mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
71 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 21601f9688 | |||
| 4c3ec87341 | |||
| b149d7fc87 | |||
| 52e6107c6e | |||
| b340637331 | |||
| 044867449a | |||
| 9e3f438823 | |||
| 887d55c3f3 | |||
| 19d54f3310 | |||
| 514a8762eb | |||
| 957c74d226 | |||
| 7b0432d6ff | |||
| 09754849be | |||
| 25ad48a97a | |||
| 3b2520afa9 | |||
| 77c2041ad3 | |||
| 8af3b53937 | |||
| 5ef2e6954e | |||
| ca94272de5 | |||
| f19a448d95 | |||
| e178765412 | |||
| 6a7de84b9c | |||
| 48810f2977 | |||
| 260eedb31d | |||
| 02e2bfcad2 | |||
| f14ece63f3 | |||
| cb7f786ec8 | |||
| ab8711d0b1 | |||
| 2354be358c | |||
| 443215bd90 | |||
| c64f125dc4 | |||
| 050b14fb53 | |||
| c7efc33463 | |||
| d0ddbed006 | |||
| 3ce8f388ab | |||
| 90731146f9 | |||
| e1ab92be6d | |||
| 8b59e46c64 | |||
| 006341eb72 | |||
| b54e0e13f6 | |||
| 835c7db864 | |||
| 53e8bb04e9 | |||
| 4aa06e3829 | |||
| 297f65733f | |||
| 5ba5e6d21b | |||
| 32eadda81f | |||
| c537044801 | |||
| a97792c23c | |||
| 4223f3575f | |||
| 284cdf3ce4 | |||
| 27afc41bf4 | |||
| 1fdda0d64a | |||
| c90a4863e9 | |||
| 94343e5b07 | |||
| 03acea6e25 | |||
| 77594700bd | |||
| 6681409e98 | |||
| 8f7837269a | |||
| a523b3aa4d | |||
| 6985ce32bb | |||
| 4be40c7720 | |||
| eeb7fd8219 | |||
| 11fbd2d2a6 | |||
| 3cecd0de5d | |||
| c50100e675 | |||
| c1da94bc18 | |||
| 7f9d6ede9d | |||
| 192a5c7aa7 | |||
| 16bbe21be9 | |||
| 5ebaf12a99 | |||
| 1834e8978a |
205
HISTORY.rst
205
HISTORY.rst
@ -3,6 +3,211 @@ History
|
||||
-------
|
||||
|
||||
|
||||
7.0.8 (2016-07-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to master version to fix debug logging encoding bug.
|
||||
|
||||
|
||||
7.0.7 (2016-07-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.7.
|
||||
- Handle unknown exceptions from requests library by deleting cached session
|
||||
object because it could be from a previous conflicting version.
|
||||
- New hostname setting in config file to set machine hostname. Hostname
|
||||
argument takes priority over hostname from config file.
|
||||
- Prevent logging unrelated exception when logging tracebacks.
|
||||
- Use correct namespace for pygments.lexers.ClassNotFound exception so it is
|
||||
caught when dependency detection not available for a language.
|
||||
|
||||
|
||||
7.0.6 (2016-06-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.5.
|
||||
- Upgrade pygments to v2.1.3 for better language coverage.
|
||||
|
||||
|
||||
7.0.5 (2016-06-08)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to master version to fix bug in urllib3 package causing
|
||||
unhandled retry exceptions.
|
||||
- Prevent tracking git branch with detached head.
|
||||
|
||||
|
||||
7.0.4 (2016-05-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.3.
|
||||
- Upgrade requests dependency to v2.10.0.
|
||||
- Support for SOCKS proxies.
|
||||
|
||||
|
||||
7.0.3 (2016-05-16)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.2.
|
||||
- Prevent popup on Mac when xcode-tools is not installed.
|
||||
|
||||
|
||||
7.0.2 (2016-04-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- Prevent implicit unicode decoding from string format when logging output
|
||||
from Python version check.
|
||||
|
||||
|
||||
7.0.1 (2016-04-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.1.
|
||||
- Fix bug which prevented plugin from being sent with extra heartbeats.
|
||||
|
||||
|
||||
7.0.0 (2016-04-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- Queue heartbeats and send to wakatime-cli after 4 seconds.
|
||||
- Nest settings menu under Package Settings.
|
||||
- Upgrade wakatime-cli to v6.0.0.
|
||||
- Increase default network timeout to 60 seconds when sending heartbeats to
|
||||
the api.
|
||||
- New --extra-heartbeats command line argument for sending a JSON array of
|
||||
extra queued heartbeats to STDIN.
|
||||
- Change --entitytype command line argument to --entity-type.
|
||||
- No longer allowing --entity-type of url.
|
||||
- Support passing an alternate language to cli to be used when a language can
|
||||
not be guessed from the code file.
|
||||
|
||||
|
||||
6.0.8 (2016-04-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v5.0.0.
|
||||
- Support regex patterns in projectmap config section for renaming projects.
|
||||
- Upgrade pytz to v2016.3.
|
||||
- Upgrade tzlocal to v1.2.2.
|
||||
|
||||
|
||||
6.0.7 (2016-03-11)
|
||||
++++++++++++++++++
|
||||
|
||||
- Fix bug causing RuntimeError when finding Python location
|
||||
|
||||
|
||||
6.0.6 (2016-03-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli to v4.1.13
|
||||
- encode TimeZone as utf-8 before adding to headers
|
||||
- encode X-Machine-Name as utf-8 before adding to headers
|
||||
|
||||
|
||||
6.0.5 (2016-03-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli to v4.1.11
|
||||
- encode machine hostname as Unicode when adding to X-Machine-Name header
|
||||
|
||||
|
||||
6.0.4 (2016-01-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix UnicodeDecodeError on ST2 with non-English locale
|
||||
|
||||
|
||||
6.0.3 (2016-01-11)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli core to v4.1.10
|
||||
- accept 201 or 202 response codes as success from api
|
||||
- upgrade requests package to v2.9.1
|
||||
|
||||
|
||||
6.0.2 (2016-01-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli core to v4.1.9
|
||||
- improve C# dependency detection
|
||||
- correctly log exception tracebacks
|
||||
- log all unknown exceptions to wakatime.log file
|
||||
- disable urllib3 SSL warning from every request
|
||||
- detect dependencies from golang files
|
||||
- use api.wakatime.com for sending heartbeats
|
||||
|
||||
|
||||
6.0.1 (2016-01-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- use embedded python if system python is broken, or doesn't output a version number
|
||||
- log output from wakatime-cli in ST console when in debug mode
|
||||
|
||||
|
||||
6.0.0 (2015-12-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- use embeddable Python instead of installing on Windows
|
||||
|
||||
|
||||
5.0.1 (2015-10-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- look for python in system PATH again
|
||||
|
||||
|
||||
5.0.0 (2015-10-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- improve logging with levels and log function
|
||||
- switch registry warnings to debug log level
|
||||
|
||||
|
||||
4.0.20 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly find python binary in non-Windows environments
|
||||
|
||||
|
||||
4.0.19 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- handle case where ST builtin python does not have _winreg or winreg module
|
||||
|
||||
|
||||
4.0.18 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- find python location from windows registry
|
||||
|
||||
|
||||
4.0.17 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- download python in non blocking background thread for Windows machines
|
||||
|
||||
|
||||
4.0.16 (2015-09-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.8
|
||||
- fix bug in guess_language function
|
||||
- improve dependency detection
|
||||
- default request timeout of 30 seconds
|
||||
- new --timeout command line argument to change request timeout in seconds
|
||||
- allow passing command line arguments using sys.argv
|
||||
- fix entry point for pypi distribution
|
||||
- new --entity and --entitytype command line arguments
|
||||
|
||||
|
||||
4.0.15 (2015-08-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.3
|
||||
- fix local session caching
|
||||
|
||||
|
||||
4.0.14 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
|
||||
@ -6,24 +6,37 @@
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"caption": "WakaTime",
|
||||
"mnemonic": "W",
|
||||
"id": "wakatime-settings",
|
||||
"caption": "Package Settings",
|
||||
"mnemonic": "P",
|
||||
"id": "package-settings",
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/WakaTime/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – Default"
|
||||
},
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/User/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – User"
|
||||
"caption": "WakaTime",
|
||||
"mnemonic": "W",
|
||||
"id": "wakatime-settings",
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/WakaTime/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – Default"
|
||||
},
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/User/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – User"
|
||||
},
|
||||
{
|
||||
"command": "wakatime_dashboard",
|
||||
"args": {},
|
||||
"caption": "WakaTime Dashboard"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
23
README.md
23
README.md
@ -1,13 +1,12 @@
|
||||
sublime-wakatime
|
||||
================
|
||||
|
||||
Fully automatic time tracking for Sublime Text 2 & 3.
|
||||
Metrics, insights, and time tracking automatically generated from your programming activity.
|
||||
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](http://www.python.org/getit/) being installed to work correctly.
|
||||
|
||||
1. Install [Package Control](https://packagecontrol.io/installation).
|
||||
|
||||
2. Using [Package Control](https://packagecontrol.io/docs/usage):
|
||||
@ -24,17 +23,31 @@ Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](ht
|
||||
|
||||
5. Visit https://wakatime.com/dashboard to see your logged time.
|
||||
|
||||
|
||||
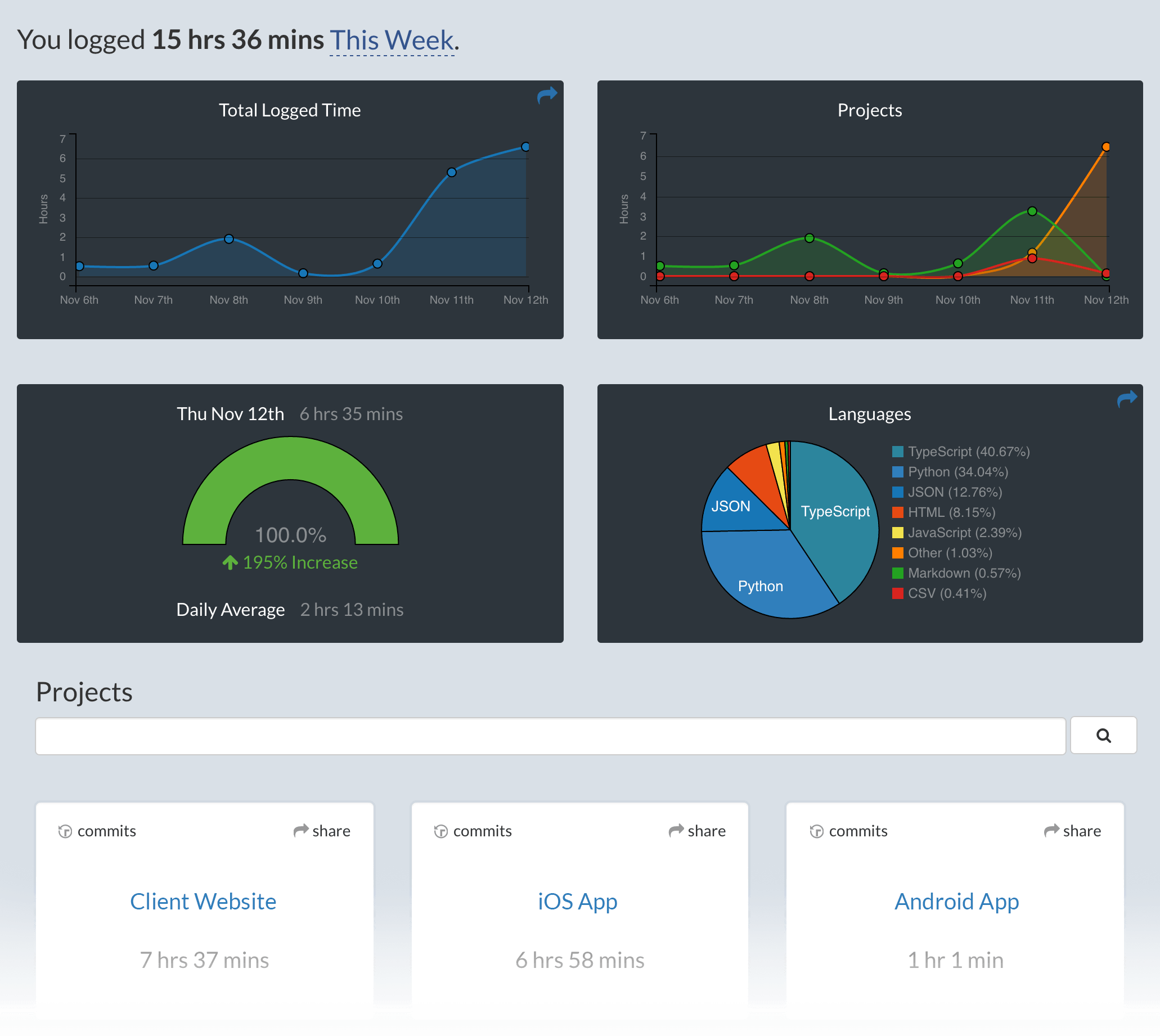
Screen Shots
|
||||
------------
|
||||
|
||||
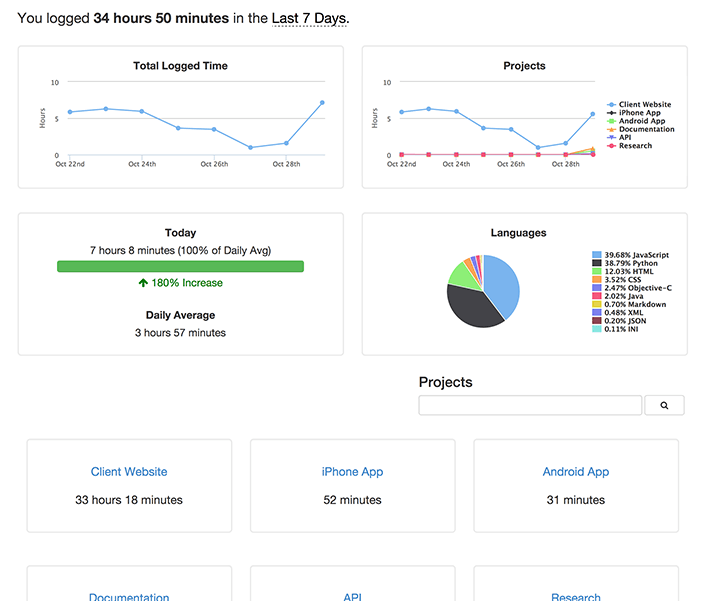
|
||||
|
||||
|
||||
|
||||
Unresponsive Plugin Warning
|
||||
---------------------------
|
||||
|
||||
In Sublime Text 2, if you get a warning message:
|
||||
|
||||
A plugin (WakaTime) may be making Sublime Text unresponsive by taking too long (0.017332s) in its on_modified callback.
|
||||
|
||||
To fix this, go to `Preferences > Settings - User` then add the following setting:
|
||||
|
||||
`"detect_slow_plugins": false`
|
||||
|
||||
|
||||
Troubleshooting
|
||||
---------------
|
||||
|
||||
First, turn on debug mode in your `WakaTime.sublime-settings` file.
|
||||
|
||||
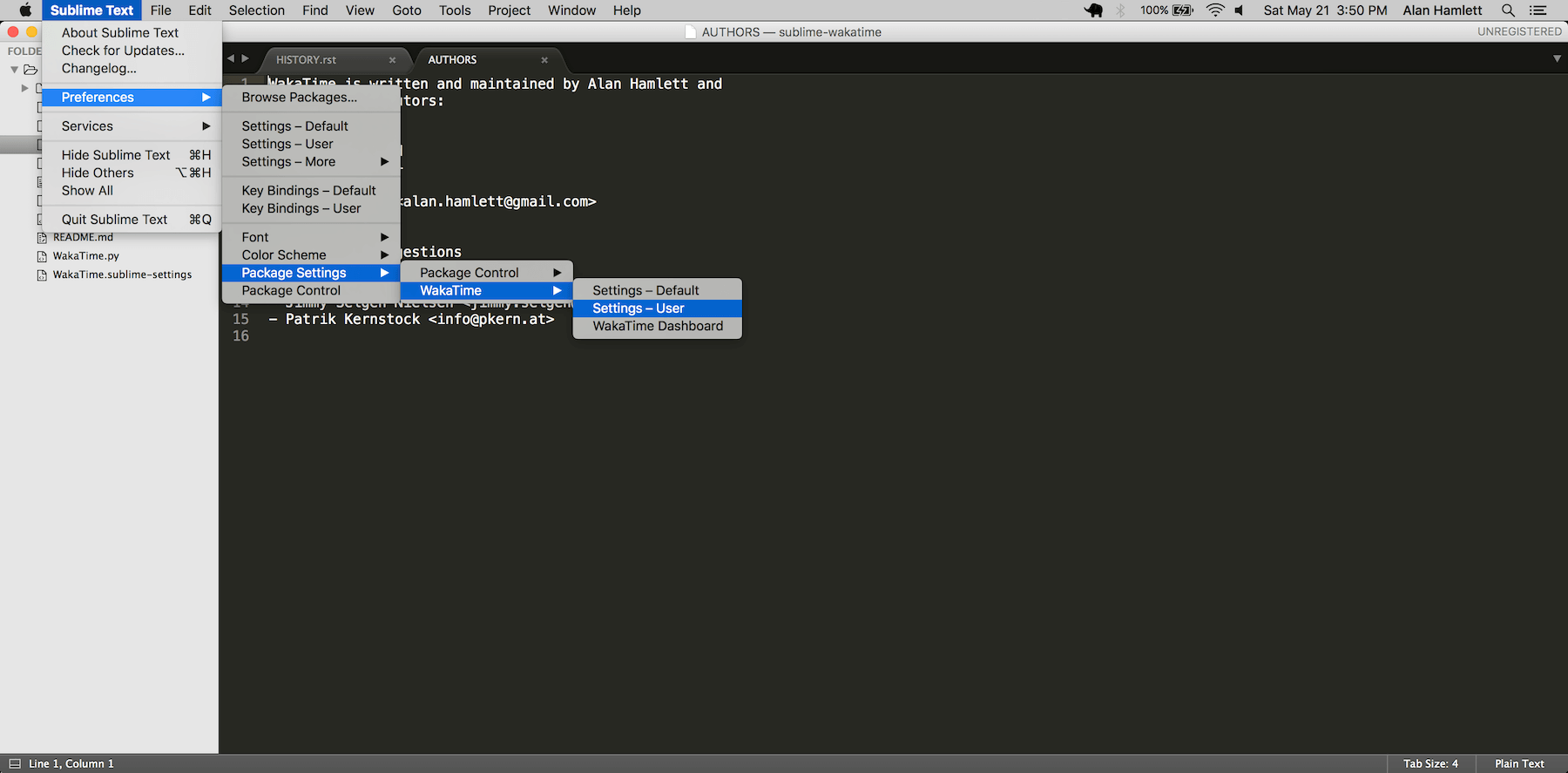
|
||||
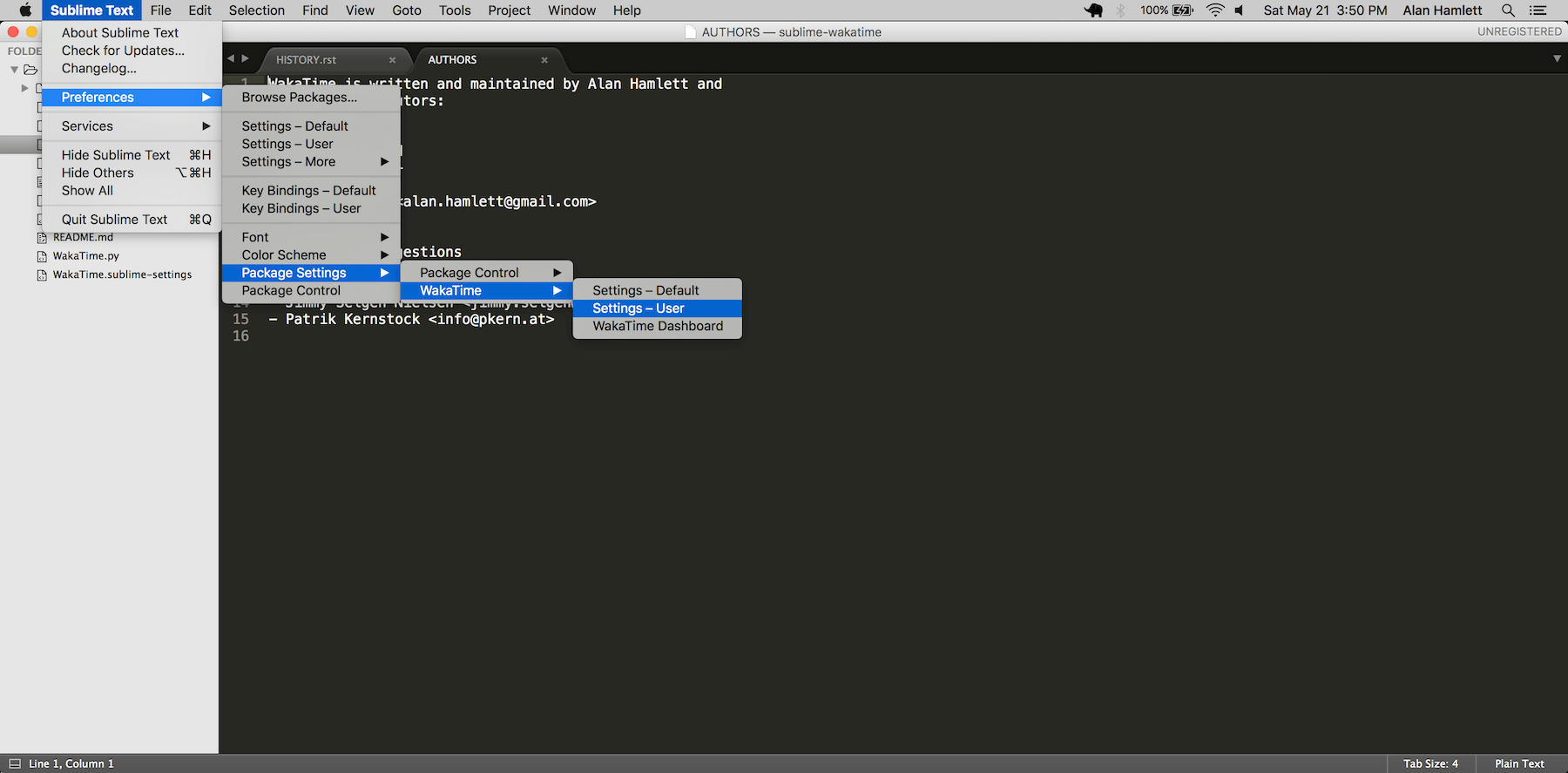
|
||||
|
||||
Add the line: `"debug": true`
|
||||
|
||||
|
||||
555
WakaTime.py
555
WakaTime.py
@ -7,22 +7,78 @@ Website: https://wakatime.com/
|
||||
==========================================================="""
|
||||
|
||||
|
||||
__version__ = '4.0.14'
|
||||
__version__ = '7.0.8'
|
||||
|
||||
|
||||
import sublime
|
||||
import sublime_plugin
|
||||
|
||||
import glob
|
||||
import json
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import threading
|
||||
import urllib
|
||||
import webbrowser
|
||||
from datetime import datetime
|
||||
from subprocess import Popen
|
||||
from zipfile import ZipFile
|
||||
from subprocess import Popen, STDOUT, PIPE
|
||||
try:
|
||||
import _winreg as winreg # py2
|
||||
except ImportError:
|
||||
try:
|
||||
import winreg # py3
|
||||
except ImportError:
|
||||
winreg = None
|
||||
try:
|
||||
import Queue as queue # py2
|
||||
except ImportError:
|
||||
import queue # py3
|
||||
|
||||
|
||||
is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
if is_py2:
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
|
||||
elif is_py3:
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
|
||||
else:
|
||||
raise Exception('Unsupported Python version: {0}.{1}.{2}'.format(
|
||||
sys.version_info[0],
|
||||
sys.version_info[1],
|
||||
sys.version_info[2],
|
||||
))
|
||||
|
||||
|
||||
# globals
|
||||
@ -37,8 +93,15 @@ LAST_HEARTBEAT = {
|
||||
'file': None,
|
||||
'is_write': False,
|
||||
}
|
||||
LOCK = threading.RLock()
|
||||
PYTHON_LOCATION = None
|
||||
HEARTBEATS = queue.Queue()
|
||||
|
||||
|
||||
# Log Levels
|
||||
DEBUG = 'DEBUG'
|
||||
INFO = 'INFO'
|
||||
WARNING = 'WARNING'
|
||||
ERROR = 'ERROR'
|
||||
|
||||
|
||||
# add wakatime package to path
|
||||
@ -49,7 +112,59 @@ except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
def createConfigFile():
|
||||
def set_timeout(callback, seconds):
|
||||
"""Runs the callback after the given seconds delay.
