mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
94 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 5e17ad88f6 | |||
| 24d0f65116 | |||
| a326046733 | |||
| 9bab00fd8b | |||
| b4a13a48b9 | |||
| 21601f9688 | |||
| 4c3ec87341 | |||
| b149d7fc87 | |||
| 52e6107c6e | |||
| b340637331 | |||
| 044867449a | |||
| 9e3f438823 | |||
| 887d55c3f3 | |||
| 19d54f3310 | |||
| 514a8762eb | |||
| 957c74d226 | |||
| 7b0432d6ff | |||
| 09754849be | |||
| 25ad48a97a | |||
| 3b2520afa9 | |||
| 77c2041ad3 | |||
| 8af3b53937 | |||
| 5ef2e6954e | |||
| ca94272de5 | |||
| f19a448d95 | |||
| e178765412 | |||
| 6a7de84b9c | |||
| 48810f2977 | |||
| 260eedb31d | |||
| 02e2bfcad2 | |||
| f14ece63f3 | |||
| cb7f786ec8 | |||
| ab8711d0b1 | |||
| 2354be358c | |||
| 443215bd90 | |||
| c64f125dc4 | |||
| 050b14fb53 | |||
| c7efc33463 | |||
| d0ddbed006 | |||
| 3ce8f388ab | |||
| 90731146f9 | |||
| e1ab92be6d | |||
| 8b59e46c64 | |||
| 006341eb72 | |||
| b54e0e13f6 | |||
| 835c7db864 | |||
| 53e8bb04e9 | |||
| 4aa06e3829 | |||
| 297f65733f | |||
| 5ba5e6d21b | |||
| 32eadda81f | |||
| c537044801 | |||
| a97792c23c | |||
| 4223f3575f | |||
| 284cdf3ce4 | |||
| 27afc41bf4 | |||
| 1fdda0d64a | |||
| c90a4863e9 | |||
| 94343e5b07 | |||
| 03acea6e25 | |||
| 77594700bd | |||
| 6681409e98 | |||
| 8f7837269a | |||
| a523b3aa4d | |||
| 6985ce32bb | |||
| 4be40c7720 | |||
| eeb7fd8219 | |||
| 11fbd2d2a6 | |||
| 3cecd0de5d | |||
| c50100e675 | |||
| c1da94bc18 | |||
| 7f9d6ede9d | |||
| 192a5c7aa7 | |||
| 16bbe21be9 | |||
| 5ebaf12a99 | |||
| 1834e8978a | |||
| 22c8ed74bd | |||
| 12bbb4e561 | |||
| c71cb21cc1 | |||
| eb11b991f0 | |||
| 7ea51d09ba | |||
| b07b59e0c8 | |||
| 9d715e95b7 | |||
| 3edaed53aa | |||
| 865b0bcee9 | |||
| d440fe912c | |||
| 627455167f | |||
| aba89d3948 | |||
| 18d87118e1 | |||
| fd91b9e032 | |||
| 16b15773bf | |||
| f0b518862a | |||
| 7ee7de70d5 | |||
| fb479f8e84 |
273
HISTORY.rst
273
HISTORY.rst
@ -3,7 +3,278 @@ History
|
||||
-------
|
||||
|
||||
|
||||
4.0.6 (2015-06-21)
|
||||
7.0.10 (2016-09-22)
|
||||
++++++++++++++++++
|
||||
|
||||
- Handle UnicodeDecodeError when looking for python. Fixes #68.
|
||||
- Upgrade wakatime-cli to v6.0.9.
|
||||
|
||||
|
||||
7.0.9 (2016-09-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.8.
|
||||
|
||||
|
||||
7.0.8 (2016-07-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to master version to fix debug logging encoding bug.
|
||||
|
||||
|
||||
7.0.7 (2016-07-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.7.
|
||||
- Handle unknown exceptions from requests library by deleting cached session
|
||||
object because it could be from a previous conflicting version.
|
||||
- New hostname setting in config file to set machine hostname. Hostname
|
||||
argument takes priority over hostname from config file.
|
||||
- Prevent logging unrelated exception when logging tracebacks.
|
||||
- Use correct namespace for pygments.lexers.ClassNotFound exception so it is
|
||||
caught when dependency detection not available for a language.
|
||||
|
||||
|
||||
7.0.6 (2016-06-13)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.5.
|
||||
- Upgrade pygments to v2.1.3 for better language coverage.
|
||||
|
||||
|
||||
7.0.5 (2016-06-08)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to master version to fix bug in urllib3 package causing
|
||||
unhandled retry exceptions.
|
||||
- Prevent tracking git branch with detached head.
|
||||
|
||||
|
||||
7.0.4 (2016-05-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.3.
|
||||
- Upgrade requests dependency to v2.10.0.
|
||||
- Support for SOCKS proxies.
|
||||
|
||||
|
||||
7.0.3 (2016-05-16)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.2.
|
||||
- Prevent popup on Mac when xcode-tools is not installed.
|
||||
|
||||
|
||||
7.0.2 (2016-04-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- Prevent implicit unicode decoding from string format when logging output
|
||||
from Python version check.
|
||||
|
||||
|
||||
7.0.1 (2016-04-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v6.0.1.
|
||||
- Fix bug which prevented plugin from being sent with extra heartbeats.
|
||||
|
||||
|
||||
7.0.0 (2016-04-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- Queue heartbeats and send to wakatime-cli after 4 seconds.
|
||||
- Nest settings menu under Package Settings.
|
||||
- Upgrade wakatime-cli to v6.0.0.
|
||||
- Increase default network timeout to 60 seconds when sending heartbeats to
|
||||
the api.
|
||||
- New --extra-heartbeats command line argument for sending a JSON array of
|
||||
extra queued heartbeats to STDIN.
|
||||
- Change --entitytype command line argument to --entity-type.
|
||||
- No longer allowing --entity-type of url.
|
||||
- Support passing an alternate language to cli to be used when a language can
|
||||
not be guessed from the code file.
|
||||
|
||||
|
||||
6.0.8 (2016-04-18)
|
||||
++++++++++++++++++
|
||||
|
||||
- Upgrade wakatime-cli to v5.0.0.
|
||||
- Support regex patterns in projectmap config section for renaming projects.
|
||||
- Upgrade pytz to v2016.3.
|
||||
- Upgrade tzlocal to v1.2.2.
|
||||
|
||||
|
||||
6.0.7 (2016-03-11)
|
||||
++++++++++++++++++
|
||||
|
||||
- Fix bug causing RuntimeError when finding Python location
|
||||
|
||||
|
||||
6.0.6 (2016-03-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli to v4.1.13
|
||||
- encode TimeZone as utf-8 before adding to headers
|
||||
- encode X-Machine-Name as utf-8 before adding to headers
|
||||
|
||||
|
||||
6.0.5 (2016-03-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli to v4.1.11
|
||||
- encode machine hostname as Unicode when adding to X-Machine-Name header
|
||||
|
||||
|
||||
6.0.4 (2016-01-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix UnicodeDecodeError on ST2 with non-English locale
|
||||
|
||||
|
||||
6.0.3 (2016-01-11)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli core to v4.1.10
|
||||
- accept 201 or 202 response codes as success from api
|
||||
- upgrade requests package to v2.9.1
|
||||
|
||||
|
||||
6.0.2 (2016-01-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime-cli core to v4.1.9
|
||||
- improve C# dependency detection
|
||||
- correctly log exception tracebacks
|
||||
- log all unknown exceptions to wakatime.log file
|
||||
- disable urllib3 SSL warning from every request
|
||||
- detect dependencies from golang files
|
||||
- use api.wakatime.com for sending heartbeats
|
||||
|
||||
|
||||
6.0.1 (2016-01-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- use embedded python if system python is broken, or doesn't output a version number
|
||||
- log output from wakatime-cli in ST console when in debug mode
|
||||
|
||||
|
||||
6.0.0 (2015-12-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- use embeddable Python instead of installing on Windows
|
||||
|
||||
|
||||
5.0.1 (2015-10-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- look for python in system PATH again
|
||||
|
||||
|
||||
5.0.0 (2015-10-02)
|
||||
++++++++++++++++++
|
||||
|
||||
- improve logging with levels and log function
|
||||
- switch registry warnings to debug log level
|
||||
|
||||
|
||||
4.0.20 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly find python binary in non-Windows environments
|
||||
|
||||
|
||||
4.0.19 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- handle case where ST builtin python does not have _winreg or winreg module
|
||||
|
||||
|
||||
4.0.18 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- find python location from windows registry
|
||||
|
||||
|
||||
4.0.17 (2015-10-01)
|
||||
++++++++++++++++++
|
||||
|
||||
- download python in non blocking background thread for Windows machines
|
||||
|
||||
|
||||
4.0.16 (2015-09-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.8
|
||||
- fix bug in guess_language function
|
||||
- improve dependency detection
|
||||
- default request timeout of 30 seconds
|
||||
- new --timeout command line argument to change request timeout in seconds
|
||||
- allow passing command line arguments using sys.argv
|
||||
- fix entry point for pypi distribution
|
||||
- new --entity and --entitytype command line arguments
|
||||
|
||||
|
||||
4.0.15 (2015-08-28)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.3
|
||||
- fix local session caching
|
||||
|
||||
|
||||
4.0.14 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.2
|
||||
- fix bug in offline caching which prevented heartbeats from being cleaned up
|
||||
|
||||
|
||||
4.0.13 (2015-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- upgrade wakatime cli to v4.1.1
|
||||
- send hostname in X-Machine-Name header
|
||||
- catch exceptions from pygments.modeline.get_filetype_from_buffer
|
||||
- upgrade requests package to v2.7.0
|
||||
- handle non-ASCII characters in import path on Windows, won't fix for Python2
|
||||
- upgrade argparse to v1.3.0
|
||||
- move language translations to api server
|
||||
- move extension rules to api server
|
||||
- detect correct header file language based on presence of .cpp or .c files named the same as the .h file
|
||||
|
||||
|
||||
4.0.12 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- correctly use urllib in Python3
|
||||
|
||||
|
||||
4.0.11 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- install python if missing on Windows OS
|
||||
|
||||
|
||||
4.0.10 (2015-07-31)
|
||||
++++++++++++++++++
|
||||
|
||||
- downgrade requests library to v2.6.0
|
||||
|
||||
|
||||
4.0.9 (2015-07-29)
|
||||
++++++++++++++++++
|
||||
|
||||
- catch exceptions from pygments.modeline.get_filetype_from_buffer
|
||||
|
||||
|
||||
4.0.8 (2015-06-23)
|
||||
++++++++++++++++++
|
||||
|
||||
- fix offline logging
|
||||
- limit language detection to known file extensions, unless file contents has a vim modeline
|
||||
- upgrade wakatime cli to v4.0.16
|
||||
|
||||
|
||||
4.0.7 (2015-06-21)
|
||||
++++++++++++++++++
|
||||
|
||||
- allow customizing status bar message in sublime-settings file
|
||||
|
||||
@ -6,24 +6,37 @@
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"caption": "WakaTime",
|
||||
"mnemonic": "W",
|
||||
"id": "wakatime-settings",
|
||||
"caption": "Package Settings",
|
||||
"mnemonic": "P",
|
||||
"id": "package-settings",
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/WakaTime/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – Default"
|
||||
},
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/User/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – User"
|
||||
"caption": "WakaTime",
|
||||
"mnemonic": "W",
|
||||
"id": "wakatime-settings",
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/WakaTime/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – Default"
|
||||
},
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/User/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – User"
|
||||
},
|
||||
{
|
||||
"command": "wakatime_dashboard",
|
||||
"args": {},
|
||||
"caption": "WakaTime Dashboard"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
33
README.md
33
README.md
@ -1,13 +1,12 @@
|
||||
sublime-wakatime
|
||||
================
|
||||
|
||||
Fully automatic time tracking for Sublime Text 2 & 3.
|
||||
Metrics, insights, and time tracking automatically generated from your programming activity.
|
||||
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](http://www.python.org/getit/) being installed to work correctly.
|
||||
|
||||
1. Install [Package Control](https://packagecontrol.io/installation).
|
||||
|
||||
2. Using [Package Control](https://packagecontrol.io/docs/usage):
|
||||
@ -24,8 +23,34 @@ Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](ht
|
||||
|
||||
5. Visit https://wakatime.com/dashboard to see your logged time.
|
||||
|
||||
|
||||
Screen Shots
|
||||
------------
|
||||
|
||||
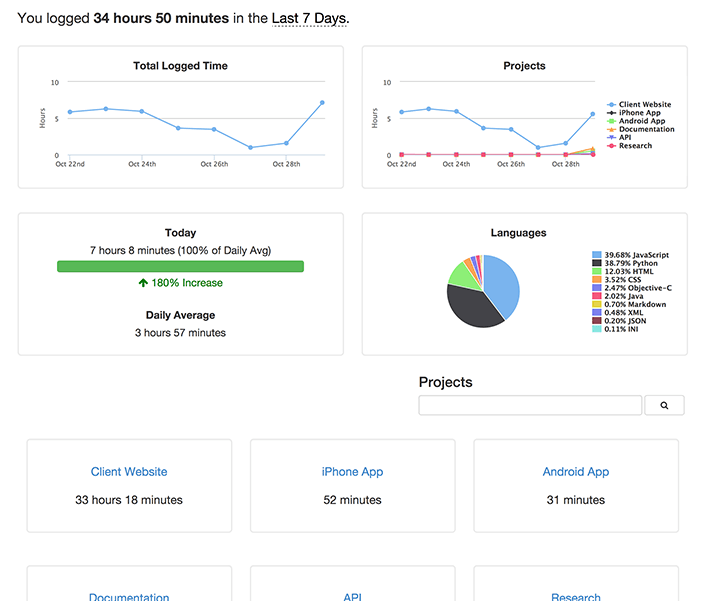
|
||||
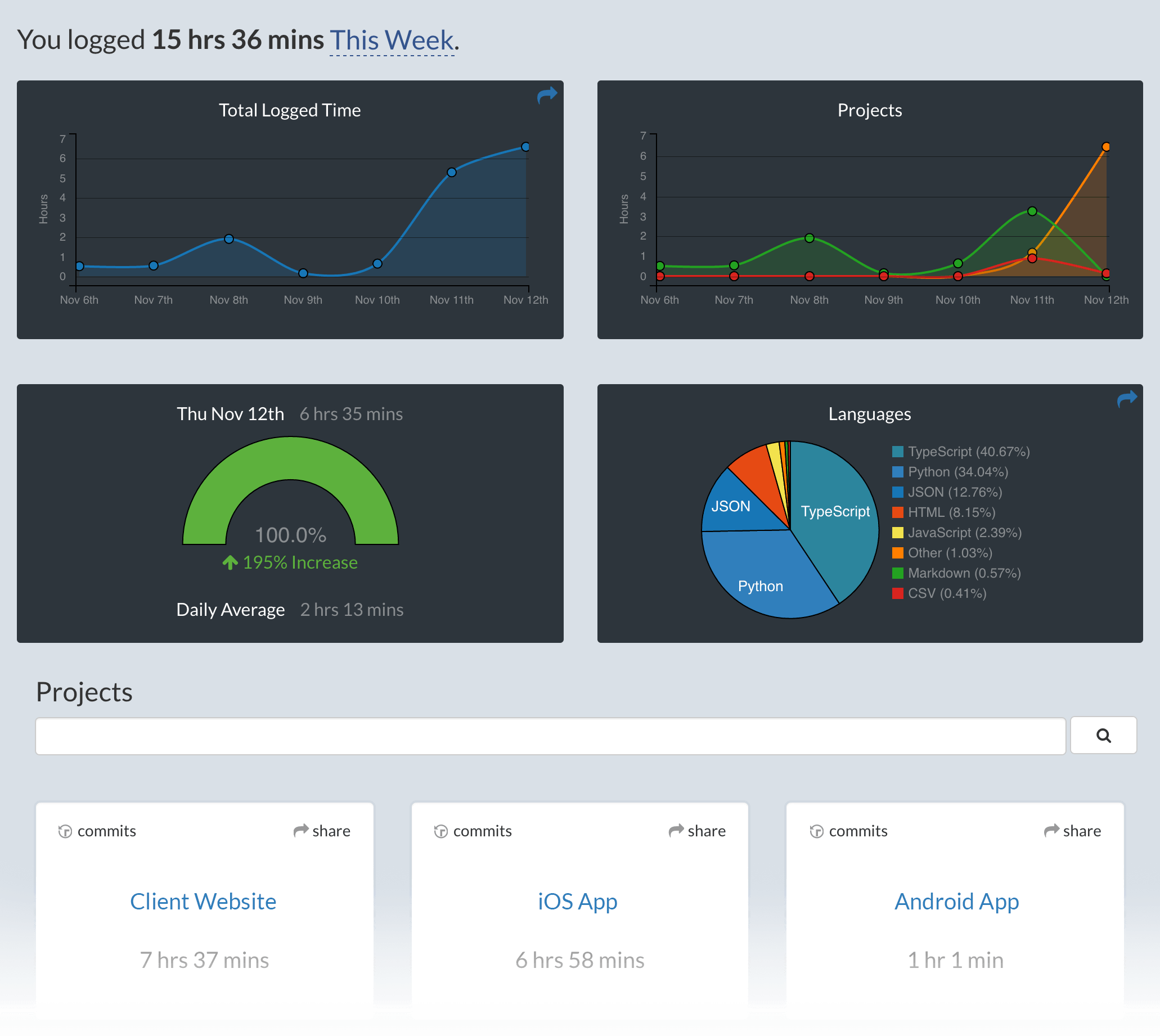
|
||||
|
||||
|
||||
Unresponsive Plugin Warning
|
||||
---------------------------
|
||||
|
||||
In Sublime Text 2, if you get a warning message:
|
||||
|
||||
A plugin (WakaTime) may be making Sublime Text unresponsive by taking too long (0.017332s) in its on_modified callback.
|
||||
|
||||
To fix this, go to `Preferences > Settings - User` then add the following setting:
|
||||
|
||||
`"detect_slow_plugins": false`
|
||||
|
||||
|
||||
Troubleshooting
|
||||
---------------
|
||||
|
||||
First, turn on debug mode in your `WakaTime.sublime-settings` file.
|
||||
|
||||
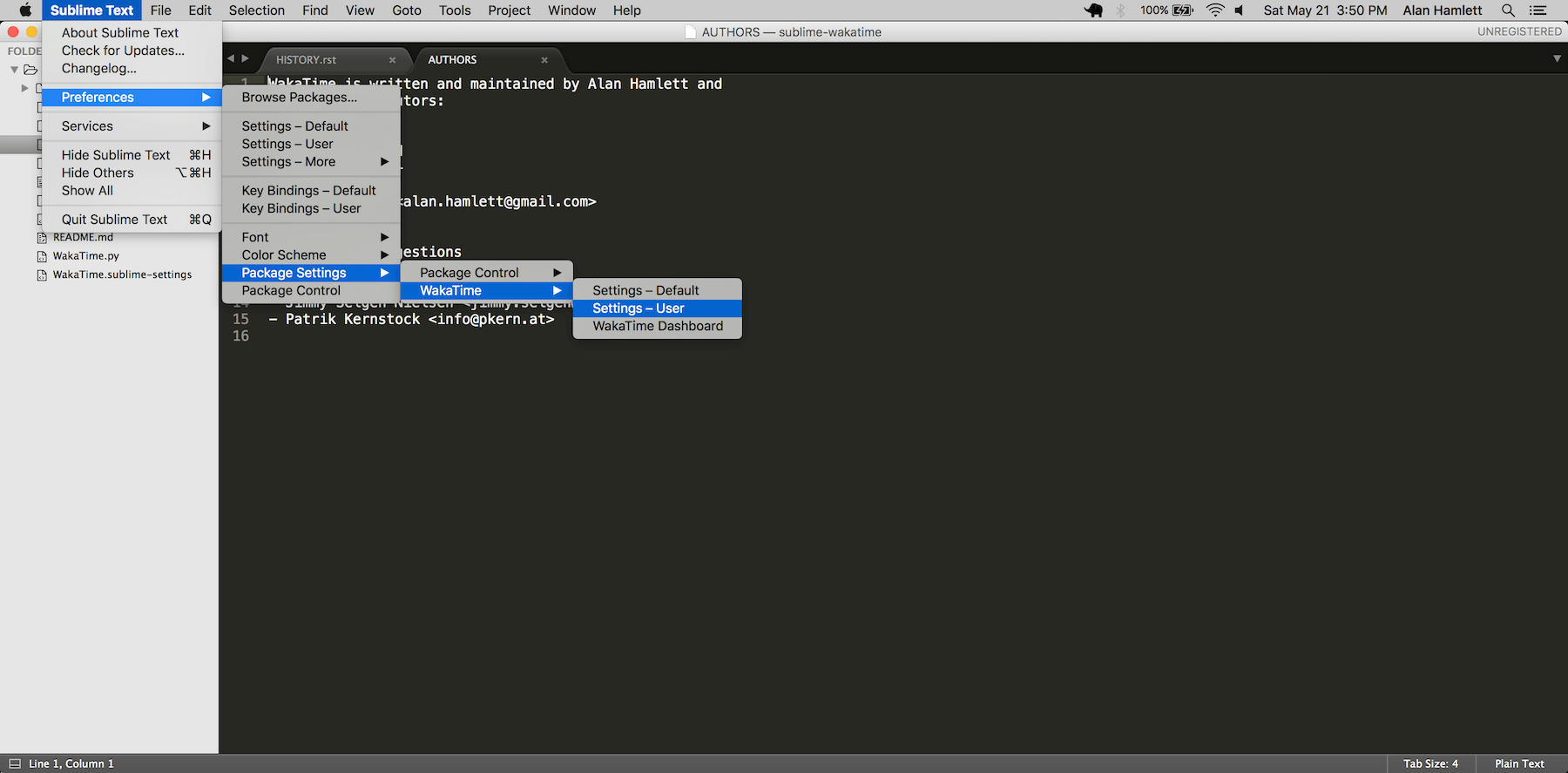
|
||||
|
||||
Add the line: `"debug": true`
|
||||
|
||||
Then, open your Sublime Console with `View -> Show Console` to see the plugin executing the wakatime cli process when sending a heartbeat. Also, tail your `$HOME/.wakatime.log` file to debug wakatime cli problems.
|
||||
|
||||
For more general troubleshooting information, see [wakatime/wakatime#troubleshooting](https://github.com/wakatime/wakatime#troubleshooting).
|
||||
|
||||
540
WakaTime.py
540
WakaTime.py
@ -7,21 +7,78 @@ Website: https://wakatime.com/
|
||||
==========================================================="""
|
||||
|
||||
|
||||
__version__ = '4.0.7'
|
||||
__version__ = '7.0.10'
|
||||
|
||||
|
||||
import sublime
|
||||
import sublime_plugin
|
||||
|
||||
import glob
|
||||
import json
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import threading
|
||||
import urllib
|
||||
import webbrowser
|
||||
from datetime import datetime
|
||||
from subprocess import Popen
|
||||
from zipfile import ZipFile
|
||||
from subprocess import Popen, STDOUT, PIPE
|
||||
try:
|
||||
import _winreg as winreg # py2
|
||||
except ImportError:
|
||||
try:
|
||||
import winreg # py3
|
||||
except ImportError:
|
||||
winreg = None
|
||||
try:
|
||||
import Queue as queue # py2
|
||||
except ImportError:
|
||||
import queue # py3
|
||||
|
||||
|
||||
is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
if is_py2:
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text.decode('utf-8', 'replace')
|
||||
|
||||
elif is_py3:
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text.decode('utf-8', 'replace')
|
||||
|
||||
else:
|
||||
raise Exception('Unsupported Python version: {0}.{1}.{2}'.format(
|
||||
sys.version_info[0],
|
||||
sys.version_info[1],
|
||||
sys.version_info[2],
|
||||
))
|
||||
|
||||
|
||||
# globals
|
||||
@ -36,8 +93,15 @@ LAST_HEARTBEAT = {
|
||||
'file': None,
|
||||
'is_write': False,
|
||||
}
|
||||
LOCK = threading.RLock()
|
||||
PYTHON_LOCATION = None
|
||||
HEARTBEATS = queue.Queue()
|
||||
|
||||
|
||||
# Log Levels
|
||||
DEBUG = 'DEBUG'
|
||||
INFO = 'INFO'
|
||||
WARNING = 'WARNING'
|
||||
ERROR = 'ERROR'
|
||||
|
||||
|
||||
# add wakatime package to path
|
||||
@ -48,7 +112,59 @@ except ImportError:
|
||||
pass
|
||||
|
||||
|
||||
def createConfigFile():
|
||||
def set_timeout(callback, seconds):
|
||||
"""Runs the callback after the given seconds delay.
|
||||
|
||||
If this is Sublime Text 3, runs the callback on an alternate thread. If this
|
||||
is Sublime Text 2, runs the callback in the main thread.
|
||||
"""
|
||||
|
||||
milliseconds = int(seconds * 1000)
|
||||
try:
|
||||
sublime.set_timeout_async(callback, milliseconds)
|
||||
except AttributeError:
|
||||
sublime.set_timeout(callback, milliseconds)
|
||||
|
||||
|
||||
def log(lvl, message, *args, **kwargs):
|
||||
try:
|
||||
if lvl == DEBUG and not SETTINGS.get('debug'):
|
||||
return
|
||||
msg = message
|
||||
if len(args) > 0:
|
||||
msg = message.format(*args)
|
||||
elif len(kwargs) > 0:
|
||||
msg = message.format(**kwargs)
|
||||
print('[WakaTime] [{lvl}] {msg}'.format(lvl=lvl, msg=msg))
|
||||
except RuntimeError:
|
||||
set_timeout(lambda: log(lvl, message, *args, **kwargs), 0)
|
||||
|
||||
|
||||
def resources_folder():
|
||||
if platform.system() == 'Windows':
|
||||
return os.path.join(os.getenv('APPDATA'), 'WakaTime')
|
||||
else:
|
||||
return os.path.join(os.path.expanduser('~'), '.wakatime')
|
||||
|
||||
|
||||
def update_status_bar(status):
|
||||
"""Updates the status bar."""
|
||||
|
||||
try:
|
||||
if SETTINGS.get('status_bar_message'):
|
||||
msg = datetime.now().strftime(SETTINGS.get('status_bar_message_fmt'))
|
||||
if '{status}' in msg:
|
||||
msg = msg.format(status=status)
|
||||
|
||||
active_window = sublime.active_window()
|
||||
if active_window:
|
||||
for view in active_window.views():
|
||||
view.set_status('wakatime', msg)
|
||||
except RuntimeError:
|
||||
set_timeout(lambda: update_status_bar(status), 0)
|
||||
|
||||
|
||||
def create_config_file():
|
||||
"""Creates the .wakatime.cfg INI file in $HOME directory, if it does
|
||||
not already exist.
|
||||
"""
|
||||
@ -69,7 +185,7 @@ def createConfigFile():
|
||||
def prompt_api_key():
|
||||
global SETTINGS
|
||||
|
||||
createConfigFile()
|
||||
create_config_file()
|
||||
|
||||
default_key = ''
|
||||
try:
|
||||
@ -92,35 +208,129 @@ def prompt_api_key():
|
||||
window.show_input_panel('[WakaTime] Enter your wakatime.com api key:', default_key, got_key, None, None)
|
||||
return True
|
||||
else:
|
||||
print('[WakaTime] Error: Could not prompt for api key because no window found.')
|
||||
log(ERROR, 'Could not prompt for api key because no window found.')
|
||||
return False
|
||||
|
||||
|
||||
def python_binary():
|
||||
global PYTHON_LOCATION
|
||||
if PYTHON_LOCATION is not None:
|
||||
return PYTHON_LOCATION
|
||||
|
||||
# look for python in PATH and common install locations
|
||||
paths = [
|
||||
"pythonw",
|
||||
"python",
|
||||
"/usr/local/bin/python",
|
||||
"/usr/bin/python",
|
||||
os.path.join(resources_folder(), 'python'),
|
||||
None,
|
||||
'/',
|
||||
'/usr/local/bin/',
|
||||
'/usr/bin/',
|
||||
]
|
||||
for path in paths:
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
for path in glob.iglob('/python*'):
|
||||
path = os.path.realpath(os.path.join(path, 'pythonw'))
|
||||
try:
|
||||
Popen([path, '--version'])
|
||||
PYTHON_LOCATION = path
|
||||
|
||||
# look for python in windows registry
|
||||
path = find_python_from_registry(r'SOFTWARE\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
path = find_python_from_registry(r'SOFTWARE\Wow6432Node\Python\PythonCore')
|
||||
if path is not None:
|
||||
set_python_binary_location(path)
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
def set_python_binary_location(path):
|
||||
global PYTHON_LOCATION
|
||||
PYTHON_LOCATION = path
|
||||
log(DEBUG, 'Found Python at: {0}'.format(path))
|
||||
|
||||
|
||||
def find_python_from_registry(location, reg=None):
|
||||
if platform.system() != 'Windows' or winreg is None:
|
||||
return None
|
||||
|
||||
if reg is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_CURRENT_USER)
|
||||
if path is None:
|
||||
path = find_python_from_registry(location, reg=winreg.HKEY_LOCAL_MACHINE)
|
||||
return path
|
||||
|
||||
val = None
|
||||
sub_key = 'InstallPath'
|
||||
compiled = re.compile(r'^\d+\.\d+$')
|
||||
|
||||
try:
|
||||
with winreg.OpenKey(reg, location) as handle:
|
||||
versions = []
|
||||
try:
|
||||
for index in range(1024):
|
||||
version = winreg.EnumKey(handle, index)
|
||||
try:
|
||||
if compiled.search(version):
|
||||
versions.append(version)
|
||||
except re.error:
|
||||
pass
|
||||
except EnvironmentError:
|
||||
pass
|
||||
versions.sort(reverse=True)
|
||||
for version in versions:
|
||||
try:
|
||||
path = winreg.QueryValue(handle, version + '\\' + sub_key)
|
||||
if path is not None:
|
||||
path = find_python_in_folder(path)
|
||||
if path is not None:
|
||||
log(DEBUG, 'Found python from {reg}\\{key}\\{version}\\{sub_key}.'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
return path
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}\\{version}\\{sub_key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
version=version,
|
||||
sub_key=sub_key,
|
||||
))
|
||||
except WindowsError:
|
||||
log(DEBUG, 'Could not read registry value "{reg}\\{key}".'.format(
|
||||
reg=reg,
|
||||
key=location,
|
||||
))
|
||||
|
||||
return val
|
||||
|
||||
|
||||
def find_python_in_folder(folder, headless=True):
|
||||
pattern = re.compile(r'\d+\.\d+')
|
||||
|
||||
path = 'python'
|
||||
if folder is not None:
|
||||
path = os.path.realpath(os.path.join(folder, 'python'))
|
||||
if headless:
|
||||
path = u(path) + u('w')
|
||||
log(DEBUG, u('Looking for Python at: {0}').format(u(path)))
|
||||
try:
|
||||
process = Popen([path, '--version'], stdout=PIPE, stderr=STDOUT)
|
||||
output, err = process.communicate()
|
||||
output = u(output).strip()
|
||||
retcode = process.poll()
|
||||
log(DEBUG, u('Python Version Output: {0}').format(output))
|
||||
if not retcode and pattern.search(output):
|
||||
return path
|
||||
except:
|
||||
pass
|
||||
except:
|
||||
log(DEBUG, u(sys.exc_info()[1]))
|
||||
|
||||
if headless:
|
||||
path = find_python_in_folder(folder, headless=False)
|
||||
if path is not None:
|
||||
return path
|
||||
|
||||
return None
|
||||
|
||||
|
||||
@ -132,14 +342,14 @@ def obfuscate_apikey(command_list):
|
||||
apikey_index = num + 1
|
||||
break
|
||||
if apikey_index is not None and apikey_index < len(cmd):
|
||||
cmd[apikey_index] = '********-****-****-****-********' + cmd[apikey_index][-4:]
|
||||
cmd[apikey_index] = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX' + cmd[apikey_index][-4:]
|
||||
return cmd
|
||||
|
||||
|
||||
def enough_time_passed(now, last_heartbeat, is_write):
|
||||
if now - last_heartbeat['time'] > HEARTBEAT_FREQUENCY * 60:
|
||||
def enough_time_passed(now, is_write):
|
||||
if now - LAST_HEARTBEAT['time'] > HEARTBEAT_FREQUENCY * 60:
|
||||
return True
|
||||
if is_write and now - last_heartbeat['time'] > 2:
|
||||
if is_write and now - LAST_HEARTBEAT['time'] > 2:
|
||||
return True
|
||||
return False
|
||||
|
||||
@ -183,111 +393,235 @@ def is_view_active(view):
|
||||
return False
|
||||
|
||||
|
||||
def handle_heartbeat(view, is_write=False):
|
||||
def handle_activity(view, is_write=False):
|
||||
window = view.window()
|
||||
if window is not None:
|
||||
target_file = view.file_name()
|
||||
project = window.project_data() if hasattr(window, 'project_data') else None
|
||||
folders = window.folders()
|
||||
thread = SendHeartbeatThread(target_file, view, is_write=is_write, project=project, folders=folders)
|
||||
thread.start()
|
||||
entity = view.file_name()
|
||||
if entity:
|
||||
timestamp = time.time()
|
||||
last_file = LAST_HEARTBEAT['file']
|
||||
if entity != last_file or enough_time_passed(timestamp, is_write):
|
||||
project = window.project_data() if hasattr(window, 'project_data') else None
|
||||
folders = window.folders()
|
||||
append_heartbeat(entity, timestamp, is_write, view, project, folders)
|
||||
|
||||
|
||||
class SendHeartbeatThread(threading.Thread):
|
||||
def append_heartbeat(entity, timestamp, is_write, view, project, folders):
|
||||
global LAST_HEARTBEAT
|
||||
|
||||
def __init__(self, target_file, view, is_write=False, project=None, folders=None, force=False):
|
||||
# add this heartbeat to queue
|
||||
heartbeat = {
|
||||
'entity': entity,
|
||||
'timestamp': timestamp,
|
||||
'is_write': is_write,
|
||||
'cursorpos': view.sel()[0].begin() if view.sel() else None,
|
||||
'project': project,
|
||||
'folders': folders,
|
||||
}
|
||||
HEARTBEATS.put_nowait(heartbeat)
|
||||
|
||||
# make this heartbeat the LAST_HEARTBEAT
|
||||
LAST_HEARTBEAT = {
|
||||
'file': entity,
|
||||
'time': timestamp,
|
||||
'is_write': is_write,
|
||||
}
|
||||
|
||||
# process the queue of heartbeats in the future
|
||||
seconds = 4
|
||||
set_timeout(process_queue, seconds)
|
||||
|
||||
|
||||
def process_queue():
|
||||
try:
|
||||
heartbeat = HEARTBEATS.get_nowait()
|
||||
except queue.Empty:
|
||||
return
|
||||
|
||||
has_extra_heartbeats = False
|
||||
extra_heartbeats = []
|
||||
try:
|
||||
while True:
|
||||
extra_heartbeats.append(HEARTBEATS.get_nowait())
|
||||
has_extra_heartbeats = True
|
||||
except queue.Empty:
|
||||
pass
|
||||
|
||||
thread = SendHeartbeatsThread(heartbeat)
|
||||
if has_extra_heartbeats:
|
||||
thread.add_extra_heartbeats(extra_heartbeats)
|
||||
thread.start()
|
||||
|
||||
|
||||
class SendHeartbeatsThread(threading.Thread):
|
||||
"""Non-blocking thread for sending heartbeats to api.
|
||||
"""
|
||||
|
||||
def __init__(self, heartbeat):
|
||||
threading.Thread.__init__(self)
|
||||
self.lock = LOCK
|
||||
self.target_file = target_file
|
||||
self.is_write = is_write
|
||||
self.project = project
|
||||
self.folders = folders
|
||||
self.force = force
|
||||
|
||||
self.debug = SETTINGS.get('debug')
|
||||
self.api_key = SETTINGS.get('api_key', '')
|
||||
self.ignore = SETTINGS.get('ignore', [])
|
||||
self.last_heartbeat = LAST_HEARTBEAT.copy()
|
||||
self.cursorpos = view.sel()[0].begin() if view.sel() else None
|
||||
self.view = view
|
||||
|
||||
self.heartbeat = heartbeat
|
||||
self.has_extra_heartbeats = False
|
||||
|
||||
def add_extra_heartbeats(self, extra_heartbeats):
|
||||
self.has_extra_heartbeats = True
|
||||
self.extra_heartbeats = extra_heartbeats
|
||||
|
||||
def run(self):
|
||||
with self.lock:
|
||||
if self.target_file:
|
||||
self.timestamp = time.time()
|
||||
if self.force or self.target_file != self.last_heartbeat['file'] or enough_time_passed(self.timestamp, self.last_heartbeat, self.is_write):
|
||||
self.send_heartbeat()
|
||||
"""Running in background thread."""
|
||||
|
||||
def send_heartbeat(self):
|
||||
if not self.api_key:
|
||||
print('[WakaTime] Error: missing api key.')
|
||||
return
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
API_CLIENT,
|
||||
'--file', self.target_file,
|
||||
'--time', str('%f' % self.timestamp),
|
||||
'--plugin', ua,
|
||||
'--key', str(bytes.decode(self.api_key.encode('utf8'))),
|
||||
]
|
||||
if self.is_write:
|
||||
cmd.append('--write')
|
||||
if self.project and self.project.get('name'):
|
||||
cmd.extend(['--alternate-project', self.project.get('name')])
|
||||
elif self.folders:
|
||||
project_name = find_project_from_folders(self.folders, self.target_file)
|
||||
self.send_heartbeats()
|
||||
|
||||
def build_heartbeat(self, entity=None, timestamp=None, is_write=None,
|
||||
cursorpos=None, project=None, folders=None):
|
||||
"""Returns a dict for passing to wakatime-cli as arguments."""
|
||||
|
||||
heartbeat = {
|
||||
'entity': entity,
|
||||
'timestamp': timestamp,
|
||||
'is_write': is_write,
|
||||
}
|
||||
|
||||
if project and project.get('name'):
|
||||
heartbeat['alternate_project'] = project.get('name')
|
||||
elif folders:
|
||||
project_name = find_project_from_folders(folders, entity)
|
||||
if project_name:
|
||||
cmd.extend(['--alternate-project', project_name])
|
||||
if self.cursorpos is not None:
|
||||
cmd.extend(['--cursorpos', '{0}'.format(self.cursorpos)])
|
||||
for pattern in self.ignore:
|
||||
cmd.extend(['--ignore', pattern])
|
||||
if self.debug:
|
||||
cmd.append('--verbose')
|
||||
heartbeat['alternate_project'] = project_name
|
||||
|
||||
if cursorpos is not None:
|
||||
heartbeat['cursorpos'] = '{0}'.format(cursorpos)
|
||||
|
||||
return heartbeat
|
||||
|
||||
def send_heartbeats(self):
|
||||
if python_binary():
|
||||
cmd.insert(0, python_binary())
|
||||
heartbeat = self.build_heartbeat(**self.heartbeat)
|
||||
ua = 'sublime/%d sublime-wakatime/%s' % (ST_VERSION, __version__)
|
||||
cmd = [
|
||||
python_binary(),
|
||||
API_CLIENT,
|
||||
'--entity', heartbeat['entity'],
|
||||
'--time', str('%f' % heartbeat['timestamp']),
|
||||
'--plugin', ua,
|
||||
]
|
||||
if self.api_key:
|
||||
cmd.extend(['--key', str(bytes.decode(self.api_key.encode('utf8')))])
|
||||
if heartbeat['is_write']:
|
||||
cmd.append('--write')
|
||||
if heartbeat.get('alternate_project'):
|
||||
cmd.extend(['--alternate-project', heartbeat['alternate_project']])
|
||||
if heartbeat.get('cursorpos') is not None:
|
||||
cmd.extend(['--cursorpos', heartbeat['cursorpos']])
|
||||
for pattern in self.ignore:
|
||||
cmd.extend(['--ignore', pattern])
|
||||
if self.debug:
|
||||
print('[WakaTime] %s' % ' '.join(obfuscate_apikey(cmd)))
|
||||
if platform.system() == 'Windows':
|
||||
Popen(cmd, shell=False)
|
||||
cmd.append('--verbose')
|
||||
if self.has_extra_heartbeats:
|
||||
cmd.append('--extra-heartbeats')
|
||||
stdin = PIPE
|
||||
extra_heartbeats = [self.build_heartbeat(**x) for x in self.extra_heartbeats]
|
||||
extra_heartbeats = json.dumps(extra_heartbeats)
|
||||
else:
|
||||
with open(os.path.join(os.path.expanduser('~'), '.wakatime.log'), 'a') as stderr:
|
||||
Popen(cmd, stderr=stderr)
|
||||
self.sent()
|
||||
extra_heartbeats = None
|
||||
stdin = None
|
||||
|
||||
log(DEBUG, ' '.join(obfuscate_apikey(cmd)))
|
||||
try:
|
||||
process = Popen(cmd, stdin=stdin, stdout=PIPE, stderr=STDOUT)
|
||||
inp = None
|
||||
if self.has_extra_heartbeats:
|
||||
inp = "{0}\n".format(extra_heartbeats)
|
||||
inp = inp.encode('utf-8')
|
||||
output, err = process.communicate(input=inp)
|
||||
output = u(output)
|
||||
retcode = process.poll()
|
||||
if (not retcode or retcode == 102) and not output:
|
||||
self.sent()
|
||||
else:
|
||||
update_status_bar('Error')
|
||||
if retcode:
|
||||
log(DEBUG if retcode == 102 else ERROR, 'wakatime-core exited with status: {0}'.format(retcode))
|
||||
if output:
|
||||
log(ERROR, u('wakatime-core output: {0}').format(output))
|
||||
except:
|
||||
log(ERROR, u(sys.exc_info()[1]))
|
||||
update_status_bar('Error')
|
||||
|
||||
else:
|
||||
print('[WakaTime] Error: Unable to find python binary.')
|
||||
log(ERROR, 'Unable to find python binary.')
