mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
53 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| f14ece63f3 | |||
| cb7f786ec8 | |||
| ab8711d0b1 | |||
| 2354be358c | |||
| 443215bd90 | |||
| c64f125dc4 | |||
| 050b14fb53 | |||
| c7efc33463 | |||
| d0ddbed006 | |||
| 3ce8f388ab | |||
| 90731146f9 | |||
| e1ab92be6d | |||
| 8b59e46c64 | |||
| 006341eb72 | |||
| b54e0e13f6 | |||
| 835c7db864 | |||
| 53e8bb04e9 | |||
| 4aa06e3829 | |||
| 297f65733f | |||
| 5ba5e6d21b | |||
| 32eadda81f | |||
| c537044801 | |||
| a97792c23c | |||
| 4223f3575f | |||
| 284cdf3ce4 | |||
| 27afc41bf4 | |||
| 1fdda0d64a | |||
| c90a4863e9 | |||
| 94343e5b07 | |||
| 03acea6e25 | |||
| 77594700bd | |||
| 6681409e98 | |||
| 8f7837269a | |||
| a523b3aa4d | |||
| 6985ce32bb | |||
| 4be40c7720 | |||
| eeb7fd8219 | |||
| 11fbd2d2a6 | |||
| 3cecd0de5d | |||
| c50100e675 | |||
| c1da94bc18 | |||
| 7f9d6ede9d | |||
| 192a5c7aa7 | |||
| 16bbe21be9 | |||
| 5ebaf12a99 | |||
| 1834e8978a | |||
| 22c8ed74bd | |||
| 12bbb4e561 | |||
| c71cb21cc1 | |||
| eb11b991f0 | |||
| 7ea51d09ba | |||
| b07b59e0c8 | |||
| 9d715e95b7 |
153
HISTORY.rst
153
HISTORY.rst
@ -3,6 +3,159 @@ History
|
||||
-------
|
||||
|
||||
|
||||
6.0.8 (2016-04-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v5.0.0.
|
||||
- Support regex patterns in projectmap config section for renaming projects.
|
||||
- Upgrade pytz to v2016.3.
|
||||
- Upgrade tzlocal to v1.2.2.
|
||||
|
||||
|
||||
6.0.7 (2016-03-11)
|
||||
++++++++++++++++++
|
||||
|
||||
- Fix bug causing RuntimeError when finding Python location
|
||||
|
||||
|
||||
6.0.6 (2016-03-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli to v4.1.13
|
||||
- encode TimeZone as utf-8 before adding to headers
|
||||
- encode X-Machine-Name as utf-8 before adding to headers
|
||||
|
||||
|
||||
6.0.5 (2016-03-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli to v4.1.11
|
||||
- encode machine hostname as Unicode when adding to X-Machine-Name header
|
||||
|
||||
|
||||
6.0.4 (2016-01-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix UnicodeDecodeError on ST2 with non-English locale
|
||||
|
||||
|
||||
6.0.3 (2016-01-11)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli core to v4.1.10
|
||||
- accept 201 or 202 response codes as success from api
|
||||
- upgrade requests package to v2.9.1
|
||||
|
||||
|
||||
6.0.2 (2016-01-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli core to v4.1.9
|
||||
- improve C# dependency detection
|
||||
- correctly log exception tracebacks
|
||||
- log all unknown exceptions to wakatime.log file
|
||||
- disable urllib3 SSL warning from every request
|
||||
- detect dependencies from golang files
|
||||
- use api.wakatime.com for sending heartbeats
|
||||
|
||||
|
||||
6.0.1 (2016-01-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- use embedded python if system python is broken, or doesn't output a version number
|
||||
- log output from wakatime-cli in ST console when in debug mode
|
||||
|
||||
|
||||
6.0.0 (2015-12-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- use embeddable Python instead of installing on Windows
|
||||
|
||||
|
||||
5.0.1 (2015-10-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- look for python in system PATH again
|
||||
|
||||
|
||||
5.0.0 (2015-10-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- improve logging with levels and log function
|
||||
- switch registry warnings to debug log level
|
||||
|
||||
|
||||
4.0.20 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly find python binary in non-Windows environments
|
||||
|
||||
|
||||
4.0.19 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- handle case where ST builtin python does not have _winreg or winreg module
|
||||
|
||||
|
||||
4.0.18 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- find python location from windows registry
|
||||
|
||||
|
||||
4.0.17 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- download python in non blocking background thread for Windows machines
|
||||
|
||||
|
||||
4.0.16 (2015-09-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.8
|
||||
- fix bug in guess_language function
|
||||
- improve dependency detection
|
||||
- default request timeout of 30 seconds
|
||||
- new --timeout command line argument to change request timeout in seconds
|
||||
- allow passing command line arguments using sys.argv
|
||||
- fix entry point for pypi distribution
|
||||
- new --entity and --entitytype command line arguments
|
||||
|
||||
|
||||
4.0.15 (2015-08-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.3
|
||||
- fix local session caching
|
||||
|
||||
|
||||
4.0.14 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.2
|
||||
- fix bug in offline caching which prevented heartbeats from being cleaned up
|
||||
|
||||
|
||||
4.0.13 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.1
|
||||
- send hostname in X-Machine-Name header
|
||||
- catch exceptions from pygments.modeline.get_filetype_from_buffer
|
||||
- upgrade requests package to v2.7.0
|
||||
- handle non-ASCII characters in import path on Windows, won't fix for Python2
|
||||
- upgrade argparse to v1.3.0
|
||||
- move language translations to api server
|
||||
- move extension rules to api server
|
||||
- detect correct header file language based on presence of .cpp or .c files named the same as the .h file
|
||||
|
||||
|
||||
4.0.12 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly use urllib in Python3
|
||||
|
||||
|
||||
4.0.11 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
|
||||
21
README.md
21
README.md
@ -1,13 +1,12 @@
|
||||
sublime-wakatime
|
||||
================
|
||||
|
||||
Fully automatic time tracking for Sublime Text 2 & 3.
|
||||
Metrics, insights, and time tracking automatically generated from your programming activity.
|
||||
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](http://www.python.org/getit/) being installed to work correctly.