|
||||
|
||||
If this is Sublime Text 3, runs the callback on an alternate thread. If this
|
||||
is Sublime Text 2, runs the callback in the main thread.
|
||||
"""
|
||||
|
||||
milliseconds = int(seconds * 1000)
|
||||
try:
|
||||
sublime.set_timeout_async(callback, milliseconds)
|
||||
except AttributeError:
|
||||
sublime.set_timeout(callback, milliseconds)
|
||||
|
||||
|
||||
def log(lvl, message, *args, **kwargs):
|
||||
try:
|
||||
if lvl == DEBUG and not SETTINGS.get('debug'):
|
||||
return
|
||||
msg = message
|
||||
if len(args) > 0:
|
||||
msg = message.format(*args)
|
||||
elif len(kwargs) > 0:
|
||||
msg = message.format(**kwargs)
|
||||
print('[WakaTime] [{lvl}] {msg}'.format(lvl=lvl, msg=msg))
|
||||
except RuntimeError:
|
||||
set_timeout(lambda: log(lvl, message, *args, **kwargs), 0)
|
||||
|
||||
|
||||
def resources_folder():
|
||||
if platform.system() == 'Windows':
|
||||
return os.path.join(os.getenv('APPDATA'), 'WakaTime')
|
||||
else:
|
||||
return os.path.join(os.path.expanduser('~'), '.wakatime')
|
||||
|
||||
|
||||
def update_status_bar(status):
|
||||
"""Updates the status bar."""
|
||||
|
||||
try:
|
||||
if SETTINGS.get('status_bar_message'):
|
||||
msg = datetime.now().strftime(SETTINGS.get('status_bar_message_fmt'))
|
||||
if '{status}' in msg:
|
||||
msg = msg.format(status=status)
|
||||
|
||||
active_window = sublime.active_window()
|
||||
if active_window:
|
||||
for view in active_window.views():
|
||||
view.set_status('wakatime', msg)
|
||||
except RuntimeError:
|
||||
set_timeout(lambda: update_status_bar(status), 0)
|
||||
|
||||
|
||||
def create_config_file():
|
||||
"""Creates the .wakatime.cfg INI file in $HOME directory, if it does
|
||||
not already exist.
|
||||
"""
|
||||
@ -70,7 +185,7 @@ def createConfigFile():
|
||||
def prompt_api_key():
|
||||
global SETTINGS
|
||||
|
||||
createConfigFile()
|
||||
create_config_file()
|
||||
|
||||
default_key = ''
|
||||
try:
|
||||
@ -93,35 +208,129 @@ def prompt_api_key():
|
||||
window.show_input_panel('[WakaTime] Enter your wakatime.com api key:', default_key, got_key, None, None)
|
||||
return True
|
||||
else:
|
||||
print('[WakaTime] Error: Could not prompt for api key because no window found.')
|
||||
log(ERROR, 'Could not prompt for api key because no window found.')
|
||||
return False
|
||||
|
||||
|
||||
def python_binary():
|
||||
global PYTHON_LOCATION
|
||||
if PYTHON_LOCATION is not None:
|
||||
return PYTHON_LOCATION
|
||||
|
||||
# look for python in PATH and common install locations
|
||||
paths = [
|
||||
"pythonw",
|
||||
"python",
|
||||
"/usr/local/bin/python",
|
||||
"/usr/bin/python",
|
||||
os.path.join(resources_folder(), 'python'),
|
||||
None,
|
||||
'/',
|
||||
'/usr/local/bin/',
|
||||
'/usr/bin/',
|
||||
]
|
||||
for path in paths:
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
for path in glob.iglob('/python*'):
|
||||
path = os.path.realpath(os.path.join(path, 'pythonw'))
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
|
||||
# look for python in windows registry
|
||||
path = find_python_from_registry(r'SOFTWARE\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
path = find_python_from_registry(r'SOFTWARE\Wow6432Node\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def set_python_binary_location(path):
|
||||
global PYTHON_LOCATION
|
||||
PYTHON_LOCATION = path
|
||||
log(DEBUG, 'Found Python at: {0}'.format(path))
|
||||
|
||||
|
||||
def find_python_from_registry(location, reg=None):
|
||||
if platform.system() != 'Windows' or winreg is None:
|
||||
return None
|
||||
|
||||
if reg is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_CURRENT_USER)
|
||||
if path is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_LOCAL_MACHINE)
|
||||
return path
|
||||
|
||||
val = None
|
||||
sub_key = 'InstallPath'
|
||||
compiled = re.compile(r'^\d+\.\d+$')
|
||||
|
||||
try:
|
||||
with winreg.OpenKey(reg, location) as handle:
|
||||
versions = []
|
||||
try:
|
||||
for index in range(1024):
|
||||
version = winreg.EnumKey(handle, index)
|
||||
try:
|
||||
if compiled.search(version):
|
||||
versions.append(version)
|
||||
except re.error:
|
||||
pass
|
||||
except EnvironmentError:
|
||||
pass
|
||||
versions.sort(reverse=True)
|
||||
for version in versions:
|
||||
try:
|
||||
path = winreg.QueryValue(handle, version + '\\' + sub_key)
|
||||
if path is not None:
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
log(DEBUG, 'Found python from {reg}\\{key}\\{version}\\{sub_key}.'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
return path
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}\\{version}\\{sub_key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
))
|
||||
|
||||
return val
|
||||
|
||||
|
||||
def find_python_in_folder(folder, headless=True):
|
||||
pattern = re.compile(r'\d+\.\d+')
|
||||
|
||||
path = 'python'
|
||||
if folder is not None:
|
||||
path = os.path.realpath(os.path.join(folder, 'python'))
|
||||
if headless:
|
||||
path = u(path) + u('w')
|
||||
log(DEBUG, u('Looking for Python at: {0}').format(path))
|
||||
try:
|
||||
process = Popen([path, '--version'], stdout=PIPE, stderr=STDOUT)
|
||||
output, err = process.communicate()
|
||||
output = u(output).strip()
|
||||
retcode = process.poll()
|
||||
log(DEBUG, u('Python Version Output: {0}').format(output))
|
||||
if not retcode and pattern.search(output):
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
except:
|
||||
log(DEBUG, u(sys.exc_info()[1]))
|
||||
|
||||
if headless:
|
||||
path = find_python_in_folder(folder, headless=False)
|
||||
if path is not None:
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
@ -133,14 +342,14 @@ def obfuscate_apikey(command_list):
|
||||
apikey_index = num + 1
|
||||
break
|
||||
if apikey_index is not None and apikey_index < len(cmd):
|
||||
cmd[apikey_index] = '********-****-****-****-********' + cmd[apikey_index][-4:]
|
||||
cmd[apikey_index] = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX' + cmd[apikey_index][-4:]
|
||||
return cmd
|
||||
|
||||
|
||||
def enough_time_passed(now, last_heartbeat, is_write):
|
||||
if now - last_heartbeat['time'] > HEARTBEAT_FREQUENCY * 60:
|
||||
def enough_time_passed(now, is_write):
|
||||
if now - LAST_HEARTBEAT['time'] > HEARTBEAT_FREQUENCY * 60:
|
||||
return True
|
||||
if is_write and now - last_heartbeat['time'] > 2:
|
||||
if is_write and now - LAST_HEARTBEAT['time'] > 2:
|
||||
return True
|
||||
return False
|
||||
|
||||
@ -184,135 +393,235 @@ def is_view_active(view):
|
||||
return False
|
||||
|
||||
|
||||
def handle_heartbeat(view, is_write=False):
|
||||
def handle_activity(view, is_write=False):
|
||||
window = view.window()
|
||||
if window is not None:
|
||||
target_file = view.file_name()
|
||||
project = window.project_data() if hasattr(window, 'project_data') else None
|
||||
folders = window.folders()
|
||||
thread = SendHeartbeatThread(target_file, view, is_write=is_write, project=project, folders=folders)
|
||||
thread.start()
|
||||
entity = view.file_name()
|
||||
if entity:
|
||||
timestamp = time.time()
|
||||
last_file = LAST_HEARTBEAT['file']
|
||||
if entity != last_file or enough_time_passed(timestamp, is_write):
|
||||
project = window.project_data() if hasattr(window, 'project_data') else None
|
||||
folders = window.folders()
|
||||
append_heartbeat(entity, timestamp, is_write, view, project, folders)
|
||||
|
||||
|
||||
class SendHeartbeatThread(threading.Thread):
|
||||
def append_heartbeat(entity, timestamp, is_write, view, project, folders):
|
||||
global LAST_HEARTBEAT
|
||||
|
||||
def __init__(self, target_file, view, is_write=False, project=None, folders=None, force=False):
|
||||
# add this heartbeat to queue
|
||||
heartbeat = {
|
||||
'entity': entity,
|
||||
'timestamp': timestamp,
|
||||
'is_write': is_write,
|
||||
'cursorpos': view.sel()[0].begin() if view.sel() else None,
|
||||
'project': project,
|
||||
'folders': folders,
|
||||
}
|
||||
HEARTBEATS.put_nowait(heartbeat)
|
||||
|
||||
# make this heartbeat the LAST_HEARTBEAT
|
||||
LAST_HEARTBEAT = {
|
||||
'file': entity,
|
||||
'time': timestamp,
|
||||
'is_write': is_write,
|
||||
}
|
||||
|
||||
# process the queue of heartbeats in the future
|
||||
seconds = 4
|
||||
set_timeout(process_queue, seconds)
|
||||
|
||||
|
||||
def process_queue():
|
||||
try:
|
||||
heartbeat = HEARTBEATS.get_nowait()
|
||||
except queue.Empty:
|
||||
return
|
||||
|
||||
has_extra_heartbeats = False
|
||||
extra_heartbeats = []
|
||||
try:
|
||||
while True:
|
||||
extra_heartbeats.append(HEARTBEATS.get_nowait())
|
||||
has_extra_heartbeats = True
|
||||
except queue.Empty:
|
||||
pass
|
||||
|
||||
thread = SendHeartbeatsThread(heartbeat)
|
||||
if has_extra_heartbeats:
|
||||
thread.add_extra_heartbeats(extra_heartbeats)
|
||||
thread.start()
|
||||
|
||||
|
||||
class SendHeartbeatsThread(threading.Thread):
|
||||
"""Non-blocking thread for sending heartbeats to api.
|
||||
"""
|
||||
|
||||
def __init__(self, heartbeat):
|
||||
threading.Thread.__init__(self)
|
||||
self.lock = LOCK
|
||||
self.target_file = target_file
|
||||
self.is_write = is_write
|
||||
self.project = project
|
||||
self.folders = folders
|
||||
self.force = force
|
||||
|
||||
self.debug = SETTINGS.get('debug')
|
||||
self.api_key = SETTINGS.get('api_key', '')
|
||||
self.ignore = SETTINGS.get('ignore', [])
|
||||
self.last_heartbeat = LAST_HEARTBEAT.copy()
|
||||
self.cursorpos = view.sel()[0].begin() if view.sel() else None
|
||||
self.view = view
|
||||
|
||||
self.heartbeat = heartbeat
|
||||
self.has_extra_heartbeats = False
|
||||
|
||||
def add_extra_heartbeats(self, extra_heartbeats):
|
||||
self.has_extra_heartbeats = True
|
||||
self.extra_heartbeats = extra_heartbeats
|
||||
|
||||
def run(self):
|
||||
with self.lock:
|
||||
if self.target_file:
|
||||
self.timestamp = time.time()
|
||||
if self.force or self.target_file != self.last_heartbeat['file'] or enough_time_passed(self.timestamp, self.last_heartbeat, self.is_write):
|
||||
self.send_heartbeat()
|
||||
"""Running in background thread."""
|
||||
|
||||
def send_heartbeat(self):
|
||||
if not self.api_key:
|
||||
print('[WakaTime] Error: missing api key.')
|
||||
return
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
API_CLIENT,
|
||||
'--file', self.target_file,
|
||||
'--time', str('%f' % self.timestamp),
|
||||
'--plugin', ua,
|
||||
'--key', str(bytes.decode(self.api_key.encode('utf8'))),
|
||||
]
|
||||
if self.is_write:
|
||||
cmd.append('--write')
|
||||
if self.project and self.project.get('name'):
|
||||
cmd.extend(['--alternate-project', self.project.get('name')])
|
||||
elif self.folders:
|
||||
project_name = find_project_from_folders(self.folders, self.target_file)
|
||||
self.send_heartbeats()
|
||||
|
||||
def build_heartbeat(self, entity=None, timestamp=None, is_write=None,
|
||||
cursorpos=None, project=None, folders=None):
|
||||
"""Returns a dict for passing to wakatime-cli as arguments."""
|
||||
|
||||
heartbeat = {
|
||||
'entity': entity,
|
||||
'timestamp': timestamp,
|
||||
'is_write': is_write,
|
||||
}
|
||||
|
||||
if project and project.get('name'):
|
||||
heartbeat['alternate_project'] = project.get('name')
|
||||
elif folders:
|
||||
project_name = find_project_from_folders(folders, entity)
|
||||
if project_name:
|
||||
cmd.extend(['--alternate-project', project_name])
|
||||
if self.cursorpos is not None:
|
||||
cmd.extend(['--cursorpos', '{0}'.format(self.cursorpos)])
|
||||
for pattern in self.ignore:
|
||||
cmd.extend(['--ignore', pattern])
|
||||
if self.debug:
|
||||
cmd.append('--verbose')
|
||||
heartbeat['alternate_project'] = project_name
|
||||
|
||||
if cursorpos is not None:
|
||||
heartbeat['cursorpos'] = '{0}'.format(cursorpos)
|
||||
|
||||
return heartbeat
|
||||
|
||||
def send_heartbeats(self):
|
||||
if python_binary():
|
||||
cmd.insert(0, python_binary())
|
||||
heartbeat = self.build_heartbeat(**self.heartbeat)
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
python_binary(),
|
||||
API_CLIENT,
|
||||
'--entity', heartbeat['entity'],
|
||||
'--time', str('%f' % heartbeat['timestamp']),
|
||||
'--plugin', ua,
|
||||
]
|
||||
if self.api_key:
|
||||
cmd.extend(['--key', str(bytes.decode(self.api_key.encode('utf8')))])
|
||||
if heartbeat['is_write']:
|
||||
cmd.append('--write')
|
||||
if heartbeat.get('alternate_project'):
|
||||
cmd.extend(['--alternate-project', heartbeat['alternate_project']])
|
||||
if heartbeat.get('cursorpos') is not None:
|
||||
cmd.extend(['--cursorpos', heartbeat['cursorpos']])
|
||||
for pattern in self.ignore:
|
||||
cmd.extend(['--ignore', pattern])
|
||||
if self.debug:
|
||||
print('[WakaTime] %s' % ' '.join(obfuscate_apikey(cmd)))
|
||||
if platform.system() == 'Windows':
|
||||
Popen(cmd, shell=False)
|
||||
cmd.append('--verbose')
|
||||
if self.has_extra_heartbeats:
|
||||
cmd.append('--extra-heartbeats')
|
||||
stdin = PIPE
|
||||
extra_heartbeats = [self.build_heartbeat(**x) for x in self.extra_heartbeats]
|
||||
extra_heartbeats = json.dumps(extra_heartbeats)
|
||||
else:
|
||||
with open(os.path.join(os.path.expanduser('~'), '.wakatime.log'), 'a') as stderr:
|
||||
Popen(cmd, stderr=stderr)
|
||||
self.sent()
|
||||
extra_heartbeats = None
|
||||
stdin = None
|
||||
|
||||
log(DEBUG, ' '.join(obfuscate_apikey(cmd)))
|
||||
try:
|
||||
process = Popen(cmd, stdin=stdin, stdout=PIPE, stderr=STDOUT)
|
||||
inp = None
|
||||
if self.has_extra_heartbeats:
|
||||
inp = "{0}\n".format(extra_heartbeats)
|
||||
inp = inp.encode('utf-8')
|
||||
output, err = process.communicate(input=inp)
|
||||
output = u(output)
|
||||
retcode = process.poll()
|
||||
if (not retcode or retcode == 102) and not output:
|
||||
self.sent()
|
||||
else:
|
||||
update_status_bar('Error')
|
||||
if retcode:
|
||||
log(DEBUG if retcode == 102 else ERROR, 'wakatime-core exited with status: {0}'.format(retcode))
|
||||
if output:
|
||||
log(ERROR, u('wakatime-core output: {0}').format(output))
|
||||
except:
|
||||
log(ERROR, u(sys.exc_info()[1]))
|
||||
update_status_bar('Error')
|
||||
|
||||
else:
|
||||
print('[WakaTime] Error: Unable to find python binary.')
|
||||
log(ERROR, 'Unable to find python binary.')
