mirror of
https://github.com/wakatime/sublime-wakatime.git
synced 2023-08-10 21:13:02 +03:00
Compare commits
494 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| ef77e1f178 | |||
| 4025decc12 | |||
| 086c700151 | |||
| 650bb6fa26 | |||
| 389c84673e | |||
| 6fa1321a95 | |||
| f1a8fcab44 | |||
| 3937b083c5 | |||
| 711aab0d18 | |||
| cb8ce3a54e | |||
| 7db5fe0a5d | |||
| cebcfaa0e9 | |||
| f8faed6e47 | |||
| fb303e048f | |||
| 4f11222c2b | |||
| 72b72dc9f0 | |||
| 1b07d0442b | |||
| fbd8e84ea1 | |||
| 01c0e7758e | |||
| 28556de3b6 | |||
| 809e43cfe5 | |||
| 22ddbe27b0 | |||
| ddaf60b8b0 | |||
| 2e6a87c67e | |||
| 01503b1c20 | |||
| 5a4ac9c11d | |||
| fa0a3aacb5 | |||
| d588451468 | |||
| 483d8f596e | |||
| 03f2d6d580 | |||
| e1390d7647 | |||
| c87bdd041c | |||
| 3a65395636 | |||
| 0b2f3aa9a4 | |||
| 58ef2cd794 | |||
| 04173d3bcc | |||
| 3206a07476 | |||
| 9330236816 | |||
| 885c11f01a | |||
| 8acda0157a | |||
| 935ddbd5f6 | |||
| b57b1eb696 | |||
| 6ec097b9d1 | |||
| b3ed36d3b2 | |||
| 3669e4df6a | |||
| 3504096082 | |||
| 5990947706 | |||
| 2246e31244 | |||
| b55fe702d3 | |||
| e0fbbb50bb | |||
| 32c0cb5a97 | |||
| 67d8b0d24f | |||
| b8b2f4944b | |||
| a20161164c | |||
| 405211bb07 | |||
| ffc879c4eb | |||
| 1e23919694 | |||
| b2086a3cd2 | |||
| 005b07520c | |||
| 60608bd322 | |||
| cde8f8f1de | |||
| 4adfca154c | |||
| f7b3924a30 | |||
| db00024455 | |||
| 9a6be7ca4e | |||
| 1ea9b2a761 | |||
| bd5e87e030 | |||
| 0256ff4a6a | |||
| 9d170b3276 | |||
| c54e575210 | |||
| 07513d8f10 | |||
| 30902cc050 | |||
| aa7962d49a | |||
| d8c662f3db | |||
| 10d88ebf2d | |||
| 2f28c561b1 | |||
| 24968507df | |||
| 641cd539ed | |||
| 0c65d7e5b2 | |||
| f0532f5b8e | |||
| 8094db9680 | |||
| bf20551849 | |||
| 2b6e32b578 | |||
| 363c3d38e2 | |||
| 88466d7db2 | |||
| 122fcbbee5 | |||
| c41fcec5d8 | |||
| be09b34d44 | |||
| e1ee1c1216 | |||
| a37061924b | |||
| da01fa268b | |||
| c279418651 | |||
| 5cf2c8f7ac | |||
| d1455e77a8 | |||
| 8499e7bafe | |||
| abc26a0864 | |||
| 71ad97ffe9 | |||
| 3ec5995c99 | |||
| 195cf4de36 | |||
| b39eefb4f5 | |||
| bbf5761e26 | |||
| c4df1dc633 | |||
| 360a491cda | |||
| f61a34eda7 | |||
| 48123d7409 | |||
| c8a15d7ac0 | |||
| 202df81e04 | |||
| 5e34f3f6a7 | |||
| d4441e5575 | |||
| 9eac8e2bd3 | |||
| 11d8fc3a09 | |||
| d1f1f51f23 | |||
| b10bb36c09 | |||
| dc9474befa | |||
| b910807e98 | |||
| bc770515f0 | |||
| 9e102d7c5c | |||
| 5c1770fb48 | |||
| 683397534c | |||
| 1c92017543 | |||
| fda1307668 | |||
| 1c84d457c5 | |||
| 1e680ce739 | |||
| 376adbb7d7 | |||
| e0040e185b | |||
| c4a88541d0 | |||
| 0cf621d177 | |||
| db9d6cec97 | |||
| 2c17f49a6b | |||
| 95116d6007 | |||
| 8c52596f8f | |||
| 3109817dc7 | |||
| 0c0f965763 | |||
| 1573e9c825 | |||
| a0b8f349c2 | |||
| 2fb60b1589 | |||
| 02786a744e | |||
| 729a4360ba | |||
| 8f45de85ec | |||
| 4672f70c87 | |||
| 46a9aae942 | |||
| 9e77ce2697 | |||
| 385ba818cc | |||
| 7492c3ce12 | |||
| 03eed88917 | |||
| 60a7ad96b5 | |||
| 2d1d5d336a | |||
| e659759b2d | |||
| a290e5d86d | |||
| d5b922bb10 | |||
| ec7b5e3530 | |||
| aa3f2e8af6 | |||
| f4e53cd682 | |||
| aba72b0f1e | |||
| 5b9d86a57d | |||
| fa40874635 | |||
| 6d4a4cf9eb | |||
| f628b8dd11 | |||
| f932ee9fc6 | |||
| 2f14009279 | |||
| 453d96bf9c | |||
| 9de153f156 | |||
| dcc782338d | |||
| 9d0dba988a | |||
| e76f2e514e | |||
| 224f7cd82a | |||
| 3cce525a84 | |||
| ce885501ad | |||
| c9448a9a19 | |||
| 04f8c61ebc | |||
| 04a4630024 | |||
| 02138220fd | |||
| d0b162bdd8 | |||
| 1b8895cd38 | |||
| 938bbb73d1 | |||
| 008fdc6b49 | |||
| a788625dd0 | |||
| bcbce681c3 | |||
| 35299db832 | |||
| eb7814624c | |||
| 1c092b2fd8 | |||
| 507ef95f71 | |||
| 9777bc7788 | |||
| 20b78defa6 | |||
| 8cb1c557d9 | |||
| 20a1965f13 | |||
| 0b802a554e | |||
| 30186c9b2c | |||
| 311a0b5309 | |||
| b7602d89fb | |||
| 305de46e32 | |||
| c574234927 | |||
| a69c50f470 | |||
| f4b40089f3 | |||
| 08394357b7 | |||
| 205d4eb163 | |||
| c4c27e4e9e | |||
| 9167eb2558 | |||
| eaa3bb5180 | |||
| 7755971d11 | |||
| 7634be5446 | |||
| 5e17ad88f6 | |||
| 24d0f65116 | |||
| a326046733 | |||
| 9bab00fd8b | |||
| b4a13a48b9 | |||
| 21601f9688 | |||
| 4c3ec87341 | |||
| b149d7fc87 | |||
| 52e6107c6e | |||
| b340637331 | |||
| 044867449a | |||
| 9e3f438823 | |||
| 887d55c3f3 | |||
| 19d54f3310 | |||
| 514a8762eb | |||
| 957c74d226 | |||
| 7b0432d6ff | |||
| 09754849be | |||
| 25ad48a97a | |||
| 3b2520afa9 | |||
| 77c2041ad3 | |||
| 8af3b53937 | |||
| 5ef2e6954e | |||
| ca94272de5 | |||
| f19a448d95 | |||
| e178765412 | |||
| 6a7de84b9c | |||
| 48810f2977 | |||
| 260eedb31d | |||
| 02e2bfcad2 | |||
| f14ece63f3 | |||
| cb7f786ec8 | |||
| ab8711d0b1 | |||
| 2354be358c | |||
| 443215bd90 | |||
| c64f125dc4 | |||
| 050b14fb53 | |||
| c7efc33463 | |||
| d0ddbed006 | |||
| 3ce8f388ab | |||
| 90731146f9 | |||
| e1ab92be6d | |||
| 8b59e46c64 | |||
| 006341eb72 | |||
| b54e0e13f6 | |||
| 835c7db864 | |||
| 53e8bb04e9 | |||
| 4aa06e3829 | |||
| 297f65733f | |||
| 5ba5e6d21b | |||
| 32eadda81f | |||
| c537044801 | |||
| a97792c23c | |||
| 4223f3575f | |||
| 284cdf3ce4 | |||
| 27afc41bf4 | |||
| 1fdda0d64a | |||
| c90a4863e9 | |||
| 94343e5b07 | |||
| 03acea6e25 | |||
| 77594700bd | |||
| 6681409e98 | |||
| 8f7837269a | |||
| a523b3aa4d | |||
| 6985ce32bb | |||
| 4be40c7720 | |||
| eeb7fd8219 | |||
| 11fbd2d2a6 | |||
| 3cecd0de5d | |||
| c50100e675 | |||
| c1da94bc18 | |||
| 7f9d6ede9d | |||
| 192a5c7aa7 | |||
| 16bbe21be9 | |||
| 5ebaf12a99 | |||
| 1834e8978a | |||
| 22c8ed74bd | |||
| 12bbb4e561 | |||
| c71cb21cc1 | |||
| eb11b991f0 | |||
| 7ea51d09ba | |||
| b07b59e0c8 | |||
| 9d715e95b7 | |||
| 3edaed53aa | |||
| 865b0bcee9 | |||
| d440fe912c | |||
| 627455167f | |||
| aba89d3948 | |||
| 18d87118e1 | |||
| fd91b9e032 | |||
| 16b15773bf | |||
| f0b518862a | |||
| 7ee7de70d5 | |||
| fb479f8e84 | |||
| 7d37193f65 | |||
| 6bd62b95db | |||
| abf4a94a59 | |||
| 9337e3173b | |||
| 57fa4d4d84 | |||
| 9b5c59e677 | |||
| 71ce25a326 | |||
| f2f14207f5 | |||
| ac2ec0e73c | |||
| 040a76b93c | |||
| dab0621b97 | |||
| 675f9ecd69 | |||
| a6f92b9c74 | |||
| bfcc242d7e | |||
| 762027644f | |||
| 3c4ceb95fa | |||
| d6d8bceca0 | |||
| acaad2dc83 | |||
| 23c5801080 | |||
| 05a3bfbb53 | |||
| 8faaa3b0e3 | |||
| 4bcddf2a98 | |||
| b51ae5c2c4 | |||
| 5cd0061653 | |||
| 651c84325e | |||
| 89368529cb | |||
| f1f408284b | |||
| 7053932731 | |||
| b6c4956521 | |||
| 68a2557884 | |||
| c7ee7258fb | |||
| aaff2503fb | |||
| 00a1193bd3 | |||
| 2371daac1b | |||
| 4395db2b2d | |||
| fc8c61fa3f | |||
| aa30110343 | |||
| b671856341 | |||
| b801759cdf | |||
| 919064200b | |||
| 911b5656d7 | |||
| 48bbab33b4 | |||
| 3b2aafe004 | |||
| aa0b2d6d70 | |||
| 1a6f588d94 | |||
| 373ebf933f | |||
| 7fb47228f9 | |||
| 4fca5e1c06 | |||
| cb2d126c47 | |||
| 17404bf848 | |||
| 510eea0a8b | |||
| d16d1ca747 | |||
| 440e33b8b7 | |||
| 307029c37a | |||
| 60c8ea4454 | |||
| e4fe604a93 | |||
| 308187b2ed | |||
| 97f4077675 | |||
| 4960289ed1 | |||
| 82530cef4f | |||
| 08172098e2 | |||
| 56f54fb064 | |||
| 1bea7cde8c | |||
| 038847e665 | |||
| d233494a39 | |||
| 070ad5a023 | |||
| 757a4c6905 | |||
| dd61a4f5f4 | |||
| 69f9bbdc78 | |||
| e1dc4039fd | |||
| 7c07925527 | |||
| ee8c0dfed8 | |||
| ad4df93b04 | |||
| 9a600df969 | |||
| a0abeac3e2 | |||
| 12b8c36c5f | |||
| 7d4d50ee62 | |||
| 520db283cb | |||
| f3179b75d9 | |||
| 1bc8b9b9c7 | |||
| 584d109357 | |||
| 327c0e448b | |||
| 3182a45bbd | |||
| 4cd4a26f91 | |||
| 85856f2c53 | |||
| 8a09559364 | |||
| 5e2e1be779 | |||
| b1d344cb46 | |||
| 7245cbeb58 | |||
| 21395579ea | |||
| 08b64b4ff6 | |||
| 20571ec085 | |||
| e43dcc1c83 | |||
| 4610ff3e0c | |||
| c86d6254e0 | |||
| df331db5cc | |||
| baff0f415d | |||
| 499dc167a5 | |||
| 83f4a29a15 | |||
| 8f02adacf9 | |||
| e631d33944 | |||
| cbd92a69b3 | |||
| b7c047102d | |||
| d0bfd04602 | |||
| 101ab38c70 | |||
| 8632c4ff08 | |||
| 80556d0cbf | |||
| 253728545c | |||
| 49d9b1d7dc | |||
| 8574abe012 | |||
| 6b6f60d8e8 | |||
| 986e592d1e | |||
| 6ec3b171e1 | |||
| bcfb9862af | |||
| 85cf9f4eb5 | |||
| d2a996e845 | |||
| c863bde54a | |||
| e19f85f081 | |||
| 7b854d4041 | |||
| e122f73e6b | |||
| 474942eb6a | |||
| a5f031b046 | |||
| 66fddc07b9 | |||
| e56a07e909 | |||
| 64ea40b3f5 | |||
| 17fd6ef8e1 | |||
| e5e399dfbe | |||
| bcf037e8a4 | |||
| 7e678a38bd | |||
| 533aaac313 | |||
| 7f4f70cc85 | |||
| 4adb8a8796 | |||
| 48e1993b24 | |||
| 8a3375bb23 | |||
| 8bd54a7427 | |||
| fcbbf05933 | |||
| 9733087094 | |||
| da4e02199a | |||
| 09a16dea1e | |||
| 4c7adf0943 | |||
| 216a8eaa0a | |||
| 81f838489d | |||
| d6228b8dce | |||
| 7a2c2b9750 | |||
| d9cc911595 | |||
| 805e2fe222 | |||
| bbcb39b2cf | |||
| 9f9b97c69f | |||
| 908ff98613 | |||
| 37f74b4b56 | |||
| a1c0d7e489 | |||
| 3127f264b4 | |||
| 049bc57019 | |||
| 03ec38bb67 | |||
| 4fc1a55ff7 | |||
| f60815b813 | |||
| ca47c2308d | |||
| 146a959747 | |||
| 906184cd88 | |||
| a13e11d24d | |||
| d34432217f | |||
| f2e8f85198 | |||
| 05b08b6ab2 | |||
| 685d242c60 | |||
| 023c1dfbe3 | |||
| 9255fd2c34 | |||
| 784ad38c38 | |||
| 36def5c8b8 | |||
| 2c8dd6c9e7 | |||
| e8151535c1 | |||
| 744116079a | |||
| 791a969a10 | |||
| 46c5171d6a | |||
| fe641d01d4 | |||
| 4f03423333 | |||
| e812e9fe15 | |||
| a92ebad2f2 | |||
| 78a7e5cbcb | |||
| 5616206b48 | |||
| 165543d867 | |||
| e933f71bcd | |||
| 8c6cb8dc9c | |||
| 3e74625963 | |||
| a19e635ba3 | |||
| 6436cf6b62 | |||
| e1e8861a6e | |||
| 097027a3d4 | |||
| 37192c6333 | |||
| 57f4ca069b | |||
| bf6a6f7310 | |||
| fce10cea07 | |||
| b836f26226 | |||
| c3e08623c1 | |||
| af0dce46aa | |||
| be54a19207 | |||
| ce8d9af149 | |||
| 840d4e17f1 | |||
| 73ede90e69 | |||
| 65094ecf74 |
17
AUTHORS
Normal file
17
AUTHORS
Normal file
@ -0,0 +1,17 @@
|
||||
WakaTime is written and maintained by Alan Hamlett and
|
||||
various contributors:
|
||||
|
||||
|
||||
Development Lead
|
||||
----------------
|
||||
|
||||
- Alan Hamlett <alan.hamlett@gmail.com>
|
||||
|
||||
|
||||
Patches and Suggestions
|
||||
-----------------------
|
||||
|
||||
- Jimmy Selgen Nielsen <jimmy.selgen@gmail.com>
|
||||
- Patrik Kernstock <info@pkern.at>
|
||||
- Krishna Glick <krishnaglick@gmail.com>
|
||||
- Carlos Henrique Gandarez <gandarez@gmail.com>
|
||||
6
Default.sublime-commands
Normal file
6
Default.sublime-commands
Normal file
@ -0,0 +1,6 @@
|
||||
[
|
||||
{
|
||||
"caption": "WakaTime: Open Dashboard",
|
||||
"command": "wakatime_dashboard"
|
||||
}
|
||||
]
|
||||
1339
HISTORY.rst
Normal file
1339
HISTORY.rst
Normal file
File diff suppressed because it is too large
Load Diff
@ -1,5 +1,6 @@
|
||||
Copyright (c) 2013 Alan Hamlett https://wakati.me
|
||||
All rights reserved.
|
||||
BSD 3-Clause License
|
||||
|
||||
Copyright (c) 2014 Alan Hamlett.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are met:
|
||||
@ -12,7 +13,7 @@ modification, are permitted provided that the following conditions are met:
|
||||
in the documentation and/or other materials provided
|
||||
with the distribution.
|
||||
|
||||
* Neither the names of Wakatime or Wakati.Me, nor the names of its
|
||||
* Neither the names of WakaTime, nor the names of its
|
||||
contributors may be used to endorse or promote products derived
|
||||
from this software without specific prior written permission.
|
||||
|
||||
@ -6,24 +6,37 @@
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"caption": "WakaTime",
|
||||
"mnemonic": "W",
|
||||
"id": "wakatime-settings",
|
||||
"caption": "Package Settings",
|
||||
"mnemonic": "P",
|
||||
"id": "package-settings",
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/WakaTime/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – Default"
|
||||
},
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/User/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – User"
|
||||
"caption": "WakaTime",
|
||||
"mnemonic": "W",
|
||||
"id": "wakatime-settings",
|
||||
"children":
|
||||
[
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/WakaTime/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – Default"
|
||||
},
|
||||
{
|
||||
"command": "open_file", "args":
|
||||
{
|
||||
"file": "${packages}/User/WakaTime.sublime-settings"
|
||||
},
|
||||
"caption": "Settings – User"
|
||||
},
|
||||
{
|
||||
"command": "wakatime_dashboard",
|
||||
"args": {},
|
||||
"caption": "WakaTime Dashboard"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
59
README.md
59
README.md
@ -1,37 +1,56 @@
|
||||
sublime-wakatime
|
||||
================
|
||||
# sublime-wakatime
|
||||
|
||||
Automatic time tracking for Sublime Text 2 & 3.
|
||||
[](https://wakatime.com/badge/github/wakatime/sublime-wakatime)
|
||||
|
||||
Installation
|
||||
------------
|
||||
[WakaTime][wakatime] is an open source Sublime Text plugin for metrics, insights, and time tracking automatically generated from your programming activity.
|
||||
|
||||
Heads Up! For Sublime Text 2 on Windows & Linux, WakaTime depends on [Python](http://www.python.org/getit/) being installed to work correctly.
|
||||
|
||||
1. Get an api key from: https://wakati.me
|
||||
## Installation
|
||||
|
||||
2. Using [Sublime Package Control](http://wbond.net/sublime_packages/package_control):
|
||||
1. Install [Package Control](https://packagecontrol.io/installation).
|
||||
|
||||
a) Press `ctrl+shift+p`(Windows, Linux) or `cmd+shift+p`(OS X).
|
||||
2. In Sublime, press `ctrl+shift+p`(Windows, Linux) or `cmd+shift+p`(OS X).
|
||||
|
||||
b) Type `install`, then press `enter` with `Package Control: Install Package` selected.
|
||||
3. Type `install`, then press `enter` with `Package Control: Install Package` selected.
|
||||
|
||||
c) Type `wakatime`, then press `enter` with the `WakaTime` plugin selected.
|
||||
4. Type `wakatime`, then press `enter` with the `WakaTime` plugin selected.
|
||||
|
||||
3. You will see a prompt at the bottom asking for your [api key](https://www.wakati.me/#apikey). Enter your api key, then press `enter`.
