mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
73 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 584d109357 | |||
| 327c0e448b | |||
| 3182a45bbd | |||
| 4cd4a26f91 | |||
| 85856f2c53 | |||
| 8a09559364 | |||
| 5e2e1be779 | |||
| b1d344cb46 | |||
| 7245cbeb58 | |||
| 21395579ea | |||
| 08b64b4ff6 | |||
| 20571ec085 | |||
| e43dcc1c83 | |||
| 4610ff3e0c | |||
| c86d6254e0 | |||
| df331db5cc | |||
| baff0f415d | |||
| 499dc167a5 | |||
| 83f4a29a15 | |||
| 8f02adacf9 | |||
| e631d33944 | |||
| cbd92a69b3 | |||
| b7c047102d | |||
| d0bfd04602 | |||
| 101ab38c70 | |||
| 8632c4ff08 | |||
| 80556d0cbf | |||
| 253728545c | |||
| 49d9b1d7dc | |||
| 8574abe012 | |||
| 6b6f60d8e8 | |||
| 986e592d1e | |||
| 6ec3b171e1 | |||
| bcfb9862af | |||
| 85cf9f4eb5 | |||
| d2a996e845 | |||
| c863bde54a | |||
| e19f85f081 | |||
| 7b854d4041 | |||
| e122f73e6b | |||
| 474942eb6a | |||
| a5f031b046 | |||
| 66fddc07b9 | |||
| e56a07e909 | |||
| 64ea40b3f5 | |||
| 17fd6ef8e1 | |||
| e5e399dfbe | |||
| bcf037e8a4 | |||
| 7e678a38bd | |||
| 533aaac313 | |||
| 7f4f70cc85 | |||
| 4adb8a8796 | |||
| 48e1993b24 | |||
| 8a3375bb23 | |||
| 8bd54a7427 | |||
| fcbbf05933 | |||
| 9733087094 | |||
| da4e02199a | |||
| 09a16dea1e | |||
| 4c7adf0943 | |||
| 216a8eaa0a | |||
| 81f838489d | |||
| d6228b8dce | |||
| 7a2c2b9750 | |||
| d9cc911595 | |||
| 805e2fe222 | |||
| bbcb39b2cf | |||
| 9f9b97c69f | |||
| 908ff98613 | |||
| 37f74b4b56 | |||
| a1c0d7e489 | |||
| 3127f264b4 | |||
| 049bc57019 |
204
HISTORY.rst
204
HISTORY.rst
@ -3,6 +3,210 @@ History
|
||||
-------
|
||||
|
||||
|
||||
2.0.20 (2014-12-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.9
|
||||
- fix bug preventing offline heartbeats from being purged after uploaded
|
||||
|
||||
|
||||
2.0.19 (2014-12-04)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.8
|
||||
- fix UnicodeDecodeError when building user agent string
|
||||
- handle case where response is None
|
||||
|
||||
|
||||
2.0.18 (2014-11-30)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.7
|
||||
- upgrade pygments to v2.0.1
|
||||
- always log an error when api key is incorrect
|
||||
|
||||
|
||||
2.0.17 (2014-11-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.6
|
||||
- fix list index error when detecting subversion project
|
||||
|
||||
|
||||
2.0.16 (2014-11-12)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.4
|
||||
- when Python was not compiled with https support, log an error to the log file
|
||||
|
||||
|
||||
2.0.15 (2014-11-10)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.3
|
||||
- correctly detect branch for subversion projects
|
||||
|
||||
|
||||
2.0.14 (2014-10-14)
|
||||
++++++++++++++++++
|
||||
|
||||
- popup error message if Python binary not found
|
||||
|
||||
|
||||
2.0.13 (2014-10-07)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.2
|
||||
- still log heartbeat when something goes wrong while reading num lines in file
|
||||
|
||||
|
||||
2.0.12 (2014-09-30)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.1
|
||||
- fix bug where binary file opened as utf-8
|
||||
|
||||
|
||||
2.0.11 (2014-09-30)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.1.0
|
||||
- python3 compatibility changes
|
||||
|
||||
|
||||
2.0.10 (2014-08-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.8
|
||||
- supress output from svn command
|
||||
|
||||
|
||||
2.0.9 (2014-08-27)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.7
|
||||
- fix support for subversion projects on Mac OS X
|
||||
|
||||
|
||||
2.0.8 (2014-08-07)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.6
|
||||
- fix unicode bug by encoding json POST data
|
||||
|
||||
|
||||
2.0.7 (2014-07-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.5
|
||||
- option in .wakatime.cfg to obfuscate file names
|
||||
|
||||
|
||||
2.0.6 (2014-07-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.4
|
||||
- use unique logger namespace to prevent collisions in shared plugin environments
|
||||
|
||||
|
||||
2.0.5 (2014-06-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.3
|
||||
- use project name from sublime-project file when no revision control project found
|
||||
|
||||
|
||||
2.0.4 (2014-06-09)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.2
|
||||
- disable offline logging when Python not compiled with sqlite3 module
|
||||
|
||||
|
||||
2.0.3 (2014-05-26)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.1
|
||||
- fix bug in queue preventing completed tasks from being purged
|
||||
|
||||
|
||||
2.0.2 (2014-05-26)
|
||||
++++++++++++++++++
|
||||
|
||||
- disable syncing offline time until bug fixed
|
||||
|
||||
|
||||
2.0.1 (2014-05-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v2.0.0
|
||||
- offline time logging using sqlite3 to queue editor events
|
||||
|
||||
|
||||
1.6.5 (2014-03-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v1.0.1
|
||||
- use new domain wakatime.com
|
||||
|
||||
|
||||
1.6.4 (2014-02-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade external wakatime package to v1.0.0
|
||||
- support for mercurial revision control
|
||||
|
||||
|
||||
1.6.3 (2014-01-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade common wakatime package to v0.5.3
|
||||
|
||||
|
||||
1.6.2 (2014-01-14)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade common wakatime package to v0.5.2
|
||||
|
||||
|
||||
1.6.1 (2013-12-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade common wakatime package to v0.5.1
|
||||
- second line in .wakatime-project now sets branch name
|
||||
|
||||
|
||||
1.6.0 (2013-12-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade common wakatime package to v0.5.0
|
||||
|
||||
|
||||
1.5.2 (2013-12-03)
|
||||
++++++++++++++++++
|
||||
|
||||
- use non-localized datetime in log
|
||||
|
||||
|
||||
1.5.1 (2013-12-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- decode file names with filesystem encoding, then encode as utf-8 for logging
|
||||
|
||||
|
||||
1.5.0 (2013-11-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- increase "ping" frequency from every 5 minutes to every 2 minutes
|
||||
- prevent sending multiple api requests when saving the same file
|
||||
|
||||
|
||||
1.4.12 (2013-11-21)
|
||||
+++++++++++++++++++
|
||||
|
||||
- handle UnicodeDecodeError exceptions when json encoding log messages
|
||||
|
||||
|
||||
1.4.11 (2013-11-13)
|
||||
+++++++++++++++++++
|
||||
|
||||
|
||||
29
LICENSE
Normal file
29
LICENSE
Normal file
@ -0,0 +1,29 @@
|
||||
Copyright (c) 2014 Alan Hamlett https://wakatime.com
|
||||
All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright
|
||||
notice, this list of conditions and the following disclaimer.
|
||||
|
||||
* Redistributions in binary form must reproduce the above copyright
|
||||
notice, this list of conditions and the following disclaimer
|
||||
in the documentation and/or other materials provided
|
||||
with the distribution.
|
||||
|
||||
* Neither the names of Wakatime or WakaTime, nor the names of its
|
||||
contributors may be used to endorse or promote products derived
|
||||
from this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE AND DOCUMENTATION IS PROVIDED BY THE COPYRIGHT HOLDERS AND
|
||||
CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT
|
||||
NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER
|
||||
OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
|
||||
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
|
||||
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
|
||||
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
|
||||
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
|
||||
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
||||
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
16
README.md
16
README.md
@ -7,27 +7,25 @@ Installation
|
||||
------------
|
||||
|
||||
Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](http://www.python.org/getit/) being installed to work correctly.
|
||||
|
||||
1. Get an api key from: https://wakati.me
|
||||
|
||||
1. Install [Sublime Package Control](https://sublime.wbond.net/installation).
|
||||
|
||||
2. Using [Sublime Package Control](http://wbond.net/sublime_packages/package_control):
|
||||
|
||||
a) Press `ctrl+shift+p`(Windows, Linux) or `cmd+shift+p`(OS X).
|
||||
a) Inside Sublime, press `ctrl+shift+p`(Windows, Linux) or `cmd+shift+p`(OS X).
|
||||
|
||||
b) Type `install`, then press `enter` with `Package Control: Install Package` selected.
|
||||
|
||||
c) Type `wakatime`, then press `enter` with the `WakaTime` plugin selected.
|
||||
|
||||
3. You will see a prompt at the bottom asking for your [api key](https://www.wakati.me/#apikey). Enter your api key, then press `enter`.
|
||||
3. Enter your [api key](https://wakatime.com/settings#apikey) from https://wakatime.com/settings#apikey, then press `enter`.
|
||||
|
||||
4. Use Sublime and your time will automatically be tracked for you.
|
||||
4. Use Sublime and your time will be tracked for you automatically.
|
||||
|
||||
5. Visit https://wakati.me to see your logged time.
|
||||
|
||||
6. Consider installing [BIND9](https://help.ubuntu.com/community/BIND9ServerHowto#Caching_Server_configuration) to cache your repeated DNS requests: `sudo apt-get install bind9`
|
||||
5. Visit https://wakatime.com/dashboard to see your logged time.
|
||||
|
||||
Screen Shots
|
||||
------------
|
||||
|
||||

|
||||
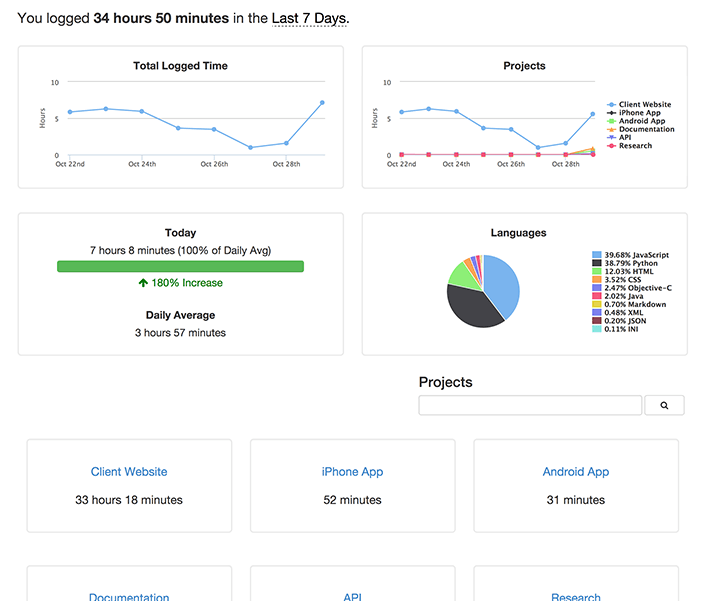
|
||||
|
||||
|
||||
87
WakaTime.py
87
WakaTime.py
@ -1,11 +1,12 @@
|
||||
""" ==========================================================
|
||||
File: WakaTime.py
|
||||
Description: Automatic time tracking for Sublime Text 2 and 3.
|
||||
Maintainer: WakaTi.me <support@wakatime.com>
|
||||
Website: https://www.wakati.me/
|
||||
Maintainer: WakaTime <support@wakatime.com>
|
||||
License: BSD, see LICENSE for more details.
|
||||
Website: https://wakatime.com/
|
||||
==========================================================="""
|
||||
|
||||
__version__ = '1.4.11'
|
||||
__version__ = '2.0.20'
|
||||
|
||||
import sublime
|
||||
import sublime_plugin
|
||||
@ -17,18 +18,21 @@ import sys
|
||||
import time
|
||||
import threading
|
||||
import uuid
|
||||
from os.path import expanduser, dirname, realpath, isfile, join, exists
|
||||
from os.path import expanduser, dirname, basename, realpath, isfile, join, exists
|
||||
|
||||
|
||||
# globals
|
||||
ACTION_FREQUENCY = 5
|
||||
ACTION_FREQUENCY = 2
|
||||
ST_VERSION = int(sublime.version())
|
||||
PLUGIN_DIR = dirname(realpath(__file__))
|
||||
API_CLIENT = '%s/packages/wakatime/wakatime-cli.py' % PLUGIN_DIR
|
||||
SETTINGS_FILE = 'WakaTime.sublime-settings'
|
||||
SETTINGS = {}
|
||||
LAST_ACTION = 0
|
||||
LAST_FILE = None
|
||||
LAST_ACTION = {
|
||||
'time': 0,
|
||||
'file': None,
|
||||
'is_write': False,
|
||||
}
|
||||
HAS_SSL = False
|
||||
LOCK = threading.RLock()
|
||||
|
||||
@ -49,17 +53,19 @@ if HAS_SSL:
|
||||
|
||||
def prompt_api_key():
|
||||
global SETTINGS
|
||||
if not SETTINGS.get('api_key'):
|
||||
if SETTINGS.get('api_key'):
|
||||
return True
|
||||
else:
|
||||
def got_key(text):
|
||||
if text:
|
||||
SETTINGS.set('api_key', str(text))
|
||||
sublime.save_settings(SETTINGS_FILE)
|
||||
window = sublime.active_window()
|
||||
if window:
|
||||
window.show_input_panel('Enter your WakaTime api key:', '', got_key, None, None)
|
||||
window.show_input_panel('[WakaTime] Enter your wakatime.com api key:', '', got_key, None, None)
|
||||
return True
|
||||
else:
|
||||
print('Error: Could not prompt for api key because no window found.')
|
||||
print('[WakaTime] Error: Could not prompt for api key because no window found.')
|
||||
return False
|
||||
|
||||
|
||||
@ -76,43 +82,60 @@ def python_binary():
|
||||
return 'python'
|
||||
|
||||
|
||||
def enough_time_passed(now):
|
||||
if now - LAST_ACTION > ACTION_FREQUENCY * 60:
|
||||
def enough_time_passed(now, last_time):
|
||||
if now - last_time > ACTION_FREQUENCY * 60:
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def find_project_name_from_folders(folders):
|
||||
for folder in folders:
|
||||
for file_name in os.listdir(folder):
|
||||
if file_name.endswith('.sublime-project'):
|
||||
return file_name.replace('.sublime-project', '', 1)
|
||||
return None
|
||||
|
||||
|
||||
def handle_action(view, is_write=False):
|
||||
global LOCK, LAST_FILE, LAST_ACTION
|
||||
global LOCK, LAST_ACTION
|
||||
with LOCK:
|
||||
target_file = view.file_name()
|
||||
thread = SendActionThread(target_file, is_write=is_write)
|
||||
thread.start()
|
||||
LAST_FILE = target_file
|
||||
LAST_ACTION = time.time()
|
||||
if target_file:
|
||||
project = view.window().project_file_name() if hasattr(view.window(), 'project_file_name') else None
|
||||
if project:
|
||||
project = basename(project).replace('.sublime-project', '', 1)
|
||||
thread = SendActionThread(target_file, is_write=is_write, project=project, folders=view.window().folders())
|
||||
thread.start()
|
||||
LAST_ACTION = {
|
||||
'file': target_file,
|
||||
'time': time.time(),
|
||||
'is_write': is_write,
|
||||
}
|
||||
|
||||
|
||||
class SendActionThread(threading.Thread):
|
||||
|
||||
def __init__(self, target_file, is_write=False, force=False):
|
||||
def __init__(self, target_file, is_write=False, project=None, folders=None, force=False):
|
||||
threading.Thread.__init__(self)
|
||||
self.target_file = target_file
|
||||
self.is_write = is_write
|
||||
self.project = project
|
||||
self.folders = folders
|
||||
self.force = force
|
||||
self.debug = SETTINGS.get('debug')
|
||||
self.api_key = SETTINGS.get('api_key', '')
|
||||
self.ignore = SETTINGS.get('ignore', [])
|
||||
self.last_file = LAST_FILE
|
||||
self.last_action = LAST_ACTION
|
||||
|
||||
def run(self):
|
||||
if self.target_file:
|
||||
self.timestamp = time.time()
|
||||
if self.force or self.is_write or self.target_file != self.last_file or enough_time_passed(self.timestamp):
|
||||
if self.force or (self.is_write and not self.last_action['is_write']) or self.target_file != self.last_action['file'] or enough_time_passed(self.timestamp, self.last_action['time']):
|
||||
self.send()
|
||||
|
||||
def send(self):
|
||||
if not self.api_key:
|
||||
print('missing api key')
|
||||
print('[WakaTime] Error: missing api key.')
|
||||
return
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
@ -124,33 +147,47 @@ class SendActionThread(threading.Thread):
|
||||
]
|
||||
if self.is_write:
|
||||
cmd.append('--write')
|
||||
if self.project:
|
||||
cmd.extend(['--project', self.project])
|
||||
elif self.folders:
|
||||
project_name = find_project_name_from_folders(self.folders)
|
||||
if project_name:
|
||||
cmd.extend(['--project', project_name])
|
||||
for pattern in self.ignore:
|
||||
cmd.extend(['--ignore', pattern])
|
||||
if self.debug:
|
||||
cmd.append('--verbose')
|
||||
if HAS_SSL:
|
||||
if self.debug:
|
||||
print(cmd)
|
||||
print('[WakaTime] %s' % ' '.join(cmd))
|
||||
code = wakatime.main(cmd)
|
||||
if code != 0:
|
||||
print('Error: Response code %d from wakatime package' % code)
|
||||
print('[WakaTime] Error: Response code %d from wakatime package.' % code)
|
||||
else:
|
||||
python = python_binary()
|
||||
if python:
|
||||
cmd.insert(0, python)
|
||||
if self.debug:
|
||||
print(cmd)
|
||||
print('[WakaTime] %s' % ' '.join(cmd))
|
||||
if platform.system() == 'Windows':
|
||||
Popen(cmd, shell=False)
|
||||
else:
|
||||
with open(join(expanduser('~'), '.wakatime.log'), 'a') as stderr:
|
||||
Popen(cmd, stderr=stderr)
|
||||
else:
|
||||
print('Error: Unable to find python binary.')
|
||||
print('[WakaTime] Error: Unable to find python binary.')
|
||||
|
||||
|
||||
def plugin_loaded():
|
||||
global SETTINGS
|
||||
print('[WakaTime] Initializing WakaTime plugin v%s' % __version__)
|
||||
|
||||
if not HAS_SSL:
|
||||
python = python_binary()
|
||||
if not python:
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
after_loaded()
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
// This settings file will be overwritten when upgrading.
|
||||
|
||||
{
|
||||
// Your api key from https://www.wakati.me/#apikey
|
||||
// Your api key from https://wakatime.com/#apikey
|
||||
// Set this in your User specific WakaTime.sublime-settings file.
|
||||
"api_key": "",
|
||||
|
||||
|
||||
4
packages/wakatime/.gitignore
vendored
4
packages/wakatime/.gitignore
vendored
@ -33,3 +33,7 @@ nosetests.xml
|
||||
.mr.developer.cfg
|
||||
.project
|
||||
.pydevproject
|
||||
|
||||
virtualenv
|
||||
venv
|
||||
.DS_Store
|
||||
|
||||
15
packages/wakatime/AUTHORS
Normal file
15
packages/wakatime/AUTHORS
Normal file
@ -0,0 +1,15 @@
|
||||
WakaTime is written and maintained by Alan Hamlett and
|
||||
various contributors:
|
||||
|
||||
|
||||
Development Lead
|
||||
----------------
|
||||
|
||||
- Alan Hamlett <alan.hamlett@gmail.com>
|
||||
|
||||
|
||||
Patches and Suggestions
|
||||
-----------------------
|
||||
|
||||
- 3onyc <3onyc@x3tech.com>
|
||||
- userid <xixico@ymail.com>
|
||||
@ -3,6 +3,166 @@ History
|
||||
-------
|
||||
|
||||
|
||||
2.1.9 (2014-12-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix bug preventing offline heartbeats from being purged after uploaded
|
||||
|
||||
|
||||
2.1.8 (2014-12-04)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix UnicodeDecodeError when building user agent string
|
||||
- handle case where response is None
|
||||
|
||||
|
||||
2.1.7 (2014-11-30)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade pygments to v2.0.1
|
||||
- always log an error when api key is incorrect
|
||||
|
||||
|
||||
2.1.6 (2014-11-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix list index error when detecting subversion project
|
||||
|
||||
|
||||
2.1.5 (2014-11-17)
|
||||
++++++++++++++++++
|
||||
|
||||
- catch exceptions when getting current machine time zone
|
||||
|
||||
|
||||
2.1.4 (2014-11-12)
|
||||
++++++++++++++++++
|
||||
|
||||
- when Python was not compiled with https support, log an error to the log file
|
||||
|
||||
|
||||
2.1.3 (2014-11-10)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly detect branch name for subversion projects
|
||||
|
||||
|
||||
2.1.2 (2014-10-07)
|
||||
++++++++++++++++++
|
||||
|
||||
- still log heartbeat when something goes wrong while reading num lines in file
|
||||
|
||||
|
||||
2.1.1 (2014-09-30)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix bug where binary file opened as utf-8
|
||||
|
||||
|
||||
2.1.0 (2014-09-30)
|
||||
++++++++++++++++++
|
||||
|
||||
- python3 compatibility changes
|
||||
|
||||
|
||||
2.0.8 (2014-08-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- supress output from svn command
|
||||
|
||||
|
||||
2.0.7 (2014-08-27)
|
||||
++++++++++++++++++
|
||||
|
||||
- find svn binary location from common install directories
|
||||
|
||||
|
||||
2.0.6 (2014-08-07)
|
||||
++++++++++++++++++
|
||||
|
||||
- encode json data as str when passing to urllib
|
||||
|
||||
|
||||
2.0.5 (2014-07-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- option in .wakatime.cfg to obfuscate file names
|
||||
|
||||
|
||||
2.0.4 (2014-07-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- use unique logger namespace to prevent collisions in shared plugin environments
|
||||
|
||||
|
||||
2.0.3 (2014-06-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- use project from command line arg when no revision control project is found
|
||||
|
||||
|
||||
2.0.2 (2014-06-09)
|
||||
++++++++++++++++++
|
||||
|
||||
- include python3.2 compatible versions of simplejson, pytz, and tzlocal
|
||||
- disable offline logging when Python was not compiled with sqlite3 module
|
||||
|
||||
|
||||
2.0.1 (2014-05-26)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix bug in queue preventing actions with NULL values from being purged
|
||||
|
||||
|
||||
2.0.0 (2014-05-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- offline time logging using sqlite3 to queue editor events
|
||||
|
||||
|
||||
1.0.2 (2014-05-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- ability to set project from command line argument
|
||||
|
||||
|
||||
1.0.1 (2014-03-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- use new domain name wakatime.com
|
||||
|
||||
|
||||
1.0.0 (2014-02-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- detect project name and branch name from mercurial revision control
|
||||
|
||||
|
||||
0.5.3 (2014-01-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- bug fix for unicode in Python3
|
||||
|
||||
|
||||
0.5.2 (2014-01-14)
|
||||
++++++++++++++++++
|
||||
|
||||
- minor bug fix for Subversion on non-English systems
|
||||
|
||||
|
||||
0.5.1 (2013-12-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- second line in .wakatime-project file now sets branch name
|
||||
|
||||
|
||||
0.5.0 (2013-12-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- Convert ~/.wakatime.conf to ~/.wakatime.cfg and use configparser format
|
||||
- new [projectmap] section in cfg file for naming projects based on folders
|
||||
|
||||
|
||||
0.4.10 (2013-11-13)
|
||||
+++++++++++++++++++
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Copyright (c) 2013 Alan Hamlett https://wakati.me
|
||||
Copyright (c) 2013 Alan Hamlett https://wakatime.com
|
||||
All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
@ -12,7 +12,7 @@ modification, are permitted provided that the following conditions are met:
|
||||
in the documentation and/or other materials provided
|
||||
with the distribution.
|
||||
|
||||
* Neither the names of Wakatime or Wakati.Me, nor the names of its
|
||||
* Neither the names of Wakatime or WakaTime, nor the names of its
|
||||
contributors may be used to endorse or promote products derived
|
||||
from this software without specific prior written permission.
|
||||
|
||||
|
||||
@ -1,12 +1,20 @@
|
||||
WakaTime
|
||||
========
|
||||
|
||||
Automatic time tracking for your text editor. This is the command line
|
||||
event appender for the WakaTime api. You shouldn't need to directly
|
||||
use this outside of a text editor plugin.
|
||||
Fully automatic time tracking for programmers.
|
||||
|
||||
This is the common interface for the WakaTime api. You shouldn't need to directly use this package unless you are creating a new plugin or your text editor's plugin asks you to install the wakatime-cli interface.
|
||||
|
||||
Go to http://wakatime.com to install the plugin for your text editor.
|
||||
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
https://www.wakati.me/help/plugins/installing-plugins
|
||||
pip install wakatime
|
||||
|
||||
|
||||
Usage
|
||||
-----
|
||||
|
||||
https://wakatime.com/
|
||||
|
||||
@ -11,13 +11,10 @@ setup(
|
||||
name='wakatime',
|
||||
version=VERSION,
|
||||
license='BSD 3 Clause',
|
||||
description=' '.join([
|
||||
'Action event appender for Wakati.Me, a time',
|
||||
'tracking api for text editors.',
|
||||
]),
|
||||
description='Interface to the WakaTime api.',
|
||||
long_description=open('README.rst').read(),
|
||||
author='Alan Hamlett',
|
||||
author_email='alan.hamlett@gmail.com',
|
||||
author_email='alan@wakatime.com',
|
||||
url='https://github.com/wakatime/wakatime',
|
||||
packages=packages,
|
||||
package_dir={'wakatime': 'wakatime'},
|
||||
@ -28,7 +25,7 @@ setup(
|
||||
'console_scripts': ['wakatime = wakatime.__init__:main'],
|
||||
},
|
||||
classifiers=(
|
||||
'Development Status :: 3 - Alpha',
|
||||
'Development Status :: 5 - Production/Stable',
|
||||
'Environment :: Console',
|
||||
'Intended Audience :: Developers',
|
||||
'License :: OSI Approved :: BSD License',
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime-cli
|
||||
~~~~~~~~~~~~
|
||||
|
||||
Action event appender for Wakati.Me, auto time tracking for text editors.
|
||||
Command-line entry point.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
|
||||
@ -3,7 +3,8 @@
|
||||
wakatime
|
||||
~~~~~~~~
|
||||
|
||||
Action event appender for Wakati.Me, auto time tracking for text editors.
|
||||
Common interface to the WakaTime api.
|
||||
http://wakatime.com
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
@ -12,10 +13,10 @@
|
||||
from __future__ import print_function
|
||||
|
||||
__title__ = 'wakatime'
|
||||
__version__ = '0.4.10'
|
||||
__version__ = '2.1.9'
|
||||
__author__ = 'Alan Hamlett'
|
||||
__license__ = 'BSD'
|
||||
__copyright__ = 'Copyright 2013 Alan Hamlett'
|
||||
__copyright__ = 'Copyright 2014 Alan Hamlett'
|
||||
|
||||
|
||||
import base64
|
||||
@ -26,23 +27,33 @@ import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
from .log import setup_logging
|
||||
from .project import find_project
|
||||
from .stats import get_file_stats
|
||||
from .packages import argparse
|
||||
from .packages import simplejson as json
|
||||
from .packages import tzlocal
|
||||
try:
|
||||
import ConfigParser as configparser
|
||||
except ImportError:
|
||||
import configparser
|
||||
try:
|
||||
from urllib2 import HTTPError, Request, urlopen
|
||||
except ImportError:
|
||||
from urllib.error import HTTPError
|
||||
from urllib.request import Request, urlopen
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
from .compat import u, open, is_py2, is_py3
|
||||
from .queue import Queue
|
||||
from .log import setup_logging
|
||||
from .project import find_project
|
||||
from .stats import get_file_stats
|
||||
from .packages import argparse
|
||||
from .packages import simplejson as json
|
||||
try:
|
||||
from .packages import tzlocal
|
||||
except:
|
||||
from .packages import tzlocal3
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class FileAction(argparse.Action):
|
||||
@ -52,45 +63,83 @@ class FileAction(argparse.Action):
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def parseConfigFile(configFile):
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.conf')
|
||||
def upgradeConfigFile(configFile):
|
||||
"""For backwards-compatibility, upgrade the existing config file
|
||||
to work with configparser and rename from .wakatime.conf to .wakatime.cfg.
|
||||
"""
|
||||
|
||||
# define default config values
|
||||
configs = {
|
||||
'api_key': None,
|
||||
'ignore': [],
|
||||
'verbose': False,
|
||||
}
|
||||
if os.path.isfile(configFile):
|
||||
# if upgraded cfg file already exists, don't overwrite it
|
||||
return
|
||||
|
||||
oldConfig = os.path.join(os.path.expanduser('~'), '.wakatime.conf')
|
||||
try:
|
||||
with open(configFile) as fh:
|
||||
for line in fh:
|
||||
configs = {
|
||||
'ignore': [],
|
||||
}
|
||||
|
||||
with open(oldConfig, 'r', encoding='utf-8') as fh:
|
||||
for line in fh.readlines():
|
||||
line = line.split('=', 1)
|
||||
if len(line) == 2 and line[0].strip() and line[1].strip():
|
||||
line[0] = line[0].strip()
|
||||
line[1] = line[1].strip()
|
||||
if line[0] in configs:
|
||||
if isinstance(configs[line[0]], list):
|
||||
configs[line[0]].append(line[1])
|
||||
elif isinstance(configs[line[0]], bool):
|
||||
configs[line[0]] = True if line[1].lower() == 'true' else False
|
||||
else:
|
||||
configs[line[0]] = line[1]
|
||||
if line[0].strip() == 'ignore':
|
||||
configs['ignore'].append(line[1].strip())
|
||||
else:
|
||||
configs[line[0]] = line[1]
|
||||
configs[line[0].strip()] = line[1].strip()
|
||||
|
||||
with open(configFile, 'w', encoding='utf-8') as fh:
|
||||
fh.write("[settings]\n")
|
||||
for name, value in configs.items():
|
||||
if isinstance(value, list):
|
||||
fh.write("%s=\n" % name)
|
||||
for item in value:
|
||||
fh.write(" %s\n" % item)
|
||||
else:
|
||||
fh.write("%s = %s\n" % (name, value))
|
||||
|
||||
os.remove(oldConfig)
|
||||
except IOError:
|
||||
print('Error: Could not read from config file ~/.wakatime.conf')
|
||||
pass
|
||||
|
||||
|
||||
def parseConfigFile(configFile):
|
||||
"""Returns a configparser.SafeConfigParser instance with configs
|
||||
read from the config file. Default location of the config file is
|
||||
at ~/.wakatime.cfg.
|
||||
"""
|
||||
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.cfg')
|
||||
|
||||
upgradeConfigFile(configFile)
|
||||
|
||||
configs = configparser.SafeConfigParser()
|
||||
try:
|
||||
with open(configFile, 'r', encoding='utf-8') as fh:
|
||||
try:
|
||||
configs.readfp(fh)
|
||||
except configparser.Error:
|
||||
print(traceback.format_exc())
|
||||
return None
|
||||
except IOError:
|
||||
print(u('Error: Could not read from config file {0}').format(u(configFile)))
|
||||
return configs
|
||||
|
||||
|
||||
def parseArguments(argv):
|
||||
"""Parse command line arguments and configs from ~/.wakatime.cfg.
|
||||
Command line arguments take precedence over config file settings.
|
||||
Returns instances of ArgumentParser and SafeConfigParser.
|
||||
"""
|
||||
|
||||
try:
|
||||
sys.argv
|
||||
except AttributeError:
|
||||
sys.argv = argv
|
||||
|
||||
# define supported command line arguments
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Wakati.Me event api appender')
|
||||
description='Common interface for the WakaTime api.')
|
||||
parser.add_argument('--file', dest='targetFile', metavar='file',
|
||||
action=FileAction, required=True,
|
||||
help='absolute path to file for current action')
|
||||
@ -104,9 +153,17 @@ def parseArguments(argv):
|
||||
parser.add_argument('--plugin', dest='plugin',
|
||||
help='optional text editor plugin name and version '+
|
||||
'for User-Agent header')
|
||||
parser.add_argument('--project', dest='project_name',
|
||||
help='optional project name; will auto-discover by default')
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakati.me api key; uses api_key from '+
|
||||
help='your wakatime api key; uses api_key from '+
|
||||
'~/.wakatime.conf by default')
|
||||
parser.add_argument('--disableoffline', dest='offline',
|
||||
action='store_false',
|
||||
help='disables offline time logging instead of queuing logged time')
|
||||
parser.add_argument('--hidefilenames', dest='hidefilenames',
|
||||
action='store_true',
|
||||
help='obfuscate file names; will not send file names to api')
|
||||
parser.add_argument('--ignore', dest='ignore', action='append',
|
||||
help='filename patterns to ignore; POSIX regex syntax; can be used more than once')
|
||||
parser.add_argument('--logfile', dest='logfile',
|
||||
@ -116,27 +173,49 @@ def parseArguments(argv):
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
help='turns on debug messages in log file')
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
|
||||
# parse command line arguments
|
||||
args = parser.parse_args(args=argv[1:])
|
||||
|
||||
# use current unix epoch timestamp by default
|
||||
if not args.timestamp:
|
||||
args.timestamp = time.time()
|
||||
|
||||
# set arguments from config file
|
||||
# parse ~/.wakatime.cfg file
|
||||
configs = parseConfigFile(args.config)
|
||||
if configs is None:
|
||||
return args, configs
|
||||
|
||||
# update args from configs
|
||||
if not args.key:
|
||||
default_key = configs.get('api_key')
|
||||
default_key = None
|
||||
if configs.has_option('settings', 'api_key'):
|
||||
default_key = configs.get('settings', 'api_key')
|
||||
if default_key:
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
for pattern in configs.get('ignore', []):
|
||||
if not args.ignore:
|
||||
args.ignore = []
|
||||
args.ignore.append(pattern)
|
||||
if not args.verbose and 'verbose' in configs:
|
||||
args.verbose = configs['verbose']
|
||||
if not args.logfile and 'logfile' in configs:
|
||||
args.logfile = configs['logfile']
|
||||
return args
|
||||
if not args.ignore:
|
||||
args.ignore = []
|
||||
if configs.has_option('settings', 'ignore'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'ignore').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.ignore.append(pattern)
|
||||
except TypeError:
|
||||
pass
|
||||
if args.offline and configs.has_option('settings', 'offline'):
|
||||
args.offline = configs.getboolean('settings', 'offline')
|
||||
if not args.hidefilenames and configs.has_option('settings', 'hidefilenames'):
|
||||
args.hidefilenames = configs.getboolean('settings', 'hidefilenames')
|
||||
if not args.verbose and configs.has_option('settings', 'verbose'):
|
||||
args.verbose = configs.getboolean('settings', 'verbose')
|
||||
if not args.verbose and configs.has_option('settings', 'debug'):
|
||||
args.verbose = configs.getboolean('settings', 'debug')
|
||||
if not args.logfile and configs.has_option('settings', 'logfile'):
|
||||
args.logfile = configs.get('settings', 'logfile')
|
||||
|
||||
return args, configs
|
||||
|
||||
|
||||
def should_ignore(fileName, patterns):
|
||||
@ -147,7 +226,10 @@ def should_ignore(fileName, patterns):
|
||||
if compiled.search(fileName):
|
||||
return pattern
|
||||
except re.error as ex:
|
||||
log.warning('Regex error (%s) for ignore pattern: %s' % (str(ex), pattern))
|
||||
log.warning(u('Regex error ({msg}) for ignore pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
pass
|
||||
return False
|
||||
@ -156,21 +238,34 @@ def should_ignore(fileName, patterns):
|
||||
def get_user_agent(plugin):
|
||||
ver = sys.version_info
|
||||
python_version = '%d.%d.%d.%s.%d' % (ver[0], ver[1], ver[2], ver[3], ver[4])
|
||||
user_agent = 'wakatime/%s (%s) Python%s' % (__version__,
|
||||
platform.platform(), python_version)
|
||||
user_agent = u('wakatime/{ver} ({platform}) Python{py_ver}').format(
|
||||
ver=u(__version__),
|
||||
platform=u(platform.platform()),
|
||||
py_ver=python_version,
|
||||
)
|
||||
if plugin:
|
||||
user_agent = user_agent+' '+plugin
|
||||
user_agent = u('{user_agent} {plugin}').format(
|
||||
user_agent=user_agent,
|
||||
plugin=u(plugin),
|
||||
)
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_action(project=None, branch=None, stats={}, key=None, targetFile=None,
|
||||
timestamp=None, isWrite=None, plugin=None, **kwargs):
|
||||
url = 'https://www.wakati.me/api/v1/actions'
|
||||
log.debug('Sending action to api at %s' % url)
|
||||
def send_action(project=None, branch=None, stats=None, key=None, targetFile=None,
|
||||
timestamp=None, isWrite=None, plugin=None, offline=None,
|
||||
hidefilenames=None, **kwargs):
|
||||
url = 'https://wakatime.com/api/v1/actions'
|
||||
log.debug('Sending heartbeat to api at %s' % url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'file': targetFile,
|
||||
}
|
||||
if hidefilenames and targetFile is not None:
|
||||
data['file'] = data['file'].rsplit('/', 1)[-1].rsplit('\\', 1)[-1]
|
||||
if len(data['file'].strip('.').split('.', 1)) > 1:
|
||||
data['file'] = u('HIDDEN.{ext}').format(ext=u(data['file'].strip('.').rsplit('.', 1)[-1]))
|
||||
else:
|
||||
data['file'] = u('HIDDEN')
|
||||
if stats.get('lines'):
|
||||
data['lines'] = stats['lines']
|
||||
if stats.get('language'):
|
||||
@ -184,16 +279,24 @@ def send_action(project=None, branch=None, stats={}, key=None, targetFile=None,
|
||||
log.debug(data)
|
||||
|
||||
# setup api request
|
||||
request = Request(url=url, data=str.encode(json.dumps(data)))
|
||||
request_body = json.dumps(data)
|
||||
request = Request(url=url, data=str.encode(request_body) if is_py3 else request_body)
|
||||
request.add_header('User-Agent', get_user_agent(plugin))
|
||||
request.add_header('Content-Type', 'application/json')
|
||||
auth = 'Basic %s' % bytes.decode(base64.b64encode(str.encode(key)))
|
||||
auth = u('Basic {key}').format(key=u(base64.b64encode(str.encode(key) if is_py3 else key)))
|
||||
request.add_header('Authorization', auth)
|
||||
|
||||
ALWAYS_LOG_CODES = [
|
||||
401,
|
||||
]
|
||||
|
||||
# add Olson timezone to request
|
||||
tz = tzlocal.get_localzone()
|
||||
try:
|
||||
tz = tzlocal.get_localzone()
|
||||
except:
|
||||
tz = None
|
||||
if tz:
|
||||
request.add_header('TimeZone', str(tz.zone))
|
||||
request.add_header('TimeZone', u(tz.zone))
|
||||
|
||||
# log time to api
|
||||
response = None
|
||||
@ -202,56 +305,123 @@ def send_action(project=None, branch=None, stats={}, key=None, targetFile=None,
|
||||
except HTTPError as exc:
|
||||
exception_data = {
|
||||
'response_code': exc.getcode(),
|
||||
sys.exc_info()[0].__name__: str(sys.exc_info()[1]),
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
}
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
exception_data['traceback'] = traceback.format_exc()
|
||||
log.error(exception_data)
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, plugin)
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
log.warn(exception_data)
|
||||
if response is not None and response.getcode() in ALWAYS_LOG_CODES:
|
||||
log.error({
|
||||
'response_code': response.getcode(),
|
||||
})
|
||||
else:
|
||||
log.error(exception_data)
|
||||
except:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: str(sys.exc_info()[1]),
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
}
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
exception_data['traceback'] = traceback.format_exc()
|
||||
log.error(exception_data)
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, plugin)
|
||||
if 'unknown url type: https' in u(sys.exc_info()[1]):
|
||||
log.error(exception_data)
|
||||
elif log.isEnabledFor(logging.DEBUG):
|
||||
log.warn(exception_data)
|
||||
if response is not None and response.getcode() in ALWAYS_LOG_CODES:
|
||||
log.error({
|
||||
'response_code': response.getcode(),
|
||||
})
|
||||
else:
|
||||
log.error(exception_data)
|
||||
else:
|
||||
if response.getcode() == 201:
|
||||
if response is not None and response.getcode() == 201:
|
||||
log.debug({
|
||||
'response_code': response.getcode(),
|
||||
})
|
||||
return True
|
||||
log.error({
|
||||
'response_code': response.getcode(),
|
||||
'response_content': response.read(),
|
||||
})
|
||||
response_code = response.getcode() if response is not None else None
|
||||
response_content = response.read() if response is not None else None
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, plugin)
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
log.warn({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
return False
|
||||
|
||||
|
||||
def main(argv=None):
|
||||
if not argv:
|
||||
argv = sys.argv
|
||||
args = parseArguments(argv)
|
||||
|
||||
args, configs = parseArguments(argv)
|
||||
if configs is None:
|
||||
return 103 # config file parsing error
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
ignore = should_ignore(args.targetFile, args.ignore)
|
||||
if ignore is not False:
|
||||
log.debug('File ignored because matches pattern: %s' % ignore)
|
||||
log.debug(u('File ignored because matches pattern: {pattern}').format(
|
||||
pattern=u(ignore),
|
||||
))
|
||||
return 0
|
||||
|
||||
if os.path.isfile(args.targetFile):
|
||||
branch = None
|
||||
name = None
|
||||
|
||||
stats = get_file_stats(args.targetFile)
|
||||
project = find_project(args.targetFile)
|
||||
|
||||
project = find_project(args.targetFile, configs=configs)
|
||||
branch = None
|
||||
project_name = args.project_name
|
||||
if project:
|
||||
branch = project.branch()
|
||||
name = project.name()
|
||||
project_name = project.name()
|
||||
|
||||
if send_action(
|
||||
project=name,
|
||||
project=project_name,
|
||||
branch=branch,
|
||||
stats=stats,
|
||||
**vars(args)
|
||||
):
|
||||
return 0
|
||||
return 102
|
||||
queue = Queue()
|
||||
while True:
|
||||
action = queue.pop()
|
||||
if action is None:
|
||||
break
|
||||
sent = send_action(project=action['project'],
|
||||
targetFile=action['file'],
|
||||
timestamp=action['time'],
|
||||
branch=action['branch'],
|
||||
stats={'language': action['language'], 'lines': action['lines']},
|
||||
key=args.key, isWrite=action['is_write'],
|
||||
plugin=action['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames)
|
||||
if not sent:
|
||||
break
|
||||
return 0 # success
|
||||
|
||||
return 102 # api error
|
||||
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this action.')
|
||||
return 101
|
||||
return 0
|
||||
|
||||
42
packages/wakatime/wakatime/compat.py
Normal file
42
packages/wakatime/wakatime/compat.py
Normal file
@ -0,0 +1,42 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.compat
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
For working with Python2 and Python3.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import codecs
|
||||
import io
|
||||
import sys
|
||||
|
||||
|
||||
is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
|
||||
if is_py2:
|
||||
|
||||
def u(text):
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
open = codecs.open
|
||||
basestring = basestring
|
||||
|
||||
|
||||
elif is_py3:
|
||||
|
||||
def u(text):
|
||||
if isinstance(text, bytes):
|
||||
return text.decode('utf-8')
|
||||
return str(text)
|
||||
open = open
|
||||
basestring = (str, bytes)
|
||||
@ -11,8 +11,10 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
||||
from .packages import simplejson as json
|
||||
from .compat import u
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
@ -25,7 +27,13 @@ class CustomEncoder(json.JSONEncoder):
|
||||
if isinstance(obj, bytes):
|
||||
obj = bytes.decode(obj)
|
||||
return json.dumps(obj)
|
||||
return super(CustomEncoder, self).default(obj)
|
||||
try:
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError:
|
||||
encoding = sys.getfilesystemencoding()
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
@ -66,10 +74,10 @@ def set_log_level(logger, args):
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
logger = logging.getLogger()
|
||||
logger = logging.getLogger('WakaTime')
|
||||
set_log_level(logger, args)
|
||||
if len(logger.handlers) > 0:
|
||||
formatter = JsonFormatter(datefmt='%a %b %d %H:%M:%S %Z %Y')
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
@ -83,7 +91,7 @@ def setup_logging(args, version):
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
handler = logging.FileHandler(os.path.expanduser(logfile))
|
||||
formatter = JsonFormatter(datefmt='%a %b %d %H:%M:%S %Z %Y')
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
|
||||
@ -1,68 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Pygments formatters.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
import os.path
|
||||
import fnmatch
|
||||
|
||||
from pygments.formatters._mapping import FORMATTERS
|
||||
from pygments.plugin import find_plugin_formatters
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
ns = globals()
|
||||
for fcls in FORMATTERS:
|
||||
ns[fcls.__name__] = fcls
|
||||
del fcls
|
||||
|
||||
__all__ = ['get_formatter_by_name', 'get_formatter_for_filename',
|
||||
'get_all_formatters'] + [cls.__name__ for cls in FORMATTERS]
|
||||
|
||||
|
||||
_formatter_alias_cache = {}
|
||||
_formatter_filename_cache = []
|
||||
|
||||
def _init_formatter_cache():
|
||||
if _formatter_alias_cache:
|
||||
return
|
||||
for cls in get_all_formatters():
|
||||
for alias in cls.aliases:
|
||||
_formatter_alias_cache[alias] = cls
|
||||
for fn in cls.filenames:
|
||||
_formatter_filename_cache.append((fn, cls))
|
||||
|
||||
|
||||
def find_formatter_class(name):
|
||||
_init_formatter_cache()
|
||||
cls = _formatter_alias_cache.get(name, None)
|
||||
return cls
|
||||
|
||||
|
||||
def get_formatter_by_name(name, **options):
|
||||
_init_formatter_cache()
|
||||
cls = _formatter_alias_cache.get(name, None)
|
||||
if not cls:
|
||||
raise ClassNotFound("No formatter found for name %r" % name)
|
||||
return cls(**options)
|
||||
|
||||
|
||||
def get_formatter_for_filename(fn, **options):
|
||||
_init_formatter_cache()
|
||||
fn = os.path.basename(fn)
|
||||
for pattern, cls in _formatter_filename_cache:
|
||||
if fnmatch.fnmatch(fn, pattern):
|
||||
return cls(**options)
|
||||
raise ClassNotFound("No formatter found for file name %r" % fn)
|
||||
|
||||
|
||||
def get_all_formatters():
|
||||
"""Return a generator for all formatters."""
|
||||
for formatter in FORMATTERS:
|
||||
yield formatter
|
||||
for _, formatter in find_plugin_formatters():
|
||||
yield formatter
|
||||
@ -1,92 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter mapping defintions. This file is generated by itself. Everytime
|
||||
you change something on a builtin formatter defintion, run this script from
|
||||
the formatters folder to update it.
|
||||
|
||||
Do not alter the FORMATTERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
# start
|
||||
from pygments.formatters.bbcode import BBCodeFormatter
|
||||
from pygments.formatters.html import HtmlFormatter
|
||||
from pygments.formatters.img import BmpImageFormatter
|
||||
from pygments.formatters.img import GifImageFormatter
|
||||
from pygments.formatters.img import ImageFormatter
|
||||
from pygments.formatters.img import JpgImageFormatter
|
||||
from pygments.formatters.latex import LatexFormatter
|
||||
from pygments.formatters.other import NullFormatter
|
||||
from pygments.formatters.other import RawTokenFormatter
|
||||
from pygments.formatters.rtf import RtfFormatter
|
||||
from pygments.formatters.svg import SvgFormatter
|
||||
from pygments.formatters.terminal import TerminalFormatter
|
||||
from pygments.formatters.terminal256 import Terminal256Formatter
|
||||
|
||||
FORMATTERS = {
|
||||
BBCodeFormatter: ('BBCode', ('bbcode', 'bb'), (), 'Format tokens with BBcodes. These formatting codes are used by many bulletin boards, so you can highlight your sourcecode with pygments before posting it there.'),
|
||||
BmpImageFormatter: ('img_bmp', ('bmp', 'bitmap'), ('*.bmp',), 'Create a bitmap image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
GifImageFormatter: ('img_gif', ('gif',), ('*.gif',), 'Create a GIF image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
HtmlFormatter: ('HTML', ('html',), ('*.html', '*.htm'), "Format tokens as HTML 4 ``<span>`` tags within a ``<pre>`` tag, wrapped in a ``<div>`` tag. The ``<div>``'s CSS class can be set by the `cssclass` option."),
|
||||
ImageFormatter: ('img', ('img', 'IMG', 'png'), ('*.png',), 'Create a PNG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
JpgImageFormatter: ('img_jpg', ('jpg', 'jpeg'), ('*.jpg',), 'Create a JPEG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
LatexFormatter: ('LaTeX', ('latex', 'tex'), ('*.tex',), 'Format tokens as LaTeX code. This needs the `fancyvrb` and `color` standard packages.'),
|
||||
NullFormatter: ('Text only', ('text', 'null'), ('*.txt',), 'Output the text unchanged without any formatting.'),
|
||||
RawTokenFormatter: ('Raw tokens', ('raw', 'tokens'), ('*.raw',), 'Format tokens as a raw representation for storing token streams.'),
|
||||
RtfFormatter: ('RTF', ('rtf',), ('*.rtf',), 'Format tokens as RTF markup. This formatter automatically outputs full RTF documents with color information and other useful stuff. Perfect for Copy and Paste into Microsoft\xc2\xae Word\xc2\xae documents.'),
|
||||
SvgFormatter: ('SVG', ('svg',), ('*.svg',), 'Format tokens as an SVG graphics file. This formatter is still experimental. Each line of code is a ``<text>`` element with explicit ``x`` and ``y`` coordinates containing ``<tspan>`` elements with the individual token styles.'),
|
||||
Terminal256Formatter: ('Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
TerminalFormatter: ('Terminal', ('terminal', 'console'), (), 'Format tokens with ANSI color sequences, for output in a text console. Color sequences are terminated at newlines, so that paging the output works correctly.')
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup formatters
|
||||
found_formatters = []
|
||||
imports = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
from pygments.util import docstring_headline
|
||||
|
||||
for filename in os.listdir('.'):
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.formatters.%s' % filename[:-3]
|
||||
print module_name
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for formatter_name in module.__all__:
|
||||
imports.append((module_name, formatter_name))
|
||||
formatter = getattr(module, formatter_name)
|
||||
found_formatters.append(
|
||||
'%s: %r' % (formatter_name,
|
||||
(formatter.name,
|
||||
tuple(formatter.aliases),
|
||||
tuple(formatter.filenames),
|
||||
docstring_headline(formatter))))
|
||||
# sort them, that should make the diff files for svn smaller
|
||||
found_formatters.sort()
|
||||
imports.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
f = open(__file__)
|
||||
try:
|
||||
content = f.read()
|
||||
finally:
|
||||
f.close()
|
||||
header = content[:content.find('# start')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
f = open(__file__, 'w')
|
||||
f.write(header)
|
||||
f.write('# start\n')
|
||||
f.write('\n'.join(['from %s import %s' % imp for imp in imports]))
|
||||
f.write('\n\n')
|
||||
f.write('FORMATTERS = {\n %s\n}\n\n' % ',\n '.join(found_formatters))
|
||||
f.write(footer)
|
||||
f.close()
|
||||
@ -1,350 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer mapping defintions. This file is generated by itself. Everytime
|
||||
you change something on a builtin lexer defintion, run this script from
|
||||
the lexers folder to update it.
|
||||
|
||||
Do not alter the LEXERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
LEXERS = {
|
||||
'ABAPLexer': ('pygments.lexers.other', 'ABAP', ('abap',), ('*.abap',), ('text/x-abap',)),
|
||||
'ActionScript3Lexer': ('pygments.lexers.web', 'ActionScript 3', ('as3', 'actionscript3'), ('*.as',), ('application/x-actionscript', 'text/x-actionscript', 'text/actionscript')),
|
||||
'ActionScriptLexer': ('pygments.lexers.web', 'ActionScript', ('as', 'actionscript'), ('*.as',), ('application/x-actionscript3', 'text/x-actionscript3', 'text/actionscript3')),
|
||||
'AdaLexer': ('pygments.lexers.compiled', 'Ada', ('ada', 'ada95ada2005'), ('*.adb', '*.ads', '*.ada'), ('text/x-ada',)),
|
||||
'AgdaLexer': ('pygments.lexers.functional', 'Agda', ('agda',), ('*.agda',), ('text/x-agda',)),
|
||||
'AntlrActionScriptLexer': ('pygments.lexers.parsers', 'ANTLR With ActionScript Target', ('antlr-as', 'antlr-actionscript'), ('*.G', '*.g'), ()),
|
||||
'AntlrCSharpLexer': ('pygments.lexers.parsers', 'ANTLR With C# Target', ('antlr-csharp', 'antlr-c#'), ('*.G', '*.g'), ()),
|
||||
'AntlrCppLexer': ('pygments.lexers.parsers', 'ANTLR With CPP Target', ('antlr-cpp',), ('*.G', '*.g'), ()),
|
||||
'AntlrJavaLexer': ('pygments.lexers.parsers', 'ANTLR With Java Target', ('antlr-java',), ('*.G', '*.g'), ()),
|
||||
'AntlrLexer': ('pygments.lexers.parsers', 'ANTLR', ('antlr',), (), ()),
|
||||
'AntlrObjectiveCLexer': ('pygments.lexers.parsers', 'ANTLR With ObjectiveC Target', ('antlr-objc',), ('*.G', '*.g'), ()),
|
||||
'AntlrPerlLexer': ('pygments.lexers.parsers', 'ANTLR With Perl Target', ('antlr-perl',), ('*.G', '*.g'), ()),
|
||||
'AntlrPythonLexer': ('pygments.lexers.parsers', 'ANTLR With Python Target', ('antlr-python',), ('*.G', '*.g'), ()),
|
||||
'AntlrRubyLexer': ('pygments.lexers.parsers', 'ANTLR With Ruby Target', ('antlr-ruby', 'antlr-rb'), ('*.G', '*.g'), ()),
|
||||
'ApacheConfLexer': ('pygments.lexers.text', 'ApacheConf', ('apacheconf', 'aconf', 'apache'), ('.htaccess', 'apache.conf', 'apache2.conf'), ('text/x-apacheconf',)),
|
||||
'AppleScriptLexer': ('pygments.lexers.other', 'AppleScript', ('applescript',), ('*.applescript',), ()),
|
||||
'AspectJLexer': ('pygments.lexers.jvm', 'AspectJ', ('aspectj',), ('*.aj',), ('text/x-aspectj',)),
|
||||
'AsymptoteLexer': ('pygments.lexers.other', 'Asymptote', ('asy', 'asymptote'), ('*.asy',), ('text/x-asymptote',)),
|
||||
'AutoItLexer': ('pygments.lexers.other', 'AutoIt', ('autoit', 'Autoit'), ('*.au3',), ('text/x-autoit',)),
|
||||
'AutohotkeyLexer': ('pygments.lexers.other', 'autohotkey', ('ahk', 'autohotkey'), ('*.ahk', '*.ahkl'), ('text/x-autohotkey',)),
|
||||
'AwkLexer': ('pygments.lexers.other', 'Awk', ('awk', 'gawk', 'mawk', 'nawk'), ('*.awk',), ('application/x-awk',)),
|
||||
'BBCodeLexer': ('pygments.lexers.text', 'BBCode', ('bbcode',), (), ('text/x-bbcode',)),
|
||||
'BaseMakefileLexer': ('pygments.lexers.text', 'Base Makefile', ('basemake',), (), ()),
|
||||
'BashLexer': ('pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '.bashrc', 'bashrc', '.bash_*', 'bash_*'), ('application/x-sh', 'application/x-shellscript')),
|
||||
'BashSessionLexer': ('pygments.lexers.shell', 'Bash Session', ('console',), ('*.sh-session',), ('application/x-shell-session',)),
|
||||
'BatchLexer': ('pygments.lexers.shell', 'Batchfile', ('bat', 'dosbatch', 'winbatch'), ('*.bat', '*.cmd'), ('application/x-dos-batch',)),
|
||||
'BefungeLexer': ('pygments.lexers.other', 'Befunge', ('befunge',), ('*.befunge',), ('application/x-befunge',)),
|
||||
'BlitzBasicLexer': ('pygments.lexers.compiled', 'BlitzBasic', ('blitzbasic', 'b3d', 'bplus'), ('*.bb', '*.decls'), ('text/x-bb',)),
|
||||
'BlitzMaxLexer': ('pygments.lexers.compiled', 'BlitzMax', ('blitzmax', 'bmax'), ('*.bmx',), ('text/x-bmx',)),
|
||||
'BooLexer': ('pygments.lexers.dotnet', 'Boo', ('boo',), ('*.boo',), ('text/x-boo',)),
|
||||
'BrainfuckLexer': ('pygments.lexers.other', 'Brainfuck', ('brainfuck', 'bf'), ('*.bf', '*.b'), ('application/x-brainfuck',)),
|
||||
'BroLexer': ('pygments.lexers.other', 'Bro', ('bro',), ('*.bro',), ()),
|
||||
'BugsLexer': ('pygments.lexers.math', 'BUGS', ('bugs', 'winbugs', 'openbugs'), ('*.bug',), ()),
|
||||
'CLexer': ('pygments.lexers.compiled', 'C', ('c',), ('*.c', '*.h', '*.idc'), ('text/x-chdr', 'text/x-csrc')),
|
||||
'CMakeLexer': ('pygments.lexers.text', 'CMake', ('cmake',), ('*.cmake', 'CMakeLists.txt'), ('text/x-cmake',)),
|
||||
'CObjdumpLexer': ('pygments.lexers.asm', 'c-objdump', ('c-objdump',), ('*.c-objdump',), ('text/x-c-objdump',)),
|
||||
'CSharpAspxLexer': ('pygments.lexers.dotnet', 'aspx-cs', ('aspx-cs',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'CSharpLexer': ('pygments.lexers.dotnet', 'C#', ('csharp', 'c#'), ('*.cs',), ('text/x-csharp',)),
|
||||
'Ca65Lexer': ('pygments.lexers.asm', 'ca65', ('ca65',), ('*.s',), ()),
|
||||
'CbmBasicV2Lexer': ('pygments.lexers.other', 'CBM BASIC V2', ('cbmbas',), ('*.bas',), ()),
|
||||
'CeylonLexer': ('pygments.lexers.jvm', 'Ceylon', ('ceylon',), ('*.ceylon',), ('text/x-ceylon',)),
|
||||
'Cfengine3Lexer': ('pygments.lexers.other', 'CFEngine3', ('cfengine3', 'cf3'), ('*.cf',), ()),
|
||||
'CheetahHtmlLexer': ('pygments.lexers.templates', 'HTML+Cheetah', ('html+cheetah', 'html+spitfire', 'htmlcheetah'), (), ('text/html+cheetah', 'text/html+spitfire')),
|
||||
'CheetahJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Cheetah', ('js+cheetah', 'javascript+cheetah', 'js+spitfire', 'javascript+spitfire'), (), ('application/x-javascript+cheetah', 'text/x-javascript+cheetah', 'text/javascript+cheetah', 'application/x-javascript+spitfire', 'text/x-javascript+spitfire', 'text/javascript+spitfire')),
|
||||
'CheetahLexer': ('pygments.lexers.templates', 'Cheetah', ('cheetah', 'spitfire'), ('*.tmpl', '*.spt'), ('application/x-cheetah', 'application/x-spitfire')),
|
||||
'CheetahXmlLexer': ('pygments.lexers.templates', 'XML+Cheetah', ('xml+cheetah', 'xml+spitfire'), (), ('application/xml+cheetah', 'application/xml+spitfire')),
|
||||
'ClayLexer': ('pygments.lexers.compiled', 'Clay', ('clay',), ('*.clay',), ('text/x-clay',)),
|
||||
'ClojureLexer': ('pygments.lexers.jvm', 'Clojure', ('clojure', 'clj'), ('*.clj',), ('text/x-clojure', 'application/x-clojure')),
|
||||
'CobolFreeformatLexer': ('pygments.lexers.compiled', 'COBOLFree', ('cobolfree',), ('*.cbl', '*.CBL'), ()),
|
||||
'CobolLexer': ('pygments.lexers.compiled', 'COBOL', ('cobol',), ('*.cob', '*.COB', '*.cpy', '*.CPY'), ('text/x-cobol',)),
|
||||
'CoffeeScriptLexer': ('pygments.lexers.web', 'CoffeeScript', ('coffee-script', 'coffeescript', 'coffee'), ('*.coffee',), ('text/coffeescript',)),
|
||||
'ColdfusionHtmlLexer': ('pygments.lexers.templates', 'Coldfusion HTML', ('cfm',), ('*.cfm', '*.cfml', '*.cfc'), ('application/x-coldfusion',)),
|
||||
'ColdfusionLexer': ('pygments.lexers.templates', 'cfstatement', ('cfs',), (), ()),
|
||||
'CommonLispLexer': ('pygments.lexers.functional', 'Common Lisp', ('common-lisp', 'cl', 'lisp'), ('*.cl', '*.lisp', '*.el'), ('text/x-common-lisp',)),
|
||||
'CoqLexer': ('pygments.lexers.functional', 'Coq', ('coq',), ('*.v',), ('text/x-coq',)),
|
||||
'CppLexer': ('pygments.lexers.compiled', 'C++', ('cpp', 'c++'), ('*.cpp', '*.hpp', '*.c++', '*.h++', '*.cc', '*.hh', '*.cxx', '*.hxx', '*.C', '*.H', '*.cp', '*.CPP'), ('text/x-c++hdr', 'text/x-c++src')),
|
||||
'CppObjdumpLexer': ('pygments.lexers.asm', 'cpp-objdump', ('cpp-objdump', 'c++-objdumb', 'cxx-objdump'), ('*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump'), ('text/x-cpp-objdump',)),
|
||||
'CrocLexer': ('pygments.lexers.agile', 'Croc', ('croc',), ('*.croc',), ('text/x-crocsrc',)),
|
||||
'CssDjangoLexer': ('pygments.lexers.templates', 'CSS+Django/Jinja', ('css+django', 'css+jinja'), (), ('text/css+django', 'text/css+jinja')),
|
||||
'CssErbLexer': ('pygments.lexers.templates', 'CSS+Ruby', ('css+erb', 'css+ruby'), (), ('text/css+ruby',)),
|
||||
'CssGenshiLexer': ('pygments.lexers.templates', 'CSS+Genshi Text', ('css+genshitext', 'css+genshi'), (), ('text/css+genshi',)),
|
||||
'CssLexer': ('pygments.lexers.web', 'CSS', ('css',), ('*.css',), ('text/css',)),
|
||||
'CssPhpLexer': ('pygments.lexers.templates', 'CSS+PHP', ('css+php',), (), ('text/css+php',)),
|
||||
'CssSmartyLexer': ('pygments.lexers.templates', 'CSS+Smarty', ('css+smarty',), (), ('text/css+smarty',)),
|
||||
'CudaLexer': ('pygments.lexers.compiled', 'CUDA', ('cuda', 'cu'), ('*.cu', '*.cuh'), ('text/x-cuda',)),
|
||||
'CythonLexer': ('pygments.lexers.compiled', 'Cython', ('cython', 'pyx', 'pyrex'), ('*.pyx', '*.pxd', '*.pxi'), ('text/x-cython', 'application/x-cython')),
|
||||
'DLexer': ('pygments.lexers.compiled', 'D', ('d',), ('*.d', '*.di'), ('text/x-dsrc',)),
|
||||
'DObjdumpLexer': ('pygments.lexers.asm', 'd-objdump', ('d-objdump',), ('*.d-objdump',), ('text/x-d-objdump',)),
|
||||
'DarcsPatchLexer': ('pygments.lexers.text', 'Darcs Patch', ('dpatch',), ('*.dpatch', '*.darcspatch'), ()),
|
||||
'DartLexer': ('pygments.lexers.web', 'Dart', ('dart',), ('*.dart',), ('text/x-dart',)),
|
||||
'DebianControlLexer': ('pygments.lexers.text', 'Debian Control file', ('control', 'debcontrol'), ('control',), ()),
|
||||
'DelphiLexer': ('pygments.lexers.compiled', 'Delphi', ('delphi', 'pas', 'pascal', 'objectpascal'), ('*.pas',), ('text/x-pascal',)),
|
||||
'DgLexer': ('pygments.lexers.agile', 'dg', ('dg',), ('*.dg',), ('text/x-dg',)),
|
||||
'DiffLexer': ('pygments.lexers.text', 'Diff', ('diff', 'udiff'), ('*.diff', '*.patch'), ('text/x-diff', 'text/x-patch')),
|
||||
'DjangoLexer': ('pygments.lexers.templates', 'Django/Jinja', ('django', 'jinja'), (), ('application/x-django-templating', 'application/x-jinja')),
|
||||
'DtdLexer': ('pygments.lexers.web', 'DTD', ('dtd',), ('*.dtd',), ('application/xml-dtd',)),
|
||||
'DuelLexer': ('pygments.lexers.web', 'Duel', ('duel', 'Duel Engine', 'Duel View', 'JBST', 'jbst', 'JsonML+BST'), ('*.duel', '*.jbst'), ('text/x-duel', 'text/x-jbst')),
|
||||
'DylanConsoleLexer': ('pygments.lexers.compiled', 'Dylan session', ('dylan-console', 'dylan-repl'), ('*.dylan-console',), ('text/x-dylan-console',)),
|
||||
'DylanLexer': ('pygments.lexers.compiled', 'Dylan', ('dylan',), ('*.dylan', '*.dyl', '*.intr'), ('text/x-dylan',)),
|
||||
'DylanLidLexer': ('pygments.lexers.compiled', 'DylanLID', ('dylan-lid', 'lid'), ('*.lid', '*.hdp'), ('text/x-dylan-lid',)),
|
||||
'ECLLexer': ('pygments.lexers.other', 'ECL', ('ecl',), ('*.ecl',), ('application/x-ecl',)),
|
||||
'ECLexer': ('pygments.lexers.compiled', 'eC', ('ec',), ('*.ec', '*.eh'), ('text/x-echdr', 'text/x-ecsrc')),
|
||||
'EbnfLexer': ('pygments.lexers.text', 'EBNF', ('ebnf',), ('*.ebnf',), ('text/x-ebnf',)),
|
||||
'ElixirConsoleLexer': ('pygments.lexers.functional', 'Elixir iex session', ('iex',), (), ('text/x-elixir-shellsession',)),
|
||||
'ElixirLexer': ('pygments.lexers.functional', 'Elixir', ('elixir', 'ex', 'exs'), ('*.ex', '*.exs'), ('text/x-elixir',)),
|
||||
'ErbLexer': ('pygments.lexers.templates', 'ERB', ('erb',), (), ('application/x-ruby-templating',)),
|
||||
'ErlangLexer': ('pygments.lexers.functional', 'Erlang', ('erlang',), ('*.erl', '*.hrl', '*.es', '*.escript'), ('text/x-erlang',)),
|
||||
'ErlangShellLexer': ('pygments.lexers.functional', 'Erlang erl session', ('erl',), ('*.erl-sh',), ('text/x-erl-shellsession',)),
|
||||
'EvoqueHtmlLexer': ('pygments.lexers.templates', 'HTML+Evoque', ('html+evoque',), ('*.html',), ('text/html+evoque',)),
|
||||
'EvoqueLexer': ('pygments.lexers.templates', 'Evoque', ('evoque',), ('*.evoque',), ('application/x-evoque',)),
|
||||
'EvoqueXmlLexer': ('pygments.lexers.templates', 'XML+Evoque', ('xml+evoque',), ('*.xml',), ('application/xml+evoque',)),
|
||||
'FSharpLexer': ('pygments.lexers.dotnet', 'FSharp', ('fsharp',), ('*.fs', '*.fsi'), ('text/x-fsharp',)),
|
||||
'FactorLexer': ('pygments.lexers.agile', 'Factor', ('factor',), ('*.factor',), ('text/x-factor',)),
|
||||
'FancyLexer': ('pygments.lexers.agile', 'Fancy', ('fancy', 'fy'), ('*.fy', '*.fancypack'), ('text/x-fancysrc',)),
|
||||
'FantomLexer': ('pygments.lexers.compiled', 'Fantom', ('fan',), ('*.fan',), ('application/x-fantom',)),
|
||||
'FelixLexer': ('pygments.lexers.compiled', 'Felix', ('felix', 'flx'), ('*.flx', '*.flxh'), ('text/x-felix',)),
|
||||
'FortranLexer': ('pygments.lexers.compiled', 'Fortran', ('fortran',), ('*.f', '*.f90', '*.F', '*.F90'), ('text/x-fortran',)),
|
||||
'FoxProLexer': ('pygments.lexers.foxpro', 'FoxPro', ('Clipper', 'XBase'), ('*.PRG', '*.prg'), ()),
|
||||
'GLShaderLexer': ('pygments.lexers.compiled', 'GLSL', ('glsl',), ('*.vert', '*.frag', '*.geo'), ('text/x-glslsrc',)),
|
||||
'GasLexer': ('pygments.lexers.asm', 'GAS', ('gas', 'asm'), ('*.s', '*.S'), ('text/x-gas',)),
|
||||
'GenshiLexer': ('pygments.lexers.templates', 'Genshi', ('genshi', 'kid', 'xml+genshi', 'xml+kid'), ('*.kid',), ('application/x-genshi', 'application/x-kid')),
|
||||
'GenshiTextLexer': ('pygments.lexers.templates', 'Genshi Text', ('genshitext',), (), ('application/x-genshi-text', 'text/x-genshi')),
|
||||
'GettextLexer': ('pygments.lexers.text', 'Gettext Catalog', ('pot', 'po'), ('*.pot', '*.po'), ('application/x-gettext', 'text/x-gettext', 'text/gettext')),
|
||||
'GherkinLexer': ('pygments.lexers.other', 'Gherkin', ('Cucumber', 'cucumber', 'Gherkin', 'gherkin'), ('*.feature',), ('text/x-gherkin',)),
|
||||
'GnuplotLexer': ('pygments.lexers.other', 'Gnuplot', ('gnuplot',), ('*.plot', '*.plt'), ('text/x-gnuplot',)),
|
||||
'GoLexer': ('pygments.lexers.compiled', 'Go', ('go',), ('*.go',), ('text/x-gosrc',)),
|
||||
'GoodDataCLLexer': ('pygments.lexers.other', 'GoodData-CL', ('gooddata-cl',), ('*.gdc',), ('text/x-gooddata-cl',)),
|
||||
'GosuLexer': ('pygments.lexers.jvm', 'Gosu', ('gosu',), ('*.gs', '*.gsx', '*.gsp', '*.vark'), ('text/x-gosu',)),
|
||||
'GosuTemplateLexer': ('pygments.lexers.jvm', 'Gosu Template', ('gst',), ('*.gst',), ('text/x-gosu-template',)),
|
||||
'GroffLexer': ('pygments.lexers.text', 'Groff', ('groff', 'nroff', 'man'), ('*.[1234567]', '*.man'), ('application/x-troff', 'text/troff')),
|
||||
'GroovyLexer': ('pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy',), ('text/x-groovy',)),
|
||||
'HamlLexer': ('pygments.lexers.web', 'Haml', ('haml', 'HAML'), ('*.haml',), ('text/x-haml',)),
|
||||
'HaskellLexer': ('pygments.lexers.functional', 'Haskell', ('haskell', 'hs'), ('*.hs',), ('text/x-haskell',)),
|
||||
'HaxeLexer': ('pygments.lexers.web', 'Haxe', ('hx', 'Haxe', 'haxe', 'haXe', 'hxsl'), ('*.hx', '*.hxsl'), ('text/haxe', 'text/x-haxe', 'text/x-hx')),
|
||||
'HtmlDjangoLexer': ('pygments.lexers.templates', 'HTML+Django/Jinja', ('html+django', 'html+jinja', 'htmldjango'), (), ('text/html+django', 'text/html+jinja')),
|
||||
'HtmlGenshiLexer': ('pygments.lexers.templates', 'HTML+Genshi', ('html+genshi', 'html+kid'), (), ('text/html+genshi',)),
|
||||
'HtmlLexer': ('pygments.lexers.web', 'HTML', ('html',), ('*.html', '*.htm', '*.xhtml', '*.xslt'), ('text/html', 'application/xhtml+xml')),
|
||||
'HtmlPhpLexer': ('pygments.lexers.templates', 'HTML+PHP', ('html+php',), ('*.phtml',), ('application/x-php', 'application/x-httpd-php', 'application/x-httpd-php3', 'application/x-httpd-php4', 'application/x-httpd-php5')),
|
||||
'HtmlSmartyLexer': ('pygments.lexers.templates', 'HTML+Smarty', ('html+smarty',), (), ('text/html+smarty',)),
|
||||
'HttpLexer': ('pygments.lexers.text', 'HTTP', ('http',), (), ()),
|
||||
'HxmlLexer': ('pygments.lexers.text', 'Hxml', ('haxeml', 'hxml'), ('*.hxml',), ()),
|
||||
'HybrisLexer': ('pygments.lexers.other', 'Hybris', ('hybris', 'hy'), ('*.hy', '*.hyb'), ('text/x-hybris', 'application/x-hybris')),
|
||||
'IDLLexer': ('pygments.lexers.math', 'IDL', ('idl',), ('*.pro',), ('text/idl',)),
|
||||
'IgorLexer': ('pygments.lexers.math', 'Igor', ('igor', 'igorpro'), ('*.ipf',), ('text/ipf',)),
|
||||
'IniLexer': ('pygments.lexers.text', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg'), ('text/x-ini',)),
|
||||
'IoLexer': ('pygments.lexers.agile', 'Io', ('io',), ('*.io',), ('text/x-iosrc',)),
|
||||
'IokeLexer': ('pygments.lexers.jvm', 'Ioke', ('ioke', 'ik'), ('*.ik',), ('text/x-iokesrc',)),
|
||||
'IrcLogsLexer': ('pygments.lexers.text', 'IRC logs', ('irc',), ('*.weechatlog',), ('text/x-irclog',)),
|
||||
'JadeLexer': ('pygments.lexers.web', 'Jade', ('jade', 'JADE'), ('*.jade',), ('text/x-jade',)),
|
||||
'JagsLexer': ('pygments.lexers.math', 'JAGS', ('jags',), ('*.jag', '*.bug'), ()),
|
||||
'JavaLexer': ('pygments.lexers.jvm', 'Java', ('java',), ('*.java',), ('text/x-java',)),
|
||||
'JavascriptDjangoLexer': ('pygments.lexers.templates', 'JavaScript+Django/Jinja', ('js+django', 'javascript+django', 'js+jinja', 'javascript+jinja'), (), ('application/x-javascript+django', 'application/x-javascript+jinja', 'text/x-javascript+django', 'text/x-javascript+jinja', 'text/javascript+django', 'text/javascript+jinja')),
|
||||
'JavascriptErbLexer': ('pygments.lexers.templates', 'JavaScript+Ruby', ('js+erb', 'javascript+erb', 'js+ruby', 'javascript+ruby'), (), ('application/x-javascript+ruby', 'text/x-javascript+ruby', 'text/javascript+ruby')),
|
||||
'JavascriptGenshiLexer': ('pygments.lexers.templates', 'JavaScript+Genshi Text', ('js+genshitext', 'js+genshi', 'javascript+genshitext', 'javascript+genshi'), (), ('application/x-javascript+genshi', 'text/x-javascript+genshi', 'text/javascript+genshi')),
|
||||
'JavascriptLexer': ('pygments.lexers.web', 'JavaScript', ('js', 'javascript'), ('*.js',), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
|
||||
'JavascriptPhpLexer': ('pygments.lexers.templates', 'JavaScript+PHP', ('js+php', 'javascript+php'), (), ('application/x-javascript+php', 'text/x-javascript+php', 'text/javascript+php')),
|
||||
'JavascriptSmartyLexer': ('pygments.lexers.templates', 'JavaScript+Smarty', ('js+smarty', 'javascript+smarty'), (), ('application/x-javascript+smarty', 'text/x-javascript+smarty', 'text/javascript+smarty')),
|
||||
'JsonLexer': ('pygments.lexers.web', 'JSON', ('json',), ('*.json',), ('application/json',)),
|
||||
'JspLexer': ('pygments.lexers.templates', 'Java Server Page', ('jsp',), ('*.jsp',), ('application/x-jsp',)),
|
||||
'JuliaConsoleLexer': ('pygments.lexers.math', 'Julia console', ('jlcon',), (), ()),
|
||||
'JuliaLexer': ('pygments.lexers.math', 'Julia', ('julia', 'jl'), ('*.jl',), ('text/x-julia', 'application/x-julia')),
|
||||
'KconfigLexer': ('pygments.lexers.other', 'Kconfig', ('kconfig', 'menuconfig', 'linux-config', 'kernel-config'), ('Kconfig', '*Config.in*', 'external.in*', 'standard-modules.in'), ('text/x-kconfig',)),
|
||||
'KokaLexer': ('pygments.lexers.functional', 'Koka', ('koka',), ('*.kk', '*.kki'), ('text/x-koka',)),
|
||||
'KotlinLexer': ('pygments.lexers.jvm', 'Kotlin', ('kotlin',), ('*.kt',), ('text/x-kotlin',)),
|
||||
'LassoCssLexer': ('pygments.lexers.templates', 'CSS+Lasso', ('css+lasso',), (), ('text/css+lasso',)),
|
||||
'LassoHtmlLexer': ('pygments.lexers.templates', 'HTML+Lasso', ('html+lasso',), (), ('text/html+lasso', 'application/x-httpd-lasso', 'application/x-httpd-lasso[89]')),
|
||||
'LassoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Lasso', ('js+lasso', 'javascript+lasso'), (), ('application/x-javascript+lasso', 'text/x-javascript+lasso', 'text/javascript+lasso')),
|
||||
'LassoLexer': ('pygments.lexers.web', 'Lasso', ('lasso', 'lassoscript'), ('*.lasso', '*.lasso[89]'), ('text/x-lasso',)),
|
||||
'LassoXmlLexer': ('pygments.lexers.templates', 'XML+Lasso', ('xml+lasso',), (), ('application/xml+lasso',)),
|
||||
'LighttpdConfLexer': ('pygments.lexers.text', 'Lighttpd configuration file', ('lighty', 'lighttpd'), (), ('text/x-lighttpd-conf',)),
|
||||
'LiterateAgdaLexer': ('pygments.lexers.functional', 'Literate Agda', ('lagda', 'literate-agda'), ('*.lagda',), ('text/x-literate-agda',)),
|
||||
'LiterateHaskellLexer': ('pygments.lexers.functional', 'Literate Haskell', ('lhs', 'literate-haskell', 'lhaskell'), ('*.lhs',), ('text/x-literate-haskell',)),
|
||||
'LiveScriptLexer': ('pygments.lexers.web', 'LiveScript', ('live-script', 'livescript'), ('*.ls',), ('text/livescript',)),
|
||||
'LlvmLexer': ('pygments.lexers.asm', 'LLVM', ('llvm',), ('*.ll',), ('text/x-llvm',)),
|
||||
'LogosLexer': ('pygments.lexers.compiled', 'Logos', ('logos',), ('*.x', '*.xi', '*.xm', '*.xmi'), ('text/x-logos',)),
|
||||
'LogtalkLexer': ('pygments.lexers.other', 'Logtalk', ('logtalk',), ('*.lgt',), ('text/x-logtalk',)),
|
||||
'LuaLexer': ('pygments.lexers.agile', 'Lua', ('lua',), ('*.lua', '*.wlua'), ('text/x-lua', 'application/x-lua')),
|
||||
'MOOCodeLexer': ('pygments.lexers.other', 'MOOCode', ('moocode', 'moo'), ('*.moo',), ('text/x-moocode',)),
|
||||
'MakefileLexer': ('pygments.lexers.text', 'Makefile', ('make', 'makefile', 'mf', 'bsdmake'), ('*.mak', 'Makefile', 'makefile', 'Makefile.*', 'GNUmakefile'), ('text/x-makefile',)),
|
||||
'MakoCssLexer': ('pygments.lexers.templates', 'CSS+Mako', ('css+mako',), (), ('text/css+mako',)),
|
||||
'MakoHtmlLexer': ('pygments.lexers.templates', 'HTML+Mako', ('html+mako',), (), ('text/html+mako',)),
|
||||
'MakoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Mako', ('js+mako', 'javascript+mako'), (), ('application/x-javascript+mako', 'text/x-javascript+mako', 'text/javascript+mako')),
|
||||
'MakoLexer': ('pygments.lexers.templates', 'Mako', ('mako',), ('*.mao',), ('application/x-mako',)),
|
||||
'MakoXmlLexer': ('pygments.lexers.templates', 'XML+Mako', ('xml+mako',), (), ('application/xml+mako',)),
|
||||
'MaqlLexer': ('pygments.lexers.other', 'MAQL', ('maql',), ('*.maql',), ('text/x-gooddata-maql', 'application/x-gooddata-maql')),
|
||||
'MasonLexer': ('pygments.lexers.templates', 'Mason', ('mason',), ('*.m', '*.mhtml', '*.mc', '*.mi', 'autohandler', 'dhandler'), ('application/x-mason',)),
|
||||
'MatlabLexer': ('pygments.lexers.math', 'Matlab', ('matlab',), ('*.m',), ('text/matlab',)),
|
||||
'MatlabSessionLexer': ('pygments.lexers.math', 'Matlab session', ('matlabsession',), (), ()),
|
||||
'MiniDLexer': ('pygments.lexers.agile', 'MiniD', ('minid',), ('*.md',), ('text/x-minidsrc',)),
|
||||
'ModelicaLexer': ('pygments.lexers.other', 'Modelica', ('modelica',), ('*.mo',), ('text/x-modelica',)),
|
||||
'Modula2Lexer': ('pygments.lexers.compiled', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
|
||||
'MoinWikiLexer': ('pygments.lexers.text', 'MoinMoin/Trac Wiki markup', ('trac-wiki', 'moin'), (), ('text/x-trac-wiki',)),
|
||||
'MonkeyLexer': ('pygments.lexers.compiled', 'Monkey', ('monkey',), ('*.monkey',), ('text/x-monkey',)),
|
||||
'MoonScriptLexer': ('pygments.lexers.agile', 'MoonScript', ('moon', 'moonscript'), ('*.moon',), ('text/x-moonscript', 'application/x-moonscript')),
|
||||
'MscgenLexer': ('pygments.lexers.other', 'Mscgen', ('mscgen', 'msc'), ('*.msc',), ()),
|
||||
'MuPADLexer': ('pygments.lexers.math', 'MuPAD', ('mupad',), ('*.mu',), ()),
|
||||
'MxmlLexer': ('pygments.lexers.web', 'MXML', ('mxml',), ('*.mxml',), ()),
|
||||
'MySqlLexer': ('pygments.lexers.sql', 'MySQL', ('mysql',), (), ('text/x-mysql',)),
|
||||
'MyghtyCssLexer': ('pygments.lexers.templates', 'CSS+Myghty', ('css+myghty',), (), ('text/css+myghty',)),
|
||||
'MyghtyHtmlLexer': ('pygments.lexers.templates', 'HTML+Myghty', ('html+myghty',), (), ('text/html+myghty',)),
|
||||
'MyghtyJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Myghty', ('js+myghty', 'javascript+myghty'), (), ('application/x-javascript+myghty', 'text/x-javascript+myghty', 'text/javascript+mygthy')),
|
||||
'MyghtyLexer': ('pygments.lexers.templates', 'Myghty', ('myghty',), ('*.myt', 'autodelegate'), ('application/x-myghty',)),
|
||||
'MyghtyXmlLexer': ('pygments.lexers.templates', 'XML+Myghty', ('xml+myghty',), (), ('application/xml+myghty',)),
|
||||
'NSISLexer': ('pygments.lexers.other', 'NSIS', ('nsis', 'nsi', 'nsh'), ('*.nsi', '*.nsh'), ('text/x-nsis',)),
|
||||
'NasmLexer': ('pygments.lexers.asm', 'NASM', ('nasm',), ('*.asm', '*.ASM'), ('text/x-nasm',)),
|
||||
'NemerleLexer': ('pygments.lexers.dotnet', 'Nemerle', ('nemerle',), ('*.n',), ('text/x-nemerle',)),
|
||||
'NesCLexer': ('pygments.lexers.compiled', 'nesC', ('nesc',), ('*.nc',), ('text/x-nescsrc',)),
|
||||
'NewLispLexer': ('pygments.lexers.functional', 'NewLisp', ('newlisp',), ('*.lsp', '*.nl'), ('text/x-newlisp', 'application/x-newlisp')),
|
||||
'NewspeakLexer': ('pygments.lexers.other', 'Newspeak', ('newspeak',), ('*.ns2',), ('text/x-newspeak',)),
|
||||
'NginxConfLexer': ('pygments.lexers.text', 'Nginx configuration file', ('nginx',), (), ('text/x-nginx-conf',)),
|
||||
'NimrodLexer': ('pygments.lexers.compiled', 'Nimrod', ('nimrod', 'nim'), ('*.nim', '*.nimrod'), ('text/x-nimrod',)),
|
||||
'NumPyLexer': ('pygments.lexers.math', 'NumPy', ('numpy',), (), ()),
|
||||
'ObjdumpLexer': ('pygments.lexers.asm', 'objdump', ('objdump',), ('*.objdump',), ('text/x-objdump',)),
|
||||
'ObjectiveCLexer': ('pygments.lexers.compiled', 'Objective-C', ('objective-c', 'objectivec', 'obj-c', 'objc'), ('*.m', '*.h'), ('text/x-objective-c',)),
|
||||
'ObjectiveCppLexer': ('pygments.lexers.compiled', 'Objective-C++', ('objective-c++', 'objectivec++', 'obj-c++', 'objc++'), ('*.mm', '*.hh'), ('text/x-objective-c++',)),
|
||||
'ObjectiveJLexer': ('pygments.lexers.web', 'Objective-J', ('objective-j', 'objectivej', 'obj-j', 'objj'), ('*.j',), ('text/x-objective-j',)),
|
||||
'OcamlLexer': ('pygments.lexers.functional', 'OCaml', ('ocaml',), ('*.ml', '*.mli', '*.mll', '*.mly'), ('text/x-ocaml',)),
|
||||
'OctaveLexer': ('pygments.lexers.math', 'Octave', ('octave',), ('*.m',), ('text/octave',)),
|
||||
'OocLexer': ('pygments.lexers.compiled', 'Ooc', ('ooc',), ('*.ooc',), ('text/x-ooc',)),
|
||||
'OpaLexer': ('pygments.lexers.functional', 'Opa', ('opa',), ('*.opa',), ('text/x-opa',)),
|
||||
'OpenEdgeLexer': ('pygments.lexers.other', 'OpenEdge ABL', ('openedge', 'abl', 'progress'), ('*.p', '*.cls'), ('text/x-openedge', 'application/x-openedge')),
|
||||
'Perl6Lexer': ('pygments.lexers.agile', 'Perl6', ('perl6', 'pl6'), ('*.pl', '*.pm', '*.nqp', '*.p6', '*.6pl', '*.p6l', '*.pl6', '*.6pm', '*.p6m', '*.pm6'), ('text/x-perl6', 'application/x-perl6')),
|
||||
'PerlLexer': ('pygments.lexers.agile', 'Perl', ('perl', 'pl'), ('*.pl', '*.pm'), ('text/x-perl', 'application/x-perl')),
|
||||
'PhpLexer': ('pygments.lexers.web', 'PHP', ('php', 'php3', 'php4', 'php5'), ('*.php', '*.php[345]', '*.inc'), ('text/x-php',)),
|
||||
'PlPgsqlLexer': ('pygments.lexers.sql', 'PL/pgSQL', ('plpgsql',), (), ('text/x-plpgsql',)),
|
||||
'PostScriptLexer': ('pygments.lexers.other', 'PostScript', ('postscript', 'postscr'), ('*.ps', '*.eps'), ('application/postscript',)),
|
||||
'PostgresConsoleLexer': ('pygments.lexers.sql', 'PostgreSQL console (psql)', ('psql', 'postgresql-console', 'postgres-console'), (), ('text/x-postgresql-psql',)),
|
||||
'PostgresLexer': ('pygments.lexers.sql', 'PostgreSQL SQL dialect', ('postgresql', 'postgres'), (), ('text/x-postgresql',)),
|
||||
'PovrayLexer': ('pygments.lexers.other', 'POVRay', ('pov',), ('*.pov', '*.inc'), ('text/x-povray',)),
|
||||
'PowerShellLexer': ('pygments.lexers.shell', 'PowerShell', ('powershell', 'posh', 'ps1', 'psm1'), ('*.ps1', '*.psm1'), ('text/x-powershell',)),
|
||||
'PrologLexer': ('pygments.lexers.compiled', 'Prolog', ('prolog',), ('*.prolog', '*.pro', '*.pl'), ('text/x-prolog',)),
|
||||
'PropertiesLexer': ('pygments.lexers.text', 'Properties', ('properties', 'jproperties'), ('*.properties',), ('text/x-java-properties',)),
|
||||
'ProtoBufLexer': ('pygments.lexers.other', 'Protocol Buffer', ('protobuf', 'proto'), ('*.proto',), ()),
|
||||
'PuppetLexer': ('pygments.lexers.other', 'Puppet', ('puppet',), ('*.pp',), ()),
|
||||
'PyPyLogLexer': ('pygments.lexers.text', 'PyPy Log', ('pypylog', 'pypy'), ('*.pypylog',), ('application/x-pypylog',)),
|
||||
'Python3Lexer': ('pygments.lexers.agile', 'Python 3', ('python3', 'py3'), (), ('text/x-python3', 'application/x-python3')),
|
||||
'Python3TracebackLexer': ('pygments.lexers.agile', 'Python 3.0 Traceback', ('py3tb',), ('*.py3tb',), ('text/x-python3-traceback',)),
|
||||
'PythonConsoleLexer': ('pygments.lexers.agile', 'Python console session', ('pycon',), (), ('text/x-python-doctest',)),
|
||||
'PythonLexer': ('pygments.lexers.agile', 'Python', ('python', 'py', 'sage'), ('*.py', '*.pyw', '*.sc', 'SConstruct', 'SConscript', '*.tac', '*.sage'), ('text/x-python', 'application/x-python')),
|
||||
'PythonTracebackLexer': ('pygments.lexers.agile', 'Python Traceback', ('pytb',), ('*.pytb',), ('text/x-python-traceback',)),
|
||||
'QmlLexer': ('pygments.lexers.web', 'QML', ('qml', 'Qt Meta Language', 'Qt modeling Language'), ('*.qml',), ('application/x-qml',)),
|
||||
'RConsoleLexer': ('pygments.lexers.math', 'RConsole', ('rconsole', 'rout'), ('*.Rout',), ()),
|
||||
'RPMSpecLexer': ('pygments.lexers.other', 'RPMSpec', ('spec',), ('*.spec',), ('text/x-rpm-spec',)),
|
||||
'RacketLexer': ('pygments.lexers.functional', 'Racket', ('racket', 'rkt'), ('*.rkt', '*.rktl'), ('text/x-racket', 'application/x-racket')),
|
||||
'RagelCLexer': ('pygments.lexers.parsers', 'Ragel in C Host', ('ragel-c',), ('*.rl',), ()),
|
||||
'RagelCppLexer': ('pygments.lexers.parsers', 'Ragel in CPP Host', ('ragel-cpp',), ('*.rl',), ()),
|
||||
'RagelDLexer': ('pygments.lexers.parsers', 'Ragel in D Host', ('ragel-d',), ('*.rl',), ()),
|
||||
'RagelEmbeddedLexer': ('pygments.lexers.parsers', 'Embedded Ragel', ('ragel-em',), ('*.rl',), ()),
|
||||
'RagelJavaLexer': ('pygments.lexers.parsers', 'Ragel in Java Host', ('ragel-java',), ('*.rl',), ()),
|
||||
'RagelLexer': ('pygments.lexers.parsers', 'Ragel', ('ragel',), (), ()),
|
||||
'RagelObjectiveCLexer': ('pygments.lexers.parsers', 'Ragel in Objective C Host', ('ragel-objc',), ('*.rl',), ()),
|
||||
'RagelRubyLexer': ('pygments.lexers.parsers', 'Ragel in Ruby Host', ('ragel-ruby', 'ragel-rb'), ('*.rl',), ()),
|
||||
'RawTokenLexer': ('pygments.lexers.special', 'Raw token data', ('raw',), (), ('application/x-pygments-tokens',)),
|
||||
'RdLexer': ('pygments.lexers.math', 'Rd', ('rd',), ('*.Rd',), ('text/x-r-doc',)),
|
||||
'RebolLexer': ('pygments.lexers.other', 'REBOL', ('rebol',), ('*.r', '*.r3'), ('text/x-rebol',)),
|
||||
'RedcodeLexer': ('pygments.lexers.other', 'Redcode', ('redcode',), ('*.cw',), ()),
|
||||