|
||||
|
||||
1. Install [Package Control](https://packagecontrol.io/installation).
|
||||
|
||||
2. Using [Package Control](https://packagecontrol.io/docs/usage):
|
||||
@ -24,10 +23,24 @@ Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](ht
|
||||
|
||||
5. Visit https://wakatime.com/dashboard to see your logged time.
|
||||
|
||||
|
||||
Screen Shots
|
||||
------------
|
||||
|
||||
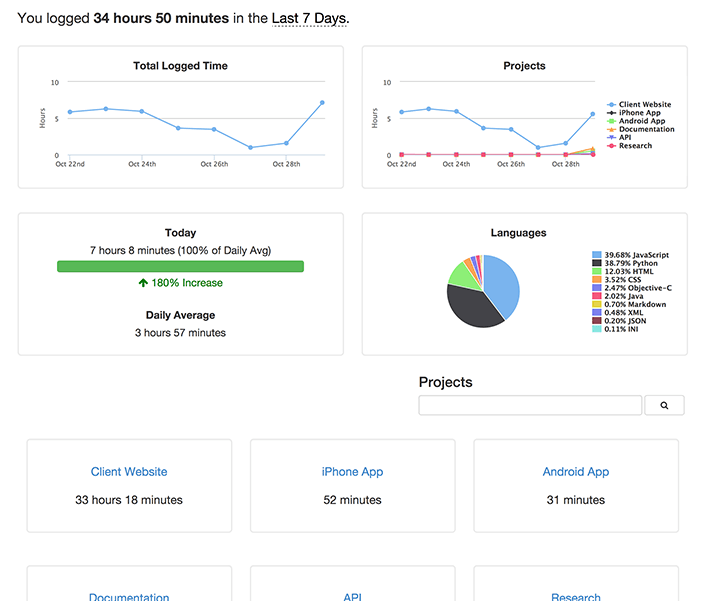
|
||||
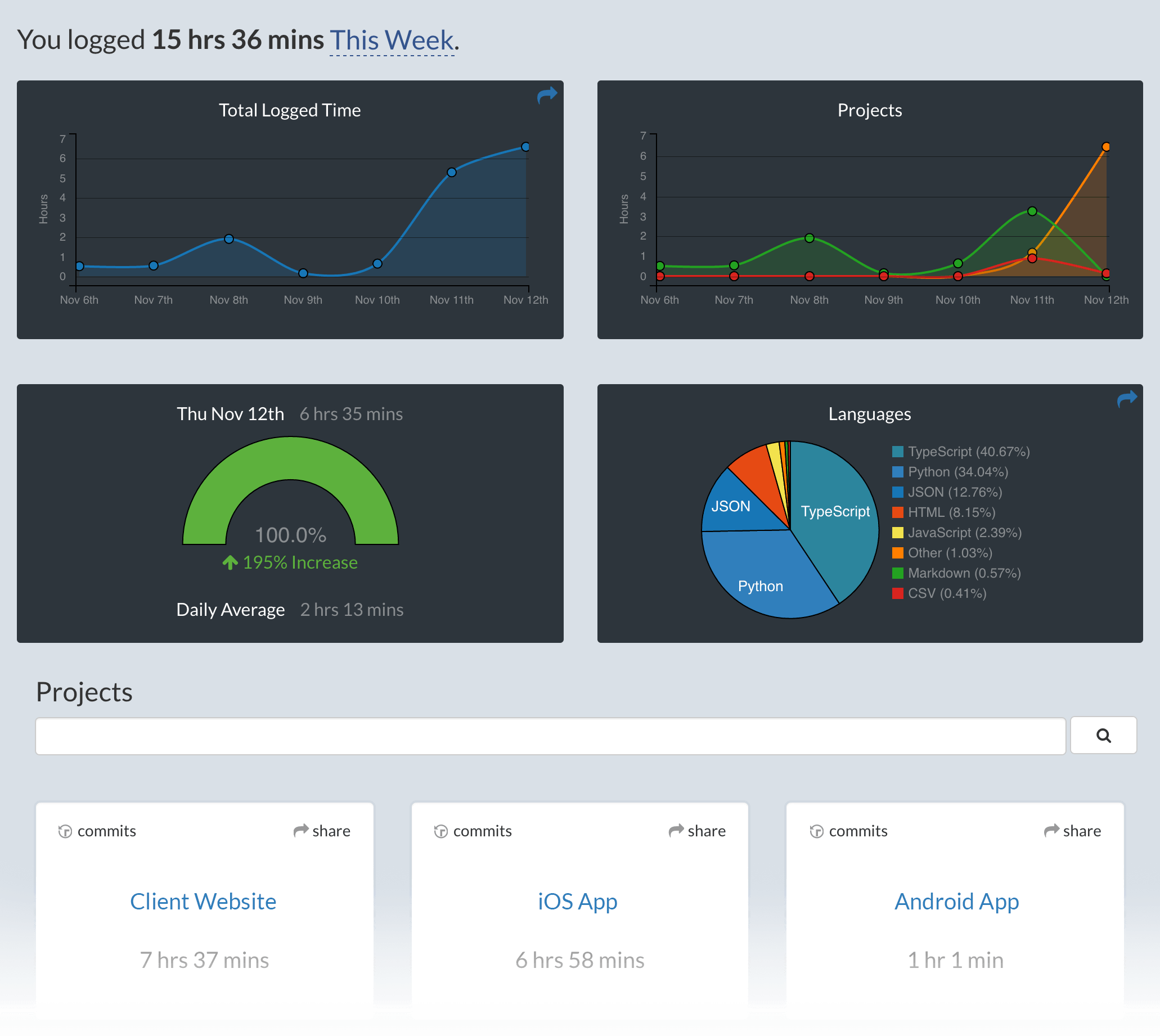
|
||||
|
||||
|
||||
Unresponsive Plugin Warning
|
||||
---------------------------
|
||||
|
||||
In Sublime Text 2, if you get a warning message:
|
||||
|
||||
A plugin (WakaTime) may be making Sublime Text unresponsive by taking too long (0.017332s) in its on_modified callback.
|
||||
|
||||
To fix this, go to `Preferences > Settings - User` then add the following setting:
|
||||
|
||||
`"detect_slow_plugins": false`
|
||||
|
||||
|
||||
Troubleshooting
|
||||
---------------
|
||||
|
||||
306
WakaTime.py
306
WakaTime.py
@ -7,22 +7,74 @@ Website: https://wakatime.com/
|
||||
==========================================================="""
|
||||
|
||||
|
||||
__version__ = '4.0.11'
|
||||
__version__ = '6.0.8'
|
||||
|
||||
|
||||
import sublime
|
||||
import sublime_plugin
|
||||
|
||||
import glob
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import threading
|
||||
import urllib
|
||||
import webbrowser
|
||||
from datetime import datetime
|
||||
from subprocess import Popen
|
||||
from zipfile import ZipFile
|
||||
from subprocess import Popen, STDOUT, PIPE
|
||||
try:
|
||||
import _winreg as winreg # py2
|
||||
except ImportError:
|
||||
try:
|
||||
import winreg # py3
|
||||
except ImportError:
|
||||
winreg = None
|
||||
|
||||
|
||||
is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
if is_py2:
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
text = str(text)
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
|
||||
elif is_py3:
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
|
||||
else:
|
||||
raise Exception('Unsupported Python version: {0}.{1}.{2}'.format(
|
||||
sys.version_info[0],
|
||||
sys.version_info[1],
|
||||
sys.version_info[2],
|
||||
))
|
||||
|
||||
|
||||
# globals
|
||||
@ -41,6 +93,13 @@ LOCK = threading.RLock()
|
||||
PYTHON_LOCATION = None
|
||||
|
||||
|
||||
# Log Levels
|
||||
DEBUG = 'DEBUG'
|
||||
INFO = 'INFO'
|
||||
WARNING = 'WARNING'
|
||||
ERROR = 'ERROR'
|
||||
|
||||
|
||||
# add wakatime package to path
|
||||
sys.path.insert(0, os.path.join(PLUGIN_DIR, 'packages'))
|
||||
try:
|
||||
@ -49,6 +108,20 @@ except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
def log(lvl, message, *args, **kwargs):
|
||||
try:
|
||||
if lvl == DEBUG and not SETTINGS.get('debug'):
|
||||
return
|
||||
msg = message
|
||||
if len(args) > 0:
|
||||
msg = message.format(*args)
|
||||
elif len(kwargs) > 0:
|
||||
msg = message.format(**kwargs)
|
||||
print('[WakaTime] [{lvl}] {msg}'.format(lvl=lvl, msg=msg))
|
||||
except RuntimeError:
|
||||
sublime.set_timeout(lambda: log(lvl, message, *args, **kwargs), 0)
|
||||
|
||||
|
||||
def createConfigFile():
|
||||
"""Creates the .wakatime.cfg INI file in $HOME directory, if it does
|
||||
not already exist.
|
||||
@ -93,35 +166,129 @@ def prompt_api_key():
|
||||
window.show_input_panel('[WakaTime] Enter your wakatime.com api key:', default_key, got_key, None, None)
|
||||
return True
|
||||
else:
|
||||
print('[WakaTime] Error: Could not prompt for api key because no window found.')
|
||||
log(ERROR, 'Could not prompt for api key because no window found.')
