|ENDSTRUC|COMMON|CPU|GROUP|UPPERCASE|IMPORT|'
|
||||
r'EXPORT|LIBRARY|MODULE')
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^\s*%', Comment.Preproc, 'preproc'),
|
||||
include('whitespace'),
|
||||
(identifier + ':', Name.Label),
|
||||
(r'(%s)(\s+)(equ)' % identifier,
|
||||
bygroups(Name.Constant, Keyword.Declaration, Keyword.Declaration),
|
||||
'instruction-args'),
|
||||
(directives, Keyword, 'instruction-args'),
|
||||
(declkw, Keyword.Declaration, 'instruction-args'),
|
||||
(identifier, Name.Function, 'instruction-args'),
|
||||
(r'[\r\n]+', Text)
|
||||
],
|
||||
'instruction-args': [
|
||||
(string, String),
|
||||
(hexn, Number.Hex),
|
||||
(octn, Number.Oct),
|
||||
(binn, Number.Bin),
|
||||
(floatn, Number.Float),
|
||||
(decn, Number.Integer),
|
||||
include('punctuation'),
|
||||
(register, Name.Builtin),
|
||||
(identifier, Name.Variable),
|
||||
(r'[\r\n]+', Text, '#pop'),
|
||||
include('whitespace')
|
||||
],
|
||||
'preproc': [
|
||||
(r'[^;\n]+', Comment.Preproc),
|
||||
(r';.*?\n', Comment.Single, '#pop'),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\n', Text),
|
||||
(r'[ \t]+', Text),
|
||||
(r';.*', Comment.Single)
|
||||
],
|
||||
'punctuation': [
|
||||
(r'[,():\[\]]+', Punctuation),
|
||||
(r'[&|^<>+*/%~-]+', Operator),
|
||||
(r'[$]+', Keyword.Constant),
|
||||
(wordop, Operator.Word),
|
||||
(type, Keyword.Type)
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class NasmObjdumpLexer(ObjdumpLexer):
|
||||
"""
|
||||
For the output of 'objdump -d -M intel'.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'objdump-nasm'
|
||||
aliases = ['objdump-nasm']
|
||||
filenames = ['*.objdump-intel']
|
||||
mimetypes = ['text/x-nasm-objdump']
|
||||
|
||||
tokens = _objdump_lexer_tokens(NasmLexer)
|
||||
|
||||
|
||||
class Ca65Lexer(RegexLexer):
|
||||
"""
|
||||
For ca65 assembler sources.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'ca65 assembler'
|
||||
aliases = ['ca65']
|
||||
filenames = ['*.s']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r';.*', Comment.Single),
|
||||
(r'\s+', Text),
|
||||
(r'[a-z_.@$][\w.@$]*:', Name.Label),
|
||||
(r'((ld|st)[axy]|(in|de)[cxy]|asl|lsr|ro[lr]|adc|sbc|cmp|cp[xy]'
|
||||
r'|cl[cvdi]|se[cdi]|jmp|jsr|bne|beq|bpl|bmi|bvc|bvs|bcc|bcs'
|
||||
r'|p[lh][ap]|rt[is]|brk|nop|ta[xy]|t[xy]a|txs|tsx|and|ora|eor'
|
||||
r'|bit)\b', Keyword),
|
||||
(r'\.\w+', Keyword.Pseudo),
|
||||
(r'[-+~*/^&|!<>=]', Operator),
|
||||
(r'"[^"\n]*.', String),
|
||||
(r"'[^'\n]*.", String.Char),
|
||||
(r'\$[0-9a-f]+|[0-9a-f]+h\b', Number.Hex),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'%[01]+', Number.Bin),
|
||||
(r'[#,.:()=\[\]]', Punctuation),
|
||||
(r'[a-z_.@$][\w.@$]*', Name),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(self, text):
|
||||
# comments in GAS start with "#"
|
||||
if re.match(r'^\s*;', text, re.MULTILINE):
|
||||
return 0.9
|
||||
@ -1,500 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.basic
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for BASIC like languages (other than VB.net).
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, default, words, include
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['BlitzBasicLexer', 'BlitzMaxLexer', 'MonkeyLexer', 'CbmBasicV2Lexer',
|
||||
'QBasicLexer']
|
||||
|
||||
|
||||
class BlitzMaxLexer(RegexLexer):
|
||||
"""
|
||||
For `BlitzMax <http://blitzbasic.com>`_ source code.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'BlitzMax'
|
||||
aliases = ['blitzmax', 'bmax']
|
||||
filenames = ['*.bmx']
|
||||
mimetypes = ['text/x-bmx']
|
||||
|
||||
bmax_vopwords = r'\b(Shl|Shr|Sar|Mod)\b'
|
||||
bmax_sktypes = r'@{1,2}|[!#$%]'
|
||||
bmax_lktypes = r'\b(Int|Byte|Short|Float|Double|Long)\b'
|
||||
bmax_name = r'[a-z_]\w*'
|
||||
bmax_var = (r'(%s)(?:(?:([ \t]*)(%s)|([ \t]*:[ \t]*\b(?:Shl|Shr|Sar|Mod)\b)'
|
||||
r'|([ \t]*)(:)([ \t]*)(?:%s|(%s)))(?:([ \t]*)(Ptr))?)') % \
|
||||
(bmax_name, bmax_sktypes, bmax_lktypes, bmax_name)
|
||||
bmax_func = bmax_var + r'?((?:[ \t]|\.\.\n)*)([(])'
|
||||
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# Text
|
||||
(r'[ \t]+', Text),
|
||||
(r'\.\.\n', Text), # Line continuation
|
||||
# Comments
|
||||
(r"'.*?\n", Comment.Single),
|
||||
(r'([ \t]*)\bRem\n(\n|.)*?\s*\bEnd([ \t]*)Rem', Comment.Multiline),
|
||||
# Data types
|
||||
('"', String.Double, 'string'),
|
||||
# Numbers
|
||||
(r'[0-9]+\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\$[0-9a-f]+', Number.Hex),
|
||||
(r'\%[10]+', Number.Bin),
|
||||
# Other
|
||||
(r'(?:(?:(:)?([ \t]*)(:?%s|([+\-*/&|~]))|Or|And|Not|[=<>^]))' %
|
||||
(bmax_vopwords), Operator),
|
||||
(r'[(),.:\[\]]', Punctuation),
|
||||
(r'(?:#[\w \t]*)', Name.Label),
|
||||
(r'(?:\?[\w \t]*)', Comment.Preproc),
|
||||
# Identifiers
|
||||
(r'\b(New)\b([ \t]?)([(]?)(%s)' % (bmax_name),
|
||||
bygroups(Keyword.Reserved, Text, Punctuation, Name.Class)),
|
||||
(r'\b(Import|Framework|Module)([ \t]+)(%s\.%s)' %
|
||||
(bmax_name, bmax_name),
|
||||
bygroups(Keyword.Reserved, Text, Keyword.Namespace)),
|
||||
(bmax_func, bygroups(Name.Function, Text, Keyword.Type,
|
||||
Operator, Text, Punctuation, Text,
|
||||
Keyword.Type, Name.Class, Text,
|
||||
Keyword.Type, Text, Punctuation)),
|
||||
(bmax_var, bygroups(Name.Variable, Text, Keyword.Type, Operator,
|
||||
Text, Punctuation, Text, Keyword.Type,
|
||||
Name.Class, Text, Keyword.Type)),
|
||||
(r'\b(Type|Extends)([ \t]+)(%s)' % (bmax_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
# Keywords
|
||||
(r'\b(Ptr)\b', Keyword.Type),
|
||||
(r'\b(Pi|True|False|Null|Self|Super)\b', Keyword.Constant),
|
||||
(r'\b(Local|Global|Const|Field)\b', Keyword.Declaration),
|
||||
(words((
|
||||
'TNullMethodException', 'TNullFunctionException',
|
||||
'TNullObjectException', 'TArrayBoundsException',
|
||||
'TRuntimeException'), prefix=r'\b', suffix=r'\b'), Name.Exception),
|
||||
(words((
|
||||
'Strict', 'SuperStrict', 'Module', 'ModuleInfo',
|
||||
'End', 'Return', 'Continue', 'Exit', 'Public', 'Private',
|
||||
'Var', 'VarPtr', 'Chr', 'Len', 'Asc', 'SizeOf', 'Sgn', 'Abs', 'Min', 'Max',
|
||||
'New', 'Release', 'Delete', 'Incbin', 'IncbinPtr', 'IncbinLen',
|
||||
'Framework', 'Include', 'Import', 'Extern', 'EndExtern',
|
||||
'Function', 'EndFunction', 'Type', 'EndType', 'Extends', 'Method', 'EndMethod',
|
||||
'Abstract', 'Final', 'If', 'Then', 'Else', 'ElseIf', 'EndIf',
|
||||
'For', 'To', 'Next', 'Step', 'EachIn', 'While', 'Wend', 'EndWhile',
|
||||
'Repeat', 'Until', 'Forever', 'Select', 'Case', 'Default', 'EndSelect',
|
||||
'Try', 'Catch', 'EndTry', 'Throw', 'Assert', 'Goto', 'DefData', 'ReadData',
|
||||
'RestoreData'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
# Final resolve (for variable names and such)
|
||||
(r'(%s)' % (bmax_name), Name.Variable),
|
||||
],
|
||||
'string': [
|
||||
(r'""', String.Double),
|
||||
(r'"C?', String.Double, '#pop'),
|
||||
(r'[^"]+', String.Double),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class BlitzBasicLexer(RegexLexer):
|
||||
"""
|
||||
For `BlitzBasic <http://blitzbasic.com>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'BlitzBasic'
|
||||
aliases = ['blitzbasic', 'b3d', 'bplus']
|
||||
filenames = ['*.bb', '*.decls']
|
||||
mimetypes = ['text/x-bb']
|
||||
|
||||
bb_sktypes = r'@{1,2}|[#$%]'
|
||||
bb_name = r'[a-z]\w*'
|
||||
bb_var = (r'(%s)(?:([ \t]*)(%s)|([ \t]*)([.])([ \t]*)(?:(%s)))?') % \
|
||||
(bb_name, bb_sktypes, bb_name)
|
||||
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# Text
|
||||
(r'[ \t]+', Text),
|
||||
# Comments
|
||||
(r";.*?\n", Comment.Single),
|
||||
# Data types
|
||||
('"', String.Double, 'string'),
|
||||
# Numbers
|
||||
(r'[0-9]+\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'\.[0-9]+(?!\.)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\$[0-9a-f]+', Number.Hex),
|
||||
(r'\%[10]+', Number.Bin),
|
||||
# Other
|
||||
(words(('Shl', 'Shr', 'Sar', 'Mod', 'Or', 'And', 'Not',
|
||||
'Abs', 'Sgn', 'Handle', 'Int', 'Float', 'Str',
|
||||
'First', 'Last', 'Before', 'After'),
|
||||
prefix=r'\b', suffix=r'\b'),
|
||||
Operator),
|
||||
(r'([+\-*/~=<>^])', Operator),
|
||||
(r'[(),:\[\]\\]', Punctuation),
|
||||
(r'\.([ \t]*)(%s)' % bb_name, Name.Label),
|
||||
# Identifiers
|
||||
(r'\b(New)\b([ \t]+)(%s)' % (bb_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
(r'\b(Gosub|Goto)\b([ \t]+)(%s)' % (bb_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Label)),
|
||||
(r'\b(Object)\b([ \t]*)([.])([ \t]*)(%s)\b' % (bb_name),
|
||||
bygroups(Operator, Text, Punctuation, Text, Name.Class)),
|
||||
(r'\b%s\b([ \t]*)(\()' % bb_var,
|
||||
bygroups(Name.Function, Text, Keyword.Type, Text, Punctuation,
|
||||
Text, Name.Class, Text, Punctuation)),
|
||||
(r'\b(Function)\b([ \t]+)%s' % bb_var,
|
||||
bygroups(Keyword.Reserved, Text, Name.Function, Text, Keyword.Type,
|
||||
Text, Punctuation, Text, Name.Class)),
|
||||
(r'\b(Type)([ \t]+)(%s)' % (bb_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
# Keywords
|
||||
(r'\b(Pi|True|False|Null)\b', Keyword.Constant),
|
||||
(r'\b(Local|Global|Const|Field|Dim)\b', Keyword.Declaration),
|
||||
(words((
|
||||
'End', 'Return', 'Exit', 'Chr', 'Len', 'Asc', 'New', 'Delete', 'Insert',
|
||||
'Include', 'Function', 'Type', 'If', 'Then', 'Else', 'ElseIf', 'EndIf',
|
||||
'For', 'To', 'Next', 'Step', 'Each', 'While', 'Wend',
|
||||
'Repeat', 'Until', 'Forever', 'Select', 'Case', 'Default',
|
||||
'Goto', 'Gosub', 'Data', 'Read', 'Restore'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
# Final resolve (for variable names and such)
|
||||
# (r'(%s)' % (bb_name), Name.Variable),
|
||||
(bb_var, bygroups(Name.Variable, Text, Keyword.Type,
|
||||
Text, Punctuation, Text, Name.Class)),
|
||||
],
|
||||
'string': [
|
||||
(r'""', String.Double),
|
||||
(r'"C?', String.Double, '#pop'),
|
||||
(r'[^"]+', String.Double),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class MonkeyLexer(RegexLexer):
|
||||
"""
|
||||
For
|
||||
`Monkey <https://en.wikipedia.org/wiki/Monkey_(programming_language)>`_
|
||||
source code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'Monkey'
|
||||
aliases = ['monkey']
|
||||
filenames = ['*.monkey']
|
||||
mimetypes = ['text/x-monkey']
|
||||
|
||||
name_variable = r'[a-z_]\w*'
|
||||
name_function = r'[A-Z]\w*'
|
||||
name_constant = r'[A-Z_][A-Z0-9_]*'
|
||||
name_class = r'[A-Z]\w*'
|
||||
name_module = r'[a-z0-9_]*'
|
||||
|
||||
keyword_type = r'(?:Int|Float|String|Bool|Object|Array|Void)'
|
||||
# ? == Bool // % == Int // # == Float // $ == String
|
||||
keyword_type_special = r'[?%#$]'
|
||||
|
||||
flags = re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Text
|
||||
(r'\s+', Text),
|
||||
# Comments
|
||||
(r"'.*", Comment),
|
||||
(r'(?i)^#rem\b', Comment.Multiline, 'comment'),
|
||||
# preprocessor directives
|
||||
(r'(?i)^(?:#If|#ElseIf|#Else|#EndIf|#End|#Print|#Error)\b', Comment.Preproc),
|
||||
# preprocessor variable (any line starting with '#' that is not a directive)
|
||||
(r'^#', Comment.Preproc, 'variables'),
|
||||
# String
|
||||
('"', String.Double, 'string'),
|
||||
# Numbers
|
||||
(r'[0-9]+\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'\.[0-9]+(?!\.)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\$[0-9a-fA-Z]+', Number.Hex),
|
||||
(r'\%[10]+', Number.Bin),
|
||||
# Native data types
|
||||
(r'\b%s\b' % keyword_type, Keyword.Type),
|
||||
# Exception handling
|
||||
(r'(?i)\b(?:Try|Catch|Throw)\b', Keyword.Reserved),
|
||||
(r'Throwable', Name.Exception),
|
||||
# Builtins
|
||||
(r'(?i)\b(?:Null|True|False)\b', Name.Builtin),
|
||||
(r'(?i)\b(?:Self|Super)\b', Name.Builtin.Pseudo),
|
||||
(r'\b(?:HOST|LANG|TARGET|CONFIG)\b', Name.Constant),
|
||||
# Keywords
|
||||
(r'(?i)^(Import)(\s+)(.*)(\n)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Namespace, Text)),
|
||||
(r'(?i)^Strict\b.*\n', Keyword.Reserved),
|
||||
(r'(?i)(Const|Local|Global|Field)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text), 'variables'),
|
||||
(r'(?i)(New|Class|Interface|Extends|Implements)(\s+)',
|
||||
bygroups(Keyword.Reserved, Text), 'classname'),
|
||||
(r'(?i)(Function|Method)(\s+)',
|
||||
bygroups(Keyword.Reserved, Text), 'funcname'),
|
||||
(r'(?i)(?:End|Return|Public|Private|Extern|Property|'
|
||||
r'Final|Abstract)\b', Keyword.Reserved),
|
||||
# Flow Control stuff
|
||||
(r'(?i)(?:If|Then|Else|ElseIf|EndIf|'
|
||||
r'Select|Case|Default|'
|
||||
r'While|Wend|'
|
||||
r'Repeat|Until|Forever|'
|
||||
r'For|To|Until|Step|EachIn|Next|'
|
||||
r'Exit|Continue)\s+', Keyword.Reserved),
|
||||
# not used yet
|
||||
(r'(?i)\b(?:Module|Inline)\b', Keyword.Reserved),
|
||||
# Array
|
||||
(r'[\[\]]', Punctuation),
|
||||
# Other
|
||||
(r'<=|>=|<>|\*=|/=|\+=|-=|&=|~=|\|=|[-&*/^+=<>|~]', Operator),
|
||||
(r'(?i)(?:Not|Mod|Shl|Shr|And|Or)', Operator.Word),
|
||||
(r'[(){}!#,.:]', Punctuation),
|
||||
# catch the rest
|
||||
(r'%s\b' % name_constant, Name.Constant),
|
||||
(r'%s\b' % name_function, Name.Function),
|
||||
(r'%s\b' % name_variable, Name.Variable),
|
||||
],
|
||||
'funcname': [
|
||||
(r'(?i)%s\b' % name_function, Name.Function),
|
||||
(r':', Punctuation, 'classname'),
|
||||
(r'\s+', Text),
|
||||
(r'\(', Punctuation, 'variables'),
|
||||
(r'\)', Punctuation, '#pop')
|
||||
],
|
||||
'classname': [
|
||||
(r'%s\.' % name_module, Name.Namespace),
|
||||
(r'%s\b' % keyword_type, Keyword.Type),
|
||||
(r'%s\b' % name_class, Name.Class),
|
||||
# array (of given size)
|
||||
(r'(\[)(\s*)(\d*)(\s*)(\])',
|
||||
bygroups(Punctuation, Text, Number.Integer, Text, Punctuation)),
|
||||
# generics
|
||||
(r'\s+(?!<)', Text, '#pop'),
|
||||
(r'<', Punctuation, '#push'),
|
||||
(r'>', Punctuation, '#pop'),
|
||||
(r'\n', Text, '#pop'),
|
||||
default('#pop')
|
||||
],
|
||||
'variables': [
|
||||
(r'%s\b' % name_constant, Name.Constant),
|
||||
(r'%s\b' % name_variable, Name.Variable),
|
||||
(r'%s' % keyword_type_special, Keyword.Type),
|
||||
(r'\s+', Text),
|
||||
(r':', Punctuation, 'classname'),
|
||||
(r',', Punctuation, '#push'),
|
||||
default('#pop')
|
||||
],
|
||||
'string': [
|
||||
(r'[^"~]+', String.Double),
|
||||
(r'~q|~n|~r|~t|~z|~~', String.Escape),
|
||||
(r'"', String.Double, '#pop'),
|
||||
],
|
||||
'comment': [
|
||||
(r'(?i)^#rem.*?', Comment.Multiline, "#push"),
|
||||
(r'(?i)^#end.*?', Comment.Multiline, "#pop"),
|
||||
(r'\n', Comment.Multiline),
|
||||
(r'.+', Comment.Multiline),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CbmBasicV2Lexer(RegexLexer):
|
||||
"""
|
||||
For CBM BASIC V2 sources.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'CBM BASIC V2'
|
||||
aliases = ['cbmbas']
|
||||
filenames = ['*.bas']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'rem.*\n', Comment.Single),
|
||||
(r'\s+', Text),
|
||||
(r'new|run|end|for|to|next|step|go(to|sub)?|on|return|stop|cont'
|
||||
r'|if|then|input#?|read|wait|load|save|verify|poke|sys|print#?'
|
||||
r'|list|clr|cmd|open|close|get#?', Keyword.Reserved),
|
||||
(r'data|restore|dim|let|def|fn', Keyword.Declaration),
|
||||
(r'tab|spc|sgn|int|abs|usr|fre|pos|sqr|rnd|log|exp|cos|sin|tan|atn'
|
||||
r'|peek|len|val|asc|(str|chr|left|right|mid)\$', Name.Builtin),
|
||||
(r'[-+*/^<>=]', Operator),
|
||||
(r'not|and|or', Operator.Word),
|
||||
(r'"[^"\n]*.', String),
|
||||
(r'\d+|[-+]?\d*\.\d*(e[-+]?\d+)?', Number.Float),
|
||||
(r'[(),:;]', Punctuation),
|
||||
(r'\w+[$%]?', Name),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(self, text):
|
||||
# if it starts with a line number, it shouldn't be a "modern" Basic
|
||||
# like VB.net
|
||||
if re.match(r'\d+', text):
|
||||
return 0.2
|
||||
|
||||
|
||||
class QBasicLexer(RegexLexer):
|
||||
"""
|
||||
For
|
||||
`QBasic <http://en.wikipedia.org/wiki/QBasic>`_
|
||||
source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'QBasic'
|
||||
aliases = ['qbasic', 'basic']
|
||||
filenames = ['*.BAS', '*.bas']
|
||||
mimetypes = ['text/basic']
|
||||
|
||||
declarations = ('DATA', 'LET')
|
||||
|
||||
functions = (
|
||||
'ABS', 'ASC', 'ATN', 'CDBL', 'CHR$', 'CINT', 'CLNG',
|
||||
'COMMAND$', 'COS', 'CSNG', 'CSRLIN', 'CVD', 'CVDMBF', 'CVI',
|
||||
'CVL', 'CVS', 'CVSMBF', 'DATE$', 'ENVIRON$', 'EOF', 'ERDEV',
|
||||
'ERDEV$', 'ERL', 'ERR', 'EXP', 'FILEATTR', 'FIX', 'FRE',
|
||||
'FREEFILE', 'HEX$', 'INKEY$', 'INP', 'INPUT$', 'INSTR', 'INT',
|
||||
'IOCTL$', 'LBOUND', 'LCASE$', 'LEFT$', 'LEN', 'LOC', 'LOF',
|
||||
'LOG', 'LPOS', 'LTRIM$', 'MID$', 'MKD$', 'MKDMBF$', 'MKI$',
|
||||
'MKL$', 'MKS$', 'MKSMBF$', 'OCT$', 'PEEK', 'PEN', 'PLAY',
|
||||
'PMAP', 'POINT', 'POS', 'RIGHT$', 'RND', 'RTRIM$', 'SADD',
|
||||
'SCREEN', 'SEEK', 'SETMEM', 'SGN', 'SIN', 'SPACE$', 'SPC',
|
||||
'SQR', 'STICK', 'STR$', 'STRIG', 'STRING$', 'TAB', 'TAN',
|
||||
'TIME$', 'TIMER', 'UBOUND', 'UCASE$', 'VAL', 'VARPTR',
|
||||
'VARPTR$', 'VARSEG'
|
||||
)
|
||||
|
||||
metacommands = ('$DYNAMIC', '$INCLUDE', '$STATIC')
|
||||
|
||||
operators = ('AND', 'EQV', 'IMP', 'NOT', 'OR', 'XOR')
|
||||
|
||||
statements = (
|
||||
'BEEP', 'BLOAD', 'BSAVE', 'CALL', 'CALL ABSOLUTE',
|
||||
'CALL INTERRUPT', 'CALLS', 'CHAIN', 'CHDIR', 'CIRCLE', 'CLEAR',
|
||||
'CLOSE', 'CLS', 'COLOR', 'COM', 'COMMON', 'CONST', 'DATA',
|
||||
'DATE$', 'DECLARE', 'DEF FN', 'DEF SEG', 'DEFDBL', 'DEFINT',
|
||||
'DEFLNG', 'DEFSNG', 'DEFSTR', 'DEF', 'DIM', 'DO', 'LOOP',
|
||||
'DRAW', 'END', 'ENVIRON', 'ERASE', 'ERROR', 'EXIT', 'FIELD',
|
||||
'FILES', 'FOR', 'NEXT', 'FUNCTION', 'GET', 'GOSUB', 'GOTO',
|
||||
'IF', 'THEN', 'INPUT', 'INPUT #', 'IOCTL', 'KEY', 'KEY',
|
||||
'KILL', 'LET', 'LINE', 'LINE INPUT', 'LINE INPUT #', 'LOCATE',
|
||||
'LOCK', 'UNLOCK', 'LPRINT', 'LSET', 'MID$', 'MKDIR', 'NAME',
|
||||
'ON COM', 'ON ERROR', 'ON KEY', 'ON PEN', 'ON PLAY',
|
||||
'ON STRIG', 'ON TIMER', 'ON UEVENT', 'ON', 'OPEN', 'OPEN COM',
|
||||
'OPTION BASE', 'OUT', 'PAINT', 'PALETTE', 'PCOPY', 'PEN',
|
||||
'PLAY', 'POKE', 'PRESET', 'PRINT', 'PRINT #', 'PRINT USING',
|
||||
'PSET', 'PUT', 'PUT', 'RANDOMIZE', 'READ', 'REDIM', 'REM',
|
||||
'RESET', 'RESTORE', 'RESUME', 'RETURN', 'RMDIR', 'RSET', 'RUN',
|
||||
'SCREEN', 'SEEK', 'SELECT CASE', 'SHARED', 'SHELL', 'SLEEP',
|
||||
'SOUND', 'STATIC', 'STOP', 'STRIG', 'SUB', 'SWAP', 'SYSTEM',
|
||||
'TIME$', 'TIMER', 'TROFF', 'TRON', 'TYPE', 'UEVENT', 'UNLOCK',
|
||||
'VIEW', 'WAIT', 'WHILE', 'WEND', 'WIDTH', 'WINDOW', 'WRITE'
|
||||
)
|
||||
|
||||
keywords = (
|
||||
'ACCESS', 'ALIAS', 'ANY', 'APPEND', 'AS', 'BASE', 'BINARY',
|
||||
'BYVAL', 'CASE', 'CDECL', 'DOUBLE', 'ELSE', 'ELSEIF', 'ENDIF',
|
||||
'INTEGER', 'IS', 'LIST', 'LOCAL', 'LONG', 'LOOP', 'MOD',
|
||||
'NEXT', 'OFF', 'ON', 'OUTPUT', 'RANDOM', 'SIGNAL', 'SINGLE',
|
||||
'STEP', 'STRING', 'THEN', 'TO', 'UNTIL', 'USING', 'WEND'
|
||||
)
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n+', Text),
|
||||
(r'\s+', Text.Whitespace),
|
||||
(r'^(\s*)(\d*)(\s*)(REM .*)$',
|
||||
bygroups(Text.Whitespace, Name.Label, Text.Whitespace,
|
||||
Comment.Single)),
|
||||
(r'^(\s*)(\d+)(\s*)',
|
||||
bygroups(Text.Whitespace, Name.Label, Text.Whitespace)),
|
||||
(r'(?=[\s]*)(\w+)(?=[\s]*=)', Name.Variable.Global),
|
||||
(r'(?=[^"]*)\'.*$', Comment.Single),
|
||||
(r'"[^\n"]*"', String.Double),
|
||||
(r'(END)(\s+)(FUNCTION|IF|SELECT|SUB)',
|
||||
bygroups(Keyword.Reserved, Text.Whitespace, Keyword.Reserved)),
|
||||
(r'(DECLARE)(\s+)([A-Z]+)(\s+)(\S+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace, Name.Variable,
|
||||
Text.Whitespace, Name)),
|
||||
(r'(DIM)(\s+)(SHARED)(\s+)([^\s(]+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace, Name.Variable,
|
||||
Text.Whitespace, Name.Variable.Global)),
|
||||
(r'(DIM)(\s+)([^\s(]+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace, Name.Variable.Global)),
|
||||
(r'^(\s*)([a-zA-Z_]+)(\s*)(\=)',
|
||||
bygroups(Text.Whitespace, Name.Variable.Global, Text.Whitespace,
|
||||
Operator)),
|
||||
(r'(GOTO|GOSUB)(\s+)(\w+\:?)',
|
||||
bygroups(Keyword.Reserved, Text.Whitespace, Name.Label)),
|
||||
(r'(SUB)(\s+)(\w+\:?)',
|
||||
bygroups(Keyword.Reserved, Text.Whitespace, Name.Label)),
|
||||
include('declarations'),
|
||||
include('functions'),
|
||||
include('metacommands'),
|
||||
include('operators'),
|
||||
include('statements'),
|
||||
include('keywords'),
|
||||
(r'[a-zA-Z_]\w*[$@#&!]', Name.Variable.Global),
|
||||
(r'[a-zA-Z_]\w*\:', Name.Label),
|
||||
(r'\-?\d*\.\d+[@|#]?', Number.Float),
|
||||
(r'\-?\d+[@|#]', Number.Float),
|
||||
(r'\-?\d+#?', Number.Integer.Long),
|
||||
(r'\-?\d+#?', Number.Integer),
|
||||
(r'!=|==|:=|\.=|<<|>>|[-~+/\\*%=<>&^|?:!.]', Operator),
|
||||
(r'[\[\]{}(),;]', Punctuation),
|
||||
(r'[\w]+', Name.Variable.Global),
|
||||
],
|
||||
# can't use regular \b because of X$()
|
||||
# XXX: use words() here
|
||||
'declarations': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, declarations)),
|
||||
Keyword.Declaration),
|
||||
],
|
||||
'functions': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, functions)),
|
||||
Keyword.Reserved),
|
||||
],
|
||||
'metacommands': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, metacommands)),
|
||||
Keyword.Constant),
|
||||
],
|
||||
'operators': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, operators)), Operator.Word),
|
||||
],
|
||||
'statements': [
|
||||
(r'\b(%s)\b' % '|'.join(map(re.escape, statements)),
|
||||
Keyword.Reserved),
|
||||
],
|
||||
'keywords': [
|
||||
(r'\b(%s)\b' % '|'.join(keywords), Keyword),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if '$DYNAMIC' in text or '$STATIC' in text:
|
||||
return 0.9
|
||||
@ -1,592 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.business
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for "business-oriented" languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words, bygroups
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error
|
||||
|
||||
from pygments.lexers._openedge_builtins import OPENEDGEKEYWORDS
|
||||
|
||||
__all__ = ['CobolLexer', 'CobolFreeformatLexer', 'ABAPLexer', 'OpenEdgeLexer',
|
||||
'GoodDataCLLexer', 'MaqlLexer']
|
||||
|
||||
|
||||
class CobolLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for OpenCOBOL code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'COBOL'
|
||||
aliases = ['cobol']
|
||||
filenames = ['*.cob', '*.COB', '*.cpy', '*.CPY']
|
||||
mimetypes = ['text/x-cobol']
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
# Data Types: by PICTURE and USAGE
|
||||
# Operators: **, *, +, -, /, <, >, <=, >=, =, <>
|
||||
# Logical (?): NOT, AND, OR
|
||||
|
||||
# Reserved words:
|
||||
# http://opencobol.add1tocobol.com/#reserved-words
|
||||
# Intrinsics:
|
||||
# http://opencobol.add1tocobol.com/#does-opencobol-implement-any-intrinsic-functions
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('comment'),
|
||||
include('strings'),
|
||||
include('core'),
|
||||
include('nums'),
|
||||
(r'[a-z0-9]([\w\-]*[a-z0-9]+)?', Name.Variable),
|
||||
# (r'[\s]+', Text),
|
||||
(r'[ \t]+', Text),
|
||||
],
|
||||
'comment': [
|
||||
(r'(^.{6}[*/].*\n|^.{6}|\*>.*\n)', Comment),
|
||||
],
|
||||
'core': [
|
||||
# Figurative constants
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(ALL\s+)?'
|
||||
r'((ZEROES)|(HIGH-VALUE|LOW-VALUE|QUOTE|SPACE|ZERO)(S)?)'
|
||||
r'\s*($|(?=[^0-9a-z_\-]))',
|
||||
Name.Constant),
|
||||
|
||||
# Reserved words STATEMENTS and other bolds
|
||||
(words((
|
||||
'ACCEPT', 'ADD', 'ALLOCATE', 'CALL', 'CANCEL', 'CLOSE', 'COMPUTE',
|
||||
'CONFIGURATION', 'CONTINUE', 'DATA', 'DELETE', 'DISPLAY', 'DIVIDE',
|
||||
'DIVISION', 'ELSE', 'END', 'END-ACCEPT',
|
||||
'END-ADD', 'END-CALL', 'END-COMPUTE', 'END-DELETE', 'END-DISPLAY',
|
||||
'END-DIVIDE', 'END-EVALUATE', 'END-IF', 'END-MULTIPLY', 'END-OF-PAGE',
|
||||
'END-PERFORM', 'END-READ', 'END-RETURN', 'END-REWRITE', 'END-SEARCH',
|
||||
'END-START', 'END-STRING', 'END-SUBTRACT', 'END-UNSTRING', 'END-WRITE',
|
||||
'ENVIRONMENT', 'EVALUATE', 'EXIT', 'FD', 'FILE', 'FILE-CONTROL', 'FOREVER',
|
||||
'FREE', 'GENERATE', 'GO', 'GOBACK', 'IDENTIFICATION', 'IF', 'INITIALIZE',
|
||||
'INITIATE', 'INPUT-OUTPUT', 'INSPECT', 'INVOKE', 'I-O-CONTROL', 'LINKAGE',
|
||||
'LOCAL-STORAGE', 'MERGE', 'MOVE', 'MULTIPLY', 'OPEN', 'PERFORM',
|
||||
'PROCEDURE', 'PROGRAM-ID', 'RAISE', 'READ', 'RELEASE', 'RESUME',
|
||||
'RETURN', 'REWRITE', 'SCREEN', 'SD', 'SEARCH', 'SECTION', 'SET',
|
||||
'SORT', 'START', 'STOP', 'STRING', 'SUBTRACT', 'SUPPRESS',
|
||||
'TERMINATE', 'THEN', 'UNLOCK', 'UNSTRING', 'USE', 'VALIDATE',
|
||||
'WORKING-STORAGE', 'WRITE'), prefix=r'(^|(?<=[^0-9a-z_\-]))',
|
||||
suffix=r'\s*($|(?=[^0-9a-z_\-]))'),
|
||||
Keyword.Reserved),
|
||||
|
||||
# Reserved words
|
||||
(words((
|
||||
'ACCESS', 'ADDRESS', 'ADVANCING', 'AFTER', 'ALL',
|
||||
'ALPHABET', 'ALPHABETIC', 'ALPHABETIC-LOWER', 'ALPHABETIC-UPPER',
|
||||
'ALPHANUMERIC', 'ALPHANUMERIC-EDITED', 'ALSO', 'ALTER', 'ALTERNATE'
|
||||
'ANY', 'ARE', 'AREA', 'AREAS', 'ARGUMENT-NUMBER', 'ARGUMENT-VALUE', 'AS',
|
||||
'ASCENDING', 'ASSIGN', 'AT', 'AUTO', 'AUTO-SKIP', 'AUTOMATIC', 'AUTOTERMINATE',
|
||||
'BACKGROUND-COLOR', 'BASED', 'BEEP', 'BEFORE', 'BELL',
|
||||
'BLANK', 'BLINK', 'BLOCK', 'BOTTOM', 'BY', 'BYTE-LENGTH', 'CHAINING',
|
||||
'CHARACTER', 'CHARACTERS', 'CLASS', 'CODE', 'CODE-SET', 'COL', 'COLLATING',
|
||||
'COLS', 'COLUMN', 'COLUMNS', 'COMMA', 'COMMAND-LINE', 'COMMIT', 'COMMON',
|
||||
'CONSTANT', 'CONTAINS', 'CONTENT', 'CONTROL',
|
||||
'CONTROLS', 'CONVERTING', 'COPY', 'CORR', 'CORRESPONDING', 'COUNT', 'CRT',
|
||||
'CURRENCY', 'CURSOR', 'CYCLE', 'DATE', 'DAY', 'DAY-OF-WEEK', 'DE', 'DEBUGGING',
|
||||
'DECIMAL-POINT', 'DECLARATIVES', 'DEFAULT', 'DELIMITED',
|
||||
'DELIMITER', 'DEPENDING', 'DESCENDING', 'DETAIL', 'DISK',
|
||||
'DOWN', 'DUPLICATES', 'DYNAMIC', 'EBCDIC',
|
||||
'ENTRY', 'ENVIRONMENT-NAME', 'ENVIRONMENT-VALUE', 'EOL', 'EOP',
|
||||
'EOS', 'ERASE', 'ERROR', 'ESCAPE', 'EXCEPTION',
|
||||
'EXCLUSIVE', 'EXTEND', 'EXTERNAL',
|
||||
'FILE-ID', 'FILLER', 'FINAL', 'FIRST', 'FIXED', 'FLOAT-LONG', 'FLOAT-SHORT',
|
||||
'FOOTING', 'FOR', 'FOREGROUND-COLOR', 'FORMAT', 'FROM', 'FULL', 'FUNCTION',
|
||||
'FUNCTION-ID', 'GIVING', 'GLOBAL', 'GROUP',
|
||||
'HEADING', 'HIGHLIGHT', 'I-O', 'ID',
|
||||
'IGNORE', 'IGNORING', 'IN', 'INDEX', 'INDEXED', 'INDICATE',
|
||||
'INITIAL', 'INITIALIZED', 'INPUT',
|
||||
'INTO', 'INTRINSIC', 'INVALID', 'IS', 'JUST', 'JUSTIFIED', 'KEY', 'LABEL',
|
||||
'LAST', 'LEADING', 'LEFT', 'LENGTH', 'LIMIT', 'LIMITS', 'LINAGE',
|
||||
'LINAGE-COUNTER', 'LINE', 'LINES', 'LOCALE', 'LOCK',
|
||||
'LOWLIGHT', 'MANUAL', 'MEMORY', 'MINUS', 'MODE',
|
||||
'MULTIPLE', 'NATIONAL', 'NATIONAL-EDITED', 'NATIVE',
|
||||
'NEGATIVE', 'NEXT', 'NO', 'NULL', 'NULLS', 'NUMBER', 'NUMBERS', 'NUMERIC',
|
||||
'NUMERIC-EDITED', 'OBJECT-COMPUTER', 'OCCURS', 'OF', 'OFF', 'OMITTED', 'ON', 'ONLY',
|
||||
'OPTIONAL', 'ORDER', 'ORGANIZATION', 'OTHER', 'OUTPUT', 'OVERFLOW',
|
||||
'OVERLINE', 'PACKED-DECIMAL', 'PADDING', 'PAGE', 'PARAGRAPH',
|
||||
'PLUS', 'POINTER', 'POSITION', 'POSITIVE', 'PRESENT', 'PREVIOUS',
|
||||
'PRINTER', 'PRINTING', 'PROCEDURE-POINTER', 'PROCEDURES',
|
||||
'PROCEED', 'PROGRAM', 'PROGRAM-POINTER', 'PROMPT', 'QUOTE',
|
||||
'QUOTES', 'RANDOM', 'RD', 'RECORD', 'RECORDING', 'RECORDS', 'RECURSIVE',
|
||||
'REDEFINES', 'REEL', 'REFERENCE', 'RELATIVE', 'REMAINDER', 'REMOVAL',
|
||||
'RENAMES', 'REPLACING', 'REPORT', 'REPORTING', 'REPORTS', 'REPOSITORY',
|
||||
'REQUIRED', 'RESERVE', 'RETURNING', 'REVERSE-VIDEO', 'REWIND',
|
||||
'RIGHT', 'ROLLBACK', 'ROUNDED', 'RUN', 'SAME', 'SCROLL',
|
||||
'SECURE', 'SEGMENT-LIMIT', 'SELECT', 'SENTENCE', 'SEPARATE',
|
||||
'SEQUENCE', 'SEQUENTIAL', 'SHARING', 'SIGN', 'SIGNED', 'SIGNED-INT',
|
||||
'SIGNED-LONG', 'SIGNED-SHORT', 'SIZE', 'SORT-MERGE', 'SOURCE',
|
||||
'SOURCE-COMPUTER', 'SPECIAL-NAMES', 'STANDARD',
|
||||
'STANDARD-1', 'STANDARD-2', 'STATUS', 'SUM',
|
||||
'SYMBOLIC', 'SYNC', 'SYNCHRONIZED', 'TALLYING', 'TAPE',
|
||||
'TEST', 'THROUGH', 'THRU', 'TIME', 'TIMES', 'TO', 'TOP', 'TRAILING',
|
||||
'TRANSFORM', 'TYPE', 'UNDERLINE', 'UNIT', 'UNSIGNED',
|
||||
'UNSIGNED-INT', 'UNSIGNED-LONG', 'UNSIGNED-SHORT', 'UNTIL', 'UP',
|
||||
'UPDATE', 'UPON', 'USAGE', 'USING', 'VALUE', 'VALUES', 'VARYING',
|
||||
'WAIT', 'WHEN', 'WITH', 'WORDS', 'YYYYDDD', 'YYYYMMDD'),
|
||||
prefix=r'(^|(?<=[^0-9a-z_\-]))', suffix=r'\s*($|(?=[^0-9a-z_\-]))'),
|
||||
Keyword.Pseudo),
|
||||
|
||||
# inactive reserved words
|
||||
(words((
|
||||
'ACTIVE-CLASS', 'ALIGNED', 'ANYCASE', 'ARITHMETIC', 'ATTRIBUTE', 'B-AND',
|
||||
'B-NOT', 'B-OR', 'B-XOR', 'BIT', 'BOOLEAN', 'CD', 'CENTER', 'CF', 'CH', 'CHAIN', 'CLASS-ID',
|
||||
'CLASSIFICATION', 'COMMUNICATION', 'CONDITION', 'DATA-POINTER',
|
||||
'DESTINATION', 'DISABLE', 'EC', 'EGI', 'EMI', 'ENABLE', 'END-RECEIVE',
|
||||
'ENTRY-CONVENTION', 'EO', 'ESI', 'EXCEPTION-OBJECT', 'EXPANDS', 'FACTORY',
|
||||
'FLOAT-BINARY-16', 'FLOAT-BINARY-34', 'FLOAT-BINARY-7',
|
||||
'FLOAT-DECIMAL-16', 'FLOAT-DECIMAL-34', 'FLOAT-EXTENDED', 'FORMAT',
|
||||
'FUNCTION-POINTER', 'GET', 'GROUP-USAGE', 'IMPLEMENTS', 'INFINITY',
|
||||
'INHERITS', 'INTERFACE', 'INTERFACE-ID', 'INVOKE', 'LC_ALL', 'LC_COLLATE',
|
||||
'LC_CTYPE', 'LC_MESSAGES', 'LC_MONETARY', 'LC_NUMERIC', 'LC_TIME',
|
||||
'LINE-COUNTER', 'MESSAGE', 'METHOD', 'METHOD-ID', 'NESTED', 'NONE', 'NORMAL',
|
||||
'OBJECT', 'OBJECT-REFERENCE', 'OPTIONS', 'OVERRIDE', 'PAGE-COUNTER', 'PF', 'PH',
|
||||
'PROPERTY', 'PROTOTYPE', 'PURGE', 'QUEUE', 'RAISE', 'RAISING', 'RECEIVE',
|
||||
'RELATION', 'REPLACE', 'REPRESENTS-NOT-A-NUMBER', 'RESET', 'RESUME', 'RETRY',
|
||||
'RF', 'RH', 'SECONDS', 'SEGMENT', 'SELF', 'SEND', 'SOURCES', 'STATEMENT', 'STEP',
|
||||
'STRONG', 'SUB-QUEUE-1', 'SUB-QUEUE-2', 'SUB-QUEUE-3', 'SUPER', 'SYMBOL',
|
||||
'SYSTEM-DEFAULT', 'TABLE', 'TERMINAL', 'TEXT', 'TYPEDEF', 'UCS-4', 'UNIVERSAL',
|
||||
'USER-DEFAULT', 'UTF-16', 'UTF-8', 'VAL-STATUS', 'VALID', 'VALIDATE',
|
||||
'VALIDATE-STATUS'),
|
||||
prefix=r'(^|(?<=[^0-9a-z_\-]))', suffix=r'\s*($|(?=[^0-9a-z_\-]))'),
|
||||
Error),
|
||||
|
||||
# Data Types
|
||||
(r'(^|(?<=[^0-9a-z_\-]))'
|
||||
r'(PIC\s+.+?(?=(\s|\.\s))|PICTURE\s+.+?(?=(\s|\.\s))|'
|
||||
r'(COMPUTATIONAL)(-[1-5X])?|(COMP)(-[1-5X])?|'
|
||||
r'BINARY-C-LONG|'
|
||||
r'BINARY-CHAR|BINARY-DOUBLE|BINARY-LONG|BINARY-SHORT|'
|
||||
r'BINARY)\s*($|(?=[^0-9a-z_\-]))', Keyword.Type),
|
||||
|
||||
# Operators
|
||||
(r'(\*\*|\*|\+|-|/|<=|>=|<|>|==|/=|=)', Operator),
|
||||
|
||||
# (r'(::)', Keyword.Declaration),
|
||||
|
||||
(r'([(),;:&%.])', Punctuation),
|
||||
|
||||
# Intrinsics
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(ABS|ACOS|ANNUITY|ASIN|ATAN|BYTE-LENGTH|'
|
||||
r'CHAR|COMBINED-DATETIME|CONCATENATE|COS|CURRENT-DATE|'
|
||||
r'DATE-OF-INTEGER|DATE-TO-YYYYMMDD|DAY-OF-INTEGER|DAY-TO-YYYYDDD|'
|
||||
r'EXCEPTION-(?:FILE|LOCATION|STATEMENT|STATUS)|EXP10|EXP|E|'
|
||||
r'FACTORIAL|FRACTION-PART|INTEGER-OF-(?:DATE|DAY|PART)|INTEGER|'
|
||||
r'LENGTH|LOCALE-(?:DATE|TIME(?:-FROM-SECONDS)?)|LOG(?:10)?|'
|
||||
r'LOWER-CASE|MAX|MEAN|MEDIAN|MIDRANGE|MIN|MOD|NUMVAL(?:-C)?|'
|
||||
r'ORD(?:-MAX|-MIN)?|PI|PRESENT-VALUE|RANDOM|RANGE|REM|REVERSE|'
|
||||
r'SECONDS-FROM-FORMATTED-TIME|SECONDS-PAST-MIDNIGHT|SIGN|SIN|SQRT|'
|
||||
r'STANDARD-DEVIATION|STORED-CHAR-LENGTH|SUBSTITUTE(?:-CASE)?|'
|
||||
r'SUM|TAN|TEST-DATE-YYYYMMDD|TEST-DAY-YYYYDDD|TRIM|'
|
||||
r'UPPER-CASE|VARIANCE|WHEN-COMPILED|YEAR-TO-YYYY)\s*'
|
||||
r'($|(?=[^0-9a-z_\-]))', Name.Function),
|
||||
|
||||
# Booleans
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(true|false)\s*($|(?=[^0-9a-z_\-]))', Name.Builtin),
|
||||
# Comparing Operators
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(equal|equals|ne|lt|le|gt|ge|'
|
||||
r'greater|less|than|not|and|or)\s*($|(?=[^0-9a-z_\-]))', Operator.Word),
|
||||
],
|
||||
|
||||
# \"[^\"\n]*\"|\'[^\'\n]*\'
|
||||
'strings': [
|
||||
# apparently strings can be delimited by EOL if they are continued
|
||||
# in the next line
|
||||
(r'"[^"\n]*("|\n)', String.Double),
|
||||
(r"'[^'\n]*('|\n)", String.Single),
|
||||
],
|
||||
|
||||
'nums': [
|
||||
(r'\d+(\s*|\.$|$)', Number.Integer),
|
||||
(r'[+-]?\d*\.\d+(E[-+]?\d+)?', Number.Float),
|
||||
(r'[+-]?\d+\.\d*(E[-+]?\d+)?', Number.Float),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CobolFreeformatLexer(CobolLexer):
|
||||
"""
|
||||
Lexer for Free format OpenCOBOL code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'COBOLFree'
|
||||
aliases = ['cobolfree']
|
||||
filenames = ['*.cbl', '*.CBL']
|
||||
mimetypes = []
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'comment': [
|
||||
(r'(\*>.*\n|^\w*\*.*$)', Comment),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ABAPLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for ABAP, SAP's integrated language.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'ABAP'
|
||||
aliases = ['abap']
|
||||
filenames = ['*.abap']
|
||||
mimetypes = ['text/x-abap']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'common': [
|
||||
(r'\s+', Text),
|
||||
(r'^\*.*$', Comment.Single),
|
||||
(r'\".*?\n', Comment.Single),
|
||||
],
|
||||
'variable-names': [
|
||||
(r'<\S+>', Name.Variable),
|
||||
(r'\w[\w~]*(?:(\[\])|->\*)?', Name.Variable),
|
||||
],
|
||||
'root': [
|
||||
include('common'),
|
||||
# function calls
|
||||
(r'(CALL\s+(?:BADI|CUSTOMER-FUNCTION|FUNCTION))(\s+)(\'?\S+\'?)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(CALL\s+(?:DIALOG|SCREEN|SUBSCREEN|SELECTION-SCREEN|'
|
||||
r'TRANSACTION|TRANSFORMATION))\b',
|
||||
Keyword),
|
||||
(r'(FORM|PERFORM)(\s+)(\w+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(PERFORM)(\s+)(\()(\w+)(\))',
|
||||
bygroups(Keyword, Text, Punctuation, Name.Variable, Punctuation)),
|
||||
(r'(MODULE)(\s+)(\S+)(\s+)(INPUT|OUTPUT)',
|
||||
bygroups(Keyword, Text, Name.Function, Text, Keyword)),
|
||||
|
||||
# method implementation
|
||||
(r'(METHOD)(\s+)([\w~]+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
# method calls
|
||||
(r'(\s+)([\w\-]+)([=\-]>)([\w\-~]+)',
|
||||
bygroups(Text, Name.Variable, Operator, Name.Function)),
|
||||
# call methodnames returning style
|
||||
(r'(?<=(=|-)>)([\w\-~]+)(?=\()', Name.Function),
|
||||
|
||||
# keywords with dashes in them.
|
||||
# these need to be first, because for instance the -ID part
|
||||
# of MESSAGE-ID wouldn't get highlighted if MESSAGE was
|
||||
# first in the list of keywords.
|
||||
(r'(ADD-CORRESPONDING|AUTHORITY-CHECK|'
|
||||
r'CLASS-DATA|CLASS-EVENTS|CLASS-METHODS|CLASS-POOL|'
|
||||
r'DELETE-ADJACENT|DIVIDE-CORRESPONDING|'
|
||||
r'EDITOR-CALL|ENHANCEMENT-POINT|ENHANCEMENT-SECTION|EXIT-COMMAND|'
|
||||
r'FIELD-GROUPS|FIELD-SYMBOLS|FUNCTION-POOL|'
|
||||
r'INTERFACE-POOL|INVERTED-DATE|'
|
||||
r'LOAD-OF-PROGRAM|LOG-POINT|'
|
||||
r'MESSAGE-ID|MOVE-CORRESPONDING|MULTIPLY-CORRESPONDING|'
|
||||
r'NEW-LINE|NEW-PAGE|NEW-SECTION|NO-EXTENSION|'
|
||||
r'OUTPUT-LENGTH|PRINT-CONTROL|'
|
||||
r'SELECT-OPTIONS|START-OF-SELECTION|SUBTRACT-CORRESPONDING|'
|
||||
r'SYNTAX-CHECK|SYSTEM-EXCEPTIONS|'
|
||||
r'TYPE-POOL|TYPE-POOLS'
|
||||
r')\b', Keyword),
|
||||
|
||||
# keyword kombinations
|
||||
(r'CREATE\s+(PUBLIC|PRIVATE|DATA|OBJECT)|'
|
||||
r'((PUBLIC|PRIVATE|PROTECTED)\s+SECTION|'
|
||||
r'(TYPE|LIKE)(\s+(LINE\s+OF|REF\s+TO|'
|
||||
r'(SORTED|STANDARD|HASHED)\s+TABLE\s+OF))?|'
|
||||
r'FROM\s+(DATABASE|MEMORY)|CALL\s+METHOD|'
|
||||
r'(GROUP|ORDER) BY|HAVING|SEPARATED BY|'
|
||||
r'GET\s+(BADI|BIT|CURSOR|DATASET|LOCALE|PARAMETER|'
|
||||
r'PF-STATUS|(PROPERTY|REFERENCE)\s+OF|'
|
||||
r'RUN\s+TIME|TIME\s+(STAMP)?)?|'
|
||||
r'SET\s+(BIT|BLANK\s+LINES|COUNTRY|CURSOR|DATASET|EXTENDED\s+CHECK|'
|
||||
r'HANDLER|HOLD\s+DATA|LANGUAGE|LEFT\s+SCROLL-BOUNDARY|'
|
||||
r'LOCALE|MARGIN|PARAMETER|PF-STATUS|PROPERTY\s+OF|'
|
||||
r'RUN\s+TIME\s+(ANALYZER|CLOCK\s+RESOLUTION)|SCREEN|'
|
||||
r'TITLEBAR|UPADTE\s+TASK\s+LOCAL|USER-COMMAND)|'
|
||||
r'CONVERT\s+((INVERTED-)?DATE|TIME|TIME\s+STAMP|TEXT)|'
|
||||
r'(CLOSE|OPEN)\s+(DATASET|CURSOR)|'
|
||||
r'(TO|FROM)\s+(DATA BUFFER|INTERNAL TABLE|MEMORY ID|'
|
||||
r'DATABASE|SHARED\s+(MEMORY|BUFFER))|'
|
||||
r'DESCRIBE\s+(DISTANCE\s+BETWEEN|FIELD|LIST|TABLE)|'
|
||||
r'FREE\s(MEMORY|OBJECT)?|'
|
||||
r'PROCESS\s+(BEFORE\s+OUTPUT|AFTER\s+INPUT|'
|
||||
r'ON\s+(VALUE-REQUEST|HELP-REQUEST))|'
|
||||
r'AT\s+(LINE-SELECTION|USER-COMMAND|END\s+OF|NEW)|'
|
||||
r'AT\s+SELECTION-SCREEN(\s+(ON(\s+(BLOCK|(HELP|VALUE)-REQUEST\s+FOR|'
|
||||
r'END\s+OF|RADIOBUTTON\s+GROUP))?|OUTPUT))?|'
|
||||
r'SELECTION-SCREEN:?\s+((BEGIN|END)\s+OF\s+((TABBED\s+)?BLOCK|LINE|'
|
||||
r'SCREEN)|COMMENT|FUNCTION\s+KEY|'
|
||||
r'INCLUDE\s+BLOCKS|POSITION|PUSHBUTTON|'
|
||||
r'SKIP|ULINE)|'
|
||||
r'LEAVE\s+(LIST-PROCESSING|PROGRAM|SCREEN|'
|
||||
r'TO LIST-PROCESSING|TO TRANSACTION)'
|
||||
r'(ENDING|STARTING)\s+AT|'
|
||||
r'FORMAT\s+(COLOR|INTENSIFIED|INVERSE|HOTSPOT|INPUT|FRAMES|RESET)|'
|
||||
r'AS\s+(CHECKBOX|SUBSCREEN|WINDOW)|'
|
||||
r'WITH\s+(((NON-)?UNIQUE)?\s+KEY|FRAME)|'
|
||||
r'(BEGIN|END)\s+OF|'
|
||||
r'DELETE(\s+ADJACENT\s+DUPLICATES\sFROM)?|'
|
||||
r'COMPARING(\s+ALL\s+FIELDS)?|'
|
||||
r'INSERT(\s+INITIAL\s+LINE\s+INTO|\s+LINES\s+OF)?|'
|
||||
r'IN\s+((BYTE|CHARACTER)\s+MODE|PROGRAM)|'
|
||||
r'END-OF-(DEFINITION|PAGE|SELECTION)|'
|
||||
r'WITH\s+FRAME(\s+TITLE)|'
|
||||
|
||||
# simple kombinations
|
||||
r'AND\s+(MARK|RETURN)|CLIENT\s+SPECIFIED|CORRESPONDING\s+FIELDS\s+OF|'
|
||||
r'IF\s+FOUND|FOR\s+EVENT|INHERITING\s+FROM|LEAVE\s+TO\s+SCREEN|'
|
||||
r'LOOP\s+AT\s+(SCREEN)?|LOWER\s+CASE|MATCHCODE\s+OBJECT|MODIF\s+ID|'
|
||||
r'MODIFY\s+SCREEN|NESTING\s+LEVEL|NO\s+INTERVALS|OF\s+STRUCTURE|'
|
||||
r'RADIOBUTTON\s+GROUP|RANGE\s+OF|REF\s+TO|SUPPRESS DIALOG|'
|
||||
r'TABLE\s+OF|UPPER\s+CASE|TRANSPORTING\s+NO\s+FIELDS|'
|
||||
r'VALUE\s+CHECK|VISIBLE\s+LENGTH|HEADER\s+LINE)\b', Keyword),
|
||||
|
||||
# single word keywords.
|
||||
(r'(^|(?<=(\s|\.)))(ABBREVIATED|ADD|ALIASES|APPEND|ASSERT|'
|
||||
r'ASSIGN(ING)?|AT(\s+FIRST)?|'
|
||||
r'BACK|BLOCK|BREAK-POINT|'
|
||||
r'CASE|CATCH|CHANGING|CHECK|CLASS|CLEAR|COLLECT|COLOR|COMMIT|'
|
||||
r'CREATE|COMMUNICATION|COMPONENTS?|COMPUTE|CONCATENATE|CONDENSE|'
|
||||
r'CONSTANTS|CONTEXTS|CONTINUE|CONTROLS|'
|
||||
r'DATA|DECIMALS|DEFAULT|DEFINE|DEFINITION|DEFERRED|DEMAND|'
|
||||
r'DETAIL|DIRECTORY|DIVIDE|DO|'
|
||||
r'ELSE(IF)?|ENDAT|ENDCASE|ENDCLASS|ENDDO|ENDFORM|ENDFUNCTION|'
|
||||
r'ENDIF|ENDLOOP|ENDMETHOD|ENDMODULE|ENDSELECT|ENDTRY|'
|
||||
r'ENHANCEMENT|EVENTS|EXCEPTIONS|EXIT|EXPORT|EXPORTING|EXTRACT|'
|
||||
r'FETCH|FIELDS?|FIND|FOR|FORM|FORMAT|FREE|FROM|'
|
||||
r'HIDE|'
|
||||
r'ID|IF|IMPORT|IMPLEMENTATION|IMPORTING|IN|INCLUDE|INCLUDING|'
|
||||
r'INDEX|INFOTYPES|INITIALIZATION|INTERFACE|INTERFACES|INTO|'
|
||||
r'LENGTH|LINES|LOAD|LOCAL|'
|
||||
r'JOIN|'
|
||||
r'KEY|'
|
||||
r'MAXIMUM|MESSAGE|METHOD[S]?|MINIMUM|MODULE|MODIFY|MOVE|MULTIPLY|'
|
||||
r'NODES|'
|
||||
r'OBLIGATORY|OF|OFF|ON|OVERLAY|'
|
||||
r'PACK|PARAMETERS|PERCENTAGE|POSITION|PROGRAM|PROVIDE|PUBLIC|PUT|'
|
||||
r'RAISE|RAISING|RANGES|READ|RECEIVE|REFRESH|REJECT|REPORT|RESERVE|'
|
||||
r'RESUME|RETRY|RETURN|RETURNING|RIGHT|ROLLBACK|'
|
||||
r'SCROLL|SEARCH|SELECT|SHIFT|SINGLE|SKIP|SORT|SPLIT|STATICS|STOP|'
|
||||
r'SUBMIT|SUBTRACT|SUM|SUMMARY|SUMMING|SUPPLY|'
|
||||
r'TABLE|TABLES|TIMES|TITLE|TO|TOP-OF-PAGE|TRANSFER|TRANSLATE|TRY|TYPES|'
|
||||
r'ULINE|UNDER|UNPACK|UPDATE|USING|'
|
||||
r'VALUE|VALUES|VIA|'
|
||||
r'WAIT|WHEN|WHERE|WHILE|WITH|WINDOW|WRITE)\b', Keyword),
|
||||
|
||||
# builtins
|
||||
(r'(abs|acos|asin|atan|'
|
||||
r'boolc|boolx|bit_set|'
|
||||
r'char_off|charlen|ceil|cmax|cmin|condense|contains|'
|
||||
r'contains_any_of|contains_any_not_of|concat_lines_of|cos|cosh|'
|
||||
r'count|count_any_of|count_any_not_of|'
|
||||
r'dbmaxlen|distance|'
|
||||
r'escape|exp|'
|
||||
r'find|find_end|find_any_of|find_any_not_of|floor|frac|from_mixed|'
|
||||
r'insert|'
|
||||
r'lines|log|log10|'
|
||||
r'match|matches|'
|
||||
r'nmax|nmin|numofchar|'
|
||||
r'repeat|replace|rescale|reverse|round|'
|
||||
r'segment|shift_left|shift_right|sign|sin|sinh|sqrt|strlen|'
|
||||
r'substring|substring_after|substring_from|substring_before|substring_to|'
|
||||
r'tan|tanh|to_upper|to_lower|to_mixed|translate|trunc|'
|
||||
r'xstrlen)(\()\b', bygroups(Name.Builtin, Punctuation)),
|
||||
|
||||
(r'&[0-9]', Name),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
|
||||
# operators which look like variable names before
|
||||
# parsing variable names.
|
||||
(r'(?<=(\s|.))(AND|EQ|NE|GT|LT|GE|LE|CO|CN|CA|NA|CS|NOT|NS|CP|NP|'
|
||||
r'BYTE-CO|BYTE-CN|BYTE-CA|BYTE-NA|BYTE-CS|BYTE-NS|'
|
||||
r'IS\s+(NOT\s+)?(INITIAL|ASSIGNED|REQUESTED|BOUND))\b', Operator),
|
||||
|
||||
include('variable-names'),
|
||||
|
||||
# standard oparators after variable names,
|
||||
# because < and > are part of field symbols.
|
||||
(r'[?*<>=\-+]', Operator),
|
||||
(r"'(''|[^'])*'", String.Single),
|
||||
(r"`([^`])*`", String.Single),
|
||||
(r'[/;:()\[\],.]', Punctuation)
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class OpenEdgeLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `OpenEdge ABL (formerly Progress)
|
||||
<http://web.progress.com/en/openedge/abl.html>`_ source code.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'OpenEdge ABL'
|
||||
aliases = ['openedge', 'abl', 'progress']
|
||||
filenames = ['*.p', '*.cls']
|
||||
mimetypes = ['text/x-openedge', 'application/x-openedge']
|
||||
|
||||
types = (r'(?i)(^|(?<=[^0-9a-z_\-]))(CHARACTER|CHAR|CHARA|CHARAC|CHARACT|CHARACTE|'
|
||||
r'COM-HANDLE|DATE|DATETIME|DATETIME-TZ|'
|
||||
r'DECIMAL|DEC|DECI|DECIM|DECIMA|HANDLE|'
|
||||
r'INT64|INTEGER|INT|INTE|INTEG|INTEGE|'
|
||||
r'LOGICAL|LONGCHAR|MEMPTR|RAW|RECID|ROWID)\s*($|(?=[^0-9a-z_\-]))')
|
||||
|
||||
keywords = words(OPENEDGEKEYWORDS,
|
||||
prefix=r'(?i)(^|(?<=[^0-9a-z_\-]))',
|
||||
suffix=r'\s*($|(?=[^0-9a-z_\-]))')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'/\*', Comment.Multiline, 'comment'),
|
||||
(r'\{', Comment.Preproc, 'preprocessor'),
|
||||
(r'\s*&.*', Comment.Preproc),
|
||||
(r'0[xX][0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'(?i)(DEFINE|DEF|DEFI|DEFIN)\b', Keyword.Declaration),
|
||||
(types, Keyword.Type),
|
||||
(keywords, Name.Builtin),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\s+', Text),
|
||||
(r'[+*/=-]', Operator),
|
||||
(r'[.:()]', Punctuation),
|
||||
(r'.', Name.Variable), # Lazy catch-all
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
],
|
||||
'preprocessor': [
|
||||
(r'[^{}]', Comment.Preproc),
|
||||
(r'\{', Comment.Preproc, '#push'),
|
||||
(r'\}', Comment.Preproc, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class GoodDataCLLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `GoodData-CL
|
||||
<http://github.com/gooddata/GoodData-CL/raw/master/cli/src/main/resources/\
|
||||
com/gooddata/processor/COMMANDS.txt>`_
|
||||
script files.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'GoodData-CL'
|
||||
aliases = ['gooddata-cl']
|
||||
filenames = ['*.gdc']
|
||||
mimetypes = ['text/x-gooddata-cl']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# Comments
|
||||
(r'#.*', Comment.Single),
|
||||
# Function call
|
||||
(r'[a-z]\w*', Name.Function),
|
||||
# Argument list
|
||||
(r'\(', Punctuation, 'args-list'),
|
||||
# Punctuation
|
||||
(r';', Punctuation),
|
||||
# Space is not significant
|
||||
(r'\s+', Text)
|
||||
],
|
||||
'args-list': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(r',', Punctuation),
|
||||
(r'[a-z]\w*', Name.Variable),
|
||||
(r'=', Operator),
|
||||
(r'"', String, 'string-literal'),
|
||||
(r'[0-9]+(?:\.[0-9]+)?(?:e[+-]?[0-9]{1,3})?', Number),
|
||||
# Space is not significant
|
||||
(r'\s', Text)
|
||||
],
|
||||
'string-literal': [
|
||||
(r'\\[tnrfbae"\\]', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
(r'[^\\"]+', String)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class MaqlLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `GoodData MAQL
|
||||
<https://secure.gooddata.com/docs/html/advanced.metric.tutorial.html>`_
|
||||
scripts.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'MAQL'
|
||||
aliases = ['maql']
|
||||
filenames = ['*.maql']
|
||||
mimetypes = ['text/x-gooddata-maql', 'application/x-gooddata-maql']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# IDENTITY
|
||||
(r'IDENTIFIER\b', Name.Builtin),
|
||||
# IDENTIFIER
|
||||
(r'\{[^}]+\}', Name.Variable),
|
||||
# NUMBER
|
||||
(r'[0-9]+(?:\.[0-9]+)?(?:e[+-]?[0-9]{1,3})?', Number),
|
||||
# STRING
|
||||
(r'"', String, 'string-literal'),
|
||||
# RELATION
|
||||
(r'\<\>|\!\=', Operator),
|
||||
(r'\=|\>\=|\>|\<\=|\<', Operator),
|
||||
# :=
|
||||
(r'\:\=', Operator),
|
||||
# OBJECT
|
||||
(r'\[[^]]+\]', Name.Variable.Class),
|
||||
# keywords
|
||||
(words((
|
||||
'DIMENSION', 'DIMENSIONS', 'BOTTOM', 'METRIC', 'COUNT', 'OTHER',
|
||||
'FACT', 'WITH', 'TOP', 'OR', 'ATTRIBUTE', 'CREATE', 'PARENT',
|
||||
'FALSE', 'ROW', 'ROWS', 'FROM', 'ALL', 'AS', 'PF', 'COLUMN',
|
||||
'COLUMNS', 'DEFINE', 'REPORT', 'LIMIT', 'TABLE', 'LIKE', 'AND',
|
||||
'BY', 'BETWEEN', 'EXCEPT', 'SELECT', 'MATCH', 'WHERE', 'TRUE',
|
||||
'FOR', 'IN', 'WITHOUT', 'FILTER', 'ALIAS', 'WHEN', 'NOT', 'ON',
|
||||
'KEYS', 'KEY', 'FULLSET', 'PRIMARY', 'LABELS', 'LABEL',
|
||||
'VISUAL', 'TITLE', 'DESCRIPTION', 'FOLDER', 'ALTER', 'DROP',
|
||||
'ADD', 'DATASET', 'DATATYPE', 'INT', 'BIGINT', 'DOUBLE', 'DATE',
|
||||
'VARCHAR', 'DECIMAL', 'SYNCHRONIZE', 'TYPE', 'DEFAULT', 'ORDER',
|
||||
'ASC', 'DESC', 'HYPERLINK', 'INCLUDE', 'TEMPLATE', 'MODIFY'),
|
||||
suffix=r'\b'),
|
||||
Keyword),
|
||||
# FUNCNAME
|
||||
(r'[a-z]\w*\b', Name.Function),
|
||||
# Comments
|
||||
(r'#.*', Comment.Single),
|
||||
# Punctuation
|
||||
(r'[,;()]', Punctuation),
|
||||
# Space is not significant
|
||||
(r'\s+', Text)
|
||||
],
|
||||
'string-literal': [
|
||||
(r'\\[tnrfbae"\\]', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
(r'[^\\"]+', String)
|
||||
],
|
||||
}
|
||||
@ -1,413 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.c_like
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for other C-like languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, inherit, words, \
|
||||
default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
from pygments.lexers.c_cpp import CLexer, CppLexer
|
||||
from pygments.lexers import _mql_builtins
|
||||
|
||||
__all__ = ['PikeLexer', 'NesCLexer', 'ClayLexer', 'ECLexer', 'ValaLexer',
|
||||
'CudaLexer', 'SwigLexer', 'MqlLexer']
|
||||
|
||||
|
||||
class PikeLexer(CppLexer):
|
||||
"""
|
||||
For `Pike <http://pike.lysator.liu.se/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Pike'
|
||||
aliases = ['pike']
|
||||
filenames = ['*.pike', '*.pmod']
|
||||
mimetypes = ['text/x-pike']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'catch', 'new', 'private', 'protected', 'public', 'gauge',
|
||||
'throw', 'throws', 'class', 'interface', 'implement', 'abstract', 'extends', 'from',
|
||||
'this', 'super', 'constant', 'final', 'static', 'import', 'use', 'extern',
|
||||
'inline', 'proto', 'break', 'continue', 'if', 'else', 'for',
|
||||
'while', 'do', 'switch', 'case', 'as', 'in', 'version', 'return', 'true', 'false', 'null',
|
||||
'__VERSION__', '__MAJOR__', '__MINOR__', '__BUILD__', '__REAL_VERSION__',
|
||||
'__REAL_MAJOR__', '__REAL_MINOR__', '__REAL_BUILD__', '__DATE__', '__TIME__',
|
||||
'__FILE__', '__DIR__', '__LINE__', '__AUTO_BIGNUM__', '__NT__', '__PIKE__',
|
||||
'__amigaos__', '_Pragma', 'static_assert', 'defined', 'sscanf'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(bool|int|long|float|short|double|char|string|object|void|mapping|'
|
||||
r'array|multiset|program|function|lambda|mixed|'
|
||||
r'[a-z_][a-z0-9_]*_t)\b',
|
||||
Keyword.Type),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'[~!%^&*+=|?:<>/@-]', Operator),
|
||||
inherit,
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
# template specification
|
||||
(r'\s*(?=>)', Text, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class NesCLexer(CLexer):
|
||||
"""
|
||||
For `nesC <https://github.com/tinyos/nesc>`_ source code with preprocessor
|
||||
directives.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'nesC'
|
||||
aliases = ['nesc']
|
||||
filenames = ['*.nc']
|
||||
mimetypes = ['text/x-nescsrc']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'abstract', 'as', 'async', 'atomic', 'call', 'command', 'component',
|
||||
'components', 'configuration', 'event', 'extends', 'generic',
|
||||
'implementation', 'includes', 'interface', 'module', 'new', 'norace',
|
||||
'post', 'provides', 'signal', 'task', 'uses'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words(('nx_struct', 'nx_union', 'nx_int8_t', 'nx_int16_t', 'nx_int32_t',
|
||||
'nx_int64_t', 'nx_uint8_t', 'nx_uint16_t', 'nx_uint32_t',
|
||||
'nx_uint64_t'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ClayLexer(RegexLexer):
|
||||
"""
|
||||
For `Clay <http://claylabs.com/clay/>`_ source.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Clay'
|
||||
filenames = ['*.clay']
|
||||
aliases = ['clay']
|
||||
mimetypes = ['text/x-clay']
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s', Text),
|
||||
(r'//.*?$', Comment.Singleline),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'\b(public|private|import|as|record|variant|instance'
|
||||
r'|define|overload|default|external|alias'
|
||||
r'|rvalue|ref|forward|inline|noinline|forceinline'
|
||||
r'|enum|var|and|or|not|if|else|goto|return|while'
|
||||
r'|switch|case|break|continue|for|in|true|false|try|catch|throw'
|
||||
r'|finally|onerror|staticassert|eval|when|newtype'
|
||||
r'|__FILE__|__LINE__|__COLUMN__|__ARG__'
|
||||
r')\b', Keyword),
|
||||
(r'[~!%^&*+=|:<>/-]', Operator),
|
||||
(r'[#(){}\[\],;.]', Punctuation),
|
||||
(r'0x[0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'\d+[LlUu]*', Number.Integer),
|
||||
(r'\b(true|false)\b', Name.Builtin),
|
||||
(r'(?i)[a-z_?][\w?]*', Name),
|
||||
(r'"""', String, 'tdqs'),
|
||||
(r'"', String, 'dqs'),
|
||||
],
|
||||
'strings': [
|
||||
(r'(?i)\\(x[0-9a-f]{2}|.)', String.Escape),
|
||||
(r'.', String),
|
||||
],
|
||||
'nl': [
|
||||
(r'\n', String),
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
include('strings'),
|
||||
],
|
||||
'tdqs': [
|
||||
(r'"""', String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ECLexer(CLexer):
|
||||
"""
|
||||
For eC source code with preprocessor directives.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'eC'
|
||||
aliases = ['ec']
|
||||
filenames = ['*.ec', '*.eh']
|
||||
mimetypes = ['text/x-echdr', 'text/x-ecsrc']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'virtual', 'class', 'private', 'public', 'property', 'import',
|
||||
'delete', 'new', 'new0', 'renew', 'renew0', 'define', 'get',
|
||||
'set', 'remote', 'dllexport', 'dllimport', 'stdcall', 'subclass',
|
||||
'__on_register_module', 'namespace', 'using', 'typed_object',
|
||||
'any_object', 'incref', 'register', 'watch', 'stopwatching', 'firewatchers',
|
||||
'watchable', 'class_designer', 'class_fixed', 'class_no_expansion', 'isset',
|
||||
'class_default_property', 'property_category', 'class_data',
|
||||
'class_property', 'thisclass', 'dbtable', 'dbindex',
|
||||
'database_open', 'dbfield'), suffix=r'\b'), Keyword),
|
||||
(words(('uint', 'uint16', 'uint32', 'uint64', 'bool', 'byte',
|
||||
'unichar', 'int64'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(null|value|this)\b', Name.Builtin),
|
||||
inherit,
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
# template specification
|
||||
(r'\s*(?=>)', Text, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ValaLexer(RegexLexer):
|
||||
"""
|
||||
For Vala source code with preprocessor directives.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'Vala'
|
||||
aliases = ['vala', 'vapi']
|
||||
filenames = ['*.vala', '*.vapi']
|
||||
mimetypes = ['text/x-vala']
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'^\s*#if\s+0', Comment.Preproc, 'if0'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'//(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
],
|
||||
'statements': [
|
||||
(r'[L@]?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'",
|
||||
String.Char),
|
||||
(r'(?s)""".*?"""', String), # verbatim strings
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[Ll]?', Number.Hex),
|
||||
(r'0[0-7]+[Ll]?', Number.Oct),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'(\[)(Compact|Immutable|(?:Boolean|Simple)Type)(\])',
|
||||
bygroups(Punctuation, Name.Decorator, Punctuation)),
|
||||
# TODO: "correctly" parse complex code attributes
|
||||
(r'(\[)(CCode|(?:Integer|Floating)Type)',
|
||||
bygroups(Punctuation, Name.Decorator)),
|
||||
(r'[()\[\],.]', Punctuation),
|
||||
(words((
|
||||
'as', 'base', 'break', 'case', 'catch', 'construct', 'continue',
|
||||
'default', 'delete', 'do', 'else', 'enum', 'finally', 'for',
|
||||
'foreach', 'get', 'if', 'in', 'is', 'lock', 'new', 'out', 'params',
|
||||
'return', 'set', 'sizeof', 'switch', 'this', 'throw', 'try',
|
||||
'typeof', 'while', 'yield'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'abstract', 'const', 'delegate', 'dynamic', 'ensures', 'extern',
|
||||
'inline', 'internal', 'override', 'owned', 'private', 'protected',
|
||||
'public', 'ref', 'requires', 'signal', 'static', 'throws', 'unowned',
|
||||
'var', 'virtual', 'volatile', 'weak', 'yields'), suffix=r'\b'),
|
||||
Keyword.Declaration),
|
||||
(r'(namespace|using)(\s+)', bygroups(Keyword.Namespace, Text),
|
||||
'namespace'),
|
||||
(r'(class|errordomain|interface|struct)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text), 'class'),
|
||||
(r'(\.)([a-zA-Z_]\w*)',
|
||||
bygroups(Operator, Name.Attribute)),
|
||||
# void is an actual keyword, others are in glib-2.0.vapi
|
||||
(words((
|
||||
'void', 'bool', 'char', 'double', 'float', 'int', 'int8', 'int16',
|
||||
'int32', 'int64', 'long', 'short', 'size_t', 'ssize_t', 'string',
|
||||
'time_t', 'uchar', 'uint', 'uint8', 'uint16', 'uint32', 'uint64',
|
||||
'ulong', 'unichar', 'ushort'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(r'(true|false|null)\b', Name.Builtin),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
default('statement'),
|
||||
],
|
||||
'statement': [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
('[{}]', Punctuation),
|
||||
(';', Punctuation, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'if0': [
|
||||
(r'^\s*#if.*?(?<!\\)\n', Comment.Preproc, '#push'),
|
||||
(r'^\s*#el(?:se|if).*\n', Comment.Preproc, '#pop'),
|
||||
(r'^\s*#endif.*?(?<!\\)\n', Comment.Preproc, '#pop'),
|
||||
(r'.*?\n', Comment),
|
||||
],
|
||||
'class': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop')
|
||||
],
|
||||
'namespace': [
|
||||
(r'[a-zA-Z_][\w.]*', Name.Namespace, '#pop')
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CudaLexer(CLexer):
|
||||
"""
|
||||
For NVIDIA `CUDA™ <http://developer.nvidia.com/category/zone/cuda-zone>`_
|
||||
source.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'CUDA'
|
||||
filenames = ['*.cu', '*.cuh']
|
||||
aliases = ['cuda', 'cu']
|
||||
mimetypes = ['text/x-cuda']
|
||||
|
||||
function_qualifiers = set(('__device__', '__global__', '__host__',
|
||||
'__noinline__', '__forceinline__'))
|
||||
variable_qualifiers = set(('__device__', '__constant__', '__shared__',
|
||||
'__restrict__'))
|
||||
vector_types = set(('char1', 'uchar1', 'char2', 'uchar2', 'char3', 'uchar3',
|
||||
'char4', 'uchar4', 'short1', 'ushort1', 'short2', 'ushort2',
|
||||
'short3', 'ushort3', 'short4', 'ushort4', 'int1', 'uint1',
|
||||
'int2', 'uint2', 'int3', 'uint3', 'int4', 'uint4', 'long1',
|
||||
'ulong1', 'long2', 'ulong2', 'long3', 'ulong3', 'long4',
|
||||
'ulong4', 'longlong1', 'ulonglong1', 'longlong2',
|
||||
'ulonglong2', 'float1', 'float2', 'float3', 'float4',
|
||||
'double1', 'double2', 'dim3'))
|
||||
variables = set(('gridDim', 'blockIdx', 'blockDim', 'threadIdx', 'warpSize'))
|
||||
functions = set(('__threadfence_block', '__threadfence', '__threadfence_system',
|
||||
'__syncthreads', '__syncthreads_count', '__syncthreads_and',
|
||||
'__syncthreads_or'))
|
||||
execution_confs = set(('<<<', '>>>'))
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in CLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name:
|
||||
if value in self.variable_qualifiers:
|
||||
token = Keyword.Type
|
||||
elif value in self.vector_types:
|
||||
token = Keyword.Type
|
||||
elif value in self.variables:
|
||||
token = Name.Builtin
|
||||
elif value in self.execution_confs:
|
||||
token = Keyword.Pseudo
|
||||
elif value in self.function_qualifiers:
|
||||
token = Keyword.Reserved
|
||||
elif value in self.functions:
|
||||
token = Name.Function
|
||||
yield index, token, value
|
||||
|
||||
|
||||
class SwigLexer(CppLexer):
|
||||
"""
|
||||
For `SWIG <http://www.swig.org/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'SWIG'
|
||||
aliases = ['swig']
|
||||
filenames = ['*.swg', '*.i']
|
||||
mimetypes = ['text/swig']
|
||||
priority = 0.04 # Lower than C/C++ and Objective C/C++
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
# SWIG directives
|
||||
(r'(%[a-z_][a-z0-9_]*)', Name.Function),
|
||||
# Special variables
|
||||
('\$\**\&?\w+', Name),
|
||||
# Stringification / additional preprocessor directives
|
||||
(r'##*[a-zA-Z_]\w*', Comment.Preproc),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
|
||||
# This is a far from complete set of SWIG directives
|
||||
swig_directives = set((
|
||||
# Most common directives
|
||||
'%apply', '%define', '%director', '%enddef', '%exception', '%extend',
|
||||
'%feature', '%fragment', '%ignore', '%immutable', '%import', '%include',
|
||||
'%inline', '%insert', '%module', '%newobject', '%nspace', '%pragma',
|
||||
'%rename', '%shared_ptr', '%template', '%typecheck', '%typemap',
|
||||
# Less common directives
|
||||
'%arg', '%attribute', '%bang', '%begin', '%callback', '%catches', '%clear',
|
||||
'%constant', '%copyctor', '%csconst', '%csconstvalue', '%csenum',
|
||||
'%csmethodmodifiers', '%csnothrowexception', '%default', '%defaultctor',
|
||||
'%defaultdtor', '%defined', '%delete', '%delobject', '%descriptor',
|
||||
'%exceptionclass', '%exceptionvar', '%extend_smart_pointer', '%fragments',
|
||||
'%header', '%ifcplusplus', '%ignorewarn', '%implicit', '%implicitconv',
|
||||
'%init', '%javaconst', '%javaconstvalue', '%javaenum', '%javaexception',
|
||||
'%javamethodmodifiers', '%kwargs', '%luacode', '%mutable', '%naturalvar',
|
||||
'%nestedworkaround', '%perlcode', '%pythonabc', '%pythonappend',
|
||||
'%pythoncallback', '%pythoncode', '%pythondynamic', '%pythonmaybecall',
|
||||
'%pythonnondynamic', '%pythonprepend', '%refobject', '%shadow', '%sizeof',
|
||||
'%trackobjects', '%types', '%unrefobject', '%varargs', '%warn',
|
||||
'%warnfilter'))
|
||||
|
||||
def analyse_text(text):