|
||||
5. Enter your [api key](https://wakatime.com/settings#apikey), then press `enter`.
|
||||
|
||||
4. Use Sublime and your time will automatically be tracked for you.
|
||||
6. Use Sublime and your coding activity will be displayed on your [WakaTime dashboard](https://wakatime.com).
|
||||
|
||||
5. Visit https://wakati.me to see your logged time.
|
||||
|
||||
6. Consider installing [BIND9](https://help.ubuntu.com/community/BIND9ServerHowto#Caching_Server_configuration) to cache your repeated DNS requests: `sudo apt-get install bind9`
|
||||
## Screen Shots
|
||||
|
||||
Screen Shots
|
||||
------------
|
||||
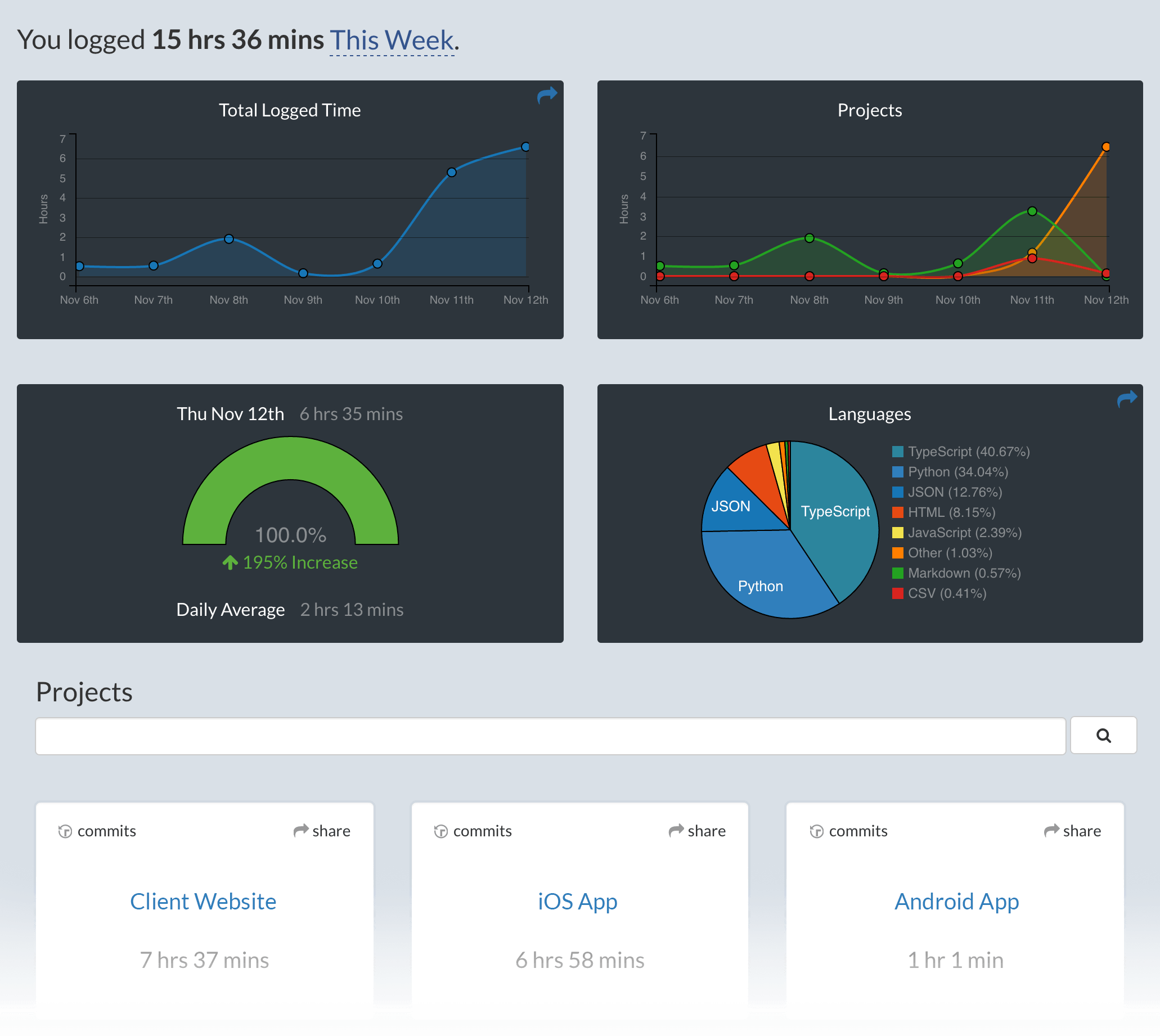
|
||||
|
||||

|
||||
|
||||

|
||||
## Unresponsive Plugin Warning
|
||||
|
||||

|
||||
In Sublime Text 2, if you get a warning message:
|
||||
|
||||
A plugin (WakaTime) may be making Sublime Text unresponsive by taking too long (0.017332s) in its on_modified callback.
|
||||
|
||||
To fix this, go to `Preferences → Settings - User` then add the following setting:
|
||||
|
||||
`"detect_slow_plugins": false`
|
||||
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
First, turn on debug mode in your `WakaTime.sublime-settings` file.
|
||||
|
||||
|
||||
|
||||
Add the line: `"debug": true`
|
||||
|
||||
Then, open your Sublime Console with `View → Show Console` ( CTRL + \` ) to see the plugin executing the wakatime cli process when sending a heartbeat.
|
||||
Also, tail your `$HOME/.wakatime.log` file to debug wakatime cli problems.
|
||||
|
||||
The [How to Debug Plugins][how to debug] guide shows how to check when coding activity was last received from your editor using the [User Agents API][user agents api].
|
||||
For more general troubleshooting info, see the [wakatime-cli Troubleshooting Section][wakatime-cli-help].
|
||||
|
||||
[wakatime]: https://wakatime.com/sublime-text
|
||||
[wakatime-cli-help]: https://github.com/wakatime/wakatime#troubleshooting
|
||||
[how to debug]: https://wakatime.com/faq#debug-plugins
|
||||
[user agents api]: https://wakatime.com/developers#user_agents
|
||||
|
||||
939
WakaTime.py
939
WakaTime.py
File diff suppressed because it is too large
Load Diff
@ -3,10 +3,38 @@
|
||||
// This settings file will be overwritten when upgrading.
|
||||
|
||||
{
|
||||
// Your api key from https://www.wakati.me/#apikey
|
||||
// Your api key from https://wakatime.com/api-key
|
||||
// Set this in your User specific WakaTime.sublime-settings file.
|
||||
"api_key": "",
|
||||
|
||||
|
||||
// Debug mode. Set to true for verbose logging. Defaults to false.
|
||||
"debug": false
|
||||
"debug": false,
|
||||
|
||||
// Proxy with format https://user:pass@host:port or socks5://user:pass@host:port or domain\\user:pass.
|
||||
"proxy": "",
|
||||
|
||||
// Ignore files; Files (including absolute paths) that match one of these
|
||||
// POSIX regular expressions will not be logged.
|
||||
"ignore": ["^/tmp/", "^/etc/", "^/var/(?!www/).*", "COMMIT_EDITMSG$", "PULLREQ_EDITMSG$", "MERGE_MSG$", "TAG_EDITMSG$"],
|
||||
|
||||
// Include files; Files (including absolute paths) that match one of these
|
||||
// POSIX regular expressions will bypass your ignore setting.
|
||||
"include": [".*"],
|
||||
|
||||
// Status bar for surfacing errors and displaying today's coding time. Set
|
||||
// to false to hide. Defaults to true.
|
||||
"status_bar_enabled": true,
|
||||
|
||||
// Show today's coding activity in WakaTime status bar item.
|
||||
// Defaults to true.
|
||||
"status_bar_coding_activity": true,
|
||||
|
||||
// Obfuscate file paths when sending to API. Your dashboard will no longer display coding activity per file.
|
||||
"hidefilenames": false,
|
||||
|
||||
// Python binary location. Uses python from your PATH by default.
|
||||
"python_binary": "",
|
||||
|
||||
// Use standalone compiled Python wakatime-cli (Will not work on ARM Macs)
|
||||
"standalone": false
|
||||
}
|
||||
|
||||
35
packages/wakatime/.gitignore
vendored
35
packages/wakatime/.gitignore
vendored
@ -1,35 +0,0 @@
|
||||
*.py[cod]
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Packages
|
||||
*.egg
|
||||
*.egg-info
|
||||
dist
|
||||
build
|
||||
eggs
|
||||
parts
|
||||
bin
|
||||
var
|
||||
sdist
|
||||
develop-eggs
|
||||
.installed.cfg
|
||||
lib
|
||||
lib64
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
.coverage
|
||||
.tox
|
||||
nosetests.xml
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
|
||||
# Mr Developer
|
||||
.mr.developer.cfg
|
||||
.project
|
||||
.pydevproject
|
||||
@ -1,65 +0,0 @@
|
||||
|
||||
History
|
||||
-------
|
||||
|
||||
|
||||
0.4.5 (2013-09-07)
|
||||
++++++++++++++++++
|
||||
|
||||
- Fixed relative import error by adding packages directory to sys path
|
||||
|
||||
|
||||
0.4.4 (2013-09-06)
|
||||
++++++++++++++++++
|
||||
|
||||
- Using urllib2 again because of intermittent problems sending json with requests library
|
||||
|
||||
|
||||
0.4.3 (2013-09-04)
|
||||
++++++++++++++++++
|
||||
|
||||
- Encoding json as utf-8 before making request
|
||||
|
||||
|
||||
0.4.2 (2013-09-04)
|
||||
++++++++++++++++++
|
||||
|
||||
- Using requests package v1.2.3 from pypi
|
||||
|
||||
|
||||
0.4.1 (2013-08-25)
|
||||
++++++++++++++++++
|
||||
|
||||
- Fix bug causing requests library to omit POST content
|
||||
|
||||
|
||||
0.4.0 (2013-08-15)
|
||||
++++++++++++++++++
|
||||
|
||||
- Sending single branch instead of multiple tags
|
||||
|
||||
|
||||
0.3.1 (2013-08-08)
|
||||
++++++++++++++++++
|
||||
|
||||
- Using requests module instead of urllib2 to verify SSL certs
|
||||
|
||||
|
||||
0.3.0 (2013-08-08)
|
||||
++++++++++++++++++
|
||||
|
||||
- Allow importing directly from Python plugins
|
||||
|
||||
|
||||
0.1.1 (2013-07-07)
|
||||
++++++++++++++++++
|
||||
|
||||
- Refactored
|
||||
- Simplified action events schema
|
||||
|
||||
|
||||
0.0.1 (2013-07-05)
|
||||
++++++++++++++++++
|
||||
|
||||
- Birth
|
||||
|
||||
@ -1,2 +0,0 @@
|
||||
include README.rst LICENSE HISTORY.rst
|
||||
recursive-include wakatime *.py
|
||||
@ -1,12 +0,0 @@
|
||||
WakaTime
|
||||
========
|
||||
|
||||
Automatic time tracking for your text editor. This is the command line
|
||||
event appender for the WakaTime api. You shouldn't need to directly
|
||||
use this outside of a text editor plugin.
|
||||
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
https://www.wakati.me/help/plugins/installing-plugins
|
||||
@ -1,39 +0,0 @@
|
||||
from setuptools import setup
|
||||
|
||||
from wakatime.__init__ import __version__ as VERSION
|
||||
|
||||
|
||||
packages = [
|
||||
'wakatime',
|
||||
]
|
||||
|
||||
setup(
|
||||
name='wakatime',
|
||||
version=VERSION,
|
||||
license='BSD 3 Clause',
|
||||
description=' '.join([
|
||||
'Action event appender for Wakati.Me, a time',
|
||||
'tracking api for text editors.',
|
||||
]),
|
||||
long_description=open('README.rst').read(),
|
||||
author='Alan Hamlett',
|
||||
author_email='alan.hamlett@gmail.com',
|
||||
url='https://github.com/wakatime/wakatime',
|
||||
packages=packages,
|
||||
package_dir={'wakatime': 'wakatime'},
|
||||
include_package_data=True,
|
||||
zip_safe=False,
|
||||
platforms='any',
|
||||
entry_points={
|
||||
'console_scripts': ['wakatime = wakatime.__init__:main'],
|
||||
},
|
||||
classifiers=(
|
||||
'Development Status :: 3 - Alpha',
|
||||
'Environment :: Console',
|
||||
'Intended Audience :: Developers',
|
||||
'License :: OSI Approved :: BSD License',
|
||||
'Natural Language :: English',
|
||||
'Programming Language :: Python',
|
||||
'Topic :: Text Editors',
|
||||
),
|
||||
)
|
||||
@ -1,21 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime-cli
|
||||
~~~~~~~~~~~~
|
||||
|
||||
Action event appender for Wakati.Me, auto time tracking for text editors.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
import os
|
||||
import sys
|
||||
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
||||
import wakatime
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(wakatime.main(sys.argv))
|
||||
@ -1,200 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime
|
||||
~~~~~~~~
|
||||
|
||||
Action event appender for Wakati.Me, auto time tracking for text editors.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
from __future__ import print_function
|
||||
|
||||
__title__ = 'wakatime'
|
||||
__version__ = '0.4.5'
|
||||
__author__ = 'Alan Hamlett'
|
||||
__license__ = 'BSD'
|
||||
__copyright__ = 'Copyright 2013 Alan Hamlett'
|
||||
|
||||
|
||||
import base64
|
||||
import logging
|
||||
import os
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
|
||||
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(os.path.abspath(__file__)), 'packages'))
|
||||
from .log import setup_logging
|
||||
from .project import find_project
|
||||
from .packages import argparse
|
||||
from .packages import simplejson as json
|
||||
try:
|
||||
from urllib2 import HTTPError, Request, urlopen
|
||||
except ImportError:
|
||||
from urllib.error import HTTPError
|
||||
from urllib.request import Request, urlopen
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class FileAction(argparse.Action):
|
||||
|
||||
def __call__(self, parser, namespace, values, option_string=None):
|
||||
values = os.path.realpath(values)
|
||||
setattr(namespace, self.dest, values)
|
||||
|
||||
|
||||
def parseArguments(argv):
|
||||
try:
|
||||
sys.argv
|
||||
except AttributeError:
|
||||
sys.argv = argv
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Wakati.Me event api appender')
|
||||
parser.add_argument('--file', dest='targetFile', metavar='file',
|
||||
action=FileAction, required=True,
|
||||
help='absolute path to file for current action')
|
||||
parser.add_argument('--time', dest='timestamp', metavar='time',
|
||||
type=float,
|
||||
help='optional floating-point unix epoch timestamp; '+
|
||||
'uses current time by default')
|
||||
parser.add_argument('--endtime', dest='endtime',
|
||||
help='optional end timestamp turning this action into '+
|
||||
'a duration; if a non-duration action occurs within a '+
|
||||
'duration, the duration is ignored')
|
||||
parser.add_argument('--write', dest='isWrite',
|
||||
action='store_true',
|
||||
help='note action was triggered from writing to a file')
|
||||
parser.add_argument('--plugin', dest='plugin',
|
||||
help='optional text editor plugin name and version '+
|
||||
'for User-Agent header')
|
||||
parser.add_argument('--key', dest='key',
|
||||
help='your wakati.me api key; uses api_key from '+
|
||||
'~/.wakatime.conf by default')
|
||||
parser.add_argument('--logfile', dest='logfile',
|
||||
help='defaults to ~/.wakatime.log')
|
||||
parser.add_argument('--config', dest='config',
|
||||
help='defaults to ~/.wakatime.conf')
|
||||
parser.add_argument('--verbose', dest='verbose', action='store_true',
|
||||
help='turns on debug messages in log file')
|
||||
parser.add_argument('--version', action='version', version=__version__)
|
||||
args = parser.parse_args(args=argv[1:])
|
||||
if not args.timestamp:
|
||||
args.timestamp = time.time()
|
||||
if not args.key:
|
||||
default_key = get_api_key(args.config)
|
||||
if default_key:
|
||||
args.key = default_key
|
||||
else:
|
||||
parser.error('Missing api key')
|
||||
return args
|
||||
|
||||
|
||||
def get_api_key(configFile):
|
||||
if not configFile:
|
||||
configFile = os.path.join(os.path.expanduser('~'), '.wakatime.conf')
|
||||
api_key = None
|
||||
try:
|
||||
cf = open(configFile)
|
||||
for line in cf:
|
||||
line = line.split('=', 1)
|
||||
if line[0] == 'api_key':
|
||||
api_key = line[1].strip()
|
||||
cf.close()
|
||||
except IOError:
|
||||
print('Error: Could not read from config file.')
|
||||
return api_key
|
||||
|
||||
|
||||
def get_user_agent(plugin):
|
||||
ver = sys.version_info
|
||||
python_version = '%d.%d.%d.%s.%d' % (ver[0], ver[1], ver[2], ver[3], ver[4])
|
||||
user_agent = 'wakatime/%s (%s) Python%s' % (__version__,
|
||||
platform.platform(), python_version)
|
||||
if plugin:
|
||||
user_agent = user_agent+' '+plugin
|
||||
return user_agent
|
||||
|
||||
|
||||
def send_action(project=None, branch=None, key=None, targetFile=None,
|
||||
timestamp=None, endtime=None, isWrite=None, plugin=None, **kwargs):
|
||||
url = 'https://www.wakati.me/api/v1/actions'
|
||||
log.debug('Sending action to api at %s' % url)
|
||||
data = {
|
||||
'time': timestamp,
|
||||
'file': targetFile,
|
||||
}
|
||||
if endtime:
|
||||
data['endtime'] = endtime
|
||||
if isWrite:
|
||||
data['is_write'] = isWrite
|
||||
if project:
|
||||
data['project'] = project
|
||||
if branch:
|
||||
data['branch'] = branch
|
||||
log.debug(data)
|
||||
|
||||
# setup api request
|
||||
request = Request(url=url, data=str.encode(json.dumps(data)))
|
||||
request.add_header('User-Agent', get_user_agent(plugin))
|
||||
request.add_header('Content-Type', 'application/json')
|
||||
auth = 'Basic %s' % bytes.decode(base64.b64encode(str.encode(key)))
|
||||
request.add_header('Authorization', auth)
|
||||
|
||||
# log time to api
|
||||
response = None
|
||||
try:
|
||||
response = urlopen(request)
|
||||
except HTTPError as exc:
|
||||
exception_data = {
|
||||
'response_code': exc.getcode(),
|
||||
sys.exc_info()[0].__name__: str(sys.exc_info()[1]),
|
||||
}
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
exception_data['traceback'] = traceback.format_exc()
|
||||
log.error(exception_data)
|
||||
except:
|
||||
exception_data = {
|
||||
sys.exc_info()[0].__name__: str(sys.exc_info()[1]),
|
||||
}
|
||||
if log.isEnabledFor(logging.DEBUG):
|
||||
exception_data['traceback'] = traceback.format_exc()
|
||||
log.error(exception_data)
|
||||
else:
|
||||
if response.getcode() == 201:
|
||||
log.debug({
|
||||
'response_code': response.getcode(),
|
||||
})
|
||||
return True
|
||||
log.error({
|
||||
'response_code': response.getcode(),
|
||||
'response_content': response.read(),
|
||||
})
|
||||
return False
|
||||
|
||||
|
||||
def main(argv=None):
|
||||
if not argv:
|
||||
argv = sys.argv
|
||||
args = parseArguments(argv)
|
||||
setup_logging(args, __version__)
|
||||
if os.path.isfile(args.targetFile):
|
||||
branch = None
|
||||
name = None
|
||||
project = find_project(args.targetFile)
|
||||
if project:
|
||||
branch = project.branch()
|
||||
name = project.name()
|
||||
if send_action(project=name, branch=branch, **vars(args)):
|
||||
return 0
|
||||
return 102
|
||||
else:
|
||||
log.debug('File does not exist; ignoring this action.')