|
||||
return False
|
||||
|
||||
|
||||
def python_binary():
|
||||
global PYTHON_LOCATION
|
||||
if PYTHON_LOCATION is not None:
|
||||
return PYTHON_LOCATION
|
||||
|
||||
# look for python in PATH and common install locations
|
||||
paths = [
|
||||
"pythonw",
|
||||
"python",
|
||||
"/usr/local/bin/python",
|
||||
"/usr/bin/python",
|
||||
os.path.join(os.path.expanduser('~'), '.wakatime', 'python'),
|
||||
None,
|
||||
'/',
|
||||
'/usr/local/bin/',
|
||||
'/usr/bin/',
|
||||
]
|
||||
for path in paths:
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
for path in glob.iglob('/python*'):
|
||||
path = os.path.realpath(os.path.join(path, 'pythonw'))
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
|
||||
# look for python in windows registry
|
||||
path = find_python_from_registry(r'SOFTWARE\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
path = find_python_from_registry(r'SOFTWARE\Wow6432Node\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def set_python_binary_location(path):
|
||||
global PYTHON_LOCATION
|
||||
PYTHON_LOCATION = path
|
||||
log(DEBUG, 'Found Python at: {0}'.format(path))
|
||||
|
||||
|
||||
def find_python_from_registry(location, reg=None):
|
||||
if platform.system() != 'Windows' or winreg is None:
|
||||
return None
|
||||
|
||||
if reg is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_CURRENT_USER)
|
||||
if path is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_LOCAL_MACHINE)
|
||||
return path
|
||||
|
||||
val = None
|
||||
sub_key = 'InstallPath'
|
||||
compiled = re.compile(r'^\d+\.\d+$')
|
||||
|
||||
try:
|
||||
with winreg.OpenKey(reg, location) as handle:
|
||||
versions = []
|
||||
try:
|
||||
for index in range(1024):
|
||||
version = winreg.EnumKey(handle, index)
|
||||
try:
|
||||
if compiled.search(version):
|
||||
versions.append(version)
|
||||
except re.error:
|
||||
pass
|
||||
except EnvironmentError:
|
||||
pass
|
||||
versions.sort(reverse=True)
|
||||
for version in versions:
|
||||
try:
|
||||
path = winreg.QueryValue(handle, version + '\\' + sub_key)
|
||||
if path is not None:
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
log(DEBUG, 'Found python from {reg}\\{key}\\{version}\\{sub_key}.'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
return path
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}\\{version}\\{sub_key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
))
|
||||
|
||||
return val
|
||||
|
||||
|
||||
def find_python_in_folder(folder, headless=True):
|
||||
pattern = re.compile(r'\d+\.\d+')
|
||||
|
||||
path = 'python'
|
||||
if folder is not None:
|
||||
path = os.path.realpath(os.path.join(folder, 'python'))
|
||||
if headless:
|
||||
path = u(path) + u('w')
|
||||
log(DEBUG, u('Looking for Python at: {0}').format(path))
|
||||
try:
|
||||
process = Popen([path, '--version'], stdout=PIPE, stderr=STDOUT)
|
||||
output, err = process.communicate()
|
||||
output = u(output).strip()
|
||||
retcode = process.poll()
|
||||
log(DEBUG, u('Python Version Output: {0}').format(output))
|
||||
if not retcode and pattern.search(output):
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
except:
|
||||
log(DEBUG, u('Python Version Output: {0}').format(u(sys.exc_info()[1])))
|
||||
|
||||
if headless:
|
||||
path = find_python_in_folder(folder, headless=False)
|
||||
if path is not None:
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
@ -133,7 +300,7 @@ def obfuscate_apikey(command_list):
|
||||
apikey_index = num + 1
|
||||
break
|
||||
if apikey_index is not None and apikey_index < len(cmd):
|
||||
cmd[apikey_index] = '********-****-****-****-********' + cmd[apikey_index][-4:]
|
||||
cmd[apikey_index] = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX' + cmd[apikey_index][-4:]
|
||||
return cmd
|
||||
|
||||
|
||||
@ -195,6 +362,8 @@ def handle_heartbeat(view, is_write=False):
|
||||
|
||||
|
||||
class SendHeartbeatThread(threading.Thread):
|
||||
"""Non-blocking thread for sending heartbeats to api.
|
||||
"""
|
||||
|
||||
def __init__(self, target_file, view, is_write=False, project=None, folders=None, force=False):
|
||||
threading.Thread.__init__(self)
|
||||
@ -220,7 +389,7 @@ class SendHeartbeatThread(threading.Thread):
|
||||
|
||||
def send_heartbeat(self):
|
||||
if not self.api_key:
|
||||
print('[WakaTime] Error: missing api key.')
|
||||
log(ERROR, 'missing api key.')
|
||||
return
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
@ -246,16 +415,26 @@ class SendHeartbeatThread(threading.Thread):
|
||||
cmd.append('--verbose')
|
||||
if python_binary():
|
||||
cmd.insert(0, python_binary())
|
||||
if self.debug:
|
||||
print('[WakaTime] %s' % ' '.join(obfuscate_apikey(cmd)))
|
||||
if platform.system() == 'Windows':
|
||||
Popen(cmd, shell=False)
|
||||
else:
|
||||
with open(os.path.join(os.path.expanduser('~'), '.wakatime.log'), 'a') as stderr:
|
||||
Popen(cmd, stderr=stderr)
|
||||
self.sent()
|
||||
log(DEBUG, ' '.join(obfuscate_apikey(cmd)))
|
||||
try:
|
||||
if not self.debug:
|
||||
Popen(cmd)
|
||||
self.sent()
|
||||
else:
|
||||
process = Popen(cmd, stdout=PIPE, stderr=STDOUT)
|
||||
output, err = process.communicate()
|
||||
output = u(output)
|
||||
retcode = process.poll()
|
||||
if (not retcode or retcode == 102) and not output:
|
||||
self.sent()
|
||||
if retcode:
|
||||
log(DEBUG if retcode == 102 else ERROR, 'wakatime-core exited with status: {0}'.format(retcode))
|
||||
if output:
|
||||
log(ERROR, u('wakatime-core output: {0}').format(output))
|
||||
except:
|
||||
log(ERROR, u(sys.exc_info()[1]))
|
||||
else:
|
||||
print('[WakaTime] Error: Unable to find python binary.')
|
||||
log(ERROR, 'Unable to find python binary.')
|
||||
|
||||
def sent(self):
|
||||
sublime.set_timeout(self.set_status_bar, 0)
|
||||
@ -274,19 +453,57 @@ class SendHeartbeatThread(threading.Thread):
|
||||
}
|
||||
|
||||
|
||||
class DownloadPython(threading.Thread):
|
||||
"""Non-blocking thread for extracting embeddable Python on Windows machines.
|
||||
"""
|
||||
|
||||
def run(self):
|
||||
log(INFO, 'Downloading embeddable Python...')
|
||||
|
||||
ver = '3.5.0'
|
||||
arch = 'amd64' if platform.architecture()[0] == '64bit' else 'win32'
|
||||
url = 'https://www.python.org/ftp/python/{ver}/python-{ver}-embed-{arch}.zip'.format(
|
||||
ver=ver,
|
||||
arch=arch,
|
||||
)
|
||||
|
||||
if not os.path.exists(os.path.join(os.path.expanduser('~'), '.wakatime')):
|
||||
os.makedirs(os.path.join(os.path.expanduser('~'), '.wakatime'))
|
||||
|
||||
zip_file = os.path.join(os.path.expanduser('~'), '.wakatime', 'python.zip')
|
||||
try:
|
||||
urllib.urlretrieve(url, zip_file)
|
||||
except AttributeError:
|
||||
urllib.request.urlretrieve(url, zip_file)
|
||||
|
||||
log(INFO, 'Extracting Python...')
|
||||
with ZipFile(zip_file) as zf:
|
||||
path = os.path.join(os.path.expanduser('~'), '.wakatime', 'python')
|
||||
zf.extractall(path)
|
||||
|
||||
try:
|
||||
os.remove(zip_file)
|
||||
except:
|
||||
pass
|
||||
|
||||
log(INFO, 'Finished extracting Python.')
|
||||
|
||||
|
||||
def plugin_loaded():
|
||||
global SETTINGS
|
||||
print('[WakaTime] Initializing WakaTime plugin v%s' % __version__)
|
||||
log(INFO, 'Initializing WakaTime plugin v%s' % __version__)
|
||||
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
|
||||
if not python_binary():
|
||||
print('[WakaTime] Warning: Python binary not found.')
|
||||
log(WARNING, 'Python binary not found.')
|
||||
if platform.system() == 'Windows':
|
||||
install_python()
|
||||
thread = DownloadPython()
|
||||
thread.start()
|
||||
else:
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
after_loaded()
|
||||
|
||||
|
||||
@ -295,23 +512,6 @@ def after_loaded():
|
||||
sublime.set_timeout(after_loaded, 500)
|
||||
|
||||
|
||||
def install_python():
|
||||
print('[WakaTime] Downloading and installing python...')