|
||||
update_status_bar('Error')
|
||||
|
||||
def sent(self):
|
||||
sublime.set_timeout(self.set_status_bar, 0)
|
||||
sublime.set_timeout(self.set_last_heartbeat, 0)
|
||||
update_status_bar('OK')
|
||||
|
||||
def set_status_bar(self):
|
||||
if SETTINGS.get('status_bar_message'):
|
||||
self.view.set_status('wakatime', datetime.now().strftime(SETTINGS.get('status_bar_message_fmt')))
|
||||
|
||||
def set_last_heartbeat(self):
|
||||
global LAST_HEARTBEAT
|
||||
LAST_HEARTBEAT = {
|
||||
'file': self.target_file,
|
||||
'time': self.timestamp,
|
||||
'is_write': self.is_write,
|
||||
}
|
||||
def download_python():
|
||||
thread = DownloadPython()
|
||||
thread.start()
|
||||
|
||||
|
||||
class DownloadPython(threading.Thread):
|
||||
"""Non-blocking thread for extracting embeddable Python on Windows machines.
|
||||
"""
|
||||
|
||||
def run(self):
|
||||
log(INFO, 'Downloading embeddable Python...')
|
||||
|
||||
ver = '3.5.0'
|
||||
arch = 'amd64' if platform.architecture()[0] == '64bit' else 'win32'
|
||||
url = 'https://www.python.org/ftp/python/{ver}/python-{ver}-embed-{arch}.zip'.format(
|
||||
ver=ver,
|
||||
arch=arch,
|
||||
)
|
||||
|
||||
if not os.path.exists(resources_folder()):
|
||||
os.makedirs(resources_folder())
|
||||
|
||||
zip_file = os.path.join(resources_folder(), 'python.zip')
|
||||
try:
|
||||
urllib.urlretrieve(url, zip_file)
|
||||
except AttributeError:
|
||||
urllib.request.urlretrieve(url, zip_file)
|
||||
|
||||
log(INFO, 'Extracting Python...')
|
||||
with ZipFile(zip_file) as zf:
|
||||
path = os.path.join(resources_folder(), 'python')
|
||||
zf.extractall(path)
|
||||
|
||||
try:
|
||||
os.remove(zip_file)
|
||||
except:
|
||||
pass
|
||||
|
||||
log(INFO, 'Finished extracting Python.')
|
||||
|
||||
|
||||
def plugin_loaded():
|
||||
global SETTINGS
|
||||
print('[WakaTime] Initializing WakaTime plugin v%s' % __version__)
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
|
||||
log(INFO, 'Initializing WakaTime plugin v%s' % __version__)
|
||||
update_status_bar('Initializing')
|
||||
|
||||
if not python_binary():
|
||||
print('[WakaTime] Warning: Python binary not found.')
|
||||
log(WARNING, 'Python binary not found.')
|
||||
if platform.system() == 'Windows':
|
||||
install_python()
|
||||
set_timeout(download_python, 0)
|
||||
else:
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
after_loaded()
|
||||
|
||||
|
||||
def after_loaded():
|
||||
if not prompt_api_key():
|
||||
sublime.set_timeout(after_loaded, 500)
|
||||
|
||||
|
||||
def install_python():
|
||||
print('[WakaTime] Downloading and installing python...')
|
||||
url = 'https://www.python.org/ftp/python/3.4.3/python-3.4.3.msi'
|
||||
if platform.architecture()[0] == '64bit':
|
||||
url = 'https://www.python.org/ftp/python/3.4.3/python-3.4.3.amd64.msi'
|
||||
python_msi = os.path.join(os.path.expanduser('~'), 'python.msi')
|
||||
try:
|
||||
urllib.urlretrieve(url, python_msi)
|
||||
except AttributeError:
|
||||
urllib.request.urlretrieve(url, python_msi)
|
||||
args = [
|
||||
'msiexec',
|
||||
'/i',
|
||||
python_msi,
|
||||
'/norestart',
|
||||
'/qb!',
|
||||
]
|
||||
Popen(args)
|
||||
set_timeout(after_loaded, 0.5)
|
||||
|
||||
|
||||
# need to call plugin_loaded because only ST3 will auto-call it
|
||||
@ -323,15 +632,15 @@ if ST_VERSION < 3000:
|
||||
class WakatimeListener(sublime_plugin.EventListener):
|
||||
|
||||
def on_post_save(self, view):
|
||||
handle_heartbeat(view, is_write=True)
|
||||
handle_activity(view, is_write=True)
|
||||
|
||||
def on_selection_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
handle_activity(view)
|
||||
|
||||
def on_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
handle_activity(view)
|
||||
|
||||
|
||||
class WakatimeDashboardCommand(sublime_plugin.ApplicationCommand):
|
||||
|
||||
@ -19,5 +19,5 @@
|
||||
"status_bar_message": true,
|
||||
|
||||
// Status bar message format.
|
||||
"status_bar_message_fmt": "WakaTime active %I:%M %p"
|
||||
"status_bar_message_fmt": "WakaTime {status} %I:%M %p"
|
||||
}
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
__title__ = 'wakatime'
|
||||
__description__ = 'Common interface to the WakaTime api.'
|
||||
__url__ = 'https://github.com/wakatime/wakatime'
|
||||
__version_info__ = ('4', '1', '2')
|
||||
__version_info__ = ('6', '0', '7')
|
||||
__version__ = '.'.join(__version_info__)
|
||||
__author__ = 'Alan Hamlett'
|
||||
__author_email__ = 'alan@wakatime.com'
|
||||
__license__ = 'BSD'
|
||||
__copyright__ = 'Copyright 2014 Alan Hamlett'
|
||||
__copyright__ = 'Copyright 2016 Alan Hamlett'
|
||||
|
||||
@ -14,4 +14,4 @@
|
||||
__all__ = ['main']
|
||||
|
||||
|
||||
from .base import main
|
||||
from .main import execute
|
||||
|
||||
@ -1,443 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.base
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
wakatime module entry point.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import base64
|
||||
import logging
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
import socket
|
||||
try:
|
||||
import ConfigParser as configparser
|
||||
except ImportError: # pragma: nocover
|
||||
import configparser
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
|
||||
from .__about__ import __version__
|
||||
from .compat import u, open, is_py3
|
||||
from .logger import setup_logging
|
||||
from .offlinequeue import Queue
|
||||
from .packages import argparse
|
||||
from .packages.requests.exceptions import RequestException
|
||||
from .project import get_project_info
|
||||
from .session_cache import SessionCache
|
||||
from .stats import get_file_stats
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError):
|
||||
import json # pragma: nocover
|
||||
try:
|
||||
from .packages import tzlocal # pragma: nocover
|
||||
except: # pragma: nocover
|
||||
from .packages import tzlocal3 as tzlocal # pragma: nocover
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class FileAction(argparse.Action):
|
||||
|
||||
def __call__(self, parser, namespace, values, option_string=None):
|
||||
values = os.path.realpath(values)
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def parseConfigFile(configFile=None):
|
||||
"""Returns a configparser.SafeConfigParser instance with configs
|
||||
read from the config file. Default location of the config file is
|
||||
at ~/.wakatime.cfg.
|
||||
"""
|
||||
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.cfg')
|
||||
|
||||
configs = configparser.SafeConfigParser()
|
||||
try:
|
||||
with open(configFile, 'r', encoding='utf-8') as fh:
|
||||
try:
|
||||
configs.readfp(fh)
|
||||
except configparser.Error:
|
||||
print(traceback.format_exc())
|
||||
return None
|
||||
except IOError:
|
||||
print(u('Error: Could not read from config file {0}').format(u(configFile)))
|
||||
return configs
|
||||
|
||||
|
||||
def parseArguments():
|
||||
"""Parse command line arguments and configs from ~/.wakatime.cfg.
|
||||
Command line arguments take precedence over config file settings.
|
||||
Returns instances of ArgumentParser and SafeConfigParser.
|
||||
"""
|
||||
|
||||
# define supported command line arguments
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Common interface for the WakaTime api.')
|
||||
parser.add_argument('--file', dest='targetFile', metavar='file',
|
||||
action=FileAction, required=True,
|
||||
help='absolute path to file for current heartbeat')
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakatime api key; uses api_key from '+
|
||||
'~/.wakatime.conf by default')
|
||||
parser.add_argument('--write', dest='isWrite',
|
||||
action='store_true',
|
||||
help='when set, tells api this heartbeat was triggered from '+
|
||||
'writing to a file')
|
||||
parser.add_argument('--plugin', dest='plugin',
|
||||
help='optional text editor plugin name and version '+
|
||||
'for User-Agent header')
|
||||
parser.add_argument('--time', dest='timestamp', metavar='time',
|
||||
type=float,
|
||||
help='optional floating-point unix epoch timestamp; '+
|
||||
'uses current time by default')
|
||||
parser.add_argument('--lineno', dest='lineno',
|
||||
help='optional line number; current line being edited')
|
||||
parser.add_argument('--cursorpos', dest='cursorpos',
|
||||
help='optional cursor position in the current file')
|
||||
parser.add_argument('--notfile', dest='notfile', action='store_true',
|
||||
help='when set, will accept any value for the file. for example, '+
|
||||
'a domain name or other item you want to log time towards.')
|
||||
parser.add_argument('--proxy', dest='proxy',
|
||||
help='optional https proxy url; for example: '+
|
||||
'https://user:pass@localhost:8080')
|
||||
parser.add_argument('--project', dest='project',
|
||||
help='optional project name')
|
||||
parser.add_argument('--alternate-project', dest='alternate_project',
|
||||
help='optional alternate project name; auto-discovered project takes priority')
|
||||
parser.add_argument('--hostname', dest='hostname', help='hostname of current machine.')
|
||||
parser.add_argument('--disableoffline', dest='offline',
|
||||
action='store_false',
|
||||
help='disables offline time logging instead of queuing logged time')
|
||||
parser.add_argument('--hidefilenames', dest='hidefilenames',
|
||||
action='store_true',
|
||||
help='obfuscate file names; will not send file names to api')
|
||||
parser.add_argument('--exclude', dest='exclude', action='append',
|
||||
help='filename patterns to exclude from logging; POSIX regex '+
|
||||
'syntax; can be used more than once')
|
||||
parser.add_argument('--include', dest='include', action='append',
|
||||
help='filename patterns to log; when used in combination with '+
|
||||
'--exclude, files matching include will still be logged; '+
|
||||
'POSIX regex syntax; can be used more than once')
|
||||
parser.add_argument('--ignore', dest='ignore', action='append',
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--logfile', dest='logfile',
|
||||
help='defaults to ~/.wakatime.log')
|
||||
parser.add_argument('--apiurl', dest='api_url',
|
||||
help='heartbeats api url; for debugging with a local server')
|
||||
parser.add_argument('--config', dest='config',
|
||||
help='defaults to ~/.wakatime.conf')
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
help='turns on debug messages in log file')
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
|
||||
# parse command line arguments
|
||||
args = parser.parse_args()
|
||||
|
||||
# use current unix epoch timestamp by default
|
||||
if not args.timestamp:
|
||||
args.timestamp = time.time()
|
||||
|
||||
# parse ~/.wakatime.cfg file
|
||||
configs = parseConfigFile(args.config)
|
||||
if configs is None:
|
||||
return args, configs
|
||||
|
||||
# update args from configs
|
||||
if not args.key:
|
||||
default_key = None
|
||||
if configs.has_option('settings', 'api_key'):
|
||||
default_key = configs.get('settings', 'api_key')
|
||||
elif configs.has_option('settings', 'apikey'):
|
||||
default_key = configs.get('settings', 'apikey')
|
||||
if default_key:
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
if not args.exclude:
|
||||
args.exclude = []
|
||||
if configs.has_option('settings', 'ignore'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'ignore').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
pass
|
||||
if configs.has_option('settings', 'exclude'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'exclude').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
pass
|
||||
if not args.include:
|
||||
args.include = []
|
||||
if configs.has_option('settings', 'include'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'include').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.include.append(pattern)
|
||||
except TypeError:
|
||||
pass
|
||||
if args.offline and configs.has_option('settings', 'offline'):
|
||||
args.offline = configs.getboolean('settings', 'offline')
|
||||
if not args.hidefilenames and configs.has_option('settings', 'hidefilenames'):
|
||||
args.hidefilenames = configs.getboolean('settings', 'hidefilenames')
|
||||
if not args.proxy and configs.has_option('settings', 'proxy'):
|
||||
args.proxy = configs.get('settings', 'proxy')
|
||||
if not args.verbose and configs.has_option('settings', 'verbose'):
|
||||
args.verbose = configs.getboolean('settings', 'verbose')
|
||||
if not args.verbose and configs.has_option('settings', 'debug'):
|
||||
args.verbose = configs.getboolean('settings', 'debug')
|
||||
if not args.logfile and configs.has_option('settings', 'logfile'):
|
||||
args.logfile = configs.get('settings', 'logfile')
|
||||
if not args.api_url and configs.has_option('settings', 'api_url'):
|
||||
args.api_url = configs.get('settings', 'api_url')
|
||||
|
||||
return args, configs
|
||||
|
||||
|
||||
def should_exclude(fileName, include, exclude):
|
||||
if fileName is not None and fileName.strip() != '':
|
||||
try:
|
||||
for pattern in include:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
return False
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for include pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
try:
|
||||
for pattern in exclude:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
return pattern
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for exclude pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
return False
|
||||
|
||||
|
||||
def get_user_agent(plugin):
|
||||
ver = sys.version_info
|
||||
python_version = '%d.%d.%d.%s.%d' % (ver[0], ver[1], ver[2], ver[3], ver[4])
|
||||
user_agent = u('wakatime/{ver} ({platform}) Python{py_ver}').format(
|
||||
ver=u(__version__),
|
||||
platform=u(platform.platform()),
|
||||
py_ver=python_version,
|
||||
)
|
||||
if plugin:
|
||||
user_agent = u('{user_agent} {plugin}').format(
|
||||
user_agent=user_agent,
|
||||
plugin=u(plugin),
|
||||
)
|
||||
else:
|
||||
user_agent = u('{user_agent} Unknown/0').format(
|
||||
user_agent=user_agent,
|
||||
)
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None, targetFile=None,
|
||||
timestamp=None, isWrite=None, plugin=None, offline=None, notfile=False,
|
||||
hidefilenames=None, proxy=None, api_url=None, **kwargs):
|
||||
"""Sends heartbeat as POST request to WakaTime api server.
|
||||
"""
|
||||
|
||||
if not api_url:
|
||||
api_url = 'https://wakatime.com/api/v1/heartbeats'
|
||||
log.debug('Sending heartbeat to api at %s' % api_url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'entity': targetFile,
|
||||
'type': 'file',
|
||||
}
|
||||
if hidefilenames and targetFile is not None and not notfile:
|
||||
extension = u(os.path.splitext(data['entity'])[1])
|
||||
data['entity'] = u('HIDDEN{0}').format(extension)
|
||||
if stats.get('lines'):
|
||||
data['lines'] = stats['lines']
|
||||
if stats.get('language'):
|
||||
data['language'] = stats['language']
|
||||
if stats.get('dependencies'):
|
||||
data['dependencies'] = stats['dependencies']
|
||||
if stats.get('lineno'):
|
||||
data['lineno'] = stats['lineno']
|
||||
if stats.get('cursorpos'):
|
||||
data['cursorpos'] = stats['cursorpos']
|
||||
if isWrite:
|
||||
data['is_write'] = isWrite
|
||||
if project:
|
||||
data['project'] = project
|
||||
if branch:
|
||||
data['branch'] = branch
|
||||
log.debug(data)
|
||||
|
||||
# setup api request
|
||||
request_body = json.dumps(data)
|
||||
api_key = u(base64.b64encode(str.encode(key) if is_py3 else key))
|
||||
auth = u('Basic {api_key}').format(api_key=api_key)
|
||||
headers = {
|
||||
'User-Agent': get_user_agent(plugin),
|
||||
'Content-Type': 'application/json',
|
||||
'Accept': 'application/json',
|
||||
'Authorization': auth,
|
||||
}
|
||||
if hostname:
|
||||
headers['X-Machine-Name'] = hostname
|
||||
proxies = {}
|
||||
if proxy:
|
||||
proxies['https'] = proxy
|
||||
|
||||
# add Olson timezone to request
|
||||
try:
|
||||
tz = tzlocal.get_localzone()
|
||||
except:
|
||||
tz = None
|
||||
if tz:
|
||||
headers['TimeZone'] = u(tz.zone)
|
||||
|
||||
session_cache = SessionCache()
|
||||
session = session_cache.get()
|
||||
|
||||
# log time to api
|
||||
response = None
|
||||
try:
|
||||
response = session.post(api_url, data=request_body, headers=headers,
|
||||
proxies=proxies)
|
||||
except RequestException:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
}
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
exception_data['traceback'] = traceback.format_exc()
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
log.warn(exception_data)
|
||||
else:
|
||||
log.error(exception_data)
|
||||
else:
|
||||
response_code = response.status_code if response is not None else None
|
||||
response_content = response.text if response is not None else None
|
||||
if response_code == 201:
|
||||
log.debug({
|
||||
'response_code': response_code,
|
||||
})
|
||||
session_cache.save(session)
|
||||
return True
|
||||
if offline:
|
||||
if response_code != 400:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
if response_code == 401:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
elif log.isEnabledFor(logging.DEBUG):
|
||||
log.warn({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return False
|
||||
|
||||
|
||||
def main(argv):
|
||||
sys.argv = ['wakatime'] + argv
|
||||
|
||||
args, configs = parseArguments()
|
||||
if configs is None:
|
||||
return 103 # config file parsing error
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
exclude = should_exclude(args.targetFile, args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
log.debug(u('File not logged because matches exclude pattern: {pattern}').format(
|
||||
pattern=u(exclude),
|
||||
))
|
||||
return 0
|
||||
|
||||
if os.path.isfile(args.targetFile) or args.notfile:
|
||||
|
||||
stats = get_file_stats(args.targetFile, notfile=args.notfile,
|
||||
lineno=args.lineno, cursorpos=args.cursorpos)
|
||||
|
||||
project, branch = None, None
|
||||
if not args.notfile:
|
||||
project, branch = get_project_info(configs=configs, args=args)
|
||||
|
||||
kwargs = vars(args)
|
||||
kwargs['project'] = project
|
||||
kwargs['branch'] = branch
|
||||
kwargs['stats'] = stats
|
||||
kwargs['hostname'] = args.hostname or socket.gethostname()
|
||||
|
||||
if send_heartbeat(**kwargs):
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
sent = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
targetFile=heartbeat['file'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
hostname=kwargs['hostname'],
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
isWrite=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
notfile=args.notfile,
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
)
|
||||
if not sent:
|
||||
break
|
||||
return 0 # success
|
||||
|
||||
return 102 # api error
|
||||
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this heartbeat.')
|
||||
return 0
|
||||
@ -32,4 +32,4 @@ except (TypeError, ImportError):
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(wakatime.main(sys.argv[1:]))
|
||||
sys.exit(wakatime.execute(sys.argv[1:]))
|
||||
|
||||
@ -26,9 +26,12 @@ if is_py2: # pragma: nocover
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
return text
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text
|
||||
open = codecs.open
|
||||
basestring = basestring
|
||||
|
||||
@ -39,8 +42,17 @@ elif is_py3: # pragma: nocover
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
return text.decode('utf-8')
|
||||
return str(text)
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text
|
||||
open = open
|
||||
basestring = (str, bytes)
|
||||
|
||||
|
||||
18
packages/wakatime/constants.py
Normal file
18
packages/wakatime/constants.py
Normal file
@ -0,0 +1,18 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.constants
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Constant variable definitions.
|
||||
|
||||
:copyright: (c) 2016 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
SUCCESS = 0
|
||||
API_ERROR = 102
|
||||
CONFIG_FILE_PARSE_ERROR = 103
|
||||
AUTH_ERROR = 104
|
||||
UNKNOWN_ERROR = 105
|
||||
MALFORMED_HEARTBEAT_ERROR = 106
|
||||
130
packages/wakatime/dependencies/__init__.py
Normal file
130
packages/wakatime/dependencies/__init__.py
Normal file
@ -0,0 +1,130 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.dependencies
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from a source code file.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import re
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from ..compat import u, open, import_module
|
||||
from ..exceptions import NotYetImplemented
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class TokenParser(object):
|
||||
"""The base class for all dependency parsers. To add support for your
|
||||
language, inherit from this class and implement the :meth:`parse` method
|
||||
to return a list of dependency strings.
|
||||
"""
|
||||
exclude = []
|
||||
|
||||
def __init__(self, source_file, lexer=None):
|
||||
self._tokens = None
|
||||
self.dependencies = []
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
self.exclude = [re.compile(x, re.IGNORECASE) for x in self.exclude]
|
||||
|
||||
@property
|
||||
def tokens(self):
|
||||
if self._tokens is None:
|
||||
self._tokens = self._extract_tokens()
|
||||
return self._tokens
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
""" Should return a list of dependencies.