|
||||
rv = 0
|
||||
# Search for SWIG directives, which are conventionally at the beginning of
|
||||
# a line. The probability of them being within a line is low, so let another
|
||||
# lexer win in this case.
|
||||
matches = re.findall(r'^\s*(%[a-z_][a-z0-9_]*)', text, re.M)
|
||||
for m in matches:
|
||||
if m in SwigLexer.swig_directives:
|
||||
rv = 0.98
|
||||
break
|
||||
else:
|
||||
rv = 0.91 # Fraction higher than MatlabLexer
|
||||
return rv
|
||||
|
||||
|
||||
class MqlLexer(CppLexer):
|
||||
"""
|
||||
For `MQL4 <http://docs.mql4.com/>`_ and
|
||||
`MQL5 <http://www.mql5.com/en/docs>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'MQL'
|
||||
aliases = ['mql', 'mq4', 'mq5', 'mql4', 'mql5']
|
||||
filenames = ['*.mq4', '*.mq5', '*.mqh']
|
||||
mimetypes = ['text/x-mql']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words(_mql_builtins.keywords, suffix=r'\b'), Keyword),
|
||||
(words(_mql_builtins.c_types, suffix=r'\b'), Keyword.Type),
|
||||
(words(_mql_builtins.types, suffix=r'\b'), Name.Function),
|
||||
(words(_mql_builtins.constants, suffix=r'\b'), Name.Constant),
|
||||
(words(_mql_builtins.colors, prefix='(clr)?', suffix=r'\b'),
|
||||
Name.Constant),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
@ -1,98 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.chapel
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for the Chapel language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['ChapelLexer']
|
||||
|
||||
|
||||
class ChapelLexer(RegexLexer):
|
||||
"""
|
||||
For `Chapel <http://chapel.cray.com/>`_ source.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Chapel'
|
||||
filenames = ['*.chpl']
|
||||
aliases = ['chapel', 'chpl']
|
||||
# mimetypes = ['text/x-chapel']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text),
|
||||
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
|
||||
(r'(config|const|in|inout|out|param|ref|type|var)\b',
|
||||
Keyword.Declaration),
|
||||
(r'(false|nil|true)\b', Keyword.Constant),
|
||||
(r'(bool|complex|imag|int|opaque|range|real|string|uint)\b',
|
||||
Keyword.Type),
|
||||
(words((
|
||||
'align', 'atomic', 'begin', 'break', 'by', 'cobegin', 'coforall',
|
||||
'continue', 'delete', 'dmapped', 'do', 'domain', 'else', 'enum',
|
||||
'export', 'extern', 'for', 'forall', 'if', 'index', 'inline',
|
||||
'iter', 'label', 'lambda', 'let', 'local', 'new', 'noinit', 'on',
|
||||
'otherwise', 'pragma', 'reduce', 'return', 'scan', 'select',
|
||||
'serial', 'single', 'sparse', 'subdomain', 'sync', 'then', 'use',
|
||||
'when', 'where', 'while', 'with', 'yield', 'zip'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(proc)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'procname'),
|
||||
(r'(class|module|record|union)(\s+)', bygroups(Keyword, Text),
|
||||
'classname'),
|
||||
|
||||
# imaginary integers
|
||||
(r'\d+i', Number),
|
||||
(r'\d+\.\d*([Ee][-+]\d+)?i', Number),
|
||||
(r'\.\d+([Ee][-+]\d+)?i', Number),
|
||||
(r'\d+[Ee][-+]\d+i', Number),
|
||||
|
||||
# reals cannot end with a period due to lexical ambiguity with
|
||||
# .. operator. See reference for rationale.
|
||||
(r'(\d*\.\d+)([eE][+-]?[0-9]+)?i?', Number.Float),
|
||||
(r'\d+[eE][+-]?[0-9]+i?', Number.Float),
|
||||
|
||||
# integer literals
|
||||
# -- binary
|
||||
(r'0[bB][01]+', Number.Bin),
|
||||
# -- hex
|
||||
(r'0[xX][0-9a-fA-F]+', Number.Hex),
|
||||
# -- octal
|
||||
(r'0[oO][0-7]+', Number.Oct),
|
||||
# -- decimal
|
||||
(r'[0-9]+', Number.Integer),
|
||||
|
||||
# strings
|
||||
(r'["\'](\\\\|\\"|[^"\'])*["\']', String),
|
||||
|
||||
# tokens
|
||||
(r'(=|\+=|-=|\*=|/=|\*\*=|%=|&=|\|=|\^=|&&=|\|\|=|<<=|>>=|'
|
||||
r'<=>|<~>|\.\.|by|#|\.\.\.|'
|
||||
r'&&|\|\||!|&|\||\^|~|<<|>>|'
|
||||
r'==|!=|<=|>=|<|>|'
|
||||
r'[+\-*/%]|\*\*)', Operator),
|
||||
(r'[:;,.?()\[\]{}]', Punctuation),
|
||||
|
||||
# identifiers
|
||||
(r'[a-zA-Z_][\w$]*', Name.Other),
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_][\w$]*', Name.Class, '#pop'),
|
||||
],
|
||||
'procname': [
|
||||
(r'[a-zA-Z_][\w$]*', Name.Function, '#pop'),
|
||||
],
|
||||
}
|
||||
@ -1,33 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.compiled
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Just export lexer classes previously contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexers.jvm import JavaLexer, ScalaLexer
|
||||
from pygments.lexers.c_cpp import CLexer, CppLexer
|
||||
from pygments.lexers.d import DLexer
|
||||
from pygments.lexers.objective import ObjectiveCLexer, \
|
||||
ObjectiveCppLexer, LogosLexer
|
||||
from pygments.lexers.go import GoLexer
|
||||
from pygments.lexers.rust import RustLexer
|
||||
from pygments.lexers.c_like import ECLexer, ValaLexer, CudaLexer
|
||||
from pygments.lexers.pascal import DelphiLexer, Modula2Lexer, AdaLexer
|
||||
from pygments.lexers.business import CobolLexer, CobolFreeformatLexer
|
||||
from pygments.lexers.fortran import FortranLexer
|
||||
from pygments.lexers.prolog import PrologLexer
|
||||
from pygments.lexers.python import CythonLexer
|
||||
from pygments.lexers.graphics import GLShaderLexer
|
||||
from pygments.lexers.ml import OcamlLexer
|
||||
from pygments.lexers.basic import BlitzBasicLexer, BlitzMaxLexer, MonkeyLexer
|
||||
from pygments.lexers.dylan import DylanLexer, DylanLidLexer, DylanConsoleLexer
|
||||
from pygments.lexers.ooc import OocLexer
|
||||
from pygments.lexers.felix import FelixLexer
|
||||
from pygments.lexers.nimrod import NimrodLexer
|
||||
|
||||
__all__ = []
|
||||
@ -1,114 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.console
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for misc console output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups
|
||||
from pygments.token import Generic, Comment, String, Text, Keyword, Name, \
|
||||
Punctuation, Number
|
||||
|
||||
__all__ = ['VCTreeStatusLexer', 'PyPyLogLexer']
|
||||
|
||||
|
||||
class VCTreeStatusLexer(RegexLexer):
|
||||
"""
|
||||
For colorizing output of version control status commans, like "hg
|
||||
status" or "svn status".
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'VCTreeStatus'
|
||||
aliases = ['vctreestatus']
|
||||
filenames = []
|
||||
mimetypes = []
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^A \+ C\s+', Generic.Error),
|
||||
(r'^A\s+\+?\s+', String),
|
||||
(r'^M\s+', Generic.Inserted),
|
||||
(r'^C\s+', Generic.Error),
|
||||
(r'^D\s+', Generic.Deleted),
|
||||
(r'^[?!]\s+', Comment.Preproc),
|
||||
(r' >\s+.*\n', Comment.Preproc),
|
||||
(r'.*\n', Text)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class PyPyLogLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for PyPy log files.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = "PyPy Log"
|
||||
aliases = ["pypylog", "pypy"]
|
||||
filenames = ["*.pypylog"]
|
||||
mimetypes = ['application/x-pypylog']
|
||||
|
||||
tokens = {
|
||||
"root": [
|
||||
(r"\[\w+\] \{jit-log-.*?$", Keyword, "jit-log"),
|
||||
(r"\[\w+\] \{jit-backend-counts$", Keyword, "jit-backend-counts"),
|
||||
include("extra-stuff"),
|
||||
],
|
||||
"jit-log": [
|
||||
(r"\[\w+\] jit-log-.*?}$", Keyword, "#pop"),
|
||||
(r"^\+\d+: ", Comment),
|
||||
(r"--end of the loop--", Comment),
|
||||
(r"[ifp]\d+", Name),
|
||||
(r"ptr\d+", Name),
|
||||
(r"(\()(\w+(?:\.\w+)?)(\))",
|
||||
bygroups(Punctuation, Name.Builtin, Punctuation)),
|
||||
(r"[\[\]=,()]", Punctuation),
|
||||
(r"(\d+\.\d+|inf|-inf)", Number.Float),
|
||||
(r"-?\d+", Number.Integer),
|
||||
(r"'.*'", String),
|
||||
(r"(None|descr|ConstClass|ConstPtr|TargetToken)", Name),
|
||||
(r"<.*?>+", Name.Builtin),
|
||||
(r"(label|debug_merge_point|jump|finish)", Name.Class),
|
||||
(r"(int_add_ovf|int_add|int_sub_ovf|int_sub|int_mul_ovf|int_mul|"
|
||||
r"int_floordiv|int_mod|int_lshift|int_rshift|int_and|int_or|"
|
||||
r"int_xor|int_eq|int_ne|int_ge|int_gt|int_le|int_lt|int_is_zero|"
|
||||
r"int_is_true|"
|
||||
r"uint_floordiv|uint_ge|uint_lt|"
|
||||
r"float_add|float_sub|float_mul|float_truediv|float_neg|"
|
||||
r"float_eq|float_ne|float_ge|float_gt|float_le|float_lt|float_abs|"
|
||||
r"ptr_eq|ptr_ne|instance_ptr_eq|instance_ptr_ne|"
|
||||
r"cast_int_to_float|cast_float_to_int|"
|
||||
r"force_token|quasiimmut_field|same_as|virtual_ref_finish|"
|
||||
r"virtual_ref|mark_opaque_ptr|"
|
||||
r"call_may_force|call_assembler|call_loopinvariant|"
|
||||
r"call_release_gil|call_pure|call|"
|
||||
r"new_with_vtable|new_array|newstr|newunicode|new|"
|
||||
r"arraylen_gc|"
|
||||
r"getarrayitem_gc_pure|getarrayitem_gc|setarrayitem_gc|"
|
||||
r"getarrayitem_raw|setarrayitem_raw|getfield_gc_pure|"
|
||||
r"getfield_gc|getinteriorfield_gc|setinteriorfield_gc|"
|
||||
r"getfield_raw|setfield_gc|setfield_raw|"
|
||||
r"strgetitem|strsetitem|strlen|copystrcontent|"
|
||||
r"unicodegetitem|unicodesetitem|unicodelen|"
|
||||
r"guard_true|guard_false|guard_value|guard_isnull|"
|
||||
r"guard_nonnull_class|guard_nonnull|guard_class|guard_no_overflow|"
|
||||
r"guard_not_forced|guard_no_exception|guard_not_invalidated)",
|
||||
Name.Builtin),
|
||||
include("extra-stuff"),
|
||||
],
|
||||
"jit-backend-counts": [
|
||||
(r"\[\w+\] jit-backend-counts}$", Keyword, "#pop"),
|
||||
(r":", Punctuation),
|
||||
(r"\d+", Number),
|
||||
include("extra-stuff"),
|
||||
],
|
||||
"extra-stuff": [
|
||||
(r"\s+", Text),
|
||||
(r"#.*?$", Comment),
|
||||
],
|
||||
}
|
||||
@ -1,498 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.css
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for CSS and related stylesheet formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import copy
|
||||
|
||||
from pygments.lexer import ExtendedRegexLexer, RegexLexer, include, bygroups, \
|
||||
default, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
from pygments.util import iteritems
|
||||
|
||||
__all__ = ['CssLexer', 'SassLexer', 'ScssLexer']
|
||||
|
||||
|
||||
class CssLexer(RegexLexer):
|
||||
"""
|
||||
For CSS (Cascading Style Sheets).
|
||||
"""
|
||||
|
||||
name = 'CSS'
|
||||
aliases = ['css']
|
||||
filenames = ['*.css']
|
||||
mimetypes = ['text/css']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('basics'),
|
||||
],
|
||||
'basics': [
|
||||
(r'\s+', Text),
|
||||
(r'/\*(?:.|\n)*?\*/', Comment),
|
||||
(r'\{', Punctuation, 'content'),
|
||||
(r'\:[\w-]+', Name.Decorator),
|
||||
(r'\.[\w-]+', Name.Class),
|
||||
(r'\#[\w-]+', Name.Function),
|
||||
(r'@[\w-]+', Keyword, 'atrule'),
|
||||
(r'[\w-]+', Name.Tag),
|
||||
(r'[~^*!%&$\[\]()<>|+=@:;,./?-]', Operator),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single)
|
||||
],
|
||||
'atrule': [
|
||||
(r'\{', Punctuation, 'atcontent'),
|
||||
(r';', Punctuation, '#pop'),
|
||||
include('basics'),
|
||||
],
|
||||
'atcontent': [
|
||||
include('basics'),
|
||||
(r'\}', Punctuation, '#pop:2'),
|
||||
],
|
||||
'content': [
|
||||
(r'\s+', Text),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
(r'url\(.*?\)', String.Other),
|
||||
(r'^@.*?$', Comment.Preproc),
|
||||
(words((
|
||||
'azimuth', 'background-attachment', 'background-color',
|
||||
'background-image', 'background-position', 'background-repeat',
|
||||
'background', 'border-bottom-color', 'border-bottom-style',
|
||||
'border-bottom-width', 'border-left-color', 'border-left-style',
|
||||
'border-left-width', 'border-right', 'border-right-color',
|
||||
'border-right-style', 'border-right-width', 'border-top-color',
|
||||
'border-top-style', 'border-top-width', 'border-bottom',
|
||||
'border-collapse', 'border-left', 'border-width', 'border-color',
|
||||
'border-spacing', 'border-style', 'border-top', 'border', 'caption-side',
|
||||
'clear', 'clip', 'color', 'content', 'counter-increment', 'counter-reset',
|
||||
'cue-after', 'cue-before', 'cue', 'cursor', 'direction', 'display',
|
||||
'elevation', 'empty-cells', 'float', 'font-family', 'font-size',
|
||||
'font-size-adjust', 'font-stretch', 'font-style', 'font-variant',
|
||||
'font-weight', 'font', 'height', 'letter-spacing', 'line-height',
|
||||
'list-style-type', 'list-style-image', 'list-style-position',
|
||||
'list-style', 'margin-bottom', 'margin-left', 'margin-right',
|
||||
'margin-top', 'margin', 'marker-offset', 'marks', 'max-height', 'max-width',
|
||||
'min-height', 'min-width', 'opacity', 'orphans', 'outline-color',
|
||||
'outline-style', 'outline-width', 'outline', 'overflow', 'overflow-x',
|
||||
'overflow-y', 'padding-bottom', 'padding-left', 'padding-right', 'padding-top',
|
||||
'padding', 'page', 'page-break-after', 'page-break-before', 'page-break-inside',
|
||||
'pause-after', 'pause-before', 'pause', 'pitch-range', 'pitch',
|
||||
'play-during', 'position', 'quotes', 'richness', 'right', 'size',
|
||||
'speak-header', 'speak-numeral', 'speak-punctuation', 'speak',
|
||||
'speech-rate', 'stress', 'table-layout', 'text-align', 'text-decoration',
|
||||
'text-indent', 'text-shadow', 'text-transform', 'top', 'unicode-bidi',
|
||||
'vertical-align', 'visibility', 'voice-family', 'volume', 'white-space',
|
||||
'widows', 'width', 'word-spacing', 'z-index', 'bottom',
|
||||
'above', 'absolute', 'always', 'armenian', 'aural', 'auto', 'avoid', 'baseline',
|
||||
'behind', 'below', 'bidi-override', 'blink', 'block', 'bolder', 'bold', 'both',
|
||||
'capitalize', 'center-left', 'center-right', 'center', 'circle',
|
||||
'cjk-ideographic', 'close-quote', 'collapse', 'condensed', 'continuous',
|
||||
'crop', 'crosshair', 'cross', 'cursive', 'dashed', 'decimal-leading-zero',
|
||||
'decimal', 'default', 'digits', 'disc', 'dotted', 'double', 'e-resize', 'embed',
|
||||
'extra-condensed', 'extra-expanded', 'expanded', 'fantasy', 'far-left',
|
||||
'far-right', 'faster', 'fast', 'fixed', 'georgian', 'groove', 'hebrew', 'help',
|
||||
'hidden', 'hide', 'higher', 'high', 'hiragana-iroha', 'hiragana', 'icon',
|
||||
'inherit', 'inline-table', 'inline', 'inset', 'inside', 'invert', 'italic',
|
||||
'justify', 'katakana-iroha', 'katakana', 'landscape', 'larger', 'large',
|
||||
'left-side', 'leftwards', 'left', 'level', 'lighter', 'line-through', 'list-item',
|
||||
'loud', 'lower-alpha', 'lower-greek', 'lower-roman', 'lowercase', 'ltr',
|
||||
'lower', 'low', 'medium', 'message-box', 'middle', 'mix', 'monospace',
|
||||
'n-resize', 'narrower', 'ne-resize', 'no-close-quote', 'no-open-quote',
|
||||
'no-repeat', 'none', 'normal', 'nowrap', 'nw-resize', 'oblique', 'once',
|
||||
'open-quote', 'outset', 'outside', 'overline', 'pointer', 'portrait', 'px',
|
||||
'relative', 'repeat-x', 'repeat-y', 'repeat', 'rgb', 'ridge', 'right-side',
|
||||
'rightwards', 's-resize', 'sans-serif', 'scroll', 'se-resize',
|
||||
'semi-condensed', 'semi-expanded', 'separate', 'serif', 'show', 'silent',
|
||||
'slower', 'slow', 'small-caps', 'small-caption', 'smaller', 'soft', 'solid',
|
||||
'spell-out', 'square', 'static', 'status-bar', 'super', 'sw-resize',
|
||||
'table-caption', 'table-cell', 'table-column', 'table-column-group',
|
||||
'table-footer-group', 'table-header-group', 'table-row',
|
||||
'table-row-group', 'text-bottom', 'text-top', 'text', 'thick', 'thin',
|
||||
'transparent', 'ultra-condensed', 'ultra-expanded', 'underline',
|
||||
'upper-alpha', 'upper-latin', 'upper-roman', 'uppercase', 'url',
|
||||
'visible', 'w-resize', 'wait', 'wider', 'x-fast', 'x-high', 'x-large', 'x-loud',
|
||||
'x-low', 'x-small', 'x-soft', 'xx-large', 'xx-small', 'yes'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'indigo', 'gold', 'firebrick', 'indianred', 'yellow', 'darkolivegreen',
|
||||
'darkseagreen', 'mediumvioletred', 'mediumorchid', 'chartreuse',
|
||||
'mediumslateblue', 'black', 'springgreen', 'crimson', 'lightsalmon', 'brown',
|
||||
'turquoise', 'olivedrab', 'cyan', 'silver', 'skyblue', 'gray', 'darkturquoise',
|
||||
'goldenrod', 'darkgreen', 'darkviolet', 'darkgray', 'lightpink', 'teal',
|
||||
'darkmagenta', 'lightgoldenrodyellow', 'lavender', 'yellowgreen', 'thistle',
|
||||
'violet', 'navy', 'orchid', 'blue', 'ghostwhite', 'honeydew', 'cornflowerblue',
|
||||
'darkblue', 'darkkhaki', 'mediumpurple', 'cornsilk', 'red', 'bisque', 'slategray',
|
||||
'darkcyan', 'khaki', 'wheat', 'deepskyblue', 'darkred', 'steelblue', 'aliceblue',
|
||||
'gainsboro', 'mediumturquoise', 'floralwhite', 'coral', 'purple', 'lightgrey',
|
||||
'lightcyan', 'darksalmon', 'beige', 'azure', 'lightsteelblue', 'oldlace',
|
||||
'greenyellow', 'royalblue', 'lightseagreen', 'mistyrose', 'sienna',
|
||||
'lightcoral', 'orangered', 'navajowhite', 'lime', 'palegreen', 'burlywood',
|
||||
'seashell', 'mediumspringgreen', 'fuchsia', 'papayawhip', 'blanchedalmond',
|
||||
'peru', 'aquamarine', 'white', 'darkslategray', 'ivory', 'dodgerblue',
|
||||
'lemonchiffon', 'chocolate', 'orange', 'forestgreen', 'slateblue', 'olive',
|
||||
'mintcream', 'antiquewhite', 'darkorange', 'cadetblue', 'moccasin',
|
||||
'limegreen', 'saddlebrown', 'darkslateblue', 'lightskyblue', 'deeppink',
|
||||
'plum', 'aqua', 'darkgoldenrod', 'maroon', 'sandybrown', 'magenta', 'tan',
|
||||
'rosybrown', 'pink', 'lightblue', 'palevioletred', 'mediumseagreen',
|
||||
'dimgray', 'powderblue', 'seagreen', 'snow', 'mediumblue', 'midnightblue',
|
||||
'paleturquoise', 'palegoldenrod', 'whitesmoke', 'darkorchid', 'salmon',
|
||||
'lightslategray', 'lawngreen', 'lightgreen', 'tomato', 'hotpink',
|
||||
'lightyellow', 'lavenderblush', 'linen', 'mediumaquamarine', 'green',
|
||||
'blueviolet', 'peachpuff'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'\!important', Comment.Preproc),
|
||||
(r'/\*(?:.|\n)*?\*/', Comment),
|
||||
(r'\#[a-zA-Z0-9]{1,6}', Number),
|
||||
(r'[.-]?[0-9]*[.]?[0-9]+(em|px|pt|pc|in|mm|cm|ex|s)\b', Number),
|
||||
# Separate regex for percentages, as can't do word boundaries with %
|
||||
(r'[.-]?[0-9]*[.]?[0-9]+%', Number),
|
||||
(r'-?[0-9]+', Number),
|
||||
(r'[~^*!%&<>|+=@:,./?-]+', Operator),
|
||||
(r'[\[\]();]+', Punctuation),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'[a-zA-Z_]\w*', Name)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
common_sass_tokens = {
|
||||
'value': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'[!$][\w-]+', Name.Variable),
|
||||
(r'url\(', String.Other, 'string-url'),
|
||||
(r'[a-z_-][\w-]*(?=\()', Name.Function),
|
||||
(words((
|
||||
'azimuth', 'background-attachment', 'background-color',
|
||||
'background-image', 'background-position', 'background-repeat',
|
||||
'background', 'border-bottom-color', 'border-bottom-style',
|
||||
'border-bottom-width', 'border-left-color', 'border-left-style',
|
||||
'border-left-width', 'border-right', 'border-right-color',
|
||||
'border-right-style', 'border-right-width', 'border-top-color',
|
||||
'border-top-style', 'border-top-width', 'border-bottom',
|
||||
'border-collapse', 'border-left', 'border-width', 'border-color',
|
||||
'border-spacing', 'border-style', 'border-top', 'border', 'caption-side',
|
||||
'clear', 'clip', 'color', 'content', 'counter-increment', 'counter-reset',
|
||||
'cue-after', 'cue-before', 'cue', 'cursor', 'direction', 'display',
|
||||
'elevation', 'empty-cells', 'float', 'font-family', 'font-size',
|
||||
'font-size-adjust', 'font-stretch', 'font-style', 'font-variant',
|
||||
'font-weight', 'font', 'height', 'letter-spacing', 'line-height',
|
||||
'list-style-type', 'list-style-image', 'list-style-position',
|
||||
'list-style', 'margin-bottom', 'margin-left', 'margin-right',
|
||||
'margin-top', 'margin', 'marker-offset', 'marks', 'max-height', 'max-width',
|
||||
'min-height', 'min-width', 'opacity', 'orphans', 'outline', 'outline-color',
|
||||
'outline-style', 'outline-width', 'overflow', 'padding-bottom',
|
||||
'padding-left', 'padding-right', 'padding-top', 'padding', 'page',
|
||||
'page-break-after', 'page-break-before', 'page-break-inside',
|
||||
'pause-after', 'pause-before', 'pause', 'pitch', 'pitch-range',
|
||||
'play-during', 'position', 'quotes', 'richness', 'right', 'size',
|
||||
'speak-header', 'speak-numeral', 'speak-punctuation', 'speak',
|
||||
'speech-rate', 'stress', 'table-layout', 'text-align', 'text-decoration',
|
||||
'text-indent', 'text-shadow', 'text-transform', 'top', 'unicode-bidi',
|
||||
'vertical-align', 'visibility', 'voice-family', 'volume', 'white-space',
|
||||
'widows', 'width', 'word-spacing', 'z-index', 'bottom', 'left',
|
||||
'above', 'absolute', 'always', 'armenian', 'aural', 'auto', 'avoid', 'baseline',
|
||||
'behind', 'below', 'bidi-override', 'blink', 'block', 'bold', 'bolder', 'both',
|
||||
'capitalize', 'center-left', 'center-right', 'center', 'circle',
|
||||
'cjk-ideographic', 'close-quote', 'collapse', 'condensed', 'continuous',
|
||||
'crop', 'crosshair', 'cross', 'cursive', 'dashed', 'decimal-leading-zero',
|
||||
'decimal', 'default', 'digits', 'disc', 'dotted', 'double', 'e-resize', 'embed',
|
||||
'extra-condensed', 'extra-expanded', 'expanded', 'fantasy', 'far-left',
|
||||
'far-right', 'faster', 'fast', 'fixed', 'georgian', 'groove', 'hebrew', 'help',
|
||||
'hidden', 'hide', 'higher', 'high', 'hiragana-iroha', 'hiragana', 'icon',
|
||||
'inherit', 'inline-table', 'inline', 'inset', 'inside', 'invert', 'italic',
|
||||
'justify', 'katakana-iroha', 'katakana', 'landscape', 'larger', 'large',
|
||||
'left-side', 'leftwards', 'level', 'lighter', 'line-through', 'list-item',
|
||||
'loud', 'lower-alpha', 'lower-greek', 'lower-roman', 'lowercase', 'ltr',
|
||||
'lower', 'low', 'medium', 'message-box', 'middle', 'mix', 'monospace',
|
||||
'n-resize', 'narrower', 'ne-resize', 'no-close-quote', 'no-open-quote',
|
||||
'no-repeat', 'none', 'normal', 'nowrap', 'nw-resize', 'oblique', 'once',
|
||||
'open-quote', 'outset', 'outside', 'overline', 'pointer', 'portrait', 'px',
|
||||
'relative', 'repeat-x', 'repeat-y', 'repeat', 'rgb', 'ridge', 'right-side',
|
||||
'rightwards', 's-resize', 'sans-serif', 'scroll', 'se-resize',
|
||||
'semi-condensed', 'semi-expanded', 'separate', 'serif', 'show', 'silent',
|
||||
'slow', 'slower', 'small-caps', 'small-caption', 'smaller', 'soft', 'solid',
|
||||
'spell-out', 'square', 'static', 'status-bar', 'super', 'sw-resize',
|
||||
'table-caption', 'table-cell', 'table-column', 'table-column-group',
|
||||
'table-footer-group', 'table-header-group', 'table-row',
|
||||
'table-row-group', 'text', 'text-bottom', 'text-top', 'thick', 'thin',
|
||||
'transparent', 'ultra-condensed', 'ultra-expanded', 'underline',
|
||||
'upper-alpha', 'upper-latin', 'upper-roman', 'uppercase', 'url',
|
||||
'visible', 'w-resize', 'wait', 'wider', 'x-fast', 'x-high', 'x-large', 'x-loud',
|
||||
'x-low', 'x-small', 'x-soft', 'xx-large', 'xx-small', 'yes'), suffix=r'\b'),
|
||||
Name.Constant),
|
||||
(words((
|
||||
'indigo', 'gold', 'firebrick', 'indianred', 'darkolivegreen',
|
||||
'darkseagreen', 'mediumvioletred', 'mediumorchid', 'chartreuse',
|
||||
'mediumslateblue', 'springgreen', 'crimson', 'lightsalmon', 'brown',
|
||||
'turquoise', 'olivedrab', 'cyan', 'skyblue', 'darkturquoise',
|
||||
'goldenrod', 'darkgreen', 'darkviolet', 'darkgray', 'lightpink',
|
||||
'darkmagenta', 'lightgoldenrodyellow', 'lavender', 'yellowgreen', 'thistle',
|
||||
'violet', 'orchid', 'ghostwhite', 'honeydew', 'cornflowerblue',
|
||||
'darkblue', 'darkkhaki', 'mediumpurple', 'cornsilk', 'bisque', 'slategray',
|
||||
'darkcyan', 'khaki', 'wheat', 'deepskyblue', 'darkred', 'steelblue', 'aliceblue',
|
||||
'gainsboro', 'mediumturquoise', 'floralwhite', 'coral', 'lightgrey',
|
||||
'lightcyan', 'darksalmon', 'beige', 'azure', 'lightsteelblue', 'oldlace',
|
||||
'greenyellow', 'royalblue', 'lightseagreen', 'mistyrose', 'sienna',
|
||||
'lightcoral', 'orangered', 'navajowhite', 'palegreen', 'burlywood',
|
||||
'seashell', 'mediumspringgreen', 'papayawhip', 'blanchedalmond',
|
||||
'peru', 'aquamarine', 'darkslategray', 'ivory', 'dodgerblue',
|
||||
'lemonchiffon', 'chocolate', 'orange', 'forestgreen', 'slateblue',
|
||||
'mintcream', 'antiquewhite', 'darkorange', 'cadetblue', 'moccasin',
|
||||
'limegreen', 'saddlebrown', 'darkslateblue', 'lightskyblue', 'deeppink',
|
||||
'plum', 'darkgoldenrod', 'sandybrown', 'magenta', 'tan',
|
||||
'rosybrown', 'pink', 'lightblue', 'palevioletred', 'mediumseagreen',
|
||||
'dimgray', 'powderblue', 'seagreen', 'snow', 'mediumblue', 'midnightblue',
|
||||
'paleturquoise', 'palegoldenrod', 'whitesmoke', 'darkorchid', 'salmon',
|
||||
'lightslategray', 'lawngreen', 'lightgreen', 'tomato', 'hotpink',
|
||||
'lightyellow', 'lavenderblush', 'linen', 'mediumaquamarine',
|
||||
'blueviolet', 'peachpuff'), suffix=r'\b'),
|
||||
Name.Entity),
|
||||
(words((
|
||||
'black', 'silver', 'gray', 'white', 'maroon', 'red', 'purple', 'fuchsia', 'green',
|
||||
'lime', 'olive', 'yellow', 'navy', 'blue', 'teal', 'aqua'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'\!(important|default)', Name.Exception),
|
||||
(r'(true|false)', Name.Pseudo),
|
||||
(r'(and|or|not)', Operator.Word),
|
||||
(r'/\*', Comment.Multiline, 'inline-comment'),
|
||||
(r'//[^\n]*', Comment.Single),
|
||||
(r'\#[a-z0-9]{1,6}', Number.Hex),
|
||||
(r'(-?\d+)(\%|[a-z]+)?', bygroups(Number.Integer, Keyword.Type)),
|
||||
(r'(-?\d*\.\d+)(\%|[a-z]+)?', bygroups(Number.Float, Keyword.Type)),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[~^*!&%<>|+=@:,./?-]+', Operator),
|
||||
(r'[\[\]()]+', Punctuation),
|
||||
(r'"', String.Double, 'string-double'),
|
||||
(r"'", String.Single, 'string-single'),
|
||||
(r'[a-z_-][\w-]*', Name),
|
||||
],
|
||||
|
||||
'interpolation': [
|
||||
(r'\}', String.Interpol, '#pop'),
|
||||
include('value'),
|
||||
],
|
||||
|
||||
'selector': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\:', Name.Decorator, 'pseudo-class'),
|
||||
(r'\.', Name.Class, 'class'),
|
||||
(r'\#', Name.Namespace, 'id'),
|
||||
(r'[\w-]+', Name.Tag),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'&', Keyword),
|
||||
(r'[~^*!&\[\]()<>|+=@:;,./?-]', Operator),
|
||||
(r'"', String.Double, 'string-double'),
|
||||
(r"'", String.Single, 'string-single'),
|
||||
],
|
||||
|
||||
'string-double': [
|
||||
(r'(\\.|#(?=[^\n{])|[^\n"#])+', String.Double),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'"', String.Double, '#pop'),
|
||||
],
|
||||
|
||||
'string-single': [
|
||||
(r"(\\.|#(?=[^\n{])|[^\n'#])+", String.Double),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r"'", String.Double, '#pop'),
|
||||
],
|
||||
|
||||
'string-url': [
|
||||
(r'(\\#|#(?=[^\n{])|[^\n#)])+', String.Other),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'\)', String.Other, '#pop'),
|
||||
],
|
||||
|
||||
'pseudo-class': [
|
||||
(r'[\w-]+', Name.Decorator),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'class': [
|
||||
(r'[\w-]+', Name.Class),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'id': [
|
||||
(r'[\w-]+', Name.Namespace),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'for': [
|
||||
(r'(from|to|through)', Operator.Word),
|
||||
include('value'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
def _indentation(lexer, match, ctx):
|
||||
indentation = match.group(0)
|
||||
yield match.start(), Text, indentation
|
||||
ctx.last_indentation = indentation
|
||||
ctx.pos = match.end()
|
||||
|
||||
if hasattr(ctx, 'block_state') and ctx.block_state and \
|
||||
indentation.startswith(ctx.block_indentation) and \
|
||||
indentation != ctx.block_indentation:
|
||||
ctx.stack.append(ctx.block_state)
|
||||
else:
|
||||
ctx.block_state = None
|
||||
ctx.block_indentation = None
|
||||
ctx.stack.append('content')
|
||||
|
||||
|
||||
def _starts_block(token, state):
|
||||
def callback(lexer, match, ctx):
|
||||
yield match.start(), token, match.group(0)
|
||||
|
||||
if hasattr(ctx, 'last_indentation'):
|
||||
ctx.block_indentation = ctx.last_indentation
|
||||
else:
|
||||
ctx.block_indentation = ''
|
||||
|
||||
ctx.block_state = state
|
||||
ctx.pos = match.end()
|
||||
|
||||
return callback
|
||||
|
||||
|
||||
class SassLexer(ExtendedRegexLexer):
|
||||
"""
|
||||
For Sass stylesheets.
|
||||
|
||||
.. versionadded:: 1.3
|
||||
"""
|
||||
|
||||
name = 'Sass'
|
||||
aliases = ['sass']
|
||||
filenames = ['*.sass']
|
||||
mimetypes = ['text/x-sass']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[ \t]*\n', Text),
|
||||
(r'[ \t]*', _indentation),
|
||||
],
|
||||
|
||||
'content': [
|
||||
(r'//[^\n]*', _starts_block(Comment.Single, 'single-comment'),
|
||||
'root'),
|
||||
(r'/\*[^\n]*', _starts_block(Comment.Multiline, 'multi-comment'),
|
||||
'root'),
|
||||
(r'@import', Keyword, 'import'),
|
||||
(r'@for', Keyword, 'for'),
|
||||
(r'@(debug|warn|if|while)', Keyword, 'value'),
|
||||
(r'(@mixin)( [\w-]+)', bygroups(Keyword, Name.Function), 'value'),
|
||||
(r'(@include)( [\w-]+)', bygroups(Keyword, Name.Decorator), 'value'),
|
||||
(r'@extend', Keyword, 'selector'),
|
||||
(r'@[\w-]+', Keyword, 'selector'),
|
||||
(r'=[\w-]+', Name.Function, 'value'),
|
||||
(r'\+[\w-]+', Name.Decorator, 'value'),
|
||||
(r'([!$][\w-]\w*)([ \t]*(?:(?:\|\|)?=|:))',
|
||||
bygroups(Name.Variable, Operator), 'value'),
|
||||
(r':', Name.Attribute, 'old-style-attr'),
|
||||
(r'(?=.+?[=:]([^a-z]|$))', Name.Attribute, 'new-style-attr'),
|
||||
default('selector'),
|
||||
],
|
||||
|
||||
'single-comment': [
|
||||
(r'.+', Comment.Single),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'multi-comment': [
|
||||
(r'.+', Comment.Multiline),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'import': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\S+', String),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'old-style-attr': [
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*=', Operator, 'value'),
|
||||
default('value'),
|
||||
],
|
||||
|
||||
'new-style-attr': [
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*[=:]', Operator, 'value'),
|
||||
],
|
||||
|
||||
'inline-comment': [
|
||||
(r"(\\#|#(?=[^\n{])|\*(?=[^\n/])|[^\n#*])+", Comment.Multiline),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r"\*/", Comment, '#pop'),
|
||||
],
|
||||
}
|
||||
for group, common in iteritems(common_sass_tokens):
|
||||
tokens[group] = copy.copy(common)
|
||||
tokens['value'].append((r'\n', Text, 'root'))
|
||||
tokens['selector'].append((r'\n', Text, 'root'))
|
||||
|
||||
|
||||
class ScssLexer(RegexLexer):
|
||||
"""
|
||||
For SCSS stylesheets.
|
||||
"""
|
||||
|
||||
name = 'SCSS'
|
||||
aliases = ['scss']
|
||||
filenames = ['*.scss']
|
||||
mimetypes = ['text/x-scss']
|
||||
|
||||
flags = re.IGNORECASE | re.DOTALL
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'@import', Keyword, 'value'),
|
||||
(r'@for', Keyword, 'for'),
|
||||
(r'@(debug|warn|if|while)', Keyword, 'value'),
|
||||
(r'(@mixin)( [\w-]+)', bygroups(Keyword, Name.Function), 'value'),
|
||||
(r'(@include)( [\w-]+)', bygroups(Keyword, Name.Decorator), 'value'),
|
||||
(r'@extend', Keyword, 'selector'),
|
||||
(r'(@media)(\s+)', bygroups(Keyword, Text), 'value'),
|
||||
(r'@[\w-]+', Keyword, 'selector'),
|
||||
(r'(\$[\w-]*\w)([ \t]*:)', bygroups(Name.Variable, Operator), 'value'),
|
||||
(r'(?=[^;{}][;}])', Name.Attribute, 'attr'),
|
||||
(r'(?=[^;{}:]+:[^a-z])', Name.Attribute, 'attr'),
|
||||
default('selector'),
|
||||
],
|
||||
|
||||
'attr': [
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*:', Operator, 'value'),
|
||||
],
|
||||
|
||||
'inline-comment': [
|
||||
(r"(\\#|#(?=[^{])|\*(?=[^/])|[^#*])+", Comment.Multiline),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r"\*/", Comment, '#pop'),
|
||||
],
|
||||
}
|
||||
for group, common in iteritems(common_sass_tokens):
|
||||
tokens[group] = copy.copy(common)
|
||||
tokens['value'].extend([(r'\n', Text), (r'[;{}]', Punctuation, '#pop')])
|
||||
tokens['selector'].extend([(r'\n', Text), (r'[;{}]', Punctuation, '#pop')])
|
||||
@ -1,530 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.data
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for data file format.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, ExtendedRegexLexer, LexerContext, \
|
||||
include, bygroups, inherit
|
||||
from pygments.token import Text, Comment, Keyword, Name, String, Number, \
|
||||
Punctuation, Literal
|
||||
|
||||
__all__ = ['YamlLexer', 'JsonLexer', 'JsonLdLexer']
|
||||
|
||||
|
||||
class YamlLexerContext(LexerContext):
|
||||
"""Indentation context for the YAML lexer."""
|
||||
|
||||
def __init__(self, *args, **kwds):
|
||||
super(YamlLexerContext, self).__init__(*args, **kwds)
|
||||
self.indent_stack = []
|
||||
self.indent = -1
|
||||
self.next_indent = 0
|
||||
self.block_scalar_indent = None
|
||||
|
||||
|
||||
class YamlLexer(ExtendedRegexLexer):
|
||||
"""
|
||||
Lexer for `YAML <http://yaml.org/>`_, a human-friendly data serialization
|
||||
language.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
|
||||
name = 'YAML'
|
||||
aliases = ['yaml']
|
||||
filenames = ['*.yaml', '*.yml']
|
||||
mimetypes = ['text/x-yaml']
|
||||
|
||||
def something(token_class):
|
||||
"""Do not produce empty tokens."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
if not text:
|
||||
return
|
||||
yield match.start(), token_class, text
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def reset_indent(token_class):
|
||||
"""Reset the indentation levels."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
context.indent_stack = []
|
||||
context.indent = -1
|
||||
context.next_indent = 0
|
||||
context.block_scalar_indent = None
|
||||
yield match.start(), token_class, text
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def save_indent(token_class, start=False):
|
||||
"""Save a possible indentation level."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
extra = ''
|
||||
if start:
|
||||
context.next_indent = len(text)
|
||||
if context.next_indent < context.indent:
|
||||
while context.next_indent < context.indent:
|
||||
context.indent = context.indent_stack.pop()
|
||||
if context.next_indent > context.indent:
|
||||
extra = text[context.indent:]
|
||||
text = text[:context.indent]
|
||||
else:
|
||||
context.next_indent += len(text)
|
||||
if text:
|
||||
yield match.start(), token_class, text
|
||||
if extra:
|
||||
yield match.start()+len(text), token_class.Error, extra
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def set_indent(token_class, implicit=False):
|
||||
"""Set the previously saved indentation level."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
if context.indent < context.next_indent:
|
||||
context.indent_stack.append(context.indent)
|
||||
context.indent = context.next_indent
|
||||
if not implicit:
|
||||
context.next_indent += len(text)
|
||||
yield match.start(), token_class, text
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def set_block_scalar_indent(token_class):
|
||||
"""Set an explicit indentation level for a block scalar."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
context.block_scalar_indent = None
|
||||
if not text:
|
||||
return
|
||||
increment = match.group(1)
|
||||
if increment:
|
||||
current_indent = max(context.indent, 0)
|
||||
increment = int(increment)
|
||||
context.block_scalar_indent = current_indent + increment
|
||||
if text:
|
||||
yield match.start(), token_class, text
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def parse_block_scalar_empty_line(indent_token_class, content_token_class):
|
||||
"""Process an empty line in a block scalar."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
if (context.block_scalar_indent is None or
|
||||
len(text) <= context.block_scalar_indent):
|
||||
if text:
|
||||
yield match.start(), indent_token_class, text
|
||||
else:
|
||||
indentation = text[:context.block_scalar_indent]
|
||||
content = text[context.block_scalar_indent:]
|
||||
yield match.start(), indent_token_class, indentation
|
||||
yield (match.start()+context.block_scalar_indent,
|
||||
content_token_class, content)
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def parse_block_scalar_indent(token_class):
|
||||
"""Process indentation spaces in a block scalar."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
if context.block_scalar_indent is None:
|
||||
if len(text) <= max(context.indent, 0):
|
||||
context.stack.pop()
|
||||
context.stack.pop()
|
||||
return
|
||||
context.block_scalar_indent = len(text)
|
||||
else:
|
||||
if len(text) < context.block_scalar_indent:
|
||||
context.stack.pop()
|
||||
context.stack.pop()
|
||||
return
|
||||
if text:
|
||||
yield match.start(), token_class, text
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
def parse_plain_scalar_indent(token_class):
|
||||
"""Process indentation spaces in a plain scalar."""
|
||||
def callback(lexer, match, context):
|
||||
text = match.group()
|
||||
if len(text) <= context.indent:
|
||||
context.stack.pop()
|
||||
context.stack.pop()
|
||||
return
|
||||
if text:
|
||||
yield match.start(), token_class, text
|
||||
context.pos = match.end()
|
||||
return callback
|
||||
|
||||
tokens = {
|
||||
# the root rules
|
||||
'root': [
|
||||
# ignored whitespaces
|
||||
(r'[ ]+(?=#|$)', Text),
|
||||
# line breaks
|
||||
(r'\n+', Text),
|
||||
# a comment
|
||||
(r'#[^\n]*', Comment.Single),
|
||||
# the '%YAML' directive
|
||||
(r'^%YAML(?=[ ]|$)', reset_indent(Name.Tag), 'yaml-directive'),
|
||||
# the %TAG directive
|
||||
(r'^%TAG(?=[ ]|$)', reset_indent(Name.Tag), 'tag-directive'),
|
||||
# document start and document end indicators
|
||||
(r'^(?:---|\.\.\.)(?=[ ]|$)', reset_indent(Name.Namespace),
|
||||
'block-line'),
|
||||
# indentation spaces
|
||||
(r'[ ]*(?!\s|$)', save_indent(Text, start=True),
|
||||
('block-line', 'indentation')),
|
||||
],
|
||||
|
||||
# trailing whitespaces after directives or a block scalar indicator
|
||||
'ignored-line': [
|
||||
# ignored whitespaces
|
||||
(r'[ ]+(?=#|$)', Text),
|
||||
# a comment
|
||||
(r'#[^\n]*', Comment.Single),
|
||||
# line break
|
||||
(r'\n', Text, '#pop:2'),
|
||||
],
|
||||
|
||||
# the %YAML directive
|
||||
'yaml-directive': [
|
||||
# the version number
|
||||
(r'([ ]+)([0-9]+\.[0-9]+)',
|
||||
bygroups(Text, Number), 'ignored-line'),
|
||||
],
|
||||
|
||||
# the %YAG directive
|
||||
'tag-directive': [
|
||||
# a tag handle and the corresponding prefix
|
||||
(r'([ ]+)(!|![\w-]*!)'
|
||||
r'([ ]+)(!|!?[\w;/?:@&=+$,.!~*\'()\[\]%-]+)',
|
||||
bygroups(Text, Keyword.Type, Text, Keyword.Type),
|
||||
'ignored-line'),
|
||||
],
|
||||
|
||||
# block scalar indicators and indentation spaces
|
||||
'indentation': [
|
||||
# trailing whitespaces are ignored
|
||||
(r'[ ]*$', something(Text), '#pop:2'),
|
||||
# whitespaces preceeding block collection indicators
|
||||
(r'[ ]+(?=[?:-](?:[ ]|$))', save_indent(Text)),
|
||||
# block collection indicators
|
||||
(r'[?:-](?=[ ]|$)', set_indent(Punctuation.Indicator)),
|
||||
# the beginning a block line
|
||||
(r'[ ]*', save_indent(Text), '#pop'),
|
||||
],
|
||||
|
||||
# an indented line in the block context
|
||||
'block-line': [
|
||||
# the line end
|
||||
(r'[ ]*(?=#|$)', something(Text), '#pop'),
|
||||
# whitespaces separating tokens
|
||||
(r'[ ]+', Text),
|
||||
# tags, anchors and aliases,
|
||||
include('descriptors'),
|
||||
# block collections and scalars
|
||||
include('block-nodes'),
|
||||
# flow collections and quoted scalars
|
||||
include('flow-nodes'),
|
||||
# a plain scalar
|
||||
(r'(?=[^\s?:,\[\]{}#&*!|>\'"%@`-]|[?:-]\S)',
|
||||
something(Name.Variable),
|
||||
'plain-scalar-in-block-context'),
|
||||
],
|
||||
|
||||
# tags, anchors, aliases
|
||||
'descriptors': [
|
||||
# a full-form tag
|
||||
(r'!<[\w;/?:@&=+$,.!~*\'()\[\]%-]+>', Keyword.Type),
|
||||
# a tag in the form '!', '!suffix' or '!handle!suffix'
|
||||
(r'!(?:[\w-]+)?'
|
||||
r'(?:![\w;/?:@&=+$,.!~*\'()\[\]%-]+)?', Keyword.Type),
|
||||
# an anchor
|
||||
(r'&[\w-]+', Name.Label),
|
||||
# an alias
|
||||
(r'\*[\w-]+', Name.Variable),
|
||||
],
|
||||
|
||||
# block collections and scalars
|
||||
'block-nodes': [
|
||||
# implicit key
|
||||
(r':(?=[ ]|$)', set_indent(Punctuation.Indicator, implicit=True)),
|
||||
# literal and folded scalars
|
||||
(r'[|>]', Punctuation.Indicator,
|
||||
('block-scalar-content', 'block-scalar-header')),
|
||||
],
|
||||
|
||||
# flow collections and quoted scalars
|
||||
'flow-nodes': [
|
||||
# a flow sequence
|
||||
(r'\[', Punctuation.Indicator, 'flow-sequence'),
|
||||
# a flow mapping
|
||||
(r'\{', Punctuation.Indicator, 'flow-mapping'),
|
||||
# a single-quoted scalar
|
||||
(r'\'', String, 'single-quoted-scalar'),
|
||||
# a double-quoted scalar
|
||||
(r'\"', String, 'double-quoted-scalar'),
|
||||
],
|
||||
|
||||
# the content of a flow collection
|
||||
'flow-collection': [
|
||||
# whitespaces
|
||||
(r'[ ]+', Text),
|
||||
# line breaks
|
||||
(r'\n+', Text),
|
||||
# a comment
|
||||
(r'#[^\n]*', Comment.Single),
|
||||
# simple indicators
|
||||
(r'[?:,]', Punctuation.Indicator),
|
||||
# tags, anchors and aliases
|
||||
include('descriptors'),
|
||||
# nested collections and quoted scalars
|
||||
include('flow-nodes'),
|
||||
# a plain scalar
|
||||
(r'(?=[^\s?:,\[\]{}#&*!|>\'"%@`])',
|
||||
something(Name.Variable),
|
||||
'plain-scalar-in-flow-context'),
|
||||
],
|
||||
|
||||
# a flow sequence indicated by '[' and ']'
|
||||
'flow-sequence': [
|
||||
# include flow collection rules
|
||||
include('flow-collection'),
|
||||
# the closing indicator
|
||||
(r'\]', Punctuation.Indicator, '#pop'),
|
||||
],
|
||||
|
||||
# a flow mapping indicated by '{' and '}'
|
||||
'flow-mapping': [
|
||||
# include flow collection rules
|
||||
include('flow-collection'),
|
||||
# the closing indicator
|
||||
(r'\}', Punctuation.Indicator, '#pop'),
|
||||
],
|
||||
|
||||
# block scalar lines
|
||||
'block-scalar-content': [
|
||||
# line break
|
||||
(r'\n', Text),
|
||||
# empty line
|
||||
(r'^[ ]+$',
|
||||
parse_block_scalar_empty_line(Text, Name.Constant)),
|
||||
# indentation spaces (we may leave the state here)
|
||||
(r'^[ ]*', parse_block_scalar_indent(Text)),
|
||||
# line content
|
||||
(r'[\S\t ]+', Name.Constant),
|
||||
],
|
||||
|
||||
# the content of a literal or folded scalar
|
||||
'block-scalar-header': [
|
||||
# indentation indicator followed by chomping flag
|
||||
(r'([1-9])?[+-]?(?=[ ]|$)',
|
||||
set_block_scalar_indent(Punctuation.Indicator),
|
||||
'ignored-line'),
|
||||
# chomping flag followed by indentation indicator
|
||||
(r'[+-]?([1-9])?(?=[ ]|$)',
|
||||
set_block_scalar_indent(Punctuation.Indicator),
|
||||
'ignored-line'),
|
||||
],
|
||||
|
||||
# ignored and regular whitespaces in quoted scalars
|
||||
'quoted-scalar-whitespaces': [
|
||||
# leading and trailing whitespaces are ignored
|
||||
(r'^[ ]+', Text),
|
||||
(r'[ ]+$', Text),
|
||||
# line breaks are ignored
|
||||
(r'\n+', Text),
|
||||
# other whitespaces are a part of the value
|
||||
(r'[ ]+', Name.Variable),
|
||||
],
|
||||
|
||||
# single-quoted scalars
|
||||
'single-quoted-scalar': [
|
||||
# include whitespace and line break rules
|
||||
include('quoted-scalar-whitespaces'),
|
||||
# escaping of the quote character
|
||||
(r'\'\'', String.Escape),
|
||||
# regular non-whitespace characters
|
||||
(r'[^\s\']+', String),
|
||||
# the closing quote
|
||||
(r'\'', String, '#pop'),
|
||||
],
|
||||
|
||||
# double-quoted scalars
|
||||
'double-quoted-scalar': [
|
||||
# include whitespace and line break rules
|
||||
include('quoted-scalar-whitespaces'),
|
||||
# escaping of special characters
|
||||
(r'\\[0abt\tn\nvfre "\\N_LP]', String),
|
||||
# escape codes
|
||||
(r'\\(?:x[0-9A-Fa-f]{2}|u[0-9A-Fa-f]{4}|U[0-9A-Fa-f]{8})',
|
||||
String.Escape),
|
||||
# regular non-whitespace characters
|
||||
(r'[^\s"\\]+', String),
|
||||
# the closing quote
|
||||
(r'"', String, '#pop'),
|
||||
],
|
||||
|
||||
# the beginning of a new line while scanning a plain scalar
|
||||
'plain-scalar-in-block-context-new-line': [
|
||||
# empty lines
|
||||
(r'^[ ]+$', Text),
|
||||
# line breaks
|
||||
(r'\n+', Text),
|
||||
# document start and document end indicators
|
||||
(r'^(?=---|\.\.\.)', something(Name.Namespace), '#pop:3'),
|
||||
# indentation spaces (we may leave the block line state here)
|
||||
(r'^[ ]*', parse_plain_scalar_indent(Text), '#pop'),
|
||||
],
|
||||
|
||||
# a plain scalar in the block context
|
||||
'plain-scalar-in-block-context': [
|
||||
# the scalar ends with the ':' indicator
|
||||
(r'[ ]*(?=:[ ]|:$)', something(Text), '#pop'),
|
||||
# the scalar ends with whitespaces followed by a comment
|
||||
(r'[ ]+(?=#)', Text, '#pop'),
|
||||
# trailing whitespaces are ignored
|
||||
(r'[ ]+$', Text),
|
||||
# line breaks are ignored
|
||||
(r'\n+', Text, 'plain-scalar-in-block-context-new-line'),
|
||||
# other whitespaces are a part of the value
|
||||
(r'[ ]+', Literal.Scalar.Plain),
|
||||
# regular non-whitespace characters
|
||||
(r'(?::(?!\s)|[^\s:])+', Literal.Scalar.Plain),
|
||||
],
|
||||
|
||||
# a plain scalar is the flow context
|
||||
'plain-scalar-in-flow-context': [
|
||||
# the scalar ends with an indicator character
|
||||
(r'[ ]*(?=[,:?\[\]{}])', something(Text), '#pop'),
|
||||
# the scalar ends with a comment
|
||||
(r'[ ]+(?=#)', Text, '#pop'),
|
||||
# leading and trailing whitespaces are ignored
|
||||
(r'^[ ]+', Text),
|
||||
(r'[ ]+$', Text),
|
||||
# line breaks are ignored
|
||||
(r'\n+', Text),
|
||||
# other whitespaces are a part of the value
|
||||
(r'[ ]+', Name.Variable),
|
||||
# regular non-whitespace characters
|
||||
(r'[^\s,:?\[\]{}]+', Name.Variable),
|
||||
],
|
||||
|
||||
}
|
||||
|
||||
def get_tokens_unprocessed(self, text=None, context=None):
|
||||
if context is None:
|
||||
context = YamlLexerContext(text, 0)
|
||||
return super(YamlLexer, self).get_tokens_unprocessed(text, context)
|
||||
|
||||
|
||||
class JsonLexer(RegexLexer):
|
||||
"""
|
||||
For JSON data structures.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = 'JSON'
|
||||
aliases = ['json']
|
||||
filenames = ['*.json']
|
||||
mimetypes = ['application/json']
|
||||
|
||||
flags = re.DOTALL
|
||||
|
||||
# integer part of a number
|
||||
int_part = r'-?(0|[1-9]\d*)'
|
||||
|
||||
# fractional part of a number
|
||||
frac_part = r'\.\d+'
|
||||
|
||||
# exponential part of a number
|
||||
exp_part = r'[eE](\+|-)?\d+'
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'\s+', Text),
|
||||
],
|
||||
|
||||
# represents a simple terminal value
|
||||
'simplevalue': [
|
||||
(r'(true|false|null)\b', Keyword.Constant),
|
||||
(('%(int_part)s(%(frac_part)s%(exp_part)s|'
|
||||
'%(exp_part)s|%(frac_part)s)') % vars(),
|
||||
Number.Float),
|
||||
(int_part, Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
],
|
||||
|
||||
|
||||
# the right hand side of an object, after the attribute name
|
||||
'objectattribute': [
|
||||
include('value'),
|
||||
(r':', Punctuation),
|
||||
# comma terminates the attribute but expects more
|
||||
(r',', Punctuation, '#pop'),
|
||||
# a closing bracket terminates the entire object, so pop twice
|
||||
(r'\}', Punctuation, ('#pop', '#pop')),
|
||||
],
|
||||
|
||||
# a json object - { attr, attr, ... }
|
||||
'objectvalue': [
|
||||
include('whitespace'),
|
||||
(r'"(\\\\|\\"|[^"])*"', Name.Tag, 'objectattribute'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
|
||||
# json array - [ value, value, ... }
|
||||
'arrayvalue': [
|
||||
include('whitespace'),
|
||||
include('value'),
|
||||
(r',', Punctuation),
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
],
|
||||
|
||||
# a json value - either a simple value or a complex value (object or array)
|
||||
'value': [
|
||||
include('whitespace'),
|
||||
include('simplevalue'),
|
||||
(r'\{', Punctuation, 'objectvalue'),
|
||||
(r'\[', Punctuation, 'arrayvalue'),
|
||||
],
|
||||
|
||||
# the root of a json document whould be a value
|
||||
'root': [
|
||||
include('value'),
|
||||
],
|
||||
}
|
||||
|
||||
class JsonLdLexer(JsonLexer):
|
||||
"""
|
||||
For `JSON-LD <http://json-ld.org/>`_ linked data.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'JSON-LD'
|
||||
aliases = ['jsonld', 'json-ld']
|
||||
filenames = ['*.jsonld']
|
||||
mimetypes = ['application/ld+json']
|
||||
|
||||
tokens = {
|
||||
'objectvalue': [
|
||||
(r'"@(context|id|value|language|type|container|list|set|'
|
||||
r'reverse|index|base|vocab|graph)"', Name.Decorator,
|
||||
'objectattribute'),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
@ -1,106 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.diff
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for diff/patch formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, Generic, \
|
||||
Literal
|
||||
|
||||
__all__ = ['DiffLexer', 'DarcsPatchLexer']
|
||||
|
||||
|
||||
class DiffLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for unified or context-style diffs or patches.
|
||||
"""
|
||||
|
||||
name = 'Diff'
|
||||
aliases = ['diff', 'udiff']
|
||||
filenames = ['*.diff', '*.patch']
|
||||
mimetypes = ['text/x-diff', 'text/x-patch']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r' .*\n', Text),
|
||||
(r'\+.*\n', Generic.Inserted),
|
||||
(r'-.*\n', Generic.Deleted),
|
||||
(r'!.*\n', Generic.Strong),
|
||||
(r'@.*\n', Generic.Subheading),
|
||||
(r'([Ii]ndex|diff).*\n', Generic.Heading),
|
||||
(r'=.*\n', Generic.Heading),
|
||||
(r'.*\n', Text),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if text[:7] == 'Index: ':
|
||||
return True
|
||||
if text[:5] == 'diff ':
|
||||
return True
|
||||
if text[:4] == '--- ':
|
||||
return 0.9
|
||||
|
||||
|
||||
class DarcsPatchLexer(RegexLexer):
|
||||
"""
|
||||
DarcsPatchLexer is a lexer for the various versions of the darcs patch
|
||||
format. Examples of this format are derived by commands such as
|
||||
``darcs annotate --patch`` and ``darcs send``.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
name = 'Darcs Patch'
|
||||
aliases = ['dpatch']
|
||||
filenames = ['*.dpatch', '*.darcspatch']
|
||||
|
||||
DPATCH_KEYWORDS = ('hunk', 'addfile', 'adddir', 'rmfile', 'rmdir', 'move',
|
||||
'replace')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'<', Operator),
|
||||
(r'>', Operator),
|
||||
(r'\{', Operator),
|
||||
(r'\}', Operator),
|
||||
(r'(\[)((?:TAG )?)(.*)(\n)(.*)(\*\*)(\d+)(\s?)(\])',
|
||||
bygroups(Operator, Keyword, Name, Text, Name, Operator,
|
||||
Literal.Date, Text, Operator)),
|
||||
(r'(\[)((?:TAG )?)(.*)(\n)(.*)(\*\*)(\d+)(\s?)',
|
||||
bygroups(Operator, Keyword, Name, Text, Name, Operator,
|
||||
Literal.Date, Text), 'comment'),
|
||||
(r'New patches:', Generic.Heading),
|
||||
(r'Context:', Generic.Heading),
|
||||
(r'Patch bundle hash:', Generic.Heading),
|
||||
(r'(\s*)(%s)(.*\n)' % '|'.join(DPATCH_KEYWORDS),
|
||||
bygroups(Text, Keyword, Text)),
|
||||
(r'\+', Generic.Inserted, "insert"),
|
||||
(r'-', Generic.Deleted, "delete"),
|
||||
(r'.*\n', Text),
|
||||
],
|
||||
'comment': [
|
||||
(r'[^\]].*\n', Comment),
|
||||
(r'\]', Operator, "#pop"),
|
||||
],
|
||||
'specialText': [ # darcs add [_CODE_] special operators for clarity
|
||||
(r'\n', Text, "#pop"), # line-based
|
||||
(r'\[_[^_]*_]', Operator),
|
||||
],
|
||||
'insert': [
|
||||
include('specialText'),
|
||||
(r'\[', Generic.Inserted),
|
||||
(r'[^\n\[]+', Generic.Inserted),
|
||||
],
|
||||
'delete': [
|
||||
include('specialText'),
|
||||
(r'\[', Generic.Deleted),
|
||||
(r'[^\n\[]+', Generic.Deleted),
|
||||
],
|
||||
}
|
||||
@ -1,514 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.dsls
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for various domain-specific languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words, include, default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Literal
|
||||
|
||||
__all__ = ['ProtoBufLexer', 'BroLexer', 'PuppetLexer', 'RslLexer',
|
||||
'MscgenLexer', 'VGLLexer', 'AlloyLexer', 'PanLexer']
|
||||
|
||||
|
||||
class ProtoBufLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Protocol Buffer <http://code.google.com/p/protobuf/>`_
|
||||
definition files.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'Protocol Buffer'
|
||||
aliases = ['protobuf', 'proto']
|
||||
filenames = ['*.proto']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'[,;{}\[\]()]', Punctuation),
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?\*(.|\n)*?\*(\\\n)?/', Comment.Multiline),
|
||||
(words((
|
||||
'import', 'option', 'optional', 'required', 'repeated', 'default',
|
||||
'packed', 'ctype', 'extensions', 'to', 'max', 'rpc', 'returns',
|
||||
'oneof'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'int32', 'int64', 'uint32', 'uint64', 'sint32', 'sint64',
|
||||
'fixed32', 'fixed64', 'sfixed32', 'sfixed64',
|
||||
'float', 'double', 'bool', 'string', 'bytes'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(r'(true|false)\b', Keyword.Constant),
|
||||
(r'(package)(\s+)', bygroups(Keyword.Namespace, Text), 'package'),
|
||||
(r'(message|extend)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text), 'message'),
|
||||
(r'(enum|group|service)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text), 'type'),
|
||||
(r'\".*?\"', String),
|
||||
(r'\'.*?\'', String),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[LlUu]*', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'(\-?(inf|nan))\b', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'0[0-7]+[LlUu]*', Number.Oct),
|
||||
(r'\d+[LlUu]*', Number.Integer),
|
||||
(r'[+-=]', Operator),
|
||||
(r'([a-zA-Z_][\w.]*)([ \t]*)(=)',
|
||||
bygroups(Name.Attribute, Text, Operator)),
|
||||
('[a-zA-Z_][\w.]*', Name),
|
||||
],
|
||||
'package': [
|
||||
(r'[a-zA-Z_]\w*', Name.Namespace, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
'message': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
'type': [
|
||||
(r'[a-zA-Z_]\w*', Name, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class BroLexer(RegexLexer):
|
||||
"""
|
||||
For `Bro <http://bro-ids.org/>`_ scripts.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'Bro'
|
||||
aliases = ['bro']
|
||||
filenames = ['*.bro']
|
||||
|
||||
_hex = r'[0-9a-fA-F_]'
|
||||
_float = r'((\d*\.?\d+)|(\d+\.?\d*))([eE][-+]?\d+)?'
|
||||
_h = r'[A-Za-z0-9][-A-Za-z0-9]*'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Whitespace
|
||||
(r'^@.*?\n', Comment.Preproc),
|
||||
(r'#.*?\n', Comment.Single),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text),
|
||||
# Keywords
|
||||
(r'(add|alarm|break|case|const|continue|delete|do|else|enum|event'
|
||||
r'|export|for|function|if|global|hook|local|module|next'
|
||||
r'|of|print|redef|return|schedule|switch|type|when|while)\b', Keyword),
|
||||
(r'(addr|any|bool|count|counter|double|file|int|interval|net'
|
||||
r'|pattern|port|record|set|string|subnet|table|time|timer'
|
||||
r'|vector)\b', Keyword.Type),
|
||||
(r'(T|F)\b', Keyword.Constant),
|
||||
(r'(&)((?:add|delete|expire)_func|attr|(?:create|read|write)_expire'
|
||||
r'|default|disable_print_hook|raw_output|encrypt|group|log'
|
||||
r'|mergeable|optional|persistent|priority|redef'
|
||||
r'|rotate_(?:interval|size)|synchronized)\b',
|
||||
bygroups(Punctuation, Keyword)),
|
||||
(r'\s+module\b', Keyword.Namespace),
|
||||
# Addresses, ports and networks
|
||||
(r'\d+/(tcp|udp|icmp|unknown)\b', Number),
|
||||
(r'(\d+\.){3}\d+', Number),
|
||||
(r'(' + _hex + r'){7}' + _hex, Number),
|
||||
(r'0x' + _hex + r'(' + _hex + r'|:)*::(' + _hex + r'|:)*', Number),
|
||||
(r'((\d+|:)(' + _hex + r'|:)*)?::(' + _hex + r'|:)*', Number),
|
||||
(r'(\d+\.\d+\.|(\d+\.){2}\d+)', Number),
|
||||
# Hostnames
|
||||
(_h + r'(\.' + _h + r')+', String),
|
||||
# Numeric
|
||||
(_float + r'\s+(day|hr|min|sec|msec|usec)s?\b', Literal.Date),
|
||||
(r'0[xX]' + _hex, Number.Hex),
|
||||
(_float, Number.Float),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'/', String.Regex, 'regex'),
|
||||
(r'"', String, 'string'),
|
||||
# Operators
|
||||
(r'[!%*/+:<=>?~|-]', Operator),
|
||||
(r'([-+=&|]{2}|[+=!><-]=)', Operator),
|
||||
(r'(in|match)\b', Operator.Word),
|
||||
(r'[{}()\[\]$.,;]', Punctuation),
|
||||
# Identfier
|
||||
(r'([_a-zA-Z]\w*)(::)', bygroups(Name, Name.Namespace)),
|
||||
(r'[a-zA-Z_]\w*', Name)
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String),
|
||||
(r'\\\n', String),
|
||||
(r'\\', String)
|
||||
],
|
||||
'regex': [
|
||||
(r'/', String.Regex, '#pop'),
|
||||
(r'\\[\\nt/]', String.Regex), # String.Escape is too intense here.
|
||||
(r'[^\\/\n]+', String.Regex),
|
||||
(r'\\\n', String.Regex),
|
||||
(r'\\', String.Regex)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class PuppetLexer(RegexLexer):
|
||||
"""
|
||||
For `Puppet <http://puppetlabs.com/>`__ configuration DSL.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'Puppet'
|
||||
aliases = ['puppet']
|
||||
filenames = ['*.pp']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('comments'),
|
||||
include('keywords'),
|
||||
include('names'),
|
||||
include('numbers'),
|
||||
include('operators'),
|
||||
include('strings'),
|
||||
|
||||
(r'[]{}:(),;[]', Punctuation),
|
||||
(r'[^\S\n]+', Text),
|
||||
],
|
||||
|
||||
'comments': [
|
||||
(r'\s*#.*$', Comment),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
],
|
||||
|
||||
'operators': [
|
||||
(r'(=>|\?|<|>|=|\+|-|/|\*|~|!|\|)', Operator),
|
||||
(r'(in|and|or|not)\b', Operator.Word),
|
||||
],
|
||||
|
||||
'names': [
|
||||
('[a-zA-Z_]\w*', Name.Attribute),
|
||||
(r'(\$\S+)(\[)(\S+)(\])', bygroups(Name.Variable, Punctuation,
|
||||
String, Punctuation)),
|
||||
(r'\$\S+', Name.Variable),
|
||||
],
|
||||
|
||||
'numbers': [
|
||||
# Copypasta from the Python lexer
|
||||
(r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?j?', Number.Float),
|
||||
(r'\d+[eE][+-]?[0-9]+j?', Number.Float),
|
||||
(r'0[0-7]+j?', Number.Oct),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+L', Number.Integer.Long),
|
||||
(r'\d+j?', Number.Integer)
|
||||
],
|
||||
|
||||
'keywords': [
|
||||
# Left out 'group' and 'require'
|
||||
# Since they're often used as attributes
|
||||
(words((
|
||||
'absent', 'alert', 'alias', 'audit', 'augeas', 'before', 'case',
|
||||
'check', 'class', 'computer', 'configured', 'contained',
|
||||
'create_resources', 'crit', 'cron', 'debug', 'default',
|
||||
'define', 'defined', 'directory', 'else', 'elsif', 'emerg',
|
||||
'err', 'exec', 'extlookup', 'fail', 'false', 'file',
|
||||
'filebucket', 'fqdn_rand', 'generate', 'host', 'if', 'import',
|
||||
'include', 'info', 'inherits', 'inline_template', 'installed',
|
||||
'interface', 'k5login', 'latest', 'link', 'loglevel',
|
||||
'macauthorization', 'mailalias', 'maillist', 'mcx', 'md5',
|
||||
'mount', 'mounted', 'nagios_command', 'nagios_contact',
|
||||
'nagios_contactgroup', 'nagios_host', 'nagios_hostdependency',
|
||||
'nagios_hostescalation', 'nagios_hostextinfo', 'nagios_hostgroup',
|
||||
'nagios_service', 'nagios_servicedependency', 'nagios_serviceescalation',
|
||||
'nagios_serviceextinfo', 'nagios_servicegroup', 'nagios_timeperiod',
|
||||
'node', 'noop', 'notice', 'notify', 'package', 'present', 'purged',
|
||||
'realize', 'regsubst', 'resources', 'role', 'router', 'running',
|
||||
'schedule', 'scheduled_task', 'search', 'selboolean', 'selmodule',
|
||||
'service', 'sha1', 'shellquote', 'split', 'sprintf',
|
||||
'ssh_authorized_key', 'sshkey', 'stage', 'stopped', 'subscribe',
|
||||
'tag', 'tagged', 'template', 'tidy', 'true', 'undef', 'unmounted',
|
||||
'user', 'versioncmp', 'vlan', 'warning', 'yumrepo', 'zfs', 'zone',
|
||||
'zpool'), prefix='(?i)', suffix=r'\b'),
|
||||
Keyword),
|
||||
],
|
||||
|
||||
'strings': [
|
||||
(r'"([^"])*"', String),
|
||||
(r"'(\\'|[^'])*'", String),
|
||||
],
|
||||
|
||||
}
|
||||
|
||||
|
||||
class RslLexer(RegexLexer):
|
||||
"""
|
||||
`RSL <http://en.wikipedia.org/wiki/RAISE>`_ is the formal specification
|
||||
language used in RAISE (Rigorous Approach to Industrial Software Engineering)
|
||||
method.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'RSL'
|
||||
aliases = ['rsl']
|
||||
filenames = ['*.rsl']
|
||||
mimetypes = ['text/rsl']
|
||||
|
||||
flags = re.MULTILINE | re.DOTALL
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(words((
|
||||
'Bool', 'Char', 'Int', 'Nat', 'Real', 'Text', 'Unit', 'abs',
|
||||
'all', 'always', 'any', 'as', 'axiom', 'card', 'case', 'channel',
|
||||
'chaos', 'class', 'devt_relation', 'dom', 'elems', 'else', 'elif',
|
||||
'end', 'exists', 'extend', 'false', 'for', 'hd', 'hide', 'if',
|
||||
'in', 'is', 'inds', 'initialise', 'int', 'inter', 'isin', 'len',
|
||||
'let', 'local', 'ltl_assertion', 'object', 'of', 'out', 'post',
|
||||
'pre', 'read', 'real', 'rng', 'scheme', 'skip', 'stop', 'swap',
|
||||
'then', 'theory', 'test_case', 'tl', 'transition_system', 'true',
|
||||
'type', 'union', 'until', 'use', 'value', 'variable', 'while',
|
||||
'with', 'write', '~isin', '-inflist', '-infset', '-list',
|
||||
'-set'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(variable|value)\b', Keyword.Declaration),
|
||||
(r'--.*?\n', Comment),
|
||||
(r'<:.*?:>', Comment),
|
||||
(r'\{!.*?!\}', Comment),
|
||||
(r'/\*.*?\*/', Comment),
|
||||
(r'^[ \t]*([\w]+)[ \t]*:[^:]', Name.Function),
|
||||
(r'(^[ \t]*)([\w]+)([ \t]*\([\w\s,]*\)[ \t]*)(is|as)',
|
||||
bygroups(Text, Name.Function, Text, Keyword)),
|
||||
(r'\b[A-Z]\w*\b', Keyword.Type),
|
||||
(r'(true|false)\b', Keyword.Constant),
|
||||
(r'".*"', String),
|
||||
(r'\'.\'', String.Char),
|
||||
(r'(><|->|-m->|/\\|<=|<<=|<\.|\|\||\|\^\||-~->|-~m->|\\/|>=|>>|'
|
||||
r'\.>|\+\+|-\\|<->|=>|:-|~=|\*\*|<<|>>=|\+>|!!|\|=\||#)',
|
||||
Operator),
|
||||
(r'[0-9]+\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-f]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'.', Text),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
"""
|
||||
Check for the most common text in the beginning of a RSL file.
