mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
74 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| c90a4863e9 | |||
| 94343e5b07 | |||
| 03acea6e25 | |||
| 77594700bd | |||
| 6681409e98 | |||
| 8f7837269a | |||
| a523b3aa4d | |||
| 6985ce32bb | |||
| 4be40c7720 | |||
| eeb7fd8219 | |||
| 11fbd2d2a6 | |||
| 3cecd0de5d | |||
| c50100e675 | |||
| c1da94bc18 | |||
| 7f9d6ede9d | |||
| 192a5c7aa7 | |||
| 16bbe21be9 | |||
| 5ebaf12a99 | |||
| 1834e8978a | |||
| 22c8ed74bd | |||
| 12bbb4e561 | |||
| c71cb21cc1 | |||
| eb11b991f0 | |||
| 7ea51d09ba | |||
| b07b59e0c8 | |||
| 9d715e95b7 | |||
| 3edaed53aa | |||
| 865b0bcee9 | |||
| d440fe912c | |||
| 627455167f | |||
| aba89d3948 | |||
| 18d87118e1 | |||
| fd91b9e032 | |||
| 16b15773bf | |||
| f0b518862a | |||
| 7ee7de70d5 | |||
| fb479f8e84 | |||
| 7d37193f65 | |||
| 6bd62b95db | |||
| abf4a94a59 | |||
| 9337e3173b | |||
| 57fa4d4d84 | |||
| 9b5c59e677 | |||
| 71ce25a326 | |||
| f2f14207f5 | |||
| ac2ec0e73c | |||
| 040a76b93c | |||
| dab0621b97 | |||
| 675f9ecd69 | |||
| a6f92b9c74 | |||
| bfcc242d7e | |||
| 762027644f | |||
| 3c4ceb95fa | |||
| d6d8bceca0 | |||
| acaad2dc83 | |||
| 23c5801080 | |||
| 05a3bfbb53 | |||
| 8faaa3b0e3 | |||
| 4bcddf2a98 | |||
| b51ae5c2c4 | |||
| 5cd0061653 | |||
| 651c84325e | |||
| 89368529cb | |||
| f1f408284b | |||
| 7053932731 | |||
| b6c4956521 | |||
| 68a2557884 | |||
| c7ee7258fb | |||
| aaff2503fb | |||
| 00a1193bd3 | |||
| 2371daac1b | |||
| 4395db2b2d | |||
| fc8c61fa3f | |||
| aa30110343 |
200
HISTORY.rst
200
HISTORY.rst
@ -3,6 +3,206 @@ History
|
||||
-------
|
||||
|
||||
|
||||
5.0.1 (2015-10-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- look for python in system PATH again
|
||||
|
||||
|
||||
5.0.0 (2015-10-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- improve logging with levels and log function
|
||||
- switch registry warnings to debug log level
|
||||
|
||||
|
||||
4.0.20 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly find python binary in non-Windows environments
|
||||
|
||||
|
||||
4.0.19 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- handle case where ST builtin python does not have _winreg or winreg module
|
||||
|
||||
|
||||
4.0.18 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- find python location from windows registry
|
||||
|
||||
|
||||
4.0.17 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- download python in non blocking background thread for Windows machines
|
||||
|
||||
|
||||
4.0.16 (2015-09-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.8
|
||||
- fix bug in guess_language function
|
||||
- improve dependency detection
|
||||
- default request timeout of 30 seconds
|
||||
- new --timeout command line argument to change request timeout in seconds
|
||||
- allow passing command line arguments using sys.argv
|
||||
- fix entry point for pypi distribution
|
||||
- new --entity and --entitytype command line arguments
|
||||
|
||||
|
||||
4.0.15 (2015-08-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.3
|
||||
- fix local session caching
|
||||
|
||||
|
||||
4.0.14 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.2
|
||||
- fix bug in offline caching which prevented heartbeats from being cleaned up
|
||||
|
||||
|
||||
4.0.13 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.1
|
||||
- send hostname in X-Machine-Name header
|
||||
- catch exceptions from pygments.modeline.get_filetype_from_buffer
|
||||
- upgrade requests package to v2.7.0
|
||||
- handle non-ASCII characters in import path on Windows, won't fix for Python2
|
||||
- upgrade argparse to v1.3.0
|
||||
- move language translations to api server
|
||||
- move extension rules to api server
|
||||
- detect correct header file language based on presence of .cpp or .c files named the same as the .h file
|
||||
|
||||
|
||||
4.0.12 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly use urllib in Python3
|
||||
|
||||
|
||||
4.0.11 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- install python if missing on Windows OS
|
||||
|
||||
|
||||
4.0.10 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- downgrade requests library to v2.6.0
|
||||
|
||||
|
||||
4.0.9 (2015-07-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- catch exceptions from pygments.modeline.get_filetype_from_buffer
|
||||
|
||||
|
||||
4.0.8 (2015-06-23)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix offline logging
|
||||
- limit language detection to known file extensions, unless file contents has a vim modeline
|
||||
- upgrade wakatime cli to v4.0.16
|
||||
|
||||
|
||||
4.0.7 (2015-06-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- allow customizing status bar message in sublime-settings file
|
||||
- guess language using multiple methods, then use most accurate guess
|
||||
- use entity and type for new heartbeats api resource schema
|
||||
- correctly log message from py.warnings module
|
||||
- upgrade wakatime cli to v4.0.15
|
||||
|
||||
|
||||
4.0.6 (2015-05-16)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix bug with auto detecting project name
|
||||
- upgrade wakatime cli to v4.0.13
|
||||
|
||||
|
||||
4.0.5 (2015-05-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly display caller and lineno in log file when debug is true
|
||||
- project passed with --project argument will always be used
|
||||
- new --alternate-project argument
|
||||
- upgrade wakatime cli to v4.0.12
|
||||
|
||||
|
||||
4.0.4 (2015-05-12)
|
||||
++++++++++++++++++
|
||||
|
||||
- reuse SSL connection over multiple processes for improved performance
|
||||
- upgrade wakatime cli to v4.0.11
|
||||
|
||||
|
||||
4.0.3 (2015-05-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- send cursorpos to wakatime cli
|
||||
- upgrade wakatime cli to v4.0.10
|
||||
|
||||
|
||||
4.0.2 (2015-05-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- only send heartbeats for the currently active buffer
|
||||
|
||||
|
||||
4.0.1 (2015-05-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- ignore git temporary files
|
||||
- don't send two write heartbeats within 2 seconds of eachother
|
||||
|
||||
|
||||
4.0.0 (2015-04-12)
|
||||
++++++++++++++++++
|
||||
|
||||
- listen for selection modified instead of buffer activated for better performance
|
||||
|
||||
|
||||
3.0.19 (2015-04-07)
|
||||
+++++++++++++++++++
|
||||
|
||||
- fix bug in project detection when folder not found
|
||||
|
||||
|
||||
3.0.18 (2015-04-04)
|
||||
+++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.0.8
|
||||
- added api_url config option to .wakatime.cfg file
|
||||
|
||||
|
||||
3.0.17 (2015-04-02)
|
||||
+++++++++++++++++++
|
||||
|
||||
- use open folder as current project when not using revision control
|
||||
|
||||
|
||||
3.0.16 (2015-04-02)
|
||||
+++++++++++++++++++
|
||||
|
||||
- copy list when obfuscating api key so original command is not modified
|
||||
|
||||
|
||||
3.0.15 (2015-04-01)
|
||||
+++++++++++++++++++
|
||||
|
||||
- obfuscate api key when logging to Sublime Text Console in debug mode
|
||||
|
||||
|
||||
3.0.14 (2015-03-31)
|
||||
+++++++++++++++++++
|
||||
|
||||
|
||||
16
README.md
16
README.md
@ -1,7 +1,7 @@
|
||||
sublime-wakatime
|
||||
================
|
||||
|
||||
Fully automatic time tracking for Sublime Text 2 & 3.
|
||||
Sublime Text 2 & 3 plugin to quantify your coding using https://wakatime.com/.
|
||||
|
||||
Installation
|
||||
------------
|
||||
@ -18,7 +18,7 @@ Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](ht
|
||||
|
||||
c) Type `wakatime`, then press `enter` with the `WakaTime` plugin selected.
|
||||
|
||||
3. Enter your [api key](https://wakatime.com/settings#apikey) from https://wakatime.com/settings#apikey, then press `enter`.
|
||||
3. Enter your [api key](https://wakatime.com/settings#apikey), then press `enter`.
|
||||
|
||||
4. Use Sublime and your time will be tracked for you automatically.
|
||||
|
||||
@ -29,3 +29,15 @@ Screen Shots
|
||||
|
||||
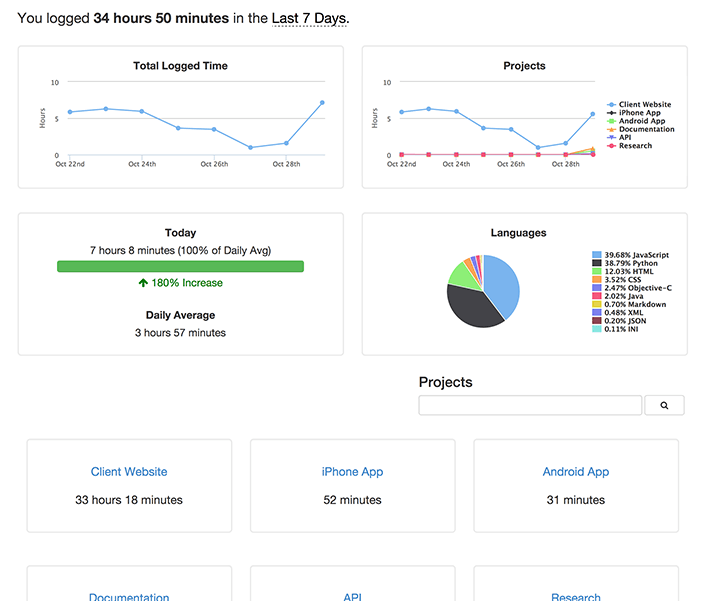
|
||||
|
||||
Troubleshooting
|
||||
---------------
|
||||
|
||||
First, turn on debug mode in your `WakaTime.sublime-settings` file.
|
||||
|
||||
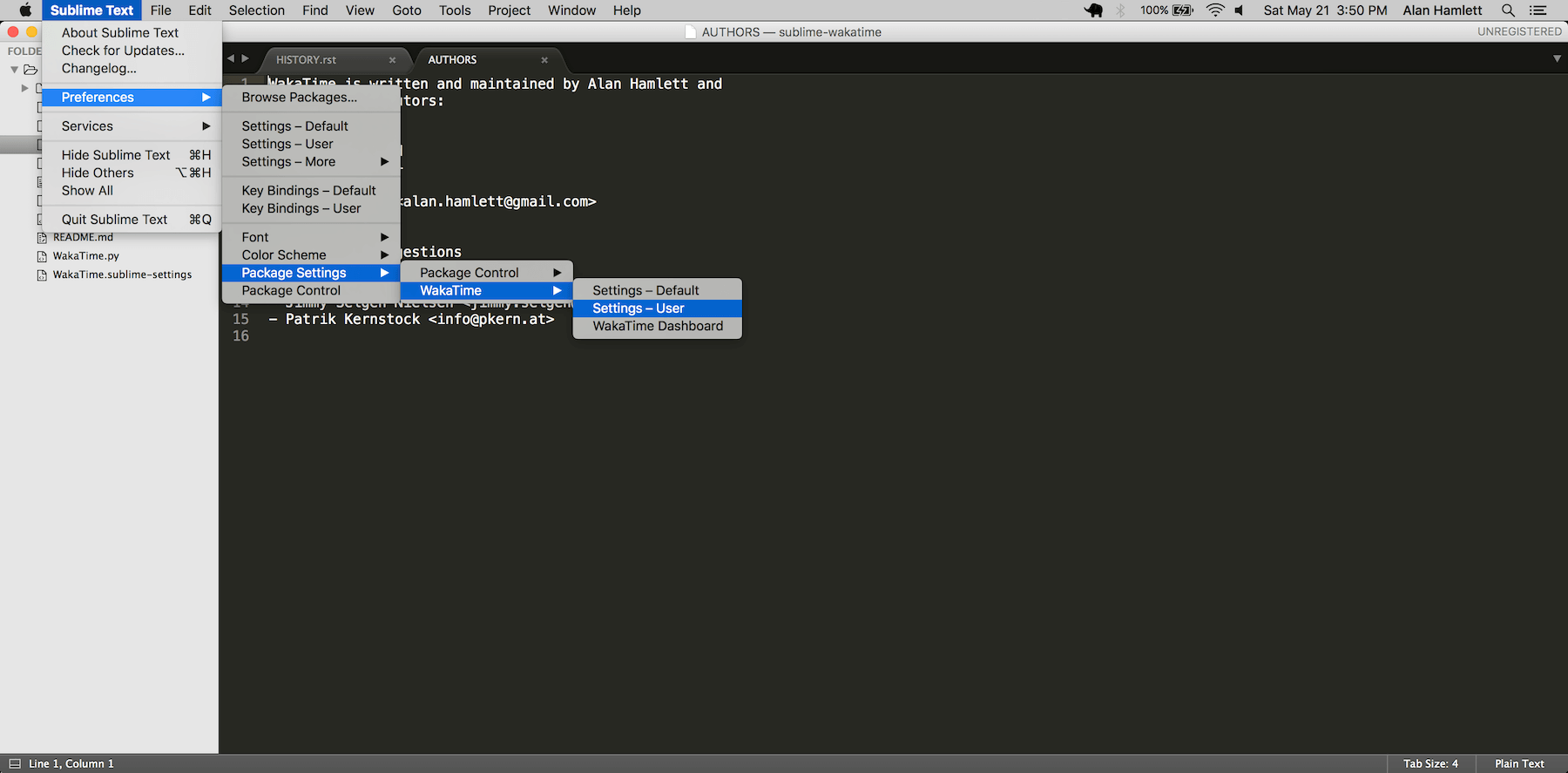
|
||||
|
||||
Add the line: `"debug": true`
|
||||
|
||||
Then, open your Sublime Console with `View -> Show Console` to see the plugin executing the wakatime cli process when sending a heartbeat. Also, tail your `$HOME/.wakatime.log` file to debug wakatime cli problems.
|
||||
|
||||
For more general troubleshooting information, see [wakatime/wakatime#troubleshooting](https://github.com/wakatime/wakatime#troubleshooting).
|
||||
|
||||
315
WakaTime.py
315
WakaTime.py
@ -7,31 +7,39 @@ Website: https://wakatime.com/
|
||||
==========================================================="""
|
||||
|
||||
|
||||
__version__ = '3.0.14'
|
||||
__version__ = '5.0.1'
|
||||
|
||||
|
||||
import sublime
|
||||
import sublime_plugin
|
||||
|
||||
import glob
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import threading
|
||||
import urllib
|
||||
import webbrowser
|
||||
from datetime import datetime
|
||||
from subprocess import Popen
|
||||
try:
|
||||
import _winreg as winreg # py2
|
||||
except ImportError:
|
||||
try:
|
||||
import winreg # py3
|
||||
except ImportError:
|
||||
winreg = None
|
||||
|
||||
|
||||
# globals
|
||||
ACTION_FREQUENCY = 2
|
||||
HEARTBEAT_FREQUENCY = 2
|
||||
ST_VERSION = int(sublime.version())
|
||||
PLUGIN_DIR = os.path.dirname(os.path.realpath(__file__))
|
||||
API_CLIENT = os.path.join(PLUGIN_DIR, 'packages', 'wakatime', 'cli.py')
|
||||
SETTINGS_FILE = 'WakaTime.sublime-settings'
|
||||
SETTINGS = {}
|
||||
LAST_ACTION = {
|
||||
LAST_HEARTBEAT = {
|
||||
'time': 0,
|
||||
'file': None,
|
||||
'is_write': False,
|
||||
@ -40,6 +48,13 @@ LOCK = threading.RLock()
|
||||
PYTHON_LOCATION = None
|
||||
|
||||
|
||||
# Log Levels
|
||||
DEBUG = 'DEBUG'
|
||||
INFO = 'INFO'
|
||||
WARNING = 'WARNING'
|
||||
ERROR = 'ERROR'
|
||||
|
||||
|
||||
# add wakatime package to path
|
||||
sys.path.insert(0, os.path.join(PLUGIN_DIR, 'packages'))
|
||||
try:
|
||||
@ -48,6 +63,20 @@ except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
def log(lvl, message, *args, **kwargs):
|
||||
try:
|
||||
if lvl == DEBUG and not SETTINGS.get('debug'):
|
||||
return
|
||||
msg = message
|
||||
if len(args) > 0:
|
||||
msg = message.format(*args)
|
||||
elif len(kwargs) > 0:
|
||||
msg = message.format(**kwargs)
|
||||
print('[WakaTime] [{lvl}] {msg}'.format(lvl=lvl, msg=msg))
|
||||
except RuntimeError:
|
||||
sublime.set_timeout(lambda: log(lvl, message, *args, **kwargs), 0)
|
||||
|
||||
|
||||
def createConfigFile():
|
||||
"""Creates the .wakatime.cfg INI file in $HOME directory, if it does
|
||||
not already exist.
|
||||
@ -92,66 +121,196 @@ def prompt_api_key():
|
||||
window.show_input_panel('[WakaTime] Enter your wakatime.com api key:', default_key, got_key, None, None)
|
||||
return True
|
||||
else:
|
||||
print('[WakaTime] Error: Could not prompt for api key because no window found.')
|
||||
log(ERROR, 'Could not prompt for api key because no window found.')
|
||||
return False
|
||||
|
||||
|
||||
def python_binary():
|
||||
global PYTHON_LOCATION
|
||||
if PYTHON_LOCATION is not None:
|
||||
return PYTHON_LOCATION
|
||||
|
||||
# look for python in PATH and common install locations
|
||||
paths = [
|
||||
"pythonw",
|
||||
"python",
|
||||
"/usr/local/bin/python",
|
||||
"/usr/bin/python",
|
||||
None,
|
||||
'/',
|
||||
'/usr/local/bin/',
|
||||
'/usr/bin/',
|
||||
]
|
||||
for path in paths:
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
for path in glob.iglob('/python*'):
|
||||
path = os.path.realpath(os.path.join(path, 'pythonw'))
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
|
||||
# look for python in windows registry
|
||||
path = find_python_from_registry(r'SOFTWARE\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
path = find_python_from_registry(r'SOFTWARE\Wow6432Node\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def enough_time_passed(now, last_time):
|
||||
if now - last_time > ACTION_FREQUENCY * 60:
|
||||
return True
|
||||
return False
|
||||
def set_python_binary_location(path):
|
||||
global PYTHON_LOCATION
|
||||
PYTHON_LOCATION = path
|
||||
log(DEBUG, 'Python Binary Found: {0}'.format(path))
|
||||
|
||||
|
||||
def find_project_name_from_folders(folders):
|
||||
def find_python_from_registry(location, reg=None):
|
||||
if platform.system() != 'Windows' or winreg is None:
|
||||
return None
|
||||
|
||||
if reg is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_CURRENT_USER)
|
||||
if path is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_LOCAL_MACHINE)
|
||||
return path
|
||||
|
||||
val = None
|
||||
sub_key = 'InstallPath'
|
||||
compiled = re.compile(r'^\d+\.\d+$')
|
||||
|
||||
try:
|
||||
for folder in folders:
|
||||
for file_name in os.listdir(folder):
|
||||
if file_name.endswith('.sublime-project'):
|
||||
return file_name.replace('.sublime-project', '', 1)
|
||||
with winreg.OpenKey(reg, location) as handle:
|
||||
versions = []
|
||||
try:
|
||||
for index in range(1024):
|
||||
version = winreg.EnumKey(handle, index)
|
||||
try:
|
||||
if compiled.search(version):
|
||||
versions.append(version)
|
||||
except re.error:
|
||||
pass
|
||||
except EnvironmentError:
|
||||
pass
|
||||
versions.sort(reverse=True)
|
||||
for version in versions:
|
||||
try:
|
||||
path = winreg.QueryValue(handle, version + '\\' + sub_key)
|
||||
if path is not None:
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
log(DEBUG, 'Found python from {reg}\\{key}\\{version}\\{sub_key}.'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
return path
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}\\{version}\\{sub_key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
except WindowsError:
|
||||
if SETTINGS.get('debug'):
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
))
|
||||
|
||||
return val
|
||||
|
||||
|
||||
def find_python_in_folder(folder):
|
||||
path = 'pythonw'
|
||||
if folder is not None:
|
||||
path = os.path.realpath(os.path.join(folder, 'pythonw'))
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
path = 'python'
|
||||
if folder is not None:
|
||||
path = os.path.realpath(os.path.join(folder, 'python'))
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
return None
|
||||
|
||||
|
||||
def handle_action(view, is_write=False):
|
||||
def obfuscate_apikey(command_list):
|
||||
cmd = list(command_list)
|
||||
apikey_index = None
|
||||
for num in range(len(cmd)):
|
||||
if cmd[num] == '--key':
|
||||
apikey_index = num + 1
|
||||
break
|
||||
if apikey_index is not None and apikey_index < len(cmd):
|
||||
cmd[apikey_index] = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX' + cmd[apikey_index][-4:]
|
||||
return cmd
|
||||
|
||||
|
||||
def enough_time_passed(now, last_heartbeat, is_write):
|
||||
if now - last_heartbeat['time'] > HEARTBEAT_FREQUENCY * 60:
|
||||
return True
|
||||
if is_write and now - last_heartbeat['time'] > 2:
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def find_folder_containing_file(folders, current_file):
|
||||
"""Returns absolute path to folder containing the file.