|
||||
return 101
|
||||
|
||||
@ -1,92 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.log
|
||||
~~~~~~~~~~~~
|
||||
|
||||
Provides the configured logger for writing JSON to the log file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
|
||||
from .packages import simplejson as json
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from .packages.ordereddict import OrderedDict
|
||||
|
||||
|
||||
class CustomEncoder(json.JSONEncoder):
|
||||
|
||||
def default(self, obj):
|
||||
if isinstance(obj, bytes):
|
||||
obj = bytes.decode(obj)
|
||||
return json.dumps(obj)
|
||||
return super(CustomEncoder, self).default(obj)
|
||||
|
||||
|
||||
class JsonFormatter(logging.Formatter):
|
||||
|
||||
def setup(self, timestamp, endtime, isWrite, targetFile, version, plugin):
|
||||
self.timestamp = timestamp
|
||||
self.endtime = endtime
|
||||
self.isWrite = isWrite
|
||||
self.targetFile = targetFile
|
||||
self.version = version
|
||||
self.plugin = plugin
|
||||
|
||||
def format(self, record):
|
||||
data = OrderedDict([
|
||||
('now', self.formatTime(record, self.datefmt)),
|
||||
('version', self.version),
|
||||
('plugin', self.plugin),
|
||||
('time', self.timestamp),
|
||||
('endtime', self.endtime),
|
||||
('isWrite', self.isWrite),
|
||||
('file', self.targetFile),
|
||||
('level', record.levelname),
|
||||
('message', record.msg),
|
||||
])
|
||||
if not self.endtime:
|
||||
del data['endtime']
|
||||
if not self.plugin:
|
||||
del data['plugin']
|
||||
if not self.isWrite:
|
||||
del data['isWrite']
|
||||
return CustomEncoder().encode(data)
|
||||
|
||||
def formatException(self, exc_info):
|
||||
return exec_info[2].format_exc()
|
||||
|
||||
|
||||
def set_log_level(logger, args):
|
||||
level = logging.WARN
|
||||
if args.verbose:
|
||||
level = logging.DEBUG
|
||||
logger.setLevel(level)
|
||||
|
||||
|
||||
def setup_logging(args, version):
|
||||
logger = logging.getLogger()
|
||||
set_log_level(logger, args)
|
||||
if len(logger.handlers) > 0:
|
||||
return logger
|
||||
logfile = args.logfile
|
||||
if not logfile:
|
||||
logfile = '~/.wakatime.log'
|
||||
handler = logging.FileHandler(os.path.expanduser(logfile))
|
||||
formatter = JsonFormatter(datefmt='%a %b %d %H:%M:%S %Z %Y')
|
||||
formatter.setup(
|
||||
timestamp=args.timestamp,
|
||||
endtime=args.endtime,
|
||||
isWrite=args.isWrite,
|
||||
targetFile=args.targetFile,
|
||||
version=version,
|
||||
plugin=args.plugin,
|
||||
)
|
||||
handler.setFormatter(formatter)
|
||||
logger.addHandler(handler)
|
||||
return logger
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,127 +0,0 @@
|
||||
# Copyright (c) 2009 Raymond Hettinger
|
||||
#
|
||||
# Permission is hereby granted, free of charge, to any person
|
||||
# obtaining a copy of this software and associated documentation files
|
||||
# (the "Software"), to deal in the Software without restriction,
|
||||
# including without limitation the rights to use, copy, modify, merge,
|
||||
# publish, distribute, sublicense, and/or sell copies of the Software,
|
||||
# and to permit persons to whom the Software is furnished to do so,
|
||||
# subject to the following conditions:
|
||||
#
|
||||
# The above copyright notice and this permission notice shall be
|
||||
# included in all copies or substantial portions of the Software.
|
||||
#
|
||||
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
||||
# EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES
|
||||
# OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
|
||||
# NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
|
||||
# HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
|
||||
# WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
|
||||
# OTHER DEALINGS IN THE SOFTWARE.
|
||||
|
||||
from UserDict import DictMixin
|
||||
|
||||
class OrderedDict(dict, DictMixin):
|
||||
|
||||
def __init__(self, *args, **kwds):
|
||||
if len(args) > 1:
|
||||
raise TypeError('expected at most 1 arguments, got %d' % len(args))
|
||||
try:
|
||||
self.__end
|
||||
except AttributeError:
|
||||
self.clear()
|
||||
self.update(*args, **kwds)
|
||||
|
||||
def clear(self):
|
||||
self.__end = end = []
|
||||
end += [None, end, end] # sentinel node for doubly linked list
|
||||
self.__map = {} # key --> [key, prev, next]
|
||||
dict.clear(self)
|
||||
|
||||
def __setitem__(self, key, value):
|
||||
if key not in self:
|
||||
end = self.__end
|
||||
curr = end[1]
|
||||
curr[2] = end[1] = self.__map[key] = [key, curr, end]
|
||||
dict.__setitem__(self, key, value)
|
||||
|
||||
def __delitem__(self, key):
|
||||
dict.__delitem__(self, key)
|
||||
key, prev, next = self.__map.pop(key)
|
||||
prev[2] = next
|
||||
next[1] = prev
|
||||
|
||||
def __iter__(self):
|
||||
end = self.__end
|
||||
curr = end[2]
|
||||
while curr is not end:
|
||||
yield curr[0]
|
||||
curr = curr[2]
|
||||
|
||||
def __reversed__(self):
|
||||
end = self.__end
|
||||
curr = end[1]
|
||||
while curr is not end:
|
||||
yield curr[0]
|
||||
curr = curr[1]
|
||||
|
||||
def popitem(self, last=True):
|
||||
if not self:
|
||||
raise KeyError('dictionary is empty')
|
||||
if last:
|
||||
key = reversed(self).next()
|
||||
else:
|
||||
key = iter(self).next()
|
||||
value = self.pop(key)
|
||||
return key, value
|
||||
|
||||
def __reduce__(self):
|
||||
items = [[k, self[k]] for k in self]
|
||||
tmp = self.__map, self.__end
|
||||
del self.__map, self.__end
|
||||
inst_dict = vars(self).copy()
|
||||
self.__map, self.__end = tmp
|
||||
if inst_dict:
|
||||
return (self.__class__, (items,), inst_dict)
|
||||
return self.__class__, (items,)
|
||||
|
||||
def keys(self):
|
||||
return list(self)
|
||||
|
||||
setdefault = DictMixin.setdefault
|
||||
update = DictMixin.update
|
||||
pop = DictMixin.pop
|
||||
values = DictMixin.values
|
||||
items = DictMixin.items
|
||||
iterkeys = DictMixin.iterkeys
|
||||
itervalues = DictMixin.itervalues
|
||||
iteritems = DictMixin.iteritems
|
||||
|
||||
def __repr__(self):
|
||||
if not self:
|
||||
return '%s()' % (self.__class__.__name__,)
|
||||
return '%s(%r)' % (self.__class__.__name__, self.items())
|
||||
|
||||
def copy(self):
|
||||
return self.__class__(self)
|
||||
|
||||
@classmethod
|
||||
def fromkeys(cls, iterable, value=None):
|
||||
d = cls()
|
||||
for key in iterable:
|
||||
d[key] = value
|
||||
return d
|
||||
|
||||
def __eq__(self, other):
|
||||
if isinstance(other, OrderedDict):
|
||||
if len(self) != len(other):
|
||||
return False
|
||||
for p, q in zip(self.items(), other.items()):
|
||||
if p != q:
|
||||
return False
|
||||
return True
|
||||
return dict.__eq__(self, other)
|
||||
|
||||
def __ne__(self, other):
|
||||
return not self == other
|
||||
@ -1,547 +0,0 @@
|
||||
r"""JSON (JavaScript Object Notation) <http://json.org> is a subset of
|
||||
JavaScript syntax (ECMA-262 3rd edition) used as a lightweight data
|
||||
interchange format.
|
||||
|
||||
:mod:`simplejson` exposes an API familiar to users of the standard library
|
||||
:mod:`marshal` and :mod:`pickle` modules. It is the externally maintained
|
||||
version of the :mod:`json` library contained in Python 2.6, but maintains
|
||||
compatibility with Python 2.4 and Python 2.5 and (currently) has
|
||||
significant performance advantages, even without using the optional C
|
||||
extension for speedups.
|
||||
|
||||
Encoding basic Python object hierarchies::
|
||||
|
||||
>>> import simplejson as json
|
||||
>>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
|
||||
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
|
||||
>>> print(json.dumps("\"foo\bar"))
|
||||
"\"foo\bar"
|
||||
>>> print(json.dumps(u'\u1234'))
|
||||
"\u1234"
|
||||
>>> print(json.dumps('\\'))
|
||||
"\\"
|
||||
>>> print(json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True))
|
||||
{"a": 0, "b": 0, "c": 0}
|
||||
>>> from simplejson.compat import StringIO
|
||||
>>> io = StringIO()
|
||||
>>> json.dump(['streaming API'], io)
|
||||
>>> io.getvalue()
|
||||
'["streaming API"]'
|
||||
|
||||
Compact encoding::
|
||||
|
||||
>>> import simplejson as json
|
||||
>>> obj = [1,2,3,{'4': 5, '6': 7}]
|
||||
>>> json.dumps(obj, separators=(',',':'), sort_keys=True)
|
||||
'[1,2,3,{"4":5,"6":7}]'
|
||||
|
||||
Pretty printing::
|
||||
|
||||
>>> import simplejson as json
|
||||
>>> print(json.dumps({'4': 5, '6': 7}, sort_keys=True, indent=' '))
|
||||
{
|
||||
"4": 5,
|
||||
"6": 7
|
||||
}
|
||||
|
||||
Decoding JSON::
|
||||
|
||||
>>> import simplejson as json
|
||||
>>> obj = [u'foo', {u'bar': [u'baz', None, 1.0, 2]}]
|
||||
>>> json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]') == obj
|
||||
True
|
||||
>>> json.loads('"\\"foo\\bar"') == u'"foo\x08ar'
|
||||
True
|
||||
>>> from simplejson.compat import StringIO
|
||||
>>> io = StringIO('["streaming API"]')
|
||||
>>> json.load(io)[0] == 'streaming API'
|
||||
True
|
||||
|
||||
Specializing JSON object decoding::
|
||||
|
||||
>>> import simplejson as json
|
||||
>>> def as_complex(dct):
|
||||
... if '__complex__' in dct:
|
||||
... return complex(dct['real'], dct['imag'])
|
||||
... return dct
|
||||
...
|
||||
>>> json.loads('{"__complex__": true, "real": 1, "imag": 2}',
|
||||
... object_hook=as_complex)
|
||||
(1+2j)
|
||||
>>> from decimal import Decimal
|
||||
>>> json.loads('1.1', parse_float=Decimal) == Decimal('1.1')
|
||||
True
|
||||
|
||||
Specializing JSON object encoding::
|
||||
|
||||
>>> import simplejson as json
|
||||
>>> def encode_complex(obj):
|
||||
... if isinstance(obj, complex):
|
||||
... return [obj.real, obj.imag]
|
||||
... raise TypeError(repr(o) + " is not JSON serializable")
|
||||
...
|
||||
>>> json.dumps(2 + 1j, default=encode_complex)
|
||||
'[2.0, 1.0]'
|
||||
>>> json.JSONEncoder(default=encode_complex).encode(2 + 1j)
|
||||
'[2.0, 1.0]'
|
||||
>>> ''.join(json.JSONEncoder(default=encode_complex).iterencode(2 + 1j))
|
||||
'[2.0, 1.0]'
|
||||
|
||||
|
||||
Using simplejson.tool from the shell to validate and pretty-print::
|
||||
|
||||
$ echo '{"json":"obj"}' | python -m simplejson.tool
|
||||
{
|
||||
"json": "obj"
|
||||
}
|
||||
$ echo '{ 1.2:3.4}' | python -m simplejson.tool
|
||||
Expecting property name: line 1 column 3 (char 2)
|
||||
"""
|
||||
from __future__ import absolute_import
|
||||
__version__ = '3.3.0'
|
||||
__all__ = [
|
||||
'dump', 'dumps', 'load', 'loads',
|
||||
'JSONDecoder', 'JSONDecodeError', 'JSONEncoder',
|
||||
'OrderedDict', 'simple_first',
|
||||
]
|
||||
|
||||
__author__ = 'Bob Ippolito <bob@redivi.com>'
|
||||
|
||||
from decimal import Decimal
|
||||
|
||||
from .scanner import JSONDecodeError
|
||||
from .decoder import JSONDecoder
|
||||
from .encoder import JSONEncoder, JSONEncoderForHTML
|
||||
def _import_OrderedDict():
|
||||
import collections
|
||||
try:
|
||||
return collections.OrderedDict
|
||||
except AttributeError:
|
||||
from . import ordered_dict
|
||||
return ordered_dict.OrderedDict
|
||||
OrderedDict = _import_OrderedDict()
|
||||
|
||||
def _import_c_make_encoder():
|
||||
try:
|
||||
from ._speedups import make_encoder
|
||||
return make_encoder
|
||||
except ImportError:
|
||||
return None
|
||||
|
||||
_default_encoder = JSONEncoder(
|
||||
skipkeys=False,
|
||||
ensure_ascii=True,
|
||||
check_circular=True,
|
||||
allow_nan=True,
|
||||
indent=None,
|
||||
separators=None,
|
||||
encoding='utf-8',
|
||||
default=None,
|
||||
use_decimal=True,
|
||||
namedtuple_as_object=True,
|
||||
tuple_as_array=True,
|
||||
bigint_as_string=False,
|
||||
item_sort_key=None,
|
||||
for_json=False,
|
||||
ignore_nan=False,
|
||||
)
|
||||
|
||||
def dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
allow_nan=True, cls=None, indent=None, separators=None,
|
||||
encoding='utf-8', default=None, use_decimal=True,
|
||||
namedtuple_as_object=True, tuple_as_array=True,
|
||||
bigint_as_string=False, sort_keys=False, item_sort_key=None,
|
||||
for_json=False, ignore_nan=False, **kw):
|
||||
"""Serialize ``obj`` as a JSON formatted stream to ``fp`` (a
|
||||
``.write()``-supporting file-like object).
|
||||
|
||||
If *skipkeys* is true then ``dict`` keys that are not basic types
|
||||
(``str``, ``unicode``, ``int``, ``long``, ``float``, ``bool``, ``None``)
|
||||
will be skipped instead of raising a ``TypeError``.
|
||||
|
||||
If *ensure_ascii* is false, then the some chunks written to ``fp``
|
||||
may be ``unicode`` instances, subject to normal Python ``str`` to
|
||||
``unicode`` coercion rules. Unless ``fp.write()`` explicitly
|
||||
understands ``unicode`` (as in ``codecs.getwriter()``) this is likely
|
||||
to cause an error.
|
||||
|
||||
If *check_circular* is false, then the circular reference check
|
||||
for container types will be skipped and a circular reference will
|
||||
result in an ``OverflowError`` (or worse).
|
||||
|
||||
If *allow_nan* is false, then it will be a ``ValueError`` to
|
||||
serialize out of range ``float`` values (``nan``, ``inf``, ``-inf``)
|
||||
in strict compliance of the original JSON specification, instead of using
|
||||
the JavaScript equivalents (``NaN``, ``Infinity``, ``-Infinity``). See
|
||||
*ignore_nan* for ECMA-262 compliant behavior.
|
||||
|
||||
If *indent* is a string, then JSON array elements and object members
|
||||
will be pretty-printed with a newline followed by that string repeated
|
||||
for each level of nesting. ``None`` (the default) selects the most compact
|
||||
representation without any newlines. For backwards compatibility with
|
||||
versions of simplejson earlier than 2.1.0, an integer is also accepted
|
||||
and is converted to a string with that many spaces.
|
||||
|
||||
If specified, *separators* should be an
|
||||
``(item_separator, key_separator)`` tuple. The default is ``(', ', ': ')``
|
||||
if *indent* is ``None`` and ``(',', ': ')`` otherwise. To get the most
|
||||
compact JSON representation, you should specify ``(',', ':')`` to eliminate
|
||||
whitespace.
|
||||
|
||||
*encoding* is the character encoding for str instances, default is UTF-8.
|
||||
|
||||
*default(obj)* is a function that should return a serializable version
|
||||
of obj or raise ``TypeError``. The default simply raises ``TypeError``.
|
||||
|
||||
If *use_decimal* is true (default: ``True``) then decimal.Decimal
|
||||
will be natively serialized to JSON with full precision.
|
||||
|
||||
If *namedtuple_as_object* is true (default: ``True``),
|
||||
:class:`tuple` subclasses with ``_asdict()`` methods will be encoded
|
||||
as JSON objects.
|
||||
|
||||
If *tuple_as_array* is true (default: ``True``),
|
||||
:class:`tuple` (and subclasses) will be encoded as JSON arrays.
|
||||
|
||||
If *bigint_as_string* is true (default: ``False``), ints 2**53 and higher
|
||||
or lower than -2**53 will be encoded as strings. This is to avoid the
|
||||
rounding that happens in Javascript otherwise. Note that this is still a
|
||||
lossy operation that will not round-trip correctly and should be used
|
||||
sparingly.
|
||||
|
||||
If specified, *item_sort_key* is a callable used to sort the items in
|
||||
each dictionary. This is useful if you want to sort items other than
|
||||
in alphabetical order by key. This option takes precedence over
|
||||
*sort_keys*.
|
||||
|
||||
If *sort_keys* is true (default: ``False``), the output of dictionaries
|
||||
will be sorted by item.
|
||||
|
||||
If *for_json* is true (default: ``False``), objects with a ``for_json()``
|
||||
method will use the return value of that method for encoding as JSON
|
||||
instead of the object.
|
||||
|
||||
If *ignore_nan* is true (default: ``False``), then out of range
|
||||
:class:`float` values (``nan``, ``inf``, ``-inf``) will be serialized as
|
||||
``null`` in compliance with the ECMA-262 specification. If true, this will
|
||||
override *allow_nan*.
|
||||
|
||||
To use a custom ``JSONEncoder`` subclass (e.g. one that overrides the
|
||||
``.default()`` method to serialize additional types), specify it with
|
||||
the ``cls`` kwarg. NOTE: You should use *default* or *for_json* instead
|
||||
of subclassing whenever possible.
|
||||
|
||||
"""
|
||||
# cached encoder
|
||||
if (not skipkeys and ensure_ascii and
|
||||
check_circular and allow_nan and
|
||||
cls is None and indent is None and separators is None and
|
||||
encoding == 'utf-8' and default is None and use_decimal
|
||||
and namedtuple_as_object and tuple_as_array
|
||||
and not bigint_as_string and not item_sort_key
|
||||
and not for_json and not ignore_nan and not kw):
|
||||
iterable = _default_encoder.iterencode(obj)
|
||||
else:
|
||||
if cls is None:
|
||||
cls = JSONEncoder
|
||||
iterable = cls(skipkeys=skipkeys, ensure_ascii=ensure_ascii,
|
||||
check_circular=check_circular, allow_nan=allow_nan, indent=indent,
|
||||
separators=separators, encoding=encoding,
|
||||
default=default, use_decimal=use_decimal,
|
||||
namedtuple_as_object=namedtuple_as_object,
|
||||
tuple_as_array=tuple_as_array,
|
||||
bigint_as_string=bigint_as_string,
|
||||
sort_keys=sort_keys,
|
||||
item_sort_key=item_sort_key,
|
||||
for_json=for_json,
|
||||
ignore_nan=ignore_nan,
|
||||
**kw).iterencode(obj)
|
||||
# could accelerate with writelines in some versions of Python, at
|
||||
# a debuggability cost
|
||||
for chunk in iterable:
|
||||
fp.write(chunk)
|
||||
|
||||
|
||||
def dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
|
||||
allow_nan=True, cls=None, indent=None, separators=None,
|
||||
encoding='utf-8', default=None, use_decimal=True,
|
||||
namedtuple_as_object=True, tuple_as_array=True,
|
||||
bigint_as_string=False, sort_keys=False, item_sort_key=None,
|
||||
for_json=False, ignore_nan=False, **kw):
|
||||
"""Serialize ``obj`` to a JSON formatted ``str``.
|
||||
|
||||
If ``skipkeys`` is false then ``dict`` keys that are not basic types
|
||||
(``str``, ``unicode``, ``int``, ``long``, ``float``, ``bool``, ``None``)
|
||||
will be skipped instead of raising a ``TypeError``.
|
||||
|
||||
If ``ensure_ascii`` is false, then the return value will be a
|
||||
``unicode`` instance subject to normal Python ``str`` to ``unicode``
|
||||
coercion rules instead of being escaped to an ASCII ``str``.
|
||||
|
||||
If ``check_circular`` is false, then the circular reference check
|
||||
for container types will be skipped and a circular reference will
|
||||
result in an ``OverflowError`` (or worse).
|
||||
|
||||
If ``allow_nan`` is false, then it will be a ``ValueError`` to
|
||||
serialize out of range ``float`` values (``nan``, ``inf``, ``-inf``) in
|
||||
strict compliance of the JSON specification, instead of using the
|
||||
JavaScript equivalents (``NaN``, ``Infinity``, ``-Infinity``).
|
||||
|
||||
If ``indent`` is a string, then JSON array elements and object members
|
||||
will be pretty-printed with a newline followed by that string repeated
|
||||
for each level of nesting. ``None`` (the default) selects the most compact
|
||||
representation without any newlines. For backwards compatibility with
|
||||
versions of simplejson earlier than 2.1.0, an integer is also accepted
|
||||
and is converted to a string with that many spaces.