'RegeditLexer': ('pygments.lexers.text', 'reg', ('registry',), ('*.reg',), ('text/x-windows-registry',)),
|
||||
'RexxLexer': ('pygments.lexers.other', 'Rexx', ('rexx', 'ARexx', 'arexx'), ('*.rexx', '*.rex', '*.rx', '*.arexx'), ('text/x-rexx',)),
|
||||
'RhtmlLexer': ('pygments.lexers.templates', 'RHTML', ('rhtml', 'html+erb', 'html+ruby'), ('*.rhtml',), ('text/html+ruby',)),
|
||||
'RobotFrameworkLexer': ('pygments.lexers.other', 'RobotFramework', ('RobotFramework', 'robotframework'), ('*.txt', '*.robot'), ('text/x-robotframework',)),
|
||||
'RstLexer': ('pygments.lexers.text', 'reStructuredText', ('rst', 'rest', 'restructuredtext'), ('*.rst', '*.rest'), ('text/x-rst', 'text/prs.fallenstein.rst')),
|
||||
'RubyConsoleLexer': ('pygments.lexers.agile', 'Ruby irb session', ('rbcon', 'irb'), (), ('text/x-ruby-shellsession',)),
|
||||
'RubyLexer': ('pygments.lexers.agile', 'Ruby', ('rb', 'ruby', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby'), ('text/x-ruby', 'application/x-ruby')),
|
||||
'RustLexer': ('pygments.lexers.compiled', 'Rust', ('rust',), ('*.rs', '*.rc'), ('text/x-rustsrc',)),
|
||||
'SLexer': ('pygments.lexers.math', 'S', ('splus', 's', 'r'), ('*.S', '*.R', '.Rhistory', '.Rprofile'), ('text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r', 'text/x-R', 'text/x-r-history', 'text/x-r-profile')),
|
||||
'SMLLexer': ('pygments.lexers.functional', 'Standard ML', ('sml',), ('*.sml', '*.sig', '*.fun'), ('text/x-standardml', 'application/x-standardml')),
|
||||
'SassLexer': ('pygments.lexers.web', 'Sass', ('sass', 'SASS'), ('*.sass',), ('text/x-sass',)),
|
||||
'ScalaLexer': ('pygments.lexers.jvm', 'Scala', ('scala',), ('*.scala',), ('text/x-scala',)),
|
||||
'ScamlLexer': ('pygments.lexers.web', 'Scaml', ('scaml', 'SCAML'), ('*.scaml',), ('text/x-scaml',)),
|
||||
'SchemeLexer': ('pygments.lexers.functional', 'Scheme', ('scheme', 'scm'), ('*.scm', '*.ss'), ('text/x-scheme', 'application/x-scheme')),
|
||||
'ScilabLexer': ('pygments.lexers.math', 'Scilab', ('scilab',), ('*.sci', '*.sce', '*.tst'), ('text/scilab',)),
|
||||
'ScssLexer': ('pygments.lexers.web', 'SCSS', ('scss',), ('*.scss',), ('text/x-scss',)),
|
||||
'ShellSessionLexer': ('pygments.lexers.shell', 'Shell Session', ('shell-session',), ('*.shell-session',), ('application/x-sh-session',)),
|
||||
'SmaliLexer': ('pygments.lexers.dalvik', 'Smali', ('smali',), ('*.smali',), ('text/smali',)),
|
||||
'SmalltalkLexer': ('pygments.lexers.other', 'Smalltalk', ('smalltalk', 'squeak', 'st'), ('*.st',), ('text/x-smalltalk',)),
|
||||
'SmartyLexer': ('pygments.lexers.templates', 'Smarty', ('smarty',), ('*.tpl',), ('application/x-smarty',)),
|
||||
'SnobolLexer': ('pygments.lexers.other', 'Snobol', ('snobol',), ('*.snobol',), ('text/x-snobol',)),
|
||||
'SourcePawnLexer': ('pygments.lexers.other', 'SourcePawn', ('sp',), ('*.sp',), ('text/x-sourcepawn',)),
|
||||
'SourcesListLexer': ('pygments.lexers.text', 'Debian Sourcelist', ('sourceslist', 'sources.list', 'debsources'), ('sources.list',), ()),
|
||||
'SqlLexer': ('pygments.lexers.sql', 'SQL', ('sql',), ('*.sql',), ('text/x-sql',)),
|
||||
'SqliteConsoleLexer': ('pygments.lexers.sql', 'sqlite3con', ('sqlite3',), ('*.sqlite3-console',), ('text/x-sqlite3-console',)),
|
||||
'SquidConfLexer': ('pygments.lexers.text', 'SquidConf', ('squidconf', 'squid.conf', 'squid'), ('squid.conf',), ('text/x-squidconf',)),
|
||||
'SspLexer': ('pygments.lexers.templates', 'Scalate Server Page', ('ssp',), ('*.ssp',), ('application/x-ssp',)),
|
||||
'StanLexer': ('pygments.lexers.math', 'Stan', ('stan',), ('*.stan',), ()),
|
||||
'SwigLexer': ('pygments.lexers.compiled', 'SWIG', ('Swig', 'swig'), ('*.swg', '*.i'), ('text/swig',)),
|
||||
'SystemVerilogLexer': ('pygments.lexers.hdl', 'systemverilog', ('systemverilog', 'sv'), ('*.sv', '*.svh'), ('text/x-systemverilog',)),
|
||||
'TclLexer': ('pygments.lexers.agile', 'Tcl', ('tcl',), ('*.tcl',), ('text/x-tcl', 'text/x-script.tcl', 'application/x-tcl')),
|
||||
'TcshLexer': ('pygments.lexers.shell', 'Tcsh', ('tcsh', 'csh'), ('*.tcsh', '*.csh'), ('application/x-csh',)),
|
||||
'TeaTemplateLexer': ('pygments.lexers.templates', 'Tea', ('tea',), ('*.tea',), ('text/x-tea',)),
|
||||
'TexLexer': ('pygments.lexers.text', 'TeX', ('tex', 'latex'), ('*.tex', '*.aux', '*.toc'), ('text/x-tex', 'text/x-latex')),
|
||||
'TextLexer': ('pygments.lexers.special', 'Text only', ('text',), ('*.txt',), ('text/plain',)),
|
||||
'TreetopLexer': ('pygments.lexers.parsers', 'Treetop', ('treetop',), ('*.treetop', '*.tt'), ()),
|
||||
'TypeScriptLexer': ('pygments.lexers.web', 'TypeScript', ('ts',), ('*.ts',), ('text/x-typescript',)),
|
||||
'UrbiscriptLexer': ('pygments.lexers.other', 'UrbiScript', ('urbiscript',), ('*.u',), ('application/x-urbiscript',)),
|
||||
'VGLLexer': ('pygments.lexers.other', 'VGL', ('vgl',), ('*.rpf',), ()),
|
||||
'ValaLexer': ('pygments.lexers.compiled', 'Vala', ('vala', 'vapi'), ('*.vala', '*.vapi'), ('text/x-vala',)),
|
||||
'VbNetAspxLexer': ('pygments.lexers.dotnet', 'aspx-vb', ('aspx-vb',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'VbNetLexer': ('pygments.lexers.dotnet', 'VB.net', ('vb.net', 'vbnet'), ('*.vb', '*.bas'), ('text/x-vbnet', 'text/x-vba')),
|
||||
'VelocityHtmlLexer': ('pygments.lexers.templates', 'HTML+Velocity', ('html+velocity',), (), ('text/html+velocity',)),
|
||||
'VelocityLexer': ('pygments.lexers.templates', 'Velocity', ('velocity',), ('*.vm', '*.fhtml'), ()),
|
||||
'VelocityXmlLexer': ('pygments.lexers.templates', 'XML+Velocity', ('xml+velocity',), (), ('application/xml+velocity',)),
|
||||
'VerilogLexer': ('pygments.lexers.hdl', 'verilog', ('verilog', 'v'), ('*.v',), ('text/x-verilog',)),
|
||||
'VhdlLexer': ('pygments.lexers.hdl', 'vhdl', ('vhdl',), ('*.vhdl', '*.vhd'), ('text/x-vhdl',)),
|
||||
'VimLexer': ('pygments.lexers.text', 'VimL', ('vim',), ('*.vim', '.vimrc', '.exrc', '.gvimrc', '_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc'), ('text/x-vim',)),
|
||||
'XQueryLexer': ('pygments.lexers.web', 'XQuery', ('xquery', 'xqy', 'xq', 'xql', 'xqm'), ('*.xqy', '*.xquery', '*.xq', '*.xql', '*.xqm'), ('text/xquery', 'application/xquery')),
|
||||
'XmlDjangoLexer': ('pygments.lexers.templates', 'XML+Django/Jinja', ('xml+django', 'xml+jinja'), (), ('application/xml+django', 'application/xml+jinja')),
|
||||
'XmlErbLexer': ('pygments.lexers.templates', 'XML+Ruby', ('xml+erb', 'xml+ruby'), (), ('application/xml+ruby',)),
|
||||
'XmlLexer': ('pygments.lexers.web', 'XML', ('xml',), ('*.xml', '*.xsl', '*.rss', '*.xslt', '*.xsd', '*.wsdl', '*.wsf'), ('text/xml', 'application/xml', 'image/svg+xml', 'application/rss+xml', 'application/atom+xml')),
|
||||
'XmlPhpLexer': ('pygments.lexers.templates', 'XML+PHP', ('xml+php',), (), ('application/xml+php',)),
|
||||
'XmlSmartyLexer': ('pygments.lexers.templates', 'XML+Smarty', ('xml+smarty',), (), ('application/xml+smarty',)),
|
||||
'XsltLexer': ('pygments.lexers.web', 'XSLT', ('xslt',), ('*.xsl', '*.xslt', '*.xpl'), ('application/xsl+xml', 'application/xslt+xml')),
|
||||
'XtendLexer': ('pygments.lexers.jvm', 'Xtend', ('xtend',), ('*.xtend',), ('text/x-xtend',)),
|
||||
'YamlLexer': ('pygments.lexers.text', 'YAML', ('yaml',), ('*.yaml', '*.yml'), ('text/x-yaml',)),
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup lexers
|
||||
found_lexers = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
for filename in os.listdir('.'):
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.lexers.%s' % filename[:-3]
|
||||
print module_name
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for lexer_name in module.__all__:
|
||||
lexer = getattr(module, lexer_name)
|
||||
found_lexers.append(
|
||||
'%r: %r' % (lexer_name,
|
||||
(module_name,
|
||||
lexer.name,
|
||||
tuple(lexer.aliases),
|
||||
tuple(lexer.filenames),
|
||||
tuple(lexer.mimetypes))))
|
||||
# sort them, that should make the diff files for svn smaller
|
||||
found_lexers.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
f = open(__file__)
|
||||
try:
|
||||
content = f.read()
|
||||
finally:
|
||||
f.close()
|
||||
header = content[:content.find('LEXERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
f = open(__file__, 'wb')
|
||||
f.write(header)
|
||||
f.write('LEXERS = {\n %s,\n}\n\n' % ',\n '.join(found_lexers))
|
||||
f.write(footer)
|
||||
f.close()
|
||||
@ -1,562 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._openedgebuiltins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Builtin list for the OpenEdgeLexer.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
OPENEDGEKEYWORDS = [
|
||||
'ABSOLUTE', 'ABS', 'ABSO', 'ABSOL', 'ABSOLU', 'ABSOLUT', 'ACCELERATOR',
|
||||
'ACCUM', 'ACCUMULATE', 'ACCUM', 'ACCUMU', 'ACCUMUL', 'ACCUMULA',
|
||||
'ACCUMULAT', 'ACTIVE-FORM', 'ACTIVE-WINDOW', 'ADD', 'ADD-BUFFER',
|
||||
'ADD-CALC-COLUMN', 'ADD-COLUMNS-FROM', 'ADD-EVENTS-PROCEDURE',
|
||||
'ADD-FIELDS-FROM', 'ADD-FIRST', 'ADD-INDEX-FIELD', 'ADD-LAST',
|
||||
'ADD-LIKE-COLUMN', 'ADD-LIKE-FIELD', 'ADD-LIKE-INDEX', 'ADD-NEW-FIELD',
|
||||
'ADD-NEW-INDEX', 'ADD-SCHEMA-LOCATION', 'ADD-SUPER-PROCEDURE', 'ADM-DATA',
|
||||
'ADVISE', 'ALERT-BOX', 'ALIAS', 'ALL', 'ALLOW-COLUMN-SEARCHING',
|
||||
'ALLOW-REPLICATION', 'ALTER', 'ALWAYS-ON-TOP', 'AMBIGUOUS', 'AMBIG',
|
||||
'AMBIGU', 'AMBIGUO', 'AMBIGUOU', 'ANALYZE', 'ANALYZ', 'AND', 'ANSI-ONLY',
|
||||
'ANY', 'ANYWHERE', 'APPEND', 'APPL-ALERT-BOXES', 'APPL-ALERT',
|
||||
'APPL-ALERT-', 'APPL-ALERT-B', 'APPL-ALERT-BO', 'APPL-ALERT-BOX',
|
||||
'APPL-ALERT-BOXE', 'APPL-CONTEXT-ID', 'APPLICATION', 'APPLY',
|
||||
'APPSERVER-INFO', 'APPSERVER-PASSWORD', 'APPSERVER-USERID', 'ARRAY-MESSAGE',
|
||||
'AS', 'ASC', 'ASCENDING', 'ASCE', 'ASCEN', 'ASCEND', 'ASCENDI', 'ASCENDIN',
|
||||
'ASK-OVERWRITE', 'ASSEMBLY', 'ASSIGN', 'ASYNCHRONOUS',
|
||||
'ASYNC-REQUEST-COUNT', 'ASYNC-REQUEST-HANDLE', 'AT', 'ATTACHED-PAIRLIST',
|
||||
'ATTR-SPACE', 'ATTR', 'ATTRI', 'ATTRIB', 'ATTRIBU', 'ATTRIBUT',
|
||||
'AUDIT-CONTROL', 'AUDIT-ENABLED', 'AUDIT-EVENT-CONTEXT', 'AUDIT-POLICY',
|
||||
'AUTHENTICATION-FAILED', 'AUTHORIZATION', 'AUTO-COMPLETION', 'AUTO-COMP',
|
||||
'AUTO-COMPL', 'AUTO-COMPLE', 'AUTO-COMPLET', 'AUTO-COMPLETI',
|
||||
'AUTO-COMPLETIO', 'AUTO-ENDKEY', 'AUTO-END-KEY', 'AUTO-GO', 'AUTO-INDENT',
|
||||
'AUTO-IND', 'AUTO-INDE', 'AUTO-INDEN', 'AUTOMATIC', 'AUTO-RESIZE',
|
||||
'AUTO-RETURN', 'AUTO-RET', 'AUTO-RETU', 'AUTO-RETUR', 'AUTO-SYNCHRONIZE',
|
||||
'AUTO-ZAP', 'AUTO-Z', 'AUTO-ZA', 'AVAILABLE', 'AVAIL', 'AVAILA', 'AVAILAB',
|
||||
'AVAILABL', 'AVAILABLE-FORMATS', 'AVERAGE', 'AVE', 'AVER', 'AVERA',
|
||||
'AVERAG', 'AVG', 'BACKGROUND', 'BACK', 'BACKG', 'BACKGR', 'BACKGRO',
|
||||
'BACKGROU', 'BACKGROUN', 'BACKWARDS', 'BACKWARD', 'BASE64-DECODE',
|
||||
'BASE64-ENCODE', 'BASE-ADE', 'BASE-KEY', 'BATCH-MODE', 'BATCH', 'BATCH-',
|
||||
'BATCH-M', 'BATCH-MO', 'BATCH-MOD', 'BATCH-SIZE', 'BEFORE-HIDE', 'BEFORE-H',
|
||||
'BEFORE-HI', 'BEFORE-HID', 'BEGIN-EVENT-GROUP', 'BEGINS', 'BELL', 'BETWEEN',
|
||||
'BGCOLOR', 'BGC', 'BGCO', 'BGCOL', 'BGCOLO', 'BIG-ENDIAN', 'BINARY', 'BIND',
|
||||
'BIND-WHERE', 'BLANK', 'BLOCK-ITERATION-DISPLAY', 'BORDER-BOTTOM-CHARS',
|
||||
'BORDER-B', 'BORDER-BO', 'BORDER-BOT', 'BORDER-BOTT', 'BORDER-BOTTO',
|
||||
'BORDER-BOTTOM-PIXELS', 'BORDER-BOTTOM-P', 'BORDER-BOTTOM-PI',
|
||||
'BORDER-BOTTOM-PIX', 'BORDER-BOTTOM-PIXE', 'BORDER-BOTTOM-PIXEL',
|
||||
'BORDER-LEFT-CHARS', 'BORDER-L', 'BORDER-LE', 'BORDER-LEF', 'BORDER-LEFT',
|
||||
'BORDER-LEFT-', 'BORDER-LEFT-C', 'BORDER-LEFT-CH', 'BORDER-LEFT-CHA',
|
||||
'BORDER-LEFT-CHAR', 'BORDER-LEFT-PIXELS', 'BORDER-LEFT-P', 'BORDER-LEFT-PI',
|
||||
'BORDER-LEFT-PIX', 'BORDER-LEFT-PIXE', 'BORDER-LEFT-PIXEL',
|
||||
'BORDER-RIGHT-CHARS', 'BORDER-R', 'BORDER-RI', 'BORDER-RIG', 'BORDER-RIGH',
|
||||
'BORDER-RIGHT', 'BORDER-RIGHT-', 'BORDER-RIGHT-C', 'BORDER-RIGHT-CH',
|
||||
'BORDER-RIGHT-CHA', 'BORDER-RIGHT-CHAR', 'BORDER-RIGHT-PIXELS',
|
||||
'BORDER-RIGHT-P', 'BORDER-RIGHT-PI', 'BORDER-RIGHT-PIX',
|
||||
'BORDER-RIGHT-PIXE', 'BORDER-RIGHT-PIXEL', 'BORDER-TOP-CHARS', 'BORDER-T',
|
||||
'BORDER-TO', 'BORDER-TOP', 'BORDER-TOP-', 'BORDER-TOP-C', 'BORDER-TOP-CH',
|
||||
'BORDER-TOP-CHA', 'BORDER-TOP-CHAR', 'BORDER-TOP-PIXELS', 'BORDER-TOP-P',
|
||||
'BORDER-TOP-PI', 'BORDER-TOP-PIX', 'BORDER-TOP-PIXE', 'BORDER-TOP-PIXEL',
|
||||
'BOX', 'BOX-SELECTABLE', 'BOX-SELECT', 'BOX-SELECTA', 'BOX-SELECTAB',
|
||||
'BOX-SELECTABL', 'BREAK', 'BROWSE', 'BUFFER', 'BUFFER-CHARS',
|
||||
'BUFFER-COMPARE', 'BUFFER-COPY', 'BUFFER-CREATE', 'BUFFER-DELETE',
|
||||
'BUFFER-FIELD', 'BUFFER-HANDLE', 'BUFFER-LINES', 'BUFFER-NAME',
|
||||
'BUFFER-RELEASE', 'BUFFER-VALUE', 'BUTTON', 'BUTTONS', 'BUTTON', 'BY',
|
||||
'BY-POINTER', 'BY-VARIANT-POINTER', 'CACHE', 'CACHE-SIZE', 'CALL',
|
||||
'CALL-NAME', 'CALL-TYPE', 'CANCEL-BREAK', 'CANCEL-BUTTON', 'CAN-CREATE',
|
||||
'CAN-DELETE', 'CAN-DO', 'CAN-FIND', 'CAN-QUERY', 'CAN-READ', 'CAN-SET',
|
||||
'CAN-WRITE', 'CAPS', 'CAREFUL-PAINT', 'CASE', 'CASE-SENSITIVE', 'CASE-SEN',
|
||||
'CASE-SENS', 'CASE-SENSI', 'CASE-SENSIT', 'CASE-SENSITI', 'CASE-SENSITIV',
|
||||
'CAST', 'CATCH', 'CDECL', 'CENTERED', 'CENTER', 'CENTERE', 'CHAINED',
|
||||
'CHARACTER_LENGTH', 'CHARSET', 'CHECK', 'CHECKED', 'CHOOSE', 'CHR', 'CLASS',
|
||||
'CLASS-TYPE', 'CLEAR', 'CLEAR-APPL-CONTEXT', 'CLEAR-LOG', 'CLEAR-SELECTION',
|
||||
'CLEAR-SELECT', 'CLEAR-SELECTI', 'CLEAR-SELECTIO', 'CLEAR-SORT-ARROWS',
|
||||
'CLEAR-SORT-ARROW', 'CLIENT-CONNECTION-ID', 'CLIENT-PRINCIPAL',
|
||||
'CLIENT-TTY', 'CLIENT-TYPE', 'CLIENT-WORKSTATION', 'CLIPBOARD', 'CLOSE',
|
||||
'CLOSE-LOG', 'CODE', 'CODEBASE-LOCATOR', 'CODEPAGE', 'CODEPAGE-CONVERT',
|
||||
'COLLATE', 'COL-OF', 'COLON', 'COLON-ALIGNED', 'COLON-ALIGN',
|
||||
'COLON-ALIGNE', 'COLOR', 'COLOR-TABLE', 'COLUMN', 'COL', 'COLU', 'COLUM',
|
||||
'COLUMN-BGCOLOR', 'COLUMN-DCOLOR', 'COLUMN-FGCOLOR', 'COLUMN-FONT',
|
||||
'COLUMN-LABEL', 'COLUMN-LAB', 'COLUMN-LABE', 'COLUMN-MOVABLE', 'COLUMN-OF',
|
||||
'COLUMN-PFCOLOR', 'COLUMN-READ-ONLY', 'COLUMN-RESIZABLE', 'COLUMNS',
|
||||
'COLUMN-SCROLLING', 'COMBO-BOX', 'COMMAND', 'COMPARES', 'COMPILE',
|
||||
'COMPILER', 'COMPLETE', 'COM-SELF', 'CONFIG-NAME', 'CONNECT', 'CONNECTED',
|
||||
'CONSTRUCTOR', 'CONTAINS', 'CONTENTS', 'CONTEXT', 'CONTEXT-HELP',
|
||||
'CONTEXT-HELP-FILE', 'CONTEXT-HELP-ID', 'CONTEXT-POPUP', 'CONTROL',
|
||||
'CONTROL-BOX', 'CONTROL-FRAME', 'CONVERT', 'CONVERT-3D-COLORS',
|
||||
'CONVERT-TO-OFFSET', 'CONVERT-TO-OFFS', 'CONVERT-TO-OFFSE', 'COPY-DATASET',
|
||||
'COPY-LOB', 'COPY-SAX-ATTRIBUTES', 'COPY-TEMP-TABLE', 'COUNT', 'COUNT-OF',
|
||||
'CPCASE', 'CPCOLL', 'CPINTERNAL', 'CPLOG', 'CPPRINT', 'CPRCODEIN',
|
||||
'CPRCODEOUT', 'CPSTREAM', 'CPTERM', 'CRC-VALUE', 'CREATE', 'CREATE-LIKE',
|
||||
'CREATE-LIKE-SEQUENTIAL', 'CREATE-NODE-NAMESPACE',
|
||||
'CREATE-RESULT-LIST-ENTRY', 'CREATE-TEST-FILE', 'CURRENT', 'CURRENT_DATE',
|
||||
'CURRENT_DATE', 'CURRENT-CHANGED', 'CURRENT-COLUMN', 'CURRENT-ENVIRONMENT',
|
||||
'CURRENT-ENV', 'CURRENT-ENVI', 'CURRENT-ENVIR', 'CURRENT-ENVIRO',
|
||||
'CURRENT-ENVIRON', 'CURRENT-ENVIRONM', 'CURRENT-ENVIRONME',
|
||||
'CURRENT-ENVIRONMEN', 'CURRENT-ITERATION', 'CURRENT-LANGUAGE',
|
||||
'CURRENT-LANG', 'CURRENT-LANGU', 'CURRENT-LANGUA', 'CURRENT-LANGUAG',
|
||||
'CURRENT-QUERY', 'CURRENT-RESULT-ROW', 'CURRENT-ROW-MODIFIED',
|
||||
'CURRENT-VALUE', 'CURRENT-WINDOW', 'CURSOR', 'CURS', 'CURSO', 'CURSOR-CHAR',
|
||||
'CURSOR-LINE', 'CURSOR-OFFSET', 'DATABASE', 'DATA-BIND',
|
||||
'DATA-ENTRY-RETURN', 'DATA-ENTRY-RET', 'DATA-ENTRY-RETU',
|
||||
'DATA-ENTRY-RETUR', 'DATA-RELATION', 'DATA-REL', 'DATA-RELA', 'DATA-RELAT',
|
||||
'DATA-RELATI', 'DATA-RELATIO', 'DATASERVERS', 'DATASET', 'DATASET-HANDLE',
|
||||
'DATA-SOURCE', 'DATA-SOURCE-COMPLETE-MAP', 'DATA-SOURCE-MODIFIED',
|
||||
'DATA-SOURCE-ROWID', 'DATA-TYPE', 'DATA-T', 'DATA-TY', 'DATA-TYP',
|
||||
'DATE-FORMAT', 'DATE-F', 'DATE-FO', 'DATE-FOR', 'DATE-FORM', 'DATE-FORMA',
|
||||
'DAY', 'DBCODEPAGE', 'DBCOLLATION', 'DBNAME', 'DBPARAM', 'DB-REFERENCES',
|
||||
'DBRESTRICTIONS', 'DBREST', 'DBRESTR', 'DBRESTRI', 'DBRESTRIC',
|
||||
'DBRESTRICT', 'DBRESTRICTI', 'DBRESTRICTIO', 'DBRESTRICTION', 'DBTASKID',
|
||||
'DBTYPE', 'DBVERSION', 'DBVERS', 'DBVERSI', 'DBVERSIO', 'DCOLOR', 'DDE',
|
||||
'DDE-ERROR', 'DDE-ID', 'DDE-I', 'DDE-ITEM', 'DDE-NAME', 'DDE-TOPIC',
|
||||
'DEBLANK', 'DEBUG', 'DEBU', 'DEBUG-ALERT', 'DEBUGGER', 'DEBUG-LIST',
|
||||
'DECIMALS', 'DECLARE', 'DECLARE-NAMESPACE', 'DECRYPT', 'DEFAULT',
|
||||
'DEFAULT-BUFFER-HANDLE', 'DEFAULT-BUTTON', 'DEFAUT-B', 'DEFAUT-BU',
|
||||
'DEFAUT-BUT', 'DEFAUT-BUTT', 'DEFAUT-BUTTO', 'DEFAULT-COMMIT',
|
||||
'DEFAULT-EXTENSION', 'DEFAULT-EX', 'DEFAULT-EXT', 'DEFAULT-EXTE',
|
||||
'DEFAULT-EXTEN', 'DEFAULT-EXTENS', 'DEFAULT-EXTENSI', 'DEFAULT-EXTENSIO',
|
||||
'DEFAULT-NOXLATE', 'DEFAULT-NOXL', 'DEFAULT-NOXLA', 'DEFAULT-NOXLAT',
|
||||
'DEFAULT-VALUE', 'DEFAULT-WINDOW', 'DEFINED', 'DEFINE-USER-EVENT-MANAGER',
|
||||
'DELETE', 'DEL', 'DELE', 'DELET', 'DELETE-CHARACTER', 'DELETE-CHAR',
|
||||
'DELETE-CHARA', 'DELETE-CHARAC', 'DELETE-CHARACT', 'DELETE-CHARACTE',
|
||||
'DELETE-CURRENT-ROW', 'DELETE-LINE', 'DELETE-RESULT-LIST-ENTRY',
|
||||
'DELETE-SELECTED-ROW', 'DELETE-SELECTED-ROWS', 'DELIMITER', 'DESC',
|
||||
'DESCENDING', 'DESC', 'DESCE', 'DESCEN', 'DESCEND', 'DESCENDI', 'DESCENDIN',
|
||||
'DESELECT-FOCUSED-ROW', 'DESELECTION', 'DESELECT-ROWS',
|
||||
'DESELECT-SELECTED-ROW', 'DESTRUCTOR', 'DIALOG-BOX', 'DICTIONARY', 'DICT',
|
||||
'DICTI', 'DICTIO', 'DICTION', 'DICTIONA', 'DICTIONAR', 'DIR', 'DISABLE',
|
||||
'DISABLE-AUTO-ZAP', 'DISABLED', 'DISABLE-DUMP-TRIGGERS',
|
||||
'DISABLE-LOAD-TRIGGERS', 'DISCONNECT', 'DISCON', 'DISCONN', 'DISCONNE',
|
||||
'DISCONNEC', 'DISP', 'DISPLAY', 'DISP', 'DISPL', 'DISPLA',
|
||||
'DISPLAY-MESSAGE', 'DISPLAY-TYPE', 'DISPLAY-T', 'DISPLAY-TY', 'DISPLAY-TYP',
|
||||
'DISTINCT', 'DO', 'DOMAIN-DESCRIPTION', 'DOMAIN-NAME', 'DOMAIN-TYPE', 'DOS',
|
||||
'DOUBLE', 'DOWN', 'DRAG-ENABLED', 'DROP', 'DROP-DOWN', 'DROP-DOWN-LIST',
|
||||
'DROP-FILE-NOTIFY', 'DROP-TARGET', 'DUMP', 'DYNAMIC', 'DYNAMIC-FUNCTION',
|
||||
'EACH', 'ECHO', 'EDGE-CHARS', 'EDGE', 'EDGE-', 'EDGE-C', 'EDGE-CH',
|
||||
'EDGE-CHA', 'EDGE-CHAR', 'EDGE-PIXELS', 'EDGE-P', 'EDGE-PI', 'EDGE-PIX',
|
||||
'EDGE-PIXE', 'EDGE-PIXEL', 'EDIT-CAN-PASTE', 'EDIT-CAN-UNDO', 'EDIT-CLEAR',
|
||||
'EDIT-COPY', 'EDIT-CUT', 'EDITING', 'EDITOR', 'EDIT-PASTE', 'EDIT-UNDO',
|
||||
'ELSE', 'EMPTY', 'EMPTY-TEMP-TABLE', 'ENABLE', 'ENABLED-FIELDS', 'ENCODE',
|
||||
'ENCRYPT', 'ENCRYPT-AUDIT-MAC-KEY', 'ENCRYPTION-SALT', 'END',
|
||||
'END-DOCUMENT', 'END-ELEMENT', 'END-EVENT-GROUP', 'END-FILE-DROP', 'ENDKEY',
|
||||
'END-KEY', 'END-MOVE', 'END-RESIZE', 'END-ROW-RESIZE', 'END-USER-PROMPT',
|
||||
'ENTERED', 'ENTRY', 'EQ', 'ERROR', 'ERROR-COLUMN', 'ERROR-COL',
|
||||
'ERROR-COLU', 'ERROR-COLUM', 'ERROR-ROW', 'ERROR-STACK-TRACE',
|
||||
'ERROR-STATUS', 'ERROR-STAT', 'ERROR-STATU', 'ESCAPE', 'ETIME',
|
||||
'EVENT-GROUP-ID', 'EVENT-PROCEDURE', 'EVENT-PROCEDURE-CONTEXT', 'EVENTS',
|
||||
'EVENT', 'EVENT-TYPE', 'EVENT-T', 'EVENT-TY', 'EVENT-TYP', 'EXCEPT',
|
||||
'EXCLUSIVE-ID', 'EXCLUSIVE-LOCK', 'EXCLUSIVE', 'EXCLUSIVE-', 'EXCLUSIVE-L',
|
||||
'EXCLUSIVE-LO', 'EXCLUSIVE-LOC', 'EXCLUSIVE-WEB-USER', 'EXECUTE', 'EXISTS',
|
||||
'EXP', 'EXPAND', 'EXPANDABLE', 'EXPLICIT', 'EXPORT', 'EXPORT-PRINCIPAL',
|
||||
'EXTENDED', 'EXTENT', 'EXTERNAL', 'FALSE', 'FETCH', 'FETCH-SELECTED-ROW',
|
||||
'FGCOLOR', 'FGC', 'FGCO', 'FGCOL', 'FGCOLO', 'FIELD', 'FIELDS', 'FIELD',
|
||||
'FILE', 'FILE-CREATE-DATE', 'FILE-CREATE-TIME', 'FILE-INFORMATION',
|
||||
'FILE-INFO', 'FILE-INFOR', 'FILE-INFORM', 'FILE-INFORMA', 'FILE-INFORMAT',
|
||||
'FILE-INFORMATI', 'FILE-INFORMATIO', 'FILE-MOD-DATE', 'FILE-MOD-TIME',
|
||||
'FILENAME', 'FILE-NAME', 'FILE-OFFSET', 'FILE-OFF', 'FILE-OFFS',
|
||||
'FILE-OFFSE', 'FILE-SIZE', 'FILE-TYPE', 'FILL', 'FILLED', 'FILL-IN',
|
||||
'FILTERS', 'FINAL', 'FINALLY', 'FIND', 'FIND-BY-ROWID',
|
||||
'FIND-CASE-SENSITIVE', 'FIND-CURRENT', 'FINDER', 'FIND-FIRST',
|
||||
'FIND-GLOBAL', 'FIND-LAST', 'FIND-NEXT-OCCURRENCE', 'FIND-PREV-OCCURRENCE',
|
||||
'FIND-SELECT', 'FIND-UNIQUE', 'FIND-WRAP-AROUND', 'FIRST',
|
||||
'FIRST-ASYNCH-REQUEST', 'FIRST-CHILD', 'FIRST-COLUMN', 'FIRST-FORM',
|
||||
'FIRST-OBJECT', 'FIRST-OF', 'FIRST-PROCEDURE', 'FIRST-PROC', 'FIRST-PROCE',
|
||||
'FIRST-PROCED', 'FIRST-PROCEDU', 'FIRST-PROCEDUR', 'FIRST-SERVER',
|
||||
'FIRST-TAB-ITEM', 'FIRST-TAB-I', 'FIRST-TAB-IT', 'FIRST-TAB-ITE',
|
||||
'FIT-LAST-COLUMN', 'FIXED-ONLY', 'FLAT-BUTTON', 'FLOAT', 'FOCUS',
|
||||
'FOCUSED-ROW', 'FOCUSED-ROW-SELECTED', 'FONT', 'FONT-TABLE', 'FOR',
|
||||
'FORCE-FILE', 'FOREGROUND', 'FORE', 'FOREG', 'FOREGR', 'FOREGRO',
|
||||
'FOREGROU', 'FOREGROUN', 'FORM', 'FORMAT', 'FORM', 'FORMA', 'FORMATTED',
|
||||
'FORMATTE', 'FORM-LONG-INPUT', 'FORWARD', 'FORWARDS', 'FORWARD', 'FRAGMENT',
|
||||
'FRAGMEN', 'FRAME', 'FRAM', 'FRAME-COL', 'FRAME-DB', 'FRAME-DOWN',
|
||||
'FRAME-FIELD', 'FRAME-FILE', 'FRAME-INDEX', 'FRAME-INDE', 'FRAME-LINE',
|
||||
'FRAME-NAME', 'FRAME-ROW', 'FRAME-SPACING', 'FRAME-SPA', 'FRAME-SPAC',
|
||||
'FRAME-SPACI', 'FRAME-SPACIN', 'FRAME-VALUE', 'FRAME-VAL', 'FRAME-VALU',
|
||||
'FRAME-X', 'FRAME-Y', 'FREQUENCY', 'FROM', 'FROM-CHARS', 'FROM-C',
|
||||
'FROM-CH', 'FROM-CHA', 'FROM-CHAR', 'FROM-CURRENT', 'FROM-CUR', 'FROM-CURR',
|
||||
'FROM-CURRE', 'FROM-CURREN', 'FROM-PIXELS', 'FROM-P', 'FROM-PI', 'FROM-PIX',
|
||||
'FROM-PIXE', 'FROM-PIXEL', 'FULL-HEIGHT-CHARS', 'FULL-HEIGHT',
|
||||
'FULL-HEIGHT-', 'FULL-HEIGHT-C', 'FULL-HEIGHT-CH', 'FULL-HEIGHT-CHA',
|
||||
'FULL-HEIGHT-CHAR', 'FULL-HEIGHT-PIXELS', 'FULL-HEIGHT-P', 'FULL-HEIGHT-PI',
|
||||
'FULL-HEIGHT-PIX', 'FULL-HEIGHT-PIXE', 'FULL-HEIGHT-PIXEL', 'FULL-PATHNAME',
|
||||
'FULL-PATHN', 'FULL-PATHNA', 'FULL-PATHNAM', 'FULL-WIDTH-CHARS',
|
||||
'FULL-WIDTH', 'FULL-WIDTH-', 'FULL-WIDTH-C', 'FULL-WIDTH-CH',
|
||||
'FULL-WIDTH-CHA', 'FULL-WIDTH-CHAR', 'FULL-WIDTH-PIXELS', 'FULL-WIDTH-P',
|
||||
'FULL-WIDTH-PI', 'FULL-WIDTH-PIX', 'FULL-WIDTH-PIXE', 'FULL-WIDTH-PIXEL',
|
||||
'FUNCTION', 'FUNCTION-CALL-TYPE', 'GATEWAYS', 'GATEWAY', 'GE',
|
||||
'GENERATE-MD5', 'GENERATE-PBE-KEY', 'GENERATE-PBE-SALT',
|
||||
'GENERATE-RANDOM-KEY', 'GENERATE-UUID', 'GET', 'GET-ATTR-CALL-TYPE',
|
||||
'GET-ATTRIBUTE-NODE', 'GET-BINARY-DATA', 'GET-BLUE-VALUE', 'GET-BLUE',
|
||||
'GET-BLUE-', 'GET-BLUE-V', 'GET-BLUE-VA', 'GET-BLUE-VAL', 'GET-BLUE-VALU',
|
||||
'GET-BROWSE-COLUMN', 'GET-BUFFER-HANDLEGETBYTE', 'GET-BYTE',
|
||||
'GET-CALLBACK-PROC-CONTEXT', 'GET-CALLBACK-PROC-NAME', 'GET-CGI-LIST',
|
||||
'GET-CGI-LONG-VALUE', 'GET-CGI-VALUE', 'GET-CODEPAGES', 'GET-COLLATIONS',
|
||||
'GET-CONFIG-VALUE', 'GET-CURRENT', 'GET-DOUBLE', 'GET-DROPPED-FILE',
|
||||
'GET-DYNAMIC', 'GET-ERROR-COLUMN', 'GET-ERROR-ROW', 'GET-FILE',
|
||||
'GET-FILE-NAME', 'GET-FILE-OFFSET', 'GET-FILE-OFFSE', 'GET-FIRST',
|
||||
'GET-FLOAT', 'GET-GREEN-VALUE', 'GET-GREEN', 'GET-GREEN-', 'GET-GREEN-V',
|
||||
'GET-GREEN-VA', 'GET-GREEN-VAL', 'GET-GREEN-VALU',
|
||||
'GET-INDEX-BY-NAMESPACE-NAME', 'GET-INDEX-BY-QNAME', 'GET-INT64',
|
||||
'GET-ITERATION', 'GET-KEY-VALUE', 'GET-KEY-VAL', 'GET-KEY-VALU', 'GET-LAST',
|
||||
'GET-LOCALNAME-BY-INDEX', 'GET-LONG', 'GET-MESSAGE', 'GET-NEXT',
|
||||
'GET-NUMBER', 'GET-POINTER-VALUE', 'GET-PREV', 'GET-PRINTERS',
|
||||
'GET-PROPERTY', 'GET-QNAME-BY-INDEX', 'GET-RED-VALUE', 'GET-RED',
|
||||
'GET-RED-', 'GET-RED-V', 'GET-RED-VA', 'GET-RED-VAL', 'GET-RED-VALU',
|
||||
'GET-REPOSITIONED-ROW', 'GET-RGB-VALUE', 'GET-SELECTED-WIDGET',
|
||||
'GET-SELECTED', 'GET-SELECTED-', 'GET-SELECTED-W', 'GET-SELECTED-WI',
|
||||
'GET-SELECTED-WID', 'GET-SELECTED-WIDG', 'GET-SELECTED-WIDGE', 'GET-SHORT',
|
||||
'GET-SIGNATURE', 'GET-SIZE', 'GET-STRING', 'GET-TAB-ITEM',
|
||||
'GET-TEXT-HEIGHT-CHARS', 'GET-TEXT-HEIGHT', 'GET-TEXT-HEIGHT-',
|
||||
'GET-TEXT-HEIGHT-C', 'GET-TEXT-HEIGHT-CH', 'GET-TEXT-HEIGHT-CHA',
|
||||
'GET-TEXT-HEIGHT-CHAR', 'GET-TEXT-HEIGHT-PIXELS', 'GET-TEXT-HEIGHT-P',
|
||||
'GET-TEXT-HEIGHT-PI', 'GET-TEXT-HEIGHT-PIX', 'GET-TEXT-HEIGHT-PIXE',
|
||||
'GET-TEXT-HEIGHT-PIXEL', 'GET-TEXT-WIDTH-CHARS', 'GET-TEXT-WIDTH',
|
||||
'GET-TEXT-WIDTH-', 'GET-TEXT-WIDTH-C', 'GET-TEXT-WIDTH-CH',
|
||||
'GET-TEXT-WIDTH-CHA', 'GET-TEXT-WIDTH-CHAR', 'GET-TEXT-WIDTH-PIXELS',
|
||||
'GET-TEXT-WIDTH-P', 'GET-TEXT-WIDTH-PI', 'GET-TEXT-WIDTH-PIX',
|
||||
'GET-TEXT-WIDTH-PIXE', 'GET-TEXT-WIDTH-PIXEL', 'GET-TYPE-BY-INDEX',
|
||||
'GET-TYPE-BY-NAMESPACE-NAME', 'GET-TYPE-BY-QNAME', 'GET-UNSIGNED-LONG',
|
||||
'GET-UNSIGNED-SHORT', 'GET-URI-BY-INDEX', 'GET-VALUE-BY-INDEX',
|
||||
'GET-VALUE-BY-NAMESPACE-NAME', 'GET-VALUE-BY-QNAME', 'GET-WAIT-STATE',
|
||||
'GLOBAL', 'GO-ON', 'GO-PENDING', 'GO-PEND', 'GO-PENDI', 'GO-PENDIN',
|
||||
'GRANT', 'GRAPHIC-EDGE', 'GRAPHIC-E', 'GRAPHIC-ED', 'GRAPHIC-EDG',
|
||||
'GRID-FACTOR-HORIZONTAL', 'GRID-FACTOR-H', 'GRID-FACTOR-HO',
|
||||
'GRID-FACTOR-HOR', 'GRID-FACTOR-HORI', 'GRID-FACTOR-HORIZ',
|
||||
'GRID-FACTOR-HORIZO', 'GRID-FACTOR-HORIZON', 'GRID-FACTOR-HORIZONT',
|
||||
'GRID-FACTOR-HORIZONTA', 'GRID-FACTOR-VERTICAL', 'GRID-FACTOR-V',
|
||||
'GRID-FACTOR-VE', 'GRID-FACTOR-VER', 'GRID-FACTOR-VERT', 'GRID-FACTOR-VERT',
|
||||
'GRID-FACTOR-VERTI', 'GRID-FACTOR-VERTIC', 'GRID-FACTOR-VERTICA',
|
||||
'GRID-SNAP', 'GRID-UNIT-HEIGHT-CHARS', 'GRID-UNIT-HEIGHT',
|
||||
'GRID-UNIT-HEIGHT-', 'GRID-UNIT-HEIGHT-C', 'GRID-UNIT-HEIGHT-CH',
|
||||
'GRID-UNIT-HEIGHT-CHA', 'GRID-UNIT-HEIGHT-PIXELS', 'GRID-UNIT-HEIGHT-P',
|
||||
'GRID-UNIT-HEIGHT-PI', 'GRID-UNIT-HEIGHT-PIX', 'GRID-UNIT-HEIGHT-PIXE',
|
||||
'GRID-UNIT-HEIGHT-PIXEL', 'GRID-UNIT-WIDTH-CHARS', 'GRID-UNIT-WIDTH',
|
||||
'GRID-UNIT-WIDTH-', 'GRID-UNIT-WIDTH-C', 'GRID-UNIT-WIDTH-CH',
|
||||
'GRID-UNIT-WIDTH-CHA', 'GRID-UNIT-WIDTH-CHAR', 'GRID-UNIT-WIDTH-PIXELS',
|
||||
'GRID-UNIT-WIDTH-P', 'GRID-UNIT-WIDTH-PI', 'GRID-UNIT-WIDTH-PIX',
|
||||
'GRID-UNIT-WIDTH-PIXE', 'GRID-UNIT-WIDTH-PIXEL', 'GRID-VISIBLE', 'GROUP',
|
||||
'GT', 'GUID', 'HANDLER', 'HAS-RECORDS', 'HAVING', 'HEADER', 'HEIGHT-CHARS',
|
||||
'HEIGHT', 'HEIGHT-', 'HEIGHT-C', 'HEIGHT-CH', 'HEIGHT-CHA', 'HEIGHT-CHAR',
|
||||
'HEIGHT-PIXELS', 'HEIGHT-P', 'HEIGHT-PI', 'HEIGHT-PIX', 'HEIGHT-PIXE',
|
||||
'HEIGHT-PIXEL', 'HELP', 'HEX-DECODE', 'HEX-ENCODE', 'HIDDEN', 'HIDE',
|
||||
'HORIZONTAL', 'HORI', 'HORIZ', 'HORIZO', 'HORIZON', 'HORIZONT', 'HORIZONTA',
|
||||
'HOST-BYTE-ORDER', 'HTML-CHARSET', 'HTML-END-OF-LINE', 'HTML-END-OF-PAGE',
|
||||
'HTML-FRAME-BEGIN', 'HTML-FRAME-END', 'HTML-HEADER-BEGIN',
|
||||
'HTML-HEADER-END', 'HTML-TITLE-BEGIN', 'HTML-TITLE-END', 'HWND', 'ICON',
|
||||
'IF', 'IMAGE', 'IMAGE-DOWN', 'IMAGE-INSENSITIVE', 'IMAGE-SIZE',
|
||||
'IMAGE-SIZE-CHARS', 'IMAGE-SIZE-C', 'IMAGE-SIZE-CH', 'IMAGE-SIZE-CHA',
|
||||
'IMAGE-SIZE-CHAR', 'IMAGE-SIZE-PIXELS', 'IMAGE-SIZE-P', 'IMAGE-SIZE-PI',
|
||||
'IMAGE-SIZE-PIX', 'IMAGE-SIZE-PIXE', 'IMAGE-SIZE-PIXEL', 'IMAGE-UP',
|
||||
'IMMEDIATE-DISPLAY', 'IMPLEMENTS', 'IMPORT', 'IMPORT-PRINCIPAL', 'IN',
|
||||
'INCREMENT-EXCLUSIVE-ID', 'INDEX', 'INDEXED-REPOSITION', 'INDEX-HINT',
|
||||
'INDEX-INFORMATION', 'INDICATOR', 'INFORMATION', 'INFO', 'INFOR', 'INFORM',
|
||||
'INFORMA', 'INFORMAT', 'INFORMATI', 'INFORMATIO', 'IN-HANDLE',
|
||||
'INHERIT-BGCOLOR', 'INHERIT-BGC', 'INHERIT-BGCO', 'INHERIT-BGCOL',
|
||||
'INHERIT-BGCOLO', 'INHERIT-FGCOLOR', 'INHERIT-FGC', 'INHERIT-FGCO',
|
||||
'INHERIT-FGCOL', 'INHERIT-FGCOLO', 'INHERITS', 'INITIAL', 'INIT', 'INITI',
|
||||
'INITIA', 'INITIAL-DIR', 'INITIAL-FILTER', 'INITIALIZE-DOCUMENT-TYPE',
|
||||
'INITIATE', 'INNER-CHARS', 'INNER-LINES', 'INPUT', 'INPUT-OUTPUT',
|
||||
'INPUT-O', 'INPUT-OU', 'INPUT-OUT', 'INPUT-OUTP', 'INPUT-OUTPU',
|
||||
'INPUT-VALUE', 'INSERT', 'INSERT-ATTRIBUTE', 'INSERT-BACKTAB', 'INSERT-B',
|
||||
'INSERT-BA', 'INSERT-BAC', 'INSERT-BACK', 'INSERT-BACKT', 'INSERT-BACKTA',
|
||||
'INSERT-FILE', 'INSERT-ROW', 'INSERT-STRING', 'INSERT-TAB', 'INSERT-T',
|
||||
'INSERT-TA', 'INTERFACE', 'INTERNAL-ENTRIES', 'INTO', 'INVOKE', 'IS',
|
||||
'IS-ATTR-SPACE', 'IS-ATTR', 'IS-ATTR-', 'IS-ATTR-S', 'IS-ATTR-SP',
|
||||
'IS-ATTR-SPA', 'IS-ATTR-SPAC', 'IS-CLASS', 'IS-CLAS', 'IS-LEAD-BYTE',
|
||||
'IS-ATTR', 'IS-OPEN', 'IS-PARAMETER-SET', 'IS-ROW-SELECTED', 'IS-SELECTED',
|
||||
'ITEM', 'ITEMS-PER-ROW', 'JOIN', 'JOIN-BY-SQLDB', 'KBLABEL',
|
||||
'KEEP-CONNECTION-OPEN', 'KEEP-FRAME-Z-ORDER', 'KEEP-FRAME-Z',
|
||||
'KEEP-FRAME-Z-', 'KEEP-FRAME-Z-O', 'KEEP-FRAME-Z-OR', 'KEEP-FRAME-Z-ORD',
|
||||
'KEEP-FRAME-Z-ORDE', 'KEEP-MESSAGES', 'KEEP-SECURITY-CACHE',
|
||||
'KEEP-TAB-ORDER', 'KEY', 'KEYCODE', 'KEY-CODE', 'KEYFUNCTION', 'KEYFUNC',
|
||||
'KEYFUNCT', 'KEYFUNCTI', 'KEYFUNCTIO', 'KEY-FUNCTION', 'KEY-FUNC',
|
||||
'KEY-FUNCT', 'KEY-FUNCTI', 'KEY-FUNCTIO', 'KEYLABEL', 'KEY-LABEL', 'KEYS',
|
||||
'KEYWORD', 'KEYWORD-ALL', 'LABEL', 'LABEL-BGCOLOR', 'LABEL-BGC',
|
||||
'LABEL-BGCO', 'LABEL-BGCOL', 'LABEL-BGCOLO', 'LABEL-DCOLOR', 'LABEL-DC',
|
||||
'LABEL-DCO', 'LABEL-DCOL', 'LABEL-DCOLO', 'LABEL-FGCOLOR', 'LABEL-FGC',
|
||||
'LABEL-FGCO', 'LABEL-FGCOL', 'LABEL-FGCOLO', 'LABEL-FONT', 'LABEL-PFCOLOR',
|
||||
'LABEL-PFC', 'LABEL-PFCO', 'LABEL-PFCOL', 'LABEL-PFCOLO', 'LABELS',
|
||||
'LANDSCAPE', 'LANGUAGES', 'LANGUAGE', 'LARGE', 'LARGE-TO-SMALL', 'LAST',
|
||||
'LAST-ASYNCH-REQUEST', 'LAST-BATCH', 'LAST-CHILD', 'LAST-EVENT',
|
||||
'LAST-EVEN', 'LAST-FORM', 'LASTKEY', 'LAST-KEY', 'LAST-OBJECT', 'LAST-OF',
|
||||
'LAST-PROCEDURE', 'LAST-PROCE', 'LAST-PROCED', 'LAST-PROCEDU',
|
||||
'LAST-PROCEDUR', 'LAST-SERVER', 'LAST-TAB-ITEM', 'LAST-TAB-I',
|
||||
'LAST-TAB-IT', 'LAST-TAB-ITE', 'LC', 'LDBNAME', 'LE', 'LEAVE',
|
||||
'LEFT-ALIGNED', 'LEFT-ALIGN', 'LEFT-ALIGNE', 'LEFT-TRIM', 'LENGTH',
|
||||
'LIBRARY', 'LIKE', 'LIKE-SEQUENTIAL', 'LINE', 'LINE-COUNTER', 'LINE-COUNT',
|
||||
'LINE-COUNTE', 'LIST-EVENTS', 'LISTING', 'LISTI', 'LISTIN',
|
||||
'LIST-ITEM-PAIRS', 'LIST-ITEMS', 'LIST-PROPERTY-NAMES', 'LIST-QUERY-ATTRS',
|
||||
'LIST-SET-ATTRS', 'LIST-WIDGETS', 'LITERAL-QUESTION', 'LITTLE-ENDIAN',
|
||||
'LOAD', 'LOAD-DOMAINS', 'LOAD-ICON', 'LOAD-IMAGE', 'LOAD-IMAGE-DOWN',
|
||||
'LOAD-IMAGE-INSENSITIVE', 'LOAD-IMAGE-UP', 'LOAD-MOUSE-POINTER',
|
||||
'LOAD-MOUSE-P', 'LOAD-MOUSE-PO', 'LOAD-MOUSE-POI', 'LOAD-MOUSE-POIN',
|
||||
'LOAD-MOUSE-POINT', 'LOAD-MOUSE-POINTE', 'LOAD-PICTURE', 'LOAD-SMALL-ICON',
|
||||
'LOCAL-NAME', 'LOCATOR-COLUMN-NUMBER', 'LOCATOR-LINE-NUMBER',
|
||||
'LOCATOR-PUBLIC-ID', 'LOCATOR-SYSTEM-ID', 'LOCATOR-TYPE', 'LOCKED',
|
||||
'LOCK-REGISTRATION', 'LOG', 'LOG-AUDIT-EVENT', 'LOGIN-EXPIRATION-TIMESTAMP',
|
||||
'LOGIN-HOST', 'LOGIN-STATE', 'LOG-MANAGER', 'LOGOUT', 'LOOKAHEAD', 'LOOKUP',
|
||||
'LT', 'MACHINE-CLASS', 'MANDATORY', 'MANUAL-HIGHLIGHT', 'MAP',
|
||||
'MARGIN-EXTRA', 'MARGIN-HEIGHT-CHARS', 'MARGIN-HEIGHT', 'MARGIN-HEIGHT-',
|
||||
'MARGIN-HEIGHT-C', 'MARGIN-HEIGHT-CH', 'MARGIN-HEIGHT-CHA',
|
||||
'MARGIN-HEIGHT-CHAR', 'MARGIN-HEIGHT-PIXELS', 'MARGIN-HEIGHT-P',
|
||||
'MARGIN-HEIGHT-PI', 'MARGIN-HEIGHT-PIX', 'MARGIN-HEIGHT-PIXE',
|
||||
'MARGIN-HEIGHT-PIXEL', 'MARGIN-WIDTH-CHARS', 'MARGIN-WIDTH',
|
||||
'MARGIN-WIDTH-', 'MARGIN-WIDTH-C', 'MARGIN-WIDTH-CH', 'MARGIN-WIDTH-CHA',
|
||||
'MARGIN-WIDTH-CHAR', 'MARGIN-WIDTH-PIXELS', 'MARGIN-WIDTH-P',
|
||||
'MARGIN-WIDTH-PI', 'MARGIN-WIDTH-PIX', 'MARGIN-WIDTH-PIXE',
|
||||
'MARGIN-WIDTH-PIXEL', 'MARK-NEW', 'MARK-ROW-STATE', 'MATCHES', 'MAX',
|
||||
'MAX-BUTTON', 'MAX-CHARS', 'MAX-DATA-GUESS', 'MAX-HEIGHT',
|
||||
'MAX-HEIGHT-CHARS', 'MAX-HEIGHT-C', 'MAX-HEIGHT-CH', 'MAX-HEIGHT-CHA',
|
||||
'MAX-HEIGHT-CHAR', 'MAX-HEIGHT-PIXELS', 'MAX-HEIGHT-P', 'MAX-HEIGHT-PI',
|
||||
'MAX-HEIGHT-PIX', 'MAX-HEIGHT-PIXE', 'MAX-HEIGHT-PIXEL', 'MAXIMIZE',
|
||||
'MAXIMUM', 'MAX', 'MAXI', 'MAXIM', 'MAXIMU', 'MAXIMUM-LEVEL', 'MAX-ROWS',
|
||||
'MAX-SIZE', 'MAX-VALUE', 'MAX-VAL', 'MAX-VALU', 'MAX-WIDTH',
|
||||
'MAX-WIDTH-CHARS', 'MAX-WIDTH', 'MAX-WIDTH-', 'MAX-WIDTH-C', 'MAX-WIDTH-CH',
|
||||
'MAX-WIDTH-CHA', 'MAX-WIDTH-CHAR', 'MAX-WIDTH-PIXELS', 'MAX-WIDTH-P',
|
||||
'MAX-WIDTH-PI', 'MAX-WIDTH-PIX', 'MAX-WIDTH-PIXE', 'MAX-WIDTH-PIXEL',
|
||||
'MD5-DIGEST', 'MEMBER', 'MEMPTR-TO-NODE-VALUE', 'MENU', 'MENUBAR',
|
||||
'MENU-BAR', 'MENU-ITEM', 'MENU-KEY', 'MENU-K', 'MENU-KE', 'MENU-MOUSE',
|
||||
'MENU-M', 'MENU-MO', 'MENU-MOU', 'MENU-MOUS', 'MERGE-BY-FIELD', 'MESSAGE',
|
||||
'MESSAGE-AREA', 'MESSAGE-AREA-FONT', 'MESSAGE-LINES', 'METHOD', 'MIN',
|
||||
'MIN-BUTTON', 'MIN-COLUMN-WIDTH-CHARS', 'MIN-COLUMN-WIDTH-C',
|
||||
'MIN-COLUMN-WIDTH-CH', 'MIN-COLUMN-WIDTH-CHA', 'MIN-COLUMN-WIDTH-CHAR',
|
||||
'MIN-COLUMN-WIDTH-PIXELS', 'MIN-COLUMN-WIDTH-P', 'MIN-COLUMN-WIDTH-PI',
|
||||
'MIN-COLUMN-WIDTH-PIX', 'MIN-COLUMN-WIDTH-PIXE', 'MIN-COLUMN-WIDTH-PIXEL',
|
||||
'MIN-HEIGHT-CHARS', 'MIN-HEIGHT', 'MIN-HEIGHT-', 'MIN-HEIGHT-C',
|
||||
'MIN-HEIGHT-CH', 'MIN-HEIGHT-CHA', 'MIN-HEIGHT-CHAR', 'MIN-HEIGHT-PIXELS',
|
||||
'MIN-HEIGHT-P', 'MIN-HEIGHT-PI', 'MIN-HEIGHT-PIX', 'MIN-HEIGHT-PIXE',
|
||||
'MIN-HEIGHT-PIXEL', 'MINIMUM', 'MIN', 'MINI', 'MINIM', 'MINIMU', 'MIN-SIZE',
|
||||
'MIN-VALUE', 'MIN-VAL', 'MIN-VALU', 'MIN-WIDTH-CHARS', 'MIN-WIDTH',
|
||||
'MIN-WIDTH-', 'MIN-WIDTH-C', 'MIN-WIDTH-CH', 'MIN-WIDTH-CHA',
|
||||
'MIN-WIDTH-CHAR', 'MIN-WIDTH-PIXELS', 'MIN-WIDTH-P', 'MIN-WIDTH-PI',
|
||||
'MIN-WIDTH-PIX', 'MIN-WIDTH-PIXE', 'MIN-WIDTH-PIXEL', 'MODIFIED', 'MODULO',
|
||||
'MOD', 'MODU', 'MODUL', 'MONTH', 'MOUSE', 'MOUSE-POINTER', 'MOUSE-P',
|
||||
'MOUSE-PO', 'MOUSE-POI', 'MOUSE-POIN', 'MOUSE-POINT', 'MOUSE-POINTE',
|
||||
'MOVABLE', 'MOVE-AFTER-TAB-ITEM', 'MOVE-AFTER', 'MOVE-AFTER-',
|
||||
'MOVE-AFTER-T', 'MOVE-AFTER-TA', 'MOVE-AFTER-TAB', 'MOVE-AFTER-TAB-',
|
||||
'MOVE-AFTER-TAB-I', 'MOVE-AFTER-TAB-IT', 'MOVE-AFTER-TAB-ITE',
|
||||
'MOVE-BEFORE-TAB-ITEM', 'MOVE-BEFOR', 'MOVE-BEFORE', 'MOVE-BEFORE-',
|
||||
'MOVE-BEFORE-T', 'MOVE-BEFORE-TA', 'MOVE-BEFORE-TAB', 'MOVE-BEFORE-TAB-',
|
||||
'MOVE-BEFORE-TAB-I', 'MOVE-BEFORE-TAB-IT', 'MOVE-BEFORE-TAB-ITE',
|
||||
'MOVE-COLUMN', 'MOVE-COL', 'MOVE-COLU', 'MOVE-COLUM', 'MOVE-TO-BOTTOM',
|
||||
'MOVE-TO-B', 'MOVE-TO-BO', 'MOVE-TO-BOT', 'MOVE-TO-BOTT', 'MOVE-TO-BOTTO',
|
||||
'MOVE-TO-EOF', 'MOVE-TO-TOP', 'MOVE-TO-T', 'MOVE-TO-TO', 'MPE',
|
||||
'MULTI-COMPILE', 'MULTIPLE', 'MULTIPLE-KEY', 'MULTITASKING-INTERVAL',
|
||||
'MUST-EXIST', 'NAME', 'NAMESPACE-PREFIX', 'NAMESPACE-URI', 'NATIVE', 'NE',
|
||||
'NEEDS-APPSERVER-PROMPT', 'NEEDS-PROMPT', 'NEW', 'NEW-INSTANCE', 'NEW-ROW',
|
||||
'NEXT', 'NEXT-COLUMN', 'NEXT-PROMPT', 'NEXT-ROWID', 'NEXT-SIBLING',
|
||||
'NEXT-TAB-ITEM', 'NEXT-TAB-I', 'NEXT-TAB-IT', 'NEXT-TAB-ITE', 'NEXT-VALUE',
|
||||
'NO', 'NO-APPLY', 'NO-ARRAY-MESSAGE', 'NO-ASSIGN', 'NO-ATTR-LIST',
|
||||
'NO-ATTR', 'NO-ATTR-', 'NO-ATTR-L', 'NO-ATTR-LI', 'NO-ATTR-LIS',
|
||||
'NO-ATTR-SPACE', 'NO-ATTR', 'NO-ATTR-', 'NO-ATTR-S', 'NO-ATTR-SP',
|
||||
'NO-ATTR-SPA', 'NO-ATTR-SPAC', 'NO-AUTO-VALIDATE', 'NO-BIND-WHERE',
|
||||
'NO-BOX', 'NO-CONSOLE', 'NO-CONVERT', 'NO-CONVERT-3D-COLORS',
|
||||
'NO-CURRENT-VALUE', 'NO-DEBUG', 'NODE-VALUE-TO-MEMPTR', 'NO-DRAG',
|
||||
'NO-ECHO', 'NO-EMPTY-SPACE', 'NO-ERROR', 'NO-FILL', 'NO-F', 'NO-FI',
|
||||
'NO-FIL', 'NO-FOCUS', 'NO-HELP', 'NO-HIDE', 'NO-INDEX-HINT',
|
||||
'NO-INHERIT-BGCOLOR', 'NO-INHERIT-BGC', 'NO-INHERIT-BGCO', 'LABEL-BGCOL',
|
||||
'LABEL-BGCOLO', 'NO-INHERIT-FGCOLOR', 'NO-INHERIT-FGC', 'NO-INHERIT-FGCO',
|
||||
'NO-INHERIT-FGCOL', 'NO-INHERIT-FGCOLO', 'NO-JOIN-BY-SQLDB', 'NO-LABELS',
|
||||
'NO-LABE', 'NO-LOBS', 'NO-LOCK', 'NO-LOOKAHEAD', 'NO-MAP', 'NO-MESSAGE',
|
||||
'NO-MES', 'NO-MESS', 'NO-MESSA', 'NO-MESSAG', 'NONAMESPACE-SCHEMA-LOCATION',
|
||||
'NONE', 'NO-PAUSE', 'NO-PREFETCH', 'NO-PREFE', 'NO-PREFET', 'NO-PREFETC',
|
||||
'NORMALIZE', 'NO-ROW-MARKERS', 'NO-SCROLLBAR-VERTICAL',
|
||||
'NO-SEPARATE-CONNECTION', 'NO-SEPARATORS', 'NOT', 'NO-TAB-STOP',
|
||||
'NOT-ACTIVE', 'NO-UNDERLINE', 'NO-UND', 'NO-UNDE', 'NO-UNDER', 'NO-UNDERL',
|
||||
'NO-UNDERLI', 'NO-UNDERLIN', 'NO-UNDO', 'NO-VALIDATE', 'NO-VAL', 'NO-VALI',
|
||||
'NO-VALID', 'NO-VALIDA', 'NO-VALIDAT', 'NOW', 'NO-WAIT', 'NO-WORD-WRAP',
|
||||
'NULL', 'NUM-ALIASES', 'NUM-ALI', 'NUM-ALIA', 'NUM-ALIAS', 'NUM-ALIASE',
|
||||
'NUM-BUFFERS', 'NUM-BUTTONS', 'NUM-BUT', 'NUM-BUTT', 'NUM-BUTTO',
|
||||
'NUM-BUTTON', 'NUM-COLUMNS', 'NUM-COL', 'NUM-COLU', 'NUM-COLUM',
|
||||
'NUM-COLUMN', 'NUM-COPIES', 'NUM-DBS', 'NUM-DROPPED-FILES', 'NUM-ENTRIES',
|
||||
'NUMERIC', 'NUMERIC-FORMAT', 'NUMERIC-F', 'NUMERIC-FO', 'NUMERIC-FOR',
|
||||
'NUMERIC-FORM', 'NUMERIC-FORMA', 'NUM-FIELDS', 'NUM-FORMATS', 'NUM-ITEMS',
|
||||
'NUM-ITERATIONS', 'NUM-LINES', 'NUM-LOCKED-COLUMNS', 'NUM-LOCKED-COL',
|
||||
'NUM-LOCKED-COLU', 'NUM-LOCKED-COLUM', 'NUM-LOCKED-COLUMN', 'NUM-MESSAGES',
|
||||
'NUM-PARAMETERS', 'NUM-REFERENCES', 'NUM-REPLACED', 'NUM-RESULTS',
|
||||
'NUM-SELECTED-ROWS', 'NUM-SELECTED-WIDGETS', 'NUM-SELECTED',
|
||||
'NUM-SELECTED-', 'NUM-SELECTED-W', 'NUM-SELECTED-WI', 'NUM-SELECTED-WID',
|
||||
'NUM-SELECTED-WIDG', 'NUM-SELECTED-WIDGE', 'NUM-SELECTED-WIDGET',
|
||||
'NUM-TABS', 'NUM-TO-RETAIN', 'NUM-VISIBLE-COLUMNS', 'OCTET-LENGTH', 'OF',
|
||||
'OFF', 'OK', 'OK-CANCEL', 'OLD', 'ON', 'ON-FRAME-BORDER', 'ON-FRAME',
|
||||
'ON-FRAME-', 'ON-FRAME-B', 'ON-FRAME-BO', 'ON-FRAME-BOR', 'ON-FRAME-BORD',
|
||||
'ON-FRAME-BORDE', 'OPEN', 'OPSYS', 'OPTION', 'OR', 'ORDERED-JOIN',
|
||||
'ORDINAL', 'OS-APPEND', 'OS-COMMAND', 'OS-COPY', 'OS-CREATE-DIR',
|
||||
'OS-DELETE', 'OS-DIR', 'OS-DRIVES', 'OS-DRIVE', 'OS-ERROR', 'OS-GETENV',
|
||||
'OS-RENAME', 'OTHERWISE', 'OUTPUT', 'OVERLAY', 'OVERRIDE', 'OWNER', 'PAGE',
|
||||
'PAGE-BOTTOM', 'PAGE-BOT', 'PAGE-BOTT', 'PAGE-BOTTO', 'PAGED',
|
||||
'PAGE-NUMBER', 'PAGE-NUM', 'PAGE-NUMB', 'PAGE-NUMBE', 'PAGE-SIZE',
|
||||
'PAGE-TOP', 'PAGE-WIDTH', 'PAGE-WID', 'PAGE-WIDT', 'PARAMETER', 'PARAM',
|
||||
'PARAME', 'PARAMET', 'PARAMETE', 'PARENT', 'PARSE-STATUS', 'PARTIAL-KEY',
|
||||
'PASCAL', 'PASSWORD-FIELD', 'PATHNAME', 'PAUSE', 'PBE-HASH-ALGORITHM',
|
||||
'PBE-HASH-ALG', 'PBE-HASH-ALGO', 'PBE-HASH-ALGOR', 'PBE-HASH-ALGORI',
|
||||
'PBE-HASH-ALGORIT', 'PBE-HASH-ALGORITH', 'PBE-KEY-ROUNDS', 'PDBNAME',
|
||||
'PERSISTENT', 'PERSIST', 'PERSISTE', 'PERSISTEN',
|
||||
'PERSISTENT-CACHE-DISABLED', 'PFCOLOR', 'PFC', 'PFCO', 'PFCOL', 'PFCOLO',
|
||||
'PIXELS', 'PIXELS-PER-COLUMN', 'PIXELS-PER-COL', 'PIXELS-PER-COLU',
|
||||
'PIXELS-PER-COLUM', 'PIXELS-PER-ROW', 'POPUP-MENU', 'POPUP-M', 'POPUP-ME',
|
||||
'POPUP-MEN', 'POPUP-ONLY', 'POPUP-O', 'POPUP-ON', 'POPUP-ONL', 'PORTRAIT',
|
||||
'POSITION', 'PRECISION', 'PREFER-DATASET', 'PREPARED', 'PREPARE-STRING',
|
||||
'PREPROCESS', 'PREPROC', 'PREPROCE', 'PREPROCES', 'PRESELECT', 'PRESEL',
|
||||
'PRESELE', 'PRESELEC', 'PREV', 'PREV-COLUMN', 'PREV-SIBLING',
|
||||
'PREV-TAB-ITEM', 'PREV-TAB-I', 'PREV-TAB-IT', 'PREV-TAB-ITE', 'PRIMARY',
|
||||
'PRINTER', 'PRINTER-CONTROL-HANDLE', 'PRINTER-HDC', 'PRINTER-NAME',
|
||||
'PRINTER-PORT', 'PRINTER-SETUP', 'PRIVATE', 'PRIVATE-DATA', 'PRIVATE-D',
|
||||
'PRIVATE-DA', 'PRIVATE-DAT', 'PRIVILEGES', 'PROCEDURE', 'PROCE', 'PROCED',
|
||||
'PROCEDU', 'PROCEDUR', 'PROCEDURE-CALL-TYPE', 'PROCESS', 'PROC-HANDLE',
|
||||
'PROC-HA', 'PROC-HAN', 'PROC-HAND', 'PROC-HANDL', 'PROC-STATUS', 'PROC-ST',
|
||||
'PROC-STA', 'PROC-STAT', 'PROC-STATU', 'proc-text', 'proc-text-buffe',
|
||||
'PROFILER', 'PROGRAM-NAME', 'PROGRESS', 'PROGRESS-SOURCE', 'PROGRESS-S',
|
||||
'PROGRESS-SO', 'PROGRESS-SOU', 'PROGRESS-SOUR', 'PROGRESS-SOURC', 'PROMPT',
|
||||
'PROMPT-FOR', 'PROMPT-F', 'PROMPT-FO', 'PROMSGS', 'PROPATH', 'PROPERTY',
|
||||
'PROTECTED', 'PROVERSION', 'PROVERS', 'PROVERSI', 'PROVERSIO', 'PROXY',
|
||||
'PROXY-PASSWORD', 'PROXY-USERID', 'PUBLIC', 'PUBLIC-ID', 'PUBLISH',
|
||||
'PUBLISHED-EVENTS', 'PUT', 'PUTBYTE', 'PUT-BYTE', 'PUT-DOUBLE', 'PUT-FLOAT',
|
||||
'PUT-INT64', 'PUT-KEY-VALUE', 'PUT-KEY-VAL', 'PUT-KEY-VALU', 'PUT-LONG',
|
||||
'PUT-SHORT', 'PUT-STRING', 'PUT-UNSIGNED-LONG', 'QUERY', 'QUERY-CLOSE',
|
||||
'QUERY-OFF-END', 'QUERY-OPEN', 'QUERY-PREPARE', 'QUERY-TUNING', 'QUESTION',
|
||||
'QUIT', 'QUOTER', 'RADIO-BUTTONS', 'RADIO-SET', 'RANDOM', 'RAW-TRANSFER',
|
||||
'RCODE-INFORMATION', 'RCODE-INFO', 'RCODE-INFOR', 'RCODE-INFORM',
|
||||
'RCODE-INFORMA', 'RCODE-INFORMAT', 'RCODE-INFORMATI', 'RCODE-INFORMATIO',
|
||||
'READ-AVAILABLE', 'READ-EXACT-NUM', 'READ-FILE', 'READKEY', 'READ-ONLY',
|
||||
'READ-XML', 'READ-XMLSCHEMA', 'REAL', 'RECORD-LENGTH', 'RECTANGLE', 'RECT',
|
||||
'RECTA', 'RECTAN', 'RECTANG', 'RECTANGL', 'RECURSIVE', 'REFERENCE-ONLY',
|
||||
'REFRESH', 'REFRESHABLE', 'REFRESH-AUDIT-POLICY', 'REGISTER-DOMAIN',
|
||||
'RELEASE', 'REMOTE', 'REMOVE-EVENTS-PROCEDURE', 'REMOVE-SUPER-PROCEDURE',
|
||||
'REPEAT', 'REPLACE', 'REPLACE-SELECTION-TEXT', 'REPOSITION',
|
||||
'REPOSITION-BACKWARD', 'REPOSITION-FORWARD', 'REPOSITION-MODE',
|
||||
'REPOSITION-TO-ROW', 'REPOSITION-TO-ROWID', 'REQUEST', 'RESET', 'RESIZABLE',
|
||||
'RESIZA', 'RESIZAB', 'RESIZABL', 'RESIZE', 'RESTART-ROW', 'RESTART-ROWID',
|
||||
'RETAIN', 'RETAIN-SHAPE', 'RETRY', 'RETRY-CANCEL', 'RETURN',
|
||||
'RETURN-INSERTED', 'RETURN-INS', 'RETURN-INSE', 'RETURN-INSER',
|
||||
'RETURN-INSERT', 'RETURN-INSERTE', 'RETURNS', 'RETURN-TO-START-DIR',
|
||||
'RETURN-TO-START-DI', 'RETURN-VALUE', 'RETURN-VAL', 'RETURN-VALU',
|
||||
'RETURN-VALUE-DATA-TYPE', 'REVERSE-FROM', 'REVERT', 'REVOKE', 'RGB-VALUE',
|
||||
'RIGHT-ALIGNED', 'RETURN-ALIGN', 'RETURN-ALIGNE', 'RIGHT-TRIM', 'R-INDEX',
|
||||
'ROLES', 'ROUND', 'ROUTINE-LEVEL', 'ROW', 'ROW-HEIGHT-CHARS', 'HEIGHT',
|
||||
'ROW-HEIGHT-PIXELS', 'HEIGHT-P', 'ROW-MARKERS', 'ROW-OF', 'ROW-RESIZABLE',
|
||||
'RULE', 'RUN', 'RUN-PROCEDURE', 'SAVE', 'SAVE-AS', 'SAVE-FILE',
|
||||
'SAX-COMPLETE', 'SAX-COMPLE', 'SAX-COMPLET', 'SAX-PARSE', 'SAX-PARSE-FIRST',
|
||||
'SAX-PARSE-NEXT', 'SAX-PARSER-ERROR', 'SAX-RUNNING', 'SAX-UNINITIALIZED',
|
||||
'SAX-WRITE-BEGIN', 'SAX-WRITE-COMPLETE', 'SAX-WRITE-CONTENT',
|
||||
'SAX-WRITE-ELEMENT', 'SAX-WRITE-ERROR', 'SAX-WRITE-IDLE', 'SAX-WRITER',
|
||||
'SAX-WRITE-TAG', 'SCHEMA', 'SCHEMA-LOCATION', 'SCHEMA-MARSHAL',
|
||||
'SCHEMA-PATH', 'SCREEN', 'SCREEN-IO', 'SCREEN-LINES', 'SCREEN-VALUE',
|
||||
'SCREEN-VAL', 'SCREEN-VALU', 'SCROLL', 'SCROLLABLE', 'SCROLLBAR-HORIZONTAL',
|
||||
'SCROLLBAR-H', 'SCROLLBAR-HO', 'SCROLLBAR-HOR', 'SCROLLBAR-HORI',
|
||||
'SCROLLBAR-HORIZ', 'SCROLLBAR-HORIZO', 'SCROLLBAR-HORIZON',
|
||||
'SCROLLBAR-HORIZONT', 'SCROLLBAR-HORIZONTA', 'SCROLL-BARS',
|
||||
'SCROLLBAR-VERTICAL', 'SCROLLBAR-V', 'SCROLLBAR-VE', 'SCROLLBAR-VER',
|
||||
'SCROLLBAR-VERT', 'SCROLLBAR-VERTI', 'SCROLLBAR-VERTIC',
|
||||
'SCROLLBAR-VERTICA', 'SCROLL-DELTA', 'SCROLLED-ROW-POSITION',
|
||||
'SCROLLED-ROW-POS', 'SCROLLED-ROW-POSI', 'SCROLLED-ROW-POSIT',
|
||||
'SCROLLED-ROW-POSITI', 'SCROLLED-ROW-POSITIO', 'SCROLLING', 'SCROLL-OFFSET',
|
||||
'SCROLL-TO-CURRENT-ROW', 'SCROLL-TO-ITEM', 'SCROLL-TO-I', 'SCROLL-TO-IT',
|
||||
'SCROLL-TO-ITE', 'SCROLL-TO-SELECTED-ROW', 'SDBNAME', 'SEAL',
|
||||
'SEAL-TIMESTAMP', 'SEARCH', 'SEARCH-SELF', 'SEARCH-TARGET', 'SECTION',
|
||||
'SECURITY-POLICY', 'SEEK', 'SELECT', 'SELECTABLE', 'SELECT-ALL', 'SELECTED',
|
||||
'SELECT-FOCUSED-ROW', 'SELECTION', 'SELECTION-END', 'SELECTION-LIST',
|
||||
'SELECTION-START', 'SELECTION-TEXT', 'SELECT-NEXT-ROW', 'SELECT-PREV-ROW',
|
||||
'SELECT-ROW', 'SELF', 'SEND', 'send-sql-statement', 'send-sql', 'SENSITIVE',
|
||||
'SEPARATE-CONNECTION', 'SEPARATOR-FGCOLOR', 'SEPARATORS', 'SERVER',
|
||||
'SERVER-CONNECTION-BOUND', 'SERVER-CONNECTION-BOUND-REQUEST',
|
||||
'SERVER-CONNECTION-CONTEXT', 'SERVER-CONNECTION-ID',
|
||||
'SERVER-OPERATING-MODE', 'SESSION', 'SESSION-ID', 'SET', 'SET-APPL-CONTEXT',
|
||||
'SET-ATTR-CALL-TYPE', 'SET-ATTRIBUTE-NODE', 'SET-BLUE-VALUE', 'SET-BLUE',
|
||||
'SET-BLUE-', 'SET-BLUE-V', 'SET-BLUE-VA', 'SET-BLUE-VAL', 'SET-BLUE-VALU',
|
||||
'SET-BREAK', 'SET-BUFFERS', 'SET-CALLBACK', 'SET-CLIENT', 'SET-COMMIT',
|
||||
'SET-CONTENTS', 'SET-CURRENT-VALUE', 'SET-DB-CLIENT', 'SET-DYNAMIC',
|
||||
'SET-EVENT-MANAGER-OPTION', 'SET-GREEN-VALUE', 'SET-GREEN', 'SET-GREEN-',
|
||||
'SET-GREEN-V', 'SET-GREEN-VA', 'SET-GREEN-VAL', 'SET-GREEN-VALU',
|
||||
'SET-INPUT-SOURCE', 'SET-OPTION', 'SET-OUTPUT-DESTINATION', 'SET-PARAMETER',
|
||||
'SET-POINTER-VALUE', 'SET-PROPERTY', 'SET-RED-VALUE', 'SET-RED', 'SET-RED-',
|
||||
'SET-RED-V', 'SET-RED-VA', 'SET-RED-VAL', 'SET-RED-VALU',
|
||||
'SET-REPOSITIONED-ROW', 'SET-RGB-VALUE', 'SET-ROLLBACK', 'SET-SELECTION',
|
||||
'SET-SIZE', 'SET-SORT-ARROW', 'SETUSERID', 'SETUSER', 'SETUSERI',
|
||||
'SET-WAIT-STATE', 'SHA1-DIGEST', 'SHARED', 'SHARE-LOCK', 'SHARE', 'SHARE-',
|
||||
'SHARE-L', 'SHARE-LO', 'SHARE-LOC', 'SHOW-IN-TASKBAR', 'SHOW-STATS',
|
||||
'SHOW-STAT', 'SIDE-LABEL-HANDLE', 'SIDE-LABEL-H', 'SIDE-LABEL-HA',
|
||||
'SIDE-LABEL-HAN', 'SIDE-LABEL-HAND', 'SIDE-LABEL-HANDL', 'SIDE-LABELS',
|
||||
'SIDE-LAB', 'SIDE-LABE', 'SIDE-LABEL', 'SILENT', 'SIMPLE', 'SINGLE', 'SIZE',
|
||||
'SIZE-CHARS', 'SIZE-C', 'SIZE-CH', 'SIZE-CHA', 'SIZE-CHAR', 'SIZE-PIXELS',
|
||||
'SIZE-P', 'SIZE-PI', 'SIZE-PIX', 'SIZE-PIXE', 'SIZE-PIXEL', 'SKIP',
|
||||
'SKIP-DELETED-RECORD', 'SLIDER', 'SMALL-ICON', 'SMALLINT', 'SMALL-TITLE',
|
||||
'SOME', 'SORT', 'SORT-ASCENDING', 'SORT-NUMBER', 'SOURCE',
|
||||
'SOURCE-PROCEDURE', 'SPACE', 'SQL', 'SQRT', 'SSL-SERVER-NAME', 'STANDALONE',
|
||||
'START', 'START-DOCUMENT', 'START-ELEMENT', 'START-MOVE', 'START-RESIZE',
|
||||
'START-ROW-RESIZE', 'STATE-DETAIL', 'STATIC', 'STATUS', 'STATUS-AREA',
|
||||
'STATUS-AREA-FONT', 'STDCALL', 'STOP', 'STOP-PARSING', 'STOPPED', 'STOPPE',
|
||||
'STORED-PROCEDURE', 'STORED-PROC', 'STORED-PROCE', 'STORED-PROCED',
|
||||
'STORED-PROCEDU', 'STORED-PROCEDUR', 'STREAM', 'STREAM-HANDLE', 'STREAM-IO',
|
||||
'STRETCH-TO-FIT', 'STRICT', 'STRING', 'STRING-VALUE', 'STRING-XREF',
|
||||
'SUB-AVERAGE', 'SUB-AVE', 'SUB-AVER', 'SUB-AVERA', 'SUB-AVERAG',
|
||||
'SUB-COUNT', 'SUB-MAXIMUM', 'SUM-MAX', 'SUM-MAXI', 'SUM-MAXIM',
|
||||
'SUM-MAXIMU', 'SUB-MENU', 'SUBSUB-', 'MINIMUM', 'SUB-MIN', 'SUBSCRIBE',
|
||||
'SUBSTITUTE', 'SUBST', 'SUBSTI', 'SUBSTIT', 'SUBSTITU', 'SUBSTITUT',
|
||||
'SUBSTRING', 'SUBSTR', 'SUBSTRI', 'SUBSTRIN', 'SUB-TOTAL', 'SUBTYPE', 'SUM',
|
||||
'SUPER', 'SUPER-PROCEDURES', 'SUPPRESS-NAMESPACE-PROCESSING',
|
||||
'SUPPRESS-WARNINGS', 'SUPPRESS-W', 'SUPPRESS-WA', 'SUPPRESS-WAR',
|
||||
'SUPPRESS-WARN', 'SUPPRESS-WARNI', 'SUPPRESS-WARNIN', 'SUPPRESS-WARNING',
|
||||
'SYMMETRIC-ENCRYPTION-ALGORITHM', 'SYMMETRIC-ENCRYPTION-IV',
|
||||
'SYMMETRIC-ENCRYPTION-KEY', 'SYMMETRIC-SUPPORT', 'SYSTEM-ALERT-BOXES',
|
||||
'SYSTEM-ALERT', 'SYSTEM-ALERT-', 'SYSTEM-ALERT-B', 'SYSTEM-ALERT-BO',
|
||||
'SYSTEM-ALERT-BOX', 'SYSTEM-ALERT-BOXE', 'SYSTEM-DIALOG', 'SYSTEM-HELP',
|
||||
'SYSTEM-ID', 'TABLE', 'TABLE-HANDLE', 'TABLE-NUMBER', 'TAB-POSITION',
|
||||
'TAB-STOP', 'TARGET', 'TARGET-PROCEDURE', 'TEMP-DIRECTORY', 'TEMP-DIR',
|
||||
'TEMP-DIRE', 'TEMP-DIREC', 'TEMP-DIRECT', 'TEMP-DIRECTO', 'TEMP-DIRECTOR',
|
||||
'TEMP-TABLE', 'TEMP-TABLE-PREPARE', 'TERM', 'TERMINAL', 'TERM', 'TERMI',
|
||||
'TERMIN', 'TERMINA', 'TERMINATE', 'TEXT', 'TEXT-CURSOR', 'TEXT-SEG-GROW',
|
||||
'TEXT-SELECTED', 'THEN', 'THIS-OBJECT', 'THIS-PROCEDURE', 'THREE-D',
|
||||
'THROW', 'THROUGH', 'THRU', 'TIC-MARKS', 'TIME', 'TIME-SOURCE', 'TITLE',
|
||||
'TITLE-BGCOLOR', 'TITLE-BGC', 'TITLE-BGCO', 'TITLE-BGCOL', 'TITLE-BGCOLO',
|
||||
'TITLE-DCOLOR', 'TITLE-DC', 'TITLE-DCO', 'TITLE-DCOL', 'TITLE-DCOLO',
|
||||
'TITLE-FGCOLOR', 'TITLE-FGC', 'TITLE-FGCO', 'TITLE-FGCOL', 'TITLE-FGCOLO',
|
||||
'TITLE-FONT', 'TITLE-FO', 'TITLE-FON', 'TO', 'TODAY', 'TOGGLE-BOX',
|
||||
'TOOLTIP', 'TOOLTIPS', 'TOPIC', 'TOP-NAV-QUERY', 'TOP-ONLY', 'TO-ROWID',
|
||||
'TOTAL', 'TRAILING', 'TRANS', 'TRANSACTION', 'TRANSACTION-MODE',
|
||||
'TRANS-INIT-PROCEDURE', 'TRANSPARENT', 'TRIGGER', 'TRIGGERS', 'TRIM',
|
||||
'TRUE', 'TRUNCATE', 'TRUNC', 'TRUNCA', 'TRUNCAT', 'TYPE', 'TYPE-OF',
|
||||
'UNBOX', 'UNBUFFERED', 'UNBUFF', 'UNBUFFE', 'UNBUFFER', 'UNBUFFERE',
|
||||
'UNDERLINE', 'UNDERL', 'UNDERLI', 'UNDERLIN', 'UNDO', 'UNFORMATTED',
|
||||
'UNFORM', 'UNFORMA', 'UNFORMAT', 'UNFORMATT', 'UNFORMATTE', 'UNION',
|
||||
'UNIQUE', 'UNIQUE-ID', 'UNIQUE-MATCH', 'UNIX', 'UNLESS-HIDDEN', 'UNLOAD',
|
||||
'UNSIGNED-LONG', 'UNSUBSCRIBE', 'UP', 'UPDATE', 'UPDATE-ATTRIBUTE', 'URL',
|
||||
'URL-DECODE', 'URL-ENCODE', 'URL-PASSWORD', 'URL-USERID', 'USE',
|
||||
'USE-DICT-EXPS', 'USE-FILENAME', 'USE-INDEX', 'USER', 'USE-REVVIDEO',
|
||||
'USERID', 'USER-ID', 'USE-TEXT', 'USE-UNDERLINE', 'USE-WIDGET-POOL',
|
||||
'USING', 'V6DISPLAY', 'V6FRAME', 'VALIDATE', 'VALIDATE-EXPRESSION',
|
||||
'VALIDATE-MESSAGE', 'VALIDATE-SEAL', 'VALIDATION-ENABLED', 'VALID-EVENT',
|
||||
'VALID-HANDLE', 'VALID-OBJECT', 'VALUE', 'VALUE-CHANGED', 'VALUES',
|
||||
'VARIABLE', 'VAR', 'VARI', 'VARIA', 'VARIAB', 'VARIABL', 'VERBOSE',
|
||||
'VERSION', 'VERTICAL', 'VERT', 'VERTI', 'VERTIC', 'VERTICA', 'VIEW',
|
||||
'VIEW-AS', 'VIEW-FIRST-COLUMN-ON-REOPEN', 'VIRTUAL-HEIGHT-CHARS',
|
||||
'VIRTUAL-HEIGHT', 'VIRTUAL-HEIGHT-', 'VIRTUAL-HEIGHT-C',
|
||||
'VIRTUAL-HEIGHT-CH', 'VIRTUAL-HEIGHT-CHA', 'VIRTUAL-HEIGHT-CHAR',
|
||||
'VIRTUAL-HEIGHT-PIXELS', 'VIRTUAL-HEIGHT-P', 'VIRTUAL-HEIGHT-PI',
|
||||
'VIRTUAL-HEIGHT-PIX', 'VIRTUAL-HEIGHT-PIXE', 'VIRTUAL-HEIGHT-PIXEL',
|
||||
'VIRTUAL-WIDTH-CHARS', 'VIRTUAL-WIDTH', 'VIRTUAL-WIDTH-', 'VIRTUAL-WIDTH-C',
|
||||
'VIRTUAL-WIDTH-CH', 'VIRTUAL-WIDTH-CHA', 'VIRTUAL-WIDTH-CHAR',
|
||||
'VIRTUAL-WIDTH-PIXELS', 'VIRTUAL-WIDTH-P', 'VIRTUAL-WIDTH-PI',
|
||||
'VIRTUAL-WIDTH-PIX', 'VIRTUAL-WIDTH-PIXE', 'VIRTUAL-WIDTH-PIXEL', 'VISIBLE',
|
||||
'VOID', 'WAIT', 'WAIT-FOR', 'WARNING', 'WEB-CONTEXT', 'WEEKDAY', 'WHEN',
|
||||
'WHERE', 'WHILE', 'WIDGET', 'WIDGET-ENTER', 'WIDGET-E', 'WIDGET-EN',
|
||||
'WIDGET-ENT', 'WIDGET-ENTE', 'WIDGET-ID', 'WIDGET-LEAVE', 'WIDGET-L',
|
||||
'WIDGET-LE', 'WIDGET-LEA', 'WIDGET-LEAV', 'WIDGET-POOL', 'WIDTH',
|
||||
'WIDTH-CHARS', 'WIDTH', 'WIDTH-', 'WIDTH-C', 'WIDTH-CH', 'WIDTH-CHA',
|
||||
'WIDTH-CHAR', 'WIDTH-PIXELS', 'WIDTH-P', 'WIDTH-PI', 'WIDTH-PIX',
|
||||
'WIDTH-PIXE', 'WIDTH-PIXEL', 'WINDOW', 'WINDOW-MAXIMIZED', 'WINDOW-MAXIM',
|
||||
'WINDOW-MAXIMI', 'WINDOW-MAXIMIZ', 'WINDOW-MAXIMIZE', 'WINDOW-MINIMIZED',
|
||||
'WINDOW-MINIM', 'WINDOW-MINIMI', 'WINDOW-MINIMIZ', 'WINDOW-MINIMIZE',
|
||||
'WINDOW-NAME', 'WINDOW-NORMAL', 'WINDOW-STATE', 'WINDOW-STA', 'WINDOW-STAT',
|
||||
'WINDOW-SYSTEM', 'WITH', 'WORD-INDEX', 'WORD-WRAP',
|
||||
'WORK-AREA-HEIGHT-PIXELS', 'WORK-AREA-WIDTH-PIXELS', 'WORK-AREA-X',
|
||||
'WORK-AREA-Y', 'WORKFILE', 'WORK-TABLE', 'WORK-TAB', 'WORK-TABL', 'WRITE',
|
||||
'WRITE-CDATA', 'WRITE-CHARACTERS', 'WRITE-COMMENT', 'WRITE-DATA-ELEMENT',
|
||||
'WRITE-EMPTY-ELEMENT', 'WRITE-ENTITY-REF', 'WRITE-EXTERNAL-DTD',
|
||||
'WRITE-FRAGMENT', 'WRITE-MESSAGE', 'WRITE-PROCESSING-INSTRUCTION',
|
||||
'WRITE-STATUS', 'WRITE-XML', 'WRITE-XMLSCHEMA', 'X', 'XCODE',
|
||||
'XML-DATA-TYPE', 'XML-NODE-TYPE', 'XML-SCHEMA-PATH',
|
||||
'XML-SUPPRESS-NAMESPACE-PROCESSING', 'X-OF', 'XREF', 'XREF-XML', 'Y',
|
||||
'YEAR', 'YEAR-OFFSET', 'YES', 'YES-NO', 'YES-NO-CANCEL', 'Y-OF'
|
||||
]
|
||||
@ -1,233 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._postgres_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Self-updating data files for PostgreSQL lexer.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import urllib
|
||||
|
||||
# One man's constant is another man's variable.
|
||||
SOURCE_URL = 'https://github.com/postgres/postgres/raw/master'
|
||||
KEYWORDS_URL = SOURCE_URL + '/doc/src/sgml/keywords.sgml'
|
||||
DATATYPES_URL = SOURCE_URL + '/doc/src/sgml/datatype.sgml'
|
||||
|
||||
def update_myself():
|
||||
data_file = list(fetch(DATATYPES_URL))
|
||||
datatypes = parse_datatypes(data_file)
|
||||
pseudos = parse_pseudos(data_file)
|
||||
|
||||
keywords = parse_keywords(fetch(KEYWORDS_URL))
|
||||
update_consts(__file__, 'DATATYPES', datatypes)
|
||||
update_consts(__file__, 'PSEUDO_TYPES', pseudos)
|
||||
update_consts(__file__, 'KEYWORDS', keywords)
|
||||
|
||||
def parse_keywords(f):
|
||||
kw = []
|
||||
for m in re.finditer(
|
||||
r'\s*<entry><token>([^<]+)</token></entry>\s*'
|
||||
r'<entry>([^<]+)</entry>', f.read()):
|
||||
kw.append(m.group(1))
|
||||
|
||||
if not kw:
|
||||
raise ValueError('no keyword found')
|
||||
|
||||
kw.sort()
|
||||
return kw
|
||||
|
||||
def parse_datatypes(f):
|
||||
dt = set()
|
||||
for line in f:
|
||||
if '<sect1' in line:
|
||||
break
|
||||
if '<entry><type>' not in line:
|
||||
continue
|
||||
|
||||
# Parse a string such as
|
||||
# time [ (<replaceable>p</replaceable>) ] [ without time zone ]
|
||||
# into types "time" and "without time zone"
|
||||
|
||||
# remove all the tags
|
||||
line = re.sub("<replaceable>[^<]+</replaceable>", "", line)
|
||||
line = re.sub("<[^>]+>", "", line)
|
||||
|
||||
# Drop the parts containing braces
|
||||
for tmp in [t for tmp in line.split('[')
|
||||
for t in tmp.split(']') if "(" not in t]:
|
||||
for t in tmp.split(','):
|
||||
t = t.strip()
|
||||
if not t: continue
|
||||
dt.add(" ".join(t.split()))
|
||||
|
||||
dt = list(dt)
|
||||
dt.sort()
|
||||
return dt
|
||||
|
||||
def parse_pseudos(f):
|
||||
dt = []
|
||||
re_start = re.compile(r'\s*<table id="datatype-pseudotypes-table">')
|
||||
re_entry = re.compile(r'\s*<entry><type>([^<]+)</></entry>')
|
||||
re_end = re.compile(r'\s*</table>')
|
||||
|
||||
f = iter(f)
|
||||
for line in f:
|
||||
if re_start.match(line) is not None:
|
||||
break
|
||||
else:
|
||||
raise ValueError('pseudo datatypes table not found')
|
||||
|
||||
for line in f:
|
||||
m = re_entry.match(line)
|
||||
if m is not None:
|
||||
dt.append(m.group(1))
|
||||
|
||||
if re_end.match(line) is not None:
|
||||
break
|
||||
else:
|
||||
raise ValueError('end of pseudo datatypes table not found')
|
||||
|
||||
if not dt:
|
||||
raise ValueError('pseudo datatypes not found')
|
||||
|
||||
return dt
|
||||
|
||||
def fetch(url):
|
||||
return urllib.urlopen(url)
|
||||
|
||||
def update_consts(filename, constname, content):
|
||||
f = open(filename)
|
||||
lines = f.readlines()
|
||||
f.close()
|
||||
|
||||
# Line to start/end inserting
|
||||
re_start = re.compile(r'^%s\s*=\s*\[\s*$' % constname)
|
||||
re_end = re.compile(r'^\s*\]\s*$')
|
||||
start = [ n for n, l in enumerate(lines) if re_start.match(l) ]
|
||||
if not start:
|
||||
raise ValueError("couldn't find line containing '%s = ['" % constname)
|
||||
if len(start) > 1:
|
||||
raise ValueError("too many lines containing '%s = ['" % constname)
|
||||
start = start[0] + 1
|
||||
|
||||
end = [ n for n, l in enumerate(lines) if n >= start and re_end.match(l) ]
|
||||
if not end:
|
||||
raise ValueError("couldn't find line containing ']' after %s " % constname)
|
||||
end = end[0]
|
||||
|
||||
# Pack the new content in lines not too long
|
||||
content = [repr(item) for item in content ]
|
||||
new_lines = [[]]
|
||||
for item in content:
|
||||
if sum(map(len, new_lines[-1])) + 2 * len(new_lines[-1]) + len(item) + 4 > 75:
|
||||
new_lines.append([])
|
||||
new_lines[-1].append(item)
|
||||
|
||||
lines[start:end] = [ " %s,\n" % ", ".join(items) for items in new_lines ]
|
||||
|
||||
f = open(filename, 'w')
|
||||
f.write(''.join(lines))
|
||||
f.close()
|
||||
|
||||
|
||||
# Autogenerated: please edit them if you like wasting your time.
|
||||
|
||||
KEYWORDS = [
|
||||
'ABORT', 'ABSOLUTE', 'ACCESS', 'ACTION', 'ADD', 'ADMIN', 'AFTER',
|
||||
'AGGREGATE', 'ALL', 'ALSO', 'ALTER', 'ALWAYS', 'ANALYSE', 'ANALYZE',
|
||||
'AND', 'ANY', 'ARRAY', 'AS', 'ASC', 'ASSERTION', 'ASSIGNMENT',
|
||||
'ASYMMETRIC', 'AT', 'ATTRIBUTE', 'AUTHORIZATION', 'BACKWARD', 'BEFORE',
|
||||
'BEGIN', 'BETWEEN', 'BIGINT', 'BINARY', 'BIT', 'BOOLEAN', 'BOTH', 'BY',
|
||||
'CACHE', 'CALLED', 'CASCADE', 'CASCADED', 'CASE', 'CAST', 'CATALOG',
|
||||
'CHAIN', 'CHAR', 'CHARACTER', 'CHARACTERISTICS', 'CHECK', 'CHECKPOINT',
|
||||
'CLASS', 'CLOSE', 'CLUSTER', 'COALESCE', 'COLLATE', 'COLLATION',
|
||||
'COLUMN', 'COMMENT', 'COMMENTS', 'COMMIT', 'COMMITTED', 'CONCURRENTLY',
|
||||
'CONFIGURATION', 'CONNECTION', 'CONSTRAINT', 'CONSTRAINTS', 'CONTENT',
|
||||
'CONTINUE', 'CONVERSION', 'COPY', 'COST', 'CREATE', 'CROSS', 'CSV',
|
||||
'CURRENT', 'CURRENT_CATALOG', 'CURRENT_DATE', 'CURRENT_ROLE',
|
||||
'CURRENT_SCHEMA', 'CURRENT_TIME', 'CURRENT_TIMESTAMP', 'CURRENT_USER',
|
||||
'CURSOR', 'CYCLE', 'DATA', 'DATABASE', 'DAY', 'DEALLOCATE', 'DEC',
|
||||
'DECIMAL', 'DECLARE', 'DEFAULT', 'DEFAULTS', 'DEFERRABLE', 'DEFERRED',
|
||||
'DEFINER', 'DELETE', 'DELIMITER', 'DELIMITERS', 'DESC', 'DICTIONARY',
|
||||
'DISABLE', 'DISCARD', 'DISTINCT', 'DO', 'DOCUMENT', 'DOMAIN', 'DOUBLE',
|
||||
'DROP', 'EACH', 'ELSE', 'ENABLE', 'ENCODING', 'ENCRYPTED', 'END',
|
||||
'ENUM', 'ESCAPE', 'EXCEPT', 'EXCLUDE', 'EXCLUDING', 'EXCLUSIVE',
|
||||
'EXECUTE', 'EXISTS', 'EXPLAIN', 'EXTENSION', 'EXTERNAL', 'EXTRACT',
|
||||
'FALSE', 'FAMILY', 'FETCH', 'FIRST', 'FLOAT', 'FOLLOWING', 'FOR',
|
||||
'FORCE', 'FOREIGN', 'FORWARD', 'FREEZE', 'FROM', 'FULL', 'FUNCTION',
|
||||
'FUNCTIONS', 'GLOBAL', 'GRANT', 'GRANTED', 'GREATEST', 'GROUP',
|
||||
'HANDLER', 'HAVING', 'HEADER', 'HOLD', 'HOUR', 'IDENTITY', 'IF',
|
||||
'ILIKE', 'IMMEDIATE', 'IMMUTABLE', 'IMPLICIT', 'IN', 'INCLUDING',
|
||||
'INCREMENT', 'INDEX', 'INDEXES', 'INHERIT', 'INHERITS', 'INITIALLY',
|
||||
'INLINE', 'INNER', 'INOUT', 'INPUT', 'INSENSITIVE', 'INSERT', 'INSTEAD',
|
||||
'INT', 'INTEGER', 'INTERSECT', 'INTERVAL', 'INTO', 'INVOKER', 'IS',
|
||||
'ISNULL', 'ISOLATION', 'JOIN', 'KEY', 'LABEL', 'LANGUAGE', 'LARGE',
|
||||
'LAST', 'LC_COLLATE', 'LC_CTYPE', 'LEADING', 'LEAST', 'LEFT', 'LEVEL',
|
||||
'LIKE', 'LIMIT', 'LISTEN', 'LOAD', 'LOCAL', 'LOCALTIME',
|
||||
'LOCALTIMESTAMP', 'LOCATION', 'LOCK', 'MAPPING', 'MATCH', 'MAXVALUE',
|
||||
'MINUTE', 'MINVALUE', 'MODE', 'MONTH', 'MOVE', 'NAME', 'NAMES',
|
||||
'NATIONAL', 'NATURAL', 'NCHAR', 'NEXT', 'NO', 'NONE', 'NOT', 'NOTHING',
|
||||
'NOTIFY', 'NOTNULL', 'NOWAIT', 'NULL', 'NULLIF', 'NULLS', 'NUMERIC',
|
||||
'OBJECT', 'OF', 'OFF', 'OFFSET', 'OIDS', 'ON', 'ONLY', 'OPERATOR',
|
||||
'OPTION', 'OPTIONS', 'OR', 'ORDER', 'OUT', 'OUTER', 'OVER', 'OVERLAPS',
|
||||
'OVERLAY', 'OWNED', 'OWNER', 'PARSER', 'PARTIAL', 'PARTITION',
|
||||
'PASSING', 'PASSWORD', 'PLACING', 'PLANS', 'POSITION', 'PRECEDING',
|
||||
'PRECISION', 'PREPARE', 'PREPARED', 'PRESERVE', 'PRIMARY', 'PRIOR',
|
||||
'PRIVILEGES', 'PROCEDURAL', 'PROCEDURE', 'QUOTE', 'RANGE', 'READ',
|
||||
'REAL', 'REASSIGN', 'RECHECK', 'RECURSIVE', 'REF', 'REFERENCES',
|
||||
'REINDEX', 'RELATIVE', 'RELEASE', 'RENAME', 'REPEATABLE', 'REPLACE',
|
||||
'REPLICA', 'RESET', 'RESTART', 'RESTRICT', 'RETURNING', 'RETURNS',
|
||||
'REVOKE', 'RIGHT', 'ROLE', 'ROLLBACK', 'ROW', 'ROWS', 'RULE',
|
||||
'SAVEPOINT', 'SCHEMA', 'SCROLL', 'SEARCH', 'SECOND', 'SECURITY',
|
||||
'SELECT', 'SEQUENCE', 'SEQUENCES', 'SERIALIZABLE', 'SERVER', 'SESSION',
|
||||
'SESSION_USER', 'SET', 'SETOF', 'SHARE', 'SHOW', 'SIMILAR', 'SIMPLE',
|
||||
'SMALLINT', 'SOME', 'STABLE', 'STANDALONE', 'START', 'STATEMENT',
|
||||
'STATISTICS', 'STDIN', 'STDOUT', 'STORAGE', 'STRICT', 'STRIP',
|
||||
'SUBSTRING', 'SYMMETRIC', 'SYSID', 'SYSTEM', 'TABLE', 'TABLES',
|
||||
'TABLESPACE', 'TEMP', 'TEMPLATE', 'TEMPORARY', 'TEXT', 'THEN', 'TIME',
|
||||
'TIMESTAMP', 'TO', 'TRAILING', 'TRANSACTION', 'TREAT', 'TRIGGER',
|
||||
'TRIM', 'TRUE', 'TRUNCATE', 'TRUSTED', 'TYPE', 'UNBOUNDED',
|
||||
'UNCOMMITTED', 'UNENCRYPTED', 'UNION', 'UNIQUE', 'UNKNOWN', 'UNLISTEN',
|
||||
'UNLOGGED', 'UNTIL', 'UPDATE', 'USER', 'USING', 'VACUUM', 'VALID',
|
||||
'VALIDATE', 'VALIDATOR', 'VALUE', 'VALUES', 'VARCHAR', 'VARIADIC',
|
||||
'VARYING', 'VERBOSE', 'VERSION', 'VIEW', 'VOLATILE', 'WHEN', 'WHERE',
|
||||
'WHITESPACE', 'WINDOW', 'WITH', 'WITHOUT', 'WORK', 'WRAPPER', 'WRITE',
|
||||
'XML', 'XMLATTRIBUTES', 'XMLCONCAT', 'XMLELEMENT', 'XMLEXISTS',
|
||||
'XMLFOREST', 'XMLPARSE', 'XMLPI', 'XMLROOT', 'XMLSERIALIZE', 'YEAR',
|
||||
'YES', 'ZONE',
|
||||
]
|
||||
|
||||
DATATYPES = [
|
||||
'bigint', 'bigserial', 'bit', 'bit varying', 'bool', 'boolean', 'box',
|
||||
'bytea', 'char', 'character', 'character varying', 'cidr', 'circle',
|
||||
'date', 'decimal', 'double precision', 'float4', 'float8', 'inet',
|
||||
'int', 'int2', 'int4', 'int8', 'integer', 'interval', 'json', 'line',
|
||||
'lseg', 'macaddr', 'money', 'numeric', 'path', 'point', 'polygon',
|
||||
'real', 'serial', 'serial2', 'serial4', 'serial8', 'smallint',
|
||||
'smallserial', 'text', 'time', 'timestamp', 'timestamptz', 'timetz',
|
||||
'tsquery', 'tsvector', 'txid_snapshot', 'uuid', 'varbit', 'varchar',
|
||||
'with time zone', 'without time zone', 'xml',
|
||||
]
|
||||
|
||||
PSEUDO_TYPES = [
|
||||
'any', 'anyelement', 'anyarray', 'anynonarray', 'anyenum', 'anyrange',
|
||||
'cstring', 'internal', 'language_handler', 'fdw_handler', 'record',
|
||||
'trigger', 'void', 'opaque',
|
||||
]
|
||||
|
||||
# Remove 'trigger' from types
|
||||
PSEUDO_TYPES = sorted(set(PSEUDO_TYPES) - set(map(str.lower, KEYWORDS)))
|
||||
|
||||
PLPGSQL_KEYWORDS = [
|
||||
'ALIAS', 'CONSTANT', 'DIAGNOSTICS', 'ELSIF', 'EXCEPTION', 'EXIT',
|
||||
'FOREACH', 'GET', 'LOOP', 'NOTICE', 'OPEN', 'PERFORM', 'QUERY', 'RAISE',
|
||||
'RETURN', 'REVERSE', 'SQLSTATE', 'WHILE',
|
||||
]
|
||||
|
||||
if __name__ == '__main__':
|
||||
update_myself()
|
||||
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,356 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.hdl
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for hardware descriptor languages.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
from pygments.lexer import RegexLexer, bygroups, include, using, this
|
||||
from pygments.token import \
|
||||
Text, Comment, Operator, Keyword, Name, String, Number, Punctuation, \
|
||||
Error
|
||||
|
||||
__all__ = ['VerilogLexer', 'SystemVerilogLexer', 'VhdlLexer']
|
||||
|
||||
|
||||
class VerilogLexer(RegexLexer):
|
||||
"""
|
||||
For verilog source code with preprocessor directives.
|
||||
|
||||
*New in Pygments 1.4.*
|
||||
"""
|
||||
name = 'verilog'
|
||||
aliases = ['verilog', 'v']
|
||||
filenames = ['*.v']
|
||||
mimetypes = ['text/x-verilog']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*].*?[*]/)+'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^\s*`define', Comment.Preproc, 'macro'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'[{}#@]', Punctuation),
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'([0-9]+)|(\'h)[0-9a-fA-F]+', Number.Hex),
|
||||
(r'([0-9]+)|(\'b)[0-1]+', Number.Hex), # should be binary
|
||||
(r'([0-9]+)|(\'d)[0-9]+', Number.Integer),
|
||||
(r'([0-9]+)|(\'o)[0-7]+', Number.Oct),
|
||||
(r'\'[01xz]', Number),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.;\']', Punctuation),
|
||||
(r'`[a-zA-Z_][a-zA-Z0-9_]*', Name.Constant),
|
||||
|
||||
(r'^(\s*)(package)(\s+)', bygroups(Text, Keyword.Namespace, Text)),
|
||||
(r'^(\s*)(import)(\s+)', bygroups(Text, Keyword.Namespace, Text),
|
||||
'import'),
|
||||
|
||||
(r'(always|always_comb|always_ff|always_latch|and|assign|automatic|'
|
||||
r'begin|break|buf|bufif0|bufif1|case|casex|casez|cmos|const|'
|
||||
r'continue|deassign|default|defparam|disable|do|edge|else|end|endcase|'
|
||||
r'endfunction|endgenerate|endmodule|endpackage|endprimitive|endspecify|'
|
||||
r'endtable|endtask|enum|event|final|for|force|forever|fork|function|'
|
||||
r'generate|genvar|highz0|highz1|if|initial|inout|input|'
|
||||
r'integer|join|large|localparam|macromodule|medium|module|'
|
||||
r'nand|negedge|nmos|nor|not|notif0|notif1|or|output|packed|'
|
||||
r'parameter|pmos|posedge|primitive|pull0|pull1|pulldown|pullup|rcmos|'
|
||||
r'ref|release|repeat|return|rnmos|rpmos|rtran|rtranif0|'
|
||||
r'rtranif1|scalared|signed|small|specify|specparam|strength|'
|
||||
r'string|strong0|strong1|struct|table|task|'
|
||||
r'tran|tranif0|tranif1|type|typedef|'
|
||||
r'unsigned|var|vectored|void|wait|weak0|weak1|while|'
|
||||
r'xnor|xor)\b', Keyword),
|
||||
|
||||
(r'`(accelerate|autoexpand_vectornets|celldefine|default_nettype|'
|
||||
r'else|elsif|endcelldefine|endif|endprotect|endprotected|'
|
||||
r'expand_vectornets|ifdef|ifndef|include|noaccelerate|noexpand_vectornets|'
|
||||
r'noremove_gatenames|noremove_netnames|nounconnected_drive|'
|
||||
r'protect|protected|remove_gatenames|remove_netnames|resetall|'
|
||||
r'timescale|unconnected_drive|undef)\b', Comment.Preproc),
|
||||
|
||||
(r'\$(bits|bitstoreal|bitstoshortreal|countdrivers|display|fclose|'
|
||||
r'fdisplay|finish|floor|fmonitor|fopen|fstrobe|fwrite|'
|
||||
r'getpattern|history|incsave|input|itor|key|list|log|'
|
||||
r'monitor|monitoroff|monitoron|nokey|nolog|printtimescale|'
|
||||
r'random|readmemb|readmemh|realtime|realtobits|reset|reset_count|'
|
||||
r'reset_value|restart|rtoi|save|scale|scope|shortrealtobits|'
|
||||
r'showscopes|showvariables|showvars|sreadmemb|sreadmemh|'
|
||||
r'stime|stop|strobe|time|timeformat|write)\b', Name.Builtin),
|
||||
|
||||
(r'(byte|shortint|int|longint|integer|time|'
|
||||
r'bit|logic|reg|'
|
||||
r'supply0|supply1|tri|triand|trior|tri0|tri1|trireg|uwire|wire|wand|wor'
|
||||
r'shortreal|real|realtime)\b', Keyword.Type),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*:(?!:)', Name.Label),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*', Name),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'import': [
|
||||
(r'[a-zA-Z0-9_:]+\*?', Name.Namespace, '#pop')
|
||||
]
|
||||
}
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
# Convention: mark all upper case names as constants
|
||||
if token is Name:
|
||||
if value.isupper():
|
||||
token = Name.Constant
|
||||
yield index, token, value
|
||||
|
||||
|
||||
class SystemVerilogLexer(RegexLexer):
|
||||
"""
|
||||
Extends verilog lexer to recognise all SystemVerilog keywords from IEEE
|
||||
1800-2009 standard.
|
||||
|
||||
*New in Pygments 1.5.*
|
||||
"""
|
||||
name = 'systemverilog'
|
||||
aliases = ['systemverilog', 'sv']
|
||||
filenames = ['*.sv', '*.svh']
|
||||
mimetypes = ['text/x-systemverilog']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*].*?[*]/)+'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^\s*`define', Comment.Preproc, 'macro'),
|
||||
(r'^(\s*)(package)(\s+)', bygroups(Text, Keyword.Namespace, Text)),
|
||||
(r'^(\s*)(import)(\s+)', bygroups(Text, Keyword.Namespace, Text), 'import'),
|
||||
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'[{}#@]', Punctuation),
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'([0-9]+)|(\'h)[0-9a-fA-F]+', Number.Hex),
|
||||
(r'([0-9]+)|(\'b)[0-1]+', Number.Hex), # should be binary
|
||||
(r'([0-9]+)|(\'d)[0-9]+', Number.Integer),
|
||||
(r'([0-9]+)|(\'o)[0-7]+', Number.Oct),
|
||||
(r'\'[01xz]', Number),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.;\']', Punctuation),
|
||||
(r'`[a-zA-Z_][a-zA-Z0-9_]*', Name.Constant),
|
||||
|
||||
(r'(accept_on|alias|always|always_comb|always_ff|always_latch|'
|
||||
r'and|assert|assign|assume|automatic|before|begin|bind|bins|'
|
||||
r'binsof|bit|break|buf|bufif0|bufif1|byte|case|casex|casez|'
|
||||
r'cell|chandle|checker|class|clocking|cmos|config|const|constraint|'
|
||||
r'context|continue|cover|covergroup|coverpoint|cross|deassign|'
|
||||
r'default|defparam|design|disable|dist|do|edge|else|end|endcase|'
|
||||
r'endchecker|endclass|endclocking|endconfig|endfunction|endgenerate|'
|
||||
r'endgroup|endinterface|endmodule|endpackage|endprimitive|'
|
||||
r'endprogram|endproperty|endsequence|endspecify|endtable|'
|
||||
r'endtask|enum|event|eventually|expect|export|extends|extern|'
|
||||
r'final|first_match|for|force|foreach|forever|fork|forkjoin|'
|
||||
r'function|generate|genvar|global|highz0|highz1|if|iff|ifnone|'
|
||||
r'ignore_bins|illegal_bins|implies|import|incdir|include|'
|
||||
r'initial|inout|input|inside|instance|int|integer|interface|'
|
||||
r'intersect|join|join_any|join_none|large|let|liblist|library|'
|
||||
r'local|localparam|logic|longint|macromodule|matches|medium|'
|
||||
r'modport|module|nand|negedge|new|nexttime|nmos|nor|noshowcancelled|'
|
||||
r'not|notif0|notif1|null|or|output|package|packed|parameter|'
|
||||
r'pmos|posedge|primitive|priority|program|property|protected|'
|
||||
r'pull0|pull1|pulldown|pullup|pulsestyle_ondetect|pulsestyle_onevent|'
|
||||
r'pure|rand|randc|randcase|randsequence|rcmos|real|realtime|'
|
||||
r'ref|reg|reject_on|release|repeat|restrict|return|rnmos|'
|
||||
r'rpmos|rtran|rtranif0|rtranif1|s_always|s_eventually|s_nexttime|'
|
||||
r's_until|s_until_with|scalared|sequence|shortint|shortreal|'
|
||||
r'showcancelled|signed|small|solve|specify|specparam|static|'
|
||||
r'string|strong|strong0|strong1|struct|super|supply0|supply1|'
|
||||
r'sync_accept_on|sync_reject_on|table|tagged|task|this|throughout|'
|
||||
r'time|timeprecision|timeunit|tran|tranif0|tranif1|tri|tri0|'
|
||||
r'tri1|triand|trior|trireg|type|typedef|union|unique|unique0|'
|
||||
r'unsigned|until|until_with|untyped|use|uwire|var|vectored|'
|
||||
r'virtual|void|wait|wait_order|wand|weak|weak0|weak1|while|'
|
||||
r'wildcard|wire|with|within|wor|xnor|xor)\b', Keyword ),
|
||||
|
||||
(r'(`__FILE__|`__LINE__|`begin_keywords|`celldefine|`default_nettype|'
|
||||
r'`define|`else|`elsif|`end_keywords|`endcelldefine|`endif|'
|
||||
r'`ifdef|`ifndef|`include|`line|`nounconnected_drive|`pragma|'
|
||||
r'`resetall|`timescale|`unconnected_drive|`undef|`undefineall)\b',
|
||||
Comment.Preproc ),
|
||||
|
||||
(r'(\$display|\$displayb|\$displayh|\$displayo|\$dumpall|\$dumpfile|'
|
||||
r'\$dumpflush|\$dumplimit|\$dumpoff|\$dumpon|\$dumpports|'
|
||||
r'\$dumpportsall|\$dumpportsflush|\$dumpportslimit|\$dumpportsoff|'
|
||||
r'\$dumpportson|\$dumpvars|\$fclose|\$fdisplay|\$fdisplayb|'
|
||||
r'\$fdisplayh|\$fdisplayo|\$feof|\$ferror|\$fflush|\$fgetc|'
|
||||
r'\$fgets|\$fmonitor|\$fmonitorb|\$fmonitorh|\$fmonitoro|'
|
||||
r'\$fopen|\$fread|\$fscanf|\$fseek|\$fstrobe|\$fstrobeb|\$fstrobeh|'
|
||||
r'\$fstrobeo|\$ftell|\$fwrite|\$fwriteb|\$fwriteh|\$fwriteo|'
|
||||
r'\$monitor|\$monitorb|\$monitorh|\$monitoro|\$monitoroff|'
|
||||
r'\$monitoron|\$plusargs|\$readmemb|\$readmemh|\$rewind|\$sformat|'
|
||||
r'\$sformatf|\$sscanf|\$strobe|\$strobeb|\$strobeh|\$strobeo|'
|
||||
r'\$swrite|\$swriteb|\$swriteh|\$swriteo|\$test|\$ungetc|'
|
||||
r'\$value\$plusargs|\$write|\$writeb|\$writeh|\$writememb|'
|
||||
r'\$writememh|\$writeo)\b' , Name.Builtin ),
|
||||
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(byte|shortint|int|longint|integer|time|'
|
||||
r'bit|logic|reg|'
|
||||
r'supply0|supply1|tri|triand|trior|tri0|tri1|trireg|uwire|wire|wand|wor'
|
||||
r'shortreal|real|realtime)\b', Keyword.Type),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*:(?!:)', Name.Label),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*', Name),
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_][a-zA-Z0-9_]*', Name.Class, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'import': [
|
||||
(r'[a-zA-Z0-9_:]+\*?', Name.Namespace, '#pop')
|
||||
]
|
||||
}
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
# Convention: mark all upper case names as constants
|
||||
if token is Name:
|
||||
if value.isupper():
|
||||
token = Name.Constant
|
||||
yield index, token, value
|
||||
|
||||
def analyse_text(text):
|
||||
if text.startswith('//') or text.startswith('/*'):
|
||||
return 0.5
|
||||
|
||||
|
||||
class VhdlLexer(RegexLexer):
|
||||
"""
|
||||
For VHDL source code.
|
||||
|
||||
*New in Pygments 1.5.*
|
||||
"""
|
||||
name = 'vhdl'
|
||||
aliases = ['vhdl']
|
||||
filenames = ['*.vhdl', '*.vhd']
|
||||
mimetypes = ['text/x-vhdl']
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'--(?![!#$%&*+./<=>?@\^|_~]).*?$', Comment.Single),
|
||||
(r"'(U|X|0|1|Z|W|L|H|-)'", String.Char),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r"'[a-zA-Z_][a-zA-Z0-9_]*", Name.Attribute),
|
||||
(r'[()\[\],.;\']', Punctuation),
|
||||
(r'"[^\n\\]*"', String),
|
||||
|
||||
(r'(library)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)',
|
||||
bygroups(Keyword, Text, Name.Namespace)),
|
||||
(r'(use)(\s+)(entity)', bygroups(Keyword, Text, Keyword)),
|
||||
(r'(use)(\s+)([a-zA-Z_][\.a-zA-Z0-9_]*)',
|
||||
bygroups(Keyword, Text, Name.Namespace)),
|
||||
(r'(entity|component)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)',
|
||||
bygroups(Keyword, Text, Name.Class)),
|
||||
(r'(architecture|configuration)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)(\s+)'
|
||||
r'(of)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)(\s+)(is)',
|
||||
bygroups(Keyword, Text, Name.Class, Text, Keyword, Text,
|
||||
Name.Class, Text, Keyword)),
|
||||
|
||||
(r'(end)(\s+)', bygroups(using(this), Text), 'endblock'),
|
||||
|
||||
include('types'),
|
||||
include('keywords'),
|
||||
include('numbers'),
|
||||
|
||||
(r'[a-zA-Z_][a-zA-Z0-9_]*', Name),
|
||||
],
|
||||
'endblock': [
|
||||
include('keywords'),
|
||||
(r'[a-zA-Z_][a-zA-Z0-9_]*', Name.Class),
|
||||
(r'(\s+)', Text),
|
||||
(r';', Punctuation, '#pop'),
|
||||
],
|
||||
'types': [
|
||||
(r'(boolean|bit|character|severity_level|integer|time|delay_length|'
|
||||
r'natural|positive|string|bit_vector|file_open_kind|'
|
||||
r'file_open_status|std_ulogic|std_ulogic_vector|std_logic|'
|
||||
r'std_logic_vector)\b', Keyword.Type),
|
||||
],
|
||||
'keywords': [
|
||||
(r'(abs|access|after|alias|all|and|'
|
||||
r'architecture|array|assert|attribute|begin|block|'
|
||||
r'body|buffer|bus|case|component|configuration|'
|
||||
r'constant|disconnect|downto|else|elsif|end|'
|
||||
r'entity|exit|file|for|function|generate|'
|
||||
r'generic|group|guarded|if|impure|in|'
|
||||
r'inertial|inout|is|label|library|linkage|'
|
||||
r'literal|loop|map|mod|nand|new|'
|
||||
r'next|nor|not|null|of|on|'
|
||||
r'open|or|others|out|package|port|'
|
||||
r'postponed|procedure|process|pure|range|record|'
|
||||
r'register|reject|return|rol|ror|select|'
|
||||
r'severity|signal|shared|sla|sli|sra|'
|
||||
r'srl|subtype|then|to|transport|type|'
|
||||
r'units|until|use|variable|wait|when|'
|
||||
r'while|with|xnor|xor)\b', Keyword),
|
||||
],
|
||||
'numbers': [
|
||||
(r'\d{1,2}#[0-9a-fA-F_]+#?', Number.Integer),
|
||||
(r'[0-1_]+(\.[0-1_])', Number.Integer),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+', Number.Float),
|
||||
(r'H"[0-9a-fA-F_]+"', Number.Oct),
|
||||
(r'O"[0-7_]+"', Number.Oct),
|
||||
(r'B"[0-1_]+"', Number.Oct),
|
||||
],
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because one or more lines are too long
@ -1,68 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Pygments formatters.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
import os.path
|
||||
import fnmatch
|
||||
|
||||
from pygments.formatters._mapping import FORMATTERS
|
||||
from pygments.plugin import find_plugin_formatters
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
ns = globals()
|
||||
for fcls in FORMATTERS:
|
||||
ns[fcls.__name__] = fcls
|
||||
del fcls
|
||||
|
||||
__all__ = ['get_formatter_by_name', 'get_formatter_for_filename',
|
||||
'get_all_formatters'] + [cls.__name__ for cls in FORMATTERS]
|
||||
|
||||
|
||||
_formatter_alias_cache = {}
|
||||
_formatter_filename_cache = []
|
||||
|
||||
def _init_formatter_cache():
|
||||
if _formatter_alias_cache:
|
||||
return
|
||||
for cls in get_all_formatters():
|
||||
for alias in cls.aliases:
|
||||
_formatter_alias_cache[alias] = cls
|
||||
for fn in cls.filenames:
|
||||
_formatter_filename_cache.append((fn, cls))
|
||||
|
||||
|
||||
def find_formatter_class(name):
|
||||
_init_formatter_cache()
|
||||
cls = _formatter_alias_cache.get(name, None)
|
||||
return cls
|
||||
|
||||
|
||||
def get_formatter_by_name(name, **options):
|
||||
_init_formatter_cache()
|
||||
cls = _formatter_alias_cache.get(name, None)
|
||||
if not cls:
|
||||
raise ClassNotFound("No formatter found for name %r" % name)
|
||||
return cls(**options)
|
||||
|
||||
|
||||
def get_formatter_for_filename(fn, **options):
|
||||
_init_formatter_cache()
|
||||
fn = os.path.basename(fn)
|
||||
for pattern, cls in _formatter_filename_cache:
|
||||
if fnmatch.fnmatch(fn, pattern):
|
||||
return cls(**options)
|
||||
raise ClassNotFound("No formatter found for file name %r" % fn)
|
||||
|
||||
|
||||
def get_all_formatters():
|
||||
"""Return a generator for all formatters."""
|
||||
for formatter in FORMATTERS:
|
||||
yield formatter
|
||||
for _, formatter in find_plugin_formatters():
|
||||
yield formatter
|
||||
@ -1,92 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter mapping defintions. This file is generated by itself. Everytime
|
||||
you change something on a builtin formatter defintion, run this script from
|
||||
the formatters folder to update it.
|
||||
|
||||
Do not alter the FORMATTERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
# start
|
||||
from pygments.formatters.bbcode import BBCodeFormatter
|
||||
from pygments.formatters.html import HtmlFormatter
|
||||
from pygments.formatters.img import BmpImageFormatter
|
||||
from pygments.formatters.img import GifImageFormatter
|
||||
from pygments.formatters.img import ImageFormatter
|
||||
from pygments.formatters.img import JpgImageFormatter
|
||||
from pygments.formatters.latex import LatexFormatter
|
||||
from pygments.formatters.other import NullFormatter
|
||||
from pygments.formatters.other import RawTokenFormatter
|
||||
from pygments.formatters.rtf import RtfFormatter
|
||||
from pygments.formatters.svg import SvgFormatter
|
||||
from pygments.formatters.terminal import TerminalFormatter
|
||||
from pygments.formatters.terminal256 import Terminal256Formatter
|
||||
|
||||
FORMATTERS = {
|
||||
BBCodeFormatter: ('BBCode', ('bbcode', 'bb'), (), 'Format tokens with BBcodes. These formatting codes are used by many bulletin boards, so you can highlight your sourcecode with pygments before posting it there.'),
|
||||
BmpImageFormatter: ('img_bmp', ('bmp', 'bitmap'), ('*.bmp',), 'Create a bitmap image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
GifImageFormatter: ('img_gif', ('gif',), ('*.gif',), 'Create a GIF image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
HtmlFormatter: ('HTML', ('html',), ('*.html', '*.htm'), "Format tokens as HTML 4 ``<span>`` tags within a ``<pre>`` tag, wrapped in a ``<div>`` tag. The ``<div>``'s CSS class can be set by the `cssclass` option."),
|
||||
ImageFormatter: ('img', ('img', 'IMG', 'png'), ('*.png',), 'Create a PNG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
JpgImageFormatter: ('img_jpg', ('jpg', 'jpeg'), ('*.jpg',), 'Create a JPEG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
LatexFormatter: ('LaTeX', ('latex', 'tex'), ('*.tex',), 'Format tokens as LaTeX code. This needs the `fancyvrb` and `color` standard packages.'),
|
||||
NullFormatter: ('Text only', ('text', 'null'), ('*.txt',), 'Output the text unchanged without any formatting.'),
|
||||
RawTokenFormatter: ('Raw tokens', ('raw', 'tokens'), ('*.raw',), 'Format tokens as a raw representation for storing token streams.'),
|
||||
RtfFormatter: ('RTF', ('rtf',), ('*.rtf',), 'Format tokens as RTF markup. This formatter automatically outputs full RTF documents with color information and other useful stuff. Perfect for Copy and Paste into Microsoft\xc2\xae Word\xc2\xae documents.'),
|
||||
SvgFormatter: ('SVG', ('svg',), ('*.svg',), 'Format tokens as an SVG graphics file. This formatter is still experimental. Each line of code is a ``<text>`` element with explicit ``x`` and ``y`` coordinates containing ``<tspan>`` elements with the individual token styles.'),
|
||||
Terminal256Formatter: ('Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
TerminalFormatter: ('Terminal', ('terminal', 'console'), (), 'Format tokens with ANSI color sequences, for output in a text console. Color sequences are terminated at newlines, so that paging the output works correctly.')