|
||||
"""
|
||||
|
||||
parent_folder = None
|
||||
|
||||
current_folder = current_file
|
||||
while True:
|
||||
for folder in folders:
|
||||
if os.path.realpath(os.path.dirname(current_folder)) == os.path.realpath(folder):
|
||||
parent_folder = folder
|
||||
break
|
||||
if parent_folder is not None:
|
||||
break
|
||||
if not current_folder or os.path.dirname(current_folder) == current_folder:
|
||||
break
|
||||
current_folder = os.path.dirname(current_folder)
|
||||
|
||||
return parent_folder
|
||||
|
||||
|
||||
def find_project_from_folders(folders, current_file):
|
||||
"""Find project name from open folders.
|
||||
"""
|
||||
|
||||
folder = find_folder_containing_file(folders, current_file)
|
||||
return os.path.basename(folder) if folder else None
|
||||
|
||||
|
||||
def is_view_active(view):
|
||||
if view:
|
||||
active_window = sublime.active_window()
|
||||
if active_window:
|
||||
active_view = active_window.active_view()
|
||||
if active_view:
|
||||
return active_view.buffer_id() == view.buffer_id()
|
||||
return False
|
||||
|
||||
|
||||
def handle_heartbeat(view, is_write=False):
|
||||
window = view.window()
|
||||
if window is not None:
|
||||
target_file = view.file_name()
|
||||
project = window.project_file_name() if hasattr(window, 'project_file_name') else None
|
||||
project = window.project_data() if hasattr(window, 'project_data') else None
|
||||
folders = window.folders()
|
||||
thread = SendActionThread(target_file, view, is_write=is_write, project=project, folders=folders)
|
||||
thread = SendHeartbeatThread(target_file, view, is_write=is_write, project=project, folders=folders)
|
||||
thread.start()
|
||||
|
||||
|
||||
class SendActionThread(threading.Thread):
|
||||
class SendHeartbeatThread(threading.Thread):
|
||||
"""Non-blocking thread for sending heartbeats to api.
|
||||
"""
|
||||
|
||||
def __init__(self, target_file, view, is_write=False, project=None, folders=None, force=False):
|
||||
threading.Thread.__init__(self)
|
||||
@ -164,19 +323,20 @@ class SendActionThread(threading.Thread):
|
||||
self.debug = SETTINGS.get('debug')
|
||||
self.api_key = SETTINGS.get('api_key', '')
|
||||
self.ignore = SETTINGS.get('ignore', [])
|
||||
self.last_action = LAST_ACTION.copy()
|
||||
self.last_heartbeat = LAST_HEARTBEAT.copy()
|
||||
self.cursorpos = view.sel()[0].begin() if view.sel() else None
|
||||
self.view = view
|
||||
|
||||
def run(self):
|
||||
with self.lock:
|
||||
if self.target_file:
|
||||
self.timestamp = time.time()
|
||||
if self.force or (self.is_write and not self.last_action['is_write']) or self.target_file != self.last_action['file'] or enough_time_passed(self.timestamp, self.last_action['time']):
|
||||
if self.force or self.target_file != self.last_heartbeat['file'] or enough_time_passed(self.timestamp, self.last_heartbeat, self.is_write):
|
||||
self.send_heartbeat()
|
||||
|
||||
def send_heartbeat(self):
|
||||
if not self.api_key:
|
||||
print('[WakaTime] Error: missing api key.')
|
||||
log(ERROR, 'missing api key.')
|
||||
return
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
@ -188,22 +348,21 @@ class SendActionThread(threading.Thread):
|
||||
]
|
||||
if self.is_write:
|
||||
cmd.append('--write')
|
||||
if self.project:
|
||||
self.project = os.path.basename(self.project).replace('.sublime-project', '', 1)
|
||||
if self.project:
|
||||
cmd.extend(['--project', self.project])
|
||||
if self.project and self.project.get('name'):
|
||||
cmd.extend(['--alternate-project', self.project.get('name')])
|
||||
elif self.folders:
|
||||
project_name = find_project_name_from_folders(self.folders)
|
||||
project_name = find_project_from_folders(self.folders, self.target_file)
|
||||
if project_name:
|
||||
cmd.extend(['--project', project_name])
|
||||
cmd.extend(['--alternate-project', project_name])
|
||||
if self.cursorpos is not None:
|
||||
cmd.extend(['--cursorpos', '{0}'.format(self.cursorpos)])
|
||||
for pattern in self.ignore:
|
||||
cmd.extend(['--ignore', pattern])
|
||||
if self.debug:
|
||||
cmd.append('--verbose')
|
||||
if python_binary():
|
||||
cmd.insert(0, python_binary())
|
||||
if self.debug:
|
||||
print('[WakaTime] %s' % ' '.join(cmd))
|
||||
log(DEBUG, ' '.join(obfuscate_apikey(cmd)))
|
||||
if platform.system() == 'Windows':
|
||||
Popen(cmd, shell=False)
|
||||
else:
|
||||
@ -211,34 +370,64 @@ class SendActionThread(threading.Thread):
|
||||
Popen(cmd, stderr=stderr)
|
||||
self.sent()
|
||||
else:
|
||||
print('[WakaTime] Error: Unable to find python binary.')
|
||||
log(ERROR, 'Unable to find python binary.')
|
||||
|
||||
def sent(self):
|
||||
sublime.set_timeout(self.set_status_bar, 0)
|
||||
sublime.set_timeout(self.set_last_action, 0)
|
||||
sublime.set_timeout(self.set_last_heartbeat, 0)
|
||||
|
||||
def set_status_bar(self):
|
||||
if SETTINGS.get('status_bar_message'):
|
||||
self.view.set_status('wakatime', 'WakaTime active {0}'.format(datetime.now().strftime('%I:%M %p')))
|
||||
self.view.set_status('wakatime', datetime.now().strftime(SETTINGS.get('status_bar_message_fmt')))
|
||||
|
||||
def set_last_action(self):
|
||||
global LAST_ACTION
|
||||
LAST_ACTION = {
|
||||
def set_last_heartbeat(self):
|
||||
global LAST_HEARTBEAT
|
||||
LAST_HEARTBEAT = {
|
||||
'file': self.target_file,
|
||||
'time': self.timestamp,
|
||||
'is_write': self.is_write,
|
||||
}
|
||||
|
||||
|
||||
class InstallPython(threading.Thread):
|
||||
"""Non-blocking thread for installing Python on Windows machines.
|
||||
"""
|
||||
|
||||
def run(self):
|
||||
log(INFO, 'Downloading and installing python...')
|
||||
url = 'https://www.python.org/ftp/python/3.4.3/python-3.4.3.msi'
|
||||
if platform.architecture()[0] == '64bit':
|
||||
url = 'https://www.python.org/ftp/python/3.4.3/python-3.4.3.amd64.msi'
|
||||
python_msi = os.path.join(os.path.expanduser('~'), 'python.msi')
|
||||
try:
|
||||
urllib.urlretrieve(url, python_msi)
|
||||
except AttributeError:
|
||||
urllib.request.urlretrieve(url, python_msi)
|
||||
args = [
|
||||
'msiexec',
|
||||
'/i',
|
||||
python_msi,
|
||||
'/norestart',
|
||||
'/qb!',
|
||||
]
|
||||
Popen(args)
|
||||
|
||||
|
||||
def plugin_loaded():
|
||||
global SETTINGS
|
||||
print('[WakaTime] Initializing WakaTime plugin v%s' % __version__)
|
||||
|
||||
if not python_binary():
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
log(INFO, 'Initializing WakaTime plugin v%s' % __version__)
|
||||
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
|
||||
if not python_binary():
|
||||
log(WARNING, 'Python binary not found.')
|
||||
if platform.system() == 'Windows':
|
||||
thread = InstallPython()
|
||||
thread.start()
|
||||
else:
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
|
||||
after_loaded()
|
||||
|
||||
|
||||
@ -255,13 +444,15 @@ if ST_VERSION < 3000:
|
||||
class WakatimeListener(sublime_plugin.EventListener):
|
||||
|
||||
def on_post_save(self, view):
|
||||
handle_action(view, is_write=True)
|
||||
handle_heartbeat(view, is_write=True)
|
||||
|
||||
def on_activated(self, view):
|
||||
handle_action(view)
|
||||
def on_selection_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
|
||||
def on_modified(self, view):
|
||||
handle_action(view)
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
|
||||
|
||||
class WakatimeDashboardCommand(sublime_plugin.ApplicationCommand):
|
||||
|
||||
@ -9,12 +9,15 @@
|
||||
|
||||
// Ignore files; Files (including absolute paths) that match one of these
|
||||
// POSIX regular expressions will not be logged.
|
||||
"ignore": ["^/tmp/", "^/etc/", "^/var/"],
|
||||
"ignore": ["^/tmp/", "^/etc/", "^/var/", "COMMIT_EDITMSG$", "PULLREQ_EDITMSG$", "MERGE_MSG$", "TAG_EDITMSG$"],
|
||||
|
||||
// Debug mode. Set to true for verbose logging. Defaults to false.
|
||||
"debug": false,
|
||||
|
||||
// Status bar message. Set to false to hide status bar message.
|
||||
// Defaults to true.
|
||||
"status_bar_message": true
|
||||
"status_bar_message": true,
|
||||
|
||||
// Status bar message format.
|
||||
"status_bar_message_fmt": "WakaTime active %I:%M %p"
|
||||
}
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
__title__ = 'wakatime'
|
||||
__description__ = 'Common interface to the WakaTime api.'
|
||||
__url__ = 'https://github.com/wakatime/wakatime'
|
||||
__version_info__ = ('4', '0', '6')
|
||||
__version_info__ = ('4', '1', '8')
|
||||
__version__ = '.'.join(__version_info__)
|
||||
__author__ = 'Alan Hamlett'
|
||||
__author_email__ = 'alan@wakatime.com'
|
||||
|
||||
@ -14,4 +14,4 @@
|
||||
__all__ = ['main']
|
||||
|
||||
|
||||
from .base import main
|
||||
from .main import execute
|
||||
|
||||
@ -11,8 +11,25 @@
|
||||
|
||||
import os
|
||||
import sys
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
import wakatime
|
||||
|
||||
|
||||
# get path to local wakatime package
|
||||
package_folder = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||
|
||||
# add local wakatime package to sys.path
|
||||
sys.path.insert(0, package_folder)
|
||||
|
||||
# import local wakatime package
|
||||
try:
|
||||
import wakatime
|
||||
except (TypeError, ImportError):
|
||||
# on Windows, non-ASCII characters in import path can be fixed using
|
||||
# the script path from sys.argv[0].
|
||||
# More info at https://github.com/wakatime/wakatime/issues/32
|
||||
package_folder = os.path.dirname(os.path.dirname(os.path.abspath(sys.argv[0])))
|
||||
sys.path.insert(0, package_folder)
|
||||
import wakatime
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(wakatime.main(sys.argv))
|
||||
sys.exit(wakatime.execute(sys.argv[1:]))
|
||||
|
||||
@ -17,32 +17,49 @@ is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
|
||||
if is_py2:
|
||||
if is_py2: # pragma: nocover
|
||||
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
return text
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
open = codecs.open
|
||||
basestring = basestring
|
||||
|
||||
|
||||
elif is_py3:
|
||||
elif is_py3: # pragma: nocover
|
||||
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
return text.decode('utf-8')
|
||||
return str(text)
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
open = open
|
||||
basestring = (str, bytes)
|
||||
|
||||
|
||||
try:
|
||||
from importlib import import_module
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
def _resolve_name(name, package, level):
|
||||
"""Return the absolute name of the module to be imported."""
|
||||
if not hasattr(package, 'rindex'):
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
wakatime.dependencies
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from a source code file.
|
||||
|
||||
@ -10,9 +10,12 @@
|
||||
"""
|
||||
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from ..compat import u, open, import_module
|
||||
from ..exceptions import NotYetImplemented
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
@ -23,26 +26,28 @@ class TokenParser(object):
|
||||
language, inherit from this class and implement the :meth:`parse` method
|
||||
to return a list of dependency strings.
|
||||
"""
|
||||
source_file = None
|
||||
lexer = None
|
||||
dependencies = []
|
||||
tokens = []
|
||||
exclude = []
|
||||
|
||||
def __init__(self, source_file, lexer=None):
|
||||
self._tokens = None
|
||||
self.dependencies = []
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
self.exclude = [re.compile(x, re.IGNORECASE) for x in self.exclude]
|
||||
|
||||
@property
|
||||
def tokens(self):
|
||||
if self._tokens is None:
|
||||
self._tokens = self._extract_tokens()
|
||||
return self._tokens
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
""" Should return a list of dependencies.
|
||||
"""
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
raise Exception('Not yet implemented.')
|
||||
raise NotYetImplemented()
|
||||
|
||||
def append(self, dep, truncate=False, separator=None, truncate_to=None,
|
||||
strip_whitespace=True):
|
||||
if dep == 'as':
|
||||
print('***************** as')
|
||||
self._save_dependency(
|
||||
dep,
|
||||
truncate=truncate,
|
||||
@ -51,10 +56,21 @@ class TokenParser(object):
|
||||
strip_whitespace=strip_whitespace,
|
||||
)
|
||||
|
||||
def partial(self, token):
|
||||
return u(token).split('.')[-1]
|
||||
|
||||
def _extract_tokens(self):
|
||||
if self.lexer:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
return []
|
||||
|
||||
def _save_dependency(self, dep, truncate=False, separator=None,
|
||||
@ -64,13 +80,21 @@ class TokenParser(object):
|
||||
separator = u('.')
|
||||
separator = u(separator)
|
||||
dep = dep.split(separator)
|
||||
if truncate_to is None or truncate_to < 0 or truncate_to > len(dep) - 1:
|
||||
truncate_to = len(dep) - 1
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[0:truncate_to])
|
||||
if truncate_to is None or truncate_to < 1:
|
||||
truncate_to = 1
|
||||
if truncate_to > len(dep):
|
||||
truncate_to = len(dep)
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[:truncate_to])
|
||||
if strip_whitespace:
|
||||
dep = dep.strip()
|
||||
if dep:
|
||||
self.dependencies.append(dep)
|
||||
if dep and (not separator or not dep.startswith(separator)):
|
||||
should_exclude = False
|
||||
for compiled in self.exclude:
|
||||
if compiled.search(dep):
|
||||
should_exclude = True
|
||||
break
|
||||
if not should_exclude:
|
||||
self.dependencies.append(dep)
|
||||
|
||||
|
||||
class DependencyParser(object):
|
||||
@ -83,7 +107,7 @@ class DependencyParser(object):
|
||||
self.lexer = lexer
|
||||
|
||||
if self.lexer:
|
||||
module_name = self.lexer.__module__.split('.')[-1]
|
||||
module_name = self.lexer.__module__.rsplit('.', 1)[-1]
|
||||
class_name = self.lexer.__class__.__name__.replace('Lexer', 'Parser', 1)
|
||||
else:
|
||||
module_name = 'unknown'
|
||||
68
packages/wakatime/dependencies/c_cpp.py
Normal file
68
packages/wakatime/dependencies/c_cpp.py
Normal file
@ -0,0 +1,68 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
|
||||
class CParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -26,10 +26,8 @@ class JsonParser(TokenParser):
|
||||
state = None
|
||||
level = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
64
packages/wakatime/dependencies/dotnet.py
Normal file
64
packages/wakatime/dependencies/dotnet.py
Normal file
@ -0,0 +1,64 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
exclude = [
|
||||
r'^system$',
|
||||
r'^microsoft$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
if self.partial(token) == 'Namespace' or self.partial(token) == 'Name':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_keyword(self, token, content):
|
||||
if content == 'using':
|
||||
self.state = 'import'
|
||||
self.buffer = u('')
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) != u('import') and u(content) != u('package') and u(content) != u('namespace') and u(content) != u('static'):
|
||||
if u(content) == u(';'): # pragma: nocover
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) == u(';'):
|
||||
self.append(self.buffer, truncate=True)
|
||||
self.buffer = u('')
|
||||
self.state = None
|
||||
elif u(content) == u('='):
|
||||
self.buffer = u('')
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
96
packages/wakatime/dependencies/jvm.py
Normal file
96
packages/wakatime/dependencies/jvm.py
Normal file
@ -0,0 +1,96 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
exclude = [
|
||||
r'^java\.',
|
||||
r'^javax\.',
|
||||
r'^import$',
|
||||
r'^package$',
|
||||
r'^namespace$',
|
||||
r'^static$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
if self.partial(token) == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif self.partial(token) == 'Attribute':
|
||||
self._process_attribute(token, content)
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if u(content) == u('import'):
|
||||
self.state = 'import'
|
||||
|
||||
elif self.state == 'import':
|
||||
keywords = [
|
||||
u('package'),
|
||||
u('namespace'),
|
||||
u('static'),
|
||||
]
|
||||
if u(content) in keywords:
|
||||
return
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
elif self.state == 'import-finished':
|
||||
content = content.split(u('.'))