|
||||
|
||||
If specified, ``separators`` should be an
|
||||
``(item_separator, key_separator)`` tuple. The default is ``(', ', ': ')``
|
||||
if *indent* is ``None`` and ``(',', ': ')`` otherwise. To get the most
|
||||
compact JSON representation, you should specify ``(',', ':')`` to eliminate
|
||||
whitespace.
|
||||
|
||||
``encoding`` is the character encoding for str instances, default is UTF-8.
|
||||
|
||||
``default(obj)`` is a function that should return a serializable version
|
||||
of obj or raise TypeError. The default simply raises TypeError.
|
||||
|
||||
If *use_decimal* is true (default: ``True``) then decimal.Decimal
|
||||
will be natively serialized to JSON with full precision.
|
||||
|
||||
If *namedtuple_as_object* is true (default: ``True``),
|
||||
:class:`tuple` subclasses with ``_asdict()`` methods will be encoded
|
||||
as JSON objects.
|
||||
|
||||
If *tuple_as_array* is true (default: ``True``),
|
||||
:class:`tuple` (and subclasses) will be encoded as JSON arrays.
|
||||
|
||||
If *bigint_as_string* is true (not the default), ints 2**53 and higher
|
||||
or lower than -2**53 will be encoded as strings. This is to avoid the
|
||||
rounding that happens in Javascript otherwise.
|
||||
|
||||
If specified, *item_sort_key* is a callable used to sort the items in
|
||||
each dictionary. This is useful if you want to sort items other than
|
||||
in alphabetical order by key. This option takes precendence over
|
||||
*sort_keys*.
|
||||
|
||||
If *sort_keys* is true (default: ``False``), the output of dictionaries
|
||||
will be sorted by item.
|
||||
|
||||
If *for_json* is true (default: ``False``), objects with a ``for_json()``
|
||||
method will use the return value of that method for encoding as JSON
|
||||
instead of the object.
|
||||
|
||||
If *ignore_nan* is true (default: ``False``), then out of range
|
||||
:class:`float` values (``nan``, ``inf``, ``-inf``) will be serialized as
|
||||
``null`` in compliance with the ECMA-262 specification. If true, this will
|
||||
override *allow_nan*.
|
||||
|
||||
To use a custom ``JSONEncoder`` subclass (e.g. one that overrides the
|
||||
``.default()`` method to serialize additional types), specify it with
|
||||
the ``cls`` kwarg. NOTE: You should use *default* instead of subclassing
|
||||
whenever possible.
|
||||
|
||||
"""
|
||||
# cached encoder
|
||||
if (not skipkeys and ensure_ascii and
|
||||
check_circular and allow_nan and
|
||||
cls is None and indent is None and separators is None and
|
||||
encoding == 'utf-8' and default is None and use_decimal
|
||||
and namedtuple_as_object and tuple_as_array
|
||||
and not bigint_as_string and not sort_keys
|
||||
and not item_sort_key and not for_json
|
||||
and not ignore_nan and not kw):
|
||||
return _default_encoder.encode(obj)
|
||||
if cls is None:
|
||||
cls = JSONEncoder
|
||||
return cls(
|
||||
skipkeys=skipkeys, ensure_ascii=ensure_ascii,
|
||||
check_circular=check_circular, allow_nan=allow_nan, indent=indent,
|
||||
separators=separators, encoding=encoding, default=default,
|
||||
use_decimal=use_decimal,
|
||||
namedtuple_as_object=namedtuple_as_object,
|
||||
tuple_as_array=tuple_as_array,
|
||||
bigint_as_string=bigint_as_string,
|
||||
sort_keys=sort_keys,
|
||||
item_sort_key=item_sort_key,
|
||||
for_json=for_json,
|
||||
ignore_nan=ignore_nan,
|
||||
**kw).encode(obj)
|
||||
|
||||
|
||||
_default_decoder = JSONDecoder(encoding=None, object_hook=None,
|
||||
object_pairs_hook=None)
|
||||
|
||||
|
||||
def load(fp, encoding=None, cls=None, object_hook=None, parse_float=None,
|
||||
parse_int=None, parse_constant=None, object_pairs_hook=None,
|
||||
use_decimal=False, namedtuple_as_object=True, tuple_as_array=True,
|
||||
**kw):
|
||||
"""Deserialize ``fp`` (a ``.read()``-supporting file-like object containing
|
||||
a JSON document) to a Python object.
|
||||
|
||||
*encoding* determines the encoding used to interpret any
|
||||
:class:`str` objects decoded by this instance (``'utf-8'`` by
|
||||
default). It has no effect when decoding :class:`unicode` objects.
|
||||
|
||||
Note that currently only encodings that are a superset of ASCII work,
|
||||
strings of other encodings should be passed in as :class:`unicode`.
|
||||
|
||||
*object_hook*, if specified, will be called with the result of every
|
||||
JSON object decoded and its return value will be used in place of the
|
||||
given :class:`dict`. This can be used to provide custom
|
||||
deserializations (e.g. to support JSON-RPC class hinting).
|
||||
|
||||
*object_pairs_hook* is an optional function that will be called with
|
||||
the result of any object literal decode with an ordered list of pairs.
|
||||
The return value of *object_pairs_hook* will be used instead of the
|
||||
:class:`dict`. This feature can be used to implement custom decoders
|
||||
that rely on the order that the key and value pairs are decoded (for
|
||||
example, :func:`collections.OrderedDict` will remember the order of
|
||||
insertion). If *object_hook* is also defined, the *object_pairs_hook*
|
||||
takes priority.
|
||||
|
||||
*parse_float*, if specified, will be called with the string of every
|
||||
JSON float to be decoded. By default, this is equivalent to
|
||||
``float(num_str)``. This can be used to use another datatype or parser
|
||||
for JSON floats (e.g. :class:`decimal.Decimal`).
|
||||
|
||||
*parse_int*, if specified, will be called with the string of every
|
||||
JSON int to be decoded. By default, this is equivalent to
|
||||
``int(num_str)``. This can be used to use another datatype or parser
|
||||
for JSON integers (e.g. :class:`float`).
|
||||
|
||||
*parse_constant*, if specified, will be called with one of the
|
||||
following strings: ``'-Infinity'``, ``'Infinity'``, ``'NaN'``. This
|
||||
can be used to raise an exception if invalid JSON numbers are
|
||||
encountered.
|
||||
|
||||
If *use_decimal* is true (default: ``False``) then it implies
|
||||
parse_float=decimal.Decimal for parity with ``dump``.
|
||||
|
||||
To use a custom ``JSONDecoder`` subclass, specify it with the ``cls``
|
||||
kwarg. NOTE: You should use *object_hook* or *object_pairs_hook* instead
|
||||
of subclassing whenever possible.
|
||||
|
||||
"""
|
||||
return loads(fp.read(),
|
||||
encoding=encoding, cls=cls, object_hook=object_hook,
|
||||
parse_float=parse_float, parse_int=parse_int,
|
||||
parse_constant=parse_constant, object_pairs_hook=object_pairs_hook,
|
||||
use_decimal=use_decimal, **kw)
|
||||
|
||||
|
||||
def loads(s, encoding=None, cls=None, object_hook=None, parse_float=None,
|
||||
parse_int=None, parse_constant=None, object_pairs_hook=None,
|
||||
use_decimal=False, **kw):
|
||||
"""Deserialize ``s`` (a ``str`` or ``unicode`` instance containing a JSON
|
||||
document) to a Python object.
|
||||
|
||||
*encoding* determines the encoding used to interpret any
|
||||
:class:`str` objects decoded by this instance (``'utf-8'`` by
|
||||
default). It has no effect when decoding :class:`unicode` objects.
|
||||
|
||||
Note that currently only encodings that are a superset of ASCII work,
|
||||
strings of other encodings should be passed in as :class:`unicode`.
|
||||
|
||||
*object_hook*, if specified, will be called with the result of every
|
||||
JSON object decoded and its return value will be used in place of the
|
||||
given :class:`dict`. This can be used to provide custom
|
||||
deserializations (e.g. to support JSON-RPC class hinting).
|
||||
|
||||
*object_pairs_hook* is an optional function that will be called with
|
||||
the result of any object literal decode with an ordered list of pairs.
|
||||
The return value of *object_pairs_hook* will be used instead of the
|
||||
:class:`dict`. This feature can be used to implement custom decoders
|
||||
that rely on the order that the key and value pairs are decoded (for
|
||||
example, :func:`collections.OrderedDict` will remember the order of
|
||||
insertion). If *object_hook* is also defined, the *object_pairs_hook*
|
||||
takes priority.
|
||||
|
||||
*parse_float*, if specified, will be called with the string of every
|
||||
JSON float to be decoded. By default, this is equivalent to
|
||||
``float(num_str)``. This can be used to use another datatype or parser
|
||||
for JSON floats (e.g. :class:`decimal.Decimal`).
|
||||
|
||||
*parse_int*, if specified, will be called with the string of every
|
||||
JSON int to be decoded. By default, this is equivalent to
|
||||
``int(num_str)``. This can be used to use another datatype or parser
|
||||
for JSON integers (e.g. :class:`float`).
|
||||
|
||||
*parse_constant*, if specified, will be called with one of the
|
||||
following strings: ``'-Infinity'``, ``'Infinity'``, ``'NaN'``. This
|
||||
can be used to raise an exception if invalid JSON numbers are
|
||||
encountered.
|
||||
|
||||
If *use_decimal* is true (default: ``False``) then it implies
|
||||
parse_float=decimal.Decimal for parity with ``dump``.
|
||||
|
||||
To use a custom ``JSONDecoder`` subclass, specify it with the ``cls``
|
||||
kwarg. NOTE: You should use *object_hook* or *object_pairs_hook* instead
|
||||
of subclassing whenever possible.
|
||||
|
||||
"""
|
||||
if (cls is None and encoding is None and object_hook is None and
|
||||
parse_int is None and parse_float is None and
|
||||
parse_constant is None and object_pairs_hook is None
|
||||
and not use_decimal and not kw):
|
||||
return _default_decoder.decode(s)
|
||||
if cls is None:
|
||||
cls = JSONDecoder
|
||||
if object_hook is not None:
|
||||
kw['object_hook'] = object_hook
|
||||
if object_pairs_hook is not None:
|
||||
kw['object_pairs_hook'] = object_pairs_hook
|
||||
if parse_float is not None:
|
||||
kw['parse_float'] = parse_float
|
||||
if parse_int is not None:
|
||||
kw['parse_int'] = parse_int
|
||||
if parse_constant is not None:
|
||||
kw['parse_constant'] = parse_constant
|
||||
if use_decimal:
|
||||
if parse_float is not None:
|
||||
raise TypeError("use_decimal=True implies parse_float=Decimal")
|
||||
kw['parse_float'] = Decimal
|
||||
return cls(encoding=encoding, **kw).decode(s)
|
||||
|
||||
|
||||
def _toggle_speedups(enabled):
|
||||
from . import decoder as dec
|
||||
from . import encoder as enc
|
||||
from . import scanner as scan
|
||||
c_make_encoder = _import_c_make_encoder()
|
||||
if enabled:
|
||||
dec.scanstring = dec.c_scanstring or dec.py_scanstring
|
||||
enc.c_make_encoder = c_make_encoder
|
||||
enc.encode_basestring_ascii = (enc.c_encode_basestring_ascii or
|
||||
enc.py_encode_basestring_ascii)
|
||||
scan.make_scanner = scan.c_make_scanner or scan.py_make_scanner
|
||||
else:
|
||||
dec.scanstring = dec.py_scanstring
|
||||
enc.c_make_encoder = None
|
||||
enc.encode_basestring_ascii = enc.py_encode_basestring_ascii
|
||||
scan.make_scanner = scan.py_make_scanner
|
||||
dec.make_scanner = scan.make_scanner
|
||||
global _default_decoder
|
||||
_default_decoder = JSONDecoder(
|
||||
encoding=None,
|
||||
object_hook=None,
|
||||
object_pairs_hook=None,
|
||||
)
|
||||
global _default_encoder
|
||||
_default_encoder = JSONEncoder(
|
||||
skipkeys=False,
|
||||
ensure_ascii=True,
|
||||
check_circular=True,
|
||||
allow_nan=True,
|
||||
indent=None,
|
||||
separators=None,
|
||||
encoding='utf-8',
|
||||
default=None,
|
||||
)
|
||||
|
||||
def simple_first(kv):
|
||||
"""Helper function to pass to item_sort_key to sort simple
|
||||
elements to the top, then container elements.
|
||||
"""
|
||||
return (isinstance(kv[1], (list, dict, tuple)), kv[0])
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,43 +0,0 @@
|
||||
"""Python 3 compatibility shims
|
||||
"""
|
||||
import sys
|
||||
if sys.version_info[0] < 3:
|
||||
PY3 = False
|
||||
def b(s):
|
||||
return s
|
||||
def u(s):
|
||||
return unicode(s, 'unicode_escape')
|
||||
import cStringIO as StringIO
|
||||
StringIO = BytesIO = StringIO.StringIO
|
||||
text_type = unicode
|
||||
binary_type = str
|
||||
string_types = (basestring,)
|
||||
integer_types = (int, long)
|
||||
unichr = unichr
|
||||
reload_module = reload
|
||||
def fromhex(s):
|
||||
return s.decode('hex')
|
||||
|
||||
else:
|
||||
PY3 = True
|
||||
from imp import reload as reload_module
|
||||
import codecs
|
||||
def b(s):
|
||||
return codecs.latin_1_encode(s)[0]
|
||||
def u(s):
|
||||
return s
|
||||
import io
|
||||
StringIO = io.StringIO
|
||||
BytesIO = io.BytesIO
|
||||
text_type = str
|
||||
binary_type = bytes
|
||||
string_types = (str,)
|
||||
integer_types = (int,)
|
||||
|
||||
def unichr(s):
|
||||
return u(chr(s))
|
||||
|
||||
def fromhex(s):
|
||||
return bytes.fromhex(s)
|
||||
|
||||
long_type = integer_types[-1]
|
||||
@ -1,389 +0,0 @@
|
||||
"""Implementation of JSONDecoder
|
||||
"""
|
||||
from __future__ import absolute_import
|
||||
import re
|
||||
import sys
|
||||
import struct
|
||||
from .compat import fromhex, b, u, text_type, binary_type, PY3, unichr
|
||||
from .scanner import make_scanner, JSONDecodeError
|
||||
|
||||
def _import_c_scanstring():
|
||||
try:
|
||||
from ._speedups import scanstring
|
||||
return scanstring
|
||||
except ImportError:
|
||||
return None
|
||||
c_scanstring = _import_c_scanstring()
|
||||
|
||||
# NOTE (3.1.0): JSONDecodeError may still be imported from this module for
|
||||
# compatibility, but it was never in the __all__
|
||||
__all__ = ['JSONDecoder']
|
||||
|
||||
FLAGS = re.VERBOSE | re.MULTILINE | re.DOTALL
|
||||
|
||||
def _floatconstants():
|
||||
_BYTES = fromhex('7FF80000000000007FF0000000000000')
|
||||
# The struct module in Python 2.4 would get frexp() out of range here
|
||||
# when an endian is specified in the format string. Fixed in Python 2.5+
|
||||
if sys.byteorder != 'big':
|
||||
_BYTES = _BYTES[:8][::-1] + _BYTES[8:][::-1]
|
||||
nan, inf = struct.unpack('dd', _BYTES)
|
||||
return nan, inf, -inf
|
||||
|
||||
NaN, PosInf, NegInf = _floatconstants()
|
||||
|
||||
_CONSTANTS = {
|
||||
'-Infinity': NegInf,
|
||||
'Infinity': PosInf,
|
||||
'NaN': NaN,
|
||||
}
|
||||
|
||||
STRINGCHUNK = re.compile(r'(.*?)(["\\\x00-\x1f])', FLAGS)
|
||||
BACKSLASH = {
|
||||
'"': u('"'), '\\': u('\u005c'), '/': u('/'),
|
||||
'b': u('\b'), 'f': u('\f'), 'n': u('\n'), 'r': u('\r'), 't': u('\t'),
|
||||
}
|
||||
|
||||
DEFAULT_ENCODING = "utf-8"
|
||||
|
||||
def py_scanstring(s, end, encoding=None, strict=True,
|
||||
_b=BACKSLASH, _m=STRINGCHUNK.match, _join=u('').join,
|
||||
_PY3=PY3, _maxunicode=sys.maxunicode):
|
||||
"""Scan the string s for a JSON string. End is the index of the
|
||||
character in s after the quote that started the JSON string.
|
||||
Unescapes all valid JSON string escape sequences and raises ValueError
|
||||
on attempt to decode an invalid string. If strict is False then literal
|
||||
control characters are allowed in the string.
|
||||
|
||||
Returns a tuple of the decoded string and the index of the character in s
|
||||
after the end quote."""
|
||||
if encoding is None:
|
||||
encoding = DEFAULT_ENCODING
|
||||
chunks = []
|
||||
_append = chunks.append
|
||||
begin = end - 1
|
||||
while 1:
|
||||
chunk = _m(s, end)
|
||||
if chunk is None:
|
||||
raise JSONDecodeError(
|
||||
"Unterminated string starting at", s, begin)
|
||||
end = chunk.end()
|
||||
content, terminator = chunk.groups()
|
||||
# Content is contains zero or more unescaped string characters
|
||||
if content:
|
||||
if not _PY3 and not isinstance(content, text_type):
|
||||
content = text_type(content, encoding)
|
||||
_append(content)
|
||||
# Terminator is the end of string, a literal control character,
|
||||
# or a backslash denoting that an escape sequence follows
|
||||
if terminator == '"':
|
||||
break
|
||||
elif terminator != '\\':
|
||||
if strict:
|
||||
msg = "Invalid control character %r at"
|
||||
raise JSONDecodeError(msg, s, end)
|
||||
else:
|
||||
_append(terminator)
|
||||
continue
|
||||
try:
|
||||
esc = s[end]
|
||||
except IndexError:
|
||||
raise JSONDecodeError(
|
||||
"Unterminated string starting at", s, begin)
|
||||
# If not a unicode escape sequence, must be in the lookup table
|
||||
if esc != 'u':
|
||||
try:
|
||||
char = _b[esc]
|
||||
except KeyError:
|
||||
msg = "Invalid \\X escape sequence %r"
|
||||
raise JSONDecodeError(msg, s, end)
|
||||
end += 1
|
||||
else:
|
||||
# Unicode escape sequence
|
||||
msg = "Invalid \\uXXXX escape sequence"
|
||||
esc = s[end + 1:end + 5]
|
||||
escX = esc[1:2]
|
||||
if len(esc) != 4 or escX == 'x' or escX == 'X':
|
||||
raise JSONDecodeError(msg, s, end - 1)
|
||||
try:
|
||||
uni = int(esc, 16)
|
||||
except ValueError:
|
||||
raise JSONDecodeError(msg, s, end - 1)
|
||||
end += 5
|
||||
# Check for surrogate pair on UCS-4 systems
|
||||
# Note that this will join high/low surrogate pairs
|
||||
# but will also pass unpaired surrogates through
|
||||
if (_maxunicode > 65535 and
|
||||
uni & 0xfc00 == 0xd800 and
|
||||
s[end:end + 2] == '\\u'):
|
||||
esc2 = s[end + 2:end + 6]
|
||||
escX = esc2[1:2]
|
||||
if len(esc2) == 4 and not (escX == 'x' or escX == 'X'):
|
||||
try:
|
||||
uni2 = int(esc2, 16)
|
||||
except ValueError:
|
||||
raise JSONDecodeError(msg, s, end)
|
||||
if uni2 & 0xfc00 == 0xdc00:
|
||||
uni = 0x10000 + (((uni - 0xd800) << 10) |
|
||||
(uni2 - 0xdc00))
|
||||
end += 6
|
||||
char = unichr(uni)
|
||||
# Append the unescaped character
|
||||
_append(char)
|
||||
return _join(chunks), end
|
||||
|
||||
|
||||
# Use speedup if available
|
||||
scanstring = c_scanstring or py_scanstring
|
||||
|
||||
WHITESPACE = re.compile(r'[ \t\n\r]*', FLAGS)
|
||||
WHITESPACE_STR = ' \t\n\r'
|
||||
|
||||
def JSONObject(state, encoding, strict, scan_once, object_hook,
|
||||
object_pairs_hook, memo=None,
|
||||
_w=WHITESPACE.match, _ws=WHITESPACE_STR):
|
||||
(s, end) = state
|
||||
# Backwards compatibility
|
||||
if memo is None:
|
||||
memo = {}
|
||||
memo_get = memo.setdefault
|
||||
pairs = []
|
||||
# Use a slice to prevent IndexError from being raised, the following
|
||||
# check will raise a more specific ValueError if the string is empty
|
||||
nextchar = s[end:end + 1]
|
||||
# Normally we expect nextchar == '"'
|
||||
if nextchar != '"':
|
||||
if nextchar in _ws:
|
||||
end = _w(s, end).end()
|
||||
nextchar = s[end:end + 1]
|
||||
# Trivial empty object
|
||||
if nextchar == '}':
|
||||
if object_pairs_hook is not None:
|
||||
result = object_pairs_hook(pairs)
|
||||
return result, end + 1
|
||||
pairs = {}
|
||||
if object_hook is not None:
|
||||
pairs = object_hook(pairs)
|
||||
return pairs, end + 1
|
||||
elif nextchar != '"':
|
||||
raise JSONDecodeError(
|
||||
"Expecting property name enclosed in double quotes",
|
||||
s, end)
|
||||
end += 1
|
||||
while True:
|
||||
key, end = scanstring(s, end, encoding, strict)
|
||||
key = memo_get(key, key)