|
||||
update_status_bar('Error')
|
||||
|
||||
def sent(self):
|
||||
sublime.set_timeout(self.set_status_bar, 0)
|
||||
sublime.set_timeout(self.set_last_heartbeat, 0)
|
||||
update_status_bar('OK')
|
||||
|
||||
def set_status_bar(self):
|
||||
if SETTINGS.get('status_bar_message'):
|
||||
self.view.set_status('wakatime', datetime.now().strftime(SETTINGS.get('status_bar_message_fmt')))
|
||||
|
||||
def set_last_heartbeat(self):
|
||||
global LAST_HEARTBEAT
|
||||
LAST_HEARTBEAT = {
|
||||
'file': self.target_file,
|
||||
'time': self.timestamp,
|
||||
'is_write': self.is_write,
|
||||
}
|
||||
def download_python():
|
||||
thread = DownloadPython()
|
||||
thread.start()
|
||||
|
||||
|
||||
class DownloadPython(threading.Thread):
|
||||
"""Non-blocking thread for extracting embeddable Python on Windows machines.
|
||||
"""
|
||||
|
||||
def run(self):
|
||||
log(INFO, 'Downloading embeddable Python...')
|
||||
|
||||
ver = '3.5.0'
|
||||
arch = 'amd64' if platform.architecture()[0] == '64bit' else 'win32'
|
||||
url = 'https://www.python.org/ftp/python/{ver}/python-{ver}-embed-{arch}.zip'.format(
|
||||
ver=ver,
|
||||
arch=arch,
|
||||
)
|
||||
|
||||
if not os.path.exists(resources_folder()):
|
||||
os.makedirs(resources_folder())
|
||||
|
||||
zip_file = os.path.join(resources_folder(), 'python.zip')
|
||||
try:
|
||||
urllib.urlretrieve(url, zip_file)
|
||||
except AttributeError:
|
||||
urllib.request.urlretrieve(url, zip_file)
|
||||
|
||||
log(INFO, 'Extracting Python...')
|
||||
with ZipFile(zip_file) as zf:
|
||||
path = os.path.join(resources_folder(), 'python')
|
||||
zf.extractall(path)
|
||||
|
||||
try:
|
||||
os.remove(zip_file)
|
||||
except:
|
||||
pass
|
||||
|
||||
log(INFO, 'Finished extracting Python.')
|
||||
|
||||
|
||||
def plugin_loaded():
|
||||
global SETTINGS
|
||||
print('[WakaTime] Initializing WakaTime plugin v%s' % __version__)
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
|
||||
log(INFO, 'Initializing WakaTime plugin v%s' % __version__)
|
||||
update_status_bar('Initializing')
|
||||
|
||||
if not python_binary():
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
log(WARNING, 'Python binary not found.')
|
||||
if platform.system() == 'Windows':
|
||||
set_timeout(download_python, 0)
|
||||
else:
|
||||
sublime.error_message("Unable to find Python binary!\nWakaTime needs Python to work correctly.\n\nGo to https://www.python.org/downloads")
|
||||
return
|
||||
|
||||
SETTINGS = sublime.load_settings(SETTINGS_FILE)
|
||||
after_loaded()
|
||||
|
||||
|
||||
def after_loaded():
|
||||
if not prompt_api_key():
|
||||
sublime.set_timeout(after_loaded, 500)
|
||||
set_timeout(after_loaded, 0.5)
|
||||
|
||||
|
||||
# need to call plugin_loaded because only ST3 will auto-call it
|
||||
@ -298,15 +632,15 @@ if ST_VERSION < 3000:
|
||||
class WakatimeListener(sublime_plugin.EventListener):
|
||||
|
||||
def on_post_save(self, view):
|
||||
handle_heartbeat(view, is_write=True)
|
||||
handle_activity(view, is_write=True)
|
||||
|
||||
def on_selection_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
handle_activity(view)
|
||||
|
||||
def on_modified(self, view):
|
||||
if is_view_active(view):
|
||||
handle_heartbeat(view)
|
||||
handle_activity(view)
|
||||
|
||||
|
||||
class WakatimeDashboardCommand(sublime_plugin.ApplicationCommand):
|
||||
|
||||
@ -19,5 +19,5 @@
|
||||
"status_bar_message": true,
|
||||
|
||||
// Status bar message format.
|
||||
"status_bar_message_fmt": "WakaTime active %I:%M %p"
|
||||
"status_bar_message_fmt": "WakaTime {status} %I:%M %p"
|
||||
}
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
__title__ = 'wakatime'
|
||||
__description__ = 'Common interface to the WakaTime api.'
|
||||
__url__ = 'https://github.com/wakatime/wakatime'
|
||||
__version_info__ = ('4', '0', '15')
|
||||
__version_info__ = ('6', '0', '9')
|
||||
__version__ = '.'.join(__version_info__)
|
||||
__author__ = 'Alan Hamlett'
|
||||
__author_email__ = 'alan@wakatime.com'
|
||||
__license__ = 'BSD'
|
||||
__copyright__ = 'Copyright 2014 Alan Hamlett'
|
||||
__copyright__ = 'Copyright 2016 Alan Hamlett'
|
||||
|
||||
@ -14,4 +14,4 @@
|
||||
__all__ = ['main']
|
||||
|
||||
|
||||
from .base import main
|
||||
from .main import execute
|
||||
|
||||
@ -11,8 +11,25 @@
|
||||
|
||||
import os
|
||||
import sys
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
import wakatime
|
||||
|
||||
|
||||
# get path to local wakatime package
|
||||
package_folder = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||
|
||||
# add local wakatime package to sys.path
|
||||
sys.path.insert(0, package_folder)
|
||||
|
||||
# import local wakatime package
|
||||
try:
|
||||
import wakatime
|
||||
except (TypeError, ImportError):
|
||||
# on Windows, non-ASCII characters in import path can be fixed using
|
||||
# the script path from sys.argv[0].
|
||||
# More info at https://github.com/wakatime/wakatime/issues/32
|
||||
package_folder = os.path.dirname(os.path.dirname(os.path.abspath(sys.argv[0])))
|
||||
sys.path.insert(0, package_folder)
|
||||
import wakatime
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(wakatime.main(sys.argv))
|
||||
sys.exit(wakatime.execute(sys.argv[1:]))
|
||||
|
||||
@ -17,32 +17,49 @@ is_py2 = (sys.version_info[0] == 2)
|
||||
is_py3 = (sys.version_info[0] == 3)
|
||||
|
||||
|
||||
if is_py2:
|
||||
if is_py2: # pragma: nocover
|
||||
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return unicode(text)
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
return text
|
||||
try:
|
||||
return unicode(text)
|
||||
except:
|
||||
return text.decode('utf-8', 'replace')
|
||||
open = codecs.open
|
||||
basestring = basestring
|
||||
|
||||
|
||||
elif is_py3:
|
||||
elif is_py3: # pragma: nocover
|
||||
|
||||
def u(text):
|
||||
if text is None:
|
||||
return None
|
||||
if isinstance(text, bytes):
|
||||
return text.decode('utf-8')
|
||||
return str(text)
|
||||
try:
|
||||
return text.decode('utf-8')
|
||||
except:
|
||||
try:
|
||||
return text.decode(sys.getdefaultencoding())
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
return str(text)
|
||||
except:
|
||||
return text.decode('utf-8', 'replace')
|
||||
open = open
|
||||
basestring = (str, bytes)
|
||||
|
||||
|
||||
try:
|
||||
from importlib import import_module
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
def _resolve_name(name, package, level):
|
||||
"""Return the absolute name of the module to be imported."""
|
||||
if not hasattr(package, 'rindex'):
|
||||
|
||||
40
packages/wakatime/constants.py
Normal file
40
packages/wakatime/constants.py
Normal file
@ -0,0 +1,40 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.constants
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Constant variable definitions.
|
||||
|
||||
:copyright: (c) 2016 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
""" Success
|
||||
Exit code used when a heartbeat was sent successfully.
|
||||
"""
|
||||
SUCCESS = 0
|
||||
|
||||
""" Api Error
|
||||
Exit code used when the WakaTime API returned an error.
|
||||
"""
|
||||
API_ERROR = 102
|
||||
|
||||
""" Config File Parse Error
|
||||
Exit code used when the ~/.wakatime.cfg config file could not be parsed.
|
||||
"""
|
||||
CONFIG_FILE_PARSE_ERROR = 103
|
||||
|
||||
""" Auth Error
|
||||
Exit code used when our api key is invalid.
|
||||
"""
|
||||
AUTH_ERROR = 104
|
||||
|
||||
""" Unknown Error
|
||||
Exit code used when there was an unhandled exception.
|
||||
"""
|
||||
UNKNOWN_ERROR = 105
|
||||
|
||||
""" Malformed Heartbeat Error
|
||||
Exit code used when the JSON input from `--extra-heartbeats` is malformed.
|
||||
"""
|
||||
MALFORMED_HEARTBEAT_ERROR = 106
|
||||
@ -1,7 +1,7 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
wakatime.dependencies
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from a source code file.
|
||||
|
||||
@ -10,9 +10,11 @@
|
||||
"""
|
||||
|
||||
import logging
|
||||
import traceback
|
||||
import re
|
||||
import sys
|
||||
|
||||
from ..compat import u, open, import_module
|
||||
from ..exceptions import NotYetImplemented
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
@ -23,26 +25,28 @@ class TokenParser(object):
|
||||
language, inherit from this class and implement the :meth:`parse` method
|
||||
to return a list of dependency strings.
|
||||
"""
|
||||
source_file = None
|
||||
lexer = None
|
||||
dependencies = []
|
||||
tokens = []
|
||||
exclude = []
|
||||
|
||||
def __init__(self, source_file, lexer=None):
|
||||
self._tokens = None
|
||||
self.dependencies = []
|
||||
self.source_file = source_file
|
||||
self.lexer = lexer
|
||||
self.exclude = [re.compile(x, re.IGNORECASE) for x in self.exclude]
|
||||
|
||||
@property
|
||||
def tokens(self):
|
||||
if self._tokens is None:
|
||||
self._tokens = self._extract_tokens()
|
||||
return self._tokens
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
""" Should return a list of dependencies.
|
||||
"""
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
raise Exception('Not yet implemented.')
|
||||
raise NotYetImplemented()
|
||||
|
||||
def append(self, dep, truncate=False, separator=None, truncate_to=None,
|
||||
strip_whitespace=True):
|
||||
if dep == 'as':
|
||||
print('***************** as')
|
||||
self._save_dependency(
|
||||
dep,
|
||||
truncate=truncate,
|
||||
@ -51,10 +55,21 @@ class TokenParser(object):
|
||||
strip_whitespace=strip_whitespace,
|
||||
)
|
||||
|
||||
def partial(self, token):
|
||||
return u(token).split('.')[-1]
|
||||
|
||||
def _extract_tokens(self):
|
||||
if self.lexer:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding='utf-8') as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000))
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
with open(self.source_file, 'r', encoding=sys.getfilesystemencoding()) as fh:
|
||||
return self.lexer.get_tokens_unprocessed(fh.read(512000)) # pragma: nocover
|
||||
except:
|
||||
pass
|
||||
return []
|
||||
|
||||
def _save_dependency(self, dep, truncate=False, separator=None,
|
||||
@ -64,13 +79,21 @@ class TokenParser(object):
|
||||
separator = u('.')
|
||||
separator = u(separator)
|
||||
dep = dep.split(separator)
|
||||
if truncate_to is None or truncate_to < 0 or truncate_to > len(dep) - 1:
|
||||
truncate_to = len(dep) - 1
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[0:truncate_to])
|
||||
if truncate_to is None or truncate_to < 1:
|
||||
truncate_to = 1
|
||||
if truncate_to > len(dep):
|
||||
truncate_to = len(dep)
|
||||
dep = dep[0] if len(dep) == 1 else separator.join(dep[:truncate_to])
|
||||
if strip_whitespace:
|
||||
dep = dep.strip()
|
||||
if dep:
|
||||
self.dependencies.append(dep)
|
||||
if dep and (not separator or not dep.startswith(separator)):
|
||||
should_exclude = False
|
||||
for compiled in self.exclude:
|
||||
if compiled.search(dep):
|
||||
should_exclude = True
|
||||
break
|
||||
if not should_exclude:
|
||||
self.dependencies.append(dep)
|
||||
|
||||
|
||||
class DependencyParser(object):
|
||||
@ -83,7 +106,7 @@ class DependencyParser(object):
|
||||
self.lexer = lexer
|
||||
|
||||
if self.lexer:
|
||||
module_name = self.lexer.__module__.split('.')[-1]
|
||||
module_name = self.lexer.__module__.rsplit('.', 1)[-1]
|
||||
class_name = self.lexer.__class__.__name__.replace('Lexer', 'Parser', 1)
|
||||
else:
|
||||
module_name = 'unknown'
|
||||
@ -96,7 +119,7 @@ class DependencyParser(object):
|
||||
except AttributeError:
|
||||
log.debug('Module {0} is missing class {1}'.format(module.__name__, class_name))
|
||||
except ImportError:
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback(logging.DEBUG)
|
||||
|
||||
def parse(self):
|
||||
if self.parser:
|
||||
51
packages/wakatime/dependencies/c_cpp.py
Normal file
51
packages/wakatime/dependencies/c_cpp.py
Normal file
@ -0,0 +1,51 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class CParser(TokenParser):
|
||||
exclude = [
|
||||
r'^stdio\.h$',
|
||||
r'^stdlib\.h$',
|
||||
r'^string\.h$',
|
||||
r'^time\.h$',
|
||||
]
|
||||
state = None
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Preproc' or self.partial(token) == 'PreprocFile':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '\n' and content != '#':
|
||||
content = content.strip().strip('"').strip('<').strip('>').strip()
|
||||
self.append(content, truncate=True, separator='/')
|
||||
self.state = None
|
||||
elif content.strip().startswith('include'):
|
||||
self.state = 'include'
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
|
||||
class CppParser(CParser):
|
||||
pass
|
||||
@ -26,10 +26,8 @@ class JsonParser(TokenParser):
|
||||
state = None
|
||||
level = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
64
packages/wakatime/dependencies/dotnet.py
Normal file
64
packages/wakatime/dependencies/dotnet.py
Normal file
@ -0,0 +1,64 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
exclude = [
|
||||
r'^system$',
|
||||
r'^microsoft$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
if self.partial(token) == 'Namespace' or self.partial(token) == 'Name':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_keyword(self, token, content):
|
||||
if content == 'using':
|
||||
self.state = 'import'
|
||||
self.buffer = u('')
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) != u('import') and u(content) != u('package') and u(content) != u('namespace') and u(content) != u('static'):
|
||||
if u(content) == u(';'): # pragma: nocover
|
||||
self._process_punctuation(token, content)
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if self.state == 'import':
|
||||
if u(content) == u(';'):
|
||||
self.append(self.buffer, truncate=True)
|
||||
self.buffer = u('')
|
||||
self.state = None
|
||||
elif u(content) == u('='):
|
||||
self.buffer = u('')
|
||||
else:
|
||||
self.buffer += u(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
77
packages/wakatime/dependencies/go.py
Normal file
77
packages/wakatime/dependencies/go.py
Normal file
@ -0,0 +1,77 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.go
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Go code.
|
||||
|
||||
:copyright: (c) 2016 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class GoParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
aliases = 0
|
||||
exclude = [
|
||||
r'^"fmt"$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif self.partial(token) == 'String':
|
||||
self._process_string(token, content)
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
elif self.partial(token) == 'Other':
|
||||
self._process_other(token, content)
|
||||
else:
|
||||
self._process_misc(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
self.state = content
|
||||
self.parens = 0
|
||||
self.aliases = 0
|
||||
|
||||
def _process_string(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.append(content, truncate=False)
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
elif content == '.':
|
||||
self.aliases += 1
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state == 'import':
|
||||
if content == "\n" and self.parens <= 0:
|
||||
self.state = None
|
||||
self.parens = 0
|
||||
self.aliases = 0
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_other(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.aliases += 1
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_misc(self, token, content):
|
||||
self.state = None
|
||||
96
packages/wakatime/dependencies/jvm.py
Normal file
96
packages/wakatime/dependencies/jvm.py
Normal file
@ -0,0 +1,96 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
exclude = [
|
||||
r'^java\.',
|
||||
r'^javax\.',
|
||||
r'^import$',
|
||||
r'^package$',
|
||||
r'^namespace$',
|
||||
r'^static$',
|
||||
]
|
||||
state = None
|
||||
buffer = u('')
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
if self.partial(token) == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif self.partial(token) == 'Attribute':
|
||||
self._process_attribute(token, content)
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if u(content) == u('import'):
|
||||
self.state = 'import'
|
||||
|
||||
elif self.state == 'import':
|
||||
keywords = [
|
||||
u('package'),
|
||||
u('namespace'),
|
||||
u('static'),
|
||||
]
|
||||
if u(content) in keywords:
|
||||
return
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
elif self.state == 'import-finished':
|
||||
content = content.split(u('.'))
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
|
||||
elif len(content) > 1:
|
||||
if len(content[0]) == 3:
|
||||
content = content[1:]
|
||||
if content[-1] == u('*'):
|
||||
content = content[:len(content) - 1]
|
||||
|
||||
if len(content) == 1:
|
||||
self.append(content[0])
|
||||
elif len(content) > 1:
|
||||
self.append(u('.').join(content[:2]))
|
||||
|
||||
self.state = None
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if u(content) == u(';'):
|
||||
self.state = 'import-finished'
|
||||
self._process_namespace(token, self.buffer)
|
||||
self.state = None
|
||||
self.buffer = u('')
|
||||
elif self.state == 'import':
|
||||
self.buffer = u('{0}{1}').format(self.buffer, u(content))
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -17,15 +17,13 @@ class PhpParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Keyword':
|
||||
if self.partial(token) == 'Keyword':
|
||||
self._process_keyword(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
@ -33,9 +31,9 @@ class PhpParser(TokenParser):
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Name.Function':
|
||||
self._process_function(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
@ -63,10 +61,10 @@ class PhpParser(TokenParser):
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if self.state == 'include':
|
||||
if content != '"':
|
||||
if content != '"' and content != "'":
|
||||
content = content.strip()
|
||||
if u(token) == 'Token.Literal.String.Double':
|
||||
content = u('"{0}"').format(content)
|
||||
content = u("'{0}'").format(content)
|
||||
self.append(content)
|
||||
self.state = None
|
||||
|
||||
83
packages/wakatime/dependencies/python.py
Normal file
83
packages/wakatime/dependencies/python.py
Normal file
@ -0,0 +1,83 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.python
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Python code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
|
||||
|
||||
class PythonParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
nonpackage = False
|
||||
exclude = [
|
||||
r'^os$',
|
||||
r'^sys$',
|
||||
r'^sys\.',
|
||||
r'^__future__$',
|
||||
]
|
||||
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if self.partial(token) == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif self.partial(token) == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
elif self.partial(token) == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif self.partial(token) == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state is None:
|
||||
self.state = content
|
||||
else:
|
||||
if content == 'as':
|
||||
self.nonpackage = True
|
||||
else:
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == "\n" and self.parens == 0:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_import(self, token, content):
|
||||
if not self.nonpackage:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
self.state = 'import-2'
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=1)
|
||||
else:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
@ -69,45 +69,22 @@ KEYWORDS = [
|
||||
]
|
||||
|
||||
|
||||
class LassoJavascriptParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Other':
|
||||
self._process_name(token, content)
|
||||
elif u(token) == 'Token.Literal.String.Single' or u(token) == 'Token.Literal.String.Double':
|
||||
self._process_literal_string(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if content.lower() in KEYWORDS:
|
||||
self.append(content.lower())
|
||||
|
||||
def _process_literal_string(self, token, content):
|
||||
if 'famous/core/' in content.strip('"').strip("'"):
|
||||
self.append('famous')
|
||||
|
||||
|
||||
class HtmlDjangoParser(TokenParser):
|
||||
tags = []
|
||||
opening_tag = False
|
||||
getting_attrs = False
|
||||
current_attr = None
|
||||
current_attr_value = None
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
def parse(self):
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token) == 'Token.Name.Tag':
|
||||
if u(token) == 'Token.Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token) == 'Token.Name.Tag':
|
||||
self._process_tag(token, content)
|
||||
elif u(token) == 'Token.Literal.String':
|
||||
self._process_string(token, content)
|
||||
@ -118,26 +95,30 @@ class HtmlDjangoParser(TokenParser):
|
||||
def current_tag(self):
|
||||
return None if len(self.tags) == 0 else self.tags[0]
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
def _process_punctuation(self, token, content):
|
||||
if content.startswith('</') or content.startswith('/'):
|
||||
try:
|
||||
self.tags.pop(0)
|
||||
except IndexError:
|
||||
# ignore errors from malformed markup
|
||||
pass
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
elif content.startswith('<'):
|
||||
self.opening_tag = True
|
||||
elif content.startswith('>'):
|
||||
self.opening_tag = False
|
||||
self.getting_attrs = False
|
||||
|
||||
def _process_tag(self, token, content):
|
||||
if self.opening_tag:
|
||||
self.tags.insert(0, content.replace('<', '', 1).strip().lower())
|
||||
self.getting_attrs = True
|
||||
elif content.startswith('>'):
|
||||
self.getting_attrs = False
|
||||
self.current_attr = None
|
||||
|
||||
def _process_attribute(self, token, content):
|
||||
if self.getting_attrs:
|
||||
self.current_attr = content.lower().strip('=')
|
||||
else:
|
||||
self.current_attr = None
|
||||
self.current_attr_value = None
|
||||
|
||||
def _process_string(self, token, content):
|
||||
@ -160,8 +141,6 @@ class HtmlDjangoParser(TokenParser):
|
||||
elif content.startswith('"') or content.startswith("'"):
|
||||
if self.current_attr_value is None:
|
||||
self.current_attr_value = content
|
||||
else:
|
||||
self.current_attr_value += content
|
||||
|
||||
|
||||
class VelocityHtmlParser(HtmlDjangoParser):
|
||||
@ -22,7 +22,7 @@ FILES = {
|
||||
|
||||
class UnknownParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
def parse(self):
|
||||
self._process_file_name(os.path.basename(self.source_file))
|
||||
return self.dependencies
|
||||
|
||||
14
packages/wakatime/exceptions.py
Normal file
14
packages/wakatime/exceptions.py
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.exceptions
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Custom exceptions.
|
||||
|
||||
:copyright: (c) 2015 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
|
||||
class NotYetImplemented(Exception):
|
||||
"""This method needs to be implemented."""
|
||||
@ -1,37 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.c_cpp
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from C++ code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CppParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Preproc':
|
||||
self._process_preproc(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_preproc(self, token, content):
|
||||
if content.strip().startswith('include ') or content.strip().startswith("include\t"):
|
||||
content = content.replace('include', '', 1).strip()
|
||||
self.append(content)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
80
packages/wakatime/languages/default.json
Normal file
80
packages/wakatime/languages/default.json
Normal file
@ -0,0 +1,80 @@
|
||||
{
|
||||
"ActionScript": "ActionScript",
|
||||
"ApacheConf": "ApacheConf",
|
||||
"AppleScript": "AppleScript",
|
||||
"ASP": "ASP",
|
||||
"Assembly": "Assembly",
|
||||
"Awk": "Awk",
|
||||
"Bash": "Bash",
|
||||
"Basic": "Basic",
|
||||
"BrightScript": "BrightScript",
|
||||
"C": "C",
|
||||
"C#": "C#",
|
||||
"C++": "C++",
|
||||
"Clojure": "Clojure",
|
||||
"Cocoa": "Cocoa",
|
||||
"CoffeeScript": "CoffeeScript",
|
||||
"ColdFusion": "ColdFusion",
|
||||
"Common Lisp": "Common Lisp",
|
||||
"CSHTML": "CSHTML",
|
||||
"CSS": "CSS",
|
||||
"Dart": "Dart",
|
||||
"Delphi": "Delphi",
|
||||
"Elixir": "Elixir",
|
||||
"Elm": "Elm",
|
||||
"Emacs Lisp": "Emacs Lisp",
|
||||
"Erlang": "Erlang",
|
||||
"F#": "F#",
|
||||
"Fortran": "Fortran",
|
||||
"Go": "Go",
|
||||
"Gous": "Gosu",
|
||||
"Groovy": "Groovy",
|
||||
"Haml": "Haml",
|
||||
"HaXe": "HaXe",
|
||||
"Haskell": "Haskell",
|
||||
"HTML": "HTML",
|
||||
"INI": "INI",
|
||||
"Jade": "Jade",
|
||||
"Java": "Java",
|
||||
"JavaScript": "JavaScript",
|
||||
"JSON": "JSON",
|
||||
"JSX": "JSX",
|
||||
"Kotlin": "Kotlin",
|
||||
"LESS": "LESS",
|
||||
"Lua": "Lua",
|
||||
"Markdown": "Markdown",
|
||||
"Matlab": "Matlab",
|
||||
"Mustache": "Mustache",
|
||||
"OCaml": "OCaml",
|
||||
"Objective-C": "Objective-C",
|
||||
"Objective-C++": "Objective-C++",
|
||||
"Objective-J": "Objective-J",
|
||||
"Perl": "Perl",
|
||||
"PHP": "PHP",
|
||||
"PowerShell": "PowerShell",
|
||||
"Prolog": "Prolog",
|
||||
"Puppet": "Puppet",
|
||||
"Python": "Python",
|
||||
"R": "R",
|
||||
"reStructuredText": "reStructuredText",
|
||||
"Ruby": "Ruby",
|
||||
"Rust": "Rust",
|
||||
"Sass": "Sass",
|
||||
"Scala": "Scala",
|
||||
"Scheme": "Scheme",
|
||||
"SCSS": "SCSS",
|
||||
"Shell": "Shell",
|
||||
"Slim": "Slim",
|
||||
"Smalltalk": "Smalltalk",
|
||||
"SQL": "SQL",
|
||||
"Swift": "Swift",
|
||||
"Text": "Text",
|
||||
"Turing": "Turing",
|
||||
"Twig": "Twig",
|
||||
"TypeScript": "TypeScript",
|
||||
"VB.net": "VB.net",
|
||||
"VimL": "VimL",
|
||||
"XAML": "XAML",
|
||||
"XML": "XML",
|
||||
"YAML": "YAML"
|
||||
}
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.dotnet
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from .NET code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class CSharpParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,36 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.java
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Java code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class JavaParser(TokenParser):
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if content != 'import' and content != 'package' and content != 'namespace':
|
||||
self.append(content, truncate=True)
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
@ -1,120 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.languages.python
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Parse dependencies from Python code.
|
||||
|
||||
:copyright: (c) 2014 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from . import TokenParser
|
||||
from ..compat import u
|
||||
|
||||
|
||||
class PythonParser(TokenParser):
|
||||
state = None
|
||||
parens = 0
|
||||
nonpackage = False
|
||||
|
||||
def parse(self, tokens=[]):
|
||||
if not tokens and not self.tokens:
|
||||
self.tokens = self._extract_tokens()
|
||||
for index, token, content in self.tokens:
|
||||
self._process_token(token, content)
|
||||
return self.dependencies
|
||||
|
||||
def _process_token(self, token, content):
|
||||
if u(token).split('.')[-1] == 'Namespace':
|
||||
self._process_namespace(token, content)
|
||||
elif u(token).split('.')[-1] == 'Name':
|
||||
self._process_name(token, content)
|
||||
elif u(token).split('.')[-1] == 'Word':
|
||||
self._process_word(token, content)
|
||||
elif u(token).split('.')[-1] == 'Operator':
|
||||
self._process_operator(token, content)
|
||||
elif u(token).split('.')[-1] == 'Punctuation':
|
||||
self._process_punctuation(token, content)
|
||||
elif u(token).split('.')[-1] == 'Text':
|
||||
self._process_text(token, content)
|
||||
else:
|
||||
self._process_other(token, content)
|
||||
|
||||
def _process_namespace(self, token, content):
|
||||
if self.state is None:
|
||||
self.state = content
|
||||
else:
|
||||
if content == 'as':
|
||||
self.nonpackage = True
|
||||
else:
|
||||
self._process_import(token, content)
|
||||
|
||||
def _process_name(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_word(self, token, content):
|
||||
if self.state is not None:
|
||||
if self.nonpackage:
|
||||
self.nonpackage = False
|
||||
else:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
if self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
|
||||
def _process_operator(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == '.':
|
||||
self.nonpackage = True
|
||||
|
||||
def _process_punctuation(self, token, content):
|
||||
if content == '(':
|
||||
self.parens += 1
|
||||
elif content == ')':
|
||||
self.parens -= 1
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_text(self, token, content):
|
||||
if self.state is not None:
|
||||
if content == "\n" and self.parens == 0:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
|
||||
def _process_other(self, token, content):
|
||||
pass
|
||||
|
||||
def _process_import(self, token, content):
|
||||
if not self.nonpackage:
|
||||
if self.state == 'from':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.state = 'from-2'
|
||||
elif self.state == 'from-2' and content != 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
elif self.state == 'import':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
self.state = 'import-2'
|
||||
elif self.state == 'import-2':
|
||||
self.append(content, truncate=True, truncate_to=0)
|
||||
else:
|
||||
self.state = None
|
||||
self.nonpackage = False
|
||||
531
packages/wakatime/languages/vim.json
Normal file
531
packages/wakatime/languages/vim.json
Normal file
@ -0,0 +1,531 @@
|
||||
{
|
||||
"a2ps": null,
|
||||
"a65": "Assembly",
|
||||
"aap": null,
|
||||
"abap": null,
|
||||
"abaqus": null,
|
||||
"abc": null,
|
||||
"abel": null,
|
||||
"acedb": null,
|
||||
"ada": null,
|
||||
"aflex": null,
|
||||
"ahdl": null,
|
||||
"alsaconf": null,
|
||||
"amiga": null,
|
||||
"aml": null,
|
||||
"ampl": null,
|
||||
"ant": null,
|
||||
"antlr": null,
|
||||
"apache": null,
|
||||
"apachestyle": null,
|
||||
"arch": null,
|
||||
"art": null,
|
||||
"asm": "Assembly",
|
||||
"asm68k": "Assembly",
|
||||
"asmh8300": "Assembly",
|
||||
"asn": null,
|
||||
"aspperl": null,
|
||||
"aspvbs": null,
|
||||
"asterisk": null,
|
||||
"asteriskvm": null,
|
||||
"atlas": null,
|
||||
"autohotkey": null,
|
||||
"autoit": null,
|
||||
"automake": null,
|
||||
"ave": null,
|
||||
"awk": null,
|
||||
"ayacc": null,
|
||||
"b": null,
|
||||
"baan": null,
|
||||
"basic": "Basic",
|
||||
"bc": null,
|
||||
"bdf": null,
|
||||
"bib": null,
|
||||
"bindzone": null,
|
||||
"blank": null,
|
||||
"bst": null,
|
||||
"btm": null,
|
||||
"bzr": null,
|
||||
"c": "C",
|
||||
"cabal": null,
|
||||
"calendar": null,
|
||||
"catalog": null,
|
||||
"cdl": null,
|
||||
"cdrdaoconf": null,
|
||||
"cdrtoc": null,
|
||||
"cf": null,
|
||||
"cfg": null,
|
||||
"ch": null,
|
||||
"chaiscript": null,
|
||||
"change": null,
|
||||
"changelog": null,
|
||||
"chaskell": null,
|
||||
"cheetah": null,
|
||||
"chill": null,
|
||||
"chordpro": null,
|
||||
"cl": null,
|
||||
"clean": null,
|
||||
"clipper": null,
|
||||
"cmake": null,
|
||||
"cmusrc": null,
|
||||
"cobol": null,
|
||||
"coco": null,
|
||||
"conaryrecipe": null,
|
||||
"conf": null,
|
||||
"config": null,
|
||||
"context": null,
|
||||
"cpp": "C++",
|
||||
"crm": null,
|
||||
"crontab": "Crontab",
|
||||
"cs": "C#",
|
||||
"csc": null,
|
||||
"csh": null,
|
||||
"csp": null,
|
||||
"css": null,
|
||||
"cterm": null,
|
||||
"ctrlh": null,
|
||||
"cucumber": null,
|
||||
"cuda": null,
|
||||
"cupl": null,
|
||||
"cuplsim": null,
|
||||
"cvs": null,
|
||||
"cvsrc": null,
|
||||
"cweb": null,
|
||||
"cynlib": null,
|
||||
"cynpp": null,
|
||||
"d": null,
|
||||
"datascript": null,
|
||||
"dcd": null,
|
||||
"dcl": null,
|
||||
"debchangelog": null,
|
||||
"debcontrol": null,
|
||||
"debsources": null,
|
||||
"def": null,
|
||||
"denyhosts": null,
|
||||
"desc": null,
|
||||
"desktop": null,
|
||||
"dictconf": null,
|
||||
"dictdconf": null,
|
||||
"diff": null,
|
||||
"dircolors": null,
|
||||
"diva": null,
|
||||
"django": null,
|
||||
"dns": null,
|
||||
"docbk": null,
|
||||
"docbksgml": null,
|
||||
"docbkxml": null,
|
||||
"dosbatch": null,
|
||||
"dosini": null,
|
||||
"dot": null,
|
||||
"doxygen": null,
|
||||
"dracula": null,
|
||||
"dsl": null,
|
||||
"dtd": null,
|
||||
"dtml": null,
|
||||
"dtrace": null,
|
||||
"dylan": null,
|
||||
"dylanintr": null,
|
||||
"dylanlid": null,
|
||||
"ecd": null,
|
||||
"edif": null,
|
||||
"eiffel": null,
|
||||
"elf": null,
|
||||
"elinks": null,
|
||||
"elmfilt": null,
|
||||
"erlang": null,
|
||||
"eruby": null,
|
||||
"esmtprc": null,
|
||||
"esqlc": null,
|
||||
"esterel": null,
|
||||
"eterm": null,
|
||||
"eviews": null,
|
||||
"exim": null,
|
||||
"expect": null,
|
||||
"exports": null,
|
||||
"fan": null,
|
||||
"fasm": null,
|
||||
"fdcc": null,
|
||||
"fetchmail": null,
|
||||
"fgl": null,
|
||||
"flexwiki": null,
|
||||
"focexec": null,
|
||||
"form": null,
|
||||
"forth": null,
|
||||
"fortran": null,
|
||||
"foxpro": null,
|
||||
"framescript": null,
|
||||
"freebasic": null,
|
||||
"fstab": null,
|
||||
"fvwm": null,
|
||||
"fvwm2m4": null,
|
||||
"gdb": null,
|
||||
"gdmo": null,
|
||||
"gedcom": null,
|
||||
"git": null,
|
||||
"gitcommit": null,
|
||||
"gitconfig": null,
|
||||
"gitrebase": null,
|
||||
"gitsendemail": null,
|
||||
"gkrellmrc": null,
|
||||
"gnuplot": null,
|
||||
"gp": null,
|
||||
"gpg": null,
|
||||
"grads": null,
|
||||
"gretl": null,
|
||||
"groff": null,
|
||||
"groovy": null,
|
||||
"group": null,
|
||||
"grub": null,
|
||||
"gsp": null,
|
||||
"gtkrc": null,
|
||||
"haml": "Haml",
|
||||
"hamster": null,
|
||||
"haskell": "Haskell",
|
||||
"haste": null,
|
||||
"hastepreproc": null,
|
||||
"hb": null,
|
||||
"help": null,
|
||||
"hercules": null,
|
||||
"hex": null,
|
||||
"hog": null,
|
||||
"hostconf": null,
|
||||
"html": "HTML",
|
||||
"htmlcheetah": "HTML",
|
||||
"htmldjango": "HTML",
|
||||
"htmlm4": "HTML",
|
||||
"htmlos": null,
|
||||
"ia64": null,
|
||||
"ibasic": null,
|
||||
"icemenu": null,
|
||||
"icon": null,
|
||||
"idl": null,
|
||||
"idlang": null,
|
||||
"indent": null,
|
||||
"inform": null,
|
||||
"initex": null,
|
||||
"initng": null,
|
||||
"inittab": null,
|
||||
"ipfilter": null,
|
||||
"ishd": null,
|
||||
"iss": null,
|
||||
"ist": null,
|
||||
"jal": null,
|
||||
"jam": null,
|
||||
"jargon": null,
|
||||
"java": "Java",
|
||||
"javacc": null,
|
||||
"javascript": "JavaScript",
|
||||
"jess": null,
|
||||
"jgraph": null,
|
||||
"jproperties": null,
|
||||
"jsp": null,
|
||||
"kconfig": null,
|
||||
"kix": null,
|
||||
"kscript": null,
|
||||
"kwt": null,
|
||||
"lace": null,
|
||||
"latte": null,
|
||||
"ld": null,
|
||||
"ldapconf": null,
|
||||
"ldif": null,
|
||||
"lex": null,
|
||||
"lftp": null,
|
||||
"lhaskell": "Haskell",
|
||||
"libao": null,
|
||||
"lifelines": null,
|
||||
"lilo": null,
|
||||
"limits": null,
|
||||
"liquid": null,
|
||||
"lisp": null,
|
||||
"lite": null,
|
||||
"litestep": null,
|
||||
"loginaccess": null,
|
||||
"logindefs": null,
|
||||
"logtalk": null,
|
||||
"lotos": null,
|
||||
"lout": null,
|
||||
"lpc": null,
|
||||
"lprolog": null,
|
||||
"lscript": null,
|
||||
"lsl": null,
|
||||
"lss": null,
|
||||
"lua": null,
|
||||
"lynx": null,
|
||||
"m4": null,
|
||||
"mail": null,
|
||||
"mailaliases": null,
|
||||
"mailcap": null,
|
||||
"make": null,
|
||||
"man": null,
|
||||
"manconf": null,
|
||||
"manual": null,
|
||||
"maple": null,
|
||||
"markdown": "Markdown",
|
||||
"masm": null,
|
||||
"mason": null,
|
||||
"master": null,
|
||||
"matlab": null,
|
||||
"maxima": null,
|
||||
"mel": null,
|
||||
"messages": null,
|
||||
"mf": null,
|
||||
"mgl": null,
|
||||
"mgp": null,
|
||||
"mib": null,
|
||||
"mma": null,
|
||||
"mmix": null,
|
||||
"mmp": null,
|
||||
"modconf": null,
|
||||
"model": null,
|
||||
"modsim3": null,
|
||||
"modula2": null,
|
||||
"modula3": null,
|
||||
"monk": null,
|
||||
"moo": null,
|
||||
"mp": null,
|
||||
"mplayerconf": null,
|
||||
"mrxvtrc": null,
|
||||
"msidl": null,
|
||||
"msmessages": null,
|
||||
"msql": null,
|
||||
"mupad": null,
|
||||
"mush": null,
|
||||
"muttrc": null,
|
||||
"mysql": null,
|
||||
"named": null,
|
||||
"nanorc": null,
|
||||
"nasm": null,
|
||||
"nastran": null,
|
||||
"natural": null,
|
||||
"ncf": null,
|
||||
"netrc": null,
|
||||
"netrw": null,
|
||||
"nosyntax": null,
|
||||
"nqc": null,
|
||||
"nroff": null,
|
||||
"nsis": null,
|
||||
"obj": null,
|
||||
"objc": "Objective-C",
|
||||
"objcpp": "Objective-C++",
|
||||
"ocaml": "OCaml",
|
||||
"occam": null,
|
||||
"omnimark": null,
|
||||
"openroad": null,
|
||||
"opl": null,
|
||||
"ora": null,
|
||||
"pamconf": null,
|
||||
"papp": null,
|
||||
"pascal": null,
|
||||
"passwd": null,
|
||||
"pcap": null,
|
||||
"pccts": null,
|
||||
"pdf": null,
|
||||
"perl": "Perl",
|
||||
"perl6": "Perl",
|
||||
"pf": null,
|
||||
"pfmain": null,
|
||||
"php": "PHP",
|
||||
"phtml": "PHP",
|
||||
"pic": null,
|
||||
"pike": null,
|
||||
"pilrc": null,
|
||||
"pine": null,
|
||||
"pinfo": null,
|
||||
"plaintex": null,
|
||||
"plm": null,
|
||||
"plp": null,
|
||||
"plsql": null,
|
||||
"po": null,
|
||||
"pod": null,
|
||||
"postscr": null,
|
||||
"pov": null,
|
||||
"povini": null,
|
||||
"ppd": null,
|
||||
"ppwiz": null,
|
||||
"prescribe": null,
|
||||
"privoxy": null,
|
||||
"procmail": null,
|
||||
"progress": null,
|
||||
"prolog": "Prolog",
|
||||
"promela": null,
|
||||
"protocols": null,
|
||||
"psf": null,
|
||||
"ptcap": null,
|
||||
"purifylog": null,
|
||||
"pyrex": null,
|
||||
"python": "Python",
|
||||
"qf": null,
|
||||
"quake": null,
|
||||
"r": "R",
|
||||
"racc": null,
|
||||
"radiance": null,
|
||||
"ratpoison": null,
|
||||
"rc": null,
|
||||
"rcs": null,
|
||||
"rcslog": null,
|
||||
"readline": null,
|
||||
"rebol": null,
|
||||
"registry": null,
|
||||
"remind": null,
|
||||
"resolv": null,
|
||||
"reva": null,
|
||||
"rexx": null,
|
||||
"rhelp": null,
|
||||
"rib": null,
|
||||
"rnc": null,
|
||||
"rnoweb": null,
|
||||
"robots": null,
|
||||
"rpcgen": null,
|
||||
"rpl": null,
|
||||
"rst": null,
|
||||
"rtf": null,
|
||||
"ruby": "Ruby",
|
||||
"samba": null,
|
||||
"sas": null,
|
||||
"sass": "Sass",
|
||||
"sather": null,
|
||||
"scheme": "Scheme",
|
||||
"scilab": null,
|
||||
"screen": null,
|
||||
"scss": "SCSS",
|
||||
"sd": null,
|
||||
"sdc": null,
|
||||
"sdl": null,
|
||||
"sed": null,
|
||||
"sendpr": null,
|
||||
"sensors": null,
|
||||
"services": null,
|
||||
"setserial": null,
|
||||
"sgml": null,
|
||||
"sgmldecl": null,
|
||||
"sgmllnx": null,
|
||||
"sh": null,
|
||||
"sicad": null,
|
||||
"sieve": null,
|
||||
"simula": null,
|
||||
"sinda": null,
|
||||
"sindacmp": null,
|
||||
"sindaout": null,
|
||||
"sisu": null,
|
||||
"skill": "SKILL",
|
||||
"sl": null,
|
||||
"slang": null,
|
||||
"slice": null,
|
||||
"slpconf": null,
|
||||
"slpreg": null,
|
||||
"slpspi": null,
|
||||
"slrnrc": null,
|
||||
"slrnsc": null,
|
||||
"sm": null,
|
||||
"smarty": null,
|
||||
"smcl": null,
|
||||
"smil": null,
|
||||
"smith": null,
|
||||
"sml": null,
|
||||
"snnsnet": null,
|
||||
"snnspat": null,
|
||||
"snnsres": null,
|
||||
"snobol4": null,
|
||||
"spec": null,
|
||||
"specman": null,
|
||||
"spice": null,
|
||||
"splint": null,
|
||||
"spup": null,
|
||||
"spyce": null,
|
||||
"sql": null,
|
||||
"sqlanywhere": null,
|
||||
"sqlforms": null,
|
||||
"sqlinformix": null,
|
||||
"sqlj": null,
|
||||
"sqloracle": null,
|
||||
"sqr": null,
|
||||
"squid": null,
|
||||
"sshconfig": null,
|
||||
"sshdconfig": null,
|
||||
"st": null,
|
||||
"stata": null,
|
||||
"stp": null,
|
||||
"strace": null,
|
||||
"sudoers": null,
|
||||
"svg": null,
|
||||
"svn": null,
|
||||
"syncolor": null,
|
||||
"synload": null,
|
||||
"syntax": null,
|
||||
"sysctl": null,
|
||||
"tads": null,
|
||||
"tags": null,
|
||||
"tak": null,
|
||||
"takcmp": null,
|
||||
"takout": null,
|
||||
"tar": null,
|
||||
"taskdata": null,
|
||||
"taskedit": null,
|
||||
"tasm": null,
|
||||
"tcl": null,
|
||||
"tcsh": null,
|
||||
"terminfo": null,
|
||||
"tex": null,
|
||||
"texinfo": null,
|
||||
"texmf": null,
|
||||
"tf": null,
|
||||
"tidy": null,
|
||||
"tilde": null,
|
||||
"tli": null,
|
||||
"tpp": null,
|
||||
"trasys": null,
|
||||
"trustees": null,
|
||||
"tsalt": null,
|
||||
"tsscl": null,
|
||||
"tssgm": null,
|
||||
"tssop": null,
|
||||
"uc": null,
|
||||
"udevconf": null,
|
||||
"udevperm": null,
|
||||
"udevrules": null,
|
||||
"uil": null,
|
||||
"updatedb": null,
|
||||
"valgrind": null,
|
||||
"vb": "VB.net",
|
||||
"vera": null,
|
||||
"verilog": null,
|
||||
"verilogams": null,
|
||||
"vgrindefs": null,
|
||||
"vhdl": null,
|
||||
"vim": "VimL",
|
||||
"viminfo": null,
|
||||
"virata": null,
|
||||
"vmasm": null,
|
||||
"voscm": null,
|
||||
"vrml": null,
|
||||
"vsejcl": null,
|
||||
"wdiff": null,
|
||||
"web": null,
|
||||
"webmacro": null,
|
||||
"wget": null,
|
||||
"winbatch": null,
|
||||
"wml": null,
|
||||
"wsh": null,
|
||||
"wsml": null,
|
||||
"wvdial": null,
|
||||
"xbl": null,
|
||||
"xdefaults": null,
|
||||
"xf86conf": null,
|
||||
"xhtml": "HTML",
|
||||
"xinetd": null,
|
||||
"xkb": null,
|
||||
"xmath": null,
|
||||
"xml": "XML",
|
||||
"xmodmap": null,
|
||||
"xpm": null,
|
||||
"xpm2": null,
|
||||
"xquery": null,
|
||||
"xs": null,
|
||||
"xsd": null,
|
||||
"xslt": null,
|
||||
"xxd": null,
|
||||
"yacc": null,
|
||||
"yaml": "YAML",
|
||||
"z8a": null,
|
||||
"zsh": null
|
||||
}
|
||||
@ -11,37 +11,27 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import traceback
|
||||
|
||||
from .packages import simplejson as json
|
||||
from .compat import u
|
||||
from .packages.requests.packages import urllib3
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from collections import OrderedDict # pragma: nocover
|
||||
except ImportError: # pragma: nocover
|
||||
from .packages.ordereddict import OrderedDict
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes):
|
||||
obj = bytes.decode(obj)
|
||||
return json.dumps(obj)
|
||||
try:
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
except UnicodeDecodeError:
|
||||
obj = u(obj)
|
||||
encoded = super(CustomEncoder, self).default(obj)
|
||||
return encoded
|
||||
try:
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, isWrite, targetFile, version, plugin, verbose,
|
||||
def setup(self, timestamp, is_write, entity, version, plugin, verbose,
|
||||
warnings=False):
|
||||
self.timestamp = timestamp
|
||||
self.isWrite = isWrite
|
||||
self.targetFile = targetFile
|
||||
self.is_write = is_write
|
||||
self.entity = entity
|
||||
self.version = version
|
||||
self.plugin = plugin
|
||||
self.verbose = verbose
|
||||
@ -51,24 +41,25 @@ class JsonFormatter(logging.Formatter):
|
||||
data = OrderedDict([
|
||||
('now', self.formatTime(record, self.datefmt)),
|
||||
])
|
||||
data['version'] = self.version
|
||||
data['plugin'] = self.plugin
|
||||
data['version'] = u(self.version)
|
||||
if self.plugin:
|
||||
data['plugin'] = u(self.plugin)
|
||||
data['time'] = self.timestamp
|
||||
if self.verbose:
|
||||
data['caller'] = record.pathname
|
||||
data['caller'] = u(record.pathname)
|
||||
data['lineno'] = record.lineno
|
||||
data['isWrite'] = self.isWrite
|
||||
data['file'] = self.targetFile
|
||||
if not self.isWrite:
|
||||
del data['isWrite']
|
||||
if self.is_write:
|
||||
data['is_write'] = self.is_write
|
||||
data['file'] = u(self.entity)
|
||||
data['level'] = record.levelname
|
||||
data['message'] = record.getMessage() if self.warnings else record.msg
|
||||
if not self.plugin:
|
||||
del data['plugin']
|
||||
return CustomEncoder().encode(data)
|
||||
data['message'] = u(record.getMessage() if self.warnings else record.msg)
|
||||
return json.dumps(data)
|
||||
|
||||
def formatException(self, exc_info):
|
||||
return sys.exec_info[2].format_exc()
|
||||
def traceback(self, lvl=None):
|
||||
logger = logging.getLogger('WakaTime')
|
||||
if not lvl:
|
||||
lvl = logger.getEffectiveLevel()
|
||||
logger.log(lvl, traceback.format_exc())
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
@ -79,20 +70,11 @@ def set_log_level(logger, args):
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
urllib3.disable_warnings()
|
||||
logger = logging.getLogger('WakaTime')
|
||||
for handler in logger.handlers:
|
||||
logger.removeHandler(handler)
|
||||
set_log_level(logger, args)
|
||||
if len(logger.handlers) > 0:
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
)
|
||||
logger.handlers[0].setFormatter(formatter)
|
||||
return logger
|
||||
logfile = args.logfile
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
@ -100,8 +82,8 @@ def setup_logging(args, version):
|
||||
formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
is_write=args.is_write,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
@ -109,11 +91,14 @@ def setup_logging(args, version):
|
||||
handler.setFormatter(formatter)
|
||||
logger.addHandler(handler)
|
||||
|
||||
# add custom traceback logging method
|
||||
logger.traceback = formatter.traceback
|
||||
|
||||
warnings_formatter = JsonFormatter(datefmt='%Y/%m/%d %H:%M:%S %z')
|
||||
warnings_formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
is_write=args.is_write,
|
||||
entity=args.entity,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
verbose=args.verbose,
|
||||
@ -124,7 +109,7 @@ def setup_logging(args, version):
|
||||
logging.getLogger('py.warnings').addHandler(warnings_handler)
|
||||
try:
|
||||
logging.captureWarnings(True)
|
||||
except AttributeError:
|
||||
except AttributeError: # pragma: nocover
|
||||
pass # Python >= 2.7 is needed to capture warnings
|
||||
|
||||
return logger
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.base
|
||||
wakatime.main
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
wakatime module entry point.