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup formatters
|
||||
found_formatters = []
|
||||
imports = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
from pygments.util import docstring_headline
|
||||
|
||||
for filename in os.listdir('.'):
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.formatters.%s' % filename[:-3]
|
||||
print(module_name)
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for formatter_name in module.__all__:
|
||||
imports.append((module_name, formatter_name))
|
||||
formatter = getattr(module, formatter_name)
|
||||
found_formatters.append(
|
||||
'%s: %r' % (formatter_name,
|
||||
(formatter.name,
|
||||
tuple(formatter.aliases),
|
||||
tuple(formatter.filenames),
|
||||
docstring_headline(formatter))))
|
||||
# sort them, that should make the diff files for svn smaller
|
||||
found_formatters.sort()
|
||||
imports.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
f = open(__file__)
|
||||
try:
|
||||
content = f.read()
|
||||
finally:
|
||||
f.close()
|
||||
header = content[:content.find('# start')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
f = open(__file__, 'w')
|
||||
f.write(header)
|
||||
f.write('# start\n')
|
||||
f.write('\n'.join(['from %s import %s' % imp for imp in imports]))
|
||||
f.write('\n\n')
|
||||
f.write('FORMATTERS = {\n %s\n}\n\n' % ',\n '.join(found_formatters))
|
||||
f.write(footer)
|
||||
f.close()
|
||||
@ -1,350 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer mapping defintions. This file is generated by itself. Everytime
|
||||
you change something on a builtin lexer defintion, run this script from
|
||||
the lexers folder to update it.
|
||||
|
||||
Do not alter the LEXERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
LEXERS = {
|
||||
'ABAPLexer': ('pygments.lexers.other', 'ABAP', ('abap',), ('*.abap',), ('text/x-abap',)),
|
||||
'ActionScript3Lexer': ('pygments.lexers.web', 'ActionScript 3', ('as3', 'actionscript3'), ('*.as',), ('application/x-actionscript', 'text/x-actionscript', 'text/actionscript')),
|
||||
'ActionScriptLexer': ('pygments.lexers.web', 'ActionScript', ('as', 'actionscript'), ('*.as',), ('application/x-actionscript3', 'text/x-actionscript3', 'text/actionscript3')),
|
||||
'AdaLexer': ('pygments.lexers.compiled', 'Ada', ('ada', 'ada95ada2005'), ('*.adb', '*.ads', '*.ada'), ('text/x-ada',)),
|
||||
'AgdaLexer': ('pygments.lexers.functional', 'Agda', ('agda',), ('*.agda',), ('text/x-agda',)),
|
||||
'AntlrActionScriptLexer': ('pygments.lexers.parsers', 'ANTLR With ActionScript Target', ('antlr-as', 'antlr-actionscript'), ('*.G', '*.g'), ()),
|
||||
'AntlrCSharpLexer': ('pygments.lexers.parsers', 'ANTLR With C# Target', ('antlr-csharp', 'antlr-c#'), ('*.G', '*.g'), ()),
|
||||
'AntlrCppLexer': ('pygments.lexers.parsers', 'ANTLR With CPP Target', ('antlr-cpp',), ('*.G', '*.g'), ()),
|
||||
'AntlrJavaLexer': ('pygments.lexers.parsers', 'ANTLR With Java Target', ('antlr-java',), ('*.G', '*.g'), ()),
|
||||
'AntlrLexer': ('pygments.lexers.parsers', 'ANTLR', ('antlr',), (), ()),
|
||||
'AntlrObjectiveCLexer': ('pygments.lexers.parsers', 'ANTLR With ObjectiveC Target', ('antlr-objc',), ('*.G', '*.g'), ()),
|
||||
'AntlrPerlLexer': ('pygments.lexers.parsers', 'ANTLR With Perl Target', ('antlr-perl',), ('*.G', '*.g'), ()),
|
||||
'AntlrPythonLexer': ('pygments.lexers.parsers', 'ANTLR With Python Target', ('antlr-python',), ('*.G', '*.g'), ()),
|
||||
'AntlrRubyLexer': ('pygments.lexers.parsers', 'ANTLR With Ruby Target', ('antlr-ruby', 'antlr-rb'), ('*.G', '*.g'), ()),
|
||||
'ApacheConfLexer': ('pygments.lexers.text', 'ApacheConf', ('apacheconf', 'aconf', 'apache'), ('.htaccess', 'apache.conf', 'apache2.conf'), ('text/x-apacheconf',)),
|
||||
'AppleScriptLexer': ('pygments.lexers.other', 'AppleScript', ('applescript',), ('*.applescript',), ()),
|
||||
'AspectJLexer': ('pygments.lexers.jvm', 'AspectJ', ('aspectj',), ('*.aj',), ('text/x-aspectj',)),
|
||||
'AsymptoteLexer': ('pygments.lexers.other', 'Asymptote', ('asy', 'asymptote'), ('*.asy',), ('text/x-asymptote',)),
|
||||
'AutoItLexer': ('pygments.lexers.other', 'AutoIt', ('autoit', 'Autoit'), ('*.au3',), ('text/x-autoit',)),
|
||||
'AutohotkeyLexer': ('pygments.lexers.other', 'autohotkey', ('ahk', 'autohotkey'), ('*.ahk', '*.ahkl'), ('text/x-autohotkey',)),
|
||||
'AwkLexer': ('pygments.lexers.other', 'Awk', ('awk', 'gawk', 'mawk', 'nawk'), ('*.awk',), ('application/x-awk',)),
|
||||
'BBCodeLexer': ('pygments.lexers.text', 'BBCode', ('bbcode',), (), ('text/x-bbcode',)),
|
||||
'BaseMakefileLexer': ('pygments.lexers.text', 'Base Makefile', ('basemake',), (), ()),
|
||||
'BashLexer': ('pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '.bashrc', 'bashrc', '.bash_*', 'bash_*'), ('application/x-sh', 'application/x-shellscript')),
|
||||
'BashSessionLexer': ('pygments.lexers.shell', 'Bash Session', ('console',), ('*.sh-session',), ('application/x-shell-session',)),
|
||||
'BatchLexer': ('pygments.lexers.shell', 'Batchfile', ('bat', 'dosbatch', 'winbatch'), ('*.bat', '*.cmd'), ('application/x-dos-batch',)),
|
||||
'BefungeLexer': ('pygments.lexers.other', 'Befunge', ('befunge',), ('*.befunge',), ('application/x-befunge',)),
|
||||
'BlitzBasicLexer': ('pygments.lexers.compiled', 'BlitzBasic', ('blitzbasic', 'b3d', 'bplus'), ('*.bb', '*.decls'), ('text/x-bb',)),
|
||||
'BlitzMaxLexer': ('pygments.lexers.compiled', 'BlitzMax', ('blitzmax', 'bmax'), ('*.bmx',), ('text/x-bmx',)),
|
||||
'BooLexer': ('pygments.lexers.dotnet', 'Boo', ('boo',), ('*.boo',), ('text/x-boo',)),
|
||||
'BrainfuckLexer': ('pygments.lexers.other', 'Brainfuck', ('brainfuck', 'bf'), ('*.bf', '*.b'), ('application/x-brainfuck',)),
|
||||
'BroLexer': ('pygments.lexers.other', 'Bro', ('bro',), ('*.bro',), ()),
|
||||
'BugsLexer': ('pygments.lexers.math', 'BUGS', ('bugs', 'winbugs', 'openbugs'), ('*.bug',), ()),
|
||||
'CLexer': ('pygments.lexers.compiled', 'C', ('c',), ('*.c', '*.h', '*.idc'), ('text/x-chdr', 'text/x-csrc')),
|
||||
'CMakeLexer': ('pygments.lexers.text', 'CMake', ('cmake',), ('*.cmake', 'CMakeLists.txt'), ('text/x-cmake',)),
|
||||
'CObjdumpLexer': ('pygments.lexers.asm', 'c-objdump', ('c-objdump',), ('*.c-objdump',), ('text/x-c-objdump',)),
|
||||
'CSharpAspxLexer': ('pygments.lexers.dotnet', 'aspx-cs', ('aspx-cs',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'CSharpLexer': ('pygments.lexers.dotnet', 'C#', ('csharp', 'c#'), ('*.cs',), ('text/x-csharp',)),
|
||||
'Ca65Lexer': ('pygments.lexers.asm', 'ca65', ('ca65',), ('*.s',), ()),
|
||||
'CbmBasicV2Lexer': ('pygments.lexers.other', 'CBM BASIC V2', ('cbmbas',), ('*.bas',), ()),
|
||||
'CeylonLexer': ('pygments.lexers.jvm', 'Ceylon', ('ceylon',), ('*.ceylon',), ('text/x-ceylon',)),
|
||||
'Cfengine3Lexer': ('pygments.lexers.other', 'CFEngine3', ('cfengine3', 'cf3'), ('*.cf',), ()),
|
||||
'CheetahHtmlLexer': ('pygments.lexers.templates', 'HTML+Cheetah', ('html+cheetah', 'html+spitfire', 'htmlcheetah'), (), ('text/html+cheetah', 'text/html+spitfire')),
|
||||
'CheetahJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Cheetah', ('js+cheetah', 'javascript+cheetah', 'js+spitfire', 'javascript+spitfire'), (), ('application/x-javascript+cheetah', 'text/x-javascript+cheetah', 'text/javascript+cheetah', 'application/x-javascript+spitfire', 'text/x-javascript+spitfire', 'text/javascript+spitfire')),
|
||||
'CheetahLexer': ('pygments.lexers.templates', 'Cheetah', ('cheetah', 'spitfire'), ('*.tmpl', '*.spt'), ('application/x-cheetah', 'application/x-spitfire')),
|
||||
'CheetahXmlLexer': ('pygments.lexers.templates', 'XML+Cheetah', ('xml+cheetah', 'xml+spitfire'), (), ('application/xml+cheetah', 'application/xml+spitfire')),
|
||||
'ClayLexer': ('pygments.lexers.compiled', 'Clay', ('clay',), ('*.clay',), ('text/x-clay',)),
|
||||
'ClojureLexer': ('pygments.lexers.jvm', 'Clojure', ('clojure', 'clj'), ('*.clj',), ('text/x-clojure', 'application/x-clojure')),
|
||||
'CobolFreeformatLexer': ('pygments.lexers.compiled', 'COBOLFree', ('cobolfree',), ('*.cbl', '*.CBL'), ()),
|
||||
'CobolLexer': ('pygments.lexers.compiled', 'COBOL', ('cobol',), ('*.cob', '*.COB', '*.cpy', '*.CPY'), ('text/x-cobol',)),
|
||||
'CoffeeScriptLexer': ('pygments.lexers.web', 'CoffeeScript', ('coffee-script', 'coffeescript', 'coffee'), ('*.coffee',), ('text/coffeescript',)),
|
||||
'ColdfusionHtmlLexer': ('pygments.lexers.templates', 'Coldfusion HTML', ('cfm',), ('*.cfm', '*.cfml', '*.cfc'), ('application/x-coldfusion',)),
|
||||
'ColdfusionLexer': ('pygments.lexers.templates', 'cfstatement', ('cfs',), (), ()),
|
||||
'CommonLispLexer': ('pygments.lexers.functional', 'Common Lisp', ('common-lisp', 'cl', 'lisp'), ('*.cl', '*.lisp', '*.el'), ('text/x-common-lisp',)),
|
||||
'CoqLexer': ('pygments.lexers.functional', 'Coq', ('coq',), ('*.v',), ('text/x-coq',)),
|
||||
'CppLexer': ('pygments.lexers.compiled', 'C++', ('cpp', 'c++'), ('*.cpp', '*.hpp', '*.c++', '*.h++', '*.cc', '*.hh', '*.cxx', '*.hxx', '*.C', '*.H', '*.cp', '*.CPP'), ('text/x-c++hdr', 'text/x-c++src')),
|
||||
'CppObjdumpLexer': ('pygments.lexers.asm', 'cpp-objdump', ('cpp-objdump', 'c++-objdumb', 'cxx-objdump'), ('*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump'), ('text/x-cpp-objdump',)),
|
||||
'CrocLexer': ('pygments.lexers.agile', 'Croc', ('croc',), ('*.croc',), ('text/x-crocsrc',)),
|
||||
'CssDjangoLexer': ('pygments.lexers.templates', 'CSS+Django/Jinja', ('css+django', 'css+jinja'), (), ('text/css+django', 'text/css+jinja')),
|
||||
'CssErbLexer': ('pygments.lexers.templates', 'CSS+Ruby', ('css+erb', 'css+ruby'), (), ('text/css+ruby',)),
|
||||
'CssGenshiLexer': ('pygments.lexers.templates', 'CSS+Genshi Text', ('css+genshitext', 'css+genshi'), (), ('text/css+genshi',)),
|
||||
'CssLexer': ('pygments.lexers.web', 'CSS', ('css',), ('*.css',), ('text/css',)),
|
||||
'CssPhpLexer': ('pygments.lexers.templates', 'CSS+PHP', ('css+php',), (), ('text/css+php',)),
|
||||
'CssSmartyLexer': ('pygments.lexers.templates', 'CSS+Smarty', ('css+smarty',), (), ('text/css+smarty',)),
|
||||
'CudaLexer': ('pygments.lexers.compiled', 'CUDA', ('cuda', 'cu'), ('*.cu', '*.cuh'), ('text/x-cuda',)),
|
||||
'CythonLexer': ('pygments.lexers.compiled', 'Cython', ('cython', 'pyx', 'pyrex'), ('*.pyx', '*.pxd', '*.pxi'), ('text/x-cython', 'application/x-cython')),
|
||||
'DLexer': ('pygments.lexers.compiled', 'D', ('d',), ('*.d', '*.di'), ('text/x-dsrc',)),
|
||||
'DObjdumpLexer': ('pygments.lexers.asm', 'd-objdump', ('d-objdump',), ('*.d-objdump',), ('text/x-d-objdump',)),
|
||||
'DarcsPatchLexer': ('pygments.lexers.text', 'Darcs Patch', ('dpatch',), ('*.dpatch', '*.darcspatch'), ()),
|
||||
'DartLexer': ('pygments.lexers.web', 'Dart', ('dart',), ('*.dart',), ('text/x-dart',)),
|
||||
'DebianControlLexer': ('pygments.lexers.text', 'Debian Control file', ('control', 'debcontrol'), ('control',), ()),
|
||||
'DelphiLexer': ('pygments.lexers.compiled', 'Delphi', ('delphi', 'pas', 'pascal', 'objectpascal'), ('*.pas',), ('text/x-pascal',)),
|
||||
'DgLexer': ('pygments.lexers.agile', 'dg', ('dg',), ('*.dg',), ('text/x-dg',)),
|
||||
'DiffLexer': ('pygments.lexers.text', 'Diff', ('diff', 'udiff'), ('*.diff', '*.patch'), ('text/x-diff', 'text/x-patch')),
|
||||
'DjangoLexer': ('pygments.lexers.templates', 'Django/Jinja', ('django', 'jinja'), (), ('application/x-django-templating', 'application/x-jinja')),
|
||||
'DtdLexer': ('pygments.lexers.web', 'DTD', ('dtd',), ('*.dtd',), ('application/xml-dtd',)),
|
||||
'DuelLexer': ('pygments.lexers.web', 'Duel', ('duel', 'Duel Engine', 'Duel View', 'JBST', 'jbst', 'JsonML+BST'), ('*.duel', '*.jbst'), ('text/x-duel', 'text/x-jbst')),
|
||||
'DylanConsoleLexer': ('pygments.lexers.compiled', 'Dylan session', ('dylan-console', 'dylan-repl'), ('*.dylan-console',), ('text/x-dylan-console',)),
|
||||
'DylanLexer': ('pygments.lexers.compiled', 'Dylan', ('dylan',), ('*.dylan', '*.dyl', '*.intr'), ('text/x-dylan',)),
|
||||
'DylanLidLexer': ('pygments.lexers.compiled', 'DylanLID', ('dylan-lid', 'lid'), ('*.lid', '*.hdp'), ('text/x-dylan-lid',)),
|
||||
'ECLLexer': ('pygments.lexers.other', 'ECL', ('ecl',), ('*.ecl',), ('application/x-ecl',)),
|
||||
'ECLexer': ('pygments.lexers.compiled', 'eC', ('ec',), ('*.ec', '*.eh'), ('text/x-echdr', 'text/x-ecsrc')),
|
||||
'EbnfLexer': ('pygments.lexers.text', 'EBNF', ('ebnf',), ('*.ebnf',), ('text/x-ebnf',)),
|
||||
'ElixirConsoleLexer': ('pygments.lexers.functional', 'Elixir iex session', ('iex',), (), ('text/x-elixir-shellsession',)),
|
||||
'ElixirLexer': ('pygments.lexers.functional', 'Elixir', ('elixir', 'ex', 'exs'), ('*.ex', '*.exs'), ('text/x-elixir',)),
|
||||
'ErbLexer': ('pygments.lexers.templates', 'ERB', ('erb',), (), ('application/x-ruby-templating',)),
|
||||
'ErlangLexer': ('pygments.lexers.functional', 'Erlang', ('erlang',), ('*.erl', '*.hrl', '*.es', '*.escript'), ('text/x-erlang',)),
|
||||
'ErlangShellLexer': ('pygments.lexers.functional', 'Erlang erl session', ('erl',), ('*.erl-sh',), ('text/x-erl-shellsession',)),
|
||||
'EvoqueHtmlLexer': ('pygments.lexers.templates', 'HTML+Evoque', ('html+evoque',), ('*.html',), ('text/html+evoque',)),
|
||||
'EvoqueLexer': ('pygments.lexers.templates', 'Evoque', ('evoque',), ('*.evoque',), ('application/x-evoque',)),
|
||||
'EvoqueXmlLexer': ('pygments.lexers.templates', 'XML+Evoque', ('xml+evoque',), ('*.xml',), ('application/xml+evoque',)),
|
||||
'FSharpLexer': ('pygments.lexers.dotnet', 'FSharp', ('fsharp',), ('*.fs', '*.fsi'), ('text/x-fsharp',)),
|
||||
'FactorLexer': ('pygments.lexers.agile', 'Factor', ('factor',), ('*.factor',), ('text/x-factor',)),
|
||||
'FancyLexer': ('pygments.lexers.agile', 'Fancy', ('fancy', 'fy'), ('*.fy', '*.fancypack'), ('text/x-fancysrc',)),
|
||||
'FantomLexer': ('pygments.lexers.compiled', 'Fantom', ('fan',), ('*.fan',), ('application/x-fantom',)),
|
||||
'FelixLexer': ('pygments.lexers.compiled', 'Felix', ('felix', 'flx'), ('*.flx', '*.flxh'), ('text/x-felix',)),
|
||||
'FortranLexer': ('pygments.lexers.compiled', 'Fortran', ('fortran',), ('*.f', '*.f90', '*.F', '*.F90'), ('text/x-fortran',)),
|
||||
'FoxProLexer': ('pygments.lexers.foxpro', 'FoxPro', ('Clipper', 'XBase'), ('*.PRG', '*.prg'), ()),
|
||||
'GLShaderLexer': ('pygments.lexers.compiled', 'GLSL', ('glsl',), ('*.vert', '*.frag', '*.geo'), ('text/x-glslsrc',)),
|
||||
'GasLexer': ('pygments.lexers.asm', 'GAS', ('gas', 'asm'), ('*.s', '*.S'), ('text/x-gas',)),
|
||||
'GenshiLexer': ('pygments.lexers.templates', 'Genshi', ('genshi', 'kid', 'xml+genshi', 'xml+kid'), ('*.kid',), ('application/x-genshi', 'application/x-kid')),
|
||||
'GenshiTextLexer': ('pygments.lexers.templates', 'Genshi Text', ('genshitext',), (), ('application/x-genshi-text', 'text/x-genshi')),
|
||||
'GettextLexer': ('pygments.lexers.text', 'Gettext Catalog', ('pot', 'po'), ('*.pot', '*.po'), ('application/x-gettext', 'text/x-gettext', 'text/gettext')),
|
||||
'GherkinLexer': ('pygments.lexers.other', 'Gherkin', ('Cucumber', 'cucumber', 'Gherkin', 'gherkin'), ('*.feature',), ('text/x-gherkin',)),
|
||||
'GnuplotLexer': ('pygments.lexers.other', 'Gnuplot', ('gnuplot',), ('*.plot', '*.plt'), ('text/x-gnuplot',)),
|
||||
'GoLexer': ('pygments.lexers.compiled', 'Go', ('go',), ('*.go',), ('text/x-gosrc',)),
|
||||
'GoodDataCLLexer': ('pygments.lexers.other', 'GoodData-CL', ('gooddata-cl',), ('*.gdc',), ('text/x-gooddata-cl',)),
|
||||
'GosuLexer': ('pygments.lexers.jvm', 'Gosu', ('gosu',), ('*.gs', '*.gsx', '*.gsp', '*.vark'), ('text/x-gosu',)),
|
||||
'GosuTemplateLexer': ('pygments.lexers.jvm', 'Gosu Template', ('gst',), ('*.gst',), ('text/x-gosu-template',)),
|
||||
'GroffLexer': ('pygments.lexers.text', 'Groff', ('groff', 'nroff', 'man'), ('*.[1234567]', '*.man'), ('application/x-troff', 'text/troff')),
|
||||
'GroovyLexer': ('pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy',), ('text/x-groovy',)),
|
||||
'HamlLexer': ('pygments.lexers.web', 'Haml', ('haml', 'HAML'), ('*.haml',), ('text/x-haml',)),
|
||||
'HaskellLexer': ('pygments.lexers.functional', 'Haskell', ('haskell', 'hs'), ('*.hs',), ('text/x-haskell',)),
|
||||
'HaxeLexer': ('pygments.lexers.web', 'Haxe', ('hx', 'Haxe', 'haxe', 'haXe', 'hxsl'), ('*.hx', '*.hxsl'), ('text/haxe', 'text/x-haxe', 'text/x-hx')),
|
||||
'HtmlDjangoLexer': ('pygments.lexers.templates', 'HTML+Django/Jinja', ('html+django', 'html+jinja', 'htmldjango'), (), ('text/html+django', 'text/html+jinja')),
|
||||
'HtmlGenshiLexer': ('pygments.lexers.templates', 'HTML+Genshi', ('html+genshi', 'html+kid'), (), ('text/html+genshi',)),
|
||||
'HtmlLexer': ('pygments.lexers.web', 'HTML', ('html',), ('*.html', '*.htm', '*.xhtml', '*.xslt'), ('text/html', 'application/xhtml+xml')),
|
||||
'HtmlPhpLexer': ('pygments.lexers.templates', 'HTML+PHP', ('html+php',), ('*.phtml',), ('application/x-php', 'application/x-httpd-php', 'application/x-httpd-php3', 'application/x-httpd-php4', 'application/x-httpd-php5')),
|
||||
'HtmlSmartyLexer': ('pygments.lexers.templates', 'HTML+Smarty', ('html+smarty',), (), ('text/html+smarty',)),
|
||||
'HttpLexer': ('pygments.lexers.text', 'HTTP', ('http',), (), ()),
|
||||
'HxmlLexer': ('pygments.lexers.text', 'Hxml', ('haxeml', 'hxml'), ('*.hxml',), ()),
|
||||
'HybrisLexer': ('pygments.lexers.other', 'Hybris', ('hybris', 'hy'), ('*.hy', '*.hyb'), ('text/x-hybris', 'application/x-hybris')),
|
||||
'IDLLexer': ('pygments.lexers.math', 'IDL', ('idl',), ('*.pro',), ('text/idl',)),
|
||||
'IgorLexer': ('pygments.lexers.math', 'Igor', ('igor', 'igorpro'), ('*.ipf',), ('text/ipf',)),
|
||||
'IniLexer': ('pygments.lexers.text', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg'), ('text/x-ini',)),
|
||||
'IoLexer': ('pygments.lexers.agile', 'Io', ('io',), ('*.io',), ('text/x-iosrc',)),
|
||||
'IokeLexer': ('pygments.lexers.jvm', 'Ioke', ('ioke', 'ik'), ('*.ik',), ('text/x-iokesrc',)),
|
||||
'IrcLogsLexer': ('pygments.lexers.text', 'IRC logs', ('irc',), ('*.weechatlog',), ('text/x-irclog',)),
|
||||
'JadeLexer': ('pygments.lexers.web', 'Jade', ('jade', 'JADE'), ('*.jade',), ('text/x-jade',)),
|
||||
'JagsLexer': ('pygments.lexers.math', 'JAGS', ('jags',), ('*.jag', '*.bug'), ()),
|
||||
'JavaLexer': ('pygments.lexers.jvm', 'Java', ('java',), ('*.java',), ('text/x-java',)),
|
||||
'JavascriptDjangoLexer': ('pygments.lexers.templates', 'JavaScript+Django/Jinja', ('js+django', 'javascript+django', 'js+jinja', 'javascript+jinja'), (), ('application/x-javascript+django', 'application/x-javascript+jinja', 'text/x-javascript+django', 'text/x-javascript+jinja', 'text/javascript+django', 'text/javascript+jinja')),
|
||||
'JavascriptErbLexer': ('pygments.lexers.templates', 'JavaScript+Ruby', ('js+erb', 'javascript+erb', 'js+ruby', 'javascript+ruby'), (), ('application/x-javascript+ruby', 'text/x-javascript+ruby', 'text/javascript+ruby')),
|
||||
'JavascriptGenshiLexer': ('pygments.lexers.templates', 'JavaScript+Genshi Text', ('js+genshitext', 'js+genshi', 'javascript+genshitext', 'javascript+genshi'), (), ('application/x-javascript+genshi', 'text/x-javascript+genshi', 'text/javascript+genshi')),
|
||||
'JavascriptLexer': ('pygments.lexers.web', 'JavaScript', ('js', 'javascript'), ('*.js',), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
|
||||
'JavascriptPhpLexer': ('pygments.lexers.templates', 'JavaScript+PHP', ('js+php', 'javascript+php'), (), ('application/x-javascript+php', 'text/x-javascript+php', 'text/javascript+php')),
|
||||
'JavascriptSmartyLexer': ('pygments.lexers.templates', 'JavaScript+Smarty', ('js+smarty', 'javascript+smarty'), (), ('application/x-javascript+smarty', 'text/x-javascript+smarty', 'text/javascript+smarty')),
|
||||
'JsonLexer': ('pygments.lexers.web', 'JSON', ('json',), ('*.json',), ('application/json',)),
|
||||
'JspLexer': ('pygments.lexers.templates', 'Java Server Page', ('jsp',), ('*.jsp',), ('application/x-jsp',)),
|
||||
'JuliaConsoleLexer': ('pygments.lexers.math', 'Julia console', ('jlcon',), (), ()),
|
||||
'JuliaLexer': ('pygments.lexers.math', 'Julia', ('julia', 'jl'), ('*.jl',), ('text/x-julia', 'application/x-julia')),
|
||||
'KconfigLexer': ('pygments.lexers.other', 'Kconfig', ('kconfig', 'menuconfig', 'linux-config', 'kernel-config'), ('Kconfig', '*Config.in*', 'external.in*', 'standard-modules.in'), ('text/x-kconfig',)),
|
||||
'KokaLexer': ('pygments.lexers.functional', 'Koka', ('koka',), ('*.kk', '*.kki'), ('text/x-koka',)),
|
||||
'KotlinLexer': ('pygments.lexers.jvm', 'Kotlin', ('kotlin',), ('*.kt',), ('text/x-kotlin',)),
|
||||
'LassoCssLexer': ('pygments.lexers.templates', 'CSS+Lasso', ('css+lasso',), (), ('text/css+lasso',)),
|
||||
'LassoHtmlLexer': ('pygments.lexers.templates', 'HTML+Lasso', ('html+lasso',), (), ('text/html+lasso', 'application/x-httpd-lasso', 'application/x-httpd-lasso[89]')),
|
||||
'LassoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Lasso', ('js+lasso', 'javascript+lasso'), (), ('application/x-javascript+lasso', 'text/x-javascript+lasso', 'text/javascript+lasso')),
|
||||
'LassoLexer': ('pygments.lexers.web', 'Lasso', ('lasso', 'lassoscript'), ('*.lasso', '*.lasso[89]'), ('text/x-lasso',)),
|
||||
'LassoXmlLexer': ('pygments.lexers.templates', 'XML+Lasso', ('xml+lasso',), (), ('application/xml+lasso',)),
|
||||
'LighttpdConfLexer': ('pygments.lexers.text', 'Lighttpd configuration file', ('lighty', 'lighttpd'), (), ('text/x-lighttpd-conf',)),
|
||||
'LiterateAgdaLexer': ('pygments.lexers.functional', 'Literate Agda', ('lagda', 'literate-agda'), ('*.lagda',), ('text/x-literate-agda',)),
|
||||
'LiterateHaskellLexer': ('pygments.lexers.functional', 'Literate Haskell', ('lhs', 'literate-haskell', 'lhaskell'), ('*.lhs',), ('text/x-literate-haskell',)),
|
||||
'LiveScriptLexer': ('pygments.lexers.web', 'LiveScript', ('live-script', 'livescript'), ('*.ls',), ('text/livescript',)),
|
||||
'LlvmLexer': ('pygments.lexers.asm', 'LLVM', ('llvm',), ('*.ll',), ('text/x-llvm',)),
|
||||
'LogosLexer': ('pygments.lexers.compiled', 'Logos', ('logos',), ('*.x', '*.xi', '*.xm', '*.xmi'), ('text/x-logos',)),
|
||||
'LogtalkLexer': ('pygments.lexers.other', 'Logtalk', ('logtalk',), ('*.lgt',), ('text/x-logtalk',)),
|
||||
'LuaLexer': ('pygments.lexers.agile', 'Lua', ('lua',), ('*.lua', '*.wlua'), ('text/x-lua', 'application/x-lua')),
|
||||
'MOOCodeLexer': ('pygments.lexers.other', 'MOOCode', ('moocode', 'moo'), ('*.moo',), ('text/x-moocode',)),
|
||||
'MakefileLexer': ('pygments.lexers.text', 'Makefile', ('make', 'makefile', 'mf', 'bsdmake'), ('*.mak', 'Makefile', 'makefile', 'Makefile.*', 'GNUmakefile'), ('text/x-makefile',)),
|
||||
'MakoCssLexer': ('pygments.lexers.templates', 'CSS+Mako', ('css+mako',), (), ('text/css+mako',)),
|
||||
'MakoHtmlLexer': ('pygments.lexers.templates', 'HTML+Mako', ('html+mako',), (), ('text/html+mako',)),
|
||||
'MakoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Mako', ('js+mako', 'javascript+mako'), (), ('application/x-javascript+mako', 'text/x-javascript+mako', 'text/javascript+mako')),
|
||||
'MakoLexer': ('pygments.lexers.templates', 'Mako', ('mako',), ('*.mao',), ('application/x-mako',)),
|
||||
'MakoXmlLexer': ('pygments.lexers.templates', 'XML+Mako', ('xml+mako',), (), ('application/xml+mako',)),
|
||||
'MaqlLexer': ('pygments.lexers.other', 'MAQL', ('maql',), ('*.maql',), ('text/x-gooddata-maql', 'application/x-gooddata-maql')),
|
||||
'MasonLexer': ('pygments.lexers.templates', 'Mason', ('mason',), ('*.m', '*.mhtml', '*.mc', '*.mi', 'autohandler', 'dhandler'), ('application/x-mason',)),
|
||||
'MatlabLexer': ('pygments.lexers.math', 'Matlab', ('matlab',), ('*.m',), ('text/matlab',)),
|
||||
'MatlabSessionLexer': ('pygments.lexers.math', 'Matlab session', ('matlabsession',), (), ()),
|
||||
'MiniDLexer': ('pygments.lexers.agile', 'MiniD', ('minid',), ('*.md',), ('text/x-minidsrc',)),
|
||||
'ModelicaLexer': ('pygments.lexers.other', 'Modelica', ('modelica',), ('*.mo',), ('text/x-modelica',)),
|
||||
'Modula2Lexer': ('pygments.lexers.compiled', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
|
||||
'MoinWikiLexer': ('pygments.lexers.text', 'MoinMoin/Trac Wiki markup', ('trac-wiki', 'moin'), (), ('text/x-trac-wiki',)),
|
||||
'MonkeyLexer': ('pygments.lexers.compiled', 'Monkey', ('monkey',), ('*.monkey',), ('text/x-monkey',)),
|
||||
'MoonScriptLexer': ('pygments.lexers.agile', 'MoonScript', ('moon', 'moonscript'), ('*.moon',), ('text/x-moonscript', 'application/x-moonscript')),
|
||||
'MscgenLexer': ('pygments.lexers.other', 'Mscgen', ('mscgen', 'msc'), ('*.msc',), ()),
|
||||
'MuPADLexer': ('pygments.lexers.math', 'MuPAD', ('mupad',), ('*.mu',), ()),
|
||||
'MxmlLexer': ('pygments.lexers.web', 'MXML', ('mxml',), ('*.mxml',), ()),
|
||||
'MySqlLexer': ('pygments.lexers.sql', 'MySQL', ('mysql',), (), ('text/x-mysql',)),
|
||||
'MyghtyCssLexer': ('pygments.lexers.templates', 'CSS+Myghty', ('css+myghty',), (), ('text/css+myghty',)),
|
||||
'MyghtyHtmlLexer': ('pygments.lexers.templates', 'HTML+Myghty', ('html+myghty',), (), ('text/html+myghty',)),
|
||||
'MyghtyJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Myghty', ('js+myghty', 'javascript+myghty'), (), ('application/x-javascript+myghty', 'text/x-javascript+myghty', 'text/javascript+mygthy')),
|
||||
'MyghtyLexer': ('pygments.lexers.templates', 'Myghty', ('myghty',), ('*.myt', 'autodelegate'), ('application/x-myghty',)),
|
||||
'MyghtyXmlLexer': ('pygments.lexers.templates', 'XML+Myghty', ('xml+myghty',), (), ('application/xml+myghty',)),
|
||||
'NSISLexer': ('pygments.lexers.other', 'NSIS', ('nsis', 'nsi', 'nsh'), ('*.nsi', '*.nsh'), ('text/x-nsis',)),
|
||||
'NasmLexer': ('pygments.lexers.asm', 'NASM', ('nasm',), ('*.asm', '*.ASM'), ('text/x-nasm',)),
|
||||
'NemerleLexer': ('pygments.lexers.dotnet', 'Nemerle', ('nemerle',), ('*.n',), ('text/x-nemerle',)),
|
||||
'NesCLexer': ('pygments.lexers.compiled', 'nesC', ('nesc',), ('*.nc',), ('text/x-nescsrc',)),
|
||||
'NewLispLexer': ('pygments.lexers.functional', 'NewLisp', ('newlisp',), ('*.lsp', '*.nl'), ('text/x-newlisp', 'application/x-newlisp')),
|
||||
'NewspeakLexer': ('pygments.lexers.other', 'Newspeak', ('newspeak',), ('*.ns2',), ('text/x-newspeak',)),
|
||||
'NginxConfLexer': ('pygments.lexers.text', 'Nginx configuration file', ('nginx',), (), ('text/x-nginx-conf',)),
|
||||
'NimrodLexer': ('pygments.lexers.compiled', 'Nimrod', ('nimrod', 'nim'), ('*.nim', '*.nimrod'), ('text/x-nimrod',)),
|
||||
'NumPyLexer': ('pygments.lexers.math', 'NumPy', ('numpy',), (), ()),
|
||||
'ObjdumpLexer': ('pygments.lexers.asm', 'objdump', ('objdump',), ('*.objdump',), ('text/x-objdump',)),
|
||||
'ObjectiveCLexer': ('pygments.lexers.compiled', 'Objective-C', ('objective-c', 'objectivec', 'obj-c', 'objc'), ('*.m', '*.h'), ('text/x-objective-c',)),
|
||||
'ObjectiveCppLexer': ('pygments.lexers.compiled', 'Objective-C++', ('objective-c++', 'objectivec++', 'obj-c++', 'objc++'), ('*.mm', '*.hh'), ('text/x-objective-c++',)),
|
||||
'ObjectiveJLexer': ('pygments.lexers.web', 'Objective-J', ('objective-j', 'objectivej', 'obj-j', 'objj'), ('*.j',), ('text/x-objective-j',)),
|
||||
'OcamlLexer': ('pygments.lexers.functional', 'OCaml', ('ocaml',), ('*.ml', '*.mli', '*.mll', '*.mly'), ('text/x-ocaml',)),
|
||||
'OctaveLexer': ('pygments.lexers.math', 'Octave', ('octave',), ('*.m',), ('text/octave',)),
|
||||
'OocLexer': ('pygments.lexers.compiled', 'Ooc', ('ooc',), ('*.ooc',), ('text/x-ooc',)),
|
||||
'OpaLexer': ('pygments.lexers.functional', 'Opa', ('opa',), ('*.opa',), ('text/x-opa',)),
|
||||
'OpenEdgeLexer': ('pygments.lexers.other', 'OpenEdge ABL', ('openedge', 'abl', 'progress'), ('*.p', '*.cls'), ('text/x-openedge', 'application/x-openedge')),
|
||||
'Perl6Lexer': ('pygments.lexers.agile', 'Perl6', ('perl6', 'pl6'), ('*.pl', '*.pm', '*.nqp', '*.p6', '*.6pl', '*.p6l', '*.pl6', '*.6pm', '*.p6m', '*.pm6'), ('text/x-perl6', 'application/x-perl6')),
|
||||
'PerlLexer': ('pygments.lexers.agile', 'Perl', ('perl', 'pl'), ('*.pl', '*.pm'), ('text/x-perl', 'application/x-perl')),
|
||||
'PhpLexer': ('pygments.lexers.web', 'PHP', ('php', 'php3', 'php4', 'php5'), ('*.php', '*.php[345]', '*.inc'), ('text/x-php',)),
|
||||
'PlPgsqlLexer': ('pygments.lexers.sql', 'PL/pgSQL', ('plpgsql',), (), ('text/x-plpgsql',)),
|
||||
'PostScriptLexer': ('pygments.lexers.other', 'PostScript', ('postscript', 'postscr'), ('*.ps', '*.eps'), ('application/postscript',)),
|
||||
'PostgresConsoleLexer': ('pygments.lexers.sql', 'PostgreSQL console (psql)', ('psql', 'postgresql-console', 'postgres-console'), (), ('text/x-postgresql-psql',)),
|
||||
'PostgresLexer': ('pygments.lexers.sql', 'PostgreSQL SQL dialect', ('postgresql', 'postgres'), (), ('text/x-postgresql',)),
|
||||
'PovrayLexer': ('pygments.lexers.other', 'POVRay', ('pov',), ('*.pov', '*.inc'), ('text/x-povray',)),
|
||||
'PowerShellLexer': ('pygments.lexers.shell', 'PowerShell', ('powershell', 'posh', 'ps1', 'psm1'), ('*.ps1', '*.psm1'), ('text/x-powershell',)),
|
||||
'PrologLexer': ('pygments.lexers.compiled', 'Prolog', ('prolog',), ('*.prolog', '*.pro', '*.pl'), ('text/x-prolog',)),
|
||||
'PropertiesLexer': ('pygments.lexers.text', 'Properties', ('properties', 'jproperties'), ('*.properties',), ('text/x-java-properties',)),
|
||||
'ProtoBufLexer': ('pygments.lexers.other', 'Protocol Buffer', ('protobuf', 'proto'), ('*.proto',), ()),
|
||||
'PuppetLexer': ('pygments.lexers.other', 'Puppet', ('puppet',), ('*.pp',), ()),
|
||||
'PyPyLogLexer': ('pygments.lexers.text', 'PyPy Log', ('pypylog', 'pypy'), ('*.pypylog',), ('application/x-pypylog',)),
|
||||
'Python3Lexer': ('pygments.lexers.agile', 'Python 3', ('python3', 'py3'), (), ('text/x-python3', 'application/x-python3')),
|
||||
'Python3TracebackLexer': ('pygments.lexers.agile', 'Python 3.0 Traceback', ('py3tb',), ('*.py3tb',), ('text/x-python3-traceback',)),
|
||||
'PythonConsoleLexer': ('pygments.lexers.agile', 'Python console session', ('pycon',), (), ('text/x-python-doctest',)),
|
||||
'PythonLexer': ('pygments.lexers.agile', 'Python', ('python', 'py', 'sage'), ('*.py', '*.pyw', '*.sc', 'SConstruct', 'SConscript', '*.tac', '*.sage'), ('text/x-python', 'application/x-python')),
|
||||
'PythonTracebackLexer': ('pygments.lexers.agile', 'Python Traceback', ('pytb',), ('*.pytb',), ('text/x-python-traceback',)),
|
||||
'QmlLexer': ('pygments.lexers.web', 'QML', ('qml', 'Qt Meta Language', 'Qt modeling Language'), ('*.qml',), ('application/x-qml',)),
|
||||
'RConsoleLexer': ('pygments.lexers.math', 'RConsole', ('rconsole', 'rout'), ('*.Rout',), ()),
|
||||
'RPMSpecLexer': ('pygments.lexers.other', 'RPMSpec', ('spec',), ('*.spec',), ('text/x-rpm-spec',)),
|
||||
'RacketLexer': ('pygments.lexers.functional', 'Racket', ('racket', 'rkt'), ('*.rkt', '*.rktl'), ('text/x-racket', 'application/x-racket')),
|
||||
'RagelCLexer': ('pygments.lexers.parsers', 'Ragel in C Host', ('ragel-c',), ('*.rl',), ()),
|
||||
'RagelCppLexer': ('pygments.lexers.parsers', 'Ragel in CPP Host', ('ragel-cpp',), ('*.rl',), ()),
|
||||
'RagelDLexer': ('pygments.lexers.parsers', 'Ragel in D Host', ('ragel-d',), ('*.rl',), ()),
|
||||
'RagelEmbeddedLexer': ('pygments.lexers.parsers', 'Embedded Ragel', ('ragel-em',), ('*.rl',), ()),
|
||||
'RagelJavaLexer': ('pygments.lexers.parsers', 'Ragel in Java Host', ('ragel-java',), ('*.rl',), ()),
|
||||
'RagelLexer': ('pygments.lexers.parsers', 'Ragel', ('ragel',), (), ()),
|
||||
'RagelObjectiveCLexer': ('pygments.lexers.parsers', 'Ragel in Objective C Host', ('ragel-objc',), ('*.rl',), ()),
|
||||
'RagelRubyLexer': ('pygments.lexers.parsers', 'Ragel in Ruby Host', ('ragel-ruby', 'ragel-rb'), ('*.rl',), ()),
|
||||
'RawTokenLexer': ('pygments.lexers.special', 'Raw token data', ('raw',), (), ('application/x-pygments-tokens',)),
|
||||
'RdLexer': ('pygments.lexers.math', 'Rd', ('rd',), ('*.Rd',), ('text/x-r-doc',)),
|
||||
'RebolLexer': ('pygments.lexers.other', 'REBOL', ('rebol',), ('*.r', '*.r3'), ('text/x-rebol',)),
|
||||
'RedcodeLexer': ('pygments.lexers.other', 'Redcode', ('redcode',), ('*.cw',), ()),
|
||||
'RegeditLexer': ('pygments.lexers.text', 'reg', ('registry',), ('*.reg',), ('text/x-windows-registry',)),
|
||||
'RexxLexer': ('pygments.lexers.other', 'Rexx', ('rexx', 'ARexx', 'arexx'), ('*.rexx', '*.rex', '*.rx', '*.arexx'), ('text/x-rexx',)),
|
||||
'RhtmlLexer': ('pygments.lexers.templates', 'RHTML', ('rhtml', 'html+erb', 'html+ruby'), ('*.rhtml',), ('text/html+ruby',)),
|
||||
'RobotFrameworkLexer': ('pygments.lexers.other', 'RobotFramework', ('RobotFramework', 'robotframework'), ('*.txt', '*.robot'), ('text/x-robotframework',)),
|
||||
'RstLexer': ('pygments.lexers.text', 'reStructuredText', ('rst', 'rest', 'restructuredtext'), ('*.rst', '*.rest'), ('text/x-rst', 'text/prs.fallenstein.rst')),
|
||||
'RubyConsoleLexer': ('pygments.lexers.agile', 'Ruby irb session', ('rbcon', 'irb'), (), ('text/x-ruby-shellsession',)),
|
||||
'RubyLexer': ('pygments.lexers.agile', 'Ruby', ('rb', 'ruby', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby'), ('text/x-ruby', 'application/x-ruby')),
|
||||
'RustLexer': ('pygments.lexers.compiled', 'Rust', ('rust',), ('*.rs', '*.rc'), ('text/x-rustsrc',)),
|
||||
'SLexer': ('pygments.lexers.math', 'S', ('splus', 's', 'r'), ('*.S', '*.R', '.Rhistory', '.Rprofile'), ('text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r', 'text/x-R', 'text/x-r-history', 'text/x-r-profile')),
|
||||
'SMLLexer': ('pygments.lexers.functional', 'Standard ML', ('sml',), ('*.sml', '*.sig', '*.fun'), ('text/x-standardml', 'application/x-standardml')),
|
||||
'SassLexer': ('pygments.lexers.web', 'Sass', ('sass', 'SASS'), ('*.sass',), ('text/x-sass',)),
|
||||
'ScalaLexer': ('pygments.lexers.jvm', 'Scala', ('scala',), ('*.scala',), ('text/x-scala',)),
|
||||
'ScamlLexer': ('pygments.lexers.web', 'Scaml', ('scaml', 'SCAML'), ('*.scaml',), ('text/x-scaml',)),
|
||||
'SchemeLexer': ('pygments.lexers.functional', 'Scheme', ('scheme', 'scm'), ('*.scm', '*.ss'), ('text/x-scheme', 'application/x-scheme')),
|
||||
'ScilabLexer': ('pygments.lexers.math', 'Scilab', ('scilab',), ('*.sci', '*.sce', '*.tst'), ('text/scilab',)),
|
||||
'ScssLexer': ('pygments.lexers.web', 'SCSS', ('scss',), ('*.scss',), ('text/x-scss',)),
|
||||
'ShellSessionLexer': ('pygments.lexers.shell', 'Shell Session', ('shell-session',), ('*.shell-session',), ('application/x-sh-session',)),
|
||||
'SmaliLexer': ('pygments.lexers.dalvik', 'Smali', ('smali',), ('*.smali',), ('text/smali',)),
|
||||
'SmalltalkLexer': ('pygments.lexers.other', 'Smalltalk', ('smalltalk', 'squeak', 'st'), ('*.st',), ('text/x-smalltalk',)),
|
||||
'SmartyLexer': ('pygments.lexers.templates', 'Smarty', ('smarty',), ('*.tpl',), ('application/x-smarty',)),
|
||||
'SnobolLexer': ('pygments.lexers.other', 'Snobol', ('snobol',), ('*.snobol',), ('text/x-snobol',)),
|
||||
'SourcePawnLexer': ('pygments.lexers.other', 'SourcePawn', ('sp',), ('*.sp',), ('text/x-sourcepawn',)),
|
||||
'SourcesListLexer': ('pygments.lexers.text', 'Debian Sourcelist', ('sourceslist', 'sources.list', 'debsources'), ('sources.list',), ()),
|
||||
'SqlLexer': ('pygments.lexers.sql', 'SQL', ('sql',), ('*.sql',), ('text/x-sql',)),
|
||||
'SqliteConsoleLexer': ('pygments.lexers.sql', 'sqlite3con', ('sqlite3',), ('*.sqlite3-console',), ('text/x-sqlite3-console',)),
|
||||
'SquidConfLexer': ('pygments.lexers.text', 'SquidConf', ('squidconf', 'squid.conf', 'squid'), ('squid.conf',), ('text/x-squidconf',)),
|
||||
'SspLexer': ('pygments.lexers.templates', 'Scalate Server Page', ('ssp',), ('*.ssp',), ('application/x-ssp',)),
|
||||
'StanLexer': ('pygments.lexers.math', 'Stan', ('stan',), ('*.stan',), ()),
|
||||
'SwigLexer': ('pygments.lexers.compiled', 'SWIG', ('Swig', 'swig'), ('*.swg', '*.i'), ('text/swig',)),
|
||||
'SystemVerilogLexer': ('pygments.lexers.hdl', 'systemverilog', ('systemverilog', 'sv'), ('*.sv', '*.svh'), ('text/x-systemverilog',)),
|
||||
'TclLexer': ('pygments.lexers.agile', 'Tcl', ('tcl',), ('*.tcl',), ('text/x-tcl', 'text/x-script.tcl', 'application/x-tcl')),
|
||||
'TcshLexer': ('pygments.lexers.shell', 'Tcsh', ('tcsh', 'csh'), ('*.tcsh', '*.csh'), ('application/x-csh',)),
|
||||
'TeaTemplateLexer': ('pygments.lexers.templates', 'Tea', ('tea',), ('*.tea',), ('text/x-tea',)),
|
||||
'TexLexer': ('pygments.lexers.text', 'TeX', ('tex', 'latex'), ('*.tex', '*.aux', '*.toc'), ('text/x-tex', 'text/x-latex')),
|
||||
'TextLexer': ('pygments.lexers.special', 'Text only', ('text',), ('*.txt',), ('text/plain',)),
|
||||
'TreetopLexer': ('pygments.lexers.parsers', 'Treetop', ('treetop',), ('*.treetop', '*.tt'), ()),
|
||||
'TypeScriptLexer': ('pygments.lexers.web', 'TypeScript', ('ts',), ('*.ts',), ('text/x-typescript',)),
|
||||
'UrbiscriptLexer': ('pygments.lexers.other', 'UrbiScript', ('urbiscript',), ('*.u',), ('application/x-urbiscript',)),
|
||||
'VGLLexer': ('pygments.lexers.other', 'VGL', ('vgl',), ('*.rpf',), ()),
|
||||
'ValaLexer': ('pygments.lexers.compiled', 'Vala', ('vala', 'vapi'), ('*.vala', '*.vapi'), ('text/x-vala',)),
|
||||
'VbNetAspxLexer': ('pygments.lexers.dotnet', 'aspx-vb', ('aspx-vb',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'VbNetLexer': ('pygments.lexers.dotnet', 'VB.net', ('vb.net', 'vbnet'), ('*.vb', '*.bas'), ('text/x-vbnet', 'text/x-vba')),
|
||||
'VelocityHtmlLexer': ('pygments.lexers.templates', 'HTML+Velocity', ('html+velocity',), (), ('text/html+velocity',)),
|
||||
'VelocityLexer': ('pygments.lexers.templates', 'Velocity', ('velocity',), ('*.vm', '*.fhtml'), ()),
|
||||
'VelocityXmlLexer': ('pygments.lexers.templates', 'XML+Velocity', ('xml+velocity',), (), ('application/xml+velocity',)),
|
||||
'VerilogLexer': ('pygments.lexers.hdl', 'verilog', ('verilog', 'v'), ('*.v',), ('text/x-verilog',)),
|
||||
'VhdlLexer': ('pygments.lexers.hdl', 'vhdl', ('vhdl',), ('*.vhdl', '*.vhd'), ('text/x-vhdl',)),
|
||||
'VimLexer': ('pygments.lexers.text', 'VimL', ('vim',), ('*.vim', '.vimrc', '.exrc', '.gvimrc', '_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc'), ('text/x-vim',)),
|
||||
'XQueryLexer': ('pygments.lexers.web', 'XQuery', ('xquery', 'xqy', 'xq', 'xql', 'xqm'), ('*.xqy', '*.xquery', '*.xq', '*.xql', '*.xqm'), ('text/xquery', 'application/xquery')),
|
||||
'XmlDjangoLexer': ('pygments.lexers.templates', 'XML+Django/Jinja', ('xml+django', 'xml+jinja'), (), ('application/xml+django', 'application/xml+jinja')),
|
||||
'XmlErbLexer': ('pygments.lexers.templates', 'XML+Ruby', ('xml+erb', 'xml+ruby'), (), ('application/xml+ruby',)),
|
||||
'XmlLexer': ('pygments.lexers.web', 'XML', ('xml',), ('*.xml', '*.xsl', '*.rss', '*.xslt', '*.xsd', '*.wsdl', '*.wsf'), ('text/xml', 'application/xml', 'image/svg+xml', 'application/rss+xml', 'application/atom+xml')),
|
||||
'XmlPhpLexer': ('pygments.lexers.templates', 'XML+PHP', ('xml+php',), (), ('application/xml+php',)),
|
||||
'XmlSmartyLexer': ('pygments.lexers.templates', 'XML+Smarty', ('xml+smarty',), (), ('application/xml+smarty',)),
|
||||
'XsltLexer': ('pygments.lexers.web', 'XSLT', ('xslt',), ('*.xsl', '*.xslt', '*.xpl'), ('application/xsl+xml', 'application/xslt+xml')),
|
||||
'XtendLexer': ('pygments.lexers.jvm', 'Xtend', ('xtend',), ('*.xtend',), ('text/x-xtend',)),
|
||||
'YamlLexer': ('pygments.lexers.text', 'YAML', ('yaml',), ('*.yaml', '*.yml'), ('text/x-yaml',)),
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup lexers
|
||||
found_lexers = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
for filename in os.listdir('.'):
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.lexers.%s' % filename[:-3]
|
||||
print(module_name)
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for lexer_name in module.__all__:
|
||||
lexer = getattr(module, lexer_name)
|
||||
found_lexers.append(
|
||||
'%r: %r' % (lexer_name,
|
||||
(module_name,
|
||||
lexer.name,
|
||||
tuple(lexer.aliases),
|
||||
tuple(lexer.filenames),
|
||||
tuple(lexer.mimetypes))))
|
||||
# sort them, that should make the diff files for svn smaller
|
||||
found_lexers.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
f = open(__file__)
|
||||
try:
|
||||
content = f.read()
|
||||
finally:
|
||||
f.close()
|
||||
header = content[:content.find('LEXERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
f = open(__file__, 'wb')
|
||||
f.write(header)
|
||||
f.write('LEXERS = {\n %s,\n}\n\n' % ',\n '.join(found_lexers))
|
||||
f.write(footer)
|
||||
f.close()
|
||||
@ -1,562 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._openedgebuiltins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Builtin list for the OpenEdgeLexer.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
OPENEDGEKEYWORDS = [
|
||||
'ABSOLUTE', 'ABS', 'ABSO', 'ABSOL', 'ABSOLU', 'ABSOLUT', 'ACCELERATOR',
|
||||
'ACCUM', 'ACCUMULATE', 'ACCUM', 'ACCUMU', 'ACCUMUL', 'ACCUMULA',
|
||||
'ACCUMULAT', 'ACTIVE-FORM', 'ACTIVE-WINDOW', 'ADD', 'ADD-BUFFER',
|
||||
'ADD-CALC-COLUMN', 'ADD-COLUMNS-FROM', 'ADD-EVENTS-PROCEDURE',
|
||||
'ADD-FIELDS-FROM', 'ADD-FIRST', 'ADD-INDEX-FIELD', 'ADD-LAST',
|
||||
'ADD-LIKE-COLUMN', 'ADD-LIKE-FIELD', 'ADD-LIKE-INDEX', 'ADD-NEW-FIELD',
|
||||
'ADD-NEW-INDEX', 'ADD-SCHEMA-LOCATION', 'ADD-SUPER-PROCEDURE', 'ADM-DATA',
|
||||
'ADVISE', 'ALERT-BOX', 'ALIAS', 'ALL', 'ALLOW-COLUMN-SEARCHING',
|
||||
'ALLOW-REPLICATION', 'ALTER', 'ALWAYS-ON-TOP', 'AMBIGUOUS', 'AMBIG',
|
||||
'AMBIGU', 'AMBIGUO', 'AMBIGUOU', 'ANALYZE', 'ANALYZ', 'AND', 'ANSI-ONLY',
|
||||
'ANY', 'ANYWHERE', 'APPEND', 'APPL-ALERT-BOXES', 'APPL-ALERT',
|
||||
'APPL-ALERT-', 'APPL-ALERT-B', 'APPL-ALERT-BO', 'APPL-ALERT-BOX',
|
||||
'APPL-ALERT-BOXE', 'APPL-CONTEXT-ID', 'APPLICATION', 'APPLY',
|
||||
'APPSERVER-INFO', 'APPSERVER-PASSWORD', 'APPSERVER-USERID', 'ARRAY-MESSAGE',
|
||||
'AS', 'ASC', 'ASCENDING', 'ASCE', 'ASCEN', 'ASCEND', 'ASCENDI', 'ASCENDIN',
|
||||
'ASK-OVERWRITE', 'ASSEMBLY', 'ASSIGN', 'ASYNCHRONOUS',
|
||||
'ASYNC-REQUEST-COUNT', 'ASYNC-REQUEST-HANDLE', 'AT', 'ATTACHED-PAIRLIST',
|
||||
'ATTR-SPACE', 'ATTR', 'ATTRI', 'ATTRIB', 'ATTRIBU', 'ATTRIBUT',
|
||||
'AUDIT-CONTROL', 'AUDIT-ENABLED', 'AUDIT-EVENT-CONTEXT', 'AUDIT-POLICY',
|
||||
'AUTHENTICATION-FAILED', 'AUTHORIZATION', 'AUTO-COMPLETION', 'AUTO-COMP',
|
||||
'AUTO-COMPL', 'AUTO-COMPLE', 'AUTO-COMPLET', 'AUTO-COMPLETI',
|
||||
'AUTO-COMPLETIO', 'AUTO-ENDKEY', 'AUTO-END-KEY', 'AUTO-GO', 'AUTO-INDENT',
|
||||
'AUTO-IND', 'AUTO-INDE', 'AUTO-INDEN', 'AUTOMATIC', 'AUTO-RESIZE',
|
||||
'AUTO-RETURN', 'AUTO-RET', 'AUTO-RETU', 'AUTO-RETUR', 'AUTO-SYNCHRONIZE',
|
||||
'AUTO-ZAP', 'AUTO-Z', 'AUTO-ZA', 'AVAILABLE', 'AVAIL', 'AVAILA', 'AVAILAB',
|
||||
'AVAILABL', 'AVAILABLE-FORMATS', 'AVERAGE', 'AVE', 'AVER', 'AVERA',
|
||||
'AVERAG', 'AVG', 'BACKGROUND', 'BACK', 'BACKG', 'BACKGR', 'BACKGRO',
|
||||
'BACKGROU', 'BACKGROUN', 'BACKWARDS', 'BACKWARD', 'BASE64-DECODE',
|
||||
'BASE64-ENCODE', 'BASE-ADE', 'BASE-KEY', 'BATCH-MODE', 'BATCH', 'BATCH-',
|
||||
'BATCH-M', 'BATCH-MO', 'BATCH-MOD', 'BATCH-SIZE', 'BEFORE-HIDE', 'BEFORE-H',
|
||||
'BEFORE-HI', 'BEFORE-HID', 'BEGIN-EVENT-GROUP', 'BEGINS', 'BELL', 'BETWEEN',
|
||||
'BGCOLOR', 'BGC', 'BGCO', 'BGCOL', 'BGCOLO', 'BIG-ENDIAN', 'BINARY', 'BIND',
|
||||
'BIND-WHERE', 'BLANK', 'BLOCK-ITERATION-DISPLAY', 'BORDER-BOTTOM-CHARS',
|
||||
'BORDER-B', 'BORDER-BO', 'BORDER-BOT', 'BORDER-BOTT', 'BORDER-BOTTO',
|
||||
'BORDER-BOTTOM-PIXELS', 'BORDER-BOTTOM-P', 'BORDER-BOTTOM-PI',
|
||||
'BORDER-BOTTOM-PIX', 'BORDER-BOTTOM-PIXE', 'BORDER-BOTTOM-PIXEL',
|
||||
'BORDER-LEFT-CHARS', 'BORDER-L', 'BORDER-LE', 'BORDER-LEF', 'BORDER-LEFT',
|
||||
'BORDER-LEFT-', 'BORDER-LEFT-C', 'BORDER-LEFT-CH', 'BORDER-LEFT-CHA',
|
||||
'BORDER-LEFT-CHAR', 'BORDER-LEFT-PIXELS', 'BORDER-LEFT-P', 'BORDER-LEFT-PI',
|
||||
'BORDER-LEFT-PIX', 'BORDER-LEFT-PIXE', 'BORDER-LEFT-PIXEL',
|
||||
'BORDER-RIGHT-CHARS', 'BORDER-R', 'BORDER-RI', 'BORDER-RIG', 'BORDER-RIGH',
|
||||
'BORDER-RIGHT', 'BORDER-RIGHT-', 'BORDER-RIGHT-C', 'BORDER-RIGHT-CH',
|
||||
'BORDER-RIGHT-CHA', 'BORDER-RIGHT-CHAR', 'BORDER-RIGHT-PIXELS',
|
||||
'BORDER-RIGHT-P', 'BORDER-RIGHT-PI', 'BORDER-RIGHT-PIX',
|
||||
'BORDER-RIGHT-PIXE', 'BORDER-RIGHT-PIXEL', 'BORDER-TOP-CHARS', 'BORDER-T',
|
||||
'BORDER-TO', 'BORDER-TOP', 'BORDER-TOP-', 'BORDER-TOP-C', 'BORDER-TOP-CH',
|
||||
'BORDER-TOP-CHA', 'BORDER-TOP-CHAR', 'BORDER-TOP-PIXELS', 'BORDER-TOP-P',
|
||||
'BORDER-TOP-PI', 'BORDER-TOP-PIX', 'BORDER-TOP-PIXE', 'BORDER-TOP-PIXEL',
|
||||
'BOX', 'BOX-SELECTABLE', 'BOX-SELECT', 'BOX-SELECTA', 'BOX-SELECTAB',
|
||||
'BOX-SELECTABL', 'BREAK', 'BROWSE', 'BUFFER', 'BUFFER-CHARS',
|
||||
'BUFFER-COMPARE', 'BUFFER-COPY', 'BUFFER-CREATE', 'BUFFER-DELETE',
|
||||
'BUFFER-FIELD', 'BUFFER-HANDLE', 'BUFFER-LINES', 'BUFFER-NAME',
|
||||
'BUFFER-RELEASE', 'BUFFER-VALUE', 'BUTTON', 'BUTTONS', 'BUTTON', 'BY',
|
||||
'BY-POINTER', 'BY-VARIANT-POINTER', 'CACHE', 'CACHE-SIZE', 'CALL',
|
||||
'CALL-NAME', 'CALL-TYPE', 'CANCEL-BREAK', 'CANCEL-BUTTON', 'CAN-CREATE',
|
||||
'CAN-DELETE', 'CAN-DO', 'CAN-FIND', 'CAN-QUERY', 'CAN-READ', 'CAN-SET',
|
||||
'CAN-WRITE', 'CAPS', 'CAREFUL-PAINT', 'CASE', 'CASE-SENSITIVE', 'CASE-SEN',
|
||||
'CASE-SENS', 'CASE-SENSI', 'CASE-SENSIT', 'CASE-SENSITI', 'CASE-SENSITIV',
|
||||
'CAST', 'CATCH', 'CDECL', 'CENTERED', 'CENTER', 'CENTERE', 'CHAINED',
|
||||
'CHARACTER_LENGTH', 'CHARSET', 'CHECK', 'CHECKED', 'CHOOSE', 'CHR', 'CLASS',
|
||||
'CLASS-TYPE', 'CLEAR', 'CLEAR-APPL-CONTEXT', 'CLEAR-LOG', 'CLEAR-SELECTION',
|
||||
'CLEAR-SELECT', 'CLEAR-SELECTI', 'CLEAR-SELECTIO', 'CLEAR-SORT-ARROWS',
|
||||
'CLEAR-SORT-ARROW', 'CLIENT-CONNECTION-ID', 'CLIENT-PRINCIPAL',
|
||||
'CLIENT-TTY', 'CLIENT-TYPE', 'CLIENT-WORKSTATION', 'CLIPBOARD', 'CLOSE',
|
||||
'CLOSE-LOG', 'CODE', 'CODEBASE-LOCATOR', 'CODEPAGE', 'CODEPAGE-CONVERT',
|
||||
'COLLATE', 'COL-OF', 'COLON', 'COLON-ALIGNED', 'COLON-ALIGN',
|
||||
'COLON-ALIGNE', 'COLOR', 'COLOR-TABLE', 'COLUMN', 'COL', 'COLU', 'COLUM',
|
||||
'COLUMN-BGCOLOR', 'COLUMN-DCOLOR', 'COLUMN-FGCOLOR', 'COLUMN-FONT',
|
||||
'COLUMN-LABEL', 'COLUMN-LAB', 'COLUMN-LABE', 'COLUMN-MOVABLE', 'COLUMN-OF',
|
||||
'COLUMN-PFCOLOR', 'COLUMN-READ-ONLY', 'COLUMN-RESIZABLE', 'COLUMNS',
|
||||
'COLUMN-SCROLLING', 'COMBO-BOX', 'COMMAND', 'COMPARES', 'COMPILE',
|
||||
'COMPILER', 'COMPLETE', 'COM-SELF', 'CONFIG-NAME', 'CONNECT', 'CONNECTED',
|
||||
'CONSTRUCTOR', 'CONTAINS', 'CONTENTS', 'CONTEXT', 'CONTEXT-HELP',
|
||||
'CONTEXT-HELP-FILE', 'CONTEXT-HELP-ID', 'CONTEXT-POPUP', 'CONTROL',
|
||||
'CONTROL-BOX', 'CONTROL-FRAME', 'CONVERT', 'CONVERT-3D-COLORS',
|
||||
'CONVERT-TO-OFFSET', 'CONVERT-TO-OFFS', 'CONVERT-TO-OFFSE', 'COPY-DATASET',
|
||||
'COPY-LOB', 'COPY-SAX-ATTRIBUTES', 'COPY-TEMP-TABLE', 'COUNT', 'COUNT-OF',
|
||||
'CPCASE', 'CPCOLL', 'CPINTERNAL', 'CPLOG', 'CPPRINT', 'CPRCODEIN',
|
||||
'CPRCODEOUT', 'CPSTREAM', 'CPTERM', 'CRC-VALUE', 'CREATE', 'CREATE-LIKE',
|
||||
'CREATE-LIKE-SEQUENTIAL', 'CREATE-NODE-NAMESPACE',
|
||||
'CREATE-RESULT-LIST-ENTRY', 'CREATE-TEST-FILE', 'CURRENT', 'CURRENT_DATE',
|
||||
'CURRENT_DATE', 'CURRENT-CHANGED', 'CURRENT-COLUMN', 'CURRENT-ENVIRONMENT',
|
||||
'CURRENT-ENV', 'CURRENT-ENVI', 'CURRENT-ENVIR', 'CURRENT-ENVIRO',
|
||||
'CURRENT-ENVIRON', 'CURRENT-ENVIRONM', 'CURRENT-ENVIRONME',
|
||||
'CURRENT-ENVIRONMEN', 'CURRENT-ITERATION', 'CURRENT-LANGUAGE',
|
||||
'CURRENT-LANG', 'CURRENT-LANGU', 'CURRENT-LANGUA', 'CURRENT-LANGUAG',
|
||||
'CURRENT-QUERY', 'CURRENT-RESULT-ROW', 'CURRENT-ROW-MODIFIED',
|
||||
'CURRENT-VALUE', 'CURRENT-WINDOW', 'CURSOR', 'CURS', 'CURSO', 'CURSOR-CHAR',
|
||||
'CURSOR-LINE', 'CURSOR-OFFSET', 'DATABASE', 'DATA-BIND',
|
||||
'DATA-ENTRY-RETURN', 'DATA-ENTRY-RET', 'DATA-ENTRY-RETU',
|
||||
'DATA-ENTRY-RETUR', 'DATA-RELATION', 'DATA-REL', 'DATA-RELA', 'DATA-RELAT',
|
||||
'DATA-RELATI', 'DATA-RELATIO', 'DATASERVERS', 'DATASET', 'DATASET-HANDLE',
|
||||
'DATA-SOURCE', 'DATA-SOURCE-COMPLETE-MAP', 'DATA-SOURCE-MODIFIED',
|
||||
'DATA-SOURCE-ROWID', 'DATA-TYPE', 'DATA-T', 'DATA-TY', 'DATA-TYP',
|
||||
'DATE-FORMAT', 'DATE-F', 'DATE-FO', 'DATE-FOR', 'DATE-FORM', 'DATE-FORMA',
|
||||
'DAY', 'DBCODEPAGE', 'DBCOLLATION', 'DBNAME', 'DBPARAM', 'DB-REFERENCES',
|
||||
'DBRESTRICTIONS', 'DBREST', 'DBRESTR', 'DBRESTRI', 'DBRESTRIC',
|
||||
'DBRESTRICT', 'DBRESTRICTI', 'DBRESTRICTIO', 'DBRESTRICTION', 'DBTASKID',
|
||||
'DBTYPE', 'DBVERSION', 'DBVERS', 'DBVERSI', 'DBVERSIO', 'DCOLOR', 'DDE',
|
||||
'DDE-ERROR', 'DDE-ID', 'DDE-I', 'DDE-ITEM', 'DDE-NAME', 'DDE-TOPIC',
|
||||
'DEBLANK', 'DEBUG', 'DEBU', 'DEBUG-ALERT', 'DEBUGGER', 'DEBUG-LIST',
|
||||
'DECIMALS', 'DECLARE', 'DECLARE-NAMESPACE', 'DECRYPT', 'DEFAULT',
|
||||
'DEFAULT-BUFFER-HANDLE', 'DEFAULT-BUTTON', 'DEFAUT-B', 'DEFAUT-BU',
|
||||
'DEFAUT-BUT', 'DEFAUT-BUTT', 'DEFAUT-BUTTO', 'DEFAULT-COMMIT',
|
||||
'DEFAULT-EXTENSION', 'DEFAULT-EX', 'DEFAULT-EXT', 'DEFAULT-EXTE',
|
||||
'DEFAULT-EXTEN', 'DEFAULT-EXTENS', 'DEFAULT-EXTENSI', 'DEFAULT-EXTENSIO',
|
||||
'DEFAULT-NOXLATE', 'DEFAULT-NOXL', 'DEFAULT-NOXLA', 'DEFAULT-NOXLAT',
|
||||
'DEFAULT-VALUE', 'DEFAULT-WINDOW', 'DEFINED', 'DEFINE-USER-EVENT-MANAGER',
|
||||
'DELETE', 'DEL', 'DELE', 'DELET', 'DELETE-CHARACTER', 'DELETE-CHAR',
|
||||
'DELETE-CHARA', 'DELETE-CHARAC', 'DELETE-CHARACT', 'DELETE-CHARACTE',
|
||||
'DELETE-CURRENT-ROW', 'DELETE-LINE', 'DELETE-RESULT-LIST-ENTRY',
|
||||
'DELETE-SELECTED-ROW', 'DELETE-SELECTED-ROWS', 'DELIMITER', 'DESC',
|
||||
'DESCENDING', 'DESC', 'DESCE', 'DESCEN', 'DESCEND', 'DESCENDI', 'DESCENDIN',
|
||||
'DESELECT-FOCUSED-ROW', 'DESELECTION', 'DESELECT-ROWS',
|
||||
'DESELECT-SELECTED-ROW', 'DESTRUCTOR', 'DIALOG-BOX', 'DICTIONARY', 'DICT',
|
||||
'DICTI', 'DICTIO', 'DICTION', 'DICTIONA', 'DICTIONAR', 'DIR', 'DISABLE',
|
||||
'DISABLE-AUTO-ZAP', 'DISABLED', 'DISABLE-DUMP-TRIGGERS',
|
||||
'DISABLE-LOAD-TRIGGERS', 'DISCONNECT', 'DISCON', 'DISCONN', 'DISCONNE',
|
||||
'DISCONNEC', 'DISP', 'DISPLAY', 'DISP', 'DISPL', 'DISPLA',
|
||||
'DISPLAY-MESSAGE', 'DISPLAY-TYPE', 'DISPLAY-T', 'DISPLAY-TY', 'DISPLAY-TYP',
|
||||
'DISTINCT', 'DO', 'DOMAIN-DESCRIPTION', 'DOMAIN-NAME', 'DOMAIN-TYPE', 'DOS',
|
||||
'DOUBLE', 'DOWN', 'DRAG-ENABLED', 'DROP', 'DROP-DOWN', 'DROP-DOWN-LIST',
|
||||
'DROP-FILE-NOTIFY', 'DROP-TARGET', 'DUMP', 'DYNAMIC', 'DYNAMIC-FUNCTION',
|
||||
'EACH', 'ECHO', 'EDGE-CHARS', 'EDGE', 'EDGE-', 'EDGE-C', 'EDGE-CH',
|
||||
'EDGE-CHA', 'EDGE-CHAR', 'EDGE-PIXELS', 'EDGE-P', 'EDGE-PI', 'EDGE-PIX',
|
||||
'EDGE-PIXE', 'EDGE-PIXEL', 'EDIT-CAN-PASTE', 'EDIT-CAN-UNDO', 'EDIT-CLEAR',
|
||||
'EDIT-COPY', 'EDIT-CUT', 'EDITING', 'EDITOR', 'EDIT-PASTE', 'EDIT-UNDO',
|
||||
'ELSE', 'EMPTY', 'EMPTY-TEMP-TABLE', 'ENABLE', 'ENABLED-FIELDS', 'ENCODE',
|
||||
'ENCRYPT', 'ENCRYPT-AUDIT-MAC-KEY', 'ENCRYPTION-SALT', 'END',
|
||||
'END-DOCUMENT', 'END-ELEMENT', 'END-EVENT-GROUP', 'END-FILE-DROP', 'ENDKEY',
|
||||
'END-KEY', 'END-MOVE', 'END-RESIZE', 'END-ROW-RESIZE', 'END-USER-PROMPT',
|
||||
'ENTERED', 'ENTRY', 'EQ', 'ERROR', 'ERROR-COLUMN', 'ERROR-COL',
|
||||
'ERROR-COLU', 'ERROR-COLUM', 'ERROR-ROW', 'ERROR-STACK-TRACE',
|
||||
'ERROR-STATUS', 'ERROR-STAT', 'ERROR-STATU', 'ESCAPE', 'ETIME',
|
||||
'EVENT-GROUP-ID', 'EVENT-PROCEDURE', 'EVENT-PROCEDURE-CONTEXT', 'EVENTS',
|
||||
'EVENT', 'EVENT-TYPE', 'EVENT-T', 'EVENT-TY', 'EVENT-TYP', 'EXCEPT',
|
||||
'EXCLUSIVE-ID', 'EXCLUSIVE-LOCK', 'EXCLUSIVE', 'EXCLUSIVE-', 'EXCLUSIVE-L',
|
||||
'EXCLUSIVE-LO', 'EXCLUSIVE-LOC', 'EXCLUSIVE-WEB-USER', 'EXECUTE', 'EXISTS',
|
||||
'EXP', 'EXPAND', 'EXPANDABLE', 'EXPLICIT', 'EXPORT', 'EXPORT-PRINCIPAL',
|
||||
'EXTENDED', 'EXTENT', 'EXTERNAL', 'FALSE', 'FETCH', 'FETCH-SELECTED-ROW',
|
||||
'FGCOLOR', 'FGC', 'FGCO', 'FGCOL', 'FGCOLO', 'FIELD', 'FIELDS', 'FIELD',
|
||||
'FILE', 'FILE-CREATE-DATE', 'FILE-CREATE-TIME', 'FILE-INFORMATION',
|
||||
'FILE-INFO', 'FILE-INFOR', 'FILE-INFORM', 'FILE-INFORMA', 'FILE-INFORMAT',
|
||||
'FILE-INFORMATI', 'FILE-INFORMATIO', 'FILE-MOD-DATE', 'FILE-MOD-TIME',
|
||||
'FILENAME', 'FILE-NAME', 'FILE-OFFSET', 'FILE-OFF', 'FILE-OFFS',
|
||||
'FILE-OFFSE', 'FILE-SIZE', 'FILE-TYPE', 'FILL', 'FILLED', 'FILL-IN',
|
||||
'FILTERS', 'FINAL', 'FINALLY', 'FIND', 'FIND-BY-ROWID',
|
||||
'FIND-CASE-SENSITIVE', 'FIND-CURRENT', 'FINDER', 'FIND-FIRST',
|
||||
'FIND-GLOBAL', 'FIND-LAST', 'FIND-NEXT-OCCURRENCE', 'FIND-PREV-OCCURRENCE',
|
||||
'FIND-SELECT', 'FIND-UNIQUE', 'FIND-WRAP-AROUND', 'FIRST',
|
||||
'FIRST-ASYNCH-REQUEST', 'FIRST-CHILD', 'FIRST-COLUMN', 'FIRST-FORM',
|
||||
'FIRST-OBJECT', 'FIRST-OF', 'FIRST-PROCEDURE', 'FIRST-PROC', 'FIRST-PROCE',
|
||||
'FIRST-PROCED', 'FIRST-PROCEDU', 'FIRST-PROCEDUR', 'FIRST-SERVER',
|
||||
'FIRST-TAB-ITEM', 'FIRST-TAB-I', 'FIRST-TAB-IT', 'FIRST-TAB-ITE',
|
||||
'FIT-LAST-COLUMN', 'FIXED-ONLY', 'FLAT-BUTTON', 'FLOAT', 'FOCUS',
|
||||
'FOCUSED-ROW', 'FOCUSED-ROW-SELECTED', 'FONT', 'FONT-TABLE', 'FOR',
|
||||
'FORCE-FILE', 'FOREGROUND', 'FORE', 'FOREG', 'FOREGR', 'FOREGRO',
|
||||
'FOREGROU', 'FOREGROUN', 'FORM', 'FORMAT', 'FORM', 'FORMA', 'FORMATTED',
|
||||
'FORMATTE', 'FORM-LONG-INPUT', 'FORWARD', 'FORWARDS', 'FORWARD', 'FRAGMENT',
|
||||
'FRAGMEN', 'FRAME', 'FRAM', 'FRAME-COL', 'FRAME-DB', 'FRAME-DOWN',
|
||||
'FRAME-FIELD', 'FRAME-FILE', 'FRAME-INDEX', 'FRAME-INDE', 'FRAME-LINE',
|
||||
'FRAME-NAME', 'FRAME-ROW', 'FRAME-SPACING', 'FRAME-SPA', 'FRAME-SPAC',
|
||||
'FRAME-SPACI', 'FRAME-SPACIN', 'FRAME-VALUE', 'FRAME-VAL', 'FRAME-VALU',
|
||||
'FRAME-X', 'FRAME-Y', 'FREQUENCY', 'FROM', 'FROM-CHARS', 'FROM-C',
|
||||
'FROM-CH', 'FROM-CHA', 'FROM-CHAR', 'FROM-CURRENT', 'FROM-CUR', 'FROM-CURR',
|
||||
'FROM-CURRE', 'FROM-CURREN', 'FROM-PIXELS', 'FROM-P', 'FROM-PI', 'FROM-PIX',
|
||||
'FROM-PIXE', 'FROM-PIXEL', 'FULL-HEIGHT-CHARS', 'FULL-HEIGHT',
|
||||
'FULL-HEIGHT-', 'FULL-HEIGHT-C', 'FULL-HEIGHT-CH', 'FULL-HEIGHT-CHA',
|
||||
'FULL-HEIGHT-CHAR', 'FULL-HEIGHT-PIXELS', 'FULL-HEIGHT-P', 'FULL-HEIGHT-PI',
|
||||
'FULL-HEIGHT-PIX', 'FULL-HEIGHT-PIXE', 'FULL-HEIGHT-PIXEL', 'FULL-PATHNAME',
|
||||
'FULL-PATHN', 'FULL-PATHNA', 'FULL-PATHNAM', 'FULL-WIDTH-CHARS',
|
||||
'FULL-WIDTH', 'FULL-WIDTH-', 'FULL-WIDTH-C', 'FULL-WIDTH-CH',
|
||||
'FULL-WIDTH-CHA', 'FULL-WIDTH-CHAR', 'FULL-WIDTH-PIXELS', 'FULL-WIDTH-P',
|
||||
'FULL-WIDTH-PI', 'FULL-WIDTH-PIX', 'FULL-WIDTH-PIXE', 'FULL-WIDTH-PIXEL',
|
||||
'FUNCTION', 'FUNCTION-CALL-TYPE', 'GATEWAYS', 'GATEWAY', 'GE',
|
||||
'GENERATE-MD5', 'GENERATE-PBE-KEY', 'GENERATE-PBE-SALT',
|
||||
'GENERATE-RANDOM-KEY', 'GENERATE-UUID', 'GET', 'GET-ATTR-CALL-TYPE',
|
||||
'GET-ATTRIBUTE-NODE', 'GET-BINARY-DATA', 'GET-BLUE-VALUE', 'GET-BLUE',
|
||||
'GET-BLUE-', 'GET-BLUE-V', 'GET-BLUE-VA', 'GET-BLUE-VAL', 'GET-BLUE-VALU',
|
||||
'GET-BROWSE-COLUMN', 'GET-BUFFER-HANDLEGETBYTE', 'GET-BYTE',
|
||||
'GET-CALLBACK-PROC-CONTEXT', 'GET-CALLBACK-PROC-NAME', 'GET-CGI-LIST',
|
||||
'GET-CGI-LONG-VALUE', 'GET-CGI-VALUE', 'GET-CODEPAGES', 'GET-COLLATIONS',
|
||||
'GET-CONFIG-VALUE', 'GET-CURRENT', 'GET-DOUBLE', 'GET-DROPPED-FILE',
|
||||
'GET-DYNAMIC', 'GET-ERROR-COLUMN', 'GET-ERROR-ROW', 'GET-FILE',
|
||||
'GET-FILE-NAME', 'GET-FILE-OFFSET', 'GET-FILE-OFFSE', 'GET-FIRST',
|
||||
'GET-FLOAT', 'GET-GREEN-VALUE', 'GET-GREEN', 'GET-GREEN-', 'GET-GREEN-V',
|
||||
'GET-GREEN-VA', 'GET-GREEN-VAL', 'GET-GREEN-VALU',
|
||||
'GET-INDEX-BY-NAMESPACE-NAME', 'GET-INDEX-BY-QNAME', 'GET-INT64',
|
||||
'GET-ITERATION', 'GET-KEY-VALUE', 'GET-KEY-VAL', 'GET-KEY-VALU', 'GET-LAST',
|
||||
'GET-LOCALNAME-BY-INDEX', 'GET-LONG', 'GET-MESSAGE', 'GET-NEXT',
|
||||
'GET-NUMBER', 'GET-POINTER-VALUE', 'GET-PREV', 'GET-PRINTERS',
|
||||
'GET-PROPERTY', 'GET-QNAME-BY-INDEX', 'GET-RED-VALUE', 'GET-RED',
|
||||
'GET-RED-', 'GET-RED-V', 'GET-RED-VA', 'GET-RED-VAL', 'GET-RED-VALU',
|
||||
'GET-REPOSITIONED-ROW', 'GET-RGB-VALUE', 'GET-SELECTED-WIDGET',
|
||||
'GET-SELECTED', 'GET-SELECTED-', 'GET-SELECTED-W', 'GET-SELECTED-WI',
|
||||
'GET-SELECTED-WID', 'GET-SELECTED-WIDG', 'GET-SELECTED-WIDGE', 'GET-SHORT',
|
||||
'GET-SIGNATURE', 'GET-SIZE', 'GET-STRING', 'GET-TAB-ITEM',
|
||||
'GET-TEXT-HEIGHT-CHARS', 'GET-TEXT-HEIGHT', 'GET-TEXT-HEIGHT-',
|
||||
'GET-TEXT-HEIGHT-C', 'GET-TEXT-HEIGHT-CH', 'GET-TEXT-HEIGHT-CHA',
|
||||
'GET-TEXT-HEIGHT-CHAR', 'GET-TEXT-HEIGHT-PIXELS', 'GET-TEXT-HEIGHT-P',
|
||||
'GET-TEXT-HEIGHT-PI', 'GET-TEXT-HEIGHT-PIX', 'GET-TEXT-HEIGHT-PIXE',
|
||||
'GET-TEXT-HEIGHT-PIXEL', 'GET-TEXT-WIDTH-CHARS', 'GET-TEXT-WIDTH',
|
||||
'GET-TEXT-WIDTH-', 'GET-TEXT-WIDTH-C', 'GET-TEXT-WIDTH-CH',
|
||||
'GET-TEXT-WIDTH-CHA', 'GET-TEXT-WIDTH-CHAR', 'GET-TEXT-WIDTH-PIXELS',
|
||||
'GET-TEXT-WIDTH-P', 'GET-TEXT-WIDTH-PI', 'GET-TEXT-WIDTH-PIX',
|
||||
'GET-TEXT-WIDTH-PIXE', 'GET-TEXT-WIDTH-PIXEL', 'GET-TYPE-BY-INDEX',
|
||||
'GET-TYPE-BY-NAMESPACE-NAME', 'GET-TYPE-BY-QNAME', 'GET-UNSIGNED-LONG',
|
||||
'GET-UNSIGNED-SHORT', 'GET-URI-BY-INDEX', 'GET-VALUE-BY-INDEX',
|
||||
'GET-VALUE-BY-NAMESPACE-NAME', 'GET-VALUE-BY-QNAME', 'GET-WAIT-STATE',
|
||||
'GLOBAL', 'GO-ON', 'GO-PENDING', 'GO-PEND', 'GO-PENDI', 'GO-PENDIN',
|
||||
'GRANT', 'GRAPHIC-EDGE', 'GRAPHIC-E', 'GRAPHIC-ED', 'GRAPHIC-EDG',
|
||||
'GRID-FACTOR-HORIZONTAL', 'GRID-FACTOR-H', 'GRID-FACTOR-HO',
|
||||
'GRID-FACTOR-HOR', 'GRID-FACTOR-HORI', 'GRID-FACTOR-HORIZ',
|
||||
'GRID-FACTOR-HORIZO', 'GRID-FACTOR-HORIZON', 'GRID-FACTOR-HORIZONT',
|
||||
'GRID-FACTOR-HORIZONTA', 'GRID-FACTOR-VERTICAL', 'GRID-FACTOR-V',
|
||||
'GRID-FACTOR-VE', 'GRID-FACTOR-VER', 'GRID-FACTOR-VERT', 'GRID-FACTOR-VERT',
|
||||
'GRID-FACTOR-VERTI', 'GRID-FACTOR-VERTIC', 'GRID-FACTOR-VERTICA',
|
||||
'GRID-SNAP', 'GRID-UNIT-HEIGHT-CHARS', 'GRID-UNIT-HEIGHT',
|
||||
'GRID-UNIT-HEIGHT-', 'GRID-UNIT-HEIGHT-C', 'GRID-UNIT-HEIGHT-CH',
|
||||
'GRID-UNIT-HEIGHT-CHA', 'GRID-UNIT-HEIGHT-PIXELS', 'GRID-UNIT-HEIGHT-P',
|
||||
'GRID-UNIT-HEIGHT-PI', 'GRID-UNIT-HEIGHT-PIX', 'GRID-UNIT-HEIGHT-PIXE',
|
||||
'GRID-UNIT-HEIGHT-PIXEL', 'GRID-UNIT-WIDTH-CHARS', 'GRID-UNIT-WIDTH',
|
||||
'GRID-UNIT-WIDTH-', 'GRID-UNIT-WIDTH-C', 'GRID-UNIT-WIDTH-CH',
|
||||
'GRID-UNIT-WIDTH-CHA', 'GRID-UNIT-WIDTH-CHAR', 'GRID-UNIT-WIDTH-PIXELS',
|
||||
'GRID-UNIT-WIDTH-P', 'GRID-UNIT-WIDTH-PI', 'GRID-UNIT-WIDTH-PIX',
|
||||
'GRID-UNIT-WIDTH-PIXE', 'GRID-UNIT-WIDTH-PIXEL', 'GRID-VISIBLE', 'GROUP',
|
||||
'GT', 'GUID', 'HANDLER', 'HAS-RECORDS', 'HAVING', 'HEADER', 'HEIGHT-CHARS',
|
||||
'HEIGHT', 'HEIGHT-', 'HEIGHT-C', 'HEIGHT-CH', 'HEIGHT-CHA', 'HEIGHT-CHAR',
|
||||
'HEIGHT-PIXELS', 'HEIGHT-P', 'HEIGHT-PI', 'HEIGHT-PIX', 'HEIGHT-PIXE',
|
||||
'HEIGHT-PIXEL', 'HELP', 'HEX-DECODE', 'HEX-ENCODE', 'HIDDEN', 'HIDE',
|
||||
'HORIZONTAL', 'HORI', 'HORIZ', 'HORIZO', 'HORIZON', 'HORIZONT', 'HORIZONTA',
|
||||
'HOST-BYTE-ORDER', 'HTML-CHARSET', 'HTML-END-OF-LINE', 'HTML-END-OF-PAGE',
|
||||
'HTML-FRAME-BEGIN', 'HTML-FRAME-END', 'HTML-HEADER-BEGIN',
|
||||
'HTML-HEADER-END', 'HTML-TITLE-BEGIN', 'HTML-TITLE-END', 'HWND', 'ICON',
|
||||
'IF', 'IMAGE', 'IMAGE-DOWN', 'IMAGE-INSENSITIVE', 'IMAGE-SIZE',
|
||||
'IMAGE-SIZE-CHARS', 'IMAGE-SIZE-C', 'IMAGE-SIZE-CH', 'IMAGE-SIZE-CHA',
|
||||
'IMAGE-SIZE-CHAR', 'IMAGE-SIZE-PIXELS', 'IMAGE-SIZE-P', 'IMAGE-SIZE-PI',
|
||||
'IMAGE-SIZE-PIX', 'IMAGE-SIZE-PIXE', 'IMAGE-SIZE-PIXEL', 'IMAGE-UP',
|
||||
'IMMEDIATE-DISPLAY', 'IMPLEMENTS', 'IMPORT', 'IMPORT-PRINCIPAL', 'IN',
|
||||
'INCREMENT-EXCLUSIVE-ID', 'INDEX', 'INDEXED-REPOSITION', 'INDEX-HINT',
|
||||
'INDEX-INFORMATION', 'INDICATOR', 'INFORMATION', 'INFO', 'INFOR', 'INFORM',
|
||||
'INFORMA', 'INFORMAT', 'INFORMATI', 'INFORMATIO', 'IN-HANDLE',
|
||||
'INHERIT-BGCOLOR', 'INHERIT-BGC', 'INHERIT-BGCO', 'INHERIT-BGCOL',
|
||||
'INHERIT-BGCOLO', 'INHERIT-FGCOLOR', 'INHERIT-FGC', 'INHERIT-FGCO',
|
||||
'INHERIT-FGCOL', 'INHERIT-FGCOLO', 'INHERITS', 'INITIAL', 'INIT', 'INITI',
|
||||
'INITIA', 'INITIAL-DIR', 'INITIAL-FILTER', 'INITIALIZE-DOCUMENT-TYPE',
|
||||
'INITIATE', 'INNER-CHARS', 'INNER-LINES', 'INPUT', 'INPUT-OUTPUT',
|
||||
'INPUT-O', 'INPUT-OU', 'INPUT-OUT', 'INPUT-OUTP', 'INPUT-OUTPU',
|
||||
'INPUT-VALUE', 'INSERT', 'INSERT-ATTRIBUTE', 'INSERT-BACKTAB', 'INSERT-B',
|
||||
'INSERT-BA', 'INSERT-BAC', 'INSERT-BACK', 'INSERT-BACKT', 'INSERT-BACKTA',
|
||||
'INSERT-FILE', 'INSERT-ROW', 'INSERT-STRING', 'INSERT-TAB', 'INSERT-T',
|
||||
'INSERT-TA', 'INTERFACE', 'INTERNAL-ENTRIES', 'INTO', 'INVOKE', 'IS',
|
||||
'IS-ATTR-SPACE', 'IS-ATTR', 'IS-ATTR-', 'IS-ATTR-S', 'IS-ATTR-SP',
|
||||
'IS-ATTR-SPA', 'IS-ATTR-SPAC', 'IS-CLASS', 'IS-CLAS', 'IS-LEAD-BYTE',
|
||||
'IS-ATTR', 'IS-OPEN', 'IS-PARAMETER-SET', 'IS-ROW-SELECTED', 'IS-SELECTED',
|
||||
'ITEM', 'ITEMS-PER-ROW', 'JOIN', 'JOIN-BY-SQLDB', 'KBLABEL',
|
||||
'KEEP-CONNECTION-OPEN', 'KEEP-FRAME-Z-ORDER', 'KEEP-FRAME-Z',
|
||||
'KEEP-FRAME-Z-', 'KEEP-FRAME-Z-O', 'KEEP-FRAME-Z-OR', 'KEEP-FRAME-Z-ORD',
|
||||
'KEEP-FRAME-Z-ORDE', 'KEEP-MESSAGES', 'KEEP-SECURITY-CACHE',
|
||||
'KEEP-TAB-ORDER', 'KEY', 'KEYCODE', 'KEY-CODE', 'KEYFUNCTION', 'KEYFUNC',
|
||||
'KEYFUNCT', 'KEYFUNCTI', 'KEYFUNCTIO', 'KEY-FUNCTION', 'KEY-FUNC',
|
||||
'KEY-FUNCT', 'KEY-FUNCTI', 'KEY-FUNCTIO', 'KEYLABEL', 'KEY-LABEL', 'KEYS',
|
||||
'KEYWORD', 'KEYWORD-ALL', 'LABEL', 'LABEL-BGCOLOR', 'LABEL-BGC',
|
||||
'LABEL-BGCO', 'LABEL-BGCOL', 'LABEL-BGCOLO', 'LABEL-DCOLOR', 'LABEL-DC',
|
||||
'LABEL-DCO', 'LABEL-DCOL', 'LABEL-DCOLO', 'LABEL-FGCOLOR', 'LABEL-FGC',
|
||||
'LABEL-FGCO', 'LABEL-FGCOL', 'LABEL-FGCOLO', 'LABEL-FONT', 'LABEL-PFCOLOR',
|
||||
'LABEL-PFC', 'LABEL-PFCO', 'LABEL-PFCOL', 'LABEL-PFCOLO', 'LABELS',
|
||||
'LANDSCAPE', 'LANGUAGES', 'LANGUAGE', 'LARGE', 'LARGE-TO-SMALL', 'LAST',
|
||||
'LAST-ASYNCH-REQUEST', 'LAST-BATCH', 'LAST-CHILD', 'LAST-EVENT',
|
||||
'LAST-EVEN', 'LAST-FORM', 'LASTKEY', 'LAST-KEY', 'LAST-OBJECT', 'LAST-OF',
|
||||
'LAST-PROCEDURE', 'LAST-PROCE', 'LAST-PROCED', 'LAST-PROCEDU',
|
||||
'LAST-PROCEDUR', 'LAST-SERVER', 'LAST-TAB-ITEM', 'LAST-TAB-I',
|
||||
'LAST-TAB-IT', 'LAST-TAB-ITE', 'LC', 'LDBNAME', 'LE', 'LEAVE',
|
||||
'LEFT-ALIGNED', 'LEFT-ALIGN', 'LEFT-ALIGNE', 'LEFT-TRIM', 'LENGTH',
|
||||
'LIBRARY', 'LIKE', 'LIKE-SEQUENTIAL', 'LINE', 'LINE-COUNTER', 'LINE-COUNT',
|
||||
'LINE-COUNTE', 'LIST-EVENTS', 'LISTING', 'LISTI', 'LISTIN',
|
||||
'LIST-ITEM-PAIRS', 'LIST-ITEMS', 'LIST-PROPERTY-NAMES', 'LIST-QUERY-ATTRS',
|
||||
'LIST-SET-ATTRS', 'LIST-WIDGETS', 'LITERAL-QUESTION', 'LITTLE-ENDIAN',
|
||||
'LOAD', 'LOAD-DOMAINS', 'LOAD-ICON', 'LOAD-IMAGE', 'LOAD-IMAGE-DOWN',
|
||||
'LOAD-IMAGE-INSENSITIVE', 'LOAD-IMAGE-UP', 'LOAD-MOUSE-POINTER',
|
||||
'LOAD-MOUSE-P', 'LOAD-MOUSE-PO', 'LOAD-MOUSE-POI', 'LOAD-MOUSE-POIN',
|
||||
'LOAD-MOUSE-POINT', 'LOAD-MOUSE-POINTE', 'LOAD-PICTURE', 'LOAD-SMALL-ICON',
|
||||
'LOCAL-NAME', 'LOCATOR-COLUMN-NUMBER', 'LOCATOR-LINE-NUMBER',
|
||||
'LOCATOR-PUBLIC-ID', 'LOCATOR-SYSTEM-ID', 'LOCATOR-TYPE', 'LOCKED',
|
||||
'LOCK-REGISTRATION', 'LOG', 'LOG-AUDIT-EVENT', 'LOGIN-EXPIRATION-TIMESTAMP',
|
||||
'LOGIN-HOST', 'LOGIN-STATE', 'LOG-MANAGER', 'LOGOUT', 'LOOKAHEAD', 'LOOKUP',
|
||||
'LT', 'MACHINE-CLASS', 'MANDATORY', 'MANUAL-HIGHLIGHT', 'MAP',
|
||||
'MARGIN-EXTRA', 'MARGIN-HEIGHT-CHARS', 'MARGIN-HEIGHT', 'MARGIN-HEIGHT-',
|
||||
'MARGIN-HEIGHT-C', 'MARGIN-HEIGHT-CH', 'MARGIN-HEIGHT-CHA',
|
||||
'MARGIN-HEIGHT-CHAR', 'MARGIN-HEIGHT-PIXELS', 'MARGIN-HEIGHT-P',
|
||||
'MARGIN-HEIGHT-PI', 'MARGIN-HEIGHT-PIX', 'MARGIN-HEIGHT-PIXE',
|
||||
'MARGIN-HEIGHT-PIXEL', 'MARGIN-WIDTH-CHARS', 'MARGIN-WIDTH',
|
||||
'MARGIN-WIDTH-', 'MARGIN-WIDTH-C', 'MARGIN-WIDTH-CH', 'MARGIN-WIDTH-CHA',
|
||||
'MARGIN-WIDTH-CHAR', 'MARGIN-WIDTH-PIXELS', 'MARGIN-WIDTH-P',
|
||||
'MARGIN-WIDTH-PI', 'MARGIN-WIDTH-PIX', 'MARGIN-WIDTH-PIXE',
|
||||
'MARGIN-WIDTH-PIXEL', 'MARK-NEW', 'MARK-ROW-STATE', 'MATCHES', 'MAX',
|
||||
'MAX-BUTTON', 'MAX-CHARS', 'MAX-DATA-GUESS', 'MAX-HEIGHT',
|
||||
'MAX-HEIGHT-CHARS', 'MAX-HEIGHT-C', 'MAX-HEIGHT-CH', 'MAX-HEIGHT-CHA',
|
||||
'MAX-HEIGHT-CHAR', 'MAX-HEIGHT-PIXELS', 'MAX-HEIGHT-P', 'MAX-HEIGHT-PI',
|
||||
'MAX-HEIGHT-PIX', 'MAX-HEIGHT-PIXE', 'MAX-HEIGHT-PIXEL', 'MAXIMIZE',
|
||||
'MAXIMUM', 'MAX', 'MAXI', 'MAXIM', 'MAXIMU', 'MAXIMUM-LEVEL', 'MAX-ROWS',
|
||||
'MAX-SIZE', 'MAX-VALUE', 'MAX-VAL', 'MAX-VALU', 'MAX-WIDTH',
|
||||
'MAX-WIDTH-CHARS', 'MAX-WIDTH', 'MAX-WIDTH-', 'MAX-WIDTH-C', 'MAX-WIDTH-CH',
|
||||
'MAX-WIDTH-CHA', 'MAX-WIDTH-CHAR', 'MAX-WIDTH-PIXELS', 'MAX-WIDTH-P',
|
||||
'MAX-WIDTH-PI', 'MAX-WIDTH-PIX', 'MAX-WIDTH-PIXE', 'MAX-WIDTH-PIXEL',
|
||||
'MD5-DIGEST', 'MEMBER', 'MEMPTR-TO-NODE-VALUE', 'MENU', 'MENUBAR',
|
||||
'MENU-BAR', 'MENU-ITEM', 'MENU-KEY', 'MENU-K', 'MENU-KE', 'MENU-MOUSE',
|
||||
'MENU-M', 'MENU-MO', 'MENU-MOU', 'MENU-MOUS', 'MERGE-BY-FIELD', 'MESSAGE',
|
||||
'MESSAGE-AREA', 'MESSAGE-AREA-FONT', 'MESSAGE-LINES', 'METHOD', 'MIN',
|
||||
'MIN-BUTTON', 'MIN-COLUMN-WIDTH-CHARS', 'MIN-COLUMN-WIDTH-C',
|
||||
'MIN-COLUMN-WIDTH-CH', 'MIN-COLUMN-WIDTH-CHA', 'MIN-COLUMN-WIDTH-CHAR',
|
||||
'MIN-COLUMN-WIDTH-PIXELS', 'MIN-COLUMN-WIDTH-P', 'MIN-COLUMN-WIDTH-PI',
|
||||
'MIN-COLUMN-WIDTH-PIX', 'MIN-COLUMN-WIDTH-PIXE', 'MIN-COLUMN-WIDTH-PIXEL',
|
||||
'MIN-HEIGHT-CHARS', 'MIN-HEIGHT', 'MIN-HEIGHT-', 'MIN-HEIGHT-C',
|
||||
'MIN-HEIGHT-CH', 'MIN-HEIGHT-CHA', 'MIN-HEIGHT-CHAR', 'MIN-HEIGHT-PIXELS',
|
||||
'MIN-HEIGHT-P', 'MIN-HEIGHT-PI', 'MIN-HEIGHT-PIX', 'MIN-HEIGHT-PIXE',
|
||||
'MIN-HEIGHT-PIXEL', 'MINIMUM', 'MIN', 'MINI', 'MINIM', 'MINIMU', 'MIN-SIZE',
|
||||
'MIN-VALUE', 'MIN-VAL', 'MIN-VALU', 'MIN-WIDTH-CHARS', 'MIN-WIDTH',
|
||||
'MIN-WIDTH-', 'MIN-WIDTH-C', 'MIN-WIDTH-CH', 'MIN-WIDTH-CHA',
|
||||
'MIN-WIDTH-CHAR', 'MIN-WIDTH-PIXELS', 'MIN-WIDTH-P', 'MIN-WIDTH-PI',
|
||||
'MIN-WIDTH-PIX', 'MIN-WIDTH-PIXE', 'MIN-WIDTH-PIXEL', 'MODIFIED', 'MODULO',
|
||||
'MOD', 'MODU', 'MODUL', 'MONTH', 'MOUSE', 'MOUSE-POINTER', 'MOUSE-P',
|
||||
'MOUSE-PO', 'MOUSE-POI', 'MOUSE-POIN', 'MOUSE-POINT', 'MOUSE-POINTE',
|
||||
'MOVABLE', 'MOVE-AFTER-TAB-ITEM', 'MOVE-AFTER', 'MOVE-AFTER-',
|
||||
'MOVE-AFTER-T', 'MOVE-AFTER-TA', 'MOVE-AFTER-TAB', 'MOVE-AFTER-TAB-',
|
||||
'MOVE-AFTER-TAB-I', 'MOVE-AFTER-TAB-IT', 'MOVE-AFTER-TAB-ITE',
|
||||
'MOVE-BEFORE-TAB-ITEM', 'MOVE-BEFOR', 'MOVE-BEFORE', 'MOVE-BEFORE-',
|
||||
'MOVE-BEFORE-T', 'MOVE-BEFORE-TA', 'MOVE-BEFORE-TAB', 'MOVE-BEFORE-TAB-',
|
||||
'MOVE-BEFORE-TAB-I', 'MOVE-BEFORE-TAB-IT', 'MOVE-BEFORE-TAB-ITE',
|
||||
'MOVE-COLUMN', 'MOVE-COL', 'MOVE-COLU', 'MOVE-COLUM', 'MOVE-TO-BOTTOM',
|
||||
'MOVE-TO-B', 'MOVE-TO-BO', 'MOVE-TO-BOT', 'MOVE-TO-BOTT', 'MOVE-TO-BOTTO',
|
||||
'MOVE-TO-EOF', 'MOVE-TO-TOP', 'MOVE-TO-T', 'MOVE-TO-TO', 'MPE',
|
||||
'MULTI-COMPILE', 'MULTIPLE', 'MULTIPLE-KEY', 'MULTITASKING-INTERVAL',
|
||||
'MUST-EXIST', 'NAME', 'NAMESPACE-PREFIX', 'NAMESPACE-URI', 'NATIVE', 'NE',
|
||||
'NEEDS-APPSERVER-PROMPT', 'NEEDS-PROMPT', 'NEW', 'NEW-INSTANCE', 'NEW-ROW',
|
||||
'NEXT', 'NEXT-COLUMN', 'NEXT-PROMPT', 'NEXT-ROWID', 'NEXT-SIBLING',
|
||||
'NEXT-TAB-ITEM', 'NEXT-TAB-I', 'NEXT-TAB-IT', 'NEXT-TAB-ITE', 'NEXT-VALUE',
|
||||
'NO', 'NO-APPLY', 'NO-ARRAY-MESSAGE', 'NO-ASSIGN', 'NO-ATTR-LIST',
|
||||
'NO-ATTR', 'NO-ATTR-', 'NO-ATTR-L', 'NO-ATTR-LI', 'NO-ATTR-LIS',
|
||||
'NO-ATTR-SPACE', 'NO-ATTR', 'NO-ATTR-', 'NO-ATTR-S', 'NO-ATTR-SP',
|
||||
'NO-ATTR-SPA', 'NO-ATTR-SPAC', 'NO-AUTO-VALIDATE', 'NO-BIND-WHERE',
|
||||
'NO-BOX', 'NO-CONSOLE', 'NO-CONVERT', 'NO-CONVERT-3D-COLORS',
|
||||
'NO-CURRENT-VALUE', 'NO-DEBUG', 'NODE-VALUE-TO-MEMPTR', 'NO-DRAG',
|
||||
'NO-ECHO', 'NO-EMPTY-SPACE', 'NO-ERROR', 'NO-FILL', 'NO-F', 'NO-FI',
|
||||
'NO-FIL', 'NO-FOCUS', 'NO-HELP', 'NO-HIDE', 'NO-INDEX-HINT',
|
||||