|
||||
|
||||
# To skip some function call overhead we optimize the fast paths where
|
||||
# the JSON key separator is ": " or just ":".
|
||||
if s[end:end + 1] != ':':
|
||||
end = _w(s, end).end()
|
||||
if s[end:end + 1] != ':':
|
||||
raise JSONDecodeError("Expecting ':' delimiter", s, end)
|
||||
|
||||
end += 1
|
||||
|
||||
try:
|
||||
if s[end] in _ws:
|
||||
end += 1
|
||||
if s[end] in _ws:
|
||||
end = _w(s, end + 1).end()
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
value, end = scan_once(s, end)
|
||||
pairs.append((key, value))
|
||||
|
||||
try:
|
||||
nextchar = s[end]
|
||||
if nextchar in _ws:
|
||||
end = _w(s, end + 1).end()
|
||||
nextchar = s[end]
|
||||
except IndexError:
|
||||
nextchar = ''
|
||||
end += 1
|
||||
|
||||
if nextchar == '}':
|
||||
break
|
||||
elif nextchar != ',':
|
||||
raise JSONDecodeError("Expecting ',' delimiter or '}'", s, end - 1)
|
||||
|
||||
try:
|
||||
nextchar = s[end]
|
||||
if nextchar in _ws:
|
||||
end += 1
|
||||
nextchar = s[end]
|
||||
if nextchar in _ws:
|
||||
end = _w(s, end + 1).end()
|
||||
nextchar = s[end]
|
||||
except IndexError:
|
||||
nextchar = ''
|
||||
|
||||
end += 1
|
||||
if nextchar != '"':
|
||||
raise JSONDecodeError(
|
||||
"Expecting property name enclosed in double quotes",
|
||||
s, end - 1)
|
||||
|
||||
if object_pairs_hook is not None:
|
||||
result = object_pairs_hook(pairs)
|
||||
return result, end
|
||||
pairs = dict(pairs)
|
||||
if object_hook is not None:
|
||||
pairs = object_hook(pairs)
|
||||
return pairs, end
|
||||
|
||||
def JSONArray(state, scan_once, _w=WHITESPACE.match, _ws=WHITESPACE_STR):
|
||||
(s, end) = state
|
||||
values = []
|
||||
nextchar = s[end:end + 1]
|
||||
if nextchar in _ws:
|
||||
end = _w(s, end + 1).end()
|
||||
nextchar = s[end:end + 1]
|
||||
# Look-ahead for trivial empty array
|
||||
if nextchar == ']':
|
||||
return values, end + 1
|
||||
elif nextchar == '':
|
||||
raise JSONDecodeError("Expecting value or ']'", s, end)
|
||||
_append = values.append
|
||||
while True:
|
||||
value, end = scan_once(s, end)
|
||||
_append(value)
|
||||
nextchar = s[end:end + 1]
|
||||
if nextchar in _ws:
|
||||
end = _w(s, end + 1).end()
|
||||
nextchar = s[end:end + 1]
|
||||
end += 1
|
||||
if nextchar == ']':
|
||||
break
|
||||
elif nextchar != ',':
|
||||
raise JSONDecodeError("Expecting ',' delimiter or ']'", s, end - 1)
|
||||
|
||||
try:
|
||||
if s[end] in _ws:
|
||||
end += 1
|
||||
if s[end] in _ws:
|
||||
end = _w(s, end + 1).end()
|
||||
except IndexError:
|
||||
pass
|
||||
|
||||
return values, end
|
||||
|
||||
class JSONDecoder(object):
|
||||
"""Simple JSON <http://json.org> decoder
|
||||
|
||||
Performs the following translations in decoding by default:
|
||||
|
||||
+---------------+-------------------+
|
||||
| JSON | Python |
|
||||
+===============+===================+
|
||||
| object | dict |
|
||||
+---------------+-------------------+
|
||||
| array | list |
|
||||
+---------------+-------------------+
|
||||
| string | unicode |
|
||||
+---------------+-------------------+
|
||||
| number (int) | int, long |
|
||||
+---------------+-------------------+
|
||||
| number (real) | float |
|
||||
+---------------+-------------------+
|
||||
| true | True |
|
||||
+---------------+-------------------+
|
||||
| false | False |
|
||||
+---------------+-------------------+
|
||||
| null | None |
|
||||
+---------------+-------------------+
|
||||
|
||||
It also understands ``NaN``, ``Infinity``, and ``-Infinity`` as
|
||||
their corresponding ``float`` values, which is outside the JSON spec.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self, encoding=None, object_hook=None, parse_float=None,
|
||||
parse_int=None, parse_constant=None, strict=True,
|
||||
object_pairs_hook=None):
|
||||
"""
|
||||
*encoding* determines the encoding used to interpret any
|
||||
:class:`str` objects decoded by this instance (``'utf-8'`` by
|
||||
default). It has no effect when decoding :class:`unicode` objects.
|
||||
|
||||
Note that currently only encodings that are a superset of ASCII work,
|
||||
strings of other encodings should be passed in as :class:`unicode`.
|
||||
|
||||
*object_hook*, if specified, will be called with the result of every
|
||||
JSON object decoded and its return value will be used in place of the
|
||||
given :class:`dict`. This can be used to provide custom
|
||||
deserializations (e.g. to support JSON-RPC class hinting).
|
||||
|
||||
*object_pairs_hook* is an optional function that will be called with
|
||||
the result of any object literal decode with an ordered list of pairs.
|
||||
The return value of *object_pairs_hook* will be used instead of the
|
||||
:class:`dict`. This feature can be used to implement custom decoders
|
||||
that rely on the order that the key and value pairs are decoded (for
|
||||
example, :func:`collections.OrderedDict` will remember the order of
|
||||
insertion). If *object_hook* is also defined, the *object_pairs_hook*
|
||||
takes priority.
|
||||
|
||||
*parse_float*, if specified, will be called with the string of every
|
||||
JSON float to be decoded. By default, this is equivalent to
|
||||
``float(num_str)``. This can be used to use another datatype or parser
|
||||
for JSON floats (e.g. :class:`decimal.Decimal`).
|
||||
|
||||
*parse_int*, if specified, will be called with the string of every
|
||||
JSON int to be decoded. By default, this is equivalent to
|
||||
``int(num_str)``. This can be used to use another datatype or parser
|
||||
for JSON integers (e.g. :class:`float`).
|
||||
|
||||
*parse_constant*, if specified, will be called with one of the
|
||||
following strings: ``'-Infinity'``, ``'Infinity'``, ``'NaN'``. This
|
||||
can be used to raise an exception if invalid JSON numbers are
|
||||
encountered.
|
||||
|
||||
*strict* controls the parser's behavior when it encounters an
|
||||
invalid control character in a string. The default setting of
|
||||
``True`` means that unescaped control characters are parse errors, if
|
||||
``False`` then control characters will be allowed in strings.
|
||||
|
||||
"""
|
||||
if encoding is None:
|
||||
encoding = DEFAULT_ENCODING
|
||||
self.encoding = encoding
|
||||
self.object_hook = object_hook
|
||||
self.object_pairs_hook = object_pairs_hook
|
||||
self.parse_float = parse_float or float
|
||||
self.parse_int = parse_int or int
|
||||
self.parse_constant = parse_constant or _CONSTANTS.__getitem__
|
||||
self.strict = strict
|
||||
self.parse_object = JSONObject
|
||||
self.parse_array = JSONArray
|
||||
self.parse_string = scanstring
|
||||
self.memo = {}
|
||||
self.scan_once = make_scanner(self)
|
||||
|
||||
def decode(self, s, _w=WHITESPACE.match, _PY3=PY3):
|
||||
"""Return the Python representation of ``s`` (a ``str`` or ``unicode``
|
||||
instance containing a JSON document)
|
||||
|
||||
"""
|
||||
if _PY3 and isinstance(s, binary_type):
|
||||
s = s.decode(self.encoding)
|
||||
obj, end = self.raw_decode(s)
|
||||
end = _w(s, end).end()
|
||||
if end != len(s):
|
||||
raise JSONDecodeError("Extra data", s, end, len(s))
|
||||
return obj
|
||||
|
||||
def raw_decode(self, s, idx=0, _w=WHITESPACE.match, _PY3=PY3):
|
||||
"""Decode a JSON document from ``s`` (a ``str`` or ``unicode``
|
||||
beginning with a JSON document) and return a 2-tuple of the Python
|
||||
representation and the index in ``s`` where the document ended.
|
||||
Optionally, ``idx`` can be used to specify an offset in ``s`` where
|
||||
the JSON document begins.
|
||||
|
||||
This can be used to decode a JSON document from a string that may
|
||||
have extraneous data at the end.
|
||||
|
||||
"""
|
||||
if _PY3 and not isinstance(s, text_type):
|
||||
raise TypeError("Input string must be text, not bytes")
|
||||
return self.scan_once(s, idx=_w(s, idx).end())
|
||||
@ -1,628 +0,0 @@
|
||||
"""Implementation of JSONEncoder
|
||||
"""
|
||||
from __future__ import absolute_import
|
||||
import re
|
||||
from operator import itemgetter
|
||||
from decimal import Decimal
|
||||
from .compat import u, unichr, binary_type, string_types, integer_types, PY3
|
||||
def _import_speedups():
|
||||
try:
|
||||
from . import _speedups
|
||||
return _speedups.encode_basestring_ascii, _speedups.make_encoder
|
||||
except ImportError:
|
||||
return None, None
|
||||
c_encode_basestring_ascii, c_make_encoder = _import_speedups()
|
||||
|
||||
from simplejson.decoder import PosInf
|
||||
|
||||
#ESCAPE = re.compile(ur'[\x00-\x1f\\"\b\f\n\r\t\u2028\u2029]')
|
||||
# This is required because u() will mangle the string and ur'' isn't valid
|
||||
# python3 syntax
|
||||
ESCAPE = re.compile(u'[\\x00-\\x1f\\\\"\\b\\f\\n\\r\\t\u2028\u2029]')
|
||||
ESCAPE_ASCII = re.compile(r'([\\"]|[^\ -~])')
|
||||
HAS_UTF8 = re.compile(r'[\x80-\xff]')
|
||||
ESCAPE_DCT = {
|
||||
'\\': '\\\\',
|
||||
'"': '\\"',
|
||||
'\b': '\\b',
|
||||
'\f': '\\f',
|
||||
'\n': '\\n',
|
||||
'\r': '\\r',
|
||||
'\t': '\\t',
|
||||
}
|
||||
for i in range(0x20):
|
||||
#ESCAPE_DCT.setdefault(chr(i), '\\u{0:04x}'.format(i))
|
||||
ESCAPE_DCT.setdefault(chr(i), '\\u%04x' % (i,))
|
||||
for i in [0x2028, 0x2029]:
|
||||
ESCAPE_DCT.setdefault(unichr(i), '\\u%04x' % (i,))
|
||||
|
||||
FLOAT_REPR = repr
|
||||
|
||||
def encode_basestring(s, _PY3=PY3, _q=u('"')):
|
||||
"""Return a JSON representation of a Python string
|
||||
|
||||
"""
|
||||
if _PY3:
|
||||
if isinstance(s, binary_type):
|
||||
s = s.decode('utf-8')
|
||||
else:
|
||||
if isinstance(s, str) and HAS_UTF8.search(s) is not None:
|
||||
s = s.decode('utf-8')
|
||||
def replace(match):
|
||||
return ESCAPE_DCT[match.group(0)]
|
||||
return _q + ESCAPE.sub(replace, s) + _q
|
||||
|
||||
|
||||
def py_encode_basestring_ascii(s, _PY3=PY3):
|
||||
"""Return an ASCII-only JSON representation of a Python string
|
||||
|
||||
"""
|
||||
if _PY3:
|
||||
if isinstance(s, binary_type):
|
||||
s = s.decode('utf-8')
|
||||
else:
|
||||
if isinstance(s, str) and HAS_UTF8.search(s) is not None:
|
||||
s = s.decode('utf-8')
|
||||
def replace(match):
|
||||
s = match.group(0)
|
||||
try:
|
||||
return ESCAPE_DCT[s]
|
||||
except KeyError:
|
||||
n = ord(s)
|
||||
if n < 0x10000:
|
||||
#return '\\u{0:04x}'.format(n)
|
||||
return '\\u%04x' % (n,)
|
||||
else:
|
||||
# surrogate pair
|
||||
n -= 0x10000
|
||||
s1 = 0xd800 | ((n >> 10) & 0x3ff)
|
||||
s2 = 0xdc00 | (n & 0x3ff)
|
||||
#return '\\u{0:04x}\\u{1:04x}'.format(s1, s2)
|
||||
return '\\u%04x\\u%04x' % (s1, s2)
|
||||
return '"' + str(ESCAPE_ASCII.sub(replace, s)) + '"'
|
||||
|
||||
|
||||
encode_basestring_ascii = (
|
||||
c_encode_basestring_ascii or py_encode_basestring_ascii)
|
||||
|
||||
class JSONEncoder(object):
|
||||
"""Extensible JSON <http://json.org> encoder for Python data structures.
|
||||
|
||||
Supports the following objects and types by default:
|
||||
|
||||
+-------------------+---------------+
|
||||
| Python | JSON |
|
||||
+===================+===============+
|
||||
| dict, namedtuple | object |
|
||||
+-------------------+---------------+
|
||||
| list, tuple | array |
|
||||
+-------------------+---------------+
|
||||
| str, unicode | string |
|
||||
+-------------------+---------------+
|
||||
| int, long, float | number |
|
||||
+-------------------+---------------+
|
||||
| True | true |
|
||||
+-------------------+---------------+
|
||||
| False | false |
|
||||
+-------------------+---------------+
|
||||
| None | null |
|
||||
+-------------------+---------------+
|
||||
|
||||
To extend this to recognize other objects, subclass and implement a
|
||||
``.default()`` method with another method that returns a serializable
|
||||
object for ``o`` if possible, otherwise it should call the superclass
|
||||
implementation (to raise ``TypeError``).
|
||||
|
||||
"""
|
||||
item_separator = ', '
|
||||
key_separator = ': '
|
||||
def __init__(self, skipkeys=False, ensure_ascii=True,
|
||||
check_circular=True, allow_nan=True, sort_keys=False,
|
||||
indent=None, separators=None, encoding='utf-8', default=None,
|
||||
use_decimal=True, namedtuple_as_object=True,
|
||||
tuple_as_array=True, bigint_as_string=False,
|
||||
item_sort_key=None, for_json=False, ignore_nan=False):
|
||||
"""Constructor for JSONEncoder, with sensible defaults.
|
||||
|
||||
If skipkeys is false, then it is a TypeError to attempt
|
||||
encoding of keys that are not str, int, long, float or None. If
|
||||
skipkeys is True, such items are simply skipped.
|
||||
|
||||
If ensure_ascii is true, the output is guaranteed to be str
|
||||
objects with all incoming unicode characters escaped. If
|
||||
ensure_ascii is false, the output will be unicode object.
|
||||
|
||||
If check_circular is true, then lists, dicts, and custom encoded
|
||||
objects will be checked for circular references during encoding to
|
||||
prevent an infinite recursion (which would cause an OverflowError).
|
||||
Otherwise, no such check takes place.
|
||||
|
||||
If allow_nan is true, then NaN, Infinity, and -Infinity will be
|
||||
encoded as such. This behavior is not JSON specification compliant,
|
||||
but is consistent with most JavaScript based encoders and decoders.
|
||||
Otherwise, it will be a ValueError to encode such floats.
|
||||
|
||||
If sort_keys is true, then the output of dictionaries will be
|
||||
sorted by key; this is useful for regression tests to ensure
|
||||
that JSON serializations can be compared on a day-to-day basis.
|
||||
|
||||
If indent is a string, then JSON array elements and object members
|
||||
will be pretty-printed with a newline followed by that string repeated
|
||||
for each level of nesting. ``None`` (the default) selects the most compact
|
||||
representation without any newlines. For backwards compatibility with
|
||||
versions of simplejson earlier than 2.1.0, an integer is also accepted
|
||||
and is converted to a string with that many spaces.
|
||||
|
||||
If specified, separators should be an (item_separator, key_separator)
|
||||
tuple. The default is (', ', ': ') if *indent* is ``None`` and
|
||||
(',', ': ') otherwise. To get the most compact JSON representation,
|
||||
you should specify (',', ':') to eliminate whitespace.
|
||||
|
||||
If specified, default is a function that gets called for objects
|
||||
that can't otherwise be serialized. It should return a JSON encodable
|
||||
version of the object or raise a ``TypeError``.
|
||||
|
||||
If encoding is not None, then all input strings will be
|
||||
transformed into unicode using that encoding prior to JSON-encoding.
|
||||
The default is UTF-8.
|
||||
|
||||
If use_decimal is true (not the default), ``decimal.Decimal`` will
|
||||
be supported directly by the encoder. For the inverse, decode JSON
|
||||
with ``parse_float=decimal.Decimal``.
|
||||
|
||||
If namedtuple_as_object is true (the default), objects with
|
||||
``_asdict()`` methods will be encoded as JSON objects.
|
||||
|
||||
If tuple_as_array is true (the default), tuple (and subclasses) will
|
||||
be encoded as JSON arrays.
|
||||
|
||||
If bigint_as_string is true (not the default), ints 2**53 and higher
|
||||
or lower than -2**53 will be encoded as strings. This is to avoid the
|
||||
rounding that happens in Javascript otherwise.
|
||||
|
||||
If specified, item_sort_key is a callable used to sort the items in
|
||||
each dictionary. This is useful if you want to sort items other than
|
||||
in alphabetical order by key.
|
||||
|
||||
If for_json is true (not the default), objects with a ``for_json()``
|
||||
method will use the return value of that method for encoding as JSON
|
||||
instead of the object.
|
||||
|
||||
If *ignore_nan* is true (default: ``False``), then out of range
|
||||
:class:`float` values (``nan``, ``inf``, ``-inf``) will be serialized
|
||||
as ``null`` in compliance with the ECMA-262 specification. If true,
|
||||
this will override *allow_nan*.
|
||||
|
||||
"""
|
||||
|
||||
self.skipkeys = skipkeys
|
||||
self.ensure_ascii = ensure_ascii
|
||||
self.check_circular = check_circular
|
||||
self.allow_nan = allow_nan
|
||||
self.sort_keys = sort_keys
|
||||
self.use_decimal = use_decimal
|
||||
self.namedtuple_as_object = namedtuple_as_object
|
||||
self.tuple_as_array = tuple_as_array
|
||||
self.bigint_as_string = bigint_as_string
|
||||
self.item_sort_key = item_sort_key
|
||||
self.for_json = for_json
|
||||
self.ignore_nan = ignore_nan
|
||||
if indent is not None and not isinstance(indent, string_types):
|
||||
indent = indent * ' '
|
||||
self.indent = indent
|
||||
if separators is not None:
|
||||
self.item_separator, self.key_separator = separators
|
||||
elif indent is not None:
|
||||
self.item_separator = ','
|
||||
if default is not None:
|
||||
self.default = default
|
||||
self.encoding = encoding
|
||||
|
||||
def default(self, o):
|
||||
"""Implement this method in a subclass such that it returns
|
||||
a serializable object for ``o``, or calls the base implementation
|
||||
(to raise a ``TypeError``).
|
||||
|
||||
For example, to support arbitrary iterators, you could
|
||||
implement default like this::
|
||||
|
||||
def default(self, o):
|
||||
try:
|
||||
iterable = iter(o)
|
||||
except TypeError:
|
||||
pass
|
||||
else:
|
||||
return list(iterable)
|
||||
return JSONEncoder.default(self, o)
|
||||
|
||||
"""
|
||||
raise TypeError(repr(o) + " is not JSON serializable")
|
||||
|
||||
def encode(self, o):
|
||||
"""Return a JSON string representation of a Python data structure.