|
||||
"""
|
||||
raise NotYetImplemented()
|
||||
|
||||
def append(self, dep, truncate=False, separator=None, truncate_to=None,
|
||||
strip_whitespace=True):
|
||||
self._save_dependency(
|
||||
dep,
|
||||
truncate=truncate,
|
||||
truncate_to=truncate_to,
|
||||
separator=separator,
|
||||
strip_whitespace=strip_whitespace,
|
||||
)
|
||||
|
||||
def partial(self, token):
|
||||
return u(token).split('.')[-1]
|
||||
|
||||
def _extract_tokens(self):
|
||||
if self.lexer:
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
return []
|
||||
|
||||
def _save_dependency(self, dep, truncate=False, separator=None,
|
||||
truncate_to=None, strip_whitespace=True):
|
||||
if truncate:
|
||||
if separator is None:
|
||||
separator = u('.')
|
||||
separator = u(separator)
|
||||
dep = dep.split(separator)
|
||||
if truncate_to is None or truncate_to < 1:
|
||||
truncate_to = 1
|
||||
if truncate_to > len(dep):
|
||||
truncate_to = len(dep)
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[:truncate_to])
|
||||
if strip_whitespace:
|
||||
dep = dep.strip()
|
||||
if dep and (not separator or not dep.startswith(separator)):
|
||||
should_exclude = False
|
||||
for compiled in self.exclude:
|
||||
if compiled.search(dep):
|
||||
should_exclude = True
|
||||
break
|
||||
if not should_exclude:
|
||||
self.dependencies.append(dep)
|
||||
|
||||
|
||||
class DependencyParser(object):
|
||||
source_file = None
|
||||
lexer = None
|
||||
parser = None
|
||||
|
||||
def __init__(self, source_file, lexer):
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
|
||||
if self.lexer:
|
||||
module_name = self.lexer.__module__.rsplit('.', 1)[-1]
|
||||
class_name = self.lexer.__class__.__name__.replace('Lexer', 'Parser', 1)
|
||||
else:
|
||||
module_name = 'unknown'
|
||||
class_name = 'UnknownParser'
|
||||
|
||||
try:
|
||||
module = import_module('.%s' % module_name, package=__package__)
|
||||
try:
|
||||
self.parser = getattr(module, class_name)
|
||||
except AttributeError:
|
||||
log.debug('Module {0} is missing class {1}'.format(module.__name__, class_name))
|
||||
except ImportError:
|
||||
log.debug(traceback.format_exc())
|
||||
|
||||
def parse(self):
|
||||
if self.parser:
|
||||
plugin = self.parser(self.source_file, lexer=self.lexer)
|
||||
dependencies = plugin.parse()
|
||||
return list(set(dependencies))
|
||||
return []
|
||||
51
packages/wakatime/dependencies/c_cpp.py
Normal file
51
packages/wakatime/dependencies/c_cpp.py
Normal file
@ -0,0 +1,51 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class CParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
state = None
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc' or self.partial(token) == 'PreprocFile':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '\n' and content != '#':
|
||||
content = content.strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content, truncate=True, separator='/')
|
||||
self.state = None
|
||||
elif content.strip().startswith('include'):
|
||||
self.state = 'include'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
|
||||
class CppParser(CParser):
|
||||
pass
|
||||
64
packages/wakatime/dependencies/data.py
Normal file
64
packages/wakatime/dependencies/data.py
Normal file
@ -0,0 +1,64 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.data
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from data files.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import os
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
FILES = {
|
||||
'bower.json': {'exact': True, 'dependency': 'bower'},
|
||||
'component.json': {'exact': True, 'dependency': 'bower'},
|
||||
'package.json': {'exact': True, 'dependency': 'npm'},
|
||||
}
|
||||
|
||||
|
||||
class JsonParser(TokenParser):
|
||||
state = None
|
||||
level = 0
|
||||
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_file_name(self, file_name):
|
||||
for key, value in FILES.items():
|
||||
found = (key == file_name) if value.get('exact') else (key.lower() in file_name.lower())
|
||||
if found:
|
||||
self.append(value['dependency'])
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Tag':
|
||||
self._process_tag(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
elif u(token) == 'Token.Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
if content.strip('"').strip("'") == 'dependencies' or content.strip('"').strip("'") == 'devDependencies':
|
||||
self.state = 'dependencies'
|
||||
elif self.state == 'dependencies' and self.level == 2:
|
||||
self.append(content.strip('"').strip("'"))
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '{':
|
||||
self.level += 1
|
||||
elif content == '}':
|
||||
self.level -= 1
|
||||
if self.state is not None and self.level <= 1:
|
||||
self.state = None
|
||||
64
packages/wakatime/dependencies/dotnet.py
Normal file
64
packages/wakatime/dependencies/dotnet.py
Normal file
@ -0,0 +1,64 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
exclude = [
|
||||
r'^system$',
|
||||
r'^microsoft$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
if self.partial(token) == 'Namespace' or self.partial(token) == 'Name':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_keyword(self, token, content):
|
||||
if content == 'using':
|
||||
self.state = 'import'
|
||||
self.buffer = u('')
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) != u('import') and u(content) != u('package') and u(content) != u('namespace') and u(content) != u('static'):
|
||||
if u(content) == u(';'): # pragma: nocover
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) == u(';'):
|
||||
self.append(self.buffer, truncate=True)
|
||||
self.buffer = u('')
|
||||
self.state = None
|
||||
elif u(content) == u('='):
|
||||
self.buffer = u('')
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
77
packages/wakatime/dependencies/go.py
Normal file
77
packages/wakatime/dependencies/go.py
Normal file
@ -0,0 +1,77 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.go
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Go code.
|
||||
|
||||
:copyright: (c) 2016 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class GoParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
aliases = 0
|
||||
exclude = [
|
||||
r'^"fmt"$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif self.partial(token) == 'String':
|
||||
self._process_string(token, content)
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
elif self.partial(token) == 'Other':
|
||||
self._process_other(token, content)
|
||||
else:
|
||||
self._process_misc(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
self.state = content
|
||||
self.parens = 0
|
||||
self.aliases = 0
|
||||
|
||||
def _process_string(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.append(content, truncate=False)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
elif content == '.':
|
||||
self.aliases += 1
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state == 'import':
|
||||
if content == "\n" and self.parens <= 0:
|
||||
self.state = None
|
||||
self.parens = 0
|
||||
self.aliases = 0
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_other(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.aliases += 1
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_misc(self, token, content):
|
||||
self.state = None
|
||||
96
packages/wakatime/dependencies/jvm.py
Normal file
96
packages/wakatime/dependencies/jvm.py
Normal file
@ -0,0 +1,96 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
exclude = [
|
||||
r'^java\.',
|
||||
r'^javax\.',
|
||||
r'^import$',
|
||||
r'^package$',
|
||||
r'^namespace$',
|
||||
r'^static$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
if self.partial(token) == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif self.partial(token) == 'Attribute':
|
||||
self._process_attribute(token, content)
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if u(content) == u('import'):
|
||||
self.state = 'import'
|
||||
|
||||
elif self.state == 'import':
|
||||
keywords = [
|
||||
u('package'),
|
||||
u('namespace'),
|
||||
u('static'),
|
||||
]
|
||||
if u(content) in keywords:
|
||||
return
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
elif self.state == 'import-finished':
|
||||
content = content.split(u('.'))
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
|
||||
elif len(content) > 1:
|
||||
if len(content[0]) == 3:
|
||||
content = content[1:]
|
||||
if content[-1] == u('*'):
|
||||
content = content[:len(content) - 1]
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
elif len(content) > 1:
|
||||
self.append(u('.').join(content[:2]))
|
||||
|
||||
self.state = None
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if u(content) == u(';'):
|
||||
self.state = 'import-finished'
|
||||
self._process_namespace(token, self.buffer)
|
||||
self.state = None
|
||||
self.buffer = u('')
|
||||
elif self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
85
packages/wakatime/dependencies/php.py
Normal file
85
packages/wakatime/dependencies/php.py
Normal file
@ -0,0 +1,85 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.php
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from PHP code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class PhpParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
elif u(token) == 'Token.Name.Other':
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Name.Function':
|
||||
self._process_function(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state == 'use':
|
||||
self.append(content, truncate=True, separator=u("\\"))
|
||||
|
||||
def _process_function(self, token, content):
|
||||
if self.state == 'use function':
|
||||
self.append(content, truncate=True, separator=u("\\"))
|
||||
self.state = 'use'
|
||||
|
||||
def _process_keyword(self, token, content):
|
||||
if content == 'include' or content == 'include_once' or content == 'require' or content == 'require_once':
|
||||
self.state = 'include'
|
||||
elif content == 'use':
|
||||
self.state = 'use'
|
||||
elif content == 'as':
|
||||
self.state = 'as'
|
||||
elif self.state == 'use' and content == 'function':
|
||||
self.state = 'use function'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '"' and content != "'":
|
||||
content = content.strip()
|
||||
if u(token) == 'Token.Literal.String.Double':
|
||||
content = u("'{0}'").format(content)
|
||||
self.append(content)
|
||||
self.state = None
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
elif (self.state == 'use' or self.state == 'as') and content == ',':
|
||||
self.state = 'use'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_text(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_other(self, token, content):
|
||||
self.state = None
|
||||
86
packages/wakatime/dependencies/python.py
Normal file
86
packages/wakatime/dependencies/python.py
Normal file
@ -0,0 +1,86 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.python
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Python code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class PythonParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
nonpackage = False
|
||||
exclude = [
|
||||
r'^os$',
|
||||
r'^sys$',
|
||||
r'^sys\.',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state is None:
|
||||
self.state = content
|
||||
else:
|
||||
if content == 'as':
|
||||
self.nonpackage = True
|
||||
else:
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == '.':
|
||||
self.nonpackage = True
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == "\n" and self.parens == 0:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_import(self, token, content):
|
||||
if not self.nonpackage:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'import-2'
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
else:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
210
packages/wakatime/dependencies/templates.py
Normal file
210
packages/wakatime/dependencies/templates.py
Normal file
@ -0,0 +1,210 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.templates
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Templates.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
""" If these keywords are found in the source file, treat them as a dependency.
|
||||
Must be lower-case strings.
|
||||
"""
|
||||
KEYWORDS = [
|
||||
'_',
|
||||
'$',
|
||||
'angular',
|
||||
'assert', # probably mocha
|
||||
'backbone',
|
||||
'batman',
|
||||
'c3',
|
||||
'can',
|
||||
'casper',
|
||||
'chai',
|
||||
'chaplin',
|
||||
'd3',
|
||||
'define', # probably require
|
||||
'describe', # mocha or jasmine
|
||||
'eco',
|
||||
'ember',
|
||||
'espresso',
|
||||
'expect', # probably jasmine
|
||||
'exports', # probably npm
|
||||
'express',
|
||||
'gulp',
|
||||
'handlebars',
|
||||
'highcharts',
|
||||
'jasmine',
|
||||
'jquery',
|
||||
'jstz',
|
||||
'ko', # probably knockout
|
||||
'm', # probably mithril
|
||||
'marionette',
|
||||
'meteor',
|
||||
'moment',
|
||||
'monitorio',
|
||||
'mustache',
|
||||
'phantom',
|
||||
'pickadate',
|
||||
'pikaday',
|
||||
'qunit',
|
||||
'react',
|
||||
'reactive',
|
||||
'require', # probably the commonjs spec
|
||||
'ripple',
|
||||
'rivets',
|
||||
'socketio',
|
||||
'spine',
|
||||
'thorax',
|
||||
'underscore',
|
||||
'vue',
|
||||
'way',
|
||||
'zombie',
|
||||
]
|
||||
|
||||
|
||||
class HtmlDjangoParser(TokenParser):
|
||||
tags = []
|
||||
opening_tag = False
|
||||
getting_attrs = False
|
||||
current_attr = None
|
||||
current_attr_value = None
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token) == 'Token.Name.Tag':
|
||||
self._process_tag(token, content)
|
||||
elif u(token) == 'Token.Literal.String':
|
||||
self._process_string(token, content)
|
||||
elif u(token) == 'Token.Name.Attribute':
|
||||
self._process_attribute(token, content)
|
||||
|
||||
@property
|
||||
def current_tag(self):
|
||||
return None if len(self.tags) == 0 else self.tags[0]
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content.startswith('</') or content.startswith('/'):
|
||||
try:
|
||||
self.tags.pop(0)
|
||||
except IndexError:
|
||||
# ignore errors from malformed markup
|
||||
pass
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
elif content.startswith('<'):
|
||||
self.opening_tag = True
|
||||
elif content.startswith('>'):
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
if self.opening_tag:
|
||||
self.tags.insert(0, content.replace('<', '', 1).strip().lower())
|
||||
self.getting_attrs = True
|
||||
elif content.startswith('>'):
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
self.current_attr = None
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.getting_attrs:
|
||||
self.current_attr = content.lower().strip('=')
|
||||
else:
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
|
||||
def _process_string(self, token, content):
|
||||
if self.getting_attrs and self.current_attr is not None:
|
||||
if content.endswith('"') or content.endswith("'"):
|
||||
if self.current_attr_value is not None:
|
||||
self.current_attr_value += content
|
||||
if self.current_tag == 'script' and self.current_attr == 'src':
|
||||
self.append(self.current_attr_value)
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
else:
|
||||
if len(content) == 1:
|
||||
self.current_attr_value = content
|
||||
else:
|
||||
if self.current_tag == 'script' and self.current_attr == 'src':
|
||||
self.append(content)
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
elif content.startswith('"') or content.startswith("'"):
|
||||
if self.current_attr_value is None:
|
||||
self.current_attr_value = content
|
||||
else:
|
||||
self.current_attr_value += content
|
||||
|
||||
|
||||
class VelocityHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class MyghtyHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class MasonParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class MakoHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class CheetahHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HtmlGenshiParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class RhtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HtmlPhpParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HtmlSmartyParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class EvoqueHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class ColdfusionHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class LassoHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HandlebarsHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class YamlJinjaParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class TwigHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
@ -22,7 +22,7 @@ FILES = {
|
||||
|
||||
class UnknownParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
return self.dependencies
|
||||
|
||||
14
packages/wakatime/exceptions.py
Normal file
14
packages/wakatime/exceptions.py
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.exceptions
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Custom exceptions.
|
||||
|
||||
:copyright: (c) 2015 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
class NotYetImplemented(Exception):
|
||||
"""This method needs to be implemented."""
|
||||
@ -1,115 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from a source code file.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from ..compat import u, open, import_module
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class TokenParser(object):
|
||||
"""The base class for all dependency parsers. To add support for your
|
||||
language, inherit from this class and implement the :meth:`parse` method
|
||||
to return a list of dependency strings.
|
||||
"""
|
||||
source_file = None
|
||||
lexer = None
|
||||
dependencies = []
|
||||
tokens = []
|
||||
|
||||
def __init__(self, source_file, lexer=None):
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
""" Should return a list of dependencies.
|
||||
"""
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
raise Exception('Not yet implemented.')
|
||||
|
||||
def append(self, dep, truncate=False, separator=None, truncate_to=None,
|
||||
strip_whitespace=True):
|
||||
if dep == 'as':
|
||||
print('***************** as')
|
||||
self._save_dependency(
|
||||
dep,
|
||||
truncate=truncate,
|
||||
truncate_to=truncate_to,
|
||||
separator=separator,
|
||||
strip_whitespace=strip_whitespace,
|
||||
)
|
||||
|
||||
def _extract_tokens(self):
|
||||
if self.lexer:
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
return []
|
||||
|
||||
def _save_dependency(self, dep, truncate=False, separator=None,
|
||||
truncate_to=None, strip_whitespace=True):
|
||||
if truncate:
|
||||
if separator is None:
|
||||
separator = u('.')
|
||||
separator = u(separator)
|
||||
dep = dep.split(separator)
|
||||
if truncate_to is None or truncate_to < 0 or truncate_to > len(dep) - 1:
|
||||
truncate_to = len(dep) - 1
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[0:truncate_to])
|
||||
if strip_whitespace:
|
||||
dep = dep.strip()
|
||||
if dep:
|
||||
self.dependencies.append(dep)
|
||||
|
||||
|
||||
class DependencyParser(object):
|
||||
source_file = None
|
||||
lexer = None
|
||||
parser = None
|
||||
|
||||
def __init__(self, source_file, lexer):
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
|
||||
if self.lexer:
|
||||
module_name = self.lexer.__module__.rsplit('.', 1)[-1]
|
||||
class_name = self.lexer.__class__.__name__.replace('Lexer', 'Parser', 1)
|
||||
else:
|
||||
module_name = 'unknown'
|
||||
class_name = 'UnknownParser'
|
||||
|
||||
try:
|
||||
module = import_module('.%s' % module_name, package=__package__)
|
||||
try:
|
||||
self.parser = getattr(module, class_name)
|
||||
except AttributeError:
|
||||
log.debug('Module {0} is missing class {1}'.format(module.__name__, class_name))
|
||||
except ImportError:
|
||||
log.debug(traceback.format_exc())
|
||||
|
||||
def parse(self):
|
||||
if self.parser:
|
||||
plugin = self.parser(self.source_file, lexer=self.lexer)
|
||||
dependencies = plugin.parse()
|
||||
return list(set(dependencies))
|
||||
return []
|
||||
@ -1,37 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,66 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.data
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from data files.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import os
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
FILES = {
|
||||
'bower.json': {'exact': True, 'dependency': 'bower'},
|
||||
'component.json': {'exact': True, 'dependency': 'bower'},
|
||||
'package.json': {'exact': True, 'dependency': 'npm'},
|
||||
}
|
||||
|
||||
|
||||
class JsonParser(TokenParser):
|
||||
state = None
|
||||
level = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_file_name(self, file_name):
|
||||
for key, value in FILES.items():
|
||||
found = (key == file_name) if value.get('exact') else (key.lower() in file_name.lower())
|
||||
if found:
|
||||
self.append(value['dependency'])
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Tag':
|
||||
self._process_tag(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
elif u(token) == 'Token.Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
if content.strip('"').strip("'") == 'dependencies' or content.strip('"').strip("'") == 'devDependencies':
|
||||
self.state = 'dependencies'
|
||||
elif self.state == 'dependencies' and self.level == 2:
|
||||
self.append(content.strip('"').strip("'"))
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '{':
|
||||
self.level += 1
|
||||
elif content == '}':
|
||||
self.level -= 1
|
||||
if self.state is not None and self.level <= 1:
|
||||
self.state = None
|
||||
80
packages/wakatime/languages/default.json
Normal file
80
packages/wakatime/languages/default.json
Normal file
@ -0,0 +1,80 @@
|
||||
{
|
||||
"ActionScript": "ActionScript",
|
||||
"ApacheConf": "ApacheConf",
|
||||
"AppleScript": "AppleScript",
|
||||
"ASP": "ASP",
|
||||
"Assembly": "Assembly",
|
||||
"Awk": "Awk",
|
||||
"Bash": "Bash",
|
||||
"Basic": "Basic",
|
||||
"BrightScript": "BrightScript",
|
||||
"C": "C",
|
||||
"C#": "C#",
|
||||
"C++": "C++",
|
||||
"Clojure": "Clojure",
|
||||
"Cocoa": "Cocoa",
|
||||
"CoffeeScript": "CoffeeScript",
|
||||
"ColdFusion": "ColdFusion",
|
||||
"Common Lisp": "Common Lisp",
|
||||
"CSHTML": "CSHTML",
|
||||
"CSS": "CSS",
|
||||
"Dart": "Dart",
|
||||
"Delphi": "Delphi",
|
||||
"Elixir": "Elixir",
|
||||
"Elm": "Elm",
|
||||
"Emacs Lisp": "Emacs Lisp",
|
||||
"Erlang": "Erlang",
|
||||
"F#": "F#",
|
||||
"Fortran": "Fortran",
|
||||
"Go": "Go",
|
||||
"Gous": "Gosu",
|
||||
"Groovy": "Groovy",
|
||||
"Haml": "Haml",
|
||||
"HaXe": "HaXe",
|
||||
"Haskell": "Haskell",
|
||||
"HTML": "HTML",
|
||||
"INI": "INI",
|
||||
"Jade": "Jade",
|
||||
"Java": "Java",
|
||||
"JavaScript": "JavaScript",
|
||||
"JSON": "JSON",
|
||||
"JSX": "JSX",
|
||||
"Kotlin": "Kotlin",
|
||||
"LESS": "LESS",
|
||||
"Lua": "Lua",
|
||||
"Markdown": "Markdown",
|
||||
"Matlab": "Matlab",
|
||||
"Mustache": "Mustache",
|
||||
"OCaml": "OCaml",
|
||||
"Objective-C": "Objective-C",
|
||||
"Objective-C++": "Objective-C++",
|
||||
"Objective-J": "Objective-J",
|
||||
"Perl": "Perl",
|
||||
"PHP": "PHP",
|
||||
"PowerShell": "PowerShell",
|
||||
"Prolog": "Prolog",
|
||||
"Puppet": "Puppet",
|
||||
"Python": "Python",
|
||||
"R": "R",
|
||||
"reStructuredText": "reStructuredText",
|
||||
"Ruby": "Ruby",
|
||||
"Rust": "Rust",
|
||||
"Sass": "Sass",
|
||||
"Scala": "Scala",
|
||||
"Scheme": "Scheme",
|
||||
"SCSS": "SCSS",
|
||||
"Shell": "Shell",
|
||||
"Slim": "Slim",
|
||||
"Smalltalk": "Smalltalk",
|
||||
"SQL": "SQL",
|
||||
"Swift": "Swift",
|
||||
"Text": "Text",
|
||||
"Turing": "Turing",
|
||||
"Twig": "Twig",
|
||||
"TypeScript": "TypeScript",
|
||||
"VB.net": "VB.net",
|
||||
"VimL": "VimL",
|
||||
"XAML": "XAML",
|
||||
"XML": "XML",
|
||||
"YAML": "YAML"
|
||||
}
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,87 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.php
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from PHP code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class PhpParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
elif u(token) == 'Token.Name.Other':
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Name.Function':
|
||||
self._process_function(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state == 'use':
|
||||
self.append(content, truncate=True, separator=u("\\"))
|
||||
|
||||
def _process_function(self, token, content):
|
||||
if self.state == 'use function':
|
||||
self.append(content, truncate=True, separator=u("\\"))
|
||||
self.state = 'use'
|
||||
|
||||
def _process_keyword(self, token, content):
|
||||
if content == 'include' or content == 'include_once' or content == 'require' or content == 'require_once':
|
||||
self.state = 'include'
|
||||
elif content == 'use':
|
||||
self.state = 'use'
|
||||
elif content == 'as':
|
||||
self.state = 'as'
|
||||
elif self.state == 'use' and content == 'function':
|
||||
self.state = 'use function'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '"':
|
||||
content = content.strip()
|
||||
if u(token) == 'Token.Literal.String.Double':
|
||||
content = u('"{0}"').format(content)
|
||||
self.append(content)
|
||||
self.state = None
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
elif (self.state == 'use' or self.state == 'as') and content == ',':
|
||||
self.state = 'use'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_text(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_other(self, token, content):
|
||||
self.state = None
|
||||
@ -1,120 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.python
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Python code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class PythonParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
nonpackage = False
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif u(token).split('.')[-1] == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif u(token).split('.')[-1] == 'Word':
|
||||
self._process_word(token, content)
|
||||
elif u(token).split('.')[-1] == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state is None:
|
||||
self.state = content
|
||||
else:
|
||||
if content == 'as':
|
||||
self.nonpackage = True
|
||||
else:
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_word(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == '.':
|
||||
self.nonpackage = True
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == "\n" and self.parens == 0:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_import(self, token, content):
|
||||
if not self.nonpackage:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.state = 'import-2'
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
@ -1,224 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.templates
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Templates.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
""" If these keywords are found in the source file, treat them as a dependency.