'NO-INHERIT-BGCOLOR', 'NO-INHERIT-BGC', 'NO-INHERIT-BGCO', 'LABEL-BGCOL',
|
||||
'LABEL-BGCOLO', 'NO-INHERIT-FGCOLOR', 'NO-INHERIT-FGC', 'NO-INHERIT-FGCO',
|
||||
'NO-INHERIT-FGCOL', 'NO-INHERIT-FGCOLO', 'NO-JOIN-BY-SQLDB', 'NO-LABELS',
|
||||
'NO-LABE', 'NO-LOBS', 'NO-LOCK', 'NO-LOOKAHEAD', 'NO-MAP', 'NO-MESSAGE',
|
||||
'NO-MES', 'NO-MESS', 'NO-MESSA', 'NO-MESSAG', 'NONAMESPACE-SCHEMA-LOCATION',
|
||||
'NONE', 'NO-PAUSE', 'NO-PREFETCH', 'NO-PREFE', 'NO-PREFET', 'NO-PREFETC',
|
||||
'NORMALIZE', 'NO-ROW-MARKERS', 'NO-SCROLLBAR-VERTICAL',
|
||||
'NO-SEPARATE-CONNECTION', 'NO-SEPARATORS', 'NOT', 'NO-TAB-STOP',
|
||||
'NOT-ACTIVE', 'NO-UNDERLINE', 'NO-UND', 'NO-UNDE', 'NO-UNDER', 'NO-UNDERL',
|
||||
'NO-UNDERLI', 'NO-UNDERLIN', 'NO-UNDO', 'NO-VALIDATE', 'NO-VAL', 'NO-VALI',
|
||||
'NO-VALID', 'NO-VALIDA', 'NO-VALIDAT', 'NOW', 'NO-WAIT', 'NO-WORD-WRAP',
|
||||
'NULL', 'NUM-ALIASES', 'NUM-ALI', 'NUM-ALIA', 'NUM-ALIAS', 'NUM-ALIASE',
|
||||
'NUM-BUFFERS', 'NUM-BUTTONS', 'NUM-BUT', 'NUM-BUTT', 'NUM-BUTTO',
|
||||
'NUM-BUTTON', 'NUM-COLUMNS', 'NUM-COL', 'NUM-COLU', 'NUM-COLUM',
|
||||
'NUM-COLUMN', 'NUM-COPIES', 'NUM-DBS', 'NUM-DROPPED-FILES', 'NUM-ENTRIES',
|
||||
'NUMERIC', 'NUMERIC-FORMAT', 'NUMERIC-F', 'NUMERIC-FO', 'NUMERIC-FOR',
|
||||
'NUMERIC-FORM', 'NUMERIC-FORMA', 'NUM-FIELDS', 'NUM-FORMATS', 'NUM-ITEMS',
|
||||
'NUM-ITERATIONS', 'NUM-LINES', 'NUM-LOCKED-COLUMNS', 'NUM-LOCKED-COL',
|
||||
'NUM-LOCKED-COLU', 'NUM-LOCKED-COLUM', 'NUM-LOCKED-COLUMN', 'NUM-MESSAGES',
|
||||
'NUM-PARAMETERS', 'NUM-REFERENCES', 'NUM-REPLACED', 'NUM-RESULTS',
|
||||
'NUM-SELECTED-ROWS', 'NUM-SELECTED-WIDGETS', 'NUM-SELECTED',
|
||||
'NUM-SELECTED-', 'NUM-SELECTED-W', 'NUM-SELECTED-WI', 'NUM-SELECTED-WID',
|
||||
'NUM-SELECTED-WIDG', 'NUM-SELECTED-WIDGE', 'NUM-SELECTED-WIDGET',
|
||||
'NUM-TABS', 'NUM-TO-RETAIN', 'NUM-VISIBLE-COLUMNS', 'OCTET-LENGTH', 'OF',
|
||||
'OFF', 'OK', 'OK-CANCEL', 'OLD', 'ON', 'ON-FRAME-BORDER', 'ON-FRAME',
|
||||
'ON-FRAME-', 'ON-FRAME-B', 'ON-FRAME-BO', 'ON-FRAME-BOR', 'ON-FRAME-BORD',
|
||||
'ON-FRAME-BORDE', 'OPEN', 'OPSYS', 'OPTION', 'OR', 'ORDERED-JOIN',
|
||||
'ORDINAL', 'OS-APPEND', 'OS-COMMAND', 'OS-COPY', 'OS-CREATE-DIR',
|
||||
'OS-DELETE', 'OS-DIR', 'OS-DRIVES', 'OS-DRIVE', 'OS-ERROR', 'OS-GETENV',
|
||||
'OS-RENAME', 'OTHERWISE', 'OUTPUT', 'OVERLAY', 'OVERRIDE', 'OWNER', 'PAGE',
|
||||
'PAGE-BOTTOM', 'PAGE-BOT', 'PAGE-BOTT', 'PAGE-BOTTO', 'PAGED',
|
||||
'PAGE-NUMBER', 'PAGE-NUM', 'PAGE-NUMB', 'PAGE-NUMBE', 'PAGE-SIZE',
|
||||
'PAGE-TOP', 'PAGE-WIDTH', 'PAGE-WID', 'PAGE-WIDT', 'PARAMETER', 'PARAM',
|
||||
'PARAME', 'PARAMET', 'PARAMETE', 'PARENT', 'PARSE-STATUS', 'PARTIAL-KEY',
|
||||
'PASCAL', 'PASSWORD-FIELD', 'PATHNAME', 'PAUSE', 'PBE-HASH-ALGORITHM',
|
||||
'PBE-HASH-ALG', 'PBE-HASH-ALGO', 'PBE-HASH-ALGOR', 'PBE-HASH-ALGORI',
|
||||
'PBE-HASH-ALGORIT', 'PBE-HASH-ALGORITH', 'PBE-KEY-ROUNDS', 'PDBNAME',
|
||||
'PERSISTENT', 'PERSIST', 'PERSISTE', 'PERSISTEN',
|
||||
'PERSISTENT-CACHE-DISABLED', 'PFCOLOR', 'PFC', 'PFCO', 'PFCOL', 'PFCOLO',
|
||||
'PIXELS', 'PIXELS-PER-COLUMN', 'PIXELS-PER-COL', 'PIXELS-PER-COLU',
|
||||
'PIXELS-PER-COLUM', 'PIXELS-PER-ROW', 'POPUP-MENU', 'POPUP-M', 'POPUP-ME',
|
||||
'POPUP-MEN', 'POPUP-ONLY', 'POPUP-O', 'POPUP-ON', 'POPUP-ONL', 'PORTRAIT',
|
||||
'POSITION', 'PRECISION', 'PREFER-DATASET', 'PREPARED', 'PREPARE-STRING',
|
||||
'PREPROCESS', 'PREPROC', 'PREPROCE', 'PREPROCES', 'PRESELECT', 'PRESEL',
|
||||
'PRESELE', 'PRESELEC', 'PREV', 'PREV-COLUMN', 'PREV-SIBLING',
|
||||
'PREV-TAB-ITEM', 'PREV-TAB-I', 'PREV-TAB-IT', 'PREV-TAB-ITE', 'PRIMARY',
|
||||
'PRINTER', 'PRINTER-CONTROL-HANDLE', 'PRINTER-HDC', 'PRINTER-NAME',
|
||||
'PRINTER-PORT', 'PRINTER-SETUP', 'PRIVATE', 'PRIVATE-DATA', 'PRIVATE-D',
|
||||
'PRIVATE-DA', 'PRIVATE-DAT', 'PRIVILEGES', 'PROCEDURE', 'PROCE', 'PROCED',
|
||||
'PROCEDU', 'PROCEDUR', 'PROCEDURE-CALL-TYPE', 'PROCESS', 'PROC-HANDLE',
|
||||
'PROC-HA', 'PROC-HAN', 'PROC-HAND', 'PROC-HANDL', 'PROC-STATUS', 'PROC-ST',
|
||||
'PROC-STA', 'PROC-STAT', 'PROC-STATU', 'proc-text', 'proc-text-buffe',
|
||||
'PROFILER', 'PROGRAM-NAME', 'PROGRESS', 'PROGRESS-SOURCE', 'PROGRESS-S',
|
||||
'PROGRESS-SO', 'PROGRESS-SOU', 'PROGRESS-SOUR', 'PROGRESS-SOURC', 'PROMPT',
|
||||
'PROMPT-FOR', 'PROMPT-F', 'PROMPT-FO', 'PROMSGS', 'PROPATH', 'PROPERTY',
|
||||
'PROTECTED', 'PROVERSION', 'PROVERS', 'PROVERSI', 'PROVERSIO', 'PROXY',
|
||||
'PROXY-PASSWORD', 'PROXY-USERID', 'PUBLIC', 'PUBLIC-ID', 'PUBLISH',
|
||||
'PUBLISHED-EVENTS', 'PUT', 'PUTBYTE', 'PUT-BYTE', 'PUT-DOUBLE', 'PUT-FLOAT',
|
||||
'PUT-INT64', 'PUT-KEY-VALUE', 'PUT-KEY-VAL', 'PUT-KEY-VALU', 'PUT-LONG',
|
||||
'PUT-SHORT', 'PUT-STRING', 'PUT-UNSIGNED-LONG', 'QUERY', 'QUERY-CLOSE',
|
||||
'QUERY-OFF-END', 'QUERY-OPEN', 'QUERY-PREPARE', 'QUERY-TUNING', 'QUESTION',
|
||||
'QUIT', 'QUOTER', 'RADIO-BUTTONS', 'RADIO-SET', 'RANDOM', 'RAW-TRANSFER',
|
||||
'RCODE-INFORMATION', 'RCODE-INFO', 'RCODE-INFOR', 'RCODE-INFORM',
|
||||
'RCODE-INFORMA', 'RCODE-INFORMAT', 'RCODE-INFORMATI', 'RCODE-INFORMATIO',
|
||||
'READ-AVAILABLE', 'READ-EXACT-NUM', 'READ-FILE', 'READKEY', 'READ-ONLY',
|
||||
'READ-XML', 'READ-XMLSCHEMA', 'REAL', 'RECORD-LENGTH', 'RECTANGLE', 'RECT',
|
||||
'RECTA', 'RECTAN', 'RECTANG', 'RECTANGL', 'RECURSIVE', 'REFERENCE-ONLY',
|
||||
'REFRESH', 'REFRESHABLE', 'REFRESH-AUDIT-POLICY', 'REGISTER-DOMAIN',
|
||||
'RELEASE', 'REMOTE', 'REMOVE-EVENTS-PROCEDURE', 'REMOVE-SUPER-PROCEDURE',
|
||||
'REPEAT', 'REPLACE', 'REPLACE-SELECTION-TEXT', 'REPOSITION',
|
||||
'REPOSITION-BACKWARD', 'REPOSITION-FORWARD', 'REPOSITION-MODE',
|
||||
'REPOSITION-TO-ROW', 'REPOSITION-TO-ROWID', 'REQUEST', 'RESET', 'RESIZABLE',
|
||||
'RESIZA', 'RESIZAB', 'RESIZABL', 'RESIZE', 'RESTART-ROW', 'RESTART-ROWID',
|
||||
'RETAIN', 'RETAIN-SHAPE', 'RETRY', 'RETRY-CANCEL', 'RETURN',
|
||||
'RETURN-INSERTED', 'RETURN-INS', 'RETURN-INSE', 'RETURN-INSER',
|
||||
'RETURN-INSERT', 'RETURN-INSERTE', 'RETURNS', 'RETURN-TO-START-DIR',
|
||||
'RETURN-TO-START-DI', 'RETURN-VALUE', 'RETURN-VAL', 'RETURN-VALU',
|
||||
'RETURN-VALUE-DATA-TYPE', 'REVERSE-FROM', 'REVERT', 'REVOKE', 'RGB-VALUE',
|
||||
'RIGHT-ALIGNED', 'RETURN-ALIGN', 'RETURN-ALIGNE', 'RIGHT-TRIM', 'R-INDEX',
|
||||
'ROLES', 'ROUND', 'ROUTINE-LEVEL', 'ROW', 'ROW-HEIGHT-CHARS', 'HEIGHT',
|
||||
'ROW-HEIGHT-PIXELS', 'HEIGHT-P', 'ROW-MARKERS', 'ROW-OF', 'ROW-RESIZABLE',
|
||||
'RULE', 'RUN', 'RUN-PROCEDURE', 'SAVE', 'SAVE-AS', 'SAVE-FILE',
|
||||
'SAX-COMPLETE', 'SAX-COMPLE', 'SAX-COMPLET', 'SAX-PARSE', 'SAX-PARSE-FIRST',
|
||||
'SAX-PARSE-NEXT', 'SAX-PARSER-ERROR', 'SAX-RUNNING', 'SAX-UNINITIALIZED',
|
||||
'SAX-WRITE-BEGIN', 'SAX-WRITE-COMPLETE', 'SAX-WRITE-CONTENT',
|
||||
'SAX-WRITE-ELEMENT', 'SAX-WRITE-ERROR', 'SAX-WRITE-IDLE', 'SAX-WRITER',
|
||||
'SAX-WRITE-TAG', 'SCHEMA', 'SCHEMA-LOCATION', 'SCHEMA-MARSHAL',
|
||||
'SCHEMA-PATH', 'SCREEN', 'SCREEN-IO', 'SCREEN-LINES', 'SCREEN-VALUE',
|
||||
'SCREEN-VAL', 'SCREEN-VALU', 'SCROLL', 'SCROLLABLE', 'SCROLLBAR-HORIZONTAL',
|
||||
'SCROLLBAR-H', 'SCROLLBAR-HO', 'SCROLLBAR-HOR', 'SCROLLBAR-HORI',
|
||||
'SCROLLBAR-HORIZ', 'SCROLLBAR-HORIZO', 'SCROLLBAR-HORIZON',
|
||||
'SCROLLBAR-HORIZONT', 'SCROLLBAR-HORIZONTA', 'SCROLL-BARS',
|
||||
'SCROLLBAR-VERTICAL', 'SCROLLBAR-V', 'SCROLLBAR-VE', 'SCROLLBAR-VER',
|
||||
'SCROLLBAR-VERT', 'SCROLLBAR-VERTI', 'SCROLLBAR-VERTIC',
|
||||
'SCROLLBAR-VERTICA', 'SCROLL-DELTA', 'SCROLLED-ROW-POSITION',
|
||||
'SCROLLED-ROW-POS', 'SCROLLED-ROW-POSI', 'SCROLLED-ROW-POSIT',
|
||||
'SCROLLED-ROW-POSITI', 'SCROLLED-ROW-POSITIO', 'SCROLLING', 'SCROLL-OFFSET',
|
||||
'SCROLL-TO-CURRENT-ROW', 'SCROLL-TO-ITEM', 'SCROLL-TO-I', 'SCROLL-TO-IT',
|
||||
'SCROLL-TO-ITE', 'SCROLL-TO-SELECTED-ROW', 'SDBNAME', 'SEAL',
|
||||
'SEAL-TIMESTAMP', 'SEARCH', 'SEARCH-SELF', 'SEARCH-TARGET', 'SECTION',
|
||||
'SECURITY-POLICY', 'SEEK', 'SELECT', 'SELECTABLE', 'SELECT-ALL', 'SELECTED',
|
||||
'SELECT-FOCUSED-ROW', 'SELECTION', 'SELECTION-END', 'SELECTION-LIST',
|
||||
'SELECTION-START', 'SELECTION-TEXT', 'SELECT-NEXT-ROW', 'SELECT-PREV-ROW',
|
||||
'SELECT-ROW', 'SELF', 'SEND', 'send-sql-statement', 'send-sql', 'SENSITIVE',
|
||||
'SEPARATE-CONNECTION', 'SEPARATOR-FGCOLOR', 'SEPARATORS', 'SERVER',
|
||||
'SERVER-CONNECTION-BOUND', 'SERVER-CONNECTION-BOUND-REQUEST',
|
||||
'SERVER-CONNECTION-CONTEXT', 'SERVER-CONNECTION-ID',
|
||||
'SERVER-OPERATING-MODE', 'SESSION', 'SESSION-ID', 'SET', 'SET-APPL-CONTEXT',
|
||||
'SET-ATTR-CALL-TYPE', 'SET-ATTRIBUTE-NODE', 'SET-BLUE-VALUE', 'SET-BLUE',
|
||||
'SET-BLUE-', 'SET-BLUE-V', 'SET-BLUE-VA', 'SET-BLUE-VAL', 'SET-BLUE-VALU',
|
||||
'SET-BREAK', 'SET-BUFFERS', 'SET-CALLBACK', 'SET-CLIENT', 'SET-COMMIT',
|
||||
'SET-CONTENTS', 'SET-CURRENT-VALUE', 'SET-DB-CLIENT', 'SET-DYNAMIC',
|
||||
'SET-EVENT-MANAGER-OPTION', 'SET-GREEN-VALUE', 'SET-GREEN', 'SET-GREEN-',
|
||||
'SET-GREEN-V', 'SET-GREEN-VA', 'SET-GREEN-VAL', 'SET-GREEN-VALU',
|
||||
'SET-INPUT-SOURCE', 'SET-OPTION', 'SET-OUTPUT-DESTINATION', 'SET-PARAMETER',
|
||||
'SET-POINTER-VALUE', 'SET-PROPERTY', 'SET-RED-VALUE', 'SET-RED', 'SET-RED-',
|
||||
'SET-RED-V', 'SET-RED-VA', 'SET-RED-VAL', 'SET-RED-VALU',
|
||||
'SET-REPOSITIONED-ROW', 'SET-RGB-VALUE', 'SET-ROLLBACK', 'SET-SELECTION',
|
||||
'SET-SIZE', 'SET-SORT-ARROW', 'SETUSERID', 'SETUSER', 'SETUSERI',
|
||||
'SET-WAIT-STATE', 'SHA1-DIGEST', 'SHARED', 'SHARE-LOCK', 'SHARE', 'SHARE-',
|
||||
'SHARE-L', 'SHARE-LO', 'SHARE-LOC', 'SHOW-IN-TASKBAR', 'SHOW-STATS',
|
||||
'SHOW-STAT', 'SIDE-LABEL-HANDLE', 'SIDE-LABEL-H', 'SIDE-LABEL-HA',
|
||||
'SIDE-LABEL-HAN', 'SIDE-LABEL-HAND', 'SIDE-LABEL-HANDL', 'SIDE-LABELS',
|
||||
'SIDE-LAB', 'SIDE-LABE', 'SIDE-LABEL', 'SILENT', 'SIMPLE', 'SINGLE', 'SIZE',
|
||||
'SIZE-CHARS', 'SIZE-C', 'SIZE-CH', 'SIZE-CHA', 'SIZE-CHAR', 'SIZE-PIXELS',
|
||||
'SIZE-P', 'SIZE-PI', 'SIZE-PIX', 'SIZE-PIXE', 'SIZE-PIXEL', 'SKIP',
|
||||
'SKIP-DELETED-RECORD', 'SLIDER', 'SMALL-ICON', 'SMALLINT', 'SMALL-TITLE',
|
||||
'SOME', 'SORT', 'SORT-ASCENDING', 'SORT-NUMBER', 'SOURCE',
|
||||
'SOURCE-PROCEDURE', 'SPACE', 'SQL', 'SQRT', 'SSL-SERVER-NAME', 'STANDALONE',
|
||||
'START', 'START-DOCUMENT', 'START-ELEMENT', 'START-MOVE', 'START-RESIZE',
|
||||
'START-ROW-RESIZE', 'STATE-DETAIL', 'STATIC', 'STATUS', 'STATUS-AREA',
|
||||
'STATUS-AREA-FONT', 'STDCALL', 'STOP', 'STOP-PARSING', 'STOPPED', 'STOPPE',
|
||||
'STORED-PROCEDURE', 'STORED-PROC', 'STORED-PROCE', 'STORED-PROCED',
|
||||
'STORED-PROCEDU', 'STORED-PROCEDUR', 'STREAM', 'STREAM-HANDLE', 'STREAM-IO',
|
||||
'STRETCH-TO-FIT', 'STRICT', 'STRING', 'STRING-VALUE', 'STRING-XREF',
|
||||
'SUB-AVERAGE', 'SUB-AVE', 'SUB-AVER', 'SUB-AVERA', 'SUB-AVERAG',
|
||||
'SUB-COUNT', 'SUB-MAXIMUM', 'SUM-MAX', 'SUM-MAXI', 'SUM-MAXIM',
|
||||
'SUM-MAXIMU', 'SUB-MENU', 'SUBSUB-', 'MINIMUM', 'SUB-MIN', 'SUBSCRIBE',
|
||||
'SUBSTITUTE', 'SUBST', 'SUBSTI', 'SUBSTIT', 'SUBSTITU', 'SUBSTITUT',
|
||||
'SUBSTRING', 'SUBSTR', 'SUBSTRI', 'SUBSTRIN', 'SUB-TOTAL', 'SUBTYPE', 'SUM',
|
||||
'SUPER', 'SUPER-PROCEDURES', 'SUPPRESS-NAMESPACE-PROCESSING',
|
||||
'SUPPRESS-WARNINGS', 'SUPPRESS-W', 'SUPPRESS-WA', 'SUPPRESS-WAR',
|
||||
'SUPPRESS-WARN', 'SUPPRESS-WARNI', 'SUPPRESS-WARNIN', 'SUPPRESS-WARNING',
|
||||
'SYMMETRIC-ENCRYPTION-ALGORITHM', 'SYMMETRIC-ENCRYPTION-IV',
|
||||
'SYMMETRIC-ENCRYPTION-KEY', 'SYMMETRIC-SUPPORT', 'SYSTEM-ALERT-BOXES',
|
||||
'SYSTEM-ALERT', 'SYSTEM-ALERT-', 'SYSTEM-ALERT-B', 'SYSTEM-ALERT-BO',
|
||||
'SYSTEM-ALERT-BOX', 'SYSTEM-ALERT-BOXE', 'SYSTEM-DIALOG', 'SYSTEM-HELP',
|
||||
'SYSTEM-ID', 'TABLE', 'TABLE-HANDLE', 'TABLE-NUMBER', 'TAB-POSITION',
|
||||
'TAB-STOP', 'TARGET', 'TARGET-PROCEDURE', 'TEMP-DIRECTORY', 'TEMP-DIR',
|
||||
'TEMP-DIRE', 'TEMP-DIREC', 'TEMP-DIRECT', 'TEMP-DIRECTO', 'TEMP-DIRECTOR',
|
||||
'TEMP-TABLE', 'TEMP-TABLE-PREPARE', 'TERM', 'TERMINAL', 'TERM', 'TERMI',
|
||||
'TERMIN', 'TERMINA', 'TERMINATE', 'TEXT', 'TEXT-CURSOR', 'TEXT-SEG-GROW',
|
||||
'TEXT-SELECTED', 'THEN', 'THIS-OBJECT', 'THIS-PROCEDURE', 'THREE-D',
|
||||
'THROW', 'THROUGH', 'THRU', 'TIC-MARKS', 'TIME', 'TIME-SOURCE', 'TITLE',
|
||||
'TITLE-BGCOLOR', 'TITLE-BGC', 'TITLE-BGCO', 'TITLE-BGCOL', 'TITLE-BGCOLO',
|
||||
'TITLE-DCOLOR', 'TITLE-DC', 'TITLE-DCO', 'TITLE-DCOL', 'TITLE-DCOLO',
|
||||
'TITLE-FGCOLOR', 'TITLE-FGC', 'TITLE-FGCO', 'TITLE-FGCOL', 'TITLE-FGCOLO',
|
||||
'TITLE-FONT', 'TITLE-FO', 'TITLE-FON', 'TO', 'TODAY', 'TOGGLE-BOX',
|
||||
'TOOLTIP', 'TOOLTIPS', 'TOPIC', 'TOP-NAV-QUERY', 'TOP-ONLY', 'TO-ROWID',
|
||||
'TOTAL', 'TRAILING', 'TRANS', 'TRANSACTION', 'TRANSACTION-MODE',
|
||||
'TRANS-INIT-PROCEDURE', 'TRANSPARENT', 'TRIGGER', 'TRIGGERS', 'TRIM',
|
||||
'TRUE', 'TRUNCATE', 'TRUNC', 'TRUNCA', 'TRUNCAT', 'TYPE', 'TYPE-OF',
|
||||
'UNBOX', 'UNBUFFERED', 'UNBUFF', 'UNBUFFE', 'UNBUFFER', 'UNBUFFERE',
|
||||
'UNDERLINE', 'UNDERL', 'UNDERLI', 'UNDERLIN', 'UNDO', 'UNFORMATTED',
|
||||
'UNFORM', 'UNFORMA', 'UNFORMAT', 'UNFORMATT', 'UNFORMATTE', 'UNION',
|
||||
'UNIQUE', 'UNIQUE-ID', 'UNIQUE-MATCH', 'UNIX', 'UNLESS-HIDDEN', 'UNLOAD',
|
||||
'UNSIGNED-LONG', 'UNSUBSCRIBE', 'UP', 'UPDATE', 'UPDATE-ATTRIBUTE', 'URL',
|
||||
'URL-DECODE', 'URL-ENCODE', 'URL-PASSWORD', 'URL-USERID', 'USE',
|
||||
'USE-DICT-EXPS', 'USE-FILENAME', 'USE-INDEX', 'USER', 'USE-REVVIDEO',
|
||||
'USERID', 'USER-ID', 'USE-TEXT', 'USE-UNDERLINE', 'USE-WIDGET-POOL',
|
||||
'USING', 'V6DISPLAY', 'V6FRAME', 'VALIDATE', 'VALIDATE-EXPRESSION',
|
||||
'VALIDATE-MESSAGE', 'VALIDATE-SEAL', 'VALIDATION-ENABLED', 'VALID-EVENT',
|
||||
'VALID-HANDLE', 'VALID-OBJECT', 'VALUE', 'VALUE-CHANGED', 'VALUES',
|
||||
'VARIABLE', 'VAR', 'VARI', 'VARIA', 'VARIAB', 'VARIABL', 'VERBOSE',
|
||||
'VERSION', 'VERTICAL', 'VERT', 'VERTI', 'VERTIC', 'VERTICA', 'VIEW',
|
||||
'VIEW-AS', 'VIEW-FIRST-COLUMN-ON-REOPEN', 'VIRTUAL-HEIGHT-CHARS',
|
||||
'VIRTUAL-HEIGHT', 'VIRTUAL-HEIGHT-', 'VIRTUAL-HEIGHT-C',
|
||||
'VIRTUAL-HEIGHT-CH', 'VIRTUAL-HEIGHT-CHA', 'VIRTUAL-HEIGHT-CHAR',
|
||||
'VIRTUAL-HEIGHT-PIXELS', 'VIRTUAL-HEIGHT-P', 'VIRTUAL-HEIGHT-PI',
|
||||
'VIRTUAL-HEIGHT-PIX', 'VIRTUAL-HEIGHT-PIXE', 'VIRTUAL-HEIGHT-PIXEL',
|
||||
'VIRTUAL-WIDTH-CHARS', 'VIRTUAL-WIDTH', 'VIRTUAL-WIDTH-', 'VIRTUAL-WIDTH-C',
|
||||
'VIRTUAL-WIDTH-CH', 'VIRTUAL-WIDTH-CHA', 'VIRTUAL-WIDTH-CHAR',
|
||||
'VIRTUAL-WIDTH-PIXELS', 'VIRTUAL-WIDTH-P', 'VIRTUAL-WIDTH-PI',
|
||||
'VIRTUAL-WIDTH-PIX', 'VIRTUAL-WIDTH-PIXE', 'VIRTUAL-WIDTH-PIXEL', 'VISIBLE',
|
||||
'VOID', 'WAIT', 'WAIT-FOR', 'WARNING', 'WEB-CONTEXT', 'WEEKDAY', 'WHEN',
|
||||
'WHERE', 'WHILE', 'WIDGET', 'WIDGET-ENTER', 'WIDGET-E', 'WIDGET-EN',
|
||||
'WIDGET-ENT', 'WIDGET-ENTE', 'WIDGET-ID', 'WIDGET-LEAVE', 'WIDGET-L',
|
||||
'WIDGET-LE', 'WIDGET-LEA', 'WIDGET-LEAV', 'WIDGET-POOL', 'WIDTH',
|
||||
'WIDTH-CHARS', 'WIDTH', 'WIDTH-', 'WIDTH-C', 'WIDTH-CH', 'WIDTH-CHA',
|
||||
'WIDTH-CHAR', 'WIDTH-PIXELS', 'WIDTH-P', 'WIDTH-PI', 'WIDTH-PIX',
|
||||
'WIDTH-PIXE', 'WIDTH-PIXEL', 'WINDOW', 'WINDOW-MAXIMIZED', 'WINDOW-MAXIM',
|
||||
'WINDOW-MAXIMI', 'WINDOW-MAXIMIZ', 'WINDOW-MAXIMIZE', 'WINDOW-MINIMIZED',
|
||||
'WINDOW-MINIM', 'WINDOW-MINIMI', 'WINDOW-MINIMIZ', 'WINDOW-MINIMIZE',
|
||||
'WINDOW-NAME', 'WINDOW-NORMAL', 'WINDOW-STATE', 'WINDOW-STA', 'WINDOW-STAT',
|
||||
'WINDOW-SYSTEM', 'WITH', 'WORD-INDEX', 'WORD-WRAP',
|
||||
'WORK-AREA-HEIGHT-PIXELS', 'WORK-AREA-WIDTH-PIXELS', 'WORK-AREA-X',
|
||||
'WORK-AREA-Y', 'WORKFILE', 'WORK-TABLE', 'WORK-TAB', 'WORK-TABL', 'WRITE',
|
||||
'WRITE-CDATA', 'WRITE-CHARACTERS', 'WRITE-COMMENT', 'WRITE-DATA-ELEMENT',
|
||||
'WRITE-EMPTY-ELEMENT', 'WRITE-ENTITY-REF', 'WRITE-EXTERNAL-DTD',
|
||||
'WRITE-FRAGMENT', 'WRITE-MESSAGE', 'WRITE-PROCESSING-INSTRUCTION',
|
||||
'WRITE-STATUS', 'WRITE-XML', 'WRITE-XMLSCHEMA', 'X', 'XCODE',
|
||||
'XML-DATA-TYPE', 'XML-NODE-TYPE', 'XML-SCHEMA-PATH',
|
||||
'XML-SUPPRESS-NAMESPACE-PROCESSING', 'X-OF', 'XREF', 'XREF-XML', 'Y',
|
||||
'YEAR', 'YEAR-OFFSET', 'YES', 'YES-NO', 'YES-NO-CANCEL', 'Y-OF'
|
||||
]
|
||||
@ -1,233 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._postgres_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Self-updating data files for PostgreSQL lexer.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import urllib.request, urllib.parse, urllib.error
|
||||
|
||||
# One man's constant is another man's variable.
|
||||
SOURCE_URL = 'https://github.com/postgres/postgres/raw/master'
|
||||
KEYWORDS_URL = SOURCE_URL + '/doc/src/sgml/keywords.sgml'
|
||||
DATATYPES_URL = SOURCE_URL + '/doc/src/sgml/datatype.sgml'
|
||||
|
||||
def update_myself():
|
||||
data_file = list(fetch(DATATYPES_URL))
|
||||
datatypes = parse_datatypes(data_file)
|
||||
pseudos = parse_pseudos(data_file)
|
||||
|
||||
keywords = parse_keywords(fetch(KEYWORDS_URL))
|
||||
update_consts(__file__, 'DATATYPES', datatypes)
|
||||
update_consts(__file__, 'PSEUDO_TYPES', pseudos)
|
||||
update_consts(__file__, 'KEYWORDS', keywords)
|
||||
|
||||
def parse_keywords(f):
|
||||
kw = []
|
||||
for m in re.finditer(
|
||||
r'\s*<entry><token>([^<]+)</token></entry>\s*'
|
||||
r'<entry>([^<]+)</entry>', f.read()):
|
||||
kw.append(m.group(1))
|
||||
|
||||
if not kw:
|
||||
raise ValueError('no keyword found')
|
||||
|
||||
kw.sort()
|
||||
return kw
|
||||
|
||||
def parse_datatypes(f):
|
||||
dt = set()
|
||||
for line in f:
|
||||
if '<sect1' in line:
|
||||
break
|
||||
if '<entry><type>' not in line:
|
||||
continue
|
||||
|
||||
# Parse a string such as
|
||||
# time [ (<replaceable>p</replaceable>) ] [ without time zone ]
|
||||
# into types "time" and "without time zone"
|
||||
|
||||
# remove all the tags
|
||||
line = re.sub("<replaceable>[^<]+</replaceable>", "", line)
|
||||
line = re.sub("<[^>]+>", "", line)
|
||||
|
||||
# Drop the parts containing braces
|
||||
for tmp in [t for tmp in line.split('[')
|
||||
for t in tmp.split(']') if "(" not in t]:
|
||||
for t in tmp.split(','):
|
||||
t = t.strip()
|
||||
if not t: continue
|
||||
dt.add(" ".join(t.split()))
|
||||
|
||||
dt = list(dt)
|
||||
dt.sort()
|
||||
return dt
|
||||
|
||||
def parse_pseudos(f):
|
||||
dt = []
|
||||
re_start = re.compile(r'\s*<table id="datatype-pseudotypes-table">')
|
||||
re_entry = re.compile(r'\s*<entry><type>([^<]+)</></entry>')
|
||||
re_end = re.compile(r'\s*</table>')
|
||||
|
||||
f = iter(f)
|
||||
for line in f:
|
||||
if re_start.match(line) is not None:
|
||||
break
|
||||
else:
|
||||
raise ValueError('pseudo datatypes table not found')
|
||||
|
||||
for line in f:
|
||||
m = re_entry.match(line)
|
||||
if m is not None:
|
||||
dt.append(m.group(1))
|
||||
|
||||
if re_end.match(line) is not None:
|
||||
break
|
||||
else:
|
||||
raise ValueError('end of pseudo datatypes table not found')
|
||||
|
||||
if not dt:
|
||||
raise ValueError('pseudo datatypes not found')
|
||||
|
||||
return dt
|
||||
|
||||
def fetch(url):
|
||||
return urllib.request.urlopen(url)
|
||||
|
||||
def update_consts(filename, constname, content):
|
||||
f = open(filename)
|
||||
lines = f.readlines()
|
||||
f.close()
|
||||
|
||||
# Line to start/end inserting
|
||||
re_start = re.compile(r'^%s\s*=\s*\[\s*$' % constname)
|
||||
re_end = re.compile(r'^\s*\]\s*$')
|
||||
start = [ n for n, l in enumerate(lines) if re_start.match(l) ]
|
||||
if not start:
|
||||
raise ValueError("couldn't find line containing '%s = ['" % constname)
|
||||
if len(start) > 1:
|
||||
raise ValueError("too many lines containing '%s = ['" % constname)
|
||||
start = start[0] + 1
|
||||
|
||||
end = [ n for n, l in enumerate(lines) if n >= start and re_end.match(l) ]
|
||||
if not end:
|
||||
raise ValueError("couldn't find line containing ']' after %s " % constname)
|
||||
end = end[0]
|
||||
|
||||
# Pack the new content in lines not too long
|
||||
content = [repr(item) for item in content ]
|
||||
new_lines = [[]]
|
||||
for item in content:
|
||||
if sum(map(len, new_lines[-1])) + 2 * len(new_lines[-1]) + len(item) + 4 > 75:
|
||||
new_lines.append([])
|
||||
new_lines[-1].append(item)
|
||||
|
||||
lines[start:end] = [ " %s,\n" % ", ".join(items) for items in new_lines ]
|
||||
|
||||
f = open(filename, 'w')
|
||||
f.write(''.join(lines))
|
||||
f.close()
|
||||
|
||||
|
||||
# Autogenerated: please edit them if you like wasting your time.
|
||||
|
||||
KEYWORDS = [
|
||||
'ABORT', 'ABSOLUTE', 'ACCESS', 'ACTION', 'ADD', 'ADMIN', 'AFTER',
|
||||
'AGGREGATE', 'ALL', 'ALSO', 'ALTER', 'ALWAYS', 'ANALYSE', 'ANALYZE',
|
||||
'AND', 'ANY', 'ARRAY', 'AS', 'ASC', 'ASSERTION', 'ASSIGNMENT',
|
||||
'ASYMMETRIC', 'AT', 'ATTRIBUTE', 'AUTHORIZATION', 'BACKWARD', 'BEFORE',
|
||||
'BEGIN', 'BETWEEN', 'BIGINT', 'BINARY', 'BIT', 'BOOLEAN', 'BOTH', 'BY',
|
||||
'CACHE', 'CALLED', 'CASCADE', 'CASCADED', 'CASE', 'CAST', 'CATALOG',
|
||||
'CHAIN', 'CHAR', 'CHARACTER', 'CHARACTERISTICS', 'CHECK', 'CHECKPOINT',
|
||||
'CLASS', 'CLOSE', 'CLUSTER', 'COALESCE', 'COLLATE', 'COLLATION',
|
||||
'COLUMN', 'COMMENT', 'COMMENTS', 'COMMIT', 'COMMITTED', 'CONCURRENTLY',
|
||||
'CONFIGURATION', 'CONNECTION', 'CONSTRAINT', 'CONSTRAINTS', 'CONTENT',
|
||||
'CONTINUE', 'CONVERSION', 'COPY', 'COST', 'CREATE', 'CROSS', 'CSV',
|
||||
'CURRENT', 'CURRENT_CATALOG', 'CURRENT_DATE', 'CURRENT_ROLE',
|
||||
'CURRENT_SCHEMA', 'CURRENT_TIME', 'CURRENT_TIMESTAMP', 'CURRENT_USER',
|
||||
'CURSOR', 'CYCLE', 'DATA', 'DATABASE', 'DAY', 'DEALLOCATE', 'DEC',
|
||||
'DECIMAL', 'DECLARE', 'DEFAULT', 'DEFAULTS', 'DEFERRABLE', 'DEFERRED',
|
||||
'DEFINER', 'DELETE', 'DELIMITER', 'DELIMITERS', 'DESC', 'DICTIONARY',
|
||||
'DISABLE', 'DISCARD', 'DISTINCT', 'DO', 'DOCUMENT', 'DOMAIN', 'DOUBLE',
|
||||
'DROP', 'EACH', 'ELSE', 'ENABLE', 'ENCODING', 'ENCRYPTED', 'END',
|
||||
'ENUM', 'ESCAPE', 'EXCEPT', 'EXCLUDE', 'EXCLUDING', 'EXCLUSIVE',
|
||||
'EXECUTE', 'EXISTS', 'EXPLAIN', 'EXTENSION', 'EXTERNAL', 'EXTRACT',
|
||||
'FALSE', 'FAMILY', 'FETCH', 'FIRST', 'FLOAT', 'FOLLOWING', 'FOR',
|
||||
'FORCE', 'FOREIGN', 'FORWARD', 'FREEZE', 'FROM', 'FULL', 'FUNCTION',
|
||||
'FUNCTIONS', 'GLOBAL', 'GRANT', 'GRANTED', 'GREATEST', 'GROUP',
|
||||
'HANDLER', 'HAVING', 'HEADER', 'HOLD', 'HOUR', 'IDENTITY', 'IF',
|
||||
'ILIKE', 'IMMEDIATE', 'IMMUTABLE', 'IMPLICIT', 'IN', 'INCLUDING',
|
||||
'INCREMENT', 'INDEX', 'INDEXES', 'INHERIT', 'INHERITS', 'INITIALLY',
|
||||
'INLINE', 'INNER', 'INOUT', 'INPUT', 'INSENSITIVE', 'INSERT', 'INSTEAD',
|
||||
'INT', 'INTEGER', 'INTERSECT', 'INTERVAL', 'INTO', 'INVOKER', 'IS',
|
||||
'ISNULL', 'ISOLATION', 'JOIN', 'KEY', 'LABEL', 'LANGUAGE', 'LARGE',
|
||||
'LAST', 'LC_COLLATE', 'LC_CTYPE', 'LEADING', 'LEAST', 'LEFT', 'LEVEL',
|
||||
'LIKE', 'LIMIT', 'LISTEN', 'LOAD', 'LOCAL', 'LOCALTIME',
|
||||
'LOCALTIMESTAMP', 'LOCATION', 'LOCK', 'MAPPING', 'MATCH', 'MAXVALUE',
|
||||
'MINUTE', 'MINVALUE', 'MODE', 'MONTH', 'MOVE', 'NAME', 'NAMES',
|
||||
'NATIONAL', 'NATURAL', 'NCHAR', 'NEXT', 'NO', 'NONE', 'NOT', 'NOTHING',
|
||||
'NOTIFY', 'NOTNULL', 'NOWAIT', 'NULL', 'NULLIF', 'NULLS', 'NUMERIC',
|
||||
'OBJECT', 'OF', 'OFF', 'OFFSET', 'OIDS', 'ON', 'ONLY', 'OPERATOR',
|
||||
'OPTION', 'OPTIONS', 'OR', 'ORDER', 'OUT', 'OUTER', 'OVER', 'OVERLAPS',
|
||||
'OVERLAY', 'OWNED', 'OWNER', 'PARSER', 'PARTIAL', 'PARTITION',
|
||||
'PASSING', 'PASSWORD', 'PLACING', 'PLANS', 'POSITION', 'PRECEDING',
|
||||
'PRECISION', 'PREPARE', 'PREPARED', 'PRESERVE', 'PRIMARY', 'PRIOR',
|
||||
'PRIVILEGES', 'PROCEDURAL', 'PROCEDURE', 'QUOTE', 'RANGE', 'READ',
|
||||
'REAL', 'REASSIGN', 'RECHECK', 'RECURSIVE', 'REF', 'REFERENCES',
|
||||
'REINDEX', 'RELATIVE', 'RELEASE', 'RENAME', 'REPEATABLE', 'REPLACE',
|
||||
'REPLICA', 'RESET', 'RESTART', 'RESTRICT', 'RETURNING', 'RETURNS',
|
||||
'REVOKE', 'RIGHT', 'ROLE', 'ROLLBACK', 'ROW', 'ROWS', 'RULE',
|
||||
'SAVEPOINT', 'SCHEMA', 'SCROLL', 'SEARCH', 'SECOND', 'SECURITY',
|
||||
'SELECT', 'SEQUENCE', 'SEQUENCES', 'SERIALIZABLE', 'SERVER', 'SESSION',
|
||||
'SESSION_USER', 'SET', 'SETOF', 'SHARE', 'SHOW', 'SIMILAR', 'SIMPLE',
|
||||
'SMALLINT', 'SOME', 'STABLE', 'STANDALONE', 'START', 'STATEMENT',
|
||||
'STATISTICS', 'STDIN', 'STDOUT', 'STORAGE', 'STRICT', 'STRIP',
|
||||
'SUBSTRING', 'SYMMETRIC', 'SYSID', 'SYSTEM', 'TABLE', 'TABLES',
|
||||
'TABLESPACE', 'TEMP', 'TEMPLATE', 'TEMPORARY', 'TEXT', 'THEN', 'TIME',
|
||||
'TIMESTAMP', 'TO', 'TRAILING', 'TRANSACTION', 'TREAT', 'TRIGGER',
|
||||
'TRIM', 'TRUE', 'TRUNCATE', 'TRUSTED', 'TYPE', 'UNBOUNDED',
|
||||
'UNCOMMITTED', 'UNENCRYPTED', 'UNION', 'UNIQUE', 'UNKNOWN', 'UNLISTEN',
|
||||
'UNLOGGED', 'UNTIL', 'UPDATE', 'USER', 'USING', 'VACUUM', 'VALID',
|
||||
'VALIDATE', 'VALIDATOR', 'VALUE', 'VALUES', 'VARCHAR', 'VARIADIC',
|
||||
'VARYING', 'VERBOSE', 'VERSION', 'VIEW', 'VOLATILE', 'WHEN', 'WHERE',
|
||||
'WHITESPACE', 'WINDOW', 'WITH', 'WITHOUT', 'WORK', 'WRAPPER', 'WRITE',
|
||||
'XML', 'XMLATTRIBUTES', 'XMLCONCAT', 'XMLELEMENT', 'XMLEXISTS',
|
||||
'XMLFOREST', 'XMLPARSE', 'XMLPI', 'XMLROOT', 'XMLSERIALIZE', 'YEAR',
|
||||
'YES', 'ZONE',
|
||||
]
|
||||
|
||||
DATATYPES = [
|
||||
'bigint', 'bigserial', 'bit', 'bit varying', 'bool', 'boolean', 'box',
|
||||
'bytea', 'char', 'character', 'character varying', 'cidr', 'circle',
|
||||
'date', 'decimal', 'double precision', 'float4', 'float8', 'inet',
|
||||
'int', 'int2', 'int4', 'int8', 'integer', 'interval', 'json', 'line',
|
||||
'lseg', 'macaddr', 'money', 'numeric', 'path', 'point', 'polygon',
|
||||
'real', 'serial', 'serial2', 'serial4', 'serial8', 'smallint',
|
||||
'smallserial', 'text', 'time', 'timestamp', 'timestamptz', 'timetz',
|
||||
'tsquery', 'tsvector', 'txid_snapshot', 'uuid', 'varbit', 'varchar',
|
||||
'with time zone', 'without time zone', 'xml',
|
||||
]
|
||||
|
||||
PSEUDO_TYPES = [
|
||||
'any', 'anyelement', 'anyarray', 'anynonarray', 'anyenum', 'anyrange',
|
||||
'cstring', 'internal', 'language_handler', 'fdw_handler', 'record',
|
||||
'trigger', 'void', 'opaque',
|
||||
]
|
||||
|
||||
# Remove 'trigger' from types
|
||||
PSEUDO_TYPES = sorted(set(PSEUDO_TYPES) - set(map(str.lower, KEYWORDS)))
|
||||
|
||||
PLPGSQL_KEYWORDS = [
|
||||
'ALIAS', 'CONSTANT', 'DIAGNOSTICS', 'ELSIF', 'EXCEPTION', 'EXIT',
|
||||
'FOREACH', 'GET', 'LOOP', 'NOTICE', 'OPEN', 'PERFORM', 'QUERY', 'RAISE',
|
||||
'RETURN', 'REVERSE', 'SQLSTATE', 'WHILE',
|
||||
]
|
||||
|
||||
if __name__ == '__main__':
|
||||
update_myself()
|
||||
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,356 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.hdl
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for hardware descriptor languages.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
from pygments.lexer import RegexLexer, bygroups, include, using, this
|
||||
from pygments.token import \
|
||||
Text, Comment, Operator, Keyword, Name, String, Number, Punctuation, \
|
||||
Error
|
||||
|
||||
__all__ = ['VerilogLexer', 'SystemVerilogLexer', 'VhdlLexer']
|
||||
|
||||
|
||||
class VerilogLexer(RegexLexer):
|
||||
"""
|
||||
For verilog source code with preprocessor directives.
|
||||
|
||||
*New in Pygments 1.4.*
|
||||
"""
|
||||
name = 'verilog'
|
||||
aliases = ['verilog', 'v']
|
||||
filenames = ['*.v']
|
||||
mimetypes = ['text/x-verilog']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*].*?[*]/)+'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^\s*`define', Comment.Preproc, 'macro'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'[{}#@]', Punctuation),
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'([0-9]+)|(\'h)[0-9a-fA-F]+', Number.Hex),
|
||||
(r'([0-9]+)|(\'b)[0-1]+', Number.Hex), # should be binary
|
||||
(r'([0-9]+)|(\'d)[0-9]+', Number.Integer),
|
||||
(r'([0-9]+)|(\'o)[0-7]+', Number.Oct),
|
||||
(r'\'[01xz]', Number),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.;\']', Punctuation),
|
||||
(r'`[a-zA-Z_][a-zA-Z0-9_]*', Name.Constant),
|
||||
|
||||
(r'^(\s*)(package)(\s+)', bygroups(Text, Keyword.Namespace, Text)),
|
||||
(r'^(\s*)(import)(\s+)', bygroups(Text, Keyword.Namespace, Text),
|
||||
'import'),
|
||||
|
||||
(r'(always|always_comb|always_ff|always_latch|and|assign|automatic|'
|
||||
r'begin|break|buf|bufif0|bufif1|case|casex|casez|cmos|const|'
|
||||
r'continue|deassign|default|defparam|disable|do|edge|else|end|endcase|'
|
||||
r'endfunction|endgenerate|endmodule|endpackage|endprimitive|endspecify|'
|
||||
r'endtable|endtask|enum|event|final|for|force|forever|fork|function|'
|
||||
r'generate|genvar|highz0|highz1|if|initial|inout|input|'
|
||||
r'integer|join|large|localparam|macromodule|medium|module|'
|
||||
r'nand|negedge|nmos|nor|not|notif0|notif1|or|output|packed|'
|
||||
r'parameter|pmos|posedge|primitive|pull0|pull1|pulldown|pullup|rcmos|'
|
||||
r'ref|release|repeat|return|rnmos|rpmos|rtran|rtranif0|'
|
||||
r'rtranif1|scalared|signed|small|specify|specparam|strength|'
|
||||
r'string|strong0|strong1|struct|table|task|'
|
||||
r'tran|tranif0|tranif1|type|typedef|'
|
||||
r'unsigned|var|vectored|void|wait|weak0|weak1|while|'
|
||||
r'xnor|xor)\b', Keyword),
|
||||
|
||||
(r'`(accelerate|autoexpand_vectornets|celldefine|default_nettype|'
|
||||
r'else|elsif|endcelldefine|endif|endprotect|endprotected|'
|
||||
r'expand_vectornets|ifdef|ifndef|include|noaccelerate|noexpand_vectornets|'
|
||||
r'noremove_gatenames|noremove_netnames|nounconnected_drive|'
|
||||
r'protect|protected|remove_gatenames|remove_netnames|resetall|'
|
||||
r'timescale|unconnected_drive|undef)\b', Comment.Preproc),
|
||||
|
||||
(r'\$(bits|bitstoreal|bitstoshortreal|countdrivers|display|fclose|'
|
||||
r'fdisplay|finish|floor|fmonitor|fopen|fstrobe|fwrite|'
|
||||
r'getpattern|history|incsave|input|itor|key|list|log|'
|
||||
r'monitor|monitoroff|monitoron|nokey|nolog|printtimescale|'
|
||||
r'random|readmemb|readmemh|realtime|realtobits|reset|reset_count|'
|
||||
r'reset_value|restart|rtoi|save|scale|scope|shortrealtobits|'
|
||||
r'showscopes|showvariables|showvars|sreadmemb|sreadmemh|'
|
||||
r'stime|stop|strobe|time|timeformat|write)\b', Name.Builtin),
|
||||
|
||||
(r'(byte|shortint|int|longint|integer|time|'
|
||||
r'bit|logic|reg|'
|
||||
r'supply0|supply1|tri|triand|trior|tri0|tri1|trireg|uwire|wire|wand|wor'
|
||||
r'shortreal|real|realtime)\b', Keyword.Type),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*:(?!:)', Name.Label),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*', Name),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'import': [
|
||||
(r'[a-zA-Z0-9_:]+\*?', Name.Namespace, '#pop')
|
||||
]
|
||||
}
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
# Convention: mark all upper case names as constants
|
||||
if token is Name:
|
||||
if value.isupper():
|
||||
token = Name.Constant
|
||||
yield index, token, value
|
||||
|
||||
|
||||
class SystemVerilogLexer(RegexLexer):
|
||||
"""
|
||||
Extends verilog lexer to recognise all SystemVerilog keywords from IEEE
|
||||
1800-2009 standard.
|
||||
|
||||
*New in Pygments 1.5.*
|
||||
"""
|
||||
name = 'systemverilog'
|
||||
aliases = ['systemverilog', 'sv']
|
||||
filenames = ['*.sv', '*.svh']
|
||||
mimetypes = ['text/x-systemverilog']
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*].*?[*]/)+'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^\s*`define', Comment.Preproc, 'macro'),
|
||||
(r'^(\s*)(package)(\s+)', bygroups(Text, Keyword.Namespace, Text)),
|
||||
(r'^(\s*)(import)(\s+)', bygroups(Text, Keyword.Namespace, Text), 'import'),
|
||||
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'/(\\\n)?/(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'[{}#@]', Punctuation),
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'([0-9]+)|(\'h)[0-9a-fA-F]+', Number.Hex),
|
||||
(r'([0-9]+)|(\'b)[0-1]+', Number.Hex), # should be binary
|
||||
(r'([0-9]+)|(\'d)[0-9]+', Number.Integer),
|
||||
(r'([0-9]+)|(\'o)[0-7]+', Number.Oct),
|
||||
(r'\'[01xz]', Number),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.;\']', Punctuation),
|
||||
(r'`[a-zA-Z_][a-zA-Z0-9_]*', Name.Constant),
|
||||
|
||||
(r'(accept_on|alias|always|always_comb|always_ff|always_latch|'
|
||||
r'and|assert|assign|assume|automatic|before|begin|bind|bins|'
|
||||
r'binsof|bit|break|buf|bufif0|bufif1|byte|case|casex|casez|'
|
||||
r'cell|chandle|checker|class|clocking|cmos|config|const|constraint|'
|
||||
r'context|continue|cover|covergroup|coverpoint|cross|deassign|'
|
||||
r'default|defparam|design|disable|dist|do|edge|else|end|endcase|'
|
||||
r'endchecker|endclass|endclocking|endconfig|endfunction|endgenerate|'
|
||||
r'endgroup|endinterface|endmodule|endpackage|endprimitive|'
|
||||
r'endprogram|endproperty|endsequence|endspecify|endtable|'
|
||||
r'endtask|enum|event|eventually|expect|export|extends|extern|'
|
||||
r'final|first_match|for|force|foreach|forever|fork|forkjoin|'
|
||||
r'function|generate|genvar|global|highz0|highz1|if|iff|ifnone|'
|
||||
r'ignore_bins|illegal_bins|implies|import|incdir|include|'
|
||||
r'initial|inout|input|inside|instance|int|integer|interface|'
|
||||
r'intersect|join|join_any|join_none|large|let|liblist|library|'
|
||||
r'local|localparam|logic|longint|macromodule|matches|medium|'
|
||||
r'modport|module|nand|negedge|new|nexttime|nmos|nor|noshowcancelled|'
|
||||
r'not|notif0|notif1|null|or|output|package|packed|parameter|'
|
||||
r'pmos|posedge|primitive|priority|program|property|protected|'
|
||||
r'pull0|pull1|pulldown|pullup|pulsestyle_ondetect|pulsestyle_onevent|'
|
||||
r'pure|rand|randc|randcase|randsequence|rcmos|real|realtime|'
|
||||
r'ref|reg|reject_on|release|repeat|restrict|return|rnmos|'
|
||||
r'rpmos|rtran|rtranif0|rtranif1|s_always|s_eventually|s_nexttime|'
|
||||
r's_until|s_until_with|scalared|sequence|shortint|shortreal|'
|
||||
r'showcancelled|signed|small|solve|specify|specparam|static|'
|
||||
r'string|strong|strong0|strong1|struct|super|supply0|supply1|'
|
||||
r'sync_accept_on|sync_reject_on|table|tagged|task|this|throughout|'
|
||||
r'time|timeprecision|timeunit|tran|tranif0|tranif1|tri|tri0|'
|
||||
r'tri1|triand|trior|trireg|type|typedef|union|unique|unique0|'
|
||||
r'unsigned|until|until_with|untyped|use|uwire|var|vectored|'
|
||||
r'virtual|void|wait|wait_order|wand|weak|weak0|weak1|while|'
|
||||
r'wildcard|wire|with|within|wor|xnor|xor)\b', Keyword ),
|
||||
|
||||
(r'(`__FILE__|`__LINE__|`begin_keywords|`celldefine|`default_nettype|'
|
||||
r'`define|`else|`elsif|`end_keywords|`endcelldefine|`endif|'
|
||||
r'`ifdef|`ifndef|`include|`line|`nounconnected_drive|`pragma|'
|
||||
r'`resetall|`timescale|`unconnected_drive|`undef|`undefineall)\b',
|
||||
Comment.Preproc ),
|
||||
|
||||
(r'(\$display|\$displayb|\$displayh|\$displayo|\$dumpall|\$dumpfile|'
|
||||
r'\$dumpflush|\$dumplimit|\$dumpoff|\$dumpon|\$dumpports|'
|
||||
r'\$dumpportsall|\$dumpportsflush|\$dumpportslimit|\$dumpportsoff|'
|
||||
r'\$dumpportson|\$dumpvars|\$fclose|\$fdisplay|\$fdisplayb|'
|
||||
r'\$fdisplayh|\$fdisplayo|\$feof|\$ferror|\$fflush|\$fgetc|'
|
||||
r'\$fgets|\$fmonitor|\$fmonitorb|\$fmonitorh|\$fmonitoro|'
|
||||
r'\$fopen|\$fread|\$fscanf|\$fseek|\$fstrobe|\$fstrobeb|\$fstrobeh|'
|
||||
r'\$fstrobeo|\$ftell|\$fwrite|\$fwriteb|\$fwriteh|\$fwriteo|'
|
||||
r'\$monitor|\$monitorb|\$monitorh|\$monitoro|\$monitoroff|'
|
||||
r'\$monitoron|\$plusargs|\$readmemb|\$readmemh|\$rewind|\$sformat|'
|
||||
r'\$sformatf|\$sscanf|\$strobe|\$strobeb|\$strobeh|\$strobeo|'
|
||||
r'\$swrite|\$swriteb|\$swriteh|\$swriteo|\$test|\$ungetc|'
|
||||
r'\$value\$plusargs|\$write|\$writeb|\$writeh|\$writememb|'
|
||||
r'\$writememh|\$writeo)\b' , Name.Builtin ),
|
||||
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(byte|shortint|int|longint|integer|time|'
|
||||
r'bit|logic|reg|'
|
||||
r'supply0|supply1|tri|triand|trior|tri0|tri1|trireg|uwire|wire|wand|wor'
|
||||
r'shortreal|real|realtime)\b', Keyword.Type),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*:(?!:)', Name.Label),
|
||||
('[a-zA-Z_][a-zA-Z0-9_]*', Name),
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_][a-zA-Z0-9_]*', Name.Class, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'import': [
|
||||
(r'[a-zA-Z0-9_:]+\*?', Name.Namespace, '#pop')
|
||||
]
|
||||
}
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
# Convention: mark all upper case names as constants
|
||||
if token is Name:
|
||||
if value.isupper():
|
||||
token = Name.Constant
|
||||
yield index, token, value
|
||||
|
||||
def analyse_text(text):
|
||||
if text.startswith('//') or text.startswith('/*'):
|
||||
return 0.5
|
||||
|
||||
|
||||
class VhdlLexer(RegexLexer):
|
||||
"""
|
||||
For VHDL source code.
|
||||
|
||||
*New in Pygments 1.5.*
|
||||
"""
|
||||
name = 'vhdl'
|
||||
aliases = ['vhdl']
|
||||
filenames = ['*.vhdl', '*.vhd']
|
||||
mimetypes = ['text/x-vhdl']
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'--(?![!#$%&*+./<=>?@\^|_~]).*?$', Comment.Single),
|
||||
(r"'(U|X|0|1|Z|W|L|H|-)'", String.Char),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r"'[a-zA-Z_][a-zA-Z0-9_]*", Name.Attribute),
|
||||
(r'[()\[\],.;\']', Punctuation),
|
||||
(r'"[^\n\\]*"', String),
|
||||
|
||||
(r'(library)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)',
|
||||
bygroups(Keyword, Text, Name.Namespace)),
|
||||
(r'(use)(\s+)(entity)', bygroups(Keyword, Text, Keyword)),
|
||||
(r'(use)(\s+)([a-zA-Z_][\.a-zA-Z0-9_]*)',
|
||||
bygroups(Keyword, Text, Name.Namespace)),
|
||||
(r'(entity|component)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)',
|
||||
bygroups(Keyword, Text, Name.Class)),
|
||||
(r'(architecture|configuration)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)(\s+)'
|
||||
r'(of)(\s+)([a-zA-Z_][a-zA-Z0-9_]*)(\s+)(is)',
|
||||
bygroups(Keyword, Text, Name.Class, Text, Keyword, Text,
|
||||
Name.Class, Text, Keyword)),
|
||||
|
||||
(r'(end)(\s+)', bygroups(using(this), Text), 'endblock'),
|
||||
|
||||
include('types'),
|
||||
include('keywords'),
|
||||
include('numbers'),
|
||||
|
||||
(r'[a-zA-Z_][a-zA-Z0-9_]*', Name),
|
||||
],
|
||||
'endblock': [
|
||||
include('keywords'),
|
||||
(r'[a-zA-Z_][a-zA-Z0-9_]*', Name.Class),
|
||||
(r'(\s+)', Text),
|
||||
(r';', Punctuation, '#pop'),
|
||||
],
|
||||
'types': [
|
||||
(r'(boolean|bit|character|severity_level|integer|time|delay_length|'
|
||||
r'natural|positive|string|bit_vector|file_open_kind|'
|
||||
r'file_open_status|std_ulogic|std_ulogic_vector|std_logic|'
|
||||
r'std_logic_vector)\b', Keyword.Type),
|
||||
],
|
||||
'keywords': [
|
||||
(r'(abs|access|after|alias|all|and|'
|
||||
r'architecture|array|assert|attribute|begin|block|'
|
||||
r'body|buffer|bus|case|component|configuration|'
|
||||
r'constant|disconnect|downto|else|elsif|end|'
|
||||
r'entity|exit|file|for|function|generate|'
|
||||
r'generic|group|guarded|if|impure|in|'
|
||||
r'inertial|inout|is|label|library|linkage|'
|
||||
r'literal|loop|map|mod|nand|new|'
|
||||
r'next|nor|not|null|of|on|'
|
||||
r'open|or|others|out|package|port|'
|
||||
r'postponed|procedure|process|pure|range|record|'
|
||||
r'register|reject|return|rol|ror|select|'
|
||||
r'severity|signal|shared|sla|sli|sra|'
|
||||
r'srl|subtype|then|to|transport|type|'
|
||||
r'units|until|use|variable|wait|when|'
|
||||
r'while|with|xnor|xor)\b', Keyword),
|
||||
],
|
||||
'numbers': [
|
||||
(r'\d{1,2}#[0-9a-fA-F_]+#?', Number.Integer),
|
||||
(r'[0-1_]+(\.[0-1_])', Number.Integer),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+', Number.Float),
|
||||
(r'H"[0-9a-fA-F_]+"', Number.Oct),
|
||||
(r'O"[0-7_]+"', Number.Oct),
|
||||
(r'B"[0-1_]+"', Number.Oct),
|
||||
],
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because one or more lines are too long
@ -22,11 +22,11 @@
|
||||
.. _Pygments tip:
|
||||
http://bitbucket.org/birkenfeld/pygments-main/get/tip.zip#egg=Pygments-dev
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
__version__ = '1.6'
|
||||
__version__ = '2.0.1'
|
||||
__docformat__ = 'restructuredtext'
|
||||
|
||||
__all__ = ['lex', 'format', 'highlight']
|
||||
@ -5,27 +5,32 @@
|
||||
|
||||
Command line interface.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import sys
|
||||
import getopt
|
||||
from textwrap import dedent
|
||||
|
||||
from pygments import __version__, highlight
|
||||
from pygments.util import ClassNotFound, OptionError, docstring_headline
|
||||
from pygments.lexers import get_all_lexers, get_lexer_by_name, get_lexer_for_filename, \
|
||||
find_lexer_class, guess_lexer, TextLexer
|
||||
from pygments.util import ClassNotFound, OptionError, docstring_headline, \
|
||||
guess_decode, guess_decode_from_terminal, terminal_encoding
|
||||
from pygments.lexers import get_all_lexers, get_lexer_by_name, guess_lexer, \
|
||||
get_lexer_for_filename, find_lexer_class, TextLexer
|
||||
from pygments.formatters.latex import LatexEmbeddedLexer, LatexFormatter
|
||||
from pygments.formatters import get_all_formatters, get_formatter_by_name, \
|
||||
get_formatter_for_filename, find_formatter_class, \
|
||||
TerminalFormatter # pylint:disable-msg=E0611
|
||||
get_formatter_for_filename, find_formatter_class, \
|
||||
TerminalFormatter # pylint:disable-msg=E0611
|
||||
from pygments.filters import get_all_filters, find_filter_class
|
||||
from pygments.styles import get_all_styles, get_style_by_name
|
||||
|
||||
|
||||
USAGE = """\
|
||||
Usage: %s [-l <lexer> | -g] [-F <filter>[:<options>]] [-f <formatter>]
|
||||
[-O <options>] [-P <option=value>] [-o <outfile>] [<infile>]
|
||||
[-O <options>] [-P <option=value>] [-s] [-o <outfile>] [<infile>]
|
||||
|
||||
%s -S <style> -f <formatter> [-a <arg>] [-O <options>] [-P <option=value>]
|
||||
%s -L [<which> ...]
|
||||
@ -37,6 +42,10 @@ Highlight the input file and write the result to <outfile>.
|
||||
|
||||
If no input file is given, use stdin, if -o is not given, use stdout.
|
||||
|
||||
If -s is passed, lexing will be done in "streaming" mode, reading and
|
||||
highlighting one line at a time. This will only work properly with
|
||||
lexers that have no constructs spanning multiple lines!
|
||||
|
||||
<lexer> is a lexer name (query all lexer names with -L). If -l is not
|
||||
given, the lexer is guessed from the extension of the input file name
|
||||
(this obviously doesn't work if the input is stdin). If -g is passed,
|
||||
@ -76,6 +85,11 @@ If no specific lexer can be determined "text" is returned.
|
||||
The -H option prints detailed help for the object <name> of type <type>,
|
||||
where <type> is one of "lexer", "formatter" or "filter".
|
||||
|
||||
The -s option processes lines one at a time until EOF, rather than
|
||||
waiting to process the entire file. This only works for stdin, and
|
||||
is intended for streaming input such as you get from 'tail -f'.
|
||||
Example usage: "tail -f sql.log | pygmentize -s -l sql"
|
||||
|
||||
The -h option prints this help.
|
||||
The -V option prints the package version.
|
||||
"""
|
||||
@ -92,7 +106,7 @@ def _parse_options(o_strs):
|
||||
for o_arg in o_args:
|
||||
o_arg = o_arg.strip()
|
||||
try:
|
||||
o_key, o_val = o_arg.split('=')
|
||||
o_key, o_val = o_arg.split('=', 1)
|
||||
o_key = o_key.strip()
|
||||
o_val = o_val.strip()
|
||||
except ValueError:
|
||||
@ -192,17 +206,9 @@ def main(args=sys.argv):
|
||||
|
||||
usage = USAGE % ((args[0],) * 6)
|
||||
|
||||
if sys.platform in ['win32', 'cygwin']:
|
||||
try:
|
||||
# Provide coloring under Windows, if possible
|
||||
import colorama
|
||||
colorama.init()
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
try:
|
||||
popts, args = getopt.getopt(args[1:], "l:f:F:o:O:P:LS:a:N:hVHg")
|
||||
except getopt.GetoptError as err:
|
||||
popts, args = getopt.getopt(args[1:], "l:f:F:o:O:P:LS:a:N:hVHgs")
|
||||
except getopt.GetoptError:
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
opts = {}
|
||||
@ -218,16 +224,12 @@ def main(args=sys.argv):
|
||||
F_opts.append(arg)
|
||||
opts[opt] = arg
|
||||
|
||||
if not opts and not args:
|
||||
print(usage)
|
||||
return 0
|
||||
|
||||
if opts.pop('-h', None) is not None:
|
||||
print(usage)
|
||||
return 0
|
||||
|
||||
if opts.pop('-V', None) is not None:
|
||||
print('Pygments version %s, (c) 2006-2013 by Georg Brandl.' % __version__)
|
||||
print('Pygments version %s, (c) 2006-2014 by Georg Brandl.' % __version__)
|
||||
return 0
|
||||
|
||||
# handle ``pygmentize -L``
|
||||
@ -274,6 +276,10 @@ def main(args=sys.argv):
|
||||
parsed_opts[name] = value
|
||||
opts.pop('-P', None)
|
||||
|
||||
# encodings
|
||||
inencoding = parsed_opts.get('inencoding', parsed_opts.get('encoding'))
|
||||
outencoding = parsed_opts.get('outencoding', parsed_opts.get('encoding'))
|
||||
|
||||
# handle ``pygmentize -N``
|
||||
infn = opts.pop('-N', None)
|
||||
if infn is not None:
|
||||
@ -324,6 +330,72 @@ def main(args=sys.argv):
|
||||
F_opts = _parse_filters(F_opts)
|
||||
opts.pop('-F', None)
|
||||
|
||||
# select lexer
|
||||
lexer = opts.pop('-l', None)
|
||||
if lexer:
|
||||
try:
|
||||
lexer = get_lexer_by_name(lexer, **parsed_opts)
|
||||
except (OptionError, ClassNotFound) as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
# read input code
|
||||
code = None
|
||||
|
||||
if args:
|
||||
if len(args) > 1:
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
|
||||
if '-s' in opts:
|
||||
print('Error: -s option not usable when input file specified',
|
||||
file=sys.stderr)
|
||||
return 1
|
||||
|
||||
infn = args[0]
|
||||
try:
|
||||
with open(infn, 'rb') as infp:
|
||||
code = infp.read()
|
||||
except Exception as err:
|
||||
print('Error: cannot read infile:', err, file=sys.stderr)
|
||||
return 1
|
||||
if not inencoding:
|
||||
code, inencoding = guess_decode(code)
|
||||
|
||||
# do we have to guess the lexer?
|
||||
if not lexer:
|
||||
try:
|
||||
lexer = get_lexer_for_filename(infn, code, **parsed_opts)
|
||||
except ClassNotFound as err:
|
||||
if '-g' in opts:
|
||||
try:
|
||||
lexer = guess_lexer(code, **parsed_opts)
|
||||
except ClassNotFound:
|
||||
lexer = TextLexer(**parsed_opts)
|
||||
else:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
except OptionError as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
elif '-s' not in opts: # treat stdin as full file (-s support is later)
|
||||
# read code from terminal, always in binary mode since we want to
|
||||
# decode ourselves and be tolerant with it
|
||||
if sys.version_info > (3,):
|
||||
# Python 3: we have to use .buffer to get a binary stream
|
||||
code = sys.stdin.buffer.read()
|
||||
else:
|
||||
code = sys.stdin.read()
|
||||
if not inencoding:
|
||||
code, inencoding = guess_decode_from_terminal(code, sys.stdin)
|
||||
# else the lexer will do the decoding
|
||||
if not lexer:
|
||||
try:
|
||||
lexer = guess_lexer(code, **parsed_opts)
|
||||
except ClassNotFound:
|
||||
lexer = TextLexer(**parsed_opts)
|
||||
|
||||
# select formatter
|
||||
outfn = opts.pop('-o', None)
|
||||
fmter = opts.pop('-f', None)
|
||||
@ -349,84 +421,80 @@ def main(args=sys.argv):
|
||||
else:
|
||||
if not fmter:
|
||||
fmter = TerminalFormatter(**parsed_opts)
|
||||
outfile = sys.stdout
|
||||
|
||||
# select lexer
|
||||
lexer = opts.pop('-l', None)
|
||||
if lexer:
|
||||
try:
|
||||
lexer = get_lexer_by_name(lexer, **parsed_opts)
|
||||
except (OptionError, ClassNotFound) as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
if args:
|
||||
if len(args) > 1:
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
|
||||
infn = args[0]
|
||||
try:
|
||||
code = open(infn, 'rb').read()
|
||||
except Exception as err:
|
||||
print('Error: cannot read infile:', err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
if not lexer:
|
||||
try:
|
||||
lexer = get_lexer_for_filename(infn, code, **parsed_opts)
|
||||
except ClassNotFound as err:
|
||||
if '-g' in opts:
|
||||
try:
|
||||
lexer = guess_lexer(code, **parsed_opts)
|
||||
except ClassNotFound:
|
||||
lexer = TextLexer(**parsed_opts)
|
||||
else:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
except OptionError as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
else:
|
||||
if '-g' in opts:
|
||||
code = sys.stdin.read()
|
||||
try:
|
||||
lexer = guess_lexer(code, **parsed_opts)
|
||||
except ClassNotFound:
|
||||
lexer = TextLexer(**parsed_opts)
|
||||
elif not lexer:
|
||||
print('Error: no lexer name given and reading ' + \
|
||||
'from stdin (try using -g or -l <lexer>)', file=sys.stderr)
|
||||
return 2
|
||||
if sys.version_info > (3,):
|
||||
# Python 3: we have to use .buffer to get a binary stream
|
||||
outfile = sys.stdout.buffer
|
||||
else:
|
||||
code = sys.stdin.read()
|
||||
outfile = sys.stdout
|
||||
|
||||
# No encoding given? Use latin1 if output file given,
|
||||
# stdin/stdout encoding otherwise.
|
||||
# (This is a compromise, I'm not too happy with it...)
|
||||
if 'encoding' not in parsed_opts and 'outencoding' not in parsed_opts:
|
||||
# determine output encoding if not explicitly selected
|
||||
if not outencoding:
|
||||
if outfn:
|
||||
# encoding pass-through
|
||||
fmter.encoding = 'latin1'
|
||||
# output file? use lexer encoding for now (can still be None)
|
||||
fmter.encoding = inencoding
|
||||
else:
|
||||
if sys.version_info < (3,):
|
||||
# use terminal encoding; Python 3's terminals already do that
|
||||
lexer.encoding = getattr(sys.stdin, 'encoding',
|
||||
None) or 'ascii'
|
||||
fmter.encoding = getattr(sys.stdout, 'encoding',
|
||||
None) or 'ascii'
|
||||
elif not outfn and sys.version_info > (3,):
|
||||
# output to terminal with encoding -> use .buffer
|
||||
outfile = sys.stdout.buffer
|
||||
# else use terminal encoding
|
||||
fmter.encoding = terminal_encoding(sys.stdout)
|
||||
|
||||
# provide coloring under Windows, if possible
|
||||
if not outfn and sys.platform in ('win32', 'cygwin') and \
|
||||
fmter.name in ('Terminal', 'Terminal256'):
|
||||
# unfortunately colorama doesn't support binary streams on Py3
|
||||
if sys.version_info > (3,):
|
||||
import io
|
||||
outfile = io.TextIOWrapper(outfile, encoding=fmter.encoding)
|
||||
fmter.encoding = None
|
||||
try:
|
||||
import colorama.initialise
|
||||
except ImportError:
|
||||
pass
|
||||
else:
|
||||
outfile = colorama.initialise.wrap_stream(
|
||||
outfile, convert=None, strip=None, autoreset=False, wrap=True)
|
||||
|
||||
# When using the LaTeX formatter and the option `escapeinside` is
|
||||
# specified, we need a special lexer which collects escaped text
|
||||
# before running the chosen language lexer.
|
||||
escapeinside = parsed_opts.get('escapeinside', '')
|
||||
if len(escapeinside) == 2 and isinstance(fmter, LatexFormatter):
|
||||
left = escapeinside[0]
|
||||
right = escapeinside[1]
|
||||
lexer = LatexEmbeddedLexer(left, right, lexer)
|
||||
|
||||
# ... and do it!
|
||||
try:
|
||||
# process filters
|
||||
for fname, fopts in F_opts:
|
||||
lexer.add_filter(fname, **fopts)
|
||||
highlight(code, lexer, fmter, outfile)
|
||||
except Exception as err:
|
||||
|
||||
if '-s' not in opts:
|
||||
# process whole input as per normal...
|
||||
highlight(code, lexer, fmter, outfile)
|
||||
else:
|
||||
if not lexer:
|
||||
print('Error: when using -s a lexer has to be selected with -l',
|
||||
file=sys.stderr)
|
||||
return 1
|
||||
# line by line processing of stdin (eg: for 'tail -f')...
|
||||
try:
|
||||
while 1:
|
||||
if sys.version_info > (3,):
|
||||
# Python 3: we have to use .buffer to get a binary stream
|
||||
line = sys.stdin.buffer.readline()
|
||||
else:
|
||||
line = sys.stdin.readline()
|
||||
if not line:
|
||||
break
|
||||
if not inencoding:
|
||||
line = guess_decode_from_terminal(line, sys.stdin)[0]
|
||||
highlight(line, lexer, fmter, outfile)
|
||||
if hasattr(outfile, 'flush'):
|
||||
outfile.flush()
|
||||
except KeyboardInterrupt:
|
||||
return 0
|
||||
|
||||
except Exception:
|
||||
raise
|
||||
import traceback
|
||||
info = traceback.format_exception(*sys.exc_info())
|
||||
msg = info[-1].strip()
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Format colored console output.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Module that implements the default filter.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -6,7 +6,7 @@
|
||||
Module containing filter lookup functions and default
|
||||
filters.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -16,14 +16,12 @@ from pygments.token import String, Comment, Keyword, Name, Error, Whitespace, \
|
||||
string_to_tokentype
|
||||
from pygments.filter import Filter
|
||||
from pygments.util import get_list_opt, get_int_opt, get_bool_opt, \
|
||||
get_choice_opt, ClassNotFound, OptionError
|
||||
get_choice_opt, ClassNotFound, OptionError, text_type, string_types
|
||||
from pygments.plugin import find_plugin_filters
|
||||
|
||||
|
||||
def find_filter_class(filtername):
|
||||
"""
|
||||
Lookup a filter by name. Return None if not found.
|
||||
"""
|
||||
"""Lookup a filter by name. Return None if not found."""
|
||||
if filtername in FILTERS:
|
||||
return FILTERS[filtername]
|
||||
for name, cls in find_plugin_filters():
|
||||
@ -33,9 +31,10 @@ def find_filter_class(filtername):
|
||||
|
||||
|
||||
def get_filter_by_name(filtername, **options):
|
||||
"""
|
||||
Return an instantiated filter. Options are passed to the filter
|
||||
initializer if wanted. Raise a ClassNotFound if not found.
|
||||
"""Return an instantiated filter.
|
||||
|
||||
Options are passed to the filter initializer if wanted.
|
||||
Raise a ClassNotFound if not found.
|
||||
"""
|
||||
cls = find_filter_class(filtername)
|
||||
if cls:
|
||||
@ -45,9 +44,7 @@ def get_filter_by_name(filtername, **options):
|
||||
|
||||
|
||||
def get_all_filters():
|
||||
"""
|
||||
Return a generator of all filter names.
|
||||
"""
|
||||
"""Return a generator of all filter names."""
|
||||
for name in FILTERS:
|
||||
yield name
|
||||
for name, _ in find_plugin_filters():
|
||||
@ -68,8 +65,7 @@ def _replace_special(ttype, value, regex, specialttype,
|
||||
|
||||
|
||||
class CodeTagFilter(Filter):
|
||||
"""
|
||||
Highlight special code tags in comments and docstrings.
|
||||
"""Highlight special code tags in comments and docstrings.
|
||||
|
||||
Options accepted:
|
||||
|
||||
@ -100,8 +96,7 @@ class CodeTagFilter(Filter):
|
||||
|
||||
|
||||
class KeywordCaseFilter(Filter):
|
||||
"""
|
||||
Convert keywords to lowercase or uppercase or capitalize them, which
|
||||
"""Convert keywords to lowercase or uppercase or capitalize them, which
|
||||
means first letter uppercase, rest lowercase.
|
||||
|
||||
This can be useful e.g. if you highlight Pascal code and want to adapt the
|
||||
@ -116,8 +111,9 @@ class KeywordCaseFilter(Filter):
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
case = get_choice_opt(options, 'case', ['lower', 'upper', 'capitalize'], 'lower')
|
||||
self.convert = getattr(str, case)
|
||||
case = get_choice_opt(options, 'case',
|
||||
['lower', 'upper', 'capitalize'], 'lower')
|
||||
self.convert = getattr(text_type, case)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
for ttype, value in stream:
|
||||
@ -128,8 +124,7 @@ class KeywordCaseFilter(Filter):
|
||||
|
||||
|
||||
class NameHighlightFilter(Filter):
|
||||
"""
|
||||
Highlight a normal Name (and Name.*) token with a different token type.
|
||||
"""Highlight a normal Name (and Name.*) token with a different token type.
|
||||
|
||||
Example::
|
||||
|
||||
@ -172,9 +167,9 @@ class NameHighlightFilter(Filter):
|
||||
class ErrorToken(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class RaiseOnErrorTokenFilter(Filter):
|
||||
"""
|
||||
Raise an exception when the lexer generates an error token.
|
||||
"""Raise an exception when the lexer generates an error token.
|
||||
|
||||
Options accepted:
|
||||
|
||||
@ -182,7 +177,7 @@ class RaiseOnErrorTokenFilter(Filter):
|
||||
The exception class to raise.
|
||||
The default is `pygments.filters.ErrorToken`.
|
||||
|
||||
*New in Pygments 0.8.*
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
@ -203,8 +198,7 @@ class RaiseOnErrorTokenFilter(Filter):
|
||||
|
||||
|
||||
class VisibleWhitespaceFilter(Filter):
|
||||
"""
|
||||
Convert tabs, newlines and/or spaces to visible characters.
|
||||
"""Convert tabs, newlines and/or spaces to visible characters.
|
||||
|
||||
Options accepted:
|
||||
|
||||
@ -230,29 +224,31 @@ class VisibleWhitespaceFilter(Filter):
|
||||
styling the visible whitespace differently (e.g. greyed out), but it can
|
||||
disrupt background colors. The default is ``True``.
|
||||
|
||||
*New in Pygments 0.8.*
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
for name, default in list({'spaces': '·', 'tabs': '»', 'newlines': '¶'}.items()):
|
||||
for name, default in [('spaces', u'·'),
|
||||
('tabs', u'»'),
|
||||
('newlines', u'¶')]:
|
||||
opt = options.get(name, False)
|
||||
if isinstance(opt, str) and len(opt) == 1:
|
||||
if isinstance(opt, string_types) and len(opt) == 1:
|
||||
setattr(self, name, opt)
|
||||
else:
|
||||
setattr(self, name, (opt and default or ''))
|
||||
tabsize = get_int_opt(options, 'tabsize', 8)
|
||||
if self.tabs:
|
||||
self.tabs += ' '*(tabsize-1)
|
||||
self.tabs += ' ' * (tabsize - 1)
|
||||
if self.newlines:
|
||||
self.newlines += '\n'
|
||||
self.wstt = get_bool_opt(options, 'wstokentype', True)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
if self.wstt:
|
||||
spaces = self.spaces or ' '
|
||||
tabs = self.tabs or '\t'
|
||||
newlines = self.newlines or '\n'
|
||||
spaces = self.spaces or u' '
|
||||
tabs = self.tabs or u'\t'
|
||||
newlines = self.newlines or u'\n'
|
||||
regex = re.compile(r'\s')
|
||||
def replacefunc(wschar):
|
||||
if wschar == ' ':
|
||||
@ -281,8 +277,7 @@ class VisibleWhitespaceFilter(Filter):
|
||||
|
||||
|
||||
class GobbleFilter(Filter):
|
||||
"""
|
||||
Gobbles source code lines (eats initial characters).
|
||||
"""Gobbles source code lines (eats initial characters).
|
||||
|
||||
This filter drops the first ``n`` characters off every line of code. This
|
||||
may be useful when the source code fed to the lexer is indented by a fixed
|
||||
@ -293,7 +288,7 @@ class GobbleFilter(Filter):
|
||||
`n` : int
|
||||
The number of characters to gobble.
|
||||
|
||||
*New in Pygments 1.2.*
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
@ -303,7 +298,7 @@ class GobbleFilter(Filter):
|
||||
if left < len(value):
|
||||
return value[left:], 0
|
||||
else:
|
||||
return '', left - len(value)
|
||||
return u'', left - len(value)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
n = self.n
|
||||
@ -314,18 +309,17 @@ class GobbleFilter(Filter):
|
||||
(parts[0], left) = self.gobble(parts[0], left)
|
||||
for i in range(1, len(parts)):
|
||||
(parts[i], left) = self.gobble(parts[i], n)
|
||||
value = '\n'.join(parts)
|
||||
value = u'\n'.join(parts)
|
||||
|
||||
if value != '':
|
||||
yield ttype, value
|
||||
|
||||
|
||||
class TokenMergeFilter(Filter):
|
||||
"""
|
||||
Merges consecutive tokens with the same token type in the output stream of a
|
||||
lexer.
|
||||
"""Merges consecutive tokens with the same token type in the output
|
||||
stream of a lexer.
|
||||
|
||||
*New in Pygments 1.2.*
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
def __init__(self, **options):
|
||||
Filter.__init__(self, **options)
|
||||
@ -5,20 +5,20 @@
|
||||
|
||||
Base formatter class.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import codecs
|
||||
|
||||
from pygments.util import get_bool_opt
|
||||
from pygments.util import get_bool_opt, string_types
|
||||
from pygments.styles import get_style_by_name
|
||||
|
||||
__all__ = ['Formatter']
|
||||
|
||||
|
||||
def _lookup_style(style):
|
||||
if isinstance(style, str):
|
||||
if isinstance(style, string_types):
|
||||
return get_style_by_name(style)
|
||||
return style
|
||||
|
||||
@ -68,10 +68,10 @@ class Formatter(object):
|
||||
self.full = get_bool_opt(options, 'full', False)
|
||||
self.title = options.get('title', '')
|
||||
self.encoding = options.get('encoding', None) or None
|
||||
if self.encoding == 'guess':
|
||||
# can happen for pygmentize -O encoding=guess
|
||||
if self.encoding in ('guess', 'chardet'):
|
||||
# can happen for e.g. pygmentize -O encoding=guess
|
||||
self.encoding = 'utf-8'
|
||||
self.encoding = options.get('outencoding', None) or self.encoding
|
||||
self.encoding = options.get('outencoding') or self.encoding
|
||||
self.options = options
|
||||
|
||||
def get_style_defs(self, arg=''):
|
||||
@ -0,0 +1,118 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Pygments formatters.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import sys
|
||||
import types
|
||||
import fnmatch
|
||||
from os.path import basename
|
||||
|
||||
from pygments.formatters._mapping import FORMATTERS
|
||||
from pygments.plugin import find_plugin_formatters
|
||||
from pygments.util import ClassNotFound, itervalues
|
||||
|
||||
__all__ = ['get_formatter_by_name', 'get_formatter_for_filename',
|
||||
'get_all_formatters'] + list(FORMATTERS)
|
||||
|
||||
_formatter_cache = {} # classes by name
|
||||
_pattern_cache = {}
|
||||
|
||||
|
||||
def _fn_matches(fn, glob):
|
||||
"""Return whether the supplied file name fn matches pattern filename."""
|
||||
if glob not in _pattern_cache:
|
||||
pattern = _pattern_cache[glob] = re.compile(fnmatch.translate(glob))
|
||||
return pattern.match(fn)
|
||||
return _pattern_cache[glob].match(fn)
|
||||
|
||||
|
||||
def _load_formatters(module_name):
|
||||
"""Load a formatter (and all others in the module too)."""
|
||||
mod = __import__(module_name, None, None, ['__all__'])
|
||||
for formatter_name in mod.__all__:
|
||||
cls = getattr(mod, formatter_name)
|
||||
_formatter_cache[cls.name] = cls
|
||||
|
||||
|
||||
def get_all_formatters():
|
||||
"""Return a generator for all formatter classes."""
|
||||
# NB: this returns formatter classes, not info like get_all_lexers().
|
||||
for info in itervalues(FORMATTERS):
|
||||
if info[1] not in _formatter_cache:
|
||||
_load_formatters(info[0])
|
||||
yield _formatter_cache[info[1]]
|
||||
for _, formatter in find_plugin_formatters():
|
||||
yield formatter
|
||||
|
||||
|
||||
def find_formatter_class(alias):
|
||||
"""Lookup a formatter by alias.
|
||||
|
||||
Returns None if not found.
|
||||
"""
|
||||
for module_name, name, aliases, _, _ in itervalues(FORMATTERS):
|
||||
if alias in aliases:
|
||||
if name not in _formatter_cache:
|
||||
_load_formatters(module_name)
|
||||
return _formatter_cache[name]
|
||||
for _, cls in find_plugin_formatters():
|
||||
if alias in cls.aliases:
|
||||
return cls
|
||||
|
||||
|
||||
def get_formatter_by_name(_alias, **options):
|
||||
"""Lookup and instantiate a formatter by alias.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
cls = find_formatter_class(_alias)
|
||||
if cls is None:
|
||||
raise ClassNotFound("No formatter found for name %r" % _alias)
|
||||
return cls(**options)
|
||||
|
||||
|
||||
def get_formatter_for_filename(fn, **options):
|
||||
"""Lookup and instantiate a formatter by filename pattern.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
fn = basename(fn)
|
||||
for modname, name, _, filenames, _ in itervalues(FORMATTERS):
|
||||
for filename in filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
if name not in _formatter_cache:
|
||||
_load_formatters(modname)
|
||||
return _formatter_cache[name](**options)
|
||||
for cls in find_plugin_formatters():
|
||||
for filename in cls.filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
return cls(**options)
|
||||
raise ClassNotFound("No formatter found for file name %r" % fn)
|
||||
|
||||
|
||||
class _automodule(types.ModuleType):
|
||||
"""Automatically import formatters."""
|
||||
|
||||
def __getattr__(self, name):
|
||||
info = FORMATTERS.get(name)
|
||||
if info:
|
||||
_load_formatters(info[0])
|
||||
cls = _formatter_cache[info[1]]
|
||||
setattr(self, name, cls)
|
||||
return cls
|
||||
raise AttributeError(name)
|
||||
|
||||
|
||||
oldmod = sys.modules[__name__]
|
||||
newmod = _automodule(__name__)
|
||||
newmod.__dict__.update(oldmod.__dict__)
|
||||
sys.modules[__name__] = newmod
|
||||
del newmod.newmod, newmod.oldmod, newmod.sys, newmod.types
|
||||
@ -0,0 +1,76 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter mapping definitions. This file is generated by itself. Everytime
|
||||
you change something on a builtin formatter definition, run this script from
|
||||
the formatters folder to update it.
|
||||
|
||||
Do not alter the FORMATTERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
FORMATTERS = {
|
||||
'BBCodeFormatter': ('pygments.formatters.bbcode', 'BBCode', ('bbcode', 'bb'), (), 'Format tokens with BBcodes. These formatting codes are used by many bulletin boards, so you can highlight your sourcecode with pygments before posting it there.'),
|
||||
'BmpImageFormatter': ('pygments.formatters.img', 'img_bmp', ('bmp', 'bitmap'), ('*.bmp',), 'Create a bitmap image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'GifImageFormatter': ('pygments.formatters.img', 'img_gif', ('gif',), ('*.gif',), 'Create a GIF image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'HtmlFormatter': ('pygments.formatters.html', 'HTML', ('html',), ('*.html', '*.htm'), "Format tokens as HTML 4 ``<span>`` tags within a ``<pre>`` tag, wrapped in a ``<div>`` tag. The ``<div>``'s CSS class can be set by the `cssclass` option."),
|
||||
'ImageFormatter': ('pygments.formatters.img', 'img', ('img', 'IMG', 'png'), ('*.png',), 'Create a PNG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'JpgImageFormatter': ('pygments.formatters.img', 'img_jpg', ('jpg', 'jpeg'), ('*.jpg',), 'Create a JPEG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'LatexFormatter': ('pygments.formatters.latex', 'LaTeX', ('latex', 'tex'), ('*.tex',), 'Format tokens as LaTeX code. This needs the `fancyvrb` and `color` standard packages.'),
|
||||
'NullFormatter': ('pygments.formatters.other', 'Text only', ('text', 'null'), ('*.txt',), 'Output the text unchanged without any formatting.'),
|
||||
'RawTokenFormatter': ('pygments.formatters.other', 'Raw tokens', ('raw', 'tokens'), ('*.raw',), 'Format tokens as a raw representation for storing token streams.'),
|
||||
'RtfFormatter': ('pygments.formatters.rtf', 'RTF', ('rtf',), ('*.rtf',), 'Format tokens as RTF markup. This formatter automatically outputs full RTF documents with color information and other useful stuff. Perfect for Copy and Paste into Microsoft(R) Word(R) documents.'),
|
||||
'SvgFormatter': ('pygments.formatters.svg', 'SVG', ('svg',), ('*.svg',), 'Format tokens as an SVG graphics file. This formatter is still experimental. Each line of code is a ``<text>`` element with explicit ``x`` and ``y`` coordinates containing ``<tspan>`` elements with the individual token styles.'),
|
||||
'Terminal256Formatter': ('pygments.formatters.terminal256', 'Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TerminalFormatter': ('pygments.formatters.terminal', 'Terminal', ('terminal', 'console'), (), 'Format tokens with ANSI color sequences, for output in a text console. Color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TestcaseFormatter': ('pygments.formatters.other', 'Testcase', ('testcase',), (), 'Format tokens as appropriate for a new testcase.')