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
|
||||
elif len(content) > 1:
|
||||
if len(content[0]) == 3:
|
||||
content = content[1:]
|
||||
if content[-1] == u('*'):
|
||||
content = content[:len(content) - 1]
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
elif len(content) > 1:
|
||||
self.append(u('.').join(content[:2]))
|
||||
|
||||
self.state = None
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if u(content) == u(';'):
|
||||
self.state = 'import-finished'
|
||||
self._process_namespace(token, self.buffer)
|
||||
self.state = None
|
||||
self.buffer = u('')
|
||||
elif self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -17,15 +17,13 @@ class PhpParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Keyword':
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
@ -33,9 +31,9 @@ class PhpParser(TokenParser):
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Name.Function':
|
||||
self._process_function(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
@ -63,10 +61,10 @@ class PhpParser(TokenParser):
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '"':
|
||||
if content != '"' and content != "'":
|
||||
content = content.strip()
|
||||
if u(token) == 'Token.Literal.String.Double':
|
||||
content = u('"{0}"').format(content)
|
||||
content = u("'{0}'").format(content)
|
||||
self.append(content)
|
||||
self.state = None
|
||||
|
||||
@ -10,33 +10,30 @@
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class PythonParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
nonpackage = False
|
||||
exclude = [
|
||||
r'^os$',
|
||||
r'^sys\.',
|
||||
]
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif u(token).split('.')[-1] == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif u(token).split('.')[-1] == 'Word':
|
||||
self._process_word(token, content)
|
||||
elif u(token).split('.')[-1] == 'Operator':
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
@ -50,38 +47,6 @@ class PythonParser(TokenParser):
|
||||
else:
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_word(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == '.':
|
||||
@ -106,15 +71,15 @@ class PythonParser(TokenParser):
|
||||
def _process_import(self, token, content):
|
||||
if not self.nonpackage:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'import-2'
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
else:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
@ -71,9 +71,7 @@ KEYWORDS = [
|
||||
|
||||
class LassoJavascriptParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
@ -99,9 +97,7 @@ class HtmlDjangoParser(TokenParser):
|
||||
current_attr = None
|
||||
current_attr_value = None
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
@ -22,7 +22,7 @@ FILES = {
|
||||
|
||||
class UnknownParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
return self.dependencies
|
||||
|
||||
14
packages/wakatime/exceptions.py
Normal file
14
packages/wakatime/exceptions.py
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.exceptions
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Custom exceptions.
|
||||
|
||||
:copyright: (c) 2015 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
class NotYetImplemented(Exception):
|
||||
"""This method needs to be implemented."""
|
||||
@ -1,37 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,103 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.log
|
||||
~~~~~~~~~~~~
|
||||
|
||||
Provides the configured logger for writing JSON to the log file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
||||
from .packages import simplejson as json
|
||||
from .compat import u
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from .packages.ordereddict import OrderedDict
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes):
|
||||
obj = bytes.decode(obj)
|
||||
return json.dumps(obj)
|
||||
try:
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError:
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, isWrite, targetFile, version, plugin):
|
||||
self.timestamp = timestamp
|
||||
self.isWrite = isWrite
|
||||
self.targetFile = targetFile
|
||||
self.version = version
|
||||
self.plugin = plugin
|
||||
|
||||
def format(self, record):
|
||||
data = OrderedDict([
|
||||
('now', self.formatTime(record, self.datefmt)),
|
||||
('version', self.version),
|
||||
('plugin', self.plugin),
|
||||
('time', self.timestamp),
|
||||
('isWrite', self.isWrite),
|
||||
('file', self.targetFile),
|
||||
('level', record.levelname),
|
||||
('message', record.msg),
|
||||
])
|
||||
if not self.plugin:
|
||||
del data['plugin']
|
||||
if not self.isWrite:
|
||||
del data['isWrite']
|
||||
return CustomEncoder().encode(data)
|
||||
|
||||
def formatException(self, exc_info):
|
||||
return sys.exec_info[2].format_exc()
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
level = logging.WARN
|
||||
if args.verbose:
|
||||
level = logging.DEBUG
|
||||
logger.setLevel(level)
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
logger = logging.getLogger('WakaTime')
|
||||
set_log_level(logger, args)
|
||||
if len(logger.handlers) > 0:
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
)
|
||||
logger.handlers[0].setFormatter(formatter)
|
||||
return logger
|
||||
logfile = args.logfile
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
handler = logging.FileHandler(os.path.expanduser(logfile))
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
)
|
||||
handler.setFormatter(formatter)
|
||||
logger.addHandler(handler)
|
||||
return logger
|
||||
123
packages/wakatime/logger.py
Normal file
123
packages/wakatime/logger.py
Normal file
@ -0,0 +1,123 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.logger
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
Provides the configured logger for writing JSON to the log file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
||||
from .compat import u
|
||||
try:
|
||||
from collections import OrderedDict # pragma: nocover
|
||||
except ImportError: # pragma: nocover
|
||||
from .packages.ordereddict import OrderedDict
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes): # pragma: nocover
|
||||
obj = u(obj)
|
||||
return json.dumps(obj)
|
||||
try: # pragma: nocover
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, isWrite, entity, version, plugin, verbose,
|
||||
warnings=False):
|
||||
self.timestamp = timestamp
|
||||
self.isWrite = isWrite
|
||||
self.entity = entity
|
||||
self.version = version
|
||||
self.plugin = plugin
|
||||
self.verbose = verbose
|
||||
self.warnings = warnings
|
||||
|
||||
def format(self, record, *args):
|
||||
data = OrderedDict([
|
||||
('now', self.formatTime(record, self.datefmt)),
|
||||
])
|
||||
data['version'] = self.version
|
||||
data['plugin'] = self.plugin
|
||||
data['time'] = self.timestamp
|
||||
if self.verbose:
|
||||
data['caller'] = record.pathname
|
||||
data['lineno'] = record.lineno
|
||||
data['isWrite'] = self.isWrite
|
||||
data['file'] = self.entity
|
||||
if not self.isWrite:
|
||||
del data['isWrite']
|
||||
data['level'] = record.levelname
|
||||
data['message'] = record.getMessage() if self.warnings else record.msg
|
||||
if not self.plugin:
|
||||
del data['plugin']
|
||||
return CustomEncoder().encode(data)
|
||||
|
||||
def formatException(self, exc_info):
|
||||
return sys.exec_info[2].format_exc()
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
level = logging.WARN
|
||||
if args.verbose:
|
||||
level = logging.DEBUG
|
||||
logger.setLevel(level)
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
logger = logging.getLogger('WakaTime')
|
||||
for handler in logger.handlers:
|
||||
logger.removeHandler(handler)
|
||||
set_log_level(logger, args)
|
||||
logfile = args.logfile
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
handler = logging.FileHandler(os.path.expanduser(logfile))
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
)
|
||||
handler.setFormatter(formatter)
|
||||
logger.addHandler(handler)
|
||||
|
||||
warnings_formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
warnings_formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
warnings=True,
|
||||
)
|
||||
warnings_handler = logging.FileHandler(os.path.expanduser(logfile))
|
||||
warnings_handler.setFormatter(warnings_formatter)
|
||||
logging.getLogger('py.warnings').addHandler(warnings_handler)
|
||||
try:
|
||||
logging.captureWarnings(True)
|
||||
except AttributeError: # pragma: nocover
|
||||
pass # Python >= 2.7 is needed to capture warnings
|
||||
|
||||
return logger
|
||||
@ -1,6 +1,6 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.base
|
||||
wakatime.main
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
wakatime module entry point.
|
||||
@ -19,28 +19,31 @@ import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
import socket
|
||||
try:
|
||||
import ConfigParser as configparser
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
import configparser
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages', 'requests', 'packages'))
|
||||
|
||||
from .__about__ import __version__
|
||||
from .compat import u, open, is_py3
|
||||
from .logger import setup_logging
|
||||
from .offlinequeue import Queue
|
||||
from .log import setup_logging
|
||||
from .project import find_project
|
||||
from .stats import get_file_stats
|
||||
from .packages import argparse
|
||||
from .packages import simplejson as json
|
||||
from .packages import requests
|
||||
from .packages.requests.exceptions import RequestException
|
||||
from .project import get_project_info
|
||||
from .session_cache import SessionCache
|
||||
from .stats import get_file_stats
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
try:
|
||||
from .packages import tzlocal
|
||||
except:
|
||||
except: # pragma: nocover
|
||||
from .packages import tzlocal3 as tzlocal
|
||||
|
||||
|
||||
@ -50,49 +53,14 @@ log = logging.getLogger('WakaTime')
|
||||
class FileAction(argparse.Action):
|
||||
|
||||
def __call__(self, parser, namespace, values, option_string=None):
|
||||
values = os.path.realpath(values)
|
||||
try:
|
||||
if os.path.isfile(values):
|
||||
values = os.path.realpath(values)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def upgradeConfigFile(configFile):
|
||||
"""For backwards-compatibility, upgrade the existing config file
|
||||
to work with configparser and rename from .wakatime.conf to .wakatime.cfg.
|
||||
"""
|
||||
|
||||
if os.path.isfile(configFile):
|
||||
# if upgraded cfg file already exists, don't overwrite it
|
||||
return
|
||||
|
||||
oldConfig = os.path.join(os.path.expanduser('~'), '.wakatime.conf')
|
||||
try:
|
||||
configs = {
|
||||
'ignore': [],
|
||||
}
|
||||
|
||||
with open(oldConfig, 'r', encoding='utf-8') as fh:
|
||||
for line in fh.readlines():
|
||||
line = line.split('=', 1)
|
||||
if len(line) == 2 and line[0].strip() and line[1].strip():
|
||||
if line[0].strip() == 'ignore':
|
||||
configs['ignore'].append(line[1].strip())
|
||||
else:
|
||||
configs[line[0].strip()] = line[1].strip()
|
||||
|
||||
with open(configFile, 'w', encoding='utf-8') as fh:
|
||||
fh.write("[settings]\n")
|
||||
for name, value in configs.items():
|
||||
if isinstance(value, list):
|
||||
fh.write("%s=\n" % name)
|
||||
for item in value:
|
||||
fh.write(" %s\n" % item)
|
||||
else:
|
||||
fh.write("%s = %s\n" % (name, value))
|
||||
|
||||
os.remove(oldConfig)
|
||||
except IOError:
|
||||
pass
|
||||
|
||||
|
||||
def parseConfigFile(configFile=None):
|
||||
"""Returns a configparser.SafeConfigParser instance with configs
|
||||
read from the config file. Default location of the config file is
|
||||
@ -102,8 +70,6 @@ def parseConfigFile(configFile=None):
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.cfg')
|
||||
|
||||
upgradeConfigFile(configFile)
|
||||
|
||||
configs = configparser.SafeConfigParser()
|
||||
try:
|
||||
with open(configFile, 'r', encoding='utf-8') as fh:
|
||||
@ -117,23 +83,21 @@ def parseConfigFile(configFile=None):
|
||||
return configs
|
||||
|
||||
|
||||
def parseArguments(argv):
|
||||
def parseArguments():
|
||||
"""Parse command line arguments and configs from ~/.wakatime.cfg.
|
||||
Command line arguments take precedence over config file settings.
|
||||
Returns instances of ArgumentParser and SafeConfigParser.
|
||||
"""
|
||||
|
||||
try:
|
||||
sys.argv
|
||||
except AttributeError:
|
||||
sys.argv = argv
|
||||
|
||||
# define supported command line arguments
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Common interface for the WakaTime api.')
|
||||
parser.add_argument('--file', dest='targetFile', metavar='file',
|
||||
action=FileAction, required=True,
|
||||
help='absolute path to file for current heartbeat')
|
||||
parser.add_argument('--entity', dest='entity', metavar='FILE',
|
||||
action=FileAction,
|
||||
help='absolute path to file for the heartbeat; can also be a '+
|
||||
'url, domain, or app when --entitytype is not file')
|
||||
parser.add_argument('--file', dest='file', action=FileAction,
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakatime api key; uses api_key from '+
|
||||
'~/.wakatime.conf by default')
|
||||
@ -148,14 +112,21 @@ def parseArguments(argv):
|
||||
type=float,
|
||||
help='optional floating-point unix epoch timestamp; '+
|
||||
'uses current time by default')
|
||||
parser.add_argument('--notfile', dest='notfile', action='store_true',
|
||||
help='when set, will accept any value for the file. for example, '+
|
||||
'a domain name or other item you want to log time towards.')
|
||||
parser.add_argument('--lineno', dest='lineno',
|
||||
help='optional line number; current line being edited')
|
||||
parser.add_argument('--cursorpos', dest='cursorpos',
|
||||
help='optional cursor position in the current file')
|
||||
parser.add_argument('--entitytype', dest='entity_type',
|
||||
help='entity type for this heartbeat. can be one of "file", '+
|
||||
'"url", "domain", or "app"; defaults to file.')
|
||||
parser.add_argument('--proxy', dest='proxy',
|
||||
help='optional https proxy url; for example: '+
|
||||
'https://user:pass@localhost:8080')
|
||||
parser.add_argument('--project', dest='project_name',
|
||||
help='optional project name; will auto-discover by default')
|
||||
parser.add_argument('--project', dest='project',
|
||||
help='optional project name')
|
||||
parser.add_argument('--alternate-project', dest='alternate_project',
|
||||
help='optional alternate project name; auto-discovered project takes priority')
|
||||
parser.add_argument('--hostname', dest='hostname', help='hostname of current machine.')
|
||||
parser.add_argument('--disableoffline', dest='offline',
|
||||
action='store_false',
|
||||
help='disables offline time logging instead of queuing logged time')
|
||||
@ -173,6 +144,10 @@ def parseArguments(argv):
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--logfile', dest='logfile',
|
||||
help='defaults to ~/.wakatime.log')
|
||||
parser.add_argument('--apiurl', dest='api_url',
|
||||
help='heartbeats api url; for debugging with a local server')
|
||||
parser.add_argument('--timeout', dest='timeout', type=int,
|
||||
help='number of seconds to wait when sending heartbeats to api')
|
||||
parser.add_argument('--config', dest='config',
|
||||
help='defaults to ~/.wakatime.conf')
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
@ -180,7 +155,7 @@ def parseArguments(argv):
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
|
||||
# parse command line arguments
|
||||
args = parser.parse_args(args=argv[1:])
|
||||
args = parser.parse_args()
|
||||
|
||||
# use current unix epoch timestamp by default
|
||||
if not args.timestamp:
|
||||
@ -202,6 +177,13 @@ def parseArguments(argv):
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
if not args.entity_type:
|
||||
args.entity_type = 'file'
|
||||
if not args.entity:
|
||||
if args.file:
|
||||
args.entity = args.file
|
||||
else:
|
||||
parser.error('argument --entity is required')
|
||||
if not args.exclude:
|
||||
args.exclude = []
|
||||
if configs.has_option('settings', 'ignore'):
|
||||
@ -209,14 +191,14 @@ def parseArguments(argv):
|
||||
for pattern in configs.get('settings', 'ignore').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if configs.has_option('settings', 'exclude'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'exclude').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if not args.include:
|
||||
args.include = []
|
||||
@ -225,7 +207,7 @@ def parseArguments(argv):
|
||||
for pattern in configs.get('settings', 'include').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.include.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if args.offline and configs.has_option('settings', 'offline'):
|
||||
args.offline = configs.getboolean('settings', 'offline')
|
||||
@ -239,37 +221,44 @@ def parseArguments(argv):
|
||||
args.verbose = configs.getboolean('settings', 'debug')
|
||||
if not args.logfile and configs.has_option('settings', 'logfile'):
|
||||
args.logfile = configs.get('settings', 'logfile')
|
||||
if not args.api_url and configs.has_option('settings', 'api_url'):
|
||||
args.api_url = configs.get('settings', 'api_url')
|
||||
if not args.timeout and configs.has_option('settings', 'timeout'):
|
||||
try:
|
||||
args.timeout = int(configs.get('settings', 'timeout'))
|
||||
except ValueError:
|
||||
print(traceback.format_exc())
|
||||
|
||||
return args, configs
|
||||
|
||||
|
||||
def should_exclude(fileName, include, exclude):
|
||||
if fileName is not None and fileName.strip() != '':
|
||||
def should_exclude(entity, include, exclude):
|
||||
if entity is not None and entity.strip() != '':
|
||||
try:
|
||||
for pattern in include:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
if compiled.search(entity):
|
||||
return False
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for include pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
try:
|
||||
for pattern in exclude:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
if compiled.search(entity):
|
||||
return pattern
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for exclude pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
return False
|
||||
|
||||
@ -294,27 +283,35 @@ def get_user_agent(plugin):
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=None,
|
||||
timestamp=None, isWrite=None, plugin=None, offline=None,
|
||||
hidefilenames=None, notfile=False, proxy=None, **kwargs):
|
||||
url = 'https://wakatime.com/api/v1/heartbeats'
|
||||
log.debug('Sending heartbeat to api at %s' % url)
|
||||
def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None, entity=None,
|
||||
timestamp=None, isWrite=None, plugin=None, offline=None, entity_type='file',
|
||||
hidefilenames=None, proxy=None, api_url=None, timeout=None, **kwargs):
|
||||
"""Sends heartbeat as POST request to WakaTime api server.
|
||||
"""
|
||||
|
||||
if not api_url:
|
||||
api_url = 'https://wakatime.com/api/v1/heartbeats'
|
||||
if not timeout:
|
||||
timeout = 30
|
||||
log.debug('Sending heartbeat to api at %s' % api_url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'file': targetFile,
|
||||
'entity': entity,
|
||||
'type': entity_type,
|
||||
}
|
||||
if hidefilenames and targetFile is not None and not notfile:
|
||||
data['file'] = data['file'].rsplit('/', 1)[-1].rsplit('\\', 1)[-1]
|
||||
if len(data['file'].strip('.').split('.', 1)) > 1:
|
||||
data['file'] = u('HIDDEN.{ext}').format(ext=u(data['file'].strip('.').rsplit('.', 1)[-1]))
|
||||
else:
|
||||
data['file'] = u('HIDDEN')
|
||||
if hidefilenames and entity is not None and entity_type == 'file':
|
||||
extension = u(os.path.splitext(data['entity'])[1])
|
||||
data['entity'] = u('HIDDEN{0}').format(extension)
|
||||
if stats.get('lines'):
|
||||
data['lines'] = stats['lines']
|
||||
if stats.get('language'):
|
||||
data['language'] = stats['language']
|
||||
if stats.get('dependencies'):
|
||||
data['dependencies'] = stats['dependencies']
|
||||
if stats.get('lineno'):
|
||||
data['lineno'] = stats['lineno']
|
||||
if stats.get('cursorpos'):
|
||||
data['cursorpos'] = stats['cursorpos']
|
||||
if isWrite:
|
||||
data['is_write'] = isWrite
|
||||
if project:
|
||||
@ -333,6 +330,8 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
'Accept': 'application/json',
|
||||
'Authorization': auth,
|
||||
}
|
||||
if hostname:
|
||||
headers['X-Machine-Name'] = hostname
|
||||
proxies = {}
|
||||
if proxy:
|
||||
proxies['https'] = proxy
|
||||
@ -345,11 +344,14 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
if tz:
|
||||
headers['TimeZone'] = u(tz.zone)
|
||||
|
||||
session_cache = SessionCache()
|
||||
session = session_cache.get()
|
||||
|
||||
# log time to api
|
||||
response = None
|
||||
try:
|
||||
response = requests.post(url, data=request_body, headers=headers,
|
||||
proxies=proxies)
|
||||
response = session.post(api_url, data=request_body, headers=headers,
|
||||
proxies=proxies, timeout=timeout)
|
||||
except RequestException:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
@ -370,6 +372,7 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
log.debug({
|
||||
'response_code': response_code,
|
||||
})
|
||||
session_cache.save(session)
|
||||
return True
|
||||
if offline:
|
||||
if response_code != 400:
|
||||
@ -395,62 +398,67 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return False
|
||||
|
||||
|
||||
def main(argv=None):
|
||||
if not argv:
|
||||
argv = sys.argv
|
||||
def execute(argv=None):
|
||||
if argv:
|
||||
sys.argv = ['wakatime'] + argv
|
||||
|
||||
args, configs = parseArguments(argv)
|
||||
args, configs = parseArguments()
|
||||
if configs is None:
|
||||
return 103 # config file parsing error
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
exclude = should_exclude(args.targetFile, args.include, args.exclude)
|
||||
exclude = should_exclude(args.entity, args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
log.debug(u('File not logged because matches exclude pattern: {pattern}').format(
|
||||
log.debug(u('Skipping because matches exclude pattern: {pattern}').format(
|
||||
pattern=u(exclude),
|
||||
))
|
||||
return 0
|
||||
|
||||
if os.path.isfile(args.targetFile) or args.notfile:
|
||||
if args.entity_type != 'file' or os.path.isfile(args.entity):
|
||||
|
||||
stats = get_file_stats(args.targetFile, notfile=args.notfile)
|
||||
stats = get_file_stats(args.entity, entity_type=args.entity_type,
|
||||
lineno=args.lineno, cursorpos=args.cursorpos)
|
||||
|
||||
project = None
|
||||
if not args.notfile:
|
||||
project = find_project(args.targetFile, configs=configs)
|
||||
project = args.project or args.alternate_project
|
||||
branch = None
|
||||
project_name = args.project_name
|
||||
if project:
|
||||
branch = project.branch()
|
||||
project_name = project.name()
|
||||
if args.entity_type == 'file':
|
||||
project, branch = get_project_info(configs, args)
|
||||
|
||||
if send_heartbeat(
|
||||
project=project_name,
|
||||
branch=branch,
|
||||
stats=stats,
|
||||
**vars(args)
|
||||
):
|
||||
kwargs = vars(args)
|
||||
kwargs['project'] = project
|
||||
kwargs['branch'] = branch
|
||||
kwargs['stats'] = stats
|
||||
kwargs['hostname'] = args.hostname or socket.gethostname()
|
||||
kwargs['timeout'] = args.timeout
|
||||
|
||||
if send_heartbeat(**kwargs):
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
sent = send_heartbeat(project=heartbeat['project'],
|
||||
targetFile=heartbeat['file'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
isWrite=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
notfile=args.notfile,
|
||||
proxy=args.proxy)
|
||||
sent = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
entity=heartbeat['entity'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
hostname=kwargs['hostname'],
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
isWrite=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
entity_type=heartbeat['type'],
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
timeout=args.timeout,
|
||||
)
|
||||
if not sent:
|
||||
break
|
||||
return 0 # success
|
||||
@ -1,10 +1,9 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.queue
|
||||
~~~~~~~~~~~~~~
|
||||
wakatime.offlinequeue
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Queue for offline time logging.