|
||||
url = 'https://www.python.org/ftp/python/3.4.3/python-3.4.3.msi'
|
||||
if platform.architecture()[0] == '64bit':
|
||||
url = 'https://www.python.org/ftp/python/3.4.3/python-3.4.3.amd64.msi'
|
||||
python_msi = os.path.join(os.path.expanduser('~'), 'python.msi')
|
||||
urllib.urlretrieve(url, python_msi)
|
||||
args = [
|
||||
'msiexec',
|
||||
'/i',
|
||||
python_msi,
|
||||
'/norestart',
|
||||
'/qb!',
|
||||
]
|
||||
Popen(args)
|
||||
|
||||
|
||||
# need to call plugin_loaded because only ST3 will auto-call it
|
||||
if ST_VERSION < 3000:
|
||||
plugin_loaded()
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
__title__ = 'wakatime'
|
||||
__description__ = 'Common interface to the WakaTime api.'
|
||||
__url__ = 'https://github.com/wakatime/wakatime'
|
||||
__version_info__ = ('4', '1', '0')
|
||||
__version_info__ = ('5', '0', '0')
|
||||
__version__ = '.'.join(__version_info__)
|
||||
__author__ = 'Alan Hamlett'
|
||||
__author_email__ = 'alan@wakatime.com'
|
||||
__license__ = 'BSD'
|
||||
__copyright__ = 'Copyright 2014 Alan Hamlett'
|
||||
__copyright__ = 'Copyright 2016 Alan Hamlett'
|
||||
|
||||
@ -14,4 +14,4 @@
|
||||
__all__ = ['main']
|
||||
|
||||
|
||||
from .base import main
|
||||
from .main import execute
|
||||
|
||||
@ -22,7 +22,7 @@ sys.path.insert(0, package_folder)
|
||||
# import local wakatime package
|
||||
try:
|
||||
import wakatime
|
||||
except TypeError:
|
||||
except (TypeError, ImportError):
|
||||
# on Windows, non-ASCII characters in import path can be fixed using
|
||||
# the script path from sys.argv[0].
|
||||
# More info at https://github.com/wakatime/wakatime/issues/32
|
||||
@ -32,4 +32,4 @@ except TypeError:
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(wakatime.main(sys.argv))
|
||||
sys.exit(wakatime.execute(sys.argv[1:]))
|
||||
|
||||
@ -17,32 +17,49 @@ is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
|
||||
if is_py2:
|
||||
if is_py2: # pragma: nocover
|
||||
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
return text
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
open = codecs.open
|
||||
basestring = basestring
|
||||
|
||||
|
||||
elif is_py3:
|
||||
elif is_py3: # pragma: nocover
|
||||
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
return text.decode('utf-8')
|
||||
return str(text)
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
open = open
|
||||
basestring = (str, bytes)
|
||||
|
||||
|
||||
try:
|
||||
from importlib import import_module
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
def _resolve_name(name, package, level):
|
||||
"""Return the absolute name of the module to be imported."""
|
||||
if not hasattr(package, 'rindex'):
|
||||
|
||||
17
packages/wakatime/constants.py
Normal file
17
packages/wakatime/constants.py
Normal file
@ -0,0 +1,17 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.constants
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Constant variable definitions.
|
||||
|
||||
:copyright: (c) 2016 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
SUCCESS = 0
|
||||
API_ERROR = 102
|
||||
CONFIG_FILE_PARSE_ERROR = 103
|
||||
AUTH_ERROR = 104
|
||||
UNKNOWN_ERROR = 105
|
||||
@ -1,7 +1,7 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
wakatime.dependencies
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from a source code file.
|
||||
|
||||
@ -10,9 +10,12 @@
|
||||
"""
|
||||
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from ..compat import u, open, import_module
|
||||
from ..exceptions import NotYetImplemented
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
@ -23,26 +26,28 @@ class TokenParser(object):
|
||||
language, inherit from this class and implement the :meth:`parse` method
|
||||
to return a list of dependency strings.
|
||||
"""
|
||||
source_file = None
|
||||
lexer = None
|
||||
dependencies = []
|
||||
tokens = []
|
||||
exclude = []
|
||||
|
||||
def __init__(self, source_file, lexer=None):
|
||||
self._tokens = None
|
||||
self.dependencies = []
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
self.exclude = [re.compile(x, re.IGNORECASE) for x in self.exclude]
|
||||
|
||||
@property
|
||||
def tokens(self):
|
||||
if self._tokens is None:
|
||||
self._tokens = self._extract_tokens()
|
||||
return self._tokens
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
""" Should return a list of dependencies.
|
||||
"""
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
raise Exception('Not yet implemented.')
|
||||
raise NotYetImplemented()
|
||||
|
||||
def append(self, dep, truncate=False, separator=None, truncate_to=None,
|
||||
strip_whitespace=True):
|
||||
if dep == 'as':
|
||||
print('***************** as')
|
||||
self._save_dependency(
|
||||
dep,
|
||||
truncate=truncate,
|
||||
@ -51,10 +56,21 @@ class TokenParser(object):
|
||||
strip_whitespace=strip_whitespace,
|
||||
)
|
||||
|
||||
def partial(self, token):
|
||||
return u(token).split('.')[-1]
|
||||
|
||||
def _extract_tokens(self):
|
||||
if self.lexer:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
return []
|
||||
|
||||
def _save_dependency(self, dep, truncate=False, separator=None,
|
||||
@ -64,13 +80,21 @@ class TokenParser(object):
|
||||
separator = u('.')
|
||||
separator = u(separator)
|
||||
dep = dep.split(separator)
|
||||
if truncate_to is None or truncate_to < 0 or truncate_to > len(dep) - 1:
|
||||
truncate_to = len(dep) - 1
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[0:truncate_to])
|
||||
if truncate_to is None or truncate_to < 1:
|
||||
truncate_to = 1
|
||||
if truncate_to > len(dep):
|
||||
truncate_to = len(dep)
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[:truncate_to])
|
||||
if strip_whitespace:
|
||||
dep = dep.strip()
|
||||
if dep:
|
||||
self.dependencies.append(dep)
|
||||
if dep and (not separator or not dep.startswith(separator)):
|
||||
should_exclude = False
|
||||
for compiled in self.exclude:
|
||||
if compiled.search(dep):
|
||||
should_exclude = True
|
||||
break
|
||||
if not should_exclude:
|
||||
self.dependencies.append(dep)
|
||||
|
||||
|
||||
class DependencyParser(object):
|
||||
@ -83,7 +107,7 @@ class DependencyParser(object):
|
||||
self.lexer = lexer
|
||||
|
||||
if self.lexer:
|
||||
module_name = self.lexer.__module__.split('.')[-1]
|
||||
module_name = self.lexer.__module__.rsplit('.', 1)[-1]
|
||||
class_name = self.lexer.__class__.__name__.replace('Lexer', 'Parser', 1)
|
||||
else:
|
||||
module_name = 'unknown'
|
||||
68
packages/wakatime/dependencies/c_cpp.py
Normal file
68
packages/wakatime/dependencies/c_cpp.py
Normal file
@ -0,0 +1,68 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
|
||||
class CParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -26,10 +26,8 @@ class JsonParser(TokenParser):
|
||||
state = None
|
||||
level = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
64
packages/wakatime/dependencies/dotnet.py
Normal file
64
packages/wakatime/dependencies/dotnet.py
Normal file
@ -0,0 +1,64 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
exclude = [
|
||||
r'^system$',
|
||||
r'^microsoft$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
if self.partial(token) == 'Namespace' or self.partial(token) == 'Name':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_keyword(self, token, content):
|
||||
if content == 'using':
|
||||
self.state = 'import'
|
||||
self.buffer = u('')
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) != u('import') and u(content) != u('package') and u(content) != u('namespace') and u(content) != u('static'):
|
||||
if u(content) == u(';'): # pragma: nocover
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) == u(';'):
|
||||
self.append(self.buffer, truncate=True)
|
||||
self.buffer = u('')
|
||||
self.state = None
|
||||
elif u(content) == u('='):
|
||||
self.buffer = u('')
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
77
packages/wakatime/dependencies/go.py
Normal file
77
packages/wakatime/dependencies/go.py
Normal file
@ -0,0 +1,77 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.go
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Go code.