|
||||
|
||||
>>> from simplejson import JSONEncoder
|
||||
>>> JSONEncoder().encode({"foo": ["bar", "baz"]})
|
||||
'{"foo": ["bar", "baz"]}'
|
||||
|
||||
"""
|
||||
# This is for extremely simple cases and benchmarks.
|
||||
if isinstance(o, binary_type):
|
||||
_encoding = self.encoding
|
||||
if (_encoding is not None and not (_encoding == 'utf-8')):
|
||||
o = o.decode(_encoding)
|
||||
if isinstance(o, string_types):
|
||||
if self.ensure_ascii:
|
||||
return encode_basestring_ascii(o)
|
||||
else:
|
||||
return encode_basestring(o)
|
||||
# This doesn't pass the iterator directly to ''.join() because the
|
||||
# exceptions aren't as detailed. The list call should be roughly
|
||||
# equivalent to the PySequence_Fast that ''.join() would do.
|
||||
chunks = self.iterencode(o, _one_shot=True)
|
||||
if not isinstance(chunks, (list, tuple)):
|
||||
chunks = list(chunks)
|
||||
if self.ensure_ascii:
|
||||
return ''.join(chunks)
|
||||
else:
|
||||
return u''.join(chunks)
|
||||
|
||||
def iterencode(self, o, _one_shot=False):
|
||||
"""Encode the given object and yield each string
|
||||
representation as available.
|
||||
|
||||
For example::
|
||||
|
||||
for chunk in JSONEncoder().iterencode(bigobject):
|
||||
mysocket.write(chunk)
|
||||
|
||||
"""
|
||||
if self.check_circular:
|
||||
markers = {}
|
||||
else:
|
||||
markers = None
|
||||
if self.ensure_ascii:
|
||||
_encoder = encode_basestring_ascii
|
||||
else:
|
||||
_encoder = encode_basestring
|
||||
if self.encoding != 'utf-8':
|
||||
def _encoder(o, _orig_encoder=_encoder, _encoding=self.encoding):
|
||||
if isinstance(o, binary_type):
|
||||
o = o.decode(_encoding)
|
||||
return _orig_encoder(o)
|
||||
|
||||
def floatstr(o, allow_nan=self.allow_nan, ignore_nan=self.ignore_nan,
|
||||
_repr=FLOAT_REPR, _inf=PosInf, _neginf=-PosInf):
|
||||
# Check for specials. Note that this type of test is processor
|
||||
# and/or platform-specific, so do tests which don't depend on
|
||||
# the internals.
|
||||
|
||||
if o != o:
|
||||
text = 'NaN'
|
||||
elif o == _inf:
|
||||
text = 'Infinity'
|
||||
elif o == _neginf:
|
||||
text = '-Infinity'
|
||||
else:
|
||||
return _repr(o)
|
||||
|
||||
if ignore_nan:
|
||||
text = 'null'
|
||||
elif not allow_nan:
|
||||
raise ValueError(
|
||||
"Out of range float values are not JSON compliant: " +
|
||||
repr(o))
|
||||
|
||||
return text
|
||||
|
||||
|
||||
key_memo = {}
|
||||
if (_one_shot and c_make_encoder is not None
|
||||
and self.indent is None):
|
||||
_iterencode = c_make_encoder(
|
||||
markers, self.default, _encoder, self.indent,
|
||||
self.key_separator, self.item_separator, self.sort_keys,
|
||||
self.skipkeys, self.allow_nan, key_memo, self.use_decimal,
|
||||
self.namedtuple_as_object, self.tuple_as_array,
|
||||
self.bigint_as_string, self.item_sort_key,
|
||||
self.encoding, self.for_json, self.ignore_nan,
|
||||
Decimal)
|
||||
else:
|
||||
_iterencode = _make_iterencode(
|
||||
markers, self.default, _encoder, self.indent, floatstr,
|
||||
self.key_separator, self.item_separator, self.sort_keys,
|
||||
self.skipkeys, _one_shot, self.use_decimal,
|
||||
self.namedtuple_as_object, self.tuple_as_array,
|
||||
self.bigint_as_string, self.item_sort_key,
|
||||
self.encoding, self.for_json,
|
||||
Decimal=Decimal)
|
||||
try:
|
||||
return _iterencode(o, 0)
|
||||
finally:
|
||||
key_memo.clear()
|
||||
|
||||
|
||||
class JSONEncoderForHTML(JSONEncoder):
|
||||
"""An encoder that produces JSON safe to embed in HTML.
|
||||
|
||||
To embed JSON content in, say, a script tag on a web page, the
|
||||
characters &, < and > should be escaped. They cannot be escaped
|
||||
with the usual entities (e.g. &) because they are not expanded
|
||||
within <script> tags.
|
||||
"""
|
||||
|
||||
def encode(self, o):
|
||||
# Override JSONEncoder.encode because it has hacks for
|
||||
# performance that make things more complicated.
|
||||
chunks = self.iterencode(o, True)
|
||||
if self.ensure_ascii:
|
||||
return ''.join(chunks)
|
||||
else:
|
||||
return u''.join(chunks)
|
||||
|
||||
def iterencode(self, o, _one_shot=False):
|
||||
chunks = super(JSONEncoderForHTML, self).iterencode(o, _one_shot)
|
||||
for chunk in chunks:
|
||||
chunk = chunk.replace('&', '\\u0026')
|
||||
chunk = chunk.replace('<', '\\u003c')
|
||||
chunk = chunk.replace('>', '\\u003e')
|
||||
yield chunk
|
||||
|
||||
|
||||
def _make_iterencode(markers, _default, _encoder, _indent, _floatstr,
|
||||
_key_separator, _item_separator, _sort_keys, _skipkeys, _one_shot,
|
||||
_use_decimal, _namedtuple_as_object, _tuple_as_array,
|
||||
_bigint_as_string, _item_sort_key, _encoding, _for_json,
|
||||
## HACK: hand-optimized bytecode; turn globals into locals
|
||||
_PY3=PY3,
|
||||
ValueError=ValueError,
|
||||
string_types=string_types,
|
||||
Decimal=Decimal,
|
||||
dict=dict,
|
||||
float=float,
|
||||
id=id,
|
||||
integer_types=integer_types,
|
||||
isinstance=isinstance,
|
||||
list=list,
|
||||
str=str,
|
||||
tuple=tuple,
|
||||
):
|
||||
if _item_sort_key and not callable(_item_sort_key):
|
||||
raise TypeError("item_sort_key must be None or callable")
|
||||
elif _sort_keys and not _item_sort_key:
|
||||
_item_sort_key = itemgetter(0)
|
||||
|
||||
def _iterencode_list(lst, _current_indent_level):
|
||||
if not lst:
|
||||
yield '[]'
|
||||
return
|
||||
if markers is not None:
|
||||
markerid = id(lst)
|
||||
if markerid in markers:
|
||||
raise ValueError("Circular reference detected")
|
||||
markers[markerid] = lst
|
||||
buf = '['
|
||||
if _indent is not None:
|
||||
_current_indent_level += 1
|
||||
newline_indent = '\n' + (_indent * _current_indent_level)
|
||||
separator = _item_separator + newline_indent
|
||||
buf += newline_indent
|
||||
else:
|
||||
newline_indent = None
|
||||
separator = _item_separator
|
||||
first = True
|
||||
for value in lst:
|
||||
if first:
|
||||
first = False
|
||||
else:
|
||||
buf = separator
|
||||
if (isinstance(value, string_types) or
|
||||
(_PY3 and isinstance(value, binary_type))):
|
||||
yield buf + _encoder(value)
|
||||
elif value is None:
|
||||
yield buf + 'null'
|
||||
elif value is True:
|
||||
yield buf + 'true'
|
||||
elif value is False:
|
||||
yield buf + 'false'
|
||||
elif isinstance(value, integer_types):
|
||||
yield ((buf + str(value))
|
||||
if (not _bigint_as_string or
|
||||
(-1 << 53) < value < (1 << 53))
|
||||
else (buf + '"' + str(value) + '"'))
|
||||
elif isinstance(value, float):
|
||||
yield buf + _floatstr(value)
|
||||
elif _use_decimal and isinstance(value, Decimal):
|
||||
yield buf + str(value)
|
||||
else:
|
||||
yield buf
|
||||
for_json = _for_json and getattr(value, 'for_json', None)
|
||||
if for_json and callable(for_json):
|
||||
chunks = _iterencode(for_json(), _current_indent_level)
|
||||
elif isinstance(value, list):
|
||||
chunks = _iterencode_list(value, _current_indent_level)
|
||||
else:
|
||||
_asdict = _namedtuple_as_object and getattr(value, '_asdict', None)
|
||||
if _asdict and callable(_asdict):
|
||||
chunks = _iterencode_dict(_asdict(),
|
||||
_current_indent_level)
|
||||
elif _tuple_as_array and isinstance(value, tuple):
|
||||
chunks = _iterencode_list(value, _current_indent_level)
|
||||
elif isinstance(value, dict):
|
||||
chunks = _iterencode_dict(value, _current_indent_level)
|
||||
else:
|
||||
chunks = _iterencode(value, _current_indent_level)
|
||||
for chunk in chunks:
|
||||
yield chunk
|
||||
if newline_indent is not None:
|
||||
_current_indent_level -= 1
|
||||
yield '\n' + (_indent * _current_indent_level)
|
||||
yield ']'
|
||||
if markers is not None:
|
||||
del markers[markerid]
|
||||
|
||||
def _stringify_key(key):
|
||||
if isinstance(key, string_types): # pragma: no cover
|
||||
pass
|
||||
elif isinstance(key, binary_type):
|
||||
key = key.decode(_encoding)
|
||||
elif isinstance(key, float):
|
||||
key = _floatstr(key)
|
||||
elif key is True:
|
||||
key = 'true'
|
||||
elif key is False:
|
||||
key = 'false'
|
||||
elif key is None:
|
||||
key = 'null'
|
||||
elif isinstance(key, integer_types):
|
||||
key = str(key)
|
||||
elif _use_decimal and isinstance(key, Decimal):
|
||||
key = str(key)
|
||||
elif _skipkeys:
|
||||
key = None
|
||||
else:
|
||||
raise TypeError("key " + repr(key) + " is not a string")
|
||||
return key
|
||||
|
||||
def _iterencode_dict(dct, _current_indent_level):
|
||||
if not dct:
|
||||
yield '{}'
|
||||
return
|
||||
if markers is not None:
|
||||
markerid = id(dct)
|
||||
if markerid in markers:
|
||||
raise ValueError("Circular reference detected")
|
||||
markers[markerid] = dct
|
||||
yield '{'
|
||||
if _indent is not None:
|
||||
_current_indent_level += 1
|
||||
newline_indent = '\n' + (_indent * _current_indent_level)
|
||||
item_separator = _item_separator + newline_indent
|
||||
yield newline_indent
|
||||
else:
|
||||
newline_indent = None
|
||||
item_separator = _item_separator
|
||||
first = True
|
||||
if _PY3:
|
||||
iteritems = dct.items()
|
||||
else:
|
||||
iteritems = dct.iteritems()
|
||||
if _item_sort_key:
|
||||
items = []
|
||||
for k, v in dct.items():
|
||||
if not isinstance(k, string_types):
|
||||
k = _stringify_key(k)
|
||||
if k is None:
|
||||
continue
|
||||
items.append((k, v))
|
||||
items.sort(key=_item_sort_key)
|
||||
else:
|
||||
items = iteritems
|
||||
for key, value in items:
|
||||
if not (_item_sort_key or isinstance(key, string_types)):
|
||||
key = _stringify_key(key)
|
||||
if key is None:
|
||||
# _skipkeys must be True
|
||||
continue
|
||||
if first:
|
||||
first = False
|
||||
else:
|
||||
yield item_separator
|
||||
yield _encoder(key)
|
||||
yield _key_separator
|
||||
if (isinstance(value, string_types) or
|
||||
(_PY3 and isinstance(value, binary_type))):
|
||||
yield _encoder(value)
|
||||
elif value is None:
|
||||
yield 'null'
|
||||
elif value is True:
|
||||
yield 'true'
|
||||
elif value is False:
|
||||
yield 'false'
|
||||
elif isinstance(value, integer_types):
|
||||
yield (str(value)
|
||||
if (not _bigint_as_string or
|
||||
(-1 << 53) < value < (1 << 53))
|
||||
else ('"' + str(value) + '"'))
|
||||
elif isinstance(value, float):
|
||||
yield _floatstr(value)
|
||||
elif _use_decimal and isinstance(value, Decimal):
|
||||
yield str(value)
|
||||
else:
|
||||
for_json = _for_json and getattr(value, 'for_json', None)
|
||||
if for_json and callable(for_json):
|
||||
chunks = _iterencode(for_json(), _current_indent_level)
|
||||
elif isinstance(value, list):
|
||||
chunks = _iterencode_list(value, _current_indent_level)
|
||||
else:
|
||||
_asdict = _namedtuple_as_object and getattr(value, '_asdict', None)
|
||||
if _asdict and callable(_asdict):
|
||||
chunks = _iterencode_dict(_asdict(),
|
||||
_current_indent_level)
|
||||
elif _tuple_as_array and isinstance(value, tuple):
|
||||
chunks = _iterencode_list(value, _current_indent_level)
|
||||
elif isinstance(value, dict):
|
||||
chunks = _iterencode_dict(value, _current_indent_level)
|
||||
else:
|
||||
chunks = _iterencode(value, _current_indent_level)
|
||||
for chunk in chunks:
|
||||
yield chunk
|
||||
if newline_indent is not None:
|
||||
_current_indent_level -= 1
|
||||
yield '\n' + (_indent * _current_indent_level)
|
||||
yield '}'
|
||||
if markers is not None:
|
||||
del markers[markerid]
|
||||
|
||||
def _iterencode(o, _current_indent_level):
|
||||
if (isinstance(o, string_types) or
|
||||
(_PY3 and isinstance(o, binary_type))):
|
||||
yield _encoder(o)
|
||||
elif o is None:
|
||||
yield 'null'
|
||||
elif o is True:
|
||||
yield 'true'
|
||||
elif o is False:
|
||||
yield 'false'
|
||||
elif isinstance(o, integer_types):
|
||||
yield (str(o)
|
||||
if (not _bigint_as_string or
|
||||
(-1 << 53) < o < (1 << 53))
|
||||
else ('"' + str(o) + '"'))
|
||||
elif isinstance(o, float):
|
||||
yield _floatstr(o)
|
||||
else:
|
||||
for_json = _for_json and getattr(o, 'for_json', None)
|
||||
if for_json and callable(for_json):
|
||||
for chunk in _iterencode(for_json(), _current_indent_level):
|
||||
yield chunk
|
||||
elif isinstance(o, list):
|
||||
for chunk in _iterencode_list(o, _current_indent_level):
|
||||
yield chunk
|
||||
else:
|
||||
_asdict = _namedtuple_as_object and getattr(o, '_asdict', None)
|
||||
if _asdict and callable(_asdict):
|
||||
for chunk in _iterencode_dict(_asdict(),
|
||||
_current_indent_level):
|
||||
yield chunk
|
||||
elif (_tuple_as_array and isinstance(o, tuple)):
|
||||
for chunk in _iterencode_list(o, _current_indent_level):
|
||||
yield chunk
|
||||
elif isinstance(o, dict):
|
||||
for chunk in _iterencode_dict(o, _current_indent_level):
|
||||
yield chunk
|
||||
elif _use_decimal and isinstance(o, Decimal):
|
||||
yield str(o)
|
||||
else:
|
||||
if markers is not None:
|
||||
markerid = id(o)
|
||||
if markerid in markers:
|
||||
raise ValueError("Circular reference detected")
|
||||
markers[markerid] = o
|
||||
o = _default(o)
|
||||
for chunk in _iterencode(o, _current_indent_level):
|
||||
yield chunk
|
||||
if markers is not None:
|
||||
del markers[markerid]
|
||||
|
||||
return _iterencode
|
||||
@ -1,119 +0,0 @@
|
||||
"""Drop-in replacement for collections.OrderedDict by Raymond Hettinger
|
||||
|
||||
http://code.activestate.com/recipes/576693/
|
||||
|
||||
"""
|
||||
from UserDict import DictMixin
|
||||
|
||||
# Modified from original to support Python 2.4, see
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=53
|
||||
try:
|
||||
all
|
||||
except NameError:
|
||||
def all(seq):
|
||||
for elem in seq:
|
||||
if not elem:
|
||||
return False
|
||||
return True
|
||||
|
||||
class OrderedDict(dict, DictMixin):
|
||||
|
||||
def __init__(self, *args, **kwds):
|
||||
if len(args) > 1:
|
||||
raise TypeError('expected at most 1 arguments, got %d' % len(args))
|
||||
try:
|
||||
self.__end
|
||||
except AttributeError:
|
||||
self.clear()
|
||||
self.update(*args, **kwds)
|
||||
|
||||
def clear(self):
|
||||
self.__end = end = []
|
||||
end += [None, end, end] # sentinel node for doubly linked list
|
||||
self.__map = {} # key --> [key, prev, next]
|
||||
dict.clear(self)
|
||||
|
||||
def __setitem__(self, key, value):
|
||||
if key not in self:
|
||||
end = self.__end
|
||||
curr = end[1]
|
||||
curr[2] = end[1] = self.__map[key] = [key, curr, end]
|
||||
dict.__setitem__(self, key, value)
|
||||
|
||||
def __delitem__(self, key):
|
||||
dict.__delitem__(self, key)
|
||||
key, prev, next = self.__map.pop(key)
|
||||
prev[2] = next
|
||||
next[1] = prev
|
||||
|
||||
def __iter__(self):
|
||||
end = self.__end
|
||||
curr = end[2]
|
||||
while curr is not end:
|
||||
yield curr[0]
|
||||
curr = curr[2]
|
||||
|
||||
def __reversed__(self):
|
||||
end = self.__end
|
||||
curr = end[1]
|
||||
while curr is not end:
|
||||
yield curr[0]
|
||||
curr = curr[1]
|
||||
|
||||
def popitem(self, last=True):
|
||||
if not self:
|
||||
raise KeyError('dictionary is empty')
|
||||
# Modified from original to support Python 2.4, see
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=53
|
||||
if last:
|
||||
key = reversed(self).next()
|
||||
else:
|
||||
key = iter(self).next()
|
||||
value = self.pop(key)
|
||||
return key, value
|
||||
|
||||
def __reduce__(self):
|
||||
items = [[k, self[k]] for k in self]
|
||||
tmp = self.__map, self.__end
|
||||
del self.__map, self.__end
|
||||
inst_dict = vars(self).copy()
|
||||
self.__map, self.__end = tmp
|
||||
if inst_dict:
|
||||
return (self.__class__, (items,), inst_dict)
|
||||
return self.__class__, (items,)
|
||||
|
||||
def keys(self):
|
||||
return list(self)
|
||||
|
||||
setdefault = DictMixin.setdefault
|
||||
update = DictMixin.update
|
||||
pop = DictMixin.pop
|
||||
values = DictMixin.values
|
||||
items = DictMixin.items
|
||||
iterkeys = DictMixin.iterkeys
|
||||
itervalues = DictMixin.itervalues
|
||||
iteritems = DictMixin.iteritems
|
||||
|
||||
def __repr__(self):
|
||||
if not self:
|
||||
return '%s()' % (self.__class__.__name__,)
|
||||
return '%s(%r)' % (self.__class__.__name__, self.items())
|
||||
|
||||
def copy(self):
|
||||
return self.__class__(self)
|
||||
|
||||
@classmethod
|
||||
def fromkeys(cls, iterable, value=None):
|
||||
d = cls()
|
||||
for key in iterable:
|
||||
d[key] = value
|
||||
return d
|
||||
|
||||
def __eq__(self, other):
|
||||
if isinstance(other, OrderedDict):
|
||||
return len(self)==len(other) and \
|
||||
all(p==q for p, q in zip(self.items(), other.items()))
|
||||
return dict.__eq__(self, other)
|
||||
|
||||
def __ne__(self, other):
|
||||
return not self == other
|
||||
@ -1,125 +0,0 @@
|
||||
"""JSON token scanner
|
||||
"""
|
||||
import re
|
||||
def _import_c_make_scanner():
|
||||
try:
|
||||
from simplejson._speedups import make_scanner
|
||||
return make_scanner
|
||||
except ImportError:
|
||||
return None
|
||||
c_make_scanner = _import_c_make_scanner()
|
||||
|
||||
__all__ = ['make_scanner', 'JSONDecodeError']
|
||||
|
||||
NUMBER_RE = re.compile(
|
||||
r'(-?(?:0|[1-9]\d*))(\.\d+)?([eE][-+]?\d+)?',
|
||||
(re.VERBOSE | re.MULTILINE | re.DOTALL))
|
||||
|
||||
class JSONDecodeError(ValueError):
|
||||
"""Subclass of ValueError with the following additional properties:
|
||||
|
||||
msg: The unformatted error message
|
||||
doc: The JSON document being parsed
|
||||
pos: The start index of doc where parsing failed
|
||||
end: The end index of doc where parsing failed (may be None)
|
||||
lineno: The line corresponding to pos
|
||||
colno: The column corresponding to pos
|
||||
endlineno: The line corresponding to end (may be None)
|
||||
endcolno: The column corresponding to end (may be None)
|
||||
|
||||
"""
|
||||
# Note that this exception is used from _speedups
|
||||
def __init__(self, msg, doc, pos, end=None):
|
||||
ValueError.__init__(self, errmsg(msg, doc, pos, end=end))
|
||||
self.msg = msg
|
||||
self.doc = doc
|
||||
self.pos = pos
|
||||
self.end = end
|
||||
self.lineno, self.colno = linecol(doc, pos)
|
||||
if end is not None:
|
||||
self.endlineno, self.endcolno = linecol(doc, end)
|
||||
else:
|
||||
self.endlineno, self.endcolno = None, None
|
||||
|
||||
|
||||
def linecol(doc, pos):
|
||||
lineno = doc.count('\n', 0, pos) + 1
|
||||
if lineno == 1:
|
||||
colno = pos + 1
|
||||
else:
|
||||
colno = pos - doc.rindex('\n', 0, pos)
|
||||
return lineno, colno
|
||||
|
||||
|
||||
def errmsg(msg, doc, pos, end=None):
|
||||
lineno, colno = linecol(doc, pos)
|
||||
msg = msg.replace('%r', repr(doc[pos:pos + 1]))
|
||||
if end is None:
|
||||
fmt = '%s: line %d column %d (char %d)'
|
||||
return fmt % (msg, lineno, colno, pos)
|
||||
endlineno, endcolno = linecol(doc, end)
|
||||
fmt = '%s: line %d column %d - line %d column %d (char %d - %d)'
|
||||
return fmt % (msg, lineno, colno, endlineno, endcolno, pos, end)
|
||||
|
||||
|
||||
def py_make_scanner(context):
|
||||
parse_object = context.parse_object
|
||||
parse_array = context.parse_array
|
||||
parse_string = context.parse_string
|
||||
match_number = NUMBER_RE.match
|
||||
encoding = context.encoding
|
||||
strict = context.strict
|
||||
parse_float = context.parse_float
|
||||
parse_int = context.parse_int
|
||||
parse_constant = context.parse_constant
|
||||
object_hook = context.object_hook
|
||||
object_pairs_hook = context.object_pairs_hook
|
||||
memo = context.memo
|
||||
|
||||
def _scan_once(string, idx):
|
||||
errmsg = 'Expecting value'
|
||||
try:
|
||||
nextchar = string[idx]
|
||||
except IndexError:
|
||||
raise JSONDecodeError(errmsg, string, idx)
|
||||
|
||||
if nextchar == '"':
|
||||
return parse_string(string, idx + 1, encoding, strict)
|
||||
elif nextchar == '{':
|
||||
return parse_object((string, idx + 1), encoding, strict,
|
||||
_scan_once, object_hook, object_pairs_hook, memo)
|
||||
elif nextchar == '[':
|
||||
return parse_array((string, idx + 1), _scan_once)
|
||||
elif nextchar == 'n' and string[idx:idx + 4] == 'null':
|
||||
return None, idx + 4
|
||||
elif nextchar == 't' and string[idx:idx + 4] == 'true':
|
||||
return True, idx + 4
|
||||
elif nextchar == 'f' and string[idx:idx + 5] == 'false':
|
||||
return False, idx + 5
|
||||
|
||||
m = match_number(string, idx)
|
||||
if m is not None:
|
||||
integer, frac, exp = m.groups()
|
||||
if frac or exp:
|
||||
res = parse_float(integer + (frac or '') + (exp or ''))
|
||||
else:
|
||||
res = parse_int(integer)
|
||||
return res, m.end()
|
||||
elif nextchar == 'N' and string[idx:idx + 3] == 'NaN':
|
||||
return parse_constant('NaN'), idx + 3
|
||||
elif nextchar == 'I' and string[idx:idx + 8] == 'Infinity':
|
||||
return parse_constant('Infinity'), idx + 8
|
||||
elif nextchar == '-' and string[idx:idx + 9] == '-Infinity':
|
||||
return parse_constant('-Infinity'), idx + 9
|
||||
else:
|
||||
raise JSONDecodeError(errmsg, string, idx)
|
||||
|
||||
def scan_once(string, idx):
|
||||
try:
|
||||
return _scan_once(string, idx)
|
||||
finally:
|
||||
memo.clear()
|
||||
|
||||
return scan_once
|
||||
|
||||
make_scanner = c_make_scanner or py_make_scanner
|
||||
@ -1,79 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
import unittest
|
||||
import doctest
|
||||
import sys
|
||||
|
||||
class OptionalExtensionTestSuite(unittest.TestSuite):
|
||||
def run(self, result):
|
||||
import simplejson
|
||||
run = unittest.TestSuite.run
|
||||
run(self, result)
|
||||
if simplejson._import_c_make_encoder() is None:
|
||||
TestMissingSpeedups().run(result)
|
||||
else:
|
||||
simplejson._toggle_speedups(False)
|
||||
run(self, result)
|
||||
simplejson._toggle_speedups(True)
|
||||
return result
|
||||
|
||||
class TestMissingSpeedups(unittest.TestCase):
|
||||
def runTest(self):
|
||||
if hasattr(sys, 'pypy_translation_info'):
|
||||
"PyPy doesn't need speedups! :)"
|
||||
elif hasattr(self, 'skipTest'):
|
||||
self.skipTest('_speedups.so is missing!')