|
||||
http://wakatime.com
|
||||
Queue for saving heartbeats while offline.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
@ -19,21 +18,28 @@ from time import sleep
|
||||
try:
|
||||
import sqlite3
|
||||
HAS_SQL = True
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
HAS_SQL = False
|
||||
|
||||
from .compat import u
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class Queue(object):
|
||||
DB_FILE = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
db_file = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
table_name = 'heartbeat_1'
|
||||
|
||||
def get_db_file(self):
|
||||
return self.db_file
|
||||
|
||||
def connect(self):
|
||||
conn = sqlite3.connect(self.DB_FILE)
|
||||
conn = sqlite3.connect(self.get_db_file())
|
||||
c = conn.cursor()
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS heartbeat (
|
||||
file text,
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS {0} (
|
||||
entity text,
|
||||
type text,
|
||||
time real,
|
||||
project text,
|
||||
branch text,
|
||||
@ -41,34 +47,33 @@ class Queue(object):
|
||||
stats text,
|
||||
misc text,
|
||||
plugin text)
|
||||
''')
|
||||
'''.format(self.table_name))
|
||||
return (conn, c)
|
||||
|
||||
|
||||
def push(self, data, stats, plugin, misc=None):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
heartbeat = {
|
||||
'file': data.get('file'),
|
||||
'entity': u(data.get('entity')),
|
||||
'type': u(data.get('type')),
|
||||
'time': data.get('time'),
|
||||
'project': data.get('project'),
|
||||
'branch': data.get('branch'),
|
||||
'project': u(data.get('project')),
|
||||
'branch': u(data.get('branch')),
|
||||
'is_write': 1 if data.get('is_write') else 0,
|
||||
'stats': stats,
|
||||
'misc': misc,
|
||||
'plugin': plugin,
|
||||
'stats': u(stats),
|
||||
'misc': u(misc),
|
||||
'plugin': u(plugin),
|
||||
}
|
||||
c.execute('INSERT INTO heartbeat VALUES (:file,:time,:project,:branch,:is_write,:stats,:misc,:plugin)', heartbeat)
|
||||
c.execute('INSERT INTO {0} VALUES (:entity,:type,:time,:project,:branch,:is_write,:stats,:misc,:plugin)'.format(self.table_name), heartbeat)
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
|
||||
def pop(self):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return None
|
||||
tries = 3
|
||||
wait = 0.1
|
||||
@ -82,42 +87,43 @@ class Queue(object):
|
||||
while loop and tries > -1:
|
||||
try:
|
||||
c.execute('BEGIN IMMEDIATE')
|
||||
c.execute('SELECT * FROM heartbeat LIMIT 1')
|
||||
c.execute('SELECT * FROM {0} LIMIT 1'.format(self.table_name))
|
||||
row = c.fetchone()
|
||||
if row is not None:
|
||||
values = []
|
||||
clauses = []
|
||||
index = 0
|
||||
for row_name in ['file', 'time', 'project', 'branch', 'is_write']:
|
||||
for row_name in ['entity', 'type', 'time', 'project', 'branch', 'is_write']:
|
||||
if row[index] is not None:
|
||||
clauses.append('{0}=?'.format(row_name))
|
||||
values.append(row[index])
|
||||
else:
|
||||
else: # pragma: nocover
|
||||
clauses.append('{0} IS NULL'.format(row_name))
|
||||
index += 1
|
||||
if len(values) > 0:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)), values)
|
||||
else:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)))
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)), values)
|
||||
else: # pragma: nocover
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)))
|
||||
conn.commit()
|
||||
if row is not None:
|
||||
heartbeat = {
|
||||
'file': row[0],
|
||||
'time': row[1],
|
||||
'project': row[2],
|
||||
'branch': row[3],
|
||||
'is_write': True if row[4] is 1 else False,
|
||||
'stats': row[5],
|
||||
'misc': row[6],
|
||||
'plugin': row[7],
|
||||
'entity': row[0],
|
||||
'type': row[1],
|
||||
'time': row[2],
|
||||
'project': row[3],
|
||||
'branch': row[4],
|
||||
'is_write': True if row[5] is 1 else False,
|
||||
'stats': row[6],
|
||||
'misc': row[7],
|
||||
'plugin': row[8],
|
||||
}
|
||||
loop = False
|
||||
except sqlite3.Error:
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.debug(traceback.format_exc())
|
||||
sleep(wait)
|
||||
tries -= 1
|
||||
try:
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.debug(traceback.format_exc())
|
||||
return heartbeat
|
||||
|
||||
@ -61,7 +61,12 @@ considered public as object names -- the API of the formatter objects is
|
||||
still considered an implementation detail.)
|
||||
"""
|
||||
|
||||
__version__ = '1.2.1'
|
||||
__version__ = '1.3.0' # we use our own version number independant of the
|
||||
# one in stdlib and we release this on pypi.
|
||||
|
||||
__external_lib__ = True # to make sure the tests really test THIS lib,
|
||||
# not the builtin one in Python stdlib
|
||||
|
||||
__all__ = [
|
||||
'ArgumentParser',
|
||||
'ArgumentError',
|
||||
@ -1045,9 +1050,13 @@ class _SubParsersAction(Action):
|
||||
|
||||
class _ChoicesPseudoAction(Action):
|
||||
|
||||
def __init__(self, name, help):
|
||||
def __init__(self, name, aliases, help):
|
||||
metavar = dest = name
|
||||
if aliases:
|
||||
metavar += ' (%s)' % ', '.join(aliases)
|
||||
sup = super(_SubParsersAction._ChoicesPseudoAction, self)
|
||||
sup.__init__(option_strings=[], dest=name, help=help)
|
||||
sup.__init__(option_strings=[], dest=dest, help=help,
|
||||
metavar=metavar)
|
||||
|
||||
def __init__(self,
|
||||
option_strings,
|
||||
@ -1075,15 +1084,22 @@ class _SubParsersAction(Action):
|
||||
if kwargs.get('prog') is None:
|
||||
kwargs['prog'] = '%s %s' % (self._prog_prefix, name)
|
||||
|
||||
aliases = kwargs.pop('aliases', ())
|
||||
|
||||
# create a pseudo-action to hold the choice help
|
||||
if 'help' in kwargs:
|
||||
help = kwargs.pop('help')
|
||||
choice_action = self._ChoicesPseudoAction(name, help)
|
||||
choice_action = self._ChoicesPseudoAction(name, aliases, help)
|
||||
self._choices_actions.append(choice_action)
|
||||
|
||||
# create the parser and add it to the map
|
||||
parser = self._parser_class(**kwargs)
|
||||
self._name_parser_map[name] = parser
|
||||
|
||||
# make parser available under aliases also
|
||||
for alias in aliases:
|
||||
self._name_parser_map[alias] = parser
|
||||
|
||||
return parser
|
||||
|
||||
def _get_subactions(self):
|
||||
|
||||
@ -6,7 +6,7 @@
|
||||
# /
|
||||
|
||||
"""
|
||||
requests HTTP library
|
||||
Requests HTTP library
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Requests is an HTTP library, written in Python, for human beings. Basic GET
|
||||
@ -42,8 +42,8 @@ is at <http://python-requests.org>.
|
||||
"""
|
||||
|
||||
__title__ = 'requests'
|
||||
__version__ = '2.6.0'
|
||||
__build__ = 0x020503
|
||||
__version__ = '2.7.0'
|
||||
__build__ = 0x020700
|
||||
__author__ = 'Kenneth Reitz'
|
||||
__license__ = 'Apache 2.0'
|
||||
__copyright__ = 'Copyright 2015 Kenneth Reitz'
|
||||
|
||||
@ -35,6 +35,7 @@ from .auth import _basic_auth_str
|
||||
DEFAULT_POOLBLOCK = False
|
||||
DEFAULT_POOLSIZE = 10
|
||||
DEFAULT_RETRIES = 0
|
||||
DEFAULT_POOL_TIMEOUT = None
|
||||
|
||||
|
||||
class BaseAdapter(object):
|
||||
@ -375,7 +376,7 @@ class HTTPAdapter(BaseAdapter):
|
||||
if hasattr(conn, 'proxy_pool'):
|
||||
conn = conn.proxy_pool
|
||||
|
||||
low_conn = conn._get_conn(timeout=timeout)
|
||||
low_conn = conn._get_conn(timeout=DEFAULT_POOL_TIMEOUT)
|
||||
|
||||
try:
|
||||
low_conn.putrequest(request.method,
|
||||
@ -407,9 +408,6 @@ class HTTPAdapter(BaseAdapter):
|
||||
# Then, reraise so that we can handle the actual exception.
|
||||
low_conn.close()
|
||||
raise
|
||||
else:
|
||||
# All is well, return the connection to the pool.
|
||||
conn._put_conn(low_conn)
|
||||
|
||||
except (ProtocolError, socket.error) as err:
|
||||
raise ConnectionError(err, request=request)
|
||||
|
||||
@ -55,17 +55,18 @@ def request(method, url, **kwargs):
|
||||
return response
|
||||
|
||||
|
||||
def get(url, **kwargs):
|
||||
def get(url, params=None, **kwargs):
|
||||
"""Sends a GET request.
|
||||
|
||||
:param url: URL for the new :class:`Request` object.
|
||||
:param params: (optional) Dictionary or bytes to be sent in the query string for the :class:`Request`.
|
||||
:param \*\*kwargs: Optional arguments that ``request`` takes.
|
||||
:return: :class:`Response <Response>` object
|
||||
:rtype: requests.Response
|
||||
"""
|
||||
|
||||
kwargs.setdefault('allow_redirects', True)
|
||||
return request('get', url, **kwargs)
|
||||
return request('get', url, params=params, **kwargs)
|
||||
|
||||
|
||||
def options(url, **kwargs):
|
||||
|
||||
@ -103,7 +103,8 @@ class HTTPDigestAuth(AuthBase):
|
||||
# XXX not implemented yet
|
||||
entdig = None
|
||||
p_parsed = urlparse(url)
|
||||
path = p_parsed.path
|
||||
#: path is request-uri defined in RFC 2616 which should not be empty
|
||||
path = p_parsed.path or "/"
|
||||
if p_parsed.query:
|
||||
path += '?' + p_parsed.query
|
||||
|
||||
@ -178,7 +179,7 @@ class HTTPDigestAuth(AuthBase):
|
||||
# Consume content and release the original connection
|
||||
# to allow our new request to reuse the same one.
|
||||
r.content
|
||||
r.raw.release_conn()
|
||||
r.close()
|
||||
prep = r.request.copy()
|
||||
extract_cookies_to_jar(prep._cookies, r.request, r.raw)
|
||||
prep.prepare_cookies(prep._cookies)
|
||||
|
||||
@ -11,6 +11,7 @@ If you are packaging Requests, e.g., for a Linux distribution or a managed
|
||||
environment, you can change the definition of where() to return a separately
|
||||
packaged CA bundle.
|
||||
"""
|
||||
import sys
|
||||
import os.path
|
||||
|
||||
try:
|
||||
@ -19,7 +20,9 @@ except ImportError:
|
||||
def where():
|
||||
"""Return the preferred certificate bundle."""
|
||||
# vendored bundle inside Requests
|
||||
return os.path.join(os.path.dirname(__file__), 'cacert.pem')
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
cacert = os.path.join(os.path.dirname(__file__), 'cacert.pem')
|
||||
return cacert.encode('utf-8') if is_py3 else cacert
|
||||
|
||||
if __name__ == '__main__':
|
||||
print(where())
|
||||
|
||||
@ -6,6 +6,7 @@ Compatibility code to be able to use `cookielib.CookieJar` with requests.
|
||||
requests.utils imports from here, so be careful with imports.
|
||||
"""
|
||||
|
||||
import copy
|
||||
import time
|
||||
import collections
|
||||
from .compat import cookielib, urlparse, urlunparse, Morsel
|
||||
@ -302,7 +303,7 @@ class RequestsCookieJar(cookielib.CookieJar, collections.MutableMapping):
|
||||
"""Updates this jar with cookies from another CookieJar or dict-like"""
|
||||
if isinstance(other, cookielib.CookieJar):
|
||||
for cookie in other:
|
||||
self.set_cookie(cookie)
|
||||
self.set_cookie(copy.copy(cookie))
|
||||
else:
|
||||
super(RequestsCookieJar, self).update(other)
|
||||
|
||||
@ -359,6 +360,21 @@ class RequestsCookieJar(cookielib.CookieJar, collections.MutableMapping):
|
||||
return new_cj
|
||||
|
||||
|
||||
def _copy_cookie_jar(jar):
|
||||
if jar is None:
|
||||
return None
|
||||
|
||||
if hasattr(jar, 'copy'):
|
||||
# We're dealing with an instane of RequestsCookieJar
|
||||
return jar.copy()
|
||||
# We're dealing with a generic CookieJar instance
|
||||
new_jar = copy.copy(jar)
|
||||
new_jar.clear()
|
||||
for cookie in jar:
|
||||
new_jar.set_cookie(copy.copy(cookie))
|
||||
return new_jar
|
||||
|
||||
|
||||
def create_cookie(name, value, **kwargs):
|
||||
"""Make a cookie from underspecified parameters.
|
||||
|
||||
@ -399,11 +415,14 @@ def morsel_to_cookie(morsel):
|
||||
|
||||
expires = None
|
||||
if morsel['max-age']:
|
||||
expires = time.time() + morsel['max-age']
|
||||
try:
|
||||
expires = int(time.time() + int(morsel['max-age']))
|
||||
except ValueError:
|
||||
raise TypeError('max-age: %s must be integer' % morsel['max-age'])
|
||||
elif morsel['expires']:
|
||||
time_template = '%a, %d-%b-%Y %H:%M:%S GMT'
|
||||
expires = time.mktime(
|
||||
time.strptime(morsel['expires'], time_template)) - time.timezone
|
||||
expires = int(time.mktime(
|
||||
time.strptime(morsel['expires'], time_template)) - time.timezone)
|
||||
return create_cookie(
|
||||
comment=morsel['comment'],
|
||||
comment_url=bool(morsel['comment']),
|
||||
|
||||
@ -15,7 +15,7 @@ from .hooks import default_hooks
|
||||
from .structures import CaseInsensitiveDict
|
||||
|
||||
from .auth import HTTPBasicAuth
|
||||
from .cookies import cookiejar_from_dict, get_cookie_header
|
||||
from .cookies import cookiejar_from_dict, get_cookie_header, _copy_cookie_jar
|
||||
from .packages.urllib3.fields import RequestField
|
||||
from .packages.urllib3.filepost import encode_multipart_formdata
|
||||
from .packages.urllib3.util import parse_url
|
||||
@ -30,7 +30,8 @@ from .utils import (
|
||||
iter_slices, guess_json_utf, super_len, to_native_string)
|
||||
from .compat import (
|
||||
cookielib, urlunparse, urlsplit, urlencode, str, bytes, StringIO,
|
||||
is_py2, chardet, json, builtin_str, basestring)
|
||||
is_py2, chardet, builtin_str, basestring)
|
||||
from .compat import json as complexjson
|
||||
from .status_codes import codes
|
||||
|
||||
#: The set of HTTP status codes that indicate an automatically
|
||||
@ -42,12 +43,11 @@ REDIRECT_STATI = (
|
||||
codes.temporary_redirect, # 307
|
||||
codes.permanent_redirect, # 308
|
||||
)
|
||||
|
||||
DEFAULT_REDIRECT_LIMIT = 30
|
||||
CONTENT_CHUNK_SIZE = 10 * 1024
|
||||
ITER_CHUNK_SIZE = 512
|
||||
|
||||
json_dumps = json.dumps
|
||||
|
||||
|
||||
class RequestEncodingMixin(object):
|
||||
@property
|
||||
@ -149,8 +149,7 @@ class RequestEncodingMixin(object):
|
||||
else:
|
||||
fdata = fp.read()
|
||||
|
||||
rf = RequestField(name=k, data=fdata,
|
||||
filename=fn, headers=fh)
|
||||
rf = RequestField(name=k, data=fdata, filename=fn, headers=fh)
|
||||
rf.make_multipart(content_type=ft)
|
||||
new_fields.append(rf)
|
||||
|
||||
@ -207,17 +206,8 @@ class Request(RequestHooksMixin):
|
||||
<PreparedRequest [GET]>
|
||||
|
||||
"""
|
||||
def __init__(self,
|
||||
method=None,
|
||||
url=None,
|
||||
headers=None,
|
||||
files=None,
|
||||
data=None,
|
||||
params=None,
|
||||
auth=None,
|
||||
cookies=None,
|
||||
hooks=None,
|
||||
json=None):
|
||||
def __init__(self, method=None, url=None, headers=None, files=None,
|
||||
data=None, params=None, auth=None, cookies=None, hooks=None, json=None):
|
||||
|
||||
# Default empty dicts for dict params.
|
||||
data = [] if data is None else data
|
||||
@ -296,8 +286,7 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
self.hooks = default_hooks()
|
||||
|
||||
def prepare(self, method=None, url=None, headers=None, files=None,
|
||||
data=None, params=None, auth=None, cookies=None, hooks=None,
|
||||
json=None):
|
||||
data=None, params=None, auth=None, cookies=None, hooks=None, json=None):
|
||||
"""Prepares the entire request with the given parameters."""