|
||||
@ -19,28 +19,39 @@ import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
import socket
|
||||
try:
|
||||
import ConfigParser as configparser
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
import configparser
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
pwd = os.path.dirname(os.path.abspath(__file__))
|
||||
sys.path.insert(0, os.path.dirname(pwd))
|
||||
sys.path.insert(0, os.path.join(pwd, 'packages'))
|
||||
|
||||
from .__about__ import __version__
|
||||
from .compat import u, open, is_py3
|
||||
from .constants import (
|
||||
API_ERROR,
|
||||
AUTH_ERROR,
|
||||
CONFIG_FILE_PARSE_ERROR,
|
||||
SUCCESS,
|
||||
UNKNOWN_ERROR,
|
||||
MALFORMED_HEARTBEAT_ERROR,
|
||||
)
|
||||
from .logger import setup_logging
|
||||
from .offlinequeue import Queue
|
||||
from .packages import argparse
|
||||
from .packages import simplejson as json
|
||||
from .packages import requests
|
||||
from .packages.requests.exceptions import RequestException
|
||||
from .project import find_project
|
||||
from .project import get_project_info
|
||||
from .session_cache import SessionCache
|
||||
from .stats import get_file_stats
|
||||
try:
|
||||
from .packages import tzlocal
|
||||
except:
|
||||
from .packages import tzlocal3 as tzlocal
|
||||
from .packages import simplejson as json # pragma: nocover
|
||||
except (ImportError, SyntaxError): # pragma: nocover
|
||||
import json
|
||||
from .packages import tzlocal
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
@ -49,49 +60,14 @@ log = logging.getLogger('WakaTime')
|
||||
class FileAction(argparse.Action):
|
||||
|
||||
def __call__(self, parser, namespace, values, option_string=None):
|
||||
values = os.path.realpath(values)
|
||||
try:
|
||||
if os.path.isfile(values):
|
||||
values = os.path.realpath(values)
|
||||
except: # pragma: nocover
|
||||
pass
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def upgradeConfigFile(configFile):
|
||||
"""For backwards-compatibility, upgrade the existing config file
|
||||
to work with configparser and rename from .wakatime.conf to .wakatime.cfg.
|
||||
"""
|
||||
|
||||
if os.path.isfile(configFile):
|
||||
# if upgraded cfg file already exists, don't overwrite it
|
||||
return
|
||||
|
||||
oldConfig = os.path.join(os.path.expanduser('~'), '.wakatime.conf')
|
||||
try:
|
||||
configs = {
|
||||
'ignore': [],
|
||||
}
|
||||
|
||||
with open(oldConfig, 'r', encoding='utf-8') as fh:
|
||||
for line in fh.readlines():
|
||||
line = line.split('=', 1)
|
||||
if len(line) == 2 and line[0].strip() and line[1].strip():
|
||||
if line[0].strip() == 'ignore':
|
||||
configs['ignore'].append(line[1].strip())
|
||||
else:
|
||||
configs[line[0].strip()] = line[1].strip()
|
||||
|
||||
with open(configFile, 'w', encoding='utf-8') as fh:
|
||||
fh.write("[settings]\n")
|
||||
for name, value in configs.items():
|
||||
if isinstance(value, list):
|
||||
fh.write("%s=\n" % name)
|
||||
for item in value:
|
||||
fh.write(" %s\n" % item)
|
||||
else:
|
||||
fh.write("%s = %s\n" % (name, value))
|
||||
|
||||
os.remove(oldConfig)
|
||||
except IOError:
|
||||
pass
|
||||
|
||||
|
||||
def parseConfigFile(configFile=None):
|
||||
"""Returns a configparser.SafeConfigParser instance with configs
|
||||
read from the config file. Default location of the config file is
|
||||
@ -101,8 +77,6 @@ def parseConfigFile(configFile=None):
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.cfg')
|
||||
|
||||
upgradeConfigFile(configFile)
|
||||
|
||||
configs = configparser.SafeConfigParser()
|
||||
try:
|
||||
with open(configFile, 'r', encoding='utf-8') as fh:
|
||||
@ -116,27 +90,25 @@ def parseConfigFile(configFile=None):
|
||||
return configs
|
||||
|
||||
|
||||
def parseArguments(argv):
|
||||
def parseArguments():
|
||||
"""Parse command line arguments and configs from ~/.wakatime.cfg.
|
||||
Command line arguments take precedence over config file settings.
|
||||
Returns instances of ArgumentParser and SafeConfigParser.
|
||||
"""
|
||||
|
||||
try:
|
||||
sys.argv
|
||||
except AttributeError:
|
||||
sys.argv = argv
|
||||
|
||||
# define supported command line arguments
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Common interface for the WakaTime api.')
|
||||
parser.add_argument('--file', dest='targetFile', metavar='file',
|
||||
action=FileAction, required=True,
|
||||
help='absolute path to file for current heartbeat')
|
||||
parser.add_argument('--entity', dest='entity', metavar='FILE',
|
||||
action=FileAction,
|
||||
help='absolute path to file for the heartbeat; can also be a '+
|
||||
'url, domain, or app when --entity-type is not file')
|
||||
parser.add_argument('--file', dest='file', action=FileAction,
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakatime api key; uses api_key from '+
|
||||
'~/.wakatime.conf by default')
|
||||
parser.add_argument('--write', dest='isWrite',
|
||||
'~/.wakatime.cfg by default')
|
||||
parser.add_argument('--write', dest='is_write',
|
||||
action='store_true',
|
||||
help='when set, tells api this heartbeat was triggered from '+
|
||||
'writing to a file')
|
||||
@ -151,16 +123,24 @@ def parseArguments(argv):
|
||||
help='optional line number; current line being edited')
|
||||
parser.add_argument('--cursorpos', dest='cursorpos',
|
||||
help='optional cursor position in the current file')
|
||||
parser.add_argument('--notfile', dest='notfile', action='store_true',
|
||||
help='when set, will accept any value for the file. for example, '+
|
||||
'a domain name or other item you want to log time towards.')
|
||||
parser.add_argument('--entity-type', dest='entity_type',
|
||||
help='entity type for this heartbeat. can be one of "file", '+
|
||||
'"domain", or "app"; defaults to file.')
|
||||
parser.add_argument('--proxy', dest='proxy',
|
||||
help='optional https proxy url; for example: '+
|
||||
'https://user:pass@localhost:8080')
|
||||
help='optional proxy configuration. Supports HTTPS '+
|
||||
'and SOCKS proxies. For example: '+
|
||||
'https://user:pass@host:port or '+
|
||||
'socks5://user:pass@host:port')
|
||||
parser.add_argument('--project', dest='project',
|
||||
help='optional project name')
|
||||
parser.add_argument('--alternate-project', dest='alternate_project',
|
||||
help='optional alternate project name; auto-discovered project takes priority')
|
||||
help='optional alternate project name; auto-discovered project '+
|
||||
'takes priority')
|
||||
parser.add_argument('--alternate-language', dest='alternate_language',
|
||||
help='optional alternate language name; auto-detected language'+
|
||||
'takes priority')
|
||||
parser.add_argument('--hostname', dest='hostname', help='hostname of '+
|
||||
'current machine.')
|
||||
parser.add_argument('--disableoffline', dest='offline',
|
||||
action='store_false',
|
||||
help='disables offline time logging instead of queuing logged time')
|
||||
@ -176,18 +156,24 @@ def parseArguments(argv):
|
||||
'POSIX regex syntax; can be used more than once')
|
||||
parser.add_argument('--ignore', dest='ignore', action='append',
|
||||
help=argparse.SUPPRESS)
|
||||
parser.add_argument('--extra-heartbeats', dest='extra_heartbeats',
|
||||
action='store_true',
|
||||
help='reads extra heartbeats from STDIN as a JSON array until EOF')
|
||||
parser.add_argument('--logfile', dest='logfile',
|
||||
help='defaults to ~/.wakatime.log')
|
||||
parser.add_argument('--apiurl', dest='api_url',
|
||||
help='heartbeats api url; for debugging with a local server')
|
||||
parser.add_argument('--timeout', dest='timeout', type=int,
|
||||
help='number of seconds to wait when sending heartbeats to api; '+
|
||||
'defaults to 60 seconds')
|
||||
parser.add_argument('--config', dest='config',
|
||||
help='defaults to ~/.wakatime.conf')
|
||||
help='defaults to ~/.wakatime.cfg')
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
help='turns on debug messages in log file')
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
|
||||
# parse command line arguments
|
||||
args = parser.parse_args(args=argv[1:])
|
||||
args = parser.parse_args()
|
||||
|
||||
# use current unix epoch timestamp by default
|
||||
if not args.timestamp:
|
||||
@ -199,6 +185,9 @@ def parseArguments(argv):
|
||||
return args, configs
|
||||
|
||||
# update args from configs
|
||||
if not args.hostname:
|
||||
if configs.has_option('settings', 'hostname'):
|
||||
args.hostname = configs.get('settings', 'hostname')
|
||||
if not args.key:
|
||||
default_key = None
|
||||
if configs.has_option('settings', 'api_key'):
|
||||
@ -209,6 +198,11 @@ def parseArguments(argv):
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
if not args.entity:
|
||||
if args.file:
|
||||
args.entity = args.file
|
||||
else:
|
||||
parser.error('argument --entity is required')
|
||||
if not args.exclude:
|
||||
args.exclude = []
|
||||
if configs.has_option('settings', 'ignore'):
|
||||
@ -216,14 +210,14 @@ def parseArguments(argv):
|
||||
for pattern in configs.get('settings', 'ignore').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if configs.has_option('settings', 'exclude'):
|
||||
try:
|
||||
for pattern in configs.get('settings', 'exclude').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.exclude.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if not args.include:
|
||||
args.include = []
|
||||
@ -232,7 +226,7 @@ def parseArguments(argv):
|
||||
for pattern in configs.get('settings', 'include').split("\n"):
|
||||
if pattern.strip() != '':
|
||||
args.include.append(pattern)
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
if args.offline and configs.has_option('settings', 'offline'):
|
||||
args.offline = configs.getboolean('settings', 'offline')
|
||||
@ -248,37 +242,42 @@ def parseArguments(argv):
|
||||
args.logfile = configs.get('settings', 'logfile')
|
||||
if not args.api_url and configs.has_option('settings', 'api_url'):
|
||||
args.api_url = configs.get('settings', 'api_url')
|
||||
if not args.timeout and configs.has_option('settings', 'timeout'):
|
||||
try:
|
||||
args.timeout = int(configs.get('settings', 'timeout'))
|
||||
except ValueError:
|
||||
print(traceback.format_exc())
|
||||
|
||||
return args, configs
|
||||
|
||||
|
||||
def should_exclude(fileName, include, exclude):
|
||||
if fileName is not None and fileName.strip() != '':
|
||||
def should_exclude(entity, include, exclude):
|
||||
if entity is not None and entity.strip() != '':
|
||||
try:
|
||||
for pattern in include:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
if compiled.search(entity):
|
||||
return False
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for include pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
try:
|
||||
for pattern in exclude:
|
||||
try:
|
||||
compiled = re.compile(pattern, re.IGNORECASE)
|
||||
if compiled.search(fileName):
|
||||
if compiled.search(entity):
|
||||
return pattern
|
||||
except re.error as ex:
|
||||
log.warning(u('Regex error ({msg}) for exclude pattern: {pattern}').format(
|
||||
msg=u(ex),
|
||||
pattern=u(pattern),
|
||||
))
|
||||
except TypeError:
|
||||
except TypeError: # pragma: nocover
|
||||
pass
|
||||
return False
|
||||
|
||||
@ -303,26 +302,29 @@ def get_user_agent(plugin):
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=None,
|
||||
timestamp=None, isWrite=None, plugin=None, offline=None, notfile=False,
|
||||
hidefilenames=None, proxy=None, api_url=None, **kwargs):
|
||||
def send_heartbeat(project=None, branch=None, hostname=None, stats={}, key=None,
|
||||
entity=None, timestamp=None, is_write=None, plugin=None,
|
||||
offline=None, entity_type='file', hidefilenames=None,
|
||||
proxy=None, api_url=None, timeout=None, **kwargs):
|
||||
"""Sends heartbeat as POST request to WakaTime api server.
|
||||
|
||||
Returns `SUCCESS` when heartbeat was sent, otherwise returns an
|
||||
error code constant.
|
||||
"""
|
||||
|
||||
if not api_url:
|
||||
api_url = 'https://wakatime.com/api/v1/heartbeats'
|
||||
api_url = 'https://api.wakatime.com/api/v1/heartbeats'
|
||||
if not timeout:
|
||||
timeout = 60
|
||||
log.debug('Sending heartbeat to api at %s' % api_url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'entity': targetFile,
|
||||
'type': 'file',
|
||||
'entity': entity,
|
||||
'type': entity_type,
|
||||
}
|
||||
if hidefilenames and targetFile is not None and not notfile:
|
||||
data['entity'] = data['entity'].rsplit('/', 1)[-1].rsplit('\\', 1)[-1]
|
||||
if len(data['entity'].strip('.').split('.', 1)) > 1:
|
||||
data['entity'] = u('HIDDEN.{ext}').format(ext=u(data['entity'].strip('.').rsplit('.', 1)[-1]))
|
||||
else:
|
||||
data['entity'] = u('HIDDEN')
|
||||
if hidefilenames and entity is not None and entity_type == 'file':
|
||||
extension = u(os.path.splitext(data['entity'])[1])
|
||||
data['entity'] = u('HIDDEN{0}').format(extension)
|
||||
if stats.get('lines'):
|
||||
data['lines'] = stats['lines']
|
||||
if stats.get('language'):
|
||||
@ -333,8 +335,8 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
data['lineno'] = stats['lineno']
|
||||
if stats.get('cursorpos'):
|
||||
data['cursorpos'] = stats['cursorpos']
|
||||
if isWrite:
|
||||
data['is_write'] = isWrite
|
||||
if is_write:
|
||||
data['is_write'] = is_write
|
||||
if project:
|
||||
data['project'] = project
|
||||
if branch:
|
||||
@ -351,6 +353,8 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
'Accept': 'application/json',
|
||||
'Authorization': auth,
|
||||
}
|
||||
if hostname:
|
||||
headers['X-Machine-Name'] = u(hostname).encode('utf-8')
|
||||
proxies = {}
|
||||
if proxy:
|
||||
proxies['https'] = proxy
|
||||
@ -361,7 +365,7 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
except:
|
||||
tz = None
|
||||
if tz:
|
||||
headers['TimeZone'] = u(tz.zone)
|
||||
headers['TimeZone'] = u(tz.zone).encode('utf-8')
|
||||
|
||||
session_cache = SessionCache()
|
||||
session = session_cache.get()
|
||||
@ -370,7 +374,7 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
response = None
|
||||
try:
|
||||
response = session.post(api_url, data=request_body, headers=headers,
|
||||
proxies=proxies)
|
||||
proxies=proxies, timeout=timeout)
|
||||
except RequestException:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
@ -384,109 +388,177 @@ def send_heartbeat(project=None, branch=None, stats={}, key=None, targetFile=Non
|
||||
log.warn(exception_data)
|
||||
else:
|
||||
log.error(exception_data)
|
||||
|
||||
except: # delete cached session when requests raises unknown exception
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: u(sys.exc_info()[1]),
|
||||
'traceback': traceback.format_exc(),
|
||||
}
|
||||
if offline:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
log.warn(exception_data)
|
||||
session_cache.delete()
|
||||
|
||||
else:
|
||||
response_code = response.status_code if response is not None else None
|
||||
response_content = response.text if response is not None else None
|
||||
if response_code == 201:
|
||||
code = response.status_code if response is not None else None
|
||||
content = response.text if response is not None else None
|
||||
if code == requests.codes.created or code == requests.codes.accepted:
|
||||
log.debug({
|
||||
'response_code': response_code,
|
||||
'response_code': code,
|
||||
})
|
||||
session_cache.save(session)
|
||||
return True
|
||||
return SUCCESS
|
||||
if offline:
|
||||
if response_code != 400:
|
||||
if code != 400:
|
||||
queue = Queue()
|
||||
queue.push(data, json.dumps(stats), plugin)
|
||||
if response_code == 401:
|
||||
if code == 401:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return AUTH_ERROR
|
||||
elif log.isEnabledFor(logging.DEBUG):
|
||||
log.warn({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
else:
|
||||
log.error({
|
||||
'response_code': response_code,
|
||||
'response_content': response_content,
|
||||
'response_code': code,
|
||||
'response_content': content,
|
||||
})
|
||||
session_cache.delete()
|
||||
return False
|
||||
return API_ERROR
|
||||
|
||||
|
||||
def main(argv=None):
|
||||
if not argv:
|
||||
argv = sys.argv
|
||||
def sync_offline_heartbeats(args, hostname):
|
||||
"""Sends all heartbeats which were cached in the offline Queue."""
|
||||
|
||||
args, configs = parseArguments(argv)
|
||||
if configs is None:
|
||||
return 103 # config file parsing error
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
status = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
entity=heartbeat['entity'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
hostname=hostname,
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
is_write=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
entity_type=heartbeat['type'],
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
timeout=args.timeout,
|
||||
)
|
||||
if status != SUCCESS:
|
||||
if status == AUTH_ERROR:
|
||||
return AUTH_ERROR
|
||||
break
|
||||
return SUCCESS
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
exclude = should_exclude(args.targetFile, args.include, args.exclude)
|
||||
def format_file_path(filepath):
|
||||
"""Formats a path as absolute and with the correct platform separator."""
|
||||
|
||||
try:
|
||||
filepath = os.path.realpath(os.path.abspath(filepath))
|
||||
filepath = re.sub(r'[/\\]', os.path.sep, filepath)
|
||||
except:
|
||||
pass # pragma: nocover
|
||||
return filepath
|
||||
|
||||
|
||||
def process_heartbeat(args, configs, hostname, heartbeat):
|
||||
exclude = should_exclude(heartbeat['entity'], args.include, args.exclude)
|
||||
if exclude is not False:
|
||||
log.debug(u('File not logged because matches exclude pattern: {pattern}').format(
|
||||
log.debug(u('Skipping because matches exclude pattern: {pattern}').format(
|
||||
pattern=u(exclude),
|
||||
))
|
||||
return 0
|
||||
return SUCCESS
|
||||
|
||||
if os.path.isfile(args.targetFile) or args.notfile:
|
||||
if heartbeat.get('entity_type') not in ['file', 'domain', 'app']:
|
||||
heartbeat['entity_type'] = 'file'
|
||||
|
||||
stats = get_file_stats(args.targetFile, notfile=args.notfile,
|
||||
lineno=args.lineno, cursorpos=args.cursorpos)
|
||||
if heartbeat['entity_type'] == 'file':
|
||||
heartbeat['entity'] = format_file_path(heartbeat['entity'])
|
||||
|
||||
project = None
|
||||
if not args.notfile:
|
||||
project = find_project(args.targetFile, configs=configs)
|
||||
if heartbeat['entity_type'] != 'file' or os.path.isfile(heartbeat['entity']):
|
||||
|
||||
stats = get_file_stats(heartbeat['entity'],
|
||||
entity_type=heartbeat['entity_type'],
|
||||
lineno=heartbeat.get('lineno'),
|
||||
cursorpos=heartbeat.get('cursorpos'),
|
||||
plugin=args.plugin,
|
||||
alternate_language=heartbeat.get('alternate_language'))
|
||||
|
||||
project = heartbeat.get('project') or heartbeat.get('alternate_project')
|
||||
branch = None
|
||||
project_name = args.project
|
||||
if project:
|
||||
branch = project.branch()
|
||||
if not project_name:
|
||||
project_name = project.name()
|
||||
if not project_name:
|
||||
project_name = args.alternate_project
|
||||
if heartbeat['entity_type'] == 'file':
|
||||
project, branch = get_project_info(configs, heartbeat)
|
||||
|
||||
kwargs = vars(args)
|
||||
kwargs['project'] = project_name
|
||||
kwargs['branch'] = branch
|
||||
kwargs['stats'] = stats
|
||||
heartbeat['project'] = project
|
||||
heartbeat['branch'] = branch
|
||||
heartbeat['stats'] = stats
|
||||
heartbeat['hostname'] = hostname
|
||||
heartbeat['timeout'] = args.timeout
|
||||
heartbeat['key'] = args.key
|
||||
heartbeat['plugin'] = args.plugin
|
||||
heartbeat['offline'] = args.offline
|
||||
heartbeat['hidefilenames'] = args.hidefilenames
|
||||
heartbeat['proxy'] = args.proxy
|
||||
heartbeat['api_url'] = args.api_url
|
||||
|
||||
if send_heartbeat(**kwargs):
|
||||
queue = Queue()
|
||||
while True:
|
||||
heartbeat = queue.pop()
|
||||
if heartbeat is None:
|
||||
break
|
||||
sent = send_heartbeat(
|
||||
project=heartbeat['project'],
|
||||
targetFile=heartbeat['file'],
|
||||
timestamp=heartbeat['time'],
|
||||
branch=heartbeat['branch'],
|
||||
stats=json.loads(heartbeat['stats']),
|
||||
key=args.key,
|
||||
isWrite=heartbeat['is_write'],
|
||||
plugin=heartbeat['plugin'],
|
||||
offline=args.offline,
|
||||
hidefilenames=args.hidefilenames,
|
||||
notfile=args.notfile,
|
||||
proxy=args.proxy,
|
||||
api_url=args.api_url,
|
||||
)
|
||||
if not sent:
|
||||
break
|
||||
return 0 # success
|
||||
|
||||
return 102 # api error
|
||||
return send_heartbeat(**heartbeat)
|
||||
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this heartbeat.')
|
||||
return 0
|
||||
return SUCCESS
|
||||
|
||||
|
||||
def execute(argv=None):
|
||||
if argv:
|
||||
sys.argv = ['wakatime'] + argv
|
||||
|
||||
args, configs = parseArguments()
|
||||
if configs is None:
|
||||
return CONFIG_FILE_PARSE_ERROR
|
||||
|
||||
setup_logging(args, __version__)
|
||||
|
||||
try:
|
||||
|
||||
hostname = args.hostname or socket.gethostname()
|
||||
|
||||
heartbeat = vars(args)
|
||||
retval = process_heartbeat(args, configs, hostname, heartbeat)
|
||||
|
||||
if args.extra_heartbeats:
|
||||
try:
|
||||
for heartbeat in json.loads(sys.stdin.readline()):
|
||||
retval = process_heartbeat(args, configs, hostname, heartbeat)
|
||||
except json.JSONDecodeError:
|
||||
retval = MALFORMED_HEARTBEAT_ERROR
|
||||
|
||||
if retval == SUCCESS:
|
||||
retval = sync_offline_heartbeats(args, hostname)
|
||||
|
||||
return retval
|
||||
|
||||
except:
|
||||
log.traceback(logging.ERROR)
|
||||
print(traceback.format_exc())
|
||||
return UNKNOWN_ERROR
|
||||
@ -12,27 +12,33 @@
|
||||
|
||||
import logging
|
||||
import os
|
||||
import traceback
|
||||
from time import sleep
|
||||
|
||||
try:
|
||||
import sqlite3
|
||||
HAS_SQL = True
|
||||
except ImportError:
|
||||
except ImportError: # pragma: nocover
|
||||
HAS_SQL = False
|
||||
|
||||
from .compat import u
|
||||
|
||||
|
||||
log = logging.getLogger('WakaTime')
|
||||
|
||||
|
||||
class Queue(object):
|
||||
DB_FILE = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
db_file = os.path.join(os.path.expanduser('~'), '.wakatime.db')
|
||||
table_name = 'heartbeat_1'
|
||||
|
||||
def get_db_file(self):
|
||||
return self.db_file
|
||||
|
||||
def connect(self):
|
||||
conn = sqlite3.connect(self.DB_FILE)
|
||||
conn = sqlite3.connect(self.get_db_file())
|
||||
c = conn.cursor()
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS heartbeat (
|
||||
file text,
|
||||
c.execute('''CREATE TABLE IF NOT EXISTS {0} (
|
||||
entity text,
|
||||
type text,
|
||||
time real,
|
||||
project text,
|
||||
branch text,
|
||||
@ -40,34 +46,33 @@ class Queue(object):
|
||||
stats text,
|
||||
misc text,
|
||||
plugin text)
|
||||
''')
|
||||
'''.format(self.table_name))
|
||||
return (conn, c)
|
||||
|
||||
|
||||
def push(self, data, stats, plugin, misc=None):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
heartbeat = {
|
||||
'file': data.get('file'),
|
||||
'entity': u(data.get('entity')),
|
||||
'type': u(data.get('type')),
|
||||
'time': data.get('time'),
|
||||
'project': data.get('project'),
|
||||
'branch': data.get('branch'),
|
||||
'project': u(data.get('project')),
|
||||
'branch': u(data.get('branch')),
|
||||
'is_write': 1 if data.get('is_write') else 0,
|
||||
'stats': stats,
|
||||
'misc': misc,
|
||||
'plugin': plugin,
|
||||
'stats': u(stats),
|
||||
'misc': u(misc),
|
||||
'plugin': u(plugin),
|
||||
}
|
||||
c.execute('INSERT INTO heartbeat VALUES (:file,:time,:project,:branch,:is_write,:stats,:misc,:plugin)', heartbeat)
|
||||
c.execute('INSERT INTO {0} VALUES (:entity,:type,:time,:project,:branch,:is_write,:stats,:misc,:plugin)'.format(self.table_name), heartbeat)
|
||||
conn.commit()
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
log.traceback()
|
||||
|
||||
def pop(self):
|
||||
if not HAS_SQL:
|
||||
if not HAS_SQL: # pragma: nocover
|
||||
return None
|
||||
tries = 3
|
||||
wait = 0.1
|
||||
@ -75,48 +80,49 @@ class Queue(object):
|
||||
try:
|
||||
conn, c = self.connect()
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
log.traceback(logging.DEBUG)
|
||||
return None
|
||||
loop = True
|
||||
while loop and tries > -1:
|
||||
try:
|
||||
c.execute('BEGIN IMMEDIATE')
|
||||
c.execute('SELECT * FROM heartbeat LIMIT 1')
|
||||
c.execute('SELECT * FROM {0} LIMIT 1'.format(self.table_name))
|
||||
row = c.fetchone()
|
||||
if row is not None:
|
||||
values = []
|
||||
clauses = []
|
||||
index = 0
|
||||
for row_name in ['file', 'time', 'project', 'branch', 'is_write']:
|
||||
for row_name in ['entity', 'type', 'time', 'project', 'branch', 'is_write']:
|
||||
if row[index] is not None:
|
||||
clauses.append('{0}=?'.format(row_name))
|
||||
values.append(row[index])
|
||||
else:
|
||||
else: # pragma: nocover
|
||||
clauses.append('{0} IS NULL'.format(row_name))
|
||||
index += 1
|
||||
if len(values) > 0:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)), values)
|
||||
else:
|
||||
c.execute('DELETE FROM heartbeat WHERE {0}'.format(' AND '.join(clauses)))
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)), values)
|
||||
else: # pragma: nocover
|
||||
c.execute('DELETE FROM {0} WHERE {1}'.format(self.table_name, ' AND '.join(clauses)))
|
||||
conn.commit()
|
||||
if row is not None:
|
||||
heartbeat = {
|
||||
'file': row[0],
|
||||
'time': row[1],
|
||||
'project': row[2],
|
||||
'branch': row[3],
|
||||
'is_write': True if row[4] is 1 else False,
|
||||
'stats': row[5],
|
||||
'misc': row[6],
|
||||
'plugin': row[7],
|
||||
'entity': row[0],
|
||||
'type': row[1],
|
||||
'time': row[2],
|
||||
'project': row[3],
|
||||
'branch': row[4],
|
||||
'is_write': True if row[5] is 1 else False,
|
||||
'stats': row[6],
|
||||
'misc': row[7],
|
||||
'plugin': row[8],
|
||||
}
|
||||
loop = False
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.traceback(logging.DEBUG)
|
||||
sleep(wait)
|
||||
tries -= 1
|
||||
try:
|
||||
conn.close()
|
||||
except sqlite3.Error:
|
||||
log.debug(traceback.format_exc())
|
||||
except sqlite3.Error: # pragma: nocover
|
||||
log.traceback(logging.DEBUG)
|
||||
return heartbeat
|
||||
|
||||
@ -0,0 +1,4 @@
|
||||
import tzlocal
|
||||
from pygments.lexers import get_lexer_by_name, guess_lexer_for_filename
|
||||
from pygments.modeline import get_filetype_from_buffer
|
||||
from pygments.util import ClassNotFound
|
||||
|
||||
@ -61,7 +61,12 @@ considered public as object names -- the API of the formatter objects is
|
||||
still considered an implementation detail.)
|
||||
"""
|
||||
|
||||
__version__ = '1.2.1'
|
||||
__version__ = '1.3.0' # we use our own version number independant of the
|
||||
# one in stdlib and we release this on pypi.
|
||||
|
||||
__external_lib__ = True # to make sure the tests really test THIS lib,
|
||||
# not the builtin one in Python stdlib
|
||||
|
||||
__all__ = [
|
||||
'ArgumentParser',
|
||||
'ArgumentError',
|
||||
@ -1045,9 +1050,13 @@ class _SubParsersAction(Action):
|
||||
|
||||
class _ChoicesPseudoAction(Action):
|
||||
|
||||
def __init__(self, name, help):
|
||||
def __init__(self, name, aliases, help):
|
||||
metavar = dest = name
|
||||
if aliases:
|
||||
metavar += ' (%s)' % ', '.join(aliases)
|
||||
sup = super(_SubParsersAction._ChoicesPseudoAction, self)
|
||||
sup.__init__(option_strings=[], dest=name, help=help)
|
||||
sup.__init__(option_strings=[], dest=dest, help=help,
|
||||
metavar=metavar)
|
||||
|
||||
def __init__(self,
|
||||
option_strings,
|
||||
@ -1075,15 +1084,22 @@ class _SubParsersAction(Action):
|
||||
if kwargs.get('prog') is None:
|
||||
kwargs['prog'] = '%s %s' % (self._prog_prefix, name)
|
||||
|
||||
aliases = kwargs.pop('aliases', ())
|
||||
|
||||
# create a pseudo-action to hold the choice help
|
||||
if 'help' in kwargs:
|
||||
help = kwargs.pop('help')
|
||||
choice_action = self._ChoicesPseudoAction(name, help)
|
||||
choice_action = self._ChoicesPseudoAction(name, aliases, help)
|
||||
self._choices_actions.append(choice_action)
|
||||
|
||||
# create the parser and add it to the map
|
||||
parser = self._parser_class(**kwargs)
|
||||
self._name_parser_map[name] = parser
|
||||
|
||||
# make parser available under aliases also
|
||||
for alias in aliases:
|
||||
self._name_parser_map[alias] = parser
|
||||
|
||||
return parser
|
||||
|
||||
def _get_subactions(self):
|
||||
|
||||
@ -22,11 +22,11 @@
|
||||
.. _Pygments tip:
|
||||
http://bitbucket.org/birkenfeld/pygments-main/get/tip.zip#egg=Pygments-dev
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
__version__ = '2.0.1'
|
||||
__version__ = '2.1.3'
|
||||
__docformat__ = 'restructuredtext'
|
||||
|
||||
__all__ = ['lex', 'format', 'highlight']
|
||||
@ -45,13 +45,14 @@ def lex(code, lexer):
|
||||
return lexer.get_tokens(code)
|
||||
except TypeError as err:
|
||||
if isinstance(err.args[0], str) and \
|
||||
'unbound method get_tokens' in err.args[0]:
|
||||
('unbound method get_tokens' in err.args[0] or
|
||||
'missing 1 required positional argument' in err.args[0]):
|
||||
raise TypeError('lex() argument must be a lexer instance, '
|
||||
'not a class')
|
||||
raise
|
||||
|
||||
|
||||
def format(tokens, formatter, outfile=None):
|
||||
def format(tokens, formatter, outfile=None): # pylint: disable=redefined-builtin
|
||||
"""
|
||||
Format a tokenlist ``tokens`` with the formatter ``formatter``.
|
||||
|
||||
@ -61,15 +62,15 @@ def format(tokens, formatter, outfile=None):
|
||||
"""
|
||||
try:
|
||||
if not outfile:
|
||||
#print formatter, 'using', formatter.encoding
|
||||
realoutfile = formatter.encoding and BytesIO() or StringIO()
|
||||
realoutfile = getattr(formatter, 'encoding', None) and BytesIO() or StringIO()
|
||||
formatter.format(tokens, realoutfile)
|
||||
return realoutfile.getvalue()
|
||||
else:
|
||||
formatter.format(tokens, outfile)
|
||||
except TypeError as err:
|
||||
if isinstance(err.args[0], str) and \
|
||||
'unbound method format' in err.args[0]:
|
||||
('unbound method format' in err.args[0] or
|
||||
'missing 1 required positional argument' in err.args[0]):
|
||||
raise TypeError('format() argument must be a formatter instance, '
|
||||
'not a class')
|
||||
raise
|
||||
@ -86,6 +87,6 @@ def highlight(code, lexer, formatter, outfile=None):
|
||||
return format(lex(code, lexer), formatter, outfile)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
from pygments.cmdline import main
|
||||
sys.exit(main(sys.argv))
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Command line interface.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -19,18 +19,19 @@ from pygments import __version__, highlight
|
||||
from pygments.util import ClassNotFound, OptionError, docstring_headline, \
|
||||
guess_decode, guess_decode_from_terminal, terminal_encoding
|
||||
from pygments.lexers import get_all_lexers, get_lexer_by_name, guess_lexer, \
|
||||
get_lexer_for_filename, find_lexer_class, TextLexer
|
||||
get_lexer_for_filename, find_lexer_class_for_filename
|
||||
from pygments.lexers.special import TextLexer
|
||||
from pygments.formatters.latex import LatexEmbeddedLexer, LatexFormatter
|
||||
from pygments.formatters import get_all_formatters, get_formatter_by_name, \
|
||||
get_formatter_for_filename, find_formatter_class, \
|
||||
TerminalFormatter # pylint:disable-msg=E0611
|
||||
get_formatter_for_filename, find_formatter_class
|
||||
from pygments.formatters.terminal import TerminalFormatter
|
||||
from pygments.filters import get_all_filters, find_filter_class
|
||||
from pygments.styles import get_all_styles, get_style_by_name
|
||||
|
||||
|
||||
USAGE = """\
|
||||
Usage: %s [-l <lexer> | -g] [-F <filter>[:<options>]] [-f <formatter>]
|
||||
[-O <options>] [-P <option=value>] [-s] [-o <outfile>] [<infile>]
|
||||
[-O <options>] [-P <option=value>] [-s] [-v] [-o <outfile>] [<infile>]
|
||||
|
||||
%s -S <style> -f <formatter> [-a <arg>] [-O <options>] [-P <option=value>]
|
||||
%s -L [<which> ...]