|
||||
"""
|
||||
if re.search(r'scheme\s*.*?=\s*class\s*type', text, re.I) is not None:
|
||||
return 1.0
|
||||
|
||||
|
||||
class MscgenLexer(RegexLexer):
|
||||
"""
|
||||
For `Mscgen <http://www.mcternan.me.uk/mscgen/>`_ files.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'Mscgen'
|
||||
aliases = ['mscgen', 'msc']
|
||||
filenames = ['*.msc']
|
||||
|
||||
_var = r'(\w+|"(?:\\"|[^"])*")'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'msc\b', Keyword.Type),
|
||||
# Options
|
||||
(r'(hscale|HSCALE|width|WIDTH|wordwraparcs|WORDWRAPARCS'
|
||||
r'|arcgradient|ARCGRADIENT)\b', Name.Property),
|
||||
# Operators
|
||||
(r'(abox|ABOX|rbox|RBOX|box|BOX|note|NOTE)\b', Operator.Word),
|
||||
(r'(\.|-|\|){3}', Keyword),
|
||||
(r'(?:-|=|\.|:){2}'
|
||||
r'|<<=>>|<->|<=>|<<>>|<:>'
|
||||
r'|->|=>>|>>|=>|:>|-x|-X'
|
||||
r'|<-|<<=|<<|<=|<:|x-|X-|=', Operator),
|
||||
# Names
|
||||
(r'\*', Name.Builtin),
|
||||
(_var, Name.Variable),
|
||||
# Other
|
||||
(r'\[', Punctuation, 'attrs'),
|
||||
(r'\{|\}|,|;', Punctuation),
|
||||
include('comments')
|
||||
],
|
||||
'attrs': [
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
(_var + r'(\s*)(=)(\s*)' + _var,
|
||||
bygroups(Name.Attribute, Text.Whitespace, Operator, Text.Whitespace,
|
||||
String)),
|
||||
(r',', Punctuation),
|
||||
include('comments')
|
||||
],
|
||||
'comments': [
|
||||
(r'(?://|#).*?\n', Comment.Single),
|
||||
(r'/\*(?:.|\n)*?\*/', Comment.Multiline),
|
||||
(r'[ \t\r\n]+', Text.Whitespace)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class VGLLexer(RegexLexer):
|
||||
"""
|
||||
For `SampleManager VGL <http://www.thermoscientific.com/samplemanager>`_
|
||||
source code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'VGL'
|
||||
aliases = ['vgl']
|
||||
filenames = ['*.rpf']
|
||||
|
||||
flags = re.MULTILINE | re.DOTALL | re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\{[^}]*\}', Comment.Multiline),
|
||||
(r'declare', Keyword.Constant),
|
||||
(r'(if|then|else|endif|while|do|endwhile|and|or|prompt|object'
|
||||
r'|create|on|line|with|global|routine|value|endroutine|constant'
|
||||
r'|global|set|join|library|compile_option|file|exists|create|copy'
|
||||
r'|delete|enable|windows|name|notprotected)(?! *[=<>.,()])',
|
||||
Keyword),
|
||||
(r'(true|false|null|empty|error|locked)', Keyword.Constant),
|
||||
(r'[~^*#!%&\[\]()<>|+=:;,./?-]', Operator),
|
||||
(r'"[^"]*"', String),
|
||||
(r'(\.)([a-z_$][\w$]*)', bygroups(Operator, Name.Attribute)),
|
||||
(r'[0-9][0-9]*(\.[0-9]+(e[+\-]?[0-9]+)?)?', Number),
|
||||
(r'[a-z_$][\w$]*', Name),
|
||||
(r'[\r\n]+', Text),
|
||||
(r'\s+', Text)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class AlloyLexer(RegexLexer):
|
||||
"""
|
||||
For `Alloy <http://alloy.mit.edu>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'Alloy'
|
||||
aliases = ['alloy']
|
||||
filenames = ['*.als']
|
||||
mimetypes = ['text/x-alloy']
|
||||
|
||||
flags = re.MULTILINE | re.DOTALL
|
||||
|
||||
iden_rex = r'[a-zA-Z_][\w\']*'
|
||||
text_tuple = (r'[^\S\n]+', Text)
|
||||
|
||||
tokens = {
|
||||
'sig': [
|
||||
(r'(extends)\b', Keyword, '#pop'),
|
||||
(iden_rex, Name),
|
||||
text_tuple,
|
||||
(r',', Punctuation),
|
||||
(r'\{', Operator, '#pop'),
|
||||
],
|
||||
'module': [
|
||||
text_tuple,
|
||||
(iden_rex, Name, '#pop'),
|
||||
],
|
||||
'fun': [
|
||||
text_tuple,
|
||||
(r'\{', Operator, '#pop'),
|
||||
(iden_rex, Name, '#pop'),
|
||||
],
|
||||
'root': [
|
||||
(r'--.*?$', Comment.Single),
|
||||
(r'//.*?$', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
text_tuple,
|
||||
(r'(module|open)(\s+)', bygroups(Keyword.Namespace, Text),
|
||||
'module'),
|
||||
(r'(sig|enum)(\s+)', bygroups(Keyword.Declaration, Text), 'sig'),
|
||||
(r'(iden|univ|none)\b', Keyword.Constant),
|
||||
(r'(int|Int)\b', Keyword.Type),
|
||||
(r'(this|abstract|extends|set|seq|one|lone|let)\b', Keyword),
|
||||
(r'(all|some|no|sum|disj|when|else)\b', Keyword),
|
||||
(r'(run|check|for|but|exactly|expect|as)\b', Keyword),
|
||||
(r'(and|or|implies|iff|in)\b', Operator.Word),
|
||||
(r'(fun|pred|fact|assert)(\s+)', bygroups(Keyword, Text), 'fun'),
|
||||
(r'!|#|&&|\+\+|<<|>>|>=|<=>|<=|\.|->', Operator),
|
||||
(r'[-+/*%=<>&!^|~{}\[\]().]', Operator),
|
||||
(iden_rex, Name),
|
||||
(r'[:,]', Punctuation),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
(r'\n', Text),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class PanLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `pan <http://github.com/quattor/pan/>`_ source files.
|
||||
|
||||
Based on tcsh lexer.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'Pan'
|
||||
aliases = ['pan']
|
||||
filenames = ['*.pan']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('basic'),
|
||||
(r'\(', Keyword, 'paren'),
|
||||
(r'\{', Keyword, 'curly'),
|
||||
include('data'),
|
||||
],
|
||||
'basic': [
|
||||
(words((
|
||||
'if', 'for', 'with', 'else', 'type', 'bind', 'while', 'valid', 'final', 'prefix',
|
||||
'unique', 'object', 'foreach', 'include', 'template', 'function', 'variable',
|
||||
'structure', 'extensible', 'declaration'), prefix=r'\b', suffix=r'\s*\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'file_contents', 'format', 'index', 'length', 'match', 'matches', 'replace',
|
||||
'splice', 'split', 'substr', 'to_lowercase', 'to_uppercase', 'debug', 'error',
|
||||
'traceback', 'deprecated', 'base64_decode', 'base64_encode', 'digest', 'escape',
|
||||
'unescape', 'append', 'create', 'first', 'nlist', 'key', 'list', 'merge', 'next',
|
||||
'prepend', 'is_boolean', 'is_defined', 'is_double', 'is_list', 'is_long',
|
||||
'is_nlist', 'is_null', 'is_number', 'is_property', 'is_resource', 'is_string',
|
||||
'to_boolean', 'to_double', 'to_long', 'to_string', 'clone', 'delete', 'exists',
|
||||
'path_exists', 'if_exists', 'return', 'value'), prefix=r'\b', suffix=r'\s*\b'),
|
||||
Name.Builtin),
|
||||
(r'#.*', Comment),
|
||||
(r'\\[\w\W]', String.Escape),
|
||||
(r'(\b\w+)(\s*)(=)', bygroups(Name.Variable, Text, Operator)),
|
||||
(r'[\[\]{}()=]+', Operator),
|
||||
(r'<<\s*(\'?)\\?(\w+)[\w\W]+?\2', String),
|
||||
(r';', Punctuation),
|
||||
],
|
||||
'data': [
|
||||
(r'(?s)"(\\\\|\\[0-7]+|\\.|[^"\\])*"', String.Double),
|
||||
(r"(?s)'(\\\\|\\[0-7]+|\\.|[^'\\])*'", String.Single),
|
||||
(r'\s+', Text),
|
||||
(r'[^=\s\[\]{}()$"\'`\\;#]+', Text),
|
||||
(r'\d+(?= |\Z)', Number),
|
||||
],
|
||||
'curly': [
|
||||
(r'\}', Keyword, '#pop'),
|
||||
(r':-', Keyword),
|
||||
(r'\w+', Name.Variable),
|
||||
(r'[^}:"\'`$]+', Punctuation),
|
||||
(r':', Punctuation),
|
||||
include('root'),
|
||||
],
|
||||
'paren': [
|
||||
(r'\)', Keyword, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
}
|
||||
@ -1,65 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.eiffel
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for the Eiffel language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['EiffelLexer']
|
||||
|
||||
|
||||
class EiffelLexer(RegexLexer):
|
||||
"""
|
||||
For `Eiffel <http://www.eiffel.com>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Eiffel'
|
||||
aliases = ['eiffel']
|
||||
filenames = ['*.e']
|
||||
mimetypes = ['text/x-eiffel']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[^\S\n]+', Text),
|
||||
(r'--.*?\n', Comment.Single),
|
||||
(r'[^\S\n]+', Text),
|
||||
# Please note that keyword and operator are case insensitive.
|
||||
(r'(?i)(true|false|void|current|result|precursor)\b', Keyword.Constant),
|
||||
(r'(?i)(and(\s+then)?|not|xor|implies|or(\s+else)?)\b', Operator.Word),
|
||||
(words((
|
||||
'across', 'agent', 'alias', 'all', 'as', 'assign', 'attached',
|
||||
'attribute', 'check', 'class', 'convert', 'create', 'debug',
|
||||
'deferred', 'detachable', 'do', 'else', 'elseif', 'end', 'ensure',
|
||||
'expanded', 'export', 'external', 'feature', 'from', 'frozen', 'if',
|
||||
'inherit', 'inspect', 'invariant', 'like', 'local', 'loop', 'none',
|
||||
'note', 'obsolete', 'old', 'once', 'only', 'redefine', 'rename',
|
||||
'require', 'rescue', 'retry', 'select', 'separate', 'then',
|
||||
'undefine', 'until', 'variant', 'when'), prefix=r'(?i)\b', suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
(r'"\[(([^\]%]|\n)|%(.|\n)|\][^"])*?\]"', String),
|
||||
(r'"([^"%\n]|%.)*?"', String),
|
||||
include('numbers'),
|
||||
(r"'([^'%]|%'|%%)'", String.Char),
|
||||
(r"(//|\\\\|>=|<=|:=|/=|~|/~|[\\?!#%&@|+/\-=>*$<^\[\]])", Operator),
|
||||
(r"([{}():;,.])", Punctuation),
|
||||
(r'([a-z]\w*)|([A-Z][A-Z0-9_]*[a-z]\w*)', Name),
|
||||
(r'([A-Z][A-Z0-9_]*)', Name.Class),
|
||||
(r'\n+', Text),
|
||||
],
|
||||
'numbers': [
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'0[bB][01]+', Number.Bin),
|
||||
(r'0[cC][0-7]+', Number.Oct),
|
||||
(r'([0-9]+\.[0-9]*)|([0-9]*\.[0-9]+)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
],
|
||||
}
|
||||
@ -1,114 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.esoteric
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for esoteric languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error
|
||||
|
||||
__all__ = ['BrainfuckLexer', 'BefungeLexer', 'RedcodeLexer']
|
||||
|
||||
|
||||
class BrainfuckLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the esoteric `BrainFuck <http://www.muppetlabs.com/~breadbox/bf/>`_
|
||||
language.
|
||||
"""
|
||||
|
||||
name = 'Brainfuck'
|
||||
aliases = ['brainfuck', 'bf']
|
||||
filenames = ['*.bf', '*.b']
|
||||
mimetypes = ['application/x-brainfuck']
|
||||
|
||||
tokens = {
|
||||
'common': [
|
||||
# use different colors for different instruction types
|
||||
(r'[.,]+', Name.Tag),
|
||||
(r'[+-]+', Name.Builtin),
|
||||
(r'[<>]+', Name.Variable),
|
||||
(r'[^.,+\-<>\[\]]+', Comment),
|
||||
],
|
||||
'root': [
|
||||
(r'\[', Keyword, 'loop'),
|
||||
(r'\]', Error),
|
||||
include('common'),
|
||||
],
|
||||
'loop': [
|
||||
(r'\[', Keyword, '#push'),
|
||||
(r'\]', Keyword, '#pop'),
|
||||
include('common'),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class BefungeLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the esoteric `Befunge <http://en.wikipedia.org/wiki/Befunge>`_
|
||||
language.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
"""
|
||||
name = 'Befunge'
|
||||
aliases = ['befunge']
|
||||
filenames = ['*.befunge']
|
||||
mimetypes = ['application/x-befunge']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[0-9a-f]', Number),
|
||||
(r'[+*/%!`-]', Operator), # Traditional math
|
||||
(r'[<>^v?\[\]rxjk]', Name.Variable), # Move, imperatives
|
||||
(r'[:\\$.,n]', Name.Builtin), # Stack ops, imperatives
|
||||
(r'[|_mw]', Keyword),
|
||||
(r'[{}]', Name.Tag), # Befunge-98 stack ops
|
||||
(r'".*?"', String.Double), # Strings don't appear to allow escapes
|
||||
(r'\'.', String.Single), # Single character
|
||||
(r'[#;]', Comment), # Trampoline... depends on direction hit
|
||||
(r'[pg&~=@iotsy]', Keyword), # Misc
|
||||
(r'[()A-Z]', Comment), # Fingerprints
|
||||
(r'\s+', Text), # Whitespace doesn't matter
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class RedcodeLexer(RegexLexer):
|
||||
"""
|
||||
A simple Redcode lexer based on ICWS'94.
|
||||
Contributed by Adam Blinkinsop <blinks@acm.org>.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
name = 'Redcode'
|
||||
aliases = ['redcode']
|
||||
filenames = ['*.cw']
|
||||
|
||||
opcodes = ('DAT', 'MOV', 'ADD', 'SUB', 'MUL', 'DIV', 'MOD',
|
||||
'JMP', 'JMZ', 'JMN', 'DJN', 'CMP', 'SLT', 'SPL',
|
||||
'ORG', 'EQU', 'END')
|
||||
modifiers = ('A', 'B', 'AB', 'BA', 'F', 'X', 'I')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Whitespace:
|
||||
(r'\s+', Text),
|
||||
(r';.*$', Comment.Single),
|
||||
# Lexemes:
|
||||
# Identifiers
|
||||
(r'\b(%s)\b' % '|'.join(opcodes), Name.Function),
|
||||
(r'\b(%s)\b' % '|'.join(modifiers), Name.Decorator),
|
||||
(r'[A-Za-z_]\w+', Name),
|
||||
# Operators
|
||||
(r'[-+*/%]', Operator),
|
||||
(r'[#$@<>]', Operator), # mode
|
||||
(r'[.,]', Punctuation), # mode
|
||||
# Numbers
|
||||
(r'[-+]?\d+', Number.Integer),
|
||||
],
|
||||
}
|
||||
@ -1,344 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.factor
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for the Factor language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, default, words
|
||||
from pygments.token import Text, Comment, Keyword, Name, String, Number
|
||||
|
||||
__all__ = ['FactorLexer']
|
||||
|
||||
|
||||
class FactorLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the `Factor <http://factorcode.org>`_ language.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
name = 'Factor'
|
||||
aliases = ['factor']
|
||||
filenames = ['*.factor']
|
||||
mimetypes = ['text/x-factor']
|
||||
|
||||
flags = re.MULTILINE | re.UNICODE
|
||||
|
||||
builtin_kernel = words((
|
||||
'-rot', '2bi', '2bi@', '2bi*', '2curry', '2dip', '2drop', '2dup', '2keep', '2nip',
|
||||
'2over', '2tri', '2tri@', '2tri*', '3bi', '3curry', '3dip', '3drop', '3dup', '3keep',
|
||||
'3tri', '4dip', '4drop', '4dup', '4keep', '<wrapper>', '=', '>boolean', 'clone',
|
||||
'?', '?execute', '?if', 'and', 'assert', 'assert=', 'assert?', 'bi', 'bi-curry',
|
||||
'bi-curry@', 'bi-curry*', 'bi@', 'bi*', 'boa', 'boolean', 'boolean?', 'both?',
|
||||
'build', 'call', 'callstack', 'callstack>array', 'callstack?', 'clear', '(clone)',
|
||||
'compose', 'compose?', 'curry', 'curry?', 'datastack', 'die', 'dip', 'do', 'drop',
|
||||
'dup', 'dupd', 'either?', 'eq?', 'equal?', 'execute', 'hashcode', 'hashcode*',
|
||||
'identity-hashcode', 'identity-tuple', 'identity-tuple?', 'if', 'if*',
|
||||
'keep', 'loop', 'most', 'new', 'nip', 'not', 'null', 'object', 'or', 'over',
|
||||
'pick', 'prepose', 'retainstack', 'rot', 'same?', 'swap', 'swapd', 'throw',
|
||||
'tri', 'tri-curry', 'tri-curry@', 'tri-curry*', 'tri@', 'tri*', 'tuple',
|
||||
'tuple?', 'unless', 'unless*', 'until', 'when', 'when*', 'while', 'with',
|
||||
'wrapper', 'wrapper?', 'xor'), suffix=r'\s')
|
||||
|
||||
builtin_assocs = words((
|
||||
'2cache', '<enum>', '>alist', '?at', '?of', 'assoc', 'assoc-all?',
|
||||
'assoc-any?', 'assoc-clone-like', 'assoc-combine', 'assoc-diff',
|
||||
'assoc-diff!', 'assoc-differ', 'assoc-each', 'assoc-empty?',
|
||||
'assoc-filter', 'assoc-filter!', 'assoc-filter-as', 'assoc-find',
|
||||
'assoc-hashcode', 'assoc-intersect', 'assoc-like', 'assoc-map',
|
||||
'assoc-map-as', 'assoc-partition', 'assoc-refine', 'assoc-size',
|
||||
'assoc-stack', 'assoc-subset?', 'assoc-union', 'assoc-union!',
|
||||
'assoc=', 'assoc>map', 'assoc?', 'at', 'at+', 'at*', 'cache', 'change-at',
|
||||
'clear-assoc', 'delete-at', 'delete-at*', 'enum', 'enum?', 'extract-keys',
|
||||
'inc-at', 'key?', 'keys', 'map>assoc', 'maybe-set-at', 'new-assoc', 'of',
|
||||
'push-at', 'rename-at', 'set-at', 'sift-keys', 'sift-values', 'substitute',
|
||||
'unzip', 'value-at', 'value-at*', 'value?', 'values', 'zip'), suffix=r'\s')
|
||||
|
||||
builtin_combinators = words((
|
||||
'2cleave', '2cleave>quot', '3cleave', '3cleave>quot', '4cleave',
|
||||
'4cleave>quot', 'alist>quot', 'call-effect', 'case', 'case-find',
|
||||
'case>quot', 'cleave', 'cleave>quot', 'cond', 'cond>quot', 'deep-spread>quot',
|
||||
'execute-effect', 'linear-case-quot', 'no-case', 'no-case?', 'no-cond',
|
||||
'no-cond?', 'recursive-hashcode', 'shallow-spread>quot', 'spread',
|
||||
'to-fixed-point', 'wrong-values', 'wrong-values?'), suffix=r'\s')
|
||||
|
||||
builtin_math = words((
|
||||
'-', '/', '/f', '/i', '/mod', '2/', '2^', '<', '<=', '<fp-nan>', '>',
|
||||
'>=', '>bignum', '>fixnum', '>float', '>integer', '(all-integers?)',
|
||||
'(each-integer)', '(find-integer)', '*', '+', '?1+',
|
||||
'abs', 'align', 'all-integers?', 'bignum', 'bignum?', 'bit?', 'bitand',
|
||||
'bitnot', 'bitor', 'bits>double', 'bits>float', 'bitxor', 'complex',
|
||||
'complex?', 'denominator', 'double>bits', 'each-integer', 'even?',
|
||||
'find-integer', 'find-last-integer', 'fixnum', 'fixnum?', 'float',
|
||||
'float>bits', 'float?', 'fp-bitwise=', 'fp-infinity?', 'fp-nan-payload',
|
||||
'fp-nan?', 'fp-qnan?', 'fp-sign', 'fp-snan?', 'fp-special?',
|
||||
'if-zero', 'imaginary-part', 'integer', 'integer>fixnum',
|
||||
'integer>fixnum-strict', 'integer?', 'log2', 'log2-expects-positive',
|
||||
'log2-expects-positive?', 'mod', 'neg', 'neg?', 'next-float',
|
||||
'next-power-of-2', 'number', 'number=', 'number?', 'numerator', 'odd?',
|
||||
'out-of-fixnum-range', 'out-of-fixnum-range?', 'power-of-2?',
|
||||
'prev-float', 'ratio', 'ratio?', 'rational', 'rational?', 'real',
|
||||
'real-part', 'real?', 'recip', 'rem', 'sgn', 'shift', 'sq', 'times',
|
||||
'u<', 'u<=', 'u>', 'u>=', 'unless-zero', 'unordered?', 'when-zero',
|
||||
'zero?'), suffix=r'\s')
|
||||
|
||||
builtin_sequences = words((
|
||||
'1sequence', '2all?', '2each', '2map', '2map-as', '2map-reduce', '2reduce',
|
||||
'2selector', '2sequence', '3append', '3append-as', '3each', '3map', '3map-as',
|
||||
'3sequence', '4sequence', '<repetition>', '<reversed>', '<slice>', '?first',
|
||||
'?last', '?nth', '?second', '?set-nth', 'accumulate', 'accumulate!',
|
||||
'accumulate-as', 'all?', 'any?', 'append', 'append!', 'append-as',
|
||||
'assert-sequence', 'assert-sequence=', 'assert-sequence?',
|
||||
'binary-reduce', 'bounds-check', 'bounds-check?', 'bounds-error',
|
||||
'bounds-error?', 'but-last', 'but-last-slice', 'cartesian-each',
|
||||
'cartesian-map', 'cartesian-product', 'change-nth', 'check-slice',
|
||||
'check-slice-error', 'clone-like', 'collapse-slice', 'collector',
|
||||
'collector-for', 'concat', 'concat-as', 'copy', 'count', 'cut', 'cut-slice',
|
||||
'cut*', 'delete-all', 'delete-slice', 'drop-prefix', 'each', 'each-from',
|
||||
'each-index', 'empty?', 'exchange', 'filter', 'filter!', 'filter-as', 'find',
|
||||
'find-from', 'find-index', 'find-index-from', 'find-last', 'find-last-from',
|
||||
'first', 'first2', 'first3', 'first4', 'flip', 'follow', 'fourth', 'glue', 'halves',
|
||||
'harvest', 'head', 'head-slice', 'head-slice*', 'head*', 'head?',
|
||||
'if-empty', 'immutable', 'immutable-sequence', 'immutable-sequence?',
|
||||
'immutable?', 'index', 'index-from', 'indices', 'infimum', 'infimum-by',
|
||||
'insert-nth', 'interleave', 'iota', 'iota-tuple', 'iota-tuple?', 'join',
|
||||
'join-as', 'last', 'last-index', 'last-index-from', 'length', 'lengthen',
|
||||
'like', 'longer', 'longer?', 'longest', 'map', 'map!', 'map-as', 'map-find',
|
||||
'map-find-last', 'map-index', 'map-integers', 'map-reduce', 'map-sum',
|
||||
'max-length', 'member-eq?', 'member?', 'midpoint@', 'min-length',
|
||||
'mismatch', 'move', 'new-like', 'new-resizable', 'new-sequence',
|
||||
'non-negative-integer-expected', 'non-negative-integer-expected?',
|
||||
'nth', 'nths', 'pad-head', 'pad-tail', 'padding', 'partition', 'pop', 'pop*',
|
||||
'prefix', 'prepend', 'prepend-as', 'produce', 'produce-as', 'product', 'push',
|
||||
'push-all', 'push-either', 'push-if', 'reduce', 'reduce-index', 'remove',
|
||||
'remove!', 'remove-eq', 'remove-eq!', 'remove-nth', 'remove-nth!', 'repetition',
|
||||
'repetition?', 'replace-slice', 'replicate', 'replicate-as', 'rest',
|
||||
'rest-slice', 'reverse', 'reverse!', 'reversed', 'reversed?', 'second',
|
||||
'selector', 'selector-for', 'sequence', 'sequence-hashcode', 'sequence=',
|
||||
'sequence?', 'set-first', 'set-fourth', 'set-last', 'set-length', 'set-nth',
|
||||
'set-second', 'set-third', 'short', 'shorten', 'shorter', 'shorter?',
|
||||
'shortest', 'sift', 'slice', 'slice-error', 'slice-error?', 'slice?',
|
||||
'snip', 'snip-slice', 'start', 'start*', 'subseq', 'subseq?', 'suffix',
|
||||
'suffix!', 'sum', 'sum-lengths', 'supremum', 'supremum-by', 'surround', 'tail',
|
||||
'tail-slice', 'tail-slice*', 'tail*', 'tail?', 'third', 'trim',
|
||||
'trim-head', 'trim-head-slice', 'trim-slice', 'trim-tail', 'trim-tail-slice',
|
||||
'unclip', 'unclip-last', 'unclip-last-slice', 'unclip-slice', 'unless-empty',
|
||||
'virtual-exemplar', 'virtual-sequence', 'virtual-sequence?', 'virtual@',
|
||||
'when-empty'), suffix=r'\s')
|
||||
|
||||
builtin_namespaces = words((
|
||||
'+@', 'change', 'change-global', 'counter', 'dec', 'get', 'get-global',
|
||||
'global', 'inc', 'init-namespaces', 'initialize', 'is-global', 'make-assoc',
|
||||
'namespace', 'namestack', 'off', 'on', 'set', 'set-global', 'set-namestack',
|
||||
'toggle', 'with-global', 'with-scope', 'with-variable', 'with-variables'),
|
||||
suffix=r'\s')
|
||||
|
||||
builtin_arrays = words((
|
||||
'1array', '2array', '3array', '4array', '<array>', '>array', 'array',
|
||||
'array?', 'pair', 'pair?', 'resize-array'), suffix=r'\s')
|
||||
|
||||
builtin_io = words((
|
||||
'(each-stream-block-slice)', '(each-stream-block)',
|
||||
'(stream-contents-by-block)', '(stream-contents-by-element)',
|
||||
'(stream-contents-by-length-or-block)',
|
||||
'(stream-contents-by-length)', '+byte+', '+character+',
|
||||
'bad-seek-type', 'bad-seek-type?', 'bl', 'contents', 'each-block',
|
||||
'each-block-size', 'each-block-slice', 'each-line', 'each-morsel',
|
||||
'each-stream-block', 'each-stream-block-slice', 'each-stream-line',
|
||||
'error-stream', 'flush', 'input-stream', 'input-stream?',
|
||||
'invalid-read-buffer', 'invalid-read-buffer?', 'lines', 'nl',
|
||||
'output-stream', 'output-stream?', 'print', 'read', 'read-into',
|
||||
'read-partial', 'read-partial-into', 'read-until', 'read1', 'readln',
|
||||
'seek-absolute', 'seek-absolute?', 'seek-end', 'seek-end?',
|
||||
'seek-input', 'seek-output', 'seek-relative', 'seek-relative?',
|
||||
'stream-bl', 'stream-contents', 'stream-contents*', 'stream-copy',
|
||||
'stream-copy*', 'stream-element-type', 'stream-flush',
|
||||
'stream-length', 'stream-lines', 'stream-nl', 'stream-print',
|
||||
'stream-read', 'stream-read-into', 'stream-read-partial',
|
||||
'stream-read-partial-into', 'stream-read-partial-unsafe',
|
||||
'stream-read-unsafe', 'stream-read-until', 'stream-read1',
|
||||
'stream-readln', 'stream-seek', 'stream-seekable?', 'stream-tell',
|
||||
'stream-write', 'stream-write1', 'tell-input', 'tell-output',
|
||||
'with-error-stream', 'with-error-stream*', 'with-error>output',
|
||||
'with-input-output+error-streams',
|
||||
'with-input-output+error-streams*', 'with-input-stream',
|
||||
'with-input-stream*', 'with-output-stream', 'with-output-stream*',
|
||||
'with-output>error', 'with-output+error-stream',
|
||||
'with-output+error-stream*', 'with-streams', 'with-streams*',
|
||||
'write', 'write1'), suffix=r'\s')
|
||||
|
||||
builtin_strings = words((
|
||||
'1string', '<string>', '>string', 'resize-string', 'string',
|
||||
'string?'), suffix=r'\s')
|
||||
|
||||
builtin_vectors = words((
|
||||
'1vector', '<vector>', '>vector', '?push', 'vector', 'vector?'),
|
||||
suffix=r'\s')
|
||||
|
||||
builtin_continuations = words((
|
||||
'<condition>', '<continuation>', '<restart>', 'attempt-all',
|
||||
'attempt-all-error', 'attempt-all-error?', 'callback-error-hook',
|
||||
'callcc0', 'callcc1', 'cleanup', 'compute-restarts', 'condition',
|
||||
'condition?', 'continuation', 'continuation?', 'continue',
|
||||
'continue-restart', 'continue-with', 'current-continuation',
|
||||
'error', 'error-continuation', 'error-in-thread', 'error-thread',
|
||||
'ifcc', 'ignore-errors', 'in-callback?', 'original-error', 'recover',
|
||||
'restart', 'restart?', 'restarts', 'rethrow', 'rethrow-restarts',
|
||||
'return', 'return-continuation', 'thread-error-hook', 'throw-continue',
|
||||
'throw-restarts', 'with-datastack', 'with-return'), suffix=r'\s')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# factor allows a file to start with a shebang
|
||||
(r'#!.*$', Comment.Preproc),
|
||||
default('base'),
|
||||
],
|
||||
'base': [
|
||||
(r'\s+', Text),
|
||||
|
||||
# defining words
|
||||
(r'((?:MACRO|MEMO|TYPED)?:[:]?)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(M:[:]?)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Class, Text, Name.Function)),
|
||||
(r'(C:)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Function, Text, Name.Class)),
|
||||
(r'(GENERIC:)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(HOOK:|GENERIC#)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Function, Text, Name.Function)),
|
||||
(r'\(\s', Name.Function, 'stackeffect'),
|
||||
(r';\s', Keyword),
|
||||
|
||||
# imports and namespaces
|
||||
(r'(USING:)(\s+)',
|
||||
bygroups(Keyword.Namespace, Text), 'vocabs'),
|
||||
(r'(USE:|UNUSE:|IN:|QUALIFIED:)(\s+)(\S+)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Namespace)),
|
||||
(r'(QUALIFIED-WITH:)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Namespace, Text, Name.Namespace)),
|
||||
(r'(FROM:|EXCLUDE:)(\s+)(\S+)(\s+=>\s)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Namespace, Text), 'words'),
|
||||
(r'(RENAME:)(\s+)(\S+)(\s+)(\S+)(\s+=>\s+)(\S+)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Function, Text, Name.Namespace, Text, Name.Function)),
|
||||
(r'(ALIAS:|TYPEDEF:)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Function, Text, Name.Function)),
|
||||
(r'(DEFER:|FORGET:|POSTPONE:)(\s+)(\S+)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Function)),
|
||||
|
||||
# tuples and classes
|
||||
(r'(TUPLE:|ERROR:)(\s+)(\S+)(\s+<\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Class, Text, Name.Class), 'slots'),
|
||||
(r'(TUPLE:|ERROR:|BUILTIN:)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Class), 'slots'),
|
||||
(r'(MIXIN:|UNION:|INTERSECTION:)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Class)),
|
||||
(r'(PREDICATE:)(\s+)(\S+)(\s+<\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Class, Text, Name.Class)),
|
||||
(r'(C:)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Function, Text, Name.Class)),
|
||||
(r'(INSTANCE:)(\s+)(\S+)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Class, Text, Name.Class)),
|
||||
(r'(SLOT:)(\s+)(\S+)', bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(SINGLETON:)(\s+)(\S+)', bygroups(Keyword, Text, Name.Class)),
|
||||
(r'SINGLETONS:', Keyword, 'classes'),
|
||||
|
||||
# other syntax
|
||||
(r'(CONSTANT:|SYMBOL:|MAIN:|HELP:)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'SYMBOLS:\s', Keyword, 'words'),
|
||||
(r'SYNTAX:\s', Keyword),
|
||||
(r'ALIEN:\s', Keyword),
|
||||
(r'(STRUCT:)(\s+)(\S+)', bygroups(Keyword, Text, Name.Class)),
|
||||
(r'(FUNCTION:)(\s+\S+\s+)(\S+)(\s+\(\s+[^)]+\)\s)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Function, Text)),
|
||||
(r'(FUNCTION-ALIAS:)(\s+)(\S+)(\s+\S+\s+)(\S+)(\s+\(\s+[^)]+\)\s)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Function, Text, Name.Function, Text)),
|
||||
|
||||
# vocab.private
|
||||
(r'(?:<PRIVATE|PRIVATE>)\s', Keyword.Namespace),
|
||||
|
||||
# strings
|
||||
(r'"""\s+(?:.|\n)*?\s+"""', String),
|
||||
(r'"(?:\\\\|\\"|[^"])*"', String),
|
||||
(r'\S+"\s+(?:\\\\|\\"|[^"])*"', String),
|
||||
(r'CHAR:\s+(?:\\[\\abfnrstv]|[^\\]\S*)\s', String.Char),
|
||||
|
||||
# comments
|
||||
(r'!\s+.*$', Comment),
|
||||
(r'#!\s+.*$', Comment),
|
||||
(r'/\*\s+(?:.|\n)*?\s\*/\s', Comment),
|
||||
|
||||
# boolean constants
|
||||
(r'[tf]\s', Name.Constant),
|
||||
|
||||
# symbols and literals
|
||||
(r'[\\$]\s+\S+', Name.Constant),
|
||||
(r'M\\\s+\S+\s+\S+', Name.Constant),
|
||||
|
||||
# numbers
|
||||
(r'[+-]?(?:[\d,]*\d)?\.(?:\d([\d,]*\d)?)?(?:[eE][+-]?\d+)?\s', Number),
|
||||
(r'[+-]?\d(?:[\d,]*\d)?(?:[eE][+-]?\d+)?\s', Number),
|
||||
(r'0x[a-fA-F\d](?:[a-fA-F\d,]*[a-fA-F\d])?(?:p\d([\d,]*\d)?)?\s', Number),
|
||||
(r'NAN:\s+[a-fA-F\d](?:[a-fA-F\d,]*[a-fA-F\d])?(?:p\d([\d,]*\d)?)?\s', Number),
|
||||
(r'0b[01]+\s', Number.Bin),
|
||||
(r'0o[0-7]+\s', Number.Oct),
|
||||
(r'(?:\d([\d,]*\d)?)?\+\d(?:[\d,]*\d)?/\d(?:[\d,]*\d)?\s', Number),
|
||||
(r'(?:\-\d([\d,]*\d)?)?\-\d(?:[\d,]*\d)?/\d(?:[\d,]*\d)?\s', Number),
|
||||
|
||||
# keywords
|
||||
(r'(?:deprecated|final|foldable|flushable|inline|recursive)\s',
|
||||
Keyword),
|
||||
|
||||
# builtins
|
||||
(builtin_kernel, Name.Builtin),
|
||||
(builtin_assocs, Name.Builtin),
|
||||
(builtin_combinators, Name.Builtin),
|
||||
(builtin_math, Name.Builtin),
|
||||
(builtin_sequences, Name.Builtin),
|
||||
(builtin_namespaces, Name.Builtin),
|
||||
(builtin_arrays, Name.Builtin),
|
||||
(builtin_io, Name.Builtin),
|
||||
(builtin_strings, Name.Builtin),
|
||||
(builtin_vectors, Name.Builtin),
|
||||
(builtin_continuations, Name.Builtin),
|
||||
|
||||
# everything else is text
|
||||
(r'\S+', Text),
|
||||
],
|
||||
'stackeffect': [
|
||||
(r'\s+', Text),
|
||||
(r'\(\s+', Name.Function, 'stackeffect'),
|
||||
(r'\)\s', Name.Function, '#pop'),
|
||||
(r'--\s', Name.Function),
|
||||
(r'\S+', Name.Variable),
|
||||
],
|
||||
'slots': [
|
||||
(r'\s+', Text),
|
||||
(r';\s', Keyword, '#pop'),
|
||||
(r'(\{\s+)(\S+)(\s+[^}]+\s+\}\s)',
|
||||
bygroups(Text, Name.Variable, Text)),
|
||||
(r'\S+', Name.Variable),
|
||||
],
|
||||
'vocabs': [
|
||||
(r'\s+', Text),
|
||||
(r';\s', Keyword, '#pop'),
|
||||
(r'\S+', Name.Namespace),
|
||||
],
|
||||
'classes': [
|
||||
(r'\s+', Text),
|
||||
(r';\s', Keyword, '#pop'),
|
||||
(r'\S+', Name.Class),
|
||||
],
|
||||
'words': [
|
||||
(r'\s+', Text),
|
||||
(r';\s', Keyword, '#pop'),
|
||||
(r'\S+', Name.Function),
|
||||
],
|
||||
}
|
||||
@ -1,250 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.fantom
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for the Fantom language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from string import Template
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, \
|
||||
this, default, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Literal
|
||||
|
||||
__all__ = ['FantomLexer']
|
||||
|
||||
|
||||
class FantomLexer(RegexLexer):
|
||||
"""
|
||||
For Fantom source code.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'Fantom'
|
||||
aliases = ['fan']
|
||||
filenames = ['*.fan']
|
||||
mimetypes = ['application/x-fantom']
|
||||
|
||||
# often used regexes
|
||||
def s(str):
|
||||
return Template(str).substitute(
|
||||
dict(
|
||||
pod=r'[\"\w\.]+',
|
||||
eos=r'\n|;',
|
||||
id=r'[a-zA-Z_]\w*',
|
||||
# all chars which can be part of type definition. Starts with
|
||||
# either letter, or [ (maps), or | (funcs)
|
||||
type=r'(?:\[|[a-zA-Z_]|\|)[:\w\[\]|\->?]*?',
|
||||
)
|
||||
)
|
||||
|
||||
tokens = {
|
||||
'comments': [
|
||||
(r'(?s)/\*.*?\*/', Comment.Multiline), # Multiline
|
||||
(r'//.*?\n', Comment.Single), # Single line
|
||||
# TODO: highlight references in fandocs
|
||||
(r'\*\*.*?\n', Comment.Special), # Fandoc
|
||||
(r'#.*\n', Comment.Single) # Shell-style
|
||||
],
|
||||
'literals': [
|
||||
(r'\b-?[\d_]+(ns|ms|sec|min|hr|day)', Number), # Duration
|
||||
(r'\b-?[\d_]*\.[\d_]+(ns|ms|sec|min|hr|day)', Number), # Duration with dot
|
||||
(r'\b-?(\d+)?\.\d+(f|F|d|D)?', Number.Float), # Float/Decimal
|
||||
(r'\b-?0x[0-9a-fA-F_]+', Number.Hex), # Hex
|
||||
(r'\b-?[\d_]+', Number.Integer), # Int
|
||||
(r"'\\.'|'[^\\]'|'\\u[0-9a-f]{4}'", String.Char), # Char
|
||||
(r'"', Punctuation, 'insideStr'), # Opening quote
|
||||
(r'`', Punctuation, 'insideUri'), # Opening accent
|
||||
(r'\b(true|false|null)\b', Keyword.Constant), # Bool & null
|
||||
(r'(?:(\w+)(::))?(\w+)(<\|)(.*?)(\|>)', # DSL
|
||||
bygroups(Name.Namespace, Punctuation, Name.Class,
|
||||
Punctuation, String, Punctuation)),
|
||||
(r'(?:(\w+)(::))?(\w+)?(#)(\w+)?', # Type/slot literal
|
||||
bygroups(Name.Namespace, Punctuation, Name.Class,
|
||||
Punctuation, Name.Function)),
|
||||
(r'\[,\]', Literal), # Empty list
|
||||
(s(r'($type)(\[,\])'), # Typed empty list
|
||||
bygroups(using(this, state='inType'), Literal)),
|
||||
(r'\[:\]', Literal), # Empty Map
|
||||
(s(r'($type)(\[:\])'),
|
||||
bygroups(using(this, state='inType'), Literal)),
|
||||
],
|
||||
'insideStr': [
|
||||
(r'\\\\', String.Escape), # Escaped backslash
|
||||
(r'\\"', String.Escape), # Escaped "
|
||||
(r'\\`', String.Escape), # Escaped `
|
||||
(r'\$\w+', String.Interpol), # Subst var
|
||||
(r'\$\{.*?\}', String.Interpol), # Subst expr
|
||||
(r'"', Punctuation, '#pop'), # Closing quot
|
||||
(r'.', String) # String content
|
||||
],
|
||||
'insideUri': [ # TODO: remove copy/paste str/uri
|
||||
(r'\\\\', String.Escape), # Escaped backslash
|
||||
(r'\\"', String.Escape), # Escaped "
|
||||
(r'\\`', String.Escape), # Escaped `
|
||||
(r'\$\w+', String.Interpol), # Subst var
|
||||
(r'\$\{.*?\}', String.Interpol), # Subst expr
|
||||
(r'`', Punctuation, '#pop'), # Closing tick
|
||||
(r'.', String.Backtick) # URI content
|
||||
],
|
||||
'protectionKeywords': [
|
||||
(r'\b(public|protected|private|internal)\b', Keyword),
|
||||
],
|
||||
'typeKeywords': [
|
||||
(r'\b(abstract|final|const|native|facet|enum)\b', Keyword),
|
||||
],
|
||||
'methodKeywords': [
|
||||
(r'\b(abstract|native|once|override|static|virtual|final)\b',
|
||||
Keyword),
|
||||
],
|
||||
'fieldKeywords': [
|
||||
(r'\b(abstract|const|final|native|override|static|virtual|'
|
||||
r'readonly)\b', Keyword)
|
||||
],
|
||||
'otherKeywords': [
|
||||
(words((
|
||||
'try', 'catch', 'throw', 'finally', 'for', 'if', 'else', 'while',
|
||||
'as', 'is', 'isnot', 'switch', 'case', 'default', 'continue',
|
||||
'break', 'do', 'return', 'get', 'set'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'\b(it|this|super)\b', Name.Builtin.Pseudo),
|
||||
],
|
||||
'operators': [
|
||||
(r'\+\+|\-\-|\+|\-|\*|/|\|\||&&|<=>|<=|<|>=|>|=|!|\[|\]', Operator)
|
||||
],
|
||||
'inType': [
|
||||
(r'[\[\]|\->:?]', Punctuation),
|
||||
(s(r'$id'), Name.Class),
|
||||
default('#pop'),
|
||||
|
||||
],
|
||||
'root': [
|
||||
include('comments'),
|
||||
include('protectionKeywords'),
|
||||
include('typeKeywords'),
|
||||
include('methodKeywords'),
|
||||
include('fieldKeywords'),
|
||||
include('literals'),
|
||||
include('otherKeywords'),
|
||||
include('operators'),
|
||||
(r'using\b', Keyword.Namespace, 'using'), # Using stmt
|
||||
(r'@\w+', Name.Decorator, 'facet'), # Symbol
|
||||
(r'(class|mixin)(\s+)(\w+)', bygroups(Keyword, Text, Name.Class),
|
||||
'inheritance'), # Inheritance list
|
||||
|
||||
# Type var := val
|
||||
(s(r'($type)([ \t]+)($id)(\s*)(:=)'),
|
||||
bygroups(using(this, state='inType'), Text,
|
||||
Name.Variable, Text, Operator)),
|
||||
|
||||
# var := val
|
||||
(s(r'($id)(\s*)(:=)'),
|
||||
bygroups(Name.Variable, Text, Operator)),
|
||||
|
||||
# .someId( or ->someId( ###
|
||||
(s(r'(\.|(?:\->))($id)(\s*)(\()'),
|
||||
bygroups(Operator, Name.Function, Text, Punctuation),
|
||||
'insideParen'),
|
||||
|
||||
# .someId or ->someId
|
||||
(s(r'(\.|(?:\->))($id)'),
|
||||
bygroups(Operator, Name.Function)),
|
||||
|
||||
# new makeXXX (
|
||||
(r'(new)(\s+)(make\w*)(\s*)(\()',
|
||||
bygroups(Keyword, Text, Name.Function, Text, Punctuation),
|
||||
'insideMethodDeclArgs'),
|
||||
|
||||
# Type name (
|
||||
(s(r'($type)([ \t]+)' # Return type and whitespace
|
||||
r'($id)(\s*)(\()'), # method name + open brace
|
||||
bygroups(using(this, state='inType'), Text,
|
||||
Name.Function, Text, Punctuation),
|
||||
'insideMethodDeclArgs'),
|
||||
|
||||
# ArgType argName,
|
||||
(s(r'($type)(\s+)($id)(\s*)(,)'),
|
||||
bygroups(using(this, state='inType'), Text, Name.Variable,
|
||||
Text, Punctuation)),
|
||||
|
||||
# ArgType argName)
|
||||
# Covered in 'insideParen' state
|
||||
|
||||
# ArgType argName -> ArgType|
|
||||
(s(r'($type)(\s+)($id)(\s*)(\->)(\s*)($type)(\|)'),
|
||||
bygroups(using(this, state='inType'), Text, Name.Variable,
|
||||
Text, Punctuation, Text, using(this, state='inType'),
|
||||
Punctuation)),
|
||||
|
||||
# ArgType argName|
|
||||
(s(r'($type)(\s+)($id)(\s*)(\|)'),
|
||||
bygroups(using(this, state='inType'), Text, Name.Variable,
|
||||
Text, Punctuation)),
|
||||
|
||||
# Type var
|
||||
(s(r'($type)([ \t]+)($id)'),
|
||||
bygroups(using(this, state='inType'), Text,
|
||||
Name.Variable)),
|
||||
|
||||
(r'\(', Punctuation, 'insideParen'),
|
||||
(r'\{', Punctuation, 'insideBrace'),
|
||||
(r'.', Text)
|
||||
],
|
||||
'insideParen': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'insideMethodDeclArgs': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(s(r'($type)(\s+)($id)(\s*)(\))'),
|
||||
bygroups(using(this, state='inType'), Text, Name.Variable,
|
||||
Text, Punctuation), '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'insideBrace': [
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'inheritance': [
|
||||
(r'\s+', Text), # Whitespace
|
||||
(r':|,', Punctuation),
|
||||
(r'(?:(\w+)(::))?(\w+)',
|
||||
bygroups(Name.Namespace, Punctuation, Name.Class)),
|
||||
(r'\{', Punctuation, '#pop')
|
||||
],
|
||||
'using': [
|
||||
(r'[ \t]+', Text), # consume whitespaces
|
||||
(r'(\[)(\w+)(\])',
|
||||
bygroups(Punctuation, Comment.Special, Punctuation)), # ffi
|
||||
(r'(\")?([\w.]+)(\")?',
|
||||
bygroups(Punctuation, Name.Namespace, Punctuation)), # podname
|
||||
(r'::', Punctuation, 'usingClass'),
|
||||
default('#pop')
|
||||
],
|
||||
'usingClass': [
|
||||
(r'[ \t]+', Text), # consume whitespaces
|
||||
(r'(as)(\s+)(\w+)',
|
||||
bygroups(Keyword.Declaration, Text, Name.Class), '#pop:2'),
|
||||
(r'[\w$]+', Name.Class),
|
||||
default('#pop:2') # jump out to root state
|
||||
],
|
||||
'facet': [
|
||||
(r'\s+', Text),
|
||||
(r'\{', Punctuation, 'facetFields'),
|
||||
default('#pop')
|
||||
],
|
||||
'facetFields': [
|
||||
include('comments'),
|
||||
include('literals'),
|
||||
include('operators'),
|
||||
(r'\s+', Text),
|
||||
(r'(\s*)(\w+)(\s*)(=)', bygroups(Text, Name, Text, Operator)),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
(r'.', Text)
|
||||
],
|
||||
}
|
||||
@ -1,273 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.felix
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for the Felix language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, default, words, \
|
||||
combined
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['FelixLexer']
|
||||
|
||||
|
||||
class FelixLexer(RegexLexer):
|
||||
"""
|
||||
For `Felix <http://www.felix-lang.org>`_ source code.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
|
||||
name = 'Felix'
|
||||
aliases = ['felix', 'flx']
|
||||
filenames = ['*.flx', '*.flxh']
|
||||
mimetypes = ['text/x-felix']
|
||||
|
||||
preproc = (
|
||||
'elif', 'else', 'endif', 'if', 'ifdef', 'ifndef',
|
||||
)
|
||||
|
||||
keywords = (
|
||||
'_', '_deref', 'all', 'as',
|
||||
'assert', 'attempt', 'call', 'callback', 'case', 'caseno', 'cclass',
|
||||
'code', 'compound', 'ctypes', 'do', 'done', 'downto', 'elif', 'else',
|
||||
'endattempt', 'endcase', 'endif', 'endmatch', 'enum', 'except',
|
||||
'exceptions', 'expect', 'finally', 'for', 'forall', 'forget', 'fork',
|
||||
'functor', 'goto', 'ident', 'if', 'incomplete', 'inherit', 'instance',
|
||||
'interface', 'jump', 'lambda', 'loop', 'match', 'module', 'namespace',
|
||||
'new', 'noexpand', 'nonterm', 'obj', 'of', 'open', 'parse', 'raise',
|
||||
'regexp', 'reglex', 'regmatch', 'rename', 'return', 'the', 'then',
|
||||
'to', 'type', 'typecase', 'typedef', 'typematch', 'typeof', 'upto',
|
||||
'when', 'whilst', 'with', 'yield',
|
||||
)
|
||||
|
||||
keyword_directives = (
|
||||
'_gc_pointer', '_gc_type', 'body', 'comment', 'const', 'export',
|
||||
'header', 'inline', 'lval', 'macro', 'noinline', 'noreturn',
|
||||
'package', 'private', 'pod', 'property', 'public', 'publish',
|
||||
'requires', 'todo', 'virtual', 'use',
|
||||
)
|
||||
|
||||
keyword_declarations = (
|
||||
'def', 'let', 'ref', 'val', 'var',
|
||||
)
|
||||
|
||||
keyword_types = (
|
||||
'unit', 'void', 'any', 'bool',
|
||||
'byte', 'offset',
|
||||
'address', 'caddress', 'cvaddress', 'vaddress',
|
||||
'tiny', 'short', 'int', 'long', 'vlong',
|
||||
'utiny', 'ushort', 'vshort', 'uint', 'ulong', 'uvlong',
|
||||
'int8', 'int16', 'int32', 'int64',
|
||||
'uint8', 'uint16', 'uint32', 'uint64',
|
||||
'float', 'double', 'ldouble',
|
||||
'complex', 'dcomplex', 'lcomplex',
|
||||
'imaginary', 'dimaginary', 'limaginary',
|
||||
'char', 'wchar', 'uchar',
|
||||
'charp', 'charcp', 'ucharp', 'ucharcp',
|
||||
'string', 'wstring', 'ustring',
|
||||
'cont',
|
||||
'array', 'varray', 'list',
|
||||
'lvalue', 'opt', 'slice',
|
||||
)
|
||||
|
||||
keyword_constants = (
|
||||
'false', 'true',
|
||||
)
|
||||
|
||||
operator_words = (
|
||||
'and', 'not', 'in', 'is', 'isin', 'or', 'xor',
|
||||
)
|
||||
|
||||
name_builtins = (
|
||||
'_svc', 'while',
|
||||
)
|
||||
|
||||
name_pseudo = (
|
||||
'root', 'self', 'this',
|
||||
)
|
||||
|
||||
decimal_suffixes = '([tTsSiIlLvV]|ll|LL|([iIuU])(8|16|32|64))?'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
|
||||
# Keywords
|
||||
(words(('axiom', 'ctor', 'fun', 'gen', 'proc', 'reduce',
|
||||
'union'), suffix=r'\b'),
|
||||
Keyword, 'funcname'),
|
||||
(words(('class', 'cclass', 'cstruct', 'obj', 'struct'), suffix=r'\b'),
|
||||
Keyword, 'classname'),
|
||||
(r'(instance|module|typeclass)\b', Keyword, 'modulename'),
|
||||
|
||||
(words(keywords, suffix=r'\b'), Keyword),
|
||||
(words(keyword_directives, suffix=r'\b'), Name.Decorator),
|
||||
(words(keyword_declarations, suffix=r'\b'), Keyword.Declaration),
|
||||
(words(keyword_types, suffix=r'\b'), Keyword.Type),
|
||||
(words(keyword_constants, suffix=r'\b'), Keyword.Constant),
|
||||
|
||||
# Operators
|
||||
include('operators'),
|
||||
|
||||
# Float Literal
|
||||
# -- Hex Float
|
||||
(r'0[xX]([0-9a-fA-F_]*\.[0-9a-fA-F_]+|[0-9a-fA-F_]+)'
|
||||
r'[pP][+\-]?[0-9_]+[lLfFdD]?', Number.Float),
|
||||
# -- DecimalFloat
|
||||
(r'[0-9_]+(\.[0-9_]+[eE][+\-]?[0-9_]+|'
|
||||
r'\.[0-9_]*|[eE][+\-]?[0-9_]+)[lLfFdD]?', Number.Float),
|
||||
(r'\.(0|[1-9][0-9_]*)([eE][+\-]?[0-9_]+)?[lLfFdD]?',
|
||||
Number.Float),
|
||||
|
||||
# IntegerLiteral
|
||||
# -- Binary
|
||||
(r'0[Bb][01_]+%s' % decimal_suffixes, Number.Bin),
|
||||
# -- Octal
|
||||
(r'0[0-7_]+%s' % decimal_suffixes, Number.Oct),
|
||||
# -- Hexadecimal
|
||||
(r'0[xX][0-9a-fA-F_]+%s' % decimal_suffixes, Number.Hex),
|
||||
# -- Decimal
|
||||
(r'(0|[1-9][0-9_]*)%s' % decimal_suffixes, Number.Integer),
|
||||
|
||||
# Strings
|
||||
('([rR][cC]?|[cC][rR])"""', String, 'tdqs'),
|
||||
("([rR][cC]?|[cC][rR])'''", String, 'tsqs'),
|
||||
('([rR][cC]?|[cC][rR])"', String, 'dqs'),
|
||||
("([rR][cC]?|[cC][rR])'", String, 'sqs'),
|
||||
('[cCfFqQwWuU]?"""', String, combined('stringescape', 'tdqs')),
|
||||
("[cCfFqQwWuU]?'''", String, combined('stringescape', 'tsqs')),
|
||||
('[cCfFqQwWuU]?"', String, combined('stringescape', 'dqs')),
|
||||
("[cCfFqQwWuU]?'", String, combined('stringescape', 'sqs')),
|
||||
|
||||
# Punctuation
|
||||
(r'[\[\]{}:(),;?]', Punctuation),
|
||||
|
||||
# Labels
|
||||
(r'[a-zA-Z_]\w*:>', Name.Label),
|
||||
|
||||
# Identifiers
|
||||
(r'(%s)\b' % '|'.join(name_builtins), Name.Builtin),
|
||||
(r'(%s)\b' % '|'.join(name_pseudo), Name.Builtin.Pseudo),
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
|
||||
include('comment'),
|
||||
|
||||
# Preprocessor
|
||||
(r'#\s*if\s+0', Comment.Preproc, 'if0'),
|
||||
(r'#', Comment.Preproc, 'macro'),
|
||||
],
|
||||
'operators': [
|
||||
(r'(%s)\b' % '|'.join(operator_words), Operator.Word),
|
||||
(r'!=|==|<<|>>|\|\||&&|[-~+/*%=<>&^|.$]', Operator),
|
||||
],
|
||||
'comment': [
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/[*]', Comment.Multiline, 'comment2'),
|
||||
],
|
||||
'comment2': [
|
||||
(r'[^/*]', Comment.Multiline),
|
||||
(r'/[*]', Comment.Multiline, '#push'),
|
||||
(r'[*]/', Comment.Multiline, '#pop'),
|
||||
(r'[/*]', Comment.Multiline),
|
||||
],
|
||||
'if0': [
|
||||
(r'^\s*#if.*?(?<!\\)\n', Comment, '#push'),
|
||||
(r'^\s*#endif.*?(?<!\\)\n', Comment, '#pop'),
|
||||
(r'.*?\n', Comment),
|
||||
],
|
||||
'macro': [
|
||||
include('comment'),
|
||||
(r'(import|include)(\s+)(<[^>]*?>)',
|
||||
bygroups(Comment.Preproc, Text, String), '#pop'),
|
||||
(r'(import|include)(\s+)("[^"]*?")',
|
||||
bygroups(Comment.Preproc, Text, String), '#pop'),
|
||||
(r"(import|include)(\s+)('[^']*?')",
|
||||
bygroups(Comment.Preproc, Text, String), '#pop'),
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
# (r'/[*](.|\n)*?[*]/', Comment),
|
||||
# (r'//.*?\n', Comment, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'funcname': [
|
||||
include('whitespace'),
|
||||
(r'[a-zA-Z_]\w*', Name.Function, '#pop'),
|
||||
# anonymous functions
|
||||
(r'(?=\()', Text, '#pop'),
|
||||
],
|
||||
'classname': [
|
||||
include('whitespace'),
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
# anonymous classes
|
||||
(r'(?=\{)', Text, '#pop'),
|
||||
],
|
||||
'modulename': [
|
||||
include('whitespace'),
|
||||
(r'\[', Punctuation, ('modulename2', 'tvarlist')),
|
||||
default('modulename2'),
|
||||
],
|
||||
'modulename2': [
|
||||
include('whitespace'),
|
||||
(r'([a-zA-Z_]\w*)', Name.Namespace, '#pop:2'),
|
||||
],
|
||||
'tvarlist': [
|
||||
include('whitespace'),
|
||||
include('operators'),
|
||||
(r'\[', Punctuation, '#push'),
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
(r',', Punctuation),
|
||||
(r'(with|where)\b', Keyword),
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
|
||||
r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
|
||||
],
|
||||
'strings': [
|
||||
(r'%(\([a-zA-Z0-9]+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
|
||||
'[hlL]?[diouxXeEfFgGcrs%]', String.Interpol),
|
||||
(r'[^\\\'"%\n]+', String),
|
||||
# quotes, percents and backslashes must be parsed one at a time
|
||||
(r'[\'"\\]', String),
|
||||
# unhandled string formatting sign
|
||||
(r'%', String)
|
||||
# newlines are an error (use "nl" state)
|
||||
],
|
||||
'nl': [
|
||||
(r'\n', String)
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
# included here again for raw strings
|
||||
(r'\\\\|\\"|\\\n', String.Escape),
|
||||
include('strings')
|
||||
],
|
||||
'sqs': [
|
||||
(r"'", String, '#pop'),
|
||||
# included here again for raw strings
|
||||
(r"\\\\|\\'|\\\n", String.Escape),
|
||||
include('strings')
|
||||
],
|
||||
'tdqs': [
|
||||
(r'"""', String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl')
|
||||
],
|
||||
'tsqs': [
|
||||
(r"'''", String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl')
|
||||
],
|
||||
}
|
||||
@ -1,101 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.go
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for the Google Go language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['GoLexer']
|
||||
|
||||
|
||||
class GoLexer(RegexLexer):
|
||||
"""
|
||||
For `Go <http://golang.org>`_ source.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
name = 'Go'
|
||||
filenames = ['*.go']
|
||||
aliases = ['go']
|
||||
mimetypes = ['text/x-gosrc']
|
||||
|
||||
flags = re.MULTILINE | re.UNICODE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuations
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'(import|package)\b', Keyword.Namespace),
|
||||
(r'(var|func|struct|map|chan|type|interface|const)\b',
|
||||
Keyword.Declaration),
|
||||
(words((
|
||||
'break', 'default', 'select', 'case', 'defer', 'go',
|
||||
'else', 'goto', 'switch', 'fallthrough', 'if', 'range',
|
||||
'continue', 'for', 'return'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(true|false|iota|nil)\b', Keyword.Constant),
|
||||
# It seems the builtin types aren't actually keywords, but
|
||||
# can be used as functions. So we need two declarations.
|
||||
(words((
|
||||
'uint', 'uint8', 'uint16', 'uint32', 'uint64',
|
||||
'int', 'int8', 'int16', 'int32', 'int64',
|
||||
'float', 'float32', 'float64',
|
||||
'complex64', 'complex128', 'byte', 'rune',
|
||||
'string', 'bool', 'error', 'uintptr',
|
||||
'print', 'println', 'panic', 'recover', 'close', 'complex',
|
||||
'real', 'imag', 'len', 'cap', 'append', 'copy', 'delete',
|
||||
'new', 'make'), suffix=r'\b(\()'),
|
||||
bygroups(Name.Builtin, Punctuation)),
|
||||
(words((
|
||||
'uint', 'uint8', 'uint16', 'uint32', 'uint64',
|
||||
'int', 'int8', 'int16', 'int32', 'int64',
|
||||
'float', 'float32', 'float64',
|
||||
'complex64', 'complex128', 'byte', 'rune',
|
||||
'string', 'bool', 'error', 'uintptr'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
# imaginary_lit
|
||||
(r'\d+i', Number),
|
||||
(r'\d+\.\d*([Ee][-+]\d+)?i', Number),
|
||||
(r'\.\d+([Ee][-+]\d+)?i', Number),
|
||||
(r'\d+[Ee][-+]\d+i', Number),
|
||||
# float_lit
|
||||
(r'\d+(\.\d+[eE][+\-]?\d+|'
|
||||
r'\.\d*|[eE][+\-]?\d+)', Number.Float),
|
||||
(r'\.\d+([eE][+\-]?\d+)?', Number.Float),
|
||||
# int_lit
|
||||
# -- octal_lit
|
||||
(r'0[0-7]+', Number.Oct),
|
||||
# -- hex_lit
|
||||
(r'0[xX][0-9a-fA-F]+', Number.Hex),
|
||||
# -- decimal_lit
|
||||
(r'(0|[1-9][0-9]*)', Number.Integer),
|
||||
# char_lit
|
||||
(r"""'(\\['"\\abfnrtv]|\\x[0-9a-fA-F]{2}|\\[0-7]{1,3}"""
|
||||
r"""|\\u[0-9a-fA-F]{4}|\\U[0-9a-fA-F]{8}|[^\\])'""",
|
||||
String.Char),
|
||||
# StringLiteral
|
||||
# -- raw_string_lit
|
||||
(r'`[^`]*`', String),
|
||||
# -- interpreted_string_lit
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
# Tokens
|
||||
(r'(<<=|>>=|<<|>>|<=|>=|&\^=|&\^|\+=|-=|\*=|/=|%=|&=|\|=|&&|\|\|'
|
||||
r'|<-|\+\+|--|==|!=|:=|\.\.\.|[+\-*/%&])', Operator),
|
||||
(r'[|^<>=!()\[\]{}.,;:]', Punctuation),
|
||||
# identifier
|
||||
(r'[^\W\d]\w*', Name.Other),
|
||||
]
|
||||
}
|
||||
@ -1,79 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.graph
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for graph query languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, this
|
||||
from pygments.token import Keyword, Punctuation, Comment, Operator, Name,\
|
||||
String, Number, Whitespace
|
||||
|
||||
|
||||
__all__ = ['CypherLexer']
|
||||
|
||||
|
||||
class CypherLexer(RegexLexer):
|
||||
"""
|
||||
For `Cypher Query Language
|
||||
<http://docs.neo4j.org/chunked/milestone/cypher-query-lang.html>`_
|
||||
|
||||
For the Cypher version in Neo4J 2.0
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Cypher'
|
||||
aliases = ['cypher']
|
||||
filenames = ['*.cyp', '*.cypher']
|
||||
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('comment'),
|
||||
include('keywords'),
|
||||
include('clauses'),
|
||||
include('relations'),
|
||||
include('strings'),
|
||||
include('whitespace'),
|
||||
include('barewords'),
|
||||
],
|
||||
'comment': [
|
||||
(r'^.*//.*\n', Comment.Single),
|
||||
],
|
||||
'keywords': [
|
||||
(r'(create|order|match|limit|set|skip|start|return|with|where|'
|
||||
r'delete|foreach|not|by)\b', Keyword),
|
||||
],
|
||||
'clauses': [
|
||||
# TODO: many missing ones, see http://docs.neo4j.org/refcard/2.0/
|
||||
(r'(all|any|as|asc|create|create\s+unique|delete|'
|
||||
r'desc|distinct|foreach|in|is\s+null|limit|match|none|'
|
||||
r'order\s+by|return|set|skip|single|start|union|where|with)\b',
|
||||
Keyword),
|
||||
],
|
||||
'relations': [
|
||||
(r'(-\[)(.*?)(\]->)', bygroups(Operator, using(this), Operator)),
|
||||
(r'(<-\[)(.*?)(\]-)', bygroups(Operator, using(this), Operator)),
|
||||
(r'-->|<--|\[|\]', Operator),
|
||||
(r'<|>|<>|=|<=|=>|\(|\)|\||:|,|;', Punctuation),
|
||||
(r'[.*{}]', Punctuation),
|
||||
],
|
||||
'strings': [
|
||||
(r'"(?:\\[tbnrf\'"\\]|[^\\"])*"', String),
|
||||
(r'`(?:``|[^`])+`', Name.Variable),
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\s+', Whitespace),
|
||||
],
|
||||
'barewords': [
|
||||
(r'[a-z]\w*', Name),
|
||||
(r'\d+', Number),
|
||||
],
|
||||
}
|
||||
@ -1,553 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.graphics
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for computer graphics and plotting related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, words, include, bygroups, using, \
|
||||
this, default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, \
|
||||
Number, Punctuation, String
|
||||
|
||||
__all__ = ['GLShaderLexer', 'PostScriptLexer', 'AsymptoteLexer', 'GnuplotLexer',
|
||||
'PovrayLexer']
|
||||
|
||||
|
||||
class GLShaderLexer(RegexLexer):
|
||||
"""
|
||||
GLSL (OpenGL Shader) lexer.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'GLSL'
|
||||
aliases = ['glsl']
|
||||
filenames = ['*.vert', '*.frag', '*.geo']
|
||||
mimetypes = ['text/x-glslsrc']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^#.*', Comment.Preproc),
|
||||
(r'//.*', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'\+|-|~|!=?|\*|/|%|<<|>>|<=?|>=?|==?|&&?|\^|\|\|?',
|
||||
Operator),
|
||||
(r'[?:]', Operator), # quick hack for ternary
|
||||
(r'\bdefined\b', Operator),
|
||||
(r'[;{}(),\[\]]', Punctuation),
|
||||
# FIXME when e is present, no decimal point needed
|
||||
(r'[+-]?\d*\.\d+([eE][-+]?\d+)?', Number.Float),
|
||||
(r'[+-]?\d+\.\d*([eE][-+]?\d+)?', Number.Float),
|
||||
(r'0[xX][0-9a-fA-F]*', Number.Hex),
|
||||
(r'0[0-7]*', Number.Oct),
|
||||
(r'[1-9][0-9]*', Number.Integer),
|
||||
(words((
|
||||
'attribute', 'const', 'uniform', 'varying', 'centroid', 'break',
|
||||
'continue', 'do', 'for', 'while', 'if', 'else', 'in', 'out',
|
||||
'inout', 'float', 'int', 'void', 'bool', 'true', 'false',
|
||||
'invariant', 'discard', 'return', 'mat2', 'mat3' 'mat4',
|
||||
'mat2x2', 'mat3x2', 'mat4x2', 'mat2x3', 'mat3x3', 'mat4x3',
|
||||
'mat2x4', 'mat3x4', 'mat4x4', 'vec2', 'vec3', 'vec4',
|
||||
'ivec2', 'ivec3', 'ivec4', 'bvec2', 'bvec3', 'bvec4',
|
||||
'sampler1D', 'sampler2D', 'sampler3D' 'samplerCube',
|
||||
'sampler1DShadow', 'sampler2DShadow', 'struct'),
|
||||
prefix=r'\b', suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'asm', 'class', 'union', 'enum', 'typedef', 'template', 'this',
|
||||
'packed', 'goto', 'switch', 'default', 'inline', 'noinline',
|
||||
'volatile', 'public', 'static', 'extern', 'external', 'interface',
|
||||
'long', 'short', 'double', 'half', 'fixed', 'unsigned', 'lowp',
|
||||
'mediump', 'highp', 'precision', 'input', 'output',
|
||||
'hvec2', 'hvec3', 'hvec4', 'dvec2', 'dvec3', 'dvec4',
|
||||
'fvec2', 'fvec3', 'fvec4', 'sampler2DRect', 'sampler3DRect',
|
||||
'sampler2DRectShadow', 'sizeof', 'cast', 'namespace', 'using'),
|
||||
prefix=r'\b', suffix=r'\b'),
|
||||
Keyword), # future use
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
(r'\.', Punctuation),
|
||||
(r'\s+', Text),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class PostScriptLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for PostScript files.
|
||||
|
||||
The PostScript Language Reference published by Adobe at
|
||||
<http://partners.adobe.com/public/developer/en/ps/PLRM.pdf>
|
||||
is the authority for this.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
name = 'PostScript'
|
||||
aliases = ['postscript', 'postscr']
|
||||
filenames = ['*.ps', '*.eps']
|
||||
mimetypes = ['application/postscript']
|
||||
|
||||
delimiter = r'()<>\[\]{}/%\s'
|
||||
delimiter_end = r'(?=[%s])' % delimiter
|
||||
|
||||
valid_name_chars = r'[^%s]' % delimiter
|
||||
valid_name = r"%s+%s" % (valid_name_chars, delimiter_end)
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# All comment types
|
||||
(r'^%!.+\n', Comment.Preproc),
|
||||
(r'%%.*\n', Comment.Special),
|
||||
(r'(^%.*\n){2,}', Comment.Multiline),
|
||||
(r'%.*\n', Comment.Single),
|
||||
|
||||
# String literals are awkward; enter separate state.
|
||||
(r'\(', String, 'stringliteral'),
|
||||
|
||||
(r'[{}<>\[\]]', Punctuation),
|
||||
|
||||
# Numbers
|
||||
(r'<[0-9A-Fa-f]+>' + delimiter_end, Number.Hex),
|
||||
# Slight abuse: use Oct to signify any explicit base system
|
||||
(r'[0-9]+\#(\-|\+)?([0-9]+\.?|[0-9]*\.[0-9]+|[0-9]+\.[0-9]*)'
|
||||
r'((e|E)[0-9]+)?' + delimiter_end, Number.Oct),
|
||||
(r'(\-|\+)?([0-9]+\.?|[0-9]*\.[0-9]+|[0-9]+\.[0-9]*)((e|E)[0-9]+)?'
|
||||
+ delimiter_end, Number.Float),
|
||||
(r'(\-|\+)?[0-9]+' + delimiter_end, Number.Integer),
|
||||
|
||||
# References
|
||||
(r'\/%s' % valid_name, Name.Variable),
|
||||
|
||||
# Names
|
||||
(valid_name, Name.Function), # Anything else is executed
|
||||
|
||||
# These keywords taken from
|
||||
# <http://www.math.ubc.ca/~cass/graphics/manual/pdf/a1.pdf>
|
||||
# Is there an authoritative list anywhere that doesn't involve
|
||||
# trawling documentation?
|
||||
|
||||
(r'(false|true)' + delimiter_end, Keyword.Constant),
|
||||
|
||||
# Conditionals / flow control
|
||||
(r'(eq|ne|g[et]|l[et]|and|or|not|if(?:else)?|for(?:all)?)'