|
||||
|
||||
self.prepare_method(method)
|
||||
@ -306,6 +295,7 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
self.prepare_cookies(cookies)
|
||||
self.prepare_body(data, files, json)
|
||||
self.prepare_auth(auth, url)
|
||||
|
||||
# Note that prepare_auth must be last to enable authentication schemes
|
||||
# such as OAuth to work on a fully prepared request.
|
||||
|
||||
@ -320,7 +310,7 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
p.method = self.method
|
||||
p.url = self.url
|
||||
p.headers = self.headers.copy() if self.headers is not None else None
|
||||
p._cookies = self._cookies.copy() if self._cookies is not None else None
|
||||
p._cookies = _copy_cookie_jar(self._cookies)
|
||||
p.body = self.body
|
||||
p.hooks = self.hooks
|
||||
return p
|
||||
@ -357,8 +347,10 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
raise InvalidURL(*e.args)
|
||||
|
||||
if not scheme:
|
||||
raise MissingSchema("Invalid URL {0!r}: No schema supplied. "
|
||||
"Perhaps you meant http://{0}?".format(url))
|
||||
error = ("Invalid URL {0!r}: No schema supplied. Perhaps you meant http://{0}?")
|
||||
error = error.format(to_native_string(url, 'utf8'))
|
||||
|
||||
raise MissingSchema(error)
|
||||
|
||||
if not host:
|
||||
raise InvalidURL("Invalid URL %r: No host supplied" % url)
|
||||
@ -424,7 +416,7 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
|
||||
if json is not None:
|
||||
content_type = 'application/json'
|
||||
body = json_dumps(json)
|
||||
body = complexjson.dumps(json)
|
||||
|
||||
is_stream = all([
|
||||
hasattr(data, '__iter__'),
|
||||
@ -501,7 +493,15 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
self.prepare_content_length(self.body)
|
||||
|
||||
def prepare_cookies(self, cookies):
|
||||
"""Prepares the given HTTP cookie data."""
|
||||
"""Prepares the given HTTP cookie data.
|
||||
|
||||
This function eventually generates a ``Cookie`` header from the
|
||||
given cookies using cookielib. Due to cookielib's design, the header
|
||||
will not be regenerated if it already exists, meaning this function
|
||||
can only be called once for the life of the
|
||||
:class:`PreparedRequest <PreparedRequest>` object. Any subsequent calls
|
||||
to ``prepare_cookies`` will have no actual effect, unless the "Cookie"
|
||||
header is removed beforehand."""
|
||||
|
||||
if isinstance(cookies, cookielib.CookieJar):
|
||||
self._cookies = cookies
|
||||
@ -514,6 +514,10 @@ class PreparedRequest(RequestEncodingMixin, RequestHooksMixin):
|
||||
|
||||
def prepare_hooks(self, hooks):
|
||||
"""Prepares the given hooks."""
|
||||
# hooks can be passed as None to the prepare method and to this
|
||||
# method. To prevent iterating over None, simply use an empty list
|
||||
# if hooks is False-y
|
||||
hooks = hooks or []
|
||||
for event in hooks:
|
||||
self.register_hook(event, hooks[event])
|
||||
|
||||
@ -524,16 +528,8 @@ class Response(object):
|
||||
"""
|
||||
|
||||
__attrs__ = [
|
||||
'_content',
|
||||
'status_code',
|
||||
'headers',
|
||||
'url',
|
||||
'history',
|
||||
'encoding',
|
||||
'reason',
|
||||
'cookies',
|
||||
'elapsed',
|
||||
'request',
|
||||
'_content', 'status_code', 'headers', 'url', 'history',
|
||||
'encoding', 'reason', 'cookies', 'elapsed', 'request'
|
||||
]
|
||||
|
||||
def __init__(self):
|
||||
@ -653,9 +649,10 @@ class Response(object):
|
||||
If decode_unicode is True, content will be decoded using the best
|
||||
available encoding based on the response.
|
||||
"""
|
||||
|
||||
def generate():
|
||||
try:
|
||||
# Special case for urllib3.
|
||||
# Special case for urllib3.
|
||||
if hasattr(self.raw, 'stream'):
|
||||
try:
|
||||
for chunk in self.raw.stream(chunk_size, decode_content=True):
|
||||
yield chunk
|
||||
@ -665,7 +662,7 @@ class Response(object):
|
||||
raise ContentDecodingError(e)
|
||||
except ReadTimeoutError as e:
|
||||
raise ConnectionError(e)
|
||||
except AttributeError:
|
||||
else:
|
||||
# Standard file-like object.
|
||||
while True:
|
||||
chunk = self.raw.read(chunk_size)
|
||||
@ -796,14 +793,16 @@ class Response(object):
|
||||
encoding = guess_json_utf(self.content)
|
||||
if encoding is not None:
|
||||
try:
|
||||
return json.loads(self.content.decode(encoding), **kwargs)
|
||||
return complexjson.loads(
|
||||
self.content.decode(encoding), **kwargs
|
||||
)
|
||||
except UnicodeDecodeError:
|
||||
# Wrong UTF codec detected; usually because it's not UTF-8
|
||||
# but some other 8-bit codec. This is an RFC violation,
|
||||
# and the server didn't bother to tell us what codec *was*
|
||||
# used.
|
||||
pass
|
||||
return json.loads(self.text, **kwargs)
|
||||
return complexjson.loads(self.text, **kwargs)
|
||||
|
||||
@property
|
||||
def links(self):
|
||||
@ -829,10 +828,10 @@ class Response(object):
|
||||
http_error_msg = ''
|
||||
|
||||
if 400 <= self.status_code < 500:
|
||||
http_error_msg = '%s Client Error: %s' % (self.status_code, self.reason)
|
||||
http_error_msg = '%s Client Error: %s for url: %s' % (self.status_code, self.reason, self.url)
|
||||
|
||||
elif 500 <= self.status_code < 600:
|
||||
http_error_msg = '%s Server Error: %s' % (self.status_code, self.reason)
|
||||
http_error_msg = '%s Server Error: %s for url: %s' % (self.status_code, self.reason, self.url)
|
||||
|
||||
if http_error_msg:
|
||||
raise HTTPError(http_error_msg, response=self)
|
||||
@ -843,4 +842,7 @@ class Response(object):
|
||||
|
||||
*Note: Should not normally need to be called explicitly.*
|
||||
"""
|
||||
if not self._content_consumed:
|
||||
return self.raw.close()
|
||||
|
||||
return self.raw.release_conn()
|
||||
|
||||
@ -1,107 +1,3 @@
|
||||
"""
|
||||
Copyright (c) Donald Stufft, pip, and individual contributors
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining
|
||||
a copy of this software and associated documentation files (the
|
||||
"Software"), to deal in the Software without restriction, including
|
||||
without limitation the rights to use, copy, modify, merge, publish,
|
||||
distribute, sublicense, and/or sell copies of the Software, and to
|
||||
permit persons to whom the Software is furnished to do so, subject to
|
||||
the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be
|
||||
included in all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
|
||||
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
|
||||
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
|
||||
LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
|
||||
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
|
||||
WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
"""
|
||||
from __future__ import absolute_import
|
||||
|
||||
import sys
|
||||
|
||||
|
||||
class VendorAlias(object):
|
||||
|
||||
def __init__(self, package_names):
|
||||
self._package_names = package_names
|
||||
self._vendor_name = __name__
|
||||
self._vendor_pkg = self._vendor_name + "."
|
||||
self._vendor_pkgs = [
|
||||
self._vendor_pkg + name for name in self._package_names
|
||||
]
|
||||
|
||||
def find_module(self, fullname, path=None):
|
||||
if fullname.startswith(self._vendor_pkg):
|
||||
return self
|
||||
|
||||
def load_module(self, name):
|
||||
# Ensure that this only works for the vendored name
|
||||
if not name.startswith(self._vendor_pkg):
|
||||
raise ImportError(
|
||||
"Cannot import %s, must be a subpackage of '%s'." % (
|
||||
name, self._vendor_name,
|
||||
)
|
||||
)
|
||||
|
||||
if not (name == self._vendor_name or
|
||||
any(name.startswith(pkg) for pkg in self._vendor_pkgs)):
|
||||
raise ImportError(
|
||||
"Cannot import %s, must be one of %s." % (
|
||||
name, self._vendor_pkgs
|
||||
)
|
||||
)
|
||||
|
||||
# Check to see if we already have this item in sys.modules, if we do
|
||||
# then simply return that.
|
||||
if name in sys.modules:
|
||||
return sys.modules[name]
|
||||
|
||||
# Check to see if we can import the vendor name
|
||||
try:
|
||||
# We do this dance here because we want to try and import this
|
||||
# module without hitting a recursion error because of a bunch of
|
||||
# VendorAlias instances on sys.meta_path
|
||||
real_meta_path = sys.meta_path[:]
|
||||
try:
|
||||
sys.meta_path = [
|
||||
m for m in sys.meta_path
|
||||
if not isinstance(m, VendorAlias)
|
||||
]
|
||||
__import__(name)
|
||||
module = sys.modules[name]
|
||||
finally:
|
||||
# Re-add any additions to sys.meta_path that were made while
|
||||
# during the import we just did, otherwise things like
|
||||
# requests.packages.urllib3.poolmanager will fail.
|
||||
for m in sys.meta_path:
|
||||
if m not in real_meta_path:
|
||||
real_meta_path.append(m)
|
||||
|
||||
# Restore sys.meta_path with any new items.
|
||||
sys.meta_path = real_meta_path
|
||||
except ImportError:
|
||||
# We can't import the vendor name, so we'll try to import the
|
||||
# "real" name.
|
||||
real_name = name[len(self._vendor_pkg):]
|
||||
try:
|
||||
__import__(real_name)
|
||||
module = sys.modules[real_name]
|
||||
except ImportError:
|
||||
raise ImportError("No module named '%s'" % (name,))
|
||||
|
||||
# If we've gotten here we've found the module we're looking for, either
|
||||
# as part of our vendored package, or as the real name, so we'll add
|
||||
# it to sys.modules as the vendored name so that we don't have to do
|
||||
# the lookup again.
|
||||
sys.modules[name] = module
|
||||
|
||||
# Finally, return the loaded module
|
||||
return module
|
||||
|
||||
|
||||
sys.meta_path.append(VendorAlias(["urllib3", "chardet"]))
|
||||
from . import urllib3
|
||||
|
||||
@ -4,7 +4,7 @@ urllib3 - Thread-safe connection pooling and re-using.
|
||||
|
||||
__author__ = 'Andrey Petrov (andrey.petrov@shazow.net)'
|
||||
__license__ = 'MIT'
|
||||
__version__ = '1.10.2'
|
||||
__version__ = '1.10.4'
|
||||
|
||||
|
||||
from .connectionpool import (
|
||||
@ -55,9 +55,12 @@ def add_stderr_logger(level=logging.DEBUG):
|
||||
del NullHandler
|
||||
|
||||
|
||||
# Set security warning to always go off by default.
|
||||
import warnings
|
||||
warnings.simplefilter('always', exceptions.SecurityWarning)
|
||||
# SecurityWarning's always go off by default.
|
||||
warnings.simplefilter('always', exceptions.SecurityWarning, append=True)
|
||||
# InsecurePlatformWarning's don't vary between requests, so we keep it default.
|
||||
warnings.simplefilter('default', exceptions.InsecurePlatformWarning,
|
||||
append=True)
|
||||
|
||||
def disable_warnings(category=exceptions.HTTPWarning):
|
||||
"""
|
||||
|
||||
@ -227,20 +227,20 @@ class HTTPHeaderDict(dict):
|
||||
# Need to convert the tuple to list for further extension
|
||||
_dict_setitem(self, key_lower, [vals[0], vals[1], val])
|
||||
|
||||
def extend(*args, **kwargs):
|
||||
def extend(self, *args, **kwargs):
|
||||
"""Generic import function for any type of header-like object.
|
||||
Adapted version of MutableMapping.update in order to insert items
|
||||
with self.add instead of self.__setitem__
|
||||
"""
|
||||
if len(args) > 2:
|
||||
raise TypeError("update() takes at most 2 positional "
|
||||
if len(args) > 1:
|
||||
raise TypeError("extend() takes at most 1 positional "
|
||||
"arguments ({} given)".format(len(args)))
|
||||
elif not args:
|
||||
raise TypeError("update() takes at least 1 argument (0 given)")
|
||||
self = args[0]
|
||||
other = args[1] if len(args) >= 2 else ()
|
||||
other = args[0] if len(args) >= 1 else ()
|
||||
|
||||
if isinstance(other, Mapping):
|
||||
if isinstance(other, HTTPHeaderDict):
|
||||
for key, val in other.iteritems():
|
||||
self.add(key, val)
|
||||
elif isinstance(other, Mapping):
|
||||
for key in other:
|
||||
self.add(key, other[key])
|
||||
elif hasattr(other, "keys"):
|
||||
@ -304,17 +304,20 @@ class HTTPHeaderDict(dict):
|
||||
return list(self.iteritems())
|
||||
|
||||
@classmethod
|
||||
def from_httplib(cls, message, duplicates=('set-cookie',)): # Python 2
|
||||
def from_httplib(cls, message): # Python 2
|
||||
"""Read headers from a Python 2 httplib message object."""
|
||||
ret = cls(message.items())
|
||||
# ret now contains only the last header line for each duplicate.
|
||||
# Importing with all duplicates would be nice, but this would
|
||||
# mean to repeat most of the raw parsing already done, when the
|
||||
# message object was created. Extracting only the headers of interest
|
||||
# separately, the cookies, should be faster and requires less
|
||||
# extra code.
|
||||
for key in duplicates:
|
||||
ret.discard(key)
|
||||
for val in message.getheaders(key):
|
||||
ret.add(key, val)
|
||||
return ret
|
||||
# python2.7 does not expose a proper API for exporting multiheaders
|
||||
# efficiently. This function re-reads raw lines from the message
|
||||
# object and extracts the multiheaders properly.
|
||||
headers = []
|
||||
|
||||
for line in message.headers:
|
||||
if line.startswith((' ', '\t')):
|
||||
key, value = headers[-1]
|
||||
headers[-1] = (key, value + '\r\n' + line.rstrip())
|
||||
continue
|
||||
|
||||
key, value = line.split(':', 1)
|
||||
headers.append((key, value.strip()))
|
||||
|
||||
return cls(headers)
|
||||
|
||||
@ -260,3 +260,5 @@ if ssl:
|
||||
# Make a copy for testing.
|
||||
UnverifiedHTTPSConnection = HTTPSConnection
|
||||
HTTPSConnection = VerifiedHTTPSConnection
|
||||
else:
|
||||
HTTPSConnection = DummyConnection
|
||||
|
||||
@ -735,7 +735,6 @@ class HTTPSConnectionPool(HTTPConnectionPool):
|
||||
% (self.num_connections, self.host))
|
||||
|
||||
if not self.ConnectionCls or self.ConnectionCls is DummyConnection:
|
||||
# Platform-specific: Python without ssl
|
||||
raise SSLError("Can't connect to HTTPS URL because the SSL "
|
||||
"module is not available.")
|
||||
|
||||
|
||||
@ -38,8 +38,6 @@ Module Variables
|
||||
----------------
|
||||
|
||||
:var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.
|
||||
Default: ``ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:
|
||||
ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+3DES:!aNULL:!MD5:!DSS``
|
||||
|
||||
.. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication
|
||||
.. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)
|
||||
@ -85,22 +83,7 @@ _openssl_verify = {
|
||||
+ OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,
|
||||
}
|
||||
|
||||
# A secure default.
|
||||
# Sources for more information on TLS ciphers:
|
||||
#
|
||||
# - https://wiki.mozilla.org/Security/Server_Side_TLS
|
||||
# - https://www.ssllabs.com/projects/best-practices/index.html
|
||||
# - https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/
|
||||
#
|
||||
# The general intent is:
|
||||
# - Prefer cipher suites that offer perfect forward secrecy (DHE/ECDHE),
|
||||
# - prefer ECDHE over DHE for better performance,
|
||||
# - prefer any AES-GCM over any AES-CBC for better performance and security,
|
||||
# - use 3DES as fallback which is secure but slow,
|
||||
# - disable NULL authentication, MD5 MACs and DSS for security reasons.
|
||||
DEFAULT_SSL_CIPHER_LIST = "ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:" + \
|
||||
"ECDH+AES128:DH+AES:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+3DES:" + \
|
||||
"!aNULL:!MD5:!DSS"
|
||||
DEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS
|
||||
|
||||
|
||||
orig_util_HAS_SNI = util.HAS_SNI
|
||||
@ -299,7 +282,9 @@ def ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,
|
||||
try:
|
||||
cnx.do_handshake()
|
||||
except OpenSSL.SSL.WantReadError:
|
||||
select.select([sock], [], [])
|
||||
rd, _, _ = select.select([sock], [], [], sock.gettimeout())
|
||||
if not rd:
|
||||
raise timeout('select timed out')
|
||||
continue
|
||||
except OpenSSL.SSL.Error as e:
|
||||
raise ssl.SSLError('bad handshake', e)
|
||||
|
||||
@ -162,3 +162,8 @@ class SystemTimeWarning(SecurityWarning):
|
||||
class InsecurePlatformWarning(SecurityWarning):
|
||||
"Warned when certain SSL configuration is not available on a platform."
|
||||
pass
|
||||
|
||||
|
||||
class ResponseNotChunked(ProtocolError, ValueError):
|
||||
"Response needs to be chunked in order to read it as chunks."
|
||||
pass
|
||||
|
||||
@ -1,9 +1,15 @@
|
||||
try:
|
||||
import http.client as httplib
|
||||
except ImportError:
|
||||
import httplib
|
||||
import zlib
|
||||
import io
|
||||
from socket import timeout as SocketTimeout
|
||||
|
||||
from ._collections import HTTPHeaderDict
|
||||
from .exceptions import ProtocolError, DecodeError, ReadTimeoutError
|
||||
from .exceptions import (
|
||||
ProtocolError, DecodeError, ReadTimeoutError, ResponseNotChunked
|
||||
)
|
||||
from .packages.six import string_types as basestring, binary_type, PY3
|
||||
from .connection import HTTPException, BaseSSLError
|
||||
from .util.response import is_fp_closed
|
||||
@ -117,7 +123,17 @@ class HTTPResponse(io.IOBase):
|
||||
if hasattr(body, 'read'):
|
||||
self._fp = body
|
||||
|
||||
if preload_content and not self._body:
|
||||
# Are we using the chunked-style of transfer encoding?
|
||||
self.chunked = False
|
||||
self.chunk_left = None
|
||||
tr_enc = self.headers.get('transfer-encoding', '').lower()
|
||||
# Don't incur the penalty of creating a list and then discarding it
|
||||
encodings = (enc.strip() for enc in tr_enc.split(","))
|
||||
if "chunked" in encodings:
|
||||
self.chunked = True
|
||||
|
||||
# We certainly don't want to preload content when the response is chunked.
|
||||
if not self.chunked and preload_content and not self._body:
|
||||
self._body = self.read(decode_content=decode_content)
|
||||
|
||||
def get_redirect_location(self):
|
||||
@ -157,6 +173,35 @@ class HTTPResponse(io.IOBase):
|
||||
"""
|
||||
return self._fp_bytes_read
|
||||
|
||||
def _init_decoder(self):
|
||||
"""
|
||||
Set-up the _decoder attribute if necessar.
|
||||
"""
|
||||
# Note: content-encoding value should be case-insensitive, per RFC 7230
|
||||
# Section 3.2
|
||||
content_encoding = self.headers.get('content-encoding', '').lower()
|
||||
if self._decoder is None and content_encoding in self.CONTENT_DECODERS:
|
||||
self._decoder = _get_decoder(content_encoding)
|
||||
|
||||
def _decode(self, data, decode_content, flush_decoder):
|
||||
"""
|
||||
Decode the data passed in and potentially flush the decoder.