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup formatters
|
||||
found_formatters = []
|
||||
imports = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
from pygments.util import docstring_headline
|
||||
|
||||
for root, dirs, files in os.walk('.'):
|
||||
for filename in files:
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.formatters%s.%s' % (
|
||||
root[1:].replace('/', '.'), filename[:-3])
|
||||
print(module_name)
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for formatter_name in module.__all__:
|
||||
formatter = getattr(module, formatter_name)
|
||||
found_formatters.append(
|
||||
'%r: %r' % (formatter_name,
|
||||
(module_name,
|
||||
formatter.name,
|
||||
tuple(formatter.aliases),
|
||||
tuple(formatter.filenames),
|
||||
docstring_headline(formatter))))
|
||||
# sort them to make the diff minimal
|
||||
found_formatters.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
with open(__file__) as fp:
|
||||
content = fp.read()
|
||||
header = content[:content.find('FORMATTERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
with open(__file__, 'w') as fp:
|
||||
fp.write(header)
|
||||
fp.write('FORMATTERS = {\n %s\n}\n\n' % ',\n '.join(found_formatters))
|
||||
fp.write(footer)
|
||||
|
||||
print ('=== %d formatters processed.' % len(found_formatters))
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
BBcode formatter.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,18 +5,20 @@
|
||||
|
||||
Formatter for HTML output.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import sys
|
||||
import os.path
|
||||
import StringIO
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.token import Token, Text, STANDARD_TYPES
|
||||
from pygments.util import get_bool_opt, get_int_opt, get_list_opt, bytes
|
||||
from pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
|
||||
StringIO, string_types, iteritems
|
||||
|
||||
try:
|
||||
import ctags
|
||||
@ -218,29 +220,34 @@ class HtmlFormatter(Formatter):
|
||||
If you set this option, the default selector for `get_style_defs()`
|
||||
will be this class.
|
||||
|
||||
*New in Pygments 0.9:* If you select the ``'table'`` line numbers, the
|
||||
wrapping table will have a CSS class of this string plus ``'table'``,
|
||||
the default is accordingly ``'highlighttable'``.
|
||||
.. versionadded:: 0.9
|
||||
If you select the ``'table'`` line numbers, the wrapping table will
|
||||
have a CSS class of this string plus ``'table'``, the default is
|
||||
accordingly ``'highlighttable'``.
|
||||
|
||||
`cssstyles`
|
||||
Inline CSS styles for the wrapping ``<div>`` tag (default: ``''``).
|
||||
|
||||
`prestyles`
|
||||
Inline CSS styles for the ``<pre>`` tag (default: ``''``). *New in
|
||||
Pygments 0.11.*
|
||||
Inline CSS styles for the ``<pre>`` tag (default: ``''``).
|
||||
|
||||
.. versionadded:: 0.11
|
||||
|
||||
`cssfile`
|
||||
If the `full` option is true and this option is given, it must be the
|
||||
name of an external file. If the filename does not include an absolute
|
||||
path, the file's path will be assumed to be relative to the main output
|
||||
file's path, if the latter can be found. The stylesheet is then written
|
||||
to this file instead of the HTML file. *New in Pygments 0.6.*
|
||||
to this file instead of the HTML file.
|
||||
|
||||
.. versionadded:: 0.6
|
||||
|
||||
`noclobber_cssfile`
|
||||
If `cssfile` is given and the specified file exists, the css file will
|
||||
not be overwritten. This allows the use of the `full` option in
|
||||
combination with a user specified css file. Default is ``False``.
|
||||
*New in Pygments 1.1.*
|
||||
|
||||
.. versionadded:: 1.1
|
||||
|
||||
`linenos`
|
||||
If set to ``'table'``, output line numbers as a table with two cells,
|
||||
@ -263,7 +270,9 @@ class HtmlFormatter(Formatter):
|
||||
125%``).
|
||||
|
||||
`hl_lines`
|
||||
Specify a list of lines to be highlighted. *New in Pygments 0.11.*
|
||||
Specify a list of lines to be highlighted.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
|
||||
`linenostart`
|
||||
The line number for the first line (default: ``1``).
|
||||
@ -279,24 +288,30 @@ class HtmlFormatter(Formatter):
|
||||
If set to ``True``, the formatter won't output the background color
|
||||
for the wrapping element (this automatically defaults to ``False``
|
||||
when there is no wrapping element [eg: no argument for the
|
||||
`get_syntax_defs` method given]) (default: ``False``). *New in
|
||||
Pygments 0.6.*
|
||||
`get_syntax_defs` method given]) (default: ``False``).
|
||||
|
||||
.. versionadded:: 0.6
|
||||
|
||||
`lineseparator`
|
||||
This string is output between lines of code. It defaults to ``"\n"``,
|
||||
which is enough to break a line inside ``<pre>`` tags, but you can
|
||||
e.g. set it to ``"<br>"`` to get HTML line breaks. *New in Pygments
|
||||
0.7.*
|
||||
e.g. set it to ``"<br>"`` to get HTML line breaks.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
|
||||
`lineanchors`
|
||||
If set to a nonempty string, e.g. ``foo``, the formatter will wrap each
|
||||
output line in an anchor tag with a ``name`` of ``foo-linenumber``.
|
||||
This allows easy linking to certain lines. *New in Pygments 0.9.*
|
||||
This allows easy linking to certain lines.
|
||||
|
||||
.. versionadded:: 0.9
|
||||
|
||||
`linespans`
|
||||
If set to a nonempty string, e.g. ``foo``, the formatter will wrap each
|
||||
output line in a span tag with an ``id`` of ``foo-linenumber``.
|
||||
This allows easy access to lines via javascript. *New in Pygments 1.6.*
|
||||
This allows easy access to lines via javascript.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
|
||||
`anchorlinenos`
|
||||
If set to `True`, will wrap line numbers in <a> tags. Used in
|
||||
@ -306,18 +321,20 @@ class HtmlFormatter(Formatter):
|
||||
If set to the path of a ctags file, wrap names in anchor tags that
|
||||
link to their definitions. `lineanchors` should be used, and the
|
||||
tags file should specify line numbers (see the `-n` option to ctags).
|
||||
*New in Pygments 1.6.*
|
||||
|
||||
.. versionadded:: 1.6
|
||||
|
||||
`tagurlformat`
|
||||
A string formatting pattern used to generate links to ctags definitions.
|
||||
Available variables are `%(path)s`, `%(fname)s` and `%(fext)s`.
|
||||
Defaults to an empty string, resulting in just `#prefix-number` links.
|
||||
*New in Pygments 1.6.*
|
||||
|
||||
.. versionadded:: 1.6
|
||||
|
||||
|
||||
**Subclassing the HTML formatter**
|
||||
|
||||
*New in Pygments 0.7.*
|
||||
.. versionadded:: 0.7
|
||||
|
||||
The HTML formatter is now built in a way that allows easy subclassing, thus
|
||||
customizing the output HTML code. The `format()` method calls
|
||||
@ -453,7 +470,7 @@ class HtmlFormatter(Formatter):
|
||||
"""
|
||||
if arg is None:
|
||||
arg = ('cssclass' in self.options and '.'+self.cssclass or '')
|
||||
if isinstance(arg, basestring):
|
||||
if isinstance(arg, string_types):
|
||||
args = [arg]
|
||||
else:
|
||||
args = list(arg)
|
||||
@ -467,7 +484,7 @@ class HtmlFormatter(Formatter):
|
||||
return ', '.join(tmp)
|
||||
|
||||
styles = [(level, ttype, cls, style)
|
||||
for cls, (style, ttype, level) in self.class2style.iteritems()
|
||||
for cls, (style, ttype, level) in iteritems(self.class2style)
|
||||
if cls and style]
|
||||
styles.sort()
|
||||
lines = ['%s { %s } /* %s */' % (prefix(cls), style, repr(ttype)[6:])
|
||||
@ -505,8 +522,9 @@ class HtmlFormatter(Formatter):
|
||||
cssfilename = os.path.join(os.path.dirname(filename),
|
||||
self.cssfile)
|
||||
except AttributeError:
|
||||
print >>sys.stderr, 'Note: Cannot determine output file name, ' \
|
||||
'using current directory as base for the CSS file name'
|
||||
print('Note: Cannot determine output file name, ' \
|
||||
'using current directory as base for the CSS file name',
|
||||
file=sys.stderr)
|
||||
cssfilename = self.cssfile
|
||||
# write CSS file only if noclobber_cssfile isn't given as an option.
|
||||
try:
|
||||
@ -515,7 +533,7 @@ class HtmlFormatter(Formatter):
|
||||
cf.write(CSSFILE_TEMPLATE %
|
||||
{'styledefs': self.get_style_defs('body')})
|
||||
cf.close()
|
||||
except IOError, err:
|
||||
except IOError as err:
|
||||
err.strerror = 'Error writing CSS file: ' + err.strerror
|
||||
raise
|
||||
|
||||
@ -534,7 +552,7 @@ class HtmlFormatter(Formatter):
|
||||
yield 0, DOC_FOOTER
|
||||
|
||||
def _wrap_tablelinenos(self, inner):
|
||||
dummyoutfile = StringIO.StringIO()
|
||||
dummyoutfile = StringIO()
|
||||
lncount = 0
|
||||
for t, line in inner:
|
||||
if t:
|
||||
@ -610,24 +628,24 @@ class HtmlFormatter(Formatter):
|
||||
style = 'background-color: #ffffc0; padding: 0 5px 0 5px'
|
||||
else:
|
||||
style = 'background-color: #f0f0f0; padding: 0 5px 0 5px'
|
||||
yield 1, '<span style="%s">%*s</span> ' % (
|
||||
yield 1, '<span style="%s">%*s </span>' % (
|
||||
style, mw, (num%st and ' ' or num)) + line
|
||||
num += 1
|
||||
else:
|
||||
for t, line in lines:
|
||||
yield 1, ('<span style="background-color: #f0f0f0; '
|
||||
'padding: 0 5px 0 5px">%*s</span> ' % (
|
||||
'padding: 0 5px 0 5px">%*s </span>' % (
|
||||
mw, (num%st and ' ' or num)) + line)
|
||||
num += 1
|
||||
elif sp:
|
||||
for t, line in lines:
|
||||
yield 1, '<span class="lineno%s">%*s</span> ' % (
|
||||
yield 1, '<span class="lineno%s">%*s </span>' % (
|
||||
num%sp == 0 and ' special' or '', mw,
|
||||
(num%st and ' ' or num)) + line
|
||||
num += 1
|
||||
else:
|
||||
for t, line in lines:
|
||||
yield 1, '<span class="lineno">%*s</span> ' % (
|
||||
yield 1, '<span class="lineno">%*s </span>' % (
|
||||
mw, (num%st and ' ' or num)) + line
|
||||
num += 1
|
||||
|
||||
@ -5,15 +5,15 @@
|
||||
|
||||
Formatter for Pixmap output.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import sys
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.util import get_bool_opt, get_int_opt, \
|
||||
get_list_opt, get_choice_opt
|
||||
from pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
|
||||
get_choice_opt, xrange
|
||||
|
||||
# Import this carefully
|
||||
try:
|
||||
@ -25,7 +25,10 @@ except ImportError:
|
||||
try:
|
||||
import _winreg
|
||||
except ImportError:
|
||||
_winreg = None
|
||||
try:
|
||||
import winreg as _winreg
|
||||
except ImportError:
|
||||
_winreg = None
|
||||
|
||||
__all__ = ['ImageFormatter', 'GifImageFormatter', 'JpgImageFormatter',
|
||||
'BmpImageFormatter']
|
||||
@ -72,7 +75,10 @@ class FontManager(object):
|
||||
self._create_nix()
|
||||
|
||||
def _get_nix_font_path(self, name, style):
|
||||
from commands import getstatusoutput
|
||||
try:
|
||||
from commands import getstatusoutput
|
||||
except ImportError:
|
||||
from subprocess import getstatusoutput
|
||||
exit, out = getstatusoutput('fc-list "%s:style=%s" file' %
|
||||
(name, style))
|
||||
if not exit:
|
||||
@ -169,7 +175,7 @@ class ImageFormatter(Formatter):
|
||||
Create a PNG image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
*New in Pygments 0.10.*
|
||||
.. versionadded:: 0.10
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
@ -258,12 +264,16 @@ class ImageFormatter(Formatter):
|
||||
Default: 6
|
||||
|
||||
`hl_lines`
|
||||
Specify a list of lines to be highlighted. *New in Pygments 1.2.*
|
||||
Specify a list of lines to be highlighted.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
|
||||
Default: empty list
|
||||
|
||||
`hl_color`
|
||||
Specify the color for highlighting lines. *New in Pygments 1.2.*
|
||||
Specify the color for highlighting lines.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
|
||||
Default: highlight color of the selected style
|
||||
"""
|
||||
@ -285,6 +295,7 @@ class ImageFormatter(Formatter):
|
||||
raise PilNotAvailable(
|
||||
'Python Imaging Library is required for this formatter')
|
||||
Formatter.__init__(self, **options)
|
||||
self.encoding = 'latin1' # let pygments.format() do the right thing
|
||||
# Read the style
|
||||
self.styles = dict(self.style)
|
||||
if self.style.background_color is None:
|
||||
@ -305,20 +316,20 @@ class ImageFormatter(Formatter):
|
||||
self.line_number_fg = options.get('line_number_fg', '#886')
|
||||
self.line_number_bg = options.get('line_number_bg', '#eed')
|
||||
self.line_number_chars = get_int_opt(options,
|
||||
'line_number_chars', 2)
|
||||
'line_number_chars', 2)
|
||||
self.line_number_bold = get_bool_opt(options,
|
||||
'line_number_bold', False)
|
||||
'line_number_bold', False)
|
||||
self.line_number_italic = get_bool_opt(options,
|
||||
'line_number_italic', False)
|
||||
'line_number_italic', False)
|
||||
self.line_number_pad = get_int_opt(options, 'line_number_pad', 6)
|
||||
self.line_numbers = get_bool_opt(options, 'line_numbers', True)
|
||||
self.line_number_separator = get_bool_opt(options,
|
||||
'line_number_separator', True)
|
||||
'line_number_separator', True)
|
||||
self.line_number_step = get_int_opt(options, 'line_number_step', 1)
|
||||
self.line_number_start = get_int_opt(options, 'line_number_start', 1)
|
||||
if self.line_numbers:
|
||||
self.line_number_width = (self.fontw * self.line_number_chars +
|
||||
self.line_number_pad * 2)
|
||||
self.line_number_pad * 2)
|
||||
else:
|
||||
self.line_number_width = 0
|
||||
self.hl_lines = []
|
||||
@ -427,7 +438,7 @@ class ImageFormatter(Formatter):
|
||||
# quite complex.
|
||||
value = value.expandtabs(4)
|
||||
lines = value.splitlines(True)
|
||||
#print lines
|
||||
# print lines
|
||||
for i, line in enumerate(lines):
|
||||
temp = line.rstrip('\n')
|
||||
if temp:
|
||||
@ -468,9 +479,8 @@ class ImageFormatter(Formatter):
|
||||
draw = ImageDraw.Draw(im)
|
||||
recth = im.size[-1]
|
||||
rectw = self.image_pad + self.line_number_width - self.line_number_pad
|
||||
draw.rectangle([(0, 0),
|
||||
(rectw, recth)],
|
||||
fill=self.line_number_bg)
|
||||
draw.rectangle([(0, 0), (rectw, recth)],
|
||||
fill=self.line_number_bg)
|
||||
draw.line([(rectw, 0), (rectw, recth)], fill=self.line_number_fg)
|
||||
del draw
|
||||
|
||||
@ -513,8 +523,7 @@ class GifImageFormatter(ImageFormatter):
|
||||
Create a GIF image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
*New in Pygments 1.0.* (You could create GIF images before by passing a
|
||||
suitable `image_format` option to the `ImageFormatter`.)
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'img_gif'
|
||||
@ -528,8 +537,7 @@ class JpgImageFormatter(ImageFormatter):
|
||||
Create a JPEG image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
*New in Pygments 1.0.* (You could create JPEG images before by passing a
|
||||
suitable `image_format` option to the `ImageFormatter`.)
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'img_jpg'
|
||||
@ -543,8 +551,7 @@ class BmpImageFormatter(ImageFormatter):
|
||||
Create a bitmap image from source code. This uses the Python Imaging Library to
|
||||
generate a pixmap from the source code.
|
||||
|
||||
*New in Pygments 1.0.* (You could create bitmap images before by passing a
|
||||
suitable `image_format` option to the `ImageFormatter`.)
|
||||
.. versionadded:: 1.0
|
||||
"""
|
||||
|
||||
name = 'img_bmp'
|
||||
@ -5,13 +5,17 @@
|
||||
|
||||
Formatter for LaTeX fancyvrb output.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import division
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.lexer import Lexer
|
||||
from pygments.token import Token, STANDARD_TYPES
|
||||
from pygments.util import get_bool_opt, get_int_opt, StringIO
|
||||
from pygments.util import get_bool_opt, get_int_opt, StringIO, xrange, \
|
||||
iteritems
|
||||
|
||||
|
||||
__all__ = ['LatexFormatter']
|
||||
@ -152,7 +156,7 @@ class LatexFormatter(Formatter):
|
||||
|
||||
.. sourcecode:: latex
|
||||
|
||||
\begin{Verbatim}[commandchars=\\{\}]
|
||||
\begin{Verbatim}[commandchars=\\\{\}]
|
||||
\PY{k}{def }\PY{n+nf}{foo}(\PY{n}{bar}):
|
||||
\PY{k}{pass}
|
||||
\end{Verbatim}
|
||||
@ -205,19 +209,40 @@ class LatexFormatter(Formatter):
|
||||
`commandprefix`
|
||||
The LaTeX commands used to produce colored output are constructed
|
||||
using this prefix and some letters (default: ``'PY'``).
|
||||
*New in Pygments 0.7.*
|
||||
|
||||
*New in Pygments 0.10:* the default is now ``'PY'`` instead of ``'C'``.
|
||||
.. versionadded:: 0.7
|
||||
.. versionchanged:: 0.10
|
||||
The default is now ``'PY'`` instead of ``'C'``.
|
||||
|
||||
`texcomments`
|
||||
If set to ``True``, enables LaTeX comment lines. That is, LaTex markup
|
||||
in comment tokens is not escaped so that LaTeX can render it (default:
|
||||
``False``). *New in Pygments 1.2.*
|
||||
``False``).
|
||||
|
||||
.. versionadded:: 1.2
|
||||
|
||||
`mathescape`
|
||||
If set to ``True``, enables LaTeX math mode escape in comments. That
|
||||
is, ``'$...$'`` inside a comment will trigger math mode (default:
|
||||
``False``). *New in Pygments 1.2.*
|
||||
``False``).
|
||||
|
||||
.. versionadded:: 1.2
|
||||
|
||||
`escapeinside`
|
||||
If set to a string of length 2, enables escaping to LaTeX. Text
|
||||
delimited by these 2 characters is read as LaTeX code and
|
||||
typeset accordingly. It has no effect in string literals. It has
|
||||
no effect in comments if `texcomments` or `mathescape` is
|
||||
set. (default: ``''``).
|
||||
|
||||
.. versionadded:: 2.0
|
||||
|
||||
`envname`
|
||||
Allows you to pick an alternative environment name replacing Verbatim.
|
||||
The alternate environment still has to support Verbatim's option syntax.
|
||||
(default: ``'Verbatim'``).
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'LaTeX'
|
||||
aliases = ['latex', 'tex']
|
||||
@ -235,10 +260,16 @@ class LatexFormatter(Formatter):
|
||||
self.commandprefix = options.get('commandprefix', 'PY')
|
||||
self.texcomments = get_bool_opt(options, 'texcomments', False)
|
||||
self.mathescape = get_bool_opt(options, 'mathescape', False)
|
||||
self.escapeinside = options.get('escapeinside', '')
|
||||
if len(self.escapeinside) == 2:
|
||||
self.left = self.escapeinside[0]
|
||||
self.right = self.escapeinside[1]
|
||||
else:
|
||||
self.escapeinside = ''
|
||||
self.envname = options.get('envname', u'Verbatim')
|
||||
|
||||
self._create_stylesheet()
|
||||
|
||||
|
||||
def _create_stylesheet(self):
|
||||
t2n = self.ttype2name = {Token: ''}
|
||||
c2d = self.cmd2def = {}
|
||||
@ -246,7 +277,7 @@ class LatexFormatter(Formatter):
|
||||
|
||||
def rgbcolor(col):
|
||||
if col:
|
||||
return ','.join(['%.2f' %(int(col[i] + col[i + 1], 16) / 255.0)
|
||||
return ','.join(['%.2f' % (int(col[i] + col[i + 1], 16) / 255.0)
|
||||
for i in (0, 2, 4)])
|
||||
else:
|
||||
return '1,1,1'
|
||||
@ -291,7 +322,7 @@ class LatexFormatter(Formatter):
|
||||
"""
|
||||
cp = self.commandprefix
|
||||
styles = []
|
||||
for name, definition in self.cmd2def.iteritems():
|
||||
for name, definition in iteritems(self.cmd2def):
|
||||
styles.append(r'\expandafter\def\csname %s@tok@%s\endcsname{%s}' %
|
||||
(cp, name, definition))
|
||||
return STYLE_TEMPLATE % {'cp': self.commandprefix,
|
||||
@ -306,14 +337,14 @@ class LatexFormatter(Formatter):
|
||||
realoutfile = outfile
|
||||
outfile = StringIO()
|
||||
|
||||
outfile.write(ur'\begin{Verbatim}[commandchars=\\\{\}')
|
||||
outfile.write(u'\\begin{' + self.envname + u'}[commandchars=\\\\\\{\\}')
|
||||
if self.linenos:
|
||||
start, step = self.linenostart, self.linenostep
|
||||
outfile.write(u',numbers=left' +
|
||||
(start and u',firstnumber=%d' % start or u'') +
|
||||
(step and u',stepnumber=%d' % step or u''))
|
||||
if self.mathescape or self.texcomments:
|
||||
outfile.write(ur',codes={\catcode`\$=3\catcode`\^=7\catcode`\_=8}')
|
||||
if self.mathescape or self.texcomments or self.escapeinside:
|
||||
outfile.write(u',codes={\\catcode`\\$=3\\catcode`\\^=7\\catcode`\\_=8}')
|
||||
if self.verboptions:
|
||||
outfile.write(u',' + self.verboptions)
|
||||
outfile.write(u']\n')
|
||||
@ -342,9 +373,22 @@ class LatexFormatter(Formatter):
|
||||
parts[i] = escape_tex(part, self.commandprefix)
|
||||
in_math = not in_math
|
||||
value = '$'.join(parts)
|
||||
elif self.escapeinside:
|
||||
text = value
|
||||
value = ''
|
||||
while len(text) > 0:
|
||||
a, sep1, text = text.partition(self.left)
|
||||
if len(sep1) > 0:
|
||||
b, sep2, text = text.partition(self.right)
|
||||
if len(sep2) > 0:
|
||||
value += escape_tex(a, self.commandprefix) + b
|
||||
else:
|
||||
value += escape_tex(a + sep1 + b, self.commandprefix)
|
||||
else:
|
||||
value = value + escape_tex(a, self.commandprefix)
|
||||
else:
|
||||
value = escape_tex(value, self.commandprefix)
|
||||
else:
|
||||
elif ttype not in Token.Escape:
|
||||
value = escape_tex(value, self.commandprefix)
|
||||
styles = []
|
||||
while ttype is not Token:
|
||||
@ -366,13 +410,67 @@ class LatexFormatter(Formatter):
|
||||
else:
|
||||
outfile.write(value)
|
||||
|
||||
outfile.write(u'\\end{Verbatim}\n')
|
||||
outfile.write(u'\\end{' + self.envname + u'}\n')
|
||||
|
||||
if self.full:
|
||||
realoutfile.write(DOC_TEMPLATE %
|
||||
dict(docclass = self.docclass,
|
||||
preamble = self.preamble,
|
||||
title = self.title,
|
||||
encoding = self.encoding or 'latin1',
|
||||
encoding = self.encoding or 'utf8',
|
||||
styledefs = self.get_style_defs(),
|
||||
code = outfile.getvalue()))
|
||||
|
||||
|
||||
class LatexEmbeddedLexer(Lexer):
|
||||
r"""
|
||||
|
||||
This lexer takes one lexer as argument, the lexer for the language
|
||||
being formatted, and the left and right delimiters for escaped text.
|
||||
|
||||
First everything is scanned using the language lexer to obtain
|
||||
strings and comments. All other consecutive tokens are merged and
|
||||
the resulting text is scanned for escaped segments, which are given
|
||||
the Token.Escape type. Finally text that is not escaped is scanned
|
||||
again with the language lexer.
|
||||
"""
|
||||
def __init__(self, left, right, lang, **options):
|
||||
self.left = left
|
||||
self.right = right
|
||||
self.lang = lang
|
||||
Lexer.__init__(self, **options)
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
buf = ''
|
||||
idx = 0
|
||||
for i, t, v in self.lang.get_tokens_unprocessed(text):
|
||||
if t in Token.Comment or t in Token.String:
|
||||
if buf:
|
||||
for x in self.get_tokens_aux(idx, buf):
|
||||
yield x
|
||||
buf = ''
|
||||
yield i, t, v
|
||||
else:
|
||||
if not buf:
|
||||
idx = i
|
||||
buf += v
|
||||
if buf:
|
||||
for x in self.get_tokens_aux(idx, buf):
|
||||
yield x
|
||||
|
||||
def get_tokens_aux(self, index, text):
|
||||
while text:
|
||||
a, sep1, text = text.partition(self.left)
|
||||
if a:
|
||||
for i, t, v in self.lang.get_tokens_unprocessed(a):
|
||||
yield index + i, t, v
|
||||
index += len(a)
|
||||
if sep1:
|
||||
b, sep2, text = text.partition(self.right)
|
||||
if sep2:
|
||||
yield index + len(sep1), Token.Escape, b
|
||||
index += len(sep1) + len(b) + len(sep2)
|
||||
else:
|
||||
yield index, Token.Error, sep1
|
||||
index += len(sep1)
|
||||
text = b
|
||||
@ -5,16 +5,16 @@
|
||||
|
||||
Other formatters: NullFormatter, RawTokenFormatter.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.util import OptionError, get_choice_opt, b
|
||||
from pygments.util import OptionError, get_choice_opt
|
||||
from pygments.token import Token
|
||||
from pygments.console import colorize
|
||||
|
||||
__all__ = ['NullFormatter', 'RawTokenFormatter']
|
||||
__all__ = ['NullFormatter', 'RawTokenFormatter', 'TestcaseFormatter']
|
||||
|
||||
|
||||
class NullFormatter(Formatter):
|
||||
@ -40,7 +40,7 @@ class RawTokenFormatter(Formatter):
|
||||
|
||||
The format is ``tokentype<TAB>repr(tokenstring)\n``. The output can later
|
||||
be converted to a token stream with the `RawTokenLexer`, described in the
|
||||
`lexer list <lexers.txt>`_.
|
||||
:doc:`lexer list <lexers>`.
|
||||
|
||||
Only two options are accepted:
|
||||
|
||||
@ -50,7 +50,8 @@ class RawTokenFormatter(Formatter):
|
||||
`error_color`
|
||||
If set to a color name, highlight error tokens using that color. If
|
||||
set but with no value, defaults to ``'red'``.
|
||||
*New in Pygments 0.11.*
|
||||
|
||||
.. versionadded:: 0.11
|
||||
|
||||
"""
|
||||
name = 'Raw tokens'
|
||||
@ -61,9 +62,9 @@ class RawTokenFormatter(Formatter):
|
||||
|
||||
def __init__(self, **options):
|
||||
Formatter.__init__(self, **options)
|
||||
if self.encoding:
|
||||
raise OptionError('the raw formatter does not support the '
|
||||
'encoding option')
|
||||
# We ignore self.encoding if it is set, since it gets set for lexer
|
||||
# and formatter if given with -Oencoding on the command line.
|
||||
# The RawTokenFormatter outputs only ASCII. Override here.
|
||||
self.encoding = 'ascii' # let pygments.format() do the right thing
|
||||
self.compress = get_choice_opt(options, 'compress',
|
||||
['', 'none', 'gz', 'bz2'], '')
|
||||
@ -79,7 +80,7 @@ class RawTokenFormatter(Formatter):
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
try:
|
||||
outfile.write(b(''))
|
||||
outfile.write(b'')
|
||||
except TypeError:
|
||||
raise TypeError('The raw tokens formatter needs a binary '
|
||||
'output file')
|
||||
@ -113,3 +114,47 @@ class RawTokenFormatter(Formatter):
|
||||
for ttype, value in tokensource:
|
||||
write("%s\t%r\n" % (ttype, value))
|
||||
flush()
|
||||
|
||||
TESTCASE_BEFORE = u'''\
|
||||
def testNeedsName(self):
|
||||
fragment = %r
|
||||
tokens = [
|
||||
'''
|
||||
TESTCASE_AFTER = u'''\
|
||||
]
|
||||
self.assertEqual(tokens, list(self.lexer.get_tokens(fragment)))
|
||||
'''
|
||||
|
||||
|
||||
class TestcaseFormatter(Formatter):
|
||||
"""
|
||||
Format tokens as appropriate for a new testcase.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Testcase'
|
||||
aliases = ['testcase']
|
||||
|
||||
def __init__(self, **options):
|
||||
Formatter.__init__(self, **options)
|
||||
if self.encoding is not None and self.encoding != 'utf-8':
|
||||
raise ValueError("Only None and utf-8 are allowed encodings.")
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
indentation = ' ' * 12
|
||||
rawbuf = []
|
||||
outbuf = []
|
||||
for ttype, value in tokensource:
|
||||
rawbuf.append(value)
|
||||
outbuf.append('%s(%s, %r),\n' % (indentation, ttype, value))
|
||||
|
||||
before = TESTCASE_BEFORE % (u''.join(rawbuf),)
|
||||
during = u''.join(outbuf)
|
||||
after = TESTCASE_AFTER
|
||||
if self.encoding is None:
|
||||
outfile.write(before + during + after)
|
||||
else:
|
||||
outfile.write(before.encode('utf-8'))
|
||||
outfile.write(during.encode('utf-8'))
|
||||
outfile.write(after.encode('utf-8'))
|
||||
outfile.flush()
|
||||
@ -5,11 +5,12 @@
|
||||
|
||||
A formatter that generates RTF files.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.util import get_int_opt, _surrogatepair
|
||||
|
||||
|
||||
__all__ = ['RtfFormatter']
|
||||
@ -19,9 +20,13 @@ class RtfFormatter(Formatter):
|
||||
"""
|
||||
Format tokens as RTF markup. This formatter automatically outputs full RTF
|
||||
documents with color information and other useful stuff. Perfect for Copy and
|
||||
Paste into Microsoft® Word® documents.
|
||||
Paste into Microsoft(R) Word(R) documents.
|
||||
|
||||
*New in Pygments 0.6.*
|
||||
Please note that ``encoding`` and ``outencoding`` options are ignored.
|
||||
The RTF format is ASCII natively, but handles unicode characters correctly
|
||||
thanks to escape sequences.
|
||||
|
||||
.. versionadded:: 0.6
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
@ -32,15 +37,19 @@ class RtfFormatter(Formatter):
|
||||
`fontface`
|
||||
The used font famliy, for example ``Bitstream Vera Sans``. Defaults to
|
||||
some generic font which is supposed to have fixed width.
|
||||
|
||||
`fontsize`
|
||||
Size of the font used. Size is specified in half points. The
|
||||
default is 24 half-points, giving a size 12 font.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'RTF'
|
||||
aliases = ['rtf']
|
||||
filenames = ['*.rtf']
|
||||
|
||||
unicodeoutput = False
|
||||
|
||||
def __init__(self, **options):
|
||||
"""
|
||||
r"""
|
||||
Additional options accepted:
|
||||
|
||||
``fontface``
|
||||
@ -49,48 +58,48 @@ class RtfFormatter(Formatter):
|
||||
specification claims that ``\fmodern`` are "Fixed-pitch serif
|
||||
and sans serif fonts". Hope every RTF implementation thinks
|
||||
the same about modern...
|
||||
|
||||
"""
|
||||
Formatter.__init__(self, **options)
|
||||
self.fontface = options.get('fontface') or ''
|
||||
self.fontsize = get_int_opt(options, 'fontsize', 0)
|
||||
|
||||
def _escape(self, text):
|
||||
return text.replace('\\', '\\\\') \
|
||||
.replace('{', '\\{') \
|
||||
.replace('}', '\\}')
|
||||
return text.replace(u'\\', u'\\\\') \
|
||||
.replace(u'{', u'\\{') \
|
||||
.replace(u'}', u'\\}')
|
||||
|
||||
def _escape_text(self, text):
|
||||
# empty strings, should give a small performance improvment
|
||||
if not text:
|
||||
return ''
|
||||
return u''
|
||||
|
||||
# escape text
|
||||
text = self._escape(text)
|
||||
if self.encoding in ('utf-8', 'utf-16', 'utf-32'):
|
||||
encoding = 'iso-8859-15'
|
||||
else:
|
||||
encoding = self.encoding or 'iso-8859-15'
|
||||
|
||||
buf = []
|
||||
for c in text:
|
||||
if ord(c) > 128:
|
||||
ansic = c.encode(encoding, 'ignore') or '?'
|
||||
if ord(ansic) > 128:
|
||||
ansic = '\\\'%x' % ord(ansic)
|
||||
else:
|
||||
ansic = c
|
||||
buf.append(r'\ud{\u%d%s}' % (ord(c), ansic))
|
||||
else:
|
||||
cn = ord(c)
|
||||
if cn < (2**7):
|
||||
# ASCII character
|
||||
buf.append(str(c))
|
||||
elif (2**7) <= cn < (2**16):
|
||||
# single unicode escape sequence
|
||||
buf.append(u'{\\u%d}' % cn)
|
||||
elif (2**16) <= cn:
|
||||
# RTF limits unicode to 16 bits.
|
||||
# Force surrogate pairs
|
||||
buf.append(u'{\\u%d}{\\u%d}' % _surrogatepair(cn))
|
||||
|
||||
return ''.join(buf).replace('\n', '\\par\n')
|
||||
return u''.join(buf).replace(u'\n', u'\\par\n')
|
||||
|
||||
def format_unencoded(self, tokensource, outfile):
|
||||
# rtf 1.8 header
|
||||
outfile.write(r'{\rtf1\ansi\deff0'
|
||||
r'{\fonttbl{\f0\fmodern\fprq1\fcharset0%s;}}'
|
||||
r'{\colortbl;' % (self.fontface and
|
||||
' ' + self._escape(self.fontface) or
|
||||
''))
|
||||
outfile.write(u'{\\rtf1\\ansi\\uc0\\deff0'
|
||||
u'{\\fonttbl{\\f0\\fmodern\\fprq1\\fcharset0%s;}}'
|
||||
u'{\\colortbl;' % (self.fontface and
|
||||
u' ' + self._escape(self.fontface) or
|
||||
u''))
|
||||
|
||||
# convert colors and save them in a mapping to access them later.
|
||||
color_mapping = {}
|
||||
@ -99,13 +108,15 @@ class RtfFormatter(Formatter):
|
||||
for color in style['color'], style['bgcolor'], style['border']:
|
||||
if color and color not in color_mapping:
|
||||
color_mapping[color] = offset
|
||||
outfile.write(r'\red%d\green%d\blue%d;' % (
|
||||
outfile.write(u'\\red%d\\green%d\\blue%d;' % (
|
||||
int(color[0:2], 16),
|
||||
int(color[2:4], 16),
|
||||
int(color[4:6], 16)
|
||||
))
|
||||
offset += 1
|
||||
outfile.write(r'}\f0')
|
||||
outfile.write(u'}\\f0 ')
|
||||
if self.fontsize:
|
||||
outfile.write(u'\\fs%d' % (self.fontsize))
|
||||
|
||||
# highlight stream
|
||||
for ttype, value in tokensource:
|
||||
@ -114,23 +125,23 @@ class RtfFormatter(Formatter):
|
||||
style = self.style.style_for_token(ttype)
|
||||
buf = []
|
||||
if style['bgcolor']:
|
||||
buf.append(r'\cb%d' % color_mapping[style['bgcolor']])
|
||||
buf.append(u'\\cb%d' % color_mapping[style['bgcolor']])
|
||||
if style['color']:
|
||||
buf.append(r'\cf%d' % color_mapping[style['color']])
|
||||
buf.append(u'\\cf%d' % color_mapping[style['color']])
|
||||
if style['bold']:
|
||||
buf.append(r'\b')
|
||||
buf.append(u'\\b')
|
||||
if style['italic']:
|
||||
buf.append(r'\i')
|
||||
buf.append(u'\\i')
|
||||
if style['underline']:
|
||||
buf.append(r'\ul')
|
||||
buf.append(u'\\ul')
|
||||
if style['border']:
|
||||
buf.append(r'\chbrdr\chcfpat%d' %
|
||||
buf.append(u'\\chbrdr\\chcfpat%d' %
|
||||
color_mapping[style['border']])
|
||||
start = ''.join(buf)
|
||||
start = u''.join(buf)
|
||||
if start:
|
||||
outfile.write('{%s ' % start)
|
||||
outfile.write(u'{%s ' % start)
|
||||
outfile.write(self._escape_text(value))
|
||||
if start:
|
||||
outfile.write('}')
|
||||
outfile.write(u'}')
|
||||
|
||||
outfile.write('}')
|
||||
outfile.write(u'}')
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for SVG output.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -35,7 +35,7 @@ class SvgFormatter(Formatter):
|
||||
By default, this formatter outputs a full SVG document including doctype
|
||||
declaration and the ``<svg>`` root element.
|
||||
|
||||
*New in Pygments 0.9.*
|
||||
.. versionadded:: 0.9
|
||||
|
||||
Additional options accepted:
|
||||
|
||||
@ -78,7 +78,6 @@ class SvgFormatter(Formatter):
|
||||
filenames = ['*.svg']
|
||||
|
||||
def __init__(self, **options):
|
||||
# XXX outencoding
|
||||
Formatter.__init__(self, **options)
|
||||
self.nowrap = get_bool_opt(options, 'nowrap', False)
|
||||
self.fontfamily = options.get('fontfamily', 'monospace')
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for terminal output with ANSI sequences.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -13,7 +13,7 @@ import sys
|
||||
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Token, Whitespace
|
||||
Number, Operator, Generic, Token, Whitespace
|
||||
from pygments.console import ansiformat
|
||||
from pygments.util import get_choice_opt
|
||||
|
||||
@ -73,6 +73,10 @@ class TerminalFormatter(Formatter):
|
||||
`colorscheme`
|
||||
A dictionary mapping token types to (lightbg, darkbg) color names or
|
||||
``None`` (default: ``None`` = use builtin colorscheme).
|
||||
|
||||
`linenos`
|
||||
Set to ``True`` to have line numbers on the terminal output as well
|
||||
(default: ``False`` = no line numbers).
|
||||
"""
|
||||
name = 'Terminal'
|
||||
aliases = ['terminal', 'console']
|
||||
@ -83,6 +87,8 @@ class TerminalFormatter(Formatter):
|
||||
self.darkbg = get_choice_opt(options, 'bg',
|
||||
['light', 'dark'], 'light') == 'dark'
|
||||
self.colorscheme = options.get('colorscheme', None) or TERMINAL_COLORS
|
||||
self.linenos = options.get('linenos', False)
|
||||
self._lineno = 0
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
# hack: if the output is a terminal and has an encoding set,
|
||||
@ -93,7 +99,40 @@ class TerminalFormatter(Formatter):
|
||||
self.encoding = outfile.encoding
|
||||
return Formatter.format(self, tokensource, outfile)
|
||||
|
||||
def _write_lineno(self, outfile):
|
||||
self._lineno += 1
|
||||
outfile.write("\n%04d: " % self._lineno)
|
||||
|
||||
def _format_unencoded_with_lineno(self, tokensource, outfile):
|
||||
self._write_lineno(outfile)
|
||||
|
||||
for ttype, value in tokensource:
|
||||
if value.endswith("\n"):
|
||||
self._write_lineno(outfile)
|
||||
value = value[:-1]
|
||||
color = self.colorscheme.get(ttype)
|
||||
while color is None:
|
||||
ttype = ttype[:-1]
|
||||
color = self.colorscheme.get(ttype)
|
||||
if color:
|
||||
color = color[self.darkbg]
|
||||
spl = value.split('\n')
|
||||
for line in spl[:-1]:
|
||||
self._write_lineno(outfile)
|
||||
if line:
|
||||
outfile.write(ansiformat(color, line[:-1]))
|
||||
if spl[-1]:
|
||||
outfile.write(ansiformat(color, spl[-1]))
|
||||
else:
|
||||
outfile.write(value)
|
||||
|
||||
outfile.write("\n")
|
||||
|
||||
def format_unencoded(self, tokensource, outfile):
|
||||
if self.linenos:
|
||||
self._format_unencoded_with_lineno(tokensource, outfile)
|
||||
return
|
||||
|
||||
for ttype, value in tokensource:
|
||||
color = self.colorscheme.get(ttype)
|
||||
while color is None:
|
||||
@ -11,7 +11,7 @@
|
||||
|
||||
Formatter version 1.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -66,6 +66,7 @@ class EscapeSequence:
|
||||
attrs.append("00")
|
||||
return self.escape(attrs)
|
||||
|
||||
|
||||
class Terminal256Formatter(Formatter):
|
||||
r"""
|
||||
Format tokens with ANSI color sequences, for output in a 256-color
|
||||
@ -76,7 +77,7 @@ class Terminal256Formatter(Formatter):
|
||||
and converts them to nearest ANSI 256-color escape sequences. Bold and
|
||||
underline attributes from the style are preserved (and displayed).
|
||||
|
||||
*New in Pygments 0.9.*
|
||||
.. versionadded:: 0.9
|
||||
|
||||
Options accepted:
|
||||
|
||||
@ -98,28 +99,28 @@ class Terminal256Formatter(Formatter):
|
||||
self.usebold = 'nobold' not in options
|
||||
self.useunderline = 'nounderline' not in options
|
||||
|
||||
self._build_color_table() # build an RGB-to-256 color conversion table
|
||||
self._setup_styles() # convert selected style's colors to term. colors
|
||||
self._build_color_table() # build an RGB-to-256 color conversion table
|
||||
self._setup_styles() # convert selected style's colors to term. colors
|
||||
|
||||
def _build_color_table(self):
|
||||
# colors 0..15: 16 basic colors
|
||||
|
||||
self.xterm_colors.append((0x00, 0x00, 0x00)) # 0
|
||||
self.xterm_colors.append((0xcd, 0x00, 0x00)) # 1
|
||||
self.xterm_colors.append((0x00, 0xcd, 0x00)) # 2
|
||||
self.xterm_colors.append((0xcd, 0xcd, 0x00)) # 3
|
||||
self.xterm_colors.append((0x00, 0x00, 0xee)) # 4
|
||||
self.xterm_colors.append((0xcd, 0x00, 0xcd)) # 5
|
||||
self.xterm_colors.append((0x00, 0xcd, 0xcd)) # 6
|
||||
self.xterm_colors.append((0xe5, 0xe5, 0xe5)) # 7
|
||||
self.xterm_colors.append((0x7f, 0x7f, 0x7f)) # 8
|
||||
self.xterm_colors.append((0xff, 0x00, 0x00)) # 9
|
||||
self.xterm_colors.append((0x00, 0xff, 0x00)) # 10
|
||||
self.xterm_colors.append((0xff, 0xff, 0x00)) # 11
|
||||
self.xterm_colors.append((0x5c, 0x5c, 0xff)) # 12
|
||||
self.xterm_colors.append((0xff, 0x00, 0xff)) # 13
|
||||
self.xterm_colors.append((0x00, 0xff, 0xff)) # 14
|
||||
self.xterm_colors.append((0xff, 0xff, 0xff)) # 15
|
||||
self.xterm_colors.append((0x00, 0x00, 0x00)) # 0
|
||||
self.xterm_colors.append((0xcd, 0x00, 0x00)) # 1
|
||||
self.xterm_colors.append((0x00, 0xcd, 0x00)) # 2
|
||||
self.xterm_colors.append((0xcd, 0xcd, 0x00)) # 3
|
||||
self.xterm_colors.append((0x00, 0x00, 0xee)) # 4
|
||||
self.xterm_colors.append((0xcd, 0x00, 0xcd)) # 5
|
||||
self.xterm_colors.append((0x00, 0xcd, 0xcd)) # 6
|
||||
self.xterm_colors.append((0xe5, 0xe5, 0xe5)) # 7
|
||||
self.xterm_colors.append((0x7f, 0x7f, 0x7f)) # 8
|
||||
self.xterm_colors.append((0xff, 0x00, 0x00)) # 9
|
||||
self.xterm_colors.append((0x00, 0xff, 0x00)) # 10
|
||||
self.xterm_colors.append((0xff, 0xff, 0x00)) # 11
|
||||
self.xterm_colors.append((0x5c, 0x5c, 0xff)) # 12
|
||||
self.xterm_colors.append((0xff, 0x00, 0xff)) # 13
|
||||
self.xterm_colors.append((0x00, 0xff, 0xff)) # 14
|
||||
self.xterm_colors.append((0xff, 0xff, 0xff)) # 15
|
||||
|
||||
# colors 16..232: the 6x6x6 color cube
|
||||
|
||||
@ -138,7 +139,7 @@ class Terminal256Formatter(Formatter):
|
||||
self.xterm_colors.append((v, v, v))
|
||||
|
||||
def _closest_color(self, r, g, b):
|
||||
distance = 257*257*3 # "infinity" (>distance from #000000 to #ffffff)
|
||||
distance = 257*257*3 # "infinity" (>distance from #000000 to #ffffff)
|
||||
match = 0
|
||||
|
||||
for i in range(0, 254):
|
||||
@ -197,7 +198,7 @@ class Terminal256Formatter(Formatter):
|
||||
not_found = True
|
||||
while ttype and not_found:
|
||||
try:
|
||||
#outfile.write( "<" + str(ttype) + ">" )
|
||||
# outfile.write( "<" + str(ttype) + ">" )
|
||||
on, off = self.style_string[str(ttype)]
|
||||
|
||||
# Like TerminalFormatter, add "reset colors" escape sequence
|
||||
@ -211,12 +212,12 @@ class Terminal256Formatter(Formatter):
|
||||
outfile.write(on + spl[-1] + off)
|
||||
|
||||
not_found = False
|
||||
#outfile.write( '#' + str(ttype) + '#' )
|
||||
# outfile.write( '#' + str(ttype) + '#' )
|
||||
|
||||
except KeyError:
|
||||
#ottype = ttype
|
||||
# ottype = ttype
|
||||
ttype = ttype[:-1]
|
||||
#outfile.write( '!' + str(ottype) + '->' + str(ttype) + '!' )
|
||||
# outfile.write( '!' + str(ottype) + '->' + str(ttype) + '!' )
|
||||
|
||||
if not_found:
|
||||
outfile.write(value)
|
||||
@ -5,27 +5,34 @@
|
||||
|
||||
Base lexer classes.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
import re, itertools
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import itertools
|
||||
|
||||
from pygments.filter import apply_filters, Filter
|
||||
from pygments.filters import get_filter_by_name
|
||||
from pygments.token import Error, Text, Other, _TokenType
|
||||
from pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
|
||||
make_analysator
|
||||
|
||||
make_analysator, text_type, add_metaclass, iteritems, Future, guess_decode
|
||||
from pygments.regexopt import regex_opt
|
||||
|
||||
__all__ = ['Lexer', 'RegexLexer', 'ExtendedRegexLexer', 'DelegatingLexer',
|
||||
'LexerContext', 'include', 'inherit', 'bygroups', 'using', 'this']
|
||||
'LexerContext', 'include', 'inherit', 'bygroups', 'using', 'this',
|
||||
'default', 'words']
|
||||
|
||||
|
||||
_encoding_map = [('\xef\xbb\xbf', 'utf-8'),
|
||||
('\xff\xfe\0\0', 'utf-32'),
|
||||
('\0\0\xfe\xff', 'utf-32be'),
|
||||
('\xff\xfe', 'utf-16'),
|
||||
('\xfe\xff', 'utf-16be')]
|
||||
_encoding_map = [(b'\xef\xbb\xbf', 'utf-8'),
|
||||
(b'\xff\xfe\0\0', 'utf-32'),
|
||||
(b'\0\0\xfe\xff', 'utf-32be'),
|
||||
(b'\xff\xfe', 'utf-16'),
|
||||
(b'\xfe\xff', 'utf-16be')]
|
||||
|
||||
_default_analyse = staticmethod(lambda x: 0.0)
|
||||
|
||||
@ -42,6 +49,7 @@ class LexerMeta(type):
|
||||
return type.__new__(cls, name, bases, d)
|
||||
|
||||
|
||||
@add_metaclass(LexerMeta)
|
||||
class Lexer(object):
|
||||
"""
|
||||
Lexer for a specific language.
|
||||
@ -55,15 +63,19 @@ class Lexer(object):
|
||||
``ensurenl``
|
||||
Make sure that the input ends with a newline (default: True). This
|
||||
is required for some lexers that consume input linewise.
|
||||
*New in Pygments 1.3.*
|
||||
|
||||
.. versionadded:: 1.3
|
||||
|
||||
``tabsize``
|
||||
If given and greater than 0, expand tabs in the input (default: 0).
|
||||
``encoding``
|
||||
If given, must be an encoding name. This encoding will be used to
|
||||
convert the input string to Unicode, if it is not already a Unicode
|
||||
string (default: ``'latin1'``).
|
||||
Can also be ``'guess'`` to use a simple UTF-8 / Latin1 detection, or
|
||||
``'chardet'`` to use the chardet library, if it is installed.
|
||||
string (default: ``'guess'``, which uses a simple UTF-8 / Locale /
|
||||
Latin1 detection. Can also be ``'chardet'`` to use the chardet
|
||||
library, if it is installed.
|
||||
``inencoding``
|
||||
Overrides the ``encoding`` if given.
|
||||
"""
|
||||
|
||||
#: Name of the lexer
|
||||
@ -84,16 +96,14 @@ class Lexer(object):
|
||||
#: Priority, should multiple lexers match and no content is provided
|
||||
priority = 0
|
||||
|
||||
__metaclass__ = LexerMeta
|
||||
|
||||
def __init__(self, **options):
|
||||
self.options = options
|
||||
self.stripnl = get_bool_opt(options, 'stripnl', True)
|
||||
self.stripall = get_bool_opt(options, 'stripall', False)
|
||||
self.ensurenl = get_bool_opt(options, 'ensurenl', True)
|
||||
self.tabsize = get_int_opt(options, 'tabsize', 0)
|
||||
self.encoding = options.get('encoding', 'latin1')
|
||||
# self.encoding = options.get('inencoding', None) or self.encoding
|
||||
self.encoding = options.get('encoding', 'guess')
|
||||
self.encoding = options.get('inencoding') or self.encoding
|
||||
self.filters = []
|
||||
for filter_ in get_list_opt(options, 'filters', ()):
|
||||
self.add_filter(filter_)
|
||||
@ -136,14 +146,9 @@ class Lexer(object):
|
||||
Also preprocess the text, i.e. expand tabs and strip it if
|
||||
wanted and applies registered filters.
|
||||
"""
|
||||
if not isinstance(text, unicode):
|
||||
if not isinstance(text, text_type):
|
||||
if self.encoding == 'guess':
|
||||
try:
|
||||
text = text.decode('utf-8')
|
||||
if text.startswith(u'\ufeff'):
|
||||
text = text[len(u'\ufeff'):]
|
||||
except UnicodeDecodeError:
|
||||
text = text.decode('latin1')
|
||||
text, _ = guess_decode(text)
|
||||
elif self.encoding == 'chardet':
|
||||
try:
|
||||
import chardet
|
||||
@ -155,17 +160,18 @@ class Lexer(object):
|
||||
decoded = None
|
||||
for bom, encoding in _encoding_map:
|
||||
if text.startswith(bom):
|
||||
decoded = unicode(text[len(bom):], encoding,
|
||||
errors='replace')
|
||||
decoded = text[len(bom):].decode(encoding, 'replace')
|
||||
break
|
||||
# no BOM found, so use chardet
|
||||
if decoded is None:
|
||||
enc = chardet.detect(text[:1024]) # Guess using first 1KB
|
||||
decoded = unicode(text, enc.get('encoding') or 'utf-8',
|
||||
errors='replace')
|
||||
enc = chardet.detect(text[:1024]) # Guess using first 1KB
|
||||
decoded = text.decode(enc.get('encoding') or 'utf-8',
|
||||
'replace')
|
||||
text = decoded
|
||||
else:
|
||||
text = text.decode(self.encoding)
|
||||
if text.startswith(u'\ufeff'):
|
||||
text = text[len(u'\ufeff'):]
|
||||
else:
|
||||
if text.startswith(u'\ufeff'):
|
||||
text = text[len(u'\ufeff'):]
|
||||
@ -192,7 +198,9 @@ class Lexer(object):
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
"""
|
||||
Return an iterable of (tokentype, value) pairs.
|
||||
Return an iterable of (index, tokentype, value) pairs where "index"
|
||||
is the starting position of the token within the input text.
|
||||
|
||||
In subclasses, implement this method as a generator to
|
||||
maximize effectiveness.
|
||||
"""
|
||||
@ -233,7 +241,7 @@ class DelegatingLexer(Lexer):
|
||||
self.root_lexer.get_tokens_unprocessed(buffered))
|
||||
|
||||
|
||||
#-------------------------------------------------------------------------------
|
||||
# ------------------------------------------------------------------------------
|
||||
# RegexLexer and ExtendedRegexLexer
|
||||
#
|
||||
|
||||
@ -379,20 +387,50 @@ def using(_other, **kwargs):
|
||||
return callback
|
||||
|
||||
|
||||
class default:
|
||||
"""
|
||||
Indicates a state or state action (e.g. #pop) to apply.
|
||||
For example default('#pop') is equivalent to ('', Token, '#pop')
|
||||
Note that state tuples may be used as well.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
def __init__(self, state):
|
||||
self.state = state
|
||||
|
||||
|
||||
class words(Future):
|
||||
"""
|
||||
Indicates a list of literal words that is transformed into an optimized
|
||||
regex that matches any of the words.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
def __init__(self, words, prefix='', suffix=''):
|
||||
self.words = words
|
||||
self.prefix = prefix
|
||||
self.suffix = suffix
|
||||
|
||||
def get(self):
|
||||
return regex_opt(self.words, prefix=self.prefix, suffix=self.suffix)
|
||||
|
||||
|
||||
class RegexLexerMeta(LexerMeta):
|
||||
"""
|
||||
Metaclass for RegexLexer, creates the self._tokens attribute from
|
||||
self.tokens on the first instantiation.
|
||||
"""
|
||||
|
||||
def _process_regex(cls, regex, rflags):
|
||||
def _process_regex(cls, regex, rflags, state):
|
||||
"""Preprocess the regular expression component of a token definition."""
|
||||
if isinstance(regex, Future):
|
||||
regex = regex.get()
|
||||
return re.compile(regex, rflags).match
|
||||
|
||||
def _process_token(cls, token):
|
||||
"""Preprocess the token component of a token definition."""
|
||||
assert type(token) is _TokenType or callable(token), \
|
||||
'token type must be simple type or callable, not %r' % (token,)
|
||||
'token type must be simple type or callable, not %r' % (token,)
|
||||
return token
|
||||
|
||||
def _process_new_state(cls, new_state, unprocessed, processed):
|
||||
@ -425,7 +463,7 @@ class RegexLexerMeta(LexerMeta):
|
||||
for istate in new_state:
|
||||
assert (istate in unprocessed or
|
||||
istate in ('#pop', '#push')), \
|
||||
'unknown new state ' + istate
|
||||
'unknown new state ' + istate
|
||||
return new_state
|
||||
else:
|
||||
assert False, 'unknown new state def %r' % new_state
|
||||
@ -446,14 +484,20 @@ class RegexLexerMeta(LexerMeta):
|
||||
str(tdef)))
|
||||
continue
|
||||
if isinstance(tdef, _inherit):
|
||||
# processed already
|
||||
# should be processed already, but may not in the case of:
|
||||
# 1. the state has no counterpart in any parent
|
||||
# 2. the state includes more than one 'inherit'
|
||||
continue
|
||||
if isinstance(tdef, default):
|
||||
new_state = cls._process_new_state(tdef.state, unprocessed, processed)
|
||||
tokens.append((re.compile('').match, None, new_state))
|
||||
continue
|
||||
|
||||
assert type(tdef) is tuple, "wrong rule def %r" % tdef
|
||||
|
||||
try:
|
||||
rex = cls._process_regex(tdef[0], rflags)
|
||||
except Exception, err:
|
||||
rex = cls._process_regex(tdef[0], rflags, state)
|
||||
except Exception as err:
|
||||
raise ValueError("uncompilable regex %r in state %r of %r: %s" %
|
||||
(tdef[0], state, cls, err))
|
||||
|
||||
@ -472,7 +516,7 @@ class RegexLexerMeta(LexerMeta):
|
||||
"""Preprocess a dictionary of token definitions."""
|
||||
processed = cls._all_tokens[name] = {}
|
||||
tokendefs = tokendefs or cls.tokens[name]
|
||||
for state in tokendefs.keys():
|
||||
for state in list(tokendefs):
|
||||
cls._process_state(tokendefs, processed, state)
|
||||
return processed
|
||||
|
||||
@ -490,12 +534,16 @@ class RegexLexerMeta(LexerMeta):
|
||||
"""
|
||||
tokens = {}
|
||||
inheritable = {}
|
||||
for c in itertools.chain((cls,), cls.__mro__):
|
||||
for c in cls.__mro__:
|
||||
toks = c.__dict__.get('tokens', {})
|
||||
|
||||
for state, items in toks.iteritems():
|
||||
for state, items in iteritems(toks):
|
||||
curitems = tokens.get(state)
|
||||
if curitems is None:
|
||||
# N.b. because this is assigned by reference, sufficiently
|
||||
# deep hierarchies are processed incrementally (e.g. for
|
||||
# A(B), B(C), C(RegexLexer), B will be premodified so X(B)
|
||||
# will not see any inherits in B).
|
||||
tokens[state] = items
|
||||
try:
|
||||
inherit_ndx = items.index(inherit)
|
||||
@ -511,6 +559,8 @@ class RegexLexerMeta(LexerMeta):
|
||||
# Replace the "inherit" value with the items
|
||||
curitems[inherit_ndx:inherit_ndx+1] = items
|
||||
try:
|
||||
# N.b. this is the index in items (that is, the superclass
|
||||
# copy), so offset required when storing below.
|
||||
new_inh_ndx = items.index(inherit)
|
||||
except ValueError:
|
||||
pass
|
||||
@ -533,13 +583,13 @@ class RegexLexerMeta(LexerMeta):
|
||||
return type.__call__(cls, *args, **kwds)
|
||||
|
||||
|
||||
@add_metaclass(RegexLexerMeta)
|
||||
class RegexLexer(Lexer):
|
||||
"""
|
||||
Base for simple stateful regular expression-based lexers.
|
||||
Simplifies the lexing process so that you need only
|
||||
provide a list of states and regular expressions.
|
||||
"""
|
||||
__metaclass__ = RegexLexerMeta
|
||||
|
||||
#: Flags for compiling the regular expressions.
|
||||
#: Defaults to MULTILINE.
|
||||
@ -578,11 +628,12 @@ class RegexLexer(Lexer):
|
||||
for rexmatch, action, new_state in statetokens:
|
||||
m = rexmatch(text, pos)
|
||||
if m:
|
||||
if type(action) is _TokenType:
|
||||
yield pos, action, m.group()
|
||||
else:
|
||||
for item in action(self, m):
|
||||
yield item
|
||||
if action is not None:
|
||||
if type(action) is _TokenType:
|
||||
yield pos, action, m.group()
|
||||
else:
|
||||
for item in action(self, m):
|
||||
yield item
|
||||
pos = m.end()
|
||||
if new_state is not None:
|
||||
# state transition
|
||||
@ -626,7 +677,7 @@ class LexerContext(object):
|
||||
def __init__(self, text, pos, stack=None, end=None):
|
||||
self.text = text
|
||||
self.pos = pos
|
||||
self.end = end or len(text) # end=0 not supported ;-)
|
||||
self.end = end or len(text) # end=0 not supported ;-)
|
||||
self.stack = stack or ['root']
|
||||
|
||||
def __repr__(self):
|
||||
@ -656,15 +707,16 @@ class ExtendedRegexLexer(RegexLexer):
|
||||
for rexmatch, action, new_state in statetokens:
|
||||
m = rexmatch(text, ctx.pos, ctx.end)
|
||||
if m:
|
||||
if type(action) is _TokenType:
|
||||
yield ctx.pos, action, m.group()
|
||||
ctx.pos = m.end()
|
||||
else:
|
||||
for item in action(self, m, ctx):
|
||||
yield item
|
||||
if not new_state:
|
||||
# altered the state stack?
|
||||
statetokens = tokendefs[ctx.stack[-1]]
|
||||
if action is not None:
|
||||
if type(action) is _TokenType:
|
||||
yield ctx.pos, action, m.group()
|
||||
ctx.pos = m.end()
|
||||
else:
|
||||
for item in action(self, m, ctx):
|
||||
yield item
|
||||
if not new_state:
|
||||
# altered the state stack?
|
||||
statetokens = tokendefs[ctx.stack[-1]]
|
||||
# CAUTION: callback must set ctx.pos!
|
||||
if new_state is not None:
|
||||
# state transition
|
||||
@ -673,7 +725,7 @@ class ExtendedRegexLexer(RegexLexer):
|
||||
if state == '#pop':
|
||||
ctx.stack.pop()
|
||||
elif state == '#push':
|
||||
ctx.stack.append(statestack[-1])
|
||||
ctx.stack.append(ctx.stack[-1])
|
||||
else:
|
||||
ctx.stack.append(state)
|
||||
elif isinstance(new_state, int):
|
||||
@ -718,7 +770,7 @@ def do_insertions(insertions, tokens):
|
||||
"""
|
||||
insertions = iter(insertions)
|
||||
try:
|
||||
index, itokens = insertions.next()
|
||||
index, itokens = next(insertions)
|
||||
except StopIteration:
|
||||
# no insertions
|
||||
for item in tokens:
|
||||
@ -744,7 +796,7 @@ def do_insertions(insertions, tokens):
|
||||
realpos += len(it_value)
|
||||
oldi = index - i
|
||||
try:
|
||||
index, itokens = insertions.next()
|
||||
index, itokens = next(insertions)
|
||||
except StopIteration:
|
||||
insleft = False
|
||||
break # not strictly necessary
|
||||
@ -759,7 +811,60 @@ def do_insertions(insertions, tokens):
|
||||
yield realpos, t, v
|
||||
realpos += len(v)
|
||||
try:
|
||||
index, itokens = insertions.next()
|
||||
index, itokens = next(insertions)
|
||||
except StopIteration:
|
||||
insleft = False
|
||||
break # not strictly necessary
|
||||
|
||||
|
||||
class ProfilingRegexLexerMeta(RegexLexerMeta):
|
||||
"""Metaclass for ProfilingRegexLexer, collects regex timing info."""
|
||||
|
||||
def _process_regex(cls, regex, rflags, state):
|
||||
if isinstance(regex, words):
|
||||
rex = regex_opt(regex.words, prefix=regex.prefix,
|
||||
suffix=regex.suffix)
|
||||
else:
|
||||
rex = regex
|
||||
compiled = re.compile(rex, rflags)
|
||||
|
||||
def match_func(text, pos, endpos=sys.maxsize):
|
||||
info = cls._prof_data[-1].setdefault((state, rex), [0, 0.0])
|
||||
t0 = time.time()
|
||||
res = compiled.match(text, pos, endpos)
|
||||
t1 = time.time()
|
||||
info[0] += 1
|
||||
info[1] += t1 - t0
|
||||
return res
|
||||
return match_func
|
||||
|
||||
|
||||
@add_metaclass(ProfilingRegexLexerMeta)
|
||||
class ProfilingRegexLexer(RegexLexer):
|
||||
"""Drop-in replacement for RegexLexer that does profiling of its regexes."""
|
||||
|
||||
_prof_data = []
|
||||
_prof_sort_index = 4 # defaults to time per call
|
||||
|
||||
def get_tokens_unprocessed(self, text, stack=('root',)):
|
||||
# this needs to be a stack, since using(this) will produce nested calls
|
||||
self.__class__._prof_data.append({})
|
||||
for tok in RegexLexer.get_tokens_unprocessed(self, text, stack):
|
||||
yield tok
|
||||
rawdata = self.__class__._prof_data.pop()
|
||||
data = sorted(((s, repr(r).strip('u\'').replace('\\\\', '\\')[:65],
|
||||
n, 1000 * t, 1000 * t / n)
|
||||
for ((s, r), (n, t)) in rawdata.items()),
|
||||
key=lambda x: x[self._prof_sort_index],
|
||||
reverse=True)
|
||||
sum_total = sum(x[3] for x in data)
|
||||
|
||||
print()
|
||||
print('Profiling result for %s lexing %d chars in %.3f ms' %
|
||||
(self.__class__.__name__, len(text), sum_total))
|
||||
print('=' * 110)
|
||||
print('%-20s %-64s ncalls tottime percall' % ('state', 'regex'))
|
||||
print('-' * 110)
|
||||
for d in data:
|
||||
print('%-20s %-65s %5d %8.4f %8.4f' % d)
|
||||
print('=' * 110)
|
||||
@ -5,10 +5,11 @@
|
||||
|
||||
Pygments lexers.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import sys
|
||||
import types
|
||||
import fnmatch
|
||||
@ -17,19 +18,26 @@ from os.path import basename
|
||||
from pygments.lexers._mapping import LEXERS
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
from pygments.plugin import find_plugin_lexers
|
||||
from pygments.util import ClassNotFound, bytes
|
||||
from pygments.util import ClassNotFound, itervalues, guess_decode
|
||||
|
||||
|
||||
__all__ = ['get_lexer_by_name', 'get_lexer_for_filename', 'find_lexer_class',
|
||||
'guess_lexer'] + LEXERS.keys()
|
||||
'guess_lexer'] + list(LEXERS)
|
||||
|
||||
_lexer_cache = {}
|
||||
_pattern_cache = {}
|
||||
|
||||
|
||||
def _fn_matches(fn, glob):
|
||||
"""Return whether the supplied file name fn matches pattern filename."""
|
||||
if glob not in _pattern_cache:
|
||||
pattern = _pattern_cache[glob] = re.compile(fnmatch.translate(glob))
|
||||
return pattern.match(fn)
|
||||
return _pattern_cache[glob].match(fn)
|
||||
|
||||
|
||||
def _load_lexers(module_name):
|
||||
"""
|
||||
Load a lexer (and all others in the module too).
|
||||
"""
|
||||
"""Load a lexer (and all others in the module too)."""
|
||||
mod = __import__(module_name, None, None, ['__all__'])
|
||||
for lexer_name in mod.__all__:
|
||||
cls = getattr(mod, lexer_name)
|
||||
@ -37,24 +45,24 @@ def _load_lexers(module_name):
|
||||
|
||||
|
||||
def get_all_lexers():
|
||||
"""
|
||||
Return a generator of tuples in the form ``(name, aliases,
|
||||
"""Return a generator of tuples in the form ``(name, aliases,
|
||||
filenames, mimetypes)`` of all know lexers.
|
||||
"""
|
||||
for item in LEXERS.itervalues():
|
||||
for item in itervalues(LEXERS):
|
||||
yield item[1:]
|
||||
for lexer in find_plugin_lexers():
|
||||
yield lexer.name, lexer.aliases, lexer.filenames, lexer.mimetypes
|
||||
|
||||
|
||||
def find_lexer_class(name):
|
||||
"""
|
||||
Lookup a lexer class by name. Return None if not found.
|
||||
"""Lookup a lexer class by name.
|
||||
|
||||
Return None if not found.
|
||||
"""
|
||||
if name in _lexer_cache:
|
||||
return _lexer_cache[name]
|
||||
# lookup builtin lexers
|
||||
for module_name, lname, aliases, _, _ in LEXERS.itervalues():
|
||||
for module_name, lname, aliases, _, _ in itervalues(LEXERS):
|
||||
if name == lname:
|
||||
_load_lexers(module_name)
|
||||
return _lexer_cache[name]
|
||||
@ -65,12 +73,16 @@ def find_lexer_class(name):
|
||||
|
||||
|
||||
def get_lexer_by_name(_alias, **options):
|
||||
"""Get a lexer by an alias.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
Get a lexer by an alias.
|
||||
"""
|
||||
if not _alias:
|
||||
raise ClassNotFound('no lexer for alias %r found' % _alias)
|
||||
|
||||
# lookup builtin lexers
|
||||
for module_name, name, aliases, _, _ in LEXERS.itervalues():
|
||||
if _alias in aliases:
|
||||
for module_name, name, aliases, _, _ in itervalues(LEXERS):
|
||||
if _alias.lower() in aliases:
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(module_name)
|
||||
return _lexer_cache[name](**options)
|
||||
@ -81,28 +93,30 @@ def get_lexer_by_name(_alias, **options):
|
||||
raise ClassNotFound('no lexer for alias %r found' % _alias)
|
||||
|
||||
|
||||
def get_lexer_for_filename(_fn, code=None, **options):
|
||||
"""
|
||||
Get a lexer for a filename. If multiple lexers match the filename
|
||||
pattern, use ``analyze_text()`` to figure out which one is more
|
||||
appropriate.
|
||||
def find_lexer_class_for_filename(_fn, code=None):
|
||||
"""Get a lexer for a filename.
|
||||
|
||||
If multiple lexers match the filename pattern, use ``analyse_text()`` to
|
||||
figure out which one is more appropriate.
|
||||
|
||||
Returns None if not found.
|
||||
"""
|
||||
matches = []
|
||||
fn = basename(_fn)
|
||||
for modname, name, _, filenames, _ in LEXERS.itervalues():
|
||||
for modname, name, _, filenames, _ in itervalues(LEXERS):
|
||||
for filename in filenames:
|
||||
if fnmatch.fnmatch(fn, filename):
|
||||
if _fn_matches(fn, filename):
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(modname)
|
||||
matches.append((_lexer_cache[name], filename))
|
||||
for cls in find_plugin_lexers():
|
||||
for filename in cls.filenames:
|
||||
if fnmatch.fnmatch(fn, filename):
|
||||
if _fn_matches(fn, filename):
|
||||
matches.append((cls, filename))
|
||||
|
||||
if sys.version_info > (3,) and isinstance(code, bytes):
|
||||
# decode it, since all analyse_text functions expect unicode
|
||||
code = code.decode('latin1')
|
||||
code = guess_decode(code)
|
||||
|
||||
def get_rating(info):
|
||||
cls, filename = info
|
||||
@ -118,16 +132,30 @@ def get_lexer_for_filename(_fn, code=None, **options):
|
||||
|
||||
if matches:
|
||||
matches.sort(key=get_rating)
|
||||
#print "Possible lexers, after sort:", matches
|
||||
return matches[-1][0](**options)
|
||||
raise ClassNotFound('no lexer for filename %r found' % _fn)
|
||||
# print "Possible lexers, after sort:", matches
|
||||
return matches[-1][0]
|
||||
|
||||
|
||||
def get_lexer_for_filename(_fn, code=None, **options):
|
||||
"""Get a lexer for a filename.
|
||||
|
||||
If multiple lexers match the filename pattern, use ``analyse_text()`` to
|
||||
figure out which one is more appropriate.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
res = find_lexer_class_for_filename(_fn, code)
|
||||
if not res:
|
||||
raise ClassNotFound('no lexer for filename %r found' % _fn)
|
||||
return res(**options)
|
||||
|
||||
|
||||
def get_lexer_for_mimetype(_mime, **options):
|
||||
"""Get a lexer for a mimetype.
|
||||
|
||||
Raises ClassNotFound if not found.
|
||||
"""
|
||||
Get a lexer for a mimetype.
|
||||
"""
|
||||
for modname, name, _, _, mimetypes in LEXERS.itervalues():
|
||||
for modname, name, _, _, mimetypes in itervalues(LEXERS):
|
||||
if _mime in mimetypes:
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(modname)
|
||||
@ -138,17 +166,16 @@ def get_lexer_for_mimetype(_mime, **options):
|
||||
raise ClassNotFound('no lexer for mimetype %r found' % _mime)
|
||||
|
||||
|
||||
def _iter_lexerclasses():
|
||||
"""
|
||||
Return an iterator over all lexer classes.
|
||||
"""
|
||||
def _iter_lexerclasses(plugins=True):
|
||||
"""Return an iterator over all lexer classes."""
|
||||
for key in sorted(LEXERS):
|
||||
module_name, name = LEXERS[key][:2]
|
||||
if name not in _lexer_cache:
|
||||
_load_lexers(module_name)
|
||||
yield _lexer_cache[name]
|
||||
for lexer in find_plugin_lexers():
|
||||
yield lexer
|
||||
if plugins:
|
||||
for lexer in find_plugin_lexers():
|
||||
yield lexer
|
||||
|
||||
|
||||
def guess_lexer_for_filename(_fn, _text, **options):
|
||||
@ -168,16 +195,17 @@ def guess_lexer_for_filename(_fn, _text, **options):
|
||||
<pygments.lexers.templates.CssPhpLexer object at 0xb7ba518c>
|
||||
"""
|
||||
fn = basename(_fn)
|
||||
primary = None
|
||||
primary = {}
|
||||
matching_lexers = set()
|
||||
for lexer in _iter_lexerclasses():
|
||||
for filename in lexer.filenames:
|
||||
if fnmatch.fnmatch(fn, filename):
|
||||
if _fn_matches(fn, filename):
|
||||
matching_lexers.add(lexer)
|
||||
primary = lexer
|
||||
primary[lexer] = True
|
||||
for filename in lexer.alias_filenames:
|
||||
if fnmatch.fnmatch(fn, filename):
|
||||
if _fn_matches(fn, filename):
|
||||
matching_lexers.add(lexer)
|
||||
primary[lexer] = False
|
||||
if not matching_lexers:
|
||||
raise ClassNotFound('no lexer for filename %r found' % fn)
|
||||
if len(matching_lexers) == 1:
|
||||
@ -188,16 +216,21 @@ def guess_lexer_for_filename(_fn, _text, **options):
|
||||
if rv == 1.0:
|
||||
return lexer(**options)
|
||||
result.append((rv, lexer))
|
||||
result.sort()
|
||||
if not result[-1][0] and primary is not None:
|
||||
return primary(**options)
|
||||
|
||||
def type_sort(t):
|
||||
# sort by:
|
||||
# - analyse score
|
||||
# - is primary filename pattern?
|
||||
# - priority
|
||||
# - last resort: class name
|
||||
return (t[0], primary[t[1]], t[1].priority, t[1].__name__)
|
||||
result.sort(key=type_sort)
|
||||
|
||||
return result[-1][1](**options)
|
||||
|
||||
|
||||
def guess_lexer(_text, **options):
|
||||
"""
|
||||
Guess a lexer by strong distinctions in the text (eg, shebang).
|
||||
"""
|
||||
"""Guess a lexer by strong distinctions in the text (eg, shebang)."""
|
||||
|
||||
# try to get a vim modeline first
|
||||
ft = get_filetype_from_buffer(_text)
|
||||
@ -233,8 +266,8 @@ class _automodule(types.ModuleType):
|
||||
raise AttributeError(name)
|
||||
|
||||
|
||||
oldmod = sys.modules['pygments.lexers']
|
||||
newmod = _automodule('pygments.lexers')
|
||||
oldmod = sys.modules[__name__]
|
||||
newmod = _automodule(__name__)
|
||||
newmod.__dict__.update(oldmod.__dict__)
|
||||
sys.modules['pygments.lexers'] = newmod
|
||||
sys.modules[__name__] = newmod
|
||||
del newmod.newmod, newmod.oldmod, newmod.sys, newmod.types
|
||||
@ -1,7 +1,7 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._asybuiltins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
pygments.lexers._asy_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This file contains the asy-function names and asy-variable names of
|
||||
Asymptote.
|
||||
@ -10,11 +10,11 @@
|
||||
TODO: perl/python script in Asymptote SVN similar to asy-list.pl but only
|
||||
for function and variable names.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
ASYFUNCNAME = set([
|
||||
ASYFUNCNAME = set((
|
||||
'AND',
|
||||
'Arc',
|
||||
'ArcArrow',
|
||||
@ -1038,9 +1038,9 @@ ASYFUNCNAME = set([
|
||||
'ztick',
|
||||
'ztick3',
|
||||
'ztrans'
|
||||
])
|
||||
))
|
||||
|
||||
ASYVARNAME = set([
|
||||
ASYVARNAME = set((
|
||||
'AliceBlue',
|
||||
'Align',
|
||||
'Allow',
|
||||
@ -1642,4 +1642,4 @@ ASYVARNAME = set([
|
||||
'ylabelwidth',
|
||||
'zerotickfuzz',
|
||||
'zerowinding'
|
||||
])
|
||||
))
|
||||
@ -1,15 +1,15 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._clbuiltins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
pygments.lexers._cl_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
ANSI Common Lisp builtins.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
BUILTIN_FUNCTIONS = [ # 638 functions
|
||||
BUILTIN_FUNCTIONS = set(( # 638 functions
|
||||
'<', '<=', '=', '>', '>=', '-', '/', '/=', '*', '+', '1-', '1+',
|
||||
'abort', 'abs', 'acons', 'acos', 'acosh', 'add-method', 'adjoin',
|
||||
'adjustable-array-p', 'adjust-array', 'allocate-instance',
|
||||
@ -157,17 +157,17 @@ BUILTIN_FUNCTIONS = [ # 638 functions
|
||||
'wild-pathname-p', 'write', 'write-byte', 'write-char', 'write-line',
|
||||
'write-sequence', 'write-string', 'write-to-string', 'yes-or-no-p',
|
||||
'y-or-n-p', 'zerop',
|
||||
]
|
||||
))
|
||||
|
||||
SPECIAL_FORMS = [
|
||||
SPECIAL_FORMS = set((
|
||||
'block', 'catch', 'declare', 'eval-when', 'flet', 'function', 'go', 'if',
|
||||
'labels', 'lambda', 'let', 'let*', 'load-time-value', 'locally', 'macrolet',
|
||||
'multiple-value-call', 'multiple-value-prog1', 'progn', 'progv', 'quote',
|
||||
'return-from', 'setq', 'symbol-macrolet', 'tagbody', 'the', 'throw',
|
||||
'unwind-protect',
|
||||
]
|
||||
))
|
||||
|
||||
MACROS = [
|
||||
MACROS = set((
|
||||
'and', 'assert', 'call-method', 'case', 'ccase', 'check-type', 'cond',
|
||||
'ctypecase', 'decf', 'declaim', 'defclass', 'defconstant', 'defgeneric',
|
||||
'define-compiler-macro', 'define-condition', 'define-method-combination',
|
||||
@ -188,19 +188,19 @@ MACROS = [
|
||||
'with-input-from-string', 'with-open-file', 'with-open-stream',
|
||||
'with-output-to-string', 'with-package-iterator', 'with-simple-restart',
|
||||
'with-slots', 'with-standard-io-syntax',
|
||||
]
|
||||
))
|
||||
|
||||
LAMBDA_LIST_KEYWORDS = [
|
||||
LAMBDA_LIST_KEYWORDS = set((
|
||||
'&allow-other-keys', '&aux', '&body', '&environment', '&key', '&optional',
|
||||
'&rest', '&whole',
|
||||
]
|
||||
))
|
||||
|
||||
DECLARATIONS = [
|
||||
DECLARATIONS = set((
|
||||
'dynamic-extent', 'ignore', 'optimize', 'ftype', 'inline', 'special',
|
||||
'ignorable', 'notinline', 'type',
|
||||
]
|
||||
))
|
||||
|
||||
BUILTIN_TYPES = [
|
||||
BUILTIN_TYPES = set((
|
||||
'atom', 'boolean', 'base-char', 'base-string', 'bignum', 'bit',
|
||||
'compiled-function', 'extended-char', 'fixnum', 'keyword', 'nil',
|
||||
'signed-byte', 'short-float', 'single-float', 'double-float', 'long-float',
|
||||
@ -217,9 +217,9 @@ BUILTIN_TYPES = [
|
||||
'simple-type-error', 'simple-warning', 'stream-error', 'storage-condition',
|
||||
'style-warning', 'type-error', 'unbound-variable', 'unbound-slot',
|
||||
'undefined-function', 'warning',
|
||||
]
|
||||
))
|
||||
|
||||
BUILTIN_CLASSES = [
|
||||
BUILTIN_CLASSES = set((
|
||||
'array', 'broadcast-stream', 'bit-vector', 'built-in-class', 'character',
|
||||
'class', 'complex', 'concatenated-stream', 'cons', 'echo-stream',
|
||||
'file-stream', 'float', 'function', 'generic-function', 'hash-table',
|
||||
@ -229,4 +229,4 @@ BUILTIN_CLASSES = [
|
||||
'standard-generic-function', 'standard-method', 'standard-object',
|
||||
'string-stream', 'stream', 'string', 'structure-class', 'structure-object',
|
||||
'symbol', 'synonym-stream', 't', 'two-way-stream', 'vector',
|
||||
]
|
||||
))
|
||||
File diff suppressed because one or more lines are too long
@ -1,16 +1,16 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._lassobuiltins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
pygments.lexers._lasso_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Built-in Lasso types, traits, methods, and members.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
BUILTINS = {
|
||||
'Types': [
|
||||
'Types': (
|
||||
'null',
|
||||
'void',
|
||||
'tag',
|
||||
@ -136,8 +136,10 @@ BUILTINS = {
|
||||
'timeonly',
|
||||
'net_tcp',
|
||||
'net_tcpssl',
|
||||
'net_tcp_ssl',
|
||||
'net_named_pipe',
|
||||
'net_udppacket',
|
||||
'net_udp_packet',
|
||||
'net_udp',
|
||||
'pdf_typebase',
|
||||
'pdf_doc',
|
||||
@ -268,8 +270,8 @@ BUILTINS = {
|
||||
'web_error_atend',
|
||||
'web_response_impl',
|
||||
'web_router'
|
||||
],
|
||||
'Traits': [
|
||||
),
|
||||
'Traits': (
|
||||
'trait_asstring',
|
||||
'any',
|
||||
'trait_generator',
|
||||
@ -342,8 +344,8 @@ BUILTINS = {
|
||||
'web_node_content_html_specialized',
|
||||
'web_node_content_css_specialized',
|
||||
'web_node_content_js_specialized'
|
||||
],
|
||||
'Unbound Methods': [
|
||||
),
|
||||
'Unbound Methods': (
|
||||
'fail_now',
|
||||
'register',
|
||||
'register_thread',
|
||||
@ -1275,6 +1277,7 @@ BUILTINS = {
|
||||
'lcapi_datasourcesortascending',
|
||||
'lcapi_datasourcesortdescending',
|
||||
'lcapi_datasourcesortcustom',
|
||||
'lcapi_updatedatasourceslist',
|
||||
'lcapi_loadmodules',
|
||||
'lasso_version',
|
||||
'lasso_uniqueid',
|
||||
@ -1842,8 +1845,8 @@ BUILTINS = {
|
||||
'web_response',
|
||||
'web_router_database',
|
||||
'web_router_initialize'
|
||||
],
|
||||
'Lasso 8 Tags': [
|
||||
),
|
||||
'Lasso 8 Tags': (
|
||||
'__char',
|
||||
'__sync_timestamp__',
|
||||
'_admin_addgroup',
|
||||
@ -3027,10 +3030,10 @@ BUILTINS = {
|
||||
'xsd_processsimpletype',
|
||||
'xsd_ref',
|
||||
'xsd_type'
|
||||
]
|
||||
)
|
||||
}
|
||||
MEMBERS = {
|
||||
'Member Methods': [
|
||||
'Member Methods': (
|
||||
'escape_member',
|
||||
'oncompare',
|
||||
'sameas',
|
||||
@ -4024,6 +4027,10 @@ MEMBERS = {
|
||||
'statuscode',
|
||||
'raw',
|
||||
'version',
|
||||
'download',
|
||||
'upload',
|
||||
'ftpdeletefile',
|
||||
'ftpgetlisting',
|
||||
'perform',
|
||||
'performonce',
|
||||
's',
|
||||
@ -4114,8 +4121,11 @@ MEMBERS = {
|
||||
'foreachaccept',
|
||||
'writeobjecttcp',
|
||||
'readobjecttcp',
|
||||
'beginssl',
|
||||
'endssl',
|
||||
'begintls',
|
||||
'endtls',
|
||||
'acceptnossl',
|
||||
'loadcerts',
|
||||
'sslerrfail',
|
||||
'fromname',
|
||||
@ -4710,8 +4720,8 @@ MEMBERS = {
|
||||
'acceptpost',
|
||||
'csscontent',
|
||||
'jscontent'
|
||||
],
|
||||
'Lasso 8 Member Tags': [
|
||||
),
|
||||
'Lasso 8 Member Tags': (
|
||||
'accept',
|
||||
'add',
|
||||
'addattachment',
|
||||
@ -5168,5 +5178,5 @@ MEMBERS = {
|
||||
'xmllang',
|
||||
'xmlschematype',
|
||||
'year'
|
||||
]
|
||||
)
|
||||
}
|
||||
@ -1,7 +1,7 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._luabuiltins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
pygments.lexers._lua_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This file contains the names and modules of lua functions
|
||||
It is able to re-generate itself, but for adding new functions you
|
||||
@ -9,11 +9,14 @@
|
||||
|
||||
Do not edit the MODULES dict by hand.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
MODULES = {'basic': ['_G',
|
||||
from __future__ import print_function
|
||||
|
||||
|
||||
MODULES = {'basic': ('_G',
|
||||
'_VERSION',
|
||||
'assert',
|
||||
'collectgarbage',
|
||||
@ -39,14 +42,14 @@ MODULES = {'basic': ['_G',
|
||||
'tostring',
|
||||
'type',
|
||||
'unpack',
|
||||
'xpcall'],
|
||||
'coroutine': ['coroutine.create',
|
||||
'xpcall'),
|
||||
'coroutine': ('coroutine.create',
|
||||
'coroutine.resume',
|
||||
'coroutine.running',
|
||||
'coroutine.status',
|
||||
'coroutine.wrap',
|
||||
'coroutine.yield'],
|
||||
'debug': ['debug.debug',
|
||||
'coroutine.yield'),
|
||||
'debug': ('debug.debug',
|
||||
'debug.getfenv',
|
||||
'debug.gethook',
|
||||
'debug.getinfo',
|
||||
@ -59,8 +62,8 @@ MODULES = {'basic': ['_G',
|
||||
'debug.setlocal',
|
||||
'debug.setmetatable',
|
||||
'debug.setupvalue',
|
||||
'debug.traceback'],
|
||||
'io': ['io.close',
|
||||
'debug.traceback'),
|
||||
'io': ('io.close',
|
||||
'io.flush',
|
||||
'io.input',
|
||||
'io.lines',
|
||||
@ -70,8 +73,8 @@ MODULES = {'basic': ['_G',
|
||||
'io.read',
|
||||
'io.tmpfile',
|
||||
'io.type',
|
||||
'io.write'],
|
||||
'math': ['math.abs',
|
||||
'io.write'),
|
||||
'math': ('math.abs',
|
||||
'math.acos',
|
||||
'math.asin',
|
||||
'math.atan2',
|
||||
@ -100,16 +103,16 @@ MODULES = {'basic': ['_G',
|
||||
'math.sin',
|
||||
'math.sqrt',
|
||||
'math.tanh',
|
||||
'math.tan'],
|
||||
'modules': ['module',
|
||||
'math.tan'),
|
||||
'modules': ('module',
|
||||
'require',
|
||||
'package.cpath',
|
||||
'package.loaded',
|
||||
'package.loadlib',
|
||||
'package.path',
|
||||
'package.preload',
|
||||
'package.seeall'],
|
||||
'os': ['os.clock',
|
||||
'package.seeall'),
|
||||
'os': ('os.clock',
|
||||
'os.date',
|
||||
'os.difftime',
|
||||
'os.execute',
|
||||
@ -119,8 +122,8 @@ MODULES = {'basic': ['_G',
|
||||
'os.rename',
|
||||
'os.setlocale',
|
||||
'os.time',
|
||||
'os.tmpname'],
|
||||
'string': ['string.byte',
|
||||
'os.tmpname'),
|
||||
'string': ('string.byte',
|
||||
'string.char',
|
||||
'string.dump',
|
||||
'string.find',
|
||||
@ -133,16 +136,19 @@ MODULES = {'basic': ['_G',
|
||||
'string.rep',
|
||||
'string.reverse',
|
||||
'string.sub',
|
||||
'string.upper'],
|
||||
'table': ['table.concat',
|
||||
'string.upper'),
|
||||
'table': ('table.concat',
|
||||
'table.insert',
|
||||
'table.maxn',
|
||||
'table.remove',
|
||||
'table.sort']}
|
||||
'table.sort')}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import re
|
||||
import urllib.request, urllib.parse, urllib.error
|
||||
try:
|
||||
from urllib import urlopen
|
||||
except ImportError:
|
||||
from urllib.request import urlopen
|
||||
import pprint
|
||||
|
||||
# you can't generally find out what module a function belongs to if you
|
||||
@ -188,7 +194,7 @@ if __name__ == '__main__':
|
||||
|
||||
|
||||
def get_newest_version():
|
||||
f = urllib.request.urlopen('http://www.lua.org/manual/')
|
||||
f = urlopen('http://www.lua.org/manual/')
|
||||
r = re.compile(r'^<A HREF="(\d\.\d)/">Lua \1</A>')
|
||||
for line in f:
|
||||
m = r.match(line)
|
||||
@ -196,7 +202,7 @@ if __name__ == '__main__':
|
||||
return m.groups()[0]
|
||||
|
||||
def get_lua_functions(version):
|
||||
f = urllib.request.urlopen('http://www.lua.org/manual/%s/' % version)
|
||||
f = urlopen('http://www.lua.org/manual/%s/' % version)
|
||||
r = re.compile(r'^<A HREF="manual.html#pdf-(.+)">\1</A>')
|
||||
functions = []
|
||||
for line in f:
|
||||
@ -215,21 +221,17 @@ if __name__ == '__main__':
|
||||
return 'basic'
|
||||
|
||||
def regenerate(filename, modules):
|
||||
f = open(filename)
|
||||
try:
|
||||
content = f.read()
|
||||
finally:
|
||||
f.close()
|
||||
with open(filename) as fp:
|
||||
content = fp.read()
|
||||
|
||||
header = content[:content.find('MODULES = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
|
||||
f = open(filename, 'w')
|
||||
f.write(header)
|
||||
f.write('MODULES = %s\n\n' % pprint.pformat(modules))
|
||||
f.write(footer)
|
||||
f.close()
|
||||
with open(filename, 'w') as fp:
|
||||
fp.write(header)
|
||||
fp.write('MODULES = %s\n\n' % pprint.pformat(modules))
|
||||
fp.write(footer)
|
||||
|
||||
def run():
|
||||
version = get_newest_version()
|
||||
@ -245,5 +247,4 @@ if __name__ == '__main__':
|
||||
|
||||
regenerate(__file__, modules)
|
||||
|
||||
|
||||
run()
|
||||
@ -0,0 +1,413 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._mapping
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer mapping definitions. This file is generated by itself. Everytime
|
||||
you change something on a builtin lexer definition, run this script from
|
||||
the lexers folder to update it.