|
||||
+ delimiter_end, Keyword.Reserved),
|
||||
|
||||
(words((
|
||||
'abs', 'add', 'aload', 'arc', 'arcn', 'array', 'atan', 'begin',
|
||||
'bind', 'ceiling', 'charpath', 'clip', 'closepath', 'concat',
|
||||
'concatmatrix', 'copy', 'cos', 'currentlinewidth', 'currentmatrix',
|
||||
'currentpoint', 'curveto', 'cvi', 'cvs', 'def', 'defaultmatrix',
|
||||
'dict', 'dictstackoverflow', 'div', 'dtransform', 'dup', 'end',
|
||||
'exch', 'exec', 'exit', 'exp', 'fill', 'findfont', 'floor', 'get',
|
||||
'getinterval', 'grestore', 'gsave', 'gt', 'identmatrix', 'idiv',
|
||||
'idtransform', 'index', 'invertmatrix', 'itransform', 'length',
|
||||
'lineto', 'ln', 'load', 'log', 'loop', 'matrix', 'mod', 'moveto',
|
||||
'mul', 'neg', 'newpath', 'pathforall', 'pathbbox', 'pop', 'print',
|
||||
'pstack', 'put', 'quit', 'rand', 'rangecheck', 'rcurveto', 'repeat',
|
||||
'restore', 'rlineto', 'rmoveto', 'roll', 'rotate', 'round', 'run',
|
||||
'save', 'scale', 'scalefont', 'setdash', 'setfont', 'setgray',
|
||||
'setlinecap', 'setlinejoin', 'setlinewidth', 'setmatrix',
|
||||
'setrgbcolor', 'shfill', 'show', 'showpage', 'sin', 'sqrt',
|
||||
'stack', 'stringwidth', 'stroke', 'strokepath', 'sub', 'syntaxerror',
|
||||
'transform', 'translate', 'truncate', 'typecheck', 'undefined',
|
||||
'undefinedfilename', 'undefinedresult'), suffix=delimiter_end),
|
||||
Name.Builtin),
|
||||
|
||||
(r'\s+', Text),
|
||||
],
|
||||
|
||||
'stringliteral': [
|
||||
(r'[^()\\]+', String),
|
||||
(r'\\', String.Escape, 'escape'),
|
||||
(r'\(', String, '#push'),
|
||||
(r'\)', String, '#pop'),
|
||||
],
|
||||
|
||||
'escape': [
|
||||
(r'[0-8]{3}|n|r|t|b|f|\\|\(|\)', String.Escape, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class AsymptoteLexer(RegexLexer):
|
||||
"""
|
||||
For `Asymptote <http://asymptote.sf.net/>`_ source code.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
name = 'Asymptote'
|
||||
aliases = ['asy', 'asymptote']
|
||||
filenames = ['*.asy']
|
||||
mimetypes = ['text/x-asymptote']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/\*.*?\*/)+'
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'//(\n|(.|\n)*?[^\\]\n)', Comment),
|
||||
(r'/(\\\n)?\*(.|\n)*?\*(\\\n)?/', Comment),
|
||||
],
|
||||
'statements': [
|
||||
# simple string (TeX friendly)
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
# C style string (with character escapes)
|
||||
(r"'", String, 'string'),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[Ll]?', Number.Hex),
|
||||
(r'0[0-7]+[Ll]?', Number.Oct),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.]', Punctuation),
|
||||
(r'\b(case)(.+?)(:)', bygroups(Keyword, using(this), Text)),
|
||||
(r'(and|controls|tension|atleast|curl|if|else|while|for|do|'
|
||||
r'return|break|continue|struct|typedef|new|access|import|'
|
||||
r'unravel|from|include|quote|static|public|private|restricted|'
|
||||
r'this|explicit|true|false|null|cycle|newframe|operator)\b', Keyword),
|
||||
# Since an asy-type-name can be also an asy-function-name,
|
||||
# in the following we test if the string " [a-zA-Z]" follows
|
||||
# the Keyword.Type.
|
||||
# Of course it is not perfect !
|
||||
(r'(Braid|FitResult|Label|Legend|TreeNode|abscissa|arc|arrowhead|'
|
||||
r'binarytree|binarytreeNode|block|bool|bool3|bounds|bqe|circle|'
|
||||
r'conic|coord|coordsys|cputime|ellipse|file|filltype|frame|grid3|'
|
||||
r'guide|horner|hsv|hyperbola|indexedTransform|int|inversion|key|'
|
||||
r'light|line|linefit|marginT|marker|mass|object|pair|parabola|path|'
|
||||
r'path3|pen|picture|point|position|projection|real|revolution|'
|
||||
r'scaleT|scientific|segment|side|slice|splitface|string|surface|'
|
||||
r'tensionSpecifier|ticklocate|ticksgridT|tickvalues|transform|'
|
||||
r'transformation|tree|triangle|trilinear|triple|vector|'
|
||||
r'vertex|void)(?=\s+[a-zA-Z])', Keyword.Type),
|
||||
# Now the asy-type-name which are not asy-function-name
|
||||
# except yours !
|
||||
# Perhaps useless
|
||||
(r'(Braid|FitResult|TreeNode|abscissa|arrowhead|block|bool|bool3|'
|
||||
r'bounds|coord|frame|guide|horner|int|linefit|marginT|pair|pen|'
|
||||
r'picture|position|real|revolution|slice|splitface|ticksgridT|'
|
||||
r'tickvalues|tree|triple|vertex|void)\b', Keyword.Type),
|
||||
('[a-zA-Z_]\w*:(?!:)', Name.Label),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
# functions
|
||||
(r'((?:[\w*\s])+?(?:\s|\*))' # return arguments
|
||||
r'([a-zA-Z_]\w*)' # method name
|
||||
r'(\s*\([^;]*?\))' # signature
|
||||
r'(' + _ws + r')(\{)',
|
||||
bygroups(using(this), Name.Function, using(this), using(this),
|
||||
Punctuation),
|
||||
'function'),
|
||||
# function declarations
|
||||
(r'((?:[\w*\s])+?(?:\s|\*))' # return arguments
|
||||
r'([a-zA-Z_]\w*)' # method name
|
||||
r'(\s*\([^;]*?\))' # signature
|
||||
r'(' + _ws + r')(;)',
|
||||
bygroups(using(this), Name.Function, using(this), using(this),
|
||||
Punctuation)),
|
||||
default('statement'),
|
||||
],
|
||||
'statement': [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
('[{}]', Punctuation),
|
||||
(';', Punctuation, '#pop'),
|
||||
],
|
||||
'function': [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
(';', Punctuation),
|
||||
(r'\{', Punctuation, '#push'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r"'", String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\'?]|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'\n', String),
|
||||
(r"[^\\'\n]+", String), # all other characters
|
||||
(r'\\\n', String),
|
||||
(r'\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
}
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
from pygments.lexers._asy_builtins import ASYFUNCNAME, ASYVARNAME
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name and value in ASYFUNCNAME:
|
||||
token = Name.Function
|
||||
elif token is Name and value in ASYVARNAME:
|
||||
token = Name.Variable
|
||||
yield index, token, value
|
||||
|
||||
|
||||
def _shortened(word):
|
||||
dpos = word.find('$')
|
||||
return '|'.join(word[:dpos] + word[dpos+1:i] + r'\b'
|
||||
for i in range(len(word), dpos, -1))
|
||||
|
||||
|
||||
def _shortened_many(*words):
|
||||
return '|'.join(map(_shortened, words))
|
||||
|
||||
|
||||
class GnuplotLexer(RegexLexer):
|
||||
"""
|
||||
For `Gnuplot <http://gnuplot.info/>`_ plotting scripts.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
|
||||
name = 'Gnuplot'
|
||||
aliases = ['gnuplot']
|
||||
filenames = ['*.plot', '*.plt']
|
||||
mimetypes = ['text/x-gnuplot']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
(_shortened('bi$nd'), Keyword, 'bind'),
|
||||
(_shortened_many('ex$it', 'q$uit'), Keyword, 'quit'),
|
||||
(_shortened('f$it'), Keyword, 'fit'),
|
||||
(r'(if)(\s*)(\()', bygroups(Keyword, Text, Punctuation), 'if'),
|
||||
(r'else\b', Keyword),
|
||||
(_shortened('pa$use'), Keyword, 'pause'),
|
||||
(_shortened_many('p$lot', 'rep$lot', 'sp$lot'), Keyword, 'plot'),
|
||||
(_shortened('sa$ve'), Keyword, 'save'),
|
||||
(_shortened('se$t'), Keyword, ('genericargs', 'optionarg')),
|
||||
(_shortened_many('sh$ow', 'uns$et'),
|
||||
Keyword, ('noargs', 'optionarg')),
|
||||
(_shortened_many('low$er', 'ra$ise', 'ca$ll', 'cd$', 'cl$ear',
|
||||
'h$elp', '\\?$', 'hi$story', 'l$oad', 'pr$int',
|
||||
'pwd$', 're$read', 'res$et', 'scr$eendump',
|
||||
'she$ll', 'sy$stem', 'up$date'),
|
||||
Keyword, 'genericargs'),
|
||||
(_shortened_many('pwd$', 're$read', 'res$et', 'scr$eendump',
|
||||
'she$ll', 'test$'),
|
||||
Keyword, 'noargs'),
|
||||
('([a-zA-Z_]\w*)(\s*)(=)',
|
||||
bygroups(Name.Variable, Text, Operator), 'genericargs'),
|
||||
('([a-zA-Z_]\w*)(\s*\(.*?\)\s*)(=)',
|
||||
bygroups(Name.Function, Text, Operator), 'genericargs'),
|
||||
(r'@[a-zA-Z_]\w*', Name.Constant), # macros
|
||||
(r';', Keyword),
|
||||
],
|
||||
'comment': [
|
||||
(r'[^\\\n]', Comment),
|
||||
(r'\\\n', Comment),
|
||||
(r'\\', Comment),
|
||||
# don't add the newline to the Comment token
|
||||
default('#pop'),
|
||||
],
|
||||
'whitespace': [
|
||||
('#', Comment, 'comment'),
|
||||
(r'[ \t\v\f]+', Text),
|
||||
],
|
||||
'noargs': [
|
||||
include('whitespace'),
|
||||
# semicolon and newline end the argument list
|
||||
(r';', Punctuation, '#pop'),
|
||||
(r'\n', Text, '#pop'),
|
||||
],
|
||||
'dqstring': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
(r'\n', String, '#pop'), # newline ends the string too
|
||||
],
|
||||
'sqstring': [
|
||||
(r"''", String), # escaped single quote
|
||||
(r"'", String, '#pop'),
|
||||
(r"[^\\'\n]+", String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # normal backslash
|
||||
(r'\n', String, '#pop'), # newline ends the string too
|
||||
],
|
||||
'genericargs': [
|
||||
include('noargs'),
|
||||
(r'"', String, 'dqstring'),
|
||||
(r"'", String, 'sqstring'),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+)', Number.Float),
|
||||
(r'-?\d+', Number.Integer),
|
||||
('[,.~!%^&*+=|?:<>/-]', Operator),
|
||||
('[{}()\[\]]', Punctuation),
|
||||
(r'(eq|ne)\b', Operator.Word),
|
||||
(r'([a-zA-Z_]\w*)(\s*)(\()',
|
||||
bygroups(Name.Function, Text, Punctuation)),
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
(r'@[a-zA-Z_]\w*', Name.Constant), # macros
|
||||
(r'\\\n', Text),
|
||||
],
|
||||
'optionarg': [
|
||||
include('whitespace'),
|
||||
(_shortened_many(
|
||||
"a$ll", "an$gles", "ar$row", "au$toscale", "b$ars", "bor$der",
|
||||
"box$width", "cl$abel", "c$lip", "cn$trparam", "co$ntour", "da$ta",
|
||||
"data$file", "dg$rid3d", "du$mmy", "enc$oding", "dec$imalsign",
|
||||
"fit$", "font$path", "fo$rmat", "fu$nction", "fu$nctions", "g$rid",
|
||||
"hid$den3d", "his$torysize", "is$osamples", "k$ey", "keyt$itle",
|
||||
"la$bel", "li$nestyle", "ls$", "loa$dpath", "loc$ale", "log$scale",
|
||||
"mac$ros", "map$ping", "map$ping3d", "mar$gin", "lmar$gin",
|
||||
"rmar$gin", "tmar$gin", "bmar$gin", "mo$use", "multi$plot",
|
||||
"mxt$ics", "nomxt$ics", "mx2t$ics", "nomx2t$ics", "myt$ics",
|
||||
"nomyt$ics", "my2t$ics", "nomy2t$ics", "mzt$ics", "nomzt$ics",
|
||||
"mcbt$ics", "nomcbt$ics", "of$fsets", "or$igin", "o$utput",
|
||||
"pa$rametric", "pm$3d", "pal$ette", "colorb$ox", "p$lot",
|
||||
"poi$ntsize", "pol$ar", "pr$int", "obj$ect", "sa$mples", "si$ze",
|
||||
"st$yle", "su$rface", "table$", "t$erminal", "termo$ptions", "ti$cs",
|
||||
"ticsc$ale", "ticsl$evel", "timef$mt", "tim$estamp", "tit$le",
|
||||
"v$ariables", "ve$rsion", "vi$ew", "xyp$lane", "xda$ta", "x2da$ta",
|
||||
"yda$ta", "y2da$ta", "zda$ta", "cbda$ta", "xl$abel", "x2l$abel",
|
||||
"yl$abel", "y2l$abel", "zl$abel", "cbl$abel", "xti$cs", "noxti$cs",
|
||||
"x2ti$cs", "nox2ti$cs", "yti$cs", "noyti$cs", "y2ti$cs", "noy2ti$cs",
|
||||
"zti$cs", "nozti$cs", "cbti$cs", "nocbti$cs", "xdti$cs", "noxdti$cs",
|
||||
"x2dti$cs", "nox2dti$cs", "ydti$cs", "noydti$cs", "y2dti$cs",
|
||||
"noy2dti$cs", "zdti$cs", "nozdti$cs", "cbdti$cs", "nocbdti$cs",
|
||||
"xmti$cs", "noxmti$cs", "x2mti$cs", "nox2mti$cs", "ymti$cs",
|
||||
"noymti$cs", "y2mti$cs", "noy2mti$cs", "zmti$cs", "nozmti$cs",
|
||||
"cbmti$cs", "nocbmti$cs", "xr$ange", "x2r$ange", "yr$ange",
|
||||
"y2r$ange", "zr$ange", "cbr$ange", "rr$ange", "tr$ange", "ur$ange",
|
||||
"vr$ange", "xzeroa$xis", "x2zeroa$xis", "yzeroa$xis", "y2zeroa$xis",
|
||||
"zzeroa$xis", "zeroa$xis", "z$ero"), Name.Builtin, '#pop'),
|
||||
],
|
||||
'bind': [
|
||||
('!', Keyword, '#pop'),
|
||||
(_shortened('all$windows'), Name.Builtin),
|
||||
include('genericargs'),
|
||||
],
|
||||
'quit': [
|
||||
(r'gnuplot\b', Keyword),
|
||||
include('noargs'),
|
||||
],
|
||||
'fit': [
|
||||
(r'via\b', Name.Builtin),
|
||||
include('plot'),
|
||||
],
|
||||
'if': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
include('genericargs'),
|
||||
],
|
||||
'pause': [
|
||||
(r'(mouse|any|button1|button2|button3)\b', Name.Builtin),
|
||||
(_shortened('key$press'), Name.Builtin),
|
||||
include('genericargs'),
|
||||
],
|
||||
'plot': [
|
||||
(_shortened_many('ax$es', 'axi$s', 'bin$ary', 'ev$ery', 'i$ndex',
|
||||
'mat$rix', 's$mooth', 'thru$', 't$itle',
|
||||
'not$itle', 'u$sing', 'w$ith'),
|
||||
Name.Builtin),
|
||||
include('genericargs'),
|
||||
],
|
||||
'save': [
|
||||
(_shortened_many('f$unctions', 's$et', 't$erminal', 'v$ariables'),
|
||||
Name.Builtin),
|
||||
include('genericargs'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class PovrayLexer(RegexLexer):
|
||||
"""
|
||||
For `Persistence of Vision Raytracer <http://www.povray.org/>`_ files.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
name = 'POVRay'
|
||||
aliases = ['pov']
|
||||
filenames = ['*.pov', '*.inc']
|
||||
mimetypes = ['text/x-povray']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'/\*[\w\W]*?\*/', Comment.Multiline),
|
||||
(r'//.*\n', Comment.Single),
|
||||
(r'(?s)"(?:\\.|[^"\\])+"', String.Double),
|
||||
(words((
|
||||
'break', 'case', 'debug', 'declare', 'default', 'define', 'else',
|
||||
'elseif', 'end', 'error', 'fclose', 'fopen', 'for', 'if', 'ifdef',
|
||||
'ifndef', 'include', 'local', 'macro', 'range', 'read', 'render',
|
||||
'statistics', 'switch', 'undef', 'version', 'warning', 'while',
|
||||
'write'), prefix=r'#', suffix=r'\b'),
|
||||
Comment.Preproc),
|
||||
(words((
|
||||
'aa_level', 'aa_threshold', 'abs', 'acos', 'acosh', 'adaptive', 'adc_bailout',
|
||||
'agate', 'agate_turb', 'all', 'alpha', 'ambient', 'ambient_light', 'angle',
|
||||
'aperture', 'arc_angle', 'area_light', 'asc', 'asin', 'asinh', 'assumed_gamma',
|
||||
'atan', 'atan2', 'atanh', 'atmosphere', 'atmospheric_attenuation',
|
||||
'attenuating', 'average', 'background', 'black_hole', 'blue', 'blur_samples',
|
||||
'bounded_by', 'box_mapping', 'bozo', 'break', 'brick', 'brick_size',
|
||||
'brightness', 'brilliance', 'bumps', 'bumpy1', 'bumpy2', 'bumpy3', 'bump_map',
|
||||
'bump_size', 'case', 'caustics', 'ceil', 'checker', 'chr', 'clipped_by', 'clock',
|
||||
'color', 'color_map', 'colour', 'colour_map', 'component', 'composite', 'concat',
|
||||
'confidence', 'conic_sweep', 'constant', 'control0', 'control1', 'cos', 'cosh',
|
||||
'count', 'crackle', 'crand', 'cube', 'cubic_spline', 'cylindrical_mapping',
|
||||
'debug', 'declare', 'default', 'degrees', 'dents', 'diffuse', 'direction',
|
||||
'distance', 'distance_maximum', 'div', 'dust', 'dust_type', 'eccentricity',
|
||||
'else', 'emitting', 'end', 'error', 'error_bound', 'exp', 'exponent',
|
||||
'fade_distance', 'fade_power', 'falloff', 'falloff_angle', 'false',
|
||||
'file_exists', 'filter', 'finish', 'fisheye', 'flatness', 'flip', 'floor',
|
||||
'focal_point', 'fog', 'fog_alt', 'fog_offset', 'fog_type', 'frequency', 'gif',
|
||||
'global_settings', 'glowing', 'gradient', 'granite', 'gray_threshold',
|
||||
'green', 'halo', 'hexagon', 'hf_gray_16', 'hierarchy', 'hollow', 'hypercomplex',
|
||||
'if', 'ifdef', 'iff', 'image_map', 'incidence', 'include', 'int', 'interpolate',
|
||||
'inverse', 'ior', 'irid', 'irid_wavelength', 'jitter', 'lambda', 'leopard',
|
||||
'linear', 'linear_spline', 'linear_sweep', 'location', 'log', 'looks_like',
|
||||
'look_at', 'low_error_factor', 'mandel', 'map_type', 'marble', 'material_map',
|
||||
'matrix', 'max', 'max_intersections', 'max_iteration', 'max_trace_level',
|
||||
'max_value', 'metallic', 'min', 'minimum_reuse', 'mod', 'mortar',
|
||||
'nearest_count', 'no', 'normal', 'normal_map', 'no_shadow', 'number_of_waves',
|
||||
'octaves', 'off', 'offset', 'omega', 'omnimax', 'on', 'once', 'onion', 'open',
|
||||
'orthographic', 'panoramic', 'pattern1', 'pattern2', 'pattern3',
|
||||
'perspective', 'pgm', 'phase', 'phong', 'phong_size', 'pi', 'pigment',
|
||||
'pigment_map', 'planar_mapping', 'png', 'point_at', 'pot', 'pow', 'ppm',
|
||||
'precision', 'pwr', 'quadratic_spline', 'quaternion', 'quick_color',
|
||||
'quick_colour', 'quilted', 'radial', 'radians', 'radiosity', 'radius', 'rainbow',
|
||||
'ramp_wave', 'rand', 'range', 'reciprocal', 'recursion_limit', 'red',
|
||||
'reflection', 'refraction', 'render', 'repeat', 'rgb', 'rgbf', 'rgbft', 'rgbt',
|
||||
'right', 'ripples', 'rotate', 'roughness', 'samples', 'scale', 'scallop_wave',
|
||||
'scattering', 'seed', 'shadowless', 'sin', 'sine_wave', 'sinh', 'sky', 'sky_sphere',
|
||||
'slice', 'slope_map', 'smooth', 'specular', 'spherical_mapping', 'spiral',
|
||||
'spiral1', 'spiral2', 'spotlight', 'spotted', 'sqr', 'sqrt', 'statistics', 'str',
|
||||
'strcmp', 'strength', 'strlen', 'strlwr', 'strupr', 'sturm', 'substr', 'switch', 'sys',
|
||||
't', 'tan', 'tanh', 'test_camera_1', 'test_camera_2', 'test_camera_3',
|
||||
'test_camera_4', 'texture', 'texture_map', 'tga', 'thickness', 'threshold',
|
||||
'tightness', 'tile2', 'tiles', 'track', 'transform', 'translate', 'transmit',
|
||||
'triangle_wave', 'true', 'ttf', 'turbulence', 'turb_depth', 'type',
|
||||
'ultra_wide_angle', 'up', 'use_color', 'use_colour', 'use_index', 'u_steps',
|
||||
'val', 'variance', 'vaxis_rotate', 'vcross', 'vdot', 'version', 'vlength',
|
||||
'vnormalize', 'volume_object', 'volume_rendered', 'vol_with_light',
|
||||
'vrotate', 'v_steps', 'warning', 'warp', 'water_level', 'waves', 'while', 'width',
|
||||
'wood', 'wrinkles', 'yes'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'bicubic_patch', 'blob', 'box', 'camera', 'cone', 'cubic', 'cylinder', 'difference',
|
||||
'disc', 'height_field', 'intersection', 'julia_fractal', 'lathe',
|
||||
'light_source', 'merge', 'mesh', 'object', 'plane', 'poly', 'polygon', 'prism',
|
||||
'quadric', 'quartic', 'smooth_triangle', 'sor', 'sphere', 'superellipsoid',
|
||||
'text', 'torus', 'triangle', 'union'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
# TODO: <=, etc
|
||||
(r'[\[\](){}<>;,]', Punctuation),
|
||||
(r'[-+*/=]', Operator),
|
||||
(r'\b(x|y|z|u|v)\b', Name.Builtin.Pseudo),
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
(r'[0-9]+\.[0-9]*', Number.Float),
|
||||
(r'\.[0-9]+', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
(r'\s+', Text),
|
||||
]
|
||||
}
|
||||
@ -1,589 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.html
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for HTML, XML and related markup.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, ExtendedRegexLexer, include, bygroups, \
|
||||
default, using
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Punctuation
|
||||
from pygments.util import looks_like_xml, html_doctype_matches
|
||||
|
||||
from pygments.lexers.javascript import JavascriptLexer
|
||||
from pygments.lexers.jvm import ScalaLexer
|
||||
from pygments.lexers.css import CssLexer, _indentation, _starts_block
|
||||
from pygments.lexers.ruby import RubyLexer
|
||||
|
||||
__all__ = ['HtmlLexer', 'DtdLexer', 'XmlLexer', 'XsltLexer', 'HamlLexer',
|
||||
'ScamlLexer', 'JadeLexer']
|
||||
|
||||
|
||||
class HtmlLexer(RegexLexer):
|
||||
"""
|
||||
For HTML 4 and XHTML 1 markup. Nested JavaScript and CSS is highlighted
|
||||
by the appropriate lexer.
|
||||
"""
|
||||
|
||||
name = 'HTML'
|
||||
aliases = ['html']
|
||||
filenames = ['*.html', '*.htm', '*.xhtml', '*.xslt']
|
||||
mimetypes = ['text/html', 'application/xhtml+xml']
|
||||
|
||||
flags = re.IGNORECASE | re.DOTALL
|
||||
tokens = {
|
||||
'root': [
|
||||
('[^<&]+', Text),
|
||||
(r'&\S*?;', Name.Entity),
|
||||
(r'\<\!\[CDATA\[.*?\]\]\>', Comment.Preproc),
|
||||
('<!--', Comment, 'comment'),
|
||||
(r'<\?.*?\?>', Comment.Preproc),
|
||||
('<![^>]*>', Comment.Preproc),
|
||||
(r'<\s*script\s*', Name.Tag, ('script-content', 'tag')),
|
||||
(r'<\s*style\s*', Name.Tag, ('style-content', 'tag')),
|
||||
# note: this allows tag names not used in HTML like <x:with-dash>,
|
||||
# this is to support yet-unknown template engines and the like
|
||||
(r'<\s*[\w:.-]+', Name.Tag, 'tag'),
|
||||
(r'<\s*/\s*[\w:.-]+\s*>', Name.Tag),
|
||||
],
|
||||
'comment': [
|
||||
('[^-]+', Comment),
|
||||
('-->', Comment, '#pop'),
|
||||
('-', Comment),
|
||||
],
|
||||
'tag': [
|
||||
(r'\s+', Text),
|
||||
(r'([\w:-]+\s*=)(\s*)', bygroups(Name.Attribute, Text), 'attr'),
|
||||
(r'[\w:-]+', Name.Attribute),
|
||||
(r'/?\s*>', Name.Tag, '#pop'),
|
||||
],
|
||||
'script-content': [
|
||||
(r'<\s*/\s*script\s*>', Name.Tag, '#pop'),
|
||||
(r'.+?(?=<\s*/\s*script\s*>)', using(JavascriptLexer)),
|
||||
],
|
||||
'style-content': [
|
||||
(r'<\s*/\s*style\s*>', Name.Tag, '#pop'),
|
||||
(r'.+?(?=<\s*/\s*style\s*>)', using(CssLexer)),
|
||||
],
|
||||
'attr': [
|
||||
('".*?"', String, '#pop'),
|
||||
("'.*?'", String, '#pop'),
|
||||
(r'[^\s>]+', String, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if html_doctype_matches(text):
|
||||
return 0.5
|
||||
|
||||
|
||||
class DtdLexer(RegexLexer):
|
||||
"""
|
||||
A lexer for DTDs (Document Type Definitions).
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
flags = re.MULTILINE | re.DOTALL
|
||||
|
||||
name = 'DTD'
|
||||
aliases = ['dtd']
|
||||
filenames = ['*.dtd']
|
||||
mimetypes = ['application/xml-dtd']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('common'),
|
||||
|
||||
(r'(<!ELEMENT)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Tag), 'element'),
|
||||
(r'(<!ATTLIST)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Tag), 'attlist'),
|
||||
(r'(<!ENTITY)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Entity), 'entity'),
|
||||
(r'(<!NOTATION)(\s+)(\S+)',
|
||||
bygroups(Keyword, Text, Name.Tag), 'notation'),
|
||||
(r'(<!\[)([^\[\s]+)(\s*)(\[)', # conditional sections
|
||||
bygroups(Keyword, Name.Entity, Text, Keyword)),
|
||||
|
||||
(r'(<!DOCTYPE)(\s+)([^>\s]+)',
|
||||
bygroups(Keyword, Text, Name.Tag)),
|
||||
(r'PUBLIC|SYSTEM', Keyword.Constant),
|
||||
(r'[\[\]>]', Keyword),
|
||||
],
|
||||
|
||||
'common': [
|
||||
(r'\s+', Text),
|
||||
(r'(%|&)[^;]*;', Name.Entity),
|
||||
('<!--', Comment, 'comment'),
|
||||
(r'[(|)*,?+]', Operator),
|
||||
(r'"[^"]*"', String.Double),
|
||||
(r'\'[^\']*\'', String.Single),
|
||||
],
|
||||
|
||||
'comment': [
|
||||
('[^-]+', Comment),
|
||||
('-->', Comment, '#pop'),
|
||||
('-', Comment),
|
||||
],
|
||||
|
||||
'element': [
|
||||
include('common'),
|
||||
(r'EMPTY|ANY|#PCDATA', Keyword.Constant),
|
||||
(r'[^>\s|()?+*,]+', Name.Tag),
|
||||
(r'>', Keyword, '#pop'),
|
||||
],
|
||||
|
||||
'attlist': [
|
||||
include('common'),
|
||||
(r'CDATA|IDREFS|IDREF|ID|NMTOKENS|NMTOKEN|ENTITIES|ENTITY|NOTATION',
|
||||
Keyword.Constant),
|
||||
(r'#REQUIRED|#IMPLIED|#FIXED', Keyword.Constant),
|
||||
(r'xml:space|xml:lang', Keyword.Reserved),
|
||||
(r'[^>\s|()?+*,]+', Name.Attribute),
|
||||
(r'>', Keyword, '#pop'),
|
||||
],
|
||||
|
||||
'entity': [
|
||||
include('common'),
|
||||
(r'SYSTEM|PUBLIC|NDATA', Keyword.Constant),
|
||||
(r'[^>\s|()?+*,]+', Name.Entity),
|
||||
(r'>', Keyword, '#pop'),
|
||||
],
|
||||
|
||||
'notation': [
|
||||
include('common'),
|
||||
(r'SYSTEM|PUBLIC', Keyword.Constant),
|
||||
(r'[^>\s|()?+*,]+', Name.Attribute),
|
||||
(r'>', Keyword, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if not looks_like_xml(text) and \
|
||||
('<!ELEMENT' in text or '<!ATTLIST' in text or '<!ENTITY' in text):
|
||||
return 0.8
|
||||
|
||||
|
||||
class XmlLexer(RegexLexer):
|
||||
"""
|
||||
Generic lexer for XML (eXtensible Markup Language).
|
||||
"""
|
||||
|
||||
flags = re.MULTILINE | re.DOTALL | re.UNICODE
|
||||
|
||||
name = 'XML'
|
||||
aliases = ['xml']
|
||||
filenames = ['*.xml', '*.xsl', '*.rss', '*.xslt', '*.xsd',
|
||||
'*.wsdl', '*.wsf']
|
||||
mimetypes = ['text/xml', 'application/xml', 'image/svg+xml',
|
||||
'application/rss+xml', 'application/atom+xml']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
('[^<&]+', Text),
|
||||
(r'&\S*?;', Name.Entity),
|
||||
(r'\<\!\[CDATA\[.*?\]\]\>', Comment.Preproc),
|
||||
('<!--', Comment, 'comment'),
|
||||
(r'<\?.*?\?>', Comment.Preproc),
|
||||
('<![^>]*>', Comment.Preproc),
|
||||
(r'<\s*[\w:.-]+', Name.Tag, 'tag'),
|
||||
(r'<\s*/\s*[\w:.-]+\s*>', Name.Tag),
|
||||
],
|
||||
'comment': [
|
||||
('[^-]+', Comment),
|
||||
('-->', Comment, '#pop'),
|
||||
('-', Comment),
|
||||
],
|
||||
'tag': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w.:-]+\s*=', Name.Attribute, 'attr'),
|
||||
(r'/?\s*>', Name.Tag, '#pop'),
|
||||
],
|
||||
'attr': [
|
||||
('\s+', Text),
|
||||
('".*?"', String, '#pop'),
|
||||
("'.*?'", String, '#pop'),
|
||||
(r'[^\s>]+', String, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if looks_like_xml(text):
|
||||
return 0.45 # less than HTML
|
||||
|
||||
|
||||
class XsltLexer(XmlLexer):
|
||||
"""
|
||||
A lexer for XSLT.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
name = 'XSLT'
|
||||
aliases = ['xslt']
|
||||
filenames = ['*.xsl', '*.xslt', '*.xpl'] # xpl is XProc
|
||||
mimetypes = ['application/xsl+xml', 'application/xslt+xml']
|
||||
|
||||
EXTRA_KEYWORDS = set((
|
||||
'apply-imports', 'apply-templates', 'attribute',
|
||||
'attribute-set', 'call-template', 'choose', 'comment',
|
||||
'copy', 'copy-of', 'decimal-format', 'element', 'fallback',
|
||||
'for-each', 'if', 'import', 'include', 'key', 'message',
|
||||
'namespace-alias', 'number', 'otherwise', 'output', 'param',
|
||||
'preserve-space', 'processing-instruction', 'sort',
|
||||
'strip-space', 'stylesheet', 'template', 'text', 'transform',
|
||||
'value-of', 'variable', 'when', 'with-param'
|
||||
))
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in XmlLexer.get_tokens_unprocessed(self, text):
|
||||
m = re.match('</?xsl:([^>]*)/?>?', value)
|
||||
|
||||
if token is Name.Tag and m and m.group(1) in self.EXTRA_KEYWORDS:
|
||||
yield index, Keyword, value
|
||||
else:
|
||||
yield index, token, value
|
||||
|
||||
def analyse_text(text):
|
||||
if looks_like_xml(text) and '<xsl' in text:
|
||||
return 0.8
|
||||
|
||||
|
||||
class HamlLexer(ExtendedRegexLexer):
|
||||
"""
|
||||
For Haml markup.
|
||||
|
||||
.. versionadded:: 1.3
|
||||
"""
|
||||
|
||||
name = 'Haml'
|
||||
aliases = ['haml']
|
||||
filenames = ['*.haml']
|
||||
mimetypes = ['text/x-haml']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
# Haml can include " |\n" anywhere,
|
||||
# which is ignored and used to wrap long lines.
|
||||
# To accomodate this, use this custom faux dot instead.
|
||||
_dot = r'(?: \|\n(?=.* \|)|.)'
|
||||
|
||||
# In certain places, a comma at the end of the line
|
||||
# allows line wrapping as well.
|
||||
_comma_dot = r'(?:,\s*\n|' + _dot + ')'
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[ \t]*\n', Text),
|
||||
(r'[ \t]*', _indentation),
|
||||
],
|
||||
|
||||
'css': [
|
||||
(r'\.[\w:-]+', Name.Class, 'tag'),
|
||||
(r'\#[\w:-]+', Name.Function, 'tag'),
|
||||
],
|
||||
|
||||
'eval-or-plain': [
|
||||
(r'[&!]?==', Punctuation, 'plain'),
|
||||
(r'([&!]?[=~])(' + _comma_dot + r'*\n)',
|
||||
bygroups(Punctuation, using(RubyLexer)),
|
||||
'root'),
|
||||
default('plain'),
|
||||
],
|
||||
|
||||
'content': [
|
||||
include('css'),
|
||||
(r'%[\w:-]+', Name.Tag, 'tag'),
|
||||
(r'!!!' + _dot + r'*\n', Name.Namespace, '#pop'),
|
||||
(r'(/)(\[' + _dot + '*?\])(' + _dot + r'*\n)',
|
||||
bygroups(Comment, Comment.Special, Comment),
|
||||
'#pop'),
|
||||
(r'/' + _dot + r'*\n', _starts_block(Comment, 'html-comment-block'),
|
||||
'#pop'),
|
||||
(r'-#' + _dot + r'*\n', _starts_block(Comment.Preproc,
|
||||
'haml-comment-block'), '#pop'),
|
||||
(r'(-)(' + _comma_dot + r'*\n)',
|
||||
bygroups(Punctuation, using(RubyLexer)),
|
||||
'#pop'),
|
||||
(r':' + _dot + r'*\n', _starts_block(Name.Decorator, 'filter-block'),
|
||||
'#pop'),
|
||||
include('eval-or-plain'),
|
||||
],
|
||||
|
||||
'tag': [
|
||||
include('css'),
|
||||
(r'\{(,\n|' + _dot + ')*?\}', using(RubyLexer)),
|
||||
(r'\[' + _dot + '*?\]', using(RubyLexer)),
|
||||
(r'\(', Text, 'html-attributes'),
|
||||
(r'/[ \t]*\n', Punctuation, '#pop:2'),
|
||||
(r'[<>]{1,2}(?=[ \t=])', Punctuation),
|
||||
include('eval-or-plain'),
|
||||
],
|
||||
|
||||
'plain': [
|
||||
(r'([^#\n]|#[^{\n]|(\\\\)*\\#\{)+', Text),
|
||||
(r'(#\{)(' + _dot + '*?)(\})',
|
||||
bygroups(String.Interpol, using(RubyLexer), String.Interpol)),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'html-attributes': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w:-]+[ \t]*=', Name.Attribute, 'html-attribute-value'),
|
||||
(r'[\w:-]+', Name.Attribute),
|
||||
(r'\)', Text, '#pop'),
|
||||
],
|
||||
|
||||
'html-attribute-value': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\w+', Name.Variable, '#pop'),
|
||||
(r'@\w+', Name.Variable.Instance, '#pop'),
|
||||
(r'\$\w+', Name.Variable.Global, '#pop'),
|
||||
(r"'(\\\\|\\'|[^'\n])*'", String, '#pop'),
|
||||
(r'"(\\\\|\\"|[^"\n])*"', String, '#pop'),
|
||||
],
|
||||
|
||||
'html-comment-block': [
|
||||
(_dot + '+', Comment),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'haml-comment-block': [
|
||||
(_dot + '+', Comment.Preproc),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'filter-block': [
|
||||
(r'([^#\n]|#[^{\n]|(\\\\)*\\#\{)+', Name.Decorator),
|
||||
(r'(#\{)(' + _dot + '*?)(\})',
|
||||
bygroups(String.Interpol, using(RubyLexer), String.Interpol)),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ScamlLexer(ExtendedRegexLexer):
|
||||
"""
|
||||
For `Scaml markup <http://scalate.fusesource.org/>`_. Scaml is Haml for Scala.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'Scaml'
|
||||
aliases = ['scaml']
|
||||
filenames = ['*.scaml']
|
||||
mimetypes = ['text/x-scaml']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
# Scaml does not yet support the " |\n" notation to
|
||||
# wrap long lines. Once it does, use the custom faux
|
||||
# dot instead.
|
||||
# _dot = r'(?: \|\n(?=.* \|)|.)'
|
||||
_dot = r'.'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[ \t]*\n', Text),
|
||||
(r'[ \t]*', _indentation),
|
||||
],
|
||||
|
||||
'css': [
|
||||
(r'\.[\w:-]+', Name.Class, 'tag'),
|
||||
(r'\#[\w:-]+', Name.Function, 'tag'),
|
||||
],
|
||||
|
||||
'eval-or-plain': [
|
||||
(r'[&!]?==', Punctuation, 'plain'),
|
||||
(r'([&!]?[=~])(' + _dot + r'*\n)',
|
||||
bygroups(Punctuation, using(ScalaLexer)),
|
||||
'root'),
|
||||
default('plain'),
|
||||
],
|
||||
|
||||
'content': [
|
||||
include('css'),
|
||||
(r'%[\w:-]+', Name.Tag, 'tag'),
|
||||
(r'!!!' + _dot + r'*\n', Name.Namespace, '#pop'),
|
||||
(r'(/)(\[' + _dot + '*?\])(' + _dot + r'*\n)',
|
||||
bygroups(Comment, Comment.Special, Comment),
|
||||
'#pop'),
|
||||
(r'/' + _dot + r'*\n', _starts_block(Comment, 'html-comment-block'),
|
||||
'#pop'),
|
||||
(r'-#' + _dot + r'*\n', _starts_block(Comment.Preproc,
|
||||
'scaml-comment-block'), '#pop'),
|
||||
(r'(-@\s*)(import)?(' + _dot + r'*\n)',
|
||||
bygroups(Punctuation, Keyword, using(ScalaLexer)),
|
||||
'#pop'),
|
||||
(r'(-)(' + _dot + r'*\n)',
|
||||
bygroups(Punctuation, using(ScalaLexer)),
|
||||
'#pop'),
|
||||
(r':' + _dot + r'*\n', _starts_block(Name.Decorator, 'filter-block'),
|
||||
'#pop'),
|
||||
include('eval-or-plain'),
|
||||
],
|
||||
|
||||
'tag': [
|
||||
include('css'),
|
||||
(r'\{(,\n|' + _dot + ')*?\}', using(ScalaLexer)),
|
||||
(r'\[' + _dot + '*?\]', using(ScalaLexer)),
|
||||
(r'\(', Text, 'html-attributes'),
|
||||
(r'/[ \t]*\n', Punctuation, '#pop:2'),
|
||||
(r'[<>]{1,2}(?=[ \t=])', Punctuation),
|
||||
include('eval-or-plain'),
|
||||
],
|
||||
|
||||
'plain': [
|
||||
(r'([^#\n]|#[^{\n]|(\\\\)*\\#\{)+', Text),
|
||||
(r'(#\{)(' + _dot + '*?)(\})',
|
||||
bygroups(String.Interpol, using(ScalaLexer), String.Interpol)),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'html-attributes': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w:-]+[ \t]*=', Name.Attribute, 'html-attribute-value'),
|
||||
(r'[\w:-]+', Name.Attribute),
|
||||
(r'\)', Text, '#pop'),
|
||||
],
|
||||
|
||||
'html-attribute-value': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\w+', Name.Variable, '#pop'),
|
||||
(r'@\w+', Name.Variable.Instance, '#pop'),
|
||||
(r'\$\w+', Name.Variable.Global, '#pop'),
|
||||
(r"'(\\\\|\\'|[^'\n])*'", String, '#pop'),
|
||||
(r'"(\\\\|\\"|[^"\n])*"', String, '#pop'),
|
||||
],
|
||||
|
||||
'html-comment-block': [
|
||||
(_dot + '+', Comment),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'scaml-comment-block': [
|
||||
(_dot + '+', Comment.Preproc),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'filter-block': [
|
||||
(r'([^#\n]|#[^{\n]|(\\\\)*\\#\{)+', Name.Decorator),
|
||||
(r'(#\{)(' + _dot + '*?)(\})',
|
||||
bygroups(String.Interpol, using(ScalaLexer), String.Interpol)),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class JadeLexer(ExtendedRegexLexer):
|
||||
"""
|
||||
For Jade markup.
|
||||
Jade is a variant of Scaml, see:
|
||||
http://scalate.fusesource.org/documentation/scaml-reference.html
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'Jade'
|
||||
aliases = ['jade']
|
||||
filenames = ['*.jade']
|
||||
mimetypes = ['text/x-jade']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
_dot = r'.'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[ \t]*\n', Text),
|
||||
(r'[ \t]*', _indentation),
|
||||
],
|
||||
|
||||
'css': [
|
||||
(r'\.[\w:-]+', Name.Class, 'tag'),
|
||||
(r'\#[\w:-]+', Name.Function, 'tag'),
|
||||
],
|
||||
|
||||
'eval-or-plain': [
|
||||
(r'[&!]?==', Punctuation, 'plain'),
|
||||
(r'([&!]?[=~])(' + _dot + r'*\n)',
|
||||
bygroups(Punctuation, using(ScalaLexer)), 'root'),
|
||||
default('plain'),
|
||||
],
|
||||
|
||||
'content': [
|
||||
include('css'),
|
||||
(r'!!!' + _dot + r'*\n', Name.Namespace, '#pop'),
|
||||
(r'(/)(\[' + _dot + '*?\])(' + _dot + r'*\n)',
|
||||
bygroups(Comment, Comment.Special, Comment),
|
||||
'#pop'),
|
||||
(r'/' + _dot + r'*\n', _starts_block(Comment, 'html-comment-block'),
|
||||
'#pop'),
|
||||
(r'-#' + _dot + r'*\n', _starts_block(Comment.Preproc,
|
||||
'scaml-comment-block'), '#pop'),
|
||||
(r'(-@\s*)(import)?(' + _dot + r'*\n)',
|
||||
bygroups(Punctuation, Keyword, using(ScalaLexer)),
|
||||
'#pop'),
|
||||
(r'(-)(' + _dot + r'*\n)',
|
||||
bygroups(Punctuation, using(ScalaLexer)),
|
||||
'#pop'),
|
||||
(r':' + _dot + r'*\n', _starts_block(Name.Decorator, 'filter-block'),
|
||||
'#pop'),
|
||||
(r'[\w:-]+', Name.Tag, 'tag'),
|
||||
(r'\|', Text, 'eval-or-plain'),
|
||||
],
|
||||
|
||||
'tag': [
|
||||
include('css'),
|
||||
(r'\{(,\n|' + _dot + ')*?\}', using(ScalaLexer)),
|
||||
(r'\[' + _dot + '*?\]', using(ScalaLexer)),
|
||||
(r'\(', Text, 'html-attributes'),
|
||||
(r'/[ \t]*\n', Punctuation, '#pop:2'),
|
||||
(r'[<>]{1,2}(?=[ \t=])', Punctuation),
|
||||
include('eval-or-plain'),
|
||||
],
|
||||
|
||||
'plain': [
|
||||
(r'([^#\n]|#[^{\n]|(\\\\)*\\#\{)+', Text),
|
||||
(r'(#\{)(' + _dot + '*?)(\})',
|
||||
bygroups(String.Interpol, using(ScalaLexer), String.Interpol)),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'html-attributes': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w:-]+[ \t]*=', Name.Attribute, 'html-attribute-value'),
|
||||
(r'[\w:-]+', Name.Attribute),
|
||||
(r'\)', Text, '#pop'),
|
||||
],
|
||||
|
||||
'html-attribute-value': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\w+', Name.Variable, '#pop'),
|
||||
(r'@\w+', Name.Variable.Instance, '#pop'),
|
||||
(r'\$\w+', Name.Variable.Global, '#pop'),
|
||||
(r"'(\\\\|\\'|[^'\n])*'", String, '#pop'),
|
||||
(r'"(\\\\|\\"|[^"\n])*"', String, '#pop'),
|
||||
],
|
||||
|
||||
'html-comment-block': [
|
||||
(_dot + '+', Comment),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'scaml-comment-block': [
|
||||
(_dot + '+', Comment.Preproc),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'filter-block': [
|
||||
(r'([^#\n]|#[^{\n]|(\\\\)*\\#\{)+', Name.Decorator),
|
||||
(r'(#\{)(' + _dot + '*?)(\})',
|
||||
bygroups(String.Interpol, using(ScalaLexer), String.Interpol)),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
}
|
||||
@ -1,262 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.idl
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for IDL.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, Number
|
||||
|
||||
__all__ = ['IDLLexer']
|
||||
|
||||
|
||||
class IDLLexer(RegexLexer):
|
||||
"""
|
||||
Pygments Lexer for IDL (Interactive Data Language).
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'IDL'
|
||||
aliases = ['idl']
|
||||
filenames = ['*.pro']
|
||||
mimetypes = ['text/idl']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
_RESERVED = (
|
||||
'and', 'begin', 'break', 'case', 'common', 'compile_opt',
|
||||
'continue', 'do', 'else', 'end', 'endcase', 'elseelse',
|
||||
'endfor', 'endforeach', 'endif', 'endrep', 'endswitch',
|
||||
'endwhile', 'eq', 'for', 'foreach', 'forward_function',
|
||||
'function', 'ge', 'goto', 'gt', 'if', 'inherits', 'le',
|
||||
'lt', 'mod', 'ne', 'not', 'of', 'on_ioerror', 'or', 'pro',
|
||||
'repeat', 'switch', 'then', 'until', 'while', 'xor')
|
||||
"""Reserved words from: http://www.exelisvis.com/docs/reswords.html"""
|
||||
|
||||
_BUILTIN_LIB = (
|
||||
'abs', 'acos', 'adapt_hist_equal', 'alog', 'alog10',
|
||||
'amoeba', 'annotate', 'app_user_dir', 'app_user_dir_query',
|
||||
'arg_present', 'array_equal', 'array_indices', 'arrow',
|
||||
'ascii_template', 'asin', 'assoc', 'atan', 'axis',
|
||||
'a_correlate', 'bandpass_filter', 'bandreject_filter',
|
||||
'barplot', 'bar_plot', 'beseli', 'beselj', 'beselk',
|
||||
'besely', 'beta', 'bilinear', 'binary_template', 'bindgen',
|
||||
'binomial', 'bin_date', 'bit_ffs', 'bit_population',
|
||||
'blas_axpy', 'blk_con', 'box_cursor', 'breakpoint',
|
||||
'broyden', 'butterworth', 'bytarr', 'byte', 'byteorder',
|
||||
'bytscl', 'caldat', 'calendar', 'call_external',
|
||||
'call_function', 'call_method', 'call_procedure', 'canny',
|
||||
'catch', 'cd', 'cdf_\w*', 'ceil', 'chebyshev',
|
||||
'check_math',
|
||||
'chisqr_cvf', 'chisqr_pdf', 'choldc', 'cholsol', 'cindgen',
|
||||
'cir_3pnt', 'close', 'cluster', 'cluster_tree', 'clust_wts',
|
||||
'cmyk_convert', 'colorbar', 'colorize_sample',
|
||||
'colormap_applicable', 'colormap_gradient',
|
||||
'colormap_rotation', 'colortable', 'color_convert',
|
||||
'color_exchange', 'color_quan', 'color_range_map', 'comfit',
|
||||
'command_line_args', 'complex', 'complexarr', 'complexround',
|
||||
'compute_mesh_normals', 'cond', 'congrid', 'conj',
|
||||
'constrained_min', 'contour', 'convert_coord', 'convol',
|
||||
'convol_fft', 'coord2to3', 'copy_lun', 'correlate', 'cos',
|
||||
'cosh', 'cpu', 'cramer', 'create_cursor', 'create_struct',
|
||||
'create_view', 'crossp', 'crvlength', 'cti_test',
|
||||
'ct_luminance', 'cursor', 'curvefit', 'cvttobm', 'cv_coord',
|
||||
'cw_animate', 'cw_animate_getp', 'cw_animate_load',
|
||||
'cw_animate_run', 'cw_arcball', 'cw_bgroup', 'cw_clr_index',
|
||||
'cw_colorsel', 'cw_defroi', 'cw_field', 'cw_filesel',
|
||||
'cw_form', 'cw_fslider', 'cw_light_editor',
|
||||
'cw_light_editor_get', 'cw_light_editor_set', 'cw_orient',
|
||||
'cw_palette_editor', 'cw_palette_editor_get',
|
||||
'cw_palette_editor_set', 'cw_pdmenu', 'cw_rgbslider',
|
||||
'cw_tmpl', 'cw_zoom', 'c_correlate', 'dblarr', 'db_exists',
|
||||
'dcindgen', 'dcomplex', 'dcomplexarr', 'define_key',
|
||||
'define_msgblk', 'define_msgblk_from_file', 'defroi',
|
||||
'defsysv', 'delvar', 'dendrogram', 'dendro_plot', 'deriv',
|
||||
'derivsig', 'determ', 'device', 'dfpmin', 'diag_matrix',
|
||||
'dialog_dbconnect', 'dialog_message', 'dialog_pickfile',
|
||||
'dialog_printersetup', 'dialog_printjob',
|
||||
'dialog_read_image', 'dialog_write_image', 'digital_filter',
|
||||
'dilate', 'dindgen', 'dissolve', 'dist', 'distance_measure',
|
||||
'dlm_load', 'dlm_register', 'doc_library', 'double',
|
||||
'draw_roi', 'edge_dog', 'efont', 'eigenql', 'eigenvec',
|
||||
'ellipse', 'elmhes', 'emboss', 'empty', 'enable_sysrtn',
|
||||
'eof', 'eos_\w*', 'erase', 'erf', 'erfc', 'erfcx',
|
||||
'erode', 'errorplot', 'errplot', 'estimator_filter',
|
||||
'execute', 'exit', 'exp', 'expand', 'expand_path', 'expint',
|
||||
'extrac', 'extract_slice', 'factorial', 'fft', 'filepath',
|
||||
'file_basename', 'file_chmod', 'file_copy', 'file_delete',
|
||||
'file_dirname', 'file_expand_path', 'file_info',
|
||||
'file_lines', 'file_link', 'file_mkdir', 'file_move',
|
||||
'file_poll_input', 'file_readlink', 'file_same',
|
||||
'file_search', 'file_test', 'file_which', 'findgen',
|
||||
'finite', 'fix', 'flick', 'float', 'floor', 'flow3',
|
||||
'fltarr', 'flush', 'format_axis_values', 'free_lun',
|
||||
'fstat', 'fulstr', 'funct', 'fv_test', 'fx_root',
|
||||
'fz_roots', 'f_cvf', 'f_pdf', 'gamma', 'gamma_ct',
|
||||
'gauss2dfit', 'gaussfit', 'gaussian_function', 'gaussint',
|
||||
'gauss_cvf', 'gauss_pdf', 'gauss_smooth', 'getenv',
|
||||
'getwindows', 'get_drive_list', 'get_dxf_objects',
|
||||
'get_kbrd', 'get_login_info', 'get_lun', 'get_screen_size',
|
||||
'greg2jul', 'grib_\w*', 'grid3', 'griddata',
|
||||
'grid_input', 'grid_tps', 'gs_iter',
|
||||
'h5[adfgirst]_\w*', 'h5_browser', 'h5_close',
|
||||
'h5_create', 'h5_get_libversion', 'h5_open', 'h5_parse',
|
||||
'hanning', 'hash', 'hdf_\w*', 'heap_free',
|
||||
'heap_gc', 'heap_nosave', 'heap_refcount', 'heap_save',
|
||||
'help', 'hilbert', 'histogram', 'hist_2d', 'hist_equal',
|
||||
'hls', 'hough', 'hqr', 'hsv', 'h_eq_ct', 'h_eq_int',
|
||||
'i18n_multibytetoutf8', 'i18n_multibytetowidechar',
|
||||
'i18n_utf8tomultibyte', 'i18n_widechartomultibyte',
|
||||
'ibeta', 'icontour', 'iconvertcoord', 'idelete', 'identity',
|
||||
'idlexbr_assistant', 'idlitsys_createtool', 'idl_base64',
|
||||
'idl_validname', 'iellipse', 'igamma', 'igetcurrent',
|
||||
'igetdata', 'igetid', 'igetproperty', 'iimage', 'image',
|
||||
'image_cont', 'image_statistics', 'imaginary', 'imap',
|
||||
'indgen', 'intarr', 'interpol', 'interpolate',
|
||||
'interval_volume', 'int_2d', 'int_3d', 'int_tabulated',
|
||||
'invert', 'ioctl', 'iopen', 'iplot', 'ipolygon',
|
||||
'ipolyline', 'iputdata', 'iregister', 'ireset', 'iresolve',
|
||||
'irotate', 'ir_filter', 'isa', 'isave', 'iscale',
|
||||
'isetcurrent', 'isetproperty', 'ishft', 'isocontour',
|
||||
'isosurface', 'isurface', 'itext', 'itranslate', 'ivector',
|
||||
'ivolume', 'izoom', 'i_beta', 'journal', 'json_parse',
|
||||
'json_serialize', 'jul2greg', 'julday', 'keyword_set',
|
||||
'krig2d', 'kurtosis', 'kw_test', 'l64indgen', 'label_date',
|
||||
'label_region', 'ladfit', 'laguerre', 'laplacian',
|
||||
'la_choldc', 'la_cholmprove', 'la_cholsol', 'la_determ',
|
||||
'la_eigenproblem', 'la_eigenql', 'la_eigenvec', 'la_elmhes',
|
||||
'la_gm_linear_model', 'la_hqr', 'la_invert',
|
||||
'la_least_squares', 'la_least_square_equality',
|
||||
'la_linear_equation', 'la_ludc', 'la_lumprove', 'la_lusol',
|
||||
'la_svd', 'la_tridc', 'la_trimprove', 'la_triql',
|
||||
'la_trired', 'la_trisol', 'least_squares_filter', 'leefilt',
|
||||
'legend', 'legendre', 'linbcg', 'lindgen', 'linfit',
|
||||
'linkimage', 'list', 'll_arc_distance', 'lmfit', 'lmgr',
|
||||
'lngamma', 'lnp_test', 'loadct', 'locale_get',
|
||||
'logical_and', 'logical_or', 'logical_true', 'lon64arr',
|
||||
'lonarr', 'long', 'long64', 'lsode', 'ludc', 'lumprove',
|
||||
'lusol', 'lu_complex', 'machar', 'make_array', 'make_dll',
|
||||
'make_rt', 'map', 'mapcontinents', 'mapgrid', 'map_2points',
|
||||
'map_continents', 'map_grid', 'map_image', 'map_patch',
|
||||
'map_proj_forward', 'map_proj_image', 'map_proj_info',
|
||||
'map_proj_init', 'map_proj_inverse', 'map_set',
|
||||
'matrix_multiply', 'matrix_power', 'max', 'md_test',
|
||||
'mean', 'meanabsdev', 'mean_filter', 'median', 'memory',
|
||||
'mesh_clip', 'mesh_decimate', 'mesh_issolid', 'mesh_merge',
|
||||
'mesh_numtriangles', 'mesh_obj', 'mesh_smooth',
|
||||
'mesh_surfacearea', 'mesh_validate', 'mesh_volume',
|
||||
'message', 'min', 'min_curve_surf', 'mk_html_help',
|
||||
'modifyct', 'moment', 'morph_close', 'morph_distance',
|
||||
'morph_gradient', 'morph_hitormiss', 'morph_open',
|
||||
'morph_thin', 'morph_tophat', 'multi', 'm_correlate',
|
||||
'ncdf_\w*', 'newton', 'noise_hurl', 'noise_pick',
|
||||
'noise_scatter', 'noise_slur', 'norm', 'n_elements',
|
||||
'n_params', 'n_tags', 'objarr', 'obj_class', 'obj_destroy',
|
||||
'obj_hasmethod', 'obj_isa', 'obj_new', 'obj_valid',
|
||||
'online_help', 'on_error', 'open', 'oplot', 'oploterr',
|
||||
'parse_url', 'particle_trace', 'path_cache', 'path_sep',
|
||||
'pcomp', 'plot', 'plot3d', 'ploterr', 'plots', 'plot_3dbox',
|
||||
'plot_field', 'pnt_line', 'point_lun', 'polarplot',
|
||||
'polar_contour', 'polar_surface', 'poly', 'polyfill',
|
||||
'polyfillv', 'polygon', 'polyline', 'polyshade', 'polywarp',
|
||||
'poly_2d', 'poly_area', 'poly_fit', 'popd', 'powell',
|
||||
'pref_commit', 'pref_get', 'pref_set', 'prewitt', 'primes',
|
||||
'print', 'printd', 'product', 'profile', 'profiler',
|
||||
'profiles', 'project_vol', 'psafm', 'pseudo',
|
||||
'ps_show_fonts', 'ptrarr', 'ptr_free', 'ptr_new',
|
||||
'ptr_valid', 'pushd', 'p_correlate', 'qgrid3', 'qhull',
|
||||
'qromb', 'qromo', 'qsimp', 'query_ascii', 'query_bmp',
|
||||
'query_csv', 'query_dicom', 'query_gif', 'query_image',
|
||||
'query_jpeg', 'query_jpeg2000', 'query_mrsid', 'query_pict',
|
||||
'query_png', 'query_ppm', 'query_srf', 'query_tiff',
|
||||
'query_wav', 'radon', 'randomn', 'randomu', 'ranks',
|
||||
'rdpix', 'read', 'reads', 'readu', 'read_ascii',
|
||||
'read_binary', 'read_bmp', 'read_csv', 'read_dicom',
|
||||
'read_gif', 'read_image', 'read_interfile', 'read_jpeg',
|
||||
'read_jpeg2000', 'read_mrsid', 'read_pict', 'read_png',
|
||||
'read_ppm', 'read_spr', 'read_srf', 'read_sylk',
|
||||
'read_tiff', 'read_wav', 'read_wave', 'read_x11_bitmap',
|
||||
'read_xwd', 'real_part', 'rebin', 'recall_commands',
|
||||
'recon3', 'reduce_colors', 'reform', 'region_grow',
|
||||
'register_cursor', 'regress', 'replicate',
|
||||
'replicate_inplace', 'resolve_all', 'resolve_routine',
|
||||
'restore', 'retall', 'return', 'reverse', 'rk4', 'roberts',
|
||||
'rot', 'rotate', 'round', 'routine_filepath',
|
||||
'routine_info', 'rs_test', 'r_correlate', 'r_test',
|
||||
'save', 'savgol', 'scale3', 'scale3d', 'scope_level',
|
||||
'scope_traceback', 'scope_varfetch', 'scope_varname',
|
||||
'search2d', 'search3d', 'sem_create', 'sem_delete',
|
||||
'sem_lock', 'sem_release', 'setenv', 'set_plot',
|
||||
'set_shading', 'sfit', 'shade_surf', 'shade_surf_irr',
|
||||
'shade_volume', 'shift', 'shift_diff', 'shmdebug', 'shmmap',
|
||||
'shmunmap', 'shmvar', 'show3', 'showfont', 'simplex', 'sin',
|
||||
'sindgen', 'sinh', 'size', 'skewness', 'skip_lun',
|
||||
'slicer3', 'slide_image', 'smooth', 'sobel', 'socket',
|
||||
'sort', 'spawn', 'spher_harm', 'sph_4pnt', 'sph_scat',
|
||||
'spline', 'spline_p', 'spl_init', 'spl_interp', 'sprsab',
|
||||
'sprsax', 'sprsin', 'sprstp', 'sqrt', 'standardize',
|
||||
'stddev', 'stop', 'strarr', 'strcmp', 'strcompress',
|
||||
'streamline', 'stregex', 'stretch', 'string', 'strjoin',
|
||||
'strlen', 'strlowcase', 'strmatch', 'strmessage', 'strmid',
|
||||
'strpos', 'strput', 'strsplit', 'strtrim', 'struct_assign',
|
||||
'struct_hide', 'strupcase', 'surface', 'surfr', 'svdc',
|
||||
'svdfit', 'svsol', 'swap_endian', 'swap_endian_inplace',
|
||||
'symbol', 'systime', 's_test', 't3d', 'tag_names', 'tan',
|
||||
'tanh', 'tek_color', 'temporary', 'tetra_clip',
|
||||
'tetra_surface', 'tetra_volume', 'text', 'thin', 'threed',
|
||||
'timegen', 'time_test2', 'tm_test', 'total', 'trace',
|
||||
'transpose', 'triangulate', 'trigrid', 'triql', 'trired',
|
||||
'trisol', 'tri_surf', 'truncate_lun', 'ts_coef', 'ts_diff',
|
||||
'ts_fcast', 'ts_smooth', 'tv', 'tvcrs', 'tvlct', 'tvrd',
|
||||
'tvscl', 'typename', 't_cvt', 't_pdf', 'uindgen', 'uint',
|
||||
'uintarr', 'ul64indgen', 'ulindgen', 'ulon64arr', 'ulonarr',
|
||||
'ulong', 'ulong64', 'uniq', 'unsharp_mask', 'usersym',
|
||||
'value_locate', 'variance', 'vector', 'vector_field', 'vel',
|
||||
'velovect', 'vert_t3d', 'voigt', 'voronoi', 'voxel_proj',
|
||||
'wait', 'warp_tri', 'watershed', 'wdelete', 'wf_draw',
|
||||
'where', 'widget_base', 'widget_button', 'widget_combobox',
|
||||
'widget_control', 'widget_displaycontextmen', 'widget_draw',
|
||||
'widget_droplist', 'widget_event', 'widget_info',
|
||||
'widget_label', 'widget_list', 'widget_propertysheet',
|
||||
'widget_slider', 'widget_tab', 'widget_table',
|
||||
'widget_text', 'widget_tree', 'widget_tree_move',
|
||||
'widget_window', 'wiener_filter', 'window', 'writeu',
|
||||
'write_bmp', 'write_csv', 'write_gif', 'write_image',
|
||||
'write_jpeg', 'write_jpeg2000', 'write_nrif', 'write_pict',
|
||||
'write_png', 'write_ppm', 'write_spr', 'write_srf',
|
||||
'write_sylk', 'write_tiff', 'write_wav', 'write_wave',
|
||||
'wset', 'wshow', 'wtn', 'wv_applet', 'wv_cwt',
|
||||
'wv_cw_wavelet', 'wv_denoise', 'wv_dwt', 'wv_fn_coiflet',
|
||||
'wv_fn_daubechies', 'wv_fn_gaussian', 'wv_fn_haar',
|
||||
'wv_fn_morlet', 'wv_fn_paul', 'wv_fn_symlet',
|
||||
'wv_import_data', 'wv_import_wavelet', 'wv_plot3d_wps',
|
||||
'wv_plot_multires', 'wv_pwt', 'wv_tool_denoise',
|
||||
'xbm_edit', 'xdisplayfile', 'xdxf', 'xfont',
|
||||
'xinteranimate', 'xloadct', 'xmanager', 'xmng_tmpl',
|
||||
'xmtool', 'xobjview', 'xobjview_rotate',
|
||||
'xobjview_write_image', 'xpalette', 'xpcolor', 'xplot3d',
|
||||
'xregistered', 'xroi', 'xsq_test', 'xsurface', 'xvaredit',
|
||||
'xvolume', 'xvolume_rotate', 'xvolume_write_image',
|
||||
'xyouts', 'zoom', 'zoom_24')
|
||||
"""Functions from: http://www.exelisvis.com/docs/routines-1.html"""
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^\s*;.*?\n', Comment.Singleline),
|
||||
(words(_RESERVED, prefix=r'\b', suffix=r'\b'), Keyword),
|
||||
(words(_BUILTIN_LIB, prefix=r'\b', suffix=r'\b'), Name.Builtin),
|
||||
(r'\+=|-=|\^=|\*=|/=|#=|##=|<=|>=|=', Operator),
|
||||
(r'\+\+|--|->|\+|-|##|#|\*|/|<|>|&&|\^|~|\|\|\?|:', Operator),
|
||||
(r'\b(mod=|lt=|le=|eq=|ne=|ge=|gt=|not=|and=|or=|xor=)', Operator),
|
||||
(r'\b(mod|lt|le|eq|ne|ge|gt|not|and|or|xor)\b', Operator),
|
||||
(r'\b[0-9](L|B|S|UL|ULL|LL)?\b', Number),
|
||||
(r'.', Text),
|
||||
]
|
||||
}
|
||||
@ -1,96 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.inferno
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for Inferno os and all the related stuff.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, default
|
||||
from pygments.token import Punctuation, Text, Comment, Operator, Keyword, \
|
||||
Name, String, Number
|
||||
|
||||
__all__ = ['LimboLexer']
|
||||
|
||||
|
||||
class LimboLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Limbo programming language <http://www.vitanuova.com/inferno/limbo.html>`_
|
||||
|
||||
TODO:
|
||||
- maybe implement better var declaration highlighting
|
||||
- some simple syntax error highlighting
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Limbo'
|
||||
aliases = ['limbo']
|
||||
filenames = ['*.b']
|
||||
mimetypes = ['text/limbo']
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'^(\s*)([a-zA-Z_]\w*:(\s*)\n)',
|
||||
bygroups(Text, Name.Label)),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'#(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|'
|
||||
r'u[a-fA-F0-9]{4}|U[a-fA-F0-9]{8}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'statements': [
|
||||
(r'"', String, 'string'),
|
||||
(r"'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])', Number.Float),
|
||||
(r'16r[0-9a-fA-F]+', Number.Hex),
|
||||
(r'8r[0-7]+', Number.Oct),
|
||||
(r'((([1-3]\d)|([2-9]))r)?(\d+)', Number.Integer),
|
||||
(r'[()\[\],.]', Punctuation),
|
||||
(r'[~!%^&*+=|?:<>/-]|(->)|(<-)|(=>)|(::)', Operator),
|
||||
(r'(alt|break|case|continue|cyclic|do|else|exit'
|
||||
r'for|hd|if|implement|import|include|len|load|or'
|
||||
r'pick|return|spawn|tagof|tl|to|while)\b', Keyword),
|
||||
(r'(byte|int|big|real|string|array|chan|list|adt'
|
||||
r'|fn|ref|of|module|self|type)\b', Keyword.Type),
|
||||
(r'(con|iota|nil)\b', Keyword.Constant),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'statement' : [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
('[{}]', Punctuation),
|
||||
(';', Punctuation, '#pop'),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
default('statement'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
# Any limbo module implements something
|
||||
if re.search(r'^implement \w+;', text, re.MULTILINE):
|
||||
return 0.7
|
||||
|
||||
# TODO:
|
||||
# - Make lexers for:
|
||||
# - asm sources
|
||||
# - man pages
|
||||
# - mkfiles
|
||||
# - module definitions
|
||||
# - namespace definitions
|
||||
# - shell scripts
|
||||
# - maybe keyfiles and fonts
|
||||
# they all seem to be quite similar to their equivalents
|
||||
# from unix world, so there should not be a lot of problems
|
||||
@ -1,322 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.installers
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for installer/packager DSLs and formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, this, default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Punctuation, Generic, Number, Whitespace
|
||||
|
||||
__all__ = ['NSISLexer', 'RPMSpecLexer', 'SourcesListLexer',
|
||||
'DebianControlLexer']
|
||||
|
||||
|
||||
class NSISLexer(RegexLexer):
|
||||
"""
|
||||
For `NSIS <http://nsis.sourceforge.net/>`_ scripts.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'NSIS'
|
||||
aliases = ['nsis', 'nsi', 'nsh']
|
||||
filenames = ['*.nsi', '*.nsh']
|
||||
mimetypes = ['text/x-nsis']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[;#].*\n', Comment),
|
||||
(r"'.*?'", String.Single),
|
||||
(r'"', String.Double, 'str_double'),
|
||||
(r'`', String.Backtick, 'str_backtick'),
|
||||
include('macro'),
|
||||
include('interpol'),
|
||||
include('basic'),
|
||||
(r'\$\{[a-z_|][\w|]*\}', Keyword.Pseudo),
|
||||
(r'/[a-z_]\w*', Name.Attribute),
|
||||
('.', Text),
|
||||
],
|
||||
'basic': [
|
||||
(r'(\n)(Function)(\s+)([._a-z][.\w]*)\b',
|
||||
bygroups(Text, Keyword, Text, Name.Function)),
|
||||
(r'\b([_a-z]\w*)(::)([a-z][a-z0-9]*)\b',
|
||||
bygroups(Keyword.Namespace, Punctuation, Name.Function)),
|
||||
(r'\b([_a-z]\w*)(:)', bygroups(Name.Label, Punctuation)),
|
||||
(r'(\b[ULS]|\B)([!<>=]?=|\<\>?|\>)\B', Operator),
|
||||
(r'[|+-]', Operator),
|
||||
(r'\\', Punctuation),
|
||||
(r'\b(Abort|Add(?:BrandingImage|Size)|'
|
||||
r'Allow(?:RootDirInstall|SkipFiles)|AutoCloseWindow|'
|
||||
r'BG(?:Font|Gradient)|BrandingText|BringToFront|Call(?:InstDLL)?|'
|
||||
r'(?:Sub)?Caption|ChangeUI|CheckBitmap|ClearErrors|CompletedText|'
|
||||
r'ComponentText|CopyFiles|CRCCheck|'
|
||||
r'Create(?:Directory|Font|Shortcut)|Delete(?:INI(?:Sec|Str)|'
|
||||
r'Reg(?:Key|Value))?|DetailPrint|DetailsButtonText|'
|
||||
r'Dir(?:Show|Text|Var|Verify)|(?:Disabled|Enabled)Bitmap|'
|
||||
r'EnableWindow|EnumReg(?:Key|Value)|Exch|Exec(?:Shell|Wait)?|'
|
||||
r'ExpandEnvStrings|File(?:BufSize|Close|ErrorText|Open|'
|
||||
r'Read(?:Byte)?|Seek|Write(?:Byte)?)?|'
|
||||
r'Find(?:Close|First|Next|Window)|FlushINI|Function(?:End)?|'
|
||||
r'Get(?:CurInstType|CurrentAddress|DlgItem|DLLVersion(?:Local)?|'
|
||||
r'ErrorLevel|FileTime(?:Local)?|FullPathName|FunctionAddress|'
|
||||
r'InstDirError|LabelAddress|TempFileName)|'
|
||||
r'Goto|HideWindow|Icon|'
|
||||
r'If(?:Abort|Errors|FileExists|RebootFlag|Silent)|'
|
||||
r'InitPluginsDir|Install(?:ButtonText|Colors|Dir(?:RegKey)?)|'
|
||||
r'Inst(?:ProgressFlags|Type(?:[GS]etText)?)|Int(?:CmpU?|Fmt|Op)|'
|
||||
r'IsWindow|LangString(?:UP)?|'
|
||||
r'License(?:BkColor|Data|ForceSelection|LangString|Text)|'
|
||||
r'LoadLanguageFile|LockWindow|Log(?:Set|Text)|MessageBox|'
|
||||
r'MiscButtonText|Name|Nop|OutFile|(?:Uninst)?Page(?:Ex(?:End)?)?|'
|
||||
r'PluginDir|Pop|Push|Quit|Read(?:(?:Env|INI|Reg)Str|RegDWORD)|'
|
||||
r'Reboot|(?:Un)?RegDLL|Rename|RequestExecutionLevel|ReserveFile|'
|
||||
r'Return|RMDir|SearchPath|Section(?:Divider|End|'
|
||||
r'(?:(?:Get|Set)(?:Flags|InstTypes|Size|Text))|Group(?:End)?|In)?|'
|
||||
r'SendMessage|Set(?:AutoClose|BrandingImage|Compress(?:ionLevel|'
|
||||
r'or(?:DictSize)?)?|CtlColors|CurInstType|DatablockOptimize|'
|
||||
r'DateSave|Details(?:Print|View)|Error(?:s|Level)|FileAttributes|'
|
||||
r'Font|OutPath|Overwrite|PluginUnload|RebootFlag|ShellVarContext|'
|
||||
r'Silent|StaticBkColor)|'
|
||||
r'Show(?:(?:I|Uni)nstDetails|Window)|Silent(?:Un)?Install|Sleep|'
|
||||
r'SpaceTexts|Str(?:CmpS?|Cpy|Len)|SubSection(?:End)?|'
|
||||
r'Uninstall(?:ButtonText|(?:Sub)?Caption|EXEName|Icon|Text)|'
|
||||
r'UninstPage|Var|VI(?:AddVersionKey|ProductVersion)|WindowIcon|'
|
||||
r'Write(?:INIStr|Reg(:?Bin|DWORD|(?:Expand)?Str)|Uninstaller)|'
|
||||
r'XPStyle)\b', Keyword),
|
||||
(r'\b(CUR|END|(?:FILE_ATTRIBUTE_)?'
|
||||
r'(?:ARCHIVE|HIDDEN|NORMAL|OFFLINE|READONLY|SYSTEM|TEMPORARY)|'
|
||||
r'HK(CC|CR|CU|DD|LM|PD|U)|'
|
||||
r'HKEY_(?:CLASSES_ROOT|CURRENT_(?:CONFIG|USER)|DYN_DATA|'
|
||||
r'LOCAL_MACHINE|PERFORMANCE_DATA|USERS)|'
|
||||
r'ID(?:ABORT|CANCEL|IGNORE|NO|OK|RETRY|YES)|'
|
||||
r'MB_(?:ABORTRETRYIGNORE|DEFBUTTON[1-4]|'
|
||||
r'ICON(?:EXCLAMATION|INFORMATION|QUESTION|STOP)|'
|
||||
r'OK(?:CANCEL)?|RETRYCANCEL|RIGHT|SETFOREGROUND|TOPMOST|USERICON|'
|
||||
r'YESNO(?:CANCEL)?)|SET|SHCTX|'
|
||||
r'SW_(?:HIDE|SHOW(?:MAXIMIZED|MINIMIZED|NORMAL))|'
|
||||
r'admin|all|auto|both|bottom|bzip2|checkbox|colored|current|false|'
|
||||
r'force|hide|highest|if(?:diff|newer)|lastused|leave|left|'
|
||||
r'listonly|lzma|nevershow|none|normal|off|on|pop|push|'
|
||||
r'radiobuttons|right|show|silent|silentlog|smooth|textonly|top|'
|
||||
r'true|try|user|zlib)\b', Name.Constant),
|
||||
],
|
||||
'macro': [
|
||||
(r'\!(addincludedir(?:dir)?|addplugindir|appendfile|cd|define|'
|
||||
r'delfilefile|echo(?:message)?|else|endif|error|execute|'
|
||||
r'if(?:macro)?n?(?:def)?|include|insertmacro|macro(?:end)?|packhdr|'
|
||||
r'search(?:parse|replace)|system|tempfilesymbol|undef|verbose|'
|
||||
r'warning)\b', Comment.Preproc),
|
||||
],
|
||||
'interpol': [
|
||||
(r'\$(R?[0-9])', Name.Builtin.Pseudo), # registers
|
||||
(r'\$(ADMINTOOLS|APPDATA|CDBURN_AREA|COOKIES|COMMONFILES(?:32|64)|'
|
||||
r'DESKTOP|DOCUMENTS|EXE(?:DIR|FILE|PATH)|FAVORITES|FONTS|HISTORY|'
|
||||
r'HWNDPARENT|INTERNET_CACHE|LOCALAPPDATA|MUSIC|NETHOOD|PICTURES|'
|
||||
r'PLUGINSDIR|PRINTHOOD|PROFILE|PROGRAMFILES(?:32|64)|QUICKLAUNCH|'
|
||||
r'RECENT|RESOURCES(?:_LOCALIZED)?|SENDTO|SM(?:PROGRAMS|STARTUP)|'
|
||||
r'STARTMENU|SYSDIR|TEMP(?:LATES)?|VIDEOS|WINDIR|\{NSISDIR\})',
|
||||
Name.Builtin),
|
||||
(r'\$(CMDLINE|INSTDIR|OUTDIR|LANGUAGE)', Name.Variable.Global),
|
||||
(r'\$[a-z_]\w*', Name.Variable),
|
||||
],
|
||||
'str_double': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\$(\\[nrt"]|\$)', String.Escape),
|
||||
include('interpol'),
|
||||
(r'.', String.Double),
|
||||
],
|
||||
'str_backtick': [
|
||||
(r'`', String, '#pop'),
|
||||
(r'\$(\\[nrt"]|\$)', String.Escape),
|
||||
include('interpol'),
|
||||
(r'.', String.Double),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class RPMSpecLexer(RegexLexer):
|
||||
"""
|
||||
For RPM ``.spec`` files.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'RPMSpec'
|
||||
aliases = ['spec']
|
||||
filenames = ['*.spec']
|
||||
mimetypes = ['text/x-rpm-spec']
|
||||
|
||||
_directives = ('(?:package|prep|build|install|clean|check|pre[a-z]*|'
|
||||
'post[a-z]*|trigger[a-z]*|files)')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'#.*\n', Comment),
|
||||
include('basic'),
|
||||
],
|
||||
'description': [
|
||||
(r'^(%' + _directives + ')(.*)$',
|
||||
bygroups(Name.Decorator, Text), '#pop'),
|
||||
(r'\n', Text),
|
||||
(r'.', Text),
|
||||
],
|
||||
'changelog': [
|
||||
(r'\*.*\n', Generic.Subheading),
|
||||
(r'^(%' + _directives + ')(.*)$',
|
||||
bygroups(Name.Decorator, Text), '#pop'),
|
||||
(r'\n', Text),
|
||||
(r'.', Text),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String.Double, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
include('interpol'),
|
||||
(r'.', String.Double),
|
||||
],
|
||||
'basic': [
|
||||
include('macro'),
|
||||
(r'(?i)^(Name|Version|Release|Epoch|Summary|Group|License|Packager|'
|
||||
r'Vendor|Icon|URL|Distribution|Prefix|Patch[0-9]*|Source[0-9]*|'
|
||||
r'Requires\(?[a-z]*\)?|[a-z]+Req|Obsoletes|Suggests|Provides|Conflicts|'
|
||||
r'Build[a-z]+|[a-z]+Arch|Auto[a-z]+)(:)(.*)$',
|
||||
bygroups(Generic.Heading, Punctuation, using(this))),
|
||||
(r'^%description', Name.Decorator, 'description'),
|
||||
(r'^%changelog', Name.Decorator, 'changelog'),
|
||||
(r'^(%' + _directives + ')(.*)$', bygroups(Name.Decorator, Text)),
|
||||
(r'%(attr|defattr|dir|doc(?:dir)?|setup|config(?:ure)?|'
|
||||
r'make(?:install)|ghost|patch[0-9]+|find_lang|exclude|verify)',
|
||||
Keyword),
|
||||
include('interpol'),
|
||||
(r"'.*?'", String.Single),
|
||||
(r'"', String.Double, 'string'),
|
||||
(r'.', Text),
|
||||
],
|
||||
'macro': [
|
||||
(r'%define.*\n', Comment.Preproc),
|
||||
(r'%\{\!\?.*%define.*\}', Comment.Preproc),
|
||||
(r'(%(?:if(?:n?arch)?|else(?:if)?|endif))(.*)$',
|
||||
bygroups(Comment.Preproc, Text)),
|
||||
],
|
||||
'interpol': [
|
||||
(r'%\{?__[a-z_]+\}?', Name.Function),
|
||||
(r'%\{?_([a-z_]+dir|[a-z_]+path|prefix)\}?', Keyword.Pseudo),
|
||||
(r'%\{\?\w+\}', Name.Variable),
|
||||
(r'\$\{?RPM_[A-Z0-9_]+\}?', Name.Variable.Global),
|
||||
(r'%\{[a-zA-Z]\w+\}', Keyword.Constant),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class SourcesListLexer(RegexLexer):
|
||||
"""
|
||||
Lexer that highlights debian sources.list files.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
"""
|
||||
|
||||
name = 'Debian Sourcelist'
|
||||
aliases = ['sourceslist', 'sources.list', 'debsources']
|
||||
filenames = ['sources.list']
|
||||
mimetype = ['application/x-debian-sourceslist']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'#.*?$', Comment),
|
||||
(r'^(deb(?:-src)?)(\s+)',
|
||||
bygroups(Keyword, Text), 'distribution')
|
||||
],
|
||||
'distribution': [
|
||||
(r'#.*?$', Comment, '#pop'),
|
||||
(r'\$\(ARCH\)', Name.Variable),
|
||||
(r'[^\s$[]+', String),
|
||||
(r'\[', String.Other, 'escaped-distribution'),
|
||||
(r'\$', String),
|
||||
(r'\s+', Text, 'components')
|
||||
],
|
||||
'escaped-distribution': [
|
||||
(r'\]', String.Other, '#pop'),
|
||||
(r'\$\(ARCH\)', Name.Variable),
|
||||
(r'[^\]$]+', String.Other),
|
||||
(r'\$', String.Other)
|
||||
],
|
||||
'components': [
|
||||
(r'#.*?$', Comment, '#pop:2'),
|
||||
(r'$', Text, '#pop:2'),
|
||||
(r'\s+', Text),
|
||||
(r'\S+', Keyword.Pseudo),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
for line in text.splitlines():
|
||||
line = line.strip()
|
||||
if line.startswith('deb ') or line.startswith('deb-src '):
|
||||
return True
|
||||
|
||||
|
||||
class DebianControlLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for Debian ``control`` files and ``apt-cache show <pkg>`` outputs.