|
||||
"""
|
||||
try:
|
||||
if decode_content and self._decoder:
|
||||
data = self._decoder.decompress(data)
|
||||
except (IOError, zlib.error) as e:
|
||||
content_encoding = self.headers.get('content-encoding', '').lower()
|
||||
raise DecodeError(
|
||||
"Received response with content-encoding: %s, but "
|
||||
"failed to decode it." % content_encoding, e)
|
||||
|
||||
if flush_decoder and decode_content and self._decoder:
|
||||
buf = self._decoder.decompress(binary_type())
|
||||
data += buf + self._decoder.flush()
|
||||
|
||||
return data
|
||||
|
||||
def read(self, amt=None, decode_content=None, cache_content=False):
|
||||
"""
|
||||
Similar to :meth:`httplib.HTTPResponse.read`, but with two additional
|
||||
@ -178,12 +223,7 @@ class HTTPResponse(io.IOBase):
|
||||
after having ``.read()`` the file object. (Overridden if ``amt`` is
|
||||
set.)
|
||||
"""
|
||||
# Note: content-encoding value should be case-insensitive, per RFC 7230
|
||||
# Section 3.2
|
||||
content_encoding = self.headers.get('content-encoding', '').lower()
|
||||
if self._decoder is None:
|
||||
if content_encoding in self.CONTENT_DECODERS:
|
||||
self._decoder = _get_decoder(content_encoding)
|
||||
self._init_decoder()
|
||||
if decode_content is None:
|
||||
decode_content = self.decode_content
|
||||
|
||||
@ -232,17 +272,7 @@ class HTTPResponse(io.IOBase):
|
||||
|
||||
self._fp_bytes_read += len(data)
|
||||
|
||||
try:
|
||||
if decode_content and self._decoder:
|
||||
data = self._decoder.decompress(data)
|
||||
except (IOError, zlib.error) as e:
|
||||
raise DecodeError(
|
||||
"Received response with content-encoding: %s, but "
|
||||
"failed to decode it." % content_encoding, e)
|
||||
|
||||
if flush_decoder and decode_content and self._decoder:
|
||||
buf = self._decoder.decompress(binary_type())
|
||||
data += buf + self._decoder.flush()
|
||||
data = self._decode(data, decode_content, flush_decoder)
|
||||
|
||||
if cache_content:
|
||||
self._body = data
|
||||
@ -269,11 +299,15 @@ class HTTPResponse(io.IOBase):
|
||||
If True, will attempt to decode the body based on the
|
||||
'content-encoding' header.
|
||||
"""
|
||||
while not is_fp_closed(self._fp):
|
||||
data = self.read(amt=amt, decode_content=decode_content)
|
||||
if self.chunked:
|
||||
for line in self.read_chunked(amt, decode_content=decode_content):
|
||||
yield line
|
||||
else:
|
||||
while not is_fp_closed(self._fp):
|
||||
data = self.read(amt=amt, decode_content=decode_content)
|
||||
|
||||
if data:
|
||||
yield data
|
||||
if data:
|
||||
yield data
|
||||
|
||||
@classmethod
|
||||
def from_httplib(ResponseCls, r, **response_kw):
|
||||
@ -351,3 +385,82 @@ class HTTPResponse(io.IOBase):
|
||||
else:
|
||||
b[:len(temp)] = temp
|
||||
return len(temp)
|
||||
|
||||
def _update_chunk_length(self):
|
||||
# First, we'll figure out length of a chunk and then
|
||||
# we'll try to read it from socket.
|
||||
if self.chunk_left is not None:
|
||||
return
|
||||
line = self._fp.fp.readline()
|
||||
line = line.split(b';', 1)[0]
|
||||
try:
|
||||
self.chunk_left = int(line, 16)
|
||||
except ValueError:
|
||||
# Invalid chunked protocol response, abort.
|
||||
self.close()
|
||||
raise httplib.IncompleteRead(line)
|
||||
|
||||
def _handle_chunk(self, amt):
|
||||
returned_chunk = None
|
||||
if amt is None:
|
||||
chunk = self._fp._safe_read(self.chunk_left)
|
||||
returned_chunk = chunk
|
||||
self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
|
||||
self.chunk_left = None
|
||||
elif amt < self.chunk_left:
|
||||
value = self._fp._safe_read(amt)
|
||||
self.chunk_left = self.chunk_left - amt
|
||||
returned_chunk = value
|
||||
elif amt == self.chunk_left:
|
||||
value = self._fp._safe_read(amt)
|
||||
self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
|
||||
self.chunk_left = None
|
||||
returned_chunk = value
|
||||
else: # amt > self.chunk_left
|
||||
returned_chunk = self._fp._safe_read(self.chunk_left)
|
||||
self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
|
||||
self.chunk_left = None
|
||||
return returned_chunk
|
||||
|
||||
def read_chunked(self, amt=None, decode_content=None):
|
||||
"""
|
||||
Similar to :meth:`HTTPResponse.read`, but with an additional
|
||||
parameter: ``decode_content``.
|
||||
|
||||
:param decode_content:
|
||||
If True, will attempt to decode the body based on the
|
||||
'content-encoding' header.
|
||||
"""
|
||||
self._init_decoder()
|
||||
# FIXME: Rewrite this method and make it a class with a better structured logic.
|
||||
if not self.chunked:
|
||||
raise ResponseNotChunked("Response is not chunked. "
|
||||
"Header 'transfer-encoding: chunked' is missing.")
|
||||
|
||||
if self._original_response and self._original_response._method.upper() == 'HEAD':
|
||||
# Don't bother reading the body of a HEAD request.
|
||||
# FIXME: Can we do this somehow without accessing private httplib _method?
|
||||
self._original_response.close()
|
||||
return
|
||||
|
||||
while True:
|
||||
self._update_chunk_length()
|
||||
if self.chunk_left == 0:
|
||||
break
|
||||
chunk = self._handle_chunk(amt)
|
||||
yield self._decode(chunk, decode_content=decode_content,
|
||||
flush_decoder=True)
|
||||
|
||||
# Chunk content ends with \r\n: discard it.
|
||||
while True:
|
||||
line = self._fp.fp.readline()
|
||||
if not line:
|
||||
# Some sites may not end with '\r\n'.
|
||||
break
|
||||
if line == b'\r\n':
|
||||
break
|
||||
|
||||
# We read everything; close the "file".
|
||||
if self._original_response:
|
||||
self._original_response.close()
|
||||
self.release_conn()
|
||||
|
||||
@ -9,10 +9,10 @@ HAS_SNI = False
|
||||
create_default_context = None
|
||||
|
||||
import errno
|
||||
import ssl
|
||||
import warnings
|
||||
|
||||
try: # Test for SSL features
|
||||
import ssl
|
||||
from ssl import wrap_socket, CERT_NONE, PROTOCOL_SSLv23
|
||||
from ssl import HAS_SNI # Has SNI?
|
||||
except ImportError:
|
||||
@ -25,14 +25,24 @@ except ImportError:
|
||||
OP_NO_SSLv2, OP_NO_SSLv3 = 0x1000000, 0x2000000
|
||||
OP_NO_COMPRESSION = 0x20000
|
||||
|
||||
try:
|
||||
from ssl import _DEFAULT_CIPHERS
|
||||
except ImportError:
|
||||
_DEFAULT_CIPHERS = (
|
||||
'ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+HIGH:'
|
||||
'DH+HIGH:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+HIGH:RSA+3DES:!aNULL:'
|
||||
'!eNULL:!MD5'
|
||||
)
|
||||
# A secure default.
|
||||
# Sources for more information on TLS ciphers:
|
||||
#
|
||||
# - https://wiki.mozilla.org/Security/Server_Side_TLS
|
||||
# - https://www.ssllabs.com/projects/best-practices/index.html
|
||||
# - https://hynek.me/articles/hardening-your-web-servers-ssl-ciphers/
|
||||
#
|
||||
# The general intent is:
|
||||
# - Prefer cipher suites that offer perfect forward secrecy (DHE/ECDHE),
|
||||
# - prefer ECDHE over DHE for better performance,
|
||||
# - prefer any AES-GCM over any AES-CBC for better performance and security,
|
||||
# - use 3DES as fallback which is secure but slow,
|
||||
# - disable NULL authentication, MD5 MACs and DSS for security reasons.
|
||||
DEFAULT_CIPHERS = (
|
||||
'ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+HIGH:'
|
||||
'DH+HIGH:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+HIGH:RSA+3DES:!aNULL:'
|
||||
'!eNULL:!MD5'
|
||||
)
|
||||
|
||||
try:
|
||||
from ssl import SSLContext # Modern SSL?
|
||||
@ -40,7 +50,8 @@ except ImportError:
|
||||
import sys
|
||||
|
||||
class SSLContext(object): # Platform-specific: Python 2 & 3.1
|
||||
supports_set_ciphers = sys.version_info >= (2, 7)
|
||||
supports_set_ciphers = ((2, 7) <= sys.version_info < (3,) or
|
||||
(3, 2) <= sys.version_info)
|
||||
|
||||
def __init__(self, protocol_version):
|
||||
self.protocol = protocol_version
|
||||
@ -167,7 +178,7 @@ def resolve_ssl_version(candidate):
|
||||
return candidate
|
||||
|
||||
|
||||
def create_urllib3_context(ssl_version=None, cert_reqs=ssl.CERT_REQUIRED,
|
||||
def create_urllib3_context(ssl_version=None, cert_reqs=None,
|
||||
options=None, ciphers=None):
|
||||
"""All arguments have the same meaning as ``ssl_wrap_socket``.
|
||||
|
||||
@ -204,6 +215,9 @@ def create_urllib3_context(ssl_version=None, cert_reqs=ssl.CERT_REQUIRED,
|
||||
"""
|
||||
context = SSLContext(ssl_version or ssl.PROTOCOL_SSLv23)
|
||||
|
||||
# Setting the default here, as we may have no ssl module on import
|
||||
cert_reqs = ssl.CERT_REQUIRED if cert_reqs is None else cert_reqs
|
||||
|
||||
if options is None:
|
||||
options = 0
|
||||
# SSLv2 is easily broken and is considered harmful and dangerous
|
||||
@ -217,7 +231,7 @@ def create_urllib3_context(ssl_version=None, cert_reqs=ssl.CERT_REQUIRED,
|
||||
context.options |= options
|
||||
|
||||
if getattr(context, 'supports_set_ciphers', True): # Platform-specific: Python 2.6
|
||||
context.set_ciphers(ciphers or _DEFAULT_CIPHERS)
|
||||
context.set_ciphers(ciphers or DEFAULT_CIPHERS)
|
||||
|
||||
context.verify_mode = cert_reqs
|
||||
if getattr(context, 'check_hostname', None) is not None: # Platform-specific: Python 3.2
|
||||
|
||||
@ -15,6 +15,8 @@ class Url(namedtuple('Url', url_attrs)):
|
||||
|
||||
def __new__(cls, scheme=None, auth=None, host=None, port=None, path=None,
|
||||
query=None, fragment=None):
|
||||
if path and not path.startswith('/'):
|
||||
path = '/' + path
|
||||
return super(Url, cls).__new__(cls, scheme, auth, host, port, path,
|
||||
query, fragment)
|
||||
|
||||
|
||||
@ -90,7 +90,7 @@ def merge_hooks(request_hooks, session_hooks, dict_class=OrderedDict):
|
||||
|
||||
class SessionRedirectMixin(object):
|
||||
def resolve_redirects(self, resp, req, stream=False, timeout=None,
|
||||
verify=True, cert=None, proxies=None):
|
||||
verify=True, cert=None, proxies=None, **adapter_kwargs):
|
||||
"""Receives a Response. Returns a generator of Responses."""
|
||||
|
||||
i = 0
|
||||
@ -193,6 +193,7 @@ class SessionRedirectMixin(object):
|
||||
cert=cert,
|
||||
proxies=proxies,
|
||||
allow_redirects=False,
|
||||
**adapter_kwargs
|
||||
)
|
||||
|
||||
extract_cookies_to_jar(self.cookies, prepared_request, resp.raw)
|
||||
@ -560,10 +561,6 @@ class Session(SessionRedirectMixin):
|
||||
# Set up variables needed for resolve_redirects and dispatching of hooks
|
||||
allow_redirects = kwargs.pop('allow_redirects', True)
|
||||
stream = kwargs.get('stream')
|
||||
timeout = kwargs.get('timeout')
|
||||
verify = kwargs.get('verify')
|
||||
cert = kwargs.get('cert')
|
||||
proxies = kwargs.get('proxies')
|
||||
hooks = request.hooks
|
||||
|
||||
# Get the appropriate adapter to use
|
||||
@ -591,12 +588,7 @@ class Session(SessionRedirectMixin):
|
||||
extract_cookies_to_jar(self.cookies, request, r.raw)
|
||||
|
||||
# Redirect resolving generator.
|
||||
gen = self.resolve_redirects(r, request,
|
||||
stream=stream,
|
||||
timeout=timeout,
|
||||
verify=verify,
|
||||
cert=cert,
|
||||
proxies=proxies)
|
||||
gen = self.resolve_redirects(r, request, **kwargs)
|
||||
|
||||
# Resolve redirects if allowed.
|
||||
history = [resp for resp in gen] if allow_redirects else []
|
||||
|
||||
@ -67,7 +67,7 @@ def super_len(o):
|
||||
return len(o.getvalue())
|
||||
|
||||
|
||||
def get_netrc_auth(url):
|
||||
def get_netrc_auth(url, raise_errors=False):
|
||||
"""Returns the Requests tuple auth for a given url from netrc."""
|
||||
|
||||
try:
|
||||
@ -105,8 +105,9 @@ def get_netrc_auth(url):
|
||||
return (_netrc[login_i], _netrc[2])
|
||||
except (NetrcParseError, IOError):
|
||||
# If there was a parsing error or a permissions issue reading the file,
|
||||
# we'll just skip netrc auth
|
||||
pass
|
||||
# we'll just skip netrc auth unless explicitly asked to raise errors.
|
||||
if raise_errors:
|
||||
raise
|
||||
|
||||
# AppEngine hackiness.
|
||||
except (ImportError, AttributeError):
|
||||
|
||||
@ -5,9 +5,8 @@ interchange format.
|
||||
:mod:`simplejson` exposes an API familiar to users of the standard library
|
||||
:mod:`marshal` and :mod:`pickle` modules. It is the externally maintained
|
||||
version of the :mod:`json` library contained in Python 2.6, but maintains
|
||||
compatibility with Python 2.4 and Python 2.5 and (currently) has
|
||||
significant performance advantages, even without using the optional C
|
||||
extension for speedups.
|
||||
compatibility back to Python 2.5 and (currently) has significant performance
|
||||
advantages, even without using the optional C extension for speedups.
|
||||
|
||||
Encoding basic Python object hierarchies::
|
||||
|
||||
@ -98,7 +97,7 @@ Using simplejson.tool from the shell to validate and pretty-print::
|
||||
Expecting property name: line 1 column 3 (char 2)
|
||||
"""
|
||||
from __future__ import absolute_import
|
||||
__version__ = '3.6.5'
|
||||
__version__ = '3.8.0'
|
||||
__all__ = [
|
||||
'dump', 'dumps', 'load', 'loads',
|
||||
'JSONDecoder', 'JSONDecodeError', 'JSONEncoder',
|
||||
@ -140,6 +139,7 @@ _default_encoder = JSONEncoder(
|
||||
use_decimal=True,
|
||||
namedtuple_as_object=True,
|
||||
tuple_as_array=True,
|
||||
iterable_as_array=False,
|
||||
bigint_as_string=False,
|
||||
item_sort_key=None,
|
||||
for_json=False,
|
||||
@ -152,7 +152,8 @@ def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
encoding='utf-8', default=None, use_decimal=True,
|
||||
namedtuple_as_object=True, tuple_as_array=True,
|
||||
bigint_as_string=False, sort_keys=False, item_sort_key=None,
|
||||
for_json=False, ignore_nan=False, int_as_string_bitcount=None, **kw):
|
||||
for_json=False, ignore_nan=False, int_as_string_bitcount=None,
|
||||
iterable_as_array=False, **kw):
|
||||
"""Serialize ``obj`` as a JSON formatted stream to ``fp`` (a
|
||||
``.write()``-supporting file-like object).
|
||||
|
||||
@ -204,6 +205,10 @@ def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
If *tuple_as_array* is true (default: ``True``),
|
||||
:class:`tuple` (and subclasses) will be encoded as JSON arrays.
|
||||
|
||||
If *iterable_as_array* is true (default: ``False``),
|
||||
any object not in the above table that implements ``__iter__()``
|
||||
will be encoded as a JSON array.
|
||||
|
||||
If *bigint_as_string* is true (default: ``False``), ints 2**53 and higher
|
||||
or lower than -2**53 will be encoded as strings. This is to avoid the
|
||||
rounding that happens in Javascript otherwise. Note that this is still a
|
||||
@ -242,7 +247,7 @@ def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
check_circular and allow_nan and
|
||||
cls is None and indent is None and separators is None and
|
||||
encoding == 'utf-8' and default is None and use_decimal
|
||||
and namedtuple_as_object and tuple_as_array
|
||||
and namedtuple_as_object and tuple_as_array and not iterable_as_array
|
||||
and not bigint_as_string and not sort_keys
|
||||
and not item_sort_key and not for_json
|
||||
and not ignore_nan and int_as_string_bitcount is None
|
||||
@ -258,6 +263,7 @@ def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
default=default, use_decimal=use_decimal,
|
||||
namedtuple_as_object=namedtuple_as_object,
|
||||
tuple_as_array=tuple_as_array,
|
||||
iterable_as_array=iterable_as_array,
|
||||
bigint_as_string=bigint_as_string,
|
||||
sort_keys=sort_keys,
|
||||
item_sort_key=item_sort_key,
|
||||
@ -276,7 +282,8 @@ def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
encoding='utf-8', default=None, use_decimal=True,
|
||||
namedtuple_as_object=True, tuple_as_array=True,
|
||||
bigint_as_string=False, sort_keys=False, item_sort_key=None,
|
||||
for_json=False, ignore_nan=False, int_as_string_bitcount=None, **kw):
|
||||
for_json=False, ignore_nan=False, int_as_string_bitcount=None,
|
||||
iterable_as_array=False, **kw):
|
||||
"""Serialize ``obj`` to a JSON formatted ``str``.
|
||||
|
||||
If ``skipkeys`` is false then ``dict`` keys that are not basic types
|
||||
@ -324,6 +331,10 @@ def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
If *tuple_as_array* is true (default: ``True``),
|
||||
:class:`tuple` (and subclasses) will be encoded as JSON arrays.
|
||||
|
||||
If *iterable_as_array* is true (default: ``False``),
|
||||
any object not in the above table that implements ``__iter__()``
|
||||
will be encoded as a JSON array.
|
||||
|
||||
If *bigint_as_string* is true (not the default), ints 2**53 and higher
|
||||
or lower than -2**53 will be encoded as strings. This is to avoid the
|
||||
rounding that happens in Javascript otherwise.