|
||||
Must be lower-case strings.
|
||||
"""
|
||||
KEYWORDS = [
|
||||
'_',
|
||||
'$',
|
||||
'angular',
|
||||
'assert', # probably mocha
|
||||
'backbone',
|
||||
'batman',
|
||||
'c3',
|
||||
'can',
|
||||
'casper',
|
||||
'chai',
|
||||
'chaplin',
|
||||
'd3',
|
||||
'define', # probably require
|
||||
'describe', # mocha or jasmine
|
||||
'eco',
|
||||
'ember',
|
||||
'espresso',
|
||||
'expect', # probably jasmine
|
||||
'exports', # probably npm
|
||||
'express',
|
||||
'gulp',
|
||||
'handlebars',
|
||||
'highcharts',
|
||||
'jasmine',
|
||||
'jquery',
|
||||
'jstz',
|
||||
'ko', # probably knockout
|
||||
'm', # probably mithril
|
||||
'marionette',
|
||||
'meteor',
|
||||
'moment',
|
||||
'monitorio',
|
||||
'mustache',
|
||||
'phantom',
|
||||
'pickadate',
|
||||
'pikaday',
|
||||
'qunit',
|
||||
'react',
|
||||
'reactive',
|
||||
'require', # probably the commonjs spec
|
||||
'ripple',
|
||||
'rivets',
|
||||
'socketio',
|
||||
'spine',
|
||||
'thorax',
|
||||
'underscore',
|
||||
'vue',
|
||||
'way',
|
||||
'zombie',
|
||||
]
|
||||
|
||||
|
||||
class LassoJavascriptParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Other':
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if content.lower() in KEYWORDS:
|
||||
self.append(content.lower())
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if 'famous/core/' in content.strip('"').strip("'"):
|
||||
self.append('famous')
|
||||
|
||||
|
||||
class HtmlDjangoParser(TokenParser):
|
||||
tags = []
|
||||
getting_attrs = False
|
||||
current_attr = None
|
||||
current_attr_value = None
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Tag':
|
||||
self._process_tag(token, content)
|
||||
elif u(token) == 'Token.Literal.String':
|
||||
self._process_string(token, content)
|
||||
elif u(token) == 'Token.Name.Attribute':
|
||||
self._process_attribute(token, content)
|
||||
|
||||
@property
|
||||
def current_tag(self):
|
||||
return None if len(self.tags) == 0 else self.tags[0]
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
if content.startswith('</') or content.startswith('/'):
|
||||
try:
|
||||
self.tags.pop(0)
|
||||
except IndexError:
|
||||
# ignore errors from malformed markup
|
||||
pass
|
||||
self.getting_attrs = False
|
||||
elif content.startswith('<'):
|
||||
self.tags.insert(0, content.replace('<', '', 1).strip().lower())
|
||||
self.getting_attrs = True
|
||||
elif content.startswith('>'):
|
||||
self.getting_attrs = False
|
||||
self.current_attr = None
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.getting_attrs:
|
||||
self.current_attr = content.lower().strip('=')
|
||||
else:
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
|
||||
def _process_string(self, token, content):
|
||||
if self.getting_attrs and self.current_attr is not None:
|
||||
if content.endswith('"') or content.endswith("'"):
|
||||
if self.current_attr_value is not None:
|
||||
self.current_attr_value += content
|
||||
if self.current_tag == 'script' and self.current_attr == 'src':
|
||||
self.append(self.current_attr_value)
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
else:
|
||||
if len(content) == 1:
|
||||
self.current_attr_value = content
|
||||
else:
|
||||
if self.current_tag == 'script' and self.current_attr == 'src':
|
||||
self.append(content)
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
elif content.startswith('"') or content.startswith("'"):
|
||||
if self.current_attr_value is None:
|
||||
self.current_attr_value = content
|
||||
else:
|
||||
self.current_attr_value += content
|
||||
|
||||
|
||||
class VelocityHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class MyghtyHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class MasonParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class MakoHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class CheetahHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HtmlGenshiParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class RhtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HtmlPhpParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HtmlSmartyParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class EvoqueHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class ColdfusionHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class LassoHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class HandlebarsHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class YamlJinjaParser(HtmlDjangoParser):
|
||||
pass
|
||||
|
||||
|
||||
class TwigHtmlParser(HtmlDjangoParser):
|
||||
pass
|
||||
531
packages/wakatime/languages/vim.json
Normal file
531
packages/wakatime/languages/vim.json
Normal file
@ -0,0 +1,531 @@
|
||||
{
|
||||
"a2ps": null,
|
||||
"a65": "Assembly",
|
||||
"aap": null,
|
||||
"abap": null,
|
||||
"abaqus": null,
|
||||
"abc": null,
|
||||
"abel": null,
|
||||
"acedb": null,
|
||||
"ada": null,
|
||||
"aflex": null,
|
||||
"ahdl": null,
|
||||
"alsaconf": null,
|
||||
"amiga": null,
|
||||
"aml": null,
|
||||
"ampl": null,
|
||||
"ant": null,
|
||||
"antlr": null,
|
||||
"apache": null,
|
||||
"apachestyle": null,
|
||||
"arch": null,
|
||||
"art": null,
|
||||
"asm": "Assembly",
|
||||
"asm68k": "Assembly",
|
||||
"asmh8300": "Assembly",
|
||||
"asn": null,
|
||||
"aspperl": null,
|
||||
"aspvbs": null,
|
||||
"asterisk": null,
|
||||
"asteriskvm": null,
|
||||
"atlas": null,
|
||||
"autohotkey": null,
|
||||
"autoit": null,
|
||||
"automake": null,
|
||||
"ave": null,
|
||||
"awk": null,
|
||||
"ayacc": null,
|
||||
"b": null,
|
||||
"baan": null,
|
||||
"basic": "Basic",
|
||||
"bc": null,
|
||||
"bdf": null,
|
||||
"bib": null,
|
||||
"bindzone": null,
|
||||
"blank": null,
|
||||
"bst": null,
|
||||
"btm": null,
|
||||
"bzr": null,
|
||||
"c": "C",
|
||||
"cabal": null,
|
||||
"calendar": null,
|
||||
"catalog": null,
|
||||
"cdl": null,
|
||||
"cdrdaoconf": null,
|
||||
"cdrtoc": null,
|
||||
"cf": null,
|
||||
"cfg": null,
|
||||
"ch": null,
|
||||
"chaiscript": null,
|
||||
"change": null,
|
||||
"changelog": null,
|
||||
"chaskell": null,
|
||||
"cheetah": null,
|
||||
"chill": null,
|
||||
"chordpro": null,
|
||||
"cl": null,
|
||||
"clean": null,
|
||||
"clipper": null,
|
||||
"cmake": null,
|
||||
"cmusrc": null,
|
||||
"cobol": null,
|
||||
"coco": null,
|
||||
"conaryrecipe": null,
|
||||
"conf": null,
|
||||
"config": null,
|
||||
"context": null,
|
||||
"cpp": "C++",
|
||||
"crm": null,
|
||||
"crontab": "Crontab",
|
||||
"cs": "C#",
|
||||
"csc": null,
|
||||
"csh": null,
|
||||
"csp": null,
|
||||
"css": null,
|
||||
"cterm": null,
|
||||
"ctrlh": null,
|
||||
"cucumber": null,
|
||||
"cuda": null,
|
||||
"cupl": null,
|
||||
"cuplsim": null,
|
||||
"cvs": null,
|
||||
"cvsrc": null,
|
||||
"cweb": null,
|
||||
"cynlib": null,
|
||||
"cynpp": null,
|
||||
"d": null,
|
||||
"datascript": null,
|
||||
"dcd": null,
|
||||
"dcl": null,
|
||||
"debchangelog": null,
|
||||
"debcontrol": null,
|
||||
"debsources": null,
|
||||
"def": null,
|
||||
"denyhosts": null,
|
||||
"desc": null,
|
||||
"desktop": null,
|
||||
"dictconf": null,
|
||||
"dictdconf": null,
|
||||
"diff": null,
|
||||
"dircolors": null,
|
||||
"diva": null,
|
||||
"django": null,
|
||||
"dns": null,
|
||||
"docbk": null,
|
||||
"docbksgml": null,
|
||||
"docbkxml": null,
|
||||
"dosbatch": null,
|
||||
"dosini": null,
|
||||
"dot": null,
|
||||
"doxygen": null,
|
||||
"dracula": null,
|
||||
"dsl": null,
|
||||
"dtd": null,
|
||||
"dtml": null,
|
||||
"dtrace": null,
|
||||
"dylan": null,
|
||||
"dylanintr": null,
|
||||
"dylanlid": null,
|
||||
"ecd": null,
|
||||
"edif": null,
|
||||
"eiffel": null,
|
||||
"elf": null,
|
||||
"elinks": null,
|
||||
"elmfilt": null,
|
||||
"erlang": null,
|
||||
"eruby": null,
|
||||
"esmtprc": null,
|
||||
"esqlc": null,
|
||||
"esterel": null,
|
||||
"eterm": null,
|
||||
"eviews": null,
|
||||
"exim": null,
|
||||
"expect": null,
|
||||
"exports": null,
|
||||
"fan": null,
|
||||
"fasm": null,
|
||||
"fdcc": null,
|
||||
"fetchmail": null,
|
||||
"fgl": null,
|
||||
"flexwiki": null,
|
||||
"focexec": null,
|
||||
"form": null,
|
||||
"forth": null,
|
||||
"fortran": null,
|
||||
"foxpro": null,
|
||||
"framescript": null,
|
||||
"freebasic": null,
|
||||
"fstab": null,
|
||||
"fvwm": null,
|
||||
"fvwm2m4": null,
|
||||
"gdb": null,
|
||||
"gdmo": null,
|
||||
"gedcom": null,
|
||||
"git": null,
|
||||
"gitcommit": null,
|
||||
"gitconfig": null,
|
||||
"gitrebase": null,
|
||||
"gitsendemail": null,
|
||||
"gkrellmrc": null,
|
||||
"gnuplot": null,
|
||||
"gp": null,
|
||||
"gpg": null,
|
||||
"grads": null,
|
||||
"gretl": null,
|
||||
"groff": null,
|
||||
"groovy": null,
|
||||
"group": null,
|
||||
"grub": null,
|
||||
"gsp": null,
|
||||
"gtkrc": null,
|
||||
"haml": "Haml",
|
||||
"hamster": null,
|
||||
"haskell": "Haskell",
|
||||
"haste": null,
|
||||
"hastepreproc": null,
|
||||
"hb": null,
|
||||
"help": null,
|
||||
"hercules": null,
|
||||
"hex": null,
|
||||
"hog": null,
|
||||
"hostconf": null,
|
||||
"html": "HTML",
|
||||
"htmlcheetah": "HTML",
|
||||
"htmldjango": "HTML",
|
||||
"htmlm4": "HTML",
|
||||
"htmlos": null,
|
||||
"ia64": null,
|
||||
"ibasic": null,
|
||||
"icemenu": null,
|
||||
"icon": null,
|
||||
"idl": null,
|
||||
"idlang": null,
|
||||
"indent": null,
|
||||
"inform": null,
|
||||
"initex": null,
|
||||
"initng": null,
|
||||
"inittab": null,
|
||||
"ipfilter": null,
|
||||
"ishd": null,
|
||||
"iss": null,
|
||||
"ist": null,
|
||||
"jal": null,
|
||||
"jam": null,
|
||||
"jargon": null,
|
||||
"java": "Java",
|
||||
"javacc": null,
|
||||
"javascript": "JavaScript",
|
||||
"jess": null,
|
||||
"jgraph": null,
|
||||
"jproperties": null,
|
||||
"jsp": null,
|
||||
"kconfig": null,
|
||||
"kix": null,
|
||||
"kscript": null,
|
||||
"kwt": null,
|
||||
"lace": null,
|
||||
"latte": null,
|
||||
"ld": null,
|
||||
"ldapconf": null,
|
||||
"ldif": null,
|
||||
"lex": null,
|
||||
"lftp": null,
|
||||
"lhaskell": "Haskell",
|
||||
"libao": null,
|
||||
"lifelines": null,
|
||||
"lilo": null,
|
||||
"limits": null,
|
||||
"liquid": null,
|
||||
"lisp": null,
|
||||
"lite": null,
|
||||
"litestep": null,
|
||||
"loginaccess": null,
|
||||
"logindefs": null,
|
||||
"logtalk": null,
|
||||
"lotos": null,
|
||||
"lout": null,
|
||||
"lpc": null,
|
||||
"lprolog": null,
|
||||
"lscript": null,
|
||||
"lsl": null,
|
||||
"lss": null,
|
||||
"lua": null,
|
||||
"lynx": null,
|
||||
"m4": null,
|
||||
"mail": null,
|
||||
"mailaliases": null,
|
||||
"mailcap": null,
|
||||
"make": null,
|
||||
"man": null,
|
||||
"manconf": null,
|
||||
"manual": null,
|
||||
"maple": null,
|
||||
"markdown": "Markdown",
|
||||
"masm": null,
|
||||
"mason": null,
|
||||
"master": null,
|
||||
"matlab": null,
|
||||
"maxima": null,
|
||||
"mel": null,
|
||||
"messages": null,
|
||||
"mf": null,
|
||||
"mgl": null,
|
||||
"mgp": null,
|
||||
"mib": null,
|
||||
"mma": null,
|
||||
"mmix": null,
|
||||
"mmp": null,
|
||||
"modconf": null,
|
||||
"model": null,
|
||||
"modsim3": null,
|
||||
"modula2": null,
|
||||
"modula3": null,
|
||||
"monk": null,
|
||||
"moo": null,
|
||||
"mp": null,
|
||||
"mplayerconf": null,
|
||||
"mrxvtrc": null,
|
||||
"msidl": null,
|
||||
"msmessages": null,
|
||||
"msql": null,
|
||||
"mupad": null,
|
||||
"mush": null,
|
||||
"muttrc": null,
|
||||
"mysql": null,
|
||||
"named": null,
|
||||
"nanorc": null,
|
||||
"nasm": null,
|
||||
"nastran": null,
|
||||
"natural": null,
|
||||
"ncf": null,
|
||||
"netrc": null,
|
||||
"netrw": null,
|
||||
"nosyntax": null,
|
||||
"nqc": null,
|
||||
"nroff": null,
|
||||
"nsis": null,
|
||||
"obj": null,
|
||||
"objc": "Objective-C",
|
||||
"objcpp": "Objective-C++",
|
||||
"ocaml": "OCaml",
|
||||
"occam": null,
|
||||
"omnimark": null,
|
||||
"openroad": null,
|
||||
"opl": null,
|
||||
"ora": null,
|
||||
"pamconf": null,
|
||||
"papp": null,
|
||||
"pascal": null,
|
||||
"passwd": null,
|
||||
"pcap": null,
|
||||
"pccts": null,
|
||||
"pdf": null,
|
||||
"perl": "Perl",
|
||||
"perl6": "Perl",
|
||||
"pf": null,
|
||||
"pfmain": null,
|
||||
"php": "PHP",
|
||||
"phtml": "PHP",
|
||||
"pic": null,
|
||||
"pike": null,
|
||||
"pilrc": null,
|
||||
"pine": null,
|
||||
"pinfo": null,
|
||||
"plaintex": null,
|
||||
"plm": null,
|
||||
"plp": null,
|
||||
"plsql": null,
|
||||
"po": null,
|
||||
"pod": null,
|
||||
"postscr": null,
|
||||
"pov": null,
|
||||
"povini": null,
|
||||
"ppd": null,
|
||||
"ppwiz": null,
|
||||
"prescribe": null,
|
||||
"privoxy": null,
|
||||
"procmail": null,
|
||||
"progress": null,
|
||||
"prolog": "Prolog",
|
||||
"promela": null,
|
||||
"protocols": null,
|
||||
"psf": null,
|
||||
"ptcap": null,
|
||||
"purifylog": null,
|
||||
"pyrex": null,
|
||||
"python": "Python",
|
||||
"qf": null,
|
||||
"quake": null,
|
||||
"r": "R",
|
||||
"racc": null,
|
||||
"radiance": null,
|
||||
"ratpoison": null,
|
||||
"rc": null,
|
||||
"rcs": null,
|
||||
"rcslog": null,
|
||||
"readline": null,
|
||||
"rebol": null,
|
||||
"registry": null,
|
||||
"remind": null,
|
||||
"resolv": null,
|
||||
"reva": null,
|
||||
"rexx": null,
|
||||
"rhelp": null,
|
||||
"rib": null,
|
||||
"rnc": null,
|
||||
"rnoweb": null,
|
||||
"robots": null,
|
||||
"rpcgen": null,
|
||||
"rpl": null,
|
||||
"rst": null,
|
||||
"rtf": null,
|
||||
"ruby": "Ruby",
|
||||
"samba": null,
|
||||
"sas": null,
|
||||
"sass": "Sass",
|
||||
"sather": null,
|
||||
"scheme": "Scheme",
|
||||
"scilab": null,
|
||||
"screen": null,
|
||||
"scss": "SCSS",
|
||||
"sd": null,
|
||||
"sdc": null,
|
||||
"sdl": null,
|
||||
"sed": null,
|
||||
"sendpr": null,
|
||||
"sensors": null,
|
||||
"services": null,
|
||||
"setserial": null,
|
||||
"sgml": null,
|
||||
"sgmldecl": null,
|
||||
"sgmllnx": null,
|
||||
"sh": null,
|
||||
"sicad": null,
|
||||
"sieve": null,
|
||||
"simula": null,
|
||||
"sinda": null,
|
||||
"sindacmp": null,
|
||||
"sindaout": null,
|
||||
"sisu": null,
|
||||
"skill": "SKILL",
|
||||
"sl": null,
|
||||
"slang": null,
|
||||
"slice": null,
|
||||
"slpconf": null,
|
||||
"slpreg": null,
|
||||
"slpspi": null,
|
||||
"slrnrc": null,
|
||||
"slrnsc": null,
|
||||
"sm": null,
|
||||
"smarty": null,
|
||||
"smcl": null,
|
||||
"smil": null,
|
||||
"smith": null,
|
||||
"sml": null,
|
||||
"snnsnet": null,
|
||||
"snnspat": null,
|
||||
"snnsres": null,
|
||||
"snobol4": null,
|
||||
"spec": null,
|
||||
"specman": null,
|
||||
"spice": null,
|
||||
"splint": null,
|
||||
"spup": null,
|
||||
"spyce": null,
|
||||
"sql": null,
|
||||
"sqlanywhere": null,
|
||||
"sqlforms": null,
|
||||
"sqlinformix": null,
|
||||
"sqlj": null,
|
||||
"sqloracle": null,
|
||||
"sqr": null,
|
||||
"squid": null,
|
||||
"sshconfig": null,
|
||||
"sshdconfig": null,
|
||||
"st": null,
|
||||
"stata": null,
|
||||
"stp": null,
|
||||
"strace": null,
|
||||
"sudoers": null,
|
||||
"svg": null,
|
||||
"svn": null,
|
||||
"syncolor": null,
|
||||
"synload": null,
|
||||
"syntax": null,
|
||||
"sysctl": null,
|
||||
"tads": null,
|
||||
"tags": null,
|
||||
"tak": null,
|
||||
"takcmp": null,
|
||||
"takout": null,
|
||||
"tar": null,
|
||||
"taskdata": null,
|
||||
"taskedit": null,
|
||||
"tasm": null,
|
||||
"tcl": null,
|
||||
"tcsh": null,
|
||||
"terminfo": null,
|
||||
"tex": null,
|
||||
"texinfo": null,
|
||||
"texmf": null,
|
||||
"tf": null,
|
||||
"tidy": null,
|
||||
"tilde": null,
|
||||
"tli": null,
|
||||
"tpp": null,
|
||||
"trasys": null,
|
||||
"trustees": null,
|
||||
"tsalt": null,
|
||||
"tsscl": null,
|
||||
"tssgm": null,
|
||||
"tssop": null,
|
||||
"uc": null,
|
||||
"udevconf": null,
|
||||
"udevperm": null,
|
||||
"udevrules": null,
|
||||
"uil": null,
|
||||
"updatedb": null,
|
||||
"valgrind": null,
|
||||
"vb": "VB.net",
|
||||
"vera": null,
|
||||
"verilog": null,
|
||||
"verilogams": null,
|
||||
"vgrindefs": null,
|
||||
"vhdl": null,
|
||||
"vim": "VimL",
|
||||
"viminfo": null,
|
||||
"virata": null,
|
||||
"vmasm": null,
|
||||
"voscm": null,
|
||||
"vrml": null,
|
||||
"vsejcl": null,
|
||||
"wdiff": null,
|
||||
"web": null,
|
||||
"webmacro": null,
|
||||
"wget": null,
|
||||
"winbatch": null,
|
||||
"wml": null,
|
||||
"wsh": null,
|
||||
"wsml": null,
|
||||
"wvdial": null,
|
||||
"xbl": null,
|
||||
"xdefaults": null,
|
||||
"xf86conf": null,
|
||||
"xhtml": "HTML",
|
||||
"xinetd": null,
|
||||
"xkb": null,
|
||||
"xmath": null,
|
||||
"xml": "XML",
|
||||
"xmodmap": null,
|
||||
"xpm": null,
|
||||
"xpm2": null,
|
||||
"xquery": null,
|
||||
"xs": null,
|
||||
"xsd": null,
|
||||
"xslt": null,
|
||||
"xxd": null,
|
||||
"yacc": null,
|
||||
"yaml": "YAML",
|
||||
"z8a": null,
|
||||
"zsh": null
|
||||
}
|
||||
@ -11,28 +11,29 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from .compat import u
|
||||
from .compat import basestring, u
|
||||
from .packages.requests.packages import urllib3
|
||||
try:
|
||||
from collections import OrderedDict # pragma: nocover
|
||||
except ImportError:
|
||||
from .packages.ordereddict import OrderedDict # pragma: nocover
|
||||
except ImportError: # pragma: nocover
|
||||
from .packages.ordereddict import OrderedDict
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError):
|
||||
import json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes):
|
||||
obj = bytes.decode(obj)
|
||||
if isinstance(obj, basestring):
|
||||
obj = u(obj)
|
||||
return json.dumps(obj)
|
||||
try:
|
||||
try: # pragma: nocover
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError:
|
||||
except UnicodeDecodeError: # pragma: nocover
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
@ -40,11 +41,11 @@ class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, isWrite, targetFile, version, plugin, verbose,
|
||||
def setup(self, timestamp, is_write, entity, version, plugin, verbose,
|
||||