|
||||
|
||||
.. versionadded:: 0.9
|
||||
"""
|
||||
name = 'Debian Control file'
|
||||
aliases = ['control', 'debcontrol']
|
||||
filenames = ['control']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^(Description)', Keyword, 'description'),
|
||||
(r'^(Maintainer)(:\s*)', bygroups(Keyword, Text), 'maintainer'),
|
||||
(r'^((Build-)?Depends)', Keyword, 'depends'),
|
||||
(r'^((?:Python-)?Version)(:\s*)(\S+)$',
|
||||
bygroups(Keyword, Text, Number)),
|
||||
(r'^((?:Installed-)?Size)(:\s*)(\S+)$',
|
||||
bygroups(Keyword, Text, Number)),
|
||||
(r'^(MD5Sum|SHA1|SHA256)(:\s*)(\S+)$',
|
||||
bygroups(Keyword, Text, Number)),
|
||||
(r'^([a-zA-Z\-0-9\.]*?)(:\s*)(.*?)$',
|
||||
bygroups(Keyword, Whitespace, String)),
|
||||
],
|
||||
'maintainer': [
|
||||
(r'<[^>]+>', Generic.Strong),
|
||||
(r'<[^>]+>$', Generic.Strong, '#pop'),
|
||||
(r',\n?', Text),
|
||||
(r'.', Text),
|
||||
],
|
||||
'description': [
|
||||
(r'(.*)(Homepage)(: )(\S+)',
|
||||
bygroups(Text, String, Name, Name.Class)),
|
||||
(r':.*\n', Generic.Strong),
|
||||
(r' .*\n', Text),
|
||||
default('#pop'),
|
||||
],
|
||||
'depends': [
|
||||
(r':\s*', Text),
|
||||
(r'(\$)(\{)(\w+\s*:\s*\w+)', bygroups(Operator, Text, Name.Entity)),
|
||||
(r'\(', Text, 'depend_vers'),
|
||||
(r',', Text),
|
||||
(r'\|', Operator),
|
||||
(r'[\s]+', Text),
|
||||
(r'[})]\s*$', Text, '#pop'),
|
||||
(r'\}', Text),
|
||||
(r'[^,]$', Name.Function, '#pop'),
|
||||
(r'([+.a-zA-Z0-9-])(\s*)', bygroups(Name.Function, Text)),
|
||||
(r'\[.*?\]', Name.Entity),
|
||||
],
|
||||
'depend_vers': [
|
||||
(r'\),', Text, '#pop'),
|
||||
(r'\)[^,]', Text, '#pop:2'),
|
||||
(r'([><=]+)(\s*)([^)]+)', bygroups(Operator, Text, Number))
|
||||
]
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,21 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.math
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Just export lexers that were contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexers.python import NumPyLexer
|
||||
from pygments.lexers.matlab import MatlabLexer, MatlabSessionLexer, \
|
||||
OctaveLexer, ScilabLexer
|
||||
from pygments.lexers.julia import JuliaLexer, JuliaConsoleLexer
|
||||
from pygments.lexers.r import RConsoleLexer, SLexer, RdLexer
|
||||
from pygments.lexers.modeling import BugsLexer, JagsLexer, StanLexer
|
||||
from pygments.lexers.idl import IDLLexer
|
||||
from pygments.lexers.algebra import MuPADLexer
|
||||
|
||||
__all__ = []
|
||||
@ -1,769 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.ml
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for ML family languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, default, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error
|
||||
|
||||
__all__ = ['SMLLexer', 'OcamlLexer', 'OpaLexer']
|
||||
|
||||
|
||||
class SMLLexer(RegexLexer):
|
||||
"""
|
||||
For the Standard ML language.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = 'Standard ML'
|
||||
aliases = ['sml']
|
||||
filenames = ['*.sml', '*.sig', '*.fun']
|
||||
mimetypes = ['text/x-standardml', 'application/x-standardml']
|
||||
|
||||
alphanumid_reserved = set((
|
||||
# Core
|
||||
'abstype', 'and', 'andalso', 'as', 'case', 'datatype', 'do', 'else',
|
||||
'end', 'exception', 'fn', 'fun', 'handle', 'if', 'in', 'infix',
|
||||
'infixr', 'let', 'local', 'nonfix', 'of', 'op', 'open', 'orelse',
|
||||
'raise', 'rec', 'then', 'type', 'val', 'with', 'withtype', 'while',
|
||||
# Modules
|
||||
'eqtype', 'functor', 'include', 'sharing', 'sig', 'signature',
|
||||
'struct', 'structure', 'where',
|
||||
))
|
||||
|
||||
symbolicid_reserved = set((
|
||||
# Core
|
||||
':', '\|', '=', '=>', '->', '#',
|
||||
# Modules
|
||||
':>',
|
||||
))
|
||||
|
||||
nonid_reserved = set(('(', ')', '[', ']', '{', '}', ',', ';', '...', '_'))
|
||||
|
||||
alphanumid_re = r"[a-zA-Z][\w']*"
|
||||
symbolicid_re = r"[!%&$#+\-/:<=>?@\\~`^|*]+"
|
||||
|
||||
# A character constant is a sequence of the form #s, where s is a string
|
||||
# constant denoting a string of size one character. This setup just parses
|
||||
# the entire string as either a String.Double or a String.Char (depending
|
||||
# on the argument), even if the String.Char is an erronous
|
||||
# multiple-character string.
|
||||
def stringy(whatkind):
|
||||
return [
|
||||
(r'[^"\\]', whatkind),
|
||||
(r'\\[\\"abtnvfr]', String.Escape),
|
||||
# Control-character notation is used for codes < 32,
|
||||
# where \^@ == \000
|
||||
(r'\\\^[\x40-\x5e]', String.Escape),
|
||||
# Docs say 'decimal digits'
|
||||
(r'\\[0-9]{3}', String.Escape),
|
||||
(r'\\u[0-9a-fA-F]{4}', String.Escape),
|
||||
(r'\\\s+\\', String.Interpol),
|
||||
(r'"', whatkind, '#pop'),
|
||||
]
|
||||
|
||||
# Callbacks for distinguishing tokens and reserved words
|
||||
def long_id_callback(self, match):
|
||||
if match.group(1) in self.alphanumid_reserved:
|
||||
token = Error
|
||||
else:
|
||||
token = Name.Namespace
|
||||
yield match.start(1), token, match.group(1)
|
||||
yield match.start(2), Punctuation, match.group(2)
|
||||
|
||||
def end_id_callback(self, match):
|
||||
if match.group(1) in self.alphanumid_reserved:
|
||||
token = Error
|
||||
elif match.group(1) in self.symbolicid_reserved:
|
||||
token = Error
|
||||
else:
|
||||
token = Name
|
||||
yield match.start(1), token, match.group(1)
|
||||
|
||||
def id_callback(self, match):
|
||||
str = match.group(1)
|
||||
if str in self.alphanumid_reserved:
|
||||
token = Keyword.Reserved
|
||||
elif str in self.symbolicid_reserved:
|
||||
token = Punctuation
|
||||
else:
|
||||
token = Name
|
||||
yield match.start(1), token, str
|
||||
|
||||
tokens = {
|
||||
# Whitespace and comments are (almost) everywhere
|
||||
'whitespace': [
|
||||
(r'\s+', Text),
|
||||
(r'\(\*', Comment.Multiline, 'comment'),
|
||||
],
|
||||
|
||||
'delimiters': [
|
||||
# This lexer treats these delimiters specially:
|
||||
# Delimiters define scopes, and the scope is how the meaning of
|
||||
# the `|' is resolved - is it a case/handle expression, or function
|
||||
# definition by cases? (This is not how the Definition works, but
|
||||
# it's how MLton behaves, see http://mlton.org/SMLNJDeviations)
|
||||
(r'\(|\[|\{', Punctuation, 'main'),
|
||||
(r'\)|\]|\}', Punctuation, '#pop'),
|
||||
(r'\b(let|if|local)\b(?!\')', Keyword.Reserved, ('main', 'main')),
|
||||
(r'\b(struct|sig|while)\b(?!\')', Keyword.Reserved, 'main'),
|
||||
(r'\b(do|else|end|in|then)\b(?!\')', Keyword.Reserved, '#pop'),
|
||||
],
|
||||
|
||||
'core': [
|
||||
# Punctuation that doesn't overlap symbolic identifiers
|
||||
(r'(%s)' % '|'.join(re.escape(z) for z in nonid_reserved),
|
||||
Punctuation),
|
||||
|
||||
# Special constants: strings, floats, numbers in decimal and hex
|
||||
(r'#"', String.Char, 'char'),
|
||||
(r'"', String.Double, 'string'),
|
||||
(r'~?0x[0-9a-fA-F]+', Number.Hex),
|
||||
(r'0wx[0-9a-fA-F]+', Number.Hex),
|
||||
(r'0w\d+', Number.Integer),
|
||||
(r'~?\d+\.\d+[eE]~?\d+', Number.Float),
|
||||
(r'~?\d+\.\d+', Number.Float),
|
||||
(r'~?\d+[eE]~?\d+', Number.Float),
|
||||
(r'~?\d+', Number.Integer),
|
||||
|
||||
# Labels
|
||||
(r'#\s*[1-9][0-9]*', Name.Label),
|
||||
(r'#\s*(%s)' % alphanumid_re, Name.Label),
|
||||
(r'#\s+(%s)' % symbolicid_re, Name.Label),
|
||||
# Some reserved words trigger a special, local lexer state change
|
||||
(r'\b(datatype|abstype)\b(?!\')', Keyword.Reserved, 'dname'),
|
||||
(r'(?=\b(exception)\b(?!\'))', Text, ('ename')),
|
||||
(r'\b(functor|include|open|signature|structure)\b(?!\')',
|
||||
Keyword.Reserved, 'sname'),
|
||||
(r'\b(type|eqtype)\b(?!\')', Keyword.Reserved, 'tname'),
|
||||
|
||||
# Regular identifiers, long and otherwise
|
||||
(r'\'[\w\']*', Name.Decorator),
|
||||
(r'(%s)(\.)' % alphanumid_re, long_id_callback, "dotted"),
|
||||
(r'(%s)' % alphanumid_re, id_callback),
|
||||
(r'(%s)' % symbolicid_re, id_callback),
|
||||
],
|
||||
'dotted': [
|
||||
(r'(%s)(\.)' % alphanumid_re, long_id_callback),
|
||||
(r'(%s)' % alphanumid_re, end_id_callback, "#pop"),
|
||||
(r'(%s)' % symbolicid_re, end_id_callback, "#pop"),
|
||||
(r'\s+', Error),
|
||||
(r'\S+', Error),
|
||||
],
|
||||
|
||||
|
||||
# Main parser (prevents errors in files that have scoping errors)
|
||||
'root': [
|
||||
default('main')
|
||||
],
|
||||
|
||||
# In this scope, I expect '|' to not be followed by a function name,
|
||||
# and I expect 'and' to be followed by a binding site
|
||||
'main': [
|
||||
include('whitespace'),
|
||||
|
||||
# Special behavior of val/and/fun
|
||||
(r'\b(val|and)\b(?!\')', Keyword.Reserved, 'vname'),
|
||||
(r'\b(fun)\b(?!\')', Keyword.Reserved,
|
||||
('#pop', 'main-fun', 'fname')),
|
||||
|
||||
include('delimiters'),
|
||||
include('core'),
|
||||
(r'\S+', Error),
|
||||
],
|
||||
|
||||
# In this scope, I expect '|' and 'and' to be followed by a function
|
||||
'main-fun': [
|
||||
include('whitespace'),
|
||||
|
||||
(r'\s', Text),
|
||||
(r'\(\*', Comment.Multiline, 'comment'),
|
||||
|
||||
# Special behavior of val/and/fun
|
||||
(r'\b(fun|and)\b(?!\')', Keyword.Reserved, 'fname'),
|
||||
(r'\b(val)\b(?!\')', Keyword.Reserved,
|
||||
('#pop', 'main', 'vname')),
|
||||
|
||||
# Special behavior of '|' and '|'-manipulating keywords
|
||||
(r'\|', Punctuation, 'fname'),
|
||||
(r'\b(case|handle)\b(?!\')', Keyword.Reserved,
|
||||
('#pop', 'main')),
|
||||
|
||||
include('delimiters'),
|
||||
include('core'),
|
||||
(r'\S+', Error),
|
||||
],
|
||||
|
||||
# Character and string parsers
|
||||
'char': stringy(String.Char),
|
||||
'string': stringy(String.Double),
|
||||
|
||||
'breakout': [
|
||||
(r'(?=\b(%s)\b(?!\'))' % '|'.join(alphanumid_reserved), Text, '#pop'),
|
||||
],
|
||||
|
||||
# Dealing with what comes after module system keywords
|
||||
'sname': [
|
||||
include('whitespace'),
|
||||
include('breakout'),
|
||||
|
||||
(r'(%s)' % alphanumid_re, Name.Namespace),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
# Dealing with what comes after the 'fun' (or 'and' or '|') keyword
|
||||
'fname': [
|
||||
include('whitespace'),
|
||||
(r'\'[\w\']*', Name.Decorator),
|
||||
(r'\(', Punctuation, 'tyvarseq'),
|
||||
|
||||
(r'(%s)' % alphanumid_re, Name.Function, '#pop'),
|
||||
(r'(%s)' % symbolicid_re, Name.Function, '#pop'),
|
||||
|
||||
# Ignore interesting function declarations like "fun (x + y) = ..."
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
# Dealing with what comes after the 'val' (or 'and') keyword
|
||||
'vname': [
|
||||
include('whitespace'),
|
||||
(r'\'[\w\']*', Name.Decorator),
|
||||
(r'\(', Punctuation, 'tyvarseq'),
|
||||
|
||||
(r'(%s)(\s*)(=(?!%s))' % (alphanumid_re, symbolicid_re),
|
||||
bygroups(Name.Variable, Text, Punctuation), '#pop'),
|
||||
(r'(%s)(\s*)(=(?!%s))' % (symbolicid_re, symbolicid_re),
|
||||
bygroups(Name.Variable, Text, Punctuation), '#pop'),
|
||||
(r'(%s)' % alphanumid_re, Name.Variable, '#pop'),
|
||||
(r'(%s)' % symbolicid_re, Name.Variable, '#pop'),
|
||||
|
||||
# Ignore interesting patterns like 'val (x, y)'
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
# Dealing with what comes after the 'type' (or 'and') keyword
|
||||
'tname': [
|
||||
include('whitespace'),
|
||||
include('breakout'),
|
||||
|
||||
(r'\'[\w\']*', Name.Decorator),
|
||||
(r'\(', Punctuation, 'tyvarseq'),
|
||||
(r'=(?!%s)' % symbolicid_re, Punctuation, ('#pop', 'typbind')),
|
||||
|
||||
(r'(%s)' % alphanumid_re, Keyword.Type),
|
||||
(r'(%s)' % symbolicid_re, Keyword.Type),
|
||||
(r'\S+', Error, '#pop'),
|
||||
],
|
||||
|
||||
# A type binding includes most identifiers
|
||||
'typbind': [
|
||||
include('whitespace'),
|
||||
|
||||
(r'\b(and)\b(?!\')', Keyword.Reserved, ('#pop', 'tname')),
|
||||
|
||||
include('breakout'),
|
||||
include('core'),
|
||||
(r'\S+', Error, '#pop'),
|
||||
],
|
||||
|
||||
# Dealing with what comes after the 'datatype' (or 'and') keyword
|
||||
'dname': [
|
||||
include('whitespace'),
|
||||
include('breakout'),
|
||||
|
||||
(r'\'[\w\']*', Name.Decorator),
|
||||
(r'\(', Punctuation, 'tyvarseq'),
|
||||
(r'(=)(\s*)(datatype)',
|
||||
bygroups(Punctuation, Text, Keyword.Reserved), '#pop'),
|
||||
(r'=(?!%s)' % symbolicid_re, Punctuation,
|
||||
('#pop', 'datbind', 'datcon')),
|
||||
|
||||
(r'(%s)' % alphanumid_re, Keyword.Type),
|
||||
(r'(%s)' % symbolicid_re, Keyword.Type),
|
||||
(r'\S+', Error, '#pop'),
|
||||
],
|
||||
|
||||
# common case - A | B | C of int
|
||||
'datbind': [
|
||||
include('whitespace'),
|
||||
|
||||
(r'\b(and)\b(?!\')', Keyword.Reserved, ('#pop', 'dname')),
|
||||
(r'\b(withtype)\b(?!\')', Keyword.Reserved, ('#pop', 'tname')),
|
||||
(r'\b(of)\b(?!\')', Keyword.Reserved),
|
||||
|
||||
(r'(\|)(\s*)(%s)' % alphanumid_re,
|
||||
bygroups(Punctuation, Text, Name.Class)),
|
||||
(r'(\|)(\s+)(%s)' % symbolicid_re,
|
||||
bygroups(Punctuation, Text, Name.Class)),
|
||||
|
||||
include('breakout'),
|
||||
include('core'),
|
||||
(r'\S+', Error),
|
||||
],
|
||||
|
||||
# Dealing with what comes after an exception
|
||||
'ename': [
|
||||
include('whitespace'),
|
||||
|
||||
(r'(exception|and)\b(\s+)(%s)' % alphanumid_re,
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
(r'(exception|and)\b(\s*)(%s)' % symbolicid_re,
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
(r'\b(of)\b(?!\')', Keyword.Reserved),
|
||||
|
||||
include('breakout'),
|
||||
include('core'),
|
||||
(r'\S+', Error),
|
||||
],
|
||||
|
||||
'datcon': [
|
||||
include('whitespace'),
|
||||
(r'(%s)' % alphanumid_re, Name.Class, '#pop'),
|
||||
(r'(%s)' % symbolicid_re, Name.Class, '#pop'),
|
||||
(r'\S+', Error, '#pop'),
|
||||
],
|
||||
|
||||
# Series of type variables
|
||||
'tyvarseq': [
|
||||
(r'\s', Text),
|
||||
(r'\(\*', Comment.Multiline, 'comment'),
|
||||
|
||||
(r'\'[\w\']*', Name.Decorator),
|
||||
(alphanumid_re, Name),
|
||||
(r',', Punctuation),
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(symbolicid_re, Name),
|
||||
],
|
||||
|
||||
'comment': [
|
||||
(r'[^(*)]', Comment.Multiline),
|
||||
(r'\(\*', Comment.Multiline, '#push'),
|
||||
(r'\*\)', Comment.Multiline, '#pop'),
|
||||
(r'[(*)]', Comment.Multiline),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class OcamlLexer(RegexLexer):
|
||||
"""
|
||||
For the OCaml language.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
"""
|
||||
|
||||
name = 'OCaml'
|
||||
aliases = ['ocaml']
|
||||
filenames = ['*.ml', '*.mli', '*.mll', '*.mly']
|
||||
mimetypes = ['text/x-ocaml']
|
||||
|
||||
keywords = (
|
||||
'as', 'assert', 'begin', 'class', 'constraint', 'do', 'done',
|
||||
'downto', 'else', 'end', 'exception', 'external', 'false',
|
||||
'for', 'fun', 'function', 'functor', 'if', 'in', 'include',
|
||||
'inherit', 'initializer', 'lazy', 'let', 'match', 'method',
|
||||
'module', 'mutable', 'new', 'object', 'of', 'open', 'private',
|
||||
'raise', 'rec', 'sig', 'struct', 'then', 'to', 'true', 'try',
|
||||
'type', 'value', 'val', 'virtual', 'when', 'while', 'with',
|
||||
)
|
||||
keyopts = (
|
||||
'!=', '#', '&', '&&', r'\(', r'\)', r'\*', r'\+', ',', '-',
|
||||
r'-\.', '->', r'\.', r'\.\.', ':', '::', ':=', ':>', ';', ';;', '<',
|
||||
'<-', '=', '>', '>]', r'>\}', r'\?', r'\?\?', r'\[', r'\[<', r'\[>',
|
||||
r'\[\|', ']', '_', '`', r'\{', r'\{<', r'\|', r'\|]', r'\}', '~'
|
||||
)
|
||||
|
||||
operators = r'[!$%&*+\./:<=>?@^|~-]'
|
||||
word_operators = ('and', 'asr', 'land', 'lor', 'lsl', 'lxor', 'mod', 'or')
|
||||
prefix_syms = r'[!?~]'
|
||||
infix_syms = r'[=<>@^|&+\*/$%-]'
|
||||
primitives = ('unit', 'int', 'float', 'bool', 'string', 'char', 'list', 'array')
|
||||
|
||||
tokens = {
|
||||
'escape-sequence': [
|
||||
(r'\\[\\"\'ntbr]', String.Escape),
|
||||
(r'\\[0-9]{3}', String.Escape),
|
||||
(r'\\x[0-9a-fA-F]{2}', String.Escape),
|
||||
],
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'false|true|\(\)|\[\]', Name.Builtin.Pseudo),
|
||||
(r'\b([A-Z][\w\']*)(?=\s*\.)', Name.Namespace, 'dotted'),
|
||||
(r'\b([A-Z][\w\']*)', Name.Class),
|
||||
(r'\(\*(?![)])', Comment, 'comment'),
|
||||
(r'\b(%s)\b' % '|'.join(keywords), Keyword),
|
||||
(r'(%s)' % '|'.join(keyopts[::-1]), Operator),
|
||||
(r'(%s|%s)?%s' % (infix_syms, prefix_syms, operators), Operator),
|
||||
(r'\b(%s)\b' % '|'.join(word_operators), Operator.Word),
|
||||
(r'\b(%s)\b' % '|'.join(primitives), Keyword.Type),
|
||||
|
||||
(r"[^\W\d][\w']*", Name),
|
||||
|
||||
(r'-?\d[\d_]*(.[\d_]*)?([eE][+\-]?\d[\d_]*)', Number.Float),
|
||||
(r'0[xX][\da-fA-F][\da-fA-F_]*', Number.Hex),
|
||||
(r'0[oO][0-7][0-7_]*', Number.Oct),
|
||||
(r'0[bB][01][01_]*', Number.Bin),
|
||||
(r'\d[\d_]*', Number.Integer),
|
||||
|
||||
(r"'(?:(\\[\\\"'ntbr ])|(\\[0-9]{3})|(\\x[0-9a-fA-F]{2}))'",
|
||||
String.Char),
|
||||
(r"'.'", String.Char),
|
||||
(r"'", Keyword), # a stray quote is another syntax element
|
||||
|
||||
(r'"', String.Double, 'string'),
|
||||
|
||||
(r'[~?][a-z][\w\']*:', Name.Variable),
|
||||
],
|
||||
'comment': [
|
||||
(r'[^(*)]+', Comment),
|
||||
(r'\(\*', Comment, '#push'),
|
||||
(r'\*\)', Comment, '#pop'),
|
||||
(r'[(*)]', Comment),
|
||||
],
|
||||
'string': [
|
||||
(r'[^\\"]+', String.Double),
|
||||
include('escape-sequence'),
|
||||
(r'\\\n', String.Double),
|
||||
(r'"', String.Double, '#pop'),
|
||||
],
|
||||
'dotted': [
|
||||
(r'\s+', Text),
|
||||
(r'\.', Punctuation),
|
||||
(r'[A-Z][\w\']*(?=\s*\.)', Name.Namespace),
|
||||
(r'[A-Z][\w\']*', Name.Class, '#pop'),
|
||||
(r'[a-z_][\w\']*', Name, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class OpaLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the Opa language (http://opalang.org).
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = 'Opa'
|
||||
aliases = ['opa']
|
||||
filenames = ['*.opa']
|
||||
mimetypes = ['text/x-opa']
|
||||
|
||||
# most of these aren't strictly keywords
|
||||
# but if you color only real keywords, you might just
|
||||
# as well not color anything
|
||||
keywords = (
|
||||
'and', 'as', 'begin', 'case', 'client', 'css', 'database', 'db', 'do',
|
||||
'else', 'end', 'external', 'forall', 'function', 'if', 'import',
|
||||
'match', 'module', 'or', 'package', 'parser', 'rec', 'server', 'then',
|
||||
'type', 'val', 'with', 'xml_parser',
|
||||
)
|
||||
|
||||
# matches both stuff and `stuff`
|
||||
ident_re = r'(([a-zA-Z_]\w*)|(`[^`]*`))'
|
||||
|
||||
op_re = r'[.=\-<>,@~%/+?*&^!]'
|
||||
punc_re = r'[()\[\],;|]' # '{' and '}' are treated elsewhere
|
||||
# because they are also used for inserts
|
||||
|
||||
tokens = {
|
||||
# copied from the caml lexer, should be adapted
|
||||
'escape-sequence': [
|
||||
(r'\\[\\"\'ntr}]', String.Escape),
|
||||
(r'\\[0-9]{3}', String.Escape),
|
||||
(r'\\x[0-9a-fA-F]{2}', String.Escape),
|
||||
],
|
||||
|
||||
# factorizing these rules, because they are inserted many times
|
||||
'comments': [
|
||||
(r'/\*', Comment, 'nested-comment'),
|
||||
(r'//.*?$', Comment),
|
||||
],
|
||||
'comments-and-spaces': [
|
||||
include('comments'),
|
||||
(r'\s+', Text),
|
||||
],
|
||||
|
||||
'root': [
|
||||
include('comments-and-spaces'),
|
||||
# keywords
|
||||
(words(keywords, prefix=r'\b', suffix=r'\b'), Keyword),
|
||||
# directives
|
||||
# we could parse the actual set of directives instead of anything
|
||||
# starting with @, but this is troublesome
|
||||
# because it needs to be adjusted all the time
|
||||
# and assuming we parse only sources that compile, it is useless
|
||||
(r'@' + ident_re + r'\b', Name.Builtin.Pseudo),
|
||||
|
||||
# number literals
|
||||
(r'-?.[\d]+([eE][+\-]?\d+)', Number.Float),
|
||||
(r'-?\d+.\d*([eE][+\-]?\d+)', Number.Float),
|
||||
(r'-?\d+[eE][+\-]?\d+', Number.Float),
|
||||
(r'0[xX][\da-fA-F]+', Number.Hex),
|
||||
(r'0[oO][0-7]+', Number.Oct),
|
||||
(r'0[bB][01]+', Number.Bin),
|
||||
(r'\d+', Number.Integer),
|
||||
# color literals
|
||||
(r'#[\da-fA-F]{3,6}', Number.Integer),
|
||||
|
||||
# string literals
|
||||
(r'"', String.Double, 'string'),
|
||||
# char literal, should be checked because this is the regexp from
|
||||
# the caml lexer
|
||||
(r"'(?:(\\[\\\"'ntbr ])|(\\[0-9]{3})|(\\x[0-9a-fA-F]{2})|.)'",
|
||||
String.Char),
|
||||
|
||||
# this is meant to deal with embedded exprs in strings
|
||||
# every time we find a '}' we pop a state so that if we were
|
||||
# inside a string, we are back in the string state
|
||||
# as a consequence, we must also push a state every time we find a
|
||||
# '{' or else we will have errors when parsing {} for instance
|
||||
(r'\{', Operator, '#push'),
|
||||
(r'\}', Operator, '#pop'),
|
||||
|
||||
# html literals
|
||||
# this is a much more strict that the actual parser,
|
||||
# since a<b would not be parsed as html
|
||||
# but then again, the parser is way too lax, and we can't hope
|
||||
# to have something as tolerant
|
||||
(r'<(?=[a-zA-Z>])', String.Single, 'html-open-tag'),
|
||||
|
||||
# db path
|
||||
# matching the '[_]' in '/a[_]' because it is a part
|
||||
# of the syntax of the db path definition
|
||||
# unfortunately, i don't know how to match the ']' in
|
||||
# /a[1], so this is somewhat inconsistent
|
||||
(r'[@?!]?(/\w+)+(\[_\])?', Name.Variable),
|
||||
# putting the same color on <- as on db path, since
|
||||
# it can be used only to mean Db.write
|
||||
(r'<-(?!'+op_re+r')', Name.Variable),
|
||||
|
||||
# 'modules'
|
||||
# although modules are not distinguished by their names as in caml
|
||||
# the standard library seems to follow the convention that modules
|
||||
# only area capitalized
|
||||
(r'\b([A-Z]\w*)(?=\.)', Name.Namespace),
|
||||
|
||||
# operators
|
||||
# = has a special role because this is the only
|
||||
# way to syntactic distinguish binding constructions
|
||||
# unfortunately, this colors the equal in {x=2} too
|
||||
(r'=(?!'+op_re+r')', Keyword),
|
||||
(r'(%s)+' % op_re, Operator),
|
||||
(r'(%s)+' % punc_re, Operator),
|
||||
|
||||
# coercions
|
||||
(r':', Operator, 'type'),
|
||||
# type variables
|
||||
# we need this rule because we don't parse specially type
|
||||
# definitions so in "type t('a) = ...", "'a" is parsed by 'root'
|
||||
("'"+ident_re, Keyword.Type),
|
||||
|
||||
# id literal, #something, or #{expr}
|
||||
(r'#'+ident_re, String.Single),
|
||||
(r'#(?=\{)', String.Single),
|
||||
|
||||
# identifiers
|
||||
# this avoids to color '2' in 'a2' as an integer
|
||||
(ident_re, Text),
|
||||
|
||||
# default, not sure if that is needed or not
|
||||
# (r'.', Text),
|
||||
],
|
||||
|
||||
# it is quite painful to have to parse types to know where they end
|
||||
# this is the general rule for a type
|
||||
# a type is either:
|
||||
# * -> ty
|
||||
# * type-with-slash
|
||||
# * type-with-slash -> ty
|
||||
# * type-with-slash (, type-with-slash)+ -> ty
|
||||
#
|
||||
# the code is pretty funky in here, but this code would roughly
|
||||
# translate in caml to:
|
||||
# let rec type stream =
|
||||
# match stream with
|
||||
# | [< "->"; stream >] -> type stream
|
||||
# | [< ""; stream >] ->
|
||||
# type_with_slash stream
|
||||
# type_lhs_1 stream;
|
||||
# and type_1 stream = ...
|
||||
'type': [
|
||||
include('comments-and-spaces'),
|
||||
(r'->', Keyword.Type),
|
||||
default(('#pop', 'type-lhs-1', 'type-with-slash')),
|
||||
],
|
||||
|
||||
# parses all the atomic or closed constructions in the syntax of type
|
||||
# expressions: record types, tuple types, type constructors, basic type
|
||||
# and type variables
|
||||
'type-1': [
|
||||
include('comments-and-spaces'),
|
||||
(r'\(', Keyword.Type, ('#pop', 'type-tuple')),
|
||||
(r'~?\{', Keyword.Type, ('#pop', 'type-record')),
|
||||
(ident_re+r'\(', Keyword.Type, ('#pop', 'type-tuple')),
|
||||
(ident_re, Keyword.Type, '#pop'),
|
||||
("'"+ident_re, Keyword.Type),
|
||||
# this case is not in the syntax but sometimes
|
||||
# we think we are parsing types when in fact we are parsing
|
||||
# some css, so we just pop the states until we get back into
|
||||
# the root state
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
# type-with-slash is either:
|
||||
# * type-1
|
||||
# * type-1 (/ type-1)+
|
||||
'type-with-slash': [
|
||||
include('comments-and-spaces'),
|
||||
default(('#pop', 'slash-type-1', 'type-1')),
|
||||
],
|
||||
'slash-type-1': [
|
||||
include('comments-and-spaces'),
|
||||
('/', Keyword.Type, ('#pop', 'type-1')),
|
||||
# same remark as above
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
# we go in this state after having parsed a type-with-slash
|
||||
# while trying to parse a type
|
||||
# and at this point we must determine if we are parsing an arrow
|
||||
# type (in which case we must continue parsing) or not (in which
|
||||
# case we stop)
|
||||
'type-lhs-1': [
|
||||
include('comments-and-spaces'),
|
||||
(r'->', Keyword.Type, ('#pop', 'type')),
|
||||
(r'(?=,)', Keyword.Type, ('#pop', 'type-arrow')),
|
||||
default('#pop'),
|
||||
],
|
||||
'type-arrow': [
|
||||
include('comments-and-spaces'),
|
||||
# the look ahead here allows to parse f(x : int, y : float -> truc)
|
||||
# correctly
|
||||
(r',(?=[^:]*?->)', Keyword.Type, 'type-with-slash'),
|
||||
(r'->', Keyword.Type, ('#pop', 'type')),
|
||||
# same remark as above
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
# no need to do precise parsing for tuples and records
|
||||
# because they are closed constructions, so we can simply
|
||||
# find the closing delimiter
|
||||
# note that this function would be not work if the source
|
||||
# contained identifiers like `{)` (although it could be patched
|
||||
# to support it)
|
||||
'type-tuple': [
|
||||
include('comments-and-spaces'),
|
||||
(r'[^()/*]+', Keyword.Type),
|
||||
(r'[/*]', Keyword.Type),
|
||||
(r'\(', Keyword.Type, '#push'),
|
||||
(r'\)', Keyword.Type, '#pop'),
|
||||
],
|
||||
'type-record': [
|
||||
include('comments-and-spaces'),
|
||||
(r'[^{}/*]+', Keyword.Type),
|
||||
(r'[/*]', Keyword.Type),
|
||||
(r'\{', Keyword.Type, '#push'),
|
||||
(r'\}', Keyword.Type, '#pop'),
|
||||
],
|
||||
|
||||
# 'type-tuple': [
|
||||
# include('comments-and-spaces'),
|
||||
# (r'\)', Keyword.Type, '#pop'),
|
||||
# default(('#pop', 'type-tuple-1', 'type-1')),
|
||||
# ],
|
||||
# 'type-tuple-1': [
|
||||
# include('comments-and-spaces'),
|
||||
# (r',?\s*\)', Keyword.Type, '#pop'), # ,) is a valid end of tuple, in (1,)
|
||||
# (r',', Keyword.Type, 'type-1'),
|
||||
# ],
|
||||
# 'type-record':[
|
||||
# include('comments-and-spaces'),
|
||||
# (r'\}', Keyword.Type, '#pop'),
|
||||
# (r'~?(?:\w+|`[^`]*`)', Keyword.Type, 'type-record-field-expr'),
|
||||
# ],
|
||||
# 'type-record-field-expr': [
|
||||
#
|
||||
# ],
|
||||
|
||||
'nested-comment': [
|
||||
(r'[^/*]+', Comment),
|
||||
(r'/\*', Comment, '#push'),
|
||||
(r'\*/', Comment, '#pop'),
|
||||
(r'[/*]', Comment),
|
||||
],
|
||||
|
||||
# the copy pasting between string and single-string
|
||||
# is kinda sad. Is there a way to avoid that??
|
||||
'string': [
|
||||
(r'[^\\"{]+', String.Double),
|
||||
(r'"', String.Double, '#pop'),
|
||||
(r'\{', Operator, 'root'),
|
||||
include('escape-sequence'),
|
||||
],
|
||||
'single-string': [
|
||||
(r'[^\\\'{]+', String.Double),
|
||||
(r'\'', String.Double, '#pop'),
|
||||
(r'\{', Operator, 'root'),
|
||||
include('escape-sequence'),
|
||||
],
|
||||
|
||||
# all the html stuff
|
||||
# can't really reuse some existing html parser
|
||||
# because we must be able to parse embedded expressions
|
||||
|
||||
# we are in this state after someone parsed the '<' that
|
||||
# started the html literal
|
||||
'html-open-tag': [
|
||||
(r'[\w\-:]+', String.Single, ('#pop', 'html-attr')),
|
||||
(r'>', String.Single, ('#pop', 'html-content')),
|
||||
],
|
||||
|
||||
# we are in this state after someone parsed the '</' that
|
||||
# started the end of the closing tag
|
||||
'html-end-tag': [
|
||||
# this is a star, because </> is allowed
|
||||
(r'[\w\-:]*>', String.Single, '#pop'),
|
||||
],
|
||||
|
||||
# we are in this state after having parsed '<ident(:ident)?'
|
||||
# we thus parse a possibly empty list of attributes
|
||||
'html-attr': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w\-:]+=', String.Single, 'html-attr-value'),
|
||||
(r'/>', String.Single, '#pop'),
|
||||
(r'>', String.Single, ('#pop', 'html-content')),
|
||||
],
|
||||
|
||||
'html-attr-value': [
|
||||
(r"'", String.Single, ('#pop', 'single-string')),
|
||||
(r'"', String.Single, ('#pop', 'string')),
|
||||
(r'#'+ident_re, String.Single, '#pop'),
|
||||
(r'#(?=\{)', String.Single, ('#pop', 'root')),
|
||||
(r'[^"\'{`=<>]+', String.Single, '#pop'),
|
||||
(r'\{', Operator, ('#pop', 'root')), # this is a tail call!
|
||||
],
|
||||
|
||||
# we should probably deal with '\' escapes here
|
||||
'html-content': [
|
||||
(r'<!--', Comment, 'html-comment'),
|
||||
(r'</', String.Single, ('#pop', 'html-end-tag')),
|
||||
(r'<', String.Single, 'html-open-tag'),
|
||||
(r'\{', Operator, 'root'),
|
||||
(r'[^<{]+', String.Single),
|
||||
],
|
||||
|
||||
'html-comment': [
|
||||
(r'-->', Comment, '#pop'),
|
||||
(r'[^\-]+|-', Comment),
|
||||
],
|
||||
}
|
||||
@ -1,40 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.other
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Just export lexer classes previously contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexers.sql import SqlLexer, MySqlLexer, SqliteConsoleLexer
|
||||
from pygments.lexers.shell import BashLexer, BashSessionLexer, BatchLexer, \
|
||||
TcshLexer
|
||||
from pygments.lexers.robotframework import RobotFrameworkLexer
|
||||
from pygments.lexers.testing import GherkinLexer
|
||||
from pygments.lexers.esoteric import BrainfuckLexer, BefungeLexer, RedcodeLexer
|
||||
from pygments.lexers.prolog import LogtalkLexer
|
||||
from pygments.lexers.snobol import SnobolLexer
|
||||
from pygments.lexers.rebol import RebolLexer
|
||||
from pygments.lexers.configs import KconfigLexer, Cfengine3Lexer
|
||||
from pygments.lexers.modeling import ModelicaLexer
|
||||
from pygments.lexers.scripting import AppleScriptLexer, MOOCodeLexer, \
|
||||
HybrisLexer
|
||||
from pygments.lexers.graphics import PostScriptLexer, GnuplotLexer, \
|
||||
AsymptoteLexer, PovrayLexer
|
||||
from pygments.lexers.business import ABAPLexer, OpenEdgeLexer, \
|
||||
GoodDataCLLexer, MaqlLexer
|
||||
from pygments.lexers.automation import AutoItLexer, AutohotkeyLexer
|
||||
from pygments.lexers.dsls import ProtoBufLexer, BroLexer, PuppetLexer, \
|
||||
MscgenLexer, VGLLexer
|
||||
from pygments.lexers.basic import CbmBasicV2Lexer
|
||||
from pygments.lexers.pawn import SourcePawnLexer, PawnLexer
|
||||
from pygments.lexers.ecl import ECLLexer
|
||||
from pygments.lexers.urbi import UrbiscriptLexer
|
||||
from pygments.lexers.smalltalk import SmalltalkLexer, NewspeakLexer
|
||||
from pygments.lexers.installers import NSISLexer, RPMSpecLexer
|
||||
from pygments.lexers.textedit import AwkLexer
|
||||
|
||||
__all__ = []
|
||||
@ -1,835 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.parsers
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for parser generators.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, DelegatingLexer, \
|
||||
include, bygroups, using
|
||||
from pygments.token import Punctuation, Other, Text, Comment, Operator, \
|
||||
Keyword, Name, String, Number, Whitespace
|
||||
from pygments.lexers.jvm import JavaLexer
|
||||
from pygments.lexers.c_cpp import CLexer, CppLexer
|
||||
from pygments.lexers.objective import ObjectiveCLexer
|
||||
from pygments.lexers.d import DLexer
|
||||
from pygments.lexers.dotnet import CSharpLexer
|
||||
from pygments.lexers.ruby import RubyLexer
|
||||
from pygments.lexers.python import PythonLexer
|
||||
from pygments.lexers.perl import PerlLexer
|
||||
|
||||
__all__ = ['RagelLexer', 'RagelEmbeddedLexer', 'RagelCLexer', 'RagelDLexer',
|
||||
'RagelCppLexer', 'RagelObjectiveCLexer', 'RagelRubyLexer',
|
||||
'RagelJavaLexer', 'AntlrLexer', 'AntlrPythonLexer',
|
||||
'AntlrPerlLexer', 'AntlrRubyLexer', 'AntlrCppLexer',
|
||||
# 'AntlrCLexer',
|
||||
'AntlrCSharpLexer', 'AntlrObjectiveCLexer',
|
||||
'AntlrJavaLexer', 'AntlrActionScriptLexer',
|
||||
'TreetopLexer', 'EbnfLexer']
|
||||
|
||||
|
||||
class RagelLexer(RegexLexer):
|
||||
"""
|
||||
A pure `Ragel <http://www.complang.org/ragel/>`_ lexer. Use this for
|
||||
fragments of Ragel. For ``.rl`` files, use RagelEmbeddedLexer instead
|
||||
(or one of the language-specific subclasses).
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel'
|
||||
aliases = ['ragel']
|
||||
filenames = []
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'\s+', Whitespace)
|
||||
],
|
||||
'comments': [
|
||||
(r'\#.*$', Comment),
|
||||
],
|
||||
'keywords': [
|
||||
(r'(access|action|alphtype)\b', Keyword),
|
||||
(r'(getkey|write|machine|include)\b', Keyword),
|
||||
(r'(any|ascii|extend|alpha|digit|alnum|lower|upper)\b', Keyword),
|
||||
(r'(xdigit|cntrl|graph|print|punct|space|zlen|empty)\b', Keyword)
|
||||
],
|
||||
'numbers': [
|
||||
(r'0x[0-9A-Fa-f]+', Number.Hex),
|
||||
(r'[+-]?[0-9]+', Number.Integer),
|
||||
],
|
||||
'literals': [
|
||||
(r'"(\\\\|\\"|[^"])*"', String), # double quote string
|
||||
(r"'(\\\\|\\'|[^'])*'", String), # single quote string
|
||||
(r'\[(\\\\|\\\]|[^\]])*\]', String), # square bracket literals
|
||||
(r'/(?!\*)(\\\\|\\/|[^/])*/', String.Regex), # regular expressions
|
||||
],
|
||||
'identifiers': [
|
||||
(r'[a-zA-Z_]\w*', Name.Variable),
|
||||
],
|
||||
'operators': [
|
||||
(r',', Operator), # Join
|
||||
(r'\||&|--?', Operator), # Union, Intersection and Subtraction
|
||||
(r'\.|<:|:>>?', Operator), # Concatention
|
||||
(r':', Operator), # Label
|
||||
(r'->', Operator), # Epsilon Transition
|
||||
(r'(>|\$|%|<|@|<>)(/|eof\b)', Operator), # EOF Actions
|
||||
(r'(>|\$|%|<|@|<>)(!|err\b)', Operator), # Global Error Actions
|
||||
(r'(>|\$|%|<|@|<>)(\^|lerr\b)', Operator), # Local Error Actions
|
||||
(r'(>|\$|%|<|@|<>)(~|to\b)', Operator), # To-State Actions
|
||||
(r'(>|\$|%|<|@|<>)(\*|from\b)', Operator), # From-State Actions
|
||||
(r'>|@|\$|%', Operator), # Transition Actions and Priorities
|
||||
(r'\*|\?|\+|\{[0-9]*,[0-9]*\}', Operator), # Repetition
|
||||
(r'!|\^', Operator), # Negation
|
||||
(r'\(|\)', Operator), # Grouping
|
||||
],
|
||||
'root': [
|
||||
include('literals'),
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
include('keywords'),
|
||||
include('numbers'),
|
||||
include('identifiers'),
|
||||
include('operators'),
|
||||
(r'\{', Punctuation, 'host'),
|
||||
(r'=', Operator),
|
||||
(r';', Punctuation),
|
||||
],
|
||||
'host': [
|
||||
(r'(' + r'|'.join(( # keep host code in largest possible chunks
|
||||
r'[^{}\'"/#]+', # exclude unsafe characters
|
||||
r'[^\\]\\[{}]', # allow escaped { or }
|
||||
|
||||
# strings and comments may safely contain unsafe characters
|
||||
r'"(\\\\|\\"|[^"])*"', # double quote string
|
||||
r"'(\\\\|\\'|[^'])*'", # single quote string
|
||||
r'//.*$\n?', # single line comment
|
||||
r'/\*(.|\n)*?\*/', # multi-line javadoc-style comment
|
||||
r'\#.*$\n?', # ruby comment
|
||||
|
||||
# regular expression: There's no reason for it to start
|
||||
# with a * and this stops confusion with comments.
|
||||
r'/(?!\*)(\\\\|\\/|[^/])*/',
|
||||
|
||||
# / is safe now that we've handled regex and javadoc comments
|
||||
r'/',
|
||||
)) + r')+', Other),
|
||||
|
||||
(r'\{', Punctuation, '#push'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class RagelEmbeddedLexer(RegexLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ embedded in a host language file.
|
||||
|
||||
This will only highlight Ragel statements. If you want host language
|
||||
highlighting then call the language-specific Ragel lexer.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Embedded Ragel'
|
||||
aliases = ['ragel-em']
|
||||
filenames = ['*.rl']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'(' + r'|'.join(( # keep host code in largest possible chunks
|
||||
r'[^%\'"/#]+', # exclude unsafe characters
|
||||
r'%(?=[^%]|$)', # a single % sign is okay, just not 2 of them
|
||||
|
||||
# strings and comments may safely contain unsafe characters
|
||||
r'"(\\\\|\\"|[^"])*"', # double quote string
|
||||
r"'(\\\\|\\'|[^'])*'", # single quote string
|
||||
r'/\*(.|\n)*?\*/', # multi-line javadoc-style comment
|
||||
r'//.*$\n?', # single line comment
|
||||
r'\#.*$\n?', # ruby/ragel comment
|
||||
r'/(?!\*)(\\\\|\\/|[^/])*/', # regular expression
|
||||
|
||||
# / is safe now that we've handled regex and javadoc comments
|
||||
r'/',
|
||||
)) + r')+', Other),
|
||||
|
||||
# Single Line FSM.
|
||||
# Please don't put a quoted newline in a single line FSM.
|
||||
# That's just mean. It will break this.
|
||||
(r'(%%)(?![{%])(.*)($|;)(\n?)', bygroups(Punctuation,
|
||||
using(RagelLexer),
|
||||
Punctuation, Text)),
|
||||
|
||||
# Multi Line FSM.
|
||||
(r'(%%%%|%%)\{', Punctuation, 'multi-line-fsm'),
|
||||
],
|
||||
'multi-line-fsm': [
|
||||
(r'(' + r'|'.join(( # keep ragel code in largest possible chunks.
|
||||
r'(' + r'|'.join((
|
||||
r'[^}\'"\[/#]', # exclude unsafe characters
|
||||
r'\}(?=[^%]|$)', # } is okay as long as it's not followed by %
|
||||
r'\}%(?=[^%]|$)', # ...well, one %'s okay, just not two...
|
||||
r'[^\\]\\[{}]', # ...and } is okay if it's escaped
|
||||
|
||||
# allow / if it's preceded with one of these symbols
|
||||
# (ragel EOF actions)
|
||||
r'(>|\$|%|<|@|<>)/',
|
||||
|
||||
# specifically allow regex followed immediately by *
|
||||
# so it doesn't get mistaken for a comment
|
||||
r'/(?!\*)(\\\\|\\/|[^/])*/\*',
|
||||
|
||||
# allow / as long as it's not followed by another / or by a *
|
||||
r'/(?=[^/*]|$)',
|
||||
|
||||
# We want to match as many of these as we can in one block.
|
||||
# Not sure if we need the + sign here,
|
||||
# does it help performance?
|
||||
)) + r')+',
|
||||
|
||||
# strings and comments may safely contain unsafe characters
|
||||
r'"(\\\\|\\"|[^"])*"', # double quote string
|
||||
r"'(\\\\|\\'|[^'])*'", # single quote string
|
||||
r"\[(\\\\|\\\]|[^\]])*\]", # square bracket literal
|
||||
r'/\*(.|\n)*?\*/', # multi-line javadoc-style comment
|
||||
r'//.*$\n?', # single line comment
|
||||
r'\#.*$\n?', # ruby/ragel comment
|
||||
)) + r')+', using(RagelLexer)),
|
||||
|
||||
(r'\}%%', Punctuation, '#pop'),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: indep' in text
|
||||
|
||||
|
||||
class RagelRubyLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ in a Ruby host file.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel in Ruby Host'
|
||||
aliases = ['ragel-ruby', 'ragel-rb']
|
||||
filenames = ['*.rl']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(RagelRubyLexer, self).__init__(RubyLexer, RagelEmbeddedLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: ruby' in text
|
||||
|
||||
|
||||
class RagelCLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ in a C host file.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel in C Host'
|
||||
aliases = ['ragel-c']
|
||||
filenames = ['*.rl']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(RagelCLexer, self).__init__(CLexer, RagelEmbeddedLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: c' in text
|
||||
|
||||
|
||||
class RagelDLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ in a D host file.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel in D Host'
|
||||
aliases = ['ragel-d']
|
||||
filenames = ['*.rl']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(RagelDLexer, self).__init__(DLexer, RagelEmbeddedLexer, **options)
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: d' in text
|
||||
|
||||
|
||||
class RagelCppLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ in a CPP host file.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel in CPP Host'
|
||||
aliases = ['ragel-cpp']
|
||||
filenames = ['*.rl']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(RagelCppLexer, self).__init__(CppLexer, RagelEmbeddedLexer, **options)
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: c++' in text
|
||||
|
||||
|
||||
class RagelObjectiveCLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ in an Objective C host file.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel in Objective C Host'
|
||||
aliases = ['ragel-objc']
|
||||
filenames = ['*.rl']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(RagelObjectiveCLexer, self).__init__(ObjectiveCLexer,
|
||||
RagelEmbeddedLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: objc' in text
|
||||
|
||||
|
||||
class RagelJavaLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Ragel`_ in a Java host file.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Ragel in Java Host'
|
||||
aliases = ['ragel-java']
|
||||
filenames = ['*.rl']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(RagelJavaLexer, self).__init__(JavaLexer, RagelEmbeddedLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return '@LANG: java' in text
|
||||
|
||||
|
||||
class AntlrLexer(RegexLexer):
|
||||
"""
|
||||
Generic `ANTLR`_ Lexer.
|
||||
Should not be called directly, instead
|
||||
use DelegatingLexer for your target language.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
|
||||
.. _ANTLR: http://www.antlr.org/
|
||||
"""
|
||||
|
||||
name = 'ANTLR'
|
||||
aliases = ['antlr']
|
||||
filenames = []
|
||||
|
||||
_id = r'[A-Za-z]\w*'
|
||||
_TOKEN_REF = r'[A-Z]\w*'
|
||||
_RULE_REF = r'[a-z]\w*'
|
||||
_STRING_LITERAL = r'\'(?:\\\\|\\\'|[^\']*)\''
|
||||
_INT = r'[0-9]+'
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'\s+', Whitespace),
|
||||
],
|
||||
'comments': [
|
||||
(r'//.*$', Comment),
|
||||
(r'/\*(.|\n)*?\*/', Comment),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
|
||||
(r'(lexer|parser|tree)?(\s*)(grammar\b)(\s*)(' + _id + ')(;)',
|
||||
bygroups(Keyword, Whitespace, Keyword, Whitespace, Name.Class,
|
||||
Punctuation)),
|
||||
# optionsSpec
|
||||
(r'options\b', Keyword, 'options'),
|
||||
# tokensSpec
|
||||
(r'tokens\b', Keyword, 'tokens'),
|
||||
# attrScope
|
||||
(r'(scope)(\s*)(' + _id + ')(\s*)(\{)',
|
||||
bygroups(Keyword, Whitespace, Name.Variable, Whitespace,
|
||||
Punctuation), 'action'),
|
||||
# exception
|
||||
(r'(catch|finally)\b', Keyword, 'exception'),
|
||||
# action
|
||||
(r'(@' + _id + ')(\s*)(::)?(\s*)(' + _id + ')(\s*)(\{)',
|
||||
bygroups(Name.Label, Whitespace, Punctuation, Whitespace,
|
||||
Name.Label, Whitespace, Punctuation), 'action'),
|
||||
# rule
|
||||
(r'((?:protected|private|public|fragment)\b)?(\s*)(' + _id + ')(!)?',
|
||||
bygroups(Keyword, Whitespace, Name.Label, Punctuation),
|
||||
('rule-alts', 'rule-prelims')),
|
||||
],
|
||||
'exception': [
|
||||
(r'\n', Whitespace, '#pop'),
|
||||
(r'\s', Whitespace),
|
||||
include('comments'),
|
||||
|
||||
(r'\[', Punctuation, 'nested-arg-action'),
|
||||
(r'\{', Punctuation, 'action'),
|
||||
],
|
||||
'rule-prelims': [
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
|
||||
(r'returns\b', Keyword),
|
||||
(r'\[', Punctuation, 'nested-arg-action'),
|
||||
(r'\{', Punctuation, 'action'),
|
||||
# throwsSpec
|
||||
(r'(throws)(\s+)(' + _id + ')',
|
||||
bygroups(Keyword, Whitespace, Name.Label)),
|
||||
(r'(,)(\s*)(' + _id + ')',
|
||||
bygroups(Punctuation, Whitespace, Name.Label)), # Additional throws
|
||||
# optionsSpec
|
||||
(r'options\b', Keyword, 'options'),
|
||||
# ruleScopeSpec - scope followed by target language code or name of action
|
||||
# TODO finish implementing other possibilities for scope
|
||||
# L173 ANTLRv3.g from ANTLR book
|
||||
(r'(scope)(\s+)(\{)', bygroups(Keyword, Whitespace, Punctuation),
|
||||
'action'),
|
||||
(r'(scope)(\s+)(' + _id + ')(\s*)(;)',
|
||||
bygroups(Keyword, Whitespace, Name.Label, Whitespace, Punctuation)),
|
||||
# ruleAction
|
||||
(r'(@' + _id + ')(\s*)(\{)',
|
||||
bygroups(Name.Label, Whitespace, Punctuation), 'action'),
|
||||
# finished prelims, go to rule alts!
|
||||
(r':', Punctuation, '#pop')
|
||||
],
|
||||
'rule-alts': [
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
|
||||
# These might need to go in a separate 'block' state triggered by (
|
||||
(r'options\b', Keyword, 'options'),
|
||||
(r':', Punctuation),
|
||||
|
||||
# literals
|
||||
(r"'(\\\\|\\'|[^'])*'", String),
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
(r'<<([^>]|>[^>])>>', String),
|
||||
# identifiers
|
||||
# Tokens start with capital letter.
|
||||
(r'\$?[A-Z_]\w*', Name.Constant),
|
||||
# Rules start with small letter.
|
||||
(r'\$?[a-z_]\w*', Name.Variable),
|
||||
# operators
|
||||
(r'(\+|\||->|=>|=|\(|\)|\.\.|\.|\?|\*|\^|!|\#|~)', Operator),
|
||||
(r',', Punctuation),
|
||||
(r'\[', Punctuation, 'nested-arg-action'),
|
||||
(r'\{', Punctuation, 'action'),
|
||||
(r';', Punctuation, '#pop')
|
||||
],
|
||||
'tokens': [
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
(r'\{', Punctuation),
|
||||
(r'(' + _TOKEN_REF + r')(\s*)(=)?(\s*)(' + _STRING_LITERAL
|
||||
+ ')?(\s*)(;)',
|
||||
bygroups(Name.Label, Whitespace, Punctuation, Whitespace,
|
||||
String, Whitespace, Punctuation)),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
'options': [
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
(r'\{', Punctuation),
|
||||
(r'(' + _id + r')(\s*)(=)(\s*)(' +
|
||||
'|'.join((_id, _STRING_LITERAL, _INT, '\*')) + ')(\s*)(;)',
|
||||
bygroups(Name.Variable, Whitespace, Punctuation, Whitespace,
|
||||
Text, Whitespace, Punctuation)),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
'action': [
|
||||
(r'(' + r'|'.join(( # keep host code in largest possible chunks
|
||||
r'[^${}\'"/\\]+', # exclude unsafe characters
|
||||
|
||||
# strings and comments may safely contain unsafe characters
|
||||
r'"(\\\\|\\"|[^"])*"', # double quote string
|
||||
r"'(\\\\|\\'|[^'])*'", # single quote string
|
||||
r'//.*$\n?', # single line comment
|
||||
r'/\*(.|\n)*?\*/', # multi-line javadoc-style comment
|
||||
|
||||
# regular expression: There's no reason for it to start
|
||||
# with a * and this stops confusion with comments.
|
||||
r'/(?!\*)(\\\\|\\/|[^/])*/',
|
||||
|
||||
# backslashes are okay, as long as we are not backslashing a %
|
||||
r'\\(?!%)',
|
||||
|
||||
# Now that we've handled regex and javadoc comments
|
||||
# it's safe to let / through.
|
||||
r'/',
|
||||
)) + r')+', Other),
|
||||
(r'(\\)(%)', bygroups(Punctuation, Other)),
|
||||
(r'(\$[a-zA-Z]+)(\.?)(text|value)?',
|
||||
bygroups(Name.Variable, Punctuation, Name.Property)),
|
||||
(r'\{', Punctuation, '#push'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
'nested-arg-action': [
|
||||
(r'(' + r'|'.join(( # keep host code in largest possible chunks.
|
||||
r'[^$\[\]\'"/]+', # exclude unsafe characters
|
||||
|
||||
# strings and comments may safely contain unsafe characters
|
||||
r'"(\\\\|\\"|[^"])*"', # double quote string
|
||||
r"'(\\\\|\\'|[^'])*'", # single quote string
|
||||
r'//.*$\n?', # single line comment
|
||||
r'/\*(.|\n)*?\*/', # multi-line javadoc-style comment
|
||||
|
||||
# regular expression: There's no reason for it to start
|
||||
# with a * and this stops confusion with comments.
|
||||
r'/(?!\*)(\\\\|\\/|[^/])*/',
|
||||
|
||||
# Now that we've handled regex and javadoc comments
|
||||
# it's safe to let / through.
|
||||
r'/',
|
||||
)) + r')+', Other),
|
||||
|
||||
|
||||
(r'\[', Punctuation, '#push'),
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
(r'(\$[a-zA-Z]+)(\.?)(text|value)?',
|
||||
bygroups(Name.Variable, Punctuation, Name.Property)),
|
||||
(r'(\\\\|\\\]|\\\[|[^\[\]])+', Other),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
return re.search(r'^\s*grammar\s+[a-zA-Z0-9]+\s*;', text, re.M)
|
||||
|
||||
# http://www.antlr.org/wiki/display/ANTLR3/Code+Generation+Targets
|
||||
|
||||
# TH: I'm not aware of any language features of C++ that will cause
|
||||
# incorrect lexing of C files. Antlr doesn't appear to make a distinction,
|
||||
# so just assume they're C++. No idea how to make Objective C work in the
|
||||
# future.
|
||||
|
||||
# class AntlrCLexer(DelegatingLexer):
|
||||
# """
|
||||
# ANTLR with C Target
|
||||
#
|
||||
# .. versionadded:: 1.1
|
||||
# """
|
||||
#
|
||||
# name = 'ANTLR With C Target'
|
||||
# aliases = ['antlr-c']
|
||||
# filenames = ['*.G', '*.g']
|
||||
#
|
||||
# def __init__(self, **options):
|
||||
# super(AntlrCLexer, self).__init__(CLexer, AntlrLexer, **options)
|
||||
#
|
||||
# def analyse_text(text):
|
||||
# return re.match(r'^\s*language\s*=\s*C\s*;', text)
|
||||
|
||||
|
||||
class AntlrCppLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with CPP Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With CPP Target'
|
||||
aliases = ['antlr-cpp']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrCppLexer, self).__init__(CppLexer, AntlrLexer, **options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*C\s*;', text, re.M)
|
||||
|
||||
|
||||
class AntlrObjectiveCLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with Objective-C Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With ObjectiveC Target'
|
||||
aliases = ['antlr-objc']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrObjectiveCLexer, self).__init__(ObjectiveCLexer,
|
||||
AntlrLexer, **options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*ObjC\s*;', text)
|
||||
|
||||
|
||||
class AntlrCSharpLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with C# Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With C# Target'
|
||||
aliases = ['antlr-csharp', 'antlr-c#']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrCSharpLexer, self).__init__(CSharpLexer, AntlrLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*CSharp2\s*;', text, re.M)
|
||||
|
||||
|
||||
class AntlrPythonLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with Python Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With Python Target'
|
||||
aliases = ['antlr-python']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrPythonLexer, self).__init__(PythonLexer, AntlrLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*Python\s*;', text, re.M)
|
||||
|
||||
|
||||
class AntlrJavaLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with Java Target
|
||||
|
||||
.. versionadded:: 1.
|
||||
"""
|
||||
|
||||
name = 'ANTLR With Java Target'
|
||||
aliases = ['antlr-java']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrJavaLexer, self).__init__(JavaLexer, AntlrLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
# Antlr language is Java by default
|
||||
return AntlrLexer.analyse_text(text) and 0.9
|
||||
|
||||
|
||||
class AntlrRubyLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with Ruby Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With Ruby Target'
|
||||
aliases = ['antlr-ruby', 'antlr-rb']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrRubyLexer, self).__init__(RubyLexer, AntlrLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*Ruby\s*;', text, re.M)
|
||||
|
||||
|
||||
class AntlrPerlLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with Perl Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With Perl Target'
|
||||
aliases = ['antlr-perl']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(AntlrPerlLexer, self).__init__(PerlLexer, AntlrLexer,
|
||||
**options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*Perl5\s*;', text, re.M)
|
||||
|
||||
|
||||
class AntlrActionScriptLexer(DelegatingLexer):
|
||||
"""
|
||||
`ANTLR`_ with ActionScript Target
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'ANTLR With ActionScript Target'
|
||||
aliases = ['antlr-as', 'antlr-actionscript']
|
||||
filenames = ['*.G', '*.g']
|
||||
|
||||
def __init__(self, **options):
|
||||
from pygments.lexers.actionscript import ActionScriptLexer
|
||||
super(AntlrActionScriptLexer, self).__init__(ActionScriptLexer,
|
||||
AntlrLexer, **options)
|
||||
|
||||
def analyse_text(text):
|
||||
return AntlrLexer.analyse_text(text) and \
|
||||
re.search(r'^\s*language\s*=\s*ActionScript\s*;', text, re.M)
|
||||
|
||||
|
||||
class TreetopBaseLexer(RegexLexer):
|
||||
"""
|
||||
A base lexer for `Treetop <http://treetop.rubyforge.org/>`_ grammars.
|
||||
Not for direct use; use TreetopLexer instead.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('space'),
|
||||
(r'require[ \t]+[^\n\r]+[\n\r]', Other),
|
||||
(r'module\b', Keyword.Namespace, 'module'),
|
||||
(r'grammar\b', Keyword, 'grammar'),
|
||||
],
|
||||
'module': [
|
||||
include('space'),
|
||||
include('end'),
|
||||
(r'module\b', Keyword, '#push'),
|
||||
(r'grammar\b', Keyword, 'grammar'),
|
||||
(r'[A-Z]\w*(?:::[A-Z]\w*)*', Name.Namespace),
|
||||
],
|
||||
'grammar': [
|
||||
include('space'),
|
||||
include('end'),
|
||||
(r'rule\b', Keyword, 'rule'),
|
||||
(r'include\b', Keyword, 'include'),
|
||||
(r'[A-Z]\w*', Name),
|
||||
],
|
||||
'include': [
|
||||
include('space'),
|
||||
(r'[A-Z]\w*(?:::[A-Z]\w*)*', Name.Class, '#pop'),
|
||||
],
|
||||
'rule': [
|
||||
include('space'),
|
||||
include('end'),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'([A-Za-z_]\w*)(:)', bygroups(Name.Label, Punctuation)),
|
||||
(r'[A-Za-z_]\w*', Name),
|
||||
(r'[()]', Punctuation),
|
||||
(r'[?+*/&!~]', Operator),
|
||||
(r'\[(?:\\.|\[:\^?[a-z]+:\]|[^\\\]])+\]', String.Regex),
|
||||
(r'([0-9]*)(\.\.)([0-9]*)',
|
||||
bygroups(Number.Integer, Operator, Number.Integer)),
|
||||
(r'(<)([^>]+)(>)', bygroups(Punctuation, Name.Class, Punctuation)),
|
||||
(r'\{', Punctuation, 'inline_module'),
|
||||
(r'\.', String.Regex),
|
||||
],
|
||||
'inline_module': [
|
||||
(r'\{', Other, 'ruby'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
(r'[^{}]+', Other),
|
||||
],
|
||||
'ruby': [
|
||||
(r'\{', Other, '#push'),
|
||||
(r'\}', Other, '#pop'),
|
||||
(r'[^{}]+', Other),
|
||||
],
|
||||
'space': [
|
||||
(r'[ \t\n\r]+', Whitespace),
|
||||
(r'#[^\n]*', Comment.Single),
|
||||
],
|
||||
'end': [
|
||||
(r'end\b', Keyword, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class TreetopLexer(DelegatingLexer):
|
||||
"""
|
||||
A lexer for `Treetop <http://treetop.rubyforge.org/>`_ grammars.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'Treetop'
|
||||
aliases = ['treetop']
|
||||
filenames = ['*.treetop', '*.tt']
|
||||
|
||||
def __init__(self, **options):
|
||||
super(TreetopLexer, self).__init__(RubyLexer, TreetopBaseLexer, **options)
|
||||
|
||||
|
||||
class EbnfLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `ISO/IEC 14977 EBNF
|
||||
<http://en.wikipedia.org/wiki/Extended_Backus%E2%80%93Naur_Form>`_
|
||||
grammars.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'EBNF'
|
||||
aliases = ['ebnf']
|
||||
filenames = ['*.ebnf']
|
||||
mimetypes = ['text/x-ebnf']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
include('comment_start'),
|
||||
include('identifier'),
|
||||
(r'=', Operator, 'production'),
|
||||
],
|
||||
'production': [
|
||||
include('whitespace'),
|
||||
include('comment_start'),
|
||||
include('identifier'),
|
||||
(r'"[^"]*"', String.Double),
|
||||
(r"'[^']*'", String.Single),
|
||||
(r'(\?[^?]*\?)', Name.Entity),
|
||||
(r'[\[\]{}(),|]', Punctuation),
|
||||
(r'-', Operator),
|
||||
(r';', Punctuation, '#pop'),
|
||||
(r'\.', Punctuation, '#pop'),
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\s+', Text),
|
||||
],
|
||||
'comment_start': [
|
||||
(r'\(\*', Comment.Multiline, 'comment'),
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*)]', Comment.Multiline),
|
||||
include('comment_start'),
|
||||
(r'\*\)', Comment.Multiline, '#pop'),
|
||||
(r'[*)]', Comment.Multiline),
|
||||
],
|
||||
'identifier': [
|
||||
(r'([a-zA-Z][\w \-]*)', Keyword),
|
||||
],
|
||||
}
|
||||
@ -1,199 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.pawn
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for the Pawn languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error
|
||||
from pygments.util import get_bool_opt
|
||||
|
||||
__all__ = ['SourcePawnLexer', 'PawnLexer']
|
||||
|
||||
|
||||
class SourcePawnLexer(RegexLexer):
|
||||
"""
|
||||
For SourcePawn source code with preprocessor directives.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'SourcePawn'
|
||||
aliases = ['sp']
|
||||
filenames = ['*.sp']
|
||||
mimetypes = ['text/x-sourcepawn']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/\*.*?\*/)+'
|
||||
#: only one /* */ style comment
|
||||
_ws1 = r'\s*(?:/[*].*?[*]/\s*)*'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# preprocessor directives: without whitespace
|
||||
('^#if\s+0', Comment.Preproc, 'if0'),
|
||||
('^#', Comment.Preproc, 'macro'),
|
||||
# or with whitespace
|
||||
('^' + _ws1 + r'#if\s+0', Comment.Preproc, 'if0'),
|
||||
('^' + _ws1 + '#', Comment.Preproc, 'macro'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?\*(.|\n)*?\*(\\\n)?/', Comment.Multiline),
|
||||
(r'[{}]', Punctuation),
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[LlUu]*', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'0[0-7]+[LlUu]*', Number.Oct),
|
||||
(r'\d+[LlUu]*', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.;]', Punctuation),
|
||||
(r'(case|const|continue|native|'
|
||||
r'default|else|enum|for|if|new|operator|'
|
||||
r'public|return|sizeof|static|decl|struct|switch)\b', Keyword),
|
||||
(r'(bool|Float)\b', Keyword.Type),
|
||||
(r'(true|false)\b', Keyword.Constant),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/\*(.|\n)*?\*/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'if0': [
|
||||
(r'^\s*#if.*?(?<!\\)\n', Comment.Preproc, '#push'),
|
||||
(r'^\s*#endif.*?(?<!\\)\n', Comment.Preproc, '#pop'),
|
||||
(r'.*?\n', Comment),
|
||||
]
|
||||
}
|
||||
|
||||
SM_TYPES = set(('Action', 'bool', 'Float', 'Plugin', 'String', 'any',
|
||||
'AdminFlag', 'OverrideType', 'OverrideRule', 'ImmunityType',
|
||||
'GroupId', 'AdminId', 'AdmAccessMode', 'AdminCachePart',
|
||||
'CookieAccess', 'CookieMenu', 'CookieMenuAction', 'NetFlow',
|
||||
'ConVarBounds', 'QueryCookie', 'ReplySource',
|
||||
'ConVarQueryResult', 'ConVarQueryFinished', 'Function',
|
||||
'Action', 'Identity', 'PluginStatus', 'PluginInfo', 'DBResult',
|
||||
'DBBindType', 'DBPriority', 'PropType', 'PropFieldType',
|
||||
'MoveType', 'RenderMode', 'RenderFx', 'EventHookMode',
|
||||
'EventHook', 'FileType', 'FileTimeMode', 'PathType',
|
||||
'ParamType', 'ExecType', 'DialogType', 'Handle', 'KvDataTypes',
|
||||
'NominateResult', 'MapChange', 'MenuStyle', 'MenuAction',
|
||||
'MenuSource', 'RegexError', 'SDKCallType', 'SDKLibrary',
|
||||
'SDKFuncConfSource', 'SDKType', 'SDKPassMethod', 'RayType',
|
||||
'TraceEntityFilter', 'ListenOverride', 'SortOrder', 'SortType',
|
||||
'SortFunc2D', 'APLRes', 'FeatureType', 'FeatureStatus',
|
||||
'SMCResult', 'SMCError', 'TFClassType', 'TFTeam', 'TFCond',
|
||||
'TFResourceType', 'Timer', 'TopMenuAction', 'TopMenuObjectType',
|
||||
'TopMenuPosition', 'TopMenuObject', 'UserMsg'))
|
||||
|
||||
def __init__(self, **options):
|
||||
self.smhighlighting = get_bool_opt(options,
|
||||
'sourcemod', True)
|
||||
|
||||
self._functions = set()
|
||||
if self.smhighlighting:
|
||||
from pygments.lexers._sourcemod_builtins import FUNCTIONS
|
||||
self._functions.update(FUNCTIONS)
|
||||
RegexLexer.__init__(self, **options)
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name:
|
||||
if self.smhighlighting:
|
||||
if value in self.SM_TYPES:
|
||||
token = Keyword.Type
|
||||
elif value in self._functions:
|
||||
token = Name.Builtin
|
||||
yield index, token, value
|
||||
|
||||
|
||||
class PawnLexer(RegexLexer):
|
||||
"""
|
||||
For Pawn source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'Pawn'
|
||||
aliases = ['pawn']
|
||||
filenames = ['*.p', '*.pwn', '*.inc']
|
||||
mimetypes = ['text/x-pawn']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*][\w\W]*?[*]/)+'
|
||||
#: only one /* */ style comment
|
||||
_ws1 = r'\s*(?:/[*].*?[*]/\s*)*'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# preprocessor directives: without whitespace
|
||||
('^#if\s+0', Comment.Preproc, 'if0'),
|
||||
('^#', Comment.Preproc, 'macro'),
|
||||
# or with whitespace
|
||||
('^' + _ws1 + r'#if\s+0', Comment.Preproc, 'if0'),
|
||||
('^' + _ws1 + '#', Comment.Preproc, 'macro'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?\*[\w\W]*?\*(\\\n)?/', Comment.Multiline),
|
||||
(r'[{}]', Punctuation),
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[LlUu]*', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'0[0-7]+[LlUu]*', Number.Oct),
|
||||
(r'\d+[LlUu]*', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.;]', Punctuation),
|
||||
(r'(switch|case|default|const|new|static|char|continue|break|'
|
||||
r'if|else|for|while|do|operator|enum|'
|
||||
r'public|return|sizeof|tagof|state|goto)\b', Keyword),
|
||||
(r'(bool|Float)\b', Keyword.Type),
|
||||
(r'(true|false)\b', Keyword.Constant),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/\*(.|\n)*?\*/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'if0': [
|
||||
(r'^\s*#if.*?(?<!\\)\n', Comment.Preproc, '#push'),
|
||||
(r'^\s*#endif.*?(?<!\\)\n', Comment.Preproc, '#pop'),
|
||||
(r'.*?\n', Comment),
|
||||
]
|
||||
}
|
||||
@ -1,245 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.php
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for PHP and related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, default, using, this
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Other
|
||||
from pygments.util import get_bool_opt, get_list_opt, iteritems
|
||||
|
||||
__all__ = ['ZephirLexer', 'PhpLexer']
|
||||
|
||||
|
||||
class ZephirLexer(RegexLexer):
|
||||
"""
|
||||
For `Zephir language <http://zephir-lang.com/>`_ source code.
|
||||
|
||||
Zephir is a compiled high level language aimed
|
||||
to the creation of C-extensions for PHP.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'Zephir'
|
||||
aliases = ['zephir']
|
||||
filenames = ['*.zep']
|
||||
|
||||
zephir_keywords = ['fetch', 'echo', 'isset', 'empty']
|
||||
zephir_type = ['bit', 'bits', 'string']
|
||||
|
||||
flags = re.DOTALL | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'commentsandwhitespace': [
|
||||
(r'\s+', Text),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline)
|
||||
],
|
||||
'slashstartsregex': [
|
||||
include('commentsandwhitespace'),
|
||||
(r'/(\\.|[^[/\\\n]|\[(\\.|[^\]\\\n])*])+/'
|
||||
r'([gim]+\b|\B)', String.Regex, '#pop'),
|
||||
default('#pop')
|
||||
],
|
||||
'badregex': [
|
||||
(r'\n', Text, '#pop')
|
||||
],
|
||||
'root': [
|
||||
(r'^(?=\s|/|<!--)', Text, 'slashstartsregex'),
|
||||
include('commentsandwhitespace'),
|
||||
(r'\+\+|--|~|&&|\?|:|\|\||\\(?=\n)|'
|
||||
r'(<<|>>>?|==?|!=?|->|[-<>+*%&|^/])=?', Operator, 'slashstartsregex'),
|
||||
(r'[{(\[;,]', Punctuation, 'slashstartsregex'),
|
||||
(r'[})\].]', Punctuation),
|
||||
(r'(for|in|while|do|break|return|continue|switch|case|default|if|else|loop|'
|
||||
r'require|inline|throw|try|catch|finally|new|delete|typeof|instanceof|void|'
|
||||
r'namespace|use|extends|this|fetch|isset|unset|echo|fetch|likely|unlikely|'
|
||||
r'empty)\b', Keyword, 'slashstartsregex'),
|
||||
(r'(var|let|with|function)\b', Keyword.Declaration, 'slashstartsregex'),
|
||||
(r'(abstract|boolean|bool|char|class|const|double|enum|export|extends|final|'
|
||||
r'native|goto|implements|import|int|string|interface|long|ulong|char|uchar|'
|
||||
r'float|unsigned|private|protected|public|short|static|self|throws|reverse|'
|
||||
r'transient|volatile)\b', Keyword.Reserved),
|
||||
(r'(true|false|null|undefined)\b', Keyword.Constant),
|
||||
(r'(Array|Boolean|Date|_REQUEST|_COOKIE|_SESSION|'
|
||||
r'_GET|_POST|_SERVER|this|stdClass|range|count|iterator|'
|
||||
r'window)\b', Name.Builtin),
|
||||
(r'[$a-zA-Z_][\w\\]*', Name.Other),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class PhpLexer(RegexLexer):
|
||||
"""
|
||||
For `PHP <http://www.php.net/>`_ source code.
|
||||
For PHP embedded in HTML, use the `HtmlPhpLexer`.