|
||||
@ -356,12 +367,11 @@ def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
|
||||
"""
|
||||
# cached encoder
|
||||
if (
|
||||
not skipkeys and ensure_ascii and
|
||||
if (not skipkeys and ensure_ascii and
|
||||
check_circular and allow_nan and
|
||||
cls is None and indent is None and separators is None and
|
||||
encoding == 'utf-8' and default is None and use_decimal
|
||||
and namedtuple_as_object and tuple_as_array
|
||||
and namedtuple_as_object and tuple_as_array and not iterable_as_array
|
||||
and not bigint_as_string and not sort_keys
|
||||
and not item_sort_key and not for_json
|
||||
and not ignore_nan and int_as_string_bitcount is None
|
||||
@ -377,6 +387,7 @@ def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
use_decimal=use_decimal,
|
||||
namedtuple_as_object=namedtuple_as_object,
|
||||
tuple_as_array=tuple_as_array,
|
||||
iterable_as_array=iterable_as_array,
|
||||
bigint_as_string=bigint_as_string,
|
||||
sort_keys=sort_keys,
|
||||
item_sort_key=item_sort_key,
|
||||
|
||||
@ -10,6 +10,7 @@
|
||||
#define PyString_AS_STRING PyBytes_AS_STRING
|
||||
#define PyString_FromStringAndSize PyBytes_FromStringAndSize
|
||||
#define PyInt_Check(obj) 0
|
||||
#define PyInt_CheckExact(obj) 0
|
||||
#define JSON_UNICHR Py_UCS4
|
||||
#define JSON_InternFromString PyUnicode_InternFromString
|
||||
#define JSON_Intern_GET_SIZE PyUnicode_GET_SIZE
|
||||
@ -168,6 +169,7 @@ typedef struct _PyEncoderObject {
|
||||
int use_decimal;
|
||||
int namedtuple_as_object;
|
||||
int tuple_as_array;
|
||||
int iterable_as_array;
|
||||
PyObject *max_long_size;
|
||||
PyObject *min_long_size;
|
||||
PyObject *item_sort_key;
|
||||
@ -660,7 +662,20 @@ encoder_stringify_key(PyEncoderObject *s, PyObject *key)
|
||||
return _encoded_const(key);
|
||||
}
|
||||
else if (PyInt_Check(key) || PyLong_Check(key)) {
|
||||
return PyObject_Str(key);
|
||||
if (!(PyInt_CheckExact(key) || PyLong_CheckExact(key))) {
|
||||
/* See #118, do not trust custom str/repr */
|
||||
PyObject *res;
|
||||
PyObject *tmp = PyObject_CallFunctionObjArgs((PyObject *)&PyLong_Type, key, NULL);
|
||||
if (tmp == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
res = PyObject_Str(tmp);
|
||||
Py_DECREF(tmp);
|
||||
return res;
|
||||
}
|
||||
else {
|
||||
return PyObject_Str(key);
|
||||
}
|
||||
}
|
||||
else if (s->use_decimal && PyObject_TypeCheck(key, (PyTypeObject *)s->Decimal)) {
|
||||
return PyObject_Str(key);
|
||||
@ -2567,7 +2582,6 @@ encoder_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
|
||||
static int
|
||||
encoder_init(PyObject *self, PyObject *args, PyObject *kwds)
|
||||
{
|
||||
/* initialize Encoder object */
|
||||
static char *kwlist[] = {
|
||||
"markers",
|
||||
"default",
|
||||
@ -2582,30 +2596,32 @@ encoder_init(PyObject *self, PyObject *args, PyObject *kwds)
|
||||
"use_decimal",
|
||||
"namedtuple_as_object",
|
||||
"tuple_as_array",
|
||||
"iterable_as_array"
|
||||
"int_as_string_bitcount",
|
||||
"item_sort_key",
|
||||
"encoding",
|
||||
"for_json",
|
||||
"ignore_nan",
|
||||
"Decimal",
|
||||
"iterable_as_array",
|
||||
NULL};
|
||||
|
||||
PyEncoderObject *s;
|
||||
PyObject *markers, *defaultfn, *encoder, *indent, *key_separator;
|
||||
PyObject *item_separator, *sort_keys, *skipkeys, *allow_nan, *key_memo;
|
||||
PyObject *use_decimal, *namedtuple_as_object, *tuple_as_array;
|
||||
PyObject *use_decimal, *namedtuple_as_object, *tuple_as_array, *iterable_as_array;
|
||||
PyObject *int_as_string_bitcount, *item_sort_key, *encoding, *for_json;
|
||||
PyObject *ignore_nan, *Decimal;
|
||||
|
||||
assert(PyEncoder_Check(self));
|
||||
s = (PyEncoderObject *)self;
|
||||
|
||||
if (!PyArg_ParseTupleAndKeywords(args, kwds, "OOOOOOOOOOOOOOOOOOO:make_encoder", kwlist,
|
||||
if (!PyArg_ParseTupleAndKeywords(args, kwds, "OOOOOOOOOOOOOOOOOOOO:make_encoder", kwlist,
|
||||
&markers, &defaultfn, &encoder, &indent, &key_separator, &item_separator,
|
||||
&sort_keys, &skipkeys, &allow_nan, &key_memo, &use_decimal,
|
||||
&namedtuple_as_object, &tuple_as_array,
|
||||
&int_as_string_bitcount, &item_sort_key, &encoding, &for_json,
|
||||
&ignore_nan, &Decimal))
|
||||
&ignore_nan, &Decimal, &iterable_as_array))
|
||||
return -1;
|
||||
|
||||
Py_INCREF(markers);
|
||||
@ -2635,9 +2651,10 @@ encoder_init(PyObject *self, PyObject *args, PyObject *kwds)
|
||||
s->use_decimal = PyObject_IsTrue(use_decimal);
|
||||
s->namedtuple_as_object = PyObject_IsTrue(namedtuple_as_object);
|
||||
s->tuple_as_array = PyObject_IsTrue(tuple_as_array);
|
||||
s->iterable_as_array = PyObject_IsTrue(iterable_as_array);
|
||||
if (PyInt_Check(int_as_string_bitcount) || PyLong_Check(int_as_string_bitcount)) {
|
||||
static const unsigned int long_long_bitsize = SIZEOF_LONG_LONG * 8;
|
||||
int int_as_string_bitcount_val = PyLong_AsLong(int_as_string_bitcount);
|
||||
int int_as_string_bitcount_val = (int)PyLong_AsLong(int_as_string_bitcount);
|
||||
if (int_as_string_bitcount_val > 0 && int_as_string_bitcount_val < long_long_bitsize) {
|
||||
s->max_long_size = PyLong_FromUnsignedLongLong(1ULL << int_as_string_bitcount_val);
|
||||
s->min_long_size = PyLong_FromLongLong(-1LL << int_as_string_bitcount_val);
|
||||
@ -2800,7 +2817,20 @@ encoder_encode_float(PyEncoderObject *s, PyObject *obj)
|
||||
}
|
||||
}
|
||||
/* Use a better float format here? */
|
||||
return PyObject_Repr(obj);
|
||||
if (PyFloat_CheckExact(obj)) {
|
||||
return PyObject_Repr(obj);
|
||||
}
|
||||
else {
|
||||
/* See #118, do not trust custom str/repr */
|
||||
PyObject *res;
|
||||
PyObject *tmp = PyObject_CallFunctionObjArgs((PyObject *)&PyFloat_Type, obj, NULL);
|
||||
if (tmp == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
res = PyObject_Repr(tmp);
|
||||
Py_DECREF(tmp);
|
||||
return res;
|
||||
}
|
||||
}
|
||||
|
||||
static PyObject *
|
||||
@ -2840,7 +2870,21 @@ encoder_listencode_obj(PyEncoderObject *s, JSON_Accu *rval, PyObject *obj, Py_ss
|
||||
rv = _steal_accumulate(rval, encoded);
|
||||
}
|
||||
else if (PyInt_Check(obj) || PyLong_Check(obj)) {
|
||||
PyObject *encoded = PyObject_Str(obj);
|
||||
PyObject *encoded;
|
||||
if (PyInt_CheckExact(obj) || PyLong_CheckExact(obj)) {
|
||||
encoded = PyObject_Str(obj);
|
||||
}
|
||||
else {
|
||||
/* See #118, do not trust custom str/repr */
|
||||
PyObject *tmp = PyObject_CallFunctionObjArgs((PyObject *)&PyLong_Type, obj, NULL);
|
||||
if (tmp == NULL) {
|
||||
encoded = NULL;
|
||||
}
|
||||
else {
|
||||
encoded = PyObject_Str(tmp);
|
||||
Py_DECREF(tmp);
|
||||
}
|
||||
}
|
||||
if (encoded != NULL) {
|
||||
encoded = maybe_quote_bigint(s, encoded, obj);
|
||||
if (encoded == NULL)
|
||||
@ -2895,6 +2939,16 @@ encoder_listencode_obj(PyEncoderObject *s, JSON_Accu *rval, PyObject *obj, Py_ss
|
||||
else {
|
||||
PyObject *ident = NULL;
|
||||
PyObject *newobj;
|
||||
if (s->iterable_as_array) {
|
||||
newobj = PyObject_GetIter(obj);
|
||||
if (newobj == NULL)
|
||||
PyErr_Clear();
|
||||
else {
|
||||
rv = encoder_listencode_list(s, rval, newobj, indent_level);
|
||||
Py_DECREF(newobj);
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (s->markers != Py_None) {
|
||||
int has_key;
|
||||
ident = PyLong_FromVoidPtr(obj);
|
||||
|
||||
@ -3,7 +3,8 @@
|
||||
from __future__ import absolute_import
|
||||
import re
|
||||
from operator import itemgetter
|
||||
from decimal import Decimal
|
||||
# Do not import Decimal directly to avoid reload issues
|
||||
import decimal
|
||||
from .compat import u, unichr, binary_type, string_types, integer_types, PY3
|
||||
def _import_speedups():
|
||||
try:
|
||||
@ -123,7 +124,7 @@ class JSONEncoder(object):
|
||||
use_decimal=True, namedtuple_as_object=True,
|
||||
tuple_as_array=True, bigint_as_string=False,
|
||||
item_sort_key=None, for_json=False, ignore_nan=False,
|
||||
int_as_string_bitcount=None):
|
||||
int_as_string_bitcount=None, iterable_as_array=False):
|
||||
"""Constructor for JSONEncoder, with sensible defaults.
|
||||
|
||||
If skipkeys is false, then it is a TypeError to attempt
|
||||
@ -178,6 +179,10 @@ class JSONEncoder(object):
|
||||
If tuple_as_array is true (the default), tuple (and subclasses) will
|
||||
be encoded as JSON arrays.
|
||||
|
||||
If *iterable_as_array* is true (default: ``False``),
|
||||
any object not in the above table that implements ``__iter__()``
|
||||
will be encoded as a JSON array.
|
||||
|
||||
If bigint_as_string is true (not the default), ints 2**53 and higher
|
||||
or lower than -2**53 will be encoded as strings. This is to avoid the
|
||||
rounding that happens in Javascript otherwise.
|
||||
@ -209,6 +214,7 @@ class JSONEncoder(object):
|
||||
self.use_decimal = use_decimal
|
||||
self.namedtuple_as_object = namedtuple_as_object
|
||||
self.tuple_as_array = tuple_as_array
|
||||
self.iterable_as_array = iterable_as_array
|
||||
self.bigint_as_string = bigint_as_string
|
||||
self.item_sort_key = item_sort_key
|
||||
self.for_json = for_json
|
||||
@ -311,6 +317,9 @@ class JSONEncoder(object):
|
||||
elif o == _neginf:
|
||||
text = '-Infinity'
|
||||
else:
|
||||
if type(o) != float:
|
||||
# See #118, do not trust custom str/repr
|
||||
o = float(o)
|
||||
return _repr(o)
|
||||
|
||||
if ignore_nan:
|
||||
@ -334,7 +343,7 @@ class JSONEncoder(object):
|
||||
self.namedtuple_as_object, self.tuple_as_array,
|
||||
int_as_string_bitcount,
|
||||
self.item_sort_key, self.encoding, self.for_json,
|
||||
self.ignore_nan, Decimal)
|
||||
self.ignore_nan, decimal.Decimal, self.iterable_as_array)
|
||||
else:
|
||||
_iterencode = _make_iterencode(
|
||||
markers, self.default, _encoder, self.indent, floatstr,
|
||||
@ -343,7 +352,7 @@ class JSONEncoder(object):
|
||||
self.namedtuple_as_object, self.tuple_as_array,
|
||||
int_as_string_bitcount,
|
||||
self.item_sort_key, self.encoding, self.for_json,
|
||||
Decimal=Decimal)
|
||||
self.iterable_as_array, Decimal=decimal.Decimal)
|
||||
try:
|
||||
return _iterencode(o, 0)
|
||||
finally:
|
||||
@ -382,11 +391,12 @@ def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
|
||||
_use_decimal, _namedtuple_as_object, _tuple_as_array,
|
||||
_int_as_string_bitcount, _item_sort_key,
|
||||
_encoding,_for_json,
|
||||
_iterable_as_array,
|
||||
## HACK: hand-optimized bytecode; turn globals into locals
|
||||
_PY3=PY3,
|
||||
ValueError=ValueError,
|
||||
string_types=string_types,
|
||||
Decimal=Decimal,
|
||||
Decimal=None,
|
||||
dict=dict,
|
||||
float=float,
|
||||
id=id,
|
||||
@ -395,7 +405,10 @@ def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
|
||||
list=list,
|
||||
str=str,
|
||||
tuple=tuple,
|
||||
iter=iter,
|
||||
):
|
||||
if _use_decimal and Decimal is None:
|
||||
Decimal = decimal.Decimal
|
||||
if _item_sort_key and not callable(_item_sort_key):
|
||||
raise TypeError("item_sort_key must be None or callable")
|
||||
elif _sort_keys and not _item_sort_key:
|
||||
@ -412,6 +425,9 @@ def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
|
||||
or
|
||||
_int_as_string_bitcount < 1
|
||||
)
|
||||
if type(value) not in integer_types:
|
||||
# See #118, do not trust custom str/repr
|
||||
value = int(value)
|
||||
if (
|
||||
skip_quoting or
|
||||
(-1 << _int_as_string_bitcount)
|
||||
@ -501,6 +517,9 @@ def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
|
||||
elif key is None:
|
||||
key = 'null'
|
||||
elif isinstance(key, integer_types):
|
||||
if type(key) not in integer_types:
|
||||
# See #118, do not trust custom str/repr
|
||||
key = int(key)
|
||||
key = str(key)
|
||||
elif _use_decimal and isinstance(key, Decimal):
|
||||
key = str(key)
|
||||
@ -634,6 +653,16 @@ def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
|
||||
elif _use_decimal and isinstance(o, Decimal):
|
||||
yield str(o)
|
||||
else:
|
||||
while _iterable_as_array:
|
||||
# Markers are not checked here because it is valid for
|
||||
# an iterable to return self.
|
||||
try:
|
||||
o = iter(o)
|
||||
except TypeError:
|
||||
break
|
||||
for chunk in _iterencode_list(o, _current_indent_level):
|
||||
yield chunk
|
||||
return
|
||||
if markers is not None:
|
||||
markerid = id(o)
|
||||
if markerid in markers:
|
||||
|
||||
@ -62,6 +62,7 @@ def all_tests_suite():
|
||||
'simplejson.tests.test_namedtuple',
|
||||
'simplejson.tests.test_tool',
|
||||
'simplejson.tests.test_for_json',
|
||||
'simplejson.tests.test_subclass',
|
||||
]))
|
||||
suite = get_suite()
|
||||
import simplejson
|
||||
|
||||
31
packages/wakatime/packages/simplejson/tests/test_iterable.py
Normal file
31
packages/wakatime/packages/simplejson/tests/test_iterable.py
Normal file
@ -0,0 +1,31 @@
|
||||
import unittest
|
||||
from StringIO import StringIO
|
||||
|
||||
import simplejson as json
|
||||
|
||||
def iter_dumps(obj, **kw):
|
||||
return ''.join(json.JSONEncoder(**kw).iterencode(obj))
|
||||
|
||||
def sio_dump(obj, **kw):
|
||||
sio = StringIO()
|
||||
json.dumps(obj, **kw)
|
||||
return sio.getvalue()
|
||||
|
||||
class TestIterable(unittest.TestCase):
|
||||
def test_iterable(self):
|
||||
l = [1, 2, 3]
|
||||
for dumps in (json.dumps, iter_dumps, sio_dump):
|
||||
expect = dumps(l)
|
||||
default_expect = dumps(sum(l))
|
||||
# Default is False
|
||||
self.assertRaises(TypeError, dumps, iter(l))
|
||||
self.assertRaises(TypeError, dumps, iter(l), iterable_as_array=False)
|
||||
self.assertEqual(expect, dumps(iter(l), iterable_as_array=True))
|
||||
# Ensure that the "default" gets called
|
||||
self.assertEqual(default_expect, dumps(iter(l), default=sum))
|
||||
self.assertEqual(default_expect, dumps(iter(l), iterable_as_array=False, default=sum))
|
||||
# Ensure that the "default" does not get called
|
||||
self.assertEqual(
|
||||
default_expect,
|
||||
dumps(iter(l), iterable_as_array=True, default=sum))
|
||||
|
||||
37
packages/wakatime/packages/simplejson/tests/test_subclass.py
Normal file
37
packages/wakatime/packages/simplejson/tests/test_subclass.py
Normal file
@ -0,0 +1,37 @@
|
||||
from unittest import TestCase
|
||||
import simplejson as json
|
||||
|
||||
from decimal import Decimal
|
||||
|
||||
class AlternateInt(int):
|
||||
def __repr__(self):
|
||||
return 'invalid json'
|
||||
__str__ = __repr__
|
||||
|
||||
|
||||
class AlternateFloat(float):
|
||||
def __repr__(self):
|
||||
return 'invalid json'
|
||||
__str__ = __repr__
|
||||
|
||||
|
||||
# class AlternateDecimal(Decimal):
|
||||
# def __repr__(self):
|
||||
# return 'invalid json'
|
||||
|
||||
|
||||
class TestSubclass(TestCase):
|
||||
def test_int(self):
|
||||
self.assertEqual(json.dumps(AlternateInt(1)), '1')
|
||||
self.assertEqual(json.dumps(AlternateInt(-1)), '-1')
|
||||
self.assertEqual(json.loads(json.dumps({AlternateInt(1): 1})), {'1': 1})
|
||||
|
||||
def test_float(self):
|
||||
self.assertEqual(json.dumps(AlternateFloat(1.0)), '1.0')
|
||||
self.assertEqual(json.dumps(AlternateFloat(-1.0)), '-1.0')
|
||||
self.assertEqual(json.loads(json.dumps({AlternateFloat(1.0): 1})), {'1.0': 1})
|
||||
|
||||
# NOTE: Decimal subclasses are not supported as-is
|
||||
# def test_decimal(self):
|
||||
# self.assertEqual(json.dumps(AlternateDecimal('1.0')), '1.0')
|
||||
# self.assertEqual(json.dumps(AlternateDecimal('-1.0')), '-1.0')
|
||||
@ -45,7 +45,3 @@ class TestTuples(unittest.TestCase):
|
||||
self.assertEqual(
|
||||
json.dumps(repr(t)),
|
||||
sio.getvalue())
|
||||
|
||||
class TestNamedTuple(unittest.TestCase):
|
||||
def test_namedtuple_dump(self):
|
||||
pass
|
||||
|
||||
@ -15,30 +15,70 @@ from .projects.git import Git
|
||||
from .projects.mercurial import Mercurial
|
||||
from .projects.projectmap import ProjectMap
|
||||
from .projects.subversion import Subversion
|
||||
from .projects.wakatime import WakaTime
|
||||
from .projects.wakatime_project_file import WakaTimeProjectFile
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
# List of plugin classes to find a project for the current file path.
|
||||
# Project plugins will be processed with priority in the order below.
|
||||
PLUGINS = [
|
||||
WakaTime,
|
||||
CONFIG_PLUGINS = [
|
||||
WakaTimeProjectFile,
|
||||
ProjectMap,
|
||||
]
|
||||
REV_CONTROL_PLUGINS = [
|
||||
Git,
|
||||
Mercurial,
|
||||
Subversion,
|
||||
]
|
||||
|
||||
|
||||
def find_project(path, configs=None):
|
||||
for plugin in PLUGINS:
|
||||
plugin_name = plugin.__name__.lower()
|
||||
plugin_configs = None
|
||||
if configs and configs.has_section(plugin_name):
|
||||
plugin_configs = dict(configs.items(plugin_name))
|
||||
project = plugin(path, configs=plugin_configs)
|
||||
def get_project_info(configs, args):
|
||||
"""Find the current project and branch.
|
||||
|
||||
First looks for a .wakatime-project file. Second, uses the --project arg.