|
||||
@ -90,6 +91,9 @@ waiting to process the entire file. This only works for stdin, and
|
||||
is intended for streaming input such as you get from 'tail -f'.
|
||||
Example usage: "tail -f sql.log | pygmentize -s -l sql"
|
||||
|
||||
The -v option prints a detailed traceback on unhandled exceptions,
|
||||
which is useful for debugging and bug reports.
|
||||
|
||||
The -h option prints this help.
|
||||
The -V option prints the package version.
|
||||
"""
|
||||
@ -100,7 +104,7 @@ def _parse_options(o_strs):
|
||||
if not o_strs:
|
||||
return opts
|
||||
for o_str in o_strs:
|
||||
if not o_str:
|
||||
if not o_str.strip():
|
||||
continue
|
||||
o_args = o_str.split(',')
|
||||
for o_arg in o_args:
|
||||
@ -132,7 +136,7 @@ def _parse_filters(f_strs):
|
||||
def _print_help(what, name):
|
||||
try:
|
||||
if what == 'lexer':
|
||||
cls = find_lexer_class(name)
|
||||
cls = get_lexer_by_name(name)
|
||||
print("Help on the %s lexer:" % cls.name)
|
||||
print(dedent(cls.__doc__))
|
||||
elif what == 'formatter':
|
||||
@ -143,8 +147,10 @@ def _print_help(what, name):
|
||||
cls = find_filter_class(name)
|
||||
print("Help on the %s filter:" % name)
|
||||
print(dedent(cls.__doc__))
|
||||
except AttributeError:
|
||||
return 0
|
||||
except (AttributeError, ValueError):
|
||||
print("%s not found!" % what, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
|
||||
def _print_list(what):
|
||||
@ -198,19 +204,7 @@ def _print_list(what):
|
||||
print(" %s" % docstring_headline(cls))
|
||||
|
||||
|
||||
def main(args=sys.argv):
|
||||
"""
|
||||
Main command line entry point.
|
||||
"""
|
||||
# pylint: disable-msg=R0911,R0912,R0915
|
||||
|
||||
usage = USAGE % ((args[0],) * 6)
|
||||
|
||||
try:
|
||||
popts, args = getopt.getopt(args[1:], "l:f:F:o:O:P:LS:a:N:hVHgs")
|
||||
except getopt.GetoptError:
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
def main_inner(popts, args, usage):
|
||||
opts = {}
|
||||
O_opts = []
|
||||
P_opts = []
|
||||
@ -229,7 +223,7 @@ def main(args=sys.argv):
|
||||
return 0
|
||||
|
||||
if opts.pop('-V', None) is not None:
|
||||
print('Pygments version %s, (c) 2006-2014 by Georg Brandl.' % __version__)
|
||||
print('Pygments version %s, (c) 2006-2015 by Georg Brandl.' % __version__)
|
||||
return 0
|
||||
|
||||
# handle ``pygmentize -L``
|
||||
@ -254,13 +248,12 @@ def main(args=sys.argv):
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
|
||||
what, name = args
|
||||
what, name = args # pylint: disable=unbalanced-tuple-unpacking
|
||||
if what not in ('lexer', 'formatter', 'filter'):
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
|
||||
_print_help(what, name)
|
||||
return 0
|
||||
return _print_help(what, name)
|
||||
|
||||
# parse -O options
|
||||
parsed_opts = _parse_options(O_opts)
|
||||
@ -277,19 +270,15 @@ def main(args=sys.argv):
|
||||
opts.pop('-P', None)
|
||||
|
||||
# encodings
|
||||
inencoding = parsed_opts.get('inencoding', parsed_opts.get('encoding'))
|
||||
inencoding = parsed_opts.get('inencoding', parsed_opts.get('encoding'))
|
||||
outencoding = parsed_opts.get('outencoding', parsed_opts.get('encoding'))
|
||||
|
||||
# handle ``pygmentize -N``
|
||||
infn = opts.pop('-N', None)
|
||||
if infn is not None:
|
||||
try:
|
||||
lexer = get_lexer_for_filename(infn, **parsed_opts)
|
||||
except ClassNotFound as err:
|
||||
lexer = TextLexer()
|
||||
except OptionError as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
lexer = find_lexer_class_for_filename(infn)
|
||||
if lexer is None:
|
||||
lexer = TextLexer
|
||||
|
||||
print(lexer.aliases[0])
|
||||
return 0
|
||||
@ -313,12 +302,7 @@ def main(args=sys.argv):
|
||||
print(err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
arg = a_opt or ''
|
||||
try:
|
||||
print(fmter.get_style_defs(arg))
|
||||
except Exception as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
print(fmter.get_style_defs(a_opt or ''))
|
||||
return 0
|
||||
|
||||
# if no -S is given, -a is not allowed
|
||||
@ -331,10 +315,13 @@ def main(args=sys.argv):
|
||||
opts.pop('-F', None)
|
||||
|
||||
# select lexer
|
||||
lexer = opts.pop('-l', None)
|
||||
if lexer:
|
||||
lexer = None
|
||||
|
||||
# given by name?
|
||||
lexername = opts.pop('-l', None)
|
||||
if lexername:
|
||||
try:
|
||||
lexer = get_lexer_by_name(lexer, **parsed_opts)
|
||||
lexer = get_lexer_by_name(lexername, **parsed_opts)
|
||||
except (OptionError, ClassNotFound) as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
@ -350,7 +337,7 @@ def main(args=sys.argv):
|
||||
if '-s' in opts:
|
||||
print('Error: -s option not usable when input file specified',
|
||||
file=sys.stderr)
|
||||
return 1
|
||||
return 2
|
||||
|
||||
infn = args[0]
|
||||
try:
|
||||
@ -396,6 +383,20 @@ def main(args=sys.argv):
|
||||
except ClassNotFound:
|
||||
lexer = TextLexer(**parsed_opts)
|
||||
|
||||
else: # -s option needs a lexer with -l
|
||||
if not lexer:
|
||||
print('Error: when using -s a lexer has to be selected with -l',
|
||||
file=sys.stderr)
|
||||
return 2
|
||||
|
||||
# process filters
|
||||
for fname, fopts in F_opts:
|
||||
try:
|
||||
lexer.add_filter(fname, **fopts)
|
||||
except ClassNotFound as err:
|
||||
print('Error:', err, file=sys.stderr)
|
||||
return 1
|
||||
|
||||
# select formatter
|
||||
outfn = opts.pop('-o', None)
|
||||
fmter = opts.pop('-f', None)
|
||||
@ -438,11 +439,11 @@ def main(args=sys.argv):
|
||||
|
||||
# provide coloring under Windows, if possible
|
||||
if not outfn and sys.platform in ('win32', 'cygwin') and \
|
||||
fmter.name in ('Terminal', 'Terminal256'):
|
||||
fmter.name in ('Terminal', 'Terminal256'): # pragma: no cover
|
||||
# unfortunately colorama doesn't support binary streams on Py3
|
||||
if sys.version_info > (3,):
|
||||
import io
|
||||
outfile = io.TextIOWrapper(outfile, encoding=fmter.encoding)
|
||||
from pygments.util import UnclosingTextIOWrapper
|
||||
outfile = UnclosingTextIOWrapper(outfile, encoding=fmter.encoding)
|
||||
fmter.encoding = None
|
||||
try:
|
||||
import colorama.initialise
|
||||
@ -462,39 +463,58 @@ def main(args=sys.argv):
|
||||
lexer = LatexEmbeddedLexer(left, right, lexer)
|
||||
|
||||
# ... and do it!
|
||||
if '-s' not in opts:
|
||||
# process whole input as per normal...
|
||||
highlight(code, lexer, fmter, outfile)
|
||||
return 0
|
||||
else:
|
||||
# line by line processing of stdin (eg: for 'tail -f')...
|
||||
try:
|
||||
while 1:
|
||||
if sys.version_info > (3,):
|
||||
# Python 3: we have to use .buffer to get a binary stream
|
||||
line = sys.stdin.buffer.readline()
|
||||
else:
|
||||
line = sys.stdin.readline()
|
||||
if not line:
|
||||
break
|
||||
if not inencoding:
|
||||
line = guess_decode_from_terminal(line, sys.stdin)[0]
|
||||
highlight(line, lexer, fmter, outfile)
|
||||
if hasattr(outfile, 'flush'):
|
||||
outfile.flush()
|
||||
return 0
|
||||
except KeyboardInterrupt: # pragma: no cover
|
||||
return 0
|
||||
|
||||
|
||||
def main(args=sys.argv):
|
||||
"""
|
||||
Main command line entry point.
|
||||
"""
|
||||
usage = USAGE % ((args[0],) * 6)
|
||||
|
||||
try:
|
||||
# process filters
|
||||
for fname, fopts in F_opts:
|
||||
lexer.add_filter(fname, **fopts)
|
||||
|
||||
if '-s' not in opts:
|
||||
# process whole input as per normal...
|
||||
highlight(code, lexer, fmter, outfile)
|
||||
else:
|
||||
if not lexer:
|
||||
print('Error: when using -s a lexer has to be selected with -l',
|
||||
file=sys.stderr)
|
||||
return 1
|
||||
# line by line processing of stdin (eg: for 'tail -f')...
|
||||
try:
|
||||
while 1:
|
||||
if sys.version_info > (3,):
|
||||
# Python 3: we have to use .buffer to get a binary stream
|
||||
line = sys.stdin.buffer.readline()
|
||||
else:
|
||||
line = sys.stdin.readline()
|
||||
if not line:
|
||||
break
|
||||
if not inencoding:
|
||||
line = guess_decode_from_terminal(line, sys.stdin)[0]
|
||||
highlight(line, lexer, fmter, outfile)
|
||||
if hasattr(outfile, 'flush'):
|
||||
outfile.flush()
|
||||
except KeyboardInterrupt:
|
||||
return 0
|
||||
popts, args = getopt.getopt(args[1:], "l:f:F:o:O:P:LS:a:N:vhVHgs")
|
||||
except getopt.GetoptError:
|
||||
print(usage, file=sys.stderr)
|
||||
return 2
|
||||
|
||||
try:
|
||||
return main_inner(popts, args, usage)
|
||||
except Exception:
|
||||
raise
|
||||
if '-v' in dict(popts):
|
||||
print(file=sys.stderr)
|
||||
print('*' * 65, file=sys.stderr)
|
||||
print('An unhandled exception occurred while highlighting.',
|
||||
file=sys.stderr)
|
||||
print('Please report the whole traceback to the issue tracker at',
|
||||
file=sys.stderr)
|
||||
print('<https://bitbucket.org/birkenfeld/pygments-main/issues>.',
|
||||
file=sys.stderr)
|
||||
print('*' * 65, file=sys.stderr)
|
||||
print(file=sys.stderr)
|
||||
raise
|
||||
import traceback
|
||||
info = traceback.format_exception(*sys.exc_info())
|
||||
msg = info[-1].strip()
|
||||
@ -504,6 +524,6 @@ def main(args=sys.argv):
|
||||
print(file=sys.stderr)
|
||||
print('*** Error while highlighting:', file=sys.stderr)
|
||||
print(msg, file=sys.stderr)
|
||||
print('*** If this is a bug you want to report, please rerun with -v.',
|
||||
file=sys.stderr)
|
||||
return 1
|
||||
|
||||
return 0
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Format colored console output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Module that implements the default filter.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -29,7 +29,7 @@ def simplefilter(f):
|
||||
Decorator that converts a function into a filter::
|
||||
|
||||
@simplefilter
|
||||
def lowercase(lexer, stream, options):
|
||||
def lowercase(self, lexer, stream, options):
|
||||
for ttype, value in stream:
|
||||
yield ttype, value.lower()
|
||||
"""
|
||||
@ -69,6 +69,6 @@ class FunctionFilter(Filter):
|
||||
Filter.__init__(self, **options)
|
||||
|
||||
def filter(self, lexer, stream):
|
||||
# pylint: disable-msg=E1102
|
||||
# pylint: disable=not-callable
|
||||
for ttype, value in self.function(lexer, stream, self.options):
|
||||
yield ttype, value
|
||||
@ -6,7 +6,7 @@
|
||||
Module containing filter lookup functions and default
|
||||
filters.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Base formatter class.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Pygments formatters.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -75,7 +75,7 @@ def get_formatter_by_name(_alias, **options):
|
||||
"""
|
||||
cls = find_formatter_class(_alias)
|
||||
if cls is None:
|
||||
raise ClassNotFound("No formatter found for name %r" % _alias)
|
||||
raise ClassNotFound("no formatter found for name %r" % _alias)
|
||||
return cls(**options)
|
||||
|
||||
|
||||
@ -95,7 +95,7 @@ def get_formatter_for_filename(fn, **options):
|
||||
for filename in cls.filenames:
|
||||
if _fn_matches(fn, filename):
|
||||
return cls(**options)
|
||||
raise ClassNotFound("No formatter found for file name %r" % fn)
|
||||
raise ClassNotFound("no formatter found for file name %r" % fn)
|
||||
|
||||
|
||||
class _automodule(types.ModuleType):
|
||||
15
packages/wakatime/packages/pygments_py2/pygments/formatters/_mapping.py → packages/wakatime/packages/pygments/formatters/_mapping.py
Normal file → Executable file
15
packages/wakatime/packages/pygments_py2/pygments/formatters/_mapping.py → packages/wakatime/packages/pygments/formatters/_mapping.py
Normal file → Executable file
@ -9,7 +9,7 @@
|
||||
|
||||
Do not alter the FORMATTERS dictionary by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -20,6 +20,7 @@ FORMATTERS = {
|
||||
'BmpImageFormatter': ('pygments.formatters.img', 'img_bmp', ('bmp', 'bitmap'), ('*.bmp',), 'Create a bitmap image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'GifImageFormatter': ('pygments.formatters.img', 'img_gif', ('gif',), ('*.gif',), 'Create a GIF image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'HtmlFormatter': ('pygments.formatters.html', 'HTML', ('html',), ('*.html', '*.htm'), "Format tokens as HTML 4 ``<span>`` tags within a ``<pre>`` tag, wrapped in a ``<div>`` tag. The ``<div>``'s CSS class can be set by the `cssclass` option."),
|
||||
'IRCFormatter': ('pygments.formatters.irc', 'IRC', ('irc', 'IRC'), (), 'Format tokens with IRC color sequences'),
|
||||
'ImageFormatter': ('pygments.formatters.img', 'img', ('img', 'IMG', 'png'), ('*.png',), 'Create a PNG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'JpgImageFormatter': ('pygments.formatters.img', 'img_jpg', ('jpg', 'jpeg'), ('*.jpg',), 'Create a JPEG image from source code. This uses the Python Imaging Library to generate a pixmap from the source code.'),
|
||||
'LatexFormatter': ('pygments.formatters.latex', 'LaTeX', ('latex', 'tex'), ('*.tex',), 'Format tokens as LaTeX code. This needs the `fancyvrb` and `color` standard packages.'),
|
||||
@ -27,12 +28,13 @@ FORMATTERS = {
|
||||
'RawTokenFormatter': ('pygments.formatters.other', 'Raw tokens', ('raw', 'tokens'), ('*.raw',), 'Format tokens as a raw representation for storing token streams.'),
|
||||
'RtfFormatter': ('pygments.formatters.rtf', 'RTF', ('rtf',), ('*.rtf',), 'Format tokens as RTF markup. This formatter automatically outputs full RTF documents with color information and other useful stuff. Perfect for Copy and Paste into Microsoft(R) Word(R) documents.'),
|
||||
'SvgFormatter': ('pygments.formatters.svg', 'SVG', ('svg',), ('*.svg',), 'Format tokens as an SVG graphics file. This formatter is still experimental. Each line of code is a ``<text>`` element with explicit ``x`` and ``y`` coordinates containing ``<tspan>`` elements with the individual token styles.'),
|
||||
'Terminal256Formatter': ('pygments.formatters.terminal256', 'Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'Terminal256Formatter': ('pygments.formatters.terminal256', 'Terminal256', ('terminal256', 'console256', '256'), (), 'Format tokens with ANSI color sequences, for output in a 256-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TerminalFormatter': ('pygments.formatters.terminal', 'Terminal', ('terminal', 'console'), (), 'Format tokens with ANSI color sequences, for output in a text console. Color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TerminalTrueColorFormatter': ('pygments.formatters.terminal256', 'TerminalTrueColor', ('terminal16m', 'console16m', '16m'), (), 'Format tokens with ANSI color sequences, for output in a true-color terminal or console. Like in `TerminalFormatter` color sequences are terminated at newlines, so that paging the output works correctly.'),
|
||||
'TestcaseFormatter': ('pygments.formatters.other', 'Testcase', ('testcase',), (), 'Format tokens as appropriate for a new testcase.')
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import sys
|
||||
import os
|
||||
|
||||
@ -64,6 +66,13 @@ if __name__ == '__main__':
|
||||
# extract useful sourcecode from this file
|
||||
with open(__file__) as fp:
|
||||
content = fp.read()
|
||||
# replace crnl to nl for Windows.
|
||||
#
|
||||
# Note that, originally, contributers should keep nl of master
|
||||
# repository, for example by using some kind of automatic
|
||||
# management EOL, like `EolExtension
|
||||
# <https://www.mercurial-scm.org/wiki/EolExtension>`.
|
||||
content = content.replace("\r\n", "\n")
|
||||
header = content[:content.find('FORMATTERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
BBcode formatter.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for HTML output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -36,21 +36,11 @@ _escape_html_table = {
|
||||
ord("'"): u''',
|
||||
}
|
||||
|
||||
|
||||
def escape_html(text, table=_escape_html_table):
|
||||
"""Escape &, <, > as well as single and double quotes for HTML."""
|
||||
return text.translate(table)
|
||||
|
||||
def get_random_id():
|
||||
"""Return a random id for javascript fields."""
|
||||
from random import random
|
||||
from time import time
|
||||
try:
|
||||
from hashlib import sha1 as sha
|
||||
except ImportError:
|
||||
import sha
|
||||
sha = sha.new
|
||||
return sha('%s|%s' % (random(), time())).hexdigest()
|
||||
|
||||
|
||||
def _get_ttype_class(ttype):
|
||||
fname = STANDARD_TYPES.get(ttype)
|
||||
@ -150,7 +140,7 @@ class HtmlFormatter(Formatter):
|
||||
|
||||
When `tagsfile` is set to the path of a ctags index file, it is used to
|
||||
generate hyperlinks from names to their definition. You must enable
|
||||
`anchorlines` and run ctags with the `-n` option for this to work. The
|
||||
`lineanchors` and run ctags with the `-n` option for this to work. The
|
||||
`python-ctags` module from PyPI must be installed to use this feature;
|
||||
otherwise a `RuntimeError` will be raised.
|
||||
|
||||
@ -331,6 +321,12 @@ class HtmlFormatter(Formatter):
|
||||
|
||||
.. versionadded:: 1.6
|
||||
|
||||
`filename`
|
||||
A string used to generate a filename when rendering <pre> blocks,
|
||||
for example if displaying source code.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
|
||||
|
||||
**Subclassing the HTML formatter**
|
||||
|
||||
@ -398,6 +394,7 @@ class HtmlFormatter(Formatter):
|
||||
self.noclobber_cssfile = get_bool_opt(options, 'noclobber_cssfile', False)
|
||||
self.tagsfile = self._decodeifneeded(options.get('tagsfile', ''))
|
||||
self.tagurlformat = self._decodeifneeded(options.get('tagurlformat', ''))
|
||||
self.filename = self._decodeifneeded(options.get('filename', ''))
|
||||
|
||||
if self.tagsfile:
|
||||
if not ctags:
|
||||
@ -438,6 +435,15 @@ class HtmlFormatter(Formatter):
|
||||
return self.classprefix + ttypeclass
|
||||
return ''
|
||||
|
||||
def _get_css_classes(self, ttype):
|
||||
"""Return the css classes of this token type prefixed with
|
||||
the classprefix option."""
|
||||
cls = self._get_css_class(ttype)
|
||||
while ttype not in STANDARD_TYPES:
|
||||
ttype = ttype.parent
|
||||
cls = self._get_css_class(ttype) + ' ' + cls
|
||||
return cls
|
||||
|
||||
def _create_stylesheet(self):
|
||||
t2c = self.ttype2class = {Token: ''}
|
||||
c2s = self.class2style = {}
|
||||
@ -522,7 +528,7 @@ class HtmlFormatter(Formatter):
|
||||
cssfilename = os.path.join(os.path.dirname(filename),
|
||||
self.cssfile)
|
||||
except AttributeError:
|
||||
print('Note: Cannot determine output file name, ' \
|
||||
print('Note: Cannot determine output file name, '
|
||||
'using current directory as base for the CSS file name',
|
||||
file=sys.stderr)
|
||||
cssfilename = self.cssfile
|
||||
@ -531,21 +537,21 @@ class HtmlFormatter(Formatter):
|
||||
if not os.path.exists(cssfilename) or not self.noclobber_cssfile:
|
||||
cf = open(cssfilename, "w")
|
||||
cf.write(CSSFILE_TEMPLATE %
|
||||
{'styledefs': self.get_style_defs('body')})
|
||||
{'styledefs': self.get_style_defs('body')})
|
||||
cf.close()
|
||||
except IOError as err:
|
||||
err.strerror = 'Error writing CSS file: ' + err.strerror
|
||||
raise
|
||||
|
||||
yield 0, (DOC_HEADER_EXTERNALCSS %
|
||||
dict(title = self.title,
|
||||
cssfile = self.cssfile,
|
||||
encoding = self.encoding))
|
||||
dict(title=self.title,
|
||||
cssfile=self.cssfile,
|
||||
encoding=self.encoding))
|
||||
else:
|
||||
yield 0, (DOC_HEADER %
|
||||
dict(title = self.title,
|
||||
styledefs = self.get_style_defs('body'),
|
||||
encoding = self.encoding))
|
||||
dict(title=self.title,
|
||||
styledefs=self.get_style_defs('body'),
|
||||
encoding=self.encoding))
|
||||
|
||||
for t, line in inner:
|
||||
yield t, line
|
||||
@ -624,35 +630,35 @@ class HtmlFormatter(Formatter):
|
||||
if self.noclasses:
|
||||
if sp:
|
||||
for t, line in lines:
|
||||
if num%sp == 0:
|
||||
if num % sp == 0:
|
||||
style = 'background-color: #ffffc0; padding: 0 5px 0 5px'
|
||||
else:
|
||||
style = 'background-color: #f0f0f0; padding: 0 5px 0 5px'
|
||||
yield 1, '<span style="%s">%*s </span>' % (
|
||||
style, mw, (num%st and ' ' or num)) + line
|
||||
style, mw, (num % st and ' ' or num)) + line
|
||||
num += 1
|
||||
else:
|
||||
for t, line in lines:
|
||||
yield 1, ('<span style="background-color: #f0f0f0; '
|
||||
'padding: 0 5px 0 5px">%*s </span>' % (
|
||||
mw, (num%st and ' ' or num)) + line)
|
||||
mw, (num % st and ' ' or num)) + line)
|
||||
num += 1
|
||||
elif sp:
|
||||
for t, line in lines:
|
||||
yield 1, '<span class="lineno%s">%*s </span>' % (
|
||||
num%sp == 0 and ' special' or '', mw,
|
||||
(num%st and ' ' or num)) + line
|
||||
num % sp == 0 and ' special' or '', mw,
|
||||
(num % st and ' ' or num)) + line
|
||||
num += 1
|
||||
else:
|
||||
for t, line in lines:
|
||||
yield 1, '<span class="lineno">%*s </span>' % (
|
||||
mw, (num%st and ' ' or num)) + line
|
||||
mw, (num % st and ' ' or num)) + line
|
||||
num += 1
|
||||
|
||||
def _wrap_lineanchors(self, inner):
|
||||
s = self.lineanchors
|
||||
i = self.linenostart - 1 # subtract 1 since we have to increment i
|
||||
# *before* yielding
|
||||
# subtract 1 since we have to increment i *before* yielding
|
||||
i = self.linenostart - 1
|
||||
for t, line in inner:
|
||||
if t:
|
||||
i += 1
|
||||
@ -673,14 +679,14 @@ class HtmlFormatter(Formatter):
|
||||
def _wrap_div(self, inner):
|
||||
style = []
|
||||
if (self.noclasses and not self.nobackground and
|
||||
self.style.background_color is not None):
|
||||
self.style.background_color is not None):
|
||||
style.append('background: %s' % (self.style.background_color,))
|
||||
if self.cssstyles:
|
||||
style.append(self.cssstyles)
|
||||
style = '; '.join(style)
|
||||
|
||||
yield 0, ('<div' + (self.cssclass and ' class="%s"' % self.cssclass)
|
||||
+ (style and (' style="%s"' % style)) + '>')
|
||||
yield 0, ('<div' + (self.cssclass and ' class="%s"' % self.cssclass) +
|
||||
(style and (' style="%s"' % style)) + '>')
|
||||
for tup in inner:
|
||||
yield tup
|
||||
yield 0, '</div>\n'
|
||||
@ -693,7 +699,12 @@ class HtmlFormatter(Formatter):
|
||||
style.append('line-height: 125%')
|
||||
style = '; '.join(style)
|
||||
|
||||
yield 0, ('<pre' + (style and ' style="%s"' % style) + '>')
|
||||
if self.filename:
|
||||
yield 0, ('<span class="filename">' + self.filename + '</span>')
|
||||
|
||||
# the empty span here is to keep leading empty lines from being
|
||||
# ignored by HTML parsers
|
||||
yield 0, ('<pre' + (style and ' style="%s"' % style) + '><span></span>')
|
||||
for tup in inner:
|
||||
yield tup
|
||||
yield 0, '</pre>'
|
||||
@ -712,7 +723,7 @@ class HtmlFormatter(Formatter):
|
||||
tagsfile = self.tagsfile
|
||||
|
||||
lspan = ''
|
||||
line = ''
|
||||
line = []
|
||||
for ttype, value in tokensource:
|
||||
if nocls:
|
||||
cclass = getcls(ttype)
|
||||
@ -721,7 +732,7 @@ class HtmlFormatter(Formatter):
|
||||
cclass = getcls(ttype)
|
||||
cspan = cclass and '<span style="%s">' % c2s[cclass][0] or ''
|
||||
else:
|
||||
cls = self._get_css_class(ttype)
|
||||
cls = self._get_css_classes(ttype)
|
||||
cspan = cls and '<span class="%s">' % cls or ''
|
||||
|
||||
parts = value.translate(escape_table).split('\n')
|
||||
@ -743,30 +754,31 @@ class HtmlFormatter(Formatter):
|
||||
for part in parts[:-1]:
|
||||
if line:
|
||||
if lspan != cspan:
|
||||
line += (lspan and '</span>') + cspan + part + \
|
||||
(cspan and '</span>') + lsep
|
||||
else: # both are the same
|
||||
line += part + (lspan and '</span>') + lsep
|
||||
yield 1, line
|
||||
line = ''
|
||||
line.extend(((lspan and '</span>'), cspan, part,
|
||||
(cspan and '</span>'), lsep))
|
||||
else: # both are the same
|
||||
line.extend((part, (lspan and '</span>'), lsep))
|
||||
yield 1, ''.join(line)
|
||||
line = []
|
||||
elif part:
|
||||
yield 1, cspan + part + (cspan and '</span>') + lsep
|
||||
yield 1, ''.join((cspan, part, (cspan and '</span>'), lsep))
|
||||
else:
|
||||
yield 1, lsep
|
||||
# for the last line
|
||||
if line and parts[-1]:
|
||||
if lspan != cspan:
|
||||
line += (lspan and '</span>') + cspan + parts[-1]
|
||||
line.extend(((lspan and '</span>'), cspan, parts[-1]))
|
||||
lspan = cspan
|
||||
else:
|
||||
line += parts[-1]
|
||||
line.append(parts[-1])
|
||||
elif parts[-1]:
|
||||
line = cspan + parts[-1]
|
||||
line = [cspan, parts[-1]]
|
||||
lspan = cspan
|
||||
# else we neither have to open a new span nor set lspan
|
||||
|
||||
if line:
|
||||
yield 1, line + (lspan and '</span>') + lsep
|
||||
line.extend(((lspan and '</span>'), lsep))
|
||||
yield 1, ''.join(line)
|
||||
|
||||
def _lookup_ctag(self, token):
|
||||
entry = ctags.TagEntry()
|
||||
@ -785,7 +797,7 @@ class HtmlFormatter(Formatter):
|
||||
for i, (t, value) in enumerate(tokensource):
|
||||
if t != 1:
|
||||
yield t, value
|
||||
if i + 1 in hls: # i + 1 because Python indexes start at 0
|
||||
if i + 1 in hls: # i + 1 because Python indexes start at 0
|
||||
if self.noclasses:
|
||||
style = ''
|
||||
if self.style.highlight_color is not None:
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for Pixmap output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -15,6 +15,8 @@ from pygments.formatter import Formatter
|
||||
from pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
|
||||
get_choice_opt, xrange
|
||||
|
||||
import subprocess
|
||||
|
||||
# Import this carefully
|
||||
try:
|
||||
from PIL import Image, ImageDraw, ImageFont
|
||||
@ -75,17 +77,18 @@ class FontManager(object):
|
||||
self._create_nix()
|
||||
|
||||
def _get_nix_font_path(self, name, style):
|
||||
try:
|
||||
from commands import getstatusoutput
|
||||
except ImportError:
|
||||
from subprocess import getstatusoutput
|
||||
exit, out = getstatusoutput('fc-list "%s:style=%s" file' %
|
||||
(name, style))
|
||||
if not exit:
|
||||
lines = out.splitlines()
|
||||
if lines:
|
||||
path = lines[0].strip().strip(':')
|
||||
return path
|
||||
proc = subprocess.Popen(['fc-list', "%s:style=%s" % (name, style), 'file'],
|
||||
stdout=subprocess.PIPE, stderr=None)
|
||||
stdout, _ = proc.communicate()
|
||||
if proc.returncode == 0:
|
||||
lines = stdout.splitlines()
|
||||
for line in lines:
|
||||
if line.startswith(b'Fontconfig warning:'):
|
||||
continue
|
||||
path = line.decode().strip().strip(':')
|
||||
if path:
|
||||
return path
|
||||
return None
|
||||
|
||||
def _create_nix(self):
|
||||
for name in STYLES['NORMAL']:
|
||||
@ -197,7 +200,7 @@ class ImageFormatter(Formatter):
|
||||
bold and italic fonts will be generated. This really should be a
|
||||
monospace font to look sane.
|
||||
|
||||
Default: "Bitstream Vera Sans Mono"
|
||||
Default: "Bitstream Vera Sans Mono" on Windows, Courier New on \*nix
|
||||
|
||||
`font_size`
|
||||
The font size in points to be used.
|
||||
@ -1,11 +1,11 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.formatters.terminal
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
pygments.formatters.irc
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Formatter for terminal output with ANSI sequences.
|
||||
Formatter for IRC output
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -14,16 +14,15 @@ import sys
|
||||
from pygments.formatter import Formatter
|
||||
from pygments.token import Keyword, Name, Comment, String, Error, \
|
||||
Number, Operator, Generic, Token, Whitespace
|
||||
from pygments.console import ansiformat
|
||||
from pygments.util import get_choice_opt
|
||||
|
||||
|
||||
__all__ = ['TerminalFormatter']
|
||||
__all__ = ['IRCFormatter']
|
||||
|
||||
|
||||
#: Map token types to a tuple of color values for light and dark
|
||||
#: backgrounds.
|
||||
TERMINAL_COLORS = {
|
||||
IRC_COLORS = {
|
||||
Token: ('', ''),
|
||||
|
||||
Whitespace: ('lightgray', 'darkgray'),
|
||||
@ -55,11 +54,52 @@ TERMINAL_COLORS = {
|
||||
}
|
||||
|
||||
|
||||
class TerminalFormatter(Formatter):
|
||||
IRC_COLOR_MAP = {
|
||||
'white': 0,
|
||||
'black': 1,
|
||||
'darkblue': 2,
|
||||
'green': 3,
|
||||
'red': 4,
|
||||
'brown': 5,
|
||||
'purple': 6,
|
||||
'orange': 7,
|
||||
'darkgreen': 7, #compat w/ ansi
|
||||
'yellow': 8,
|
||||
'lightgreen': 9,
|
||||
'turquoise': 9, # compat w/ ansi
|
||||
'teal': 10,
|
||||
'lightblue': 11,
|
||||
'darkred': 11, # compat w/ ansi
|
||||
'blue': 12,
|
||||
'fuchsia': 13,
|
||||
'darkgray': 14,
|
||||
'lightgray': 15,
|
||||
}
|
||||
|
||||
def ircformat(color, text):
|
||||
if len(color) < 1:
|
||||
return text
|
||||
add = sub = ''
|
||||
if '_' in color: # italic
|
||||
add += '\x1D'
|
||||
sub = '\x1D' + sub
|
||||
color = color.strip('_')
|
||||
if '*' in color: # bold
|
||||
add += '\x02'
|
||||
sub = '\x02' + sub
|
||||
color = color.strip('*')
|
||||
# underline (\x1F) not supported
|
||||
# backgrounds (\x03FF,BB) not supported
|
||||
if len(color) > 0: # actual color - may have issues with ircformat("red", "blah")+"10" type stuff
|
||||
add += '\x03' + str(IRC_COLOR_MAP[color]).zfill(2)
|
||||
sub = '\x03' + sub
|
||||
return add + text + sub
|
||||
return '<'+add+'>'+text+'</'+sub+'>'
|
||||
|
||||
|
||||
class IRCFormatter(Formatter):
|
||||
r"""
|
||||
Format tokens with ANSI color sequences, for output in a text console.
|
||||
Color sequences are terminated at newlines, so that paging the output
|
||||
works correctly.
|
||||
Format tokens with IRC color sequences
|
||||
|
||||
The `get_style_defs()` method doesn't do anything special since there is
|
||||
no support for common styles.
|
||||
@ -75,30 +115,21 @@ class TerminalFormatter(Formatter):
|
||||
``None`` (default: ``None`` = use builtin colorscheme).
|
||||
|
||||
`linenos`
|
||||
Set to ``True`` to have line numbers on the terminal output as well
|
||||
Set to ``True`` to have line numbers in the output as well
|
||||
(default: ``False`` = no line numbers).
|
||||
"""
|
||||
name = 'Terminal'
|
||||
aliases = ['terminal', 'console']
|
||||
name = 'IRC'
|
||||
aliases = ['irc', 'IRC']
|
||||
filenames = []
|
||||
|
||||
def __init__(self, **options):
|
||||
Formatter.__init__(self, **options)
|
||||
self.darkbg = get_choice_opt(options, 'bg',
|
||||
['light', 'dark'], 'light') == 'dark'
|
||||
self.colorscheme = options.get('colorscheme', None) or TERMINAL_COLORS
|
||||
self.colorscheme = options.get('colorscheme', None) or IRC_COLORS
|
||||
self.linenos = options.get('linenos', False)
|
||||
self._lineno = 0
|
||||
|
||||
def format(self, tokensource, outfile):
|
||||
# hack: if the output is a terminal and has an encoding set,
|
||||
# use that to avoid unicode encode problems
|
||||
if not self.encoding and hasattr(outfile, "encoding") and \
|
||||
hasattr(outfile, "isatty") and outfile.isatty() and \
|
||||
sys.version_info < (3,):
|
||||
self.encoding = outfile.encoding
|
||||
return Formatter.format(self, tokensource, outfile)
|
||||
|
||||
def _write_lineno(self, outfile):
|
||||
self._lineno += 1
|
||||
outfile.write("\n%04d: " % self._lineno)
|
||||
@ -120,9 +151,9 @@ class TerminalFormatter(Formatter):
|
||||
for line in spl[:-1]:
|
||||
self._write_lineno(outfile)
|
||||
if line:
|
||||
outfile.write(ansiformat(color, line[:-1]))
|
||||
outfile.write(ircformat(color, line[:-1]))
|
||||
if spl[-1]:
|
||||
outfile.write(ansiformat(color, spl[-1]))
|
||||
outfile.write(ircformat(color, spl[-1]))
|
||||
else:
|
||||
outfile.write(value)
|
||||
|
||||
@ -143,9 +174,9 @@ class TerminalFormatter(Formatter):
|
||||
spl = value.split('\n')
|
||||
for line in spl[:-1]:
|
||||
if line:
|
||||
outfile.write(ansiformat(color, line))
|
||||
outfile.write(ircformat(color, line))
|
||||
outfile.write('\n')
|
||||
if spl[-1]:
|
||||
outfile.write(ansiformat(color, spl[-1]))
|
||||
outfile.write(ircformat(color, spl[-1]))
|
||||
else:
|
||||
outfile.write(value)
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for LaTeX fancyvrb output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -360,7 +360,7 @@ class LatexFormatter(Formatter):
|
||||
start += value[i]
|
||||
|
||||
value = value[len(start):]
|
||||
start = escape_tex(start, self.commandprefix)
|
||||
start = escape_tex(start, cp)
|
||||
|
||||
# ... but do not escape inside comment.
|
||||
value = start + value
|
||||
@ -370,26 +370,26 @@ class LatexFormatter(Formatter):
|
||||
in_math = False
|
||||
for i, part in enumerate(parts):
|
||||
if not in_math:
|
||||
parts[i] = escape_tex(part, self.commandprefix)
|
||||
parts[i] = escape_tex(part, cp)
|
||||
in_math = not in_math
|
||||
value = '$'.join(parts)
|
||||
elif self.escapeinside:
|
||||
text = value
|
||||
value = ''
|
||||
while len(text) > 0:
|
||||
while text:
|
||||
a, sep1, text = text.partition(self.left)
|
||||
if len(sep1) > 0:
|
||||
if sep1:
|
||||
b, sep2, text = text.partition(self.right)
|
||||
if len(sep2) > 0:
|
||||
value += escape_tex(a, self.commandprefix) + b
|
||||
if sep2:
|
||||
value += escape_tex(a, cp) + b
|
||||
else:
|
||||
value += escape_tex(a + sep1 + b, self.commandprefix)
|
||||
value += escape_tex(a + sep1 + b, cp)
|
||||
else:
|
||||
value = value + escape_tex(a, self.commandprefix)
|
||||
value += escape_tex(a, cp)
|
||||
else:
|
||||
value = escape_tex(value, self.commandprefix)
|
||||
value = escape_tex(value, cp)
|
||||
elif ttype not in Token.Escape:
|
||||
value = escape_tex(value, self.commandprefix)
|
||||
value = escape_tex(value, cp)
|
||||
styles = []
|
||||
while ttype is not Token:
|
||||
try:
|
||||
@ -413,18 +413,24 @@ class LatexFormatter(Formatter):
|
||||
outfile.write(u'\\end{' + self.envname + u'}\n')
|
||||
|
||||
if self.full:
|
||||
encoding = self.encoding or 'utf8'
|
||||
# map known existings encodings from LaTeX distribution
|
||||
encoding = {
|
||||
'utf_8': 'utf8',
|
||||
'latin_1': 'latin1',
|
||||
'iso_8859_1': 'latin1',
|
||||
}.get(encoding.replace('-', '_'), encoding)
|
||||
realoutfile.write(DOC_TEMPLATE %
|
||||
dict(docclass = self.docclass,
|
||||
preamble = self.preamble,
|
||||
title = self.title,
|
||||
encoding = self.encoding or 'utf8',
|
||||
encoding = encoding,
|
||||
styledefs = self.get_style_defs(),
|
||||
code = outfile.getvalue()))
|
||||
|
||||
|
||||
class LatexEmbeddedLexer(Lexer):
|
||||
r"""
|
||||
|
||||
"""
|
||||
This lexer takes one lexer as argument, the lexer for the language
|
||||
being formatted, and the left and right delimiters for escaped text.