warnings=False):
|
||||
self.timestamp = timestamp
|
||||
self.isWrite = isWrite
|
||||
self.targetFile = targetFile
|
||||
self.is_write = is_write
|
||||
self.entity = entity
|
||||
self.version = version
|
||||
self.plugin = plugin
|
||||
self.verbose = verbose
|
||||
@ -60,18 +61,29 @@ class JsonFormatter(logging.Formatter):
|
||||
if self.verbose:
|
||||
data['caller'] = record.pathname
|
||||
data['lineno'] = record.lineno
|
||||
data['isWrite'] = self.isWrite
|
||||
data['file'] = self.targetFile
|
||||
if not self.isWrite:
|
||||
del data['isWrite']
|
||||
data['is_write'] = self.is_write
|
||||
data['file'] = self.entity
|
||||
if not self.is_write:
|
||||
del data['is_write']
|
||||
data['level'] = record.levelname
|
||||
data['message'] = record.getMessage() if self.warnings else record.msg
|
||||
if not self.plugin:
|
||||
del data['plugin']
|
||||
return CustomEncoder().encode(data)
|
||||
|
||||
def formatException(self, exc_info):
|
||||
return sys.exec_info[2].format_exc()
|
||||
|
||||
def traceback_formatter(*args, **kwargs):
|
||||
level = kwargs.get('level', args[0] if len(args) else None)
|
||||
if level:
|
||||
level = level.lower()
|
||||
if level == 'warn' or level == 'warning':
|
||||
logging.getLogger('WakaTime').warning(traceback.format_exc())
|
||||
elif level == 'info':
|
||||
logging.getLogger('WakaTime').info(traceback.format_exc())
|
||||
elif level == 'debug':
|
||||
logging.getLogger('WakaTime').debug(traceback.format_exc())
|
||||
else:
|
||||
logging.getLogger('WakaTime').error(traceback.format_exc())
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
@ -82,20 +94,11 @@ def set_log_level(logger, args):
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
urllib3.disable_warnings()
|
||||
logger = logging.getLogger('WakaTime')
|
||||
for handler in logger.handlers:
|
||||
logger.removeHandler(handler)
|
||||
set_log_level(logger, args)
|
||||
if len(logger.handlers) > 0:
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
)
|
||||
logger.handlers[0].setFormatter(formatter)
|
||||
return logger
|
||||
logfile = args.logfile
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
@ -103,8 +106,8 @@ def setup_logging(args, version):
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
is_write=args.is_write,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
@ -112,11 +115,14 @@ def setup_logging(args, version):
|
||||
handler.setFormatter(formatter)
|
||||
logger.addHandler(handler)
|
||||
|
||||
# add custom traceback logging method
|
||||
logger.traceback = traceback_formatter
|
||||
|
||||
warnings_formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
warnings_formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
is_write=args.is_write,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
@ -127,7 +133,7 @@ def setup_logging(args, version):
|
||||
logging.getLogger('py.warnings').addHandler(warnings_handler)
|
||||
try:
|
||||
logging.captureWarnings(True)
|
||||
except AttributeError:
|
||||
except AttributeError: # pragma: nocover
|
||||
pass # Python >= 2.7 is needed to capture warnings
|
||||
|
||||
return logger
|
||||
|
||||
550
packages/wakatime/main.py
Normal file
550
packages/wakatime/main.py
Normal file
@ -0,0 +1,550 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.main
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
wakatime module entry point.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import base64
|
||||
import logging
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
import socket
|
||||
try:
|
||||
import ConfigParser as configparser
|
||||
except ImportError: # pragma: nocover
|
||||
import configparser
|
||||
|
||||
pwd = os.path.dirname(os.path.abspath(__file__))
|
||||
sys.path.insert(0, os.path.dirname(pwd))
|
||||
sys.path.insert(0, os.path.join(pwd, 'packages'))
|
||||
|
||||
from .__about__ import __version__
|
||||
from .compat import u, open, is_py3
|
||||
from .constants import (
|
||||
API_ERROR,
|
||||
AUTH_ERROR,
|
||||
CONFIG_FILE_PARSE_ERROR,
|
||||
SUCCESS,
|
||||
UNKNOWN_ERROR,
|
||||
MALFORMED_HEARTBEAT_ERROR,
|
||||
)
|
||||
from .logger import setup_logging
|
||||
from .offlinequeue import Queue
|
||||
from .packages import argparse
|
||||
from .packages import requests
|
||||
from .packages.requests.exceptions import RequestException
|
||||
from .project import get_project_info
|
||||
from .session_cache import SessionCache
|
||||
from .stats import get_file_stats
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
from .packages import tzlocal
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class FileAction(argparse.Action):
|
||||
|
||||
def __call__(self, parser, namespace, values, option_string=None):
|
||||
try:
|
||||
if os.path.isfile(values):
|
||||
values = os.path.realpath(values)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def parseConfigFile(configFile=None):
|
||||
"""Returns a configparser.SafeConfigParser instance with configs
|
||||
read from the config file. Default location of the config file is
|
||||
at ~/.wakatime.cfg.
|
||||
"""
|
||||
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.cfg')
|
||||
|
||||
configs = configparser.SafeConfigParser()
|
||||
try:
|
||||
with open(configFile, 'r', encoding='utf-8') as fh:
|
||||
try:
|
||||
configs.readfp(fh)
|
||||
except configparser.Error:
|
||||
print(traceback.format_exc())
|
||||
return None
|
||||
except IOError:
|
||||
print(u('Error: Could not read from config file {0}').format(u(configFile)))
|
||||
return configs
|
||||
|
||||
|
||||
def parseArguments():
|
||||
"""Parse command line arguments and configs from ~/.wakatime.cfg.
|
||||
Command line arguments take precedence over config file settings.
|
||||
Returns instances of ArgumentParser and SafeConfigParser.
|
||||
"""
|
||||
|
||||
# define supported command line arguments
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Common interface for the WakaTime api.')
|
||||
parser.add_argument('--entity', dest='entity', metavar='FILE',
|
||||
action=FileAction,
|
||||
help='absolute path to file for the heartbeat; can also be a '+
|
||||
'url, domain, or app when --entity-type is not file')
|
||||
parser.add_argument('--file', dest='file', action=FileAction,
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakatime api key; uses api_key from '+
|
||||
'~/.wakatime.cfg by default')
|
||||
parser.add_argument('--write', dest='is_write',
|
||||
action='store_true',
|
||||
help='when set, tells api this heartbeat was triggered from '+
|
||||
'writing to a file')
|
||||
parser.add_argument('--plugin', dest='plugin',
|
||||
help='optional text editor plugin name and version '+
|
||||
'for User-Agent header')
|
||||
parser.add_argument('--time', dest='timestamp', metavar='time',
|
||||
type=float,
|
||||
help='optional floating-point unix epoch timestamp; '+
|
||||
'uses current time by default')
|
||||
parser.add_argument('--lineno', dest='lineno',
|
||||
help='optional line number; current line being edited')
|
||||
parser.add_argument('--cursorpos', dest='cursorpos',
|
||||
help='optional cursor position in the current file')
|
||||
parser.add_argument('--entity-type', dest='entity_type',
|
||||
help='entity type for this heartbeat. can be one of "file", '+
|
||||
'"domain", or "app"; defaults to file.')
|
||||
parser.add_argument('--proxy', dest='proxy',
|
||||
help='optional proxy configuration. Supports HTTPS '+
|
||||
'and SOCKS proxies. For example: '+
|
||||
'https://user:pass@host:port or '+
|
||||
'socks5://user:pass@host:port')
|
||||
parser.add_argument('--project', dest='project',
|
||||
help='optional project name')
|
||||
parser.add_argument('--alternate-project', dest='alternate_project',
|
||||
help='optional alternate project name; auto-discovered project '+
|
||||
'takes priority')
|
||||
parser.add_argument('--alternate-language', dest='alternate_language',
|
||||
help='optional alternate language name; auto-detected language'+
|
||||
'takes priority')
|
||||
parser.add_argument('--hostname', dest='hostname', help='hostname of '+
|
||||
'current machine.')
|
||||
parser.add_argument('--disableoffline', dest='offline',
|
||||
action='store_false',
|
||||
help='disables offline time logging instead of queuing logged time')
|
||||
parser.add_argument('--hidefilenames', dest='hidefilenames',
|
||||
action='store_true',
|
||||
help='obfuscate file names; will not send file names to api')
|
||||
parser.add_argument('--exclude', dest='exclude', action='append',
|
||||
help='filename patterns to exclude from logging; POSIX regex '+
|
||||
'syntax; can be used more than once')
|
||||
parser.add_argument('--include', dest='include', action='append',
|
||||
help='filename patterns to log; when used in combination with '+
|
||||
'--exclude, files matching include will still be logged; '+
|
||||
'POSIX regex syntax; can be used more than once')
|
||||
parser.add_argument('--ignore', dest='ignore', action='append',
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--extra-heartbeats', dest='extra_heartbeats',
|
||||
action='store_true',
|
||||
help='reads extra heartbeats from STDIN as a JSON array until EOF')
|
||||
parser.add_argument('--logfile', dest='logfile',
|
||||
help='defaults to ~/.wakatime.log')
|
||||
parser.add_argument('--apiurl', dest='api_url',
|
||||
help='heartbeats api url; for debugging with a local server')
|
||||
parser.add_argument('--timeout', dest='timeout', type=int,
|
||||
help='number of seconds to wait when sending heartbeats to api; '+
|
||||
'defaults to 60 seconds')
|
||||
parser.add_argument('--config', dest='config',
|
||||
help='defaults to ~/.wakatime.cfg')
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
help='turns on debug messages in log file')
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
|
||||
# parse command line arguments
|
||||
args = parser.parse_args()
|
||||
|
||||
# use current unix epoch timestamp by default
|
||||
if not args.timestamp:
|
||||
args.timestamp = time.time()
|
||||
|
||||
# parse ~/.wakatime.cfg file
|
||||
configs = parseConfigFile(args.config)
|
||||
if configs is None:
|
||||
return args, configs
|
||||
|
||||
# update args from configs
|
||||
if not args.hostname:
|
||||
if configs.has_option('settings', 'hostname'):
|
||||
args.hostname = configs.get('settings', 'hostname')
|
||||
if not args.key:
|
||||
default_key = None
|
||||
if configs.has_option('settings', 'api_key'):
|
||||
default_key = configs.get('settings', 'api_key')
|
||||
elif configs.has_option('settings', 'apikey'):
|
||||
default_key = configs.get('settings', 'apikey')
|
||||
if default_key:
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
if not args.entity:
|
||||
if args.file:
|
||||
args.entity = args.file
|
||||
else:
|
||||
parser.error('argument --entity is required')
|
||||
if not args.exclude:
|
||||
args.exclude = []
|
||||
if configs.has_option('settings', 'ignore'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'ignore').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if configs.has_option('settings', 'exclude'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'exclude').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if not args.include:
|
||||
args.include = []
|
||||
if configs.has_option('settings', 'include'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'include').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.include.append(pattern)
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if args.offline and configs.has_option('settings', 'offline'):
|
||||
args.offline = configs.getboolean('settings', 'offline')
|
||||
if not args.hidefilenames and configs.has_option('settings', 'hidefilenames'):
|
||||
args.hidefilenames = configs.getboolean('settings', 'hidefilenames')
|
||||
if not args.proxy and configs.has_option('settings', 'proxy'):
|
||||
args.proxy = configs.get('settings', 'proxy')
|
||||
if not args.verbose and configs.has_option('settings', 'verbose'):
|
||||
args.verbose = configs.getboolean('settings', 'verbose')
|
||||
if not args.verbose and configs.has_option('settings', 'debug'):
|
||||
args.verbose = configs.getboolean('settings', 'debug')
|
||||
if not args.logfile and configs.has_option('settings', 'logfile'):
|
||||
args.logfile = configs.get('settings', 'logfile')
|
||||
if not args.api_url and configs.has_option('settings', 'api_url'):
|
||||
args.api_url = configs.get('settings', 'api_url')
|
||||
if not args.timeout and configs.has_option('settings', 'timeout'):
|
||||
try:
|
||||
args.timeout = int(configs.get('settings', 'timeout'))
|
||||
except ValueError:
|
||||
print(traceback.format_exc())
|
||||
|
||||
return args, configs
|
||||
|
||||
|
||||
def should_exclude(entity, include, exclude):
|
||||
if entity is not None and entity.strip() != '':
|
||||
try:
|
||||
for pattern in include:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(entity):
|
||||
return False
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for include pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
try:
|
||||
for pattern in exclude:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(entity):
|
||||
return pattern
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for exclude pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
return False
|
||||
|
||||
|
||||
def get_user_agent(plugin):
|
||||
ver = sys.version_info
|
||||
python_version = '%d.%d.%d.%s.%d' % (ver[0], ver[1], ver[2], ver[3], ver[4])
|
||||
user_agent = u('wakatime/{ver} ({platform}) Python{py_ver}').format(
|
||||
ver=u(__version__),
|
||||
platform=u(platform.platform()),
|
||||
py_ver=python_version,
|
||||
)
|
||||
if plugin:
|
||||
user_agent = u('{user_agent} {plugin}').format(
|
||||
user_agent=user_agent,
|
||||
plugin=u(plugin),
|
||||
)
|
||||
else:
|
||||
user_agent = u('{user_agent} Unknown/0').format(
|
||||
user_agent=user_agent,
|
||||
)
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
entity=None, timestamp=None, is_write=None, plugin=None,
|
||||
offline=None, entity_type='file', hidefilenames=None,
|
||||
proxy=None, api_url=None, timeout=None, **kwargs):
|
||||
"""Sends heartbeat as POST request to WakaTime api server.
|
||||
|
||||
Returns `SUCCESS` when heartbeat was sent, otherwise returns an
|
||||
error code constant.
|
||||
"""
|
||||
|
||||
if not api_url:
|
||||
api_url = 'https://api.wakatime.com/api/v1/heartbeats'
|
||||
if not timeout:
|
||||
timeout = 60
|
||||
log.debug('Sending heartbeat to api at %s' % api_url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'entity': entity,
|
||||
'type': entity_type,
|
||||
}
|
||||
if hidefilenames and entity is not None and entity_type == 'file':
|
||||
extension = u(os.path.splitext(data['entity'])[1])
|
||||
data['entity'] = u('HIDDEN{0}').format(extension)
|
||||
if stats.get('lines'):
|
||||
data['lines'] = stats['lines']
|
||||
if stats.get('language'):
|
||||
data['language'] = stats['language']
|
||||
if stats.get('dependencies'):
|
||||
data['dependencies'] = stats['dependencies']
|
||||
if stats.get('lineno'):
|
||||
data['lineno'] = stats['lineno']
|
||||
if stats.get('cursorpos'):
|
||||
data['cursorpos'] = stats['cursorpos']
|
||||
if is_write:
|
||||
data['is_write'] = is_write
|
||||
if project:
|
||||
data['project'] = project
|
||||
if branch:
|
||||
data['branch'] = branch
|
||||
log.debug(data)
|
||||
|
||||
# setup api request
|
||||
request_body = json.dumps(data)
|
||||
api_key = u(base64.b64encode(str.encode(key) if is_py3 else key))
|
||||
auth = u('Basic {api_key}').format(api_key=api_key)
|
||||
headers = {
|
||||
'User-Agent': get_user_agent(plugin),
|
||||
'Content-Type': 'application/json',
|
||||
'Accept': 'application/json',
|
||||
'Authorization': auth,
|
||||
}
|
||||
if hostname:
|
||||
headers['X-Machine-Name'] = u(hostname).encode('utf-8')
|
||||
proxies = {}
|
||||
if proxy:
|
||||
proxies['https'] = proxy
|
||||
|
||||
# add Olson timezone to request
|
||||
try:
|
||||
tz = tzlocal.get_localzone()
|
||||
except:
|
||||
tz = None
|
||||
if tz:
|
||||
headers['TimeZone'] = u(tz.zone).encode('utf-8')
|
||||
|
||||
session_cache = SessionCache()
|
||||
session = session_cache.get()
|
||||
|
||||
# log time to api
|
||||
response = None
|
||||
try:
|
||||
response = session.post(api_url, data=request_body, headers=headers,
|
||||
proxies=proxies, timeout=timeout)
|
||||
except RequestException:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
}
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
exception_data['traceback'] = traceback.format_exc()
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
log.warn(exception_data)
|
||||
else:
|
||||
log.error(exception_data)
|
||||
|
||||
except: # delete cached session when requests raises unknown exception
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
'traceback': traceback.format_exc(),
|
||||
}
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
log.warn(exception_data)
|
||||
session_cache.delete()
|
||||
|
||||
else:
|
||||
code = response.status_code if response is not None else None
|
||||
content = response.text if response is not None else None
|
||||
if code == requests.codes.created or code == requests.codes.accepted:
|
||||
log.debug({
|
||||
'response_code': code,
|
||||
})
|
||||
session_cache.save(session)
|
||||
return SUCCESS
|
||||
if offline:
|
||||
if code != 400:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
if code == 401:
|
||||
log.error({
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return AUTH_ERROR
|
||||
elif log.isEnabledFor(logging.DEBUG):
|
||||
log.warn({
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return API_ERROR
|
||||
|
||||
|
||||
def sync_offline_heartbeats(args, hostname):
|
||||
"""Sends all heartbeats which were cached in the offline Queue."""