|
||||
|
||||
:copyright: (c) 2016 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class GoParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
aliases = 0
|
||||
exclude = [
|
||||
r'^"fmt"$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif self.partial(token) == 'String':
|
||||
self._process_string(token, content)
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
elif self.partial(token) == 'Other':
|
||||
self._process_other(token, content)
|
||||
else:
|
||||
self._process_misc(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
self.state = content
|
||||
self.parens = 0
|
||||
self.aliases = 0
|
||||
|
||||
def _process_string(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.append(content, truncate=False)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
elif content == '.':
|
||||
self.aliases += 1
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state == 'import':
|
||||
if content == "\n" and self.parens <= 0:
|
||||
self.state = None
|
||||
self.parens = 0
|
||||
self.aliases = 0
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_other(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.aliases += 1
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_misc(self, token, content):
|
||||
self.state = None
|
||||
96
packages/wakatime/dependencies/jvm.py
Normal file
96
packages/wakatime/dependencies/jvm.py
Normal file
@ -0,0 +1,96 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
exclude = [
|
||||
r'^java\.',
|
||||
r'^javax\.',
|
||||
r'^import$',
|
||||
r'^package$',
|
||||
r'^namespace$',
|
||||
r'^static$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
if self.partial(token) == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif self.partial(token) == 'Attribute':
|
||||
self._process_attribute(token, content)
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if u(content) == u('import'):
|
||||
self.state = 'import'
|
||||
|
||||
elif self.state == 'import':
|
||||
keywords = [
|
||||
u('package'),
|
||||
u('namespace'),
|
||||
u('static'),
|
||||
]
|
||||
if u(content) in keywords:
|
||||
return
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
elif self.state == 'import-finished':
|
||||
content = content.split(u('.'))
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
|
||||
elif len(content) > 1:
|
||||
if len(content[0]) == 3:
|
||||
content = content[1:]
|
||||
if content[-1] == u('*'):
|
||||
content = content[:len(content) - 1]
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
elif len(content) > 1:
|
||||
self.append(u('.').join(content[:2]))
|
||||
|
||||
self.state = None
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if u(content) == u(';'):
|
||||
self.state = 'import-finished'
|
||||
self._process_namespace(token, self.buffer)
|
||||
self.state = None
|
||||
self.buffer = u('')
|
||||
elif self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -17,15 +17,13 @@ class PhpParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Keyword':
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
@ -33,9 +31,9 @@ class PhpParser(TokenParser):
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Name.Function':
|
||||
self._process_function(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
@ -63,10 +61,10 @@ class PhpParser(TokenParser):
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '"':
|
||||
if content != '"' and content != "'":
|
||||
content = content.strip()
|
||||
if u(token) == 'Token.Literal.String.Double':
|
||||
content = u('"{0}"').format(content)
|
||||
content = u("'{0}'").format(content)
|
||||
self.append(content)
|
||||
self.state = None
|
||||
|
||||
@ -10,33 +10,30 @@
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class PythonParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
nonpackage = False
|
||||
exclude = [
|
||||
r'^os$',
|
||||
r'^sys\.',
|
||||
]
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif u(token).split('.')[-1] == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif u(token).split('.')[-1] == 'Word':
|
||||
self._process_word(token, content)
|
||||
elif u(token).split('.')[-1] == 'Operator':
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
@ -50,38 +47,6 @@ class PythonParser(TokenParser):
|
||||
else:
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_word(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == '.':
|
||||
@ -106,15 +71,15 @@ class PythonParser(TokenParser):
|
||||
def _process_import(self, token, content):
|
||||
if not self.nonpackage:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'import-2'
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
else:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
@ -71,9 +71,7 @@ KEYWORDS = [
|
||||
|
||||
class LassoJavascriptParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
@ -99,9 +97,7 @@ class HtmlDjangoParser(TokenParser):
|
||||
current_attr = None
|
||||
current_attr_value = None
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
@ -22,7 +22,7 @@ FILES = {
|
||||
|
||||
class UnknownParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
return self.dependencies
|
||||
|
||||
14
packages/wakatime/exceptions.py
Normal file
14
packages/wakatime/exceptions.py
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.exceptions
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Custom exceptions.
|
||||
|
||||
:copyright: (c) 2015 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
class NotYetImplemented(Exception):
|
||||
"""This method needs to be implemented."""
|
||||
@ -1,37 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -11,25 +11,29 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from .packages import simplejson as json
|
||||
from .compat import u
|
||||
from .packages.requests.packages import urllib3
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from collections import OrderedDict # pragma: nocover
|
||||
except ImportError: # pragma: nocover
|
||||
from .packages.ordereddict import OrderedDict
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes):
|
||||
obj = bytes.decode(obj)
|
||||
if isinstance(obj, bytes): # pragma: nocover
|
||||
obj = u(obj)
|
||||
return json.dumps(obj)
|
||||
try:
|
||||
try: # pragma: nocover
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError:
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
@ -37,11 +41,11 @@ class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, isWrite, targetFile, version, plugin, verbose,
|
||||
def setup(self, timestamp, isWrite, entity, version, plugin, verbose,
|
||||
warnings=False):
|
||||
self.timestamp = timestamp
|
||||
self.isWrite = isWrite
|
||||
self.targetFile = targetFile
|
||||
self.entity = entity
|
||||
self.version = version
|
||||
self.plugin = plugin
|
||||
self.verbose = verbose
|
||||
@ -58,7 +62,7 @@ class JsonFormatter(logging.Formatter):
|
||||
data['caller'] = record.pathname
|
||||
data['lineno'] = record.lineno
|
||||
data['isWrite'] = self.isWrite
|
||||
data['file'] = self.targetFile
|
||||
data['file'] = self.entity
|
||||
if not self.isWrite:
|
||||
del data['isWrite']
|
||||
data['level'] = record.levelname
|
||||
@ -67,8 +71,16 @@ class JsonFormatter(logging.Formatter):
|
||||
del data['plugin']
|
||||
return CustomEncoder().encode(data)
|
||||
|
||||
def formatException(self, exc_info):
|
||||
return sys.exec_info[2].format_exc()
|
||||
|
||||
def traceback_formatter(*args, **kwargs):
|
||||
if 'level' in kwargs and (kwargs['level'].lower() == 'warn' or kwargs['level'].lower() == 'warning'):
|
||||
logging.getLogger('WakaTime').warning(traceback.format_exc())
|
||||
elif 'level' in kwargs and kwargs['level'].lower() == 'info':
|
||||
logging.getLogger('WakaTime').info(traceback.format_exc())
|
||||
elif 'level' in kwargs and kwargs['level'].lower() == 'debug':
|
||||
logging.getLogger('WakaTime').debug(traceback.format_exc())
|
||||
else:
|
||||
logging.getLogger('WakaTime').error(traceback.format_exc())
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
@ -79,20 +91,11 @@ def set_log_level(logger, args):
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
urllib3.disable_warnings()
|
||||
logger = logging.getLogger('WakaTime')
|
||||
for handler in logger.handlers:
|
||||
logger.removeHandler(handler)
|
||||
set_log_level(logger, args)
|
||||
if len(logger.handlers) > 0:
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
)
|
||||
logger.handlers[0].setFormatter(formatter)
|
||||
return logger
|
||||
logfile = args.logfile
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
@ -101,7 +104,7 @@ def setup_logging(args, version):
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
@ -109,11 +112,14 @@ def setup_logging(args, version):
|
||||
handler.setFormatter(formatter)
|
||||
logger.addHandler(handler)
|
||||
|
||||
# add custom traceback logging method
|
||||
logger.traceback = traceback_formatter
|
||||
|
||||
warnings_formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
warnings_formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
@ -124,7 +130,7 @@ def setup_logging(args, version):
|
||||
logging.getLogger('py.warnings').addHandler(warnings_handler)
|
||||
try:
|
||||
logging.captureWarnings(True)
|
||||
except AttributeError:
|
||||
except AttributeError: # pragma: nocover
|
||||
pass # Python >= 2.7 is needed to capture warnings
|
||||
|
||||
return logger
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.base
|
||||
wakatime.main
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
wakatime module entry point.