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Other formatters: NullFormatter, RawTokenFormatter.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
A formatter that generates RTF files.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for SVG output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Formatter for terminal output with ANSI sequences.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -49,6 +49,7 @@ TERMINAL_COLORS = {
|
||||
Generic.Inserted: ('darkgreen', 'green'),
|
||||
Generic.Heading: ('**', '**'),
|
||||
Generic.Subheading: ('*purple*', '*fuchsia*'),
|
||||
Generic.Prompt: ('**', '**'),
|
||||
Generic.Error: ('red', 'red'),
|
||||
|
||||
Error: ('_red_', '_red_'),
|
||||
@ -101,51 +102,35 @@ class TerminalFormatter(Formatter):
|
||||
|
||||
def _write_lineno(self, outfile):
|
||||
self._lineno += 1
|
||||
outfile.write("\n%04d: " % self._lineno)
|
||||
outfile.write("%s%04d: " % (self._lineno != 1 and '\n' or '', self._lineno))
|
||||
|
||||
def _format_unencoded_with_lineno(self, tokensource, outfile):
|
||||
self._write_lineno(outfile)
|
||||
|
||||
for ttype, value in tokensource:
|
||||
if value.endswith("\n"):
|
||||
self._write_lineno(outfile)
|
||||
value = value[:-1]
|
||||
color = self.colorscheme.get(ttype)
|
||||
while color is None:
|
||||
ttype = ttype[:-1]
|
||||
color = self.colorscheme.get(ttype)
|
||||
if color:
|
||||
color = color[self.darkbg]
|
||||
spl = value.split('\n')
|
||||
for line in spl[:-1]:
|
||||
self._write_lineno(outfile)
|
||||
if line:
|
||||
outfile.write(ansiformat(color, line[:-1]))
|
||||
if spl[-1]:
|
||||
outfile.write(ansiformat(color, spl[-1]))
|
||||
else:
|
||||
outfile.write(value)
|
||||
|
||||
outfile.write("\n")
|
||||
def _get_color(self, ttype):
|
||||
# self.colorscheme is a dict containing usually generic types, so we
|
||||
# have to walk the tree of dots. The base Token type must be a key,
|
||||
# even if it's empty string, as in the default above.
|
||||
colors = self.colorscheme.get(ttype)
|
||||
while colors is None:
|
||||
ttype = ttype.parent
|
||||
colors = self.colorscheme.get(ttype)
|
||||
return colors[self.darkbg]
|
||||
|
||||
def format_unencoded(self, tokensource, outfile):
|
||||
if self.linenos:
|
||||
self._format_unencoded_with_lineno(tokensource, outfile)
|
||||
return
|
||||
self._write_lineno(outfile)
|
||||
|
||||
for ttype, value in tokensource:
|
||||
color = self.colorscheme.get(ttype)
|
||||
while color is None:
|
||||
ttype = ttype[:-1]
|
||||
color = self.colorscheme.get(ttype)
|
||||
if color:
|
||||
color = color[self.darkbg]
|
||||
spl = value.split('\n')
|
||||
for line in spl[:-1]:
|
||||
if line:
|
||||
outfile.write(ansiformat(color, line))
|
||||
outfile.write('\n')
|
||||
if spl[-1]:
|
||||
outfile.write(ansiformat(color, spl[-1]))
|
||||
else:
|
||||
outfile.write(value)
|
||||
color = self._get_color(ttype)
|
||||
|
||||
for line in value.splitlines(True):
|
||||
if color:
|
||||
outfile.write(ansiformat(color, line.rstrip('\n')))
|
||||
else:
|
||||
outfile.write(line.rstrip('\n'))
|
||||
if line.endswith('\n'):
|
||||
if self.linenos:
|
||||
self._write_lineno(outfile)
|
||||
else:
|
||||
outfile.write('\n')
|
||||
|
||||
if self.linenos:
|
||||
outfile.write("\n")
|
||||
@ -11,7 +11,7 @@
|
||||
|
||||
Formatter version 1.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -29,7 +29,7 @@ import sys
|
||||
from pygments.formatter import Formatter
|
||||
|
||||
|
||||
__all__ = ['Terminal256Formatter']
|
||||
__all__ = ['Terminal256Formatter', 'TerminalTrueColorFormatter']
|
||||
|
||||
|
||||
class EscapeSequence:
|
||||
@ -56,6 +56,18 @@ class EscapeSequence:
|
||||
attrs.append("04")
|
||||
return self.escape(attrs)
|
||||
|
||||
def true_color_string(self):
|
||||
attrs = []
|
||||
if self.fg:
|
||||
attrs.extend(("38", "2", str(self.fg[0]), str(self.fg[1]), str(self.fg[2])))
|
||||
if self.bg:
|
||||
attrs.extend(("48", "2", str(self.bg[0]), str(self.bg[1]), str(self.bg[2])))
|
||||
if self.bold:
|
||||
attrs.append("01")
|
||||
if self.underline:
|
||||
attrs.append("04")
|
||||
return self.escape(attrs)
|
||||
|
||||
def reset_string(self):
|
||||
attrs = []
|
||||
if self.fg is not None:
|
||||
@ -68,9 +80,9 @@ class EscapeSequence:
|
||||
|
||||
|
||||
class Terminal256Formatter(Formatter):
|
||||
r"""
|
||||
"""
|
||||
Format tokens with ANSI color sequences, for output in a 256-color
|
||||
terminal or console. Like in `TerminalFormatter` color sequences
|
||||
terminal or console. Like in `TerminalFormatter` color sequences
|
||||
are terminated at newlines, so that paging the output works correctly.
|
||||
|
||||
The formatter takes colors from a style defined by the `style` option
|
||||
@ -221,3 +233,49 @@ class Terminal256Formatter(Formatter):
|
||||
|
||||
if not_found:
|
||||
outfile.write(value)
|
||||
|
||||
|
||||
class TerminalTrueColorFormatter(Terminal256Formatter):
|
||||
r"""
|
||||
Format tokens with ANSI color sequences, for output in a true-color
|
||||
terminal or console. Like in `TerminalFormatter` color sequences
|
||||
are terminated at newlines, so that paging the output works correctly.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
|
||||
Options accepted:
|
||||
|
||||
`style`
|
||||
The style to use, can be a string or a Style subclass (default:
|
||||
``'default'``).
|
||||
"""
|
||||
name = 'TerminalTrueColor'
|
||||
aliases = ['terminal16m', 'console16m', '16m']
|
||||
filenames = []
|
||||
|
||||
def _build_color_table(self):
|
||||
pass
|
||||
|
||||
def _color_tuple(self, color):
|
||||
try:
|
||||
rgb = int(str(color), 16)
|
||||
except ValueError:
|
||||
return None
|
||||
r = (rgb >> 16) & 0xff
|
||||
g = (rgb >> 8) & 0xff
|
||||
b = rgb & 0xff
|
||||
return (r, g, b)
|
||||
|
||||
def _setup_styles(self):
|
||||
for ttype, ndef in self.style:
|
||||
escape = EscapeSequence()
|
||||
if ndef['color']:
|
||||
escape.fg = self._color_tuple(ndef['color'])
|
||||
if ndef['bgcolor']:
|
||||
escape.bg = self._color_tuple(ndef['bgcolor'])
|
||||
if self.usebold and ndef['bold']:
|
||||
escape.bold = True
|
||||
if self.useunderline and ndef['underline']:
|
||||
escape.underline = True
|
||||
self.style_string[str(ttype)] = (escape.true_color_string(),
|
||||
escape.reset_string())
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Base lexer classes.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -14,7 +14,6 @@ from __future__ import print_function
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import itertools
|
||||
|
||||
from pygments.filter import apply_filters, Filter
|
||||
from pygments.filters import get_filter_by_name
|
||||
@ -43,10 +42,10 @@ class LexerMeta(type):
|
||||
static methods which always return float values.
|
||||
"""
|
||||
|
||||
def __new__(cls, name, bases, d):
|
||||
def __new__(mcs, name, bases, d):
|
||||
if 'analyse_text' in d:
|
||||
d['analyse_text'] = make_analysator(d['analyse_text'])
|
||||
return type.__new__(cls, name, bases, d)
|
||||
return type.__new__(mcs, name, bases, d)
|
||||
|
||||
|
||||
@add_metaclass(LexerMeta)
|
||||
@ -189,7 +188,7 @@ class Lexer(object):
|
||||
text += '\n'
|
||||
|
||||
def streamer():
|
||||
for i, t, v in self.get_tokens_unprocessed(text):
|
||||
for _, t, v in self.get_tokens_unprocessed(text):
|
||||
yield t, v
|
||||
stream = streamer()
|
||||
if not unfiltered:
|
||||
@ -246,7 +245,7 @@ class DelegatingLexer(Lexer):
|
||||
#
|
||||
|
||||
|
||||
class include(str):
|
||||
class include(str): # pylint: disable=invalid-name
|
||||
"""
|
||||
Indicates that a state should include rules from another state.
|
||||
"""
|
||||
@ -260,10 +259,10 @@ class _inherit(object):
|
||||
def __repr__(self):
|
||||
return 'inherit'
|
||||
|
||||
inherit = _inherit()
|
||||
inherit = _inherit() # pylint: disable=invalid-name
|
||||
|
||||
|
||||
class combined(tuple):
|
||||
class combined(tuple): # pylint: disable=invalid-name
|
||||
"""
|
||||
Indicates a state combined from multiple states.
|
||||
"""
|
||||
@ -320,8 +319,8 @@ def bygroups(*args):
|
||||
if data is not None:
|
||||
if ctx:
|
||||
ctx.pos = match.start(i + 1)
|
||||
for item in action(lexer, _PseudoMatch(match.start(i + 1),
|
||||
data), ctx):
|
||||
for item in action(
|
||||
lexer, _PseudoMatch(match.start(i + 1), data), ctx):
|
||||
if item:
|
||||
yield item
|
||||
if ctx:
|
||||
@ -655,6 +654,8 @@ class RegexLexer(Lexer):
|
||||
statetokens = tokendefs[statestack[-1]]
|
||||
break
|
||||
else:
|
||||
# We are here only if all state tokens have been considered
|
||||
# and there was not a match on any of them.
|
||||
try:
|
||||
if text[pos] == '\n':
|
||||
# at EOL, reset state to "root"
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Pygments lexers.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -88,7 +88,7 @@ def get_lexer_by_name(_alias, **options):
|
||||
return _lexer_cache[name](**options)
|
||||
# continue with lexers from setuptools entrypoints
|
||||
for cls in find_plugin_lexers():
|
||||
if _alias in cls.aliases:
|
||||
if _alias.lower() in cls.aliases:
|
||||
return cls(**options)
|
||||
raise ClassNotFound('no lexer for alias %r found' % _alias)
|
||||
|
||||
@ -10,7 +10,7 @@
|
||||
TODO: perl/python script in Asymptote SVN similar to asy-list.pl but only
|
||||
for function and variable names.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
ANSI Common Lisp builtins.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
File diff suppressed because one or more lines are too long
1346
packages/wakatime/packages/pygments/lexers/_csound_builtins.py
Normal file
1346
packages/wakatime/packages/pygments/lexers/_csound_builtins.py
Normal file
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -9,7 +9,7 @@
|
||||
|
||||
Do not edit the MODULES dict by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -143,7 +143,8 @@ MODULES = {'basic': ('_G',
|
||||
'table.remove',
|
||||
'table.sort')}
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import re
|
||||
try:
|
||||
from urllib import urlopen
|
||||
@ -16,11 +16,13 @@
|
||||
from __future__ import print_function
|
||||
|
||||
LEXERS = {
|
||||
'ABAPLexer': ('pygments.lexers.business', 'ABAP', ('abap',), ('*.abap',), ('text/x-abap',)),
|
||||
'ABAPLexer': ('pygments.lexers.business', 'ABAP', ('abap',), ('*.abap', '*.ABAP'), ('text/x-abap',)),
|
||||
'APLLexer': ('pygments.lexers.apl', 'APL', ('apl',), ('*.apl',), ()),
|
||||
'AbnfLexer': ('pygments.lexers.grammar_notation', 'ABNF', ('abnf',), ('*.abnf',), ('text/x-abnf',)),
|
||||
'ActionScript3Lexer': ('pygments.lexers.actionscript', 'ActionScript 3', ('as3', 'actionscript3'), ('*.as',), ('application/x-actionscript3', 'text/x-actionscript3', 'text/actionscript3')),
|
||||
'ActionScriptLexer': ('pygments.lexers.actionscript', 'ActionScript', ('as', 'actionscript'), ('*.as',), ('application/x-actionscript', 'text/x-actionscript', 'text/actionscript')),
|
||||
'AdaLexer': ('pygments.lexers.pascal', 'Ada', ('ada', 'ada95', 'ada2005'), ('*.adb', '*.ads', '*.ada'), ('text/x-ada',)),
|
||||
'AdlLexer': ('pygments.lexers.archetype', 'ADL', ('adl',), ('*.adl', '*.adls', '*.adlf', '*.adlx'), ()),
|
||||
'AgdaLexer': ('pygments.lexers.haskell', 'Agda', ('agda',), ('*.agda',), ('text/x-agda',)),
|
||||
'AlloyLexer': ('pygments.lexers.dsls', 'Alloy', ('alloy',), ('*.als',), ('text/x-alloy',)),
|
||||
'AmbientTalkLexer': ('pygments.lexers.ambient', 'AmbientTalk', ('at', 'ambienttalk', 'ambienttalk/2'), ('*.at',), ('text/x-ambienttalk',)),
|
||||
@ -35,29 +37,36 @@ LEXERS = {
|
||||
'AntlrRubyLexer': ('pygments.lexers.parsers', 'ANTLR With Ruby Target', ('antlr-ruby', 'antlr-rb'), ('*.G', '*.g'), ()),
|
||||
'ApacheConfLexer': ('pygments.lexers.configs', 'ApacheConf', ('apacheconf', 'aconf', 'apache'), ('.htaccess', 'apache.conf', 'apache2.conf'), ('text/x-apacheconf',)),
|
||||
'AppleScriptLexer': ('pygments.lexers.scripting', 'AppleScript', ('applescript',), ('*.applescript',), ()),
|
||||
'ArduinoLexer': ('pygments.lexers.c_like', 'Arduino', ('arduino',), ('*.ino',), ('text/x-arduino',)),
|
||||
'AspectJLexer': ('pygments.lexers.jvm', 'AspectJ', ('aspectj',), ('*.aj',), ('text/x-aspectj',)),
|
||||
'AsymptoteLexer': ('pygments.lexers.graphics', 'Asymptote', ('asy', 'asymptote'), ('*.asy',), ('text/x-asymptote',)),
|
||||
'AutoItLexer': ('pygments.lexers.automation', 'AutoIt', ('autoit',), ('*.au3',), ('text/x-autoit',)),
|
||||
'AutohotkeyLexer': ('pygments.lexers.automation', 'autohotkey', ('ahk', 'autohotkey'), ('*.ahk', '*.ahkl'), ('text/x-autohotkey',)),
|
||||
'AwkLexer': ('pygments.lexers.textedit', 'Awk', ('awk', 'gawk', 'mawk', 'nawk'), ('*.awk',), ('application/x-awk',)),
|
||||
'BBCodeLexer': ('pygments.lexers.markup', 'BBCode', ('bbcode',), (), ('text/x-bbcode',)),
|
||||
'BCLexer': ('pygments.lexers.algebra', 'BC', ('bc',), ('*.bc',), ()),
|
||||
'BaseMakefileLexer': ('pygments.lexers.make', 'Base Makefile', ('basemake',), (), ()),
|
||||
'BashLexer': ('pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh', 'shell'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '.bashrc', 'bashrc', '.bash_*', 'bash_*', 'PKGBUILD'), ('application/x-sh', 'application/x-shellscript')),
|
||||
'BashSessionLexer': ('pygments.lexers.shell', 'Bash Session', ('console',), ('*.sh-session',), ('application/x-shell-session',)),
|
||||
'BashLexer': ('pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh', 'shell'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '*.exheres-0', '*.exlib', '.bashrc', 'bashrc', '.bash_*', 'bash_*', 'PKGBUILD'), ('application/x-sh', 'application/x-shellscript')),
|
||||
'BashSessionLexer': ('pygments.lexers.shell', 'Bash Session', ('console', 'shell-session'), ('*.sh-session', '*.shell-session'), ('application/x-shell-session', 'application/x-sh-session')),
|
||||
'BatchLexer': ('pygments.lexers.shell', 'Batchfile', ('bat', 'batch', 'dosbatch', 'winbatch'), ('*.bat', '*.cmd'), ('application/x-dos-batch',)),
|
||||
'BefungeLexer': ('pygments.lexers.esoteric', 'Befunge', ('befunge',), ('*.befunge',), ('application/x-befunge',)),
|
||||
'BlitzBasicLexer': ('pygments.lexers.basic', 'BlitzBasic', ('blitzbasic', 'b3d', 'bplus'), ('*.bb', '*.decls'), ('text/x-bb',)),
|
||||
'BlitzMaxLexer': ('pygments.lexers.basic', 'BlitzMax', ('blitzmax', 'bmax'), ('*.bmx',), ('text/x-bmx',)),
|
||||
'BnfLexer': ('pygments.lexers.grammar_notation', 'BNF', ('bnf',), ('*.bnf',), ('text/x-bnf',)),
|
||||
'BooLexer': ('pygments.lexers.dotnet', 'Boo', ('boo',), ('*.boo',), ('text/x-boo',)),
|
||||
'BoogieLexer': ('pygments.lexers.esoteric', 'Boogie', ('boogie',), ('*.bpl',), ()),
|
||||
'BrainfuckLexer': ('pygments.lexers.esoteric', 'Brainfuck', ('brainfuck', 'bf'), ('*.bf', '*.b'), ('application/x-brainfuck',)),
|
||||
'BroLexer': ('pygments.lexers.dsls', 'Bro', ('bro',), ('*.bro',), ()),
|
||||
'BugsLexer': ('pygments.lexers.modeling', 'BUGS', ('bugs', 'winbugs', 'openbugs'), ('*.bug',), ()),
|
||||
'CAmkESLexer': ('pygments.lexers.esoteric', 'CAmkES', ('camkes', 'idl4'), ('*.camkes', '*.idl4'), ()),
|
||||
'CLexer': ('pygments.lexers.c_cpp', 'C', ('c',), ('*.c', '*.h', '*.idc'), ('text/x-chdr', 'text/x-csrc')),
|
||||
'CMakeLexer': ('pygments.lexers.make', 'CMake', ('cmake',), ('*.cmake', 'CMakeLists.txt'), ('text/x-cmake',)),
|
||||
'CObjdumpLexer': ('pygments.lexers.asm', 'c-objdump', ('c-objdump',), ('*.c-objdump',), ('text/x-c-objdump',)),
|
||||
'CPSALexer': ('pygments.lexers.lisp', 'CPSA', ('cpsa',), ('*.cpsa',), ()),
|
||||
'CSharpAspxLexer': ('pygments.lexers.dotnet', 'aspx-cs', ('aspx-cs',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
|
||||
'CSharpLexer': ('pygments.lexers.dotnet', 'C#', ('csharp', 'c#'), ('*.cs',), ('text/x-csharp',)),
|
||||
'Ca65Lexer': ('pygments.lexers.asm', 'ca65 assembler', ('ca65',), ('*.s',), ()),
|
||||
'CadlLexer': ('pygments.lexers.archetype', 'cADL', ('cadl',), ('*.cadl',), ()),
|
||||
'CbmBasicV2Lexer': ('pygments.lexers.basic', 'CBM BASIC V2', ('cbmbas',), ('*.bas',), ()),
|
||||
'CeylonLexer': ('pygments.lexers.jvm', 'Ceylon', ('ceylon',), ('*.ceylon',), ('text/x-ceylon',)),
|
||||
'Cfengine3Lexer': ('pygments.lexers.configs', 'CFEngine3', ('cfengine3', 'cf3'), ('*.cf',), ()),
|
||||
@ -67,7 +76,7 @@ LEXERS = {
|
||||
'CheetahJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Cheetah', ('js+cheetah', 'javascript+cheetah', 'js+spitfire', 'javascript+spitfire'), (), ('application/x-javascript+cheetah', 'text/x-javascript+cheetah', 'text/javascript+cheetah', 'application/x-javascript+spitfire', 'text/x-javascript+spitfire', 'text/javascript+spitfire')),
|
||||
'CheetahLexer': ('pygments.lexers.templates', 'Cheetah', ('cheetah', 'spitfire'), ('*.tmpl', '*.spt'), ('application/x-cheetah', 'application/x-spitfire')),
|
||||
'CheetahXmlLexer': ('pygments.lexers.templates', 'XML+Cheetah', ('xml+cheetah', 'xml+spitfire'), (), ('application/xml+cheetah', 'application/xml+spitfire')),
|
||||
'CirruLexer': ('pygments.lexers.webmisc', 'Cirru', ('cirru',), ('*.cirru', '*.cr'), ('text/x-cirru',)),
|
||||
'CirruLexer': ('pygments.lexers.webmisc', 'Cirru', ('cirru',), ('*.cirru',), ('text/x-cirru',)),
|
||||
'ClayLexer': ('pygments.lexers.c_like', 'Clay', ('clay',), ('*.clay',), ('text/x-clay',)),
|
||||
'ClojureLexer': ('pygments.lexers.jvm', 'Clojure', ('clojure', 'clj'), ('*.clj',), ('text/x-clojure', 'application/x-clojure')),
|
||||
'ClojureScriptLexer': ('pygments.lexers.jvm', 'ClojureScript', ('clojurescript', 'cljs'), ('*.cljs',), ('text/x-clojurescript', 'application/x-clojurescript')),
|
||||
@ -77,12 +86,17 @@ LEXERS = {
|
||||
'ColdfusionCFCLexer': ('pygments.lexers.templates', 'Coldfusion CFC', ('cfc',), ('*.cfc',), ()),
|
||||
'ColdfusionHtmlLexer': ('pygments.lexers.templates', 'Coldfusion HTML', ('cfm',), ('*.cfm', '*.cfml'), ('application/x-coldfusion',)),
|
||||
'ColdfusionLexer': ('pygments.lexers.templates', 'cfstatement', ('cfs',), (), ()),
|
||||
'CommonLispLexer': ('pygments.lexers.lisp', 'Common Lisp', ('common-lisp', 'cl', 'lisp', 'elisp', 'emacs', 'emacs-lisp'), ('*.cl', '*.lisp', '*.el'), ('text/x-common-lisp',)),
|
||||
'CommonLispLexer': ('pygments.lexers.lisp', 'Common Lisp', ('common-lisp', 'cl', 'lisp'), ('*.cl', '*.lisp'), ('text/x-common-lisp',)),
|
||||
'ComponentPascalLexer': ('pygments.lexers.oberon', 'Component Pascal', ('componentpascal', 'cp'), ('*.cp', '*.cps'), ('text/x-component-pascal',)),
|
||||
'CoqLexer': ('pygments.lexers.theorem', 'Coq', ('coq',), ('*.v',), ('text/x-coq',)),
|
||||
'CppLexer': ('pygments.lexers.c_cpp', 'C++', ('cpp', 'c++'), ('*.cpp', '*.hpp', '*.c++', '*.h++', '*.cc', '*.hh', '*.cxx', '*.hxx', '*.C', '*.H', '*.cp', '*.CPP'), ('text/x-c++hdr', 'text/x-c++src')),
|
||||
'CppObjdumpLexer': ('pygments.lexers.asm', 'cpp-objdump', ('cpp-objdump', 'c++-objdumb', 'cxx-objdump'), ('*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump'), ('text/x-cpp-objdump',)),
|
||||
'CrmshLexer': ('pygments.lexers.dsls', 'Crmsh', ('crmsh', 'pcmk'), ('*.crmsh', '*.pcmk'), ()),
|
||||
'CrocLexer': ('pygments.lexers.d', 'Croc', ('croc',), ('*.croc',), ('text/x-crocsrc',)),
|
||||
'CryptolLexer': ('pygments.lexers.haskell', 'Cryptol', ('cryptol', 'cry'), ('*.cry',), ('text/x-cryptol',)),
|
||||
'CsoundDocumentLexer': ('pygments.lexers.csound', 'Csound Document', ('csound-document', 'csound-csd'), ('*.csd',), ()),
|
||||
'CsoundOrchestraLexer': ('pygments.lexers.csound', 'Csound Orchestra', ('csound', 'csound-orc'), ('*.orc',), ()),
|
||||
'CsoundScoreLexer': ('pygments.lexers.csound', 'Csound Score', ('csound-score', 'csound-sco'), ('*.sco',), ()),
|
||||
'CssDjangoLexer': ('pygments.lexers.templates', 'CSS+Django/Jinja', ('css+django', 'css+jinja'), (), ('text/css+django', 'text/css+jinja')),
|
||||
'CssErbLexer': ('pygments.lexers.templates', 'CSS+Ruby', ('css+erb', 'css+ruby'), (), ('text/css+ruby',)),
|
||||
'CssGenshiLexer': ('pygments.lexers.templates', 'CSS+Genshi Text', ('css+genshitext', 'css+genshi'), (), ('text/css+genshi',)),
|
||||
@ -109,22 +123,29 @@ LEXERS = {
|
||||
'DylanLidLexer': ('pygments.lexers.dylan', 'DylanLID', ('dylan-lid', 'lid'), ('*.lid', '*.hdp'), ('text/x-dylan-lid',)),
|
||||
'ECLLexer': ('pygments.lexers.ecl', 'ECL', ('ecl',), ('*.ecl',), ('application/x-ecl',)),
|
||||
'ECLexer': ('pygments.lexers.c_like', 'eC', ('ec',), ('*.ec', '*.eh'), ('text/x-echdr', 'text/x-ecsrc')),
|
||||
'EarlGreyLexer': ('pygments.lexers.javascript', 'Earl Grey', ('earl-grey', 'earlgrey', 'eg'), ('*.eg',), ('text/x-earl-grey',)),
|
||||
'EasytrieveLexer': ('pygments.lexers.scripting', 'Easytrieve', ('easytrieve',), ('*.ezt', '*.mac'), ('text/x-easytrieve',)),
|
||||
'EbnfLexer': ('pygments.lexers.parsers', 'EBNF', ('ebnf',), ('*.ebnf',), ('text/x-ebnf',)),
|
||||
'EiffelLexer': ('pygments.lexers.eiffel', 'Eiffel', ('eiffel',), ('*.e',), ('text/x-eiffel',)),
|
||||
'ElixirConsoleLexer': ('pygments.lexers.erlang', 'Elixir iex session', ('iex',), (), ('text/x-elixir-shellsession',)),
|
||||
'ElixirLexer': ('pygments.lexers.erlang', 'Elixir', ('elixir', 'ex', 'exs'), ('*.ex', '*.exs'), ('text/x-elixir',)),
|
||||
'ElmLexer': ('pygments.lexers.elm', 'Elm', ('elm',), ('*.elm',), ('text/x-elm',)),
|
||||
'EmacsLispLexer': ('pygments.lexers.lisp', 'EmacsLisp', ('emacs', 'elisp', 'emacs-lisp'), ('*.el',), ('text/x-elisp', 'application/x-elisp')),
|
||||
'ErbLexer': ('pygments.lexers.templates', 'ERB', ('erb',), (), ('application/x-ruby-templating',)),
|
||||
'ErlangLexer': ('pygments.lexers.erlang', 'Erlang', ('erlang',), ('*.erl', '*.hrl', '*.es', '*.escript'), ('text/x-erlang',)),
|
||||
'ErlangShellLexer': ('pygments.lexers.erlang', 'Erlang erl session', ('erl',), ('*.erl-sh',), ('text/x-erl-shellsession',)),
|
||||
'EvoqueHtmlLexer': ('pygments.lexers.templates', 'HTML+Evoque', ('html+evoque',), ('*.html',), ('text/html+evoque',)),
|
||||
'EvoqueLexer': ('pygments.lexers.templates', 'Evoque', ('evoque',), ('*.evoque',), ('application/x-evoque',)),
|
||||
'EvoqueXmlLexer': ('pygments.lexers.templates', 'XML+Evoque', ('xml+evoque',), ('*.xml',), ('application/xml+evoque',)),
|
||||
'EzhilLexer': ('pygments.lexers.ezhil', 'Ezhil', ('ezhil',), ('*.n',), ('text/x-ezhil',)),
|
||||
'FSharpLexer': ('pygments.lexers.dotnet', 'FSharp', ('fsharp',), ('*.fs', '*.fsi'), ('text/x-fsharp',)),
|
||||
'FactorLexer': ('pygments.lexers.factor', 'Factor', ('factor',), ('*.factor',), ('text/x-factor',)),
|
||||
'FancyLexer': ('pygments.lexers.ruby', 'Fancy', ('fancy', 'fy'), ('*.fy', '*.fancypack'), ('text/x-fancysrc',)),
|
||||
'FantomLexer': ('pygments.lexers.fantom', 'Fantom', ('fan',), ('*.fan',), ('application/x-fantom',)),
|
||||
'FelixLexer': ('pygments.lexers.felix', 'Felix', ('felix', 'flx'), ('*.flx', '*.flxh'), ('text/x-felix',)),
|
||||
'FortranLexer': ('pygments.lexers.fortran', 'Fortran', ('fortran',), ('*.f', '*.f90', '*.F', '*.F90'), ('text/x-fortran',)),
|
||||
'FishShellLexer': ('pygments.lexers.shell', 'Fish', ('fish', 'fishshell'), ('*.fish', '*.load'), ('application/x-fish',)),
|
||||
'FortranFixedLexer': ('pygments.lexers.fortran', 'FortranFixed', ('fortranfixed',), ('*.f', '*.F'), ()),
|
||||
'FortranLexer': ('pygments.lexers.fortran', 'Fortran', ('fortran',), ('*.f03', '*.f90', '*.F03', '*.F90'), ('text/x-fortran',)),
|
||||
'FoxProLexer': ('pygments.lexers.foxpro', 'FoxPro', ('foxpro', 'vfp', 'clipper', 'xbase'), ('*.PRG', '*.prg'), ()),
|
||||
'GAPLexer': ('pygments.lexers.algebra', 'GAP', ('gap',), ('*.g', '*.gd', '*.gi', '*.gap'), ()),
|
||||
'GLShaderLexer': ('pygments.lexers.graphics', 'GLSL', ('glsl',), ('*.vert', '*.frag', '*.geo'), ('text/x-glslsrc',)),
|
||||
@ -140,12 +161,13 @@ LEXERS = {
|
||||
'GosuLexer': ('pygments.lexers.jvm', 'Gosu', ('gosu',), ('*.gs', '*.gsx', '*.gsp', '*.vark'), ('text/x-gosu',)),
|
||||
'GosuTemplateLexer': ('pygments.lexers.jvm', 'Gosu Template', ('gst',), ('*.gst',), ('text/x-gosu-template',)),
|
||||
'GroffLexer': ('pygments.lexers.markup', 'Groff', ('groff', 'nroff', 'man'), ('*.[1234567]', '*.man'), ('application/x-troff', 'text/troff')),
|
||||
'GroovyLexer': ('pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy',), ('text/x-groovy',)),
|
||||
'GroovyLexer': ('pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy', '*.gradle'), ('text/x-groovy',)),
|
||||
'HamlLexer': ('pygments.lexers.html', 'Haml', ('haml',), ('*.haml',), ('text/x-haml',)),
|
||||
'HandlebarsHtmlLexer': ('pygments.lexers.templates', 'HTML+Handlebars', ('html+handlebars',), ('*.handlebars', '*.hbs'), ('text/html+handlebars', 'text/x-handlebars-template')),
|
||||
'HandlebarsLexer': ('pygments.lexers.templates', 'Handlebars', ('handlebars',), (), ()),
|
||||
'HaskellLexer': ('pygments.lexers.haskell', 'Haskell', ('haskell', 'hs'), ('*.hs',), ('text/x-haskell',)),
|
||||
'HaxeLexer': ('pygments.lexers.haxe', 'Haxe', ('hx', 'haxe', 'hxsl'), ('*.hx', '*.hxsl'), ('text/haxe', 'text/x-haxe', 'text/x-hx')),
|
||||
'HexdumpLexer': ('pygments.lexers.hexdump', 'Hexdump', ('hexdump',), (), ()),
|
||||
'HtmlDjangoLexer': ('pygments.lexers.templates', 'HTML+Django/Jinja', ('html+django', 'html+jinja', 'htmldjango'), (), ('text/html+django', 'text/html+jinja')),
|
||||
'HtmlGenshiLexer': ('pygments.lexers.templates', 'HTML+Genshi', ('html+genshi', 'html+kid'), (), ('text/html+genshi',)),
|
||||
'HtmlLexer': ('pygments.lexers.html', 'HTML', ('html',), ('*.html', '*.htm', '*.xhtml', '*.xslt'), ('text/html', 'application/xhtml+xml')),
|
||||
@ -161,11 +183,12 @@ LEXERS = {
|
||||
'Inform6Lexer': ('pygments.lexers.int_fiction', 'Inform 6', ('inform6', 'i6'), ('*.inf',), ()),
|
||||
'Inform6TemplateLexer': ('pygments.lexers.int_fiction', 'Inform 6 template', ('i6t',), ('*.i6t',), ()),
|
||||
'Inform7Lexer': ('pygments.lexers.int_fiction', 'Inform 7', ('inform7', 'i7'), ('*.ni', '*.i7x'), ()),
|
||||
'IniLexer': ('pygments.lexers.configs', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg'), ('text/x-ini',)),
|
||||
'IniLexer': ('pygments.lexers.configs', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg', '*.inf'), ('text/x-ini', 'text/inf')),
|
||||
'IoLexer': ('pygments.lexers.iolang', 'Io', ('io',), ('*.io',), ('text/x-iosrc',)),
|
||||
'IokeLexer': ('pygments.lexers.jvm', 'Ioke', ('ioke', 'ik'), ('*.ik',), ('text/x-iokesrc',)),
|
||||
'IrcLogsLexer': ('pygments.lexers.textfmts', 'IRC logs', ('irc',), ('*.weechatlog',), ('text/x-irclog',)),
|
||||
'IsabelleLexer': ('pygments.lexers.theorem', 'Isabelle', ('isabelle',), ('*.thy',), ('text/x-isabelle',)),
|
||||
'JLexer': ('pygments.lexers.j', 'J', ('j',), ('*.ijs',), ('text/x-j',)),
|
||||
'JadeLexer': ('pygments.lexers.html', 'Jade', ('jade',), ('*.jade',), ('text/x-jade',)),
|
||||
'JagsLexer': ('pygments.lexers.modeling', 'JAGS', ('jags',), ('*.jag', '*.bug'), ()),
|
||||
'JasminLexer': ('pygments.lexers.jvm', 'Jasmin', ('jasmin', 'jasminxt'), ('*.j',), ()),
|
||||
@ -173,9 +196,10 @@ LEXERS = {
|
||||
'JavascriptDjangoLexer': ('pygments.lexers.templates', 'JavaScript+Django/Jinja', ('js+django', 'javascript+django', 'js+jinja', 'javascript+jinja'), (), ('application/x-javascript+django', 'application/x-javascript+jinja', 'text/x-javascript+django', 'text/x-javascript+jinja', 'text/javascript+django', 'text/javascript+jinja')),
|
||||
'JavascriptErbLexer': ('pygments.lexers.templates', 'JavaScript+Ruby', ('js+erb', 'javascript+erb', 'js+ruby', 'javascript+ruby'), (), ('application/x-javascript+ruby', 'text/x-javascript+ruby', 'text/javascript+ruby')),
|
||||
'JavascriptGenshiLexer': ('pygments.lexers.templates', 'JavaScript+Genshi Text', ('js+genshitext', 'js+genshi', 'javascript+genshitext', 'javascript+genshi'), (), ('application/x-javascript+genshi', 'text/x-javascript+genshi', 'text/javascript+genshi')),
|
||||
'JavascriptLexer': ('pygments.lexers.javascript', 'JavaScript', ('js', 'javascript'), ('*.js',), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
|
||||
'JavascriptLexer': ('pygments.lexers.javascript', 'JavaScript', ('js', 'javascript'), ('*.js', '*.jsm'), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
|
||||
'JavascriptPhpLexer': ('pygments.lexers.templates', 'JavaScript+PHP', ('js+php', 'javascript+php'), (), ('application/x-javascript+php', 'text/x-javascript+php', 'text/javascript+php')),
|
||||
'JavascriptSmartyLexer': ('pygments.lexers.templates', 'JavaScript+Smarty', ('js+smarty', 'javascript+smarty'), (), ('application/x-javascript+smarty', 'text/x-javascript+smarty', 'text/javascript+smarty')),
|
||||
'JclLexer': ('pygments.lexers.scripting', 'JCL', ('jcl',), ('*.jcl',), ('text/x-jcl',)),
|
||||
'JsonLdLexer': ('pygments.lexers.data', 'JSON-LD', ('jsonld', 'json-ld'), ('*.jsonld',), ('application/ld+json',)),
|
||||
'JsonLexer': ('pygments.lexers.data', 'JSON', ('json',), ('*.json',), ('application/json',)),
|
||||
'JspLexer': ('pygments.lexers.templates', 'Java Server Page', ('jsp',), ('*.jsp',), ('application/x-jsp',)),
|
||||
@ -192,6 +216,7 @@ LEXERS = {
|
||||
'LassoLexer': ('pygments.lexers.javascript', 'Lasso', ('lasso', 'lassoscript'), ('*.lasso', '*.lasso[89]'), ('text/x-lasso',)),
|
||||
'LassoXmlLexer': ('pygments.lexers.templates', 'XML+Lasso', ('xml+lasso',), (), ('application/xml+lasso',)),
|
||||
'LeanLexer': ('pygments.lexers.theorem', 'Lean', ('lean',), ('*.lean',), ('text/x-lean',)),
|
||||
'LessCssLexer': ('pygments.lexers.css', 'LessCss', ('less',), ('*.less',), ('text/x-less-css',)),
|
||||
'LighttpdConfLexer': ('pygments.lexers.configs', 'Lighttpd configuration file', ('lighty', 'lighttpd'), (), ('text/x-lighttpd-conf',)),
|
||||
'LimboLexer': ('pygments.lexers.inferno', 'Limbo', ('limbo',), ('*.b',), ('text/limbo',)),
|
||||
'LiquidLexer': ('pygments.lexers.templates', 'liquid', ('liquid',), ('*.liquid',), ()),
|
||||
@ -205,6 +230,7 @@ LEXERS = {
|
||||
'LogtalkLexer': ('pygments.lexers.prolog', 'Logtalk', ('logtalk',), ('*.lgt', '*.logtalk'), ('text/x-logtalk',)),
|
||||
'LuaLexer': ('pygments.lexers.scripting', 'Lua', ('lua',), ('*.lua', '*.wlua'), ('text/x-lua', 'application/x-lua')),
|
||||
'MOOCodeLexer': ('pygments.lexers.scripting', 'MOOCode', ('moocode', 'moo'), ('*.moo',), ('text/x-moocode',)),
|
||||
'MSDOSSessionLexer': ('pygments.lexers.shell', 'MSDOS Session', ('doscon',), (), ()),
|
||||
'MakefileLexer': ('pygments.lexers.make', 'Makefile', ('make', 'makefile', 'mf', 'bsdmake'), ('*.mak', '*.mk', 'Makefile', 'makefile', 'Makefile.*', 'GNUmakefile'), ('text/x-makefile',)),
|
||||
'MakoCssLexer': ('pygments.lexers.templates', 'CSS+Mako', ('css+mako',), (), ('text/css+mako',)),
|
||||
'MakoHtmlLexer': ('pygments.lexers.templates', 'HTML+Mako', ('html+mako',), (), ('text/html+mako',)),
|
||||
@ -219,7 +245,7 @@ LEXERS = {
|
||||
'MatlabSessionLexer': ('pygments.lexers.matlab', 'Matlab session', ('matlabsession',), (), ()),
|
||||
'MiniDLexer': ('pygments.lexers.d', 'MiniD', ('minid',), (), ('text/x-minidsrc',)),
|
||||
'ModelicaLexer': ('pygments.lexers.modeling', 'Modelica', ('modelica',), ('*.mo',), ('text/x-modelica',)),
|
||||
'Modula2Lexer': ('pygments.lexers.pascal', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
|
||||
'Modula2Lexer': ('pygments.lexers.modula2', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
|
||||
'MoinWikiLexer': ('pygments.lexers.markup', 'MoinMoin/Trac Wiki markup', ('trac-wiki', 'moin'), (), ('text/x-trac-wiki',)),
|
||||
'MonkeyLexer': ('pygments.lexers.basic', 'Monkey', ('monkey',), ('*.monkey',), ('text/x-monkey',)),
|
||||
'MoonScriptLexer': ('pygments.lexers.scripting', 'MoonScript', ('moon', 'moonscript'), ('*.moon',), ('text/x-moonscript', 'application/x-moonscript')),
|
||||
@ -256,22 +282,28 @@ LEXERS = {
|
||||
'ObjectiveJLexer': ('pygments.lexers.javascript', 'Objective-J', ('objective-j', 'objectivej', 'obj-j', 'objj'), ('*.j',), ('text/x-objective-j',)),
|
||||
'OcamlLexer': ('pygments.lexers.ml', 'OCaml', ('ocaml',), ('*.ml', '*.mli', '*.mll', '*.mly'), ('text/x-ocaml',)),
|
||||
'OctaveLexer': ('pygments.lexers.matlab', 'Octave', ('octave',), ('*.m',), ('text/octave',)),
|
||||
'OdinLexer': ('pygments.lexers.archetype', 'ODIN', ('odin',), ('*.odin',), ('text/odin',)),
|
||||
'OocLexer': ('pygments.lexers.ooc', 'Ooc', ('ooc',), ('*.ooc',), ('text/x-ooc',)),
|
||||
'OpaLexer': ('pygments.lexers.ml', 'Opa', ('opa',), ('*.opa',), ('text/x-opa',)),
|
||||
'OpenEdgeLexer': ('pygments.lexers.business', 'OpenEdge ABL', ('openedge', 'abl', 'progress'), ('*.p', '*.cls'), ('text/x-openedge', 'application/x-openedge')),
|
||||
'PacmanConfLexer': ('pygments.lexers.configs', 'PacmanConf', ('pacmanconf',), ('pacman.conf',), ()),
|
||||
'PanLexer': ('pygments.lexers.dsls', 'Pan', ('pan',), ('*.pan',), ()),
|
||||
'ParaSailLexer': ('pygments.lexers.parasail', 'ParaSail', ('parasail',), ('*.psi', '*.psl'), ('text/x-parasail',)),
|
||||
'PawnLexer': ('pygments.lexers.pawn', 'Pawn', ('pawn',), ('*.p', '*.pwn', '*.inc'), ('text/x-pawn',)),
|
||||