|
||||
|
||||
def additional_tests(suite=None):
|
||||
import simplejson
|
||||
import simplejson.encoder
|
||||
import simplejson.decoder
|
||||
if suite is None:
|
||||
suite = unittest.TestSuite()
|
||||
for mod in (simplejson, simplejson.encoder, simplejson.decoder):
|
||||
suite.addTest(doctest.DocTestSuite(mod))
|
||||
suite.addTest(doctest.DocFileSuite('../../index.rst'))
|
||||
return suite
|
||||
|
||||
|
||||
def all_tests_suite():
|
||||
suite = unittest.TestLoader().loadTestsFromNames([
|
||||
'simplejson.tests.test_bigint_as_string',
|
||||
'simplejson.tests.test_check_circular',
|
||||
'simplejson.tests.test_decode',
|
||||
'simplejson.tests.test_default',
|
||||
'simplejson.tests.test_dump',
|
||||
'simplejson.tests.test_encode_basestring_ascii',
|
||||
'simplejson.tests.test_encode_for_html',
|
||||
'simplejson.tests.test_errors',
|
||||
'simplejson.tests.test_fail',
|
||||
'simplejson.tests.test_float',
|
||||
'simplejson.tests.test_indent',
|
||||
'simplejson.tests.test_pass1',
|
||||
'simplejson.tests.test_pass2',
|
||||
'simplejson.tests.test_pass3',
|
||||
'simplejson.tests.test_recursion',
|
||||
'simplejson.tests.test_scanstring',
|
||||
'simplejson.tests.test_separators',
|
||||
'simplejson.tests.test_speedups',
|
||||
'simplejson.tests.test_unicode',
|
||||
'simplejson.tests.test_decimal',
|
||||
'simplejson.tests.test_tuple',
|
||||
'simplejson.tests.test_namedtuple',
|
||||
'simplejson.tests.test_tool',
|
||||
'simplejson.tests.test_for_json',
|
||||
])
|
||||
suite = additional_tests(suite)
|
||||
return OptionalExtensionTestSuite([suite])
|
||||
|
||||
|
||||
def main():
|
||||
runner = unittest.TextTestRunner(verbosity=1 + sys.argv.count('-v'))
|
||||
suite = all_tests_suite()
|
||||
raise SystemExit(not runner.run(suite).wasSuccessful())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
import os
|
||||
import sys
|
||||
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
|
||||
main()
|
||||
@ -1,58 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
from simplejson.compat import long_type
|
||||
|
||||
class TestBigintAsString(TestCase):
|
||||
# Python 2.5, at least the one that ships on Mac OS X, calculates
|
||||
# 2 ** 53 as 0! It manages to calculate 1 << 53 correctly.
|
||||
values = [(200, 200),
|
||||
((1 << 53) - 1, 9007199254740991),
|
||||
((1 << 53), '9007199254740992'),
|
||||
((1 << 53) + 1, '9007199254740993'),
|
||||
(-100, -100),
|
||||
((-1 << 53), '-9007199254740992'),
|
||||
((-1 << 53) - 1, '-9007199254740993'),
|
||||
((-1 << 53) + 1, -9007199254740991)]
|
||||
|
||||
def test_ints(self):
|
||||
for val, expect in self.values:
|
||||
self.assertEqual(
|
||||
val,
|
||||
json.loads(json.dumps(val)))
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.loads(json.dumps(val, bigint_as_string=True)))
|
||||
|
||||
def test_lists(self):
|
||||
for val, expect in self.values:
|
||||
val = [val, val]
|
||||
expect = [expect, expect]
|
||||
self.assertEqual(
|
||||
val,
|
||||
json.loads(json.dumps(val)))
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.loads(json.dumps(val, bigint_as_string=True)))
|
||||
|
||||
def test_dicts(self):
|
||||
for val, expect in self.values:
|
||||
val = {'k': val}
|
||||
expect = {'k': expect}
|
||||
self.assertEqual(
|
||||
val,
|
||||
json.loads(json.dumps(val)))
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.loads(json.dumps(val, bigint_as_string=True)))
|
||||
|
||||
def test_dict_keys(self):
|
||||
for val, _ in self.values:
|
||||
expect = {str(val): 'value'}
|
||||
val = {val: 'value'}
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.loads(json.dumps(val)))
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.loads(json.dumps(val, bigint_as_string=True)))
|
||||
@ -1,30 +0,0 @@
|
||||
from unittest import TestCase
|
||||
import simplejson as json
|
||||
|
||||
def default_iterable(obj):
|
||||
return list(obj)
|
||||
|
||||
class TestCheckCircular(TestCase):
|
||||
def test_circular_dict(self):
|
||||
dct = {}
|
||||
dct['a'] = dct
|
||||
self.assertRaises(ValueError, json.dumps, dct)
|
||||
|
||||
def test_circular_list(self):
|
||||
lst = []
|
||||
lst.append(lst)
|
||||
self.assertRaises(ValueError, json.dumps, lst)
|
||||
|
||||
def test_circular_composite(self):
|
||||
dct2 = {}
|
||||
dct2['a'] = []
|
||||
dct2['a'].append(dct2)
|
||||
self.assertRaises(ValueError, json.dumps, dct2)
|
||||
|
||||
def test_circular_default(self):
|
||||
json.dumps([set()], default=default_iterable)
|
||||
self.assertRaises(TypeError, json.dumps, [set()])
|
||||
|
||||
def test_circular_off_default(self):
|
||||
json.dumps([set()], default=default_iterable, check_circular=False)
|
||||
self.assertRaises(TypeError, json.dumps, [set()], check_circular=False)
|
||||
@ -1,71 +0,0 @@
|
||||
import decimal
|
||||
from decimal import Decimal
|
||||
from unittest import TestCase
|
||||
from simplejson.compat import StringIO, reload_module
|
||||
|
||||
import simplejson as json
|
||||
|
||||
class TestDecimal(TestCase):
|
||||
NUMS = "1.0", "10.00", "1.1", "1234567890.1234567890", "500"
|
||||
def dumps(self, obj, **kw):
|
||||
sio = StringIO()
|
||||
json.dump(obj, sio, **kw)
|
||||
res = json.dumps(obj, **kw)
|
||||
self.assertEqual(res, sio.getvalue())
|
||||
return res
|
||||
|
||||
def loads(self, s, **kw):
|
||||
sio = StringIO(s)
|
||||
res = json.loads(s, **kw)
|
||||
self.assertEqual(res, json.load(sio, **kw))
|
||||
return res
|
||||
|
||||
def test_decimal_encode(self):
|
||||
for d in map(Decimal, self.NUMS):
|
||||
self.assertEqual(self.dumps(d, use_decimal=True), str(d))
|
||||
|
||||
def test_decimal_decode(self):
|
||||
for s in self.NUMS:
|
||||
self.assertEqual(self.loads(s, parse_float=Decimal), Decimal(s))
|
||||
|
||||
def test_stringify_key(self):
|
||||
for d in map(Decimal, self.NUMS):
|
||||
v = {d: d}
|
||||
self.assertEqual(
|
||||
self.loads(
|
||||
self.dumps(v, use_decimal=True), parse_float=Decimal),
|
||||
{str(d): d})
|
||||
|
||||
def test_decimal_roundtrip(self):
|
||||
for d in map(Decimal, self.NUMS):
|
||||
# The type might not be the same (int and Decimal) but they
|
||||
# should still compare equal.
|
||||
for v in [d, [d], {'': d}]:
|
||||
self.assertEqual(
|
||||
self.loads(
|
||||
self.dumps(v, use_decimal=True), parse_float=Decimal),
|
||||
v)
|
||||
|
||||
def test_decimal_defaults(self):
|
||||
d = Decimal('1.1')
|
||||
# use_decimal=True is the default
|
||||
self.assertRaises(TypeError, json.dumps, d, use_decimal=False)
|
||||
self.assertEqual('1.1', json.dumps(d))
|
||||
self.assertEqual('1.1', json.dumps(d, use_decimal=True))
|
||||
self.assertRaises(TypeError, json.dump, d, StringIO(),
|
||||
use_decimal=False)
|
||||
sio = StringIO()
|
||||
json.dump(d, sio)
|
||||
self.assertEqual('1.1', sio.getvalue())
|
||||
sio = StringIO()
|
||||
json.dump(d, sio, use_decimal=True)
|
||||
self.assertEqual('1.1', sio.getvalue())
|
||||
|
||||
def test_decimal_reload(self):
|
||||
# Simulate a subinterpreter that reloads the Python modules but not
|
||||
# the C code https://github.com/simplejson/simplejson/issues/34
|
||||
global Decimal
|
||||
Decimal = reload_module(decimal).Decimal
|
||||
import simplejson.encoder
|
||||
simplejson.encoder.Decimal = Decimal
|
||||
self.test_decimal_roundtrip()
|
||||
@ -1,88 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
import decimal
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
from simplejson.compat import StringIO
|
||||
from simplejson import OrderedDict
|
||||
|
||||
class TestDecode(TestCase):
|
||||
if not hasattr(TestCase, 'assertIs'):
|
||||
def assertIs(self, a, b):
|
||||
self.assertTrue(a is b, '%r is %r' % (a, b))
|
||||
|
||||
def test_decimal(self):
|
||||
rval = json.loads('1.1', parse_float=decimal.Decimal)
|
||||
self.assertTrue(isinstance(rval, decimal.Decimal))
|
||||
self.assertEqual(rval, decimal.Decimal('1.1'))
|
||||
|
||||
def test_float(self):
|
||||
rval = json.loads('1', parse_int=float)
|
||||
self.assertTrue(isinstance(rval, float))
|
||||
self.assertEqual(rval, 1.0)
|
||||
|
||||
def test_decoder_optimizations(self):
|
||||
# Several optimizations were made that skip over calls to
|
||||
# the whitespace regex, so this test is designed to try and
|
||||
# exercise the uncommon cases. The array cases are already covered.
|
||||
rval = json.loads('{ "key" : "value" , "k":"v" }')
|
||||
self.assertEqual(rval, {"key":"value", "k":"v"})
|
||||
|
||||
def test_empty_objects(self):
|
||||
s = '{}'
|
||||
self.assertEqual(json.loads(s), eval(s))
|
||||
s = '[]'
|
||||
self.assertEqual(json.loads(s), eval(s))
|
||||
s = '""'
|
||||
self.assertEqual(json.loads(s), eval(s))
|
||||
|
||||
def test_object_pairs_hook(self):
|
||||
s = '{"xkd":1, "kcw":2, "art":3, "hxm":4, "qrt":5, "pad":6, "hoy":7}'
|
||||
p = [("xkd", 1), ("kcw", 2), ("art", 3), ("hxm", 4),
|
||||
("qrt", 5), ("pad", 6), ("hoy", 7)]
|
||||
self.assertEqual(json.loads(s), eval(s))
|
||||
self.assertEqual(json.loads(s, object_pairs_hook=lambda x: x), p)
|
||||
self.assertEqual(json.load(StringIO(s),
|
||||
object_pairs_hook=lambda x: x), p)
|
||||
od = json.loads(s, object_pairs_hook=OrderedDict)
|
||||
self.assertEqual(od, OrderedDict(p))
|
||||
self.assertEqual(type(od), OrderedDict)
|
||||
# the object_pairs_hook takes priority over the object_hook
|
||||
self.assertEqual(json.loads(s,
|
||||
object_pairs_hook=OrderedDict,
|
||||
object_hook=lambda x: None),
|
||||
OrderedDict(p))
|
||||
|
||||
def check_keys_reuse(self, source, loads):
|
||||
rval = loads(source)
|
||||
(a, b), (c, d) = sorted(rval[0]), sorted(rval[1])
|
||||
self.assertIs(a, c)
|
||||
self.assertIs(b, d)
|
||||
|
||||
def test_keys_reuse_str(self):
|
||||
s = u'[{"a_key": 1, "b_\xe9": 2}, {"a_key": 3, "b_\xe9": 4}]'.encode('utf8')
|
||||
self.check_keys_reuse(s, json.loads)
|
||||
|
||||
def test_keys_reuse_unicode(self):
|
||||
s = u'[{"a_key": 1, "b_\xe9": 2}, {"a_key": 3, "b_\xe9": 4}]'
|
||||
self.check_keys_reuse(s, json.loads)
|
||||
|
||||
def test_empty_strings(self):
|
||||
self.assertEqual(json.loads('""'), "")
|
||||
self.assertEqual(json.loads(u'""'), u"")
|
||||
self.assertEqual(json.loads('[""]'), [""])
|
||||
self.assertEqual(json.loads(u'[""]'), [u""])
|
||||
|
||||
def test_raw_decode(self):
|
||||
cls = json.decoder.JSONDecoder
|
||||
self.assertEqual(
|
||||
({'a': {}}, 9),
|
||||
cls().raw_decode("{\"a\": {}}"))
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=85
|
||||
self.assertEqual(
|
||||
({'a': {}}, 9),
|
||||
cls(object_pairs_hook=dict).raw_decode("{\"a\": {}}"))
|
||||
# https://github.com/simplejson/simplejson/pull/38
|
||||
self.assertEqual(
|
||||
({'a': {}}, 11),
|
||||
cls().raw_decode(" \n{\"a\": {}}"))
|
||||
@ -1,9 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
|
||||
class TestDefault(TestCase):
|
||||
def test_default(self):
|
||||
self.assertEqual(
|
||||
json.dumps(type, default=repr),
|
||||
json.dumps(repr(type)))
|
||||
@ -1,121 +0,0 @@
|
||||
from unittest import TestCase
|
||||
from simplejson.compat import StringIO, long_type, b, binary_type, PY3
|
||||
import simplejson as json
|
||||
|
||||
def as_text_type(s):
|
||||
if PY3 and isinstance(s, binary_type):
|
||||
return s.decode('ascii')
|
||||
return s
|
||||
|
||||
class TestDump(TestCase):
|
||||
def test_dump(self):
|
||||
sio = StringIO()
|
||||
json.dump({}, sio)
|
||||
self.assertEqual(sio.getvalue(), '{}')
|
||||
|
||||
def test_constants(self):
|
||||
for c in [None, True, False]:
|
||||
self.assertTrue(json.loads(json.dumps(c)) is c)
|
||||
self.assertTrue(json.loads(json.dumps([c]))[0] is c)
|
||||
self.assertTrue(json.loads(json.dumps({'a': c}))['a'] is c)
|
||||
|
||||
def test_stringify_key(self):
|
||||
items = [(b('bytes'), 'bytes'),
|
||||
(1.0, '1.0'),
|
||||
(10, '10'),
|
||||
(True, 'true'),
|
||||
(False, 'false'),
|
||||
(None, 'null'),
|
||||
(long_type(100), '100')]
|
||||
for k, expect in items:
|
||||
self.assertEqual(
|
||||
json.loads(json.dumps({k: expect})),
|
||||
{expect: expect})
|
||||
self.assertEqual(
|
||||
json.loads(json.dumps({k: expect}, sort_keys=True)),
|
||||
{expect: expect})
|
||||
self.assertRaises(TypeError, json.dumps, {json: 1})
|
||||
for v in [{}, {'other': 1}, {b('derp'): 1, 'herp': 2}]:
|
||||
for sort_keys in [False, True]:
|
||||
v0 = dict(v)
|
||||
v0[json] = 1
|
||||
v1 = dict((as_text_type(key), val) for (key, val) in v.items())
|
||||
self.assertEqual(
|
||||
json.loads(json.dumps(v0, skipkeys=True, sort_keys=sort_keys)),
|
||||
v1)
|
||||
self.assertEqual(
|
||||
json.loads(json.dumps({'': v0}, skipkeys=True, sort_keys=sort_keys)),
|
||||
{'': v1})
|
||||
self.assertEqual(
|
||||
json.loads(json.dumps([v0], skipkeys=True, sort_keys=sort_keys)),
|
||||
[v1])
|
||||
|
||||
def test_dumps(self):
|
||||
self.assertEqual(json.dumps({}), '{}')
|
||||
|
||||
def test_encode_truefalse(self):
|
||||
self.assertEqual(json.dumps(
|
||||
{True: False, False: True}, sort_keys=True),
|
||||
'{"false": true, "true": false}')
|
||||
self.assertEqual(
|
||||
json.dumps(
|
||||
{2: 3.0,
|
||||
4.0: long_type(5),
|
||||
False: 1,
|
||||
long_type(6): True,
|
||||
"7": 0},
|
||||
sort_keys=True),
|
||||
'{"2": 3.0, "4.0": 5, "6": true, "7": 0, "false": 1}')
|
||||
|
||||
def test_ordered_dict(self):
|
||||
# http://bugs.python.org/issue6105
|
||||
items = [('one', 1), ('two', 2), ('three', 3), ('four', 4), ('five', 5)]
|
||||
s = json.dumps(json.OrderedDict(items))
|
||||
self.assertEqual(
|
||||
s,
|
||||
'{"one": 1, "two": 2, "three": 3, "four": 4, "five": 5}')
|
||||
|
||||
def test_indent_unknown_type_acceptance(self):
|
||||
"""
|
||||
A test against the regression mentioned at `github issue 29`_.