|
||||
@ -22,26 +22,35 @@ import traceback
|
||||
import socket
|
||||
try:
|
||||
import ConfigParser as configparser
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
import configparser
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
pwd = os.path.dirname(os.path.abspath(__file__))
|
||||
sys.path.insert(0, os.path.dirname(pwd))
|
||||
sys.path.insert(0, os.path.join(pwd, 'packages'))
|
||||
|
||||
from .__about__ import __version__
|
||||
from .compat import u, open, is_py3
|
||||
from .constants import (
|
||||
API_ERROR,
|
||||
AUTH_ERROR,
|
||||
CONFIG_FILE_PARSE_ERROR,
|
||||
SUCCESS,
|
||||
UNKNOWN_ERROR,
|
||||
)
|
||||
from .logger import setup_logging
|
||||
from .offlinequeue import Queue
|
||||
from .packages import argparse
|
||||
from .packages import simplejson as json
|
||||
from .packages import requests
|
||||
from .packages.requests.exceptions import RequestException
|
||||
from .project import get_project_info
|
||||
from .session_cache import SessionCache
|
||||
from .stats import get_file_stats
|
||||
try:
|
||||
from .packages import tzlocal
|
||||
except:
|
||||
from .packages import tzlocal3 as tzlocal
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
from .packages import tzlocal
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
@ -50,49 +59,14 @@ log = logging.getLogger('WakaTime')
|
||||
class FileAction(argparse.Action):
|
||||
|
||||
def __call__(self, parser, namespace, values, option_string=None):
|
||||
values = os.path.realpath(values)
|
||||
try:
|
||||
if os.path.isfile(values):
|
||||
values = os.path.realpath(values)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def upgradeConfigFile(configFile):
|
||||
"""For backwards-compatibility, upgrade the existing config file
|
||||
to work with configparser and rename from .wakatime.conf to .wakatime.cfg.
|
||||
"""
|
||||
|
||||
if os.path.isfile(configFile):
|
||||
# if upgraded cfg file already exists, don't overwrite it
|
||||
return
|
||||
|
||||
oldConfig = os.path.join(os.path.expanduser('~'), '.wakatime.conf')
|
||||
try:
|
||||
configs = {
|
||||
'ignore': [],
|
||||
}
|
||||
|
||||
with open(oldConfig, 'r', encoding='utf-8') as fh:
|
||||
for line in fh.readlines():
|
||||
line = line.split('=', 1)
|
||||
if len(line) == 2 and line[0].strip() and line[1].strip():
|
||||
if line[0].strip() == 'ignore':
|
||||
configs['ignore'].append(line[1].strip())
|
||||
else:
|
||||
configs[line[0].strip()] = line[1].strip()
|
||||
|
||||
with open(configFile, 'w', encoding='utf-8') as fh:
|
||||
fh.write("[settings]\n")
|
||||
for name, value in configs.items():
|
||||
if isinstance(value, list):
|
||||
fh.write("%s=\n" % name)
|
||||
for item in value:
|
||||
fh.write(" %s\n" % item)
|
||||
else:
|
||||
fh.write("%s = %s\n" % (name, value))
|
||||
|
||||
os.remove(oldConfig)
|
||||
except IOError:
|
||||
pass
|
||||
|
||||
|
||||
def parseConfigFile(configFile=None):
|
||||
"""Returns a configparser.SafeConfigParser instance with configs
|
||||
read from the config file. Default location of the config file is
|
||||
@ -102,8 +76,6 @@ def parseConfigFile(configFile=None):
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.cfg')
|
||||
|
||||
upgradeConfigFile(configFile)
|
||||
|
||||
configs = configparser.SafeConfigParser()
|
||||
try:
|
||||
with open(configFile, 'r', encoding='utf-8') as fh:
|
||||
@ -117,23 +89,21 @@ def parseConfigFile(configFile=None):
|
||||
return configs
|
||||
|
||||
|
||||
def parseArguments(argv):
|
||||
def parseArguments():
|
||||
"""Parse command line arguments and configs from ~/.wakatime.cfg.
|
||||
Command line arguments take precedence over config file settings.
|
||||
Returns instances of ArgumentParser and SafeConfigParser.
|
||||
"""
|
||||
|
||||
try:
|
||||
sys.argv
|
||||
except AttributeError:
|
||||
sys.argv = argv
|
||||
|
||||
# define supported command line arguments
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Common interface for the WakaTime api.')
|
||||
parser.add_argument('--file', dest='targetFile', metavar='file',
|
||||
action=FileAction, required=True,
|
||||
help='absolute path to file for current heartbeat')
|
||||
parser.add_argument('--entity', dest='entity', metavar='FILE',
|
||||
action=FileAction,
|
||||
help='absolute path to file for the heartbeat; can also be a '+
|
||||
'url, domain, or app when --entitytype is not file')
|
||||
parser.add_argument('--file', dest='file', action=FileAction,
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakatime api key; uses api_key from '+
|
||||
'~/.wakatime.conf by default')
|
||||
@ -152,17 +122,19 @@ def parseArguments(argv):
|
||||
help='optional line number; current line being edited')
|
||||
parser.add_argument('--cursorpos', dest='cursorpos',
|
||||
help='optional cursor position in the current file')
|
||||
parser.add_argument('--notfile', dest='notfile', action='store_true',
|
||||
help='when set, will accept any value for the file. for example, '+
|
||||
'a domain name or other item you want to log time towards.')
|
||||
parser.add_argument('--entitytype', dest='entity_type',
|
||||
help='entity type for this heartbeat. can be one of "file", '+
|
||||
'"url", "domain", or "app"; defaults to file.')
|
||||
parser.add_argument('--proxy', dest='proxy',
|
||||
help='optional https proxy url; for example: '+
|
||||
'https://user:pass@localhost:8080')
|
||||
'https://user:pass@localhost:8080')
|
||||
parser.add_argument('--project', dest='project',
|
||||
help='optional project name')
|
||||
parser.add_argument('--alternate-project', dest='alternate_project',
|
||||
help='optional alternate project name; auto-discovered project takes priority')
|
||||
parser.add_argument('--hostname', dest='hostname', help='hostname of current machine.')
|
||||
help='optional alternate project name; auto-discovered project '+
|
||||
'takes priority')
|
||||
parser.add_argument('--hostname', dest='hostname', help='hostname of '+
|
||||
'current machine.')