'Perl6Lexer': ('pygments.lexers.perl', 'Perl6', ('perl6', 'pl6'), ('*.pl', '*.pm', '*.nqp', '*.p6', '*.6pl', '*.p6l', '*.pl6', '*.6pm', '*.p6m', '*.pm6', '*.t'), ('text/x-perl6', 'application/x-perl6')),
|
||||
'PerlLexer': ('pygments.lexers.perl', 'Perl', ('perl', 'pl'), ('*.pl', '*.pm', '*.t'), ('text/x-perl', 'application/x-perl')),
|
||||
'PhpLexer': ('pygments.lexers.php', 'PHP', ('php', 'php3', 'php4', 'php5'), ('*.php', '*.php[345]', '*.inc'), ('text/x-php',)),
|
||||
'PigLexer': ('pygments.lexers.jvm', 'Pig', ('pig',), ('*.pig',), ('text/x-pig',)),
|
||||
'PikeLexer': ('pygments.lexers.c_like', 'Pike', ('pike',), ('*.pike', '*.pmod'), ('text/x-pike',)),
|
||||
'PkgConfigLexer': ('pygments.lexers.configs', 'PkgConfig', ('pkgconfig',), ('*.pc',), ()),
|
||||
'PlPgsqlLexer': ('pygments.lexers.sql', 'PL/pgSQL', ('plpgsql',), (), ('text/x-plpgsql',)),
|
||||
'PostScriptLexer': ('pygments.lexers.graphics', 'PostScript', ('postscript', 'postscr'), ('*.ps', '*.eps'), ('application/postscript',)),
|
||||
'PostgresConsoleLexer': ('pygments.lexers.sql', 'PostgreSQL console (psql)', ('psql', 'postgresql-console', 'postgres-console'), (), ('text/x-postgresql-psql',)),
|
||||
'PostgresLexer': ('pygments.lexers.sql', 'PostgreSQL SQL dialect', ('postgresql', 'postgres'), (), ('text/x-postgresql',)),
|
||||
'PovrayLexer': ('pygments.lexers.graphics', 'POVRay', ('pov',), ('*.pov', '*.inc'), ('text/x-povray',)),
|
||||
'PowerShellLexer': ('pygments.lexers.shell', 'PowerShell', ('powershell', 'posh', 'ps1', 'psm1'), ('*.ps1', '*.psm1'), ('text/x-powershell',)),
|
||||
'PowerShellSessionLexer': ('pygments.lexers.shell', 'PowerShell Session', ('ps1con',), (), ()),
|
||||
'PraatLexer': ('pygments.lexers.praat', 'Praat', ('praat',), ('*.praat', '*.proc', '*.psc'), ()),
|
||||
'PrologLexer': ('pygments.lexers.prolog', 'Prolog', ('prolog',), ('*.ecl', '*.prolog', '*.pro', '*.pl'), ('text/x-prolog',)),
|
||||
'PropertiesLexer': ('pygments.lexers.configs', 'Properties', ('properties', 'jproperties'), ('*.properties',), ('text/x-java-properties',)),
|
||||
'ProtoBufLexer': ('pygments.lexers.dsls', 'Protocol Buffer', ('protobuf', 'proto'), ('*.proto',), ()),
|
||||
@ -283,7 +315,8 @@ LEXERS = {
|
||||
'PythonLexer': ('pygments.lexers.python', 'Python', ('python', 'py', 'sage'), ('*.py', '*.pyw', '*.sc', 'SConstruct', 'SConscript', '*.tac', '*.sage'), ('text/x-python', 'application/x-python')),
|
||||
'PythonTracebackLexer': ('pygments.lexers.python', 'Python Traceback', ('pytb',), ('*.pytb',), ('text/x-python-traceback',)),
|
||||
'QBasicLexer': ('pygments.lexers.basic', 'QBasic', ('qbasic', 'basic'), ('*.BAS', '*.bas'), ('text/basic',)),
|
||||
'QmlLexer': ('pygments.lexers.webmisc', 'QML', ('qml',), ('*.qml',), ('application/x-qml',)),
|
||||
'QVToLexer': ('pygments.lexers.qvt', 'QVTO', ('qvto', 'qvt'), ('*.qvto',), ()),
|
||||
'QmlLexer': ('pygments.lexers.webmisc', 'QML', ('qml', 'qbs'), ('*.qml', '*.qbs'), ('application/x-qml', 'application/x-qt.qbs+qml')),
|
||||
'RConsoleLexer': ('pygments.lexers.r', 'RConsole', ('rconsole', 'rout'), ('*.Rout',), ()),
|
||||
'RPMSpecLexer': ('pygments.lexers.installers', 'RPMSpec', ('spec',), ('*.spec',), ('text/x-rpm-spec',)),
|
||||
'RacketLexer': ('pygments.lexers.lisp', 'Racket', ('racket', 'rkt'), ('*.rkt', '*.rktd', '*.rktl'), ('text/x-racket', 'application/x-racket')),
|
||||
@ -304,13 +337,16 @@ LEXERS = {
|
||||
'ResourceLexer': ('pygments.lexers.resource', 'ResourceBundle', ('resource', 'resourcebundle'), ('*.txt',), ()),
|
||||
'RexxLexer': ('pygments.lexers.scripting', 'Rexx', ('rexx', 'arexx'), ('*.rexx', '*.rex', '*.rx', '*.arexx'), ('text/x-rexx',)),
|
||||
'RhtmlLexer': ('pygments.lexers.templates', 'RHTML', ('rhtml', 'html+erb', 'html+ruby'), ('*.rhtml',), ('text/html+ruby',)),
|
||||
'RoboconfGraphLexer': ('pygments.lexers.roboconf', 'Roboconf Graph', ('roboconf-graph',), ('*.graph',), ()),
|
||||
'RoboconfInstancesLexer': ('pygments.lexers.roboconf', 'Roboconf Instances', ('roboconf-instances',), ('*.instances',), ()),
|
||||
'RobotFrameworkLexer': ('pygments.lexers.robotframework', 'RobotFramework', ('robotframework',), ('*.txt', '*.robot'), ('text/x-robotframework',)),
|
||||
'RqlLexer': ('pygments.lexers.sql', 'RQL', ('rql',), ('*.rql',), ('text/x-rql',)),
|
||||
'RslLexer': ('pygments.lexers.dsls', 'RSL', ('rsl',), ('*.rsl',), ('text/rsl',)),
|
||||
'RstLexer': ('pygments.lexers.markup', 'reStructuredText', ('rst', 'rest', 'restructuredtext'), ('*.rst', '*.rest'), ('text/x-rst', 'text/prs.fallenstein.rst')),
|
||||
'RtsLexer': ('pygments.lexers.trafficscript', 'TrafficScript', ('rts', 'trafficscript'), ('*.rts',), ()),
|
||||
'RubyConsoleLexer': ('pygments.lexers.ruby', 'Ruby irb session', ('rbcon', 'irb'), (), ('text/x-ruby-shellsession',)),
|
||||
'RubyLexer': ('pygments.lexers.ruby', 'Ruby', ('rb', 'ruby', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby'), ('text/x-ruby', 'application/x-ruby')),
|
||||
'RustLexer': ('pygments.lexers.rust', 'Rust', ('rust',), ('*.rs',), ('text/x-rustsrc',)),
|
||||
'RubyLexer': ('pygments.lexers.ruby', 'Ruby', ('rb', 'ruby', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby', 'Gemfile'), ('text/x-ruby', 'application/x-ruby')),
|
||||
'RustLexer': ('pygments.lexers.rust', 'Rust', ('rust',), ('*.rs', '*.rs.in'), ('text/rust',)),
|
||||
'SLexer': ('pygments.lexers.r', 'S', ('splus', 's', 'r'), ('*.S', '*.R', '.Rhistory', '.Rprofile', '.Renviron'), ('text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r', 'text/x-R', 'text/x-r-history', 'text/x-r-profile')),
|
||||
'SMLLexer': ('pygments.lexers.ml', 'Standard ML', ('sml',), ('*.sml', '*.sig', '*.fun'), ('text/x-standardml', 'application/x-standardml')),
|
||||
'SassLexer': ('pygments.lexers.css', 'Sass', ('sass',), ('*.sass',), ('text/x-sass',)),
|
||||
@ -319,7 +355,7 @@ LEXERS = {
|
||||
'SchemeLexer': ('pygments.lexers.lisp', 'Scheme', ('scheme', 'scm'), ('*.scm', '*.ss'), ('text/x-scheme', 'application/x-scheme')),
|
||||
'ScilabLexer': ('pygments.lexers.matlab', 'Scilab', ('scilab',), ('*.sci', '*.sce', '*.tst'), ('text/scilab',)),
|
||||
'ScssLexer': ('pygments.lexers.css', 'SCSS', ('scss',), ('*.scss',), ('text/x-scss',)),
|
||||
'ShellSessionLexer': ('pygments.lexers.shell', 'Shell Session', ('shell-session',), ('*.shell-session',), ('application/x-sh-session',)),
|
||||
'ShenLexer': ('pygments.lexers.lisp', 'Shen', ('shen',), ('*.shen',), ('text/x-shen', 'application/x-shen')),
|
||||
'SlimLexer': ('pygments.lexers.webmisc', 'Slim', ('slim',), ('*.slim',), ('text/x-slim',)),
|
||||
'SmaliLexer': ('pygments.lexers.dalvik', 'Smali', ('smali',), ('*.smali',), ('text/smali',)),
|
||||
'SmalltalkLexer': ('pygments.lexers.smalltalk', 'Smalltalk', ('smalltalk', 'squeak', 'st'), ('*.st',), ('text/x-smalltalk',)),
|
||||
@ -333,20 +369,28 @@ LEXERS = {
|
||||
'SquidConfLexer': ('pygments.lexers.configs', 'SquidConf', ('squidconf', 'squid.conf', 'squid'), ('squid.conf',), ('text/x-squidconf',)),
|
||||
'SspLexer': ('pygments.lexers.templates', 'Scalate Server Page', ('ssp',), ('*.ssp',), ('application/x-ssp',)),
|
||||
'StanLexer': ('pygments.lexers.modeling', 'Stan', ('stan',), ('*.stan',), ()),
|
||||
'SuperColliderLexer': ('pygments.lexers.supercollider', 'SuperCollider', ('sc', 'supercollider'), ('*.sc', '*.scd'), ('application/supercollider', 'text/supercollider')),
|
||||
'SwiftLexer': ('pygments.lexers.objective', 'Swift', ('swift',), ('*.swift',), ('text/x-swift',)),
|
||||
'SwigLexer': ('pygments.lexers.c_like', 'SWIG', ('swig',), ('*.swg', '*.i'), ('text/swig',)),
|
||||
'SystemVerilogLexer': ('pygments.lexers.hdl', 'systemverilog', ('systemverilog', 'sv'), ('*.sv', '*.svh'), ('text/x-systemverilog',)),
|
||||
'TAPLexer': ('pygments.lexers.testing', 'TAP', ('tap',), ('*.tap',), ()),
|
||||
'Tads3Lexer': ('pygments.lexers.int_fiction', 'TADS 3', ('tads3',), ('*.t',), ()),
|
||||
'TclLexer': ('pygments.lexers.tcl', 'Tcl', ('tcl',), ('*.tcl', '*.rvt'), ('text/x-tcl', 'text/x-script.tcl', 'application/x-tcl')),
|
||||
'TcshLexer': ('pygments.lexers.shell', 'Tcsh', ('tcsh', 'csh'), ('*.tcsh', '*.csh'), ('application/x-csh',)),
|
||||
'TcshSessionLexer': ('pygments.lexers.shell', 'Tcsh Session', ('tcshcon',), (), ()),
|
||||
'TeaTemplateLexer': ('pygments.lexers.templates', 'Tea', ('tea',), ('*.tea',), ('text/x-tea',)),
|
||||
'TermcapLexer': ('pygments.lexers.configs', 'Termcap', ('termcap',), ('termcap', 'termcap.src'), ()),
|
||||
'TerminfoLexer': ('pygments.lexers.configs', 'Terminfo', ('terminfo',), ('terminfo', 'terminfo.src'), ()),
|
||||
'TerraformLexer': ('pygments.lexers.configs', 'Terraform', ('terraform', 'tf'), ('*.tf',), ('application/x-tf', 'application/x-terraform')),
|
||||
'TexLexer': ('pygments.lexers.markup', 'TeX', ('tex', 'latex'), ('*.tex', '*.aux', '*.toc'), ('text/x-tex', 'text/x-latex')),
|
||||
'TextLexer': ('pygments.lexers.special', 'Text only', ('text',), ('*.txt',), ('text/plain',)),
|
||||
'ThriftLexer': ('pygments.lexers.dsls', 'Thrift', ('thrift',), ('*.thrift',), ('application/x-thrift',)),
|
||||
'TodotxtLexer': ('pygments.lexers.textfmts', 'Todotxt', ('todotxt',), ('todo.txt', '*.todotxt'), ('text/x-todo',)),
|
||||
'TreetopLexer': ('pygments.lexers.parsers', 'Treetop', ('treetop',), ('*.treetop', '*.tt'), ()),
|
||||
'TurtleLexer': ('pygments.lexers.rdf', 'Turtle', ('turtle',), ('*.ttl',), ('text/turtle', 'application/x-turtle')),
|
||||
'TwigHtmlLexer': ('pygments.lexers.templates', 'HTML+Twig', ('html+twig',), ('*.twig',), ('text/html+twig',)),
|
||||
'TwigLexer': ('pygments.lexers.templates', 'Twig', ('twig',), (), ('application/x-twig',)),
|
||||
'TypeScriptLexer': ('pygments.lexers.javascript', 'TypeScript', ('ts',), ('*.ts',), ('text/x-typescript',)),
|
||||
'TypeScriptLexer': ('pygments.lexers.javascript', 'TypeScript', ('ts', 'typescript'), ('*.ts',), ('text/x-typescript',)),
|
||||
'UrbiscriptLexer': ('pygments.lexers.urbi', 'UrbiScript', ('urbiscript',), ('*.u',), ('application/x-urbiscript',)),
|
||||
'VCTreeStatusLexer': ('pygments.lexers.console', 'VCTreeStatus', ('vctreestatus',), (), ()),
|
||||
'VGLLexer': ('pygments.lexers.dsls', 'VGL', ('vgl',), ('*.rpf',), ()),
|
||||
@ -359,6 +403,7 @@ LEXERS = {
|
||||
'VerilogLexer': ('pygments.lexers.hdl', 'verilog', ('verilog', 'v'), ('*.v',), ('text/x-verilog',)),
|
||||
'VhdlLexer': ('pygments.lexers.hdl', 'vhdl', ('vhdl',), ('*.vhdl', '*.vhd'), ('text/x-vhdl',)),
|
||||
'VimLexer': ('pygments.lexers.textedit', 'VimL', ('vim',), ('*.vim', '.vimrc', '.exrc', '.gvimrc', '_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc'), ('text/x-vim',)),
|
||||
'X10Lexer': ('pygments.lexers.x10', 'X10', ('x10', 'xten'), ('*.x10',), ('text/x-x10',)),
|
||||
'XQueryLexer': ('pygments.lexers.webmisc', 'XQuery', ('xquery', 'xqy', 'xq', 'xql', 'xqm'), ('*.xqy', '*.xquery', '*.xq', '*.xql', '*.xqm'), ('text/xquery', 'application/xquery')),
|
||||
'XmlDjangoLexer': ('pygments.lexers.templates', 'XML+Django/Jinja', ('xml+django', 'xml+jinja'), (), ('application/xml+django', 'application/xml+jinja')),
|
||||
'XmlErbLexer': ('pygments.lexers.templates', 'XML+Ruby', ('xml+erb', 'xml+ruby'), (), ('application/xml+ruby',)),
|
||||
@ -372,7 +417,7 @@ LEXERS = {
|
||||
'ZephirLexer': ('pygments.lexers.php', 'Zephir', ('zephir',), ('*.zep',), ()),
|
||||
}
|
||||
|
||||
if __name__ == '__main__':
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import sys
|
||||
import os
|
||||
|
||||
@ -401,6 +446,13 @@ if __name__ == '__main__':
|
||||
# extract useful sourcecode from this file
|
||||
with open(__file__) as fp:
|
||||
content = fp.read()
|
||||
# replace crnl to nl for Windows.
|
||||
#
|
||||
# Note that, originally, contributers should keep nl of master
|
||||
# repository, for example by using some kind of automatic
|
||||
# management EOL, like `EolExtension
|
||||
# <https://www.mercurial-scm.org/wiki/EolExtension>`.
|
||||
content = content.replace("\r\n", "\n")
|
||||
header = content[:content.find('LEXERS = {')]
|
||||
footer = content[content.find("if __name__ == '__main__':"):]
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Builtins for the MqlLexer.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
types = (
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Builtin list for the OpenEdgeLexer.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
internet connection. don't run that at home, use
|
||||
a server ;-)
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -4672,7 +4672,8 @@ MODULES = {'.NET': ('dotnet_load',),
|
||||
'xdiff_string_patch',
|
||||
'xdiff_string_rabdiff')}
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import glob
|
||||
import os
|
||||
import pprint
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Self-updating data files for PostgreSQL lexer.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -507,7 +507,8 @@ PLPGSQL_KEYWORDS = (
|
||||
'RETURN', 'REVERSE', 'SQLSTATE', 'WHILE',
|
||||
)
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import re
|
||||
try:
|
||||
from urllib import urlopen
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Builtin list for the ScilabLexer.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -3051,7 +3051,8 @@ variables_kw = (
|
||||
'xcoslib',
|
||||
)
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import subprocess
|
||||
from pygments.util import format_lines, duplicates_removed
|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
|
||||
Do not edit the FUNCTIONS list by hand.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -1091,7 +1091,9 @@ FUNCTIONS = (
|
||||
'SDKCall',
|
||||
'GetPlayerResourceEntity',
|
||||
)
|
||||
if __name__ == '__main__':
|
||||
|
||||
|
||||
if __name__ == '__main__': # pragma: no cover
|
||||
import re
|
||||
import sys
|
||||
try:
|
||||
@ -4,9 +4,9 @@
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This file contains the names of functions for Stan used by
|
||||
``pygments.lexers.math.StanLexer. This is for Stan language version 2.4.0.
|
||||
``pygments.lexers.math.StanLexer. This is for Stan language version 2.8.0.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -16,10 +16,12 @@ KEYWORDS = (
|
||||
'if',
|
||||
'in',
|
||||
'increment_log_prob',
|
||||
'integrate_ode',
|
||||
'lp__',
|
||||
'print',
|
||||
'reject',
|
||||
'return',
|
||||
'while',
|
||||
'while'
|
||||
)
|
||||
|
||||
TYPES = (
|
||||
@ -33,11 +35,11 @@ TYPES = (
|
||||
'positive_ordered',
|
||||
'real',
|
||||
'row_vector',
|
||||
'row_vectormatrix',
|
||||
'simplex',
|
||||
'unit_vector',
|
||||
'vector',
|
||||
'void',
|
||||
)
|
||||
'void')
|
||||
|
||||
FUNCTIONS = (
|
||||
'Phi',
|
||||
@ -45,6 +47,8 @@ FUNCTIONS = (
|
||||
'abs',
|
||||
'acos',
|
||||
'acosh',
|
||||
'append_col',
|
||||
'append_row',
|
||||
'asin',
|
||||
'asinh',
|
||||
'atan',
|
||||
@ -100,6 +104,11 @@ FUNCTIONS = (
|
||||
'cos',
|
||||
'cosh',
|
||||
'crossprod',
|
||||
'csr_extract_u',
|
||||
'csr_extract_v',
|
||||
'csr_extract_w',
|
||||
'csr_matrix_times_vector',
|
||||
'csr_to_dense_matrix',
|
||||
'cumulative_sum',
|
||||
'determinant',
|
||||
'diag_matrix',
|
||||
@ -144,6 +153,11 @@ FUNCTIONS = (
|
||||
'fmax',
|
||||
'fmin',
|
||||
'fmod',
|
||||
'frechet_ccdf_log',
|
||||
'frechet_cdf',
|
||||
'frechet_cdf_log',
|
||||
'frechet_log',
|
||||
'frechet_rng',
|
||||
'gamma_ccdf_log',
|
||||
'gamma_cdf',
|
||||
'gamma_cdf_log',
|
||||
@ -152,6 +166,7 @@ FUNCTIONS = (
|
||||
'gamma_q',
|
||||
'gamma_rng',
|
||||
'gaussian_dlm_obs_log',
|
||||
'get_lp',
|
||||
'gumbel_ccdf_log',
|
||||
'gumbel_cdf',
|
||||
'gumbel_cdf_log',
|
||||
@ -176,19 +191,21 @@ FUNCTIONS = (
|
||||
'inv_gamma_log',
|
||||
'inv_gamma_rng',
|
||||
'inv_logit',
|
||||
'inv_phi',
|
||||
'inv_sqrt',
|
||||
'inv_square',
|
||||
'inv_wishart_log',
|
||||
'inv_wishart_rng',
|
||||
'inverse',
|
||||
'inverse_spd',
|
||||
'is_inf',
|
||||
'is_nan',
|
||||
'lbeta',
|
||||
'lgamma',
|
||||
'lkj_corr_cholesky_log',
|
||||
'lkj_corr_cholesky_rng',
|
||||
'lkj_corr_log',
|
||||
'lkj_corr_rng',
|
||||
'lkj_cov_log',
|
||||
'lmgamma',
|
||||
'log',
|
||||
'log10',
|
||||
@ -202,6 +219,7 @@ FUNCTIONS = (
|
||||
'log_diff_exp',
|
||||
'log_falling_factorial',
|
||||
'log_inv_logit',
|
||||
'log_mix',
|
||||
'log_rising_factorial',
|
||||
'log_softmax',
|
||||
'log_sum_exp',
|
||||
@ -224,6 +242,7 @@ FUNCTIONS = (
|
||||
'min',
|
||||
'modified_bessel_first_kind',
|
||||
'modified_bessel_second_kind',
|
||||
'multi_gp_cholesky_log',
|
||||
'multi_gp_log',
|
||||
'multi_normal_cholesky_log',
|
||||
'multi_normal_cholesky_rng',
|
||||
@ -236,6 +255,9 @@ FUNCTIONS = (
|
||||
'multinomial_rng',
|
||||
'multiply_log',
|
||||
'multiply_lower_tri_self_transpose',
|
||||
'neg_binomial_2_ccdf_log',
|
||||
'neg_binomial_2_cdf',
|
||||
'neg_binomial_2_cdf_log',
|
||||
'neg_binomial_2_log',
|
||||
'neg_binomial_2_log_log',
|
||||
'neg_binomial_2_log_rng',
|
||||
@ -252,6 +274,7 @@ FUNCTIONS = (
|
||||
'normal_log',
|
||||
'normal_rng',
|
||||
'not_a_number',
|
||||
'num_elements',
|
||||
'ordered_logistic_log',
|
||||
'ordered_logistic_rng',
|
||||
'owens_t',
|
||||
@ -260,12 +283,18 @@ FUNCTIONS = (
|
||||
'pareto_cdf_log',
|
||||
'pareto_log',
|
||||
'pareto_rng',
|
||||
'pareto_type_2_ccdf_log',
|
||||
'pareto_type_2_cdf',
|
||||
'pareto_type_2_cdf_log',
|
||||
'pareto_type_2_log',
|
||||
'pareto_type_2_rng',
|
||||
'pi',
|
||||
'poisson_ccdf_log',
|
||||
'poisson_cdf',
|
||||
'poisson_cdf_log',
|
||||
'poisson_log',
|
||||
'poisson_log_log',
|
||||
'poisson_log_rng',
|
||||
'poisson_rng',
|
||||
'positive_infinity',
|
||||
'pow',
|
||||
@ -353,8 +382,9 @@ FUNCTIONS = (
|
||||
'weibull_cdf_log',
|
||||
'weibull_log',
|
||||
'weibull_rng',
|
||||
'wiener_log',
|
||||
'wishart_log',
|
||||
'wishart_rng',
|
||||
'wishart_rng'
|
||||
)
|
||||
|
||||
DISTRIBUTIONS = (
|
||||
@ -372,6 +402,7 @@ DISTRIBUTIONS = (
|
||||
'double_exponential',
|
||||
'exp_mod_normal',
|
||||
'exponential',
|
||||
'frechet',
|
||||
'gamma',
|
||||
'gaussian_dlm_obs',
|
||||
'gumbel',
|
||||
@ -381,10 +412,10 @@ DISTRIBUTIONS = (
|
||||
'inv_wishart',
|
||||
'lkj_corr',
|
||||
'lkj_corr_cholesky',
|
||||
'lkj_cov',
|
||||
'logistic',
|
||||
'lognormal',
|
||||
'multi_gp',
|
||||
'multi_gp_cholesky',
|
||||
'multi_normal',
|
||||
'multi_normal_cholesky',
|
||||
'multi_normal_prec',
|
||||
@ -396,6 +427,7 @@ DISTRIBUTIONS = (
|
||||
'normal',
|
||||
'ordered_logistic',
|
||||
'pareto',
|
||||
'pareto_type_2',
|
||||
'poisson',
|
||||
'poisson_log',
|
||||
'rayleigh',
|
||||
@ -405,7 +437,8 @@ DISTRIBUTIONS = (
|
||||
'uniform',
|
||||
'von_mises',
|
||||
'weibull',
|
||||
'wishart',
|
||||
'wiener',
|
||||
'wishart'
|
||||
)
|
||||
|
||||
RESERVED = (
|
||||
@ -494,5 +527,6 @@ RESERVED = (
|
||||
'volatile',
|
||||
'wchar_t',
|
||||
'xor',
|
||||
'xor_eq',
|
||||
'xor_eq'
|
||||
)
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
This file is autogenerated by scripts/get_vimkw.py
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for ActionScript and MXML.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Just export lexer classes previously contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for computer algebra systems.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -15,7 +15,7 @@ from pygments.lexer import RegexLexer, bygroups, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
|
||||
__all__ = ['GAPLexer', 'MathematicaLexer', 'MuPADLexer']
|
||||
__all__ = ['GAPLexer', 'MathematicaLexer', 'MuPADLexer', 'BCLexer']
|
||||
|
||||
|
||||
class GAPLexer(RegexLexer):
|
||||
@ -65,7 +65,7 @@ class GAPLexer(RegexLexer):
|
||||
(r'[0-9]+(?:\.[0-9]*)?(?:e[0-9]+)?', Number),
|
||||
(r'\.[0-9]+(?:e[0-9]+)?', Number),
|
||||
(r'.', Text)
|
||||
]
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
@ -183,5 +183,39 @@ class MuPADLexer(RegexLexer):
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
]
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class BCLexer(RegexLexer):
|
||||
"""
|
||||
A `BC <https://www.gnu.org/software/bc/>`_ lexer.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'BC'
|
||||
aliases = ['bc']
|
||||
filenames = ['*.bc']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'/\*', Comment.Multiline, 'comment'),
|
||||
(r'"(?:[^"\\]|\\.)*"', String),
|
||||
(r'[{}();,]', Punctuation),
|
||||
(words(('if', 'else', 'while', 'for', 'break', 'continue',
|
||||
'halt', 'return', 'define', 'auto', 'print', 'read',
|
||||
'length', 'scale', 'sqrt', 'limits', 'quit',
|
||||
'warranty'), suffix=r'\b'), Keyword),
|
||||
(r'\+\+|--|\|\||&&|'
|
||||
r'([-<>+*%\^/!=])=?', Operator),
|
||||
# bc doesn't support exponential
|
||||
(r'[0-9]+(\.[0-9]*)?', Number),
|
||||
(r'\.[0-9]+', Number),
|
||||
(r'.', Text)
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]+', Comment.Multiline),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
],
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for AmbientTalk language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for APL.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
318
packages/wakatime/packages/pygments/lexers/archetype.py
Normal file
318
packages/wakatime/packages/pygments/lexers/archetype.py
Normal file
@ -0,0 +1,318 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.archetype
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for Archetype-related syntaxes, including:
|
||||
|
||||
- ODIN syntax <https://github.com/openEHR/odin>
|
||||
- ADL syntax <http://www.openehr.org/releases/trunk/architecture/am/adl2.pdf>
|
||||
- cADL sub-syntax of ADL
|
||||
|
||||
For uses of this syntax, see the openEHR archetypes <http://www.openEHR.org/ckm>
|
||||
|
||||
Contributed by Thomas Beale <https://github.com/wolandscat>,
|
||||
<https://bitbucket.org/thomas_beale>.
|
||||
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, bygroups, using, default
|
||||
from pygments.token import Text, Comment, Name, Literal, Number, String, \
|
||||
Punctuation, Keyword, Operator, Generic
|
||||
|
||||
__all__ = ['OdinLexer', 'CadlLexer', 'AdlLexer']
|
||||
|
||||
|
||||
class AtomsLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for Values used in ADL and ODIN.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
tokens = {
|
||||
# ----- pseudo-states for inclusion -----
|
||||
'whitespace': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'[ \t]*--.*$', Comment),
|
||||
],
|
||||
'archetype_id': [
|
||||
(r'[ \t]*([a-zA-Z]\w+(\.[a-zA-Z]\w+)*::)?[a-zA-Z]\w+(-[a-zA-Z]\w+){2}'
|
||||
r'\.\w+[\w-]*\.v\d+(\.\d+){,2}((-[a-z]+)(\.\d+)?)?', Name.Decorator),
|
||||
],
|
||||
'date_constraints': [
|
||||
# ISO 8601-based date/time constraints
|
||||
(r'[Xx?YyMmDdHhSs\d]{2,4}([:-][Xx?YyMmDdHhSs\d]{2}){2}', Literal.Date),
|
||||
# ISO 8601-based duration constraints + optional trailing slash
|
||||
(r'(P[YyMmWwDd]+(T[HhMmSs]+)?|PT[HhMmSs]+)/?', Literal.Date),
|
||||
],
|
||||
'ordered_values': [
|
||||
# ISO 8601 date with optional 'T' ligature
|
||||
(r'\d{4}-\d{2}-\d{2}T?', Literal.Date),
|
||||
# ISO 8601 time
|
||||
(r'\d{2}:\d{2}:\d{2}(\.\d+)?([+-]\d{4}|Z)?', Literal.Date),
|
||||
# ISO 8601 duration
|
||||
(r'P((\d*(\.\d+)?[YyMmWwDd]){1,3}(T(\d*(\.\d+)?[HhMmSs]){,3})?|'
|
||||
r'T(\d*(\.\d+)?[HhMmSs]){,3})', Literal.Date),
|
||||
(r'[+-]?(\d+\.\d*|\.\d+|\d+)[eE][+-]?\d+', Number.Float),
|
||||
(r'[+-]?(\d+)*\.\d+%?', Number.Float),
|
||||
(r'0x[0-9a-fA-F]+', Number.Hex),
|
||||
(r'[+-]?\d+%?', Number.Integer),
|
||||
],
|
||||
'values': [
|
||||
include('ordered_values'),
|
||||
(r'([Tt]rue|[Ff]alse)', Literal),
|
||||
(r'"', String, 'string'),
|
||||
(r"'(\\.|\\[0-7]{1,3}|\\x[a-fA-F0-9]{1,2}|[^\\\'\n])'", String.Char),
|
||||
(r'[a-z][a-z0-9+.-]*:', Literal, 'uri'),
|
||||
# term code
|
||||
(r'(\[)(\w[\w-]*(?:\([^)\n]+\))?)(::)(\w[\w-]*)(\])',
|
||||
bygroups(Punctuation, Name.Decorator, Punctuation, Name.Decorator,
|
||||
Punctuation)),
|
||||
(r'\|', Punctuation, 'interval'),
|
||||
# list continuation
|
||||
(r'\.\.\.', Punctuation),
|
||||
],
|
||||
'constraint_values': [
|
||||
(r'(\[)(\w[\w-]*(?:\([^)\n]+\))?)(::)',
|
||||
bygroups(Punctuation, Name.Decorator, Punctuation), 'adl14_code_constraint'),
|
||||
# ADL 1.4 ordinal constraint
|
||||
(r'(\d*)(\|)(\[\w[\w-]*::\w[\w-]*\])((?:[,;])?)',
|
||||
bygroups(Number, Punctuation, Name.Decorator, Punctuation)),
|
||||
include('date_constraints'),
|
||||
include('values'),
|
||||
],
|
||||
|
||||
# ----- real states -----
|
||||
'string': [
|
||||
('"', String, '#pop'),
|
||||
(r'\\([\\abfnrtv"\']|x[a-fA-F0-9]{2,4}|'
|
||||
r'u[a-fA-F0-9]{4}|U[a-fA-F0-9]{8}|[0-7]{1,3})', String.Escape),
|
||||
# all other characters
|
||||
(r'[^\\"]+', String),
|
||||
# stray backslash
|
||||
(r'\\', String),
|
||||
],
|
||||
'uri': [
|
||||
# effective URI terminators
|
||||
(r'[,>\s]', Punctuation, '#pop'),
|
||||
(r'[^>\s,]+', Literal),
|
||||
],
|
||||
'interval': [
|
||||
(r'\|', Punctuation, '#pop'),
|
||||
include('ordered_values'),
|
||||
(r'\.\.', Punctuation),
|
||||
(r'[<>=] *', Punctuation),
|
||||
# handle +/-
|
||||
(r'\+/-', Punctuation),
|
||||
(r'\s+', Text),
|
||||
],
|
||||
'any_code': [
|
||||
include('archetype_id'),
|
||||
# if it is a code
|
||||
(r'[a-z_]\w*[0-9.]+(@[^\]]+)?', Name.Decorator),
|
||||
# if it is tuple with attribute names
|
||||
(r'[a-z_]\w*', Name.Class),
|
||||
# if it is an integer, i.e. Xpath child index
|
||||
(r'[0-9]+', Text),
|
||||
(r'\|', Punctuation, 'code_rubric'),
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
# handle use_archetype statement
|
||||
(r'\s*,\s*', Punctuation),
|
||||
],
|
||||
'code_rubric': [
|
||||
(r'\|', Punctuation, '#pop'),
|
||||
(r'[^|]+', String),
|
||||
],
|
||||
'adl14_code_constraint': [
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
(r'\|', Punctuation, 'code_rubric'),
|
||||
(r'(\w[\w-]*)([;,]?)', bygroups(Name.Decorator, Punctuation)),
|
||||
include('whitespace'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class OdinLexer(AtomsLexer):
|
||||
"""
|
||||
Lexer for ODIN syntax.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'ODIN'
|
||||
aliases = ['odin']
|
||||
filenames = ['*.odin']
|
||||
mimetypes = ['text/odin']
|
||||
|
||||
tokens = {
|
||||
'path': [
|
||||
(r'>', Punctuation, '#pop'),
|
||||
# attribute name
|
||||
(r'[a-z_]\w*', Name.Class),
|
||||
(r'/', Punctuation),
|
||||
(r'\[', Punctuation, 'key'),
|
||||
(r'\s*,\s*', Punctuation, '#pop'),
|
||||
(r'\s+', Text, '#pop'),
|
||||
],
|
||||
'key': [
|
||||
include('values'),
|
||||
(r'\]', Punctuation, '#pop'),
|
||||
],
|
||||
'type_cast': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(r'[^)]+', Name.Class),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
(r'([Tt]rue|[Ff]alse)', Literal),
|
||||
include('values'),
|
||||
# x-ref path
|
||||
(r'/', Punctuation, 'path'),
|
||||
# x-ref path starting with key
|
||||
(r'\[', Punctuation, 'key'),
|
||||
# attribute name
|
||||
(r'[a-z_]\w*', Name.Class),
|
||||
(r'=', Operator),
|
||||
(r'\(', Punctuation, 'type_cast'),
|
||||
(r',', Punctuation),
|
||||
(r'<', Punctuation),
|
||||
(r'>', Punctuation),
|
||||
(r';', Punctuation),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CadlLexer(AtomsLexer):
|
||||
"""
|
||||
Lexer for cADL syntax.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'cADL'
|
||||
aliases = ['cadl']
|
||||
filenames = ['*.cadl']
|
||||
|
||||
tokens = {
|
||||
'path': [
|
||||
# attribute name
|
||||
(r'[a-z_]\w*', Name.Class),
|
||||
(r'/', Punctuation),
|
||||
(r'\[', Punctuation, 'any_code'),
|
||||
(r'\s+', Punctuation, '#pop'),
|
||||
],
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
(r'(cardinality|existence|occurrences|group|include|exclude|'
|
||||
r'allow_archetype|use_archetype|use_node)\W', Keyword.Type),
|
||||
(r'(and|or|not|there_exists|xor|implies|for_all)\W', Keyword.Type),
|
||||
(r'(after|before|closed)\W', Keyword.Type),
|
||||
(r'(not)\W', Operator),
|
||||
(r'(matches|is_in)\W', Operator),
|
||||
# is_in / not is_in char
|
||||
(u'(\u2208|\u2209)', Operator),
|
||||
# there_exists / not there_exists / for_all / and / or
|
||||
(u'(\u2203|\u2204|\u2200|\u2227|\u2228|\u22BB|\223C)',
|
||||
Operator),
|
||||
# regex in slot or as string constraint
|
||||
(r'(\{)(\s*/[^}]+/\s*)(\})',
|
||||
bygroups(Punctuation, String.Regex, Punctuation)),
|
||||
# regex in slot or as string constraint
|
||||
(r'(\{)(\s*\^[^}]+\^\s*)(\})',
|
||||
bygroups(Punctuation, String.Regex, Punctuation)),
|
||||
(r'/', Punctuation, 'path'),
|
||||
# for cardinality etc
|
||||
(r'(\{)((?:\d+\.\.)?(?:\d+|\*))'
|
||||
r'((?:\s*;\s*(?:ordered|unordered|unique)){,2})(\})',
|
||||
bygroups(Punctuation, Number, Number, Punctuation)),
|
||||
# [{ is start of a tuple value
|
||||
(r'\[\{', Punctuation),
|
||||
(r'\}\]', Punctuation),
|
||||
(r'\{', Punctuation),
|
||||
(r'\}', Punctuation),
|
||||
include('constraint_values'),
|
||||
# type name
|
||||
(r'[A-Z]\w+(<[A-Z]\w+([A-Za-z_<>]*)>)?', Name.Class),
|
||||
# attribute name
|
||||
(r'[a-z_]\w*', Name.Class),
|
||||
(r'\[', Punctuation, 'any_code'),
|
||||
(r'(~|//|\\\\|\+|-|/|\*|\^|!=|=|<=|>=|<|>]?)', Operator),
|
||||
(r'\(', Punctuation),
|
||||
(r'\)', Punctuation),
|
||||
# for lists of values
|
||||
(r',', Punctuation),
|
||||
(r'"', String, 'string'),
|
||||
# for assumed value
|
||||
(r';', Punctuation),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class AdlLexer(AtomsLexer):
|
||||
"""
|
||||
Lexer for ADL syntax.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'ADL'
|
||||
aliases = ['adl']
|
||||
filenames = ['*.adl', '*.adls', '*.adlf', '*.adlx']
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
# blank line ends
|
||||
(r'\s*\n', Text),
|
||||
# comment-only line
|
||||
(r'^[ \t]*--.*$', Comment),
|
||||
],
|
||||
'odin_section': [
|
||||
# repeating the following two rules from the root state enable multi-line
|
||||
# strings that start in the first column to be dealt with
|
||||
(r'^(language|description|ontology|terminology|annotations|'
|
||||
r'component_terminologies|revision_history)[ \t]*\n', Generic.Heading),
|
||||
(r'^(definition)[ \t]*\n', Generic.Heading, 'cadl_section'),
|
||||
(r'^([ \t]*|[ \t]+.*)\n', using(OdinLexer)),
|
||||
(r'^([^"]*")(>[ \t]*\n)', bygroups(String, Punctuation)),
|
||||
# template overlay delimiter
|
||||
(r'^----------*\n', Text, '#pop'),
|
||||
(r'^.*\n', String),
|
||||
default('#pop'),
|
||||
],
|
||||
'cadl_section': [
|
||||
(r'^([ \t]*|[ \t]+.*)\n', using(CadlLexer)),
|
||||
default('#pop'),
|
||||
],
|
||||
'rules_section': [
|
||||
(r'^[ \t]+.*\n', using(CadlLexer)),
|
||||
default('#pop'),
|
||||
],
|
||||
'metadata': [
|
||||
(r'\)', Punctuation, '#pop'),
|
||||
(r';', Punctuation),
|
||||
(r'([Tt]rue|[Ff]alse)', Literal),
|
||||
# numbers and version ids
|
||||
(r'\d+(\.\d+)*', Literal),
|
||||
# Guids
|
||||
(r'(\d|[a-fA-F])+(-(\d|[a-fA-F])+){3,}', Literal),
|
||||
(r'\w+', Name.Class),
|
||||
(r'"', String, 'string'),
|
||||
(r'=', Operator),
|
||||
(r'[ \t]+', Text),
|
||||
default('#pop'),
|
||||
],
|
||||
'root': [
|
||||
(r'^(archetype|template_overlay|operational_template|template|'
|
||||
r'speciali[sz]e)', Generic.Heading),
|
||||
(r'^(language|description|ontology|terminology|annotations|'
|
||||
r'component_terminologies|revision_history)[ \t]*\n',
|
||||
Generic.Heading, 'odin_section'),
|
||||
(r'^(definition)[ \t]*\n', Generic.Heading, 'cadl_section'),
|
||||
(r'^(rules)[ \t]*\n', Generic.Heading, 'rules_section'),
|
||||
include('archetype_id'),
|
||||
(r'[ \t]*\(', Punctuation, 'metadata'),
|
||||
include('whitespace'),
|
||||
],
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for assembly languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -87,7 +87,7 @@ class GasLexer(RegexLexer):
|
||||
(r'#.*?\n', Comment)
|
||||
],
|
||||
'punctuation': [
|
||||
(r'[-*,.():]+', Punctuation)
|
||||
(r'[-*,.()\[\]!:]+', Punctuation)
|
||||
]
|
||||
}
|
||||
|
||||
@ -286,7 +286,8 @@ class LlvmLexer(RegexLexer):
|
||||
r'|lshr|ashr|and|or|xor|icmp|fcmp'
|
||||
|
||||
r'|phi|call|trunc|zext|sext|fptrunc|fpext|uitofp|sitofp|fptoui'
|
||||
r'|fptosi|inttoptr|ptrtoint|bitcast|select|va_arg|ret|br|switch'
|
||||
r'|fptosi|inttoptr|ptrtoint|bitcast|addrspacecast'
|
||||
r'|select|va_arg|ret|br|switch'
|
||||
r'|invoke|unwind|unreachable'
|
||||
r'|indirectbr|landingpad|resume'
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for automation scripting languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -316,7 +316,8 @@ class AutoItLexer(RegexLexer):
|
||||
tokens = {
|
||||
'root': [
|
||||
(r';.*\n', Comment.Single),
|
||||
(r'(#comments-start|#cs).*?(#comments-end|#ce)', Comment.Multiline),
|
||||
(r'(#comments-start|#cs)(.|\n)*?(#comments-end|#ce)',
|
||||
Comment.Multiline),
|
||||
(r'[\[\]{}(),;]', Punctuation),
|
||||
(r'(and|or|not)\b', Operator.Word),
|
||||
(r'[$|@][a-zA-Z_]\w*', Name.Variable),
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for BASIC like languages (other than VB.net).