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
`startinline`
|
||||
If given and ``True`` the lexer starts highlighting with
|
||||
php code (i.e.: no starting ``<?php`` required). The default
|
||||
is ``False``.
|
||||
`funcnamehighlighting`
|
||||
If given and ``True``, highlight builtin function names
|
||||
(default: ``True``).
|
||||
`disabledmodules`
|
||||
If given, must be a list of module names whose function names
|
||||
should not be highlighted. By default all modules are highlighted
|
||||
except the special ``'unknown'`` module that includes functions
|
||||
that are known to php but are undocumented.
|
||||
|
||||
To get a list of allowed modules have a look into the
|
||||
`_php_builtins` module:
|
||||
|
||||
.. sourcecode:: pycon
|
||||
|
||||
>>> from pygments.lexers._php_builtins import MODULES
|
||||
>>> MODULES.keys()
|
||||
['PHP Options/Info', 'Zip', 'dba', ...]
|
||||
|
||||
In fact the names of those modules match the module names from
|
||||
the php documentation.
|
||||
"""
|
||||
|
||||
name = 'PHP'
|
||||
aliases = ['php', 'php3', 'php4', 'php5']
|
||||
filenames = ['*.php', '*.php[345]', '*.inc']
|
||||
mimetypes = ['text/x-php']
|
||||
|
||||
# Note that a backslash is included in the following two patterns
|
||||
# PHP uses a backslash as a namespace separator
|
||||
_ident_char = r'[\\\w]|[^\x00-\x7f]'
|
||||
_ident_begin = r'(?:[\\_a-z]|[^\x00-\x7f])'
|
||||
_ident_end = r'(?:' + _ident_char + ')*'
|
||||
_ident_inner = _ident_begin + _ident_end
|
||||
|
||||
flags = re.IGNORECASE | re.DOTALL | re.MULTILINE
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'<\?(php)?', Comment.Preproc, 'php'),
|
||||
(r'[^<]+', Other),
|
||||
(r'<', Other)
|
||||
],
|
||||
'php': [
|
||||
(r'\?>', Comment.Preproc, '#pop'),
|
||||
(r'<<<([\'"]?)(' + _ident_inner + r')\1\n.*?\n\s*\2;?\n', String),
|
||||
(r'\s+', Text),
|
||||
(r'#.*?\n', Comment.Single),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
# put the empty comment here, it is otherwise seen as
|
||||
# the start of a docstring
|
||||
(r'/\*\*/', Comment.Multiline),
|
||||
(r'/\*\*.*?\*/', String.Doc),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'(->|::)(\s*)(' + _ident_inner + ')',
|
||||
bygroups(Operator, Text, Name.Attribute)),
|
||||
(r'[~!%^&*+=|:.<>/@-]+', Operator),
|
||||
(r'\?', Operator), # don't add to the charclass above!
|
||||
(r'[\[\]{}();,]+', Punctuation),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(function)(\s*)(?=\()', bygroups(Keyword, Text)),
|
||||
(r'(function)(\s+)(&?)(\s*)',
|
||||
bygroups(Keyword, Text, Operator, Text), 'functionname'),
|
||||
(r'(const)(\s+)(' + _ident_inner + ')',
|
||||
bygroups(Keyword, Text, Name.Constant)),
|
||||
(r'(and|E_PARSE|old_function|E_ERROR|or|as|E_WARNING|parent|'
|
||||
r'eval|PHP_OS|break|exit|case|extends|PHP_VERSION|cfunction|'
|
||||
r'FALSE|print|for|require|continue|foreach|require_once|'
|
||||
r'declare|return|default|static|do|switch|die|stdClass|'
|
||||
r'echo|else|TRUE|elseif|var|empty|if|xor|enddeclare|include|'
|
||||
r'virtual|endfor|include_once|while|endforeach|global|__FILE__|'
|
||||
r'endif|list|__LINE__|endswitch|new|__sleep|endwhile|not|'
|
||||
r'array|__wakeup|E_ALL|NULL|final|php_user_filter|interface|'
|
||||
r'implements|public|private|protected|abstract|clone|try|'
|
||||
r'catch|throw|this|use|namespace|trait|yield|'
|
||||
r'finally)\b', Keyword),
|
||||
(r'(true|false|null)\b', Keyword.Constant),
|
||||
(r'\$\{\$+' + _ident_inner + '\}', Name.Variable),
|
||||
(r'\$+' + _ident_inner, Name.Variable),
|
||||
(_ident_inner, Name.Other),
|
||||
(r'(\d+\.\d*|\d*\.\d+)(e[+-]?[0-9]+)?', Number.Float),
|
||||
(r'\d+e[+-]?[0-9]+', Number.Float),
|
||||
(r'0[0-7]+', Number.Oct),
|
||||
(r'0x[a-f0-9]+', Number.Hex),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'0b[01]+', Number.Bin),
|
||||
(r"'([^'\\]*(?:\\.[^'\\]*)*)'", String.Single),
|
||||
(r'`([^`\\]*(?:\\.[^`\\]*)*)`', String.Backtick),
|
||||
(r'"', String.Double, 'string'),
|
||||
],
|
||||
'classname': [
|
||||
(_ident_inner, Name.Class, '#pop')
|
||||
],
|
||||
'functionname': [
|
||||
(_ident_inner, Name.Function, '#pop')
|
||||
],
|
||||
'string': [
|
||||
(r'"', String.Double, '#pop'),
|
||||
(r'[^{$"\\]+', String.Double),
|
||||
(r'\\([nrt"$\\]|[0-7]{1,3}|x[0-9a-f]{1,2})', String.Escape),
|
||||
(r'\$' + _ident_inner + '(\[\S+?\]|->' + _ident_inner + ')?',
|
||||
String.Interpol),
|
||||
(r'(\{\$\{)(.*?)(\}\})',
|
||||
bygroups(String.Interpol, using(this, _startinline=True),
|
||||
String.Interpol)),
|
||||
(r'(\{)(\$.*?)(\})',
|
||||
bygroups(String.Interpol, using(this, _startinline=True),
|
||||
String.Interpol)),
|
||||
(r'(\$\{)(\S+)(\})',
|
||||
bygroups(String.Interpol, Name.Variable, String.Interpol)),
|
||||
(r'[${\\]+', String.Double)
|
||||
],
|
||||
}
|
||||
|
||||
def __init__(self, **options):
|
||||
self.funcnamehighlighting = get_bool_opt(
|
||||
options, 'funcnamehighlighting', True)
|
||||
self.disabledmodules = get_list_opt(
|
||||
options, 'disabledmodules', ['unknown'])
|
||||
self.startinline = get_bool_opt(options, 'startinline', False)
|
||||
|
||||
# private option argument for the lexer itself
|
||||
if '_startinline' in options:
|
||||
self.startinline = options.pop('_startinline')
|
||||
|
||||
# collect activated functions in a set
|
||||
self._functions = set()
|
||||
if self.funcnamehighlighting:
|
||||
from pygments.lexers._php_builtins import MODULES
|
||||
for key, value in iteritems(MODULES):
|
||||
if key not in self.disabledmodules:
|
||||
self._functions.update(value)
|
||||
RegexLexer.__init__(self, **options)
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
stack = ['root']
|
||||
if self.startinline:
|
||||
stack.append('php')
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text, stack):
|
||||
if token is Name.Other:
|
||||
if value in self._functions:
|
||||
yield index, Name.Builtin, value
|
||||
continue
|
||||
yield index, token, value
|
||||
|
||||
def analyse_text(text):
|
||||
rv = 0.0
|
||||
if re.search(r'<\?(?!xml)', text):
|
||||
rv += 0.3
|
||||
return rv
|
||||
@ -1,833 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.python
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for Python and related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import Lexer, RegexLexer, include, bygroups, using, \
|
||||
default, words, combined, do_insertions
|
||||
from pygments.util import get_bool_opt, shebang_matches
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Generic, Other, Error
|
||||
from pygments import unistring as uni
|
||||
|
||||
__all__ = ['PythonLexer', 'PythonConsoleLexer', 'PythonTracebackLexer',
|
||||
'Python3Lexer', 'Python3TracebackLexer', 'CythonLexer',
|
||||
'DgLexer', 'NumPyLexer']
|
||||
|
||||
line_re = re.compile('.*?\n')
|
||||
|
||||
|
||||
class PythonLexer(RegexLexer):
|
||||
"""
|
||||
For `Python <http://www.python.org>`_ source code.
|
||||
"""
|
||||
|
||||
name = 'Python'
|
||||
aliases = ['python', 'py', 'sage']
|
||||
filenames = ['*.py', '*.pyw', '*.sc', 'SConstruct', 'SConscript', '*.tac', '*.sage']
|
||||
mimetypes = ['text/x-python', 'application/x-python']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'^(\s*)([rRuU]{,2}"""(?:.|\n)*?""")', bygroups(Text, String.Doc)),
|
||||
(r"^(\s*)([rRuU]{,2}'''(?:.|\n)*?''')", bygroups(Text, String.Doc)),
|
||||
(r'[^\S\n]+', Text),
|
||||
(r'#.*$', Comment),
|
||||
(r'[]{}:(),;[]', Punctuation),
|
||||
(r'\\\n', Text),
|
||||
(r'\\', Text),
|
||||
(r'(in|is|and|or|not)\b', Operator.Word),
|
||||
(r'!=|==|<<|>>|[-~+/*%=<>&^|.]', Operator),
|
||||
include('keywords'),
|
||||
(r'(def)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'funcname'),
|
||||
(r'(class)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(from)((?:\s|\\\s)+)', bygroups(Keyword.Namespace, Text),
|
||||
'fromimport'),
|
||||
(r'(import)((?:\s|\\\s)+)', bygroups(Keyword.Namespace, Text),
|
||||
'import'),
|
||||
include('builtins'),
|
||||
include('backtick'),
|
||||
('(?:[rR]|[uU][rR]|[rR][uU])"""', String, 'tdqs'),
|
||||
("(?:[rR]|[uU][rR]|[rR][uU])'''", String, 'tsqs'),
|
||||
('(?:[rR]|[uU][rR]|[rR][uU])"', String, 'dqs'),
|
||||
("(?:[rR]|[uU][rR]|[rR][uU])'", String, 'sqs'),
|
||||
('[uU]?"""', String, combined('stringescape', 'tdqs')),
|
||||
("[uU]?'''", String, combined('stringescape', 'tsqs')),
|
||||
('[uU]?"', String, combined('stringescape', 'dqs')),
|
||||
("[uU]?'", String, combined('stringescape', 'sqs')),
|
||||
include('name'),
|
||||
include('numbers'),
|
||||
],
|
||||
'keywords': [
|
||||
(words((
|
||||
'assert', 'break', 'continue', 'del', 'elif', 'else', 'except',
|
||||
'exec', 'finally', 'for', 'global', 'if', 'lambda', 'pass',
|
||||
'print', 'raise', 'return', 'try', 'while', 'yield',
|
||||
'yield from', 'as', 'with'), suffix=r'\b'),
|
||||
Keyword),
|
||||
],
|
||||
'builtins': [
|
||||
(words((
|
||||
'__import__', 'abs', 'all', 'any', 'apply', 'basestring', 'bin',
|
||||
'bool', 'buffer', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod',
|
||||
'cmp', 'coerce', 'compile', 'complex', 'delattr', 'dict', 'dir', 'divmod',
|
||||
'enumerate', 'eval', 'execfile', 'exit', 'file', 'filter', 'float',
|
||||
'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'hex', 'id',
|
||||
'input', 'int', 'intern', 'isinstance', 'issubclass', 'iter', 'len',
|
||||
'list', 'locals', 'long', 'map', 'max', 'min', 'next', 'object',
|
||||
'oct', 'open', 'ord', 'pow', 'property', 'range', 'raw_input', 'reduce',
|
||||
'reload', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice',
|
||||
'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type',
|
||||
'unichr', 'unicode', 'vars', 'xrange', 'zip'),
|
||||
prefix=r'(?<!\.)', suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'(?<!\.)(self|None|Ellipsis|NotImplemented|False|True'
|
||||
r')\b', Name.Builtin.Pseudo),
|
||||
(words((
|
||||
'ArithmeticError', 'AssertionError', 'AttributeError',
|
||||
'BaseException', 'DeprecationWarning', 'EOFError', 'EnvironmentError',
|
||||
'Exception', 'FloatingPointError', 'FutureWarning', 'GeneratorExit',
|
||||
'IOError', 'ImportError', 'ImportWarning', 'IndentationError',
|
||||
'IndexError', 'KeyError', 'KeyboardInterrupt', 'LookupError',
|
||||
'MemoryError', 'NameError', 'NotImplemented', 'NotImplementedError',
|
||||
'OSError', 'OverflowError', 'OverflowWarning', 'PendingDeprecationWarning',
|
||||
'ReferenceError', 'RuntimeError', 'RuntimeWarning', 'StandardError',
|
||||
'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError',
|
||||
'SystemExit', 'TabError', 'TypeError', 'UnboundLocalError',
|
||||
'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError',
|
||||
'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning',
|
||||
'ValueError', 'VMSError', 'Warning', 'WindowsError',
|
||||
'ZeroDivisionError'), prefix=r'(?<!\.)', suffix=r'\b'),
|
||||
Name.Exception),
|
||||
],
|
||||
'numbers': [
|
||||
(r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?j?', Number.Float),
|
||||
(r'\d+[eE][+-]?[0-9]+j?', Number.Float),
|
||||
(r'0[0-7]+j?', Number.Oct),
|
||||
(r'0[bB][01]+', Number.Bin),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+L', Number.Integer.Long),
|
||||
(r'\d+j?', Number.Integer)
|
||||
],
|
||||
'backtick': [
|
||||
('`.*?`', String.Backtick),
|
||||
],
|
||||
'name': [
|
||||
(r'@[\w.]+', Name.Decorator),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'funcname': [
|
||||
('[a-zA-Z_]\w*', Name.Function, '#pop')
|
||||
],
|
||||
'classname': [
|
||||
('[a-zA-Z_]\w*', Name.Class, '#pop')
|
||||
],
|
||||
'import': [
|
||||
(r'(?:[ \t]|\\\n)+', Text),
|
||||
(r'as\b', Keyword.Namespace),
|
||||
(r',', Operator),
|
||||
(r'[a-zA-Z_][\w.]*', Name.Namespace),
|
||||
default('#pop') # all else: go back
|
||||
],
|
||||
'fromimport': [
|
||||
(r'(?:[ \t]|\\\n)+', Text),
|
||||
(r'import\b', Keyword.Namespace, '#pop'),
|
||||
# if None occurs here, it's "raise x from None", since None can
|
||||
# never be a module name
|
||||
(r'None\b', Name.Builtin.Pseudo, '#pop'),
|
||||
# sadly, in "raise x from y" y will be highlighted as namespace too
|
||||
(r'[a-zA-Z_.][\w.]*', Name.Namespace),
|
||||
# anything else here also means "raise x from y" and is therefore
|
||||
# not an error
|
||||
default('#pop'),
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
|
||||
r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
|
||||
],
|
||||
'strings': [
|
||||
(r'%(\(\w+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
|
||||
'[hlL]?[diouxXeEfFgGcrs%]', String.Interpol),
|
||||
(r'[^\\\'"%\n]+', String),
|
||||
# quotes, percents and backslashes must be parsed one at a time
|
||||
(r'[\'"\\]', String),
|
||||
# unhandled string formatting sign
|
||||
(r'%', String)
|
||||
# newlines are an error (use "nl" state)
|
||||
],
|
||||
'nl': [
|
||||
(r'\n', String)
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\\\|\\"|\\\n', String.Escape), # included here for raw strings
|
||||
include('strings')
|
||||
],
|
||||
'sqs': [
|
||||
(r"'", String, '#pop'),
|
||||
(r"\\\\|\\'|\\\n", String.Escape), # included here for raw strings
|
||||
include('strings')
|
||||
],
|
||||
'tdqs': [
|
||||
(r'"""', String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl')
|
||||
],
|
||||
'tsqs': [
|
||||
(r"'''", String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl')
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
return shebang_matches(text, r'pythonw?(2(\.\d)?)?') or \
|
||||
'import ' in text[:1000]
|
||||
|
||||
|
||||
class Python3Lexer(RegexLexer):
|
||||
"""
|
||||
For `Python <http://www.python.org>`_ source code (version 3.0).
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
name = 'Python 3'
|
||||
aliases = ['python3', 'py3']
|
||||
filenames = [] # Nothing until Python 3 gets widespread
|
||||
mimetypes = ['text/x-python3', 'application/x-python3']
|
||||
|
||||
flags = re.MULTILINE | re.UNICODE
|
||||
|
||||
uni_name = "[%s][%s]*" % (uni.xid_start, uni.xid_continue)
|
||||
|
||||
tokens = PythonLexer.tokens.copy()
|
||||
tokens['keywords'] = [
|
||||
(words((
|
||||
'assert', 'break', 'continue', 'del', 'elif', 'else', 'except',
|
||||
'finally', 'for', 'global', 'if', 'lambda', 'pass', 'raise',
|
||||
'nonlocal', 'return', 'try', 'while', 'yield', 'yield from', 'as',
|
||||
'with', 'True', 'False', 'None'), suffix=r'\b'),
|
||||
Keyword),
|
||||
]
|
||||
tokens['builtins'] = [
|
||||
(words((
|
||||
'__import__', 'abs', 'all', 'any', 'bin', 'bool', 'bytearray', 'bytes',
|
||||
'chr', 'classmethod', 'cmp', 'compile', 'complex', 'delattr', 'dict',
|
||||
'dir', 'divmod', 'enumerate', 'eval', 'filter', 'float', 'format',
|
||||
'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'hex', 'id',
|
||||
'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'list',
|
||||
'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct',
|
||||
'open', 'ord', 'pow', 'print', 'property', 'range', 'repr', 'reversed',
|
||||
'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str',
|
||||
'sum', 'super', 'tuple', 'type', 'vars', 'zip'), prefix=r'(?<!\.)',
|
||||
suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'(?<!\.)(self|Ellipsis|NotImplemented)\b', Name.Builtin.Pseudo),
|
||||
(words((
|
||||
'ArithmeticError', 'AssertionError', 'AttributeError',
|
||||
'BaseException', 'BufferError', 'BytesWarning', 'DeprecationWarning',
|
||||
'EOFError', 'EnvironmentError', 'Exception', 'FloatingPointError',
|
||||
'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError',
|
||||
'ImportWarning', 'IndentationError', 'IndexError', 'KeyError',
|
||||
'KeyboardInterrupt', 'LookupError', 'MemoryError', 'NameError',
|
||||
'NotImplementedError', 'OSError', 'OverflowError',
|
||||
'PendingDeprecationWarning', 'ReferenceError',
|
||||
'RuntimeError', 'RuntimeWarning', 'StopIteration',
|
||||
'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError',
|
||||
'TypeError', 'UnboundLocalError', 'UnicodeDecodeError',
|
||||
'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError',
|
||||
'UnicodeWarning', 'UserWarning', 'ValueError', 'VMSError', 'Warning',
|
||||
'WindowsError', 'ZeroDivisionError',
|
||||
# new builtin exceptions from PEP 3151
|
||||
'BlockingIOError', 'ChildProcessError', 'ConnectionError',
|
||||
'BrokenPipeError', 'ConnectionAbortedError', 'ConnectionRefusedError',
|
||||
'ConnectionResetError', 'FileExistsError', 'FileNotFoundError',
|
||||
'InterruptedError', 'IsADirectoryError', 'NotADirectoryError',
|
||||
'PermissionError', 'ProcessLookupError', 'TimeoutError'),
|
||||
prefix=r'(?<!\.)', suffix=r'\b'),
|
||||
Name.Exception),
|
||||
]
|
||||
tokens['numbers'] = [
|
||||
(r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', Number.Float),
|
||||
(r'0[oO][0-7]+', Number.Oct),
|
||||
(r'0[bB][01]+', Number.Bin),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+', Number.Integer)
|
||||
]
|
||||
tokens['backtick'] = []
|
||||
tokens['name'] = [
|
||||
(r'@\w+', Name.Decorator),
|
||||
(uni_name, Name),
|
||||
]
|
||||
tokens['funcname'] = [
|
||||
(uni_name, Name.Function, '#pop')
|
||||
]
|
||||
tokens['classname'] = [
|
||||
(uni_name, Name.Class, '#pop')
|
||||
]
|
||||
tokens['import'] = [
|
||||
(r'(\s+)(as)(\s+)', bygroups(Text, Keyword, Text)),
|
||||
(r'\.', Name.Namespace),
|
||||
(uni_name, Name.Namespace),
|
||||
(r'(\s*)(,)(\s*)', bygroups(Text, Operator, Text)),
|
||||
default('#pop') # all else: go back
|
||||
]
|
||||
tokens['fromimport'] = [
|
||||
(r'(\s+)(import)\b', bygroups(Text, Keyword), '#pop'),
|
||||
(r'\.', Name.Namespace),
|
||||
(uni_name, Name.Namespace),
|
||||
default('#pop'),
|
||||
]
|
||||
# don't highlight "%s" substitutions
|
||||
tokens['strings'] = [
|
||||
(r'[^\\\'"%\n]+', String),
|
||||
# quotes, percents and backslashes must be parsed one at a time
|
||||
(r'[\'"\\]', String),
|
||||
# unhandled string formatting sign
|
||||
(r'%', String)
|
||||
# newlines are an error (use "nl" state)
|
||||
]
|
||||
|
||||
def analyse_text(text):
|
||||
return shebang_matches(text, r'pythonw?3(\.\d)?')
|
||||
|
||||
|
||||
class PythonConsoleLexer(Lexer):
|
||||
"""
|
||||
For Python console output or doctests, such as:
|
||||
|
||||
.. sourcecode:: pycon
|
||||
|
||||
>>> a = 'foo'
|
||||
>>> print a
|
||||
foo
|
||||
>>> 1 / 0
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
ZeroDivisionError: integer division or modulo by zero
|
||||
|
||||
Additional options:
|
||||
|
||||
`python3`
|
||||
Use Python 3 lexer for code. Default is ``False``.
|
||||
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
name = 'Python console session'
|
||||
aliases = ['pycon']
|
||||
mimetypes = ['text/x-python-doctest']
|
||||
|
||||
def __init__(self, **options):
|
||||
self.python3 = get_bool_opt(options, 'python3', False)
|
||||
Lexer.__init__(self, **options)
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
if self.python3:
|
||||
pylexer = Python3Lexer(**self.options)
|
||||
tblexer = Python3TracebackLexer(**self.options)
|
||||
else:
|
||||
pylexer = PythonLexer(**self.options)
|
||||
tblexer = PythonTracebackLexer(**self.options)
|
||||
|
||||
curcode = ''
|
||||
insertions = []
|
||||
curtb = ''
|
||||
tbindex = 0
|
||||
tb = 0
|
||||
for match in line_re.finditer(text):
|
||||
line = match.group()
|
||||
if line.startswith(u'>>> ') or line.startswith(u'... '):
|
||||
tb = 0
|
||||
insertions.append((len(curcode),
|
||||
[(0, Generic.Prompt, line[:4])]))
|
||||
curcode += line[4:]
|
||||
elif line.rstrip() == u'...' and not tb:
|
||||
# only a new >>> prompt can end an exception block
|
||||
# otherwise an ellipsis in place of the traceback frames
|
||||
# will be mishandled
|
||||
insertions.append((len(curcode),
|
||||
[(0, Generic.Prompt, u'...')]))
|
||||
curcode += line[3:]
|
||||
else:
|
||||
if curcode:
|
||||
for item in do_insertions(
|
||||
insertions, pylexer.get_tokens_unprocessed(curcode)):
|
||||
yield item
|
||||
curcode = ''
|
||||
insertions = []
|
||||
if (line.startswith(u'Traceback (most recent call last):') or
|
||||
re.match(u' File "[^"]+", line \\d+\\n$', line)):
|
||||
tb = 1
|
||||
curtb = line
|
||||
tbindex = match.start()
|
||||
elif line == 'KeyboardInterrupt\n':
|
||||
yield match.start(), Name.Class, line
|
||||
elif tb:
|
||||
curtb += line
|
||||
if not (line.startswith(' ') or line.strip() == u'...'):
|
||||
tb = 0
|
||||
for i, t, v in tblexer.get_tokens_unprocessed(curtb):
|
||||
yield tbindex+i, t, v
|
||||
else:
|
||||
yield match.start(), Generic.Output, line
|
||||
if curcode:
|
||||
for item in do_insertions(insertions,
|
||||
pylexer.get_tokens_unprocessed(curcode)):
|
||||
yield item
|
||||
if curtb:
|
||||
for i, t, v in tblexer.get_tokens_unprocessed(curtb):
|
||||
yield tbindex+i, t, v
|
||||
|
||||
|
||||
class PythonTracebackLexer(RegexLexer):
|
||||
"""
|
||||
For Python tracebacks.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
"""
|
||||
|
||||
name = 'Python Traceback'
|
||||
aliases = ['pytb']
|
||||
filenames = ['*.pytb']
|
||||
mimetypes = ['text/x-python-traceback']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^Traceback \(most recent call last\):\n',
|
||||
Generic.Traceback, 'intb'),
|
||||
# SyntaxError starts with this.
|
||||
(r'^(?= File "[^"]+", line \d+)', Generic.Traceback, 'intb'),
|
||||
(r'^.*\n', Other),
|
||||
],
|
||||
'intb': [
|
||||
(r'^( File )("[^"]+")(, line )(\d+)(, in )(.+)(\n)',
|
||||
bygroups(Text, Name.Builtin, Text, Number, Text, Name, Text)),
|
||||
(r'^( File )("[^"]+")(, line )(\d+)(\n)',
|
||||
bygroups(Text, Name.Builtin, Text, Number, Text)),
|
||||
(r'^( )(.+)(\n)',
|
||||
bygroups(Text, using(PythonLexer), Text)),
|
||||
(r'^([ \t]*)(\.\.\.)(\n)',
|
||||
bygroups(Text, Comment, Text)), # for doctests...
|
||||
(r'^([^:]+)(: )(.+)(\n)',
|
||||
bygroups(Generic.Error, Text, Name, Text), '#pop'),
|
||||
(r'^([a-zA-Z_]\w*)(:?\n)',
|
||||
bygroups(Generic.Error, Text), '#pop')
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class Python3TracebackLexer(RegexLexer):
|
||||
"""
|
||||
For Python 3.0 tracebacks, with support for chained exceptions.
|
||||
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'Python 3.0 Traceback'
|
||||
aliases = ['py3tb']
|
||||
filenames = ['*.py3tb']
|
||||
mimetypes = ['text/x-python3-traceback']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'^Traceback \(most recent call last\):\n', Generic.Traceback, 'intb'),
|
||||
(r'^During handling of the above exception, another '
|
||||
r'exception occurred:\n\n', Generic.Traceback),
|
||||
(r'^The above exception was the direct cause of the '
|
||||
r'following exception:\n\n', Generic.Traceback),
|
||||
(r'^(?= File "[^"]+", line \d+)', Generic.Traceback, 'intb'),
|
||||
],
|
||||
'intb': [
|
||||
(r'^( File )("[^"]+")(, line )(\d+)(, in )(.+)(\n)',
|
||||
bygroups(Text, Name.Builtin, Text, Number, Text, Name, Text)),
|
||||
(r'^( File )("[^"]+")(, line )(\d+)(\n)',
|
||||
bygroups(Text, Name.Builtin, Text, Number, Text)),
|
||||
(r'^( )(.+)(\n)',
|
||||
bygroups(Text, using(Python3Lexer), Text)),
|
||||
(r'^([ \t]*)(\.\.\.)(\n)',
|
||||
bygroups(Text, Comment, Text)), # for doctests...
|
||||
(r'^([^:]+)(: )(.+)(\n)',
|
||||
bygroups(Generic.Error, Text, Name, Text), '#pop'),
|
||||
(r'^([a-zA-Z_]\w*)(:?\n)',
|
||||
bygroups(Generic.Error, Text), '#pop')
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CythonLexer(RegexLexer):
|
||||
"""
|
||||
For Pyrex and `Cython <http://cython.org>`_ source code.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Cython'
|
||||
aliases = ['cython', 'pyx', 'pyrex']
|
||||
filenames = ['*.pyx', '*.pxd', '*.pxi']
|
||||
mimetypes = ['text/x-cython', 'application/x-cython']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'^(\s*)("""(?:.|\n)*?""")', bygroups(Text, String.Doc)),
|
||||
(r"^(\s*)('''(?:.|\n)*?''')", bygroups(Text, String.Doc)),
|
||||
(r'[^\S\n]+', Text),
|
||||
(r'#.*$', Comment),
|
||||
(r'[]{}:(),;[]', Punctuation),
|
||||
(r'\\\n', Text),
|
||||
(r'\\', Text),
|
||||
(r'(in|is|and|or|not)\b', Operator.Word),
|
||||
(r'(<)([a-zA-Z0-9.?]+)(>)',
|
||||
bygroups(Punctuation, Keyword.Type, Punctuation)),
|
||||
(r'!=|==|<<|>>|[-~+/*%=<>&^|.?]', Operator),
|
||||
(r'(from)(\d+)(<=)(\s+)(<)(\d+)(:)',
|
||||
bygroups(Keyword, Number.Integer, Operator, Name, Operator,
|
||||
Name, Punctuation)),
|
||||
include('keywords'),
|
||||
(r'(def|property)(\s+)', bygroups(Keyword, Text), 'funcname'),
|
||||
(r'(cp?def)(\s+)', bygroups(Keyword, Text), 'cdef'),
|
||||
(r'(class|struct)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(from)(\s+)', bygroups(Keyword, Text), 'fromimport'),
|
||||
(r'(c?import)(\s+)', bygroups(Keyword, Text), 'import'),
|
||||
include('builtins'),
|
||||
include('backtick'),
|
||||
('(?:[rR]|[uU][rR]|[rR][uU])"""', String, 'tdqs'),
|
||||
("(?:[rR]|[uU][rR]|[rR][uU])'''", String, 'tsqs'),
|
||||
('(?:[rR]|[uU][rR]|[rR][uU])"', String, 'dqs'),
|
||||
("(?:[rR]|[uU][rR]|[rR][uU])'", String, 'sqs'),
|
||||
('[uU]?"""', String, combined('stringescape', 'tdqs')),
|
||||
("[uU]?'''", String, combined('stringescape', 'tsqs')),
|
||||
('[uU]?"', String, combined('stringescape', 'dqs')),
|
||||
("[uU]?'", String, combined('stringescape', 'sqs')),
|
||||
include('name'),
|
||||
include('numbers'),
|
||||
],
|
||||
'keywords': [
|
||||
(words((
|
||||
'assert', 'break', 'by', 'continue', 'ctypedef', 'del', 'elif',
|
||||
'else', 'except', 'except?', 'exec', 'finally', 'for', 'gil',
|
||||
'global', 'if', 'include', 'lambda', 'nogil', 'pass', 'print',
|
||||
'raise', 'return', 'try', 'while', 'yield', 'as', 'with'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(DEF|IF|ELIF|ELSE)\b', Comment.Preproc),
|
||||
],
|
||||
'builtins': [
|
||||
(words((
|
||||
'__import__', 'abs', 'all', 'any', 'apply', 'basestring', 'bin',
|
||||
'bool', 'buffer', 'bytearray', 'bytes', 'callable', 'chr',
|
||||
'classmethod', 'cmp', 'coerce', 'compile', 'complex', 'delattr',
|
||||
'dict', 'dir', 'divmod', 'enumerate', 'eval', 'execfile', 'exit',
|
||||
'file', 'filter', 'float', 'frozenset', 'getattr', 'globals',
|
||||
'hasattr', 'hash', 'hex', 'id', 'input', 'int', 'intern', 'isinstance',
|
||||
'issubclass', 'iter', 'len', 'list', 'locals', 'long', 'map', 'max',
|
||||
'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'property',
|
||||
'range', 'raw_input', 'reduce', 'reload', 'repr', 'reversed',
|
||||
'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod',
|
||||
'str', 'sum', 'super', 'tuple', 'type', 'unichr', 'unicode',
|
||||
'vars', 'xrange', 'zip'), prefix=r'(?<!\.)', suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'(?<!\.)(self|None|Ellipsis|NotImplemented|False|True|NULL'
|
||||
r')\b', Name.Builtin.Pseudo),
|
||||
(words((
|
||||
'ArithmeticError', 'AssertionError', 'AttributeError',
|
||||
'BaseException', 'DeprecationWarning', 'EOFError', 'EnvironmentError',
|
||||
'Exception', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError',
|
||||
'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'KeyError',
|
||||
'KeyboardInterrupt', 'LookupError', 'MemoryError', 'NameError',
|
||||
'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError',
|
||||
'OverflowWarning', 'PendingDeprecationWarning', 'ReferenceError',
|
||||
'RuntimeError', 'RuntimeWarning', 'StandardError', 'StopIteration',
|
||||
'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError',
|
||||
'TypeError', 'UnboundLocalError', 'UnicodeDecodeError',
|
||||
'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError',
|
||||
'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning',
|
||||
'ZeroDivisionError'), prefix=r'(?<!\.)', suffix=r'\b'),
|
||||
Name.Exception),
|
||||
],
|
||||
'numbers': [
|
||||
(r'(\d+\.?\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', Number.Float),
|
||||
(r'0\d+', Number.Oct),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+L', Number.Integer.Long),
|
||||
(r'\d+', Number.Integer)
|
||||
],
|
||||
'backtick': [
|
||||
('`.*?`', String.Backtick),
|
||||
],
|
||||
'name': [
|
||||
(r'@\w+', Name.Decorator),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'funcname': [
|
||||
('[a-zA-Z_]\w*', Name.Function, '#pop')
|
||||
],
|
||||
'cdef': [
|
||||
(r'(public|readonly|extern|api|inline)\b', Keyword.Reserved),
|
||||
(r'(struct|enum|union|class)\b', Keyword),
|
||||
(r'([a-zA-Z_]\w*)(\s*)(?=[(:#=]|$)',
|
||||
bygroups(Name.Function, Text), '#pop'),
|
||||
(r'([a-zA-Z_]\w*)(\s*)(,)',
|
||||
bygroups(Name.Function, Text, Punctuation)),
|
||||
(r'from\b', Keyword, '#pop'),
|
||||
(r'as\b', Keyword),
|
||||
(r':', Punctuation, '#pop'),
|
||||
(r'(?=["\'])', Text, '#pop'),
|
||||
(r'[a-zA-Z_]\w*', Keyword.Type),
|
||||
(r'.', Text),
|
||||
],
|
||||
'classname': [
|
||||
('[a-zA-Z_]\w*', Name.Class, '#pop')
|
||||
],
|
||||
'import': [
|
||||
(r'(\s+)(as)(\s+)', bygroups(Text, Keyword, Text)),
|
||||
(r'[a-zA-Z_][\w.]*', Name.Namespace),
|
||||
(r'(\s*)(,)(\s*)', bygroups(Text, Operator, Text)),
|
||||
default('#pop') # all else: go back
|
||||
],
|
||||
'fromimport': [
|
||||
(r'(\s+)(c?import)\b', bygroups(Text, Keyword), '#pop'),
|
||||
(r'[a-zA-Z_.][\w.]*', Name.Namespace),
|
||||
# ``cdef foo from "header"``, or ``for foo from 0 < i < 10``
|
||||
default('#pop'),
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
|
||||
r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
|
||||
],
|
||||
'strings': [
|
||||
(r'%(\([a-zA-Z0-9]+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
|
||||
'[hlL]?[diouxXeEfFgGcrs%]', String.Interpol),
|
||||
(r'[^\\\'"%\n]+', String),
|
||||
# quotes, percents and backslashes must be parsed one at a time
|
||||
(r'[\'"\\]', String),
|
||||
# unhandled string formatting sign
|
||||
(r'%', String)
|
||||
# newlines are an error (use "nl" state)
|
||||
],
|
||||
'nl': [
|
||||
(r'\n', String)
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\\\|\\"|\\\n', String.Escape), # included here again for raw strings
|
||||
include('strings')
|
||||
],
|
||||
'sqs': [
|
||||
(r"'", String, '#pop'),
|
||||
(r"\\\\|\\'|\\\n", String.Escape), # included here again for raw strings
|
||||
include('strings')
|
||||
],
|
||||
'tdqs': [
|
||||
(r'"""', String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl')
|
||||
],
|
||||
'tsqs': [
|
||||
(r"'''", String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl')
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class DgLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `dg <http://pyos.github.com/dg>`_,
|
||||
a functional and object-oriented programming language
|
||||
running on the CPython 3 VM.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'dg'
|
||||
aliases = ['dg']
|
||||
filenames = ['*.dg']
|
||||
mimetypes = ['text/x-dg']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'#.*?$', Comment.Single),
|
||||
|
||||
(r'(?i)0b[01]+', Number.Bin),
|
||||
(r'(?i)0o[0-7]+', Number.Oct),
|
||||
(r'(?i)0x[0-9a-f]+', Number.Hex),
|
||||
(r'(?i)[+-]?[0-9]+\.[0-9]+(e[+-]?[0-9]+)?j?', Number.Float),
|
||||
(r'(?i)[+-]?[0-9]+e[+-]?\d+j?', Number.Float),
|
||||
(r'(?i)[+-]?[0-9]+j?', Number.Integer),
|
||||
|
||||
(r"(?i)(br|r?b?)'''", String, combined('stringescape', 'tsqs', 'string')),
|
||||
(r'(?i)(br|r?b?)"""', String, combined('stringescape', 'tdqs', 'string')),
|
||||
(r"(?i)(br|r?b?)'", String, combined('stringescape', 'sqs', 'string')),
|
||||
(r'(?i)(br|r?b?)"', String, combined('stringescape', 'dqs', 'string')),
|
||||
|
||||
(r"`\w+'*`", Operator),
|
||||
(r'\b(and|in|is|or|where)\b', Operator.Word),
|
||||
(r'[!$%&*+\-./:<-@\\^|~;,]+', Operator),
|
||||
|
||||
(words((
|
||||
'bool', 'bytearray', 'bytes', 'classmethod', 'complex', 'dict', 'dict\'',
|
||||
'float', 'frozenset', 'int', 'list', 'list\'', 'memoryview', 'object',
|
||||
'property', 'range', 'set', 'set\'', 'slice', 'staticmethod', 'str', 'super',
|
||||
'tuple', 'tuple\'', 'type'), prefix=r'(?<!\.)', suffix=r'(?![\'\w])'),
|
||||
Name.Builtin),
|
||||
(words((
|
||||
'__import__', 'abs', 'all', 'any', 'bin', 'bind', 'chr', 'cmp', 'compile',
|
||||
'complex', 'delattr', 'dir', 'divmod', 'drop', 'dropwhile', 'enumerate',
|
||||
'eval', 'exhaust', 'filter', 'flip', 'foldl1?', 'format', 'fst', 'getattr',
|
||||
'globals', 'hasattr', 'hash', 'head', 'hex', 'id', 'init', 'input',
|
||||
'isinstance', 'issubclass', 'iter', 'iterate', 'last', 'len', 'locals',
|
||||
'map', 'max', 'min', 'next', 'oct', 'open', 'ord', 'pow', 'print', 'repr',
|
||||
'reversed', 'round', 'setattr', 'scanl1?', 'snd', 'sorted', 'sum', 'tail',
|
||||
'take', 'takewhile', 'vars', 'zip'), prefix=r'(?<!\.)', suffix=r'(?![\'\w])'),
|
||||
Name.Builtin),
|
||||
(r"(?<!\.)(self|Ellipsis|NotImplemented|None|True|False)(?!['\w])",
|
||||
Name.Builtin.Pseudo),
|
||||
|
||||
(r"(?<!\.)[A-Z]\w*(Error|Exception|Warning)'*(?!['\w])",
|
||||
Name.Exception),
|
||||
(r"(?<!\.)(Exception|GeneratorExit|KeyboardInterrupt|StopIteration|"
|
||||
r"SystemExit)(?!['\w])", Name.Exception),
|
||||
|
||||
(r"(?<![\w.])(except|finally|for|if|import|not|otherwise|raise|"
|
||||
r"subclass|while|with|yield)(?!['\w])", Keyword.Reserved),
|
||||
|
||||
(r"[A-Z_]+'*(?!['\w])", Name),
|
||||
(r"[A-Z]\w+'*(?!['\w])", Keyword.Type),
|
||||
(r"\w+'*", Name),
|
||||
|
||||
(r'[()]', Punctuation),
|
||||
(r'.', Error),
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\\([\\abfnrtv"\']|\n|N\{.*?\}|u[a-fA-F0-9]{4}|'
|
||||
r'U[a-fA-F0-9]{8}|x[a-fA-F0-9]{2}|[0-7]{1,3})', String.Escape)
|
||||
],
|
||||
'string': [
|
||||
(r'%(\(\w+\))?[-#0 +]*([0-9]+|[*])?(\.([0-9]+|[*]))?'
|
||||
'[hlL]?[diouxXeEfFgGcrs%]', String.Interpol),
|
||||
(r'[^\\\'"%\n]+', String),
|
||||
# quotes, percents and backslashes must be parsed one at a time
|
||||
(r'[\'"\\]', String),
|
||||
# unhandled string formatting sign
|
||||
(r'%', String),
|
||||
(r'\n', String)
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop')
|
||||
],
|
||||
'sqs': [
|
||||
(r"'", String, '#pop')
|
||||
],
|
||||
'tdqs': [
|
||||
(r'"""', String, '#pop')
|
||||
],
|
||||
'tsqs': [
|
||||
(r"'''", String, '#pop')
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class NumPyLexer(PythonLexer):
|
||||
"""
|
||||
A Python lexer recognizing Numerical Python builtins.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
name = 'NumPy'
|
||||
aliases = ['numpy']
|
||||
|
||||
# override the mimetypes to not inherit them from python
|
||||
mimetypes = []
|
||||
filenames = []
|
||||
|
||||
EXTRA_KEYWORDS = set((
|
||||
'abs', 'absolute', 'accumulate', 'add', 'alen', 'all', 'allclose',
|
||||
'alltrue', 'alterdot', 'amax', 'amin', 'angle', 'any', 'append',
|
||||
'apply_along_axis', 'apply_over_axes', 'arange', 'arccos', 'arccosh',
|
||||
'arcsin', 'arcsinh', 'arctan', 'arctan2', 'arctanh', 'argmax', 'argmin',
|
||||
'argsort', 'argwhere', 'around', 'array', 'array2string', 'array_equal',
|
||||
'array_equiv', 'array_repr', 'array_split', 'array_str', 'arrayrange',
|
||||
'asanyarray', 'asarray', 'asarray_chkfinite', 'ascontiguousarray',
|
||||
'asfarray', 'asfortranarray', 'asmatrix', 'asscalar', 'astype',
|
||||
'atleast_1d', 'atleast_2d', 'atleast_3d', 'average', 'bartlett',
|
||||
'base_repr', 'beta', 'binary_repr', 'bincount', 'binomial',
|
||||
'bitwise_and', 'bitwise_not', 'bitwise_or', 'bitwise_xor', 'blackman',
|
||||
'bmat', 'broadcast', 'byte_bounds', 'bytes', 'byteswap', 'c_',
|
||||
'can_cast', 'ceil', 'choose', 'clip', 'column_stack', 'common_type',
|
||||
'compare_chararrays', 'compress', 'concatenate', 'conj', 'conjugate',
|
||||
'convolve', 'copy', 'corrcoef', 'correlate', 'cos', 'cosh', 'cov',
|
||||
'cross', 'cumprod', 'cumproduct', 'cumsum', 'delete', 'deprecate',
|
||||
'diag', 'diagflat', 'diagonal', 'diff', 'digitize', 'disp', 'divide',
|
||||
'dot', 'dsplit', 'dstack', 'dtype', 'dump', 'dumps', 'ediff1d', 'empty',
|
||||
'empty_like', 'equal', 'exp', 'expand_dims', 'expm1', 'extract', 'eye',
|
||||
'fabs', 'fastCopyAndTranspose', 'fft', 'fftfreq', 'fftshift', 'fill',
|
||||
'finfo', 'fix', 'flat', 'flatnonzero', 'flatten', 'fliplr', 'flipud',
|
||||
'floor', 'floor_divide', 'fmod', 'frexp', 'fromarrays', 'frombuffer',
|
||||
'fromfile', 'fromfunction', 'fromiter', 'frompyfunc', 'fromstring',
|
||||
'generic', 'get_array_wrap', 'get_include', 'get_numarray_include',
|
||||
'get_numpy_include', 'get_printoptions', 'getbuffer', 'getbufsize',
|
||||
'geterr', 'geterrcall', 'geterrobj', 'getfield', 'gradient', 'greater',
|
||||
'greater_equal', 'gumbel', 'hamming', 'hanning', 'histogram',
|
||||
'histogram2d', 'histogramdd', 'hsplit', 'hstack', 'hypot', 'i0',
|
||||
'identity', 'ifft', 'imag', 'index_exp', 'indices', 'inf', 'info',
|
||||
'inner', 'insert', 'int_asbuffer', 'interp', 'intersect1d',
|
||||
'intersect1d_nu', 'inv', 'invert', 'iscomplex', 'iscomplexobj',
|
||||
'isfinite', 'isfortran', 'isinf', 'isnan', 'isneginf', 'isposinf',
|
||||
'isreal', 'isrealobj', 'isscalar', 'issctype', 'issubclass_',
|
||||
'issubdtype', 'issubsctype', 'item', 'itemset', 'iterable', 'ix_',
|
||||
'kaiser', 'kron', 'ldexp', 'left_shift', 'less', 'less_equal', 'lexsort',
|
||||
'linspace', 'load', 'loads', 'loadtxt', 'log', 'log10', 'log1p', 'log2',
|
||||
'logical_and', 'logical_not', 'logical_or', 'logical_xor', 'logspace',
|
||||
'lstsq', 'mat', 'matrix', 'max', 'maximum', 'maximum_sctype',
|
||||
'may_share_memory', 'mean', 'median', 'meshgrid', 'mgrid', 'min',
|
||||
'minimum', 'mintypecode', 'mod', 'modf', 'msort', 'multiply', 'nan',
|
||||
'nan_to_num', 'nanargmax', 'nanargmin', 'nanmax', 'nanmin', 'nansum',
|
||||
'ndenumerate', 'ndim', 'ndindex', 'negative', 'newaxis', 'newbuffer',
|
||||
'newbyteorder', 'nonzero', 'not_equal', 'obj2sctype', 'ogrid', 'ones',
|
||||
'ones_like', 'outer', 'permutation', 'piecewise', 'pinv', 'pkgload',
|
||||
'place', 'poisson', 'poly', 'poly1d', 'polyadd', 'polyder', 'polydiv',
|
||||
'polyfit', 'polyint', 'polymul', 'polysub', 'polyval', 'power', 'prod',
|
||||
'product', 'ptp', 'put', 'putmask', 'r_', 'randint', 'random_integers',
|
||||
'random_sample', 'ranf', 'rank', 'ravel', 'real', 'real_if_close',
|
||||
'recarray', 'reciprocal', 'reduce', 'remainder', 'repeat', 'require',
|
||||
'reshape', 'resize', 'restoredot', 'right_shift', 'rint', 'roll',
|
||||
'rollaxis', 'roots', 'rot90', 'round', 'round_', 'row_stack', 's_',
|
||||
'sample', 'savetxt', 'sctype2char', 'searchsorted', 'seed', 'select',
|
||||
'set_numeric_ops', 'set_printoptions', 'set_string_function',
|
||||
'setbufsize', 'setdiff1d', 'seterr', 'seterrcall', 'seterrobj',
|
||||
'setfield', 'setflags', 'setmember1d', 'setxor1d', 'shape',
|
||||
'show_config', 'shuffle', 'sign', 'signbit', 'sin', 'sinc', 'sinh',
|
||||
'size', 'slice', 'solve', 'sometrue', 'sort', 'sort_complex', 'source',
|
||||
'split', 'sqrt', 'square', 'squeeze', 'standard_normal', 'std',
|
||||
'subtract', 'sum', 'svd', 'swapaxes', 'take', 'tan', 'tanh', 'tensordot',
|
||||
'test', 'tile', 'tofile', 'tolist', 'tostring', 'trace', 'transpose',
|
||||
'trapz', 'tri', 'tril', 'trim_zeros', 'triu', 'true_divide', 'typeDict',
|
||||
'typename', 'uniform', 'union1d', 'unique', 'unique1d', 'unravel_index',
|
||||
'unwrap', 'vander', 'var', 'vdot', 'vectorize', 'view', 'vonmises',
|
||||
'vsplit', 'vstack', 'weibull', 'where', 'who', 'zeros', 'zeros_like'
|
||||
))
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
PythonLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name and value in self.EXTRA_KEYWORDS:
|
||||
yield index, Keyword.Pseudo, value
|
||||
else:
|
||||
yield index, token, value
|
||||
|
||||
def analyse_text(text):
|
||||
return (shebang_matches(text, r'pythonw?(2(\.\d)?)?') or
|
||||
'import ' in text[:1000]) \
|
||||
and ('import numpy' in text or 'from numpy import' in text)
|
||||
@ -1,453 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.r
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for the R/S languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import Lexer, RegexLexer, include, words, do_insertions
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Generic
|
||||
|
||||
__all__ = ['RConsoleLexer', 'SLexer', 'RdLexer']
|
||||
|
||||
|
||||
line_re = re.compile('.*?\n')
|
||||
|
||||
|
||||
class RConsoleLexer(Lexer):
|
||||
"""
|
||||
For R console transcripts or R CMD BATCH output files.
|
||||
"""
|
||||
|
||||
name = 'RConsole'
|
||||
aliases = ['rconsole', 'rout']
|
||||
filenames = ['*.Rout']
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
slexer = SLexer(**self.options)
|
||||
|
||||
current_code_block = ''
|
||||
insertions = []
|
||||
|
||||
for match in line_re.finditer(text):
|
||||
line = match.group()
|
||||
if line.startswith('>') or line.startswith('+'):
|
||||
# Colorize the prompt as such,
|
||||
# then put rest of line into current_code_block
|
||||
insertions.append((len(current_code_block),
|
||||
[(0, Generic.Prompt, line[:2])]))
|
||||
current_code_block += line[2:]
|
||||
else:
|
||||
# We have reached a non-prompt line!
|
||||
# If we have stored prompt lines, need to process them first.
|
||||
if current_code_block:
|
||||
# Weave together the prompts and highlight code.
|
||||
for item in do_insertions(
|
||||
insertions, slexer.get_tokens_unprocessed(current_code_block)):
|
||||
yield item
|
||||
# Reset vars for next code block.
|
||||
current_code_block = ''
|
||||
insertions = []
|
||||
# Now process the actual line itself, this is output from R.
|
||||
yield match.start(), Generic.Output, line
|
||||
|
||||
# If we happen to end on a code block with nothing after it, need to
|
||||
# process the last code block. This is neither elegant nor DRY so
|
||||
# should be changed.
|
||||
if current_code_block:
|
||||
for item in do_insertions(
|
||||
insertions, slexer.get_tokens_unprocessed(current_code_block)):
|
||||
yield item
|
||||
|
||||
|
||||
class SLexer(RegexLexer):
|
||||
"""
|
||||
For S, S-plus, and R source code.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
name = 'S'
|
||||
aliases = ['splus', 's', 'r']
|
||||
filenames = ['*.S', '*.R', '.Rhistory', '.Rprofile', '.Renviron']
|
||||
mimetypes = ['text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r',
|
||||
'text/x-R', 'text/x-r-history', 'text/x-r-profile']
|
||||
|
||||
builtins_base = (
|
||||
'Arg', 'Conj', 'Cstack_info', 'Encoding', 'FALSE',
|
||||
'Filter', 'Find', 'I', 'ISOdate', 'ISOdatetime', 'Im', 'Inf',
|
||||
'La.svd', 'Map', 'Math.Date', 'Math.POSIXt', 'Math.data.frame',
|
||||
'Math.difftime', 'Math.factor', 'Mod', 'NA_character_',
|
||||
'NA_complex_', 'NA_real_', 'NCOL', 'NROW', 'NULLNA_integer_', 'NaN',
|
||||
'Negate', 'NextMethod', 'Ops.Date', 'Ops.POSIXt', 'Ops.data.frame',
|
||||
'Ops.difftime', 'Ops.factor', 'Ops.numeric_version', 'Ops.ordered',
|
||||
'Position', 'R.Version', 'R.home', 'R.version', 'R.version.string',
|
||||
'RNGkind', 'RNGversion', 'R_system_version', 'Re', 'Recall',
|
||||
'Reduce', 'Summary.Date', 'Summary.POSIXct', 'Summary.POSIXlt',
|
||||
'Summary.data.frame', 'Summary.difftime', 'Summary.factor',
|
||||
'Summary.numeric_version', 'Summary.ordered', 'Sys.Date',
|
||||
'Sys.chmod', 'Sys.getenv', 'Sys.getlocale', 'Sys.getpid',
|
||||
'Sys.glob', 'Sys.info', 'Sys.localeconv', 'Sys.readlink',
|
||||
'Sys.setFileTime', 'Sys.setenv', 'Sys.setlocale', 'Sys.sleep',
|
||||
'Sys.time', 'Sys.timezone', 'Sys.umask', 'Sys.unsetenv',
|
||||
'Sys.which', 'TRUE', 'UseMethod', 'Vectorize', 'abbreviate', 'abs',
|
||||
'acos', 'acosh', 'addNA', 'addTaskCallback', 'agrep', 'alist',
|
||||
'all', 'all.equal', 'all.equal.POSIXct', 'all.equal.character',
|
||||
'all.equal.default', 'all.equal.factor', 'all.equal.formula',
|
||||
'all.equal.language', 'all.equal.list', 'all.equal.numeric',
|
||||
'all.equal.raw', 'all.names', 'all.vars', 'any', 'anyDuplicated',
|
||||
'anyDuplicated.array', 'anyDuplicated.data.frame',
|
||||
'anyDuplicated.default', 'anyDuplicated.matrix', 'aperm',
|
||||
'aperm.default', 'aperm.table', 'append', 'apply', 'args',
|
||||
'arrayInd', 'as.Date', 'as.Date.POSIXct', 'as.Date.POSIXlt',
|
||||
'as.Date.character', 'as.Date.date', 'as.Date.dates',
|
||||
'as.Date.default', 'as.Date.factor', 'as.Date.numeric',
|
||||
'as.POSIXct', 'as.POSIXct.Date', 'as.POSIXct.POSIXlt',
|
||||
'as.POSIXct.date', 'as.POSIXct.dates', 'as.POSIXct.default',
|
||||
'as.POSIXct.numeric', 'as.POSIXlt', 'as.POSIXlt.Date',
|
||||
'as.POSIXlt.POSIXct', 'as.POSIXlt.character', 'as.POSIXlt.date',
|
||||
'as.POSIXlt.dates', 'as.POSIXlt.default', 'as.POSIXlt.factor',
|
||||
'as.POSIXlt.numeric', 'as.array', 'as.array.default', 'as.call',
|
||||
'as.character', 'as.character.Date', 'as.character.POSIXt',
|
||||
'as.character.condition', 'as.character.default',
|
||||
'as.character.error', 'as.character.factor', 'as.character.hexmode',
|
||||
'as.character.numeric_version', 'as.character.octmode',
|
||||
'as.character.srcref', 'as.complex', 'as.data.frame',
|
||||
'as.data.frame.AsIs', 'as.data.frame.Date', 'as.data.frame.POSIXct',
|
||||
'as.data.frame.POSIXlt', 'as.data.frame.array',
|
||||
'as.data.frame.character', 'as.data.frame.complex',
|
||||
'as.data.frame.data.frame', 'as.data.frame.default',
|
||||
'as.data.frame.difftime', 'as.data.frame.factor',
|
||||
'as.data.frame.integer', 'as.data.frame.list',
|
||||
'as.data.frame.logical', 'as.data.frame.matrix',
|
||||
'as.data.frame.model.matrix', 'as.data.frame.numeric',
|
||||
'as.data.frame.numeric_version', 'as.data.frame.ordered',
|
||||
'as.data.frame.raw', 'as.data.frame.table', 'as.data.frame.ts',
|
||||
'as.data.frame.vector', 'as.difftime', 'as.double',
|
||||
'as.double.POSIXlt', 'as.double.difftime', 'as.environment',
|
||||
'as.expression', 'as.expression.default', 'as.factor',
|
||||
'as.function', 'as.function.default', 'as.hexmode', 'as.integer',
|
||||
'as.list', 'as.list.Date', 'as.list.POSIXct', 'as.list.data.frame',
|
||||
'as.list.default', 'as.list.environment', 'as.list.factor',
|
||||
'as.list.function', 'as.list.numeric_version', 'as.logical',
|
||||
'as.logical.factor', 'as.matrix', 'as.matrix.POSIXlt',
|
||||
'as.matrix.data.frame', 'as.matrix.default', 'as.matrix.noquote',
|
||||
'as.name', 'as.null', 'as.null.default', 'as.numeric',
|
||||
'as.numeric_version', 'as.octmode', 'as.ordered',
|
||||
'as.package_version', 'as.pairlist', 'as.qr', 'as.raw', 'as.single',
|
||||
'as.single.default', 'as.symbol', 'as.table', 'as.table.default',
|
||||
'as.vector', 'as.vector.factor', 'asNamespace', 'asS3', 'asS4',
|
||||
'asin', 'asinh', 'assign', 'atan', 'atan2', 'atanh',
|
||||
'attachNamespace', 'attr', 'attr.all.equal', 'attributes',
|
||||
'autoload', 'autoloader', 'backsolve', 'baseenv', 'basename',
|
||||
'besselI', 'besselJ', 'besselK', 'besselY', 'beta',
|
||||
'bindingIsActive', 'bindingIsLocked', 'bindtextdomain', 'bitwAnd',
|
||||
'bitwNot', 'bitwOr', 'bitwShiftL', 'bitwShiftR', 'bitwXor', 'body',
|
||||
'bquote', 'browser', 'browserCondition', 'browserSetDebug',
|
||||
'browserText', 'builtins', 'by', 'by.data.frame', 'by.default',
|
||||
'bzfile', 'c.Date', 'c.POSIXct', 'c.POSIXlt', 'c.noquote',
|
||||
'c.numeric_version', 'call', 'callCC', 'capabilities', 'casefold',
|
||||
'cat', 'category', 'cbind', 'cbind.data.frame', 'ceiling',
|
||||
'char.expand', 'charToRaw', 'charmatch', 'chartr', 'check_tzones',
|
||||
'chol', 'chol.default', 'chol2inv', 'choose', 'class',
|
||||
'clearPushBack', 'close', 'close.connection', 'close.srcfile',
|
||||
'close.srcfilealias', 'closeAllConnections', 'col', 'colMeans',
|
||||
'colSums', 'colnames', 'commandArgs', 'comment', 'computeRestarts',
|
||||
'conditionCall', 'conditionCall.condition', 'conditionMessage',
|
||||
'conditionMessage.condition', 'conflicts', 'contributors', 'cos',
|
||||
'cosh', 'crossprod', 'cummax', 'cummin', 'cumprod', 'cumsum', 'cut',
|
||||
'cut.Date', 'cut.POSIXt', 'cut.default', 'dQuote', 'data.class',
|
||||
'data.matrix', 'date', 'debug', 'debugonce',
|
||||
'default.stringsAsFactors', 'delayedAssign', 'deparse', 'det',
|
||||
'determinant', 'determinant.matrix', 'dget', 'diag', 'diff',
|
||||
'diff.Date', 'diff.POSIXt', 'diff.default', 'difftime', 'digamma',
|
||||
'dim', 'dim.data.frame', 'dimnames', 'dimnames.data.frame', 'dir',
|
||||
'dir.create', 'dirname', 'do.call', 'dput', 'drop', 'droplevels',
|
||||
'droplevels.data.frame', 'droplevels.factor', 'dump', 'duplicated',
|
||||
'duplicated.POSIXlt', 'duplicated.array', 'duplicated.data.frame',
|
||||
'duplicated.default', 'duplicated.matrix',
|
||||
'duplicated.numeric_version', 'dyn.load', 'dyn.unload', 'eapply',
|
||||
'eigen', 'else', 'emptyenv', 'enc2native', 'enc2utf8',
|
||||
'encodeString', 'enquote', 'env.profile', 'environment',
|
||||
'environmentIsLocked', 'environmentName', 'eval', 'eval.parent',
|
||||
'evalq', 'exists', 'exp', 'expand.grid', 'expm1', 'expression',
|
||||
'factor', 'factorial', 'fifo', 'file', 'file.access', 'file.append',
|
||||
'file.choose', 'file.copy', 'file.create', 'file.exists',
|
||||
'file.info', 'file.link', 'file.path', 'file.remove', 'file.rename',
|
||||
'file.show', 'file.symlink', 'find.package', 'findInterval',
|
||||
'findPackageEnv', 'findRestart', 'floor', 'flush',
|
||||
'flush.connection', 'force', 'formals', 'format',
|
||||
'format.AsIs', 'format.Date', 'format.POSIXct', 'format.POSIXlt',
|
||||
'format.data.frame', 'format.default', 'format.difftime',
|
||||
'format.factor', 'format.hexmode', 'format.info',
|
||||
'format.libraryIQR', 'format.numeric_version', 'format.octmode',
|
||||
'format.packageInfo', 'format.pval', 'format.summaryDefault',
|
||||
'formatC', 'formatDL', 'forwardsolve', 'gamma', 'gc', 'gc.time',
|
||||
'gcinfo', 'gctorture', 'gctorture2', 'get', 'getAllConnections',
|
||||
'getCallingDLL', 'getCallingDLLe', 'getConnection',
|
||||
'getDLLRegisteredRoutines', 'getDLLRegisteredRoutines.DLLInfo',
|
||||
'getDLLRegisteredRoutines.character', 'getElement',
|
||||
'getExportedValue', 'getHook', 'getLoadedDLLs', 'getNamespace',
|
||||
'getNamespaceExports', 'getNamespaceImports', 'getNamespaceInfo',
|
||||
'getNamespaceName', 'getNamespaceUsers', 'getNamespaceVersion',
|
||||
'getNativeSymbolInfo', 'getOption', 'getRversion', 'getSrcLines',
|
||||
'getTaskCallbackNames', 'geterrmessage', 'gettext', 'gettextf',
|
||||
'getwd', 'gl', 'globalenv', 'gregexpr', 'grep', 'grepRaw', 'grepl',
|
||||
'gsub', 'gzcon', 'gzfile', 'head', 'iconv', 'iconvlist',
|
||||
'icuSetCollate', 'identical', 'identity', 'ifelse', 'importIntoEnv',
|
||||
'in', 'inherits', 'intToBits', 'intToUtf8', 'interaction', 'interactive',
|
||||
'intersect', 'inverse.rle', 'invisible', 'invokeRestart',
|
||||
'invokeRestartInteractively', 'is.R', 'is.array', 'is.atomic',
|
||||
'is.call', 'is.character', 'is.complex', 'is.data.frame',
|
||||
'is.double', 'is.element', 'is.environment', 'is.expression',
|
||||
'is.factor', 'is.finite', 'is.function', 'is.infinite',
|
||||
'is.integer', 'is.language', 'is.list', 'is.loaded', 'is.logical',
|
||||
'is.matrix', 'is.na', 'is.na.POSIXlt', 'is.na.data.frame',
|
||||
'is.na.numeric_version', 'is.name', 'is.nan', 'is.null',
|
||||
'is.numeric', 'is.numeric.Date', 'is.numeric.POSIXt',
|
||||
'is.numeric.difftime', 'is.numeric_version', 'is.object',
|
||||
'is.ordered', 'is.package_version', 'is.pairlist', 'is.primitive',
|
||||
'is.qr', 'is.raw', 'is.recursive', 'is.single', 'is.symbol',
|
||||
'is.table', 'is.unsorted', 'is.vector', 'isBaseNamespace',
|
||||
'isIncomplete', 'isNamespace', 'isOpen', 'isRestart', 'isS4',
|
||||
'isSeekable', 'isSymmetric', 'isSymmetric.matrix', 'isTRUE',
|
||||
'isatty', 'isdebugged', 'jitter', 'julian', 'julian.Date',
|
||||
'julian.POSIXt', 'kappa', 'kappa.default', 'kappa.lm', 'kappa.qr',
|
||||
'kronecker', 'l10n_info', 'labels', 'labels.default', 'lapply',
|
||||
'lazyLoad', 'lazyLoadDBexec', 'lazyLoadDBfetch', 'lbeta', 'lchoose',
|
||||
'length', 'length.POSIXlt', 'letters', 'levels', 'levels.default',
|
||||
'lfactorial', 'lgamma', 'library.dynam', 'library.dynam.unload',
|
||||
'licence', 'license', 'list.dirs', 'list.files', 'list2env', 'load',
|
||||
'loadNamespace', 'loadedNamespaces', 'loadingNamespaceInfo',
|
||||
'local', 'lockBinding', 'lockEnvironment', 'log', 'log10', 'log1p',
|
||||
'log2', 'logb', 'lower.tri', 'ls', 'make.names', 'make.unique',
|
||||
'makeActiveBinding', 'mapply', 'margin.table', 'mat.or.vec',
|
||||
'match', 'match.arg', 'match.call', 'match.fun', 'max', 'max.col',
|
||||
'mean', 'mean.Date', 'mean.POSIXct', 'mean.POSIXlt', 'mean.default',
|
||||
'mean.difftime', 'mem.limits', 'memCompress', 'memDecompress',
|
||||
'memory.profile', 'merge', 'merge.data.frame', 'merge.default',
|
||||
'message', 'mget', 'min', 'missing', 'mode', 'month.abb',
|
||||
'month.name', 'months', 'months.Date', 'months.POSIXt',
|
||||
'months.abb', 'months.nameletters', 'names', 'names.POSIXlt',
|
||||
'namespaceExport', 'namespaceImport', 'namespaceImportClasses',
|
||||
'namespaceImportFrom', 'namespaceImportMethods', 'nargs', 'nchar',
|
||||
'ncol', 'new.env', 'ngettext', 'nlevels', 'noquote', 'norm',
|
||||
'normalizePath', 'nrow', 'numeric_version', 'nzchar', 'objects',
|
||||
'oldClass', 'on.exit', 'open', 'open.connection', 'open.srcfile',
|
||||
'open.srcfilealias', 'open.srcfilecopy', 'options', 'order',
|
||||
'ordered', 'outer', 'packBits', 'packageEvent',
|
||||
'packageHasNamespace', 'packageStartupMessage', 'package_version',
|
||||
'pairlist', 'parent.env', 'parent.frame', 'parse',
|
||||
'parseNamespaceFile', 'paste', 'paste0', 'path.expand',
|
||||
'path.package', 'pipe', 'pmatch', 'pmax', 'pmax.int', 'pmin',
|
||||
'pmin.int', 'polyroot', 'pos.to.env', 'pretty', 'pretty.default',
|
||||
'prettyNum', 'print', 'print.AsIs', 'print.DLLInfo',
|
||||
'print.DLLInfoList', 'print.DLLRegisteredRoutines', 'print.Date',
|
||||
'print.NativeRoutineList', 'print.POSIXct', 'print.POSIXlt',
|
||||
'print.by', 'print.condition', 'print.connection',
|
||||
'print.data.frame', 'print.default', 'print.difftime',
|
||||
'print.factor', 'print.function', 'print.hexmode',
|
||||
'print.libraryIQR', 'print.listof', 'print.noquote',
|
||||
'print.numeric_version', 'print.octmode', 'print.packageInfo',
|
||||
'print.proc_time', 'print.restart', 'print.rle',
|
||||
'print.simple.list', 'print.srcfile', 'print.srcref',
|
||||
'print.summary.table', 'print.summaryDefault', 'print.table',
|
||||
'print.warnings', 'prmatrix', 'proc.time', 'prod', 'prop.table',
|
||||
'provideDimnames', 'psigamma', 'pushBack', 'pushBackLength', 'q',
|
||||
'qr', 'qr.Q', 'qr.R', 'qr.X', 'qr.coef', 'qr.default', 'qr.fitted',
|
||||
'qr.qty', 'qr.qy', 'qr.resid', 'qr.solve', 'quarters',
|
||||
'quarters.Date', 'quarters.POSIXt', 'quit', 'quote', 'range',
|
||||
'range.default', 'rank', 'rapply', 'raw', 'rawConnection',
|
||||
'rawConnectionValue', 'rawShift', 'rawToBits', 'rawToChar', 'rbind',
|
||||
'rbind.data.frame', 'rcond', 'read.dcf', 'readBin', 'readChar',
|
||||
'readLines', 'readRDS', 'readRenviron', 'readline', 'reg.finalizer',
|
||||
'regexec', 'regexpr', 'registerS3method', 'registerS3methods',
|
||||
'regmatches', 'remove', 'removeTaskCallback', 'rep', 'rep.Date',
|
||||
'rep.POSIXct', 'rep.POSIXlt', 'rep.factor', 'rep.int',
|
||||
'rep.numeric_version', 'rep_len', 'replace', 'replicate',
|
||||
'requireNamespace', 'restartDescription', 'restartFormals',
|
||||
'retracemem', 'rev', 'rev.default', 'rle', 'rm', 'round',
|
||||
'round.Date', 'round.POSIXt', 'row', 'row.names',
|
||||
'row.names.data.frame', 'row.names.default', 'rowMeans', 'rowSums',
|
||||
'rownames', 'rowsum', 'rowsum.data.frame', 'rowsum.default',
|
||||
'sQuote', 'sample', 'sample.int', 'sapply', 'save', 'save.image',
|
||||
'saveRDS', 'scale', 'scale.default', 'scan', 'search',
|
||||
'searchpaths', 'seek', 'seek.connection', 'seq', 'seq.Date',
|
||||
'seq.POSIXt', 'seq.default', 'seq.int', 'seq_along', 'seq_len',
|
||||
'sequence', 'serialize', 'set.seed', 'setHook', 'setNamespaceInfo',
|
||||
'setSessionTimeLimit', 'setTimeLimit', 'setdiff', 'setequal',
|
||||
'setwd', 'shQuote', 'showConnections', 'sign', 'signalCondition',
|
||||
'signif', 'simpleCondition', 'simpleError', 'simpleMessage',
|
||||
'simpleWarning', 'simplify2array', 'sin', 'single',
|
||||
'sinh', 'sink', 'sink.number', 'slice.index', 'socketConnection',
|
||||
'socketSelect', 'solve', 'solve.default', 'solve.qr', 'sort',
|
||||
'sort.POSIXlt', 'sort.default', 'sort.int', 'sort.list', 'split',
|
||||
'split.Date', 'split.POSIXct', 'split.data.frame', 'split.default',
|
||||
'sprintf', 'sqrt', 'srcfile', 'srcfilealias', 'srcfilecopy',
|
||||
'srcref', 'standardGeneric', 'stderr', 'stdin', 'stdout', 'stop',
|
||||
'stopifnot', 'storage.mode', 'strftime', 'strptime', 'strsplit',
|
||||
'strtoi', 'strtrim', 'structure', 'strwrap', 'sub', 'subset',
|
||||
'subset.data.frame', 'subset.default', 'subset.matrix',
|
||||
'substitute', 'substr', 'substring', 'sum', 'summary',
|
||||
'summary.Date', 'summary.POSIXct', 'summary.POSIXlt',
|
||||
'summary.connection', 'summary.data.frame', 'summary.default',
|
||||
'summary.factor', 'summary.matrix', 'summary.proc_time',
|
||||
'summary.srcfile', 'summary.srcref', 'summary.table',
|
||||
'suppressMessages', 'suppressPackageStartupMessages',
|
||||
'suppressWarnings', 'svd', 'sweep', 'sys.call', 'sys.calls',
|
||||
'sys.frame', 'sys.frames', 'sys.function', 'sys.load.image',
|
||||
'sys.nframe', 'sys.on.exit', 'sys.parent', 'sys.parents',
|
||||
'sys.save.image', 'sys.source', 'sys.status', 'system',
|
||||
'system.file', 'system.time', 'system2', 't', 't.data.frame',
|
||||
't.default', 'table', 'tabulate', 'tail', 'tan', 'tanh', 'tapply',
|
||||
'taskCallbackManager', 'tcrossprod', 'tempdir', 'tempfile',
|
||||
'testPlatformEquivalence', 'textConnection', 'textConnectionValue',
|
||||
'toString', 'toString.default', 'tolower', 'topenv', 'toupper',
|
||||
'trace', 'traceback', 'tracemem', 'tracingState', 'transform',
|
||||
'transform.data.frame', 'transform.default', 'trigamma', 'trunc',
|
||||
'trunc.Date', 'trunc.POSIXt', 'truncate', 'truncate.connection',
|
||||
'try', 'tryCatch', 'typeof', 'unclass', 'undebug', 'union',
|
||||
'unique', 'unique.POSIXlt', 'unique.array', 'unique.data.frame',
|
||||
'unique.default', 'unique.matrix', 'unique.numeric_version',
|
||||
'units', 'units.difftime', 'unix.time', 'unlink', 'unlist',
|
||||
'unloadNamespace', 'unlockBinding', 'unname', 'unserialize',
|
||||
'unsplit', 'untrace', 'untracemem', 'unz', 'upper.tri', 'url',
|
||||
'utf8ToInt', 'vapply', 'version', 'warning', 'warnings', 'weekdays',
|
||||
'weekdays.Date', 'weekdays.POSIXt', 'which', 'which.max',
|
||||
'which.min', 'with', 'with.default', 'withCallingHandlers',
|
||||
'withRestarts', 'withVisible', 'within', 'within.data.frame',
|
||||
'within.list', 'write', 'write.dcf', 'writeBin', 'writeChar',
|
||||
'writeLines', 'xor', 'xor.hexmode', 'xor.octmode',
|
||||
'xpdrows.data.frame', 'xtfrm', 'xtfrm.AsIs', 'xtfrm.Date',
|
||||
'xtfrm.POSIXct', 'xtfrm.POSIXlt', 'xtfrm.Surv', 'xtfrm.default',
|
||||
'xtfrm.difftime', 'xtfrm.factor', 'xtfrm.numeric_version', 'xzfile',
|
||||
'zapsmall'
|
||||
)
|
||||
|
||||
tokens = {
|
||||
'comments': [
|
||||
(r'#.*$', Comment.Single),
|
||||
],
|
||||
'valid_name': [
|
||||
(r'[a-zA-Z][\w.]*', Text),
|
||||
# can begin with ., but not if that is followed by a digit
|
||||
(r'\.[a-zA-Z_][\w.]*', Text),
|
||||
],
|
||||
'punctuation': [
|
||||
(r'\[{1,2}|\]{1,2}|\(|\)|;|,', Punctuation),
|
||||
],
|
||||
'keywords': [
|
||||
(words(builtins_base, suffix=r'(?![\w. =])'),
|
||||
Keyword.Pseudo),
|
||||
(r'(if|else|for|while|repeat|in|next|break|return|switch|function)'
|
||||
r'(?![\w.])',
|
||||
Keyword.Reserved),
|
||||
(r'(array|category|character|complex|double|function|integer|list|'
|
||||
r'logical|matrix|numeric|vector|data.frame|c)'
|
||||
r'(?![\w.])',
|
||||
Keyword.Type),
|
||||
(r'(library|require|attach|detach|source)'
|
||||
r'(?![\w.])',
|
||||
Keyword.Namespace)
|
||||
],
|
||||
'operators': [
|
||||
(r'<<?-|->>?|-|==|<=|>=|<|>|&&?|!=|\|\|?|\?', Operator),
|
||||
(r'\*|\+|\^|/|!|%[^%]*%|=|~|\$|@|:{1,3}', Operator)
|
||||
],
|
||||
'builtin_symbols': [
|
||||
(r'(NULL|NA(_(integer|real|complex|character)_)?|'
|
||||
r'letters|LETTERS|Inf|TRUE|FALSE|NaN|pi|\.\.(\.|[0-9]+))'
|
||||
r'(?![\w.])',
|
||||
Keyword.Constant),
|
||||
(r'(T|F)\b', Name.Builtin.Pseudo),
|
||||
],
|
||||
'numbers': [
|
||||
# hex number
|
||||
(r'0[xX][a-fA-F0-9]+([pP][0-9]+)?[Li]?', Number.Hex),
|
||||
# decimal number
|
||||
(r'[+-]?([0-9]+(\.[0-9]+)?|\.[0-9]+|\.)([eE][+-]?[0-9]+)?[Li]?',
|
||||
Number),
|
||||
],
|
||||
'statements': [
|
||||
include('comments'),
|
||||
# whitespaces
|
||||
(r'\s+', Text),
|
||||
(r'`.*?`', String.Backtick),
|
||||
(r'\'', String, 'string_squote'),
|
||||
(r'\"', String, 'string_dquote'),
|
||||
include('builtin_symbols'),
|
||||
include('numbers'),
|
||||
include('keywords'),
|
||||
include('punctuation'),
|
||||
include('operators'),
|
||||
include('valid_name'),
|
||||
],
|
||||
'root': [
|
||||
include('statements'),
|
||||
# blocks:
|
||||
(r'\{|\}', Punctuation),
|
||||
# (r'\{', Punctuation, 'block'),
|
||||
(r'.', Text),
|
||||
],
|
||||
# 'block': [
|
||||
# include('statements'),
|
||||
# ('\{', Punctuation, '#push'),
|
||||
# ('\}', Punctuation, '#pop')
|
||||
# ],
|
||||
'string_squote': [
|
||||
(r'([^\'\\]|\\.)*\'', String, '#pop'),
|
||||
],
|
||||
'string_dquote': [
|
||||
(r'([^"\\]|\\.)*"', String, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if re.search(r'[a-z0-9_\])\s]<-(?!-)', text):
|
||||
return 0.11
|
||||
|
||||
|
||||
class RdLexer(RegexLexer):
|
||||
"""
|
||||
Pygments Lexer for R documentation (Rd) files
|
||||
|
||||
This is a very minimal implementation, highlighting little more
|
||||
than the macros. A description of Rd syntax is found in `Writing R
|
||||
Extensions <http://cran.r-project.org/doc/manuals/R-exts.html>`_
|
||||
and `Parsing Rd files <developer.r-project.org/parseRd.pdf>`_.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'Rd'
|
||||
aliases = ['rd']
|
||||
filenames = ['*.Rd']
|
||||
mimetypes = ['text/x-r-doc']