|
||||
|
||||
Do not alter the LEXERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
LEXERS = {
|
||||
'ABAPLexer': ('pygments.lexers.business', 'ABAP', ('abap',), ('*.abap',), ('text/x-abap',)),
|
||||
'APLLexer': ('pygments.lexers.apl', 'APL', ('apl',), ('*.apl',), ()),
|
||||
'ActionScript3Lexer': ('pygments.lexers.actionscript', 'ActionScript 3', ('as3', 'actionscript3'), ('*.as',), ('application/x-actionscript3', 'text/x-actionscript3', 'text/actionscript3')),
|
||||
'ActionScriptLexer': ('pygments.lexers.actionscript', 'ActionScript', ('as', 'actionscript'), ('*.as',), ('application/x-actionscript', 'text/x-actionscript', 'text/actionscript')),
|
||||
'AdaLexer': ('pygments.lexers.pascal', 'Ada', ('ada', 'ada95', 'ada2005'), ('*.adb', '*.ads', '*.ada'), ('text/x-ada',)),
|
||||
'AgdaLexer': ('pygments.lexers.haskell', 'Agda', ('agda',), ('*.agda',), ('text/x-agda',)),
|
||||
'AlloyLexer': ('pygments.lexers.dsls', 'Alloy', ('alloy',), ('*.als',), ('text/x-alloy',)),
|
||||
'AmbientTalkLexer': ('pygments.lexers.ambient', 'AmbientTalk', ('at', 'ambienttalk', 'ambienttalk/2'), ('*.at',), ('text/x-ambienttalk',)),
|
||||
'AntlrActionScriptLexer': ('pygments.lexers.parsers', 'ANTLR With ActionScript Target', ('antlr-as', 'antlr-actionscript'), ('*.G', '*.g'), ()),
|
||||
'AntlrCSharpLexer': ('pygments.lexers.parsers', 'ANTLR With C# Target', ('antlr-csharp', 'antlr-c#'), ('*.G', '*.g'), ()),
|
||||
'AntlrCppLexer': ('pygments.lexers.parsers', 'ANTLR With CPP Target', ('antlr-cpp',), ('*.G', '*.g'), ()),
|
||||
'AntlrJavaLexer': ('pygments.lexers.parsers', 'ANTLR With Java Target', ('antlr-java',), ('*.G', '*.g'), ()),
|
||||
'AntlrLexer': ('pygments.lexers.parsers', 'ANTLR', ('antlr',), (), ()),
|
||||
'AntlrObjectiveCLexer': ('pygments.lexers.parsers', 'ANTLR With ObjectiveC Target', ('antlr-objc',), ('*.G', '*.g'), ()),
|
||||
'AntlrPerlLexer': ('pygments.lexers.parsers', 'ANTLR With Perl Target', ('antlr-perl',), ('*.G', '*.g'), ()),
|
||||
'AntlrPythonLexer': ('pygments.lexers.parsers', 'ANTLR With Python Target', ('antlr-python',), ('*.G', '*.g'), ()),
|
||||
'AntlrRubyLexer': ('pygments.lexers.parsers', 'ANTLR With Ruby Target', ('antlr-ruby', 'antlr-rb'), ('*.G', '*.g'), ()),
|
||||
'ApacheConfLexer': ('pygments.lexers.configs', 'ApacheConf', ('apacheconf', 'aconf', 'apache'), ('.htaccess', 'apache.conf', 'apache2.conf'), ('text/x-apacheconf',)),
|
||||
'AppleScriptLexer': ('pygments.lexers.scripting', 'AppleScript', ('applescript',), ('*.applescript',), ()),
|
||||
'AspectJLexer': ('pygments.lexers.jvm', 'AspectJ', ('aspectj',), ('*.aj',), ('text/x-aspectj',)),
|
||||
'AsymptoteLexer': ('pygments.lexers.graphics', 'Asymptote', ('asy', 'asymptote'), ('*.asy',), ('text/x-asymptote',)),
|
||||
'AutoItLexer': ('pygments.lexers.automation', 'AutoIt', ('autoit',), ('*.au3',), ('text/x-autoit',)),
|
||||
'AutohotkeyLexer': ('pygments.lexers.automation', 'autohotkey', ('ahk', 'autohotkey'), ('*.ahk', '*.ahkl'), ('text/x-autohotkey',)),
|
||||
'AwkLexer': ('pygments.lexers.textedit', 'Awk', ('awk', 'gawk', 'mawk', 'nawk'), ('*.awk',), ('application/x-awk',)),
|
||||
'BBCodeLexer': ('pygments.lexers.markup', 'BBCode', ('bbcode',), (), ('text/x-bbcode',)),
|
||||
'BaseMakefileLexer': ('pygments.lexers.make', 'Base Makefile', ('basemake',), (), ()),
|
||||
'BashLexer': ('pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh', 'shell'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '.bashrc', 'bashrc', '.bash_*', 'bash_*', 'PKGBUILD'), ('application/x-sh', 'application/x-shellscript')),
|
||||
'BashSessionLexer': ('pygments.lexers.shell', 'Bash Session', ('console',), ('*.sh-session',), ('application/x-shell-session',)),
|
||||
'BatchLexer': ('pygments.lexers.shell', 'Batchfile', ('bat', 'batch', 'dosbatch', 'winbatch'), ('*.bat', '*.cmd'), ('application/x-dos-batch',)),
|
||||
'BefungeLexer': ('pygments.lexers.esoteric', 'Befunge', ('befunge',), ('*.befunge',), ('application/x-befunge',)),
|
||||
'BlitzBasicLexer': ('pygments.lexers.basic', 'BlitzBasic', ('blitzbasic', 'b3d', 'bplus'), ('*.bb', '*.decls'), ('text/x-bb',)),
|
||||
'BlitzMaxLexer': ('pygments.lexers.basic', 'BlitzMax', ('blitzmax', 'bmax'), ('*.bmx',), ('text/x-bmx',)),
|
||||
'BooLexer': ('pygments.lexers.dotnet', 'Boo', ('boo',), ('*.boo',), ('text/x-boo',)),
|
||||
'BrainfuckLexer': ('pygments.lexers.esoteric', 'Brainfuck', ('brainfuck', 'bf'), ('*.bf', '*.b'), ('application/x-brainfuck',)),
|
||||
'BroLexer': ('pygments.lexers.dsls', 'Bro', ('bro',), ('*.bro',), ()),
|
||||
'BugsLexer': ('pygments.lexers.modeling', 'BUGS', ('bugs', 'winbugs', 'openbugs'), ('*.bug',), ()),
|
||||
'CLexer': ('pygments.lexers.c_cpp', 'C', ('c',), ('*.c', '*.h', '*.idc'), ('text/x-chdr', 'text/x-csrc')),
|
||||
'CMakeLexer': ('pygments.lexers.make', 'CMake', ('cmake',), ('*.cmake', 'CMakeLists.txt'), ('text/x-cmake',)),
|
||||
'CObjdumpLexer': ('pygments.lexers.asm', 'c-objdump', ('c-objdump',), ('*.c-objdump',), ('text/x-c-objdump',)),
|
||||
'CSharpAspxLexer': ('pygments.lexers.dotnet', 'aspx-cs', ('aspx-cs',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'CSharpLexer': ('pygments.lexers.dotnet', 'C#', ('csharp', 'c#'), ('*.cs',), ('text/x-csharp',)),
|
||||
'Ca65Lexer': ('pygments.lexers.asm', 'ca65 assembler', ('ca65',), ('*.s',), ()),
|
||||
'CbmBasicV2Lexer': ('pygments.lexers.basic', 'CBM BASIC V2', ('cbmbas',), ('*.bas',), ()),
|
||||
'CeylonLexer': ('pygments.lexers.jvm', 'Ceylon', ('ceylon',), ('*.ceylon',), ('text/x-ceylon',)),
|
||||
'Cfengine3Lexer': ('pygments.lexers.configs', 'CFEngine3', ('cfengine3', 'cf3'), ('*.cf',), ()),
|
||||
'ChaiscriptLexer': ('pygments.lexers.scripting', 'ChaiScript', ('chai', 'chaiscript'), ('*.chai',), ('text/x-chaiscript', 'application/x-chaiscript')),
|
||||
'ChapelLexer': ('pygments.lexers.chapel', 'Chapel', ('chapel', 'chpl'), ('*.chpl',), ()),
|
||||
'CheetahHtmlLexer': ('pygments.lexers.templates', 'HTML+Cheetah', ('html+cheetah', 'html+spitfire', 'htmlcheetah'), (), ('text/html+cheetah', 'text/html+spitfire')),
|
||||
'CheetahJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Cheetah', ('js+cheetah', 'javascript+cheetah', 'js+spitfire', 'javascript+spitfire'), (), ('application/x-javascript+cheetah', 'text/x-javascript+cheetah', 'text/javascript+cheetah', 'application/x-javascript+spitfire', 'text/x-javascript+spitfire', 'text/javascript+spitfire')),
|
||||
'CheetahLexer': ('pygments.lexers.templates', 'Cheetah', ('cheetah', 'spitfire'), ('*.tmpl', '*.spt'), ('application/x-cheetah', 'application/x-spitfire')),
|
||||
'CheetahXmlLexer': ('pygments.lexers.templates', 'XML+Cheetah', ('xml+cheetah', 'xml+spitfire'), (), ('application/xml+cheetah', 'application/xml+spitfire')),
|
||||
'CirruLexer': ('pygments.lexers.webmisc', 'Cirru', ('cirru',), ('*.cirru', '*.cr'), ('text/x-cirru',)),
|
||||
'ClayLexer': ('pygments.lexers.c_like', 'Clay', ('clay',), ('*.clay',), ('text/x-clay',)),
|
||||
'ClojureLexer': ('pygments.lexers.jvm', 'Clojure', ('clojure', 'clj'), ('*.clj',), ('text/x-clojure', 'application/x-clojure')),
|
||||
'ClojureScriptLexer': ('pygments.lexers.jvm', 'ClojureScript', ('clojurescript', 'cljs'), ('*.cljs',), ('text/x-clojurescript', 'application/x-clojurescript')),
|
||||
'CobolFreeformatLexer': ('pygments.lexers.business', 'COBOLFree', ('cobolfree',), ('*.cbl', '*.CBL'), ()),
|
||||
'CobolLexer': ('pygments.lexers.business', 'COBOL', ('cobol',), ('*.cob', '*.COB', '*.cpy', '*.CPY'), ('text/x-cobol',)),
|
||||
'CoffeeScriptLexer': ('pygments.lexers.javascript', 'CoffeeScript', ('coffee-script', 'coffeescript', 'coffee'), ('*.coffee',), ('text/coffeescript',)),
|
||||
'ColdfusionCFCLexer': ('pygments.lexers.templates', 'Coldfusion CFC', ('cfc',), ('*.cfc',), ()),
|
||||
'ColdfusionHtmlLexer': ('pygments.lexers.templates', 'Coldfusion HTML', ('cfm',), ('*.cfm', '*.cfml'), ('application/x-coldfusion',)),
|
||||
'ColdfusionLexer': ('pygments.lexers.templates', 'cfstatement', ('cfs',), (), ()),
|
||||
'CommonLispLexer': ('pygments.lexers.lisp', 'Common Lisp', ('common-lisp', 'cl', 'lisp', 'elisp', 'emacs', 'emacs-lisp'), ('*.cl', '*.lisp', '*.el'), ('text/x-common-lisp',)),
|
||||
'CoqLexer': ('pygments.lexers.theorem', 'Coq', ('coq',), ('*.v',), ('text/x-coq',)),
|
||||
'CppLexer': ('pygments.lexers.c_cpp', 'C++', ('cpp', 'c++'), ('*.cpp', '*.hpp', '*.c++', '*.h++', '*.cc', '*.hh', '*.cxx', '*.hxx', '*.C', '*.H', '*.cp', '*.CPP'), ('text/x-c++hdr', 'text/x-c++src')),
|
||||
'CppObjdumpLexer': ('pygments.lexers.asm', 'cpp-objdump', ('cpp-objdump', 'c++-objdumb', 'cxx-objdump'), ('*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump'), ('text/x-cpp-objdump',)),
|
||||
'CrocLexer': ('pygments.lexers.d', 'Croc', ('croc',), ('*.croc',), ('text/x-crocsrc',)),
|
||||
'CryptolLexer': ('pygments.lexers.haskell', 'Cryptol', ('cryptol', 'cry'), ('*.cry',), ('text/x-cryptol',)),
|
||||
'CssDjangoLexer': ('pygments.lexers.templates', 'CSS+Django/Jinja', ('css+django', 'css+jinja'), (), ('text/css+django', 'text/css+jinja')),
|
||||
'CssErbLexer': ('pygments.lexers.templates', 'CSS+Ruby', ('css+erb', 'css+ruby'), (), ('text/css+ruby',)),
|
||||
'CssGenshiLexer': ('pygments.lexers.templates', 'CSS+Genshi Text', ('css+genshitext', 'css+genshi'), (), ('text/css+genshi',)),
|
||||
'CssLexer': ('pygments.lexers.css', 'CSS', ('css',), ('*.css',), ('text/css',)),
|
||||
'CssPhpLexer': ('pygments.lexers.templates', 'CSS+PHP', ('css+php',), (), ('text/css+php',)),
|
||||
'CssSmartyLexer': ('pygments.lexers.templates', 'CSS+Smarty', ('css+smarty',), (), ('text/css+smarty',)),
|
||||
'CudaLexer': ('pygments.lexers.c_like', 'CUDA', ('cuda', 'cu'), ('*.cu', '*.cuh'), ('text/x-cuda',)),
|
||||
'CypherLexer': ('pygments.lexers.graph', 'Cypher', ('cypher',), ('*.cyp', '*.cypher'), ()),
|
||||
'CythonLexer': ('pygments.lexers.python', 'Cython', ('cython', 'pyx', 'pyrex'), ('*.pyx', '*.pxd', '*.pxi'), ('text/x-cython', 'application/x-cython')),
|
||||
'DLexer': ('pygments.lexers.d', 'D', ('d',), ('*.d', '*.di'), ('text/x-dsrc',)),
|
||||
'DObjdumpLexer': ('pygments.lexers.asm', 'd-objdump', ('d-objdump',), ('*.d-objdump',), ('text/x-d-objdump',)),
|
||||
'DarcsPatchLexer': ('pygments.lexers.diff', 'Darcs Patch', ('dpatch',), ('*.dpatch', '*.darcspatch'), ()),
|
||||
'DartLexer': ('pygments.lexers.javascript', 'Dart', ('dart',), ('*.dart',), ('text/x-dart',)),
|
||||
'DebianControlLexer': ('pygments.lexers.installers', 'Debian Control file', ('control', 'debcontrol'), ('control',), ()),
|
||||
'DelphiLexer': ('pygments.lexers.pascal', 'Delphi', ('delphi', 'pas', 'pascal', 'objectpascal'), ('*.pas',), ('text/x-pascal',)),
|
||||
'DgLexer': ('pygments.lexers.python', 'dg', ('dg',), ('*.dg',), ('text/x-dg',)),
|
||||
'DiffLexer': ('pygments.lexers.diff', 'Diff', ('diff', 'udiff'), ('*.diff', '*.patch'), ('text/x-diff', 'text/x-patch')),
|
||||
'DjangoLexer': ('pygments.lexers.templates', 'Django/Jinja', ('django', 'jinja'), (), ('application/x-django-templating', 'application/x-jinja')),
|
||||
'DockerLexer': ('pygments.lexers.configs', 'Docker', ('docker', 'dockerfile'), ('Dockerfile', '*.docker'), ('text/x-dockerfile-config',)),
|
||||
'DtdLexer': ('pygments.lexers.html', 'DTD', ('dtd',), ('*.dtd',), ('application/xml-dtd',)),
|
||||
'DuelLexer': ('pygments.lexers.webmisc', 'Duel', ('duel', 'jbst', 'jsonml+bst'), ('*.duel', '*.jbst'), ('text/x-duel', 'text/x-jbst')),
|
||||
'DylanConsoleLexer': ('pygments.lexers.dylan', 'Dylan session', ('dylan-console', 'dylan-repl'), ('*.dylan-console',), ('text/x-dylan-console',)),
|
||||
'DylanLexer': ('pygments.lexers.dylan', 'Dylan', ('dylan',), ('*.dylan', '*.dyl', '*.intr'), ('text/x-dylan',)),
|
||||
'DylanLidLexer': ('pygments.lexers.dylan', 'DylanLID', ('dylan-lid', 'lid'), ('*.lid', '*.hdp'), ('text/x-dylan-lid',)),
|
||||
'ECLLexer': ('pygments.lexers.ecl', 'ECL', ('ecl',), ('*.ecl',), ('application/x-ecl',)),
|
||||
'ECLexer': ('pygments.lexers.c_like', 'eC', ('ec',), ('*.ec', '*.eh'), ('text/x-echdr', 'text/x-ecsrc')),
|
||||
'EbnfLexer': ('pygments.lexers.parsers', 'EBNF', ('ebnf',), ('*.ebnf',), ('text/x-ebnf',)),
|
||||
'EiffelLexer': ('pygments.lexers.eiffel', 'Eiffel', ('eiffel',), ('*.e',), ('text/x-eiffel',)),
|
||||
'ElixirConsoleLexer': ('pygments.lexers.erlang', 'Elixir iex session', ('iex',), (), ('text/x-elixir-shellsession',)),
|
||||
'ElixirLexer': ('pygments.lexers.erlang', 'Elixir', ('elixir', 'ex', 'exs'), ('*.ex', '*.exs'), ('text/x-elixir',)),
|
||||
'ErbLexer': ('pygments.lexers.templates', 'ERB', ('erb',), (), ('application/x-ruby-templating',)),
|
||||
'ErlangLexer': ('pygments.lexers.erlang', 'Erlang', ('erlang',), ('*.erl', '*.hrl', '*.es', '*.escript'), ('text/x-erlang',)),
|
||||
'ErlangShellLexer': ('pygments.lexers.erlang', 'Erlang erl session', ('erl',), ('*.erl-sh',), ('text/x-erl-shellsession',)),
|
||||
'EvoqueHtmlLexer': ('pygments.lexers.templates', 'HTML+Evoque', ('html+evoque',), ('*.html',), ('text/html+evoque',)),
|
||||
'EvoqueLexer': ('pygments.lexers.templates', 'Evoque', ('evoque',), ('*.evoque',), ('application/x-evoque',)),
|
||||
'EvoqueXmlLexer': ('pygments.lexers.templates', 'XML+Evoque', ('xml+evoque',), ('*.xml',), ('application/xml+evoque',)),
|
||||
'FSharpLexer': ('pygments.lexers.dotnet', 'FSharp', ('fsharp',), ('*.fs', '*.fsi'), ('text/x-fsharp',)),
|
||||
'FactorLexer': ('pygments.lexers.factor', 'Factor', ('factor',), ('*.factor',), ('text/x-factor',)),
|
||||
'FancyLexer': ('pygments.lexers.ruby', 'Fancy', ('fancy', 'fy'), ('*.fy', '*.fancypack'), ('text/x-fancysrc',)),
|
||||
'FantomLexer': ('pygments.lexers.fantom', 'Fantom', ('fan',), ('*.fan',), ('application/x-fantom',)),
|
||||
'FelixLexer': ('pygments.lexers.felix', 'Felix', ('felix', 'flx'), ('*.flx', '*.flxh'), ('text/x-felix',)),
|
||||
'FortranLexer': ('pygments.lexers.fortran', 'Fortran', ('fortran',), ('*.f', '*.f90', '*.F', '*.F90'), ('text/x-fortran',)),
|
||||
'FoxProLexer': ('pygments.lexers.foxpro', 'FoxPro', ('foxpro', 'vfp', 'clipper', 'xbase'), ('*.PRG', '*.prg'), ()),
|
||||
'GAPLexer': ('pygments.lexers.algebra', 'GAP', ('gap',), ('*.g', '*.gd', '*.gi', '*.gap'), ()),
|
||||
'GLShaderLexer': ('pygments.lexers.graphics', 'GLSL', ('glsl',), ('*.vert', '*.frag', '*.geo'), ('text/x-glslsrc',)),
|
||||
'GasLexer': ('pygments.lexers.asm', 'GAS', ('gas', 'asm'), ('*.s', '*.S'), ('text/x-gas',)),
|
||||
'GenshiLexer': ('pygments.lexers.templates', 'Genshi', ('genshi', 'kid', 'xml+genshi', 'xml+kid'), ('*.kid',), ('application/x-genshi', 'application/x-kid')),
|
||||
'GenshiTextLexer': ('pygments.lexers.templates', 'Genshi Text', ('genshitext',), (), ('application/x-genshi-text', 'text/x-genshi')),
|
||||
'GettextLexer': ('pygments.lexers.textfmts', 'Gettext Catalog', ('pot', 'po'), ('*.pot', '*.po'), ('application/x-gettext', 'text/x-gettext', 'text/gettext')),
|
||||
'GherkinLexer': ('pygments.lexers.testing', 'Gherkin', ('cucumber', 'gherkin'), ('*.feature',), ('text/x-gherkin',)),
|
||||
'GnuplotLexer': ('pygments.lexers.graphics', 'Gnuplot', ('gnuplot',), ('*.plot', '*.plt'), ('text/x-gnuplot',)),
|
||||
'GoLexer': ('pygments.lexers.go', 'Go', ('go',), ('*.go',), ('text/x-gosrc',)),
|
||||
'GoloLexer': ('pygments.lexers.jvm', 'Golo', ('golo',), ('*.golo',), ()),
|
||||
'GoodDataCLLexer': ('pygments.lexers.business', 'GoodData-CL', ('gooddata-cl',), ('*.gdc',), ('text/x-gooddata-cl',)),
|
||||
'GosuLexer': ('pygments.lexers.jvm', 'Gosu', ('gosu',), ('*.gs', '*.gsx', '*.gsp', '*.vark'), ('text/x-gosu',)),
|
||||
'GosuTemplateLexer': ('pygments.lexers.jvm', 'Gosu Template', ('gst',), ('*.gst',), ('text/x-gosu-template',)),
|
||||
'GroffLexer': ('pygments.lexers.markup', 'Groff', ('groff', 'nroff', 'man'), ('*.[1234567]', '*.man'), ('application/x-troff', 'text/troff')),
|
||||
'GroovyLexer': ('pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy',), ('text/x-groovy',)),
|
||||
'HamlLexer': ('pygments.lexers.html', 'Haml', ('haml',), ('*.haml',), ('text/x-haml',)),
|
||||
'HandlebarsHtmlLexer': ('pygments.lexers.templates', 'HTML+Handlebars', ('html+handlebars',), ('*.handlebars', '*.hbs'), ('text/html+handlebars', 'text/x-handlebars-template')),
|
||||
'HandlebarsLexer': ('pygments.lexers.templates', 'Handlebars', ('handlebars',), (), ()),
|
||||
'HaskellLexer': ('pygments.lexers.haskell', 'Haskell', ('haskell', 'hs'), ('*.hs',), ('text/x-haskell',)),
|
||||
'HaxeLexer': ('pygments.lexers.haxe', 'Haxe', ('hx', 'haxe', 'hxsl'), ('*.hx', '*.hxsl'), ('text/haxe', 'text/x-haxe', 'text/x-hx')),
|
||||
'HtmlDjangoLexer': ('pygments.lexers.templates', 'HTML+Django/Jinja', ('html+django', 'html+jinja', 'htmldjango'), (), ('text/html+django', 'text/html+jinja')),
|
||||
'HtmlGenshiLexer': ('pygments.lexers.templates', 'HTML+Genshi', ('html+genshi', 'html+kid'), (), ('text/html+genshi',)),
|
||||
'HtmlLexer': ('pygments.lexers.html', 'HTML', ('html',), ('*.html', '*.htm', '*.xhtml', '*.xslt'), ('text/html', 'application/xhtml+xml')),
|
||||
'HtmlPhpLexer': ('pygments.lexers.templates', 'HTML+PHP', ('html+php',), ('*.phtml',), ('application/x-php', 'application/x-httpd-php', 'application/x-httpd-php3', 'application/x-httpd-php4', 'application/x-httpd-php5')),
|
||||
'HtmlSmartyLexer': ('pygments.lexers.templates', 'HTML+Smarty', ('html+smarty',), (), ('text/html+smarty',)),
|
||||
'HttpLexer': ('pygments.lexers.textfmts', 'HTTP', ('http',), (), ()),
|
||||
'HxmlLexer': ('pygments.lexers.haxe', 'Hxml', ('haxeml', 'hxml'), ('*.hxml',), ()),
|
||||
'HyLexer': ('pygments.lexers.lisp', 'Hy', ('hylang',), ('*.hy',), ('text/x-hy', 'application/x-hy')),
|
||||
'HybrisLexer': ('pygments.lexers.scripting', 'Hybris', ('hybris', 'hy'), ('*.hy', '*.hyb'), ('text/x-hybris', 'application/x-hybris')),
|
||||
'IDLLexer': ('pygments.lexers.idl', 'IDL', ('idl',), ('*.pro',), ('text/idl',)),
|
||||
'IdrisLexer': ('pygments.lexers.haskell', 'Idris', ('idris', 'idr'), ('*.idr',), ('text/x-idris',)),
|
||||
'IgorLexer': ('pygments.lexers.igor', 'Igor', ('igor', 'igorpro'), ('*.ipf',), ('text/ipf',)),
|
||||
'Inform6Lexer': ('pygments.lexers.int_fiction', 'Inform 6', ('inform6', 'i6'), ('*.inf',), ()),
|
||||
'Inform6TemplateLexer': ('pygments.lexers.int_fiction', 'Inform 6 template', ('i6t',), ('*.i6t',), ()),
|
||||
'Inform7Lexer': ('pygments.lexers.int_fiction', 'Inform 7', ('inform7', 'i7'), ('*.ni', '*.i7x'), ()),
|
||||
'IniLexer': ('pygments.lexers.configs', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg'), ('text/x-ini',)),
|
||||
'IoLexer': ('pygments.lexers.iolang', 'Io', ('io',), ('*.io',), ('text/x-iosrc',)),
|
||||
'IokeLexer': ('pygments.lexers.jvm', 'Ioke', ('ioke', 'ik'), ('*.ik',), ('text/x-iokesrc',)),
|
||||
'IrcLogsLexer': ('pygments.lexers.textfmts', 'IRC logs', ('irc',), ('*.weechatlog',), ('text/x-irclog',)),
|
||||
'IsabelleLexer': ('pygments.lexers.theorem', 'Isabelle', ('isabelle',), ('*.thy',), ('text/x-isabelle',)),
|
||||
'JadeLexer': ('pygments.lexers.html', 'Jade', ('jade',), ('*.jade',), ('text/x-jade',)),
|
||||
'JagsLexer': ('pygments.lexers.modeling', 'JAGS', ('jags',), ('*.jag', '*.bug'), ()),
|
||||
'JasminLexer': ('pygments.lexers.jvm', 'Jasmin', ('jasmin', 'jasminxt'), ('*.j',), ()),
|
||||
'JavaLexer': ('pygments.lexers.jvm', 'Java', ('java',), ('*.java',), ('text/x-java',)),
|
||||
'JavascriptDjangoLexer': ('pygments.lexers.templates', 'JavaScript+Django/Jinja', ('js+django', 'javascript+django', 'js+jinja', 'javascript+jinja'), (), ('application/x-javascript+django', 'application/x-javascript+jinja', 'text/x-javascript+django', 'text/x-javascript+jinja', 'text/javascript+django', 'text/javascript+jinja')),
|
||||
'JavascriptErbLexer': ('pygments.lexers.templates', 'JavaScript+Ruby', ('js+erb', 'javascript+erb', 'js+ruby', 'javascript+ruby'), (), ('application/x-javascript+ruby', 'text/x-javascript+ruby', 'text/javascript+ruby')),
|
||||
'JavascriptGenshiLexer': ('pygments.lexers.templates', 'JavaScript+Genshi Text', ('js+genshitext', 'js+genshi', 'javascript+genshitext', 'javascript+genshi'), (), ('application/x-javascript+genshi', 'text/x-javascript+genshi', 'text/javascript+genshi')),
|
||||
'JavascriptLexer': ('pygments.lexers.javascript', 'JavaScript', ('js', 'javascript'), ('*.js',), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
|
||||
'JavascriptPhpLexer': ('pygments.lexers.templates', 'JavaScript+PHP', ('js+php', 'javascript+php'), (), ('application/x-javascript+php', 'text/x-javascript+php', 'text/javascript+php')),
|
||||
'JavascriptSmartyLexer': ('pygments.lexers.templates', 'JavaScript+Smarty', ('js+smarty', 'javascript+smarty'), (), ('application/x-javascript+smarty', 'text/x-javascript+smarty', 'text/javascript+smarty')),
|
||||
'JsonLdLexer': ('pygments.lexers.data', 'JSON-LD', ('jsonld', 'json-ld'), ('*.jsonld',), ('application/ld+json',)),
|
||||
'JsonLexer': ('pygments.lexers.data', 'JSON', ('json',), ('*.json',), ('application/json',)),
|
||||
'JspLexer': ('pygments.lexers.templates', 'Java Server Page', ('jsp',), ('*.jsp',), ('application/x-jsp',)),
|
||||
'JuliaConsoleLexer': ('pygments.lexers.julia', 'Julia console', ('jlcon',), (), ()),
|
||||
'JuliaLexer': ('pygments.lexers.julia', 'Julia', ('julia', 'jl'), ('*.jl',), ('text/x-julia', 'application/x-julia')),
|
||||
'KalLexer': ('pygments.lexers.javascript', 'Kal', ('kal',), ('*.kal',), ('text/kal', 'application/kal')),
|
||||
'KconfigLexer': ('pygments.lexers.configs', 'Kconfig', ('kconfig', 'menuconfig', 'linux-config', 'kernel-config'), ('Kconfig', '*Config.in*', 'external.in*', 'standard-modules.in'), ('text/x-kconfig',)),
|
||||
'KokaLexer': ('pygments.lexers.haskell', 'Koka', ('koka',), ('*.kk', '*.kki'), ('text/x-koka',)),
|
||||
'KotlinLexer': ('pygments.lexers.jvm', 'Kotlin', ('kotlin',), ('*.kt',), ('text/x-kotlin',)),
|
||||
'LSLLexer': ('pygments.lexers.scripting', 'LSL', ('lsl',), ('*.lsl',), ('text/x-lsl',)),
|
||||
'LassoCssLexer': ('pygments.lexers.templates', 'CSS+Lasso', ('css+lasso',), (), ('text/css+lasso',)),
|
||||
'LassoHtmlLexer': ('pygments.lexers.templates', 'HTML+Lasso', ('html+lasso',), (), ('text/html+lasso', 'application/x-httpd-lasso', 'application/x-httpd-lasso[89]')),
|
||||
'LassoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Lasso', ('js+lasso', 'javascript+lasso'), (), ('application/x-javascript+lasso', 'text/x-javascript+lasso', 'text/javascript+lasso')),
|
||||
'LassoLexer': ('pygments.lexers.javascript', 'Lasso', ('lasso', 'lassoscript'), ('*.lasso', '*.lasso[89]'), ('text/x-lasso',)),
|
||||
'LassoXmlLexer': ('pygments.lexers.templates', 'XML+Lasso', ('xml+lasso',), (), ('application/xml+lasso',)),
|
||||
'LeanLexer': ('pygments.lexers.theorem', 'Lean', ('lean',), ('*.lean',), ('text/x-lean',)),
|
||||
'LighttpdConfLexer': ('pygments.lexers.configs', 'Lighttpd configuration file', ('lighty', 'lighttpd'), (), ('text/x-lighttpd-conf',)),
|
||||
'LimboLexer': ('pygments.lexers.inferno', 'Limbo', ('limbo',), ('*.b',), ('text/limbo',)),
|
||||
'LiquidLexer': ('pygments.lexers.templates', 'liquid', ('liquid',), ('*.liquid',), ()),
|
||||
'LiterateAgdaLexer': ('pygments.lexers.haskell', 'Literate Agda', ('lagda', 'literate-agda'), ('*.lagda',), ('text/x-literate-agda',)),
|
||||
'LiterateCryptolLexer': ('pygments.lexers.haskell', 'Literate Cryptol', ('lcry', 'literate-cryptol', 'lcryptol'), ('*.lcry',), ('text/x-literate-cryptol',)),
|
||||
'LiterateHaskellLexer': ('pygments.lexers.haskell', 'Literate Haskell', ('lhs', 'literate-haskell', 'lhaskell'), ('*.lhs',), ('text/x-literate-haskell',)),
|
||||
'LiterateIdrisLexer': ('pygments.lexers.haskell', 'Literate Idris', ('lidr', 'literate-idris', 'lidris'), ('*.lidr',), ('text/x-literate-idris',)),
|
||||
'LiveScriptLexer': ('pygments.lexers.javascript', 'LiveScript', ('live-script', 'livescript'), ('*.ls',), ('text/livescript',)),
|
||||
'LlvmLexer': ('pygments.lexers.asm', 'LLVM', ('llvm',), ('*.ll',), ('text/x-llvm',)),
|
||||
'LogosLexer': ('pygments.lexers.objective', 'Logos', ('logos',), ('*.x', '*.xi', '*.xm', '*.xmi'), ('text/x-logos',)),
|
||||
'LogtalkLexer': ('pygments.lexers.prolog', 'Logtalk', ('logtalk',), ('*.lgt', '*.logtalk'), ('text/x-logtalk',)),
|
||||
'LuaLexer': ('pygments.lexers.scripting', 'Lua', ('lua',), ('*.lua', '*.wlua'), ('text/x-lua', 'application/x-lua')),
|
||||
'MOOCodeLexer': ('pygments.lexers.scripting', 'MOOCode', ('moocode', 'moo'), ('*.moo',), ('text/x-moocode',)),
|
||||
'MakefileLexer': ('pygments.lexers.make', 'Makefile', ('make', 'makefile', 'mf', 'bsdmake'), ('*.mak', '*.mk', 'Makefile', 'makefile', 'Makefile.*', 'GNUmakefile'), ('text/x-makefile',)),
|
||||
'MakoCssLexer': ('pygments.lexers.templates', 'CSS+Mako', ('css+mako',), (), ('text/css+mako',)),
|
||||
'MakoHtmlLexer': ('pygments.lexers.templates', 'HTML+Mako', ('html+mako',), (), ('text/html+mako',)),
|
||||
'MakoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Mako', ('js+mako', 'javascript+mako'), (), ('application/x-javascript+mako', 'text/x-javascript+mako', 'text/javascript+mako')),
|
||||
'MakoLexer': ('pygments.lexers.templates', 'Mako', ('mako',), ('*.mao',), ('application/x-mako',)),
|
||||
'MakoXmlLexer': ('pygments.lexers.templates', 'XML+Mako', ('xml+mako',), (), ('application/xml+mako',)),
|
||||
'MaqlLexer': ('pygments.lexers.business', 'MAQL', ('maql',), ('*.maql',), ('text/x-gooddata-maql', 'application/x-gooddata-maql')),
|
||||
'MaskLexer': ('pygments.lexers.javascript', 'Mask', ('mask',), ('*.mask',), ('text/x-mask',)),
|
||||
'MasonLexer': ('pygments.lexers.templates', 'Mason', ('mason',), ('*.m', '*.mhtml', '*.mc', '*.mi', 'autohandler', 'dhandler'), ('application/x-mason',)),
|
||||
'MathematicaLexer': ('pygments.lexers.algebra', 'Mathematica', ('mathematica', 'mma', 'nb'), ('*.nb', '*.cdf', '*.nbp', '*.ma'), ('application/mathematica', 'application/vnd.wolfram.mathematica', 'application/vnd.wolfram.mathematica.package', 'application/vnd.wolfram.cdf')),
|
||||
'MatlabLexer': ('pygments.lexers.matlab', 'Matlab', ('matlab',), ('*.m',), ('text/matlab',)),
|
||||
'MatlabSessionLexer': ('pygments.lexers.matlab', 'Matlab session', ('matlabsession',), (), ()),
|
||||
'MiniDLexer': ('pygments.lexers.d', 'MiniD', ('minid',), (), ('text/x-minidsrc',)),
|
||||
'ModelicaLexer': ('pygments.lexers.modeling', 'Modelica', ('modelica',), ('*.mo',), ('text/x-modelica',)),
|
||||
'Modula2Lexer': ('pygments.lexers.pascal', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
|
||||
'MoinWikiLexer': ('pygments.lexers.markup', 'MoinMoin/Trac Wiki markup', ('trac-wiki', 'moin'), (), ('text/x-trac-wiki',)),
|
||||
'MonkeyLexer': ('pygments.lexers.basic', 'Monkey', ('monkey',), ('*.monkey',), ('text/x-monkey',)),
|
||||
'MoonScriptLexer': ('pygments.lexers.scripting', 'MoonScript', ('moon', 'moonscript'), ('*.moon',), ('text/x-moonscript', 'application/x-moonscript')),
|
||||
'MozPreprocCssLexer': ('pygments.lexers.markup', 'CSS+mozpreproc', ('css+mozpreproc',), ('*.css.in',), ()),
|
||||
'MozPreprocHashLexer': ('pygments.lexers.markup', 'mozhashpreproc', ('mozhashpreproc',), (), ()),
|
||||
'MozPreprocJavascriptLexer': ('pygments.lexers.markup', 'Javascript+mozpreproc', ('javascript+mozpreproc',), ('*.js.in',), ()),
|
||||
'MozPreprocPercentLexer': ('pygments.lexers.markup', 'mozpercentpreproc', ('mozpercentpreproc',), (), ()),
|
||||
'MozPreprocXulLexer': ('pygments.lexers.markup', 'XUL+mozpreproc', ('xul+mozpreproc',), ('*.xul.in',), ()),
|
||||
'MqlLexer': ('pygments.lexers.c_like', 'MQL', ('mql', 'mq4', 'mq5', 'mql4', 'mql5'), ('*.mq4', '*.mq5', '*.mqh'), ('text/x-mql',)),
|
||||
'MscgenLexer': ('pygments.lexers.dsls', 'Mscgen', ('mscgen', 'msc'), ('*.msc',), ()),
|
||||
'MuPADLexer': ('pygments.lexers.algebra', 'MuPAD', ('mupad',), ('*.mu',), ()),
|
||||
'MxmlLexer': ('pygments.lexers.actionscript', 'MXML', ('mxml',), ('*.mxml',), ()),
|
||||
'MySqlLexer': ('pygments.lexers.sql', 'MySQL', ('mysql',), (), ('text/x-mysql',)),
|
||||
'MyghtyCssLexer': ('pygments.lexers.templates', 'CSS+Myghty', ('css+myghty',), (), ('text/css+myghty',)),
|
||||
'MyghtyHtmlLexer': ('pygments.lexers.templates', 'HTML+Myghty', ('html+myghty',), (), ('text/html+myghty',)),
|
||||
'MyghtyJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Myghty', ('js+myghty', 'javascript+myghty'), (), ('application/x-javascript+myghty', 'text/x-javascript+myghty', 'text/javascript+mygthy')),
|
||||
'MyghtyLexer': ('pygments.lexers.templates', 'Myghty', ('myghty',), ('*.myt', 'autodelegate'), ('application/x-myghty',)),
|
||||
'MyghtyXmlLexer': ('pygments.lexers.templates', 'XML+Myghty', ('xml+myghty',), (), ('application/xml+myghty',)),
|
||||
'NSISLexer': ('pygments.lexers.installers', 'NSIS', ('nsis', 'nsi', 'nsh'), ('*.nsi', '*.nsh'), ('text/x-nsis',)),
|
||||
'NasmLexer': ('pygments.lexers.asm', 'NASM', ('nasm',), ('*.asm', '*.ASM'), ('text/x-nasm',)),
|
||||
'NasmObjdumpLexer': ('pygments.lexers.asm', 'objdump-nasm', ('objdump-nasm',), ('*.objdump-intel',), ('text/x-nasm-objdump',)),
|
||||
'NemerleLexer': ('pygments.lexers.dotnet', 'Nemerle', ('nemerle',), ('*.n',), ('text/x-nemerle',)),
|
||||
'NesCLexer': ('pygments.lexers.c_like', 'nesC', ('nesc',), ('*.nc',), ('text/x-nescsrc',)),
|
||||
'NewLispLexer': ('pygments.lexers.lisp', 'NewLisp', ('newlisp',), ('*.lsp', '*.nl'), ('text/x-newlisp', 'application/x-newlisp')),
|
||||
'NewspeakLexer': ('pygments.lexers.smalltalk', 'Newspeak', ('newspeak',), ('*.ns2',), ('text/x-newspeak',)),
|
||||
'NginxConfLexer': ('pygments.lexers.configs', 'Nginx configuration file', ('nginx',), (), ('text/x-nginx-conf',)),
|
||||
'NimrodLexer': ('pygments.lexers.nimrod', 'Nimrod', ('nimrod', 'nim'), ('*.nim', '*.nimrod'), ('text/x-nimrod',)),
|
||||
'NitLexer': ('pygments.lexers.nit', 'Nit', ('nit',), ('*.nit',), ()),
|
||||
'NixLexer': ('pygments.lexers.nix', 'Nix', ('nixos', 'nix'), ('*.nix',), ('text/x-nix',)),
|
||||
'NumPyLexer': ('pygments.lexers.python', 'NumPy', ('numpy',), (), ()),
|
||||
'ObjdumpLexer': ('pygments.lexers.asm', 'objdump', ('objdump',), ('*.objdump',), ('text/x-objdump',)),
|
||||
'ObjectiveCLexer': ('pygments.lexers.objective', 'Objective-C', ('objective-c', 'objectivec', 'obj-c', 'objc'), ('*.m', '*.h'), ('text/x-objective-c',)),
|
||||
'ObjectiveCppLexer': ('pygments.lexers.objective', 'Objective-C++', ('objective-c++', 'objectivec++', 'obj-c++', 'objc++'), ('*.mm', '*.hh'), ('text/x-objective-c++',)),
|
||||
'ObjectiveJLexer': ('pygments.lexers.javascript', 'Objective-J', ('objective-j', 'objectivej', 'obj-j', 'objj'), ('*.j',), ('text/x-objective-j',)),
|
||||
'OcamlLexer': ('pygments.lexers.ml', 'OCaml', ('ocaml',), ('*.ml', '*.mli', '*.mll', '*.mly'), ('text/x-ocaml',)),
|
||||
'OctaveLexer': ('pygments.lexers.matlab', 'Octave', ('octave',), ('*.m',), ('text/octave',)),
|
||||
'OocLexer': ('pygments.lexers.ooc', 'Ooc', ('ooc',), ('*.ooc',), ('text/x-ooc',)),
|
||||
'OpaLexer': ('pygments.lexers.ml', 'Opa', ('opa',), ('*.opa',), ('text/x-opa',)),
|
||||
'OpenEdgeLexer': ('pygments.lexers.business', 'OpenEdge ABL', ('openedge', 'abl', 'progress'), ('*.p', '*.cls'), ('text/x-openedge', 'application/x-openedge')),
|
||||
'PanLexer': ('pygments.lexers.dsls', 'Pan', ('pan',), ('*.pan',), ()),
|
||||
'PawnLexer': ('pygments.lexers.pawn', 'Pawn', ('pawn',), ('*.p', '*.pwn', '*.inc'), ('text/x-pawn',)),
|
||||
'Perl6Lexer': ('pygments.lexers.perl', 'Perl6', ('perl6', 'pl6'), ('*.pl', '*.pm', '*.nqp', '*.p6', '*.6pl', '*.p6l', '*.pl6', '*.6pm', '*.p6m', '*.pm6', '*.t'), ('text/x-perl6', 'application/x-perl6')),
|
||||
'PerlLexer': ('pygments.lexers.perl', 'Perl', ('perl', 'pl'), ('*.pl', '*.pm', '*.t'), ('text/x-perl', 'application/x-perl')),
|
||||
'PhpLexer': ('pygments.lexers.php', 'PHP', ('php', 'php3', 'php4', 'php5'), ('*.php', '*.php[345]', '*.inc'), ('text/x-php',)),
|
||||
'PigLexer': ('pygments.lexers.jvm', 'Pig', ('pig',), ('*.pig',), ('text/x-pig',)),
|
||||
'PikeLexer': ('pygments.lexers.c_like', 'Pike', ('pike',), ('*.pike', '*.pmod'), ('text/x-pike',)),
|
||||
'PlPgsqlLexer': ('pygments.lexers.sql', 'PL/pgSQL', ('plpgsql',), (), ('text/x-plpgsql',)),
|
||||
'PostScriptLexer': ('pygments.lexers.graphics', 'PostScript', ('postscript', 'postscr'), ('*.ps', '*.eps'), ('application/postscript',)),
|
||||
'PostgresConsoleLexer': ('pygments.lexers.sql', 'PostgreSQL console (psql)', ('psql', 'postgresql-console', 'postgres-console'), (), ('text/x-postgresql-psql',)),
|
||||
'PostgresLexer': ('pygments.lexers.sql', 'PostgreSQL SQL dialect', ('postgresql', 'postgres'), (), ('text/x-postgresql',)),
|
||||
'PovrayLexer': ('pygments.lexers.graphics', 'POVRay', ('pov',), ('*.pov', '*.inc'), ('text/x-povray',)),
|
||||
'PowerShellLexer': ('pygments.lexers.shell', 'PowerShell', ('powershell', 'posh', 'ps1', 'psm1'), ('*.ps1', '*.psm1'), ('text/x-powershell',)),
|
||||
'PrologLexer': ('pygments.lexers.prolog', 'Prolog', ('prolog',), ('*.ecl', '*.prolog', '*.pro', '*.pl'), ('text/x-prolog',)),
|
||||
'PropertiesLexer': ('pygments.lexers.configs', 'Properties', ('properties', 'jproperties'), ('*.properties',), ('text/x-java-properties',)),
|
||||
'ProtoBufLexer': ('pygments.lexers.dsls', 'Protocol Buffer', ('protobuf', 'proto'), ('*.proto',), ()),
|
||||
'PuppetLexer': ('pygments.lexers.dsls', 'Puppet', ('puppet',), ('*.pp',), ()),
|
||||
'PyPyLogLexer': ('pygments.lexers.console', 'PyPy Log', ('pypylog', 'pypy'), ('*.pypylog',), ('application/x-pypylog',)),
|
||||
'Python3Lexer': ('pygments.lexers.python', 'Python 3', ('python3', 'py3'), (), ('text/x-python3', 'application/x-python3')),
|
||||
'Python3TracebackLexer': ('pygments.lexers.python', 'Python 3.0 Traceback', ('py3tb',), ('*.py3tb',), ('text/x-python3-traceback',)),
|
||||
'PythonConsoleLexer': ('pygments.lexers.python', 'Python console session', ('pycon',), (), ('text/x-python-doctest',)),
|
||||
'PythonLexer': ('pygments.lexers.python', 'Python', ('python', 'py', 'sage'), ('*.py', '*.pyw', '*.sc', 'SConstruct', 'SConscript', '*.tac', '*.sage'), ('text/x-python', 'application/x-python')),
|
||||
'PythonTracebackLexer': ('pygments.lexers.python', 'Python Traceback', ('pytb',), ('*.pytb',), ('text/x-python-traceback',)),
|
||||
'QBasicLexer': ('pygments.lexers.basic', 'QBasic', ('qbasic', 'basic'), ('*.BAS', '*.bas'), ('text/basic',)),
|
||||
'QmlLexer': ('pygments.lexers.webmisc', 'QML', ('qml',), ('*.qml',), ('application/x-qml',)),
|
||||
'RConsoleLexer': ('pygments.lexers.r', 'RConsole', ('rconsole', 'rout'), ('*.Rout',), ()),
|
||||
'RPMSpecLexer': ('pygments.lexers.installers', 'RPMSpec', ('spec',), ('*.spec',), ('text/x-rpm-spec',)),
|
||||
'RacketLexer': ('pygments.lexers.lisp', 'Racket', ('racket', 'rkt'), ('*.rkt', '*.rktd', '*.rktl'), ('text/x-racket', 'application/x-racket')),
|
||||
'RagelCLexer': ('pygments.lexers.parsers', 'Ragel in C Host', ('ragel-c',), ('*.rl',), ()),
|
||||
'RagelCppLexer': ('pygments.lexers.parsers', 'Ragel in CPP Host', ('ragel-cpp',), ('*.rl',), ()),
|
||||
'RagelDLexer': ('pygments.lexers.parsers', 'Ragel in D Host', ('ragel-d',), ('*.rl',), ()),
|
||||
'RagelEmbeddedLexer': ('pygments.lexers.parsers', 'Embedded Ragel', ('ragel-em',), ('*.rl',), ()),
|
||||
'RagelJavaLexer': ('pygments.lexers.parsers', 'Ragel in Java Host', ('ragel-java',), ('*.rl',), ()),
|
||||
'RagelLexer': ('pygments.lexers.parsers', 'Ragel', ('ragel',), (), ()),
|
||||
'RagelObjectiveCLexer': ('pygments.lexers.parsers', 'Ragel in Objective C Host', ('ragel-objc',), ('*.rl',), ()),
|
||||
'RagelRubyLexer': ('pygments.lexers.parsers', 'Ragel in Ruby Host', ('ragel-ruby', 'ragel-rb'), ('*.rl',), ()),
|
||||
'RawTokenLexer': ('pygments.lexers.special', 'Raw token data', ('raw',), (), ('application/x-pygments-tokens',)),
|
||||
'RdLexer': ('pygments.lexers.r', 'Rd', ('rd',), ('*.Rd',), ('text/x-r-doc',)),
|
||||
'RebolLexer': ('pygments.lexers.rebol', 'REBOL', ('rebol',), ('*.r', '*.r3', '*.reb'), ('text/x-rebol',)),
|
||||
'RedLexer': ('pygments.lexers.rebol', 'Red', ('red', 'red/system'), ('*.red', '*.reds'), ('text/x-red', 'text/x-red-system')),
|
||||
'RedcodeLexer': ('pygments.lexers.esoteric', 'Redcode', ('redcode',), ('*.cw',), ()),
|
||||
'RegeditLexer': ('pygments.lexers.configs', 'reg', ('registry',), ('*.reg',), ('text/x-windows-registry',)),
|
||||
'ResourceLexer': ('pygments.lexers.resource', 'ResourceBundle', ('resource', 'resourcebundle'), ('*.txt',), ()),
|
||||
'RexxLexer': ('pygments.lexers.scripting', 'Rexx', ('rexx', 'arexx'), ('*.rexx', '*.rex', '*.rx', '*.arexx'), ('text/x-rexx',)),
|
||||
'RhtmlLexer': ('pygments.lexers.templates', 'RHTML', ('rhtml', 'html+erb', 'html+ruby'), ('*.rhtml',), ('text/html+ruby',)),
|
||||
'RobotFrameworkLexer': ('pygments.lexers.robotframework', 'RobotFramework', ('robotframework',), ('*.txt', '*.robot'), ('text/x-robotframework',)),
|
||||
'RqlLexer': ('pygments.lexers.sql', 'RQL', ('rql',), ('*.rql',), ('text/x-rql',)),
|
||||
'RslLexer': ('pygments.lexers.dsls', 'RSL', ('rsl',), ('*.rsl',), ('text/rsl',)),
|
||||
'RstLexer': ('pygments.lexers.markup', 'reStructuredText', ('rst', 'rest', 'restructuredtext'), ('*.rst', '*.rest'), ('text/x-rst', 'text/prs.fallenstein.rst')),
|
||||
'RubyConsoleLexer': ('pygments.lexers.ruby', 'Ruby irb session', ('rbcon', 'irb'), (), ('text/x-ruby-shellsession',)),
|
||||
'RubyLexer': ('pygments.lexers.ruby', 'Ruby', ('rb', 'ruby', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby'), ('text/x-ruby', 'application/x-ruby')),
|
||||
'RustLexer': ('pygments.lexers.rust', 'Rust', ('rust',), ('*.rs',), ('text/x-rustsrc',)),
|
||||
'SLexer': ('pygments.lexers.r', 'S', ('splus', 's', 'r'), ('*.S', '*.R', '.Rhistory', '.Rprofile', '.Renviron'), ('text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r', 'text/x-R', 'text/x-r-history', 'text/x-r-profile')),
|
||||
'SMLLexer': ('pygments.lexers.ml', 'Standard ML', ('sml',), ('*.sml', '*.sig', '*.fun'), ('text/x-standardml', 'application/x-standardml')),
|
||||
'SassLexer': ('pygments.lexers.css', 'Sass', ('sass',), ('*.sass',), ('text/x-sass',)),
|
||||
'ScalaLexer': ('pygments.lexers.jvm', 'Scala', ('scala',), ('*.scala',), ('text/x-scala',)),
|
||||
'ScamlLexer': ('pygments.lexers.html', 'Scaml', ('scaml',), ('*.scaml',), ('text/x-scaml',)),
|
||||
'SchemeLexer': ('pygments.lexers.lisp', 'Scheme', ('scheme', 'scm'), ('*.scm', '*.ss'), ('text/x-scheme', 'application/x-scheme')),
|
||||
'ScilabLexer': ('pygments.lexers.matlab', 'Scilab', ('scilab',), ('*.sci', '*.sce', '*.tst'), ('text/scilab',)),
|
||||
'ScssLexer': ('pygments.lexers.css', 'SCSS', ('scss',), ('*.scss',), ('text/x-scss',)),
|
||||
'ShellSessionLexer': ('pygments.lexers.shell', 'Shell Session', ('shell-session',), ('*.shell-session',), ('application/x-sh-session',)),
|
||||
'SlimLexer': ('pygments.lexers.webmisc', 'Slim', ('slim',), ('*.slim',), ('text/x-slim',)),
|
||||
'SmaliLexer': ('pygments.lexers.dalvik', 'Smali', ('smali',), ('*.smali',), ('text/smali',)),
|
||||
'SmalltalkLexer': ('pygments.lexers.smalltalk', 'Smalltalk', ('smalltalk', 'squeak', 'st'), ('*.st',), ('text/x-smalltalk',)),
|
||||
'SmartyLexer': ('pygments.lexers.templates', 'Smarty', ('smarty',), ('*.tpl',), ('application/x-smarty',)),
|
||||
'SnobolLexer': ('pygments.lexers.snobol', 'Snobol', ('snobol',), ('*.snobol',), ('text/x-snobol',)),
|
||||
'SourcePawnLexer': ('pygments.lexers.pawn', 'SourcePawn', ('sp',), ('*.sp',), ('text/x-sourcepawn',)),
|
||||
'SourcesListLexer': ('pygments.lexers.installers', 'Debian Sourcelist', ('sourceslist', 'sources.list', 'debsources'), ('sources.list',), ()),
|
||||
'SparqlLexer': ('pygments.lexers.rdf', 'SPARQL', ('sparql',), ('*.rq', '*.sparql'), ('application/sparql-query',)),
|
||||
'SqlLexer': ('pygments.lexers.sql', 'SQL', ('sql',), ('*.sql',), ('text/x-sql',)),
|
||||
'SqliteConsoleLexer': ('pygments.lexers.sql', 'sqlite3con', ('sqlite3',), ('*.sqlite3-console',), ('text/x-sqlite3-console',)),
|
||||
'SquidConfLexer': ('pygments.lexers.configs', 'SquidConf', ('squidconf', 'squid.conf', 'squid'), ('squid.conf',), ('text/x-squidconf',)),
|
||||
'SspLexer': ('pygments.lexers.templates', 'Scalate Server Page', ('ssp',), ('*.ssp',), ('application/x-ssp',)),
|
||||
'StanLexer': ('pygments.lexers.modeling', 'Stan', ('stan',), ('*.stan',), ()),
|
||||
'SwiftLexer': ('pygments.lexers.objective', 'Swift', ('swift',), ('*.swift',), ('text/x-swift',)),
|
||||
'SwigLexer': ('pygments.lexers.c_like', 'SWIG', ('swig',), ('*.swg', '*.i'), ('text/swig',)),
|
||||
'SystemVerilogLexer': ('pygments.lexers.hdl', 'systemverilog', ('systemverilog', 'sv'), ('*.sv', '*.svh'), ('text/x-systemverilog',)),
|
||||
'Tads3Lexer': ('pygments.lexers.int_fiction', 'TADS 3', ('tads3',), ('*.t',), ()),
|
||||
'TclLexer': ('pygments.lexers.tcl', 'Tcl', ('tcl',), ('*.tcl', '*.rvt'), ('text/x-tcl', 'text/x-script.tcl', 'application/x-tcl')),
|
||||
'TcshLexer': ('pygments.lexers.shell', 'Tcsh', ('tcsh', 'csh'), ('*.tcsh', '*.csh'), ('application/x-csh',)),
|
||||
'TeaTemplateLexer': ('pygments.lexers.templates', 'Tea', ('tea',), ('*.tea',), ('text/x-tea',)),
|
||||
'TexLexer': ('pygments.lexers.markup', 'TeX', ('tex', 'latex'), ('*.tex', '*.aux', '*.toc'), ('text/x-tex', 'text/x-latex')),
|
||||
'TextLexer': ('pygments.lexers.special', 'Text only', ('text',), ('*.txt',), ('text/plain',)),
|
||||
'TodotxtLexer': ('pygments.lexers.textfmts', 'Todotxt', ('todotxt',), ('todo.txt', '*.todotxt'), ('text/x-todo',)),
|
||||
'TreetopLexer': ('pygments.lexers.parsers', 'Treetop', ('treetop',), ('*.treetop', '*.tt'), ()),
|
||||
'TwigHtmlLexer': ('pygments.lexers.templates', 'HTML+Twig', ('html+twig',), ('*.twig',), ('text/html+twig',)),
|
||||
'TwigLexer': ('pygments.lexers.templates', 'Twig', ('twig',), (), ('application/x-twig',)),
|
||||
'TypeScriptLexer': ('pygments.lexers.javascript', 'TypeScript', ('ts',), ('*.ts',), ('text/x-typescript',)),
|
||||
'UrbiscriptLexer': ('pygments.lexers.urbi', 'UrbiScript', ('urbiscript',), ('*.u',), ('application/x-urbiscript',)),
|
||||
'VCTreeStatusLexer': ('pygments.lexers.console', 'VCTreeStatus', ('vctreestatus',), (), ()),
|
||||
'VGLLexer': ('pygments.lexers.dsls', 'VGL', ('vgl',), ('*.rpf',), ()),
|
||||
'ValaLexer': ('pygments.lexers.c_like', 'Vala', ('vala', 'vapi'), ('*.vala', '*.vapi'), ('text/x-vala',)),
|
||||
'VbNetAspxLexer': ('pygments.lexers.dotnet', 'aspx-vb', ('aspx-vb',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'VbNetLexer': ('pygments.lexers.dotnet', 'VB.net', ('vb.net', 'vbnet'), ('*.vb', '*.bas'), ('text/x-vbnet', 'text/x-vba')),
|
||||
'VelocityHtmlLexer': ('pygments.lexers.templates', 'HTML+Velocity', ('html+velocity',), (), ('text/html+velocity',)),
|
||||
'VelocityLexer': ('pygments.lexers.templates', 'Velocity', ('velocity',), ('*.vm', '*.fhtml'), ()),
|
||||
'VelocityXmlLexer': ('pygments.lexers.templates', 'XML+Velocity', ('xml+velocity',), (), ('application/xml+velocity',)),
|
||||
'VerilogLexer': ('pygments.lexers.hdl', 'verilog', ('verilog', 'v'), ('*.v',), ('text/x-verilog',)),
|
||||
'VhdlLexer': ('pygments.lexers.hdl', 'vhdl', ('vhdl',), ('*.vhdl', '*.vhd'), ('text/x-vhdl',)),
|
||||
'VimLexer': ('pygments.lexers.textedit', 'VimL', ('vim',), ('*.vim', '.vimrc', '.exrc', '.gvimrc', '_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc'), ('text/x-vim',)),
|
||||
'XQueryLexer': ('pygments.lexers.webmisc', 'XQuery', ('xquery', 'xqy', 'xq', 'xql', 'xqm'), ('*.xqy', '*.xquery', '*.xq', '*.xql', '*.xqm'), ('text/xquery', 'application/xquery')),
|
||||
'XmlDjangoLexer': ('pygments.lexers.templates', 'XML+Django/Jinja', ('xml+django', 'xml+jinja'), (), ('application/xml+django', 'application/xml+jinja')),
|
||||
'XmlErbLexer': ('pygments.lexers.templates', 'XML+Ruby', ('xml+erb', 'xml+ruby'), (), ('application/xml+ruby',)),
|
||||
'XmlLexer': ('pygments.lexers.html', 'XML', ('xml',), ('*.xml', '*.xsl', '*.rss', '*.xslt', '*.xsd', '*.wsdl', '*.wsf'), ('text/xml', 'application/xml', 'image/svg+xml', 'application/rss+xml', 'application/atom+xml')),
|
||||
'XmlPhpLexer': ('pygments.lexers.templates', 'XML+PHP', ('xml+php',), (), ('application/xml+php',)),
|
||||
'XmlSmartyLexer': ('pygments.lexers.templates', 'XML+Smarty', ('xml+smarty',), (), ('application/xml+smarty',)),
|
||||
'XsltLexer': ('pygments.lexers.html', 'XSLT', ('xslt',), ('*.xsl', '*.xslt', '*.xpl'), ('application/xsl+xml', 'application/xslt+xml')),
|
||||
'XtendLexer': ('pygments.lexers.jvm', 'Xtend', ('xtend',), ('*.xtend',), ('text/x-xtend',)),
|
||||
'YamlJinjaLexer': ('pygments.lexers.templates', 'YAML+Jinja', ('yaml+jinja', 'salt', 'sls'), ('*.sls',), ('text/x-yaml+jinja', 'text/x-sls')),
|
||||
'YamlLexer': ('pygments.lexers.data', 'YAML', ('yaml',), ('*.yaml', '*.yml'), ('text/x-yaml',)),
|
||||
'ZephirLexer': ('pygments.lexers.php', 'Zephir', ('zephir',), ('*.zep',), ()),
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
import os
|
||||
|
||||
# lookup lexers
|
||||
found_lexers = []
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
|
||||
for root, dirs, files in os.walk('.'):
|
||||
for filename in files:
|
||||
if filename.endswith('.py') and not filename.startswith('_'):
|
||||
module_name = 'pygments.lexers%s.%s' % (
|
||||
root[1:].replace('/', '.'), filename[:-3])
|
||||
print(module_name)
|
||||
module = __import__(module_name, None, None, [''])
|
||||
for lexer_name in module.__all__:
|
||||
lexer = getattr(module, lexer_name)
|
||||
found_lexers.append(
|
||||
'%r: %r' % (lexer_name,
|
||||
(module_name,
|
||||
lexer.name,
|
||||
tuple(lexer.aliases),
|
||||
tuple(lexer.filenames),
|
||||
tuple(lexer.mimetypes))))
|
||||
# sort them to make the diff minimal
|
||||
found_lexers.sort()
|
||||
|
||||
# extract useful sourcecode from this file
|
||||
with open(__file__) as fp:
|
||||
content = fp.read()
|
||||
header = content[:content.find('LEXERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
# write new file
|
||||
with open(__file__, 'w') as fp:
|
||||
fp.write(header)
|
||||
fp.write('LEXERS = {\n %s,\n}\n\n' % ',\n '.join(found_lexers))
|
||||
fp.write(footer)
|
||||
|
||||
print ('=== %d lexers processed.' % len(found_lexers))
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,620 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._postgres_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Self-updating data files for PostgreSQL lexer.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
|
||||
# Autogenerated: please edit them if you like wasting your time.
|
||||
|
||||
KEYWORDS = (
|
||||
'ABORT',
|
||||
'ABSOLUTE',
|
||||
'ACCESS',
|
||||
'ACTION',
|
||||
'ADD',
|
||||
'ADMIN',
|
||||
'AFTER',
|
||||
'AGGREGATE',
|
||||
'ALL',
|
||||
'ALSO',
|
||||
'ALTER',
|
||||
'ALWAYS',
|
||||
'ANALYSE',
|
||||
'ANALYZE',
|
||||
'AND',
|
||||
'ANY',
|
||||
'ARRAY',
|
||||
'AS',
|
||||
'ASC',
|
||||
'ASSERTION',
|
||||
'ASSIGNMENT',
|
||||
'ASYMMETRIC',
|
||||
'AT',
|
||||
'ATTRIBUTE',
|
||||
'AUTHORIZATION',
|
||||
'BACKWARD',
|
||||
'BEFORE',
|
||||
'BEGIN',
|
||||
'BETWEEN',
|
||||
'BIGINT',
|
||||
'BINARY',
|
||||
'BIT',
|
||||
'BOOLEAN',
|
||||
'BOTH',
|
||||
'BY',
|
||||
'CACHE',
|
||||
'CALLED',
|
||||
'CASCADE',
|
||||
'CASCADED',
|
||||
'CASE',
|
||||
'CAST',
|
||||
'CATALOG',
|
||||
'CHAIN',
|
||||
'CHAR',
|
||||
'CHARACTER',
|
||||
'CHARACTERISTICS',
|
||||
'CHECK',
|
||||
'CHECKPOINT',
|
||||
'CLASS',
|
||||
'CLOSE',
|
||||
'CLUSTER',
|
||||
'COALESCE',
|
||||
'COLLATE',
|
||||
'COLLATION',
|
||||
'COLUMN',
|
||||
'COMMENT',
|
||||
'COMMENTS',
|
||||
'COMMIT',
|
||||
'COMMITTED',
|
||||
'CONCURRENTLY',
|
||||
'CONFIGURATION',
|
||||
'CONNECTION',
|
||||
'CONSTRAINT',
|
||||
'CONSTRAINTS',
|
||||
'CONTENT',
|
||||
'CONTINUE',
|
||||
'CONVERSION',
|
||||
'COPY',
|
||||
'COST',
|
||||
'CREATE',
|
||||
'CROSS',
|
||||
'CSV',
|
||||
'CURRENT',
|
||||
'CURRENT_CATALOG',
|
||||
'CURRENT_DATE',
|
||||
'CURRENT_ROLE',
|
||||
'CURRENT_SCHEMA',
|
||||
'CURRENT_TIME',
|
||||
'CURRENT_TIMESTAMP',
|
||||
'CURRENT_USER',
|
||||
'CURSOR',
|
||||
'CYCLE',
|
||||
'DATA',
|
||||
'DATABASE',
|
||||
'DAY',
|
||||
'DEALLOCATE',
|
||||
'DEC',
|
||||
'DECIMAL',
|
||||
'DECLARE',
|
||||
'DEFAULT',
|
||||
'DEFAULTS',
|
||||
'DEFERRABLE',
|
||||
'DEFERRED',
|
||||
'DEFINER',
|
||||
'DELETE',
|
||||
'DELIMITER',
|
||||
'DELIMITERS',
|
||||
'DESC',
|
||||
'DICTIONARY',
|
||||
'DISABLE',
|
||||
'DISCARD',
|
||||
'DISTINCT',
|
||||
'DO',
|
||||
'DOCUMENT',
|
||||
'DOMAIN',
|
||||
'DOUBLE',
|
||||
'DROP',
|
||||
'EACH',
|
||||
'ELSE',
|
||||
'ENABLE',
|
||||
'ENCODING',
|
||||
'ENCRYPTED',
|
||||
'END',
|
||||
'ENUM',
|
||||
'ESCAPE',
|
||||
'EVENT',
|
||||
'EXCEPT',
|
||||
'EXCLUDE',
|
||||
'EXCLUDING',
|
||||
'EXCLUSIVE',
|
||||
'EXECUTE',
|
||||
'EXISTS',
|
||||
'EXPLAIN',
|
||||
'EXTENSION',
|
||||
'EXTERNAL',
|
||||
'EXTRACT',
|
||||
'FALSE',
|
||||
'FAMILY',
|
||||
'FETCH',
|
||||
'FILTER',
|
||||
'FIRST',
|
||||
'FLOAT',
|
||||
'FOLLOWING',
|
||||
'FOR',
|
||||
'FORCE',
|
||||
'FOREIGN',
|
||||
'FORWARD',
|
||||
'FREEZE',
|
||||
'FROM',
|
||||
'FULL',
|
||||
'FUNCTION',
|
||||
'FUNCTIONS',
|
||||
'GLOBAL',
|
||||
'GRANT',
|
||||
'GRANTED',
|
||||
'GREATEST',
|
||||
'GROUP',
|
||||
'HANDLER',
|
||||
'HAVING',
|
||||
'HEADER',
|
||||
'HOLD',
|
||||
'HOUR',
|
||||
'IDENTITY',
|
||||
'IF',
|
||||
'ILIKE',
|
||||
'IMMEDIATE',
|
||||
'IMMUTABLE',
|
||||
'IMPLICIT',
|
||||
'IN',
|
||||
'INCLUDING',
|
||||
'INCREMENT',
|
||||
'INDEX',
|
||||
'INDEXES',
|
||||
'INHERIT',
|
||||
'INHERITS',
|
||||
'INITIALLY',
|
||||
'INLINE',
|
||||
'INNER',
|
||||
'INOUT',
|
||||
'INPUT',
|
||||
'INSENSITIVE',
|
||||
'INSERT',
|
||||
'INSTEAD',
|
||||
'INT',
|
||||
'INTEGER',
|
||||
'INTERSECT',
|
||||
'INTERVAL',
|
||||
'INTO',
|
||||
'INVOKER',
|
||||
'IS',
|
||||
'ISNULL',
|
||||
'ISOLATION',
|
||||
'JOIN',
|
||||
'KEY',
|
||||
'LABEL',
|
||||
'LANGUAGE',
|
||||
'LARGE',
|
||||
'LAST',
|
||||
'LATERAL',
|
||||
'LC_COLLATE',
|
||||
'LC_CTYPE',
|
||||
'LEADING',
|
||||
'LEAKPROOF',
|
||||
'LEAST',
|
||||
'LEFT',
|
||||
'LEVEL',
|
||||
'LIKE',
|
||||
'LIMIT',
|
||||
'LISTEN',
|
||||
'LOAD',
|
||||
'LOCAL',
|
||||
'LOCALTIME',
|
||||
'LOCALTIMESTAMP',
|
||||
'LOCATION',
|
||||
'LOCK',
|
||||
'MAPPING',
|
||||
'MATCH',
|
||||
'MATERIALIZED',
|
||||
'MAXVALUE',
|
||||
'MINUTE',
|
||||
'MINVALUE',
|
||||
'MODE',
|
||||
'MONTH',
|
||||
'MOVE',
|
||||
'NAME',
|
||||
'NAMES',
|
||||
'NATIONAL',
|
||||
'NATURAL',
|
||||
'NCHAR',
|
||||
'NEXT',
|
||||
'NO',
|
||||
'NONE',
|
||||
'NOT',
|
||||
'NOTHING',
|
||||
'NOTIFY',
|
||||
'NOTNULL',
|
||||
'NOWAIT',
|
||||
'NULL',
|
||||
'NULLIF',
|
||||
'NULLS',
|
||||
'NUMERIC',
|
||||
'OBJECT',
|
||||
'OF',
|
||||
'OFF',
|
||||
'OFFSET',
|
||||
'OIDS',
|
||||
'ON',
|
||||
'ONLY',
|
||||
'OPERATOR',
|
||||
'OPTION',
|
||||
'OPTIONS',
|
||||
'OR',
|
||||
'ORDER',
|
||||
'ORDINALITY',
|
||||
'OUT',
|
||||
'OUTER',
|
||||
'OVER',
|
||||
'OVERLAPS',
|
||||
'OVERLAY',
|
||||
'OWNED',
|
||||
'OWNER',
|
||||
'PARSER',
|
||||
'PARTIAL',
|
||||
'PARTITION',
|
||||
'PASSING',
|
||||
'PASSWORD',
|
||||
'PLACING',
|
||||
'PLANS',
|
||||
'POLICY',
|
||||
'POSITION',
|
||||
'PRECEDING',
|
||||
'PRECISION',
|
||||
'PREPARE',
|
||||
'PREPARED',
|
||||
'PRESERVE',
|
||||
'PRIMARY',
|
||||
'PRIOR',
|
||||
'PRIVILEGES',
|
||||
'PROCEDURAL',
|
||||
'PROCEDURE',
|
||||
'PROGRAM',
|
||||
'QUOTE',
|
||||
'RANGE',
|
||||
'READ',
|
||||
'REAL',
|
||||
'REASSIGN',
|
||||
'RECHECK',
|
||||
'RECURSIVE',
|
||||
'REF',
|
||||
'REFERENCES',
|
||||
'REFRESH',
|
||||
'REINDEX',
|
||||
'RELATIVE',
|
||||
'RELEASE',
|
||||
'RENAME',
|
||||
'REPEATABLE',
|
||||
'REPLACE',
|
||||
'REPLICA',
|
||||
'RESET',
|
||||
'RESTART',
|
||||
'RESTRICT',
|
||||
'RETURNING',
|
||||
'RETURNS',
|
||||
'REVOKE',
|
||||
'RIGHT',
|
||||
'ROLE',
|
||||
'ROLLBACK',
|
||||
'ROW',
|
||||
'ROWS',
|
||||
'RULE',
|
||||
'SAVEPOINT',
|
||||
'SCHEMA',
|
||||
'SCROLL',
|
||||
'SEARCH',
|
||||
'SECOND',
|
||||
'SECURITY',
|
||||
'SELECT',
|
||||
'SEQUENCE',
|
||||
'SEQUENCES',
|
||||
'SERIALIZABLE',
|
||||
'SERVER',
|
||||
'SESSION',
|
||||
'SESSION_USER',
|
||||
'SET',
|
||||
'SETOF',
|
||||
'SHARE',
|
||||
'SHOW',
|
||||
'SIMILAR',
|
||||
'SIMPLE',
|
||||
'SMALLINT',
|
||||
'SNAPSHOT',
|
||||
'SOME',
|
||||
'STABLE',
|
||||
'STANDALONE',
|
||||
'START',
|
||||
'STATEMENT',
|
||||
'STATISTICS',
|
||||
'STDIN',
|
||||
'STDOUT',
|
||||
'STORAGE',
|
||||
'STRICT',
|
||||
'STRIP',
|
||||
'SUBSTRING',
|
||||
'SYMMETRIC',
|
||||
'SYSID',
|
||||
'SYSTEM',
|
||||
'TABLE',
|
||||
'TABLES',
|
||||
'TABLESPACE',
|
||||
'TEMP',
|
||||
'TEMPLATE',
|
||||
'TEMPORARY',
|
||||
'TEXT',
|
||||
'THEN',
|
||||
'TIME',
|
||||
'TIMESTAMP',
|
||||
'TO',
|
||||
'TRAILING',
|
||||
'TRANSACTION',
|
||||
'TREAT',
|
||||
'TRIGGER',
|
||||
'TRIM',
|
||||
'TRUE',
|
||||
'TRUNCATE',
|
||||
'TRUSTED',
|
||||
'TYPE',
|
||||
'TYPES',
|
||||
'UNBOUNDED',
|
||||
'UNCOMMITTED',
|
||||
'UNENCRYPTED',
|
||||
'UNION',
|
||||
'UNIQUE',
|
||||
'UNKNOWN',
|
||||
'UNLISTEN',
|
||||
'UNLOGGED',
|
||||
'UNTIL',
|
||||
'UPDATE',
|
||||
'USER',
|
||||
'USING',
|
||||
'VACUUM',
|
||||
'VALID',
|
||||
'VALIDATE',
|
||||
'VALIDATOR',
|
||||
'VALUE',
|
||||
'VALUES',
|
||||
'VARCHAR',
|
||||
'VARIADIC',
|
||||
'VARYING',
|
||||
'VERBOSE',
|
||||
'VERSION',
|
||||
'VIEW',
|
||||
'VIEWS',
|
||||
'VOLATILE',
|
||||
'WHEN',
|
||||
'WHERE',
|
||||
'WHITESPACE',
|
||||
'WINDOW',
|
||||
'WITH',
|
||||
'WITHIN',
|
||||
'WITHOUT',
|
||||
'WORK',
|
||||
'WRAPPER',
|
||||
'WRITE',
|
||||
'XML',
|
||||
'XMLATTRIBUTES',
|
||||
'XMLCONCAT',
|
||||
'XMLELEMENT',
|
||||
'XMLEXISTS',
|
||||
'XMLFOREST',
|
||||
'XMLPARSE',
|
||||
'XMLPI',
|
||||
'XMLROOT',
|
||||
'XMLSERIALIZE',
|
||||
'YEAR',
|
||||
'YES',
|
||||
'ZONE',
|
||||
)
|
||||
|
||||
DATATYPES = (
|
||||
'bigint',
|
||||
'bigserial',
|
||||
'bit',
|
||||
'bit varying',
|
||||
'bool',
|
||||
'boolean',
|
||||
'box',
|
||||
'bytea',
|
||||
'char',
|
||||
'character',
|
||||
'character varying',
|
||||
'cidr',
|
||||
'circle',
|
||||
'date',
|
||||
'decimal',
|
||||
'double precision',
|
||||
'float4',
|
||||
'float8',
|
||||
'inet',
|
||||
'int',
|
||||
'int2',
|
||||
'int4',
|
||||
'int8',
|
||||
'integer',
|
||||
'interval',
|
||||
'json',
|
||||
'jsonb',
|
||||
'line',
|
||||
'lseg',
|
||||
'macaddr',
|
||||
'money',
|
||||
'numeric',
|
||||
'path',
|
||||
'pg_lsn',
|
||||
'point',
|
||||
'polygon',
|
||||
'real',
|
||||
'serial',
|
||||
'serial2',
|
||||
'serial4',
|
||||
'serial8',
|
||||
'smallint',
|
||||
'smallserial',
|
||||
'text',
|
||||
'time',
|
||||
'timestamp',
|
||||
'timestamptz',
|
||||
'timetz',
|
||||
'tsquery',
|
||||
'tsvector',
|
||||
'txid_snapshot',
|
||||
'uuid',
|
||||
'varbit',
|
||||
'varchar',
|
||||
'with time zone',
|
||||
'without time zone',
|
||||
'xml',
|
||||
)
|
||||
|
||||
PSEUDO_TYPES = (
|
||||
'any',
|
||||
'anyelement',
|
||||
'anyarray',
|
||||
'anynonarray',
|
||||
'anyenum',
|
||||
'anyrange',
|
||||
'cstring',
|
||||
'internal',
|
||||
'language_handler',
|
||||
'fdw_handler',
|
||||
'record',
|
||||
'trigger',
|
||||
'void',
|
||||
'opaque',
|
||||
)
|
||||
|
||||
# Remove 'trigger' from types
|
||||
PSEUDO_TYPES = tuple(sorted(set(PSEUDO_TYPES) - set(map(str.lower, KEYWORDS))))
|
||||
|
||||
PLPGSQL_KEYWORDS = (
|
||||
'ALIAS', 'CONSTANT', 'DIAGNOSTICS', 'ELSIF', 'EXCEPTION', 'EXIT',
|
||||
'FOREACH', 'GET', 'LOOP', 'NOTICE', 'OPEN', 'PERFORM', 'QUERY', 'RAISE',
|
||||
'RETURN', 'REVERSE', 'SQLSTATE', 'WHILE',
|
||||
)
|
||||
|
||||
if __name__ == '__main__':
|
||||
import re
|
||||
try:
|
||||
from urllib import urlopen
|
||||
except ImportError:
|
||||
from urllib.request import urlopen
|
||||
|
||||
from pygments.util import format_lines
|
||||
|
||||
# One man's constant is another man's variable.
|
||||
SOURCE_URL = 'https://github.com/postgres/postgres/raw/master'
|
||||
KEYWORDS_URL = SOURCE_URL + '/doc/src/sgml/keywords.sgml'
|
||||
DATATYPES_URL = SOURCE_URL + '/doc/src/sgml/datatype.sgml'
|
||||
|
||||
def update_myself():
|
||||
data_file = list(urlopen(DATATYPES_URL))
|
||||
datatypes = parse_datatypes(data_file)
|
||||
pseudos = parse_pseudos(data_file)
|
||||
|
||||
keywords = parse_keywords(urlopen(KEYWORDS_URL))
|
||||
update_consts(__file__, 'DATATYPES', datatypes)
|
||||
update_consts(__file__, 'PSEUDO_TYPES', pseudos)
|
||||
update_consts(__file__, 'KEYWORDS', keywords)
|
||||
|
||||
def parse_keywords(f):
|
||||
kw = []
|
||||
for m in re.finditer(
|
||||
r'\s*<entry><token>([^<]+)</token></entry>\s*'
|
||||
r'<entry>([^<]+)</entry>', f.read()):
|
||||
kw.append(m.group(1))
|
||||
|
||||
if not kw:
|
||||
raise ValueError('no keyword found')
|
||||
|
||||
kw.sort()
|
||||
return kw
|
||||
|
||||
def parse_datatypes(f):
|
||||
dt = set()
|
||||
for line in f:
|
||||
if '<sect1' in line:
|
||||
break
|
||||
if '<entry><type>' not in line:
|
||||
continue
|
||||
|
||||
# Parse a string such as
|
||||
# time [ (<replaceable>p</replaceable>) ] [ without time zone ]
|
||||
# into types "time" and "without time zone"
|
||||
|
||||
# remove all the tags
|
||||
line = re.sub("<replaceable>[^<]+</replaceable>", "", line)
|
||||
line = re.sub("<[^>]+>", "", line)
|
||||
|
||||
# Drop the parts containing braces
|
||||
for tmp in [t for tmp in line.split('[')
|
||||
for t in tmp.split(']') if "(" not in t]:
|
||||
for t in tmp.split(','):
|
||||
t = t.strip()
|
||||
if not t: continue
|
||||
dt.add(" ".join(t.split()))
|
||||
|
||||
dt = list(dt)
|
||||
dt.sort()
|
||||
return dt
|
||||
|
||||
def parse_pseudos(f):
|
||||
dt = []
|
||||
re_start = re.compile(r'\s*<table id="datatype-pseudotypes-table">')
|
||||
re_entry = re.compile(r'\s*<entry><type>([^<]+)</></entry>')
|
||||
re_end = re.compile(r'\s*</table>')
|
||||
|
||||
f = iter(f)
|
||||
for line in f:
|
||||
if re_start.match(line) is not None:
|
||||
break
|
||||
else:
|
||||
raise ValueError('pseudo datatypes table not found')
|
||||
|
||||
for line in f:
|
||||
m = re_entry.match(line)
|
||||
if m is not None:
|
||||
dt.append(m.group(1))
|
||||
|
||||
if re_end.match(line) is not None:
|
||||
break
|
||||
else:
|
||||
raise ValueError('end of pseudo datatypes table not found')
|
||||
|
||||
if not dt:
|
||||
raise ValueError('pseudo datatypes not found')
|
||||
|
||||
return dt
|
||||
|
||||
def update_consts(filename, constname, content):
|
||||
with open(filename) as f:
|
||||
data = f.read()
|
||||
|
||||
# Line to start/end inserting
|
||||
re_match = re.compile(r'^%s\s*=\s*\($.*?^\s*\)$' % constname, re.M | re.S)
|
||||
m = re_match.search(data)
|
||||
if not m:
|
||||
raise ValueError('Could not find existing definition for %s' %
|
||||
(constname,))
|
||||
|
||||
new_block = format_lines(constname, content)
|
||||
data = data[:m.start()] + new_block + data[m.end():]
|
||||
|
||||
with open(filename, 'w') as f:
|
||||
f.write(data)
|
||||
|
||||
update_myself()
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,18 +1,31 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers._stan_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
pygments.lexers._stan_builtins
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This file contains the names of functions for Stan used by
|
||||
``pygments.lexers.math.StanLexer.
|
||||
This file contains the names of functions for Stan used by
|
||||
``pygments.lexers.math.StanLexer. This is for Stan language version 2.4.0.
|
||||
|
||||
:copyright: Copyright 2013 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
KEYWORDS = ['else', 'for', 'if', 'in', 'lower', 'lp__', 'print', 'upper', 'while']
|
||||
KEYWORDS = (
|
||||
'else',
|
||||
'for',
|
||||
'if',
|
||||
'in',
|
||||
'increment_log_prob',
|
||||
'lp__',
|
||||
'print',
|
||||
'return',
|
||||
'while',
|
||||
)
|
||||
|
||||
TYPES = [ 'corr_matrix',
|
||||
TYPES = (
|
||||
'cholesky_factor_corr',
|
||||
'cholesky_factor_cov',
|
||||
'corr_matrix',
|
||||
'cov_matrix',
|
||||
'int',
|
||||
'matrix',
|
||||
@ -22,9 +35,12 @@ TYPES = [ 'corr_matrix',
|
||||
'row_vector',
|
||||
'simplex',
|
||||
'unit_vector',
|
||||
'vector']
|
||||
'vector',
|
||||
'void',
|
||||
)
|
||||
|
||||
FUNCTIONS = [ 'Phi',
|
||||
FUNCTIONS = (
|
||||
'Phi',
|
||||
'Phi_approx',
|
||||
'abs',
|
||||
'acos',
|
||||
@ -34,35 +50,53 @@ FUNCTIONS = [ 'Phi',
|
||||
'atan',
|
||||
'atan2',
|
||||
'atanh',
|
||||
'bernoulli_ccdf_log',
|
||||
'bernoulli_cdf',
|
||||
'bernoulli_cdf_log',
|
||||
'bernoulli_log',
|
||||
'bernoulli_logit_log',
|
||||
'bernoulli_rng',
|
||||
'bessel_first_kind',
|
||||
'bessel_second_kind',
|
||||
'beta_binomial_ccdf_log',
|
||||
'beta_binomial_cdf',
|
||||
'beta_binomial_cdf_log',
|
||||
'beta_binomial_log',
|
||||
'beta_binomial_rng',
|
||||
'beta_ccdf_log',
|
||||
'beta_cdf',
|
||||
'beta_cdf_log',
|
||||
'beta_log',
|
||||
'beta_rng',
|
||||
'binary_log_loss',
|
||||
'binomial_ccdf_log',
|
||||
'binomial_cdf',
|
||||
'binomial_cdf_log',
|
||||
'binomial_coefficient_log',
|
||||
'binomial_log',
|
||||
'binomial_logit_log',
|
||||
'binomial_rng',
|
||||
'block',
|
||||
'categorical_log',
|
||||
'categorical_logit_log',
|
||||
'categorical_rng',
|
||||
'cauchy_ccdf_log',
|
||||
'cauchy_cdf',
|
||||
'cauchy_cdf_log',
|
||||
'cauchy_log',
|
||||
'cauchy_rng',
|
||||
'cbrt',
|
||||
'ceil',
|
||||
'chi_square_ccdf_log',
|
||||
'chi_square_cdf',
|
||||
'chi_square_cdf_log',
|
||||
'chi_square_log',
|
||||
'chi_square_rng',
|
||||
'cholesky_decompose',
|
||||
'col',
|
||||
'cols',
|
||||
'columns_dot_product',
|
||||
'columns_dot_self',
|
||||
'cos',
|
||||
'cosh',
|
||||
'crossprod',
|
||||
@ -72,56 +106,82 @@ FUNCTIONS = [ 'Phi',
|
||||
'diag_post_multiply',
|
||||
'diag_pre_multiply',
|
||||
'diagonal',
|
||||
'digamma',
|
||||
'dims',
|
||||
'dirichlet_log',
|
||||
'dirichlet_rng',
|
||||
'distance',
|
||||
'dot_product',
|
||||
'dot_self',
|
||||
'double_exponential_ccdf_log',
|
||||
'double_exponential_cdf',
|
||||
'double_exponential_cdf_log',
|
||||
'double_exponential_log',
|
||||
'double_exponential_rng',
|
||||
'e',
|
||||
'eigenvalues_sym',
|
||||
'eigenvectors_sym',
|
||||
'epsilon',
|
||||
'erf',
|
||||
'erfc',
|
||||
'exp',
|
||||
'exp2',
|
||||
'exp_mod_normal_ccdf_log',
|
||||
'exp_mod_normal_cdf',
|
||||
'exp_mod_normal_cdf_log',
|
||||
'exp_mod_normal_log',
|
||||
'exp_mod_normal_rng',
|
||||
'expm1',
|
||||
'exponential_ccdf_log',
|
||||
'exponential_cdf',
|
||||
'exponential_cdf_log',
|
||||
'exponential_log',
|
||||
'exponential_rng',
|
||||
'fabs',
|
||||
'falling_factorial',
|
||||
'fdim',
|
||||
'floor',
|
||||
'fma',
|
||||
'fmax',
|
||||
'fmin',
|
||||
'fmod',
|
||||
'gamma_ccdf_log',
|
||||
'gamma_cdf',
|
||||
'gamma_cdf_log',
|
||||
'gamma_log',
|
||||
'gamma_p',
|
||||
'gamma_q',
|
||||
'gamma_rng',
|
||||
'gaussian_dlm_obs_log',
|
||||
'gumbel_ccdf_log',
|
||||
'gumbel_cdf',
|
||||
'gumbel_cdf_log',
|
||||
'gumbel_log',
|
||||
'gumbel_rng',
|
||||
'head',
|
||||
'hypergeometric_log',
|
||||
'hypergeometric_rng',
|
||||
'hypot',
|
||||
'if_else',
|
||||
'int_step',
|
||||
'inv',
|
||||
'inv_chi_square_ccdf_log',
|
||||
'inv_chi_square_cdf',
|
||||
'inv_chi_square_cdf_log',
|
||||
'inv_chi_square_log',
|
||||
'inv_chi_square_rng',
|
||||
'inv_cloglog',
|
||||
'inv_gamma_ccdf_log',
|
||||
'inv_gamma_cdf',
|
||||
'inv_gamma_cdf_log',
|
||||
'inv_gamma_log',
|
||||
'inv_gamma_rng',
|
||||
'inv_logit',
|
||||
'inv_sqrt',
|
||||
'inv_square',
|
||||
'inv_wishart_log',
|
||||
'inv_wishart_rng',
|
||||
'inverse',
|
||||
'inverse_spd',
|
||||
'lbeta',
|
||||
'lgamma',
|
||||
'lkj_corr_cholesky_log',
|
||||
@ -133,109 +193,179 @@ FUNCTIONS = [ 'Phi',
|
||||
'log',
|
||||
'log10',
|
||||
'log1m',
|
||||
'log1m_exp',
|
||||
'log1m_inv_logit',
|
||||
'log1p',
|
||||
'log1p_exp',
|
||||
'log2',
|
||||
'log_determinant',
|
||||
'log_diff_exp',
|
||||
'log_falling_factorial',
|
||||
'log_inv_logit',
|
||||
'log_rising_factorial',
|
||||
'log_softmax',
|
||||
'log_sum_exp',
|
||||
'logistic_ccdf_log',
|
||||
'logistic_cdf',
|
||||
'logistic_cdf_log',
|
||||
'logistic_log',
|
||||
'logistic_rng',
|
||||
'logit',
|
||||
'lognormal_ccdf_log',
|
||||
'lognormal_cdf',
|
||||
'lognormal_cdf_log',
|
||||
'lognormal_log',
|
||||
'lognormal_rng',
|
||||
'machine_precision',
|
||||
'max',
|
||||
'mdivide_left_tri_low',
|
||||
'mdivide_right_tri_low',
|
||||
'mean',
|
||||
'min',
|
||||
'modified_bessel_first_kind',
|
||||
'modified_bessel_second_kind',
|
||||
'multi_gp_log',
|
||||
'multi_normal_cholesky_log',
|
||||
'multi_normal_cholesky_rng',
|
||||
'multi_normal_log',
|
||||
'multi_normal_prec_log',
|
||||
'multi_normal_rng',
|
||||
'multi_student_t_log',
|
||||
'multi_student_t_rng',
|
||||
'multinomial_cdf',
|
||||
'multinomial_log',
|
||||
'multinomial_rng',
|
||||
'multiply_log',
|
||||
'multiply_lower_tri_self_transpose',
|
||||
'neg_binomial_2_log',
|
||||
'neg_binomial_2_log_log',
|
||||
'neg_binomial_2_log_rng',
|
||||
'neg_binomial_2_rng',
|
||||
'neg_binomial_ccdf_log',
|
||||
'neg_binomial_cdf',
|
||||
'neg_binomial_cdf_log',
|
||||
'neg_binomial_log',
|
||||
'neg_binomial_rng',
|
||||
'negative_epsilon',
|
||||
'negative_infinity',
|
||||
'normal_ccdf_log',
|
||||
'normal_cdf',
|
||||
'normal_cdf_log',
|
||||
'normal_log',
|
||||
'normal_rng',
|
||||
'not_a_number',
|
||||
'ordered_logistic_log',
|
||||
'ordered_logistic_rng',
|
||||
'owens_t',
|
||||
'pareto_ccdf_log',
|
||||
'pareto_cdf',
|
||||
'pareto_cdf_log',
|
||||
'pareto_log',
|
||||
'pareto_rng',
|
||||
'pi',
|
||||
'poisson_ccdf_log',
|
||||
'poisson_cdf',
|
||||
'poisson_cdf_log',
|
||||
'poisson_log',
|
||||
'poisson_log_log',
|
||||
'poisson_rng',
|
||||
'positive_infinity',
|
||||
'pow',
|
||||
'prod',
|
||||
'qr_Q',
|
||||
'qr_R',
|
||||
'quad_form',
|
||||
'quad_form_diag',
|
||||
'quad_form_sym',
|
||||
'rank',
|
||||
'rayleigh_ccdf_log',
|
||||
'rayleigh_cdf',
|
||||
'rayleigh_cdf_log',
|
||||
'rayleigh_log',
|
||||
'rayleigh_rng',
|
||||
'rep_array',
|
||||
'rep_matrix',
|
||||
'rep_row_vector',
|
||||
'rep_vector',
|
||||
'rising_factorial',
|
||||
'round',
|
||||
'row',
|
||||
'rows',
|
||||
'rows_dot_product',
|
||||
'rows_dot_self',
|
||||
'scaled_inv_chi_square_ccdf_log',
|
||||
'scaled_inv_chi_square_cdf',
|
||||
'scaled_inv_chi_square_cdf_log',
|
||||
'scaled_inv_chi_square_log',
|
||||
'scaled_inv_chi_square_rng',
|
||||
'sd',
|
||||
'segment',
|
||||
'sin',
|
||||
'singular_values',
|
||||
'sinh',
|
||||
'size',
|
||||
'skew_normal_ccdf_log',
|
||||
'skew_normal_cdf',
|
||||
'skew_normal_cdf_log',
|
||||
'skew_normal_log',
|
||||
'skew_normal_rng',
|
||||
'softmax',
|
||||
'sort_asc',
|
||||
'sort_desc',
|
||||
'sort_indices_asc',
|
||||
'sort_indices_desc',
|
||||
'sqrt',
|
||||
'sqrt2',
|
||||
'square',
|
||||
'squared_distance',
|
||||
'step',
|
||||
'student_t_ccdf_log',
|
||||
'student_t_cdf',
|
||||
'student_t_cdf_log',
|
||||
'student_t_log',
|
||||
'student_t_rng',
|
||||
'sub_col',
|
||||
'sub_row',
|
||||
'sum',
|
||||
'tail',
|
||||
'tan',
|
||||
'tanh',
|
||||
'tcrossprod',
|
||||
'tgamma',
|
||||
'to_array_1d',
|
||||
'to_array_2d',
|
||||
'to_matrix',
|
||||
'to_row_vector',
|
||||
'to_vector',
|
||||
'trace',
|
||||
'trace_gen_quad_form',
|
||||
'trace_quad_form',
|
||||
'trigamma',
|
||||
'trunc',
|
||||
'uniform_ccdf_log',
|
||||
'uniform_cdf',
|
||||
'uniform_cdf_log',
|
||||
'uniform_log',
|
||||
'uniform_rng',
|
||||
'variance',
|
||||
'von_mises_log',
|
||||
'von_mises_rng',
|
||||
'weibull_ccdf_log',
|
||||
'weibull_cdf',
|
||||
'weibull_cdf_log',
|
||||
'weibull_log',
|
||||
'weibull_rng',
|
||||
'wishart_log',
|
||||
'wishart_rng']
|
||||
'wishart_rng',
|
||||
)
|
||||
|
||||
DISTRIBUTIONS = [ 'bernoulli',
|
||||
DISTRIBUTIONS = (
|
||||
'bernoulli',
|
||||
'bernoulli_logit',
|
||||
'beta',
|
||||
'beta_binomial',
|
||||
'binomial',
|
||||
'binomial_coefficient',
|
||||
'binomial_logit',
|
||||
'categorical',
|
||||
'categorical_logit',
|
||||
'cauchy',
|
||||
'chi_square',
|
||||
'dirichlet',
|
||||
@ -243,6 +373,7 @@ DISTRIBUTIONS = [ 'bernoulli',
|
||||
'exp_mod_normal',
|
||||
'exponential',
|
||||
'gamma',
|
||||
'gaussian_dlm_obs',
|
||||
'gumbel',
|
||||
'hypergeometric',
|
||||
'inv_chi_square',
|
||||
@ -253,26 +384,32 @@ DISTRIBUTIONS = [ 'bernoulli',
|
||||
'lkj_cov',
|
||||
'logistic',
|
||||
'lognormal',
|
||||
'multi_gp',
|
||||
'multi_normal',
|
||||
'multi_normal_cholesky',
|
||||
'multi_normal_prec',
|
||||
'multi_student_t',
|
||||
'multinomial',
|
||||
'multiply',
|
||||
'neg_binomial',
|
||||
'neg_binomial_2',
|
||||
'neg_binomial_2_log',
|
||||
'normal',
|
||||
'ordered_logistic',
|
||||
'pareto',
|
||||
'poisson',
|
||||
'poisson_log',
|
||||
'rayleigh',
|
||||
'scaled_inv_chi_square',
|
||||
'skew_normal',
|
||||
'student_t',
|
||||
'uniform',
|
||||
'von_mises',
|
||||
'weibull',
|
||||
'wishart']
|
||||
'wishart',
|
||||
)
|
||||
|
||||
RESERVED = [ 'alignas',
|
||||
RESERVED = (
|
||||
'alignas',
|
||||
'alignof',
|
||||
'and',
|
||||
'and_eq',
|
||||
@ -307,6 +444,7 @@ RESERVED = [ 'alignas',
|
||||
'false',
|
||||
'float',
|
||||
'friend',
|
||||
'fvar',
|
||||
'goto',
|
||||
'inline',
|
||||
'int',
|
||||
@ -327,7 +465,6 @@ RESERVED = [ 'alignas',
|
||||
'register',
|
||||
'reinterpret_cast',
|
||||
'repeat',
|
||||
'return',
|
||||
'short',
|
||||
'signed',
|
||||
'sizeof',
|
||||
@ -351,10 +488,11 @@ RESERVED = [ 'alignas',
|
||||
'unsigned',
|
||||
'until',
|
||||
'using',
|
||||
'var',
|
||||
'virtual',
|
||||
'void',
|
||||
'volatile',
|
||||
'wchar_t',
|
||||
'xor',
|
||||
'xor_eq']
|
||||
|
||||
'xor_eq',
|
||||
)
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,240 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.actionscript
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for ActionScript and MXML.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, using, this, words, default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['ActionScriptLexer', 'ActionScript3Lexer', 'MxmlLexer']
|
||||
|
||||
|
||||
class ActionScriptLexer(RegexLexer):
|
||||
"""
|
||||
For ActionScript source code.
|
||||
|
||||
.. versionadded:: 0.9
|
||||
"""
|
||||
|
||||
name = 'ActionScript'
|
||||
aliases = ['as', 'actionscript']
|
||||
filenames = ['*.as']
|
||||
mimetypes = ['application/x-actionscript', 'text/x-actionscript',
|
||||
'text/actionscript']
|
||||
|
||||
flags = re.DOTALL
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'/(\\\\|\\/|[^/\n])*/[gim]*', String.Regex),
|
||||
(r'[~^*!%&<>|+=:;,/?\\-]+', Operator),
|
||||
(r'[{}\[\]();.]+', Punctuation),
|
||||
(words((
|
||||
'case', 'default', 'for', 'each', 'in', 'while', 'do', 'break',
|
||||
'return', 'continue', 'if', 'else', 'throw', 'try', 'catch',
|
||||
'var', 'with', 'new', 'typeof', 'arguments', 'instanceof', 'this',
|
||||
'switch'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'class', 'public', 'final', 'internal', 'native', 'override', 'private',
|
||||
'protected', 'static', 'import', 'extends', 'implements', 'interface',
|
||||
'intrinsic', 'return', 'super', 'dynamic', 'function', 'const', 'get',
|
||||
'namespace', 'package', 'set'), suffix=r'\b'),
|
||||
Keyword.Declaration),
|
||||
(r'(true|false|null|NaN|Infinity|-Infinity|undefined|Void)\b',
|
||||
Keyword.Constant),
|
||||
(words((
|
||||
'Accessibility', 'AccessibilityProperties', 'ActionScriptVersion',
|
||||
'ActivityEvent', 'AntiAliasType', 'ApplicationDomain', 'AsBroadcaster', 'Array',
|
||||
'AsyncErrorEvent', 'AVM1Movie', 'BevelFilter', 'Bitmap', 'BitmapData',
|
||||
'BitmapDataChannel', 'BitmapFilter', 'BitmapFilterQuality', 'BitmapFilterType',
|
||||
'BlendMode', 'BlurFilter', 'Boolean', 'ByteArray', 'Camera', 'Capabilities', 'CapsStyle',
|
||||
'Class', 'Color', 'ColorMatrixFilter', 'ColorTransform', 'ContextMenu',
|
||||
'ContextMenuBuiltInItems', 'ContextMenuEvent', 'ContextMenuItem',
|
||||
'ConvultionFilter', 'CSMSettings', 'DataEvent', 'Date', 'DefinitionError',
|
||||
'DeleteObjectSample', 'Dictionary', 'DisplacmentMapFilter', 'DisplayObject',
|
||||
'DisplacmentMapFilterMode', 'DisplayObjectContainer', 'DropShadowFilter',
|
||||
'Endian', 'EOFError', 'Error', 'ErrorEvent', 'EvalError', 'Event', 'EventDispatcher',
|
||||
'EventPhase', 'ExternalInterface', 'FileFilter', 'FileReference',
|
||||
'FileReferenceList', 'FocusDirection', 'FocusEvent', 'Font', 'FontStyle', 'FontType',
|
||||
'FrameLabel', 'FullScreenEvent', 'Function', 'GlowFilter', 'GradientBevelFilter',
|
||||
'GradientGlowFilter', 'GradientType', 'Graphics', 'GridFitType', 'HTTPStatusEvent',
|
||||
'IBitmapDrawable', 'ID3Info', 'IDataInput', 'IDataOutput', 'IDynamicPropertyOutput'
|
||||
'IDynamicPropertyWriter', 'IEventDispatcher', 'IExternalizable',
|
||||
'IllegalOperationError', 'IME', 'IMEConversionMode', 'IMEEvent', 'int',
|
||||
'InteractiveObject', 'InterpolationMethod', 'InvalidSWFError', 'InvokeEvent',
|
||||
'IOError', 'IOErrorEvent', 'JointStyle', 'Key', 'Keyboard', 'KeyboardEvent', 'KeyLocation',
|
||||
'LineScaleMode', 'Loader', 'LoaderContext', 'LoaderInfo', 'LoadVars', 'LocalConnection',
|
||||
'Locale', 'Math', 'Matrix', 'MemoryError', 'Microphone', 'MorphShape', 'Mouse', 'MouseEvent',
|
||||
'MovieClip', 'MovieClipLoader', 'Namespace', 'NetConnection', 'NetStatusEvent',
|
||||
'NetStream', 'NewObjectSample', 'Number', 'Object', 'ObjectEncoding', 'PixelSnapping',
|
||||
'Point', 'PrintJob', 'PrintJobOptions', 'PrintJobOrientation', 'ProgressEvent', 'Proxy',
|
||||
'QName', 'RangeError', 'Rectangle', 'ReferenceError', 'RegExp', 'Responder', 'Sample',
|
||||
'Scene', 'ScriptTimeoutError', 'Security', 'SecurityDomain', 'SecurityError',
|
||||
'SecurityErrorEvent', 'SecurityPanel', 'Selection', 'Shape', 'SharedObject',
|
||||
'SharedObjectFlushStatus', 'SimpleButton', 'Socket', 'Sound', 'SoundChannel',
|
||||
'SoundLoaderContext', 'SoundMixer', 'SoundTransform', 'SpreadMethod', 'Sprite',
|
||||
'StackFrame', 'StackOverflowError', 'Stage', 'StageAlign', 'StageDisplayState',
|
||||
'StageQuality', 'StageScaleMode', 'StaticText', 'StatusEvent', 'String', 'StyleSheet',
|
||||
'SWFVersion', 'SyncEvent', 'SyntaxError', 'System', 'TextColorType', 'TextField',
|
||||
'TextFieldAutoSize', 'TextFieldType', 'TextFormat', 'TextFormatAlign',
|
||||
'TextLineMetrics', 'TextRenderer', 'TextSnapshot', 'Timer', 'TimerEvent', 'Transform',
|
||||
'TypeError', 'uint', 'URIError', 'URLLoader', 'URLLoaderDataFormat', 'URLRequest',
|
||||
'URLRequestHeader', 'URLRequestMethod', 'URLStream', 'URLVariabeles', 'VerifyError',
|
||||
'Video', 'XML', 'XMLDocument', 'XMLList', 'XMLNode', 'XMLNodeType', 'XMLSocket',
|
||||
'XMLUI'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(words((
|
||||
'decodeURI', 'decodeURIComponent', 'encodeURI', 'escape', 'eval', 'isFinite', 'isNaN',
|
||||
'isXMLName', 'clearInterval', 'fscommand', 'getTimer', 'getURL', 'getVersion',
|
||||
'parseFloat', 'parseInt', 'setInterval', 'trace', 'updateAfterEvent',
|
||||
'unescape'), suffix=r'\b'),
|
||||
Name.Function),
|
||||
(r'[$a-zA-Z_]\w*', Name.Other),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-f]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class ActionScript3Lexer(RegexLexer):
|
||||
"""
|
||||
For ActionScript 3 source code.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
|
||||
name = 'ActionScript 3'
|
||||
aliases = ['as3', 'actionscript3']
|
||||
filenames = ['*.as']
|
||||
mimetypes = ['application/x-actionscript3', 'text/x-actionscript3',
|
||||
'text/actionscript3']
|
||||
|
||||
identifier = r'[$a-zA-Z_]\w*'
|
||||
typeidentifier = identifier + '(?:\.<\w+>)?'
|
||||
|
||||
flags = re.DOTALL | re.MULTILINE
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'(function\s+)(' + identifier + r')(\s*)(\()',
|
||||
bygroups(Keyword.Declaration, Name.Function, Text, Operator),
|
||||
'funcparams'),
|
||||
(r'(var|const)(\s+)(' + identifier + r')(\s*)(:)(\s*)(' +
|
||||
typeidentifier + r')',
|
||||
bygroups(Keyword.Declaration, Text, Name, Text, Punctuation, Text,
|
||||
Keyword.Type)),
|
||||
(r'(import|package)(\s+)((?:' + identifier + r'|\.)+)(\s*)',
|
||||
bygroups(Keyword, Text, Name.Namespace, Text)),
|
||||
(r'(new)(\s+)(' + typeidentifier + r')(\s*)(\()',
|
||||
bygroups(Keyword, Text, Keyword.Type, Text, Operator)),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'/(\\\\|\\/|[^\n])*/[gisx]*', String.Regex),
|
||||
(r'(\.)(' + identifier + r')', bygroups(Operator, Name.Attribute)),
|
||||
(r'(case|default|for|each|in|while|do|break|return|continue|if|else|'
|
||||
r'throw|try|catch|with|new|typeof|arguments|instanceof|this|'
|
||||
r'switch|import|include|as|is)\b',
|
||||
Keyword),
|
||||
(r'(class|public|final|internal|native|override|private|protected|'
|
||||
r'static|import|extends|implements|interface|intrinsic|return|super|'
|
||||
r'dynamic|function|const|get|namespace|package|set)\b',
|
||||
Keyword.Declaration),
|
||||
(r'(true|false|null|NaN|Infinity|-Infinity|undefined|void)\b',
|
||||
Keyword.Constant),
|
||||
(r'(decodeURI|decodeURIComponent|encodeURI|escape|eval|isFinite|isNaN|'
|
||||
r'isXMLName|clearInterval|fscommand|getTimer|getURL|getVersion|'
|
||||
r'isFinite|parseFloat|parseInt|setInterval|trace|updateAfterEvent|'
|
||||
r'unescape)\b', Name.Function),
|
||||
(identifier, Name),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'0x[0-9a-f]+', Number.Hex),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'[~^*!%&<>|+=:;,/?\\{}\[\]().-]+', Operator),
|
||||
],
|
||||
'funcparams': [
|
||||
(r'\s+', Text),
|
||||
(r'(\s*)(\.\.\.)?(' + identifier + r')(\s*)(:)(\s*)(' +
|
||||
typeidentifier + r'|\*)(\s*)',
|
||||
bygroups(Text, Punctuation, Name, Text, Operator, Text,
|
||||
Keyword.Type, Text), 'defval'),
|
||||
(r'\)', Operator, 'type')
|
||||
],
|
||||
'type': [
|
||||
(r'(\s*)(:)(\s*)(' + typeidentifier + r'|\*)',
|
||||
bygroups(Text, Operator, Text, Keyword.Type), '#pop:2'),
|
||||
(r'\s+', Text, '#pop:2'),
|
||||
default('#pop:2')
|
||||
],
|
||||
'defval': [
|
||||
(r'(=)(\s*)([^(),]+)(\s*)(,?)',
|
||||
bygroups(Operator, Text, using(this), Text, Operator), '#pop'),
|
||||
(r',', Operator, '#pop'),
|
||||
default('#pop')
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if re.match(r'\w+\s*:\s*\w', text):
|
||||
return 0.3
|
||||
return 0
|
||||
|
||||
|
||||
class MxmlLexer(RegexLexer):
|
||||
"""
|
||||
For MXML markup.
|
||||
Nested AS3 in <script> tags is highlighted by the appropriate lexer.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
flags = re.MULTILINE | re.DOTALL
|
||||
name = 'MXML'
|
||||
aliases = ['mxml']
|
||||
filenames = ['*.mxml']
|
||||
mimetimes = ['text/xml', 'application/xml']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
('[^<&]+', Text),
|
||||
(r'&\S*?;', Name.Entity),
|
||||
(r'(\<\!\[CDATA\[)(.*?)(\]\]\>)',
|
||||
bygroups(String, using(ActionScript3Lexer), String)),
|
||||
('<!--', Comment, 'comment'),
|
||||
(r'<\?.*?\?>', Comment.Preproc),
|
||||
('<![^>]*>', Comment.Preproc),
|
||||
(r'<\s*[\w:.-]+', Name.Tag, 'tag'),
|
||||
(r'<\s*/\s*[\w:.-]+\s*>', Name.Tag),
|
||||
],
|
||||
'comment': [
|
||||
('[^-]+', Comment),
|
||||
('-->', Comment, '#pop'),
|
||||
('-', Comment),
|
||||
],
|
||||
'tag': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w.:-]+\s*=', Name.Attribute, 'attr'),
|
||||
(r'/?\s*>', Name.Tag, '#pop'),
|
||||
],
|
||||
'attr': [
|
||||
('\s+', Text),
|
||||
('".*?"', String, '#pop'),
|
||||
("'.*?'", String, '#pop'),
|
||||
(r'[^\s>]+', String, '#pop'),
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,24 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.agile
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Just export lexer classes previously contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexers.lisp import SchemeLexer
|
||||
from pygments.lexers.jvm import IokeLexer, ClojureLexer
|
||||
from pygments.lexers.python import PythonLexer, PythonConsoleLexer, \
|
||||
PythonTracebackLexer, Python3Lexer, Python3TracebackLexer, DgLexer
|
||||
from pygments.lexers.ruby import RubyLexer, RubyConsoleLexer, FancyLexer
|
||||
from pygments.lexers.perl import PerlLexer, Perl6Lexer
|
||||
from pygments.lexers.d import CrocLexer, MiniDLexer
|
||||
from pygments.lexers.iolang import IoLexer
|
||||
from pygments.lexers.tcl import TclLexer
|
||||
from pygments.lexers.factor import FactorLexer
|
||||
from pygments.lexers.scripting import LuaLexer, MoonScriptLexer
|
||||
|
||||
__all__ = []
|
||||
@ -0,0 +1,187 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.algebra
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for computer algebra systems.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['GAPLexer', 'MathematicaLexer', 'MuPADLexer']
|
||||
|
||||
|
||||
class GAPLexer(RegexLexer):
|
||||
"""
|
||||
For `GAP <http://www.gap-system.org>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'GAP'
|
||||
aliases = ['gap']
|
||||
filenames = ['*.g', '*.gd', '*.gi', '*.gap']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'#.*$', Comment.Single),
|
||||
(r'"(?:[^"\\]|\\.)*"', String),
|
||||
(r'\(|\)|\[|\]|\{|\}', Punctuation),
|
||||
(r'''(?x)\b(?:
|
||||
if|then|elif|else|fi|
|
||||
for|while|do|od|
|
||||
repeat|until|
|
||||
break|continue|
|
||||
function|local|return|end|
|
||||
rec|
|
||||
quit|QUIT|
|
||||
IsBound|Unbind|
|
||||
TryNextMethod|
|
||||
Info|Assert
|
||||
)\b''', Keyword),
|
||||
(r'''(?x)\b(?:
|
||||
true|false|fail|infinity
|
||||
)\b''',
|
||||
Name.Constant),
|
||||
(r'''(?x)\b(?:
|
||||
(Declare|Install)([A-Z][A-Za-z]+)|
|
||||
BindGlobal|BIND_GLOBAL
|
||||
)\b''',
|
||||
Name.Builtin),
|
||||
(r'\.|,|:=|;|=|\+|-|\*|/|\^|>|<', Operator),
|
||||
(r'''(?x)\b(?:
|
||||
and|or|not|mod|in
|
||||
)\b''',
|
||||
Operator.Word),
|
||||
(r'''(?x)
|
||||
(?:\w+|`[^`]*`)
|
||||
(?:::\w+|`[^`]*`)*''', Name.Variable),
|
||||
(r'[0-9]+(?:\.[0-9]*)?(?:e[0-9]+)?', Number),
|
||||
(r'\.[0-9]+(?:e[0-9]+)?', Number),
|
||||
(r'.', Text)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class MathematicaLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Mathematica <http://www.wolfram.com/mathematica/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Mathematica'
|
||||
aliases = ['mathematica', 'mma', 'nb']
|
||||
filenames = ['*.nb', '*.cdf', '*.nbp', '*.ma']
|
||||
mimetypes = ['application/mathematica',
|
||||
'application/vnd.wolfram.mathematica',
|
||||
'application/vnd.wolfram.mathematica.package',
|
||||
'application/vnd.wolfram.cdf']
|
||||
|
||||
# http://reference.wolfram.com/mathematica/guide/Syntax.html
|
||||
operators = (
|
||||
";;", "=", "=.", "!=" "==", ":=", "->", ":>", "/.", "+", "-", "*", "/",
|
||||
"^", "&&", "||", "!", "<>", "|", "/;", "?", "@", "//", "/@", "@@",
|
||||
"@@@", "~~", "===", "&", "<", ">", "<=", ">=",
|
||||
)
|
||||
|
||||
punctuation = (",", ";", "(", ")", "[", "]", "{", "}")
|
||||
|
||||
def _multi_escape(entries):
|
||||
return '(%s)' % ('|'.join(re.escape(entry) for entry in entries))
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'(?s)\(\*.*?\*\)', Comment),
|
||||
|
||||
(r'([a-zA-Z]+[A-Za-z0-9]*`)', Name.Namespace),
|
||||
(r'([A-Za-z0-9]*_+[A-Za-z0-9]*)', Name.Variable),
|
||||
(r'#\d*', Name.Variable),
|
||||
(r'([a-zA-Z]+[a-zA-Z0-9]*)', Name),
|
||||
|
||||
(r'-?[0-9]+\.[0-9]*', Number.Float),
|
||||
(r'-?[0-9]*\.[0-9]+', Number.Float),
|
||||
(r'-?[0-9]+', Number.Integer),
|
||||
|
||||
(words(operators), Operator),
|
||||
(words(punctuation), Punctuation),
|
||||
(r'".*?"', String),
|
||||
(r'\s+', Text.Whitespace),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class MuPADLexer(RegexLexer):
|
||||
"""
|
||||
A `MuPAD <http://www.mupad.com>`_ lexer.