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for "business-oriented" languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -244,7 +244,7 @@ class ABAPLexer(RegexLexer):
|
||||
"""
|
||||
name = 'ABAP'
|
||||
aliases = ['abap']
|
||||
filenames = ['*.abap']
|
||||
filenames = ['*.abap', '*.ABAP']
|
||||
mimetypes = ['text/x-abap']
|
||||
|
||||
flags = re.IGNORECASE | re.MULTILINE
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for C/C++ languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -28,8 +28,10 @@ class CFamilyLexer(RegexLexer):
|
||||
|
||||
#: optional Comment or Whitespace
|
||||
_ws = r'(?:\s|//.*?\n|/[*].*?[*]/)+'
|
||||
|
||||
# The trailing ?, rather than *, avoids a geometric performance drop here.
|
||||
#: only one /* */ style comment
|
||||
_ws1 = r'\s*(?:/[*].*?[*]/\s*)*'
|
||||
_ws1 = r'\s*(?:/[*].*?[*]/\s*)?'
|
||||
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
@ -63,8 +65,7 @@ class CFamilyLexer(RegexLexer):
|
||||
'restricted', 'return', 'sizeof', 'static', 'struct',
|
||||
'switch', 'typedef', 'union', 'volatile', 'while'),
|
||||
suffix=r'\b'), Keyword),
|
||||
(r'(bool|int|long|float|short|double|char|unsigned|signed|void|'
|
||||
r'[a-z_][a-z0-9_]*_t)\b',
|
||||
(r'(bool|int|long|float|short|double|char|unsigned|signed|void)\b',
|
||||
Keyword.Type),
|
||||
(words(('inline', '_inline', '__inline', 'naked', 'restrict',
|
||||
'thread', 'typename'), suffix=r'\b'), Keyword.Reserved),
|
||||
@ -87,7 +88,7 @@ class CFamilyLexer(RegexLexer):
|
||||
(r'((?:[\w*\s])+?(?:\s|[*]))' # return arguments
|
||||
r'([a-zA-Z_]\w*)' # method name
|
||||
r'(\s*\([^;]*?\))' # signature
|
||||
r'(' + _ws + r')?(\{)',
|
||||
r'([^;{]*)(\{)',
|
||||
bygroups(using(this), Name.Function, using(this), using(this),
|
||||
Punctuation),
|
||||
'function'),
|
||||
@ -95,7 +96,7 @@ class CFamilyLexer(RegexLexer):
|
||||
(r'((?:[\w*\s])+?(?:\s|[*]))' # return arguments
|
||||
r'([a-zA-Z_]\w*)' # method name
|
||||
r'(\s*\([^;]*?\))' # signature
|
||||
r'(' + _ws + r')?(;)',
|
||||
r'([^;]*)(;)',
|
||||
bygroups(using(this), Name.Function, using(this), using(this),
|
||||
Punctuation)),
|
||||
default('statement'),
|
||||
@ -122,6 +123,7 @@ class CFamilyLexer(RegexLexer):
|
||||
(r'\\', String), # stray backslash
|
||||
],
|
||||
'macro': [
|
||||
(r'(include)(' + _ws1 + ')([^\n]+)', bygroups(Comment.Preproc, Text, Comment.PreprocFile)),
|
||||
(r'[^/\n]+', Comment.Preproc),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'//.*?\n', Comment.Single, '#pop'),
|
||||
@ -137,22 +139,26 @@ class CFamilyLexer(RegexLexer):
|
||||
]
|
||||
}
|
||||
|
||||
stdlib_types = ['size_t', 'ssize_t', 'off_t', 'wchar_t', 'ptrdiff_t',
|
||||
'sig_atomic_t', 'fpos_t', 'clock_t', 'time_t', 'va_list',
|
||||
'jmp_buf', 'FILE', 'DIR', 'div_t', 'ldiv_t', 'mbstate_t',
|
||||
'wctrans_t', 'wint_t', 'wctype_t']
|
||||
c99_types = ['_Bool', '_Complex', 'int8_t', 'int16_t', 'int32_t', 'int64_t',
|
||||
'uint8_t', 'uint16_t', 'uint32_t', 'uint64_t', 'int_least8_t',
|
||||
'int_least16_t', 'int_least32_t', 'int_least64_t',
|
||||
'uint_least8_t', 'uint_least16_t', 'uint_least32_t',
|
||||
'uint_least64_t', 'int_fast8_t', 'int_fast16_t', 'int_fast32_t',
|
||||
'int_fast64_t', 'uint_fast8_t', 'uint_fast16_t', 'uint_fast32_t',
|
||||
'uint_fast64_t', 'intptr_t', 'uintptr_t', 'intmax_t',
|
||||
'uintmax_t']
|
||||
stdlib_types = set((
|
||||
'size_t', 'ssize_t', 'off_t', 'wchar_t', 'ptrdiff_t', 'sig_atomic_t', 'fpos_t',
|
||||
'clock_t', 'time_t', 'va_list', 'jmp_buf', 'FILE', 'DIR', 'div_t', 'ldiv_t',
|
||||
'mbstate_t', 'wctrans_t', 'wint_t', 'wctype_t'))
|
||||
c99_types = set((
|
||||
'_Bool', '_Complex', 'int8_t', 'int16_t', 'int32_t', 'int64_t', 'uint8_t',
|
||||
'uint16_t', 'uint32_t', 'uint64_t', 'int_least8_t', 'int_least16_t',
|
||||
'int_least32_t', 'int_least64_t', 'uint_least8_t', 'uint_least16_t',
|
||||
'uint_least32_t', 'uint_least64_t', 'int_fast8_t', 'int_fast16_t', 'int_fast32_t',
|
||||
'int_fast64_t', 'uint_fast8_t', 'uint_fast16_t', 'uint_fast32_t', 'uint_fast64_t',
|
||||
'intptr_t', 'uintptr_t', 'intmax_t', 'uintmax_t'))
|
||||
linux_types = set((
|
||||
'clockid_t', 'cpu_set_t', 'cpumask_t', 'dev_t', 'gid_t', 'id_t', 'ino_t', 'key_t',
|
||||
'mode_t', 'nfds_t', 'pid_t', 'rlim_t', 'sig_t', 'sighandler_t', 'siginfo_t',
|
||||
'sigset_t', 'sigval_t', 'socklen_t', 'timer_t', 'uid_t'))
|
||||
|
||||
def __init__(self, **options):
|
||||
self.stdlibhighlighting = get_bool_opt(options, 'stdlibhighlighting', True)
|
||||
self.c99highlighting = get_bool_opt(options, 'c99highlighting', True)
|
||||
self.platformhighlighting = get_bool_opt(options, 'platformhighlighting', True)
|
||||
RegexLexer.__init__(self, **options)
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
@ -163,6 +169,8 @@ class CFamilyLexer(RegexLexer):
|
||||
token = Keyword.Type
|
||||
elif self.c99highlighting and value in self.c99_types:
|
||||
token = Keyword.Type
|
||||
elif self.platformhighlighting and value in self.linux_types:
|
||||
token = Keyword.Type
|
||||
yield index, token, value
|
||||
|
||||
|
||||
@ -179,7 +187,7 @@ class CLexer(CFamilyLexer):
|
||||
def analyse_text(text):
|
||||
if re.search('^\s*#include [<"]', text, re.MULTILINE):
|
||||
return 0.1
|
||||
if re.search('^\s*#ifdef ', text, re.MULTILINE):
|
||||
if re.search('^\s*#ifn?def ', text, re.MULTILINE):
|
||||
return 0.1
|
||||
|
||||
|
||||
@ -202,12 +210,14 @@ class CppLexer(CFamilyLexer):
|
||||
'export', 'friend', 'mutable', 'namespace', 'new', 'operator',
|
||||
'private', 'protected', 'public', 'reinterpret_cast',
|
||||
'restrict', 'static_cast', 'template', 'this', 'throw', 'throws',
|
||||
'typeid', 'typename', 'using', 'virtual',
|
||||
'try', 'typeid', 'typename', 'using', 'virtual',
|
||||
'constexpr', 'nullptr', 'decltype', 'thread_local',
|
||||
'alignas', 'alignof', 'static_assert', 'noexcept', 'override',
|
||||
'final'), suffix=r'\b'), Keyword),
|
||||
(r'char(16_t|32_t)\b', Keyword.Type),
|
||||
(r'(class)(\s+)', bygroups(Keyword, Text), 'classname'),
|
||||
# C++11 raw strings
|
||||
(r'R"\(', String, 'rawstring'),
|
||||
inherit,
|
||||
],
|
||||
'root': [
|
||||
@ -224,10 +234,15 @@ class CppLexer(CFamilyLexer):
|
||||
# template specification
|
||||
(r'\s*(?=>)', Text, '#pop'),
|
||||
],
|
||||
'rawstring': [
|
||||
(r'\)"', String, '#pop'),
|
||||
(r'[^)]+', String),
|
||||
(r'\)', String),
|
||||
],
|
||||
}
|
||||
|
||||
def analyse_text(text):
|
||||
if re.search('#include <[a-z]+>', text):
|
||||
if re.search('#include <[a-z_]+>', text):
|
||||
return 0.2
|
||||
if re.search('using namespace ', text):
|
||||
return 0.4
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for other C-like languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -20,7 +20,7 @@ from pygments.lexers.c_cpp import CLexer, CppLexer
|
||||
from pygments.lexers import _mql_builtins
|
||||
|
||||
__all__ = ['PikeLexer', 'NesCLexer', 'ClayLexer', 'ECLexer', 'ValaLexer',
|
||||
'CudaLexer', 'SwigLexer', 'MqlLexer']
|
||||
'CudaLexer', 'SwigLexer', 'MqlLexer', 'ArduinoLexer']
|
||||
|
||||
|
||||
class PikeLexer(CppLexer):
|
||||
@ -411,3 +411,131 @@ class MqlLexer(CppLexer):
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
|
||||
class ArduinoLexer(CppLexer):
|
||||
"""
|
||||
For `Arduino(tm) <https://arduino.cc/>`_ source.
|
||||
|
||||
This is an extension of the CppLexer, as the Arduino® Language is a superset
|
||||
of C++
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'Arduino'
|
||||
aliases = ['arduino']
|
||||
filenames = ['*.ino']
|
||||
mimetypes = ['text/x-arduino']
|
||||
|
||||
# Language constants
|
||||
constants = set(('DIGITAL_MESSAGE', 'FIRMATA_STRING', 'ANALOG_MESSAGE',
|
||||
'REPORT_DIGITAL', 'REPORT_ANALOG', 'INPUT_PULLUP',
|
||||
'SET_PIN_MODE', 'INTERNAL2V56', 'SYSTEM_RESET', 'LED_BUILTIN',
|
||||
'INTERNAL1V1', 'SYSEX_START', 'INTERNAL', 'EXTERNAL',
|
||||
'DEFAULT', 'OUTPUT', 'INPUT', 'HIGH', 'LOW'))
|
||||
|
||||
# Language sketch main structure functions
|
||||
structure = set(('setup', 'loop'))
|
||||
|
||||
# Language variable types
|
||||
storage = set(('boolean', 'const', 'byte', 'word', 'string', 'String', 'array'))
|
||||
|
||||
# Language shipped functions and class ( )
|
||||
functions = set(('KeyboardController', 'MouseController', 'SoftwareSerial',
|
||||
'EthernetServer', 'EthernetClient', 'LiquidCrystal',
|
||||
'RobotControl', 'GSMVoiceCall', 'EthernetUDP', 'EsploraTFT',
|
||||
'HttpClient', 'RobotMotor', 'WiFiClient', 'GSMScanner',
|
||||
'FileSystem', 'Scheduler', 'GSMServer', 'YunClient', 'YunServer',
|
||||
'IPAddress', 'GSMClient', 'GSMModem', 'Keyboard', 'Ethernet',
|
||||
'Console', 'GSMBand', 'Esplora', 'Stepper', 'Process',
|
||||
'WiFiUDP', 'GSM_SMS', 'Mailbox', 'USBHost', 'Firmata', 'PImage',
|
||||
'Client', 'Server', 'GSMPIN', 'FileIO', 'Bridge', 'Serial',
|
||||
'EEPROM', 'Stream', 'Mouse', 'Audio', 'Servo', 'File', 'Task',
|
||||
'GPRS', 'WiFi', 'Wire', 'TFT', 'GSM', 'SPI', 'SD',
|
||||
'runShellCommandAsynchronously', 'analogWriteResolution',
|
||||
'retrieveCallingNumber', 'printFirmwareVersion',
|
||||
'analogReadResolution', 'sendDigitalPortPair',
|
||||
'noListenOnLocalhost', 'readJoystickButton', 'setFirmwareVersion',
|
||||
'readJoystickSwitch', 'scrollDisplayRight', 'getVoiceCallStatus',
|
||||
'scrollDisplayLeft', 'writeMicroseconds', 'delayMicroseconds',
|
||||
'beginTransmission', 'getSignalStrength', 'runAsynchronously',
|
||||
'getAsynchronously', 'listenOnLocalhost', 'getCurrentCarrier',
|
||||
'readAccelerometer', 'messageAvailable', 'sendDigitalPorts',
|
||||
'lineFollowConfig', 'countryNameWrite', 'runShellCommand',
|
||||
'readStringUntil', 'rewindDirectory', 'readTemperature',
|
||||
'setClockDivider', 'readLightSensor', 'endTransmission',
|
||||
'analogReference', 'detachInterrupt', 'countryNameRead',
|
||||
'attachInterrupt', 'encryptionType', 'readBytesUntil',
|
||||
'robotNameWrite', 'readMicrophone', 'robotNameRead', 'cityNameWrite',
|
||||
'userNameWrite', 'readJoystickY', 'readJoystickX', 'mouseReleased',
|
||||
'openNextFile', 'scanNetworks', 'noInterrupts', 'digitalWrite',
|
||||
'beginSpeaker', 'mousePressed', 'isActionDone', 'mouseDragged',
|
||||
'displayLogos', 'noAutoscroll', 'addParameter', 'remoteNumber',
|
||||
'getModifiers', 'keyboardRead', 'userNameRead', 'waitContinue',
|
||||
'processInput', 'parseCommand', 'printVersion', 'readNetworks',
|
||||
'writeMessage', 'blinkVersion', 'cityNameRead', 'readMessage',
|
||||
'setDataMode', 'parsePacket', 'isListening', 'setBitOrder',
|
||||
'beginPacket', 'isDirectory', 'motorsWrite', 'drawCompass',
|
||||
'digitalRead', 'clearScreen', 'serialEvent', 'rightToLeft',
|
||||
'setTextSize', 'leftToRight', 'requestFrom', 'keyReleased',
|
||||
'compassRead', 'analogWrite', 'interrupts', 'WiFiServer',
|
||||
'disconnect', 'playMelody', 'parseFloat', 'autoscroll',
|
||||
'getPINUsed', 'setPINUsed', 'setTimeout', 'sendAnalog',
|
||||
'readSlider', 'analogRead', 'beginWrite', 'createChar',
|
||||
'motorsStop', 'keyPressed', 'tempoWrite', 'readButton',
|
||||
'subnetMask', 'debugPrint', 'macAddress', 'writeGreen',
|
||||
'randomSeed', 'attachGPRS', 'readString', 'sendString',
|
||||
'remotePort', 'releaseAll', 'mouseMoved', 'background',
|
||||
'getXChange', 'getYChange', 'answerCall', 'getResult',
|
||||
'voiceCall', 'endPacket', 'constrain', 'getSocket', 'writeJSON',
|
||||
'getButton', 'available', 'connected', 'findUntil', 'readBytes',
|
||||
'exitValue', 'readGreen', 'writeBlue', 'startLoop', 'IPAddress',
|
||||
'isPressed', 'sendSysex', 'pauseMode', 'gatewayIP', 'setCursor',
|
||||
'getOemKey', 'tuneWrite', 'noDisplay', 'loadImage', 'switchPIN',
|
||||
'onRequest', 'onReceive', 'changePIN', 'playFile', 'noBuffer',
|
||||
'parseInt', 'overflow', 'checkPIN', 'knobRead', 'beginTFT',
|
||||
'bitClear', 'updateIR', 'bitWrite', 'position', 'writeRGB',
|
||||
'highByte', 'writeRed', 'setSpeed', 'readBlue', 'noStroke',
|
||||
'remoteIP', 'transfer', 'shutdown', 'hangCall', 'beginSMS',
|
||||
'endWrite', 'attached', 'maintain', 'noCursor', 'checkReg',
|
||||
'checkPUK', 'shiftOut', 'isValid', 'shiftIn', 'pulseIn',
|
||||
'connect', 'println', 'localIP', 'pinMode', 'getIMEI',
|
||||
'display', 'noBlink', 'process', 'getBand', 'running', 'beginSD',
|
||||
'drawBMP', 'lowByte', 'setBand', 'release', 'bitRead', 'prepare',
|
||||
'pointTo', 'readRed', 'setMode', 'noFill', 'remove', 'listen',
|
||||
'stroke', 'detach', 'attach', 'noTone', 'exists', 'buffer',
|
||||
'height', 'bitSet', 'circle', 'config', 'cursor', 'random',
|
||||
'IRread', 'sizeof', 'setDNS', 'endSMS', 'getKey', 'micros',
|
||||
'millis', 'begin', 'print', 'write', 'ready', 'flush', 'width',
|
||||
'isPIN', 'blink', 'clear', 'press', 'mkdir', 'rmdir', 'close',
|
||||
'point', 'yield', 'image', 'float', 'BSSID', 'click', 'delay',
|
||||
'read', 'text', 'move', 'peek', 'beep', 'rect', 'line', 'open',
|
||||
'seek', 'fill', 'size', 'turn', 'stop', 'home', 'find', 'char',
|
||||
'byte', 'step', 'word', 'long', 'tone', 'sqrt', 'RSSI', 'SSID',
|
||||
'end', 'bit', 'tan', 'cos', 'sin', 'pow', 'map', 'abs', 'max',
|
||||
'min', 'int', 'get', 'run', 'put'))
|
||||
|
||||
|
||||
def get_tokens_unprocessed(self, text):
|
||||
for index, token, value in CppLexer.get_tokens_unprocessed(self, text):
|
||||
if token is Name:
|
||||
if value in self.constants:
|
||||
yield index, Keyword.Constant, value
|
||||
elif value in self.functions:
|
||||
yield index, Name.Function, value
|
||||
elif value in self.storage:
|
||||
yield index, Keyword.Type, value
|
||||
else:
|
||||
yield index, token, value
|
||||
elif token is Name.Function:
|
||||
if value in self.structure:
|
||||
yield index, Name.Other, value
|
||||
else:
|
||||
yield index, token, value
|
||||
elif token is Keyword:
|
||||
if value in self.storage:
|
||||
yield index, Keyword.Type, value
|
||||
else:
|
||||
yield index, token, value
|
||||
else:
|
||||
yield index, token, value
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexer for the Chapel language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -44,11 +44,13 @@ class ChapelLexer(RegexLexer):
|
||||
(words((
|
||||
'align', 'atomic', 'begin', 'break', 'by', 'cobegin', 'coforall',
|
||||
'continue', 'delete', 'dmapped', 'do', 'domain', 'else', 'enum',
|
||||
'export', 'extern', 'for', 'forall', 'if', 'index', 'inline',
|
||||
'iter', 'label', 'lambda', 'let', 'local', 'new', 'noinit', 'on',
|
||||
'otherwise', 'pragma', 'reduce', 'return', 'scan', 'select',
|
||||
'serial', 'single', 'sparse', 'subdomain', 'sync', 'then', 'use',
|
||||
'when', 'where', 'while', 'with', 'yield', 'zip'), suffix=r'\b'),
|
||||
'except', 'export', 'extern', 'for', 'forall', 'if', 'index',
|
||||
'inline', 'iter', 'label', 'lambda', 'let', 'local', 'new',
|
||||
'noinit', 'on', 'only', 'otherwise', 'pragma', 'private',
|
||||
'public', 'reduce', 'require', 'return', 'scan', 'select',
|
||||
'serial', 'single', 'sparse', 'subdomain', 'sync', 'then',
|
||||
'use', 'when', 'where', 'while', 'with', 'yield', 'zip'),
|
||||
suffix=r'\b'),
|
||||
Keyword),
|
||||
(r'(proc)((?:\s|\\\s)+)', bygroups(Keyword, Text), 'procname'),
|
||||
(r'(class|module|record|union)(\s+)', bygroups(Keyword, Text),
|
||||
@ -76,7 +78,8 @@ class ChapelLexer(RegexLexer):
|
||||
(r'[0-9]+', Number.Integer),
|
||||
|
||||
# strings
|
||||
(r'["\'](\\\\|\\"|[^"\'])*["\']', String),
|
||||
(r'"(\\\\|\\"|[^"])*"', String),
|
||||
(r"'(\\\\|\\'|[^'])*'", String),
|
||||
|
||||
# tokens
|
||||
(r'(=|\+=|-=|\*=|/=|\*\*=|%=|&=|\|=|\^=|&&=|\|\|=|<<=|>>=|'
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Just export lexer classes previously contained in this module.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for configuration file formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -13,12 +13,14 @@ import re
|
||||
|
||||
from pygments.lexer import RegexLexer, default, words, bygroups, include, using
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Whitespace
|
||||
Number, Punctuation, Whitespace, Literal
|
||||
from pygments.lexers.shell import BashLexer
|
||||
|
||||
__all__ = ['IniLexer', 'RegeditLexer', 'PropertiesLexer', 'KconfigLexer',
|
||||
'Cfengine3Lexer', 'ApacheConfLexer', 'SquidConfLexer',
|
||||
'NginxConfLexer', 'LighttpdConfLexer', 'DockerLexer']
|
||||
'NginxConfLexer', 'LighttpdConfLexer', 'DockerLexer',
|
||||
'TerraformLexer', 'TermcapLexer', 'TerminfoLexer',
|
||||
'PkgConfigLexer', 'PacmanConfLexer']
|
||||
|
||||
|
||||
class IniLexer(RegexLexer):
|
||||
@ -28,8 +30,8 @@ class IniLexer(RegexLexer):
|
||||
|
||||
name = 'INI'
|
||||
aliases = ['ini', 'cfg', 'dosini']
|
||||
filenames = ['*.ini', '*.cfg']
|
||||
mimetypes = ['text/x-ini']
|
||||
filenames = ['*.ini', '*.cfg', '*.inf']
|
||||
mimetypes = ['text/x-ini', 'text/inf']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
@ -540,7 +542,286 @@ class DockerLexer(RegexLexer):
|
||||
bygroups(Name.Keyword, Whitespace, Keyword)),
|
||||
(r'^(%s)\b(.*)' % (_keywords,), bygroups(Keyword, String)),
|
||||
(r'#.*', Comment),
|
||||
(r'RUN', Keyword), # Rest of line falls through
|
||||
(r'RUN', Keyword), # Rest of line falls through
|
||||
(r'(.*\\\n)*.+', using(BashLexer)),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class TerraformLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `terraformi .tf files <https://www.terraform.io/>`_.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'Terraform'
|
||||
aliases = ['terraform', 'tf']
|
||||
filenames = ['*.tf']
|
||||
mimetypes = ['application/x-tf', 'application/x-terraform']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('string'),
|
||||
include('punctuation'),
|
||||
include('curly'),
|
||||
include('basic'),
|
||||
include('whitespace'),
|
||||
(r'[0-9]+', Number),
|
||||
],
|
||||
'basic': [
|
||||
(words(('true', 'false'), prefix=r'\b', suffix=r'\b'), Keyword.Type),
|
||||
(r'\s*/\*', Comment.Multiline, 'comment'),
|
||||
(r'\s*#.*\n', Comment.Single),
|
||||
(r'(.*?)(\s*)(=)', bygroups(Name.Attribute, Text, Operator)),
|
||||
(words(('variable', 'resource', 'provider', 'provisioner', 'module'),
|
||||
prefix=r'\b', suffix=r'\b'), Keyword.Reserved, 'function'),
|
||||
(words(('ingress', 'egress', 'listener', 'default', 'connection'),
|
||||
prefix=r'\b', suffix=r'\b'), Keyword.Declaration),
|
||||
('\$\{', String.Interpol, 'var_builtin'),
|
||||
],
|
||||
'function': [
|
||||
(r'(\s+)(".*")(\s+)', bygroups(Text, String, Text)),
|
||||
include('punctuation'),
|
||||
include('curly'),
|
||||
],
|
||||
'var_builtin': [
|
||||
(r'\$\{', String.Interpol, '#push'),
|
||||
(words(('concat', 'file', 'join', 'lookup', 'element'),
|
||||
prefix=r'\b', suffix=r'\b'), Name.Builtin),
|
||||
include('string'),
|
||||
include('punctuation'),
|
||||
(r'\s+', Text),
|
||||
(r'\}', String.Interpol, '#pop'),
|
||||
],
|
||||
'string': [
|
||||
(r'(".*")', bygroups(String.Double)),
|
||||
],
|
||||
'punctuation': [
|
||||
(r'[\[\]\(\),.]', Punctuation),
|
||||
],
|
||||
# Keep this seperate from punctuation - we sometimes want to use different
|
||||
# Tokens for { }
|
||||
'curly': [
|
||||
(r'\{', Text.Punctuation),
|
||||
(r'\}', Text.Punctuation),
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline)
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\n', Text),
|
||||
(r'\s+', Text),
|
||||
(r'\\\n', Text),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class TermcapLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for termcap database source.
|
||||
|
||||
This is very simple and minimal.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'Termcap'
|
||||
aliases = ['termcap',]
|
||||
|
||||
filenames = ['termcap', 'termcap.src',]
|
||||
mimetypes = []
|
||||
|
||||
# NOTE:
|
||||
# * multiline with trailing backslash
|
||||
# * separator is ':'
|
||||
# * to embed colon as data, we must use \072
|
||||
# * space after separator is not allowed (mayve)
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^#.*$', Comment),
|
||||
(r'^[^\s#:\|]+', Name.Tag, 'names'),
|
||||
],
|
||||
'names': [
|
||||
(r'\n', Text, '#pop'),
|
||||
(r':', Punctuation, 'defs'),
|
||||
(r'\|', Punctuation),
|
||||
(r'[^:\|]+', Name.Attribute),
|
||||
],
|
||||
'defs': [
|
||||
(r'\\\n[ \t]*', Text),
|
||||
(r'\n[ \t]*', Text, '#pop:2'),
|
||||
(r'(#)([0-9]+)', bygroups(Operator, Number)),
|
||||
(r'=', Operator, 'data'),
|
||||
(r':', Punctuation),
|
||||
(r'[^\s:=#]+', Name.Class),
|
||||
],
|
||||
'data': [
|
||||
(r'\\072', Literal),
|
||||
(r':', Punctuation, '#pop'),
|
||||
(r'[^:\\]+', Literal), # for performance
|
||||
(r'.', Literal),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class TerminfoLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for terminfo database source.
|
||||
|
||||
This is very simple and minimal.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'Terminfo'
|
||||
aliases = ['terminfo',]
|
||||
|
||||
filenames = ['terminfo', 'terminfo.src',]
|
||||
mimetypes = []
|
||||
|
||||
# NOTE:
|
||||
# * multiline with leading whitespace
|
||||
# * separator is ','
|
||||
# * to embed comma as data, we can use \,
|
||||
# * space after separator is allowed
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^#.*$', Comment),
|
||||
(r'^[^\s#,\|]+', Name.Tag, 'names'),
|
||||
],
|
||||
'names': [
|
||||
(r'\n', Text, '#pop'),
|
||||
(r'(,)([ \t]*)', bygroups(Punctuation, Text), 'defs'),
|
||||
(r'\|', Punctuation),
|
||||
(r'[^,\|]+', Name.Attribute),
|
||||
],
|
||||
'defs': [
|
||||
(r'\n[ \t]+', Text),
|
||||
(r'\n', Text, '#pop:2'),
|
||||
(r'(#)([0-9]+)', bygroups(Operator, Number)),
|
||||
(r'=', Operator, 'data'),
|
||||
(r'(,)([ \t]*)', bygroups(Punctuation, Text)),
|
||||
(r'[^\s,=#]+', Name.Class),
|
||||
],
|
||||
'data': [
|
||||
(r'\\[,\\]', Literal),
|
||||
(r'(,)([ \t]*)', bygroups(Punctuation, Text), '#pop'),
|
||||
(r'[^\\,]+', Literal), # for performance
|
||||
(r'.', Literal),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class PkgConfigLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `pkg-config
|
||||
<http://www.freedesktop.org/wiki/Software/pkg-config/>`_
|
||||
(see also `manual page <http://linux.die.net/man/1/pkg-config>`_).
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'PkgConfig'
|
||||
aliases = ['pkgconfig',]
|
||||
filenames = ['*.pc',]
|
||||
mimetypes = []
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'#.*$', Comment.Single),
|
||||
|
||||
# variable definitions
|
||||
(r'^(\w+)(=)', bygroups(Name.Attribute, Operator)),
|
||||
|
||||
# keyword lines
|
||||
(r'^([\w.]+)(:)',
|
||||
bygroups(Name.Tag, Punctuation), 'spvalue'),
|
||||
|
||||
# variable references
|
||||
include('interp'),
|
||||
|
||||
# fallback
|
||||
(r'[^${}#=:\n.]+', Text),
|
||||
(r'.', Text),
|
||||
],
|
||||
'interp': [
|
||||
# you can escape literal "$" as "$$"
|
||||
(r'\$\$', Text),
|
||||
|
||||
# variable references
|
||||
(r'\$\{', String.Interpol, 'curly'),
|
||||
],
|
||||
'curly': [
|
||||
(r'\}', String.Interpol, '#pop'),
|
||||
(r'\w+', Name.Attribute),
|
||||
],
|
||||
'spvalue': [
|
||||
include('interp'),
|
||||
|
||||
(r'#.*$', Comment.Single, '#pop'),
|
||||
(r'\n', Text, '#pop'),
|
||||
|
||||
# fallback
|
||||
(r'[^${}#\n]+', Text),
|
||||
(r'.', Text),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class PacmanConfLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `pacman.conf
|
||||
<https://www.archlinux.org/pacman/pacman.conf.5.html>`_.
|
||||
|
||||
Actually, IniLexer works almost fine for this format,
|
||||
but it yield error token. It is because pacman.conf has
|
||||
a form without assignment like:
|
||||
|
||||
UseSyslog
|
||||
Color
|
||||
TotalDownload
|
||||
CheckSpace
|
||||
VerbosePkgLists
|
||||
|
||||
These are flags to switch on.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'PacmanConf'
|
||||
aliases = ['pacmanconf',]
|
||||
filenames = ['pacman.conf',]
|
||||
mimetypes = []
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# comment
|
||||
(r'#.*$', Comment.Single),
|
||||
|
||||
# section header
|
||||
(r'^\s*\[.*?\]\s*$', Keyword),
|
||||
|
||||
# variable definitions
|
||||
# (Leading space is allowed...)
|
||||
(r'(\w+)(\s*)(=)',
|
||||
bygroups(Name.Attribute, Text, Operator)),
|
||||
|
||||
# flags to on
|
||||
(r'^(\s*)(\w+)(\s*)$',
|
||||
bygroups(Text, Name.Attribute, Text)),
|
||||
|
||||
# built-in special values
|
||||
(words((
|
||||
'$repo', # repository
|
||||
'$arch', # architecture
|
||||
'%o', # outfile
|
||||
'%u', # url
|
||||
), suffix=r'\b'),
|
||||
Name.Variable),
|
||||
|
||||
# fallback
|
||||
(r'.', Text),
|
||||
],
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for misc console output.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -18,7 +18,7 @@ __all__ = ['VCTreeStatusLexer', 'PyPyLogLexer']
|
||||
|
||||
class VCTreeStatusLexer(RegexLexer):
|
||||
"""
|
||||
For colorizing output of version control status commans, like "hg
|
||||
For colorizing output of version control status commands, like "hg
|
||||
status" or "svn status".
|
||||
|
||||
.. versionadded:: 2.0
|
||||
366
packages/wakatime/packages/pygments/lexers/csound.py
Normal file
366
packages/wakatime/packages/pygments/lexers/csound.py
Normal file
@ -0,0 +1,366 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.csound
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for CSound languages.
|
||||
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import copy, re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, default, include, using, words
|
||||
from pygments.token import Comment, Keyword, Name, Number, Operator, Punctuation, \
|
||||
String, Text
|
||||
from pygments.lexers._csound_builtins import OPCODES
|
||||
from pygments.lexers.html import HtmlLexer
|
||||
from pygments.lexers.python import PythonLexer
|
||||
from pygments.lexers.scripting import LuaLexer
|
||||
|
||||
__all__ = ['CsoundScoreLexer', 'CsoundOrchestraLexer', 'CsoundDocumentLexer']
|
||||
|
||||
newline = (r'((?:;|//).*)*(\n)', bygroups(Comment.Single, Text))
|
||||
|
||||
|
||||
class CsoundLexer(RegexLexer):
|
||||
# Subclasses must define a 'single-line string' state.
|
||||
tokens = {
|
||||
'whitespace': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'\\\n', Text),
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline)
|
||||
],
|
||||
|
||||
'macro call': [
|
||||
(r'(\$\w+\.?)(\()', bygroups(Comment.Preproc, Punctuation),
|
||||
'function macro call'),
|
||||
(r'\$\w+(\.|\b)', Comment.Preproc)
|
||||
],
|
||||
'function macro call': [
|
||||
(r"((?:\\['\)]|[^'\)])+)(')", bygroups(Comment.Preproc, Punctuation)),
|
||||
(r"([^'\)]+)(\))", bygroups(Comment.Preproc, Punctuation), '#pop')
|
||||
],
|
||||
|
||||
'whitespace or macro call': [
|
||||
include('whitespace'),
|
||||
include('macro call')
|
||||
],
|
||||
|
||||
'preprocessor directives': [
|
||||
(r'#(e(nd(if)?|lse)|ifn?def|undef)\b|##', Comment.Preproc),
|
||||
(r'#include\b', Comment.Preproc, 'include'),
|
||||
(r'#[ \t]*define\b', Comment.Preproc, 'macro name'),
|
||||
(r'@+[ \t]*\d*', Comment.Preproc)
|
||||
],
|
||||
|
||||
'include': [
|
||||
include('whitespace'),
|
||||
(r'"', String, 'single-line string')
|
||||
],
|
||||
|
||||
'macro name': [
|
||||
include('whitespace'),
|
||||
(r'(\w+)(\()', bygroups(Comment.Preproc, Text),
|
||||
'function macro argument list'),
|
||||
(r'\w+', Comment.Preproc, 'object macro definition after name')
|
||||
],
|
||||
'object macro definition after name': [
|
||||
include('whitespace'),
|
||||
(r'#', Punctuation, 'object macro replacement text')
|
||||
],
|
||||
'object macro replacement text': [
|
||||
(r'(\\#|[^#])+', Comment.Preproc),
|
||||
(r'#', Punctuation, '#pop:3')
|
||||
],
|
||||
'function macro argument list': [
|
||||
(r"(\w+)(['#])", bygroups(Comment.Preproc, Punctuation)),
|
||||
(r'(\w+)(\))', bygroups(Comment.Preproc, Punctuation),
|
||||
'function macro definition after name')
|
||||
],
|
||||
'function macro definition after name': [
|
||||
(r'[ \t]+', Text),
|
||||
(r'#', Punctuation, 'function macro replacement text')
|
||||
],
|
||||
'function macro replacement text': [
|
||||
(r'(\\#|[^#])+', Comment.Preproc),
|
||||
(r'#', Punctuation, '#pop:4')
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class CsoundScoreLexer(CsoundLexer):
|
||||
"""
|
||||
For `Csound <http://csound.github.io>`_ scores.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'Csound Score'
|
||||
aliases = ['csound-score', 'csound-sco']
|
||||
filenames = ['*.sco']
|
||||
|
||||
tokens = {
|
||||
'partial statement': [
|
||||
include('preprocessor directives'),
|
||||
(r'\d+e[+-]?\d+|(\d+\.\d*|\d*\.\d+)(e[+-]?\d+)?', Number.Float),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'"', String, 'single-line string'),
|
||||
(r'[+\-*/%^!=<>|&#~.]', Operator),
|
||||
(r'[]()[]', Punctuation),
|
||||
(r'\w+', Comment.Preproc)
|
||||
],
|
||||
|
||||
'statement': [
|
||||
include('whitespace or macro call'),
|
||||
newline + ('#pop',),
|
||||
include('partial statement')
|
||||
],
|
||||
|
||||
'root': [
|
||||
newline,
|
||||
include('whitespace or macro call'),
|
||||
(r'[{}]', Punctuation, 'statement'),
|
||||
(r'[abefimq-tv-z]|[nN][pP]?', Keyword, 'statement')
|
||||
],
|
||||
|
||||
'single-line string': [
|
||||
(r'"', String, '#pop'),
|
||||
(r'[^\\"]+', String)
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class CsoundOrchestraLexer(CsoundLexer):
|
||||
"""
|
||||
For `Csound <http://csound.github.io>`_ orchestras.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'Csound Orchestra'
|
||||
aliases = ['csound', 'csound-orc']
|
||||
filenames = ['*.orc']
|
||||
|
||||
user_defined_opcodes = set()
|
||||
|
||||
def opcode_name_callback(lexer, match):
|
||||
opcode = match.group(0)
|
||||
lexer.user_defined_opcodes.add(opcode)
|
||||
yield match.start(), Name.Function, opcode
|
||||
|
||||
def name_callback(lexer, match):
|
||||
name = match.group(0)
|
||||
if re.match('p\d+$', name) or name in OPCODES:
|
||||
yield match.start(), Name.Builtin, name
|
||||
elif name in lexer.user_defined_opcodes:
|
||||
yield match.start(), Name.Function, name
|
||||
else:
|
||||
nameMatch = re.search(r'^(g?[aikSw])(\w+)', name)
|
||||
if nameMatch:
|
||||
yield nameMatch.start(1), Keyword.Type, nameMatch.group(1)
|
||||
yield nameMatch.start(2), Name, nameMatch.group(2)
|
||||
else:
|
||||
yield match.start(), Name, name
|
||||
|
||||
tokens = {
|
||||
'label': [
|
||||
(r'\b(\w+)(:)', bygroups(Name.Label, Punctuation))
|
||||
],
|
||||
|
||||
'partial expression': [
|
||||
include('preprocessor directives'),
|
||||
(r'\b(0dbfs|k(r|smps)|nchnls(_i)?|sr)\b', Name.Variable.Global),
|
||||
(r'\d+e[+-]?\d+|(\d+\.\d*|\d*\.\d+)(e[+-]?\d+)?', Number.Float),
|
||||
(r'0[xX][a-fA-F0-9]+', Number.Hex),
|
||||
(r'\d+', Number.Integer),
|
||||
(r'"', String, 'single-line string'),
|
||||
(r'{{', String, 'multi-line string'),
|
||||
(r'[+\-*/%^!=&|<>#~¬]', Operator),
|
||||
(r'[](),?:[]', Punctuation),
|
||||
(words((
|
||||
# Keywords
|
||||
'do', 'else', 'elseif', 'endif', 'enduntil', 'fi', 'if', 'ithen', 'kthen',
|
||||
'od', 'then', 'until', 'while',
|
||||
# Opcodes that act as control structures
|
||||
'return', 'timout'
|
||||
), prefix=r'\b', suffix=r'\b'), Keyword),
|
||||
(words(('goto', 'igoto', 'kgoto', 'rigoto', 'tigoto'),
|
||||
prefix=r'\b', suffix=r'\b'), Keyword, 'goto label'),
|
||||
(words(('cggoto', 'cigoto', 'cingoto', 'ckgoto', 'cngoto'),
|
||||
prefix=r'\b', suffix=r'\b'), Keyword,
|
||||
('goto label', 'goto expression')),
|
||||
(words(('loop_ge', 'loop_gt', 'loop_le', 'loop_lt'),
|
||||
prefix=r'\b', suffix=r'\b'), Keyword,
|
||||
('goto label', 'goto expression', 'goto expression', 'goto expression')),
|
||||
(r'\bscoreline(_i)?\b', Name.Builtin, 'scoreline opcode'),
|
||||
(r'\bpyl?run[it]?\b', Name.Builtin, 'python opcode'),
|
||||
(r'\blua_(exec|opdef)\b', Name.Builtin, 'lua opcode'),
|
||||
(r'\b[a-zA-Z_]\w*\b', name_callback)
|
||||
],
|
||||
|
||||
'expression': [
|
||||
include('whitespace or macro call'),
|
||||
newline + ('#pop',),
|
||||
include('partial expression')
|
||||
],
|
||||
|
||||
'root': [
|
||||
newline,
|
||||
include('whitespace or macro call'),
|
||||
(r'\binstr\b', Keyword, ('instrument block', 'instrument name list')),
|
||||
(r'\bopcode\b', Keyword, ('opcode block', 'opcode parameter list',
|
||||
'opcode types', 'opcode types', 'opcode name')),
|
||||
include('label'),
|
||||
default('expression')
|
||||
],
|
||||
|
||||
'instrument name list': [
|
||||
include('whitespace or macro call'),
|
||||
(r'\d+|\+?[a-zA-Z_]\w*', Name.Function),
|
||||
(r',', Punctuation),
|
||||
newline + ('#pop',)
|
||||
],
|
||||
'instrument block': [
|
||||
newline,
|
||||
include('whitespace or macro call'),
|
||||
(r'\bendin\b', Keyword, '#pop'),
|
||||
include('label'),
|
||||
default('expression')
|
||||
],
|
||||
|
||||
'opcode name': [
|
||||
include('whitespace or macro call'),
|
||||
(r'[a-zA-Z_]\w*', opcode_name_callback, '#pop')
|
||||
],
|
||||
'opcode types': [
|
||||
include('whitespace or macro call'),
|
||||
(r'0|[]afijkKoOpPStV[]+', Keyword.Type, '#pop'),
|
||||
(r',', Punctuation)
|
||||
],
|
||||
'opcode parameter list': [
|
||||
include('whitespace or macro call'),
|
||||
newline + ('#pop',)
|
||||
],
|
||||
'opcode block': [
|
||||
newline,
|
||||
include('whitespace or macro call'),
|
||||
(r'\bendop\b', Keyword, '#pop'),
|
||||
include('label'),
|
||||
default('expression')
|
||||
],
|
||||
|
||||
'goto label': [
|
||||
include('whitespace or macro call'),
|
||||
(r'\w+', Name.Label, '#pop'),
|
||||
default('#pop')
|
||||
],
|
||||
'goto expression': [
|
||||
include('whitespace or macro call'),
|
||||
(r',', Punctuation, '#pop'),
|
||||
include('partial expression')
|
||||
],
|
||||
|
||||
'single-line string': [
|
||||
include('macro call'),
|
||||
(r'"', String, '#pop'),
|
||||
# From https://github.com/csound/csound/blob/develop/Opcodes/fout.c#L1405
|
||||
(r'%\d*(\.\d+)?[cdhilouxX]', String.Interpol),
|
||||
(r'%[!%nNrRtT]|[~^]|\\([\\aAbBnNrRtT"]|[0-7]{1,3})', String.Escape),
|
||||
(r'[^\\"~$%\^\n]+', String),
|
||||
(r'[\\"~$%\^\n]', String)
|
||||
],
|
||||
'multi-line string': [
|
||||
(r'}}', String, '#pop'),
|
||||
(r'[^\}]+|\}(?!\})', String)
|
||||
],
|
||||
|
||||
'scoreline opcode': [
|
||||
include('whitespace or macro call'),
|
||||
(r'{{', String, 'scoreline'),
|
||||
default('#pop')
|
||||
],
|
||||
'scoreline': [
|
||||
(r'}}', String, '#pop'),
|
||||
(r'([^\}]+)|\}(?!\})', using(CsoundScoreLexer))
|
||||
],
|
||||
|
||||
'python opcode': [
|
||||
include('whitespace or macro call'),
|
||||
(r'{{', String, 'python'),
|
||||
default('#pop')
|
||||
],
|
||||
'python': [
|
||||
(r'}}', String, '#pop'),
|
||||
(r'([^\}]+)|\}(?!\})', using(PythonLexer))
|
||||
],
|
||||
|
||||
'lua opcode': [
|
||||
include('whitespace or macro call'),
|
||||
(r'"', String, 'single-line string'),
|
||||
(r'{{', String, 'lua'),
|
||||
(r',', Punctuation),
|
||||
default('#pop')
|
||||
],
|
||||
'lua': [
|
||||
(r'}}', String, '#pop'),
|
||||
(r'([^\}]+)|\}(?!\})', using(LuaLexer))
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class CsoundDocumentLexer(RegexLexer):
|
||||
"""
|
||||
For `Csound <http://csound.github.io>`_ documents.