|
||||
parser.add_argument('--disableoffline', dest='offline',
|
||||
action='store_false',
|
||||
help='disables offline time logging instead of queuing logged time')
|
||||
@ -182,6 +154,8 @@ def parseArguments(argv):
|
||||
help='defaults to ~/.wakatime.log')
|
||||
parser.add_argument('--apiurl', dest='api_url',
|
||||
help='heartbeats api url; for debugging with a local server')
|
||||
parser.add_argument('--timeout', dest='timeout', type=int,
|
||||
help='number of seconds to wait when sending heartbeats to api')
|
||||
parser.add_argument('--config', dest='config',
|
||||
help='defaults to ~/.wakatime.conf')
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
@ -189,7 +163,7 @@ def parseArguments(argv):
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
|
||||
# parse command line arguments
|
||||
args = parser.parse_args(args=argv[1:])
|
||||
args = parser.parse_args()
|
||||
|
||||
# use current unix epoch timestamp by default
|
||||
if not args.timestamp:
|
||||
@ -211,6 +185,13 @@ def parseArguments(argv):
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
if not args.entity_type:
|
||||
args.entity_type = 'file'
|
||||
if not args.entity:
|
||||
if args.file:
|
||||
args.entity = args.file
|
||||
else:
|
||||
parser.error('argument --entity is required')
|
||||
if not args.exclude:
|
||||
args.exclude = []
|
||||
if configs.has_option('settings', 'ignore'):
|
||||
@ -218,14 +199,14 @@ def parseArguments(argv):
|
||||
for pattern in configs.get('settings', 'ignore').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if configs.has_option('settings', 'exclude'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'exclude').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if not args.include:
|
||||
args.include = []
|
||||
@ -234,7 +215,7 @@ def parseArguments(argv):
|
||||
for pattern in configs.get('settings', 'include').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.include.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if args.offline and configs.has_option('settings', 'offline'):
|
||||
args.offline = configs.getboolean('settings', 'offline')
|
||||
@ -250,37 +231,42 @@ def parseArguments(argv):
|
||||
args.logfile = configs.get('settings', 'logfile')
|
||||
if not args.api_url and configs.has_option('settings', 'api_url'):
|
||||
args.api_url = configs.get('settings', 'api_url')
|
||||
if not args.timeout and configs.has_option('settings', 'timeout'):
|
||||
try:
|
||||
args.timeout = int(configs.get('settings', 'timeout'))
|
||||
except ValueError:
|
||||
print(traceback.format_exc())
|
||||
|
||||
return args, configs
|
||||
|
||||
|
||||
def should_exclude(fileName, include, exclude):
|
||||
if fileName is not None and fileName.strip() != '':
|
||||
def should_exclude(entity, include, exclude):
|
||||
if entity is not None and entity.strip() != '':
|
||||
try:
|
||||
for pattern in include:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
if compiled.search(entity):
|
||||
return False
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for include pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
try:
|
||||
for pattern in exclude:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
if compiled.search(entity):
|
||||
return pattern
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for exclude pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
return False
|
||||
|
||||
@ -305,26 +291,29 @@ def get_user_agent(plugin):
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None, targetFile=None,
|
||||
timestamp=None, isWrite=None, plugin=None, offline=None, notfile=False,
|
||||
hidefilenames=None, proxy=None, api_url=None, **kwargs):
|
||||
def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
entity=None, timestamp=None, isWrite=None, plugin=None,
|
||||
offline=None, entity_type='file', hidefilenames=None,
|
||||
proxy=None, api_url=None, timeout=None, **kwargs):
|
||||
"""Sends heartbeat as POST request to WakaTime api server.
|
||||
|
||||
Returns `SUCCESS` when heartbeat was sent, otherwise returns an
|
||||
error code constant.
|
||||
"""
|
||||
|
||||
if not api_url:
|
||||
api_url = 'https://wakatime.com/api/v1/heartbeats'
|
||||
api_url = 'https://api.wakatime.com/api/v1/heartbeats'
|
||||
if not timeout:
|
||||
timeout = 30
|
||||
log.debug('Sending heartbeat to api at %s' % api_url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'entity': targetFile,
|
||||
'type': 'file',
|
||||
'entity': entity,
|
||||
'type': entity_type,
|
||||
}
|
||||
if hidefilenames and targetFile is not None and not notfile:
|
||||
data['entity'] = data['entity'].rsplit('/', 1)[-1].rsplit('\\', 1)[-1]
|
||||
if len(data['entity'].strip('.').split('.', 1)) > 1:
|
||||
data['entity'] = u('HIDDEN.{ext}').format(ext=u(data['entity'].strip('.').rsplit('.', 1)[-1]))
|
||||
else:
|
||||
data['entity'] = u('HIDDEN')
|
||||
if hidefilenames and entity is not None and entity_type == 'file':
|
||||
extension = u(os.path.splitext(data['entity'])[1])
|
||||
data['entity'] = u('HIDDEN{0}').format(extension)
|
||||
if stats.get('lines'):
|
||||
data['lines'] = stats['lines']
|
||||
if stats.get('language'):
|
||||
@ -354,7 +343,7 @@ def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
'Authorization': auth,
|
||||
}
|
||||
if hostname:
|
||||
headers['X-Machine-Name'] = hostname
|
||||
headers['X-Machine-Name'] = u(hostname).encode('utf-8')
|
||||
proxies = {}
|
||||
if proxy:
|
||||
proxies['https'] = proxy
|
||||
@ -365,7 +354,7 @@ def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
except:
|
||||
tz = None
|
||||
if tz:
|
||||
headers['TimeZone'] = u(tz.zone)
|
||||
headers['TimeZone'] = u(tz.zone).encode('utf-8')
|
||||
|
||||
session_cache = SessionCache()
|
||||
session = session_cache.get()
|
||||
@ -374,7 +363,7 @@ def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
response = None
|
||||
try:
|
||||
response = session.post(api_url, data=request_body, headers=headers,
|
||||
proxies=proxies)
|
||||
proxies=proxies, timeout=timeout)
|
||||
except RequestException:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
@ -389,102 +378,123 @@ def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
else:
|
||||
log.error(exception_data)
|
||||
else:
|
||||
response_code = response.status_code if response is not None else None
|
||||
response_content = response.text if response is not None else None
|
||||
if response_code == 201:
|
||||
code = response.status_code if response is not None else None
|
||||
content = response.text if response is not None else None
|
||||
if code == requests.codes.created or code == requests.codes.accepted:
|
||||
log.debug({
|
||||
'response_code': response_code,
|
||||
'response_code': code,
|
||||
})
|
||||
session_cache.save(session)
|
||||
return True
|
||||
return SUCCESS
|
||||
if offline:
|
||||
if response_code != 400:
|
||||
if code != 400:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
if response_code == 401:
|
||||
if code == 401:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return AUTH_ERROR
|
||||
elif log.isEnabledFor(logging.DEBUG):
|
||||
log.warn({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return False
|
||||
return API_ERROR
|
||||
|
||||
|
||||
def main(argv=None):
|
||||
if not argv:
|
||||
argv = sys.argv
|
||||
def sync_offline_heartbeats(args, hostname):
|
||||
"""Sends all heartbeats which were cached in the offline Queue."""
|
||||
|
||||
args, configs = parseArguments(argv)
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
status = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
entity=heartbeat['entity'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
hostname=hostname,
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
isWrite=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
entity_type=heartbeat['type'],
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
timeout=args.timeout,
|
||||
)
|
||||
if status != SUCCESS:
|
||||
if status == AUTH_ERROR:
|
||||
return AUTH_ERROR
|
||||
break
|
||||
return SUCCESS
|
||||
|
||||
|
||||
def execute(argv=None):
|
||||
if argv:
|
||||
sys.argv = ['wakatime'] + argv
|
||||
|
||||
args, configs = parseArguments()
|
||||
if configs is None:
|
||||
return 103 # config file parsing error
|
||||
return CONFIG_FILE_PARSE_ERROR
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
exclude = should_exclude(args.targetFile, args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
log.debug(u('File not logged because matches exclude pattern: {pattern}').format(
|
||||
pattern=u(exclude),
|
||||
))
|
||||
return 0
|
||||
try:
|
||||
exclude = should_exclude(args.entity, args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
log.debug(u('Skipping because matches exclude pattern: {pattern}').format(
|
||||
pattern=u(exclude),
|
||||
))
|
||||
return SUCCESS
|
||||
|
||||
if os.path.isfile(args.targetFile) or args.notfile:
|
||||
if args.entity_type != 'file' or os.path.isfile(args.entity):
|
||||
|
||||
stats = get_file_stats(args.targetFile, notfile=args.notfile,
|
||||
lineno=args.lineno, cursorpos=args.cursorpos)
|
||||
stats = get_file_stats(args.entity,
|
||||
entity_type=args.entity_type,
|
||||
lineno=args.lineno,
|
||||
cursorpos=args.cursorpos)
|
||||
|
||||
project, branch = None, None
|
||||
if not args.notfile:
|
||||
project, branch = get_project_info(configs=configs, args=args)
|
||||
project = args.project or args.alternate_project
|
||||
branch = None
|
||||
if args.entity_type == 'file':
|
||||
project, branch = get_project_info(configs, args)
|
||||
|
||||
kwargs = vars(args)
|
||||
kwargs['project'] = project
|
||||
kwargs['branch'] = branch
|
||||
kwargs['stats'] = stats
|
||||
kwargs['hostname'] = args.hostname or socket.gethostname()
|
||||
kwargs = vars(args)
|
||||
kwargs['project'] = project
|
||||
kwargs['branch'] = branch
|
||||
kwargs['stats'] = stats
|
||||
hostname = args.hostname or socket.gethostname()
|
||||
kwargs['hostname'] = hostname
|
||||
kwargs['timeout'] = args.timeout
|
||||
|
||||
if send_heartbeat(**kwargs):
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
sent = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
targetFile=heartbeat['file'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
hostname=kwargs['hostname'],
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
isWrite=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
notfile=args.notfile,
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
)
|
||||
if not sent:
|
||||
break
|
||||
return 0 # success
|
||||
status = send_heartbeat(**kwargs)
|
||||
if status == SUCCESS:
|
||||
return sync_offline_heartbeats(args, hostname)
|
||||
else:
|
||||
return status
|
||||
|
||||
return 102 # api error
|
||||
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this heartbeat.')