|
||||
Contributed by Christopher Creutzig <christopher@creutzig.de>.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
name = 'MuPAD'
|
||||
aliases = ['mupad']
|
||||
filenames = ['*.mu']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'//.*?$', Comment.Single),
|
||||
(r'/\*', Comment.Multiline, 'comment'),
|
||||
(r'"(?:[^"\\]|\\.)*"', String),
|
||||
(r'\(|\)|\[|\]|\{|\}', Punctuation),
|
||||
(r'''(?x)\b(?:
|
||||
next|break|end|
|
||||
axiom|end_axiom|category|end_category|domain|end_domain|inherits|
|
||||
if|%if|then|elif|else|end_if|
|
||||
case|of|do|otherwise|end_case|
|
||||
while|end_while|
|
||||
repeat|until|end_repeat|
|
||||
for|from|to|downto|step|end_for|
|
||||
proc|local|option|save|begin|end_proc|
|
||||
delete|frame
|
||||
)\b''', Keyword),
|
||||
(r'''(?x)\b(?:
|
||||
DOM_ARRAY|DOM_BOOL|DOM_COMPLEX|DOM_DOMAIN|DOM_EXEC|DOM_EXPR|
|
||||
DOM_FAIL|DOM_FLOAT|DOM_FRAME|DOM_FUNC_ENV|DOM_HFARRAY|DOM_IDENT|
|
||||
DOM_INT|DOM_INTERVAL|DOM_LIST|DOM_NIL|DOM_NULL|DOM_POLY|DOM_PROC|
|
||||
DOM_PROC_ENV|DOM_RAT|DOM_SET|DOM_STRING|DOM_TABLE|DOM_VAR
|
||||
)\b''', Name.Class),
|
||||
(r'''(?x)\b(?:
|
||||
PI|EULER|E|CATALAN|
|
||||
NIL|FAIL|undefined|infinity|
|
||||
TRUE|FALSE|UNKNOWN
|
||||
)\b''',
|
||||
Name.Constant),
|
||||
(r'\b(?:dom|procname)\b', Name.Builtin.Pseudo),
|
||||
(r'\.|,|:|;|=|\+|-|\*|/|\^|@|>|<|\$|\||!|\'|%|~=', Operator),
|
||||
(r'''(?x)\b(?:
|
||||
and|or|not|xor|
|
||||
assuming|
|
||||
div|mod|
|
||||
union|minus|intersect|in|subset
|
||||
)\b''',
|
||||
Operator.Word),
|
||||
(r'\b(?:I|RDN_INF|RD_NINF|RD_NAN)\b', Number),
|
||||
# (r'\b(?:adt|linalg|newDomain|hold)\b', Name.Builtin),
|
||||
(r'''(?x)
|
||||
((?:[a-zA-Z_#][\w#]*|`[^`]*`)
|
||||
(?:::[a-zA-Z_#][\w#]*|`[^`]*`)*)(\s*)([(])''',
|
||||
bygroups(Name.Function, Text, Punctuation)),
|
||||
(r'''(?x)
|
||||
(?:[a-zA-Z_#][\w#]*|`[^`]*`)
|
||||
(?:::[a-zA-Z_#][\w#]*|`[^`]*`)*''', Name.Variable),
|
||||
(r'[0-9]+(?:\.[0-9]*)?(?:e[0-9]+)?', Number),
|
||||
(r'\.[0-9]+(?:e[0-9]+)?', Number),
|
||||
(r'.', Text)
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
]
|
||||
}
|
||||
@ -0,0 +1,76 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.ambient
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for AmbientTalk language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['AmbientTalkLexer']
|
||||
|
||||
|
||||
class AmbientTalkLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `AmbientTalk <https://code.google.com/p/ambienttalk>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'AmbientTalk'
|
||||
filenames = ['*.at']
|
||||
aliases = ['at', 'ambienttalk', 'ambienttalk/2']
|
||||
mimetypes = ['text/x-ambienttalk']
|
||||
|
||||
flags = re.MULTILINE | re.DOTALL
|
||||
|
||||
builtin = words(('if:', 'then:', 'else:', 'when:', 'whenever:', 'discovered:',
|
||||
'disconnected:', 'reconnected:', 'takenOffline:', 'becomes:',
|
||||
'export:', 'as:', 'object:', 'actor:', 'mirror:', 'taggedAs:',
|
||||
'mirroredBy:', 'is:'))
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'(def|deftype|import|alias|exclude)\b', Keyword),
|
||||
(builtin, Name.Builtin),
|
||||
(r'(true|false|nil)\b', Keyword.Constant),
|
||||
(r'(~|lobby|jlobby|/)\.', Keyword.Constant, 'namespace'),
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
(r'\|', Punctuation, 'arglist'),
|
||||
(r'<:|[*^!%&<>+=,./?-]|:=', Operator),
|
||||
(r"`[a-zA-Z_]\w*", String.Symbol),
|
||||
(r"[a-zA-Z_]\w*:", Name.Function),
|
||||
(r"[{}()\[\];`]", Punctuation),
|
||||
(r'(self|super)\b', Name.Variable.Instance),
|
||||
(r"[a-zA-Z_]\w*", Name.Variable),
|
||||
(r"@[a-zA-Z_]\w*", Name.Class),
|
||||
(r"@\[", Name.Class, 'annotations'),
|
||||
include('numbers'),
|
||||
],
|
||||
'numbers': [
|
||||
(r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', Number.Float),
|
||||
(r'\d+', Number.Integer)
|
||||
],
|
||||
'namespace': [
|
||||
(r'[a-zA-Z_]\w*\.', Name.Namespace),
|
||||
(r'[a-zA-Z_]\w*:', Name.Function, '#pop'),
|
||||
(r'[a-zA-Z_]\w*(?!\.)', Name.Function, '#pop')
|
||||
],
|
||||
'annotations': [
|
||||
(r"(.*?)\]", Name.Class, '#pop')
|
||||
],
|
||||
'arglist': [
|
||||
(r'\|', Punctuation, '#pop'),
|
||||
(r'\s*(,)\s*', Punctuation),
|
||||
(r'[a-zA-Z_]\w*', Name.Variable),
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,101 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.apl
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for APL.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['APLLexer']
|
||||
|
||||
|
||||
class APLLexer(RegexLexer):
|
||||
"""
|
||||
A simple APL lexer.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'APL'
|
||||
aliases = ['apl']
|
||||
filenames = ['*.apl']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Whitespace
|
||||
# ==========
|
||||
(r'\s+', Text),
|
||||
#
|
||||
# Comment
|
||||
# =======
|
||||
# '⍝' is traditional; '#' is supported by GNU APL and NGN (but not Dyalog)
|
||||
(u'[⍝#].*$', Comment.Single),
|
||||
#
|
||||
# Strings
|
||||
# =======
|
||||
(r'\'((\'\')|[^\'])*\'', String.Single),
|
||||
(r'"(("")|[^"])*"', String.Double), # supported by NGN APL
|
||||
#
|
||||
# Punctuation
|
||||
# ===========
|
||||
# This token type is used for diamond and parenthesis
|
||||
# but not for bracket and ; (see below)
|
||||
(u'[⋄◇()]', Punctuation),
|
||||
#
|
||||
# Array indexing
|
||||
# ==============
|
||||
# Since this token type is very important in APL, it is not included in
|
||||
# the punctuation token type but rather in the following one
|
||||
(r'[\[\];]', String.Regex),
|
||||
#
|
||||
# Distinguished names
|
||||
# ===================
|
||||
# following IBM APL2 standard
|
||||
(u'⎕[A-Za-zΔ∆⍙][A-Za-zΔ∆⍙_¯0-9]*', Name.Function),
|
||||
#
|
||||
# Labels
|
||||
# ======
|
||||
# following IBM APL2 standard
|
||||
# (u'[A-Za-zΔ∆⍙][A-Za-zΔ∆⍙_¯0-9]*:', Name.Label),
|
||||
#
|
||||
# Variables
|
||||
# =========
|
||||
# following IBM APL2 standard
|
||||
(u'[A-Za-zΔ∆⍙][A-Za-zΔ∆⍙_¯0-9]*', Name.Variable),
|
||||
#
|
||||
# Numbers
|
||||
# =======
|
||||
(u'¯?(0[Xx][0-9A-Fa-f]+|[0-9]*\.?[0-9]+([Ee][+¯]?[0-9]+)?|¯|∞)'
|
||||
u'([Jj]¯?(0[Xx][0-9A-Fa-f]+|[0-9]*\.?[0-9]+([Ee][+¯]?[0-9]+)?|¯|∞))?',
|
||||
Number),
|
||||
#
|
||||
# Operators
|
||||
# ==========
|
||||
(u'[\.\\\/⌿⍀¨⍣⍨⍠⍤∘]', Name.Attribute), # closest token type
|
||||
(u'[+\-×÷⌈⌊∣|⍳?*⍟○!⌹<≤=>≥≠≡≢∊⍷∪∩~∨∧⍱⍲⍴,⍪⌽⊖⍉↑↓⊂⊃⌷⍋⍒⊤⊥⍕⍎⊣⊢⍁⍂≈⌸⍯↗]',
|
||||
Operator),
|
||||
#
|
||||
# Constant
|
||||
# ========
|
||||
(u'⍬', Name.Constant),
|
||||
#
|
||||
# Quad symbol
|
||||
# ===========
|
||||
(u'[⎕⍞]', Name.Variable.Global),
|
||||
#
|
||||
# Arrows left/right
|
||||
# =================
|
||||
(u'[←→]', Keyword.Declaration),
|
||||
#
|
||||
# D-Fn
|
||||
# ====
|
||||
(u'[⍺⍵⍶⍹∇:]', Name.Builtin.Pseudo),
|
||||
(r'[{}]', Keyword.Type),
|
||||
],
|
||||
}
|
||||
@ -5,19 +5,21 @@
|
||||
|
||||
Lexers for assembly languages.
|
||||
|
||||
:copyright: Copyright 2006-2013 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, DelegatingLexer
|
||||
from pygments.lexers.compiled import DLexer, CppLexer, CLexer
|
||||
from pygments.lexers.c_cpp import CppLexer, CLexer
|
||||
from pygments.lexers.d import DLexer
|
||||
from pygments.token import Text, Name, Number, String, Comment, Punctuation, \
|
||||
Other, Keyword, Operator
|
||||
Other, Keyword, Operator
|
||||
|
||||
__all__ = ['GasLexer', 'ObjdumpLexer','DObjdumpLexer', 'CppObjdumpLexer',
|
||||
'CObjdumpLexer', 'LlvmLexer', 'NasmLexer', 'Ca65Lexer']
|
||||
__all__ = ['GasLexer', 'ObjdumpLexer', 'DObjdumpLexer', 'CppObjdumpLexer',
|
||||
'CObjdumpLexer', 'LlvmLexer', 'NasmLexer', 'NasmObjdumpLexer',
|
||||
'Ca65Lexer']
|
||||
|
||||
|
||||
class GasLexer(RegexLexer):
|
||||
@ -31,7 +33,7 @@ class GasLexer(RegexLexer):
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
string = r'"(\\"|[^"])*"'
|
||||
char = r'[a-zA-Z$._0-9@-]'
|
||||
char = r'[\w$.@-]'
|
||||
identifier = r'(?:[a-zA-Z$_]' + char + '*|\.' + char + '+)'
|
||||
number = r'(?:0[xX][a-zA-Z0-9]+|\d+)'
|
||||
|
||||
@ -96,18 +98,12 @@ class GasLexer(RegexLexer):
|
||||
return 0.1
|
||||
|
||||
|
||||
class ObjdumpLexer(RegexLexer):
|
||||
def _objdump_lexer_tokens(asm_lexer):
|
||||
"""
|
||||
For the output of 'objdump -dr'
|
||||
Common objdump lexer tokens to wrap an ASM lexer.
|
||||
"""
|
||||
name = 'objdump'
|
||||
aliases = ['objdump']
|
||||
filenames = ['*.objdump']
|
||||
mimetypes = ['text/x-objdump']
|
||||
|
||||
hex = r'[0-9A-Za-z]'
|
||||
|
||||
tokens = {
|
||||
hex_re = r'[0-9A-Za-z]'
|
||||
return {
|
||||
'root': [
|
||||
# File name & format:
|
||||
('(.*?)(:)( +file format )(.*?)$',
|
||||
@ -117,33 +113,33 @@ class ObjdumpLexer(RegexLexer):
|
||||
bygroups(Text, Name.Label, Punctuation)),
|
||||
# Function labels
|
||||
# (With offset)
|
||||
('('+hex+'+)( )(<)(.*?)([-+])(0[xX][A-Za-z0-9]+)(>:)$',
|
||||
('('+hex_re+'+)( )(<)(.*?)([-+])(0[xX][A-Za-z0-9]+)(>:)$',
|
||||
bygroups(Number.Hex, Text, Punctuation, Name.Function,
|
||||
Punctuation, Number.Hex, Punctuation)),
|
||||
# (Without offset)
|
||||
('('+hex+'+)( )(<)(.*?)(>:)$',
|
||||
('('+hex_re+'+)( )(<)(.*?)(>:)$',
|
||||
bygroups(Number.Hex, Text, Punctuation, Name.Function,
|
||||
Punctuation)),
|
||||
# Code line with disassembled instructions
|
||||
('( *)('+hex+r'+:)(\t)((?:'+hex+hex+' )+)( *\t)([a-zA-Z].*?)$',
|
||||
('( *)('+hex_re+r'+:)(\t)((?:'+hex_re+hex_re+' )+)( *\t)([a-zA-Z].*?)$',
|
||||
bygroups(Text, Name.Label, Text, Number.Hex, Text,
|
||||
using(GasLexer))),
|
||||
using(asm_lexer))),
|
||||
# Code line with ascii
|
||||
('( *)('+hex+r'+:)(\t)((?:'+hex+hex+' )+)( *)(.*?)$',
|
||||
('( *)('+hex_re+r'+:)(\t)((?:'+hex_re+hex_re+' )+)( *)(.*?)$',
|
||||
bygroups(Text, Name.Label, Text, Number.Hex, Text, String)),
|
||||
# Continued code line, only raw opcodes without disassembled
|
||||
# instruction
|
||||
('( *)('+hex+r'+:)(\t)((?:'+hex+hex+' )+)$',
|
||||
('( *)('+hex_re+r'+:)(\t)((?:'+hex_re+hex_re+' )+)$',
|
||||
bygroups(Text, Name.Label, Text, Number.Hex)),
|
||||
# Skipped a few bytes
|
||||
(r'\t\.\.\.$', Text),
|
||||
# Relocation line
|
||||
# (With offset)
|
||||
(r'(\t\t\t)('+hex+r'+:)( )([^\t]+)(\t)(.*?)([-+])(0x' + hex + '+)$',
|
||||
(r'(\t\t\t)('+hex_re+r'+:)( )([^\t]+)(\t)(.*?)([-+])(0x'+hex_re+'+)$',
|
||||
bygroups(Text, Name.Label, Text, Name.Property, Text,
|
||||
Name.Constant, Punctuation, Number.Hex)),
|
||||
# (Without offset)
|
||||
(r'(\t\t\t)('+hex+r'+:)( )([^\t]+)(\t)(.*?)$',
|
||||
(r'(\t\t\t)('+hex_re+r'+:)( )([^\t]+)(\t)(.*?)$',
|
||||
bygroups(Text, Name.Label, Text, Name.Property, Text,
|
||||
Name.Constant)),
|
||||
(r'[^\n]+\n', Other)
|
||||
@ -151,6 +147,18 @@ class ObjdumpLexer(RegexLexer):
|
||||
}
|
||||
|
||||
|
||||
class ObjdumpLexer(RegexLexer):
|
||||
"""
|
||||
For the output of 'objdump -dr'
|
||||
"""
|
||||
name = 'objdump'
|
||||
aliases = ['objdump']
|
||||
filenames = ['*.objdump']
|
||||
mimetypes = ['text/x-objdump']
|
||||
|
||||
tokens = _objdump_lexer_tokens(GasLexer)
|
||||
|
||||
|
||||
class DObjdumpLexer(DelegatingLexer):
|
||||
"""
|
||||
For the output of 'objdump -Sr on compiled D files'
|
||||
@ -201,7 +209,7 @@ class LlvmLexer(RegexLexer):
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
string = r'"[^"]*?"'
|
||||
identifier = r'([-a-zA-Z$._][-a-zA-Z$._0-9]*|' + string + ')'
|
||||
identifier = r'([-a-zA-Z$._][\w\-$.]*|' + string + ')'
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
@ -212,10 +220,11 @@ class LlvmLexer(RegexLexer):
|
||||
|
||||
include('keyword'),
|
||||
|
||||
(r'%' + identifier, Name.Variable),#Name.Identifier.Local),
|
||||
(r'@' + identifier, Name.Variable.Global),#Name.Identifier.Global),
|
||||
(r'%\d+', Name.Variable.Anonymous),#Name.Identifier.Anonymous),
|
||||
(r'@\d+', Name.Variable.Global),#Name.Identifier.Anonymous),
|
||||
(r'%' + identifier, Name.Variable),
|
||||
(r'@' + identifier, Name.Variable.Global),
|
||||
(r'%\d+', Name.Variable.Anonymous),
|
||||
(r'@\d+', Name.Variable.Global),
|
||||
(r'#\d+', Name.Variable.Global),
|
||||
(r'!' + identifier, Name.Variable),
|
||||
(r'!\d+', Name.Variable.Anonymous),
|
||||
(r'c?' + string, String),
|
||||
@ -242,17 +251,24 @@ class LlvmLexer(RegexLexer):
|
||||
r'|thread_local|zeroinitializer|undef|null|to|tail|target|triple'
|
||||
r'|datalayout|volatile|nuw|nsw|nnan|ninf|nsz|arcp|fast|exact|inbounds'
|
||||
r'|align|addrspace|section|alias|module|asm|sideeffect|gc|dbg'
|
||||
r'|linker_private_weak'
|
||||
r'|attributes|blockaddress|initialexec|localdynamic|localexec'
|
||||
r'|prefix|unnamed_addr'
|
||||
|
||||
r'|ccc|fastcc|coldcc|x86_stdcallcc|x86_fastcallcc|arm_apcscc'
|
||||
r'|arm_aapcscc|arm_aapcs_vfpcc|ptx_device|ptx_kernel'
|
||||
r'|intel_ocl_bicc|msp430_intrcc|spir_func|spir_kernel'
|
||||
r'|x86_64_sysvcc|x86_64_win64cc|x86_thiscallcc'
|
||||
|
||||
r'|cc|c'
|
||||
|
||||
r'|signext|zeroext|inreg|sret|nounwind|noreturn|noalias|nocapture'
|
||||
r'|byval|nest|readnone|readonly'
|
||||
|
||||
r'|inlinehint|noinline|alwaysinline|optsize|ssp|sspreq|noredzone'
|
||||
r'|noimplicitfloat|naked'
|
||||
r'|builtin|cold|nobuiltin|noduplicate|nonlazybind|optnone'
|
||||
r'|returns_twice|sanitize_address|sanitize_memory|sanitize_thread'
|
||||
r'|sspstrong|uwtable|returned'
|
||||
|
||||
r'|type|opaque'
|
||||
|
||||
@ -261,24 +277,30 @@ class LlvmLexer(RegexLexer):
|
||||
r'|oeq|one|olt|ogt|ole'
|
||||
r'|oge|ord|uno|ueq|une'
|
||||
r'|x'
|
||||
r'|acq_rel|acquire|alignstack|atomic|catch|cleanup|filter'
|
||||
r'|inteldialect|max|min|monotonic|nand|personality|release'
|
||||
r'|seq_cst|singlethread|umax|umin|unordered|xchg'
|
||||
|
||||
# instructions
|
||||
r'|add|fadd|sub|fsub|mul|fmul|udiv|sdiv|fdiv|urem|srem|frem|shl'
|
||||
r'|lshr|ashr|and|or|xor|icmp|fcmp'
|
||||
|
||||
r'|phi|call|trunc|zext|sext|fptrunc|fpext|uitofp|sitofp|fptoui'
|
||||
r'fptosi|inttoptr|ptrtoint|bitcast|select|va_arg|ret|br|switch'
|
||||
r'|fptosi|inttoptr|ptrtoint|bitcast|select|va_arg|ret|br|switch'
|
||||
r'|invoke|unwind|unreachable'
|
||||
r'|indirectbr|landingpad|resume'
|
||||
|
||||
r'|malloc|alloca|free|load|store|getelementptr'
|
||||
|
||||
r'|extractelement|insertelement|shufflevector|getresult'
|
||||
r'|extractvalue|insertvalue'
|
||||
|
||||
r'|atomicrmw|cmpxchg|fence'
|
||||
|
||||
r')\b', Keyword),
|
||||
|
||||
# Types
|
||||
(r'void|float|double|x86_fp80|fp128|ppc_fp128|label|metadata',
|
||||
(r'void|half|float|double|x86_fp80|fp128|ppc_fp128|label|metadata',
|
||||
Keyword.Type),
|
||||
|
||||
# Integer types
|
||||
@ -296,8 +318,8 @@ class NasmLexer(RegexLexer):
|
||||
filenames = ['*.asm', '*.ASM']
|
||||
mimetypes = ['text/x-nasm']
|
||||
|
||||
identifier = r'[a-zA-Z$._?][a-zA-Z0-9$._?#@~]*'
|
||||
hexn = r'(?:0[xX][0-9a-fA-F]+|$0[0-9a-fA-F]*|[0-9]+[0-9a-fA-F]*h)'
|
||||
identifier = r'[a-z$._?][\w$.?#@~]*'
|
||||
hexn = r'(?:0x[0-9a-f]+|$0[0-9a-f]*|[0-9]+[0-9a-f]*h)'
|
||||
octn = r'[0-7]+q'
|
||||
binn = r'[01]+b'
|
||||
decn = r'[0-9]+'
|
||||
@ -316,8 +338,8 @@ class NasmLexer(RegexLexer):
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
(r'^\s*%', Comment.Preproc, 'preproc'),
|
||||
include('whitespace'),
|
||||
(identifier + ':', Name.Label),
|
||||
(r'(%s)(\s+)(equ)' % identifier,
|
||||
bygroups(Name.Constant, Keyword.Declaration, Keyword.Declaration),
|
||||
@ -331,7 +353,7 @@ class NasmLexer(RegexLexer):
|
||||
(string, String),
|
||||
(hexn, Number.Hex),
|
||||
(octn, Number.Oct),
|
||||
(binn, Number),
|
||||
(binn, Number.Bin),
|
||||
(floatn, Number.Float),
|
||||
(decn, Number.Integer),
|
||||
include('punctuation'),
|
||||
@ -360,13 +382,27 @@ class NasmLexer(RegexLexer):
|
||||
}
|
||||
|
||||
|
||||
class NasmObjdumpLexer(ObjdumpLexer):
|
||||
"""
|
||||
For the output of 'objdump -d -M intel'.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'objdump-nasm'
|
||||
aliases = ['objdump-nasm']
|
||||
filenames = ['*.objdump-intel']
|
||||
mimetypes = ['text/x-nasm-objdump']
|
||||
|
||||
tokens = _objdump_lexer_tokens(NasmLexer)
|
||||
|
||||
|
||||
class Ca65Lexer(RegexLexer):
|
||||
"""
|
||||
For ca65 assembler sources.
|
||||
|
||||
*New in Pygments 1.6.*
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'ca65'
|
||||
name = 'ca65 assembler'
|
||||
aliases = ['ca65']
|
||||
filenames = ['*.s']
|
||||
|
||||
@ -381,13 +417,14 @@ class Ca65Lexer(RegexLexer):
|
||||
r'|cl[cvdi]|se[cdi]|jmp|jsr|bne|beq|bpl|bmi|bvc|bvs|bcc|bcs'
|
||||
r'|p[lh][ap]|rt[is]|brk|nop|ta[xy]|t[xy]a|txs|tsx|and|ora|eor'
|
||||
r'|bit)\b', Keyword),
|
||||
(r'\.[a-z0-9_]+', Keyword.Pseudo),
|
||||
(r'\.\w+', Keyword.Pseudo),
|
||||
(r'[-+~*/^&|!<>=]', Operator),
|
||||
(r'"[^"\n]*.', String),
|
||||
(r"'[^'\n]*.", String.Char),
|
||||
(r'\$[0-9a-f]+|[0-9a-f]+h\b', Number.Hex),
|
||||
(r'\d+|%[01]+', Number.Integer),
|
||||
(r'[#,.:()=]', Punctuation),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'%[01]+', Number.Bin),
|
||||
(r'[#,.:()=\[\]]', Punctuation),
|
||||
(r'[a-z_.@$][\w.@$]*', Name),
|
||||
]
|
||||
}
|
||||
@ -0,0 +1,373 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.automation
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for automation scripting languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, combined
|
||||
from pygments.token import Text, Comment, Operator, Name, String, \
|
||||
Number, Punctuation, Generic
|
||||
|
||||
__all__ = ['AutohotkeyLexer', 'AutoItLexer']
|
||||
|
||||
|
||||
class AutohotkeyLexer(RegexLexer):
|
||||
"""
|
||||
For `autohotkey <http://www.autohotkey.com/>`_ source code.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
name = 'autohotkey'
|
||||
aliases = ['ahk', 'autohotkey']
|
||||
filenames = ['*.ahk', '*.ahkl']
|
||||
mimetypes = ['text/x-autohotkey']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^(\s*)(/\*)', bygroups(Text, Comment.Multiline), 'incomment'),
|
||||
(r'^(\s*)(\()', bygroups(Text, Generic), 'incontinuation'),
|
||||
(r'\s+;.*?$', Comment.Singleline),
|
||||
(r'^;.*?$', Comment.Singleline),
|
||||
(r'[]{}(),;[]', Punctuation),
|
||||
(r'(in|is|and|or|not)\b', Operator.Word),
|
||||
(r'\%[a-zA-Z_#@$][\w#@$]*\%', Name.Variable),
|
||||
(r'!=|==|:=|\.=|<<|>>|[-~+/*%=<>&^|?:!.]', Operator),
|
||||
include('commands'),
|
||||
include('labels'),
|
||||
include('builtInFunctions'),
|
||||
include('builtInVariables'),
|
||||
(r'"', String, combined('stringescape', 'dqs')),
|
||||
include('numbers'),
|
||||
(r'[a-zA-Z_#@$][\w#@$]*', Name),
|
||||
(r'\\|\'', Text),
|
||||
(r'\`([,%`abfnrtv\-+;])', String.Escape),
|
||||
include('garbage'),
|
||||
],
|
||||
'incomment': [
|
||||
(r'^\s*\*/', Comment.Multiline, '#pop'),
|
||||
(r'[^*/]', Comment.Multiline),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
],
|
||||
'incontinuation': [
|
||||
(r'^\s*\)', Generic, '#pop'),
|
||||
(r'[^)]', Generic),
|
||||
(r'[)]', Generic),
|
||||
],
|
||||
'commands': [
|
||||
(r'(?i)^(\s*)(global|local|static|'
|
||||
r'#AllowSameLineComments|#ClipboardTimeout|#CommentFlag|'
|
||||
r'#ErrorStdOut|#EscapeChar|#HotkeyInterval|#HotkeyModifierTimeout|'
|
||||
r'#Hotstring|#IfWinActive|#IfWinExist|#IfWinNotActive|'
|
||||
r'#IfWinNotExist|#IncludeAgain|#Include|#InstallKeybdHook|'
|
||||
r'#InstallMouseHook|#KeyHistory|#LTrim|#MaxHotkeysPerInterval|'
|
||||
r'#MaxMem|#MaxThreads|#MaxThreadsBuffer|#MaxThreadsPerHotkey|'
|
||||
r'#NoEnv|#NoTrayIcon|#Persistent|#SingleInstance|#UseHook|'
|
||||
r'#WinActivateForce|AutoTrim|BlockInput|Break|Click|ClipWait|'
|
||||
r'Continue|Control|ControlClick|ControlFocus|ControlGetFocus|'
|
||||
r'ControlGetPos|ControlGetText|ControlGet|ControlMove|ControlSend|'
|
||||
r'ControlSendRaw|ControlSetText|CoordMode|Critical|'
|
||||
r'DetectHiddenText|DetectHiddenWindows|Drive|DriveGet|'
|
||||
r'DriveSpaceFree|Edit|Else|EnvAdd|EnvDiv|EnvGet|EnvMult|EnvSet|'
|
||||
r'EnvSub|EnvUpdate|Exit|ExitApp|FileAppend|'
|
||||
r'FileCopy|FileCopyDir|FileCreateDir|FileCreateShortcut|'
|
||||
r'FileDelete|FileGetAttrib|FileGetShortcut|FileGetSize|'
|
||||
r'FileGetTime|FileGetVersion|FileInstall|FileMove|FileMoveDir|'
|
||||
r'FileRead|FileReadLine|FileRecycle|FileRecycleEmpty|'
|
||||
r'FileRemoveDir|FileSelectFile|FileSelectFolder|FileSetAttrib|'
|
||||
r'FileSetTime|FormatTime|GetKeyState|Gosub|Goto|GroupActivate|'
|
||||
r'GroupAdd|GroupClose|GroupDeactivate|Gui|GuiControl|'
|
||||
r'GuiControlGet|Hotkey|IfEqual|IfExist|IfGreaterOrEqual|IfGreater|'
|
||||
r'IfInString|IfLess|IfLessOrEqual|IfMsgBox|IfNotEqual|IfNotExist|'
|
||||
r'IfNotInString|IfWinActive|IfWinExist|IfWinNotActive|'
|
||||
r'IfWinNotExist|If |ImageSearch|IniDelete|IniRead|IniWrite|'
|
||||
r'InputBox|Input|KeyHistory|KeyWait|ListHotkeys|ListLines|'
|
||||
r'ListVars|Loop|Menu|MouseClickDrag|MouseClick|MouseGetPos|'
|
||||
r'MouseMove|MsgBox|OnExit|OutputDebug|Pause|PixelGetColor|'
|
||||
r'PixelSearch|PostMessage|Process|Progress|Random|RegDelete|'
|
||||
r'RegRead|RegWrite|Reload|Repeat|Return|RunAs|RunWait|Run|'
|
||||
r'SendEvent|SendInput|SendMessage|SendMode|SendPlay|SendRaw|Send|'
|
||||
r'SetBatchLines|SetCapslockState|SetControlDelay|'
|
||||
r'SetDefaultMouseSpeed|SetEnv|SetFormat|SetKeyDelay|'
|
||||
r'SetMouseDelay|SetNumlockState|SetScrollLockState|'
|
||||
r'SetStoreCapslockMode|SetTimer|SetTitleMatchMode|'
|
||||
r'SetWinDelay|SetWorkingDir|Shutdown|Sleep|Sort|SoundBeep|'
|
||||
r'SoundGet|SoundGetWaveVolume|SoundPlay|SoundSet|'
|
||||
r'SoundSetWaveVolume|SplashImage|SplashTextOff|SplashTextOn|'
|
||||
r'SplitPath|StatusBarGetText|StatusBarWait|StringCaseSense|'
|
||||
r'StringGetPos|StringLeft|StringLen|StringLower|StringMid|'
|
||||
r'StringReplace|StringRight|StringSplit|StringTrimLeft|'
|
||||
r'StringTrimRight|StringUpper|Suspend|SysGet|Thread|ToolTip|'
|
||||
r'Transform|TrayTip|URLDownloadToFile|While|WinActivate|'
|
||||
r'WinActivateBottom|WinClose|WinGetActiveStats|WinGetActiveTitle|'
|
||||
r'WinGetClass|WinGetPos|WinGetText|WinGetTitle|WinGet|WinHide|'
|
||||
r'WinKill|WinMaximize|WinMenuSelectItem|WinMinimizeAllUndo|'
|
||||
r'WinMinimizeAll|WinMinimize|WinMove|WinRestore|WinSetTitle|'
|
||||
r'WinSet|WinShow|WinWaitActive|WinWaitClose|WinWaitNotActive|'
|
||||
r'WinWait)\b', bygroups(Text, Name.Builtin)),
|
||||
],
|
||||
'builtInFunctions': [
|
||||
(r'(?i)(Abs|ACos|Asc|ASin|ATan|Ceil|Chr|Cos|DllCall|Exp|FileExist|'
|
||||
r'Floor|GetKeyState|IL_Add|IL_Create|IL_Destroy|InStr|IsFunc|'
|
||||
r'IsLabel|Ln|Log|LV_Add|LV_Delete|LV_DeleteCol|LV_GetCount|'
|
||||
r'LV_GetNext|LV_GetText|LV_Insert|LV_InsertCol|LV_Modify|'
|
||||
r'LV_ModifyCol|LV_SetImageList|Mod|NumGet|NumPut|OnMessage|'
|
||||
r'RegExMatch|RegExReplace|RegisterCallback|Round|SB_SetIcon|'
|
||||
r'SB_SetParts|SB_SetText|Sin|Sqrt|StrLen|SubStr|Tan|TV_Add|'
|
||||
r'TV_Delete|TV_GetChild|TV_GetCount|TV_GetNext|TV_Get|'
|
||||
r'TV_GetParent|TV_GetPrev|TV_GetSelection|TV_GetText|TV_Modify|'
|
||||
r'VarSetCapacity|WinActive|WinExist|Object|ComObjActive|'
|
||||
r'ComObjArray|ComObjEnwrap|ComObjUnwrap|ComObjParameter|'
|
||||
r'ComObjType|ComObjConnect|ComObjCreate|ComObjGet|ComObjError|'
|
||||
r'ComObjValue|Insert|MinIndex|MaxIndex|Remove|SetCapacity|'
|
||||
r'GetCapacity|GetAddress|_NewEnum|FileOpen|Read|Write|ReadLine|'
|
||||
r'WriteLine|ReadNumType|WriteNumType|RawRead|RawWrite|Seek|Tell|'
|
||||
r'Close|Next|IsObject|StrPut|StrGet|Trim|LTrim|RTrim)\b',
|
||||
Name.Function),
|
||||
],
|
||||
'builtInVariables': [
|
||||
(r'(?i)(A_AhkPath|A_AhkVersion|A_AppData|A_AppDataCommon|'
|
||||
r'A_AutoTrim|A_BatchLines|A_CaretX|A_CaretY|A_ComputerName|'
|
||||
r'A_ControlDelay|A_Cursor|A_DDDD|A_DDD|A_DD|A_DefaultMouseSpeed|'
|
||||
r'A_Desktop|A_DesktopCommon|A_DetectHiddenText|'
|
||||
r'A_DetectHiddenWindows|A_EndChar|A_EventInfo|A_ExitReason|'
|
||||
r'A_FormatFloat|A_FormatInteger|A_Gui|A_GuiEvent|A_GuiControl|'
|
||||
r'A_GuiControlEvent|A_GuiHeight|A_GuiWidth|A_GuiX|A_GuiY|A_Hour|'
|
||||
r'A_IconFile|A_IconHidden|A_IconNumber|A_IconTip|A_Index|'
|
||||
r'A_IPAddress1|A_IPAddress2|A_IPAddress3|A_IPAddress4|A_ISAdmin|'
|
||||
r'A_IsCompiled|A_IsCritical|A_IsPaused|A_IsSuspended|A_KeyDelay|'
|
||||
r'A_Language|A_LastError|A_LineFile|A_LineNumber|A_LoopField|'
|
||||
r'A_LoopFileAttrib|A_LoopFileDir|A_LoopFileExt|A_LoopFileFullPath|'
|
||||
r'A_LoopFileLongPath|A_LoopFileName|A_LoopFileShortName|'
|
||||
r'A_LoopFileShortPath|A_LoopFileSize|A_LoopFileSizeKB|'
|
||||
r'A_LoopFileSizeMB|A_LoopFileTimeAccessed|A_LoopFileTimeCreated|'
|
||||
r'A_LoopFileTimeModified|A_LoopReadLine|A_LoopRegKey|'
|
||||
r'A_LoopRegName|A_LoopRegSubkey|A_LoopRegTimeModified|'
|
||||
r'A_LoopRegType|A_MDAY|A_Min|A_MM|A_MMM|A_MMMM|A_Mon|A_MouseDelay|'
|
||||
r'A_MSec|A_MyDocuments|A_Now|A_NowUTC|A_NumBatchLines|A_OSType|'
|
||||
r'A_OSVersion|A_PriorHotkey|A_ProgramFiles|A_Programs|'
|
||||
r'A_ProgramsCommon|A_ScreenHeight|A_ScreenWidth|A_ScriptDir|'
|
||||
r'A_ScriptFullPath|A_ScriptName|A_Sec|A_Space|A_StartMenu|'
|
||||
r'A_StartMenuCommon|A_Startup|A_StartupCommon|A_StringCaseSense|'
|
||||
r'A_Tab|A_Temp|A_ThisFunc|A_ThisHotkey|A_ThisLabel|A_ThisMenu|'
|
||||
r'A_ThisMenuItem|A_ThisMenuItemPos|A_TickCount|A_TimeIdle|'
|
||||
r'A_TimeIdlePhysical|A_TimeSincePriorHotkey|A_TimeSinceThisHotkey|'
|
||||
r'A_TitleMatchMode|A_TitleMatchModeSpeed|A_UserName|A_WDay|'
|
||||
r'A_WinDelay|A_WinDir|A_WorkingDir|A_YDay|A_YEAR|A_YWeek|A_YYYY|'
|
||||
r'Clipboard|ClipboardAll|ComSpec|ErrorLevel|ProgramFiles|True|'
|
||||
r'False|A_IsUnicode|A_FileEncoding|A_OSVersion|A_PtrSize)\b',
|
||||
Name.Variable),
|
||||
],
|
||||
'labels': [
|
||||
# hotkeys and labels
|
||||
# technically, hotkey names are limited to named keys and buttons
|
||||
(r'(^\s*)([^:\s("]+?:{1,2})', bygroups(Text, Name.Label)),
|
||||
(r'(^\s*)(::[^:\s]+?::)', bygroups(Text, Name.Label)),
|
||||
],
|
||||
'numbers': [
|
||||
(r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', Number.Float),
|
||||
(r'\d+[eE][+-]?[0-9]+', Number.Float),
|
||||
(r'0\d+', Number.Oct),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+L', Number.Integer.Long),
|
||||
(r'\d+', Number.Integer)
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\"\"|\`([,%`abfnrtv])', String.Escape),
|
||||
],
|
||||
'strings': [
|
||||
(r'[^"\n]+', String),
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
include('strings')
|
||||
],
|
||||
'garbage': [
|
||||
(r'[^\S\n]', Text),
|
||||
# (r'.', Text), # no cheating
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class AutoItLexer(RegexLexer):
|
||||
"""
|
||||
For `AutoIt <http://www.autoitscript.com/site/autoit/>`_ files.
|
||||
|
||||
AutoIt is a freeware BASIC-like scripting language
|
||||
designed for automating the Windows GUI and general scripting
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'AutoIt'
|
||||
aliases = ['autoit']
|
||||
filenames = ['*.au3']
|
||||
mimetypes = ['text/x-autoit']
|
||||
|
||||
# Keywords, functions, macros from au3.keywords.properties
|
||||
# which can be found in AutoIt installed directory, e.g.
|
||||
# c:\Program Files (x86)\AutoIt3\SciTE\au3.keywords.properties
|
||||
|
||||
keywords = """\
|
||||
#include-once #include #endregion #forcedef #forceref #region
|
||||
and byref case continueloop dim do else elseif endfunc endif
|
||||
endselect exit exitloop for func global
|
||||
if local next not or return select step
|
||||
then to until wend while exit""".split()
|
||||
|
||||
functions = """\
|
||||
abs acos adlibregister adlibunregister asc ascw asin assign atan
|
||||
autoitsetoption autoitwingettitle autoitwinsettitle beep binary binarylen
|
||||
binarymid binarytostring bitand bitnot bitor bitrotate bitshift bitxor
|
||||
blockinput break call cdtray ceiling chr chrw clipget clipput consoleread
|
||||
consolewrite consolewriteerror controlclick controlcommand controldisable
|
||||
controlenable controlfocus controlgetfocus controlgethandle controlgetpos
|
||||
controlgettext controlhide controllistview controlmove controlsend
|
||||
controlsettext controlshow controltreeview cos dec dircopy dircreate
|
||||
dirgetsize dirmove dirremove dllcall dllcalladdress dllcallbackfree
|
||||
dllcallbackgetptr dllcallbackregister dllclose dllopen dllstructcreate
|
||||
dllstructgetdata dllstructgetptr dllstructgetsize dllstructsetdata
|
||||
drivegetdrive drivegetfilesystem drivegetlabel drivegetserial drivegettype
|
||||
drivemapadd drivemapdel drivemapget drivesetlabel drivespacefree
|
||||
drivespacetotal drivestatus envget envset envupdate eval execute exp
|
||||
filechangedir fileclose filecopy filecreatentfslink filecreateshortcut
|
||||
filedelete fileexists filefindfirstfile filefindnextfile fileflush
|
||||
filegetattrib filegetencoding filegetlongname filegetpos filegetshortcut
|
||||
filegetshortname filegetsize filegettime filegetversion fileinstall filemove
|
||||
fileopen fileopendialog fileread filereadline filerecycle filerecycleempty
|
||||
filesavedialog fileselectfolder filesetattrib filesetpos filesettime
|
||||
filewrite filewriteline floor ftpsetproxy guicreate guictrlcreateavi
|
||||
guictrlcreatebutton guictrlcreatecheckbox guictrlcreatecombo
|
||||
guictrlcreatecontextmenu guictrlcreatedate guictrlcreatedummy
|
||||
guictrlcreateedit guictrlcreategraphic guictrlcreategroup guictrlcreateicon
|
||||
guictrlcreateinput guictrlcreatelabel guictrlcreatelist
|
||||
guictrlcreatelistview guictrlcreatelistviewitem guictrlcreatemenu
|
||||
guictrlcreatemenuitem guictrlcreatemonthcal guictrlcreateobj
|
||||
guictrlcreatepic guictrlcreateprogress guictrlcreateradio
|
||||
guictrlcreateslider guictrlcreatetab guictrlcreatetabitem
|
||||
guictrlcreatetreeview guictrlcreatetreeviewitem guictrlcreateupdown
|
||||
guictrldelete guictrlgethandle guictrlgetstate guictrlread guictrlrecvmsg
|
||||
guictrlregisterlistviewsort guictrlsendmsg guictrlsendtodummy
|
||||
guictrlsetbkcolor guictrlsetcolor guictrlsetcursor guictrlsetdata
|
||||
guictrlsetdefbkcolor guictrlsetdefcolor guictrlsetfont guictrlsetgraphic
|
||||
guictrlsetimage guictrlsetlimit guictrlsetonevent guictrlsetpos
|
||||
guictrlsetresizing guictrlsetstate guictrlsetstyle guictrlsettip guidelete
|
||||
guigetcursorinfo guigetmsg guigetstyle guiregistermsg guisetaccelerators
|
||||
guisetbkcolor guisetcoord guisetcursor guisetfont guisethelp guiseticon
|
||||
guisetonevent guisetstate guisetstyle guistartgroup guiswitch hex hotkeyset
|
||||
httpsetproxy httpsetuseragent hwnd inetclose inetget inetgetinfo inetgetsize
|
||||
inetread inidelete iniread inireadsection inireadsectionnames
|
||||
inirenamesection iniwrite iniwritesection inputbox int isadmin isarray
|
||||
isbinary isbool isdeclared isdllstruct isfloat ishwnd isint iskeyword
|
||||
isnumber isobj isptr isstring log memgetstats mod mouseclick mouseclickdrag
|
||||
mousedown mousegetcursor mousegetpos mousemove mouseup mousewheel msgbox
|
||||
number objcreate objcreateinterface objevent objevent objget objname
|
||||
onautoitexitregister onautoitexitunregister opt ping pixelchecksum
|
||||
pixelgetcolor pixelsearch pluginclose pluginopen processclose processexists
|
||||
processgetstats processlist processsetpriority processwait processwaitclose
|
||||
progressoff progresson progressset ptr random regdelete regenumkey
|
||||
regenumval regread regwrite round run runas runaswait runwait send
|
||||
sendkeepactive seterror setextended shellexecute shellexecutewait shutdown
|
||||
sin sleep soundplay soundsetwavevolume splashimageon splashoff splashtexton
|
||||
sqrt srandom statusbargettext stderrread stdinwrite stdioclose stdoutread
|
||||
string stringaddcr stringcompare stringformat stringfromasciiarray
|
||||
stringinstr stringisalnum stringisalpha stringisascii stringisdigit
|
||||
stringisfloat stringisint stringislower stringisspace stringisupper
|
||||
stringisxdigit stringleft stringlen stringlower stringmid stringregexp
|
||||
stringregexpreplace stringreplace stringright stringsplit stringstripcr
|
||||
stringstripws stringtoasciiarray stringtobinary stringtrimleft
|
||||
stringtrimright stringupper tan tcpaccept tcpclosesocket tcpconnect
|
||||
tcplisten tcpnametoip tcprecv tcpsend tcpshutdown tcpstartup timerdiff
|
||||
timerinit tooltip traycreateitem traycreatemenu traygetmsg trayitemdelete
|
||||
trayitemgethandle trayitemgetstate trayitemgettext trayitemsetonevent
|
||||
trayitemsetstate trayitemsettext traysetclick trayseticon traysetonevent
|
||||
traysetpauseicon traysetstate traysettooltip traytip ubound udpbind
|
||||
udpclosesocket udpopen udprecv udpsend udpshutdown udpstartup vargettype
|
||||
winactivate winactive winclose winexists winflash wingetcaretpos
|
||||
wingetclasslist wingetclientsize wingethandle wingetpos wingetprocess
|
||||
wingetstate wingettext wingettitle winkill winlist winmenuselectitem
|
||||
winminimizeall winminimizeallundo winmove winsetontop winsetstate
|
||||
winsettitle winsettrans winwait winwaitactive winwaitclose
|
||||
winwaitnotactive""".split()
|
||||
|
||||
macros = """\
|
||||
@appdatacommondir @appdatadir @autoitexe @autoitpid @autoitversion
|
||||
@autoitx64 @com_eventobj @commonfilesdir @compiled @computername @comspec
|
||||
@cpuarch @cr @crlf @desktopcommondir @desktopdepth @desktopdir
|
||||
@desktopheight @desktoprefresh @desktopwidth @documentscommondir @error
|
||||
@exitcode @exitmethod @extended @favoritescommondir @favoritesdir
|
||||
@gui_ctrlhandle @gui_ctrlid @gui_dragfile @gui_dragid @gui_dropid
|
||||
@gui_winhandle @homedrive @homepath @homeshare @hotkeypressed @hour
|
||||
@ipaddress1 @ipaddress2 @ipaddress3 @ipaddress4 @kblayout @lf
|
||||
@logondnsdomain @logondomain @logonserver @mday @min @mon @msec @muilang
|
||||
@mydocumentsdir @numparams @osarch @osbuild @oslang @osservicepack @ostype
|
||||
@osversion @programfilesdir @programscommondir @programsdir @scriptdir
|
||||
@scriptfullpath @scriptlinenumber @scriptname @sec @startmenucommondir
|
||||
@startmenudir @startupcommondir @startupdir @sw_disable @sw_enable @sw_hide
|
||||
@sw_lock @sw_maximize @sw_minimize @sw_restore @sw_show @sw_showdefault
|
||||
@sw_showmaximized @sw_showminimized @sw_showminnoactive @sw_showna
|
||||
@sw_shownoactivate @sw_shownormal @sw_unlock @systemdir @tab @tempdir
|
||||
@tray_id @trayiconflashing @trayiconvisible @username @userprofiledir @wday
|
||||
@windowsdir @workingdir @yday @year""".split()
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r';.*\n', Comment.Single),
|
||||
(r'(#comments-start|#cs).*?(#comments-end|#ce)', Comment.Multiline),
|
||||
(r'[\[\]{}(),;]', Punctuation),
|
||||
(r'(and|or|not)\b', Operator.Word),
|
||||
(r'[$|@][a-zA-Z_]\w*', Name.Variable),
|
||||
(r'!=|==|:=|\.=|<<|>>|[-~+/*%=<>&^|?:!.]', Operator),
|
||||
include('commands'),
|
||||
include('labels'),
|
||||
include('builtInFunctions'),
|
||||
include('builtInMarcros'),
|
||||
(r'"', String, combined('stringescape', 'dqs')),
|
||||
include('numbers'),
|
||||
(r'[a-zA-Z_#@$][\w#@$]*', Name),
|
||||
(r'\\|\'', Text),
|
||||
(r'\`([,%`abfnrtv\-+;])', String.Escape),
|
||||
(r'_\n', Text), # Line continuation
|
||||
include('garbage'),
|
||||
],
|
||||
'commands': [
|
||||
(r'(?i)(\s*)(%s)\b' % '|'.join(keywords),
|
||||
bygroups(Text, Name.Builtin)),
|
||||
],
|
||||
'builtInFunctions': [
|
||||
(r'(?i)(%s)\b' % '|'.join(functions),
|
||||
Name.Function),
|
||||
],
|
||||
'builtInMarcros': [
|
||||
(r'(?i)(%s)\b' % '|'.join(macros),
|
||||
Name.Variable.Global),
|
||||
],
|
||||
'labels': [
|
||||
# sendkeys
|
||||
(r'(^\s*)(\{\S+?\})', bygroups(Text, Name.Label)),
|
||||
],
|
||||
'numbers': [
|
||||
(r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?', Number.Float),
|
||||
(r'\d+[eE][+-]?[0-9]+', Number.Float),
|
||||
(r'0\d+', Number.Oct),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+L', Number.Integer.Long),
|
||||
(r'\d+', Number.Integer)
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\"\"|\`([,%`abfnrtv])', String.Escape),
|
||||
],
|
||||
'strings': [
|
||||
(r'[^"\n]+', String),
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
include('strings')
|
||||
],
|
||||
'garbage': [
|
||||
(r'[^\S\n]', Text),
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,500 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.basic
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for BASIC like languages (other than VB.net).
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, default, words, include
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['BlitzBasicLexer', 'BlitzMaxLexer', 'MonkeyLexer', 'CbmBasicV2Lexer',
|
||||
'QBasicLexer']
|
||||
|
||||
|
||||
class BlitzMaxLexer(RegexLexer):
|
||||
"""
|
||||
For `BlitzMax <http://blitzbasic.com>`_ source code.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'BlitzMax'
|
||||
aliases = ['blitzmax', 'bmax']
|
||||
filenames = ['*.bmx']
|
||||
mimetypes = ['text/x-bmx']
|
||||
|
||||
bmax_vopwords = r'\b(Shl|Shr|Sar|Mod)\b'
|
||||
bmax_sktypes = r'@{1,2}|[!#$%]'
|
||||
bmax_lktypes = r'\b(Int|Byte|Short|Float|Double|Long)\b'
|
||||
bmax_name = r'[a-z_]\w*'
|
||||
bmax_var = (r'(%s)(?:(?:([ \t]*)(%s)|([ \t]*:[ \t]*\b(?:Shl|Shr|Sar|Mod)\b)'
|
||||
r'|([ \t]*)(:)([ \t]*)(?:%s|(%s)))(?:([ \t]*)(Ptr))?)') % \
|
||||
(bmax_name, bmax_sktypes, bmax_lktypes, bmax_name)
|
||||
bmax_func = bmax_var + r'?((?:[ \t]|\.\.\n)*)([(])'
|
||||
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# Text
|
||||
(r'[ \t]+', Text),
|
||||
(r'\.\.\n', Text), # Line continuation
|
||||
# Comments
|
||||
(r"'.*?\n", Comment.Single),
|
||||
(r'([ \t]*)\bRem\n(\n|.)*?\s*\bEnd([ \t]*)Rem', Comment.Multiline),
|
||||
# Data types
|
||||
('"', String.Double, 'string'),
|
||||
# Numbers
|
||||
(r'[0-9]+\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\$[0-9a-f]+', Number.Hex),
|
||||
(r'\%[10]+', Number.Bin),
|
||||
# Other
|
||||
(r'(?:(?:(:)?([ \t]*)(:?%s|([+\-*/&|~]))|Or|And|Not|[=<>^]))' %
|
||||
(bmax_vopwords), Operator),
|
||||
(r'[(),.:\[\]]', Punctuation),
|
||||
(r'(?:#[\w \t]*)', Name.Label),
|
||||
(r'(?:\?[\w \t]*)', Comment.Preproc),
|
||||
# Identifiers
|
||||
(r'\b(New)\b([ \t]?)([(]?)(%s)' % (bmax_name),
|
||||
bygroups(Keyword.Reserved, Text, Punctuation, Name.Class)),
|
||||
(r'\b(Import|Framework|Module)([ \t]+)(%s\.%s)' %
|
||||
(bmax_name, bmax_name),
|
||||
bygroups(Keyword.Reserved, Text, Keyword.Namespace)),
|
||||
(bmax_func, bygroups(Name.Function, Text, Keyword.Type,
|
||||
Operator, Text, Punctuation, Text,
|
||||
Keyword.Type, Name.Class, Text,
|
||||
Keyword.Type, Text, Punctuation)),
|
||||
(bmax_var, bygroups(Name.Variable, Text, Keyword.Type, Operator,
|
||||
Text, Punctuation, Text, Keyword.Type,
|
||||
Name.Class, Text, Keyword.Type)),
|
||||
(r'\b(Type|Extends)([ \t]+)(%s)' % (bmax_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
# Keywords
|
||||
(r'\b(Ptr)\b', Keyword.Type),
|
||||
(r'\b(Pi|True|False|Null|Self|Super)\b', Keyword.Constant),
|
||||
(r'\b(Local|Global|Const|Field)\b', Keyword.Declaration),
|
||||
(words((
|
||||
'TNullMethodException', 'TNullFunctionException',
|
||||
'TNullObjectException', 'TArrayBoundsException',
|
||||
'TRuntimeException'), prefix=r'\b', suffix=r'\b'), Name.Exception),
|
||||
(words((
|
||||
'Strict', 'SuperStrict', 'Module', 'ModuleInfo',
|
||||
'End', 'Return', 'Continue', 'Exit', 'Public', 'Private',
|
||||
'Var', 'VarPtr', 'Chr', 'Len', 'Asc', 'SizeOf', 'Sgn', 'Abs', 'Min', 'Max',
|
||||
'New', 'Release', 'Delete', 'Incbin', 'IncbinPtr', 'IncbinLen',
|
||||
'Framework', 'Include', 'Import', 'Extern', 'EndExtern',
|
||||
'Function', 'EndFunction', 'Type', 'EndType', 'Extends', 'Method', 'EndMethod',
|
||||
'Abstract', 'Final', 'If', 'Then', 'Else', 'ElseIf', 'EndIf',
|
||||
'For', 'To', 'Next', 'Step', 'EachIn', 'While', 'Wend', 'EndWhile',
|
||||
'Repeat', 'Until', 'Forever', 'Select', 'Case', 'Default', 'EndSelect',
|
||||
'Try', 'Catch', 'EndTry', 'Throw', 'Assert', 'Goto', 'DefData', 'ReadData',
|
||||
'RestoreData'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
# Final resolve (for variable names and such)
|
||||
(r'(%s)' % (bmax_name), Name.Variable),
|
||||
],
|
||||
'string': [
|
||||
(r'""', String.Double),
|
||||
(r'"C?', String.Double, '#pop'),
|
||||
(r'[^"]+', String.Double),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class BlitzBasicLexer(RegexLexer):
|
||||
"""
|
||||
For `BlitzBasic <http://blitzbasic.com>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'BlitzBasic'
|
||||
aliases = ['blitzbasic', 'b3d', 'bplus']
|
||||
filenames = ['*.bb', '*.decls']
|
||||
mimetypes = ['text/x-bb']
|
||||
|
||||
bb_sktypes = r'@{1,2}|[#$%]'
|
||||
bb_name = r'[a-z]\w*'
|
||||
bb_var = (r'(%s)(?:([ \t]*)(%s)|([ \t]*)([.])([ \t]*)(?:(%s)))?') % \
|
||||
(bb_name, bb_sktypes, bb_name)
|
||||
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# Text
|
||||
(r'[ \t]+', Text),
|
||||
# Comments
|
||||
(r";.*?\n", Comment.Single),
|
||||
# Data types
|
||||
('"', String.Double, 'string'),
|
||||
# Numbers
|
||||
(r'[0-9]+\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'\.[0-9]+(?!\.)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\$[0-9a-f]+', Number.Hex),
|
||||
(r'\%[10]+', Number.Bin),
|
||||
# Other
|
||||
(words(('Shl', 'Shr', 'Sar', 'Mod', 'Or', 'And', 'Not',
|
||||
'Abs', 'Sgn', 'Handle', 'Int', 'Float', 'Str',
|
||||
'First', 'Last', 'Before', 'After'),
|
||||
prefix=r'\b', suffix=r'\b'),
|
||||
Operator),
|
||||
(r'([+\-*/~=<>^])', Operator),
|
||||
(r'[(),:\[\]\\]', Punctuation),
|
||||
(r'\.([ \t]*)(%s)' % bb_name, Name.Label),
|
||||
# Identifiers
|
||||
(r'\b(New)\b([ \t]+)(%s)' % (bb_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
(r'\b(Gosub|Goto)\b([ \t]+)(%s)' % (bb_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Label)),
|
||||
(r'\b(Object)\b([ \t]*)([.])([ \t]*)(%s)\b' % (bb_name),
|
||||
bygroups(Operator, Text, Punctuation, Text, Name.Class)),
|
||||
(r'\b%s\b([ \t]*)(\()' % bb_var,
|
||||
bygroups(Name.Function, Text, Keyword.Type, Text, Punctuation,
|
||||
Text, Name.Class, Text, Punctuation)),
|
||||
(r'\b(Function)\b([ \t]+)%s' % bb_var,
|
||||
bygroups(Keyword.Reserved, Text, Name.Function, Text, Keyword.Type,
|
||||
Text, Punctuation, Text, Name.Class)),
|
||||
(r'\b(Type)([ \t]+)(%s)' % (bb_name),
|
||||
bygroups(Keyword.Reserved, Text, Name.Class)),
|
||||
# Keywords
|
||||
(r'\b(Pi|True|False|Null)\b', Keyword.Constant),
|
||||
(r'\b(Local|Global|Const|Field|Dim)\b', Keyword.Declaration),
|
||||
(words((
|
||||
'End', 'Return', 'Exit', 'Chr', 'Len', 'Asc', 'New', 'Delete', 'Insert',
|
||||
'Include', 'Function', 'Type', 'If', 'Then', 'Else', 'ElseIf', 'EndIf',
|
||||
'For', 'To', 'Next', 'Step', 'Each', 'While', 'Wend',
|
||||
'Repeat', 'Until', 'Forever', 'Select', 'Case', 'Default',
|
||||
'Goto', 'Gosub', 'Data', 'Read', 'Restore'), prefix=r'\b', suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
# Final resolve (for variable names and such)
|
||||
# (r'(%s)' % (bb_name), Name.Variable),
|
||||
(bb_var, bygroups(Name.Variable, Text, Keyword.Type,
|
||||
Text, Punctuation, Text, Name.Class)),
|
||||
],
|
||||
'string': [
|
||||
(r'""', String.Double),
|
||||
(r'"C?', String.Double, '#pop'),
|
||||
(r'[^"]+', String.Double),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class MonkeyLexer(RegexLexer):
|
||||
"""
|
||||
For
|
||||
`Monkey <https://en.wikipedia.org/wiki/Monkey_(programming_language)>`_
|
||||
source code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'Monkey'
|
||||
aliases = ['monkey']
|
||||
filenames = ['*.monkey']
|
||||
mimetypes = ['text/x-monkey']
|
||||
|
||||
name_variable = r'[a-z_]\w*'
|
||||
name_function = r'[A-Z]\w*'
|
||||
name_constant = r'[A-Z_][A-Z0-9_]*'
|
||||
name_class = r'[A-Z]\w*'
|
||||
name_module = r'[a-z0-9_]*'
|
||||
|
||||
keyword_type = r'(?:Int|Float|String|Bool|Object|Array|Void)'
|
||||
# ? == Bool // % == Int // # == Float // $ == String
|
||||
keyword_type_special = r'[?%#$]'
|
||||
|
||||
flags = re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Text
|
||||
(r'\s+', Text),
|
||||
# Comments
|
||||
(r"'.*", Comment),
|
||||
(r'(?i)^#rem\b', Comment.Multiline, 'comment'),
|
||||
# preprocessor directives
|
||||
(r'(?i)^(?:#If|#ElseIf|#Else|#EndIf|#End|#Print|#Error)\b', Comment.Preproc),
|
||||
# preprocessor variable (any line starting with '#' that is not a directive)
|
||||
(r'^#', Comment.Preproc, 'variables'),
|
||||
# String
|
||||
('"', String.Double, 'string'),
|
||||
# Numbers
|
||||
(r'[0-9]+\.[0-9]*(?!\.)', Number.Float),
|
||||
(r'\.[0-9]+(?!\.)', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\$[0-9a-fA-Z]+', Number.Hex),
|
||||
(r'\%[10]+', Number.Bin),
|
||||
# Native data types
|
||||
(r'\b%s\b' % keyword_type, Keyword.Type),
|
||||
# Exception handling
|
||||
(r'(?i)\b(?:Try|Catch|Throw)\b', Keyword.Reserved),
|
||||
(r'Throwable', Name.Exception),
|
||||
# Builtins
|
||||
(r'(?i)\b(?:Null|True|False)\b', Name.Builtin),
|
||||
(r'(?i)\b(?:Self|Super)\b', Name.Builtin.Pseudo),
|
||||
(r'\b(?:HOST|LANG|TARGET|CONFIG)\b', Name.Constant),
|
||||
# Keywords
|
||||
(r'(?i)^(Import)(\s+)(.*)(\n)',
|
||||
bygroups(Keyword.Namespace, Text, Name.Namespace, Text)),
|
||||
(r'(?i)^Strict\b.*\n', Keyword.Reserved),
|
||||
(r'(?i)(Const|Local|Global|Field)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text), 'variables'),
|
||||
(r'(?i)(New|Class|Interface|Extends|Implements)(\s+)',
|
||||
bygroups(Keyword.Reserved, Text), 'classname'),
|
||||
(r'(?i)(Function|Method)(\s+)',
|
||||
bygroups(Keyword.Reserved, Text), 'funcname'),
|
||||
(r'(?i)(?:End|Return|Public|Private|Extern|Property|'
|
||||
r'Final|Abstract)\b', Keyword.Reserved),
|
||||
# Flow Control stuff
|
||||
(r'(?i)(?:If|Then|Else|ElseIf|EndIf|'
|
||||
r'Select|Case|Default|'
|
||||
r'While|Wend|'
|
||||
r'Repeat|Until|Forever|'
|
||||
r'For|To|Until|Step|EachIn|Next|'
|
||||
r'Exit|Continue)\s+', Keyword.Reserved),
|
||||
# not used yet
|
||||
(r'(?i)\b(?:Module|Inline)\b', Keyword.Reserved),
|
||||
# Array
|
||||
(r'[\[\]]', Punctuation),
|
||||
# Other
|
||||
(r'<=|>=|<>|\*=|/=|\+=|-=|&=|~=|\|=|[-&*/^+=<>|~]', Operator),
|
||||
(r'(?i)(?:Not|Mod|Shl|Shr|And|Or)', Operator.Word),
|
||||
(r'[(){}!#,.:]', Punctuation),
|
||||
# catch the rest
|
||||
(r'%s\b' % name_constant, Name.Constant),
|
||||
(r'%s\b' % name_function, Name.Function),
|
||||
(r'%s\b' % name_variable, Name.Variable),
|
||||
],
|
||||
'funcname': [
|
||||
(r'(?i)%s\b' % name_function, Name.Function),
|
||||
(r':', Punctuation, 'classname'),
|
||||
(r'\s+', Text),
|
||||
(r'\(', Punctuation, 'variables'),
|
||||
(r'\)', Punctuation, '#pop')
|
||||
],
|
||||
'classname': [
|
||||
(r'%s\.' % name_module, Name.Namespace),
|
||||
(r'%s\b' % keyword_type, Keyword.Type),
|
||||
(r'%s\b' % name_class, Name.Class),
|
||||
# array (of given size)
|
||||
(r'(\[)(\s*)(\d*)(\s*)(\])',
|
||||
bygroups(Punctuation, Text, Number.Integer, Text, Punctuation)),
|
||||
# generics
|
||||
(r'\s+(?!<)', Text, '#pop'),
|
||||
(r'<', Punctuation, '#push'),
|
||||
(r'>', Punctuation, '#pop'),
|
||||
(r'\n', Text, '#pop'),
|
||||
default('#pop')
|
||||
],
|
||||
'variables': [
|
||||
(r'%s\b' % name_constant, Name.Constant),
|
||||
(r'%s\b' % name_variable, Name.Variable),
|
||||
(r'%s' % keyword_type_special, Keyword.Type),
|
||||
(r'\s+', Text),
|
||||
(r':', Punctuation, 'classname'),
|
||||
(r',', Punctuation, '#push'),
|
||||
default('#pop')
|
||||
],
|
||||
'string': [
|
||||
(r'[^"~]+', String.Double),
|
||||
(r'~q|~n|~r|~t|~z|~~', String.Escape),
|
||||
(r'"', String.Double, '#pop'),
|
||||
],
|
||||
'comment': [
|
||||
(r'(?i)^#rem.*?', Comment.Multiline, "#push"),
|
||||
(r'(?i)^#end.*?', Comment.Multiline, "#pop"),
|
||||
(r'\n', Comment.Multiline),
|
||||
(r'.+', Comment.Multiline),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CbmBasicV2Lexer(RegexLexer):
|
||||
"""
|
||||
For CBM BASIC V2 sources.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'CBM BASIC V2'
|
||||
aliases = ['cbmbas']
|
||||
filenames = ['*.bas']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'rem.*\n', Comment.Single),
|
||||
(r'\s+', Text),
|
||||
(r'new|run|end|for|to|next|step|go(to|sub)?|on|return|stop|cont'
|
||||
r'|if|then|input#?|read|wait|load|save|verify|poke|sys|print#?'
|
||||
r'|list|clr|cmd|open|close|get#?', Keyword.Reserved),
|
||||
(r'data|restore|dim|let|def|fn', Keyword.Declaration),
|
||||
(r'tab|spc|sgn|int|abs|usr|fre|pos|sqr|rnd|log|exp|cos|sin|tan|atn'
|
||||
r'|peek|len|val|asc|(str|chr|left|right|mid)\$', Name.Builtin),
|
||||
(r'[-+*/^<>=]', Operator),
|
||||
(r'not|and|or', Operator.Word),
|
||||
(r'"[^"\n]*.', String),
|
||||
(r'\d+|[-+]?\d*\.\d*(e[-+]?\d+)?', Number.Float),
|
||||
(r'[(),:;]', Punctuation),
|
||||
(r'\w+[$%]?', Name),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(self, text):
|
||||
# if it starts with a line number, it shouldn't be a "modern" Basic
|
||||
# like VB.net
|
||||
if re.match(r'\d+', text):
|
||||
return 0.2
|
||||
|
||||
|
||||
class QBasicLexer(RegexLexer):
|
||||
"""
|
||||
For
|
||||
`QBasic <http://en.wikipedia.org/wiki/QBasic>`_
|
||||
source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
|
||||
name = 'QBasic'
|
||||
aliases = ['qbasic', 'basic']
|
||||
filenames = ['*.BAS', '*.bas']
|
||||
mimetypes = ['text/basic']
|
||||
|
||||
declarations = ('DATA', 'LET')
|
||||
|
||||
functions = (
|
||||
'ABS', 'ASC', 'ATN', 'CDBL', 'CHR$', 'CINT', 'CLNG',
|
||||
'COMMAND$', 'COS', 'CSNG', 'CSRLIN', 'CVD', 'CVDMBF', 'CVI',
|
||||
'CVL', 'CVS', 'CVSMBF', 'DATE$', 'ENVIRON$', 'EOF', 'ERDEV',
|
||||
'ERDEV$', 'ERL', 'ERR', 'EXP', 'FILEATTR', 'FIX', 'FRE',
|
||||
'FREEFILE', 'HEX$', 'INKEY$', 'INP', 'INPUT$', 'INSTR', 'INT',
|
||||
'IOCTL$', 'LBOUND', 'LCASE$', 'LEFT$', 'LEN', 'LOC', 'LOF',
|
||||
'LOG', 'LPOS', 'LTRIM$', 'MID$', 'MKD$', 'MKDMBF$', 'MKI$',
|
||||
'MKL$', 'MKS$', 'MKSMBF$', 'OCT$', 'PEEK', 'PEN', 'PLAY',
|
||||
'PMAP', 'POINT', 'POS', 'RIGHT$', 'RND', 'RTRIM$', 'SADD',
|
||||
'SCREEN', 'SEEK', 'SETMEM', 'SGN', 'SIN', 'SPACE$', 'SPC',
|
||||
'SQR', 'STICK', 'STR$', 'STRIG', 'STRING$', 'TAB', 'TAN',
|
||||
'TIME$', 'TIMER', 'UBOUND', 'UCASE$', 'VAL', 'VARPTR',
|
||||
'VARPTR$', 'VARSEG'
|
||||
)
|
||||
|
||||
metacommands = ('$DYNAMIC', '$INCLUDE', '$STATIC')
|
||||
|
||||
operators = ('AND', 'EQV', 'IMP', 'NOT', 'OR', 'XOR')
|
||||
|
||||
statements = (
|
||||
'BEEP', 'BLOAD', 'BSAVE', 'CALL', 'CALL ABSOLUTE',
|
||||
'CALL INTERRUPT', 'CALLS', 'CHAIN', 'CHDIR', 'CIRCLE', 'CLEAR',
|
||||
'CLOSE', 'CLS', 'COLOR', 'COM', 'COMMON', 'CONST', 'DATA',
|
||||
'DATE$', 'DECLARE', 'DEF FN', 'DEF SEG', 'DEFDBL', 'DEFINT',
|
||||
'DEFLNG', 'DEFSNG', 'DEFSTR', 'DEF', 'DIM', 'DO', 'LOOP',
|
||||
'DRAW', 'END', 'ENVIRON', 'ERASE', 'ERROR', 'EXIT', 'FIELD',
|
||||
'FILES', 'FOR', 'NEXT', 'FUNCTION', 'GET', 'GOSUB', 'GOTO',
|
||||
'IF', 'THEN', 'INPUT', 'INPUT #', 'IOCTL', 'KEY', 'KEY',
|
||||
'KILL', 'LET', 'LINE', 'LINE INPUT', 'LINE INPUT #', 'LOCATE',
|
||||
'LOCK', 'UNLOCK', 'LPRINT', 'LSET', 'MID$', 'MKDIR', 'NAME',
|
||||
'ON COM', 'ON ERROR', 'ON KEY', 'ON PEN', 'ON PLAY',
|
||||
'ON STRIG', 'ON TIMER', 'ON UEVENT', 'ON', 'OPEN', 'OPEN COM',
|
||||
'OPTION BASE', 'OUT', 'PAINT', 'PALETTE', 'PCOPY', 'PEN',
|
||||
'PLAY', 'POKE', 'PRESET', 'PRINT', 'PRINT #', 'PRINT USING',
|
||||
'PSET', 'PUT', 'PUT', 'RANDOMIZE', 'READ', 'REDIM', 'REM',
|
||||
'RESET', 'RESTORE', 'RESUME', 'RETURN', 'RMDIR', 'RSET', 'RUN',
|
||||
'SCREEN', 'SEEK', 'SELECT CASE', 'SHARED', 'SHELL', 'SLEEP',
|
||||
'SOUND', 'STATIC', 'STOP', 'STRIG', 'SUB', 'SWAP', 'SYSTEM',
|
||||
'TIME$', 'TIMER', 'TROFF', 'TRON', 'TYPE', 'UEVENT', 'UNLOCK',
|
||||
'VIEW', 'WAIT', 'WHILE', 'WEND', 'WIDTH', 'WINDOW', 'WRITE'
|
||||
)
|
||||
|
||||
keywords = (
|
||||
'ACCESS', 'ALIAS', 'ANY', 'APPEND', 'AS', 'BASE', 'BINARY',
|
||||
'BYVAL', 'CASE', 'CDECL', 'DOUBLE', 'ELSE', 'ELSEIF', 'ENDIF',
|
||||
'INTEGER', 'IS', 'LIST', 'LOCAL', 'LONG', 'LOOP', 'MOD',
|
||||
'NEXT', 'OFF', 'ON', 'OUTPUT', 'RANDOM', 'SIGNAL', 'SINGLE',
|
||||
'STEP', 'STRING', 'THEN', 'TO', 'UNTIL', 'USING', 'WEND'
|
||||
)
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n+', Text),
|
||||
(r'\s+', Text.Whitespace),
|
||||
(r'^(\s*)(\d*)(\s*)(REM .*)$',
|
||||
bygroups(Text.Whitespace, Name.Label, Text.Whitespace,
|
||||
Comment.Single)),
|
||||
(r'^(\s*)(\d+)(\s*)',
|
||||
bygroups(Text.Whitespace, Name.Label, Text.Whitespace)),
|
||||
(r'(?=[\s]*)(\w+)(?=[\s]*=)', Name.Variable.Global),
|
||||
(r'(?=[^"]*)\'.*$', Comment.Single),
|
||||
(r'"[^\n"]*"', String.Double),
|
||||
(r'(END)(\s+)(FUNCTION|IF|SELECT|SUB)',
|
||||
bygroups(Keyword.Reserved, Text.Whitespace, Keyword.Reserved)),
|
||||
(r'(DECLARE)(\s+)([A-Z]+)(\s+)(\S+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace, Name.Variable,
|
||||
Text.Whitespace, Name)),
|
||||
(r'(DIM)(\s+)(SHARED)(\s+)([^\s(]+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace, Name.Variable,
|
||||
Text.Whitespace, Name.Variable.Global)),
|
||||
(r'(DIM)(\s+)([^\s(]+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace, Name.Variable.Global)),
|
||||
(r'^(\s*)([a-zA-Z_]+)(\s*)(\=)',
|
||||
bygroups(Text.Whitespace, Name.Variable.Global, Text.Whitespace,
|
||||
Operator)),
|
||||
(r'(GOTO|GOSUB)(\s+)(\w+\:?)',
|
||||
bygroups(Keyword.Reserved, Text.Whitespace, Name.Label)),
|
||||
(r'(SUB)(\s+)(\w+\:?)',
|
||||
bygroups(Keyword.Reserved, Text.Whitespace, Name.Label)),
|
||||
include('declarations'),
|
||||
include('functions'),
|
||||
include('metacommands'),
|
||||
include('operators'),
|
||||
include('statements'),
|
||||
include('keywords'),
|
||||
(r'[a-zA-Z_]\w*[$@#&!]', Name.Variable.Global),
|
||||
(r'[a-zA-Z_]\w*\:', Name.Label),
|
||||
(r'\-?\d*\.\d+[@|#]?', Number.Float),
|
||||
(r'\-?\d+[@|#]', Number.Float),
|
||||
(r'\-?\d+#?', Number.Integer.Long),
|
||||
(r'\-?\d+#?', Number.Integer),
|
||||
(r'!=|==|:=|\.=|<<|>>|[-~+/\\*%=<>&^|?:!.]', Operator),
|
||||
(r'[\[\]{}(),;]', Punctuation),
|
||||
(r'[\w]+', Name.Variable.Global),
|
||||
],
|
||||
# can't use regular \b because of X$()
|
||||
# XXX: use words() here
|
||||
'declarations': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, declarations)),
|
||||
Keyword.Declaration),
|
||||
],
|
||||
'functions': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, functions)),
|
||||
Keyword.Reserved),
|
||||
],
|
||||
'metacommands': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, metacommands)),
|
||||
Keyword.Constant),
|
||||
],
|
||||
'operators': [
|
||||
(r'\b(%s)(?=\(|\b)' % '|'.join(map(re.escape, operators)), Operator.Word),
|
||||
],
|
||||
'statements': [
|
||||
(r'\b(%s)\b' % '|'.join(map(re.escape, statements)),
|
||||
Keyword.Reserved),
|
||||
],
|
||||
'keywords': [
|
||||
(r'\b(%s)\b' % '|'.join(keywords), Keyword),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if '$DYNAMIC' in text or '$STATIC' in text:
|
||||
return 0.9
|
||||
@ -0,0 +1,592 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.business
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for "business-oriented" languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words, bygroups
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error
|
||||
|
||||
from pygments.lexers._openedge_builtins import OPENEDGEKEYWORDS
|
||||
|
||||
__all__ = ['CobolLexer', 'CobolFreeformatLexer', 'ABAPLexer', 'OpenEdgeLexer',
|
||||
'GoodDataCLLexer', 'MaqlLexer']
|
||||
|
||||
|
||||
class CobolLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for OpenCOBOL code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'COBOL'
|
||||
aliases = ['cobol']
|
||||
filenames = ['*.cob', '*.COB', '*.cpy', '*.CPY']
|
||||
mimetypes = ['text/x-cobol']
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
# Data Types: by PICTURE and USAGE
|
||||
# Operators: **, *, +, -, /, <, >, <=, >=, =, <>
|
||||
# Logical (?): NOT, AND, OR
|
||||
|
||||
# Reserved words:
|
||||
# http://opencobol.add1tocobol.com/#reserved-words
|
||||
# Intrinsics:
|
||||
# http://opencobol.add1tocobol.com/#does-opencobol-implement-any-intrinsic-functions
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('comment'),
|
||||
include('strings'),
|
||||
include('core'),
|
||||
include('nums'),
|
||||
(r'[a-z0-9]([\w\-]*[a-z0-9]+)?', Name.Variable),
|
||||
# (r'[\s]+', Text),
|
||||
(r'[ \t]+', Text),
|
||||
],
|
||||
'comment': [
|
||||
(r'(^.{6}[*/].*\n|^.{6}|\*>.*\n)', Comment),
|
||||
],
|
||||
'core': [
|
||||
# Figurative constants
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(ALL\s+)?'
|
||||
r'((ZEROES)|(HIGH-VALUE|LOW-VALUE|QUOTE|SPACE|ZERO)(S)?)'
|
||||
r'\s*($|(?=[^0-9a-z_\-]))',
|
||||
Name.Constant),
|
||||
|
||||
# Reserved words STATEMENTS and other bolds
|
||||
(words((
|
||||
'ACCEPT', 'ADD', 'ALLOCATE', 'CALL', 'CANCEL', 'CLOSE', 'COMPUTE',
|
||||
'CONFIGURATION', 'CONTINUE', 'DATA', 'DELETE', 'DISPLAY', 'DIVIDE',
|
||||
'DIVISION', 'ELSE', 'END', 'END-ACCEPT',
|
||||
'END-ADD', 'END-CALL', 'END-COMPUTE', 'END-DELETE', 'END-DISPLAY',
|
||||
'END-DIVIDE', 'END-EVALUATE', 'END-IF', 'END-MULTIPLY', 'END-OF-PAGE',
|
||||
'END-PERFORM', 'END-READ', 'END-RETURN', 'END-REWRITE', 'END-SEARCH',
|
||||
'END-START', 'END-STRING', 'END-SUBTRACT', 'END-UNSTRING', 'END-WRITE',
|
||||
'ENVIRONMENT', 'EVALUATE', 'EXIT', 'FD', 'FILE', 'FILE-CONTROL', 'FOREVER',
|
||||
'FREE', 'GENERATE', 'GO', 'GOBACK', 'IDENTIFICATION', 'IF', 'INITIALIZE',
|
||||
'INITIATE', 'INPUT-OUTPUT', 'INSPECT', 'INVOKE', 'I-O-CONTROL', 'LINKAGE',
|
||||
'LOCAL-STORAGE', 'MERGE', 'MOVE', 'MULTIPLY', 'OPEN', 'PERFORM',
|
||||
'PROCEDURE', 'PROGRAM-ID', 'RAISE', 'READ', 'RELEASE', 'RESUME',
|
||||
'RETURN', 'REWRITE', 'SCREEN', 'SD', 'SEARCH', 'SECTION', 'SET',
|
||||
'SORT', 'START', 'STOP', 'STRING', 'SUBTRACT', 'SUPPRESS',
|
||||
'TERMINATE', 'THEN', 'UNLOCK', 'UNSTRING', 'USE', 'VALIDATE',
|
||||
'WORKING-STORAGE', 'WRITE'), prefix=r'(^|(?<=[^0-9a-z_\-]))',
|
||||
suffix=r'\s*($|(?=[^0-9a-z_\-]))'),
|
||||
Keyword.Reserved),
|
||||
|
||||
# Reserved words
|
||||
(words((
|
||||
'ACCESS', 'ADDRESS', 'ADVANCING', 'AFTER', 'ALL',
|
||||
'ALPHABET', 'ALPHABETIC', 'ALPHABETIC-LOWER', 'ALPHABETIC-UPPER',
|
||||
'ALPHANUMERIC', 'ALPHANUMERIC-EDITED', 'ALSO', 'ALTER', 'ALTERNATE'
|
||||
'ANY', 'ARE', 'AREA', 'AREAS', 'ARGUMENT-NUMBER', 'ARGUMENT-VALUE', 'AS',
|
||||
'ASCENDING', 'ASSIGN', 'AT', 'AUTO', 'AUTO-SKIP', 'AUTOMATIC', 'AUTOTERMINATE',
|
||||
'BACKGROUND-COLOR', 'BASED', 'BEEP', 'BEFORE', 'BELL',
|
||||
'BLANK', 'BLINK', 'BLOCK', 'BOTTOM', 'BY', 'BYTE-LENGTH', 'CHAINING',
|
||||
'CHARACTER', 'CHARACTERS', 'CLASS', 'CODE', 'CODE-SET', 'COL', 'COLLATING',
|
||||
'COLS', 'COLUMN', 'COLUMNS', 'COMMA', 'COMMAND-LINE', 'COMMIT', 'COMMON',
|
||||
'CONSTANT', 'CONTAINS', 'CONTENT', 'CONTROL',
|
||||
'CONTROLS', 'CONVERTING', 'COPY', 'CORR', 'CORRESPONDING', 'COUNT', 'CRT',
|
||||
'CURRENCY', 'CURSOR', 'CYCLE', 'DATE', 'DAY', 'DAY-OF-WEEK', 'DE', 'DEBUGGING',
|
||||
'DECIMAL-POINT', 'DECLARATIVES', 'DEFAULT', 'DELIMITED',
|
||||
'DELIMITER', 'DEPENDING', 'DESCENDING', 'DETAIL', 'DISK',
|
||||
'DOWN', 'DUPLICATES', 'DYNAMIC', 'EBCDIC',
|
||||
'ENTRY', 'ENVIRONMENT-NAME', 'ENVIRONMENT-VALUE', 'EOL', 'EOP',
|
||||
'EOS', 'ERASE', 'ERROR', 'ESCAPE', 'EXCEPTION',
|
||||
'EXCLUSIVE', 'EXTEND', 'EXTERNAL',
|
||||
'FILE-ID', 'FILLER', 'FINAL', 'FIRST', 'FIXED', 'FLOAT-LONG', 'FLOAT-SHORT',
|
||||
'FOOTING', 'FOR', 'FOREGROUND-COLOR', 'FORMAT', 'FROM', 'FULL', 'FUNCTION',
|
||||
'FUNCTION-ID', 'GIVING', 'GLOBAL', 'GROUP',
|
||||
'HEADING', 'HIGHLIGHT', 'I-O', 'ID',
|
||||
'IGNORE', 'IGNORING', 'IN', 'INDEX', 'INDEXED', 'INDICATE',
|
||||
'INITIAL', 'INITIALIZED', 'INPUT',
|
||||
'INTO', 'INTRINSIC', 'INVALID', 'IS', 'JUST', 'JUSTIFIED', 'KEY', 'LABEL',
|
||||
'LAST', 'LEADING', 'LEFT', 'LENGTH', 'LIMIT', 'LIMITS', 'LINAGE',
|
||||
'LINAGE-COUNTER', 'LINE', 'LINES', 'LOCALE', 'LOCK',
|
||||
'LOWLIGHT', 'MANUAL', 'MEMORY', 'MINUS', 'MODE',
|
||||
'MULTIPLE', 'NATIONAL', 'NATIONAL-EDITED', 'NATIVE',
|
||||
'NEGATIVE', 'NEXT', 'NO', 'NULL', 'NULLS', 'NUMBER', 'NUMBERS', 'NUMERIC',
|
||||
'NUMERIC-EDITED', 'OBJECT-COMPUTER', 'OCCURS', 'OF', 'OFF', 'OMITTED', 'ON', 'ONLY',
|
||||
'OPTIONAL', 'ORDER', 'ORGANIZATION', 'OTHER', 'OUTPUT', 'OVERFLOW',
|
||||
'OVERLINE', 'PACKED-DECIMAL', 'PADDING', 'PAGE', 'PARAGRAPH',
|
||||
'PLUS', 'POINTER', 'POSITION', 'POSITIVE', 'PRESENT', 'PREVIOUS',
|
||||
'PRINTER', 'PRINTING', 'PROCEDURE-POINTER', 'PROCEDURES',
|
||||
'PROCEED', 'PROGRAM', 'PROGRAM-POINTER', 'PROMPT', 'QUOTE',
|
||||
'QUOTES', 'RANDOM', 'RD', 'RECORD', 'RECORDING', 'RECORDS', 'RECURSIVE',
|
||||
'REDEFINES', 'REEL', 'REFERENCE', 'RELATIVE', 'REMAINDER', 'REMOVAL',
|
||||
'RENAMES', 'REPLACING', 'REPORT', 'REPORTING', 'REPORTS', 'REPOSITORY',
|
||||
'REQUIRED', 'RESERVE', 'RETURNING', 'REVERSE-VIDEO', 'REWIND',
|
||||
'RIGHT', 'ROLLBACK', 'ROUNDED', 'RUN', 'SAME', 'SCROLL',
|
||||
'SECURE', 'SEGMENT-LIMIT', 'SELECT', 'SENTENCE', 'SEPARATE',
|
||||
'SEQUENCE', 'SEQUENTIAL', 'SHARING', 'SIGN', 'SIGNED', 'SIGNED-INT',
|
||||
'SIGNED-LONG', 'SIGNED-SHORT', 'SIZE', 'SORT-MERGE', 'SOURCE',
|
||||
'SOURCE-COMPUTER', 'SPECIAL-NAMES', 'STANDARD',
|
||||
'STANDARD-1', 'STANDARD-2', 'STATUS', 'SUM',
|
||||
'SYMBOLIC', 'SYNC', 'SYNCHRONIZED', 'TALLYING', 'TAPE',
|
||||
'TEST', 'THROUGH', 'THRU', 'TIME', 'TIMES', 'TO', 'TOP', 'TRAILING',
|
||||
'TRANSFORM', 'TYPE', 'UNDERLINE', 'UNIT', 'UNSIGNED',
|
||||
'UNSIGNED-INT', 'UNSIGNED-LONG', 'UNSIGNED-SHORT', 'UNTIL', 'UP',
|
||||
'UPDATE', 'UPON', 'USAGE', 'USING', 'VALUE', 'VALUES', 'VARYING',
|
||||
'WAIT', 'WHEN', 'WITH', 'WORDS', 'YYYYDDD', 'YYYYMMDD'),
|
||||
prefix=r'(^|(?<=[^0-9a-z_\-]))', suffix=r'\s*($|(?=[^0-9a-z_\-]))'),
|
||||
Keyword.Pseudo),
|
||||
|
||||
# inactive reserved words
|
||||
(words((
|
||||
'ACTIVE-CLASS', 'ALIGNED', 'ANYCASE', 'ARITHMETIC', 'ATTRIBUTE', 'B-AND',
|
||||
'B-NOT', 'B-OR', 'B-XOR', 'BIT', 'BOOLEAN', 'CD', 'CENTER', 'CF', 'CH', 'CHAIN', 'CLASS-ID',
|
||||
'CLASSIFICATION', 'COMMUNICATION', 'CONDITION', 'DATA-POINTER',
|
||||
'DESTINATION', 'DISABLE', 'EC', 'EGI', 'EMI', 'ENABLE', 'END-RECEIVE',
|
||||
'ENTRY-CONVENTION', 'EO', 'ESI', 'EXCEPTION-OBJECT', 'EXPANDS', 'FACTORY',
|
||||
'FLOAT-BINARY-16', 'FLOAT-BINARY-34', 'FLOAT-BINARY-7',
|
||||
'FLOAT-DECIMAL-16', 'FLOAT-DECIMAL-34', 'FLOAT-EXTENDED', 'FORMAT',
|
||||
'FUNCTION-POINTER', 'GET', 'GROUP-USAGE', 'IMPLEMENTS', 'INFINITY',
|
||||
'INHERITS', 'INTERFACE', 'INTERFACE-ID', 'INVOKE', 'LC_ALL', 'LC_COLLATE',
|
||||
'LC_CTYPE', 'LC_MESSAGES', 'LC_MONETARY', 'LC_NUMERIC', 'LC_TIME',
|
||||
'LINE-COUNTER', 'MESSAGE', 'METHOD', 'METHOD-ID', 'NESTED', 'NONE', 'NORMAL',
|
||||
'OBJECT', 'OBJECT-REFERENCE', 'OPTIONS', 'OVERRIDE', 'PAGE-COUNTER', 'PF', 'PH',
|
||||
'PROPERTY', 'PROTOTYPE', 'PURGE', 'QUEUE', 'RAISE', 'RAISING', 'RECEIVE',
|
||||
'RELATION', 'REPLACE', 'REPRESENTS-NOT-A-NUMBER', 'RESET', 'RESUME', 'RETRY',
|
||||
'RF', 'RH', 'SECONDS', 'SEGMENT', 'SELF', 'SEND', 'SOURCES', 'STATEMENT', 'STEP',
|
||||
'STRONG', 'SUB-QUEUE-1', 'SUB-QUEUE-2', 'SUB-QUEUE-3', 'SUPER', 'SYMBOL',
|
||||
'SYSTEM-DEFAULT', 'TABLE', 'TERMINAL', 'TEXT', 'TYPEDEF', 'UCS-4', 'UNIVERSAL',
|
||||
'USER-DEFAULT', 'UTF-16', 'UTF-8', 'VAL-STATUS', 'VALID', 'VALIDATE',
|
||||
'VALIDATE-STATUS'),
|
||||
prefix=r'(^|(?<=[^0-9a-z_\-]))', suffix=r'\s*($|(?=[^0-9a-z_\-]))'),
|
||||
Error),
|
||||
|
||||
# Data Types
|
||||
(r'(^|(?<=[^0-9a-z_\-]))'
|
||||
r'(PIC\s+.+?(?=(\s|\.\s))|PICTURE\s+.+?(?=(\s|\.\s))|'
|
||||
r'(COMPUTATIONAL)(-[1-5X])?|(COMP)(-[1-5X])?|'
|
||||
r'BINARY-C-LONG|'
|
||||
r'BINARY-CHAR|BINARY-DOUBLE|BINARY-LONG|BINARY-SHORT|'
|
||||
r'BINARY)\s*($|(?=[^0-9a-z_\-]))', Keyword.Type),
|
||||
|
||||
# Operators
|
||||
(r'(\*\*|\*|\+|-|/|<=|>=|<|>|==|/=|=)', Operator),
|
||||
|
||||
# (r'(::)', Keyword.Declaration),
|
||||
|
||||
(r'([(),;:&%.])', Punctuation),
|
||||
|
||||
# Intrinsics
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(ABS|ACOS|ANNUITY|ASIN|ATAN|BYTE-LENGTH|'
|
||||
r'CHAR|COMBINED-DATETIME|CONCATENATE|COS|CURRENT-DATE|'
|
||||
r'DATE-OF-INTEGER|DATE-TO-YYYYMMDD|DAY-OF-INTEGER|DAY-TO-YYYYDDD|'
|
||||
r'EXCEPTION-(?:FILE|LOCATION|STATEMENT|STATUS)|EXP10|EXP|E|'
|
||||
r'FACTORIAL|FRACTION-PART|INTEGER-OF-(?:DATE|DAY|PART)|INTEGER|'
|
||||
r'LENGTH|LOCALE-(?:DATE|TIME(?:-FROM-SECONDS)?)|LOG(?:10)?|'
|
||||
r'LOWER-CASE|MAX|MEAN|MEDIAN|MIDRANGE|MIN|MOD|NUMVAL(?:-C)?|'
|
||||
r'ORD(?:-MAX|-MIN)?|PI|PRESENT-VALUE|RANDOM|RANGE|REM|REVERSE|'
|
||||
r'SECONDS-FROM-FORMATTED-TIME|SECONDS-PAST-MIDNIGHT|SIGN|SIN|SQRT|'
|
||||
r'STANDARD-DEVIATION|STORED-CHAR-LENGTH|SUBSTITUTE(?:-CASE)?|'
|
||||
r'SUM|TAN|TEST-DATE-YYYYMMDD|TEST-DAY-YYYYDDD|TRIM|'
|
||||
r'UPPER-CASE|VARIANCE|WHEN-COMPILED|YEAR-TO-YYYY)\s*'
|
||||
r'($|(?=[^0-9a-z_\-]))', Name.Function),
|
||||
|
||||
# Booleans
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(true|false)\s*($|(?=[^0-9a-z_\-]))', Name.Builtin),
|
||||
# Comparing Operators
|
||||
(r'(^|(?<=[^0-9a-z_\-]))(equal|equals|ne|lt|le|gt|ge|'
|
||||
r'greater|less|than|not|and|or)\s*($|(?=[^0-9a-z_\-]))', Operator.Word),
|
||||
],
|
||||
|
||||
# \"[^\"\n]*\"|\'[^\'\n]*\'
|
||||
'strings': [
|
||||
# apparently strings can be delimited by EOL if they are continued
|
||||
# in the next line
|
||||
(r'"[^"\n]*("|\n)', String.Double),
|
||||
(r"'[^'\n]*('|\n)", String.Single),
|
||||
],
|
||||
|
||||
'nums': [
|
||||
(r'\d+(\s*|\.$|$)', Number.Integer),
|
||||
(r'[+-]?\d*\.\d+(E[-+]?\d+)?', Number.Float),
|
||||
(r'[+-]?\d+\.\d*(E[-+]?\d+)?', Number.Float),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CobolFreeformatLexer(CobolLexer):
|
||||
"""
|
||||
Lexer for Free format OpenCOBOL code.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'COBOLFree'
|
||||
aliases = ['cobolfree']
|
||||
filenames = ['*.cbl', '*.CBL']
|
||||
mimetypes = []
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'comment': [
|
||||
(r'(\*>.*\n|^\w*\*.*$)', Comment),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ABAPLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for ABAP, SAP's integrated language.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'ABAP'
|
||||
aliases = ['abap']
|
||||
filenames = ['*.abap']
|
||||
mimetypes = ['text/x-abap']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'common': [
|
||||
(r'\s+', Text),
|
||||
(r'^\*.*$', Comment.Single),
|
||||
(r'\".*?\n', Comment.Single),
|
||||
],
|
||||
'variable-names': [
|
||||
(r'<\S+>', Name.Variable),
|
||||
(r'\w[\w~]*(?:(\[\])|->\*)?', Name.Variable),
|
||||
],
|
||||
'root': [
|
||||
include('common'),
|
||||
# function calls
|
||||
(r'(CALL\s+(?:BADI|CUSTOMER-FUNCTION|FUNCTION))(\s+)(\'?\S+\'?)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(CALL\s+(?:DIALOG|SCREEN|SUBSCREEN|SELECTION-SCREEN|'
|
||||
r'TRANSACTION|TRANSFORMATION))\b',
|
||||
Keyword),
|
||||
(r'(FORM|PERFORM)(\s+)(\w+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
(r'(PERFORM)(\s+)(\()(\w+)(\))',
|
||||
bygroups(Keyword, Text, Punctuation, Name.Variable, Punctuation)),
|
||||
(r'(MODULE)(\s+)(\S+)(\s+)(INPUT|OUTPUT)',
|
||||
bygroups(Keyword, Text, Name.Function, Text, Keyword)),
|
||||
|
||||
# method implementation
|
||||
(r'(METHOD)(\s+)([\w~]+)',
|
||||
bygroups(Keyword, Text, Name.Function)),
|
||||
# method calls
|
||||
(r'(\s+)([\w\-]+)([=\-]>)([\w\-~]+)',
|
||||
bygroups(Text, Name.Variable, Operator, Name.Function)),
|
||||
# call methodnames returning style
|
||||
(r'(?<=(=|-)>)([\w\-~]+)(?=\()', Name.Function),
|
||||
|
||||
# keywords with dashes in them.
|
||||
# these need to be first, because for instance the -ID part
|
||||
# of MESSAGE-ID wouldn't get highlighted if MESSAGE was
|
||||
# first in the list of keywords.
|
||||
(r'(ADD-CORRESPONDING|AUTHORITY-CHECK|'
|
||||
r'CLASS-DATA|CLASS-EVENTS|CLASS-METHODS|CLASS-POOL|'
|
||||
r'DELETE-ADJACENT|DIVIDE-CORRESPONDING|'
|
||||
r'EDITOR-CALL|ENHANCEMENT-POINT|ENHANCEMENT-SECTION|EXIT-COMMAND|'
|
||||
r'FIELD-GROUPS|FIELD-SYMBOLS|FUNCTION-POOL|'
|
||||
r'INTERFACE-POOL|INVERTED-DATE|'
|
||||
r'LOAD-OF-PROGRAM|LOG-POINT|'
|
||||
r'MESSAGE-ID|MOVE-CORRESPONDING|MULTIPLY-CORRESPONDING|'
|
||||
r'NEW-LINE|NEW-PAGE|NEW-SECTION|NO-EXTENSION|'
|
||||
r'OUTPUT-LENGTH|PRINT-CONTROL|'
|
||||
r'SELECT-OPTIONS|START-OF-SELECTION|SUBTRACT-CORRESPONDING|'
|
||||
r'SYNTAX-CHECK|SYSTEM-EXCEPTIONS|'
|
||||
r'TYPE-POOL|TYPE-POOLS'
|
||||
r')\b', Keyword),
|
||||
|
||||
# keyword kombinations
|
||||
(r'CREATE\s+(PUBLIC|PRIVATE|DATA|OBJECT)|'
|
||||
r'((PUBLIC|PRIVATE|PROTECTED)\s+SECTION|'
|
||||
r'(TYPE|LIKE)(\s+(LINE\s+OF|REF\s+TO|'
|
||||
r'(SORTED|STANDARD|HASHED)\s+TABLE\s+OF))?|'
|
||||
r'FROM\s+(DATABASE|MEMORY)|CALL\s+METHOD|'
|
||||
r'(GROUP|ORDER) BY|HAVING|SEPARATED BY|'
|
||||
r'GET\s+(BADI|BIT|CURSOR|DATASET|LOCALE|PARAMETER|'
|
||||
r'PF-STATUS|(PROPERTY|REFERENCE)\s+OF|'
|
||||
r'RUN\s+TIME|TIME\s+(STAMP)?)?|'
|
||||
r'SET\s+(BIT|BLANK\s+LINES|COUNTRY|CURSOR|DATASET|EXTENDED\s+CHECK|'
|
||||
r'HANDLER|HOLD\s+DATA|LANGUAGE|LEFT\s+SCROLL-BOUNDARY|'
|
||||
r'LOCALE|MARGIN|PARAMETER|PF-STATUS|PROPERTY\s+OF|'
|
||||
r'RUN\s+TIME\s+(ANALYZER|CLOCK\s+RESOLUTION)|SCREEN|'
|
||||
r'TITLEBAR|UPADTE\s+TASK\s+LOCAL|USER-COMMAND)|'
|
||||
r'CONVERT\s+((INVERTED-)?DATE|TIME|TIME\s+STAMP|TEXT)|'
|
||||
r'(CLOSE|OPEN)\s+(DATASET|CURSOR)|'
|
||||
r'(TO|FROM)\s+(DATA BUFFER|INTERNAL TABLE|MEMORY ID|'
|
||||
r'DATABASE|SHARED\s+(MEMORY|BUFFER))|'
|
||||
r'DESCRIBE\s+(DISTANCE\s+BETWEEN|FIELD|LIST|TABLE)|'
|
||||
r'FREE\s(MEMORY|OBJECT)?|'
|
||||
r'PROCESS\s+(BEFORE\s+OUTPUT|AFTER\s+INPUT|'
|
||||
r'ON\s+(VALUE-REQUEST|HELP-REQUEST))|'
|
||||
r'AT\s+(LINE-SELECTION|USER-COMMAND|END\s+OF|NEW)|'
|
||||
r'AT\s+SELECTION-SCREEN(\s+(ON(\s+(BLOCK|(HELP|VALUE)-REQUEST\s+FOR|'
|
||||
r'END\s+OF|RADIOBUTTON\s+GROUP))?|OUTPUT))?|'
|
||||
r'SELECTION-SCREEN:?\s+((BEGIN|END)\s+OF\s+((TABBED\s+)?BLOCK|LINE|'
|
||||
r'SCREEN)|COMMENT|FUNCTION\s+KEY|'
|
||||
r'INCLUDE\s+BLOCKS|POSITION|PUSHBUTTON|'
|
||||
r'SKIP|ULINE)|'
|
||||
r'LEAVE\s+(LIST-PROCESSING|PROGRAM|SCREEN|'
|
||||
r'TO LIST-PROCESSING|TO TRANSACTION)'
|
||||
r'(ENDING|STARTING)\s+AT|'
|
||||
r'FORMAT\s+(COLOR|INTENSIFIED|INVERSE|HOTSPOT|INPUT|FRAMES|RESET)|'
|
||||
r'AS\s+(CHECKBOX|SUBSCREEN|WINDOW)|'
|
||||
r'WITH\s+(((NON-)?UNIQUE)?\s+KEY|FRAME)|'
|
||||
r'(BEGIN|END)\s+OF|'
|
||||
r'DELETE(\s+ADJACENT\s+DUPLICATES\sFROM)?|'
|
||||
r'COMPARING(\s+ALL\s+FIELDS)?|'
|
||||
r'INSERT(\s+INITIAL\s+LINE\s+INTO|\s+LINES\s+OF)?|'
|
||||
r'IN\s+((BYTE|CHARACTER)\s+MODE|PROGRAM)|'
|
||||
r'END-OF-(DEFINITION|PAGE|SELECTION)|'
|
||||
r'WITH\s+FRAME(\s+TITLE)|'
|
||||
|
||||
# simple kombinations
|
||||
r'AND\s+(MARK|RETURN)|CLIENT\s+SPECIFIED|CORRESPONDING\s+FIELDS\s+OF|'
|
||||
r'IF\s+FOUND|FOR\s+EVENT|INHERITING\s+FROM|LEAVE\s+TO\s+SCREEN|'
|
||||
r'LOOP\s+AT\s+(SCREEN)?|LOWER\s+CASE|MATCHCODE\s+OBJECT|MODIF\s+ID|'
|
||||
r'MODIFY\s+SCREEN|NESTING\s+LEVEL|NO\s+INTERVALS|OF\s+STRUCTURE|'
|
||||
r'RADIOBUTTON\s+GROUP|RANGE\s+OF|REF\s+TO|SUPPRESS DIALOG|'
|
||||
r'TABLE\s+OF|UPPER\s+CASE|TRANSPORTING\s+NO\s+FIELDS|'
|
||||
r'VALUE\s+CHECK|VISIBLE\s+LENGTH|HEADER\s+LINE)\b', Keyword),
|
||||
|
||||
# single word keywords.
|
||||
(r'(^|(?<=(\s|\.)))(ABBREVIATED|ADD|ALIASES|APPEND|ASSERT|'
|
||||
r'ASSIGN(ING)?|AT(\s+FIRST)?|'
|
||||
r'BACK|BLOCK|BREAK-POINT|'
|
||||
r'CASE|CATCH|CHANGING|CHECK|CLASS|CLEAR|COLLECT|COLOR|COMMIT|'
|
||||
r'CREATE|COMMUNICATION|COMPONENTS?|COMPUTE|CONCATENATE|CONDENSE|'
|
||||
r'CONSTANTS|CONTEXTS|CONTINUE|CONTROLS|'
|
||||
r'DATA|DECIMALS|DEFAULT|DEFINE|DEFINITION|DEFERRED|DEMAND|'
|
||||
r'DETAIL|DIRECTORY|DIVIDE|DO|'
|
||||
r'ELSE(IF)?|ENDAT|ENDCASE|ENDCLASS|ENDDO|ENDFORM|ENDFUNCTION|'
|
||||
r'ENDIF|ENDLOOP|ENDMETHOD|ENDMODULE|ENDSELECT|ENDTRY|'
|
||||
r'ENHANCEMENT|EVENTS|EXCEPTIONS|EXIT|EXPORT|EXPORTING|EXTRACT|'
|
||||
r'FETCH|FIELDS?|FIND|FOR|FORM|FORMAT|FREE|FROM|'
|
||||
r'HIDE|'
|
||||
r'ID|IF|IMPORT|IMPLEMENTATION|IMPORTING|IN|INCLUDE|INCLUDING|'
|
||||
r'INDEX|INFOTYPES|INITIALIZATION|INTERFACE|INTERFACES|INTO|'
|
||||
r'LENGTH|LINES|LOAD|LOCAL|'
|
||||
r'JOIN|'
|
||||
r'KEY|'
|
||||
r'MAXIMUM|MESSAGE|METHOD[S]?|MINIMUM|MODULE|MODIFY|MOVE|MULTIPLY|'
|
||||
r'NODES|'
|
||||
r'OBLIGATORY|OF|OFF|ON|OVERLAY|'
|
||||
r'PACK|PARAMETERS|PERCENTAGE|POSITION|PROGRAM|PROVIDE|PUBLIC|PUT|'
|
||||
r'RAISE|RAISING|RANGES|READ|RECEIVE|REFRESH|REJECT|REPORT|RESERVE|'
|
||||
r'RESUME|RETRY|RETURN|RETURNING|RIGHT|ROLLBACK|'
|
||||
r'SCROLL|SEARCH|SELECT|SHIFT|SINGLE|SKIP|SORT|SPLIT|STATICS|STOP|'
|
||||
r'SUBMIT|SUBTRACT|SUM|SUMMARY|SUMMING|SUPPLY|'
|
||||
r'TABLE|TABLES|TIMES|TITLE|TO|TOP-OF-PAGE|TRANSFER|TRANSLATE|TRY|TYPES|'
|
||||
r'ULINE|UNDER|UNPACK|UPDATE|USING|'
|
||||
r'VALUE|VALUES|VIA|'
|
||||
r'WAIT|WHEN|WHERE|WHILE|WITH|WINDOW|WRITE)\b', Keyword),
|
||||
|
||||
# builtins
|
||||
(r'(abs|acos|asin|atan|'
|
||||
r'boolc|boolx|bit_set|'
|
||||
r'char_off|charlen|ceil|cmax|cmin|condense|contains|'
|
||||
r'contains_any_of|contains_any_not_of|concat_lines_of|cos|cosh|'
|
||||
r'count|count_any_of|count_any_not_of|'
|
||||
r'dbmaxlen|distance|'
|
||||
r'escape|exp|'
|
||||
r'find|find_end|find_any_of|find_any_not_of|floor|frac|from_mixed|'
|
||||
r'insert|'
|
||||
r'lines|log|log10|'
|
||||
r'match|matches|'
|
||||
r'nmax|nmin|numofchar|'
|
||||
r'repeat|replace|rescale|reverse|round|'
|
||||
r'segment|shift_left|shift_right|sign|sin|sinh|sqrt|strlen|'
|
||||
r'substring|substring_after|substring_from|substring_before|substring_to|'
|
||||
r'tan|tanh|to_upper|to_lower|to_mixed|translate|trunc|'
|
||||
r'xstrlen)(\()\b', bygroups(Name.Builtin, Punctuation)),
|
||||
|
||||
(r'&[0-9]', Name),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
|
||||
# operators which look like variable names before
|
||||
# parsing variable names.
|
||||
(r'(?<=(\s|.))(AND|EQ|NE|GT|LT|GE|LE|CO|CN|CA|NA|CS|NOT|NS|CP|NP|'
|
||||
r'BYTE-CO|BYTE-CN|BYTE-CA|BYTE-NA|BYTE-CS|BYTE-NS|'
|
||||
r'IS\s+(NOT\s+)?(INITIAL|ASSIGNED|REQUESTED|BOUND))\b', Operator),
|
||||
|
||||
include('variable-names'),
|
||||
|
||||
# standard oparators after variable names,
|
||||
# because < and > are part of field symbols.
|
||||
(r'[?*<>=\-+]', Operator),
|
||||
(r"'(''|[^'])*'", String.Single),
|
||||
(r"`([^`])*`", String.Single),
|
||||
(r'[/;:()\[\],.]', Punctuation)
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class OpenEdgeLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `OpenEdge ABL (formerly Progress)
|
||||
<http://web.progress.com/en/openedge/abl.html>`_ source code.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'OpenEdge ABL'
|
||||
aliases = ['openedge', 'abl', 'progress']
|
||||
filenames = ['*.p', '*.cls']
|
||||
mimetypes = ['text/x-openedge', 'application/x-openedge']
|
||||
|
||||
types = (r'(?i)(^|(?<=[^0-9a-z_\-]))(CHARACTER|CHAR|CHARA|CHARAC|CHARACT|CHARACTE|'
|
||||
r'COM-HANDLE|DATE|DATETIME|DATETIME-TZ|'
|
||||
r'DECIMAL|DEC|DECI|DECIM|DECIMA|HANDLE|'
|
||||
r'INT64|INTEGER|INT|INTE|INTEG|INTEGE|'
|
||||
r'LOGICAL|LONGCHAR|MEMPTR|RAW|RECID|ROWID)\s*($|(?=[^0-9a-z_\-]))')
|
||||
|
||||
keywords = words(OPENEDGEKEYWORDS,
|
||||
prefix=r'(?i)(^|(?<=[^0-9a-z_\-]))',
|
||||
suffix=r'\s*($|(?=[^0-9a-z_\-]))')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'/\*', Comment.Multiline, 'comment'),
|
||||
(r'\{', Comment.Preproc, 'preprocessor'),
|
||||
(r'\s*&.*', Comment.Preproc),
|
||||
(r'0[xX][0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'(?i)(DEFINE|DEF|DEFI|DEFIN)\b', Keyword.Declaration),
|
||||
(types, Keyword.Type),
|
||||
(keywords, Name.Builtin),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'[0-9][0-9]*\.[0-9]+([eE][0-9]+)?[fd]?', Number.Float),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r'\s+', Text),
|
||||
(r'[+*/=-]', Operator),
|
||||
(r'[.:()]', Punctuation),
|
||||
(r'.', Name.Variable), # Lazy catch-all
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
],
|
||||
'preprocessor': [
|
||||
(r'[^{}]', Comment.Preproc),
|
||||
(r'\{', Comment.Preproc, '#push'),
|
||||
(r'\}', Comment.Preproc, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class GoodDataCLLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `GoodData-CL
|
||||
<http://github.com/gooddata/GoodData-CL/raw/master/cli/src/main/resources/\
|
||||
com/gooddata/processor/COMMANDS.txt>`_
|
||||
script files.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'GoodData-CL'
|
||||
aliases = ['gooddata-cl']
|
||||
filenames = ['*.gdc']
|
||||
mimetypes = ['text/x-gooddata-cl']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# Comments
|
||||
(r'#.*', Comment.Single),
|
||||
# Function call
|
||||
(r'[a-z]\w*', Name.Function),
|
||||
# Argument list
|
||||
(r'\(', Punctuation, 'args-list'),
|
||||
# Punctuation
|
||||
(r';', Punctuation),
|
||||
# Space is not significant
|
||||
(r'\s+', Text)
|
||||
],
|
||||
'args-list': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(r',', Punctuation),
|
||||
(r'[a-z]\w*', Name.Variable),
|
||||
(r'=', Operator),
|
||||
(r'"', String, 'string-literal'),
|
||||
(r'[0-9]+(?:\.[0-9]+)?(?:e[+-]?[0-9]{1,3})?', Number),
|
||||
# Space is not significant
|
||||
(r'\s', Text)
|
||||
],
|
||||
'string-literal': [
|
||||
(r'\\[tnrfbae"\\]', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
(r'[^\\"]+', String)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class MaqlLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `GoodData MAQL
|
||||
<https://secure.gooddata.com/docs/html/advanced.metric.tutorial.html>`_
|
||||
scripts.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'MAQL'
|
||||
aliases = ['maql']
|
||||
filenames = ['*.maql']
|
||||
mimetypes = ['text/x-gooddata-maql', 'application/x-gooddata-maql']
|
||||
|
||||
flags = re.IGNORECASE
|
||||
tokens = {
|
||||
'root': [
|
||||
# IDENTITY
|
||||
(r'IDENTIFIER\b', Name.Builtin),
|
||||
# IDENTIFIER
|
||||
(r'\{[^}]+\}', Name.Variable),
|
||||
# NUMBER
|
||||
(r'[0-9]+(?:\.[0-9]+)?(?:e[+-]?[0-9]{1,3})?', Number),
|
||||
# STRING
|
||||
(r'"', String, 'string-literal'),
|
||||
# RELATION
|
||||
(r'\<\>|\!\=', Operator),
|
||||
(r'\=|\>\=|\>|\<\=|\<', Operator),
|
||||
# :=
|
||||
(r'\:\=', Operator),
|
||||
# OBJECT
|
||||
(r'\[[^]]+\]', Name.Variable.Class),
|
||||
# keywords
|
||||
(words((
|
||||
'DIMENSION', 'DIMENSIONS', 'BOTTOM', 'METRIC', 'COUNT', 'OTHER',
|
||||
'FACT', 'WITH', 'TOP', 'OR', 'ATTRIBUTE', 'CREATE', 'PARENT',
|
||||
'FALSE', 'ROW', 'ROWS', 'FROM', 'ALL', 'AS', 'PF', 'COLUMN',
|
||||
'COLUMNS', 'DEFINE', 'REPORT', 'LIMIT', 'TABLE', 'LIKE', 'AND',
|
||||
'BY', 'BETWEEN', 'EXCEPT', 'SELECT', 'MATCH', 'WHERE', 'TRUE',
|
||||
'FOR', 'IN', 'WITHOUT', 'FILTER', 'ALIAS', 'WHEN', 'NOT', 'ON',
|
||||
'KEYS', 'KEY', 'FULLSET', 'PRIMARY', 'LABELS', 'LABEL',
|
||||
'VISUAL', 'TITLE', 'DESCRIPTION', 'FOLDER', 'ALTER', 'DROP',
|
||||
'ADD', 'DATASET', 'DATATYPE', 'INT', 'BIGINT', 'DOUBLE', 'DATE',
|
||||
'VARCHAR', 'DECIMAL', 'SYNCHRONIZE', 'TYPE', 'DEFAULT', 'ORDER',
|
||||
'ASC', 'DESC', 'HYPERLINK', 'INCLUDE', 'TEMPLATE', 'MODIFY'),
|
||||
suffix=r'\b'),
|
||||
Keyword),
|
||||
# FUNCNAME
|
||||
(r'[a-z]\w*\b', Name.Function),
|
||||
# Comments
|
||||
(r'#.*', Comment.Single),
|
||||
# Punctuation
|
||||
(r'[,;()]', Punctuation),
|
||||
# Space is not significant
|
||||
(r'\s+', Text)
|
||||
],
|
||||
'string-literal': [
|
||||
(r'\\[tnrfbae"\\]', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
(r'[^\\"]+', String)
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,233 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for C/C++ languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, \
|
||||
this, inherit, default, words
|
||||
from pygments.util import get_bool_opt
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error
|
||||
|
||||
__all__ = ['CLexer', 'CppLexer']
|
||||
|
||||
|
||||
class CFamilyLexer(RegexLexer):
|
||||
"""
|
||||
For C family source code. This is used as a base class to avoid repetitious
|
||||
definitions.