|
||||
Third, uses the folder name from a revision control repository. Last, uses
|
||||
the --alternate-project arg.
|
||||
|
||||
Returns a project, branch tuple.
|
||||
"""
|
||||
|
||||
project_name, branch_name = None, None
|
||||
|
||||
for plugin_cls in CONFIG_PLUGINS:
|
||||
|
||||
plugin_name = plugin_cls.__name__.lower()
|
||||
plugin_configs = get_configs_for_plugin(plugin_name, configs)
|
||||
|
||||
project = plugin_cls(args.entity, configs=plugin_configs)
|
||||
if project.process():
|
||||
return project
|
||||
project_name = project_name or project.name()
|
||||
branch_name = project.branch()
|
||||
break
|
||||
|
||||
if project_name is None:
|
||||
project_name = args.project
|
||||
|
||||
if project_name is None or branch_name is None:
|
||||
|
||||
for plugin_cls in REV_CONTROL_PLUGINS:
|
||||
|
||||
plugin_name = plugin_cls.__name__.lower()
|
||||
plugin_configs = get_configs_for_plugin(plugin_name, configs)
|
||||
|
||||
project = plugin_cls(args.entity, configs=plugin_configs)
|
||||
if project.process():
|
||||
project_name = project_name or project.name()
|
||||
branch_name = branch_name or project.branch()
|
||||
break
|
||||
|
||||
if project_name is None:
|
||||
project_name = args.alternate_project
|
||||
|
||||
return project_name, branch_name
|
||||
|
||||
|
||||
def get_configs_for_plugin(plugin_name, configs):
|
||||
if configs and configs.has_section(plugin_name):
|
||||
return dict(configs.items(plugin_name))
|
||||
return None
|
||||
|
||||
@ -11,6 +11,8 @@
|
||||
|
||||
import logging
|
||||
|
||||
from ..exceptions import NotYetImplemented
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
@ -25,29 +27,19 @@ class BaseProject(object):
|
||||
self.path = path
|
||||
self._configs = configs
|
||||
|
||||
def project_type(self):
|
||||
""" Returns None if this is the base class.
|
||||
Returns the type of project if this is a
|
||||
valid project.
|
||||
"""
|
||||
project_type = self.__class__.__name__.lower()
|
||||
if project_type == 'baseproject':
|
||||
project_type = None
|
||||
return project_type
|
||||
|
||||
def process(self):
|
||||
""" Processes self.path into a project and
|
||||
returns True if project is valid, otherwise
|
||||
returns False.
|
||||
"""
|
||||
return False
|
||||
raise NotYetImplemented()
|
||||
|
||||
def name(self):
|
||||
""" Returns the project's name.
|
||||
"""
|
||||
return None
|
||||
raise NotYetImplemented()
|
||||
|
||||
def branch(self):
|
||||
""" Returns the current branch.
|
||||
"""
|
||||
return None
|
||||
raise NotYetImplemented()
|
||||
|
||||
@ -11,6 +11,7 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
||||
from .base import BaseProject
|
||||
from ..compat import u, open
|
||||
@ -29,7 +30,7 @@ class Git(BaseProject):
|
||||
base = self._project_base()
|
||||
if base:
|
||||
return u(os.path.basename(base))
|
||||
return None
|
||||
return None # pragma: nocover
|
||||
|
||||
def branch(self):
|
||||
base = self._project_base()
|
||||
@ -38,8 +39,14 @@ class Git(BaseProject):
|
||||
try:
|
||||
with open(head, 'r', encoding='utf-8') as fh:
|
||||
return u(fh.readline().strip().rsplit('/', 1)[-1])
|
||||
except IOError:
|
||||
pass
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
try:
|
||||
with open(head, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return u(fh.readline().strip().rsplit('/', 1)[-1])
|
||||
except:
|
||||
log.exception("Exception:")
|
||||
except IOError: # pragma: nocover
|
||||
log.exception("Exception:")
|
||||
return None
|
||||
|
||||
def _project_base(self):
|
||||
|
||||
@ -11,6 +11,7 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
||||
from .base import BaseProject
|
||||
from ..compat import u, open
|
||||
@ -28,7 +29,7 @@ class Mercurial(BaseProject):
|
||||
def name(self):
|
||||
if self.configDir:
|
||||
return u(os.path.basename(os.path.dirname(self.configDir)))
|
||||
return None
|
||||
return None # pragma: nocover
|
||||
|
||||
def branch(self):
|
||||
if self.configDir:
|
||||
@ -36,8 +37,14 @@ class Mercurial(BaseProject):
|
||||
try:
|
||||
with open(branch_file, 'r', encoding='utf-8') as fh:
|
||||
return u(fh.readline().strip().rsplit('/', 1)[-1])
|
||||
except IOError:
|
||||
pass
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
try:
|
||||
with open(branch_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return u(fh.readline().strip().rsplit('/', 1)[-1])
|
||||
except:
|
||||
log.exception("Exception:")
|
||||
except IOError: # pragma: nocover
|
||||
log.exception("Exception:")
|
||||
return u('default')
|
||||
|
||||
def _find_hg_config_dir(self, path):
|
||||
|
||||
@ -47,14 +47,14 @@ class ProjectMap(BaseProject):
|
||||
|
||||
if self._configs.get(path.lower()):
|
||||
return self._configs.get(path.lower())
|
||||
if self._configs.get('%s/' % path.lower()):
|
||||
if self._configs.get('%s/' % path.lower()): # pragma: nocover
|
||||
return self._configs.get('%s/' % path.lower())
|
||||
if self._configs.get('%s\\' % path.lower()):
|
||||
if self._configs.get('%s\\' % path.lower()): # pragma: nocover
|
||||
return self._configs.get('%s\\' % path.lower())
|
||||
|
||||
split_path = os.path.split(path)
|
||||
if split_path[1] == '':
|
||||
return None
|
||||
return None # pragma: nocover
|
||||
return self._find_project(split_path[0])
|
||||
|
||||
def branch(self):
|
||||
@ -63,4 +63,4 @@ class ProjectMap(BaseProject):
|
||||
def name(self):
|
||||
if self.project:
|
||||
return u(self.project)
|
||||
return None
|
||||
return None # pragma: nocover
|
||||
|
||||
@ -18,8 +18,8 @@ from .base import BaseProject
|
||||
from ..compat import u, open
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from ..packages.ordereddict import OrderedDict
|
||||
except ImportError: # pragma: nocover
|
||||
from ..packages.ordereddict import OrderedDict # pragma: nocover
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
@ -32,10 +32,14 @@ class Subversion(BaseProject):
|
||||
return self._find_project_base(self.path)
|
||||
|
||||
def name(self):
|
||||
return u(self.info['Repository Root'].split('/')[-1])
|
||||
if 'Repository Root' not in self.info:
|
||||
return None # pragma: nocover
|
||||
return u(self.info['Repository Root'].split('/')[-1].split('\\')[-1])
|
||||
|
||||
def branch(self):
|
||||
return u(self.info['URL'].split('/')[-1])
|
||||
if 'URL' not in self.info:
|
||||
return None # pragma: nocover
|
||||
return u(self.info['URL'].split('/')[-1].split('\\')[-1])
|
||||
|
||||
def _find_binary(self):
|
||||
if self.binary_location:
|
||||
@ -46,13 +50,13 @@ class Subversion(BaseProject):
|
||||
'/usr/local/bin/svn',
|
||||
]
|
||||
for location in locations:
|
||||
with open(os.devnull, 'wb') as DEVNULL:
|
||||
try:
|
||||
try:
|
||||
with open(os.devnull, 'wb') as DEVNULL:
|
||||
Popen([location, '--version'], stdout=DEVNULL, stderr=DEVNULL)
|
||||
self.binary_location = location
|
||||
return location
|
||||
except:
|
||||
pass
|
||||
except:
|
||||
pass
|
||||
self.binary_location = 'svn'
|
||||
return 'svn'
|
||||
|
||||
@ -69,8 +73,7 @@ class Subversion(BaseProject):
|
||||
else:
|
||||
if stdout:
|
||||
for line in stdout.splitlines():
|
||||
if isinstance(line, bytes):
|
||||
line = bytes.decode(line)
|
||||
line = u(line)
|
||||
line = line.split(': ', 1)
|
||||
if len(line) == 2:
|
||||
info[line[0]] = line[1]
|
||||
@ -78,7 +81,7 @@ class Subversion(BaseProject):
|
||||
|
||||
def _find_project_base(self, path, found=False):
|
||||
if platform.system() == 'Windows':
|
||||
return False
|
||||
return False # pragma: nocover
|
||||
path = os.path.realpath(path)
|
||||
if os.path.isfile(path):
|
||||
path = os.path.split(path)[0]
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.projects.wakatime
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
wakatime.projects.wakatime_project_file
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Information from a .wakatime-project file about the project for
|
||||
a given file. First line of .wakatime-project sets the project
|
||||
@ -13,6 +13,7 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
|
||||
from .base import BaseProject
|
||||
from ..compat import u, open
|
||||
@ -21,7 +22,7 @@ from ..compat import u, open
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class WakaTime(BaseProject):
|
||||
class WakaTimeProjectFile(BaseProject):
|
||||
|
||||
def process(self):
|
||||
self.config = self._find_config(self.path)
|
||||
@ -34,7 +35,14 @@ class WakaTime(BaseProject):
|
||||
with open(self.config, 'r', encoding='utf-8') as fh:
|
||||
self._project_name = u(fh.readline().strip())
|
||||
self._project_branch = u(fh.readline().strip())
|
||||
except IOError:
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
try:
|
||||
with open(self.config, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
self._project_name = u(fh.readline().strip())
|
||||
self._project_branch = u(fh.readline().strip())
|
||||
except:
|
||||
log.exception("Exception:")
|
||||
except IOError: # pragma: nocover
|
||||
log.exception("Exception:")
|
||||
|
||||
return True
|
||||
109
packages/wakatime/session_cache.py
Normal file
109
packages/wakatime/session_cache.py
Normal file
@ -0,0 +1,109 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.session_cache
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Persist requests.Session for multiprocess SSL handshake pooling.
|
||||
|
||||
:copyright: (c) 2015 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
import logging
|
||||
import os
|
||||
import pickle
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
try:
|
||||
import sqlite3
|
||||
HAS_SQL = True
|
||||
except ImportError: # pragma: nocover
|
||||
HAS_SQL = False
|
||||
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
|
||||
from .packages import requests
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class SessionCache(object):
|
||||
DB_FILE = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
|
||||
def connect(self):
|
||||
conn = sqlite3.connect(self.DB_FILE)
|
||||
c = conn.cursor()
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS session (
|
||||
value BLOB)
|
||||
''')
|
||||
return (conn, c)
|
||||
|
||||
|
||||
def save(self, session):
|
||||
"""Saves a requests.Session object for the next heartbeat process.
|
||||
"""
|
||||
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
c.execute('DELETE FROM session')
|
||||
values = {
|
||||
'value': sqlite3.Binary(pickle.dumps(session, protocol=2)),
|
||||
}
|
||||
c.execute('INSERT INTO session VALUES (:value)', values)
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except: # pragma: nocover
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
|
||||
def get(self):
|
||||
"""Returns a requests.Session object.
|
||||
|
||||
Gets Session from sqlite3 cache or creates a new Session.
|
||||
"""
|
||||
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return requests.session()
|
||||
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
except:
|
||||
log.error(traceback.format_exc())
|
||||
return requests.session()
|
||||
|
||||
session = None
|
||||
try:
|
||||
c.execute('BEGIN IMMEDIATE')
|
||||
c.execute('SELECT value FROM session LIMIT 1')
|
||||
row = c.fetchone()
|
||||
if row is not None:
|
||||
session = pickle.loads(row[0])
|
||||
except: # pragma: nocover
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
try:
|
||||
conn.close()
|
||||
except: # pragma: nocover
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
return session if session is not None else requests.session()
|
||||
|
||||
|
||||
def delete(self):
|
||||
"""Clears all cached Session objects.
|
||||
"""
|
||||
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
c.execute('DELETE FROM session')
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except:
|
||||
log.error(traceback.format_exc())
|
||||
@ -14,84 +14,155 @@ import os
|
||||
import sys
|
||||
|
||||
from .compat import u, open
|
||||
from .languages import DependencyParser
|
||||
from .dependencies import DependencyParser
|
||||
|
||||
if sys.version_info[0] == 2:
|
||||
if sys.version_info[0] == 2: # pragma: nocover
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages', 'pygments_py2'))
|
||||
else:
|
||||
else: # pragma: nocover
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages', 'pygments_py3'))
|
||||
from pygments.lexers import guess_lexer_for_filename
|
||||
from pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
# force file name extensions to be recognized as a certain language
|
||||
EXTENSIONS = {
|
||||
'j2': 'HTML',
|
||||
'markdown': 'Markdown',
|
||||
'md': 'Markdown',
|
||||
'mdown': 'Markdown',
|
||||
'twig': 'Twig',
|
||||
}
|
||||
TRANSLATIONS = {
|
||||
'CSS+Genshi Text': 'CSS',
|
||||
'CSS+Lasso': 'CSS',
|
||||
'HTML+Django/Jinja': 'HTML',
|
||||
'HTML+Lasso': 'HTML',
|
||||
'JavaScript+Genshi Text': 'JavaScript',
|
||||
'JavaScript+Lasso': 'JavaScript',
|
||||
'Perl6': 'Perl',
|
||||
'RHTML': 'HTML',
|
||||
}
|
||||
|
||||
|
||||
def guess_language(file_name):
|
||||
language, lexer = None, None
|
||||
try:
|
||||
with open(file_name, 'r', encoding='utf-8') as fh:
|
||||
lexer = guess_lexer_for_filename(file_name, fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
if file_name:
|
||||
language = guess_language_from_extension(file_name.rsplit('.', 1)[-1])
|
||||
if lexer and language is None:
|
||||
language = translate_language(u(lexer.name))
|
||||
"""Guess lexer and language for a file.
|
||||
|
||||
Returns (language, lexer) tuple where language is a unicode string.
|
||||
"""
|
||||
|
||||
language = get_language_from_extension(file_name)
|
||||
lexer = smart_guess_lexer(file_name)
|
||||
if language is None and lexer is not None:
|
||||
language = u(lexer.name)
|
||||
|
||||
return language, lexer
|
||||
|
||||
|
||||
def guess_language_from_extension(extension):
|
||||
if extension:
|
||||
if extension in EXTENSIONS:
|
||||
return EXTENSIONS[extension]
|
||||
if extension.lower() in EXTENSIONS:
|
||||
return EXTENSIONS[extension.lower()]
|
||||
def smart_guess_lexer(file_name):
|
||||
"""Guess Pygments lexer for a file.
|
||||
|
||||
Looks for a vim modeline in file contents, then compares the accuracy
|
||||
of that lexer with a second guess. The second guess looks up all lexers
|
||||
matching the file name, then runs a text analysis for the best choice.
|
||||
"""
|
||||
lexer = None
|
||||
|
||||
text = get_file_contents(file_name)
|
||||
|
||||
lexer1, accuracy1 = guess_lexer_using_filename(file_name, text)
|
||||
lexer2, accuracy2 = guess_lexer_using_modeline(text)
|
||||
|
||||
if lexer1:
|
||||
lexer = lexer1
|
||||
if (lexer2 and accuracy2 and
|
||||
(not accuracy1 or accuracy2 > accuracy1)):
|
||||
lexer = lexer2 # pragma: nocover
|
||||
|
||||
return lexer
|
||||
|
||||
|
||||
def guess_lexer_using_filename(file_name, text):
|
||||
"""Guess lexer for given text, limited to lexers for this file's extension.
|
||||
|
||||
Returns a tuple of (lexer, accuracy).
|
||||
"""
|
||||
|
||||
lexer, accuracy = None, None
|
||||
|
||||
try:
|
||||
lexer = guess_lexer_for_filename(file_name, text)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
|
||||
if lexer is not None:
|
||||
try:
|
||||
accuracy = lexer.analyse_text(text)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
|
||||
return lexer, accuracy
|
||||
|
||||
|
||||
def guess_lexer_using_modeline(text):
|
||||
"""Guess lexer for given text using Vim modeline.
|
||||
|
||||
Returns a tuple of (lexer, accuracy).
|
||||
"""
|
||||
|
||||
lexer, accuracy = None, None
|
||||
|
||||
file_type = None
|
||||
try:
|
||||
file_type = get_filetype_from_buffer(text)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
|
||||
if file_type is not None:
|
||||
try:
|
||||
lexer = get_lexer_by_name(file_type)
|
||||
except ClassNotFound: # pragma: nocover
|
||||
pass
|
||||
|
||||
if lexer is not None:
|
||||
try:
|
||||
accuracy = lexer.analyse_text(text)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
|
||||
return lexer, accuracy
|
||||
|
||||
|
||||
def get_language_from_extension(file_name):
|
||||
"""Returns a matching language for the given file extension.
|
||||
"""
|
||||
|
||||
filepart, extension = os.path.splitext(file_name)
|
||||
|
||||
if os.path.exists(u('{0}{1}').format(u(filepart), u('.c'))) or os.path.exists(u('{0}{1}').format(u(filepart), u('.C'))):
|
||||
return 'C'
|
||||
|
||||
extension = extension.lower()
|
||||
if extension == '.h':
|
||||
directory = os.path.dirname(file_name)
|
||||
available_files = os.listdir(directory)
|
||||
available_extensions = list(zip(*map(os.path.splitext, available_files)))[1]
|
||||
available_extensions = [ext.lower() for ext in available_extensions]
|
||||
if '.cpp' in available_extensions:
|
||||
return 'C++'
|
||||
if '.c' in available_extensions:
|
||||
return 'C'
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def translate_language(language):
|
||||
if language in TRANSLATIONS:
|
||||
language = TRANSLATIONS[language]
|
||||
return language
|
||||
|
||||
|
||||
def number_lines_in_file(file_name):
|
||||
lines = 0
|
||||
try:
|
||||
with open(file_name, 'r', encoding='utf-8') as fh:
|
||||
for line in fh:
|
||||
lines += 1
|
||||
except:
|
||||
return None
|
||||
except: # pragma: nocover
|
||||
try:
|
||||
with open(file_name, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
for line in fh:
|
||||
lines += 1
|
||||
except:
|
||||
return None
|
||||
return lines
|
||||
|
||||
|
||||
def get_file_stats(file_name, notfile=False):
|
||||
if notfile:
|
||||
def get_file_stats(file_name, entity_type='file', lineno=None, cursorpos=None):
|
||||
if entity_type != 'file':
|
||||
stats = {
|
||||
'language': None,
|
||||
'dependencies': [],
|
||||
'lines': None,
|
||||
'lineno': lineno,
|
||||
'cursorpos': cursorpos,
|
||||
}
|
||||
else:
|
||||
language, lexer = guess_language(file_name)
|
||||
@ -101,5 +172,24 @@ def get_file_stats(file_name, notfile=False):
|
||||
'language': language,
|
||||
'dependencies': dependencies,
|
||||
'lines': number_lines_in_file(file_name),
|
||||
'lineno': lineno,
|
||||
'cursorpos': cursorpos,
|
||||
}
|
||||
return stats
|
||||
|
||||
|
||||
def get_file_contents(file_name):
|
||||
"""Returns the first 512000 bytes of the file's contents.
|
||||
"""
|
||||
|
||||
text = None
|
||||
try:
|
||||
with open(file_name, 'r', encoding='utf-8') as fh:
|
||||
text = fh.read(512000)
|
||||
except: # pragma: nocover
|
||||
try:
|
||||
with open(file_name, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
text = fh.read(512000)
|
||||
except:
|
||||
log.exception("Exception:")
|
||||
return text
|
||||
|
||||
Reference in New Issue
Block a user