|
||||
return 0
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this heartbeat.')
|
||||
return SUCCESS
|
||||
except:
|
||||
log.traceback()
|
||||
return UNKNOWN_ERROR
|
||||
@ -18,21 +18,28 @@ from time import sleep
|
||||
try:
|
||||
import sqlite3
|
||||
HAS_SQL = True
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
HAS_SQL = False
|
||||
|
||||
from .compat import u
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class Queue(object):
|
||||
DB_FILE = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
db_file = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
table_name = 'heartbeat_1'
|
||||
|
||||
def get_db_file(self):
|
||||
return self.db_file
|
||||
|
||||
def connect(self):
|
||||
conn = sqlite3.connect(self.DB_FILE)
|
||||
conn = sqlite3.connect(self.get_db_file())
|
||||
c = conn.cursor()
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS heartbeat (
|
||||
file text,
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS {0} (
|
||||
entity text,
|
||||
type text,
|
||||
time real,
|
||||
project text,
|
||||
branch text,
|
||||
@ -40,34 +47,33 @@ class Queue(object):
|
||||
stats text,
|
||||
misc text,
|
||||
plugin text)
|
||||
''')
|
||||
'''.format(self.table_name))
|
||||
return (conn, c)
|
||||
|
||||
|
||||
def push(self, data, stats, plugin, misc=None):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
heartbeat = {
|
||||
'file': data.get('entity'),
|
||||
'entity': u(data.get('entity')),
|
||||
'type': u(data.get('type')),
|
||||
'time': data.get('time'),
|
||||
'project': data.get('project'),
|
||||
'branch': data.get('branch'),
|
||||
'project': u(data.get('project')),
|
||||
'branch': u(data.get('branch')),
|
||||
'is_write': 1 if data.get('is_write') else 0,
|
||||
'stats': stats,
|
||||
'misc': misc,
|
||||
'plugin': plugin,
|
||||
'stats': u(stats),
|
||||
'misc': u(misc),
|
||||
'plugin': u(plugin),
|
||||
}
|
||||
c.execute('INSERT INTO heartbeat VALUES (:file,:time,:project,:branch,:is_write,:stats,:misc,:plugin)', heartbeat)
|
||||
c.execute('INSERT INTO {0} VALUES (:entity,:type,:time,:project,:branch,:is_write,:stats,:misc,:plugin)'.format(self.table_name), heartbeat)
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
|
||||
def pop(self):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return None
|
||||
tries = 3
|
||||
wait = 0.1
|
||||
@ -81,42 +87,43 @@ class Queue(object):
|
||||
while loop and tries > -1:
|
||||
try:
|
||||
c.execute('BEGIN IMMEDIATE')
|
||||
c.execute('SELECT * FROM heartbeat LIMIT 1')
|
||||
c.execute('SELECT * FROM {0} LIMIT 1'.format(self.table_name))
|
||||
row = c.fetchone()
|
||||
if row is not None:
|
||||
values = []
|
||||
clauses = []
|
||||
index = 0
|
||||
for row_name in ['file', 'time', 'project', 'branch', 'is_write']:
|
||||
for row_name in ['entity', 'type', 'time', 'project', 'branch', 'is_write']:
|
||||
if row[index] is not None:
|
||||
clauses.append('{0}=?'.format(row_name))
|
||||
values.append(row[index])
|
||||
else:
|
||||
else: # pragma: nocover
|
||||
clauses.append('{0} IS NULL'.format(row_name))
|
||||
index += 1
|
||||
if len(values) > 0:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)), values)
|
||||
else:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)))
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)), values)
|
||||
else: # pragma: nocover
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)))
|
||||
conn.commit()
|
||||
if row is not None:
|
||||
heartbeat = {
|
||||
'file': row[0],
|
||||
'time': row[1],
|
||||
'project': row[2],
|
||||
'branch': row[3],
|
||||
'is_write': True if row[4] is 1 else False,
|
||||
'stats': row[5],
|
||||
'misc': row[6],
|
||||
'plugin': row[7],
|
||||
'entity': row[0],
|
||||
'type': row[1],
|
||||
'time': row[2],
|
||||
'project': row[3],
|
||||
'branch': row[4],
|
||||
'is_write': True if row[5] is 1 else False,
|
||||
'stats': row[6],
|
||||
'misc': row[7],
|
||||
'plugin': row[8],
|
||||
}
|
||||
loop = False
|
||||
except sqlite3.Error:
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.debug(traceback.format_exc())
|
||||
sleep(wait)
|
||||
tries -= 1
|
||||
try:
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.debug(traceback.format_exc())
|
||||
return heartbeat
|
||||
|
||||
@ -0,0 +1,14 @@
|
||||
import os
|
||||
import sys
|
||||
|
||||
from ..compat import is_py2
|
||||
|
||||
if is_py2:
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'py2'))
|
||||
else:
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'py3'))
|
||||
|
||||
import tzlocal
|
||||
from pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
@ -61,7 +61,12 @@ considered public as object names -- the API of the formatter objects is
|
||||
still considered an implementation detail.)
|
||||
"""
|
||||
|
||||
__version__ = '1.2.1'
|
||||
__version__ = '1.3.0' # we use our own version number independant of the
|
||||
# one in stdlib and we release this on pypi.
|
||||
|
||||
__external_lib__ = True # to make sure the tests really test THIS lib,
|
||||
# not the builtin one in Python stdlib
|
||||
|
||||
__all__ = [
|
||||
'ArgumentParser',
|
||||
'ArgumentError',
|
||||
@ -1045,9 +1050,13 @@ class _SubParsersAction(Action):
|
||||
|
||||
class _ChoicesPseudoAction(Action):
|
||||
|
||||
def __init__(self, name, help):
|
||||
def __init__(self, name, aliases, help):
|
||||
metavar = dest = name
|
||||
if aliases:
|
||||
metavar += ' (%s)' % ', '.join(aliases)
|
||||
sup = super(_SubParsersAction._ChoicesPseudoAction, self)
|
||||
sup.__init__(option_strings=[], dest=name, help=help)
|
||||
sup.__init__(option_strings=[], dest=dest, help=help,
|
||||
metavar=metavar)
|
||||
|
||||
def __init__(self,
|
||||
option_strings,
|
||||
@ -1075,15 +1084,22 @@ class _SubParsersAction(Action):
|
||||
if kwargs.get('prog') is None:
|
||||
kwargs['prog'] = '%s %s' % (self._prog_prefix, name)
|
||||
|
||||
aliases = kwargs.pop('aliases', ())
|
||||
|
||||
# create a pseudo-action to hold the choice help
|
||||
if 'help' in kwargs:
|
||||
help = kwargs.pop('help')
|
||||
choice_action = self._ChoicesPseudoAction(name, help)
|
||||
choice_action = self._ChoicesPseudoAction(name, aliases, help)
|
||||
self._choices_actions.append(choice_action)
|
||||
|
||||
# create the parser and add it to the map
|
||||
parser = self._parser_class(**kwargs)
|
||||
self._name_parser_map[name] = parser
|
||||
|
||||
# make parser available under aliases also
|
||||
for alias in aliases:
|
||||
self._name_parser_map[alias] = parser
|
||||
|
||||
return parser
|
||||
|
||||
def _get_subactions(self):
|
||||
|
||||
0
packages/wakatime/packages/py2/__init__.py
Normal file
0
packages/wakatime/packages/py2/__init__.py
Normal file
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user