|
||||
"""
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*].*?[*]/)+'
|
||||
#: only one /* */ style comment
|
||||
_ws1 = r'\s*(?:/[*].*?[*]/\s*)*'
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
# preprocessor directives: without whitespace
|
||||
('^#if\s+0', Comment.Preproc, 'if0'),
|
||||
('^#', Comment.Preproc, 'macro'),
|
||||
# or with whitespace
|
||||
('^(' + _ws1 + r')(#if\s+0)',
|
||||
bygroups(using(this), Comment.Preproc), 'if0'),
|
||||
('^(' + _ws1 + ')(#)',
|
||||
bygroups(using(this), Comment.Preproc), 'macro'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'//(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
],
|
||||
'statements': [
|
||||
(r'L?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[LlUu]*', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'0[0-7]+[LlUu]*', Number.Oct),
|
||||
(r'\d+[LlUu]*', Number.Integer),
|
||||
(r'\*/', Error),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'[()\[\],.]', Punctuation),
|
||||
(words(('auto', 'break', 'case', 'const', 'continue', 'default', 'do',
|
||||
'else', 'enum', 'extern', 'for', 'goto', 'if', 'register',
|
||||
'restricted', 'return', 'sizeof', 'static', 'struct',
|
||||
'switch', 'typedef', 'union', 'volatile', 'while'),
|
||||
suffix=r'\b'), Keyword),
|
||||
(r'(bool|int|long|float|short|double|char|unsigned|signed|void|'
|
||||
r'[a-z_][a-z0-9_]*_t)\b',
|
||||
Keyword.Type),
|
||||
(words(('inline', '_inline', '__inline', 'naked', 'restrict',
|
||||
'thread', 'typename'), suffix=r'\b'), Keyword.Reserved),
|
||||
# Vector intrinsics
|
||||
(r'(__m(128i|128d|128|64))\b', Keyword.Reserved),
|
||||
# Microsoft-isms
|
||||
(words((
|
||||
'asm', 'int8', 'based', 'except', 'int16', 'stdcall', 'cdecl',
|
||||
'fastcall', 'int32', 'declspec', 'finally', 'int64', 'try',
|
||||
'leave', 'wchar_t', 'w64', 'unaligned', 'raise', 'noop',
|
||||
'identifier', 'forceinline', 'assume'),
|
||||
prefix=r'__', suffix=r'\b'), Keyword.Reserved),
|
||||
(r'(true|false|NULL)\b', Name.Builtin),
|
||||
(r'([a-zA-Z_]\w*)(\s*)(:)(?!:)', bygroups(Name.Label, Text, Punctuation)),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
# functions
|
||||
(r'((?:[\w*\s])+?(?:\s|[*]))' # return arguments
|
||||
r'([a-zA-Z_]\w*)' # method name
|
||||
r'(\s*\([^;]*?\))' # signature
|
||||
r'(' + _ws + r')?(\{)',
|
||||
bygroups(using(this), Name.Function, using(this), using(this),
|
||||
Punctuation),
|
||||
'function'),
|
||||
# function declarations
|
||||
(r'((?:[\w*\s])+?(?:\s|[*]))' # return arguments
|
||||
r'([a-zA-Z_]\w*)' # method name
|
||||
r'(\s*\([^;]*?\))' # signature
|
||||
r'(' + _ws + r')?(;)',
|
||||
bygroups(using(this), Name.Function, using(this), using(this),
|
||||
Punctuation)),
|
||||
default('statement'),
|
||||
],
|
||||
'statement': [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
('[{}]', Punctuation),
|
||||
(';', Punctuation, '#pop'),
|
||||
],
|
||||
'function': [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
(';', Punctuation),
|
||||
(r'\{', Punctuation, '#push'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|'
|
||||
r'u[a-fA-F0-9]{4}|U[a-fA-F0-9]{8}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
(r'/', Comment.Preproc),
|
||||
(r'(?<=\\)\n', Comment.Preproc),
|
||||
(r'\n', Comment.Preproc, '#pop'),
|
||||
],
|
||||
'if0': [
|
||||
(r'^\s*#if.*?(?<!\\)\n', Comment.Preproc, '#push'),
|
||||
(r'^\s*#el(?:se|if).*\n', Comment.Preproc, '#pop'),
|
||||
(r'^\s*#endif.*?(?<!\\)\n', Comment.Preproc, '#pop'),
|
||||
(r'.*?\n', Comment),
|
||||
]
|
||||
}
|
||||
|
||||
stdlib_types = ['size_t', 'ssize_t', 'off_t', 'wchar_t', 'ptrdiff_t',
|
||||
'sig_atomic_t', 'fpos_t', 'clock_t', 'time_t', 'va_list',
|
||||
'jmp_buf', 'FILE', 'DIR', 'div_t', 'ldiv_t', 'mbstate_t',
|
||||
'wctrans_t', 'wint_t', 'wctype_t']
|
||||
c99_types = ['_Bool', '_Complex', 'int8_t', 'int16_t', 'int32_t', 'int64_t',
|
||||
'uint8_t', 'uint16_t', 'uint32_t', 'uint64_t', 'int_least8_t',
|
||||
'int_least16_t', 'int_least32_t', 'int_least64_t',
|
||||
'uint_least8_t', 'uint_least16_t', 'uint_least32_t',
|
||||
'uint_least64_t', 'int_fast8_t', 'int_fast16_t', 'int_fast32_t',
|
||||
'int_fast64_t', 'uint_fast8_t', 'uint_fast16_t', 'uint_fast32_t',
|
||||
'uint_fast64_t', 'intptr_t', 'uintptr_t', 'intmax_t',
|
||||
'uintmax_t']
|
||||
|
||||
def __init__(self, **options):
|
||||
self.stdlibhighlighting = get_bool_opt(options, 'stdlibhighlighting', True)
|
||||
self.c99highlighting = get_bool_opt(options, 'c99highlighting', True)
|
||||
RegexLexer.__init__(self, **options)
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in \
|
||||
RegexLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name:
|
||||
if self.stdlibhighlighting and value in self.stdlib_types:
|
||||
token = Keyword.Type
|
||||
elif self.c99highlighting and value in self.c99_types:
|
||||
token = Keyword.Type
|
||||
yield index, token, value
|
||||
|
||||
|
||||
class CLexer(CFamilyLexer):
|
||||
"""
|
||||
For C source code with preprocessor directives.
|
||||
"""
|
||||
name = 'C'
|
||||
aliases = ['c']
|
||||
filenames = ['*.c', '*.h', '*.idc']
|
||||
mimetypes = ['text/x-chdr', 'text/x-csrc']
|
||||
priority = 0.1
|
||||
|
||||
def analyse_text(text):
|
||||
if re.search('^\s*#include [<"]', text, re.MULTILINE):
|
||||
return 0.1
|
||||
if re.search('^\s*#ifdef ', text, re.MULTILINE):
|
||||
return 0.1
|
||||
|
||||
|
||||
class CppLexer(CFamilyLexer):
|
||||
"""
|
||||
For C++ source code with preprocessor directives.
|
||||
"""
|
||||
name = 'C++'
|
||||
aliases = ['cpp', 'c++']
|
||||
filenames = ['*.cpp', '*.hpp', '*.c++', '*.h++',
|
||||
'*.cc', '*.hh', '*.cxx', '*.hxx',
|
||||
'*.C', '*.H', '*.cp', '*.CPP']
|
||||
mimetypes = ['text/x-c++hdr', 'text/x-c++src']
|
||||
priority = 0.1
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'asm', 'catch', 'const_cast', 'delete', 'dynamic_cast', 'explicit',
|
||||
'export', 'friend', 'mutable', 'namespace', 'new', 'operator',
|
||||
'private', 'protected', 'public', 'reinterpret_cast',
|
||||
'restrict', 'static_cast', 'template', 'this', 'throw', 'throws',
|
||||
'typeid', 'typename', 'using', 'virtual',
|
||||
'constexpr', 'nullptr', 'decltype', 'thread_local',
|
||||
'alignas', 'alignof', 'static_assert', 'noexcept', 'override',
|
||||
'final'), suffix=r'\b'), Keyword),
|
||||
(r'char(16_t|32_t)\b', Keyword.Type),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
inherit,
|
||||
],
|
||||
'root': [
|
||||
inherit,
|
||||
# C++ Microsoft-isms
|
||||
(words(('virtual_inheritance', 'uuidof', 'super', 'single_inheritance',
|
||||
'multiple_inheritance', 'interface', 'event'),
|
||||
prefix=r'__', suffix=r'\b'), Keyword.Reserved),
|
||||
# Offload C++ extensions, http://offload.codeplay.com/
|
||||
(r'__(offload|blockingoffload|outer)\b', Keyword.Pseudo),
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
# template specification
|
||||
(r'\s*(?=>)', Text, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if re.search('#include <[a-z]+>', text):
|
||||
return 0.2
|
||||
if re.search('using namespace ', text):
|
||||
return 0.4
|
||||
@ -0,0 +1,413 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.c_like
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for other C-like languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, inherit, words, \
|
||||
default
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
from pygments.lexers.c_cpp import CLexer, CppLexer
|
||||
from pygments.lexers import _mql_builtins
|
||||
|
||||
__all__ = ['PikeLexer', 'NesCLexer', 'ClayLexer', 'ECLexer', 'ValaLexer',
|
||||
'CudaLexer', 'SwigLexer', 'MqlLexer']
|
||||
|
||||
|
||||
class PikeLexer(CppLexer):
|
||||
"""
|
||||
For `Pike <http://pike.lysator.liu.se/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Pike'
|
||||
aliases = ['pike']
|
||||
filenames = ['*.pike', '*.pmod']
|
||||
mimetypes = ['text/x-pike']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'catch', 'new', 'private', 'protected', 'public', 'gauge',
|
||||
'throw', 'throws', 'class', 'interface', 'implement', 'abstract', 'extends', 'from',
|
||||
'this', 'super', 'constant', 'final', 'static', 'import', 'use', 'extern',
|
||||
'inline', 'proto', 'break', 'continue', 'if', 'else', 'for',
|
||||
'while', 'do', 'switch', 'case', 'as', 'in', 'version', 'return', 'true', 'false', 'null',
|
||||
'__VERSION__', '__MAJOR__', '__MINOR__', '__BUILD__', '__REAL_VERSION__',
|
||||
'__REAL_MAJOR__', '__REAL_MINOR__', '__REAL_BUILD__', '__DATE__', '__TIME__',
|
||||
'__FILE__', '__DIR__', '__LINE__', '__AUTO_BIGNUM__', '__NT__', '__PIKE__',
|
||||
'__amigaos__', '_Pragma', 'static_assert', 'defined', 'sscanf'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(bool|int|long|float|short|double|char|string|object|void|mapping|'
|
||||
r'array|multiset|program|function|lambda|mixed|'
|
||||
r'[a-z_][a-z0-9_]*_t)\b',
|
||||
Keyword.Type),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'[~!%^&*+=|?:<>/@-]', Operator),
|
||||
inherit,
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
# template specification
|
||||
(r'\s*(?=>)', Text, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class NesCLexer(CLexer):
|
||||
"""
|
||||
For `nesC <https://github.com/tinyos/nesc>`_ source code with preprocessor
|
||||
directives.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'nesC'
|
||||
aliases = ['nesc']
|
||||
filenames = ['*.nc']
|
||||
mimetypes = ['text/x-nescsrc']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'abstract', 'as', 'async', 'atomic', 'call', 'command', 'component',
|
||||
'components', 'configuration', 'event', 'extends', 'generic',
|
||||
'implementation', 'includes', 'interface', 'module', 'new', 'norace',
|
||||
'post', 'provides', 'signal', 'task', 'uses'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words(('nx_struct', 'nx_union', 'nx_int8_t', 'nx_int16_t', 'nx_int32_t',
|
||||
'nx_int64_t', 'nx_uint8_t', 'nx_uint16_t', 'nx_uint32_t',
|
||||
'nx_uint64_t'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ClayLexer(RegexLexer):
|
||||
"""
|
||||
For `Clay <http://claylabs.com/clay/>`_ source.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Clay'
|
||||
filenames = ['*.clay']
|
||||
aliases = ['clay']
|
||||
mimetypes = ['text/x-clay']
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s', Text),
|
||||
(r'//.*?$', Comment.Singleline),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'\b(public|private|import|as|record|variant|instance'
|
||||
r'|define|overload|default|external|alias'
|
||||
r'|rvalue|ref|forward|inline|noinline|forceinline'
|
||||
r'|enum|var|and|or|not|if|else|goto|return|while'
|
||||
r'|switch|case|break|continue|for|in|true|false|try|catch|throw'
|
||||
r'|finally|onerror|staticassert|eval|when|newtype'
|
||||
r'|__FILE__|__LINE__|__COLUMN__|__ARG__'
|
||||
r')\b', Keyword),
|
||||
(r'[~!%^&*+=|:<>/-]', Operator),
|
||||
(r'[#(){}\[\],;.]', Punctuation),
|
||||
(r'0x[0-9a-fA-F]+[LlUu]*', Number.Hex),
|
||||
(r'\d+[LlUu]*', Number.Integer),
|
||||
(r'\b(true|false)\b', Name.Builtin),
|
||||
(r'(?i)[a-z_?][\w?]*', Name),
|
||||
(r'"""', String, 'tdqs'),
|
||||
(r'"', String, 'dqs'),
|
||||
],
|
||||
'strings': [
|
||||
(r'(?i)\\(x[0-9a-f]{2}|.)', String.Escape),
|
||||
(r'.', String),
|
||||
],
|
||||
'nl': [
|
||||
(r'\n', String),
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String, '#pop'),
|
||||
include('strings'),
|
||||
],
|
||||
'tdqs': [
|
||||
(r'"""', String, '#pop'),
|
||||
include('strings'),
|
||||
include('nl'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ECLexer(CLexer):
|
||||
"""
|
||||
For eC source code with preprocessor directives.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = 'eC'
|
||||
aliases = ['ec']
|
||||
filenames = ['*.ec', '*.eh']
|
||||
mimetypes = ['text/x-echdr', 'text/x-ecsrc']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words((
|
||||
'virtual', 'class', 'private', 'public', 'property', 'import',
|
||||
'delete', 'new', 'new0', 'renew', 'renew0', 'define', 'get',
|
||||
'set', 'remote', 'dllexport', 'dllimport', 'stdcall', 'subclass',
|
||||
'__on_register_module', 'namespace', 'using', 'typed_object',
|
||||
'any_object', 'incref', 'register', 'watch', 'stopwatching', 'firewatchers',
|
||||
'watchable', 'class_designer', 'class_fixed', 'class_no_expansion', 'isset',
|
||||
'class_default_property', 'property_category', 'class_data',
|
||||
'class_property', 'thisclass', 'dbtable', 'dbindex',
|
||||
'database_open', 'dbfield'), suffix=r'\b'), Keyword),
|
||||
(words(('uint', 'uint16', 'uint32', 'uint64', 'bool', 'byte',
|
||||
'unichar', 'int64'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
(r'(null|value|this)\b', Name.Builtin),
|
||||
inherit,
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
# template specification
|
||||
(r'\s*(?=>)', Text, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ValaLexer(RegexLexer):
|
||||
"""
|
||||
For Vala source code with preprocessor directives.
|
||||
|
||||
.. versionadded:: 1.1
|
||||
"""
|
||||
name = 'Vala'
|
||||
aliases = ['vala', 'vapi']
|
||||
filenames = ['*.vala', '*.vapi']
|
||||
mimetypes = ['text/x-vala']
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'^\s*#if\s+0', Comment.Preproc, 'if0'),
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text), # line continuation
|
||||
(r'//(\n|(.|\n)*?[^\\]\n)', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
],
|
||||
'statements': [
|
||||
(r'[L@]?"', String, 'string'),
|
||||
(r"L?'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'",
|
||||
String.Char),
|
||||
(r'(?s)""".*?"""', String), # verbatim strings
|
||||
(r'(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+[lL]?', Number.Float),
|
||||
(r'(\d+\.\d*|\.\d+|\d+[fF])[fF]?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+[Ll]?', Number.Hex),
|
||||
(r'0[0-7]+[Ll]?', Number.Oct),
|
||||
(r'\d+[Ll]?', Number.Integer),
|
||||
(r'[~!%^&*+=|?:<>/-]', Operator),
|
||||
(r'(\[)(Compact|Immutable|(?:Boolean|Simple)Type)(\])',
|
||||
bygroups(Punctuation, Name.Decorator, Punctuation)),
|
||||
# TODO: "correctly" parse complex code attributes
|
||||
(r'(\[)(CCode|(?:Integer|Floating)Type)',
|
||||
bygroups(Punctuation, Name.Decorator)),
|
||||
(r'[()\[\],.]', Punctuation),
|
||||
(words((
|
||||
'as', 'base', 'break', 'case', 'catch', 'construct', 'continue',
|
||||
'default', 'delete', 'do', 'else', 'enum', 'finally', 'for',
|
||||
'foreach', 'get', 'if', 'in', 'is', 'lock', 'new', 'out', 'params',
|
||||
'return', 'set', 'sizeof', 'switch', 'this', 'throw', 'try',
|
||||
'typeof', 'while', 'yield'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'abstract', 'const', 'delegate', 'dynamic', 'ensures', 'extern',
|
||||
'inline', 'internal', 'override', 'owned', 'private', 'protected',
|
||||
'public', 'ref', 'requires', 'signal', 'static', 'throws', 'unowned',
|
||||
'var', 'virtual', 'volatile', 'weak', 'yields'), suffix=r'\b'),
|
||||
Keyword.Declaration),
|
||||
(r'(namespace|using)(\s+)', bygroups(Keyword.Namespace, Text),
|
||||
'namespace'),
|
||||
(r'(class|errordomain|interface|struct)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text), 'class'),
|
||||
(r'(\.)([a-zA-Z_]\w*)',
|
||||
bygroups(Operator, Name.Attribute)),
|
||||
# void is an actual keyword, others are in glib-2.0.vapi
|
||||
(words((
|
||||
'void', 'bool', 'char', 'double', 'float', 'int', 'int8', 'int16',
|
||||
'int32', 'int64', 'long', 'short', 'size_t', 'ssize_t', 'string',
|
||||
'time_t', 'uchar', 'uint', 'uint8', 'uint16', 'uint32', 'uint64',
|
||||
'ulong', 'unichar', 'ushort'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(r'(true|false|null)\b', Name.Builtin),
|
||||
('[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
default('statement'),
|
||||
],
|
||||
'statement': [
|
||||
include('whitespace'),
|
||||
include('statements'),
|
||||
('[{}]', Punctuation),
|
||||
(';', Punctuation, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"\n]+', String), # all other characters
|
||||
(r'\\\n', String), # line continuation
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'if0': [
|
||||
(r'^\s*#if.*?(?<!\\)\n', Comment.Preproc, '#push'),
|
||||
(r'^\s*#el(?:se|if).*\n', Comment.Preproc, '#pop'),
|
||||
(r'^\s*#endif.*?(?<!\\)\n', Comment.Preproc, '#pop'),
|
||||
(r'.*?\n', Comment),
|
||||
],
|
||||
'class': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop')
|
||||
],
|
||||
'namespace': [
|
||||
(r'[a-zA-Z_][\w.]*', Name.Namespace, '#pop')
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CudaLexer(CLexer):
|
||||
"""
|
||||
For NVIDIA `CUDA™ <http://developer.nvidia.com/category/zone/cuda-zone>`_
|
||||
source.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
name = 'CUDA'
|
||||
filenames = ['*.cu', '*.cuh']
|
||||
aliases = ['cuda', 'cu']
|
||||
mimetypes = ['text/x-cuda']
|
||||
|
||||
function_qualifiers = set(('__device__', '__global__', '__host__',
|
||||
'__noinline__', '__forceinline__'))
|
||||
variable_qualifiers = set(('__device__', '__constant__', '__shared__',
|
||||
'__restrict__'))
|
||||
vector_types = set(('char1', 'uchar1', 'char2', 'uchar2', 'char3', 'uchar3',
|
||||
'char4', 'uchar4', 'short1', 'ushort1', 'short2', 'ushort2',
|
||||
'short3', 'ushort3', 'short4', 'ushort4', 'int1', 'uint1',
|
||||
'int2', 'uint2', 'int3', 'uint3', 'int4', 'uint4', 'long1',
|
||||
'ulong1', 'long2', 'ulong2', 'long3', 'ulong3', 'long4',
|
||||
'ulong4', 'longlong1', 'ulonglong1', 'longlong2',
|
||||
'ulonglong2', 'float1', 'float2', 'float3', 'float4',
|
||||
'double1', 'double2', 'dim3'))
|
||||
variables = set(('gridDim', 'blockIdx', 'blockDim', 'threadIdx', 'warpSize'))
|
||||
functions = set(('__threadfence_block', '__threadfence', '__threadfence_system',
|
||||
'__syncthreads', '__syncthreads_count', '__syncthreads_and',
|
||||
'__syncthreads_or'))
|
||||
execution_confs = set(('<<<', '>>>'))
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in CLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name:
|
||||
if value in self.variable_qualifiers:
|
||||
token = Keyword.Type
|
||||
elif value in self.vector_types:
|
||||
token = Keyword.Type
|
||||
elif value in self.variables:
|
||||
token = Name.Builtin
|
||||
elif value in self.execution_confs:
|
||||
token = Keyword.Pseudo
|
||||
elif value in self.function_qualifiers:
|
||||
token = Keyword.Reserved
|
||||
elif value in self.functions:
|
||||
token = Name.Function
|
||||
yield index, token, value
|
||||
|
||||
|
||||
class SwigLexer(CppLexer):
|
||||
"""
|
||||
For `SWIG <http://www.swig.org/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'SWIG'
|
||||
aliases = ['swig']
|
||||
filenames = ['*.swg', '*.i']
|
||||
mimetypes = ['text/swig']
|
||||
priority = 0.04 # Lower than C/C++ and Objective C/C++
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
# SWIG directives
|
||||
(r'(%[a-z_][a-z0-9_]*)', Name.Function),
|
||||
# Special variables
|
||||
('\$\**\&?\w+', Name),
|
||||
# Stringification / additional preprocessor directives
|
||||
(r'##*[a-zA-Z_]\w*', Comment.Preproc),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
|
||||
# This is a far from complete set of SWIG directives
|
||||
swig_directives = set((
|
||||
# Most common directives
|
||||
'%apply', '%define', '%director', '%enddef', '%exception', '%extend',
|
||||
'%feature', '%fragment', '%ignore', '%immutable', '%import', '%include',
|
||||
'%inline', '%insert', '%module', '%newobject', '%nspace', '%pragma',
|
||||
'%rename', '%shared_ptr', '%template', '%typecheck', '%typemap',
|
||||
# Less common directives
|
||||
'%arg', '%attribute', '%bang', '%begin', '%callback', '%catches', '%clear',
|
||||
'%constant', '%copyctor', '%csconst', '%csconstvalue', '%csenum',
|
||||
'%csmethodmodifiers', '%csnothrowexception', '%default', '%defaultctor',
|
||||
'%defaultdtor', '%defined', '%delete', '%delobject', '%descriptor',
|
||||
'%exceptionclass', '%exceptionvar', '%extend_smart_pointer', '%fragments',
|
||||
'%header', '%ifcplusplus', '%ignorewarn', '%implicit', '%implicitconv',
|
||||
'%init', '%javaconst', '%javaconstvalue', '%javaenum', '%javaexception',
|
||||
'%javamethodmodifiers', '%kwargs', '%luacode', '%mutable', '%naturalvar',
|
||||
'%nestedworkaround', '%perlcode', '%pythonabc', '%pythonappend',
|
||||
'%pythoncallback', '%pythoncode', '%pythondynamic', '%pythonmaybecall',
|
||||
'%pythonnondynamic', '%pythonprepend', '%refobject', '%shadow', '%sizeof',
|
||||
'%trackobjects', '%types', '%unrefobject', '%varargs', '%warn',
|
||||
'%warnfilter'))
|
||||
|
||||
def analyse_text(text):
|
||||
rv = 0
|
||||
# Search for SWIG directives, which are conventionally at the beginning of
|
||||
# a line. The probability of them being within a line is low, so let another
|
||||
# lexer win in this case.
|
||||
matches = re.findall(r'^\s*(%[a-z_][a-z0-9_]*)', text, re.M)
|
||||
for m in matches:
|
||||
if m in SwigLexer.swig_directives:
|
||||
rv = 0.98
|
||||
break
|
||||
else:
|
||||
rv = 0.91 # Fraction higher than MatlabLexer
|
||||
return rv
|
||||
|
||||
|
||||
class MqlLexer(CppLexer):
|
||||
"""
|
||||
For `MQL4 <http://docs.mql4.com/>`_ and
|
||||
`MQL5 <http://www.mql5.com/en/docs>`_ source code.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'MQL'
|
||||
aliases = ['mql', 'mq4', 'mq5', 'mql4', 'mql5']
|
||||
filenames = ['*.mq4', '*.mq5', '*.mqh']
|
||||
mimetypes = ['text/x-mql']
|
||||
|
||||
tokens = {
|
||||
'statements': [
|
||||
(words(_mql_builtins.keywords, suffix=r'\b'), Keyword),
|
||||
(words(_mql_builtins.c_types, suffix=r'\b'), Keyword.Type),
|
||||
(words(_mql_builtins.types, suffix=r'\b'), Name.Function),
|
||||
(words(_mql_builtins.constants, suffix=r'\b'), Name.Constant),
|
||||
(words(_mql_builtins.colors, prefix='(clr)?', suffix=r'\b'),
|
||||
Name.Constant),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,98 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.chapel
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for the Chapel language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['ChapelLexer']
|
||||
|
||||
|
||||
class ChapelLexer(RegexLexer):
|
||||
"""
|
||||
For `Chapel <http://chapel.cray.com/>`_ source.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Chapel'
|
||||
filenames = ['*.chpl']
|
||||
aliases = ['chapel', 'chpl']
|
||||
# mimetypes = ['text/x-chapel']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text),
|
||||
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
|
||||
(r'(config|const|in|inout|out|param|ref|type|var)\b',
|
||||
Keyword.Declaration),
|
||||
(r'(false|nil|true)\b', Keyword.Constant),
|
||||
(r'(bool|complex|imag|int|opaque|range|real|string|uint)\b',
|
||||
Keyword.Type),
|
||||
(words((
|
||||
'align', 'atomic', 'begin', 'break', 'by', 'cobegin', 'coforall',
|
||||
'continue', 'delete', 'dmapped', 'do', 'domain', 'else', 'enum',
|
||||
'export', 'extern', 'for', 'forall', 'if', 'index', 'inline',
|
||||
'iter', 'label', 'lambda', 'let', 'local', 'new', 'noinit', 'on',
|
||||
'otherwise', 'pragma', 'reduce', 'return', 'scan', 'select',
|
||||
'serial', 'single', 'sparse', 'subdomain', 'sync', 'then', 'use',
|
||||
'when', 'where', 'while', 'with', 'yield', 'zip'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(proc)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'procname'),
|
||||
(r'(class|module|record|union)(\s+)', bygroups(Keyword, Text),
|
||||
'classname'),
|
||||
|
||||
# imaginary integers
|
||||
(r'\d+i', Number),
|
||||
(r'\d+\.\d*([Ee][-+]\d+)?i', Number),
|
||||
(r'\.\d+([Ee][-+]\d+)?i', Number),
|
||||
(r'\d+[Ee][-+]\d+i', Number),
|
||||
|
||||
# reals cannot end with a period due to lexical ambiguity with
|
||||
# .. operator. See reference for rationale.
|
||||
(r'(\d*\.\d+)([eE][+-]?[0-9]+)?i?', Number.Float),
|
||||
(r'\d+[eE][+-]?[0-9]+i?', Number.Float),
|
||||
|
||||
# integer literals
|
||||
# -- binary
|
||||
(r'0[bB][01]+', Number.Bin),
|
||||
# -- hex
|
||||
(r'0[xX][0-9a-fA-F]+', Number.Hex),
|
||||
# -- octal
|
||||
(r'0[oO][0-7]+', Number.Oct),
|
||||
# -- decimal
|
||||
(r'[0-9]+', Number.Integer),
|
||||
|
||||
# strings
|
||||
(r'["\'](\\\\|\\"|[^"\'])*["\']', String),
|
||||
|
||||
# tokens
|
||||
(r'(=|\+=|-=|\*=|/=|\*\*=|%=|&=|\|=|\^=|&&=|\|\|=|<<=|>>=|'
|
||||
r'<=>|<~>|\.\.|by|#|\.\.\.|'
|
||||
r'&&|\|\||!|&|\||\^|~|<<|>>|'
|
||||
r'==|!=|<=|>=|<|>|'
|
||||
r'[+\-*/%]|\*\*)', Operator),
|
||||
(r'[:;,.?()\[\]{}]', Punctuation),
|
||||
|
||||
# identifiers
|
||||
(r'[a-zA-Z_][\w$]*', Name.Other),
|
||||
],
|
||||
'classname': [
|
||||
(r'[a-zA-Z_][\w$]*', Name.Class, '#pop'),
|
||||
],
|
||||
'procname': [
|
||||
(r'[a-zA-Z_][\w$]*', Name.Function, '#pop'),
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,33 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.compiled
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Just export lexer classes previously contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexers.jvm import JavaLexer, ScalaLexer
|
||||
from pygments.lexers.c_cpp import CLexer, CppLexer
|
||||
from pygments.lexers.d import DLexer
|
||||
from pygments.lexers.objective import ObjectiveCLexer, \
|
||||
ObjectiveCppLexer, LogosLexer
|
||||
from pygments.lexers.go import GoLexer
|
||||
from pygments.lexers.rust import RustLexer
|
||||
from pygments.lexers.c_like import ECLexer, ValaLexer, CudaLexer
|
||||
from pygments.lexers.pascal import DelphiLexer, Modula2Lexer, AdaLexer
|
||||
from pygments.lexers.business import CobolLexer, CobolFreeformatLexer
|
||||
from pygments.lexers.fortran import FortranLexer
|
||||
from pygments.lexers.prolog import PrologLexer
|
||||
from pygments.lexers.python import CythonLexer
|
||||
from pygments.lexers.graphics import GLShaderLexer
|
||||
from pygments.lexers.ml import OcamlLexer
|
||||
from pygments.lexers.basic import BlitzBasicLexer, BlitzMaxLexer, MonkeyLexer
|
||||
from pygments.lexers.dylan import DylanLexer, DylanLidLexer, DylanConsoleLexer
|
||||
from pygments.lexers.ooc import OocLexer
|
||||
from pygments.lexers.felix import FelixLexer
|
||||
from pygments.lexers.nimrod import NimrodLexer
|
||||
|
||||
__all__ = []
|
||||
@ -0,0 +1,546 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.configs
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for configuration file formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, default, words, bygroups, include, using
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Whitespace
|
||||
from pygments.lexers.shell import BashLexer
|
||||
|
||||
__all__ = ['IniLexer', 'RegeditLexer', 'PropertiesLexer', 'KconfigLexer',
|
||||
'Cfengine3Lexer', 'ApacheConfLexer', 'SquidConfLexer',
|
||||
'NginxConfLexer', 'LighttpdConfLexer', 'DockerLexer']
|
||||
|
||||
|
||||
class IniLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for configuration files in INI style.
|
||||
"""
|
||||
|
||||
name = 'INI'
|
||||
aliases = ['ini', 'cfg', 'dosini']
|
||||
filenames = ['*.ini', '*.cfg']
|
||||
mimetypes = ['text/x-ini']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'[;#].*', Comment.Single),
|
||||
(r'\[.*?\]$', Keyword),
|
||||
(r'(.*?)([ \t]*)(=)([ \t]*)(.*(?:\n[ \t].+)*)',
|
||||
bygroups(Name.Attribute, Text, Operator, Text, String))
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
npos = text.find('\n')
|
||||
if npos < 3:
|
||||
return False
|
||||
return text[0] == '[' and text[npos-1] == ']'
|
||||
|
||||
|
||||
class RegeditLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Windows Registry
|
||||
<http://en.wikipedia.org/wiki/Windows_Registry#.REG_files>`_ files produced
|
||||
by regedit.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'reg'
|
||||
aliases = ['registry']
|
||||
filenames = ['*.reg']
|
||||
mimetypes = ['text/x-windows-registry']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'Windows Registry Editor.*', Text),
|
||||
(r'\s+', Text),
|
||||
(r'[;#].*', Comment.Single),
|
||||
(r'(\[)(-?)(HKEY_[A-Z_]+)(.*?\])$',
|
||||
bygroups(Keyword, Operator, Name.Builtin, Keyword)),
|
||||
# String keys, which obey somewhat normal escaping
|
||||
(r'("(?:\\"|\\\\|[^"])+")([ \t]*)(=)([ \t]*)',
|
||||
bygroups(Name.Attribute, Text, Operator, Text),
|
||||
'value'),
|
||||
# Bare keys (includes @)
|
||||
(r'(.*?)([ \t]*)(=)([ \t]*)',
|
||||
bygroups(Name.Attribute, Text, Operator, Text),
|
||||
'value'),
|
||||
],
|
||||
'value': [
|
||||
(r'-', Operator, '#pop'), # delete value
|
||||
(r'(dword|hex(?:\([0-9a-fA-F]\))?)(:)([0-9a-fA-F,]+)',
|
||||
bygroups(Name.Variable, Punctuation, Number), '#pop'),
|
||||
# As far as I know, .reg files do not support line continuation.
|
||||
(r'.+', String, '#pop'),
|
||||
default('#pop'),
|
||||
]
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
return text.startswith('Windows Registry Editor')
|
||||
|
||||
|
||||
class PropertiesLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for configuration files in Java's properties format.
|
||||
|
||||
.. versionadded:: 1.4
|
||||
"""
|
||||
|
||||
name = 'Properties'
|
||||
aliases = ['properties', 'jproperties']
|
||||
filenames = ['*.properties']
|
||||
mimetypes = ['text/x-java-properties']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'(?:[;#]|//).*$', Comment),
|
||||
(r'(.*?)([ \t]*)([=:])([ \t]*)(.*(?:(?<=\\)\n.*)*)',
|
||||
bygroups(Name.Attribute, Text, Operator, Text, String)),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
def _rx_indent(level):
|
||||
# Kconfig *always* interprets a tab as 8 spaces, so this is the default.
|
||||
# Edit this if you are in an environment where KconfigLexer gets expanded
|
||||
# input (tabs expanded to spaces) and the expansion tab width is != 8,
|
||||
# e.g. in connection with Trac (trac.ini, [mimeviewer], tab_width).
|
||||
# Value range here is 2 <= {tab_width} <= 8.
|
||||
tab_width = 8
|
||||
# Regex matching a given indentation {level}, assuming that indentation is
|
||||
# a multiple of {tab_width}. In other cases there might be problems.
|
||||
if tab_width == 2:
|
||||
space_repeat = '+'
|
||||
else:
|
||||
space_repeat = '{1,%d}' % (tab_width - 1)
|
||||
if level == 1:
|
||||
level_repeat = ''
|
||||
else:
|
||||
level_repeat = '{%s}' % level
|
||||
return r'(?:\t| %s\t| {%s})%s.*\n' % (space_repeat, tab_width, level_repeat)
|
||||
|
||||
|
||||
class KconfigLexer(RegexLexer):
|
||||
"""
|
||||
For Linux-style Kconfig files.
|
||||
|
||||
.. versionadded:: 1.6
|
||||
"""
|
||||
|
||||
name = 'Kconfig'
|
||||
aliases = ['kconfig', 'menuconfig', 'linux-config', 'kernel-config']
|
||||
# Adjust this if new kconfig file names appear in your environment
|
||||
filenames = ['Kconfig', '*Config.in*', 'external.in*',
|
||||
'standard-modules.in']
|
||||
mimetypes = ['text/x-kconfig']
|
||||
# No re.MULTILINE, indentation-aware help text needs line-by-line handling
|
||||
flags = 0
|
||||
|
||||
def call_indent(level):
|
||||
# If indentation >= {level} is detected, enter state 'indent{level}'
|
||||
return (_rx_indent(level), String.Doc, 'indent%s' % level)
|
||||
|
||||
def do_indent(level):
|
||||
# Print paragraphs of indentation level >= {level} as String.Doc,
|
||||
# ignoring blank lines. Then return to 'root' state.
|
||||
return [
|
||||
(_rx_indent(level), String.Doc),
|
||||
(r'\s*\n', Text),
|
||||
default('#pop:2')
|
||||
]
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'#.*?\n', Comment.Single),
|
||||
(words((
|
||||
'mainmenu', 'config', 'menuconfig', 'choice', 'endchoice',
|
||||
'comment', 'menu', 'endmenu', 'visible if', 'if', 'endif',
|
||||
'source', 'prompt', 'select', 'depends on', 'default',
|
||||
'range', 'option'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(---help---|help)[\t ]*\n', Keyword, 'help'),
|
||||
(r'(bool|tristate|string|hex|int|defconfig_list|modules|env)\b',
|
||||
Name.Builtin),
|
||||
(r'[!=&|]', Operator),
|
||||
(r'[()]', Punctuation),
|
||||
(r'[0-9]+', Number.Integer),
|
||||
(r"'(''|[^'])*'", String.Single),
|
||||
(r'"(""|[^"])*"', String.Double),
|
||||
(r'\S+', Text),
|
||||
],
|
||||
# Help text is indented, multi-line and ends when a lower indentation
|
||||
# level is detected.
|
||||
'help': [
|
||||
# Skip blank lines after help token, if any
|
||||
(r'\s*\n', Text),
|
||||
# Determine the first help line's indentation level heuristically(!).
|
||||
# Attention: this is not perfect, but works for 99% of "normal"
|
||||
# indentation schemes up to a max. indentation level of 7.
|
||||
call_indent(7),
|
||||
call_indent(6),
|
||||
call_indent(5),
|
||||
call_indent(4),
|
||||
call_indent(3),
|
||||
call_indent(2),
|
||||
call_indent(1),
|
||||
default('#pop'), # for incomplete help sections without text
|
||||
],
|
||||
# Handle text for indentation levels 7 to 1
|
||||
'indent7': do_indent(7),
|
||||
'indent6': do_indent(6),
|
||||
'indent5': do_indent(5),
|
||||
'indent4': do_indent(4),
|
||||
'indent3': do_indent(3),
|
||||
'indent2': do_indent(2),
|
||||
'indent1': do_indent(1),
|
||||
}
|
||||
|
||||
|
||||
class Cfengine3Lexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `CFEngine3 <http://cfengine.org>`_ policy files.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
|
||||
name = 'CFEngine3'
|
||||
aliases = ['cfengine3', 'cf3']
|
||||
filenames = ['*.cf']
|
||||
mimetypes = []
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'#.*?\n', Comment),
|
||||
(r'(body)(\s+)(\S+)(\s+)(control)',
|
||||
bygroups(Keyword, Text, Keyword, Text, Keyword)),
|
||||
(r'(body|bundle)(\s+)(\S+)(\s+)(\w+)(\()',
|
||||
bygroups(Keyword, Text, Keyword, Text, Name.Function, Punctuation),
|
||||
'arglist'),
|
||||
(r'(body|bundle)(\s+)(\S+)(\s+)(\w+)',
|
||||
bygroups(Keyword, Text, Keyword, Text, Name.Function)),
|
||||
(r'(")([^"]+)(")(\s+)(string|slist|int|real)(\s*)(=>)(\s*)',
|
||||
bygroups(Punctuation, Name.Variable, Punctuation,
|
||||
Text, Keyword.Type, Text, Operator, Text)),
|
||||
(r'(\S+)(\s*)(=>)(\s*)',
|
||||
bygroups(Keyword.Reserved, Text, Operator, Text)),
|
||||
(r'"', String, 'string'),
|
||||
(r'(\w+)(\()', bygroups(Name.Function, Punctuation)),
|
||||
(r'([\w.!&|()]+)(::)', bygroups(Name.Class, Punctuation)),
|
||||
(r'(\w+)(:)', bygroups(Keyword.Declaration, Punctuation)),
|
||||
(r'@[{(][^)}]+[})]', Name.Variable),
|
||||
(r'[(){},;]', Punctuation),
|
||||
(r'=>', Operator),
|
||||
(r'->', Operator),
|
||||
(r'\d+\.\d+', Number.Float),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'\w+', Name.Function),
|
||||
(r'\s+', Text),
|
||||
],
|
||||
'string': [
|
||||
(r'\$[{(]', String.Interpol, 'interpol'),
|
||||
(r'\\.', String.Escape),
|
||||
(r'"', String, '#pop'),
|
||||
(r'\n', String),
|
||||
(r'.', String),
|
||||
],
|
||||
'interpol': [
|
||||
(r'\$[{(]', String.Interpol, '#push'),
|
||||
(r'[})]', String.Interpol, '#pop'),
|
||||
(r'[^${()}]+', String.Interpol),
|
||||
],
|
||||
'arglist': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(r',', Punctuation),
|
||||
(r'\w+', Name.Variable),
|
||||
(r'\s+', Text),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class ApacheConfLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for configuration files following the Apache config file
|
||||
format.
|
||||
|
||||
.. versionadded:: 0.6
|
||||
"""
|
||||
|
||||
name = 'ApacheConf'
|
||||
aliases = ['apacheconf', 'aconf', 'apache']
|
||||
filenames = ['.htaccess', 'apache.conf', 'apache2.conf']
|
||||
mimetypes = ['text/x-apacheconf']
|
||||
flags = re.MULTILINE | re.IGNORECASE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'(#.*?)$', Comment),
|
||||
(r'(<[^\s>]+)(?:(\s+)(.*?))?(>)',
|
||||
bygroups(Name.Tag, Text, String, Name.Tag)),
|
||||
(r'([a-z]\w*)(\s+)',
|
||||
bygroups(Name.Builtin, Text), 'value'),
|
||||
(r'\.+', Text),
|
||||
],
|
||||
'value': [
|
||||
(r'\\\n', Text),
|
||||
(r'$', Text, '#pop'),
|
||||
(r'\\', Text),
|
||||
(r'[^\S\n]+', Text),
|
||||
(r'\d+\.\d+\.\d+\.\d+(?:/\d+)?', Number),
|
||||
(r'\d+', Number),
|
||||
(r'/([a-z0-9][\w./-]+)', String.Other),
|
||||
(r'(on|off|none|any|all|double|email|dns|min|minimal|'
|
||||
r'os|productonly|full|emerg|alert|crit|error|warn|'
|
||||
r'notice|info|debug|registry|script|inetd|standalone|'
|
||||
r'user|group)\b', Keyword),
|
||||
(r'"([^"\\]*(?:\\.[^"\\]*)*)"', String.Double),
|
||||
(r'[^\s"\\]+', Text)
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class SquidConfLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `squid <http://www.squid-cache.org/>`_ configuration files.
|
||||
|
||||
.. versionadded:: 0.9
|
||||
"""
|
||||
|
||||
name = 'SquidConf'
|
||||
aliases = ['squidconf', 'squid.conf', 'squid']
|
||||
filenames = ['squid.conf']
|
||||
mimetypes = ['text/x-squidconf']
|
||||
flags = re.IGNORECASE
|
||||
|
||||
keywords = (
|
||||
"access_log", "acl", "always_direct", "announce_host",
|
||||
"announce_period", "announce_port", "announce_to", "anonymize_headers",
|
||||
"append_domain", "as_whois_server", "auth_param_basic",
|
||||
"authenticate_children", "authenticate_program", "authenticate_ttl",
|
||||
"broken_posts", "buffered_logs", "cache_access_log", "cache_announce",
|
||||
"cache_dir", "cache_dns_program", "cache_effective_group",
|
||||
"cache_effective_user", "cache_host", "cache_host_acl",
|
||||
"cache_host_domain", "cache_log", "cache_mem", "cache_mem_high",
|
||||
"cache_mem_low", "cache_mgr", "cachemgr_passwd", "cache_peer",
|
||||
"cache_peer_access", "cahce_replacement_policy", "cache_stoplist",
|
||||
"cache_stoplist_pattern", "cache_store_log", "cache_swap",
|
||||
"cache_swap_high", "cache_swap_log", "cache_swap_low", "client_db",
|
||||
"client_lifetime", "client_netmask", "connect_timeout", "coredump_dir",
|
||||
"dead_peer_timeout", "debug_options", "delay_access", "delay_class",
|
||||
"delay_initial_bucket_level", "delay_parameters", "delay_pools",
|
||||
"deny_info", "dns_children", "dns_defnames", "dns_nameservers",
|
||||
"dns_testnames", "emulate_httpd_log", "err_html_text",
|
||||
"fake_user_agent", "firewall_ip", "forwarded_for", "forward_snmpd_port",
|
||||
"fqdncache_size", "ftpget_options", "ftpget_program", "ftp_list_width",
|
||||
"ftp_passive", "ftp_user", "half_closed_clients", "header_access",
|
||||
"header_replace", "hierarchy_stoplist", "high_response_time_warning",
|
||||
"high_page_fault_warning", "hosts_file", "htcp_port", "http_access",
|
||||
"http_anonymizer", "httpd_accel", "httpd_accel_host",
|
||||
"httpd_accel_port", "httpd_accel_uses_host_header",
|
||||
"httpd_accel_with_proxy", "http_port", "http_reply_access",
|
||||
"icp_access", "icp_hit_stale", "icp_port", "icp_query_timeout",
|
||||
"ident_lookup", "ident_lookup_access", "ident_timeout",
|
||||
"incoming_http_average", "incoming_icp_average", "inside_firewall",
|
||||
"ipcache_high", "ipcache_low", "ipcache_size", "local_domain",
|
||||
"local_ip", "logfile_rotate", "log_fqdn", "log_icp_queries",
|
||||
"log_mime_hdrs", "maximum_object_size", "maximum_single_addr_tries",
|
||||
"mcast_groups", "mcast_icp_query_timeout", "mcast_miss_addr",
|
||||
"mcast_miss_encode_key", "mcast_miss_port", "memory_pools",
|
||||
"memory_pools_limit", "memory_replacement_policy", "mime_table",
|
||||
"min_http_poll_cnt", "min_icp_poll_cnt", "minimum_direct_hops",
|
||||
"minimum_object_size", "minimum_retry_timeout", "miss_access",
|
||||
"negative_dns_ttl", "negative_ttl", "neighbor_timeout",
|
||||
"neighbor_type_domain", "netdb_high", "netdb_low", "netdb_ping_period",
|
||||
"netdb_ping_rate", "never_direct", "no_cache", "passthrough_proxy",
|
||||
"pconn_timeout", "pid_filename", "pinger_program", "positive_dns_ttl",
|
||||
"prefer_direct", "proxy_auth", "proxy_auth_realm", "query_icmp",
|
||||
"quick_abort", "quick_abort_max", "quick_abort_min",
|
||||
"quick_abort_pct", "range_offset_limit", "read_timeout",
|
||||
"redirect_children", "redirect_program",
|
||||
"redirect_rewrites_host_header", "reference_age",
|
||||
"refresh_pattern", "reload_into_ims", "request_body_max_size",
|
||||
"request_size", "request_timeout", "shutdown_lifetime",
|
||||
"single_parent_bypass", "siteselect_timeout", "snmp_access",
|
||||
"snmp_incoming_address", "snmp_port", "source_ping", "ssl_proxy",
|
||||
"store_avg_object_size", "store_objects_per_bucket",
|
||||
"strip_query_terms", "swap_level1_dirs", "swap_level2_dirs",
|
||||
"tcp_incoming_address", "tcp_outgoing_address", "tcp_recv_bufsize",
|
||||
"test_reachability", "udp_hit_obj", "udp_hit_obj_size",
|
||||
"udp_incoming_address", "udp_outgoing_address", "unique_hostname",
|
||||
"unlinkd_program", "uri_whitespace", "useragent_log",
|
||||
"visible_hostname", "wais_relay", "wais_relay_host", "wais_relay_port",
|
||||
)
|
||||
|
||||
opts = (
|
||||
"proxy-only", "weight", "ttl", "no-query", "default", "round-robin",
|
||||
"multicast-responder", "on", "off", "all", "deny", "allow", "via",
|
||||
"parent", "no-digest", "heap", "lru", "realm", "children", "q1", "q2",
|
||||
"credentialsttl", "none", "disable", "offline_toggle", "diskd",
|
||||
)
|
||||
|
||||
actions = (
|
||||
"shutdown", "info", "parameter", "server_list", "client_list",
|
||||
r'squid.conf',
|
||||
)
|
||||
|
||||
actions_stats = (
|
||||
"objects", "vm_objects", "utilization", "ipcache", "fqdncache", "dns",
|
||||
"redirector", "io", "reply_headers", "filedescriptors", "netdb",
|
||||
)
|
||||
|
||||
actions_log = ("status", "enable", "disable", "clear")
|
||||
|
||||
acls = (
|
||||
"url_regex", "urlpath_regex", "referer_regex", "port", "proto",
|
||||
"req_mime_type", "rep_mime_type", "method", "browser", "user", "src",
|
||||
"dst", "time", "dstdomain", "ident", "snmp_community",
|
||||
)
|
||||
|
||||
ip_re = (
|
||||
r'(?:(?:(?:[3-9]\d?|2(?:5[0-5]|[0-4]?\d)?|1\d{0,2}|0x0*[0-9a-f]{1,2}|'
|
||||
r'0+[1-3]?[0-7]{0,2})(?:\.(?:[3-9]\d?|2(?:5[0-5]|[0-4]?\d)?|1\d{0,2}|'
|
||||
r'0x0*[0-9a-f]{1,2}|0+[1-3]?[0-7]{0,2})){3})|(?!.*::.*::)(?:(?!:)|'
|
||||
r':(?=:))(?:[0-9a-f]{0,4}(?:(?<=::)|(?<!::):)){6}(?:[0-9a-f]{0,4}'
|
||||
r'(?:(?<=::)|(?<!::):)[0-9a-f]{0,4}(?:(?<=::)|(?<!:)|(?<=:)(?<!::):)|'
|
||||
r'(?:25[0-4]|2[0-4]\d|1\d\d|[1-9]?\d)(?:\.(?:25[0-4]|2[0-4]\d|1\d\d|'
|
||||
r'[1-9]?\d)){3}))'
|
||||
)
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Whitespace),
|
||||
(r'#', Comment, 'comment'),
|
||||
(words(keywords, prefix=r'\b', suffix=r'\b'), Keyword),
|
||||
(words(opts, prefix=r'\b', suffix=r'\b'), Name.Constant),
|
||||
# Actions
|
||||
(words(actions, prefix=r'\b', suffix=r'\b'), String),
|
||||
(words(actions_stats, prefix=r'stats/', suffix=r'\b'), String),
|
||||
(words(actions_log, prefix=r'log/', suffix=r'='), String),
|
||||
(words(acls, prefix=r'\b', suffix=r'\b'), Keyword),
|
||||
(ip_re + r'(?:/(?:' + ip_re + r'|\b\d+\b))?', Number.Float),
|
||||
(r'(?:\b\d+\b(?:-\b\d+|%)?)', Number),
|
||||
(r'\S+', Text),
|
||||
],
|
||||
'comment': [
|
||||
(r'\s*TAG:.*', String.Escape, '#pop'),
|
||||
(r'.+', Comment, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class NginxConfLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Nginx <http://nginx.net/>`_ configuration files.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
name = 'Nginx configuration file'
|
||||
aliases = ['nginx']
|
||||
filenames = []
|
||||
mimetypes = ['text/x-nginx-conf']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'(include)(\s+)([^\s;]+)', bygroups(Keyword, Text, Name)),
|
||||
(r'[^\s;#]+', Keyword, 'stmt'),
|
||||
include('base'),
|
||||
],
|
||||
'block': [
|
||||
(r'\}', Punctuation, '#pop:2'),
|
||||
(r'[^\s;#]+', Keyword.Namespace, 'stmt'),
|
||||
include('base'),
|
||||
],
|
||||
'stmt': [
|
||||
(r'\{', Punctuation, 'block'),
|
||||
(r';', Punctuation, '#pop'),
|
||||
include('base'),
|
||||
],
|
||||
'base': [
|
||||
(r'#.*\n', Comment.Single),
|
||||
(r'on|off', Name.Constant),
|
||||
(r'\$[^\s;#()]+', Name.Variable),
|
||||
(r'([a-z0-9.-]+)(:)([0-9]+)',
|
||||
bygroups(Name, Punctuation, Number.Integer)),
|
||||
(r'[a-z-]+/[a-z-+]+', String), # mimetype
|
||||
# (r'[a-zA-Z._-]+', Keyword),
|
||||
(r'[0-9]+[km]?\b', Number.Integer),
|
||||
(r'(~)(\s*)([^\s{]+)', bygroups(Punctuation, Text, String.Regex)),
|
||||
(r'[:=~]', Punctuation),
|
||||
(r'[^\s;#{}$]+', String), # catch all
|
||||
(r'/[^\s;#]*', Name), # pathname
|
||||
(r'\s+', Text),
|
||||
(r'[$;]', Text), # leftover characters
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class LighttpdConfLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Lighttpd <http://lighttpd.net/>`_ configuration files.
|
||||
|
||||
.. versionadded:: 0.11
|
||||
"""
|
||||
name = 'Lighttpd configuration file'
|
||||
aliases = ['lighty', 'lighttpd']
|
||||
filenames = []
|
||||
mimetypes = ['text/x-lighttpd-conf']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'#.*\n', Comment.Single),
|
||||
(r'/\S*', Name), # pathname
|
||||
(r'[a-zA-Z._-]+', Keyword),
|
||||
(r'\d+\.\d+\.\d+\.\d+(?:/\d+)?', Number),
|
||||
(r'[0-9]+', Number),
|
||||
(r'=>|=~|\+=|==|=|\+', Operator),
|
||||
(r'\$[A-Z]+', Name.Builtin),
|
||||
(r'[(){}\[\],]', Punctuation),
|
||||
(r'"([^"\\]*(?:\\.[^"\\]*)*)"', String.Double),
|
||||
(r'\s+', Text),
|
||||
],
|
||||
|
||||
}
|
||||
|
||||
|
||||
class DockerLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Docker <http://docker.io>`_ configuration files.
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'Docker'
|
||||
aliases = ['docker', 'dockerfile']
|
||||
filenames = ['Dockerfile', '*.docker']
|
||||
mimetypes = ['text/x-dockerfile-config']
|
||||
|
||||
_keywords = (r'(?:FROM|MAINTAINER|CMD|EXPOSE|ENV|ADD|ENTRYPOINT|'
|
||||
r'VOLUME|WORKDIR)')
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^(ONBUILD)(\s+)(%s)\b' % (_keywords,),
|
||||
bygroups(Name.Keyword, Whitespace, Keyword)),
|
||||
(r'^(%s)\b(.*)' % (_keywords,), bygroups(Keyword, String)),
|
||||
(r'#.*', Comment),
|
||||
(r'RUN', Keyword), # Rest of line falls through
|
||||
(r'(.*\\\n)*.+', using(BashLexer)),
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,114 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.console
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for misc console output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups
|
||||
from pygments.token import Generic, Comment, String, Text, Keyword, Name, \
|
||||
Punctuation, Number
|
||||
|
||||
__all__ = ['VCTreeStatusLexer', 'PyPyLogLexer']
|
||||
|
||||
|
||||
class VCTreeStatusLexer(RegexLexer):
|
||||
"""
|
||||
For colorizing output of version control status commans, like "hg
|
||||
status" or "svn status".
|
||||
|
||||
.. versionadded:: 2.0
|
||||
"""
|
||||
name = 'VCTreeStatus'
|
||||
aliases = ['vctreestatus']
|
||||
filenames = []
|
||||
mimetypes = []
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^A \+ C\s+', Generic.Error),
|
||||
(r'^A\s+\+?\s+', String),
|
||||
(r'^M\s+', Generic.Inserted),
|
||||
(r'^C\s+', Generic.Error),
|
||||
(r'^D\s+', Generic.Deleted),
|
||||
(r'^[?!]\s+', Comment.Preproc),
|
||||
(r' >\s+.*\n', Comment.Preproc),
|
||||
(r'.*\n', Text)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class PyPyLogLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for PyPy log files.
|
||||
|
||||
.. versionadded:: 1.5
|
||||
"""
|
||||
name = "PyPy Log"
|
||||
aliases = ["pypylog", "pypy"]
|
||||
filenames = ["*.pypylog"]
|
||||
mimetypes = ['application/x-pypylog']
|
||||
|
||||
tokens = {
|
||||
"root": [
|
||||
(r"\[\w+\] \{jit-log-.*?$", Keyword, "jit-log"),
|
||||
(r"\[\w+\] \{jit-backend-counts$", Keyword, "jit-backend-counts"),
|
||||
include("extra-stuff"),
|
||||
],
|
||||
"jit-log": [
|
||||
(r"\[\w+\] jit-log-.*?}$", Keyword, "#pop"),
|
||||
(r"^\+\d+: ", Comment),
|
||||
(r"--end of the loop--", Comment),
|
||||
(r"[ifp]\d+", Name),
|
||||
(r"ptr\d+", Name),
|
||||
(r"(\()(\w+(?:\.\w+)?)(\))",
|
||||
bygroups(Punctuation, Name.Builtin, Punctuation)),
|
||||
(r"[\[\]=,()]", Punctuation),
|
||||
(r"(\d+\.\d+|inf|-inf)", Number.Float),
|
||||
(r"-?\d+", Number.Integer),
|
||||
(r"'.*'", String),
|
||||
(r"(None|descr|ConstClass|ConstPtr|TargetToken)", Name),
|
||||
(r"<.*?>+", Name.Builtin),
|
||||
(r"(label|debug_merge_point|jump|finish)", Name.Class),
|
||||
(r"(int_add_ovf|int_add|int_sub_ovf|int_sub|int_mul_ovf|int_mul|"
|
||||
r"int_floordiv|int_mod|int_lshift|int_rshift|int_and|int_or|"
|
||||
r"int_xor|int_eq|int_ne|int_ge|int_gt|int_le|int_lt|int_is_zero|"
|
||||
r"int_is_true|"
|
||||
r"uint_floordiv|uint_ge|uint_lt|"
|
||||
r"float_add|float_sub|float_mul|float_truediv|float_neg|"
|
||||
r"float_eq|float_ne|float_ge|float_gt|float_le|float_lt|float_abs|"
|
||||
r"ptr_eq|ptr_ne|instance_ptr_eq|instance_ptr_ne|"
|
||||
r"cast_int_to_float|cast_float_to_int|"
|
||||
r"force_token|quasiimmut_field|same_as|virtual_ref_finish|"
|
||||
r"virtual_ref|mark_opaque_ptr|"
|
||||
r"call_may_force|call_assembler|call_loopinvariant|"
|
||||
r"call_release_gil|call_pure|call|"
|
||||
r"new_with_vtable|new_array|newstr|newunicode|new|"
|
||||
r"arraylen_gc|"
|
||||
r"getarrayitem_gc_pure|getarrayitem_gc|setarrayitem_gc|"
|
||||
r"getarrayitem_raw|setarrayitem_raw|getfield_gc_pure|"
|
||||
r"getfield_gc|getinteriorfield_gc|setinteriorfield_gc|"
|
||||
r"getfield_raw|setfield_gc|setfield_raw|"
|
||||
r"strgetitem|strsetitem|strlen|copystrcontent|"
|
||||
r"unicodegetitem|unicodesetitem|unicodelen|"
|
||||
r"guard_true|guard_false|guard_value|guard_isnull|"
|
||||
r"guard_nonnull_class|guard_nonnull|guard_class|guard_no_overflow|"
|
||||
r"guard_not_forced|guard_no_exception|guard_not_invalidated)",
|
||||
Name.Builtin),
|
||||
include("extra-stuff"),
|
||||
],
|
||||
"jit-backend-counts": [
|
||||
(r"\[\w+\] jit-backend-counts}$", Keyword, "#pop"),
|
||||
(r":", Punctuation),
|
||||
(r"\d+", Number),
|
||||
include("extra-stuff"),
|
||||
],
|
||||
"extra-stuff": [
|
||||
(r"\s+", Text),
|
||||
(r"#.*?$", Comment),
|
||||
],
|
||||
}
|
||||
@ -0,0 +1,498 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.css
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for CSS and related stylesheet formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
import copy
|
||||
|
||||
from pygments.lexer import ExtendedRegexLexer, RegexLexer, include, bygroups, \
|
||||
default, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
from pygments.util import iteritems
|
||||
|
||||
__all__ = ['CssLexer', 'SassLexer', 'ScssLexer']
|
||||
|
||||
|
||||
class CssLexer(RegexLexer):
|
||||
"""
|
||||
For CSS (Cascading Style Sheets).
|
||||
"""
|
||||
|
||||
name = 'CSS'
|
||||
aliases = ['css']
|
||||
filenames = ['*.css']
|
||||
mimetypes = ['text/css']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('basics'),
|
||||
],
|
||||
'basics': [
|
||||
(r'\s+', Text),
|
||||
(r'/\*(?:.|\n)*?\*/', Comment),
|
||||
(r'\{', Punctuation, 'content'),
|
||||
(r'\:[\w-]+', Name.Decorator),
|
||||
(r'\.[\w-]+', Name.Class),
|
||||
(r'\#[\w-]+', Name.Function),
|
||||
(r'@[\w-]+', Keyword, 'atrule'),
|
||||
(r'[\w-]+', Name.Tag),
|
||||
(r'[~^*!%&$\[\]()<>|+=@:;,./?-]', Operator),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single)
|
||||
],
|
||||
'atrule': [
|
||||
(r'\{', Punctuation, 'atcontent'),
|
||||
(r';', Punctuation, '#pop'),
|
||||
include('basics'),
|
||||
],
|
||||
'atcontent': [
|
||||
include('basics'),
|
||||
(r'\}', Punctuation, '#pop:2'),
|
||||
],
|
||||
'content': [
|
||||
(r'\s+', Text),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
(r'url\(.*?\)', String.Other),
|
||||
(r'^@.*?$', Comment.Preproc),
|
||||
(words((
|
||||
'azimuth', 'background-attachment', 'background-color',
|
||||
'background-image', 'background-position', 'background-repeat',
|
||||
'background', 'border-bottom-color', 'border-bottom-style',
|
||||
'border-bottom-width', 'border-left-color', 'border-left-style',
|
||||
'border-left-width', 'border-right', 'border-right-color',
|
||||
'border-right-style', 'border-right-width', 'border-top-color',
|
||||
'border-top-style', 'border-top-width', 'border-bottom',
|
||||
'border-collapse', 'border-left', 'border-width', 'border-color',
|
||||
'border-spacing', 'border-style', 'border-top', 'border', 'caption-side',
|
||||
'clear', 'clip', 'color', 'content', 'counter-increment', 'counter-reset',
|
||||
'cue-after', 'cue-before', 'cue', 'cursor', 'direction', 'display',
|
||||
'elevation', 'empty-cells', 'float', 'font-family', 'font-size',
|
||||
'font-size-adjust', 'font-stretch', 'font-style', 'font-variant',
|
||||
'font-weight', 'font', 'height', 'letter-spacing', 'line-height',
|
||||
'list-style-type', 'list-style-image', 'list-style-position',
|
||||
'list-style', 'margin-bottom', 'margin-left', 'margin-right',
|
||||
'margin-top', 'margin', 'marker-offset', 'marks', 'max-height', 'max-width',
|
||||
'min-height', 'min-width', 'opacity', 'orphans', 'outline-color',
|
||||
'outline-style', 'outline-width', 'outline', 'overflow', 'overflow-x',
|
||||
'overflow-y', 'padding-bottom', 'padding-left', 'padding-right', 'padding-top',
|
||||
'padding', 'page', 'page-break-after', 'page-break-before', 'page-break-inside',
|
||||
'pause-after', 'pause-before', 'pause', 'pitch-range', 'pitch',
|
||||
'play-during', 'position', 'quotes', 'richness', 'right', 'size',
|
||||
'speak-header', 'speak-numeral', 'speak-punctuation', 'speak',
|
||||
'speech-rate', 'stress', 'table-layout', 'text-align', 'text-decoration',
|
||||
'text-indent', 'text-shadow', 'text-transform', 'top', 'unicode-bidi',
|
||||
'vertical-align', 'visibility', 'voice-family', 'volume', 'white-space',
|
||||
'widows', 'width', 'word-spacing', 'z-index', 'bottom',
|
||||
'above', 'absolute', 'always', 'armenian', 'aural', 'auto', 'avoid', 'baseline',
|
||||
'behind', 'below', 'bidi-override', 'blink', 'block', 'bolder', 'bold', 'both',
|
||||
'capitalize', 'center-left', 'center-right', 'center', 'circle',
|
||||
'cjk-ideographic', 'close-quote', 'collapse', 'condensed', 'continuous',
|
||||
'crop', 'crosshair', 'cross', 'cursive', 'dashed', 'decimal-leading-zero',
|
||||
'decimal', 'default', 'digits', 'disc', 'dotted', 'double', 'e-resize', 'embed',
|
||||
'extra-condensed', 'extra-expanded', 'expanded', 'fantasy', 'far-left',
|
||||
'far-right', 'faster', 'fast', 'fixed', 'georgian', 'groove', 'hebrew', 'help',
|
||||
'hidden', 'hide', 'higher', 'high', 'hiragana-iroha', 'hiragana', 'icon',
|
||||
'inherit', 'inline-table', 'inline', 'inset', 'inside', 'invert', 'italic',
|
||||
'justify', 'katakana-iroha', 'katakana', 'landscape', 'larger', 'large',
|
||||
'left-side', 'leftwards', 'left', 'level', 'lighter', 'line-through', 'list-item',
|
||||
'loud', 'lower-alpha', 'lower-greek', 'lower-roman', 'lowercase', 'ltr',
|
||||
'lower', 'low', 'medium', 'message-box', 'middle', 'mix', 'monospace',
|
||||
'n-resize', 'narrower', 'ne-resize', 'no-close-quote', 'no-open-quote',
|
||||
'no-repeat', 'none', 'normal', 'nowrap', 'nw-resize', 'oblique', 'once',
|
||||
'open-quote', 'outset', 'outside', 'overline', 'pointer', 'portrait', 'px',
|
||||
'relative', 'repeat-x', 'repeat-y', 'repeat', 'rgb', 'ridge', 'right-side',
|
||||
'rightwards', 's-resize', 'sans-serif', 'scroll', 'se-resize',
|
||||
'semi-condensed', 'semi-expanded', 'separate', 'serif', 'show', 'silent',
|
||||
'slower', 'slow', 'small-caps', 'small-caption', 'smaller', 'soft', 'solid',
|
||||
'spell-out', 'square', 'static', 'status-bar', 'super', 'sw-resize',
|
||||
'table-caption', 'table-cell', 'table-column', 'table-column-group',
|
||||
'table-footer-group', 'table-header-group', 'table-row',
|
||||
'table-row-group', 'text-bottom', 'text-top', 'text', 'thick', 'thin',
|
||||
'transparent', 'ultra-condensed', 'ultra-expanded', 'underline',
|
||||
'upper-alpha', 'upper-latin', 'upper-roman', 'uppercase', 'url',
|
||||
'visible', 'w-resize', 'wait', 'wider', 'x-fast', 'x-high', 'x-large', 'x-loud',
|
||||
'x-low', 'x-small', 'x-soft', 'xx-large', 'xx-small', 'yes'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'indigo', 'gold', 'firebrick', 'indianred', 'yellow', 'darkolivegreen',
|
||||
'darkseagreen', 'mediumvioletred', 'mediumorchid', 'chartreuse',
|
||||
'mediumslateblue', 'black', 'springgreen', 'crimson', 'lightsalmon', 'brown',
|
||||
'turquoise', 'olivedrab', 'cyan', 'silver', 'skyblue', 'gray', 'darkturquoise',
|
||||
'goldenrod', 'darkgreen', 'darkviolet', 'darkgray', 'lightpink', 'teal',
|
||||
'darkmagenta', 'lightgoldenrodyellow', 'lavender', 'yellowgreen', 'thistle',
|
||||
'violet', 'navy', 'orchid', 'blue', 'ghostwhite', 'honeydew', 'cornflowerblue',
|
||||
'darkblue', 'darkkhaki', 'mediumpurple', 'cornsilk', 'red', 'bisque', 'slategray',
|
||||
'darkcyan', 'khaki', 'wheat', 'deepskyblue', 'darkred', 'steelblue', 'aliceblue',
|
||||
'gainsboro', 'mediumturquoise', 'floralwhite', 'coral', 'purple', 'lightgrey',
|
||||
'lightcyan', 'darksalmon', 'beige', 'azure', 'lightsteelblue', 'oldlace',
|
||||
'greenyellow', 'royalblue', 'lightseagreen', 'mistyrose', 'sienna',
|
||||
'lightcoral', 'orangered', 'navajowhite', 'lime', 'palegreen', 'burlywood',
|
||||
'seashell', 'mediumspringgreen', 'fuchsia', 'papayawhip', 'blanchedalmond',
|
||||
'peru', 'aquamarine', 'white', 'darkslategray', 'ivory', 'dodgerblue',
|
||||
'lemonchiffon', 'chocolate', 'orange', 'forestgreen', 'slateblue', 'olive',
|
||||
'mintcream', 'antiquewhite', 'darkorange', 'cadetblue', 'moccasin',
|
||||
'limegreen', 'saddlebrown', 'darkslateblue', 'lightskyblue', 'deeppink',
|
||||
'plum', 'aqua', 'darkgoldenrod', 'maroon', 'sandybrown', 'magenta', 'tan',
|
||||
'rosybrown', 'pink', 'lightblue', 'palevioletred', 'mediumseagreen',
|
||||
'dimgray', 'powderblue', 'seagreen', 'snow', 'mediumblue', 'midnightblue',
|
||||
'paleturquoise', 'palegoldenrod', 'whitesmoke', 'darkorchid', 'salmon',
|
||||
'lightslategray', 'lawngreen', 'lightgreen', 'tomato', 'hotpink',
|
||||
'lightyellow', 'lavenderblush', 'linen', 'mediumaquamarine', 'green',
|
||||
'blueviolet', 'peachpuff'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'\!important', Comment.Preproc),
|
||||
(r'/\*(?:.|\n)*?\*/', Comment),
|
||||
(r'\#[a-zA-Z0-9]{1,6}', Number),
|
||||
(r'[.-]?[0-9]*[.]?[0-9]+(em|px|pt|pc|in|mm|cm|ex|s)\b', Number),
|
||||
# Separate regex for percentages, as can't do word boundaries with %
|
||||
(r'[.-]?[0-9]*[.]?[0-9]+%', Number),
|
||||
(r'-?[0-9]+', Number),
|
||||
(r'[~^*!%&<>|+=@:,./?-]+', Operator),
|
||||
(r'[\[\]();]+', Punctuation),
|
||||
(r'"(\\\\|\\"|[^"])*"', String.Double),
|
||||
(r"'(\\\\|\\'|[^'])*'", String.Single),
|
||||
(r'[a-zA-Z_]\w*', Name)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
common_sass_tokens = {
|
||||
'value': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'[!$][\w-]+', Name.Variable),
|
||||
(r'url\(', String.Other, 'string-url'),
|
||||
(r'[a-z_-][\w-]*(?=\()', Name.Function),
|
||||
(words((
|
||||
'azimuth', 'background-attachment', 'background-color',
|
||||
'background-image', 'background-position', 'background-repeat',
|
||||
'background', 'border-bottom-color', 'border-bottom-style',
|
||||
'border-bottom-width', 'border-left-color', 'border-left-style',
|
||||
'border-left-width', 'border-right', 'border-right-color',
|
||||
'border-right-style', 'border-right-width', 'border-top-color',
|
||||
'border-top-style', 'border-top-width', 'border-bottom',
|
||||
'border-collapse', 'border-left', 'border-width', 'border-color',
|
||||
'border-spacing', 'border-style', 'border-top', 'border', 'caption-side',
|
||||
'clear', 'clip', 'color', 'content', 'counter-increment', 'counter-reset',
|
||||
'cue-after', 'cue-before', 'cue', 'cursor', 'direction', 'display',
|
||||
'elevation', 'empty-cells', 'float', 'font-family', 'font-size',
|
||||
'font-size-adjust', 'font-stretch', 'font-style', 'font-variant',
|
||||
'font-weight', 'font', 'height', 'letter-spacing', 'line-height',
|
||||
'list-style-type', 'list-style-image', 'list-style-position',
|
||||
'list-style', 'margin-bottom', 'margin-left', 'margin-right',
|
||||
'margin-top', 'margin', 'marker-offset', 'marks', 'max-height', 'max-width',
|
||||
'min-height', 'min-width', 'opacity', 'orphans', 'outline', 'outline-color',
|
||||
'outline-style', 'outline-width', 'overflow', 'padding-bottom',
|
||||
'padding-left', 'padding-right', 'padding-top', 'padding', 'page',
|
||||
'page-break-after', 'page-break-before', 'page-break-inside',
|
||||
'pause-after', 'pause-before', 'pause', 'pitch', 'pitch-range',
|
||||
'play-during', 'position', 'quotes', 'richness', 'right', 'size',
|
||||
'speak-header', 'speak-numeral', 'speak-punctuation', 'speak',
|
||||
'speech-rate', 'stress', 'table-layout', 'text-align', 'text-decoration',
|
||||
'text-indent', 'text-shadow', 'text-transform', 'top', 'unicode-bidi',
|
||||
'vertical-align', 'visibility', 'voice-family', 'volume', 'white-space',
|
||||
'widows', 'width', 'word-spacing', 'z-index', 'bottom', 'left',
|
||||
'above', 'absolute', 'always', 'armenian', 'aural', 'auto', 'avoid', 'baseline',
|
||||
'behind', 'below', 'bidi-override', 'blink', 'block', 'bold', 'bolder', 'both',
|
||||
'capitalize', 'center-left', 'center-right', 'center', 'circle',
|
||||
'cjk-ideographic', 'close-quote', 'collapse', 'condensed', 'continuous',
|
||||
'crop', 'crosshair', 'cross', 'cursive', 'dashed', 'decimal-leading-zero',
|
||||
'decimal', 'default', 'digits', 'disc', 'dotted', 'double', 'e-resize', 'embed',
|
||||
'extra-condensed', 'extra-expanded', 'expanded', 'fantasy', 'far-left',
|
||||
'far-right', 'faster', 'fast', 'fixed', 'georgian', 'groove', 'hebrew', 'help',
|
||||
'hidden', 'hide', 'higher', 'high', 'hiragana-iroha', 'hiragana', 'icon',
|
||||
'inherit', 'inline-table', 'inline', 'inset', 'inside', 'invert', 'italic',
|
||||
'justify', 'katakana-iroha', 'katakana', 'landscape', 'larger', 'large',
|
||||
'left-side', 'leftwards', 'level', 'lighter', 'line-through', 'list-item',
|
||||
'loud', 'lower-alpha', 'lower-greek', 'lower-roman', 'lowercase', 'ltr',
|
||||
'lower', 'low', 'medium', 'message-box', 'middle', 'mix', 'monospace',
|
||||
'n-resize', 'narrower', 'ne-resize', 'no-close-quote', 'no-open-quote',
|
||||
'no-repeat', 'none', 'normal', 'nowrap', 'nw-resize', 'oblique', 'once',
|
||||
'open-quote', 'outset', 'outside', 'overline', 'pointer', 'portrait', 'px',
|
||||
'relative', 'repeat-x', 'repeat-y', 'repeat', 'rgb', 'ridge', 'right-side',
|
||||
'rightwards', 's-resize', 'sans-serif', 'scroll', 'se-resize',
|
||||
'semi-condensed', 'semi-expanded', 'separate', 'serif', 'show', 'silent',
|
||||
'slow', 'slower', 'small-caps', 'small-caption', 'smaller', 'soft', 'solid',
|
||||
'spell-out', 'square', 'static', 'status-bar', 'super', 'sw-resize',
|
||||
'table-caption', 'table-cell', 'table-column', 'table-column-group',
|
||||
'table-footer-group', 'table-header-group', 'table-row',
|
||||
'table-row-group', 'text', 'text-bottom', 'text-top', 'thick', 'thin',
|
||||
'transparent', 'ultra-condensed', 'ultra-expanded', 'underline',
|
||||
'upper-alpha', 'upper-latin', 'upper-roman', 'uppercase', 'url',
|
||||
'visible', 'w-resize', 'wait', 'wider', 'x-fast', 'x-high', 'x-large', 'x-loud',
|
||||
'x-low', 'x-small', 'x-soft', 'xx-large', 'xx-small', 'yes'), suffix=r'\b'),
|
||||
Name.Constant),
|
||||
(words((
|
||||
'indigo', 'gold', 'firebrick', 'indianred', 'darkolivegreen',
|
||||
'darkseagreen', 'mediumvioletred', 'mediumorchid', 'chartreuse',
|
||||
'mediumslateblue', 'springgreen', 'crimson', 'lightsalmon', 'brown',
|
||||
'turquoise', 'olivedrab', 'cyan', 'skyblue', 'darkturquoise',
|
||||
'goldenrod', 'darkgreen', 'darkviolet', 'darkgray', 'lightpink',
|
||||
'darkmagenta', 'lightgoldenrodyellow', 'lavender', 'yellowgreen', 'thistle',
|
||||
'violet', 'orchid', 'ghostwhite', 'honeydew', 'cornflowerblue',
|
||||
'darkblue', 'darkkhaki', 'mediumpurple', 'cornsilk', 'bisque', 'slategray',
|
||||
'darkcyan', 'khaki', 'wheat', 'deepskyblue', 'darkred', 'steelblue', 'aliceblue',
|
||||
'gainsboro', 'mediumturquoise', 'floralwhite', 'coral', 'lightgrey',
|
||||
'lightcyan', 'darksalmon', 'beige', 'azure', 'lightsteelblue', 'oldlace',
|
||||
'greenyellow', 'royalblue', 'lightseagreen', 'mistyrose', 'sienna',
|
||||
'lightcoral', 'orangered', 'navajowhite', 'palegreen', 'burlywood',
|
||||
'seashell', 'mediumspringgreen', 'papayawhip', 'blanchedalmond',
|
||||
'peru', 'aquamarine', 'darkslategray', 'ivory', 'dodgerblue',
|
||||
'lemonchiffon', 'chocolate', 'orange', 'forestgreen', 'slateblue',
|
||||
'mintcream', 'antiquewhite', 'darkorange', 'cadetblue', 'moccasin',
|
||||
'limegreen', 'saddlebrown', 'darkslateblue', 'lightskyblue', 'deeppink',
|
||||
'plum', 'darkgoldenrod', 'sandybrown', 'magenta', 'tan',
|
||||
'rosybrown', 'pink', 'lightblue', 'palevioletred', 'mediumseagreen',
|
||||
'dimgray', 'powderblue', 'seagreen', 'snow', 'mediumblue', 'midnightblue',
|
||||
'paleturquoise', 'palegoldenrod', 'whitesmoke', 'darkorchid', 'salmon',
|
||||
'lightslategray', 'lawngreen', 'lightgreen', 'tomato', 'hotpink',
|
||||
'lightyellow', 'lavenderblush', 'linen', 'mediumaquamarine',
|
||||
'blueviolet', 'peachpuff'), suffix=r'\b'),
|
||||
Name.Entity),
|
||||
(words((
|
||||
'black', 'silver', 'gray', 'white', 'maroon', 'red', 'purple', 'fuchsia', 'green',
|
||||
'lime', 'olive', 'yellow', 'navy', 'blue', 'teal', 'aqua'), suffix=r'\b'),
|
||||
Name.Builtin),
|
||||
(r'\!(important|default)', Name.Exception),
|
||||
(r'(true|false)', Name.Pseudo),
|
||||
(r'(and|or|not)', Operator.Word),
|
||||
(r'/\*', Comment.Multiline, 'inline-comment'),
|
||||
(r'//[^\n]*', Comment.Single),
|
||||
(r'\#[a-z0-9]{1,6}', Number.Hex),
|
||||
(r'(-?\d+)(\%|[a-z]+)?', bygroups(Number.Integer, Keyword.Type)),
|
||||
(r'(-?\d*\.\d+)(\%|[a-z]+)?', bygroups(Number.Float, Keyword.Type)),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[~^*!&%<>|+=@:,./?-]+', Operator),
|
||||
(r'[\[\]()]+', Punctuation),
|
||||
(r'"', String.Double, 'string-double'),
|
||||
(r"'", String.Single, 'string-single'),
|
||||
(r'[a-z_-][\w-]*', Name),
|
||||
],
|
||||
|
||||
'interpolation': [
|
||||
(r'\}', String.Interpol, '#pop'),
|
||||
include('value'),
|
||||
],
|
||||
|
||||
'selector': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\:', Name.Decorator, 'pseudo-class'),
|
||||
(r'\.', Name.Class, 'class'),
|
||||
(r'\#', Name.Namespace, 'id'),
|
||||
(r'[\w-]+', Name.Tag),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'&', Keyword),
|
||||
(r'[~^*!&\[\]()<>|+=@:;,./?-]', Operator),
|
||||
(r'"', String.Double, 'string-double'),
|
||||
(r"'", String.Single, 'string-single'),
|
||||
],
|
||||
|
||||
'string-double': [
|
||||
(r'(\\.|#(?=[^\n{])|[^\n"#])+', String.Double),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'"', String.Double, '#pop'),
|
||||
],
|
||||
|
||||
'string-single': [
|
||||
(r"(\\.|#(?=[^\n{])|[^\n'#])+", String.Double),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r"'", String.Double, '#pop'),
|
||||
],
|
||||
|
||||
'string-url': [
|
||||
(r'(\\#|#(?=[^\n{])|[^\n#)])+', String.Other),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'\)', String.Other, '#pop'),
|
||||
],
|
||||
|
||||
'pseudo-class': [
|
||||
(r'[\w-]+', Name.Decorator),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'class': [
|
||||
(r'[\w-]+', Name.Class),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'id': [
|
||||
(r'[\w-]+', Name.Namespace),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'for': [
|
||||
(r'(from|to|through)', Operator.Word),
|
||||
include('value'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
def _indentation(lexer, match, ctx):
|
||||
indentation = match.group(0)
|
||||
yield match.start(), Text, indentation
|
||||
ctx.last_indentation = indentation
|
||||
ctx.pos = match.end()
|
||||
|
||||
if hasattr(ctx, 'block_state') and ctx.block_state and \
|
||||
indentation.startswith(ctx.block_indentation) and \
|
||||
indentation != ctx.block_indentation:
|
||||
ctx.stack.append(ctx.block_state)
|
||||
else:
|
||||
ctx.block_state = None
|
||||
ctx.block_indentation = None
|
||||
ctx.stack.append('content')
|
||||
|
||||
|
||||
def _starts_block(token, state):
|
||||
def callback(lexer, match, ctx):
|
||||
yield match.start(), token, match.group(0)
|
||||
|
||||
if hasattr(ctx, 'last_indentation'):
|
||||
ctx.block_indentation = ctx.last_indentation
|
||||
else:
|
||||
ctx.block_indentation = ''
|
||||
|
||||
ctx.block_state = state
|
||||
ctx.pos = match.end()
|
||||
|
||||
return callback
|
||||
|
||||
|
||||
class SassLexer(ExtendedRegexLexer):
|
||||
"""
|
||||
For Sass stylesheets.
|
||||
|
||||
.. versionadded:: 1.3
|
||||
"""
|
||||
|
||||
name = 'Sass'
|
||||
aliases = ['sass']
|
||||
filenames = ['*.sass']
|
||||
mimetypes = ['text/x-sass']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[ \t]*\n', Text),
|
||||
(r'[ \t]*', _indentation),
|
||||
],
|
||||
|
||||
'content': [
|
||||
(r'//[^\n]*', _starts_block(Comment.Single, 'single-comment'),
|
||||
'root'),
|
||||
(r'/\*[^\n]*', _starts_block(Comment.Multiline, 'multi-comment'),
|
||||
'root'),
|
||||
(r'@import', Keyword, 'import'),
|
||||
(r'@for', Keyword, 'for'),
|
||||
(r'@(debug|warn|if|while)', Keyword, 'value'),
|
||||
(r'(@mixin)( [\w-]+)', bygroups(Keyword, Name.Function), 'value'),
|
||||
(r'(@include)( [\w-]+)', bygroups(Keyword, Name.Decorator), 'value'),
|
||||
(r'@extend', Keyword, 'selector'),
|
||||
(r'@[\w-]+', Keyword, 'selector'),
|
||||
(r'=[\w-]+', Name.Function, 'value'),
|
||||
(r'\+[\w-]+', Name.Decorator, 'value'),
|
||||
(r'([!$][\w-]\w*)([ \t]*(?:(?:\|\|)?=|:))',
|
||||
bygroups(Name.Variable, Operator), 'value'),
|
||||
(r':', Name.Attribute, 'old-style-attr'),
|
||||
(r'(?=.+?[=:]([^a-z]|$))', Name.Attribute, 'new-style-attr'),
|
||||
default('selector'),
|
||||
],
|
||||
|
||||
'single-comment': [
|
||||
(r'.+', Comment.Single),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'multi-comment': [
|
||||
(r'.+', Comment.Multiline),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'import': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\S+', String),
|
||||
(r'\n', Text, 'root'),
|
||||
],
|
||||
|
||||
'old-style-attr': [
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*=', Operator, 'value'),
|
||||
default('value'),
|
||||
],
|
||||
|
||||
'new-style-attr': [
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*[=:]', Operator, 'value'),
|
||||
],
|
||||
|
||||
'inline-comment': [
|
||||
(r"(\\#|#(?=[^\n{])|\*(?=[^\n/])|[^\n#*])+", Comment.Multiline),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r"\*/", Comment, '#pop'),
|
||||
],
|
||||
}
|
||||
for group, common in iteritems(common_sass_tokens):
|
||||
tokens[group] = copy.copy(common)
|
||||
tokens['value'].append((r'\n', Text, 'root'))
|
||||
tokens['selector'].append((r'\n', Text, 'root'))
|
||||
|
||||
|
||||
class ScssLexer(RegexLexer):
|
||||
"""
|
||||
For SCSS stylesheets.
|
||||
"""
|
||||
|
||||
name = 'SCSS'
|
||||
aliases = ['scss']
|
||||
filenames = ['*.scss']
|
||||
mimetypes = ['text/x-scss']
|
||||
|
||||
flags = re.IGNORECASE | re.DOTALL
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\s+', Text),
|
||||
(r'//.*?\n', Comment.Single),
|
||||
(r'/\*.*?\*/', Comment.Multiline),
|
||||
(r'@import', Keyword, 'value'),
|
||||
(r'@for', Keyword, 'for'),
|
||||
(r'@(debug|warn|if|while)', Keyword, 'value'),
|
||||
(r'(@mixin)( [\w-]+)', bygroups(Keyword, Name.Function), 'value'),
|
||||
(r'(@include)( [\w-]+)', bygroups(Keyword, Name.Decorator), 'value'),
|
||||
(r'@extend', Keyword, 'selector'),
|
||||
(r'(@media)(\s+)', bygroups(Keyword, Text), 'value'),
|
||||
(r'@[\w-]+', Keyword, 'selector'),
|
||||
(r'(\$[\w-]*\w)([ \t]*:)', bygroups(Name.Variable, Operator), 'value'),
|
||||
(r'(?=[^;{}][;}])', Name.Attribute, 'attr'),
|
||||
(r'(?=[^;{}:]+:[^a-z])', Name.Attribute, 'attr'),
|
||||
default('selector'),
|
||||
],
|
||||
|
||||
'attr': [
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*:', Operator, 'value'),
|
||||
],
|
||||
|
||||
'inline-comment': [
|
||||
(r"(\\#|#(?=[^{])|\*(?=[^/])|[^#*])+", Comment.Multiline),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r"\*/", Comment, '#pop'),
|
||||
],
|
||||
}
|
||||
for group, common in iteritems(common_sass_tokens):
|
||||
tokens[group] = copy.copy(common)
|
||||
tokens['value'].extend([(r'\n', Text), (r'[;{}]', Punctuation, '#pop')])
|
||||
tokens['selector'].extend([(r'\n', Text), (r'[;{}]', Punctuation, '#pop')])
|
||||
@ -0,0 +1,251 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.d
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for D languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words
|
||||
from pygments.token import Text, Comment, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['DLexer', 'CrocLexer', 'MiniDLexer']
|
||||
|
||||
|
||||
class DLexer(RegexLexer):
|
||||
"""
|
||||
For D source.
|
||||
|
||||
.. versionadded:: 1.2
|
||||
"""
|
||||
name = 'D'
|
||||
filenames = ['*.d', '*.di']
|
||||
aliases = ['d']
|
||||
mimetypes = ['text/x-dsrc']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
# (r'\\\n', Text), # line continuations
|
||||
# Comments
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/(\\\n)?[*](.|\n)*?[*](\\\n)?/', Comment.Multiline),
|
||||
(r'/\+', Comment.Multiline, 'nested_comment'),
|
||||
# Keywords
|
||||
(words((
|
||||
'abstract', 'alias', 'align', 'asm', 'assert', 'auto', 'body',
|
||||
'break', 'case', 'cast', 'catch', 'class', 'const', 'continue',
|
||||
'debug', 'default', 'delegate', 'delete', 'deprecated', 'do', 'else',
|
||||
'enum', 'export', 'extern', 'finally', 'final', 'foreach_reverse',
|
||||
'foreach', 'for', 'function', 'goto', 'if', 'immutable', 'import',
|
||||
'interface', 'invariant', 'inout', 'in', 'is', 'lazy', 'mixin',
|
||||
'module', 'new', 'nothrow', 'out', 'override', 'package', 'pragma',
|
||||
'private', 'protected', 'public', 'pure', 'ref', 'return', 'scope',
|
||||
'shared', 'static', 'struct', 'super', 'switch', 'synchronized',
|
||||
'template', 'this', 'throw', 'try', 'typedef', 'typeid', 'typeof',
|
||||
'union', 'unittest', 'version', 'volatile', 'while', 'with',
|
||||
'__gshared', '__traits', '__vector', '__parameters'),
|
||||
suffix=r'\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'bool', 'byte', 'cdouble', 'cent', 'cfloat', 'char', 'creal',
|
||||
'dchar', 'double', 'float', 'idouble', 'ifloat', 'int', 'ireal',
|
||||
'long', 'real', 'short', 'ubyte', 'ucent', 'uint', 'ulong',
|
||||
'ushort', 'void', 'wchar'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(r'(false|true|null)\b', Keyword.Constant),
|
||||
(words((
|
||||
'__FILE__', '__MODULE__', '__LINE__', '__FUNCTION__', '__PRETTY_FUNCTION__'
|
||||
'', '__DATE__', '__EOF__', '__TIME__', '__TIMESTAMP__', '__VENDOR__',
|
||||
'__VERSION__'), suffix=r'\b'),
|
||||
Keyword.Pseudo),
|
||||
(r'macro\b', Keyword.Reserved),
|
||||
(r'(string|wstring|dstring|size_t|ptrdiff_t)\b', Name.Builtin),
|
||||
# FloatLiteral
|
||||
# -- HexFloat
|
||||
(r'0[xX]([0-9a-fA-F_]*\.[0-9a-fA-F_]+|[0-9a-fA-F_]+)'
|
||||
r'[pP][+\-]?[0-9_]+[fFL]?[i]?', Number.Float),
|
||||
# -- DecimalFloat
|
||||
(r'[0-9_]+(\.[0-9_]+[eE][+\-]?[0-9_]+|'
|
||||
r'\.[0-9_]*|[eE][+\-]?[0-9_]+)[fFL]?[i]?', Number.Float),
|
||||
(r'\.(0|[1-9][0-9_]*)([eE][+\-]?[0-9_]+)?[fFL]?[i]?', Number.Float),
|
||||
# IntegerLiteral
|
||||
# -- Binary
|
||||
(r'0[Bb][01_]+', Number.Bin),
|
||||
# -- Octal
|
||||
(r'0[0-7_]+', Number.Oct),
|
||||
# -- Hexadecimal
|
||||
(r'0[xX][0-9a-fA-F_]+', Number.Hex),
|
||||
# -- Decimal
|
||||
(r'(0|[1-9][0-9_]*)([LUu]|Lu|LU|uL|UL)?', Number.Integer),
|
||||
# CharacterLiteral
|
||||
(r"""'(\\['"?\\abfnrtv]|\\x[0-9a-fA-F]{2}|\\[0-7]{1,3}"""
|
||||
r"""|\\u[0-9a-fA-F]{4}|\\U[0-9a-fA-F]{8}|\\&\w+;|.)'""",
|
||||
String.Char),
|
||||
# StringLiteral
|
||||
# -- WysiwygString
|
||||
(r'r"[^"]*"[cwd]?', String),
|
||||
# -- AlternateWysiwygString
|
||||
(r'`[^`]*`[cwd]?', String),
|
||||
# -- DoubleQuotedString
|
||||
(r'"(\\\\|\\"|[^"])*"[cwd]?', String),
|
||||
# -- EscapeSequence
|
||||
(r"\\(['\"?\\abfnrtv]|x[0-9a-fA-F]{2}|[0-7]{1,3}"
|
||||
r"|u[0-9a-fA-F]{4}|U[0-9a-fA-F]{8}|&\w+;)",
|
||||
String),
|
||||
# -- HexString
|
||||
(r'x"[0-9a-fA-F_\s]*"[cwd]?', String),
|
||||
# -- DelimitedString
|
||||
(r'q"\[', String, 'delimited_bracket'),
|
||||
(r'q"\(', String, 'delimited_parenthesis'),
|
||||
(r'q"<', String, 'delimited_angle'),
|
||||
(r'q"\{', String, 'delimited_curly'),
|
||||
(r'q"([a-zA-Z_]\w*)\n.*?\n\1"', String),
|
||||
(r'q"(.).*?\1"', String),
|
||||
# -- TokenString
|
||||
(r'q\{', String, 'token_string'),
|
||||
# Attributes
|
||||
(r'@([a-zA-Z_]\w*)?', Name.Decorator),
|
||||
# Tokens
|
||||
(r'(~=|\^=|%=|\*=|==|!>=|!<=|!<>=|!<>|!<|!>|!=|>>>=|>>>|>>=|>>|>='
|
||||
r'|<>=|<>|<<=|<<|<=|\+\+|\+=|--|-=|\|\||\|=|&&|&=|\.\.\.|\.\.|/=)'
|
||||
r'|[/.&|\-+<>!()\[\]{}?,;:$=*%^~]', Punctuation),
|
||||
# Identifier
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
# Line
|
||||
(r'#line\s.*\n', Comment.Special),
|
||||
],
|
||||
'nested_comment': [
|
||||
(r'[^+/]+', Comment.Multiline),
|
||||
(r'/\+', Comment.Multiline, '#push'),
|
||||
(r'\+/', Comment.Multiline, '#pop'),
|
||||
(r'[+/]', Comment.Multiline),
|
||||
],
|
||||
'token_string': [
|
||||
(r'\{', Punctuation, 'token_string_nest'),
|
||||
(r'\}', String, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'token_string_nest': [
|
||||
(r'\{', Punctuation, '#push'),
|
||||
(r'\}', Punctuation, '#pop'),
|
||||
include('root'),
|
||||
],
|
||||
'delimited_bracket': [
|
||||
(r'[^\[\]]+', String),
|
||||
(r'\[', String, 'delimited_inside_bracket'),
|
||||
(r'\]"', String, '#pop'),
|
||||
],
|
||||
'delimited_inside_bracket': [
|
||||
(r'[^\[\]]+', String),
|
||||
(r'\[', String, '#push'),
|
||||
(r'\]', String, '#pop'),
|
||||
],
|
||||
'delimited_parenthesis': [
|
||||
(r'[^()]+', String),
|
||||
(r'\(', String, 'delimited_inside_parenthesis'),
|
||||
(r'\)"', String, '#pop'),
|
||||
],
|
||||
'delimited_inside_parenthesis': [
|
||||
(r'[^()]+', String),
|
||||
(r'\(', String, '#push'),
|
||||
(r'\)', String, '#pop'),
|
||||
],
|
||||
'delimited_angle': [
|
||||
(r'[^<>]+', String),
|
||||
(r'<', String, 'delimited_inside_angle'),
|
||||
(r'>"', String, '#pop'),
|
||||
],
|
||||
'delimited_inside_angle': [
|
||||
(r'[^<>]+', String),
|
||||
(r'<', String, '#push'),
|
||||
(r'>', String, '#pop'),
|
||||
],
|
||||
'delimited_curly': [
|
||||
(r'[^{}]+', String),
|
||||
(r'\{', String, 'delimited_inside_curly'),
|
||||
(r'\}"', String, '#pop'),
|
||||
],
|
||||
'delimited_inside_curly': [
|
||||
(r'[^{}]+', String),
|
||||
(r'\{', String, '#push'),
|
||||
(r'\}', String, '#pop'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CrocLexer(RegexLexer):
|
||||
"""
|
||||
For `Croc <http://jfbillingsley.com/croc>`_ source.
|
||||
"""
|
||||
name = 'Croc'
|
||||
filenames = ['*.croc']
|
||||
aliases = ['croc']
|
||||
mimetypes = ['text/x-crocsrc']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
# Comments
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/\*', Comment.Multiline, 'nestedcomment'),
|
||||
# Keywords
|
||||
(words((
|
||||
'as', 'assert', 'break', 'case', 'catch', 'class', 'continue',
|
||||
'default', 'do', 'else', 'finally', 'for', 'foreach', 'function',
|
||||
'global', 'namespace', 'if', 'import', 'in', 'is', 'local',
|
||||
'module', 'return', 'scope', 'super', 'switch', 'this', 'throw',
|
||||
'try', 'vararg', 'while', 'with', 'yield'), suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(false|true|null)\b', Keyword.Constant),
|
||||
# FloatLiteral
|
||||
(r'([0-9][0-9_]*)(?=[.eE])(\.[0-9][0-9_]*)?([eE][+\-]?[0-9_]+)?',
|
||||
Number.Float),
|
||||
# IntegerLiteral
|
||||
# -- Binary
|
||||
(r'0[bB][01][01_]*', Number.Bin),
|
||||
# -- Hexadecimal
|
||||
(r'0[xX][0-9a-fA-F][0-9a-fA-F_]*', Number.Hex),
|
||||
# -- Decimal
|
||||
(r'([0-9][0-9_]*)(?![.eE])', Number.Integer),
|
||||
# CharacterLiteral
|
||||
(r"""'(\\['"\\nrt]|\\x[0-9a-fA-F]{2}|\\[0-9]{1,3}"""
|
||||
r"""|\\u[0-9a-fA-F]{4}|\\U[0-9a-fA-F]{8}|.)'""",
|
||||
String.Char),
|
||||
# StringLiteral
|
||||
# -- WysiwygString
|
||||
(r'@"(""|[^"])*"', String),
|
||||
(r'@`(``|[^`])*`', String),
|
||||
(r"@'(''|[^'])*'", String),
|
||||
# -- DoubleQuotedString
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
# Tokens
|
||||
(r'(~=|\^=|%=|\*=|==|!=|>>>=|>>>|>>=|>>|>=|<=>|\?=|-\>'
|
||||
r'|<<=|<<|<=|\+\+|\+=|--|-=|\|\||\|=|&&|&=|\.\.|/=)'
|
||||
r'|[-/.&$@|\+<>!()\[\]{}?,;:=*%^~#\\]', Punctuation),
|
||||
# Identifier
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'nestedcomment': [
|
||||
(r'[^*/]+', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class MiniDLexer(CrocLexer):
|
||||
"""
|
||||
For MiniD source. MiniD is now known as Croc.
|
||||
"""
|
||||
name = 'MiniD'
|
||||
filenames = [] # don't lex .md as MiniD, reserve for Markdown
|
||||
aliases = ['minid']
|
||||
mimetypes = ['text/x-minidsrc']
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user