|
||||
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
status = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
entity=heartbeat['entity'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
hostname=hostname,
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
is_write=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
entity_type=heartbeat['type'],
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
timeout=args.timeout,
|
||||
)
|
||||
if status != SUCCESS:
|
||||
if status == AUTH_ERROR:
|
||||
return AUTH_ERROR
|
||||
break
|
||||
return SUCCESS
|
||||
|
||||
|
||||
def process_heartbeat(args, configs, hostname, heartbeat):
|
||||
exclude = should_exclude(heartbeat['entity'], args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
log.debug(u('Skipping because matches exclude pattern: {pattern}').format(
|
||||
pattern=u(exclude),
|
||||
))
|
||||
return SUCCESS
|
||||
|
||||
if heartbeat.get('entity_type') not in ['file', 'domain', 'app']:
|
||||
heartbeat['entity_type'] = 'file'
|
||||
|
||||
if heartbeat['entity_type'] != 'file' or os.path.isfile(heartbeat['entity']):
|
||||
|
||||
stats = get_file_stats(heartbeat['entity'],
|
||||
entity_type=heartbeat['entity_type'],
|
||||
lineno=heartbeat.get('lineno'),
|
||||
cursorpos=heartbeat.get('cursorpos'),
|
||||
plugin=args.plugin,
|
||||
alternate_language=heartbeat.get('alternate_language'))
|
||||
|
||||
project = heartbeat.get('project') or heartbeat.get('alternate_project')
|
||||
branch = None
|
||||
if heartbeat['entity_type'] == 'file':
|
||||
project, branch = get_project_info(configs, heartbeat)
|
||||
|
||||
heartbeat['project'] = project
|
||||
heartbeat['branch'] = branch
|
||||
heartbeat['stats'] = stats
|
||||
heartbeat['hostname'] = hostname
|
||||
heartbeat['timeout'] = args.timeout
|
||||
heartbeat['key'] = args.key
|
||||
heartbeat['plugin'] = args.plugin
|
||||
heartbeat['offline'] = args.offline
|
||||
heartbeat['hidefilenames'] = args.hidefilenames
|
||||
heartbeat['proxy'] = args.proxy
|
||||
heartbeat['api_url'] = args.api_url
|
||||
|
||||
return send_heartbeat(**heartbeat)
|
||||
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this heartbeat.')
|
||||
return SUCCESS
|
||||
|
||||
|
||||
def execute(argv=None):
|
||||
if argv:
|
||||
sys.argv = ['wakatime'] + argv
|
||||
|
||||
args, configs = parseArguments()
|
||||
if configs is None:
|
||||
return CONFIG_FILE_PARSE_ERROR
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
try:
|
||||
|
||||
hostname = args.hostname or socket.gethostname()
|
||||
|
||||
heartbeat = vars(args)
|
||||
retval = process_heartbeat(args, configs, hostname, heartbeat)
|
||||
|
||||
if args.extra_heartbeats:
|
||||
try:
|
||||
for heartbeat in json.loads(sys.stdin.readline()):
|
||||
retval = process_heartbeat(args, configs, hostname, heartbeat)
|
||||
except json.JSONDecodeError:
|
||||
retval = MALFORMED_HEARTBEAT_ERROR
|
||||
|
||||
if retval == SUCCESS:
|
||||
retval = sync_offline_heartbeats(args, hostname)
|
||||
|
||||
return retval
|
||||
|
||||
except:
|
||||
log.traceback()
|
||||
print(traceback.format_exc())
|
||||
return UNKNOWN_ERROR
|
||||
@ -12,13 +12,12 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import traceback
|
||||
from time import sleep
|
||||
|
||||
try:
|
||||
import sqlite3
|
||||
HAS_SQL = True
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
HAS_SQL = False
|
||||
|
||||
from .compat import u
|
||||
@ -28,13 +27,18 @@ log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class Queue(object):
|
||||
DB_FILE = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
db_file = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
table_name = 'heartbeat_1'
|
||||
|
||||
def get_db_file(self):
|
||||
return self.db_file
|
||||
|
||||
def connect(self):
|
||||
conn = sqlite3.connect(self.DB_FILE)
|
||||
conn = sqlite3.connect(self.get_db_file())
|
||||
c = conn.cursor()
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS heartbeat (
|
||||
file text,
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS {0} (
|
||||
entity text,
|
||||
type text,
|
||||
time real,
|
||||
project text,
|
||||
branch text,
|
||||
@ -42,17 +46,17 @@ class Queue(object):
|
||||
stats text,
|
||||
misc text,
|
||||
plugin text)
|
||||
''')
|
||||
'''.format(self.table_name))
|
||||
return (conn, c)
|
||||
|
||||
|
||||
def push(self, data, stats, plugin, misc=None):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
heartbeat = {
|
||||
'file': u(data.get('entity')),
|
||||
'entity': u(data.get('entity')),
|
||||
'type': u(data.get('type')),
|
||||
'time': data.get('time'),
|
||||
'project': u(data.get('project')),
|
||||
'branch': u(data.get('branch')),
|
||||
@ -61,15 +65,14 @@ class Queue(object):
|
||||
'misc': u(misc),
|
||||
'plugin': u(plugin),
|
||||
}
|
||||
c.execute('INSERT INTO heartbeat VALUES (:file,:time,:project,:branch,:is_write,:stats,:misc,:plugin)', heartbeat)
|
||||
c.execute('INSERT INTO {0} VALUES (:entity,:type,:time,:project,:branch,:is_write,:stats,:misc,:plugin)'.format(self.table_name), heartbeat)
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
log.traceback()
|
||||
|
||||
def pop(self):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return None
|
||||
tries = 3
|
||||
wait = 0.1
|
||||
@ -77,48 +80,49 @@ class Queue(object):
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback('debug')
|
||||
return None
|
||||
loop = True
|
||||
while loop and tries > -1:
|
||||
try:
|
||||
c.execute('BEGIN IMMEDIATE')
|
||||
c.execute('SELECT * FROM heartbeat LIMIT 1')
|
||||
c.execute('SELECT * FROM {0} LIMIT 1'.format(self.table_name))
|
||||
row = c.fetchone()
|
||||
if row is not None:
|
||||
values = []
|
||||
clauses = []
|
||||
index = 0
|
||||
for row_name in ['file', 'time', 'project', 'branch', 'is_write']:
|
||||
for row_name in ['entity', 'type', 'time', 'project', 'branch', 'is_write']:
|
||||
if row[index] is not None:
|
||||
clauses.append('{0}=?'.format(row_name))
|
||||
values.append(row[index])
|
||||
else:
|
||||
else: # pragma: nocover
|
||||
clauses.append('{0} IS NULL'.format(row_name))
|
||||
index += 1
|
||||
if len(values) > 0:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)), values)
|
||||
else:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)))
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)), values)
|
||||
else: # pragma: nocover
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)))
|
||||
conn.commit()
|
||||
if row is not None:
|
||||
heartbeat = {
|
||||
'file': row[0],
|
||||
'time': row[1],
|
||||
'project': row[2],
|
||||
'branch': row[3],
|
||||
'is_write': True if row[4] is 1 else False,
|
||||
'stats': row[5],
|
||||
'misc': row[6],
|
||||
'plugin': row[7],
|
||||
'entity': row[0],
|
||||
'type': row[1],
|
||||
'time': row[2],
|
||||
'project': row[3],
|
||||
'branch': row[4],
|
||||
'is_write': True if row[5] is 1 else False,
|
||||
'stats': row[6],
|
||||
'misc': row[7],
|
||||
'plugin': row[8],
|
||||
}
|
||||
loop = False
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.traceback('debug')
|
||||
sleep(wait)
|
||||
tries -= 1
|
||||
try:
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.traceback('debug')
|
||||
return heartbeat
|
||||
|
||||
@ -0,0 +1,14 @@
|
||||
import os
|
||||
import sys
|
||||
|
||||
from ..compat import is_py2
|
||||
|
||||
if is_py2:
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'py2'))
|
||||
else:
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'py3'))
|
||||
|
||||
import tzlocal
|
||||
from pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
0
packages/wakatime/packages/py2/__init__.py
Normal file
0
packages/wakatime/packages/py2/__init__.py
Normal file
1519
packages/wakatime/packages/py2/pytz/__init__.py
Normal file
1519
packages/wakatime/packages/py2/pytz/__init__.py
Normal file
File diff suppressed because it is too large
Load Diff
168
packages/wakatime/packages/py2/pytz/lazy.py
Normal file
168
packages/wakatime/packages/py2/pytz/lazy.py
Normal file
@ -0,0 +1,168 @@
|
||||
from threading import RLock
|
||||
try:
|
||||
from UserDict import DictMixin
|
||||
except ImportError:
|
||||
from collections import Mapping as DictMixin
|
||||
|
||||
|
||||
# With lazy loading, we might end up with multiple threads triggering
|
||||
# it at the same time. We need a lock.
|
||||
_fill_lock = RLock()
|
||||
|
||||
|
||||
class LazyDict(DictMixin):
|
||||
"""Dictionary populated on first use."""
|
||||
data = None
|
||||
def __getitem__(self, key):
|
||||
if self.data is None:
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if self.data is None:
|
||||
self._fill()
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return self.data[key.upper()]
|
||||
|
||||
def __contains__(self, key):
|
||||
if self.data is None:
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if self.data is None:
|
||||
self._fill()
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return key in self.data
|
||||
|
||||
def __iter__(self):
|
||||
if self.data is None:
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if self.data is None:
|
||||
self._fill()
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return iter(self.data)
|
||||
|
||||
def __len__(self):
|
||||
if self.data is None:
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if self.data is None:
|
||||
self._fill()
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return len(self.data)
|
||||
|
||||
def keys(self):
|
||||
if self.data is None:
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if self.data is None:
|
||||
self._fill()
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return self.data.keys()
|
||||
|
||||
|
||||
class LazyList(list):
|
||||
"""List populated on first use."""
|
||||
|
||||
_props = [
|
||||
'__str__', '__repr__', '__unicode__',
|
||||
'__hash__', '__sizeof__', '__cmp__',
|
||||
'__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__',
|
||||
'append', 'count', 'index', 'extend', 'insert', 'pop', 'remove',
|
||||
'reverse', 'sort', '__add__', '__radd__', '__iadd__', '__mul__',
|
||||
'__rmul__', '__imul__', '__contains__', '__len__', '__nonzero__',
|
||||
'__getitem__', '__setitem__', '__delitem__', '__iter__',
|
||||
'__reversed__', '__getslice__', '__setslice__', '__delslice__']
|
||||
|
||||
def __new__(cls, fill_iter=None):
|
||||
|
||||
if fill_iter is None:
|
||||
return list()
|
||||
|
||||
# We need a new class as we will be dynamically messing with its
|
||||
# methods.
|
||||
class LazyList(list):
|
||||
pass
|
||||
|
||||
fill_iter = [fill_iter]
|
||||
|
||||
def lazy(name):
|
||||
def _lazy(self, *args, **kw):
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if len(fill_iter) > 0:
|
||||
list.extend(self, fill_iter.pop())
|
||||
for method_name in cls._props:
|
||||
delattr(LazyList, method_name)
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return getattr(list, name)(self, *args, **kw)
|
||||
return _lazy
|
||||
|
||||
for name in cls._props:
|
||||
setattr(LazyList, name, lazy(name))
|
||||
|
||||
new_list = LazyList()
|
||||
return new_list
|
||||
|
||||
# Not all versions of Python declare the same magic methods.
|
||||
# Filter out properties that don't exist in this version of Python
|
||||
# from the list.
|
||||
LazyList._props = [prop for prop in LazyList._props if hasattr(list, prop)]
|
||||
|
||||
|
||||
class LazySet(set):
|
||||
"""Set populated on first use."""
|
||||
|
||||
_props = (
|
||||
'__str__', '__repr__', '__unicode__',
|
||||
'__hash__', '__sizeof__', '__cmp__',
|
||||
'__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__',
|
||||
'__contains__', '__len__', '__nonzero__',
|
||||
'__getitem__', '__setitem__', '__delitem__', '__iter__',
|
||||
'__sub__', '__and__', '__xor__', '__or__',
|
||||
'__rsub__', '__rand__', '__rxor__', '__ror__',
|
||||
'__isub__', '__iand__', '__ixor__', '__ior__',
|
||||
'add', 'clear', 'copy', 'difference', 'difference_update',
|
||||
'discard', 'intersection', 'intersection_update', 'isdisjoint',
|
||||
'issubset', 'issuperset', 'pop', 'remove',
|
||||
'symmetric_difference', 'symmetric_difference_update',
|
||||
'union', 'update')
|
||||
|
||||
def __new__(cls, fill_iter=None):
|
||||
|
||||
if fill_iter is None:
|
||||
return set()
|
||||
|
||||
class LazySet(set):
|
||||
pass
|
||||
|
||||
fill_iter = [fill_iter]
|
||||
|
||||
def lazy(name):
|
||||
def _lazy(self, *args, **kw):
|
||||
_fill_lock.acquire()
|
||||
try:
|
||||
if len(fill_iter) > 0:
|
||||
for i in fill_iter.pop():
|
||||
set.add(self, i)
|
||||
for method_name in cls._props:
|
||||
delattr(LazySet, method_name)
|
||||
finally:
|
||||
_fill_lock.release()
|
||||
return getattr(set, name)(self, *args, **kw)
|
||||
return _lazy
|
||||
|
||||
for name in cls._props:
|
||||
setattr(LazySet, name, lazy(name))
|
||||
|
||||
new_set = LazySet()
|
||||
return new_set
|
||||
|
||||
# Not all versions of Python declare the same magic methods.
|
||||
# Filter out properties that don't exist in this version of Python
|
||||
# from the list.
|
||||
LazySet._props = [prop for prop in LazySet._props if hasattr(set, prop)]
|
||||
564
packages/wakatime/packages/py2/pytz/tzinfo.py
Normal file
564
packages/wakatime/packages/py2/pytz/tzinfo.py
Normal file
@ -0,0 +1,564 @@
|
||||
'''Base classes and helpers for building zone specific tzinfo classes'''
|
||||
|
||||
from datetime import datetime, timedelta, tzinfo
|
||||
from bisect import bisect_right
|
||||
try:
|
||||
set
|
||||
except NameError:
|
||||
from sets import Set as set
|
||||
|
||||
import pytz
|
||||
from pytz.exceptions import AmbiguousTimeError, NonExistentTimeError
|
||||
|
||||
__all__ = []
|
||||
|
||||
_timedelta_cache = {}
|
||||
def memorized_timedelta(seconds):
|
||||
'''Create only one instance of each distinct timedelta'''
|
||||
try:
|
||||
return _timedelta_cache[seconds]
|
||||
except KeyError:
|
||||
delta = timedelta(seconds=seconds)
|
||||
_timedelta_cache[seconds] = delta
|
||||
return delta
|
||||
|
||||
_epoch = datetime.utcfromtimestamp(0)
|
||||
_datetime_cache = {0: _epoch}
|
||||
def memorized_datetime(seconds):
|
||||
'''Create only one instance of each distinct datetime'''
|
||||
try:
|
||||
return _datetime_cache[seconds]
|
||||
except KeyError:
|
||||
# NB. We can't just do datetime.utcfromtimestamp(seconds) as this
|
||||
# fails with negative values under Windows (Bug #90096)
|
||||
dt = _epoch + timedelta(seconds=seconds)
|
||||
_datetime_cache[seconds] = dt
|
||||
return dt
|
||||
|
||||
_ttinfo_cache = {}
|
||||
def memorized_ttinfo(*args):
|
||||
'''Create only one instance of each distinct tuple'''
|
||||
try:
|
||||
return _ttinfo_cache[args]
|
||||
except KeyError:
|
||||
ttinfo = (
|
||||
memorized_timedelta(args[0]),
|
||||
memorized_timedelta(args[1]),
|
||||
args[2]
|
||||
)
|
||||
_ttinfo_cache[args] = ttinfo
|
||||
return ttinfo
|
||||
|
||||
_notime = memorized_timedelta(0)
|
||||
|
||||
def _to_seconds(td):
|
||||
'''Convert a timedelta to seconds'''
|
||||
return td.seconds + td.days * 24 * 60 * 60
|
||||
|
||||
|
||||
class BaseTzInfo(tzinfo):
|
||||
# Overridden in subclass
|
||||
_utcoffset = None
|
||||
_tzname = None
|
||||
zone = None
|
||||
|
||||
def __str__(self):
|
||||
return self.zone
|
||||
|
||||
|
||||
class StaticTzInfo(BaseTzInfo):
|
||||
'''A timezone that has a constant offset from UTC
|
||||
|
||||
These timezones are rare, as most locations have changed their
|
||||
offset at some point in their history
|
||||
'''
|
||||
def fromutc(self, dt):
|
||||
'''See datetime.tzinfo.fromutc'''
|
||||
if dt.tzinfo is not None and dt.tzinfo is not self:
|
||||
raise ValueError('fromutc: dt.tzinfo is not self')
|
||||
return (dt + self._utcoffset).replace(tzinfo=self)
|
||||
|
||||
def utcoffset(self, dt, is_dst=None):
|
||||
'''See datetime.tzinfo.utcoffset
|
||||
|
||||
is_dst is ignored for StaticTzInfo, and exists only to
|
||||
retain compatibility with DstTzInfo.
|
||||
'''
|
||||
return self._utcoffset
|
||||
|
||||
def dst(self, dt, is_dst=None):
|
||||
'''See datetime.tzinfo.dst
|
||||
|
||||
is_dst is ignored for StaticTzInfo, and exists only to
|
||||
retain compatibility with DstTzInfo.
|
||||
'''
|
||||
return _notime
|
||||
|
||||
def tzname(self, dt, is_dst=None):
|
||||
'''See datetime.tzinfo.tzname
|
||||
|
||||
is_dst is ignored for StaticTzInfo, and exists only to
|
||||
retain compatibility with DstTzInfo.
|
||||
'''
|
||||
return self._tzname
|
||||
|
||||
def localize(self, dt, is_dst=False):
|
||||
'''Convert naive time to local time'''
|
||||
if dt.tzinfo is not None:
|
||||
raise ValueError('Not naive datetime (tzinfo is already set)')
|
||||
return dt.replace(tzinfo=self)
|
||||
|
||||
def normalize(self, dt, is_dst=False):
|
||||
'''Correct the timezone information on the given datetime.
|
||||
|
||||
This is normally a no-op, as StaticTzInfo timezones never have
|
||||
ambiguous cases to correct:
|
||||
|
||||
>>> from pytz import timezone
|
||||
>>> gmt = timezone('GMT')
|
||||
>>> isinstance(gmt, StaticTzInfo)
|
||||
True
|
||||
>>> dt = datetime(2011, 5, 8, 1, 2, 3, tzinfo=gmt)
|
||||
>>> gmt.normalize(dt) is dt
|
||||
True
|
||||
|
||||
The supported method of converting between timezones is to use
|
||||
datetime.astimezone(). Currently normalize() also works:
|
||||
|
||||
>>> la = timezone('America/Los_Angeles')
|
||||
>>> dt = la.localize(datetime(2011, 5, 7, 1, 2, 3))
|
||||
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
|
||||
>>> gmt.normalize(dt).strftime(fmt)
|
||||
'2011-05-07 08:02:03 GMT (+0000)'
|
||||
'''
|
||||
if dt.tzinfo is self:
|
||||
return dt
|
||||
if dt.tzinfo is None:
|
||||
raise ValueError('Naive time - no tzinfo set')
|
||||
return dt.astimezone(self)
|
||||
|
||||
def __repr__(self):
|
||||
return '<StaticTzInfo %r>' % (self.zone,)
|
||||
|
||||
def __reduce__(self):
|
||||
# Special pickle to zone remains a singleton and to cope with
|
||||
# database changes.
|
||||
return pytz._p, (self.zone,)
|
||||
|
||||
|
||||
class DstTzInfo(BaseTzInfo):
|
||||
'''A timezone that has a variable offset from UTC
|
||||
|
||||
The offset might change if daylight saving time comes into effect,
|
||||
or at a point in history when the region decides to change their
|
||||
timezone definition.