|
||||
|
||||
|
||||
"""
|
||||
|
||||
name = 'Csound Document'
|
||||
aliases = ['csound-document', 'csound-csd']
|
||||
filenames = ['*.csd']
|
||||
|
||||
# These tokens are based on those in XmlLexer in pygments/lexers/html.py. Making
|
||||
# CsoundDocumentLexer a subclass of XmlLexer rather than RegexLexer may seem like a
|
||||
# better idea, since Csound Document files look like XML files. However, Csound
|
||||
# Documents can contain Csound comments (preceded by //, for example) before and
|
||||
# after the root element, unescaped bitwise AND & and less than < operators, etc. In
|
||||
# other words, while Csound Document files look like XML files, they may not actually
|
||||
# be XML files.
|
||||
tokens = {
|
||||
'root': [
|
||||
newline,
|
||||
(r'/[*](.|\n)*?[*]/', Comment.Multiline),
|
||||
(r'[^<&;/]+', Text),
|
||||
(r'<\s*CsInstruments', Name.Tag, ('orchestra', 'tag')),
|
||||
(r'<\s*CsScore', Name.Tag, ('score', 'tag')),
|
||||
(r'<\s*[hH][tT][mM][lL]', Name.Tag, ('HTML', 'tag')),
|
||||
(r'<\s*[\w:.-]+', Name.Tag, 'tag'),
|
||||
(r'<\s*/\s*[\w:.-]+\s*>', Name.Tag)
|
||||
],
|
||||
'orchestra': [
|
||||
(r'<\s*/\s*CsInstruments\s*>', Name.Tag, '#pop'),
|
||||
(r'(.|\n)+?(?=<\s*/\s*CsInstruments\s*>)', using(CsoundOrchestraLexer))
|
||||
],
|
||||
'score': [
|
||||
(r'<\s*/\s*CsScore\s*>', Name.Tag, '#pop'),
|
||||
(r'(.|\n)+?(?=<\s*/\s*CsScore\s*>)', using(CsoundScoreLexer))
|
||||
],
|
||||
'HTML': [
|
||||
(r'<\s*/\s*[hH][tT][mM][lL]\s*>', Name.Tag, '#pop'),
|
||||
(r'(.|\n)+?(?=<\s*/\s*[hH][tT][mM][lL]\s*>)', using(HtmlLexer))
|
||||
],
|
||||
'tag': [
|
||||
(r'\s+', Text),
|
||||
(r'[\w.:-]+\s*=', Name.Attribute, 'attr'),
|
||||
(r'/?\s*>', Name.Tag, '#pop')
|
||||
],
|
||||
'attr': [
|
||||
(r'\s+', Text),
|
||||
(r'".*?"', String, '#pop'),
|
||||
(r"'.*?'", String, '#pop'),
|
||||
(r'[^\s>]+', String, '#pop')
|
||||
]
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for CSS and related stylesheet formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -13,12 +13,12 @@ import re
|
||||
import copy
|
||||
|
||||
from pygments.lexer import ExtendedRegexLexer, RegexLexer, include, bygroups, \
|
||||
default, words
|
||||
default, words, inherit
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation
|
||||
from pygments.util import iteritems
|
||||
|
||||
__all__ = ['CssLexer', 'SassLexer', 'ScssLexer']
|
||||
__all__ = ['CssLexer', 'SassLexer', 'ScssLexer', 'LessCssLexer']
|
||||
|
||||
|
||||
class CssLexer(RegexLexer):
|
||||
@ -41,7 +41,7 @@ class CssLexer(RegexLexer):
|
||||
(r'\{', Punctuation, 'content'),
|
||||
(r'\:[\w-]+', Name.Decorator),
|
||||
(r'\.[\w-]+', Name.Class),
|
||||
(r'\#[\w-]+', Name.Function),
|
||||
(r'\#[\w-]+', Name.Namespace),
|
||||
(r'@[\w-]+', Keyword, 'atrule'),
|
||||
(r'[\w-]+', Name.Tag),
|
||||
(r'[~^*!%&$\[\]()<>|+=@:;,./?-]', Operator),
|
||||
@ -120,7 +120,7 @@ class CssLexer(RegexLexer):
|
||||
'upper-alpha', 'upper-latin', 'upper-roman', 'uppercase', 'url',
|
||||
'visible', 'w-resize', 'wait', 'wider', 'x-fast', 'x-high', 'x-large', 'x-loud',
|
||||
'x-low', 'x-small', 'x-soft', 'xx-large', 'xx-small', 'yes'), suffix=r'\b'),
|
||||
Keyword),
|
||||
Name.Builtin),
|
||||
(words((
|
||||
'indigo', 'gold', 'firebrick', 'indianred', 'yellow', 'darkolivegreen',
|
||||
'darkseagreen', 'mediumvioletred', 'mediumorchid', 'chartreuse',
|
||||
@ -475,8 +475,9 @@ class ScssLexer(RegexLexer):
|
||||
(r'(@media)(\s+)', bygroups(Keyword, Text), 'value'),
|
||||
(r'@[\w-]+', Keyword, 'selector'),
|
||||
(r'(\$[\w-]*\w)([ \t]*:)', bygroups(Name.Variable, Operator), 'value'),
|
||||
(r'(?=[^;{}][;}])', Name.Attribute, 'attr'),
|
||||
(r'(?=[^;{}:]+:[^a-z])', Name.Attribute, 'attr'),
|
||||
# TODO: broken, and prone to infinite loops.
|
||||
#(r'(?=[^;{}][;}])', Name.Attribute, 'attr'),
|
||||
#(r'(?=[^;{}:]+:[^a-z])', Name.Attribute, 'attr'),
|
||||
default('selector'),
|
||||
],
|
||||
|
||||
@ -484,6 +485,7 @@ class ScssLexer(RegexLexer):
|
||||
(r'[^\s:="\[]+', Name.Attribute),
|
||||
(r'#\{', String.Interpol, 'interpolation'),
|
||||
(r'[ \t]*:', Operator, 'value'),
|
||||
default('#pop'),
|
||||
],
|
||||
|
||||
'inline-comment': [
|
||||
@ -496,3 +498,27 @@ class ScssLexer(RegexLexer):
|
||||
tokens[group] = copy.copy(common)
|
||||
tokens['value'].extend([(r'\n', Text), (r'[;{}]', Punctuation, '#pop')])
|
||||
tokens['selector'].extend([(r'\n', Text), (r'[;{}]', Punctuation, '#pop')])
|
||||
|
||||
|
||||
class LessCssLexer(CssLexer):
|
||||
"""
|
||||
For `LESS <http://lesscss.org/>`_ styleshets.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'LessCss'
|
||||
aliases = ['less']
|
||||
filenames = ['*.less']
|
||||
mimetypes = ['text/x-less-css']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'@\w+', Name.Variable),
|
||||
inherit,
|
||||
],
|
||||
'content': [
|
||||
(r'{', Punctuation, '#push'),
|
||||
inherit,
|
||||
],
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for D languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Pygments lexers for Dalvik VM-related languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for data file format.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for diff/patch formats.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for .net languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
import re
|
||||
@ -97,17 +97,17 @@ class CSharpLexer(RegexLexer):
|
||||
Comment.Preproc),
|
||||
(r'\b(extern)(\s+)(alias)\b', bygroups(Keyword, Text,
|
||||
Keyword)),
|
||||
(r'(abstract|as|async|await|base|break|case|catch|'
|
||||
(r'(abstract|as|async|await|base|break|by|case|catch|'
|
||||
r'checked|const|continue|default|delegate|'
|
||||
r'do|else|enum|event|explicit|extern|false|finally|'
|
||||
r'fixed|for|foreach|goto|if|implicit|in|interface|'
|
||||
r'internal|is|lock|new|null|operator|'
|
||||
r'internal|is|let|lock|new|null|on|operator|'
|
||||
r'out|override|params|private|protected|public|readonly|'
|
||||
r'ref|return|sealed|sizeof|stackalloc|static|'
|
||||
r'switch|this|throw|true|try|typeof|'
|
||||
r'unchecked|unsafe|virtual|void|while|'
|
||||
r'get|set|new|partial|yield|add|remove|value|alias|ascending|'
|
||||
r'descending|from|group|into|orderby|select|where|'
|
||||
r'descending|from|group|into|orderby|select|thenby|where|'
|
||||
r'join|equals)\b', Keyword),
|
||||
(r'(global)(::)', bygroups(Keyword, Punctuation)),
|
||||
(r'(bool|byte|char|decimal|double|dynamic|float|int|long|object|'
|
||||
@ -497,7 +497,7 @@ class GenericAspxLexer(RegexLexer):
|
||||
# TODO support multiple languages within the same source file
|
||||
class CSharpAspxLexer(DelegatingLexer):
|
||||
"""
|
||||
Lexer for highligting C# within ASP.NET pages.
|
||||
Lexer for highlighting C# within ASP.NET pages.
|
||||
"""
|
||||
|
||||
name = 'aspx-cs'
|
||||
@ -518,7 +518,7 @@ class CSharpAspxLexer(DelegatingLexer):
|
||||
|
||||
class VbNetAspxLexer(DelegatingLexer):
|
||||
"""
|
||||
Lexer for highligting Visual Basic.net within ASP.NET pages.
|
||||
Lexer for highlighting Visual Basic.net within ASP.NET pages.
|
||||
"""
|
||||
|
||||
name = 'aspx-vb'
|
||||
@ -623,6 +623,7 @@ class FSharpLexer(RegexLexer):
|
||||
(r'\b(member|override)(\s+)(\w+)(\.)(\w+)',
|
||||
bygroups(Keyword, Text, Name, Punctuation, Name.Function)),
|
||||
(r'\b(%s)\b' % '|'.join(keywords), Keyword),
|
||||
(r'``([^`\n\r\t]|`[^`\n\r\t])+``', Name),
|
||||
(r'(%s)' % '|'.join(keyopts), Operator),
|
||||
(r'(%s|%s)?%s' % (infix_syms, prefix_syms, operators), Operator),
|
||||
(r'\b(%s)\b' % '|'.join(word_operators), Operator.Word),
|
||||
@ -5,18 +5,20 @@
|
||||
|
||||
Lexers for various domain-specific languages.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
|
||||
from pygments.lexer import RegexLexer, bygroups, words, include, default
|
||||
from pygments.lexer import RegexLexer, bygroups, words, include, default, \
|
||||
this, using, combined
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Literal
|
||||
Number, Punctuation, Literal, Whitespace
|
||||
|
||||
__all__ = ['ProtoBufLexer', 'BroLexer', 'PuppetLexer', 'RslLexer',
|
||||
'MscgenLexer', 'VGLLexer', 'AlloyLexer', 'PanLexer']
|
||||
'MscgenLexer', 'VGLLexer', 'AlloyLexer', 'PanLexer',
|
||||
'CrmshLexer', 'ThriftLexer']
|
||||
|
||||
|
||||
class ProtoBufLexer(RegexLexer):
|
||||
@ -81,6 +83,111 @@ class ProtoBufLexer(RegexLexer):
|
||||
}
|
||||
|
||||
|
||||
class ThriftLexer(RegexLexer):
|
||||
"""
|
||||
For `Thrift <https://thrift.apache.org/>`__ interface definitions.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'Thrift'
|
||||
aliases = ['thrift']
|
||||
filenames = ['*.thrift']
|
||||
mimetypes = ['application/x-thrift']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
include('whitespace'),
|
||||
include('comments'),
|
||||
(r'"', String.Double, combined('stringescape', 'dqs')),
|
||||
(r'\'', String.Single, combined('stringescape', 'sqs')),
|
||||
(r'(namespace)(\s+)',
|
||||
bygroups(Keyword.Namespace, Text.Whitespace), 'namespace'),
|
||||
(r'(enum|union|struct|service|exception)(\s+)',
|
||||
bygroups(Keyword.Declaration, Text.Whitespace), 'class'),
|
||||
(r'((?:(?:[^\W\d]|\$)[\w.\[\]$<>]*\s+)+?)' # return arguments
|
||||
r'((?:[^\W\d]|\$)[\w$]*)' # method name
|
||||
r'(\s*)(\()', # signature start
|
||||
bygroups(using(this), Name.Function, Text, Operator)),
|
||||
include('keywords'),
|
||||
include('numbers'),
|
||||
(r'[&=]', Operator),
|
||||
(r'[:;\,\{\}\(\)\<>\[\]]', Punctuation),
|
||||
(r'[a-zA-Z_](\.[a-zA-Z_0-9]|[a-zA-Z_0-9])*', Name),
|
||||
],
|
||||
'whitespace': [
|
||||
(r'\n', Text.Whitespace),
|
||||
(r'\s+', Text.Whitespace),
|
||||
],
|
||||
'comments': [
|
||||
(r'#.*$', Comment),
|
||||
(r'//.*?\n', Comment),
|
||||
(r'/\*[\w\W]*?\*/', Comment.Multiline),
|
||||
],
|
||||
'stringescape': [
|
||||
(r'\\([\\nrt"\'])', String.Escape),
|
||||
],
|
||||
'dqs': [
|
||||
(r'"', String.Double, '#pop'),
|
||||
(r'[^\\"\n]+', String.Double),
|
||||
],
|
||||
'sqs': [
|
||||
(r"'", String.Single, '#pop'),
|
||||
(r'[^\\\'\n]+', String.Single),
|
||||
],
|
||||
'namespace': [
|
||||
(r'[a-z\*](\.[a-zA-Z_0-9]|[a-zA-Z_0-9])*', Name.Namespace, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
'class': [
|
||||
(r'[a-zA-Z_]\w*', Name.Class, '#pop'),
|
||||
default('#pop'),
|
||||
],
|
||||
'keywords': [
|
||||
(r'(async|oneway|extends|throws|required|optional)\b', Keyword),
|
||||
(r'(true|false)\b', Keyword.Constant),
|
||||
(r'(const|typedef)\b', Keyword.Declaration),
|
||||
(words((
|
||||
'cpp_namespace', 'cpp_include', 'cpp_type', 'java_package',
|
||||
'cocoa_prefix', 'csharp_namespace', 'delphi_namespace',
|
||||
'php_namespace', 'py_module', 'perl_package',
|
||||
'ruby_namespace', 'smalltalk_category', 'smalltalk_prefix',
|
||||
'xsd_all', 'xsd_optional', 'xsd_nillable', 'xsd_namespace',
|
||||
'xsd_attrs', 'include'), suffix=r'\b'),
|
||||
Keyword.Namespace),
|
||||
(words((
|
||||
'void', 'bool', 'byte', 'i16', 'i32', 'i64', 'double',
|
||||
'string', 'binary', 'void', 'map', 'list', 'set', 'slist',
|
||||
'senum'), suffix=r'\b'),
|
||||
Keyword.Type),
|
||||
(words((
|
||||
'BEGIN', 'END', '__CLASS__', '__DIR__', '__FILE__',
|
||||
'__FUNCTION__', '__LINE__', '__METHOD__', '__NAMESPACE__',
|
||||
'abstract', 'alias', 'and', 'args', 'as', 'assert', 'begin',
|
||||
'break', 'case', 'catch', 'class', 'clone', 'continue',
|
||||
'declare', 'def', 'default', 'del', 'delete', 'do', 'dynamic',
|
||||
'elif', 'else', 'elseif', 'elsif', 'end', 'enddeclare',
|
||||
'endfor', 'endforeach', 'endif', 'endswitch', 'endwhile',
|
||||
'ensure', 'except', 'exec', 'finally', 'float', 'for',
|
||||
'foreach', 'function', 'global', 'goto', 'if', 'implements',
|
||||
'import', 'in', 'inline', 'instanceof', 'interface', 'is',
|
||||
'lambda', 'module', 'native', 'new', 'next', 'nil', 'not',
|
||||
'or', 'pass', 'public', 'print', 'private', 'protected',
|
||||
'raise', 'redo', 'rescue', 'retry', 'register', 'return',
|
||||
'self', 'sizeof', 'static', 'super', 'switch', 'synchronized',
|
||||
'then', 'this', 'throw', 'transient', 'try', 'undef',
|
||||
'unless', 'unsigned', 'until', 'use', 'var', 'virtual',
|
||||
'volatile', 'when', 'while', 'with', 'xor', 'yield'),
|
||||
prefix=r'\b', suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
],
|
||||
'numbers': [
|
||||
(r'[+-]?(\d+\.\d+([eE][+-]?\d+)?|\.?\d+[eE][+-]?\d+)', Number.Float),
|
||||
(r'[+-]?0x[0-9A-Fa-f]+', Number.Hex),
|
||||
(r'[+-]?[0-9]+', Number.Integer),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class BroLexer(RegexLexer):
|
||||
"""
|
||||
For `Bro <http://bro-ids.org/>`_ scripts.
|
||||
@ -471,19 +578,22 @@ class PanLexer(RegexLexer):
|
||||
],
|
||||
'basic': [
|
||||
(words((
|
||||
'if', 'for', 'with', 'else', 'type', 'bind', 'while', 'valid', 'final', 'prefix',
|
||||
'unique', 'object', 'foreach', 'include', 'template', 'function', 'variable',
|
||||
'structure', 'extensible', 'declaration'), prefix=r'\b', suffix=r'\s*\b'),
|
||||
'if', 'for', 'with', 'else', 'type', 'bind', 'while', 'valid', 'final',
|
||||
'prefix', 'unique', 'object', 'foreach', 'include', 'template',
|
||||
'function', 'variable', 'structure', 'extensible', 'declaration'),
|
||||
prefix=r'\b', suffix=r'\s*\b'),
|
||||
Keyword),
|
||||
(words((
|
||||
'file_contents', 'format', 'index', 'length', 'match', 'matches', 'replace',
|
||||
'splice', 'split', 'substr', 'to_lowercase', 'to_uppercase', 'debug', 'error',
|
||||
'traceback', 'deprecated', 'base64_decode', 'base64_encode', 'digest', 'escape',
|
||||
'unescape', 'append', 'create', 'first', 'nlist', 'key', 'list', 'merge', 'next',
|
||||
'prepend', 'is_boolean', 'is_defined', 'is_double', 'is_list', 'is_long',
|
||||
'is_nlist', 'is_null', 'is_number', 'is_property', 'is_resource', 'is_string',
|
||||
'to_boolean', 'to_double', 'to_long', 'to_string', 'clone', 'delete', 'exists',
|
||||
'path_exists', 'if_exists', 'return', 'value'), prefix=r'\b', suffix=r'\s*\b'),
|
||||
'file_contents', 'format', 'index', 'length', 'match', 'matches',
|
||||
'replace', 'splice', 'split', 'substr', 'to_lowercase', 'to_uppercase',
|
||||
'debug', 'error', 'traceback', 'deprecated', 'base64_decode',
|
||||
'base64_encode', 'digest', 'escape', 'unescape', 'append', 'create',
|
||||
'first', 'nlist', 'key', 'list', 'merge', 'next', 'prepend', 'is_boolean',
|
||||
'is_defined', 'is_double', 'is_list', 'is_long', 'is_nlist', 'is_null',
|
||||
'is_number', 'is_property', 'is_resource', 'is_string', 'to_boolean',
|
||||
'to_double', 'to_long', 'to_string', 'clone', 'delete', 'exists',
|
||||
'path_exists', 'if_exists', 'return', 'value'),
|
||||
prefix=r'\b', suffix=r'\s*\b'),
|
||||
Name.Builtin),
|
||||
(r'#.*', Comment),
|
||||
(r'\\[\w\W]', String.Escape),
|
||||
@ -512,3 +622,73 @@ class PanLexer(RegexLexer):
|
||||
include('root'),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CrmshLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `crmsh <http://crmsh.github.io/>`_ configuration files
|
||||
for Pacemaker clusters.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'Crmsh'
|
||||
aliases = ['crmsh', 'pcmk']
|
||||
filenames = ['*.crmsh', '*.pcmk']
|
||||
mimetypes = []
|
||||
|
||||
elem = words((
|
||||
'node', 'primitive', 'group', 'clone', 'ms', 'location',
|
||||
'colocation', 'order', 'fencing_topology', 'rsc_ticket',
|
||||
'rsc_template', 'property', 'rsc_defaults',
|
||||
'op_defaults', 'acl_target', 'acl_group', 'user', 'role',
|
||||
'tag'), suffix=r'(?![\w#$-])')
|
||||
sub = words((
|
||||
'params', 'meta', 'operations', 'op', 'rule',
|
||||
'attributes', 'utilization'), suffix=r'(?![\w#$-])')
|
||||
acl = words(('read', 'write', 'deny'), suffix=r'(?![\w#$-])')
|
||||
bin_rel = words(('and', 'or'), suffix=r'(?![\w#$-])')
|
||||
un_ops = words(('defined', 'not_defined'), suffix=r'(?![\w#$-])')
|
||||
date_exp = words(('in_range', 'date', 'spec', 'in'), suffix=r'(?![\w#$-])')
|
||||
acl_mod = (r'(?:tag|ref|reference|attribute|type|xpath)')
|
||||
bin_ops = (r'(?:lt|gt|lte|gte|eq|ne)')
|
||||
val_qual = (r'(?:string|version|number)')
|
||||
rsc_role_action = (r'(?:Master|Started|Slave|Stopped|'
|
||||
r'start|promote|demote|stop)')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'^#.*\n?', Comment),
|
||||
# attr=value (nvpair)
|
||||
(r'([\w#$-]+)(=)("(?:""|[^"])*"|\S+)',
|
||||
bygroups(Name.Attribute, Punctuation, String)),
|
||||
# need this construct, otherwise numeric node ids
|
||||
# are matched as scores
|
||||
# elem id:
|
||||
(r'(node)(\s+)([\w#$-]+)(:)',
|
||||
bygroups(Keyword, Whitespace, Name, Punctuation)),
|
||||
# scores
|
||||
(r'([+-]?([0-9]+|inf)):', Number),
|
||||
# keywords (elements and other)
|
||||
(elem, Keyword),
|
||||
(sub, Keyword),
|
||||
(acl, Keyword),
|
||||
# binary operators
|
||||
(r'(?:%s:)?(%s)(?![\w#$-])' % (val_qual, bin_ops), Operator.Word),
|
||||
# other operators
|
||||
(bin_rel, Operator.Word),
|
||||
(un_ops, Operator.Word),
|
||||
(date_exp, Operator.Word),
|
||||
# builtin attributes (e.g. #uname)
|
||||
(r'#[a-z]+(?![\w#$-])', Name.Builtin),
|
||||
# acl_mod:blah
|
||||
(r'(%s)(:)("(?:""|[^"])*"|\S+)' % acl_mod,
|
||||
bygroups(Keyword, Punctuation, Name)),
|
||||
# rsc_id[:(role|action)]
|
||||
# NB: this matches all other identifiers
|
||||
(r'([\w#$-]+)(?:(:)(%s))?(?![\w#$-])' % rsc_role_action,
|
||||
bygroups(Name, Punctuation, Operator.Word)),
|
||||
# punctuation
|
||||
(r'(\\(?=\n)|[[\](){}/:@])', Punctuation),
|
||||
(r'\s+|\n', Whitespace),
|
||||
],
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for the Dylan language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for the ECL language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexer for the Eiffel language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
121
packages/wakatime/packages/pygments/lexers/elm.py
Normal file
121
packages/wakatime/packages/pygments/lexers/elm.py
Normal file
@ -0,0 +1,121 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.elm
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexer for the Elm programming language.
|
||||
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, words, include
|
||||
from pygments.token import Comment, Keyword, Name, Number, Punctuation, String, Text
|
||||
|
||||
__all__ = ['ElmLexer']
|
||||
|
||||
|
||||
class ElmLexer(RegexLexer):
|
||||
"""
|
||||
For `Elm <http://elm-lang.org/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
|
||||
name = 'Elm'
|
||||
aliases = ['elm']
|
||||
filenames = ['*.elm']
|
||||
mimetypes = ['text/x-elm']
|
||||
|
||||
validName = r'[a-z_][a-zA-Z_\']*'
|
||||
|
||||
specialName = r'^main '
|
||||
|
||||
builtinOps = (
|
||||
'~', '||', '|>', '|', '`', '^', '\\', '\'', '>>', '>=', '>', '==',
|
||||
'=', '<~', '<|', '<=', '<<', '<-', '<', '::', ':', '/=', '//', '/',
|
||||
'..', '.', '->', '-', '++', '+', '*', '&&', '%',
|
||||
)
|
||||
|
||||
reservedWords = words((
|
||||
'alias', 'as', 'case', 'else', 'if', 'import', 'in',
|
||||
'let', 'module', 'of', 'port', 'then', 'type', 'where',
|
||||
), suffix=r'\b')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
|
||||
# Comments
|
||||
(r'{-', Comment.Multiline, 'comment'),
|
||||
(r'--.*', Comment.Single),
|
||||
|
||||
# Whitespace
|
||||
(r'\s+', Text),
|
||||
|
||||
# Strings
|
||||
(r'"', String, 'doublequote'),
|
||||
|
||||
# Modules
|
||||
(r'^\s*module\s*', Keyword.Namespace, 'imports'),
|
||||
|
||||
# Imports
|
||||
(r'^\s*import\s*', Keyword.Namespace, 'imports'),
|
||||
|
||||
# Shaders
|
||||
(r'\[glsl\|.*', Name.Entity, 'shader'),
|
||||
|
||||
# Keywords
|
||||
(reservedWords, Keyword.Reserved),
|
||||
|
||||
# Types
|
||||
(r'[A-Z]\w*', Keyword.Type),
|
||||
|
||||
# Main
|
||||
(specialName, Keyword.Reserved),
|
||||
|
||||
# Prefix Operators
|
||||
(words((builtinOps), prefix=r'\(', suffix=r'\)'), Name.Function),
|
||||
|
||||
# Infix Operators
|
||||
(words((builtinOps)), Name.Function),
|
||||
|
||||
# Numbers
|
||||
include('numbers'),
|
||||
|
||||
# Variable Names
|
||||
(validName, Name.Variable),
|
||||
|
||||
# Parens
|
||||
(r'[,\(\)\[\]{}]', Punctuation),
|
||||
|
||||
],
|
||||
|
||||
'comment': [
|
||||
(r'-(?!})', Comment.Multiline),
|
||||
(r'{-', Comment.Multiline, 'comment'),
|
||||
(r'[^-}]', Comment.Multiline),
|
||||
(r'-}', Comment.Multiline, '#pop'),
|
||||
],
|
||||
|
||||
'doublequote': [
|
||||
(r'\\u[0-9a-fA-F]\{4}', String.Escape),
|
||||
(r'\\[nrfvb\\\"]', String.Escape),
|
||||
(r'[^"]', String),
|
||||
(r'"', String, '#pop'),
|
||||
],
|
||||
|
||||
'imports': [
|
||||
(r'\w+(\.\w+)*', Name.Class, '#pop'),
|
||||
],
|
||||
|
||||
'numbers': [
|
||||
(r'_?\d+\.(?=\d+)', Number.Float),
|
||||
(r'_?\d+', Number.Integer),
|
||||
],
|
||||
|
||||
'shader': [
|
||||
(r'\|(?!\])', Name.Entity),
|
||||
(r'\|\]', Name.Entity, '#pop'),
|
||||
(r'.*\n', Name.Entity),
|
||||
],
|
||||
}
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for Erlang.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
219
packages/wakatime/packages/pygments/lexers/esoteric.py
Normal file
219
packages/wakatime/packages/pygments/lexers/esoteric.py
Normal file
@ -0,0 +1,219 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.esoteric
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Lexers for esoteric languages.
|
||||
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
from pygments.lexer import RegexLexer, include, words
|
||||
from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
|
||||
Number, Punctuation, Error, Whitespace
|
||||
|
||||
__all__ = ['BrainfuckLexer', 'BefungeLexer', 'BoogieLexer', 'RedcodeLexer', 'CAmkESLexer']
|
||||
|
||||
|
||||
class BrainfuckLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the esoteric `BrainFuck <http://www.muppetlabs.com/~breadbox/bf/>`_
|
||||
language.
|
||||
"""
|
||||
|
||||
name = 'Brainfuck'
|
||||
aliases = ['brainfuck', 'bf']
|
||||
filenames = ['*.bf', '*.b']
|
||||
mimetypes = ['application/x-brainfuck']
|
||||
|
||||
tokens = {
|
||||
'common': [
|
||||
# use different colors for different instruction types
|
||||
(r'[.,]+', Name.Tag),
|
||||
(r'[+-]+', Name.Builtin),
|
||||
(r'[<>]+', Name.Variable),
|
||||
(r'[^.,+\-<>\[\]]+', Comment),
|
||||
],
|
||||
'root': [
|
||||
(r'\[', Keyword, 'loop'),
|
||||
(r'\]', Error),
|
||||
include('common'),
|
||||
],
|
||||
'loop': [
|
||||
(r'\[', Keyword, '#push'),
|
||||
(r'\]', Keyword, '#pop'),
|
||||
include('common'),
|
||||
]
|
||||
}
|
||||
|
||||
|
||||
class BefungeLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for the esoteric `Befunge <http://en.wikipedia.org/wiki/Befunge>`_
|
||||
language.
|
||||
|
||||
.. versionadded:: 0.7
|
||||
"""
|
||||
name = 'Befunge'
|
||||
aliases = ['befunge']
|
||||
filenames = ['*.befunge']
|
||||
mimetypes = ['application/x-befunge']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
(r'[0-9a-f]', Number),
|
||||
(r'[+*/%!`-]', Operator), # Traditional math
|
||||
(r'[<>^v?\[\]rxjk]', Name.Variable), # Move, imperatives
|
||||
(r'[:\\$.,n]', Name.Builtin), # Stack ops, imperatives
|
||||
(r'[|_mw]', Keyword),
|
||||
(r'[{}]', Name.Tag), # Befunge-98 stack ops
|
||||
(r'".*?"', String.Double), # Strings don't appear to allow escapes
|
||||
(r'\'.', String.Single), # Single character
|
||||
(r'[#;]', Comment), # Trampoline... depends on direction hit
|
||||
(r'[pg&~=@iotsy]', Keyword), # Misc
|
||||
(r'[()A-Z]', Comment), # Fingerprints
|
||||
(r'\s+', Text), # Whitespace doesn't matter
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class CAmkESLexer(RegexLexer):
|
||||
"""
|
||||
Basic lexer for the input language for the
|
||||
`CAmkES <https://sel4.systems/CAmkES/>`_ component platform.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'CAmkES'
|
||||
aliases = ['camkes', 'idl4']
|
||||
filenames = ['*.camkes', '*.idl4']
|
||||
|
||||
tokens = {
|
||||
'root':[
|
||||
# C pre-processor directive
|
||||
(r'^\s*#.*\n', Comment.Preproc),
|
||||
|
||||
# Whitespace, comments
|
||||
(r'\s+', Text),
|
||||
(r'/\*(.|\n)*?\*/', Comment),
|
||||
(r'//.*\n', Comment),
|
||||
|
||||
(r'[\[\(\){},\.;=\]]', Punctuation),
|
||||
|
||||
(words(('assembly', 'attribute', 'component', 'composition',
|
||||
'configuration', 'connection', 'connector', 'consumes',
|
||||
'control', 'dataport', 'Dataport', 'emits', 'event',
|
||||
'Event', 'from', 'group', 'hardware', 'has', 'interface',
|
||||
'Interface', 'maybe', 'procedure', 'Procedure', 'provides',
|
||||
'template', 'to', 'uses'), suffix=r'\b'), Keyword),
|
||||
|
||||
(words(('bool', 'boolean', 'Buf', 'char', 'character', 'double',
|
||||
'float', 'in', 'inout', 'int', 'int16_6', 'int32_t',
|
||||
'int64_t', 'int8_t', 'integer', 'mutex', 'out', 'real',
|
||||
'refin', 'semaphore', 'signed', 'string', 'uint16_t',
|
||||
'uint32_t', 'uint64_t', 'uint8_t', 'uintptr_t', 'unsigned',
|
||||
'void'), suffix=r'\b'), Keyword.Type),
|
||||
|
||||
# Recognised attributes
|
||||
(r'[a-zA-Z_]\w*_(priority|domain|buffer)', Keyword.Reserved),
|
||||
(words(('dma_pool', 'from_access', 'to_access'), suffix=r'\b'),
|
||||
Keyword.Reserved),
|
||||
|
||||
# CAmkES-level include
|
||||
(r'import\s+(<[^>]*>|"[^"]*");', Comment.Preproc),
|
||||
|
||||
# C-level include
|
||||
(r'include\s+(<[^>]*>|"[^"]*");', Comment.Preproc),
|
||||
|
||||
# Literals
|
||||
(r'0[xX][\da-fA-F]+', Number.Hex),
|
||||
(r'-?[\d]+', Number),
|
||||
(r'-?[\d]+\.[\d]+', Number.Float),
|
||||
(r'"[^"]*"', String),
|
||||
|
||||
# Identifiers
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class RedcodeLexer(RegexLexer):
|
||||
"""
|
||||
A simple Redcode lexer based on ICWS'94.
|
||||
Contributed by Adam Blinkinsop <blinks@acm.org>.
|
||||
|
||||
.. versionadded:: 0.8
|
||||
"""
|
||||
name = 'Redcode'
|
||||
aliases = ['redcode']
|
||||
filenames = ['*.cw']
|
||||
|
||||
opcodes = ('DAT', 'MOV', 'ADD', 'SUB', 'MUL', 'DIV', 'MOD',
|
||||
'JMP', 'JMZ', 'JMN', 'DJN', 'CMP', 'SLT', 'SPL',
|
||||
'ORG', 'EQU', 'END')
|
||||
modifiers = ('A', 'B', 'AB', 'BA', 'F', 'X', 'I')
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Whitespace:
|
||||
(r'\s+', Text),
|
||||
(r';.*$', Comment.Single),
|
||||
# Lexemes:
|
||||
# Identifiers
|
||||
(r'\b(%s)\b' % '|'.join(opcodes), Name.Function),
|
||||
(r'\b(%s)\b' % '|'.join(modifiers), Name.Decorator),
|
||||
(r'[A-Za-z_]\w+', Name),
|
||||
# Operators
|
||||
(r'[-+*/%]', Operator),
|
||||
(r'[#$@<>]', Operator), # mode
|
||||
(r'[.,]', Punctuation), # mode
|
||||
# Numbers
|
||||
(r'[-+]?\d+', Number.Integer),
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
class BoogieLexer(RegexLexer):
|
||||
"""
|
||||
For `Boogie <https://boogie.codeplex.com/>`_ source code.
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'Boogie'
|
||||
aliases = ['boogie']
|
||||
filenames = ['*.bpl']
|
||||
|
||||
tokens = {
|
||||
'root': [
|
||||
# Whitespace and Comments
|
||||
(r'\n', Whitespace),
|
||||
(r'\s+', Whitespace),
|
||||
(r'//[/!](.*?)\n', Comment.Doc),
|
||||
(r'//(.*?)\n', Comment.Single),
|
||||
(r'/\*', Comment.Multiline, 'comment'),
|
||||
|
||||
(words((
|
||||
'axiom', 'break', 'call', 'ensures', 'else', 'exists', 'function',
|
||||
'forall', 'if', 'invariant', 'modifies', 'procedure', 'requires',
|
||||
'then', 'var', 'while'),
|
||||
suffix=r'\b'), Keyword),
|
||||
(words(('const',), suffix=r'\b'), Keyword.Reserved),
|
||||
|
||||
(words(('bool', 'int', 'ref'), suffix=r'\b'), Keyword.Type),
|
||||
include('numbers'),
|
||||
(r"(>=|<=|:=|!=|==>|&&|\|\||[+/\-=>*<\[\]])", Operator),
|
||||
(r"([{}():;,.])", Punctuation),
|
||||
# Identifier
|
||||
(r'[a-zA-Z_]\w*', Name),
|
||||
],
|
||||
'comment': [
|
||||
(r'[^*/]+', Comment.Multiline),
|
||||
(r'/\*', Comment.Multiline, '#push'),
|
||||
(r'\*/', Comment.Multiline, '#pop'),
|
||||
(r'[*/]', Comment.Multiline),
|
||||
],
|
||||
'numbers': [
|
||||
(r'[0-9]+', Number.Integer),
|
||||
],
|
||||
}
|
||||
68
packages/wakatime/packages/pygments/lexers/ezhil.py
Normal file
68
packages/wakatime/packages/pygments/lexers/ezhil.py
Normal file
@ -0,0 +1,68 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
pygments.lexers.ezhil
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Pygments lexers for Ezhil language.
|
||||
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
import re
|
||||
from pygments.lexer import RegexLexer, include, words
|
||||
from pygments.token import Keyword, Text, Comment, Name
|
||||
from pygments.token import String, Number, Punctuation, Operator
|
||||
|
||||
__all__ = ['EzhilLexer']
|
||||
|
||||
class EzhilLexer(RegexLexer):
|
||||
"""
|
||||
Lexer for `Ezhil, a Tamil script-based programming language <http://ezhillang.org>`_
|
||||
|
||||
.. versionadded:: 2.1
|
||||
"""
|
||||
name = 'Ezhil'
|
||||
aliases = ['ezhil']
|
||||
filenames = ['*.n']
|
||||
mimetypes = ['text/x-ezhil']
|
||||
flags = re.MULTILINE | re.UNICODE
|
||||
# Refer to tamil.utf8.tamil_letters from open-tamil for a stricter version of this.
|
||||
# This much simpler version is close enough, and includes combining marks.
|
||||
_TALETTERS = u'[a-zA-Z_]|[\u0b80-\u0bff]'
|
||||
tokens = {
|
||||
'root': [
|
||||
include('keywords'),
|
||||
(r'#.*\n', Comment.Single),
|
||||
(r'[@+/*,^\-%]|[!<>=]=?|&&?|\|\|?', Operator),
|
||||
(u'இல்', Operator.Word),
|
||||
(words(('assert', 'max', 'min',
|
||||
'நீளம்','சரம்_இடமாற்று','சரம்_கண்டுபிடி',
|
||||
'பட்டியல்','பின்இணை','வரிசைப்படுத்து',
|
||||
'எடு','தலைகீழ்','நீட்டிக்க','நுழைக்க','வை',
|
||||
'கோப்பை_திற','கோப்பை_எழுது','கோப்பை_மூடு',
|
||||
'pi','sin','cos','tan','sqrt','hypot','pow','exp','log','log10'
|
||||
'min','max','exit',
|
||||
), suffix=r'\b'), Name.Builtin),
|
||||
(r'(True|False)\b', Keyword.Constant),
|
||||
(r'[^\S\n]+', Text),
|
||||
include('identifier'),
|
||||
include('literal'),
|
||||
(r'[(){}\[\]:;.]', Punctuation),
|
||||
],
|
||||
'keywords': [
|
||||
(u'பதிப்பி|தேர்ந்தெடு|தேர்வு|ஏதேனில்|ஆனால்|இல்லைஆனால்|இல்லை|ஆக|ஒவ்வொன்றாக|இல்|வரை|செய்|முடியேனில்|பின்கொடு|முடி|நிரல்பாகம்|தொடர்|நிறுத்து|நிரல்பாகம்', Keyword),
|
||||
],
|
||||
'identifier': [
|
||||
(u'(?:'+_TALETTERS+u')(?:[0-9]|'+_TALETTERS+u')*', Name),
|
||||
],
|
||||
'literal': [
|
||||
(r'".*?"', String),
|
||||
(r'(?u)\d+((\.\d*)?[eE][+-]?\d+|\.\d*)', Number.Float),
|
||||
(r'(?u)\d+', Number.Integer),
|
||||
]
|
||||
}
|
||||
|
||||
def __init__(self, **options):
|
||||
super(EzhilLexer, self).__init__(**options)
|
||||
self.encoding = options.get('encoding', 'utf-8')
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexers for the Factor language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
@ -5,7 +5,7 @@
|
||||
|
||||
Lexer for the Fantom language.
|
||||
|
||||
:copyright: Copyright 2006-2014 by the Pygments team, see AUTHORS.
|
||||
:copyright: Copyright 2006-2015 by the Pygments team, see AUTHORS.
|
||||
:license: BSD, see LICENSE for details.
|
||||
"""
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user