|
||||
|
||||
# To account for verbatim / LaTeX-like / and R-like areas
|
||||
# would require parsing.
|
||||
tokens = {
|
||||
'root': [
|
||||
# catch escaped brackets and percent sign
|
||||
(r'\\[\\{}%]', String.Escape),
|
||||
# comments
|
||||
(r'%.*$', Comment),
|
||||
# special macros with no arguments
|
||||
(r'\\(?:cr|l?dots|R|tab)\b', Keyword.Constant),
|
||||
# macros
|
||||
(r'\\[a-zA-Z]+\b', Keyword),
|
||||
# special preprocessor macros
|
||||
(r'^\s*#(?:ifn?def|endif).*\b', Comment.Preproc),
|
||||
# non-escaped brackets
|
||||
(r'[{}]', Name.Builtin),
|
||||
# everything else
|
||||
(r'[^\\%\n{}]+', Text),
|
||||
(r'.', Text),
|
||||
]
|
||||
}
|
||||
@ -1,99 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.rdf
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for semantic web and RDF query languages and markup.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, default
|
||||
from pygments.token import Keyword, Punctuation, String, Number, Operator, \
|
||||
Whitespace, Name, Literal, Comment, Text
|
||||
|
||||
__all__ = ['SparqlLexer']
|
||||
|
||||
|
||||
class SparqlLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `SPARQL <http://www.w3.org/TR/rdf-sparql-query/>`_ query language.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'SPARQL'
|
||||
aliases = ['sparql']
|
||||
filenames = ['*.rq', '*.sparql']
|
||||
mimetypes = ['application/sparql-query']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Whitespace),
|
||||
(r'(select|construct|describe|ask|where|filter|group\s+by|minus|'
|
||||
r'distinct|reduced|from named|from|order\s+by|limit|'
|
||||
r'offset|bindings|load|clear|drop|create|add|move|copy|'
|
||||
r'insert\s+data|delete\s+data|delete\s+where|delete|insert|'
|
||||
r'using named|using|graph|default|named|all|optional|service|'
|
||||
r'silent|bind|union|not in|in|as|a)', Keyword),
|
||||
(r'(prefix|base)(\s+)([a-z][\w-]*)(\s*)(\:)',
|
||||
bygroups(Keyword, Whitespace, Name.Namespace, Whitespace,
|
||||
Punctuation)),
|
||||
(r'\?[a-z_]\w*', Name.Variable),
|
||||
(r'<[^>]+>', Name.Label),
|
||||
(r'([a-z][\w-]*)(\:)([a-z][\w-]*)',
|
||||
bygroups(Name.Namespace, Punctuation, Name.Tag)),
|
||||
(r'(str|lang|langmatches|datatype|bound|iri|uri|bnode|rand|abs|'
|
||||
r'ceil|floor|round|concat|strlen|ucase|lcase|encode_for_uri|'
|
||||
r'contains|strstarts|strends|strbefore|strafter|year|month|day|'
|
||||
r'hours|minutes|seconds|timezone|tz|now|md5|sha1|sha256|sha384|'
|
||||
r'sha512|coalesce|if|strlang|strdt|sameterm|isiri|isuri|isblank|'
|
||||
r'isliteral|isnumeric|regex|substr|replace|exists|not exists|'
|
||||
r'count|sum|min|max|avg|sample|group_concat|separator)\b',
|
||||
Name.Function),
|
||||
(r'(true|false)', Literal),
|
||||
(r'[+\-]?\d*\.\d+', Number.Float),
|
||||
(r'[+\-]?\d*(:?\.\d+)?E[+\-]?\d+', Number.Float),
|
||||
(r'[+\-]?\d+', Number.Integer),
|
||||
(r'(\|\||&&|=|\*|\-|\+|/)', Operator),
|
||||
(r'[(){}.;,:^]', Punctuation),
|
||||
(r'#[^\n]+', Comment),
|
||||
(r'"""', String, 'triple-double-quoted-string'),
|
||||
(r'"', String, 'single-double-quoted-string'),
|
||||
(r"'''", String, 'triple-single-quoted-string'),
|
||||
(r"'", String, 'single-single-quoted-string'),
|
||||
],
|
||||
'triple-double-quoted-string': [
|
||||
(r'"""', String, 'end-of-string'),
|
||||
(r'[^\\]+', String),
|
||||
(r'\\', String, 'string-escape'),
|
||||
],
|
||||
'single-double-quoted-string': [
|
||||
(r'"', String, 'end-of-string'),
|
||||
(r'[^"\\\n]+', String),
|
||||
(r'\\', String, 'string-escape'),
|
||||
],
|
||||
'triple-single-quoted-string': [
|
||||
(r"'''", String, 'end-of-string'),
|
||||
(r'[^\\]+', String),
|
||||
(r'\\', String, 'string-escape'),
|
||||
],
|
||||
'single-single-quoted-string': [
|
||||
(r"'", String, 'end-of-string'),
|
||||
(r"[^'\\\n]+", String),
|
||||
(r'\\', String, 'string-escape'),
|
||||
],
|
||||
'string-escape': [
|
||||
(r'.', String, '#pop'),
|
||||
],
|
||||
'end-of-string': [
|
||||
(r'(@)([a-z]+(:?-[a-z0-9]+)*)',
|
||||
bygroups(Operator, Name.Function), '#pop:2'),
|
||||
(r'\^\^', Operator, '#pop:2'),
|
||||
default('#pop:2'),
|
||||
],
|
||||
}
|
||||
@ -1,431 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.rebol
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for the REBOL and related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Generic, Whitespace
|
||||
|
||||
__all__ = ['RebolLexer', 'RedLexer']
|
||||
|
||||
|
||||
class RebolLexer(RegexLexer):
|
||||
"""
|
||||
A `REBOL <http://www.rebol.com/>`_ lexer.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'REBOL'
|
||||
aliases = ['rebol']
|
||||
filenames = ['*.r', '*.r3', '*.reb']
|
||||
mimetypes = ['text/x-rebol']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
escape_re = r'(?:\^\([0-9a-f]{1,4}\)*)'
|
||||
|
||||
def word_callback(lexer, match):
|
||||
word = match.group()
|
||||
|
||||
if re.match(".*:$", word):
|
||||
yield match.start(), Generic.Subheading, word
|
||||
elif re.match(
|
||||
r'(native|alias|all|any|as-string|as-binary|bind|bound\?|case|'
|
||||
r'catch|checksum|comment|debase|dehex|exclude|difference|disarm|'
|
||||
r'either|else|enbase|foreach|remove-each|form|free|get|get-env|if|'
|
||||
r'in|intersect|loop|minimum-of|maximum-of|mold|new-line|'
|
||||
r'new-line\?|not|now|prin|print|reduce|compose|construct|repeat|'
|
||||
r'reverse|save|script\?|set|shift|switch|throw|to-hex|trace|try|'
|
||||
r'type\?|union|unique|unless|unprotect|unset|until|use|value\?|'
|
||||
r'while|compress|decompress|secure|open|close|read|read-io|'
|
||||
r'write-io|write|update|query|wait|input\?|exp|log-10|log-2|'
|
||||
r'log-e|square-root|cosine|sine|tangent|arccosine|arcsine|'
|
||||
r'arctangent|protect|lowercase|uppercase|entab|detab|connected\?|'
|
||||
r'browse|launch|stats|get-modes|set-modes|to-local-file|'
|
||||
r'to-rebol-file|encloak|decloak|create-link|do-browser|bind\?|'
|
||||
r'hide|draw|show|size-text|textinfo|offset-to-caret|'
|
||||
r'caret-to-offset|local-request-file|rgb-to-hsv|hsv-to-rgb|'
|
||||
r'crypt-strength\?|dh-make-key|dh-generate-key|dh-compute-key|'
|
||||
r'dsa-make-key|dsa-generate-key|dsa-make-signature|'
|
||||
r'dsa-verify-signature|rsa-make-key|rsa-generate-key|'
|
||||
r'rsa-encrypt)$', word):
|
||||
yield match.start(), Name.Builtin, word
|
||||
elif re.match(
|
||||
r'(add|subtract|multiply|divide|remainder|power|and~|or~|xor~|'
|
||||
r'minimum|maximum|negate|complement|absolute|random|head|tail|'
|
||||
r'next|back|skip|at|pick|first|second|third|fourth|fifth|sixth|'
|
||||
r'seventh|eighth|ninth|tenth|last|path|find|select|make|to|copy\*|'
|
||||
r'insert|remove|change|poke|clear|trim|sort|min|max|abs|cp|'
|
||||
r'copy)$', word):
|
||||
yield match.start(), Name.Function, word
|
||||
elif re.match(
|
||||
r'(error|source|input|license|help|install|echo|Usage|with|func|'
|
||||
r'throw-on-error|function|does|has|context|probe|\?\?|as-pair|'
|
||||
r'mod|modulo|round|repend|about|set-net|append|join|rejoin|reform|'
|
||||
r'remold|charset|array|replace|move|extract|forskip|forall|alter|'
|
||||
r'first+|also|take|for|forever|dispatch|attempt|what-dir|'
|
||||
r'change-dir|clean-path|list-dir|dirize|rename|split-path|delete|'
|
||||
r'make-dir|delete-dir|in-dir|confirm|dump-obj|upgrade|what|'
|
||||
r'build-tag|process-source|build-markup|decode-cgi|read-cgi|'
|
||||
r'write-user|save-user|set-user-name|protect-system|parse-xml|'
|
||||
r'cvs-date|cvs-version|do-boot|get-net-info|desktop|layout|'
|
||||
r'scroll-para|get-face|alert|set-face|uninstall|unfocus|'
|
||||
r'request-dir|center-face|do-events|net-error|decode-url|'
|
||||
r'parse-header|parse-header-date|parse-email-addrs|import-email|'
|
||||
r'send|build-attach-body|resend|show-popup|hide-popup|open-events|'
|
||||
r'find-key-face|do-face|viewtop|confine|find-window|'
|
||||
r'insert-event-func|remove-event-func|inform|dump-pane|dump-face|'
|
||||
r'flag-face|deflag-face|clear-fields|read-net|vbug|path-thru|'
|
||||
r'read-thru|load-thru|do-thru|launch-thru|load-image|'
|
||||
r'request-download|do-face-alt|set-font|set-para|get-style|'
|
||||
r'set-style|make-face|stylize|choose|hilight-text|hilight-all|'
|
||||
r'unlight-text|focus|scroll-drag|clear-face|reset-face|scroll-face|'
|
||||
r'resize-face|load-stock|load-stock-block|notify|request|flash|'
|
||||
r'request-color|request-pass|request-text|request-list|'
|
||||
r'request-date|request-file|dbug|editor|link-relative-path|'
|
||||
r'emailer|parse-error)$', word):
|
||||
yield match.start(), Keyword.Namespace, word
|
||||
elif re.match(
|
||||
r'(halt|quit|do|load|q|recycle|call|run|ask|parse|view|unview|'
|
||||
r'return|exit|break)$', word):
|
||||
yield match.start(), Name.Exception, word
|
||||
elif re.match('REBOL$', word):
|
||||
yield match.start(), Generic.Heading, word
|
||||
elif re.match("to-.*", word):
|
||||
yield match.start(), Keyword, word
|
||||
elif re.match('(\+|-|\*|/|//|\*\*|and|or|xor|=\?|=|==|<>|<|>|<=|>=)$',
|
||||
word):
|
||||
yield match.start(), Operator, word
|
||||
elif re.match(".*\?$", word):
|
||||
yield match.start(), Keyword, word
|
||||
elif re.match(".*\!$", word):
|
||||
yield match.start(), Keyword.Type, word
|
||||
elif re.match("'.*", word):
|
||||
yield match.start(), Name.Variable.Instance, word # lit-word
|
||||
elif re.match("#.*", word):
|
||||
yield match.start(), Name.Label, word # issue
|
||||
elif re.match("%.*", word):
|
||||
yield match.start(), Name.Decorator, word # file
|
||||
else:
|
||||
yield match.start(), Name.Variable, word
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[^R]+', Comment),
|
||||
(r'REBOL\s+\[', Generic.Strong, 'script'),
|
||||
(r'R', Comment)
|
||||
],
|
||||
'script': [
|
||||
(r'\s+', Text),
|
||||
(r'#"', String.Char, 'char'),
|
||||
(r'#\{[0-9a-f]*\}', Number.Hex),
|
||||
(r'2#\{', Number.Hex, 'bin2'),
|
||||
(r'64#\{[0-9a-z+/=\s]*\}', Number.Hex),
|
||||
(r'"', String, 'string'),
|
||||
(r'\{', String, 'string2'),
|
||||
(r';#+.*\n', Comment.Special),
|
||||
(r';\*+.*\n', Comment.Preproc),
|
||||
(r';.*\n', Comment),
|
||||
(r'%"', Name.Decorator, 'stringFile'),
|
||||
(r'%[^(^{")\s\[\]]+', Name.Decorator),
|
||||
(r'[+-]?([a-z]{1,3})?\$\d+(\.\d+)?', Number.Float), # money
|
||||
(r'[+-]?\d+\:\d+(\:\d+)?(\.\d+)?', String.Other), # time
|
||||
(r'\d+[\-/][0-9a-z]+[\-/]\d+(\/\d+\:\d+((\:\d+)?'
|
||||
r'([.\d+]?([+-]?\d+:\d+)?)?)?)?', String.Other), # date
|
||||
(r'\d+(\.\d+)+\.\d+', Keyword.Constant), # tuple
|
||||
(r'\d+X\d+', Keyword.Constant), # pair
|
||||
(r'[+-]?\d+(\'\d+)?([.,]\d*)?E[+-]?\d+', Number.Float),
|
||||
(r'[+-]?\d+(\'\d+)?[.,]\d*', Number.Float),
|
||||
(r'[+-]?\d+(\'\d+)?', Number),
|
||||
(r'[\[\]()]', Generic.Strong),
|
||||
(r'[a-z]+[^(^{"\s:)]*://[^(^{"\s)]*', Name.Decorator), # url
|
||||
(r'mailto:[^(^{"@\s)]+@[^(^{"@\s)]+', Name.Decorator), # url
|
||||
(r'[^(^{"@\s)]+@[^(^{"@\s)]+', Name.Decorator), # email
|
||||
(r'comment\s"', Comment, 'commentString1'),
|
||||
(r'comment\s\{', Comment, 'commentString2'),
|
||||
(r'comment\s\[', Comment, 'commentBlock'),
|
||||
(r'comment\s[^(\s{"\[]+', Comment),
|
||||
(r'/[^(^{")\s/[\]]*', Name.Attribute),
|
||||
(r'([^(^{")\s/[\]]+)(?=[:({"\s/\[\]])', word_callback),
|
||||
(r'<[\w:.-]*>', Name.Tag),
|
||||
(r'<[^(<>\s")]+', Name.Tag, 'tag'),
|
||||
(r'([^(^{")\s]+)', Text),
|
||||
],
|
||||
'string': [
|
||||
(r'[^(^")]+', String),
|
||||
(escape_re, String.Escape),
|
||||
(r'[(|)]+', String),
|
||||
(r'\^.', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
],
|
||||
'string2': [
|
||||
(r'[^(^{})]+', String),
|
||||
(escape_re, String.Escape),
|
||||
(r'[(|)]+', String),
|
||||
(r'\^.', String.Escape),
|
||||
(r'\{', String, '#push'),
|
||||
(r'\}', String, '#pop'),
|
||||
],
|
||||
'stringFile': [
|
||||
(r'[^(^")]+', Name.Decorator),
|
||||
(escape_re, Name.Decorator),
|
||||
(r'\^.', Name.Decorator),
|
||||
(r'"', Name.Decorator, '#pop'),
|
||||
],
|
||||
'char': [
|
||||
(escape_re + '"', String.Char, '#pop'),
|
||||
(r'\^."', String.Char, '#pop'),
|
||||
(r'."', String.Char, '#pop'),
|
||||
],
|
||||
'tag': [
|
||||
(escape_re, Name.Tag),
|
||||
(r'"', Name.Tag, 'tagString'),
|
||||
(r'[^(<>\r\n")]+', Name.Tag),
|
||||
(r'>', Name.Tag, '#pop'),
|
||||
],
|
||||
'tagString': [
|
||||
(r'[^(^")]+', Name.Tag),
|
||||
(escape_re, Name.Tag),
|
||||
(r'[(|)]+', Name.Tag),
|
||||
(r'\^.', Name.Tag),
|
||||
(r'"', Name.Tag, '#pop'),
|
||||
],
|
||||
'tuple': [
|
||||
(r'(\d+\.)+', Keyword.Constant),
|
||||
(r'\d+', Keyword.Constant, '#pop'),
|
||||
],
|
||||
'bin2': [
|
||||
(r'\s+', Number.Hex),
|
||||
(r'([01]\s*){8}', Number.Hex),
|
||||
(r'\}', Number.Hex, '#pop'),
|
||||
],
|
||||
'commentString1': [
|
||||
(r'[^(^")]+', Comment),
|
||||
(escape_re, Comment),
|
||||
(r'[(|)]+', Comment),
|
||||
(r'\^.', Comment),
|
||||
(r'"', Comment, '#pop'),
|
||||
],
|
||||
'commentString2': [
|
||||
(r'[^(^{})]+', Comment),
|
||||
(escape_re, Comment),
|
||||
(r'[(|)]+', Comment),
|
||||
(r'\^.', Comment),
|
||||
(r'\{', Comment, '#push'),
|
||||
(r'\}', Comment, '#pop'),
|
||||
],
|
||||
'commentBlock': [
|
||||
(r'\[', Comment, '#push'),
|
||||
(r'\]', Comment, '#pop'),
|
||||
(r'"', Comment, "commentString1"),
|
||||
(r'\{', Comment, "commentString2"),
|
||||
(r'[^(\[\]"{)]+', Comment),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
"""
|
||||
Check if code contains REBOL header and so it probably not R code
|
||||
"""
|
||||
if re.match(r'^\s*REBOL\s*\[', text, re.IGNORECASE):
|
||||
# The code starts with REBOL header
|
||||
return 1.0
|
||||
elif re.search(r'\s*REBOL\s*[', text, re.IGNORECASE):
|
||||
# The code contains REBOL header but also some text before it
|
||||
return 0.5
|
||||
|
||||
|
||||
class RedLexer(RegexLexer):
|
||||
"""
|
||||
A `Red-language <http://www.red-lang.org/>`_ lexer.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Red'
|
||||
aliases = ['red', 'red/system']
|
||||
filenames = ['*.red', '*.reds']
|
||||
mimetypes = ['text/x-red', 'text/x-red-system']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
escape_re = r'(?:\^\([0-9a-f]{1,4}\)*)'
|
||||
|
||||
def word_callback(lexer, match):
|
||||
word = match.group()
|
||||
|
||||
if re.match(".*:$", word):
|
||||
yield match.start(), Generic.Subheading, word
|
||||
elif re.match(r'(if|unless|either|any|all|while|until|loop|repeat|'
|
||||
r'foreach|forall|func|function|does|has|switch|'
|
||||
r'case|reduce|compose|get|set|print|prin|equal\?|'
|
||||
r'not-equal\?|strict-equal\?|lesser\?|greater\?|lesser-or-equal\?|'
|
||||
r'greater-or-equal\?|same\?|not|type\?|stats|'
|
||||
r'bind|union|replace|charset|routine)$', word):
|
||||
yield match.start(), Name.Builtin, word
|
||||
elif re.match(r'(make|random|reflect|to|form|mold|absolute|add|divide|multiply|negate|'
|
||||
r'power|remainder|round|subtract|even\?|odd\?|and~|complement|or~|xor~|'
|
||||
r'append|at|back|change|clear|copy|find|head|head\?|index\?|insert|'
|
||||
r'length\?|next|pick|poke|remove|reverse|select|sort|skip|swap|tail|tail\?|'
|
||||
r'take|trim|create|close|delete|modify|open|open\?|query|read|rename|'
|
||||
r'update|write)$', word):
|
||||
yield match.start(), Name.Function, word
|
||||
elif re.match(r'(yes|on|no|off|true|false|tab|cr|lf|newline|escape|slash|sp|space|null|'
|
||||
r'none|crlf|dot|null-byte)$', word):
|
||||
yield match.start(), Name.Builtin.Pseudo, word
|
||||
elif re.match(r'(#system-global|#include|#enum|#define|#either|#if|#import|#export|'
|
||||
r'#switch|#default|#get-definition)$', word):
|
||||
yield match.start(), Keyword.Namespace, word
|
||||
elif re.match(r'(system|halt|quit|quit-return|do|load|q|recycle|call|run|ask|parse|'
|
||||
r'raise-error|return|exit|break|alias|push|pop|probe|\?\?|spec-of|body-of|'
|
||||
r'quote|forever)$', word):
|
||||
yield match.start(), Name.Exception, word
|
||||
elif re.match(r'(action\?|block\?|char\?|datatype\?|file\?|function\?|get-path\?|zero\?|'
|
||||
r'get-word\?|integer\?|issue\?|lit-path\?|lit-word\?|logic\?|native\?|'
|
||||
r'op\?|paren\?|path\?|refinement\?|set-path\?|set-word\?|string\?|unset\?|'
|
||||
r'any-struct\?|none\?|word\?|any-series\?)$', word):
|
||||
yield match.start(), Keyword, word
|
||||
elif re.match(r'(JNICALL|stdcall|cdecl|infix)$', word):
|
||||
yield match.start(), Keyword.Namespace, word
|
||||
elif re.match("to-.*", word):
|
||||
yield match.start(), Keyword, word
|
||||
elif re.match('(\+|-\*\*|-|\*\*|//|/|\*|and|or|xor|=\?|===|==|=|<>|<=|>=|'
|
||||
'<<<|>>>|<<|>>|<|>%)$', word):
|
||||
yield match.start(), Operator, word
|
||||
elif re.match(".*\!$", word):
|
||||
yield match.start(), Keyword.Type, word
|
||||
elif re.match("'.*", word):
|
||||
yield match.start(), Name.Variable.Instance, word # lit-word
|
||||
elif re.match("#.*", word):
|
||||
yield match.start(), Name.Label, word # issue
|
||||
elif re.match("%.*", word):
|
||||
yield match.start(), Name.Decorator, word # file
|
||||
elif re.match(":.*", word):
|
||||
yield match.start(), Generic.Subheading, word # get-word
|
||||
else:
|
||||
yield match.start(), Name.Variable, word
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[^R]+', Comment),
|
||||
(r'Red/System\s+\[', Generic.Strong, 'script'),
|
||||
(r'Red\s+\[', Generic.Strong, 'script'),
|
||||
(r'R', Comment)
|
||||
],
|
||||
'script': [
|
||||
(r'\s+', Text),
|
||||
(r'#"', String.Char, 'char'),
|
||||
(r'#\{[0-9a-f\s]*\}', Number.Hex),
|
||||
(r'2#\{', Number.Hex, 'bin2'),
|
||||
(r'64#\{[0-9a-z+/=\s]*\}', Number.Hex),
|
||||
(r'([0-9a-f]+)(h)((\s)|(?=[\[\]{}"()]))',
|
||||
bygroups(Number.Hex, Name.Variable, Whitespace)),
|
||||
(r'"', String, 'string'),
|
||||
(r'\{', String, 'string2'),
|
||||
(r';#+.*\n', Comment.Special),
|
||||
(r';\*+.*\n', Comment.Preproc),
|
||||
(r';.*\n', Comment),
|
||||
(r'%"', Name.Decorator, 'stringFile'),
|
||||
(r'%[^(^{")\s\[\]]+', Name.Decorator),
|
||||
(r'[+-]?([a-z]{1,3})?\$\d+(\.\d+)?', Number.Float), # money
|
||||
(r'[+-]?\d+\:\d+(\:\d+)?(\.\d+)?', String.Other), # time
|
||||
(r'\d+[\-/][0-9a-z]+[\-/]\d+(/\d+:\d+((:\d+)?'
|
||||
r'([\.\d+]?([+-]?\d+:\d+)?)?)?)?', String.Other), # date
|
||||
(r'\d+(\.\d+)+\.\d+', Keyword.Constant), # tuple
|
||||
(r'\d+X\d+', Keyword.Constant), # pair
|
||||
(r'[+-]?\d+(\'\d+)?([.,]\d*)?E[+-]?\d+', Number.Float),
|
||||
(r'[+-]?\d+(\'\d+)?[.,]\d*', Number.Float),
|
||||
(r'[+-]?\d+(\'\d+)?', Number),
|
||||
(r'[\[\]()]', Generic.Strong),
|
||||
(r'[a-z]+[^(^{"\s:)]*://[^(^{"\s)]*', Name.Decorator), # url
|
||||
(r'mailto:[^(^{"@\s)]+@[^(^{"@\s)]+', Name.Decorator), # url
|
||||
(r'[^(^{"@\s)]+@[^(^{"@\s)]+', Name.Decorator), # email
|
||||
(r'comment\s"', Comment, 'commentString1'),
|
||||
(r'comment\s\{', Comment, 'commentString2'),
|
||||
(r'comment\s\[', Comment, 'commentBlock'),
|
||||
(r'comment\s[^(\s{"\[]+', Comment),
|
||||
(r'/[^(^{^")\s/[\]]*', Name.Attribute),
|
||||
(r'([^(^{^")\s/[\]]+)(?=[:({"\s/\[\]])', word_callback),
|
||||
(r'<[\w:.-]*>', Name.Tag),
|
||||
(r'<[^(<>\s")]+', Name.Tag, 'tag'),
|
||||
(r'([^(^{")\s]+)', Text),
|
||||
],
|
||||
'string': [
|
||||
(r'[^(^")]+', String),
|
||||
(escape_re, String.Escape),
|
||||
(r'[(|)]+', String),
|
||||
(r'\^.', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
],
|
||||
'string2': [
|
||||
(r'[^(^{})]+', String),
|
||||
(escape_re, String.Escape),
|
||||
(r'[(|)]+', String),
|
||||
(r'\^.', String.Escape),
|
||||
(r'\{', String, '#push'),
|
||||
(r'\}', String, '#pop'),
|
||||
],
|
||||
'stringFile': [
|
||||
(r'[^(^")]+', Name.Decorator),
|
||||
(escape_re, Name.Decorator),
|
||||
(r'\^.', Name.Decorator),
|
||||
(r'"', Name.Decorator, '#pop'),
|
||||
],
|
||||
'char': [
|
||||
(escape_re + '"', String.Char, '#pop'),
|
||||
(r'\^."', String.Char, '#pop'),
|
||||
(r'."', String.Char, '#pop'),
|
||||
],
|
||||
'tag': [
|
||||
(escape_re, Name.Tag),
|
||||
(r'"', Name.Tag, 'tagString'),
|
||||
(r'[^(<>\r\n")]+', Name.Tag),
|
||||
(r'>', Name.Tag, '#pop'),
|
||||
],
|
||||
'tagString': [
|
||||
(r'[^(^")]+', Name.Tag),
|
||||
(escape_re, Name.Tag),
|
||||
(r'[(|)]+', Name.Tag),
|
||||
(r'\^.', Name.Tag),
|
||||
(r'"', Name.Tag, '#pop'),
|
||||
],
|
||||
'tuple': [
|
||||
(r'(\d+\.)+', Keyword.Constant),
|
||||
(r'\d+', Keyword.Constant, '#pop'),
|
||||
],
|
||||
'bin2': [
|
||||
(r'\s+', Number.Hex),
|
||||
(r'([01]\s*){8}', Number.Hex),
|
||||
(r'\}', Number.Hex, '#pop'),
|
||||
],
|
||||
'commentString1': [
|
||||
(r'[^(^")]+', Comment),
|
||||
(escape_re, Comment),
|
||||
(r'[(|)]+', Comment),
|
||||
(r'\^.', Comment),
|
||||
(r'"', Comment, '#pop'),
|
||||
],
|
||||
'commentString2': [
|
||||
(r'[^(^{})]+', Comment),
|
||||
(escape_re, Comment),
|
||||
(r'[(|)]+', Comment),
|
||||
(r'\^.', Comment),
|
||||
(r'\{', Comment, '#push'),
|
||||
(r'\}', Comment, '#pop'),
|
||||
],
|
||||
'commentBlock': [
|
||||
(r'\[', Comment, '#push'),
|
||||
(r'\]', Comment, '#pop'),
|
||||
(r'"', Comment, "commentString1"),
|
||||
(r'\{', Comment, "commentString2"),
|
||||
(r'[^(\[\]"{)]+', Comment),
|
||||
],
|
||||
}
|
||||
@ -1,437 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.shell
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for various shells.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import Lexer, RegexLexer, do_insertions, bygroups, include
|
||||
from pygments.token import Punctuation, \
|
||||
Text, Comment, Operator, Keyword, Name, String, Number, Generic
|
||||
from pygments.util import shebang_matches
|
||||
|
||||
|
||||
__all__ = ['BashLexer', 'BashSessionLexer', 'TcshLexer', 'BatchLexer',
|
||||
'PowerShellLexer', 'ShellSessionLexer']
|
||||
|
||||
line_re = re.compile('.*?\n')
|
||||
|
||||
|
||||
class BashLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for (ba|k|)sh shell scripts.
|
||||
|
||||
.. versionadded:: 0.6
|
||||
"""
|
||||
|
||||
name = 'Bash'
|
||||
aliases = ['bash', 'sh', 'ksh', 'shell']
|
||||
filenames = ['*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass',
|
||||
'.bashrc', 'bashrc', '.bash_*', 'bash_*', 'PKGBUILD']
|
||||
mimetypes = ['application/x-sh', 'application/x-shellscript']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('basic'),
|
||||
(r'`', String.Backtick, 'backticks'),
|
||||
include('data'),
|
||||
include('interp'),
|
||||
],
|
||||
'interp': [
|
||||
(r'\$\(\(', Keyword, 'math'),
|
||||
(r'\$\(', Keyword, 'paren'),
|
||||
(r'\$\{#?', String.Interpol, 'curly'),
|
||||
(r'\$#?(\w+|.)', Name.Variable),
|
||||
],
|
||||
'basic': [
|
||||
(r'\b(if|fi|else|while|do|done|for|then|return|function|case|'
|
||||
r'select|continue|until|esac|elif)(\s*)\b',
|
||||
bygroups(Keyword, Text)),
|
||||
(r'\b(alias|bg|bind|break|builtin|caller|cd|command|compgen|'
|
||||
r'complete|declare|dirs|disown|echo|enable|eval|exec|exit|'
|
||||
r'export|false|fc|fg|getopts|hash|help|history|jobs|kill|let|'
|
||||
r'local|logout|popd|printf|pushd|pwd|read|readonly|set|shift|'
|
||||
r'shopt|source|suspend|test|time|times|trap|true|type|typeset|'
|
||||
r'ulimit|umask|unalias|unset|wait)\s*\b(?!\.)',
|
||||
Name.Builtin),
|
||||
(r'#.*\n', Comment),
|
||||
(r'\\[\w\W]', String.Escape),
|
||||
(r'(\b\w+)(\s*)(=)', bygroups(Name.Variable, Text, Operator)),
|
||||
(r'[\[\]{}()=]', Operator),
|
||||
(r'<<<', Operator), # here-string
|
||||
(r'<<-?\s*(\'?)\\?(\w+)[\w\W]+?\2', String),
|
||||
(r'&&|\|\|', Operator),
|
||||
],
|
||||
'data': [
|
||||
(r'(?s)\$?"(\\\\|\\[0-7]+|\\.|[^"\\$])*"', String.Double),
|
||||
(r'"', String.Double, 'string'),
|
||||
(r"(?s)\$'(\\\\|\\[0-7]+|\\.|[^'\\])*'", String.Single),
|
||||
(r"(?s)'.*?'", String.Single),
|
||||
(r';', Punctuation),
|
||||
(r'&', Punctuation),
|
||||
(r'\|', Punctuation),
|
||||
(r'\s+', Text),
|
||||
(r'\d+(?= |\Z)', Number),
|
||||
(r'[^=\s\[\]{}()$"\'`\\<&|;]+', Text),
|
||||
(r'<', Text),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String.Double, '#pop'),
|
||||
(r'(?s)(\\\\|\\[0-7]+|\\.|[^"\\$])+', String.Double),
|
||||
include('interp'),
|
||||
],
|
||||
'curly': [
|
||||
(r'\}', String.Interpol, '#pop'),
|
||||
(r':-', Keyword),
|
||||
(r'\w+', Name.Variable),
|
||||
(r'[^}:"\'`$\\]+', Punctuation),
|
||||
(r':', Punctuation),
|
||||
include('root'),
|
||||
],
|
||||
'paren': [
|
||||
(r'\)', Keyword, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'math': [
|
||||
(r'\)\)', Keyword, '#pop'),
|
||||
(r'[-+*/%^|&]|\*\*|\|\|', Operator),
|
||||
(r'\d+#\d+', Number),
|
||||
(r'\d+#(?! )', Number),
|
||||
(r'\d+', Number),
|
||||
include('root'),
|
||||
],
|
||||
'backticks': [
|
||||
(r'`', String.Backtick, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if shebang_matches(text, r'(ba|z|)sh'):
|
||||
return 1
|
||||
if text.startswith('$ '):
|
||||
return 0.2
|
||||
|
||||
|
||||
class BashSessionLexer(Lexer):
|
||||
"""
|
||||
Lexer for simplistic shell sessions.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
|
||||
name = 'Bash Session'
|
||||
aliases = ['console']
|
||||
filenames = ['*.sh-session']
|
||||
mimetypes = ['application/x-shell-session']
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
bashlexer = BashLexer(**self.options)
|
||||
|
||||
pos = 0
|
||||
curcode = ''
|
||||
insertions = []
|
||||
|
||||
for match in line_re.finditer(text):
|
||||
line = match.group()
|
||||
m = re.match(r'^((?:\(\S+\))?(?:|sh\S*?|\w+\S+[@:]\S+(?:\s+\S+)'
|
||||
r'?|\[\S+[@:][^\n]+\].+)[$#%])(.*\n?)' , line)
|
||||
if m:
|
||||
# To support output lexers (say diff output), the output
|
||||
# needs to be broken by prompts whenever the output lexer
|
||||
# changes.
|
||||
if not insertions:
|
||||
pos = match.start()
|
||||
|
||||
insertions.append((len(curcode),
|
||||
[(0, Generic.Prompt, m.group(1))]))
|
||||
curcode += m.group(2)
|
||||
elif line.startswith('>'):
|
||||
insertions.append((len(curcode),
|
||||
[(0, Generic.Prompt, line[:1])]))
|
||||
curcode += line[1:]
|
||||
else:
|
||||
if insertions:
|
||||
toks = bashlexer.get_tokens_unprocessed(curcode)
|
||||
for i, t, v in do_insertions(insertions, toks):
|
||||
yield pos+i, t, v
|
||||
yield match.start(), Generic.Output, line
|
||||
insertions = []
|
||||
curcode = ''
|
||||
if insertions:
|
||||
for i, t, v in do_insertions(insertions,
|
||||
bashlexer.get_tokens_unprocessed(curcode)):
|
||||
yield pos+i, t, v
|
||||
|
||||
|
||||
class ShellSessionLexer(Lexer):
|
||||
"""
|
||||
Lexer for shell sessions that works with different command prompts
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'Shell Session'
|
||||
aliases = ['shell-session']
|
||||
filenames = ['*.shell-session']
|
||||
mimetypes = ['application/x-sh-session']
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
bashlexer = BashLexer(**self.options)
|
||||
|
||||
pos = 0
|
||||
curcode = ''
|
||||
insertions = []
|
||||
|
||||
for match in line_re.finditer(text):
|
||||
line = match.group()
|
||||
m = re.match(r'^((?:\[?\S+@[^$#%]+\]?\s*)[$#%])(.*\n?)', line)
|
||||
if m:
|
||||
# To support output lexers (say diff output), the output
|
||||
# needs to be broken by prompts whenever the output lexer
|
||||
# changes.
|
||||
if not insertions:
|
||||
pos = match.start()
|
||||
|
||||
insertions.append((len(curcode),
|
||||
[(0, Generic.Prompt, m.group(1))]))
|
||||
curcode += m.group(2)
|
||||
else:
|
||||
if insertions:
|
||||
toks = bashlexer.get_tokens_unprocessed(curcode)
|
||||
for i, t, v in do_insertions(insertions, toks):
|
||||
yield pos+i, t, v
|
||||
yield match.start(), Generic.Output, line
|
||||
insertions = []
|
||||
curcode = ''
|
||||
if insertions:
|
||||
for i, t, v in do_insertions(insertions,
|
||||
bashlexer.get_tokens_unprocessed(curcode)):
|
||||
yield pos+i, t, v
|
||||
|
||||
|
||||
class BatchLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the DOS/Windows Batch file format.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
"""
|
||||
name = 'Batchfile'
|
||||
aliases = ['bat', 'batch', 'dosbatch', 'winbatch']
|
||||
filenames = ['*.bat', '*.cmd']
|
||||
mimetypes = ['application/x-dos-batch']
|
||||
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Lines can start with @ to prevent echo
|
||||
(r'^\s*@', Punctuation),
|
||||
(r'^(\s*)(rem\s.*)$', bygroups(Text, Comment)),
|
||||
(r'".*?"', String.Double),
|
||||
(r"'.*?'", String.Single),
|
||||
# If made more specific, make sure you still allow expansions
|
||||
# like %~$VAR:zlt
|
||||
(r'%%?[~$:\w]+%?', Name.Variable),
|
||||
(r'::.*', Comment), # Technically :: only works at BOL
|
||||
(r'\b(set)(\s+)(\w+)', bygroups(Keyword, Text, Name.Variable)),
|
||||
(r'\b(call)(\s+)(:\w+)', bygroups(Keyword, Text, Name.Label)),
|
||||
(r'\b(goto)(\s+)(\w+)', bygroups(Keyword, Text, Name.Label)),
|
||||
(r'\b(set|call|echo|on|off|endlocal|for|do|goto|if|pause|'
|
||||
r'setlocal|shift|errorlevel|exist|defined|cmdextversion|'
|
||||
r'errorlevel|else|cd|md|del|deltree|cls|choice)\b', Keyword),
|
||||
(r'\b(equ|neq|lss|leq|gtr|geq)\b', Operator),
|
||||
include('basic'),
|
||||
(r'.', Text),
|
||||
],
|
||||
'echo': [
|
||||
# Escapes only valid within echo args?
|
||||
(r'\^\^|\^<|\^>|\^\|', String.Escape),
|
||||
(r'\n', Text, '#pop'),
|
||||
include('basic'),
|
||||
(r'[^\'"^]+', Text),
|
||||
],
|
||||
'basic': [
|
||||
(r'".*?"', String.Double),
|
||||
(r"'.*?'", String.Single),
|
||||
(r'`.*?`', String.Backtick),
|
||||
(r'-?\d+', Number),
|
||||
(r',', Punctuation),
|
||||
(r'=', Operator),
|
||||
(r'/\S+', Name),
|
||||
(r':\w+', Name.Label),
|
||||
(r'\w:\w+', Text),
|
||||
(r'([<>|])(\s*)(\w+)', bygroups(Punctuation, Text, Name)),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class TcshLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for tcsh scripts.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
name = 'Tcsh'
|
||||
aliases = ['tcsh', 'csh']
|
||||
filenames = ['*.tcsh', '*.csh']
|
||||
mimetypes = ['application/x-csh']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('basic'),
|
||||
(r'\$\(', Keyword, 'paren'),
|
||||
(r'\$\{#?', Keyword, 'curly'),
|
||||
(r'`', String.Backtick, 'backticks'),
|
||||
include('data'),
|
||||
],
|
||||
'basic': [
|
||||
(r'\b(if|endif|else|while|then|foreach|case|default|'
|
||||
r'continue|goto|breaksw|end|switch|endsw)\s*\b',
|
||||
Keyword),
|
||||
(r'\b(alias|alloc|bg|bindkey|break|builtins|bye|caller|cd|chdir|'
|
||||
r'complete|dirs|echo|echotc|eval|exec|exit|fg|filetest|getxvers|'
|
||||
r'glob|getspath|hashstat|history|hup|inlib|jobs|kill|'
|
||||
r'limit|log|login|logout|ls-F|migrate|newgrp|nice|nohup|notify|'
|
||||
r'onintr|popd|printenv|pushd|rehash|repeat|rootnode|popd|pushd|'
|
||||
r'set|shift|sched|setenv|setpath|settc|setty|setxvers|shift|'
|
||||
r'source|stop|suspend|source|suspend|telltc|time|'
|
||||
r'umask|unalias|uncomplete|unhash|universe|unlimit|unset|unsetenv|'
|
||||
r'ver|wait|warp|watchlog|where|which)\s*\b',
|
||||
Name.Builtin),
|
||||
(r'#.*', Comment),
|
||||
(r'\\[\w\W]', String.Escape),
|
||||
(r'(\b\w+)(\s*)(=)', bygroups(Name.Variable, Text, Operator)),
|
||||
(r'[\[\]{}()=]+', Operator),
|
||||
(r'<<\s*(\'?)\\?(\w+)[\w\W]+?\2', String),
|
||||
(r';', Punctuation),
|
||||
],
|
||||
'data': [
|
||||
(r'(?s)"(\\\\|\\[0-7]+|\\.|[^"\\])*"', String.Double),
|
||||
(r"(?s)'(\\\\|\\[0-7]+|\\.|[^'\\])*'", String.Single),
|
||||
(r'\s+', Text),
|
||||
(r'[^=\s\[\]{}()$"\'`\\;#]+', Text),
|
||||
(r'\d+(?= |\Z)', Number),
|
||||
(r'\$#?(\w+|.)', Name.Variable),
|
||||
],
|
||||
'curly': [
|
||||
(r'\}', Keyword, '#pop'),
|
||||
(r':-', Keyword),
|
||||
(r'\w+', Name.Variable),
|
||||
(r'[^}:"\'`$]+', Punctuation),
|
||||
(r':', Punctuation),
|
||||
include('root'),
|
||||
],
|
||||
'paren': [
|
||||
(r'\)', Keyword, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'backticks': [
|
||||
(r'`', String.Backtick, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class PowerShellLexer(RegexLexer):
|
||||
"""
|
||||
For Windows PowerShell code.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'PowerShell'
|
||||
aliases = ['powershell', 'posh', 'ps1', 'psm1']
|
||||
filenames = ['*.ps1','*.psm1']
|
||||
mimetypes = ['text/x-powershell']
|
||||
|
||||
flags = re.DOTALL | re.IGNORECASE | re.MULTILINE
|
||||
|
||||
keywords = (
|
||||
'while validateset validaterange validatepattern validatelength '
|
||||
'validatecount until trap switch return ref process param parameter in '
|
||||
'if global: function foreach for finally filter end elseif else '
|
||||
'dynamicparam do default continue cmdletbinding break begin alias \\? '
|
||||
'% #script #private #local #global mandatory parametersetname position '
|
||||
'valuefrompipeline valuefrompipelinebypropertyname '
|
||||
'valuefromremainingarguments helpmessage try catch throw').split()
|
||||
|
||||
operators = (
|
||||
'and as band bnot bor bxor casesensitive ccontains ceq cge cgt cle '
|
||||
'clike clt cmatch cne cnotcontains cnotlike cnotmatch contains '
|
||||
'creplace eq exact f file ge gt icontains ieq ige igt ile ilike ilt '
|
||||
'imatch ine inotcontains inotlike inotmatch ireplace is isnot le like '
|
||||
'lt match ne not notcontains notlike notmatch or regex replace '
|
||||
'wildcard').split()
|
||||
|
||||
verbs = (
|
||||
'write where wait use update unregister undo trace test tee take '
|
||||
'suspend stop start split sort skip show set send select scroll resume '
|
||||
'restore restart resolve resize reset rename remove register receive '
|
||||
'read push pop ping out new move measure limit join invoke import '
|
||||
'group get format foreach export expand exit enter enable disconnect '
|
||||
'disable debug cxnew copy convertto convertfrom convert connect '
|
||||
'complete compare clear checkpoint aggregate add').split()
|
||||
|
||||
commenthelp = (
|
||||
'component description example externalhelp forwardhelpcategory '
|
||||
'forwardhelptargetname functionality inputs link '
|
||||
'notes outputs parameter remotehelprunspace role synopsis').split()
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# we need to count pairs of parentheses for correct highlight
|
||||
# of '$(...)' blocks in strings
|
||||
(r'\(', Punctuation, 'child'),
|
||||
(r'\s+', Text),
|
||||
(r'^(\s*#[#\s]*)(\.(?:%s))([^\n]*$)' % '|'.join(commenthelp),
|
||||
bygroups(Comment, String.Doc, Comment)),
|
||||
(r'#[^\n]*?$', Comment),
|
||||
(r'(<|<)#', Comment.Multiline, 'multline'),
|
||||
(r'@"\n', String.Heredoc, 'heredoc-double'),
|
||||
(r"@'\n.*?\n'@", String.Heredoc),
|
||||
# escaped syntax
|
||||
(r'`[\'"$@-]', Punctuation),
|
||||
(r'"', String.Double, 'string'),
|
||||
(r"'([^']|'')*'", String.Single),
|
||||
(r'(\$|@@|@)((global|script|private|env):)?\w+',
|
||||
Name.Variable),
|
||||
(r'(%s)\b' % '|'.join(keywords), Keyword),
|
||||
(r'-(%s)\b' % '|'.join(operators), Operator),
|
||||
(r'(%s)-[a-z_]\w*\b' % '|'.join(verbs), Name.Builtin),
|
||||
(r'\[[a-z_\[][\w. `,\[\]]*\]', Name.Constant), # .net [type]s
|
||||
(r'-[a-z_]\w*', Name),
|
||||
(r'\w+', Name),
|
||||
(r'[.,;@{}\[\]$()=+*/\\&%!~?^`|<>-]|::', Punctuation),
|
||||
],
|
||||
'child': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'multline': [
|
||||
(r'[^#&.]+', Comment.Multiline),
|
||||
(r'#(>|>)', Comment.Multiline, '#pop'),
|
||||
(r'\.(%s)' % '|'.join(commenthelp), String.Doc),
|
||||
(r'[#&.]', Comment.Multiline),
|
||||
],
|
||||
'string': [
|
||||
(r"`[0abfnrtv'\"$`]", String.Escape),
|
||||
(r'[^$`"]+', String.Double),
|
||||
(r'\$\(', Punctuation, 'child'),
|
||||
(r'""', String.Double),
|
||||
(r'[`$]', String.Double),
|
||||
(r'"', String.Double, '#pop'),
|
||||
],
|
||||
'heredoc-double': [
|
||||
(r'\n"@', String.Heredoc, '#pop'),
|
||||
(r'\$\(', Punctuation, 'child'),
|
||||
(r'[^@\n]+"]', String.Heredoc),
|
||||
(r".", String.Heredoc),
|
||||
]
|
||||
}
|
||||
@ -1,195 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.smalltalk
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for Smalltalk and related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['SmalltalkLexer', 'NewspeakLexer']
|
||||
|
||||
|
||||
class SmalltalkLexer(RegexLexer):
|
||||
"""
|
||||
For `Smalltalk <http://www.smalltalk.org/>`_ syntax.
|
||||
Contributed by Stefan Matthias Aust.
|
||||
Rewritten by Nils Winter.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
name = 'Smalltalk'
|
||||
filenames = ['*.st']
|
||||
aliases = ['smalltalk', 'squeak', 'st']
|
||||
mimetypes = ['text/x-smalltalk']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'(<)(\w+:)(.*?)(>)', bygroups(Text, Keyword, Text, Text)),
|
||||
include('squeak fileout'),
|
||||
include('whitespaces'),
|
||||
include('method definition'),
|
||||
(r'(\|)([\w\s]*)(\|)', bygroups(Operator, Name.Variable, Operator)),
|
||||
include('objects'),
|
||||
(r'\^|\:=|\_', Operator),
|
||||
# temporaries
|
||||
(r'[\]({}.;!]', Text),
|
||||
],
|
||||
'method definition': [
|
||||
# Not perfect can't allow whitespaces at the beginning and the
|
||||
# without breaking everything
|
||||
(r'([a-zA-Z]+\w*:)(\s*)(\w+)',
|
||||
bygroups(Name.Function, Text, Name.Variable)),
|
||||
(r'^(\b[a-zA-Z]+\w*\b)(\s*)$', bygroups(Name.Function, Text)),
|
||||
(r'^([-+*/\\~<>=|&!?,@%]+)(\s*)(\w+)(\s*)$',
|
||||
bygroups(Name.Function, Text, Name.Variable, Text)),
|
||||
],
|
||||
'blockvariables': [
|
||||
include('whitespaces'),
|
||||
(r'(:)(\s*)(\w+)',
|
||||
bygroups(Operator, Text, Name.Variable)),
|
||||
(r'\|', Operator, '#pop'),
|
||||
default('#pop'), # else pop
|
||||
],
|
||||
'literals': [
|
||||
(r"'(''|[^'])*'", String, 'afterobject'),
|
||||
(r'\$.', String.Char, 'afterobject'),
|
||||
(r'#\(', String.Symbol, 'parenth'),
|
||||
(r'\)', Text, 'afterobject'),
|
||||
(r'(\d+r)?-?\d+(\.\d+)?(e-?\d+)?', Number, 'afterobject'),
|
||||
],
|
||||
'_parenth_helper': [
|
||||
include('whitespaces'),
|
||||
(r'(\d+r)?-?\d+(\.\d+)?(e-?\d+)?', Number),
|
||||
(r'[-+*/\\~<>=|&#!?,@%\w:]+', String.Symbol),
|
||||
# literals
|
||||
(r"'(''|[^'])*'", String),
|
||||
(r'\$.', String.Char),
|
||||
(r'#*\(', String.Symbol, 'inner_parenth'),
|
||||
],
|
||||
'parenth': [
|
||||
# This state is a bit tricky since
|
||||
# we can't just pop this state
|
||||
(r'\)', String.Symbol, ('root', 'afterobject')),
|
||||
include('_parenth_helper'),
|
||||
],
|
||||
'inner_parenth': [
|
||||
(r'\)', String.Symbol, '#pop'),
|
||||
include('_parenth_helper'),
|
||||
],
|
||||
'whitespaces': [
|
||||
# skip whitespace and comments
|
||||
(r'\s+', Text),
|
||||
(r'"(""|[^"])*"', Comment),
|
||||
],
|
||||
'objects': [
|
||||
(r'\[', Text, 'blockvariables'),
|
||||
(r'\]', Text, 'afterobject'),
|
||||
(r'\b(self|super|true|false|nil|thisContext)\b',
|
||||
Name.Builtin.Pseudo, 'afterobject'),
|
||||
(r'\b[A-Z]\w*(?!:)\b', Name.Class, 'afterobject'),
|
||||
(r'\b[a-z]\w*(?!:)\b', Name.Variable, 'afterobject'),
|
||||
(r'#("(""|[^"])*"|[-+*/\\~<>=|&!?,@%]+|[\w:]+)',
|
||||
String.Symbol, 'afterobject'),
|
||||
include('literals'),
|
||||
],
|
||||
'afterobject': [
|
||||
(r'! !$', Keyword, '#pop'), # squeak chunk delimiter
|
||||
include('whitespaces'),
|
||||
(r'\b(ifTrue:|ifFalse:|whileTrue:|whileFalse:|timesRepeat:)',
|
||||
Name.Builtin, '#pop'),
|
||||
(r'\b(new\b(?!:))', Name.Builtin),
|
||||
(r'\:=|\_', Operator, '#pop'),
|
||||
(r'\b[a-zA-Z]+\w*:', Name.Function, '#pop'),
|
||||
(r'\b[a-zA-Z]+\w*', Name.Function),
|
||||
(r'\w+:?|[-+*/\\~<>=|&!?,@%]+', Name.Function, '#pop'),
|
||||
(r'\.', Punctuation, '#pop'),
|
||||
(r';', Punctuation),
|
||||
(r'[\])}]', Text),
|
||||
(r'[\[({]', Text, '#pop'),
|
||||
],
|
||||
'squeak fileout': [
|
||||
# Squeak fileout format (optional)
|
||||
(r'^"(""|[^"])*"!', Keyword),
|
||||
(r"^'(''|[^'])*'!", Keyword),
|
||||
(r'^(!)(\w+)( commentStamp: )(.*?)( prior: .*?!\n)(.*?)(!)',
|
||||
bygroups(Keyword, Name.Class, Keyword, String, Keyword, Text, Keyword)),
|
||||
(r"^(!)(\w+(?: class)?)( methodsFor: )('(?:''|[^'])*')(.*?!)",
|
||||
bygroups(Keyword, Name.Class, Keyword, String, Keyword)),
|
||||
(r'^(\w+)( subclass: )(#\w+)'
|
||||
r'(\s+instanceVariableNames: )(.*?)'
|
||||
r'(\s+classVariableNames: )(.*?)'
|
||||
r'(\s+poolDictionaries: )(.*?)'
|
||||
r'(\s+category: )(.*?)(!)',
|
||||
bygroups(Name.Class, Keyword, String.Symbol, Keyword, String, Keyword,
|
||||
String, Keyword, String, Keyword, String, Keyword)),
|
||||
(r'^(\w+(?: class)?)(\s+instanceVariableNames: )(.*?)(!)',
|
||||
bygroups(Name.Class, Keyword, String, Keyword)),
|
||||
(r'(!\n)(\].*)(! !)$', bygroups(Keyword, Text, Keyword)),
|
||||
(r'! !$', Keyword),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class NewspeakLexer(RegexLexer):
|
||||
"""
|
||||
For `Newspeak <http://newspeaklanguage.org/>` syntax.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'Newspeak'
|
||||
filenames = ['*.ns2']
|
||||
aliases = ['newspeak', ]
|
||||
mimetypes = ['text/x-newspeak']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\b(Newsqueak2)\b', Keyword.Declaration),
|
||||
(r"'[^']*'", String),
|
||||
(r'\b(class)(\s+)(\w+)(\s*)',
|
||||
bygroups(Keyword.Declaration, Text, Name.Class, Text)),
|
||||
(r'\b(mixin|self|super|private|public|protected|nil|true|false)\b',
|
||||
Keyword),
|
||||
(r'(\w+\:)(\s*)([a-zA-Z_]\w+)',
|
||||
bygroups(Name.Function, Text, Name.Variable)),
|
||||
(r'(\w+)(\s*)(=)',
|
||||
bygroups(Name.Attribute, Text, Operator)),
|
||||
(r'<\w+>', Comment.Special),
|
||||
include('expressionstat'),
|
||||
include('whitespace')
|
||||
],
|
||||
|
||||
'expressionstat': [
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'\d+', Number.Integer),
|
||||
(r':\w+', Name.Variable),
|
||||
(r'(\w+)(::)', bygroups(Name.Variable, Operator)),
|
||||
(r'\w+:', Name.Function),
|
||||
(r'\w+', Name.Variable),
|
||||
(r'\(|\)', Punctuation),
|
||||
(r'\[|\]', Punctuation),
|
||||
(r'\{|\}', Punctuation),
|
||||
|
||||
(r'(\^|\+|\/|~|\*|<|>|=|@|%|\||&|\?|!|,|-|:)', Operator),
|
||||
(r'\.|;', Punctuation),
|
||||
include('whitespace'),
|
||||
include('literals'),
|
||||
],
|
||||
'literals': [
|
||||
(r'\$.', String),
|
||||
(r"'[^']*'", String),
|
||||
(r"#'[^']*'", String.Symbol),
|
||||
(r"#\w+:?", String.Symbol),
|
||||
(r"#(\+|\/|~|\*|<|>|=|@|%|\||&|\?|!|,|-)+", String.Symbol)
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\s+', Text),
|
||||
(r'"[^"]*"', Comment)
|
||||
],
|
||||
}
|
||||
@ -1,83 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.snobol
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for the SNOBOL language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['SnobolLexer']
|
||||
|
||||
|
||||
class SnobolLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the SNOBOL4 programming language.
|
||||
|
||||
Recognizes the common ASCII equivalents of the original SNOBOL4 operators.
|
||||
Does not require spaces around binary operators.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = "Snobol"
|
||||
aliases = ["snobol"]
|
||||
filenames = ['*.snobol']
|
||||
mimetypes = ['text/x-snobol']
|
||||
|
||||
tokens = {
|
||||
# root state, start of line
|
||||
# comments, continuation lines, and directives start in column 1
|
||||
# as do labels
|
||||
'root': [
|
||||
(r'\*.*\n', Comment),
|
||||
(r'[+.] ', Punctuation, 'statement'),
|
||||
(r'-.*\n', Comment),
|
||||
(r'END\s*\n', Name.Label, 'heredoc'),
|
||||
(r'[A-Za-z$][\w$]*', Name.Label, 'statement'),
|
||||
(r'\s+', Text, 'statement'),
|
||||
],
|
||||
# statement state, line after continuation or label
|
||||
'statement': [
|
||||
(r'\s*\n', Text, '#pop'),
|
||||
(r'\s+', Text),
|
||||
(r'(?<=[^\w.])(LT|LE|EQ|NE|GE|GT|INTEGER|IDENT|DIFFER|LGT|SIZE|'
|
||||
r'REPLACE|TRIM|DUPL|REMDR|DATE|TIME|EVAL|APPLY|OPSYN|LOAD|UNLOAD|'
|
||||
r'LEN|SPAN|BREAK|ANY|NOTANY|TAB|RTAB|REM|POS|RPOS|FAIL|FENCE|'
|
||||
r'ABORT|ARB|ARBNO|BAL|SUCCEED|INPUT|OUTPUT|TERMINAL)(?=[^\w.])',
|
||||
Name.Builtin),
|
||||
(r'[A-Za-z][\w.]*', Name),
|
||||
# ASCII equivalents of original operators
|
||||
# | for the EBCDIC equivalent, ! likewise
|
||||
# \ for EBCDIC negation
|
||||
(r'\*\*|[?$.!%*/#+\-@|&\\=]', Operator),
|
||||
(r'"[^"]*"', String),
|
||||
(r"'[^']*'", String),
|
||||
# Accept SPITBOL syntax for real numbers
|
||||
# as well as Macro SNOBOL4
|
||||
(r'[0-9]+(?=[^.EeDd])', Number.Integer),
|
||||
(r'[0-9]+(\.[0-9]*)?([EDed][-+]?[0-9]+)?', Number.Float),
|
||||
# Goto
|
||||
(r':', Punctuation, 'goto'),
|
||||
(r'[()<>,;]', Punctuation),
|
||||
],
|
||||
# Goto block
|
||||
'goto': [
|
||||
(r'\s*\n', Text, "#pop:2"),
|
||||
(r'\s+', Text),
|
||||
(r'F|S', Keyword),
|
||||
(r'(\()([A-Za-z][\w.]*)(\))',
|
||||
bygroups(Punctuation, Name.Label, Punctuation))
|
||||
],
|
||||
# everything after the END statement is basically one
|
||||
# big heredoc.
|
||||
'heredoc': [
|
||||
(r'.*\n', String.Heredoc)
|
||||
]
|
||||
}
|
||||
@ -1,100 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.special
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Special lexers.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import Lexer
|
||||
from pygments.token import Token, Error, Text
|
||||
from pygments.util import get_choice_opt, text_type, BytesIO
|
||||
|
||||
|
||||
__all__ = ['TextLexer', 'RawTokenLexer']
|
||||
|
||||
|
||||
class TextLexer(Lexer):
|
||||
"""
|
||||
"Null" lexer, doesn't highlight anything.
|
||||
"""
|
||||
name = 'Text only'
|
||||
aliases = ['text']
|
||||
filenames = ['*.txt']
|
||||
mimetypes = ['text/plain']
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
yield 0, Text, text
|
||||
|
||||
|
||||
_ttype_cache = {}
|
||||
|
||||
line_re = re.compile(b'.*?\n')
|
||||
|
||||
|
||||
class RawTokenLexer(Lexer):
|
||||
"""
|
||||
Recreate a token stream formatted with the `RawTokenFormatter`. This
|
||||
lexer raises exceptions during parsing if the token stream in the
|
||||
file is malformed.
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
`compress`
|
||||
If set to ``"gz"`` or ``"bz2"``, decompress the token stream with
|
||||
the given compression algorithm before lexing (default: ``""``).
|
||||
"""
|
||||
name = 'Raw token data'
|
||||
aliases = ['raw']
|
||||
filenames = []
|
||||
mimetypes = ['application/x-pygments-tokens']
|
||||
|
||||
def __init__(self, **options):
|
||||
self.compress = get_choice_opt(options, 'compress',
|
||||
['', 'none', 'gz', 'bz2'], '')
|
||||
Lexer.__init__(self, **options)
|
||||
|
||||
def get_tokens(self, text):
|
||||
if isinstance(text, text_type):
|
||||
# raw token stream never has any non-ASCII characters
|
||||
text = text.encode('ascii')
|
||||
if self.compress == 'gz':
|
||||
import gzip
|
||||
gzipfile = gzip.GzipFile('', 'rb', 9, BytesIO(text))
|
||||
text = gzipfile.read()
|
||||
elif self.compress == 'bz2':
|
||||
import bz2
|
||||
text = bz2.decompress(text)
|
||||
|
||||
# do not call Lexer.get_tokens() because we do not want Unicode
|
||||
# decoding to occur, and stripping is not optional.
|
||||
text = text.strip(b'\n') + b'\n'
|
||||
for i, t, v in self.get_tokens_unprocessed(text):
|
||||
yield t, v
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
length = 0
|
||||
for match in line_re.finditer(text):
|
||||
try:
|
||||
ttypestr, val = match.group().split(b'\t', 1)
|
||||
except ValueError:
|
||||
val = match.group().decode('ascii', 'replace')
|
||||
ttype = Error
|
||||
else:
|
||||
ttype = _ttype_cache.get(ttypestr)
|
||||
if not ttype:
|
||||
ttype = Token
|
||||
ttypes = ttypestr.split('.')[1:]
|
||||
for ttype_ in ttypes:
|
||||
if not ttype_ or not ttype_[0].isupper():
|
||||
raise ValueError('malformed token name')
|
||||
ttype = getattr(ttype, ttype_)
|
||||
_ttype_cache[ttypestr] = ttype
|
||||
val = val[2:-2].decode('unicode-escape')
|
||||
yield length, ttype, val
|
||||
length += len(val)
|
||||
@ -1,145 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.tcl
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for Tcl and related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number
|
||||
from pygments.util import shebang_matches
|
||||
|
||||
__all__ = ['TclLexer']
|
||||
|
||||
|
||||
class TclLexer(RegexLexer):
|
||||
"""
|
||||
For Tcl source code.