|
||||
'''
|
||||
# Overridden in subclass
|
||||
_utc_transition_times = None # Sorted list of DST transition times in UTC
|
||||
_transition_info = None # [(utcoffset, dstoffset, tzname)] corresponding
|
||||
# to _utc_transition_times entries
|
||||
zone = None
|
||||
|
||||
# Set in __init__
|
||||
_tzinfos = None
|
||||
_dst = None # DST offset
|
||||
|
||||
def __init__(self, _inf=None, _tzinfos=None):
|
||||
if _inf:
|
||||
self._tzinfos = _tzinfos
|
||||
self._utcoffset, self._dst, self._tzname = _inf
|
||||
else:
|
||||
_tzinfos = {}
|
||||
self._tzinfos = _tzinfos
|
||||
self._utcoffset, self._dst, self._tzname = self._transition_info[0]
|
||||
_tzinfos[self._transition_info[0]] = self
|
||||
for inf in self._transition_info[1:]:
|
||||
if inf not in _tzinfos:
|
||||
_tzinfos[inf] = self.__class__(inf, _tzinfos)
|
||||
|
||||
def fromutc(self, dt):
|
||||
'''See datetime.tzinfo.fromutc'''
|
||||
if (dt.tzinfo is not None
|
||||
and getattr(dt.tzinfo, '_tzinfos', None) is not self._tzinfos):
|
||||
raise ValueError('fromutc: dt.tzinfo is not self')
|
||||
dt = dt.replace(tzinfo=None)
|
||||
idx = max(0, bisect_right(self._utc_transition_times, dt) - 1)
|
||||
inf = self._transition_info[idx]
|
||||
return (dt + inf[0]).replace(tzinfo=self._tzinfos[inf])
|
||||
|
||||
def normalize(self, dt):
|
||||
'''Correct the timezone information on the given datetime
|
||||
|
||||
If date arithmetic crosses DST boundaries, the tzinfo
|
||||
is not magically adjusted. This method normalizes the
|
||||
tzinfo to the correct one.
|
||||
|
||||
To test, first we need to do some setup
|
||||
|
||||
>>> from pytz import timezone
|
||||
>>> utc = timezone('UTC')
|
||||
>>> eastern = timezone('US/Eastern')
|
||||
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
|
||||
|
||||
We next create a datetime right on an end-of-DST transition point,
|
||||
the instant when the wallclocks are wound back one hour.
|
||||
|
||||
>>> utc_dt = datetime(2002, 10, 27, 6, 0, 0, tzinfo=utc)
|
||||
>>> loc_dt = utc_dt.astimezone(eastern)
|
||||
>>> loc_dt.strftime(fmt)
|
||||
'2002-10-27 01:00:00 EST (-0500)'
|
||||
|
||||
Now, if we subtract a few minutes from it, note that the timezone
|
||||
information has not changed.
|
||||
|
||||
>>> before = loc_dt - timedelta(minutes=10)
|
||||
>>> before.strftime(fmt)
|
||||
'2002-10-27 00:50:00 EST (-0500)'
|
||||
|
||||
But we can fix that by calling the normalize method
|
||||
|
||||
>>> before = eastern.normalize(before)
|
||||
>>> before.strftime(fmt)
|
||||
'2002-10-27 01:50:00 EDT (-0400)'
|
||||
|
||||
The supported method of converting between timezones is to use
|
||||
datetime.astimezone(). Currently, normalize() also works:
|
||||
|
||||
>>> th = timezone('Asia/Bangkok')
|
||||
>>> am = timezone('Europe/Amsterdam')
|
||||
>>> dt = th.localize(datetime(2011, 5, 7, 1, 2, 3))
|
||||
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
|
||||
>>> am.normalize(dt).strftime(fmt)
|
||||
'2011-05-06 20:02:03 CEST (+0200)'
|
||||
'''
|
||||
if dt.tzinfo is None:
|
||||
raise ValueError('Naive time - no tzinfo set')
|
||||
|
||||
# Convert dt in localtime to UTC
|
||||
offset = dt.tzinfo._utcoffset
|
||||
dt = dt.replace(tzinfo=None)
|
||||
dt = dt - offset
|
||||
# convert it back, and return it
|
||||
return self.fromutc(dt)
|
||||
|
||||
def localize(self, dt, is_dst=False):
|
||||
'''Convert naive time to local time.
|
||||
|
||||
This method should be used to construct localtimes, rather
|
||||
than passing a tzinfo argument to a datetime constructor.
|
||||
|
||||
is_dst is used to determine the correct timezone in the ambigous
|
||||
period at the end of daylight saving time.
|
||||
|
||||
>>> from pytz import timezone
|
||||
>>> fmt = '%Y-%m-%d %H:%M:%S %Z (%z)'
|
||||
>>> amdam = timezone('Europe/Amsterdam')
|
||||
>>> dt = datetime(2004, 10, 31, 2, 0, 0)
|
||||
>>> loc_dt1 = amdam.localize(dt, is_dst=True)
|
||||
>>> loc_dt2 = amdam.localize(dt, is_dst=False)
|
||||
>>> loc_dt1.strftime(fmt)
|
||||
'2004-10-31 02:00:00 CEST (+0200)'
|
||||
>>> loc_dt2.strftime(fmt)
|
||||
'2004-10-31 02:00:00 CET (+0100)'
|
||||
>>> str(loc_dt2 - loc_dt1)
|
||||
'1:00:00'
|
||||
|
||||
Use is_dst=None to raise an AmbiguousTimeError for ambiguous
|
||||
times at the end of daylight saving time
|
||||
|
||||
>>> try:
|
||||
... loc_dt1 = amdam.localize(dt, is_dst=None)
|
||||
... except AmbiguousTimeError:
|
||||
... print('Ambiguous')
|
||||
Ambiguous
|
||||
|
||||
is_dst defaults to False
|
||||
|
||||
>>> amdam.localize(dt) == amdam.localize(dt, False)
|
||||
True
|
||||
|
||||
is_dst is also used to determine the correct timezone in the
|
||||
wallclock times jumped over at the start of daylight saving time.
|
||||
|
||||
>>> pacific = timezone('US/Pacific')
|
||||
>>> dt = datetime(2008, 3, 9, 2, 0, 0)
|
||||
>>> ploc_dt1 = pacific.localize(dt, is_dst=True)
|
||||
>>> ploc_dt2 = pacific.localize(dt, is_dst=False)
|
||||
>>> ploc_dt1.strftime(fmt)
|
||||
'2008-03-09 02:00:00 PDT (-0700)'
|
||||
>>> ploc_dt2.strftime(fmt)
|
||||
'2008-03-09 02:00:00 PST (-0800)'
|
||||
>>> str(ploc_dt2 - ploc_dt1)
|
||||
'1:00:00'
|
||||
|
||||
Use is_dst=None to raise a NonExistentTimeError for these skipped
|
||||
times.
|
||||
|
||||
>>> try:
|
||||
... loc_dt1 = pacific.localize(dt, is_dst=None)
|
||||
... except NonExistentTimeError:
|
||||
... print('Non-existent')
|
||||
Non-existent
|
||||
'''
|
||||
if dt.tzinfo is not None:
|
||||
raise ValueError('Not naive datetime (tzinfo is already set)')
|
||||
|
||||
# Find the two best possibilities.
|
||||
possible_loc_dt = set()
|
||||
for delta in [timedelta(days=-1), timedelta(days=1)]:
|
||||
loc_dt = dt + delta
|
||||
idx = max(0, bisect_right(
|
||||
self._utc_transition_times, loc_dt) - 1)
|
||||
inf = self._transition_info[idx]
|
||||
tzinfo = self._tzinfos[inf]
|
||||
loc_dt = tzinfo.normalize(dt.replace(tzinfo=tzinfo))
|
||||
if loc_dt.replace(tzinfo=None) == dt:
|
||||
possible_loc_dt.add(loc_dt)
|
||||
|
||||
if len(possible_loc_dt) == 1:
|
||||
return possible_loc_dt.pop()
|
||||
|
||||
# If there are no possibly correct timezones, we are attempting
|
||||
# to convert a time that never happened - the time period jumped
|
||||
# during the start-of-DST transition period.
|
||||
if len(possible_loc_dt) == 0:
|
||||
# If we refuse to guess, raise an exception.
|
||||
if is_dst is None:
|
||||
raise NonExistentTimeError(dt)
|
||||
|
||||
# If we are forcing the pre-DST side of the DST transition, we
|
||||
# obtain the correct timezone by winding the clock forward a few
|
||||
# hours.
|
||||
elif is_dst:
|
||||
return self.localize(
|
||||
dt + timedelta(hours=6), is_dst=True) - timedelta(hours=6)
|
||||
|
||||
# If we are forcing the post-DST side of the DST transition, we
|
||||
# obtain the correct timezone by winding the clock back.
|
||||
else:
|
||||
return self.localize(
|
||||
dt - timedelta(hours=6), is_dst=False) + timedelta(hours=6)
|
||||
|
||||
|
||||
# If we get this far, we have multiple possible timezones - this
|
||||
# is an ambiguous case occuring during the end-of-DST transition.
|
||||
|
||||
# If told to be strict, raise an exception since we have an
|
||||
# ambiguous case
|
||||
if is_dst is None:
|
||||
raise AmbiguousTimeError(dt)
|
||||
|
||||
# Filter out the possiblilities that don't match the requested
|
||||
# is_dst
|
||||
filtered_possible_loc_dt = [
|
||||
p for p in possible_loc_dt
|
||||
if bool(p.tzinfo._dst) == is_dst
|
||||
]
|
||||
|
||||
# Hopefully we only have one possibility left. Return it.
|
||||
if len(filtered_possible_loc_dt) == 1:
|
||||
return filtered_possible_loc_dt[0]
|
||||
|
||||
if len(filtered_possible_loc_dt) == 0:
|
||||
filtered_possible_loc_dt = list(possible_loc_dt)
|
||||
|
||||
# If we get this far, we have in a wierd timezone transition
|
||||
# where the clocks have been wound back but is_dst is the same
|
||||
# in both (eg. Europe/Warsaw 1915 when they switched to CET).
|
||||
# At this point, we just have to guess unless we allow more
|
||||
# hints to be passed in (such as the UTC offset or abbreviation),
|
||||
# but that is just getting silly.
|
||||
#
|
||||
# Choose the earliest (by UTC) applicable timezone if is_dst=True
|
||||
# Choose the latest (by UTC) applicable timezone if is_dst=False
|
||||
# i.e., behave like end-of-DST transition
|
||||
dates = {} # utc -> local
|
||||
for local_dt in filtered_possible_loc_dt:
|
||||
utc_time = local_dt.replace(tzinfo=None) - local_dt.tzinfo._utcoffset
|
||||
assert utc_time not in dates
|
||||
dates[utc_time] = local_dt
|
||||
return dates[[min, max][not is_dst](dates)]
|
||||
|
||||
def utcoffset(self, dt, is_dst=None):
|
||||
'''See datetime.tzinfo.utcoffset
|
||||
|
||||
The is_dst parameter may be used to remove ambiguity during DST
|
||||
transitions.
|
||||
|
||||
>>> from pytz import timezone
|
||||
>>> tz = timezone('America/St_Johns')
|
||||
>>> ambiguous = datetime(2009, 10, 31, 23, 30)
|
||||
|
||||
>>> tz.utcoffset(ambiguous, is_dst=False)
|
||||
datetime.timedelta(-1, 73800)
|
||||
|
||||
>>> tz.utcoffset(ambiguous, is_dst=True)
|
||||
datetime.timedelta(-1, 77400)
|
||||
|
||||
>>> try:
|
||||
... tz.utcoffset(ambiguous)
|
||||
... except AmbiguousTimeError:
|
||||
... print('Ambiguous')
|
||||
Ambiguous
|
||||
|
||||
'''
|
||||
if dt is None:
|
||||
return None
|
||||
elif dt.tzinfo is not self:
|
||||
dt = self.localize(dt, is_dst)
|
||||
return dt.tzinfo._utcoffset
|
||||
else:
|
||||
return self._utcoffset
|
||||
|
||||
def dst(self, dt, is_dst=None):
|
||||
'''See datetime.tzinfo.dst
|
||||
|
||||
The is_dst parameter may be used to remove ambiguity during DST
|
||||
transitions.
|
||||
|
||||
>>> from pytz import timezone
|
||||
>>> tz = timezone('America/St_Johns')
|
||||
|
||||
>>> normal = datetime(2009, 9, 1)
|
||||
|
||||
>>> tz.dst(normal)
|
||||
datetime.timedelta(0, 3600)
|
||||
>>> tz.dst(normal, is_dst=False)
|
||||
datetime.timedelta(0, 3600)
|
||||
>>> tz.dst(normal, is_dst=True)
|
||||
datetime.timedelta(0, 3600)
|
||||
|
||||
>>> ambiguous = datetime(2009, 10, 31, 23, 30)
|
||||
|
||||
>>> tz.dst(ambiguous, is_dst=False)
|
||||
datetime.timedelta(0)
|
||||
>>> tz.dst(ambiguous, is_dst=True)
|
||||
datetime.timedelta(0, 3600)
|
||||
>>> try:
|
||||
... tz.dst(ambiguous)
|
||||
... except AmbiguousTimeError:
|
||||
... print('Ambiguous')
|
||||
Ambiguous
|
||||
|
||||
'''
|
||||
if dt is None:
|
||||
return None
|
||||
elif dt.tzinfo is not self:
|
||||
dt = self.localize(dt, is_dst)
|
||||
return dt.tzinfo._dst
|
||||
else:
|
||||
return self._dst
|
||||
|
||||
def tzname(self, dt, is_dst=None):
|
||||
'''See datetime.tzinfo.tzname
|
||||
|
||||
The is_dst parameter may be used to remove ambiguity during DST
|
||||
transitions.
|
||||
|
||||
>>> from pytz import timezone
|
||||
>>> tz = timezone('America/St_Johns')
|
||||
|
||||
>>> normal = datetime(2009, 9, 1)
|
||||
|
||||
>>> tz.tzname(normal)
|
||||
'NDT'
|
||||
>>> tz.tzname(normal, is_dst=False)
|
||||
'NDT'
|
||||
>>> tz.tzname(normal, is_dst=True)
|
||||
'NDT'
|
||||
|
||||
>>> ambiguous = datetime(2009, 10, 31, 23, 30)
|
||||
|
||||
>>> tz.tzname(ambiguous, is_dst=False)
|
||||
'NST'
|
||||
>>> tz.tzname(ambiguous, is_dst=True)
|
||||
'NDT'
|
||||
>>> try:
|
||||
... tz.tzname(ambiguous)
|
||||
... except AmbiguousTimeError:
|
||||
... print('Ambiguous')
|
||||
Ambiguous
|
||||
'''
|
||||
if dt is None:
|
||||
return self.zone
|
||||
elif dt.tzinfo is not self:
|
||||
dt = self.localize(dt, is_dst)
|
||||
return dt.tzinfo._tzname
|
||||
else:
|
||||
return self._tzname
|
||||
|
||||
def __repr__(self):
|
||||
if self._dst:
|
||||
dst = 'DST'
|
||||
else:
|
||||
dst = 'STD'
|
||||
if self._utcoffset > _notime:
|
||||
return '<DstTzInfo %r %s+%s %s>' % (
|
||||
self.zone, self._tzname, self._utcoffset, dst
|
||||
)
|
||||
else:
|
||||
return '<DstTzInfo %r %s%s %s>' % (
|
||||
self.zone, self._tzname, self._utcoffset, dst
|
||||
)
|
||||
|
||||
def __reduce__(self):
|
||||
# Special pickle to zone remains a singleton and to cope with
|
||||
# database changes.
|
||||
return pytz._p, (
|
||||
self.zone,
|
||||
_to_seconds(self._utcoffset),
|
||||
_to_seconds(self._dst),
|
||||
self._tzname
|
||||
)
|
||||
|
||||
|
||||
|
||||
def unpickler(zone, utcoffset=None, dstoffset=None, tzname=None):
|
||||
"""Factory function for unpickling pytz tzinfo instances.
|
||||
|
||||
This is shared for both StaticTzInfo and DstTzInfo instances, because
|
||||
database changes could cause a zones implementation to switch between
|
||||
these two base classes and we can't break pickles on a pytz version
|
||||
upgrade.
|
||||
"""
|
||||
# Raises a KeyError if zone no longer exists, which should never happen
|
||||
# and would be a bug.
|
||||
tz = pytz.timezone(zone)
|
||||
|
||||
# A StaticTzInfo - just return it
|
||||
if utcoffset is None:
|
||||
return tz
|
||||
|
||||
# This pickle was created from a DstTzInfo. We need to
|
||||
# determine which of the list of tzinfo instances for this zone
|
||||
# to use in order to restore the state of any datetime instances using
|
||||
# it correctly.
|
||||
utcoffset = memorized_timedelta(utcoffset)
|
||||
dstoffset = memorized_timedelta(dstoffset)
|
||||
try:
|
||||
return tz._tzinfos[(utcoffset, dstoffset, tzname)]
|
||||
except KeyError:
|
||||
# The particular state requested in this timezone no longer exists.
|
||||
# This indicates a corrupt pickle, or the timezone database has been
|
||||
# corrected violently enough to make this particular
|
||||
# (utcoffset,dstoffset) no longer exist in the zone, or the
|
||||
# abbreviation has been changed.
|
||||
pass
|
||||
|
||||
# See if we can find an entry differing only by tzname. Abbreviations
|
||||
# get changed from the initial guess by the database maintainers to
|
||||
# match reality when this information is discovered.
|
||||
for localized_tz in tz._tzinfos.values():
|
||||
if (localized_tz._utcoffset == utcoffset
|
||||
and localized_tz._dst == dstoffset):
|
||||
return localized_tz
|
||||
|
||||
# This (utcoffset, dstoffset) information has been removed from the
|
||||
# zone. Add it back. This might occur when the database maintainers have
|
||||
# corrected incorrect information. datetime instances using this
|
||||
# incorrect information will continue to do so, exactly as they were
|
||||
# before being pickled. This is purely an overly paranoid safety net - I
|
||||
# doubt this will ever been needed in real life.
|
||||
inf = (utcoffset, dstoffset, tzname)
|
||||
tz._tzinfos[inf] = tz.__class__(inf, tz._tzinfos)
|
||||
return tz._tzinfos[inf]
|
||||
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Abidjan
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Abidjan
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Accra
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Accra
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Addis_Ababa
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Addis_Ababa
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Algiers
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Algiers
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Asmara
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Asmara
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Asmera
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Asmera
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bamako
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bamako
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bangui
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bangui
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Banjul
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Banjul
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bissau
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bissau
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Blantyre
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Blantyre
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Brazzaville
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Brazzaville
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bujumbura
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Bujumbura
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Cairo
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Cairo
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Casablanca
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Casablanca
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Ceuta
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Ceuta
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Conakry
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Conakry
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Dakar
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Dakar
Normal file
Binary file not shown.
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Djibouti
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Djibouti
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Douala
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Douala
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/El_Aaiun
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/El_Aaiun
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Freetown
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Freetown
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Gaborone
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Gaborone
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Harare
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Harare
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Johannesburg
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Johannesburg
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Juba
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Juba
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Kampala
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Kampala
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Khartoum
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Khartoum
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Kigali
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Kigali
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Kinshasa
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Kinshasa
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lagos
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lagos
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Libreville
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Libreville
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lome
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lome
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Luanda
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Luanda
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lubumbashi
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lubumbashi
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lusaka
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Lusaka
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Malabo
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Malabo
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Maputo
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Maputo
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Maseru
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Maseru
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Mbabane
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Mbabane
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Mogadishu
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Mogadishu
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Monrovia
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Monrovia
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Nairobi
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Nairobi
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Ndjamena
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Ndjamena
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Niamey
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Niamey
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Nouakchott
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Nouakchott
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Ouagadougou
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Ouagadougou
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Porto-Novo
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Porto-Novo
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Sao_Tome
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Sao_Tome
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Timbuktu
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Timbuktu
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Tripoli
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Tripoli
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Tunis
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Tunis
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Windhoek
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/Africa/Windhoek
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/America/Adak
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/America/Adak
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/America/Anchorage
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/America/Anchorage
Normal file
Binary file not shown.
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/America/Anguilla
Normal file
BIN
packages/wakatime/packages/py2/pytz/zoneinfo/America/Anguilla
Normal file
Binary file not shown.
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user