|
||||
|
||||
.. versionadded:: 0.10
|
||||
"""
|
||||
|
||||
keyword_cmds_re = words((
|
||||
'after', 'apply', 'array', 'break', 'catch', 'continue', 'elseif', 'else', 'error',
|
||||
'eval', 'expr', 'for', 'foreach', 'global', 'if', 'namespace', 'proc', 'rename', 'return',
|
||||
'set', 'switch', 'then', 'trace', 'unset', 'update', 'uplevel', 'upvar', 'variable',
|
||||
'vwait', 'while'), prefix=r'\b', suffix=r'\b')
|
||||
|
||||
builtin_cmds_re = words((
|
||||
'append', 'bgerror', 'binary', 'cd', 'chan', 'clock', 'close', 'concat', 'dde', 'dict',
|
||||
'encoding', 'eof', 'exec', 'exit', 'fblocked', 'fconfigure', 'fcopy', 'file',
|
||||
'fileevent', 'flush', 'format', 'gets', 'glob', 'history', 'http', 'incr', 'info', 'interp',
|
||||
'join', 'lappend', 'lassign', 'lindex', 'linsert', 'list', 'llength', 'load', 'loadTk',
|
||||
'lrange', 'lrepeat', 'lreplace', 'lreverse', 'lsearch', 'lset', 'lsort', 'mathfunc',
|
||||
'mathop', 'memory', 'msgcat', 'open', 'package', 'pid', 'pkg::create', 'pkg_mkIndex',
|
||||
'platform', 'platform::shell', 'puts', 'pwd', 're_syntax', 'read', 'refchan',
|
||||
'regexp', 'registry', 'regsub', 'scan', 'seek', 'socket', 'source', 'split', 'string',
|
||||
'subst', 'tell', 'time', 'tm', 'unknown', 'unload'), prefix=r'\b', suffix=r'\b')
|
||||
|
||||
name = 'Tcl'
|
||||
aliases = ['tcl']
|
||||
filenames = ['*.tcl', '*.rvt']
|
||||
mimetypes = ['text/x-tcl', 'text/x-script.tcl', 'application/x-tcl']
|
||||
|
||||
def _gen_command_rules(keyword_cmds_re, builtin_cmds_re, context=""):
|
||||
return [
|
||||
(keyword_cmds_re, Keyword, 'params' + context),
|
||||
(builtin_cmds_re, Name.Builtin, 'params' + context),
|
||||
(r'([\w.-]+)', Name.Variable, 'params' + context),
|
||||
(r'#', Comment, 'comment'),
|
||||
]
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('command'),
|
||||
include('basic'),
|
||||
include('data'),
|
||||
(r'\}', Keyword), # HACK: somehow we miscounted our braces
|
||||
],
|
||||
'command': _gen_command_rules(keyword_cmds_re, builtin_cmds_re),
|
||||
'command-in-brace': _gen_command_rules(keyword_cmds_re,
|
||||
builtin_cmds_re,
|
||||
"-in-brace"),
|
||||
'command-in-bracket': _gen_command_rules(keyword_cmds_re,
|
||||
builtin_cmds_re,
|
||||
"-in-bracket"),
|
||||
'command-in-paren': _gen_command_rules(keyword_cmds_re,
|
||||
builtin_cmds_re,
|
||||
"-in-paren"),
|
||||
'basic': [
|
||||
(r'\(', Keyword, 'paren'),
|
||||
(r'\[', Keyword, 'bracket'),
|
||||
(r'\{', Keyword, 'brace'),
|
||||
(r'"', String.Double, 'string'),
|
||||
(r'(eq|ne|in|ni)\b', Operator.Word),
|
||||
(r'!=|==|<<|>>|<=|>=|&&|\|\||\*\*|[-+~!*/%<>&^|?:]', Operator),
|
||||
],
|
||||
'data': [
|
||||
(r'\s+', Text),
|
||||
(r'0x[a-fA-F0-9]+', Number.Hex),
|
||||
(r'0[0-7]+', Number.Oct),
|
||||
(r'\d+\.\d+', Number.Float),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'\$([\w.:-]+)', Name.Variable),
|
||||
(r'([\w.:-]+)', Text),
|
||||
],
|
||||
'params': [
|
||||
(r';', Keyword, '#pop'),
|
||||
(r'\n', Text, '#pop'),
|
||||
(r'(else|elseif|then)\b', Keyword),
|
||||
include('basic'),
|
||||
include('data'),
|
||||
],
|
||||
'params-in-brace': [
|
||||
(r'\}', Keyword, ('#pop', '#pop')),
|
||||
include('params')
|
||||
],
|
||||
'params-in-paren': [
|
||||
(r'\)', Keyword, ('#pop', '#pop')),
|
||||
include('params')
|
||||
],
|
||||
'params-in-bracket': [
|
||||
(r'\]', Keyword, ('#pop', '#pop')),
|
||||
include('params')
|
||||
],
|
||||
'string': [
|
||||
(r'\[', String.Double, 'string-square'),
|
||||
(r'(?s)(\\\\|\\[0-7]+|\\.|[^"\\])', String.Double),
|
||||
(r'"', String.Double, '#pop')
|
||||
],
|
||||
'string-square': [
|
||||
(r'\[', String.Double, 'string-square'),
|
||||
(r'(?s)(\\\\|\\[0-7]+|\\.|\\\n|[^\]\\])', String.Double),
|
||||
(r'\]', String.Double, '#pop')
|
||||
],
|
||||
'brace': [
|
||||
(r'\}', Keyword, '#pop'),
|
||||
include('command-in-brace'),
|
||||
include('basic'),
|
||||
include('data'),
|
||||
],
|
||||
'paren': [
|
||||
(r'\)', Keyword, '#pop'),
|
||||
include('command-in-paren'),
|
||||
include('basic'),
|
||||
include('data'),
|
||||
],
|
||||
'bracket': [
|
||||
(r'\]', Keyword, '#pop'),
|
||||
include('command-in-bracket'),
|
||||
include('basic'),
|
||||
include('data'),
|
||||
],
|
||||
'comment': [
|
||||
(r'.*[^\\]\n', Comment, '#pop'),
|
||||
(r'.*\\\n', Comment),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
return shebang_matches(text, r'(tcl)')
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,131 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.testing
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for testing languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups
|
||||
from pygments.token import Comment, Keyword, Name, String
|
||||
|
||||
__all__ = ['GherkinLexer']
|
||||
|
||||
|
||||
class GherkinLexer(RegexLexer):
|
||||
"""
|
||||
For `Gherkin <http://github.com/aslakhellesoy/gherkin/>` syntax.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
name = 'Gherkin'
|
||||
aliases = ['cucumber', 'gherkin']
|
||||
filenames = ['*.feature']
|
||||
mimetypes = ['text/x-gherkin']
|
||||
|
||||
feature_keywords = u'^(기능|機能|功能|フィーチャ|خاصية|תכונה|Функціонал|Функционалност|Функционал|Фича|Особина|Могућност|Özellik|Właściwość|Tính năng|Trajto|Savybė|Požiadavka|Požadavek|Osobina|Ominaisuus|Omadus|OH HAI|Mogućnost|Mogucnost|Jellemző|Fīča|Funzionalità|Funktionalität|Funkcionalnost|Funkcionalitāte|Funcționalitate|Functionaliteit|Functionalitate|Funcionalitat|Funcionalidade|Fonctionnalité|Fitur|Feature|Egenskap|Egenskab|Crikey|Característica|Arwedd)(:)(.*)$'
|
||||
feature_element_keywords = u'^(\\s*)(시나리오 개요|시나리오|배경|背景|場景大綱|場景|场景大纲|场景|劇本大綱|劇本|テンプレ|シナリオテンプレート|シナリオテンプレ|シナリオアウトライン|シナリオ|سيناريو مخطط|سيناريو|الخلفية|תרחיש|תבנית תרחיש|רקע|Тарих|Сценарій|Сценарио|Сценарий структураси|Сценарий|Структура сценарію|Структура сценарија|Структура сценария|Скица|Рамка на сценарий|Пример|Предыстория|Предистория|Позадина|Передумова|Основа|Концепт|Контекст|Założenia|Wharrimean is|Tình huống|The thing of it is|Tausta|Taust|Tapausaihio|Tapaus|Szenariogrundriss|Szenario|Szablon scenariusza|Stsenaarium|Struktura scenarija|Skica|Skenario konsep|Skenario|Situācija|Senaryo taslağı|Senaryo|Scénář|Scénario|Schema dello scenario|Scenārijs pēc parauga|Scenārijs|Scenár|Scenaro|Scenariusz|Scenariul de şablon|Scenariul de sablon|Scenariu|Scenario Outline|Scenario Amlinellol|Scenario|Scenarijus|Scenarijaus šablonas|Scenarij|Scenarie|Rerefons|Raamstsenaarium|Primer|Pozadí|Pozadina|Pozadie|Plan du scénario|Plan du Scénario|Osnova scénáře|Osnova|Náčrt Scénáře|Náčrt Scenáru|Mate|MISHUN SRSLY|MISHUN|Kịch bản|Konturo de la scenaro|Kontext|Konteksts|Kontekstas|Kontekst|Koncept|Khung tình huống|Khung kịch bản|Háttér|Grundlage|Geçmiş|Forgatókönyv vázlat|Forgatókönyv|Fono|Esquema do Cenário|Esquema do Cenario|Esquema del escenario|Esquema de l\'escenari|Escenario|Escenari|Dis is what went down|Dasar|Contexto|Contexte|Contesto|Condiţii|Conditii|Cenário|Cenario|Cefndir|Bối cảnh|Blokes|Bakgrunn|Bakgrund|Baggrund|Background|B4|Antecedents|Antecedentes|All y\'all|Achtergrond|Abstrakt Scenario|Abstract Scenario)(:)(.*)$'
|
||||
examples_keywords = u'^(\\s*)(예|例子|例|サンプル|امثلة|דוגמאות|Сценарији|Примери|Приклади|Мисоллар|Значения|Örnekler|Voorbeelden|Variantai|Tapaukset|Scenarios|Scenariji|Scenarijai|Příklady|Példák|Príklady|Przykłady|Primjeri|Primeri|Piemēri|Pavyzdžiai|Paraugs|Juhtumid|Exemplos|Exemples|Exemplele|Exempel|Examples|Esempi|Enghreifftiau|Ekzemploj|Eksempler|Ejemplos|EXAMPLZ|Dữ liệu|Contoh|Cobber|Beispiele)(:)(.*)$'
|
||||
step_keywords = u'^(\\s*)(하지만|조건|먼저|만일|만약|단|그리고|그러면|那麼|那么|而且|當|当|前提|假設|假如|但是|但し|並且|もし|ならば|ただし|しかし|かつ|و |متى |لكن |عندما |ثم |بفرض |اذاً |כאשר |וגם |בהינתן |אזי |אז |אבל |Якщо |Унда |То |Припустимо, що |Припустимо |Онда |Но |Нехай |Лекин |Когато |Када |Кад |К тому же |И |Задато |Задати |Задате |Если |Допустим |Дадено |Ва |Бирок |Аммо |Али |Але |Агар |А |І |Și |És |Zatati |Zakładając |Zadato |Zadate |Zadano |Zadani |Zadan |Youse know when youse got |Youse know like when |Yna |Ya know how |Ya gotta |Y |Wun |Wtedy |When y\'all |When |Wenn |WEN |Và |Ve |Und |Un |Thì |Then y\'all |Then |Tapi |Tak |Tada |Tad |Så |Stel |Soit |Siis |Si |Sed |Se |Quando |Quand |Quan |Pryd |Pokud |Pokiaľ |Però |Pero |Pak |Oraz |Onda |Ond |Oletetaan |Og |Och |O zaman |Når |När |Niin |Nhưng |N |Mutta |Men |Mas |Maka |Majd |Mais |Maar |Ma |Lorsque |Lorsqu\'|Kun |Kuid |Kui |Khi |Keď |Ketika |Když |Kaj |Kai |Kada |Kad |Jeżeli |Ja |Ir |I CAN HAZ |I |Ha |Givun |Givet |Given y\'all |Given |Gitt |Gegeven |Gegeben sei |Fakat |Eğer ki |Etant donné |Et |Então |Entonces |Entao |En |Eeldades |E |Duota |Dun |Donitaĵo |Donat |Donada |Do |Diyelim ki |Dengan |Den youse gotta |De |Dato |Dar |Dann |Dan |Dado |Dacă |Daca |DEN |Când |Cuando |Cho |Cept |Cand |Cal |But y\'all |But |Buh |Biết |Bet |BUT |Atès |Atunci |Atesa |Anrhegedig a |Angenommen |And y\'all |And |An |Ama |Als |Alors |Allora |Ali |Aleshores |Ale |Akkor |Aber |AN |A také |A |\* )'
|
||||
|
||||
tokens = {
|
||||
'comments': [
|
||||
(r'^\s*#.*$', Comment),
|
||||
],
|
||||
'feature_elements': [
|
||||
(step_keywords, Keyword, "step_content_stack"),
|
||||
include('comments'),
|
||||
(r"(\s|.)", Name.Function),
|
||||
],
|
||||
'feature_elements_on_stack': [
|
||||
(step_keywords, Keyword, "#pop:2"),
|
||||
include('comments'),
|
||||
(r"(\s|.)", Name.Function),
|
||||
],
|
||||
'examples_table': [
|
||||
(r"\s+\|", Keyword, 'examples_table_header'),
|
||||
include('comments'),
|
||||
(r"(\s|.)", Name.Function),
|
||||
],
|
||||
'examples_table_header': [
|
||||
(r"\s+\|\s*$", Keyword, "#pop:2"),
|
||||
include('comments'),
|
||||
(r"\\\|", Name.Variable),
|
||||
(r"\s*\|", Keyword),
|
||||
(r"[^|]", Name.Variable),
|
||||
],
|
||||
'scenario_sections_on_stack': [
|
||||
(feature_element_keywords,
|
||||
bygroups(Name.Function, Keyword, Keyword, Name.Function),
|
||||
"feature_elements_on_stack"),
|
||||
],
|
||||
'narrative': [
|
||||
include('scenario_sections_on_stack'),
|
||||
include('comments'),
|
||||
(r"(\s|.)", Name.Function),
|
||||
],
|
||||
'table_vars': [
|
||||
(r'(<[^>]+>)', Name.Variable),
|
||||
],
|
||||
'numbers': [
|
||||
(r'(\d+\.?\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', String),
|
||||
],
|
||||
'string': [
|
||||
include('table_vars'),
|
||||
(r'(\s|.)', String),
|
||||
],
|
||||
'py_string': [
|
||||
(r'"""', Keyword, "#pop"),
|
||||
include('string'),
|
||||
],
|
||||
'step_content_root': [
|
||||
(r"$", Keyword, "#pop"),
|
||||
include('step_content'),
|
||||
],
|
||||
'step_content_stack': [
|
||||
(r"$", Keyword, "#pop:2"),
|
||||
include('step_content'),
|
||||
],
|
||||
'step_content': [
|
||||
(r'"', Name.Function, "double_string"),
|
||||
include('table_vars'),
|
||||
include('numbers'),
|
||||
include('comments'),
|
||||
(r'(\s|.)', Name.Function),
|
||||
],
|
||||
'table_content': [
|
||||
(r"\s+\|\s*$", Keyword, "#pop"),
|
||||
include('comments'),
|
||||
(r"\\\|", String),
|
||||
(r"\s*\|", Keyword),
|
||||
include('string'),
|
||||
],
|
||||
'double_string': [
|
||||
(r'"', Name.Function, "#pop"),
|
||||
include('string'),
|
||||
],
|
||||
'root': [
|
||||
(r'\n', Name.Function),
|
||||
include('comments'),
|
||||
(r'"""', Keyword, "py_string"),
|
||||
(r'\s+\|', Keyword, 'table_content'),
|
||||
(r'"', Name.Function, "double_string"),
|
||||
include('table_vars'),
|
||||
include('numbers'),
|
||||
(r'(\s*)(@[^@\r\n\t ]+)', bygroups(Name.Function, Name.Tag)),
|
||||
(step_keywords, bygroups(Name.Function, Keyword),
|
||||
'step_content_root'),
|
||||
(feature_keywords, bygroups(Keyword, Keyword, Name.Function),
|
||||
'narrative'),
|
||||
(feature_element_keywords,
|
||||
bygroups(Name.Function, Keyword, Keyword, Name.Function),
|
||||
'feature_elements'),
|
||||
(examples_keywords,
|
||||
bygroups(Name.Function, Keyword, Keyword, Name.Function),
|
||||
'examples_table'),
|
||||
(r'(\s|.)', Name.Function),
|
||||
]
|
||||
}
|
||||
@ -1,25 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.text
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for non-source code file types.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexers.configs import ApacheConfLexer, NginxConfLexer, \
|
||||
SquidConfLexer, LighttpdConfLexer, IniLexer, RegeditLexer, PropertiesLexer
|
||||
from pygments.lexers.console import PyPyLogLexer
|
||||
from pygments.lexers.textedit import VimLexer
|
||||
from pygments.lexers.markup import BBCodeLexer, MoinWikiLexer, RstLexer, \
|
||||
TexLexer, GroffLexer
|
||||
from pygments.lexers.installers import DebianControlLexer, SourcesListLexer
|
||||
from pygments.lexers.make import MakefileLexer, BaseMakefileLexer, CMakeLexer
|
||||
from pygments.lexers.haxe import HxmlLexer
|
||||
from pygments.lexers.diff import DiffLexer, DarcsPatchLexer
|
||||
from pygments.lexers.data import YamlLexer
|
||||
from pygments.lexers.textfmts import IrcLogsLexer, GettextLexer, HttpLexer
|
||||
|
||||
__all__ = []
|
||||
@ -1,169 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.textedit
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for languages related to text processing.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
from bisect import bisect
|
||||
|
||||
from pygments.lexer import RegexLexer, include, default, bygroups, using, this
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
from pygments.lexers.python import PythonLexer
|
||||
|
||||
__all__ = ['AwkLexer', 'VimLexer']
|
||||
|
||||
|
||||
class AwkLexer(RegexLexer):
|
||||
"""
|
||||
For Awk scripts.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = 'Awk'
|
||||
aliases = ['awk', 'gawk', 'mawk', 'nawk']
|
||||
filenames = ['*.awk']
|
||||
mimetypes = ['application/x-awk']
|
||||
|
||||
tokens = {
|
||||
'commentsandwhitespace': [
|
||||
(r'\s+', Text),
|
||||
(r'#.*$', Comment.Single)
|
||||
],
|
||||
'slashstartsregex': [
|
||||
include('commentsandwhitespace'),
|
||||
(r'/(\\.|[^[/\\\n]|\[(\\.|[^\]\\\n])*])+/'
|
||||
r'\B', String.Regex, '#pop'),
|
||||
(r'(?=/)', Text, ('#pop', 'badregex')),
|
||||
default('#pop')
|
||||
],
|
||||
'badregex': [
|
||||
(r'\n', Text, '#pop')
|
||||
],
|
||||
'root': [
|
||||
(r'^(?=\s|/)', Text, 'slashstartsregex'),
|
||||
include('commentsandwhitespace'),
|
||||
(r'\+\+|--|\|\||&&|in\b|\$|!?~|'
|
||||
r'(\*\*|[-<>+*%\^/!=|])=?', Operator, 'slashstartsregex'),
|
||||
(r'[{(\[;,]', Punctuation, 'slashstartsregex'),
|
||||
(r'[})\].]', Punctuation),
|
||||
(r'(break|continue|do|while|exit|for|if|else|'
|
||||
r'return)\b', Keyword, 'slashstartsregex'),
|
||||
(r'function\b', Keyword.Declaration, 'slashstartsregex'),
|
||||
(r'(atan2|cos|exp|int|log|rand|sin|sqrt|srand|gensub|gsub|index|'
|
||||
r'length|match|split|sprintf|sub|substr|tolower|toupper|close|'
|
||||
r'fflush|getline|next|nextfile|print|printf|strftime|systime|'
|
||||
r'delete|system)\b', Keyword.Reserved),
|
||||
(r'(ARGC|ARGIND|ARGV|BEGIN|CONVFMT|ENVIRON|END|ERRNO|FIELDWIDTHS|'
|
||||
r'FILENAME|FNR|FS|IGNORECASE|NF|NR|OFMT|OFS|ORFS|RLENGTH|RS|'
|
||||
r'RSTART|RT|SUBSEP)\b', Name.Builtin),
|
||||
(r'[$a-zA-Z_]\w*', Name.Other),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class VimLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for VimL script files.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
name = 'VimL'
|
||||
aliases = ['vim']
|
||||
filenames = ['*.vim', '.vimrc', '.exrc', '.gvimrc',
|
||||
'_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc']
|
||||
mimetypes = ['text/x-vim']
|
||||
flags = re.MULTILINE
|
||||
|
||||
_python = r'py(?:t(?:h(?:o(?:n)?)?)?)?'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^([ \t:]*)(' + _python + r')([ \t]*)(<<)([ \t]*)(.*)((?:\n|.)*)(\6)',
|
||||
bygroups(using(this), Keyword, Text, Operator, Text, Text,
|
||||
using(PythonLexer), Text)),
|
||||
(r'^([ \t:]*)(' + _python + r')([ \t])(.*)',
|
||||
bygroups(using(this), Keyword, Text, using(PythonLexer))),
|
||||
|
||||
(r'^\s*".*', Comment),
|
||||
|
||||
(r'[ \t]+', Text),
|
||||
# TODO: regexes can have other delims
|
||||
(r'/(\\\\|\\/|[^\n/])*/', String.Regex),
|
||||
(r'"(\\\\|\\"|[^\n"])*"', String.Double),
|
||||
(r"'(''|[^\n'])*'", String.Single),
|
||||
|
||||
# Who decided that doublequote was a good comment character??
|
||||
(r'(?<=\s)"[^\-:.%#=*].*', Comment),
|
||||
(r'-?\d+', Number),
|
||||
(r'#[0-9a-f]{6}', Number.Hex),
|
||||
(r'^:', Punctuation),
|
||||
(r'[()<>+=!|,~-]', Punctuation), # Inexact list. Looks decent.
|
||||
(r'\b(let|if|else|endif|elseif|fun|function|endfunction)\b',
|
||||
Keyword),
|
||||
(r'\b(NONE|bold|italic|underline|dark|light)\b', Name.Builtin),
|
||||
(r'\b\w+\b', Name.Other), # These are postprocessed below
|
||||
(r'.', Text),
|
||||
],
|
||||
}
|
||||
|
||||
def __init__(self, **options):
|
||||
from pygments.lexers._vim_builtins import command, option, auto
|
||||
self._cmd = command
|
||||
self._opt = option
|
||||
self._aut = auto
|
||||
|
||||
RegexLexer.__init__(self, **options)
|
||||
|
||||
def is_in(self, w, mapping):
|
||||
r"""
|
||||
It's kind of difficult to decide if something might be a keyword
|
||||
in VimL because it allows you to abbreviate them. In fact,
|
||||
'ab[breviate]' is a good example. :ab, :abbre, or :abbreviate are
|
||||
valid ways to call it so rather than making really awful regexps
|
||||
like::
|
||||
|
||||
\bab(?:b(?:r(?:e(?:v(?:i(?:a(?:t(?:e)?)?)?)?)?)?)?)?\b
|
||||
|
||||
we match `\b\w+\b` and then call is_in() on those tokens. See
|
||||
`scripts/get_vimkw.py` for how the lists are extracted.
|
||||
"""
|
||||
p = bisect(mapping, (w,))
|
||||
if p > 0:
|
||||
if mapping[p-1][0] == w[:len(mapping[p-1][0])] and \
|
||||
mapping[p-1][1][:len(w)] == w:
|
||||
return True
|
||||
if p < len(mapping):
|
||||
return mapping[p][0] == w[:len(mapping[p][0])] and \
|
||||
mapping[p][1][:len(w)] == w
|
||||
return False
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
# TODO: builtins are only subsequent tokens on lines
|
||||
# and 'keywords' only happen at the beginning except
|
||||
# for :au ones
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name.Other:
|
||||
if self.is_in(value, self._cmd):
|
||||
yield index, Keyword, value
|
||||
elif self.is_in(value, self._opt) or \
|
||||
self.is_in(value, self._aut):
|
||||
yield index, Name.Builtin, value
|
||||
else:
|
||||
yield index, Text, value
|
||||
else:
|
||||
yield index, token, value
|
||||
@ -1,292 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.textfmts
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for various text formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Generic, Literal
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
__all__ = ['IrcLogsLexer', 'TodotxtLexer', 'HttpLexer', 'GettextLexer']
|
||||
|
||||
|
||||
class IrcLogsLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for IRC logs in *irssi*, *xchat* or *weechat* style.
|
||||
"""
|
||||
|
||||
name = 'IRC logs'
|
||||
aliases = ['irc']
|
||||
filenames = ['*.weechatlog']
|
||||
mimetypes = ['text/x-irclog']
|
||||
|
||||
flags = re.VERBOSE | re.MULTILINE
|
||||
timestamp = r"""
|
||||
(
|
||||
# irssi / xchat and others
|
||||
(?: \[|\()? # Opening bracket or paren for the timestamp
|
||||
(?: # Timestamp
|
||||
(?: (?:\d{1,4} [-/])* # Date as - or /-separated groups of digits
|
||||
(?:\d{1,4})
|
||||
[T ])? # Date/time separator: T or space
|
||||
(?: \d?\d [:.])* # Time as :/.-separated groups of 1 or 2 digits
|
||||
(?: \d?\d [:.])
|
||||
)
|
||||
(?: \]|\))?\s+ # Closing bracket or paren for the timestamp
|
||||
|
|
||||
# weechat
|
||||
\d{4}\s\w{3}\s\d{2}\s # Date
|
||||
\d{2}:\d{2}:\d{2}\s+ # Time + Whitespace
|
||||
|
|
||||
# xchat
|
||||
\w{3}\s\d{2}\s # Date
|
||||
\d{2}:\d{2}:\d{2}\s+ # Time + Whitespace
|
||||
)?
|
||||
"""
|
||||
tokens = {
|
||||
'root': [
|
||||
# log start/end
|
||||
(r'^\*\*\*\*(.*)\*\*\*\*$', Comment),
|
||||
# hack
|
||||
("^" + timestamp + r'(\s*<[^>]*>\s*)$', bygroups(Comment.Preproc, Name.Tag)),
|
||||
# normal msgs
|
||||
("^" + timestamp + r"""
|
||||
(\s*<.*?>\s*) # Nick """,
|
||||
bygroups(Comment.Preproc, Name.Tag), 'msg'),
|
||||
# /me msgs
|
||||
("^" + timestamp + r"""
|
||||
(\s*[*]\s+) # Star
|
||||
(\S+\s+.*?\n) # Nick + rest of message """,
|
||||
bygroups(Comment.Preproc, Keyword, Generic.Inserted)),
|
||||
# join/part msgs
|
||||
("^" + timestamp + r"""
|
||||
(\s*(?:\*{3}|<?-[!@=P]?->?)\s*) # Star(s) or symbols
|
||||
(\S+\s+) # Nick + Space
|
||||
(.*?\n) # Rest of message """,
|
||||
bygroups(Comment.Preproc, Keyword, String, Comment)),
|
||||
(r"^.*?\n", Text),
|
||||
],
|
||||
'msg': [
|
||||
(r"\S+:(?!//)", Name.Attribute), # Prefix
|
||||
(r".*\n", Text, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class GettextLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for Gettext catalog files.
|
||||
|
||||
.. versionadded:: 0.9
|
||||
"""
|
||||
name = 'Gettext Catalog'
|
||||
aliases = ['pot', 'po']
|
||||
filenames = ['*.pot', '*.po']
|
||||
mimetypes = ['application/x-gettext', 'text/x-gettext', 'text/gettext']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^#,\s.*?$', Keyword.Type),
|
||||
(r'^#:\s.*?$', Keyword.Declaration),
|
||||
# (r'^#$', Comment),
|
||||
(r'^(#|#\.\s|#\|\s|#~\s|#\s).*$', Comment.Single),
|
||||
(r'^(")([A-Za-z-]+:)(.*")$',
|
||||
bygroups(String, Name.Property, String)),
|
||||
(r'^".*"$', String),
|
||||
(r'^(msgid|msgid_plural|msgstr)(\s+)(".*")$',
|
||||
bygroups(Name.Variable, Text, String)),
|
||||
(r'^(msgstr\[)(\d)(\])(\s+)(".*")$',
|
||||
bygroups(Name.Variable, Number.Integer, Name.Variable, Text, String)),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class HttpLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for HTTP sessions.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = 'HTTP'
|
||||
aliases = ['http']
|
||||
|
||||
flags = re.DOTALL
|
||||
|
||||
def header_callback(self, match):
|
||||
if match.group(1).lower() == 'content-type':
|
||||
content_type = match.group(5).strip()
|
||||
if ';' in content_type:
|
||||
content_type = content_type[:content_type.find(';')].strip()
|
||||
self.content_type = content_type
|
||||
yield match.start(1), Name.Attribute, match.group(1)
|
||||
yield match.start(2), Text, match.group(2)
|
||||
yield match.start(3), Operator, match.group(3)
|
||||
yield match.start(4), Text, match.group(4)
|
||||
yield match.start(5), Literal, match.group(5)
|
||||
yield match.start(6), Text, match.group(6)
|
||||
|
||||
def continuous_header_callback(self, match):
|
||||
yield match.start(1), Text, match.group(1)
|
||||
yield match.start(2), Literal, match.group(2)
|
||||
yield match.start(3), Text, match.group(3)
|
||||
|
||||
def content_callback(self, match):
|
||||
content_type = getattr(self, 'content_type', None)
|
||||
content = match.group()
|
||||
offset = match.start()
|
||||
if content_type:
|
||||
from pygments.lexers import get_lexer_for_mimetype
|
||||
possible_lexer_mimetypes = [content_type]
|
||||
if '+' in content_type:
|
||||
# application/calendar+xml can be treated as application/xml
|
||||
# if there's not a better match.
|
||||
general_type = re.sub(r'^(.*)/.*\+(.*)$', r'\1/\2',
|
||||
content_type)
|
||||
possible_lexer_mimetypes.append(general_type)
|
||||
|
||||
for i in possible_lexer_mimetypes:
|
||||
try:
|
||||
lexer = get_lexer_for_mimetype(i)
|
||||
except ClassNotFound:
|
||||
pass
|
||||
else:
|
||||
for idx, token, value in lexer.get_tokens_unprocessed(content):
|
||||
yield offset + idx, token, value
|
||||
return
|
||||
yield offset, Text, content
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'(GET|POST|PUT|DELETE|HEAD|OPTIONS|TRACE|PATCH)( +)([^ ]+)( +)'
|
||||
r'(HTTP)(/)(1\.[01])(\r?\n|\Z)',
|
||||
bygroups(Name.Function, Text, Name.Namespace, Text,
|
||||
Keyword.Reserved, Operator, Number, Text),
|
||||
'headers'),
|
||||
(r'(HTTP)(/)(1\.[01])( +)(\d{3})( +)([^\r\n]+)(\r?\n|\Z)',
|
||||
bygroups(Keyword.Reserved, Operator, Number, Text, Number,
|
||||
Text, Name.Exception, Text),
|
||||
'headers'),
|
||||
],
|
||||
'headers': [
|
||||
(r'([^\s:]+)( *)(:)( *)([^\r\n]+)(\r?\n|\Z)', header_callback),
|
||||
(r'([\t ]+)([^\r\n]+)(\r?\n|\Z)', continuous_header_callback),
|
||||
(r'\r?\n', Text, 'content')
|
||||
],
|
||||
'content': [
|
||||
(r'.+', content_callback)
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
return text.startswith(('GET /', 'POST /', 'PUT /', 'DELETE /', 'HEAD /',
|
||||
'OPTIONS /', 'TRACE /', 'PATCH /'))
|
||||
|
||||
|
||||
class TodotxtLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Todo.txt <http://todotxt.com/>`_ todo list format.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'Todotxt'
|
||||
aliases = ['todotxt']
|
||||
# *.todotxt is not a standard extension for Todo.txt files; including it
|
||||
# makes testing easier, and also makes autodetecting file type easier.
|
||||
filenames = ['todo.txt', '*.todotxt']
|
||||
mimetypes = ['text/x-todo']
|
||||
|
||||
# Aliases mapping standard token types of Todo.txt format concepts
|
||||
CompleteTaskText = Operator # Chosen to de-emphasize complete tasks
|
||||
IncompleteTaskText = Text # Incomplete tasks should look like plain text
|
||||
|
||||
# Priority should have most emphasis to indicate importance of tasks
|
||||
Priority = Generic.Heading
|
||||
# Dates should have next most emphasis because time is important
|
||||
Date = Generic.Subheading
|
||||
|
||||
# Project and context should have equal weight, and be in different colors
|
||||
Project = Generic.Error
|
||||
Context = String
|
||||
|
||||
# If tag functionality is added, it should have the same weight as Project
|
||||
# and Context, and a different color. Generic.Traceback would work well.
|
||||
|
||||
# Regex patterns for building up rules; dates, priorities, projects, and
|
||||
# contexts are all atomic
|
||||
# TODO: Make date regex more ISO 8601 compliant
|
||||
date_regex = r'\d{4,}-\d{2}-\d{2}'
|
||||
priority_regex = r'\([A-Z]\)'
|
||||
project_regex = r'\+\S+'
|
||||
context_regex = r'@\S+'
|
||||
|
||||
# Compound regex expressions
|
||||
complete_one_date_regex = r'(x )(' + date_regex + r')'
|
||||
complete_two_date_regex = (complete_one_date_regex + r'( )(' +
|
||||
date_regex + r')')
|
||||
priority_date_regex = r'(' + priority_regex + r')( )(' + date_regex + r')'
|
||||
|
||||
tokens = {
|
||||
# Should parse starting at beginning of line; each line is a task
|
||||
'root': [
|
||||
# Complete task entry points: two total:
|
||||
# 1. Complete task with two dates
|
||||
(complete_two_date_regex, bygroups(CompleteTaskText, Date,
|
||||
CompleteTaskText, Date),
|
||||
'complete'),
|
||||
# 2. Complete task with one date
|
||||
(complete_one_date_regex, bygroups(CompleteTaskText, Date),
|
||||
'complete'),
|
||||
|
||||
# Incomplete task entry points: six total:
|
||||
# 1. Priority plus date
|
||||
(priority_date_regex, bygroups(Priority, IncompleteTaskText, Date),
|
||||
'incomplete'),
|
||||
# 2. Priority only
|
||||
(priority_regex, Priority, 'incomplete'),
|
||||
# 3. Leading date
|
||||
(date_regex, Date, 'incomplete'),
|
||||
# 4. Leading context
|
||||
(context_regex, Context, 'incomplete'),
|
||||
# 5. Leading project
|
||||
(project_regex, Project, 'incomplete'),
|
||||
# 6. Non-whitespace catch-all
|
||||
('\S+', IncompleteTaskText, 'incomplete'),
|
||||
],
|
||||
|
||||
# Parse a complete task
|
||||
'complete': [
|
||||
# Newline indicates end of task, should return to root
|
||||
(r'\s*\n', CompleteTaskText, '#pop'),
|
||||
# Tokenize contexts and projects
|
||||
(context_regex, Context),
|
||||
(project_regex, Project),
|
||||
# Tokenize non-whitespace text
|
||||
('\S+', CompleteTaskText),
|
||||
# Tokenize whitespace not containing a newline
|
||||
('\s+', CompleteTaskText),
|
||||
],
|
||||
|
||||
# Parse an incomplete task
|
||||
'incomplete': [
|
||||
# Newline indicates end of task, should return to root
|
||||
(r'\s*\n', IncompleteTaskText, '#pop'),
|
||||
# Tokenize contexts and projects
|
||||
(context_regex, Context),
|
||||
(project_regex, Project),
|
||||
# Tokenize non-whitespace text
|
||||
('\S+', IncompleteTaskText),
|
||||
# Tokenize whitespace not containing a newline
|
||||
('\s+', IncompleteTaskText),
|
||||
],
|
||||
}
|
||||
@ -1,155 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.sphinxext
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Sphinx extension to generate automatic documentation of lexers,
|
||||
formatters and filters.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import sys
|
||||
|
||||
from docutils import nodes
|
||||
from docutils.statemachine import ViewList
|
||||
from sphinx.util.compat import Directive
|
||||
from sphinx.util.nodes import nested_parse_with_titles
|
||||
|
||||
|
||||
MODULEDOC = '''
|
||||
.. module:: %s
|
||||
|
||||
%s
|
||||
%s
|
||||
'''
|
||||
|
||||
LEXERDOC = '''
|
||||
.. class:: %s
|
||||
|
||||
:Short names: %s
|
||||
:Filenames: %s
|
||||
:MIME types: %s
|
||||
|
||||
%s
|
||||
|
||||
'''
|
||||
|
||||
FMTERDOC = '''
|
||||
.. class:: %s
|
||||
|
||||
:Short names: %s
|
||||
:Filenames: %s
|
||||
|
||||
%s
|
||||
|
||||
'''
|
||||
|
||||
FILTERDOC = '''
|
||||
.. class:: %s
|
||||
|
||||
:Name: %s
|
||||
|
||||
%s
|
||||
|
||||
'''
|
||||
|
||||
class PygmentsDoc(Directive):
|
||||
"""
|
||||
A directive to collect all lexers/formatters/filters and generate
|
||||
autoclass directives for them.
|
||||
"""
|
||||
has_content = False
|
||||
required_arguments = 1
|
||||
optional_arguments = 0
|
||||
final_argument_whitespace = False
|
||||
option_spec = {}
|
||||
|
||||
def run(self):
|
||||
self.filenames = set()
|
||||
if self.arguments[0] == 'lexers':
|
||||
out = self.document_lexers()
|
||||
elif self.arguments[0] == 'formatters':
|
||||
out = self.document_formatters()
|
||||
elif self.arguments[0] == 'filters':
|
||||
out = self.document_filters()
|
||||
else:
|
||||
raise Exception('invalid argument for "pygmentsdoc" directive')
|
||||
node = nodes.compound()
|
||||
vl = ViewList(out.split('\n'), source='')
|
||||
nested_parse_with_titles(self.state, vl, node)
|
||||
for fn in self.filenames:
|
||||
self.state.document.settings.record_dependencies.add(fn)
|
||||
return node.children
|
||||
|
||||
def document_lexers(self):
|
||||
from pygments.lexers._mapping import LEXERS
|
||||
out = []
|
||||
modules = {}
|
||||
moduledocstrings = {}
|
||||
for classname, data in sorted(LEXERS.items(), key=lambda x: x[0]):
|
||||
module = data[0]
|
||||
mod = __import__(module, None, None, [classname])
|
||||
self.filenames.add(mod.__file__)
|
||||
cls = getattr(mod, classname)
|
||||
if not cls.__doc__:
|
||||
print("Warning: %s does not have a docstring." % classname)
|
||||
docstring = cls.__doc__
|
||||
if isinstance(docstring, bytes):
|
||||
docstring = docstring.decode('utf8')
|
||||
modules.setdefault(module, []).append((
|
||||
classname,
|
||||
', '.join(data[2]) or 'None',
|
||||
', '.join(data[3]).replace('*', '\\*').replace('_', '\\') or 'None',
|
||||
', '.join(data[4]) or 'None',
|
||||
docstring))
|
||||
if module not in moduledocstrings:
|
||||
moddoc = mod.__doc__
|
||||
if isinstance(moddoc, bytes):
|
||||
moddoc = moddoc.decode('utf8')
|
||||
moduledocstrings[module] = moddoc
|
||||
|
||||
for module, lexers in sorted(modules.items(), key=lambda x: x[0]):
|
||||
heading = moduledocstrings[module].splitlines()[4].strip().rstrip('.')
|
||||
out.append(MODULEDOC % (module, heading, '-'*len(heading)))
|
||||
for data in lexers:
|
||||
out.append(LEXERDOC % data)
|
||||
|
||||
return ''.join(out)
|
||||
|
||||
def document_formatters(self):
|
||||
from pygments.formatters import FORMATTERS
|
||||
|
||||
out = []
|
||||
for classname, data in sorted(FORMATTERS.items(), key=lambda x: x[0]):
|
||||
module = data[0]
|
||||
mod = __import__(module, None, None, [classname])
|
||||
self.filenames.add(mod.__file__)
|
||||
cls = getattr(mod, classname)
|
||||
docstring = cls.__doc__
|
||||
if isinstance(docstring, bytes):
|
||||
docstring = docstring.decode('utf8')
|
||||
heading = cls.__name__
|
||||
out.append(FMTERDOC % (heading, ', '.join(data[1]) or 'None',
|
||||
', '.join(data[2]).replace('*', '\\*') or 'None',
|
||||
docstring))
|
||||
return ''.join(out)
|
||||
|
||||
def document_filters(self):
|
||||
from pygments.filters import FILTERS
|
||||
|
||||
out = []
|
||||
for name, cls in FILTERS.items():
|
||||
self.filenames.add(sys.modules[cls.__module__].__file__)
|
||||
docstring = cls.__doc__
|
||||
if isinstance(docstring, bytes):
|
||||
docstring = docstring.decode('utf8')
|
||||
out.append(FILTERDOC % (cls.__name__, name, docstring))
|
||||
return ''.join(out)
|
||||
|
||||
|
||||
def setup(app):
|
||||
app.add_directive('pygmentsdoc', PygmentsDoc)
|
||||
@ -1,118 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.style
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
Basic style object.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.token import Token, STANDARD_TYPES
|
||||
from pygments.util import add_metaclass
|
||||
|
||||
|
||||
class StyleMeta(type):
|
||||
|
||||
def __new__(mcs, name, bases, dct):
|
||||
obj = type.__new__(mcs, name, bases, dct)
|
||||
for token in STANDARD_TYPES:
|
||||
if token not in obj.styles:
|
||||
obj.styles[token] = ''
|
||||
|
||||
def colorformat(text):
|
||||
if text[0:1] == '#':
|
||||
col = text[1:]
|
||||
if len(col) == 6:
|
||||
return col
|
||||
elif len(col) == 3:
|
||||
return col[0]*2 + col[1]*2 + col[2]*2
|
||||
elif text == '':
|
||||
return ''
|
||||
assert False, "wrong color format %r" % text
|
||||
|
||||
_styles = obj._styles = {}
|
||||
|
||||
for ttype in obj.styles:
|
||||
for token in ttype.split():
|
||||
if token in _styles:
|
||||
continue
|
||||
ndef = _styles.get(token.parent, None)
|
||||
styledefs = obj.styles.get(token, '').split()
|
||||
if not ndef or token is None:
|
||||
ndef = ['', 0, 0, 0, '', '', 0, 0, 0]
|
||||
elif 'noinherit' in styledefs and token is not Token:
|
||||
ndef = _styles[Token][:]
|
||||
else:
|
||||
ndef = ndef[:]
|
||||
_styles[token] = ndef
|
||||
for styledef in obj.styles.get(token, '').split():
|
||||
if styledef == 'noinherit':
|
||||
pass
|
||||
elif styledef == 'bold':
|
||||
ndef[1] = 1
|
||||
elif styledef == 'nobold':
|
||||
ndef[1] = 0
|
||||
elif styledef == 'italic':
|
||||
ndef[2] = 1
|
||||
elif styledef == 'noitalic':
|
||||
ndef[2] = 0
|
||||
elif styledef == 'underline':
|
||||
ndef[3] = 1
|
||||
elif styledef == 'nounderline':
|
||||
ndef[3] = 0
|
||||
elif styledef[:3] == 'bg:':
|
||||
ndef[4] = colorformat(styledef[3:])
|
||||
elif styledef[:7] == 'border:':
|
||||
ndef[5] = colorformat(styledef[7:])
|
||||
elif styledef == 'roman':
|
||||
ndef[6] = 1
|
||||
elif styledef == 'sans':
|
||||
ndef[7] = 1
|
||||
elif styledef == 'mono':
|
||||
ndef[8] = 1
|
||||
else:
|
||||
ndef[0] = colorformat(styledef)
|
||||
|
||||
return obj
|
||||
|
||||
def style_for_token(cls, token):
|
||||
t = cls._styles[token]
|
||||
return {
|
||||
'color': t[0] or None,
|
||||
'bold': bool(t[1]),
|
||||
'italic': bool(t[2]),
|
||||
'underline': bool(t[3]),
|
||||
'bgcolor': t[4] or None,
|
||||
'border': t[5] or None,
|
||||
'roman': bool(t[6]) or None,
|
||||
'sans': bool(t[7]) or None,
|
||||
'mono': bool(t[8]) or None,
|
||||
}
|
||||
|
||||
def list_styles(cls):
|
||||
return list(cls)
|
||||
|
||||
def styles_token(cls, ttype):
|
||||
return ttype in cls._styles
|
||||
|
||||
def __iter__(cls):
|
||||
for token in cls._styles:
|
||||
yield token, cls.style_for_token(token)
|
||||
|
||||
def __len__(cls):
|
||||
return len(cls._styles)
|
||||
|
||||
|
||||
@add_metaclass(StyleMeta)
|
||||
class Style(object):
|
||||
|
||||
#: overall background color (``None`` means transparent)
|
||||
background_color = '#ffffff'
|
||||
|
||||
#: highlight background color
|
||||
highlight_color = '#ffffcc'
|
||||
|
||||
#: Style definitions for individual token types.
|
||||
styles = {}
|
||||
@ -1,74 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
Contains built-in styles.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.plugin import find_plugin_styles
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
|
||||
#: Maps style names to 'submodule::classname'.
|
||||
STYLE_MAP = {
|
||||
'default': 'default::DefaultStyle',
|
||||
'emacs': 'emacs::EmacsStyle',
|
||||
'friendly': 'friendly::FriendlyStyle',
|
||||
'colorful': 'colorful::ColorfulStyle',
|
||||
'autumn': 'autumn::AutumnStyle',
|
||||
'murphy': 'murphy::MurphyStyle',
|
||||
'manni': 'manni::ManniStyle',
|
||||
'monokai': 'monokai::MonokaiStyle',
|
||||
'perldoc': 'perldoc::PerldocStyle',
|
||||
'pastie': 'pastie::PastieStyle',
|
||||
'borland': 'borland::BorlandStyle',
|
||||
'trac': 'trac::TracStyle',
|
||||
'native': 'native::NativeStyle',
|
||||
'fruity': 'fruity::FruityStyle',
|
||||
'bw': 'bw::BlackWhiteStyle',
|
||||
'vim': 'vim::VimStyle',
|
||||
'vs': 'vs::VisualStudioStyle',
|
||||
'tango': 'tango::TangoStyle',
|
||||
'rrt': 'rrt::RrtStyle',
|
||||
'xcode': 'xcode::XcodeStyle',
|
||||
'igor': 'igor::IgorStyle',
|
||||
'paraiso-light': 'paraiso_light::ParaisoLightStyle',
|
||||
'paraiso-dark': 'paraiso_dark::ParaisoDarkStyle',
|
||||
}
|
||||
|
||||
|
||||
def get_style_by_name(name):
|
||||
if name in STYLE_MAP:
|
||||
mod, cls = STYLE_MAP[name].split('::')
|
||||
builtin = "yes"
|
||||
else:
|
||||
for found_name, style in find_plugin_styles():
|
||||
if name == found_name:
|
||||
return style
|
||||
# perhaps it got dropped into our styles package
|
||||
builtin = ""
|
||||
mod = name
|
||||
cls = name.title() + "Style"
|
||||
|
||||
try:
|
||||
mod = __import__('pygments.styles.' + mod, None, None, [cls])
|
||||
except ImportError:
|
||||
raise ClassNotFound("Could not find style module %r" % mod +
|
||||
(builtin and ", though it should be builtin") + ".")
|
||||
try:
|
||||
return getattr(mod, cls)
|
||||
except AttributeError:
|
||||
raise ClassNotFound("Could not find style class %r in style module." % cls)
|
||||
|
||||
|
||||
def get_all_styles():
|
||||
"""Return an generator for all styles by name,
|
||||
both builtin and plugin."""
|
||||
for name in STYLE_MAP:
|
||||
yield name
|
||||
for name, _ in find_plugin_styles():
|
||||
yield name
|
||||
@ -1,65 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.autumn
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
A colorful style, inspired by the terminal highlighting style.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Whitespace
|
||||
|
||||
|
||||
class AutumnStyle(Style):
|
||||
"""
|
||||
A colorful style, inspired by the terminal highlighting style.
|
||||
"""
|
||||
|
||||
default_style = ""
|
||||
|
||||
styles = {
|
||||
Whitespace: '#bbbbbb',
|
||||
|
||||
Comment: 'italic #aaaaaa',
|
||||
Comment.Preproc: 'noitalic #4c8317',
|
||||
Comment.Special: 'italic #0000aa',
|
||||
|
||||
Keyword: '#0000aa',
|
||||
Keyword.Type: '#00aaaa',
|
||||
|
||||
Operator.Word: '#0000aa',
|
||||
|
||||
Name.Builtin: '#00aaaa',
|
||||
Name.Function: '#00aa00',
|
||||
Name.Class: 'underline #00aa00',
|
||||
Name.Namespace: 'underline #00aaaa',
|
||||
Name.Variable: '#aa0000',
|
||||
Name.Constant: '#aa0000',
|
||||
Name.Entity: 'bold #800',
|
||||
Name.Attribute: '#1e90ff',
|
||||
Name.Tag: 'bold #1e90ff',
|
||||
Name.Decorator: '#888888',
|
||||
|
||||
String: '#aa5500',
|
||||
String.Symbol: '#0000aa',
|
||||
String.Regex: '#009999',
|
||||
|
||||
Number: '#009999',
|
||||
|
||||
Generic.Heading: 'bold #000080',
|
||||
Generic.Subheading: 'bold #800080',
|
||||
Generic.Deleted: '#aa0000',
|
||||
Generic.Inserted: '#00aa00',
|
||||
Generic.Error: '#aa0000',
|
||||
Generic.Emph: 'italic',
|
||||
Generic.Strong: 'bold',
|
||||
Generic.Prompt: '#555555',
|
||||
Generic.Output: '#888888',
|
||||
Generic.Traceback: '#aa0000',
|
||||
|
||||
Error: '#F00 bg:#FAA'
|
||||
}
|
||||
@ -1,49 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.bw
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Simple black/white only style.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Operator, Generic
|
||||
|
||||
|
||||
class BlackWhiteStyle(Style):
|
||||
|
||||
background_color = "#ffffff"
|
||||
default_style = ""
|
||||
|
||||
styles = {
|
||||
Comment: "italic",
|
||||
Comment.Preproc: "noitalic",
|
||||
|
||||
Keyword: "bold",
|
||||
Keyword.Pseudo: "nobold",
|
||||
Keyword.Type: "nobold",
|
||||
|
||||
Operator.Word: "bold",
|
||||
|
||||
Name.Class: "bold",
|
||||
Name.Namespace: "bold",
|
||||
Name.Exception: "bold",
|
||||
Name.Entity: "bold",
|
||||
Name.Tag: "bold",
|
||||
|
||||
String: "italic",
|
||||
String.Interpol: "bold",
|
||||
String.Escape: "bold",
|
||||
|
||||
Generic.Heading: "bold",
|
||||
Generic.Subheading: "bold",
|
||||
Generic.Emph: "italic",
|
||||
Generic.Strong: "bold",
|
||||
Generic.Prompt: "bold",
|
||||
|
||||
Error: "border:#FF0000"
|
||||
}
|
||||
@ -1,73 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.default
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
The default highlighting style.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Whitespace
|
||||
|
||||
|
||||
class DefaultStyle(Style):
|
||||
"""
|
||||
The default style (inspired by Emacs 22).
|
||||
"""
|
||||
|
||||
background_color = "#f8f8f8"
|
||||
default_style = ""
|
||||
|
||||
styles = {
|
||||
Whitespace: "#bbbbbb",
|
||||
Comment: "italic #408080",
|
||||
Comment.Preproc: "noitalic #BC7A00",
|
||||
|
||||
#Keyword: "bold #AA22FF",
|
||||
Keyword: "bold #008000",
|
||||
Keyword.Pseudo: "nobold",
|
||||
Keyword.Type: "nobold #B00040",
|
||||
|
||||
Operator: "#666666",
|
||||
Operator.Word: "bold #AA22FF",
|
||||
|
||||
Name.Builtin: "#008000",
|
||||
Name.Function: "#0000FF",
|
||||
Name.Class: "bold #0000FF",
|
||||
Name.Namespace: "bold #0000FF",
|
||||
Name.Exception: "bold #D2413A",
|
||||
Name.Variable: "#19177C",
|
||||
Name.Constant: "#880000",
|
||||
Name.Label: "#A0A000",
|
||||
Name.Entity: "bold #999999",
|
||||
Name.Attribute: "#7D9029",
|
||||
Name.Tag: "bold #008000",
|
||||
Name.Decorator: "#AA22FF",
|
||||
|
||||
String: "#BA2121",
|
||||
String.Doc: "italic",
|
||||
String.Interpol: "bold #BB6688",
|
||||
String.Escape: "bold #BB6622",
|
||||
String.Regex: "#BB6688",
|
||||
#String.Symbol: "#B8860B",
|
||||
String.Symbol: "#19177C",
|
||||
String.Other: "#008000",
|
||||
Number: "#666666",
|
||||
|
||||
Generic.Heading: "bold #000080",
|
||||
Generic.Subheading: "bold #800080",
|
||||
Generic.Deleted: "#A00000",
|
||||
Generic.Inserted: "#00A000",
|
||||
Generic.Error: "#FF0000",
|
||||
Generic.Emph: "italic",
|
||||
Generic.Strong: "bold",
|
||||
Generic.Prompt: "bold #000080",
|
||||
Generic.Output: "#888",
|
||||
Generic.Traceback: "#04D",
|
||||
|
||||
Error: "border:#FF0000"
|
||||
}
|
||||
@ -1,72 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.friendly
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
A modern style based on the VIM pyte theme.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Whitespace
|
||||
|
||||
|
||||
class FriendlyStyle(Style):
|
||||
"""
|
||||
A modern style based on the VIM pyte theme.
|
||||
"""
|
||||
|
||||
background_color = "#f0f0f0"
|
||||
default_style = ""
|
||||
|
||||
styles = {
|
||||
Whitespace: "#bbbbbb",
|
||||
Comment: "italic #60a0b0",
|
||||
Comment.Preproc: "noitalic #007020",
|
||||
Comment.Special: "noitalic bg:#fff0f0",
|
||||
|
||||
Keyword: "bold #007020",
|
||||
Keyword.Pseudo: "nobold",
|
||||
Keyword.Type: "nobold #902000",
|
||||
|
||||
Operator: "#666666",
|
||||
Operator.Word: "bold #007020",
|
||||
|
||||
Name.Builtin: "#007020",
|
||||
Name.Function: "#06287e",
|
||||
Name.Class: "bold #0e84b5",
|
||||
Name.Namespace: "bold #0e84b5",
|
||||
Name.Exception: "#007020",
|
||||
Name.Variable: "#bb60d5",
|
||||
Name.Constant: "#60add5",
|
||||
Name.Label: "bold #002070",
|
||||
Name.Entity: "bold #d55537",
|
||||
Name.Attribute: "#4070a0",
|
||||
Name.Tag: "bold #062873",
|
||||
Name.Decorator: "bold #555555",
|
||||
|
||||
String: "#4070a0",
|
||||
String.Doc: "italic",
|
||||
String.Interpol: "italic #70a0d0",
|
||||
String.Escape: "bold #4070a0",
|
||||
String.Regex: "#235388",
|
||||
String.Symbol: "#517918",
|
||||
String.Other: "#c65d09",
|
||||
Number: "#40a070",
|
||||
|
||||
Generic.Heading: "bold #000080",
|
||||
Generic.Subheading: "bold #800080",
|
||||
Generic.Deleted: "#A00000",
|
||||
Generic.Inserted: "#00A000",
|
||||
Generic.Error: "#FF0000",
|
||||
Generic.Emph: "italic",
|
||||
Generic.Strong: "bold",
|
||||
Generic.Prompt: "bold #c65d09",
|
||||
Generic.Output: "#888",
|
||||
Generic.Traceback: "#04D",
|
||||
|
||||
Error: "border:#FF0000"
|
||||
}
|
||||
@ -1,106 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.monokai
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Mimic the Monokai color scheme. Based on tango.py.
|
||||
|
||||
http://www.monokai.nl/blog/2006/07/15/textmate-color-theme/
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, Text, \
|
||||
Number, Operator, Generic, Whitespace, Punctuation, Other, Literal
|
||||
|
||||
class MonokaiStyle(Style):
|
||||
"""
|
||||
This style mimics the Monokai color scheme.
|
||||
"""
|
||||
|
||||
background_color = "#272822"
|
||||
highlight_color = "#49483e"
|
||||
|
||||
styles = {
|
||||
# No corresponding class for the following:
|
||||
Text: "#f8f8f2", # class: ''
|
||||
Whitespace: "", # class: 'w'
|
||||
Error: "#960050 bg:#1e0010", # class: 'err'
|
||||
Other: "", # class 'x'
|
||||
|
||||
Comment: "#75715e", # class: 'c'
|
||||
Comment.Multiline: "", # class: 'cm'
|
||||
Comment.Preproc: "", # class: 'cp'
|
||||
Comment.Single: "", # class: 'c1'
|
||||
Comment.Special: "", # class: 'cs'
|
||||
|
||||
Keyword: "#66d9ef", # class: 'k'
|
||||
Keyword.Constant: "", # class: 'kc'
|
||||
Keyword.Declaration: "", # class: 'kd'
|
||||
Keyword.Namespace: "#f92672", # class: 'kn'
|
||||
Keyword.Pseudo: "", # class: 'kp'
|
||||
Keyword.Reserved: "", # class: 'kr'
|
||||
Keyword.Type: "", # class: 'kt'
|
||||
|
||||
Operator: "#f92672", # class: 'o'
|
||||
Operator.Word: "", # class: 'ow' - like keywords
|
||||
|
||||
Punctuation: "#f8f8f2", # class: 'p'
|
||||
|
||||
Name: "#f8f8f2", # class: 'n'
|
||||
Name.Attribute: "#a6e22e", # class: 'na' - to be revised
|
||||
Name.Builtin: "", # class: 'nb'
|
||||
Name.Builtin.Pseudo: "", # class: 'bp'
|
||||
Name.Class: "#a6e22e", # class: 'nc' - to be revised
|
||||
Name.Constant: "#66d9ef", # class: 'no' - to be revised
|
||||
Name.Decorator: "#a6e22e", # class: 'nd' - to be revised
|
||||
Name.Entity: "", # class: 'ni'
|
||||
Name.Exception: "#a6e22e", # class: 'ne'
|
||||
Name.Function: "#a6e22e", # class: 'nf'
|
||||
Name.Property: "", # class: 'py'
|
||||
Name.Label: "", # class: 'nl'
|
||||
Name.Namespace: "", # class: 'nn' - to be revised
|
||||
Name.Other: "#a6e22e", # class: 'nx'
|
||||
Name.Tag: "#f92672", # class: 'nt' - like a keyword
|
||||
Name.Variable: "", # class: 'nv' - to be revised
|
||||
Name.Variable.Class: "", # class: 'vc' - to be revised
|
||||
Name.Variable.Global: "", # class: 'vg' - to be revised
|
||||
Name.Variable.Instance: "", # class: 'vi' - to be revised
|
||||
|
||||
Number: "#ae81ff", # class: 'm'
|
||||
Number.Float: "", # class: 'mf'
|
||||
Number.Hex: "", # class: 'mh'
|
||||
Number.Integer: "", # class: 'mi'
|
||||
Number.Integer.Long: "", # class: 'il'
|
||||
Number.Oct: "", # class: 'mo'
|
||||
|
||||
Literal: "#ae81ff", # class: 'l'
|
||||
Literal.Date: "#e6db74", # class: 'ld'
|
||||
|
||||
String: "#e6db74", # class: 's'
|
||||
String.Backtick: "", # class: 'sb'
|
||||
String.Char: "", # class: 'sc'
|
||||
String.Doc: "", # class: 'sd' - like a comment
|
||||
String.Double: "", # class: 's2'
|
||||
String.Escape: "#ae81ff", # class: 'se'
|
||||
String.Heredoc: "", # class: 'sh'
|
||||
String.Interpol: "", # class: 'si'
|
||||
String.Other: "", # class: 'sx'
|
||||
String.Regex: "", # class: 'sr'
|
||||
String.Single: "", # class: 's1'
|
||||
String.Symbol: "", # class: 'ss'
|
||||
|
||||
Generic: "", # class: 'g'
|
||||
Generic.Deleted: "#f92672", # class: 'gd',
|
||||
Generic.Emph: "italic", # class: 'ge'
|
||||
Generic.Error: "", # class: 'gr'
|
||||
Generic.Heading: "", # class: 'gh'
|
||||
Generic.Inserted: "#a6e22e", # class: 'gi'
|
||||
Generic.Output: "", # class: 'go'
|
||||
Generic.Prompt: "", # class: 'gp'
|
||||
Generic.Strong: "bold", # class: 'gs'
|
||||
Generic.Subheading: "#75715e", # class: 'gu'
|
||||
Generic.Traceback: "", # class: 'gt'
|
||||
}
|
||||
@ -1,125 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.paraiso_dark
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Paraíso (Dark) by Jan T. Sott
|
||||
|
||||
Pygments template by Jan T. Sott (https://github.com/idleberg)
|
||||
Created with Base16 Builder by Chris Kempson
|
||||
(https://github.com/chriskempson/base16-builder).
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, Text, \
|
||||
Number, Operator, Generic, Whitespace, Punctuation, Other, Literal
|
||||
|
||||
|
||||
BACKGROUND = "#2f1e2e"
|
||||
CURRENT_LINE = "#41323f"
|
||||
SELECTION = "#4f424c"
|
||||
FOREGROUND = "#e7e9db"
|
||||
COMMENT = "#776e71"
|
||||
RED = "#ef6155"
|
||||
ORANGE = "#f99b15"
|
||||
YELLOW = "#fec418"
|
||||
GREEN = "#48b685"
|
||||
AQUA = "#5bc4bf"
|
||||
BLUE = "#06b6ef"
|
||||
PURPLE = "#815ba4"
|
||||
|
||||
|
||||
class ParaisoDarkStyle(Style):
|
||||
|
||||
default_style = ''
|
||||
|
||||
background_color = BACKGROUND
|
||||
highlight_color = SELECTION
|
||||
|
||||
background_color = BACKGROUND
|
||||
highlight_color = SELECTION
|
||||
|
||||
styles = {
|
||||
# No corresponding class for the following:
|
||||
Text: FOREGROUND, # class: ''
|
||||
Whitespace: "", # class: 'w'
|
||||
Error: RED, # class: 'err'
|
||||
Other: "", # class 'x'
|
||||
|
||||
Comment: COMMENT, # class: 'c'
|
||||
Comment.Multiline: "", # class: 'cm'
|
||||
Comment.Preproc: "", # class: 'cp'
|
||||
Comment.Single: "", # class: 'c1'
|
||||
Comment.Special: "", # class: 'cs'
|
||||
|
||||
Keyword: PURPLE, # class: 'k'
|
||||
Keyword.Constant: "", # class: 'kc'
|
||||
Keyword.Declaration: "", # class: 'kd'
|
||||
Keyword.Namespace: AQUA, # class: 'kn'
|
||||
Keyword.Pseudo: "", # class: 'kp'
|
||||
Keyword.Reserved: "", # class: 'kr'
|
||||
Keyword.Type: YELLOW, # class: 'kt'
|
||||
|
||||
Operator: AQUA, # class: 'o'
|
||||
Operator.Word: "", # class: 'ow' - like keywords
|
||||
|
||||
Punctuation: FOREGROUND, # class: 'p'
|
||||
|
||||
Name: FOREGROUND, # class: 'n'
|
||||
Name.Attribute: BLUE, # class: 'na' - to be revised
|
||||
Name.Builtin: "", # class: 'nb'
|
||||
Name.Builtin.Pseudo: "", # class: 'bp'
|
||||
Name.Class: YELLOW, # class: 'nc' - to be revised
|
||||
Name.Constant: RED, # class: 'no' - to be revised
|
||||
Name.Decorator: AQUA, # class: 'nd' - to be revised
|
||||
Name.Entity: "", # class: 'ni'
|
||||
Name.Exception: RED, # class: 'ne'
|
||||
Name.Function: BLUE, # class: 'nf'
|
||||
Name.Property: "", # class: 'py'
|
||||
Name.Label: "", # class: 'nl'
|
||||
Name.Namespace: YELLOW, # class: 'nn' - to be revised
|
||||
Name.Other: BLUE, # class: 'nx'
|
||||
Name.Tag: AQUA, # class: 'nt' - like a keyword
|
||||
Name.Variable: RED, # class: 'nv' - to be revised
|
||||
Name.Variable.Class: "", # class: 'vc' - to be revised
|
||||
Name.Variable.Global: "", # class: 'vg' - to be revised
|
||||
Name.Variable.Instance: "", # class: 'vi' - to be revised
|
||||
|
||||
Number: ORANGE, # class: 'm'
|
||||
Number.Float: "", # class: 'mf'
|
||||
Number.Hex: "", # class: 'mh'
|
||||
Number.Integer: "", # class: 'mi'
|
||||
Number.Integer.Long: "", # class: 'il'
|
||||
Number.Oct: "", # class: 'mo'
|
||||
|
||||
Literal: ORANGE, # class: 'l'
|
||||
Literal.Date: GREEN, # class: 'ld'
|
||||
|
||||
String: GREEN, # class: 's'
|
||||
String.Backtick: "", # class: 'sb'
|
||||
String.Char: FOREGROUND, # class: 'sc'
|
||||
String.Doc: COMMENT, # class: 'sd' - like a comment
|
||||
String.Double: "", # class: 's2'
|
||||
String.Escape: ORANGE, # class: 'se'
|
||||
String.Heredoc: "", # class: 'sh'
|
||||
String.Interpol: ORANGE, # class: 'si'
|
||||
String.Other: "", # class: 'sx'
|
||||
String.Regex: "", # class: 'sr'
|
||||
String.Single: "", # class: 's1'
|
||||
String.Symbol: "", # class: 'ss'
|
||||
|
||||
Generic: "", # class: 'g'
|
||||
Generic.Deleted: RED, # class: 'gd',
|
||||
Generic.Emph: "italic", # class: 'ge'
|
||||
Generic.Error: "", # class: 'gr'
|
||||
Generic.Heading: "bold " + FOREGROUND, # class: 'gh'
|
||||
Generic.Inserted: GREEN, # class: 'gi'
|
||||
Generic.Output: "", # class: 'go'
|
||||
Generic.Prompt: "bold " + COMMENT, # class: 'gp'
|
||||
Generic.Strong: "bold", # class: 'gs'
|
||||
Generic.Subheading: "bold " + AQUA, # class: 'gu'
|
||||
Generic.Traceback: "", # class: 'gt'
|
||||
}
|
||||
@ -1,125 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.paraiso_light
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Paraíso (Light) by Jan T. Sott
|
||||
|
||||
Pygments template by Jan T. Sott (https://github.com/idleberg)
|
||||
Created with Base16 Builder by Chris Kempson
|
||||
(https://github.com/chriskempson/base16-builder).
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, Text, \
|
||||
Number, Operator, Generic, Whitespace, Punctuation, Other, Literal
|
||||
|
||||
|
||||
BACKGROUND = "#e7e9db"
|
||||
CURRENT_LINE = "#b9b6b0"
|
||||
SELECTION = "#a39e9b"
|
||||
FOREGROUND = "#2f1e2e"
|
||||
COMMENT = "#8d8687"
|
||||
RED = "#ef6155"
|
||||
ORANGE = "#f99b15"
|
||||
YELLOW = "#fec418"
|
||||
GREEN = "#48b685"
|
||||
AQUA = "#5bc4bf"
|
||||
BLUE = "#06b6ef"
|
||||
PURPLE = "#815ba4"
|
||||
|
||||
|
||||
class ParaisoLightStyle(Style):
|
||||
|
||||
default_style = ''
|
||||
|
||||
background_color = BACKGROUND
|
||||
highlight_color = SELECTION
|
||||
|
||||
background_color = BACKGROUND
|
||||
highlight_color = SELECTION
|
||||
|
||||
styles = {
|
||||
# No corresponding class for the following:
|
||||
Text: FOREGROUND, # class: ''
|
||||
Whitespace: "", # class: 'w'
|
||||
Error: RED, # class: 'err'
|
||||
Other: "", # class 'x'
|
||||
|
||||
Comment: COMMENT, # class: 'c'
|
||||
Comment.Multiline: "", # class: 'cm'
|
||||
Comment.Preproc: "", # class: 'cp'
|
||||
Comment.Single: "", # class: 'c1'
|
||||
Comment.Special: "", # class: 'cs'
|
||||
|
||||
Keyword: PURPLE, # class: 'k'
|
||||
Keyword.Constant: "", # class: 'kc'
|
||||
Keyword.Declaration: "", # class: 'kd'
|
||||
Keyword.Namespace: AQUA, # class: 'kn'
|
||||
Keyword.Pseudo: "", # class: 'kp'
|
||||
Keyword.Reserved: "", # class: 'kr'
|
||||
Keyword.Type: YELLOW, # class: 'kt'
|
||||
|
||||
Operator: AQUA, # class: 'o'
|
||||
Operator.Word: "", # class: 'ow' - like keywords
|
||||
|
||||
Punctuation: FOREGROUND, # class: 'p'
|
||||
|
||||
Name: FOREGROUND, # class: 'n'
|
||||
Name.Attribute: BLUE, # class: 'na' - to be revised
|
||||
Name.Builtin: "", # class: 'nb'
|
||||
Name.Builtin.Pseudo: "", # class: 'bp'
|
||||
Name.Class: YELLOW, # class: 'nc' - to be revised
|
||||
Name.Constant: RED, # class: 'no' - to be revised
|
||||
Name.Decorator: AQUA, # class: 'nd' - to be revised
|
||||
Name.Entity: "", # class: 'ni'
|
||||
Name.Exception: RED, # class: 'ne'
|
||||
Name.Function: BLUE, # class: 'nf'
|
||||
Name.Property: "", # class: 'py'
|
||||
Name.Label: "", # class: 'nl'
|
||||
Name.Namespace: YELLOW, # class: 'nn' - to be revised
|
||||
Name.Other: BLUE, # class: 'nx'
|
||||
Name.Tag: AQUA, # class: 'nt' - like a keyword
|
||||
Name.Variable: RED, # class: 'nv' - to be revised
|
||||
Name.Variable.Class: "", # class: 'vc' - to be revised
|
||||
Name.Variable.Global: "", # class: 'vg' - to be revised
|
||||
Name.Variable.Instance: "", # class: 'vi' - to be revised
|
||||
|
||||
Number: ORANGE, # class: 'm'
|
||||
Number.Float: "", # class: 'mf'
|
||||
Number.Hex: "", # class: 'mh'
|
||||
Number.Integer: "", # class: 'mi'
|
||||
Number.Integer.Long: "", # class: 'il'
|
||||
Number.Oct: "", # class: 'mo'
|
||||
|
||||
Literal: ORANGE, # class: 'l'
|
||||
Literal.Date: GREEN, # class: 'ld'
|
||||
|
||||
String: GREEN, # class: 's'
|
||||
String.Backtick: "", # class: 'sb'
|
||||
String.Char: FOREGROUND, # class: 'sc'
|
||||
String.Doc: COMMENT, # class: 'sd' - like a comment
|
||||
String.Double: "", # class: 's2'
|
||||
String.Escape: ORANGE, # class: 'se'
|
||||
String.Heredoc: "", # class: 'sh'
|
||||
String.Interpol: ORANGE, # class: 'si'
|
||||
String.Other: "", # class: 'sx'
|
||||
String.Regex: "", # class: 'sr'
|
||||
String.Single: "", # class: 's1'
|
||||
String.Symbol: "", # class: 'ss'
|
||||
|
||||
Generic: "", # class: 'g'
|
||||
Generic.Deleted: RED, # class: 'gd',
|
||||
Generic.Emph: "italic", # class: 'ge'
|
||||
Generic.Error: "", # class: 'gr'
|
||||
Generic.Heading: "bold " + FOREGROUND, # class: 'gh'
|
||||
Generic.Inserted: GREEN, # class: 'gi'
|
||||
Generic.Output: "", # class: 'go'
|
||||
Generic.Prompt: "bold " + COMMENT, # class: 'gp'
|
||||
Generic.Strong: "bold", # class: 'gs'
|
||||
Generic.Subheading: "bold " + AQUA, # class: 'gu'
|
||||
Generic.Traceback: "", # class: 'gt'
|
||||
}
|
||||
@ -1,75 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.pastie
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Style similar to the `pastie`_ default style.
|
||||
|
||||
.. _pastie: http://pastie.caboo.se/
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Whitespace
|
||||
|
||||
|
||||
class PastieStyle(Style):
|
||||
"""
|
||||
Style similar to the pastie default style.
|
||||
"""
|
||||
|
||||
default_style = ''
|
||||
|
||||
styles = {
|
||||
Whitespace: '#bbbbbb',
|
||||
Comment: '#888888',
|
||||
Comment.Preproc: 'bold #cc0000',
|
||||
Comment.Special: 'bg:#fff0f0 bold #cc0000',
|
||||
|
||||
String: 'bg:#fff0f0 #dd2200',
|
||||
String.Regex: 'bg:#fff0ff #008800',
|
||||
String.Other: 'bg:#f0fff0 #22bb22',
|
||||
String.Symbol: '#aa6600',
|
||||
String.Interpol: '#3333bb',
|
||||
String.Escape: '#0044dd',
|
||||
|
||||
Operator.Word: '#008800',
|
||||
|
||||
Keyword: 'bold #008800',
|
||||
Keyword.Pseudo: 'nobold',
|
||||
Keyword.Type: '#888888',
|
||||
|
||||
Name.Class: 'bold #bb0066',
|
||||
Name.Exception: 'bold #bb0066',
|
||||
Name.Function: 'bold #0066bb',
|
||||
Name.Property: 'bold #336699',
|
||||
Name.Namespace: 'bold #bb0066',
|
||||
Name.Builtin: '#003388',
|
||||
Name.Variable: '#336699',
|
||||
Name.Variable.Class: '#336699',
|
||||
Name.Variable.Instance: '#3333bb',
|
||||
Name.Variable.Global: '#dd7700',
|
||||
Name.Constant: 'bold #003366',
|
||||
Name.Tag: 'bold #bb0066',
|
||||
Name.Attribute: '#336699',
|
||||
Name.Decorator: '#555555',
|
||||
Name.Label: 'italic #336699',
|
||||
|
||||
Number: 'bold #0000DD',
|
||||
|
||||
Generic.Heading: '#333',
|
||||
Generic.Subheading: '#666',
|
||||
Generic.Deleted: 'bg:#ffdddd #000000',
|
||||
Generic.Inserted: 'bg:#ddffdd #000000',
|
||||
Generic.Error: '#aa0000',
|
||||
Generic.Emph: 'italic',
|
||||
Generic.Strong: 'bold',
|
||||
Generic.Prompt: '#555555',
|
||||
Generic.Output: '#888888',
|
||||
Generic.Traceback: '#aa0000',
|
||||
|
||||
Error: 'bg:#e3d2d2 #a61717'
|
||||
}
|
||||
@ -1,69 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.perldoc
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Style similar to the style used in the `perldoc`_ code blocks.
|
||||
|
||||
.. _perldoc: http://perldoc.perl.org/
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Whitespace
|
||||
|
||||
|
||||
class PerldocStyle(Style):
|
||||
"""
|
||||
Style similar to the style used in the perldoc code blocks.
|
||||
"""
|
||||
|
||||
background_color = '#eeeedd'
|
||||
default_style = ''
|
||||
|
||||
styles = {
|
||||
Whitespace: '#bbbbbb',
|
||||
Comment: '#228B22',
|
||||
Comment.Preproc: '#1e889b',
|
||||
Comment.Special: '#8B008B bold',
|
||||
|
||||
String: '#CD5555',
|
||||
String.Heredoc: '#1c7e71 italic',
|
||||
String.Regex: '#B452CD',
|
||||
String.Other: '#cb6c20',
|
||||
String.Regex: '#1c7e71',
|
||||
|
||||
Number: '#B452CD',
|
||||
|
||||
Operator.Word: '#8B008B',
|
||||
|
||||
Keyword: '#8B008B bold',
|
||||
Keyword.Type: '#a7a7a7',
|
||||
|
||||
Name.Class: '#008b45 bold',
|
||||
Name.Exception: '#008b45 bold',
|
||||
Name.Function: '#008b45',
|
||||
Name.Namespace: '#008b45 underline',
|
||||
Name.Variable: '#00688B',
|
||||
Name.Constant: '#00688B',
|
||||
Name.Decorator: '#707a7c',
|
||||
Name.Tag: '#8B008B bold',
|
||||
Name.Attribute: '#658b00',
|
||||
Name.Builtin: '#658b00',
|
||||
|
||||
Generic.Heading: 'bold #000080',
|
||||
Generic.Subheading: 'bold #800080',
|
||||
Generic.Deleted: '#aa0000',
|
||||
Generic.Inserted: '#00aa00',
|
||||
Generic.Error: '#aa0000',
|
||||
Generic.Emph: 'italic',
|
||||
Generic.Strong: 'bold',
|
||||
Generic.Prompt: '#555555',
|
||||
Generic.Output: '#888888',
|
||||
Generic.Traceback: '#aa0000',
|
||||
|
||||
Error: 'bg:#e3d2d2 #a61717'
|
||||
}
|
||||
@ -1,63 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.trac
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Port of the default trac highlighter design.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Whitespace
|
||||
|
||||
|
||||
class TracStyle(Style):
|
||||
"""
|
||||
Port of the default trac highlighter design.
|
||||
"""
|
||||
|
||||
default_style = ''
|
||||
|
||||
styles = {
|
||||
Whitespace: '#bbbbbb',
|
||||
Comment: 'italic #999988',
|
||||
Comment.Preproc: 'bold noitalic #999999',
|
||||
Comment.Special: 'bold #999999',
|
||||
|
||||
Operator: 'bold',
|
||||
|
||||
String: '#bb8844',
|
||||
String.Regex: '#808000',
|
||||
|
||||
Number: '#009999',
|
||||
|
||||
Keyword: 'bold',
|
||||
Keyword.Type: '#445588',
|
||||
|
||||
Name.Builtin: '#999999',
|
||||
Name.Function: 'bold #990000',
|
||||
Name.Class: 'bold #445588',
|
||||
Name.Exception: 'bold #990000',
|
||||
Name.Namespace: '#555555',
|
||||
Name.Variable: '#008080',
|
||||
Name.Constant: '#008080',
|
||||
Name.Tag: '#000080',
|
||||
Name.Attribute: '#008080',
|
||||
Name.Entity: '#800080',
|
||||
|
||||
Generic.Heading: '#999999',
|
||||
Generic.Subheading: '#aaaaaa',
|
||||
Generic.Deleted: 'bg:#ffdddd #000000',
|
||||
Generic.Inserted: 'bg:#ddffdd #000000',
|
||||
Generic.Error: '#aa0000',
|
||||
Generic.Emph: 'italic',
|
||||
Generic.Strong: 'bold',
|
||||
Generic.Prompt: '#555555',
|
||||
Generic.Output: '#888888',
|
||||
Generic.Traceback: '#aa0000',
|
||||
|
||||
Error: 'bg:#e3d2d2 #a61717'
|
||||
}
|
||||
@ -1,38 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.styles.vs
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Simple style with MS Visual Studio colors.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.style import Style
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Operator, Generic
|
||||
|
||||
|
||||
class VisualStudioStyle(Style):
|
||||
|
||||
background_color = "#ffffff"
|
||||
default_style = ""
|
||||
|
||||
styles = {
|
||||
Comment: "#008000",
|
||||
Comment.Preproc: "#0000ff",
|
||||
Keyword: "#0000ff",
|
||||
Operator.Word: "#0000ff",
|
||||
Keyword.Type: "#2b91af",
|
||||
Name.Class: "#2b91af",
|
||||
String: "#a31515",
|
||||
|
||||
Generic.Heading: "bold",
|
||||
Generic.Subheading: "bold",
|
||||
Generic.Emph: "italic",
|
||||
Generic.Strong: "bold",
|
||||
Generic.Prompt: "bold",
|
||||
|
||||
Error: "border:#FF0000"
|
||||
}
|
||||
@ -1,198 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.token
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
Basic token types and the standard tokens.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
class _TokenType(tuple):
|
||||
parent = None
|
||||
|
||||
def split(self):
|
||||
buf = []
|
||||
node = self
|
||||
while node is not None:
|
||||
buf.append(node)
|
||||
node = node.parent
|
||||
buf.reverse()
|
||||
return buf
|
||||
|
||||
def __init__(self, *args):
|
||||
# no need to call super.__init__
|
||||
self.subtypes = set()
|
||||
|
||||
def __contains__(self, val):
|
||||
return self is val or (
|
||||
type(val) is self.__class__ and
|
||||
val[:len(self)] == self
|
||||
)
|
||||
|
||||
def __getattr__(self, val):
|
||||
if not val or not val[0].isupper():
|
||||
return tuple.__getattribute__(self, val)
|
||||
new = _TokenType(self + (val,))
|
||||
setattr(self, val, new)
|
||||
self.subtypes.add(new)
|
||||
new.parent = self
|
||||
return new
|
||||
|
||||
def __repr__(self):
|
||||
return 'Token' + (self and '.' or '') + '.'.join(self)
|
||||
|
||||
|
||||
Token = _TokenType()
|
||||
|
||||
# Special token types
|
||||
Text = Token.Text
|
||||
Whitespace = Text.Whitespace
|
||||
Escape = Token.Escape
|
||||
Error = Token.Error
|
||||
# Text that doesn't belong to this lexer (e.g. HTML in PHP)
|
||||
Other = Token.Other
|
||||
|
||||
# Common token types for source code
|
||||
Keyword = Token.Keyword
|
||||
Name = Token.Name
|
||||
Literal = Token.Literal
|
||||
String = Literal.String
|
||||
Number = Literal.Number
|
||||
Punctuation = Token.Punctuation
|
||||
Operator = Token.Operator
|
||||
Comment = Token.Comment
|
||||
|
||||
# Generic types for non-source code
|
||||
Generic = Token.Generic
|
||||
|
||||
# String and some others are not direct childs of Token.
|
||||
# alias them:
|
||||
Token.Token = Token
|
||||
Token.String = String
|
||||
Token.Number = Number
|
||||
|
||||
|
||||
def is_token_subtype(ttype, other):
|
||||
"""
|
||||
Return True if ``ttype`` is a subtype of ``other``.
|
||||
|
||||
exists for backwards compatibility. use ``ttype in other`` now.
|
||||
"""
|
||||
return ttype in other
|
||||
|
||||
|
||||
def string_to_tokentype(s):
|
||||
"""
|
||||
Convert a string into a token type::
|
||||
|
||||
>>> string_to_token('String.Double')
|
||||
Token.Literal.String.Double
|
||||
>>> string_to_token('Token.Literal.Number')
|
||||
Token.Literal.Number
|
||||
>>> string_to_token('')
|
||||
Token
|
||||
|
||||
Tokens that are already tokens are returned unchanged:
|
||||
|
||||
>>> string_to_token(String)
|
||||
Token.Literal.String
|
||||
"""
|
||||
if isinstance(s, _TokenType):
|
||||
return s
|
||||
if not s:
|
||||
return Token
|
||||
node = Token
|
||||
for item in s.split('.'):
|
||||
node = getattr(node, item)
|
||||
return node
|
||||
|
||||
|
||||
# Map standard token types to short names, used in CSS class naming.
|
||||
# If you add a new item, please be sure to run this file to perform
|
||||
# a consistency check for duplicate values.
|
||||
STANDARD_TYPES = {
|
||||
Token: '',
|
||||
|
||||
Text: '',
|
||||
Whitespace: 'w',
|
||||
Escape: 'esc',
|
||||
Error: 'err',
|
||||
Other: 'x',
|
||||
|
||||
Keyword: 'k',
|
||||
Keyword.Constant: 'kc',
|
||||
Keyword.Declaration: 'kd',
|
||||
Keyword.Namespace: 'kn',
|
||||
Keyword.Pseudo: 'kp',
|
||||
Keyword.Reserved: 'kr',
|
||||
Keyword.Type: 'kt',
|
||||
|
||||
Name: 'n',
|
||||
Name.Attribute: 'na',
|
||||
Name.Builtin: 'nb',
|
||||
Name.Builtin.Pseudo: 'bp',
|
||||
Name.Class: 'nc',
|
||||
Name.Constant: 'no',
|
||||
Name.Decorator: 'nd',
|
||||
Name.Entity: 'ni',
|
||||
Name.Exception: 'ne',
|
||||
Name.Function: 'nf',
|
||||
Name.Property: 'py',
|
||||
Name.Label: 'nl',
|
||||
Name.Namespace: 'nn',
|
||||
Name.Other: 'nx',
|
||||
Name.Tag: 'nt',
|
||||
Name.Variable: 'nv',
|
||||
Name.Variable.Class: 'vc',
|
||||
Name.Variable.Global: 'vg',
|
||||
Name.Variable.Instance: 'vi',
|
||||
|
||||
Literal: 'l',
|
||||
Literal.Date: 'ld',
|
||||
|
||||
String: 's',
|
||||
String.Backtick: 'sb',
|
||||
String.Char: 'sc',
|
||||
String.Doc: 'sd',
|
||||
String.Double: 's2',
|
||||
String.Escape: 'se',
|
||||
String.Heredoc: 'sh',
|
||||
String.Interpol: 'si',
|
||||
String.Other: 'sx',
|
||||
String.Regex: 'sr',
|
||||
String.Single: 's1',
|
||||
String.Symbol: 'ss',
|
||||
|
||||
Number: 'm',
|
||||
Number.Bin: 'mb',
|
||||
Number.Float: 'mf',
|
||||
Number.Hex: 'mh',
|
||||
Number.Integer: 'mi',
|
||||
Number.Integer.Long: 'il',
|
||||
Number.Oct: 'mo',
|
||||
|
||||
Operator: 'o',
|
||||
Operator.Word: 'ow',
|
||||
|
||||
Punctuation: 'p',
|
||||
|
||||
Comment: 'c',
|
||||
Comment.Multiline: 'cm',
|
||||
Comment.Preproc: 'cp',
|
||||
Comment.Single: 'c1',
|
||||
Comment.Special: 'cs',
|
||||
|
||||
Generic: 'g',
|
||||
Generic.Deleted: 'gd',
|
||||
Generic.Emph: 'ge',
|
||||
Generic.Error: 'gr',
|
||||
Generic.Heading: 'gh',
|
||||
Generic.Inserted: 'gi',
|
||||
Generic.Output: 'go',
|
||||
Generic.Prompt: 'gp',
|
||||
Generic.Strong: 'gs',
|
||||
Generic.Subheading: 'gu',
|
||||
Generic.Traceback: 'gt',
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user