|
||||
|
||||
The indent parameter should accept any type which pretends to be
|
||||
an instance of int or long when it comes to being multiplied by
|
||||
strings, even if it is not actually an int or long, for
|
||||
backwards compatibility.
|
||||
|
||||
.. _github issue 29:
|
||||
http://github.com/simplejson/simplejson/issue/29
|
||||
"""
|
||||
|
||||
class AwesomeInt(object):
|
||||
"""An awesome reimplementation of integers"""
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
if len(args) > 0:
|
||||
# [construct from literals, objects, etc.]
|
||||
# ...
|
||||
|
||||
# Finally, if args[0] is an integer, store it
|
||||
if isinstance(args[0], int):
|
||||
self._int = args[0]
|
||||
|
||||
# [various methods]
|
||||
|
||||
def __mul__(self, other):
|
||||
# [various ways to multiply AwesomeInt objects]
|
||||
# ... finally, if the right-hand operand is not awesome enough,
|
||||
# try to do a normal integer multiplication
|
||||
if hasattr(self, '_int'):
|
||||
return self._int * other
|
||||
else:
|
||||
raise NotImplementedError("To do non-awesome things with"
|
||||
" this object, please construct it from an integer!")
|
||||
|
||||
s = json.dumps([0, 1, 2], indent=AwesomeInt(3))
|
||||
self.assertEqual(s, '[\n 0,\n 1,\n 2\n]')
|
||||
|
||||
def test_accumulator(self):
|
||||
# the C API uses an accumulator that collects after 100,000 appends
|
||||
lst = [0] * 100000
|
||||
self.assertEqual(json.loads(json.dumps(lst)), lst)
|
||||
@ -1,47 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson.encoder
|
||||
from simplejson.compat import b
|
||||
|
||||
CASES = [
|
||||
(u'/\\"\ucafe\ubabe\uab98\ufcde\ubcda\uef4a\x08\x0c\n\r\t`1~!@#$%^&*()_+-=[]{}|;:\',./<>?', '"/\\\\\\"\\ucafe\\ubabe\\uab98\\ufcde\\ubcda\\uef4a\\b\\f\\n\\r\\t`1~!@#$%^&*()_+-=[]{}|;:\',./<>?"'),
|
||||
(u'\u0123\u4567\u89ab\ucdef\uabcd\uef4a', '"\\u0123\\u4567\\u89ab\\ucdef\\uabcd\\uef4a"'),
|
||||
(u'controls', '"controls"'),
|
||||
(u'\x08\x0c\n\r\t', '"\\b\\f\\n\\r\\t"'),
|
||||
(u'{"object with 1 member":["array with 1 element"]}', '"{\\"object with 1 member\\":[\\"array with 1 element\\"]}"'),
|
||||
(u' s p a c e d ', '" s p a c e d "'),
|
||||
(u'\U0001d120', '"\\ud834\\udd20"'),
|
||||
(u'\u03b1\u03a9', '"\\u03b1\\u03a9"'),
|
||||
(b('\xce\xb1\xce\xa9'), '"\\u03b1\\u03a9"'),
|
||||
(u'\u03b1\u03a9', '"\\u03b1\\u03a9"'),
|
||||
(b('\xce\xb1\xce\xa9'), '"\\u03b1\\u03a9"'),
|
||||
(u'\u03b1\u03a9', '"\\u03b1\\u03a9"'),
|
||||
(u'\u03b1\u03a9', '"\\u03b1\\u03a9"'),
|
||||
(u"`1~!@#$%^&*()_+-={':[,]}|;.</>?", '"`1~!@#$%^&*()_+-={\':[,]}|;.</>?"'),
|
||||
(u'\x08\x0c\n\r\t', '"\\b\\f\\n\\r\\t"'),
|
||||
(u'\u0123\u4567\u89ab\ucdef\uabcd\uef4a', '"\\u0123\\u4567\\u89ab\\ucdef\\uabcd\\uef4a"'),
|
||||
]
|
||||
|
||||
class TestEncodeBaseStringAscii(TestCase):
|
||||
def test_py_encode_basestring_ascii(self):
|
||||
self._test_encode_basestring_ascii(simplejson.encoder.py_encode_basestring_ascii)
|
||||
|
||||
def test_c_encode_basestring_ascii(self):
|
||||
if not simplejson.encoder.c_encode_basestring_ascii:
|
||||
return
|
||||
self._test_encode_basestring_ascii(simplejson.encoder.c_encode_basestring_ascii)
|
||||
|
||||
def _test_encode_basestring_ascii(self, encode_basestring_ascii):
|
||||
fname = encode_basestring_ascii.__name__
|
||||
for input_string, expect in CASES:
|
||||
result = encode_basestring_ascii(input_string)
|
||||
#self.assertEqual(result, expect,
|
||||
# '{0!r} != {1!r} for {2}({3!r})'.format(
|
||||
# result, expect, fname, input_string))
|
||||
self.assertEqual(result, expect,
|
||||
'%r != %r for %s(%r)' % (result, expect, fname, input_string))
|
||||
|
||||
def test_sorted_dict(self):
|
||||
items = [('one', 1), ('two', 2), ('three', 3), ('four', 4), ('five', 5)]
|
||||
s = simplejson.dumps(dict(items), sort_keys=True)
|
||||
self.assertEqual(s, '{"five": 5, "four": 4, "one": 1, "three": 3, "two": 2}')
|
||||
@ -1,30 +0,0 @@
|
||||
import unittest
|
||||
|
||||
import simplejson as json
|
||||
|
||||
class TestEncodeForHTML(unittest.TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.decoder = json.JSONDecoder()
|
||||
self.encoder = json.JSONEncoderForHTML()
|
||||
|
||||
def test_basic_encode(self):
|
||||
self.assertEqual(r'"\u0026"', self.encoder.encode('&'))
|
||||
self.assertEqual(r'"\u003c"', self.encoder.encode('<'))
|
||||
self.assertEqual(r'"\u003e"', self.encoder.encode('>'))
|
||||
|
||||
def test_basic_roundtrip(self):
|
||||
for char in '&<>':
|
||||
self.assertEqual(
|
||||
char, self.decoder.decode(
|
||||
self.encoder.encode(char)))
|
||||
|
||||
def test_prevent_script_breakout(self):
|
||||
bad_string = '</script><script>alert("gotcha")</script>'
|
||||
self.assertEqual(
|
||||
r'"\u003c/script\u003e\u003cscript\u003e'
|
||||
r'alert(\"gotcha\")\u003c/script\u003e"',
|
||||
self.encoder.encode(bad_string))
|
||||
self.assertEqual(
|
||||
bad_string, self.decoder.decode(
|
||||
self.encoder.encode(bad_string)))
|
||||
@ -1,35 +0,0 @@
|
||||
import sys
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
from simplejson.compat import u, b
|
||||
|
||||
class TestErrors(TestCase):
|
||||
def test_string_keys_error(self):
|
||||
data = [{'a': 'A', 'b': (2, 4), 'c': 3.0, ('d',): 'D tuple'}]
|
||||
self.assertRaises(TypeError, json.dumps, data)
|
||||
|
||||
def test_decode_error(self):
|
||||
err = None
|
||||
try:
|
||||
json.loads('{}\na\nb')
|
||||
except json.JSONDecodeError:
|
||||
err = sys.exc_info()[1]
|
||||
else:
|
||||
self.fail('Expected JSONDecodeError')
|
||||
self.assertEqual(err.lineno, 2)
|
||||
self.assertEqual(err.colno, 1)
|
||||
self.assertEqual(err.endlineno, 3)
|
||||
self.assertEqual(err.endcolno, 2)
|
||||
|
||||
def test_scan_error(self):
|
||||
err = None
|
||||
for t in (u, b):
|
||||
try:
|
||||
json.loads(t('{"asdf": "'))
|
||||
except json.JSONDecodeError:
|
||||
err = sys.exc_info()[1]
|
||||
else:
|
||||
self.fail('Expected JSONDecodeError')
|
||||
self.assertEqual(err.lineno, 1)
|
||||
self.assertEqual(err.colno, 10)
|
||||
@ -1,176 +0,0 @@
|
||||
import sys
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
|
||||
# 2007-10-05
|
||||
JSONDOCS = [
|
||||
# http://json.org/JSON_checker/test/fail1.json
|
||||
'"A JSON payload should be an object or array, not a string."',
|
||||
# http://json.org/JSON_checker/test/fail2.json
|
||||
'["Unclosed array"',
|
||||
# http://json.org/JSON_checker/test/fail3.json
|
||||
'{unquoted_key: "keys must be quoted"}',
|
||||
# http://json.org/JSON_checker/test/fail4.json
|
||||
'["extra comma",]',
|
||||
# http://json.org/JSON_checker/test/fail5.json
|
||||
'["double extra comma",,]',
|
||||
# http://json.org/JSON_checker/test/fail6.json
|
||||
'[ , "<-- missing value"]',
|
||||
# http://json.org/JSON_checker/test/fail7.json
|
||||
'["Comma after the close"],',
|
||||
# http://json.org/JSON_checker/test/fail8.json
|
||||
'["Extra close"]]',
|
||||
# http://json.org/JSON_checker/test/fail9.json
|
||||
'{"Extra comma": true,}',
|
||||
# http://json.org/JSON_checker/test/fail10.json
|
||||
'{"Extra value after close": true} "misplaced quoted value"',
|
||||
# http://json.org/JSON_checker/test/fail11.json
|
||||
'{"Illegal expression": 1 + 2}',
|
||||
# http://json.org/JSON_checker/test/fail12.json
|
||||
'{"Illegal invocation": alert()}',
|
||||
# http://json.org/JSON_checker/test/fail13.json
|
||||
'{"Numbers cannot have leading zeroes": 013}',
|
||||
# http://json.org/JSON_checker/test/fail14.json
|
||||
'{"Numbers cannot be hex": 0x14}',
|
||||
# http://json.org/JSON_checker/test/fail15.json
|
||||
'["Illegal backslash escape: \\x15"]',
|
||||
# http://json.org/JSON_checker/test/fail16.json
|
||||
'[\\naked]',
|
||||
# http://json.org/JSON_checker/test/fail17.json
|
||||
'["Illegal backslash escape: \\017"]',
|
||||
# http://json.org/JSON_checker/test/fail18.json
|
||||
'[[[[[[[[[[[[[[[[[[[["Too deep"]]]]]]]]]]]]]]]]]]]]',
|
||||
# http://json.org/JSON_checker/test/fail19.json
|
||||
'{"Missing colon" null}',
|
||||
# http://json.org/JSON_checker/test/fail20.json
|
||||
'{"Double colon":: null}',
|
||||
# http://json.org/JSON_checker/test/fail21.json
|
||||
'{"Comma instead of colon", null}',
|
||||
# http://json.org/JSON_checker/test/fail22.json
|
||||
'["Colon instead of comma": false]',
|
||||
# http://json.org/JSON_checker/test/fail23.json
|
||||
'["Bad value", truth]',
|
||||
# http://json.org/JSON_checker/test/fail24.json
|
||||
"['single quote']",
|
||||
# http://json.org/JSON_checker/test/fail25.json
|
||||
'["\ttab\tcharacter\tin\tstring\t"]',
|
||||
# http://json.org/JSON_checker/test/fail26.json
|
||||
'["tab\\ character\\ in\\ string\\ "]',
|
||||
# http://json.org/JSON_checker/test/fail27.json
|
||||
'["line\nbreak"]',
|
||||
# http://json.org/JSON_checker/test/fail28.json
|
||||
'["line\\\nbreak"]',
|
||||
# http://json.org/JSON_checker/test/fail29.json
|
||||
'[0e]',
|
||||
# http://json.org/JSON_checker/test/fail30.json
|
||||
'[0e+]',
|
||||
# http://json.org/JSON_checker/test/fail31.json
|
||||
'[0e+-1]',
|
||||
# http://json.org/JSON_checker/test/fail32.json
|
||||
'{"Comma instead if closing brace": true,',
|
||||
# http://json.org/JSON_checker/test/fail33.json
|
||||
'["mismatch"}',
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=3
|
||||
u'["A\u001FZ control characters in string"]',
|
||||
# misc based on coverage
|
||||
'{',
|
||||
'{]',
|
||||
'{"foo": "bar"]',
|
||||
'{"foo": "bar"',
|
||||
'nul',
|
||||
'nulx',
|
||||
'-',
|
||||
'-x',
|
||||
'-e',
|
||||
'-e0',
|
||||
'-Infinite',
|
||||
'-Inf',
|
||||
'Infinit',
|
||||
'Infinite',
|
||||
'NaM',
|
||||
'NuN',
|
||||
'falsy',
|
||||
'fal',
|
||||
'trug',
|
||||
'tru',
|
||||
'1e',
|
||||
'1ex',
|
||||
'1e-',
|
||||
'1e-x',
|
||||
]
|
||||
|
||||
SKIPS = {
|
||||
1: "why not have a string payload?",
|
||||
18: "spec doesn't specify any nesting limitations",
|
||||
}
|
||||
|
||||
class TestFail(TestCase):
|
||||
def test_failures(self):
|
||||
for idx, doc in enumerate(JSONDOCS):
|
||||
idx = idx + 1
|
||||
if idx in SKIPS:
|
||||
json.loads(doc)
|
||||
continue
|
||||
try:
|
||||
json.loads(doc)
|
||||
except json.JSONDecodeError:
|
||||
pass
|
||||
else:
|
||||
self.fail("Expected failure for fail%d.json: %r" % (idx, doc))
|
||||
|
||||
def test_array_decoder_issue46(self):
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=46
|
||||
for doc in [u'[,]', '[,]']:
|
||||
try:
|
||||
json.loads(doc)
|
||||
except json.JSONDecodeError:
|
||||
e = sys.exc_info()[1]
|
||||
self.assertEqual(e.pos, 1)
|
||||
self.assertEqual(e.lineno, 1)
|
||||
self.assertEqual(e.colno, 2)
|
||||
except Exception:
|
||||
e = sys.exc_info()[1]
|
||||
self.fail("Unexpected exception raised %r %s" % (e, e))
|
||||
else:
|
||||
self.fail("Unexpected success parsing '[,]'")
|
||||
|
||||
def test_truncated_input(self):
|
||||
test_cases = [
|
||||
('', 'Expecting value', 0),
|
||||
('[', "Expecting value or ']'", 1),
|
||||
('[42', "Expecting ',' delimiter", 3),
|
||||
('[42,', 'Expecting value', 4),
|
||||
('["', 'Unterminated string starting at', 1),
|
||||
('["spam', 'Unterminated string starting at', 1),
|
||||
('["spam"', "Expecting ',' delimiter", 7),
|
||||
('["spam",', 'Expecting value', 8),
|
||||
('{', 'Expecting property name enclosed in double quotes', 1),
|
||||
('{"', 'Unterminated string starting at', 1),
|
||||
('{"spam', 'Unterminated string starting at', 1),
|
||||
('{"spam"', "Expecting ':' delimiter", 7),
|
||||
('{"spam":', 'Expecting value', 8),
|
||||
('{"spam":42', "Expecting ',' delimiter", 10),
|
||||
('{"spam":42,', 'Expecting property name enclosed in double quotes',
|
||||
11),
|
||||
('"', 'Unterminated string starting at', 0),
|
||||
('"spam', 'Unterminated string starting at', 0),
|
||||
('[,', "Expecting value", 1),
|
||||
]
|
||||
for data, msg, idx in test_cases:
|
||||
try:
|
||||
json.loads(data)
|
||||
except json.JSONDecodeError:
|
||||
e = sys.exc_info()[1]
|
||||
self.assertEqual(
|
||||
e.msg[:len(msg)],
|
||||
msg,
|
||||
"%r doesn't start with %r for %r" % (e.msg, msg, data))
|
||||
self.assertEqual(
|
||||
e.pos, idx,
|
||||
"pos %r != %r for %r" % (e.pos, idx, data))
|
||||
except Exception:
|
||||
e = sys.exc_info()[1]
|
||||
self.fail("Unexpected exception raised %r %s" % (e, e))
|
||||
else:
|
||||
self.fail("Unexpected success parsing '%r'" % (data,))
|
||||
@ -1,35 +0,0 @@
|
||||
import math
|
||||
from unittest import TestCase
|
||||
from simplejson.compat import long_type, text_type
|
||||
import simplejson as json
|
||||
from simplejson.decoder import NaN, PosInf, NegInf
|
||||
|
||||
class TestFloat(TestCase):
|
||||
def test_degenerates_allow(self):
|
||||
for inf in (PosInf, NegInf):
|
||||
self.assertEqual(json.loads(json.dumps(inf)), inf)
|
||||
# Python 2.5 doesn't have math.isnan
|
||||
nan = json.loads(json.dumps(NaN))
|
||||
self.assertTrue((0 + nan) != nan)
|
||||
|
||||
def test_degenerates_ignore(self):
|
||||
for f in (PosInf, NegInf, NaN):
|
||||
self.assertEqual(json.loads(json.dumps(f, ignore_nan=True)), None)
|
||||
|
||||
def test_degenerates_deny(self):
|
||||
for f in (PosInf, NegInf, NaN):
|
||||
self.assertRaises(ValueError, json.dumps, f, allow_nan=False)
|
||||
|
||||
def test_floats(self):
|
||||
for num in [1617161771.7650001, math.pi, math.pi**100,
|
||||
math.pi**-100, 3.1]:
|
||||
self.assertEqual(float(json.dumps(num)), num)
|
||||
self.assertEqual(json.loads(json.dumps(num)), num)
|
||||
self.assertEqual(json.loads(text_type(json.dumps(num))), num)
|
||||
|
||||
def test_ints(self):
|
||||
for num in [1, long_type(1), 1<<32, 1<<64]:
|
||||
self.assertEqual(json.dumps(num), str(num))
|
||||
self.assertEqual(int(json.dumps(num)), num)
|
||||
self.assertEqual(json.loads(json.dumps(num)), num)
|
||||
self.assertEqual(json.loads(text_type(json.dumps(num))), num)
|
||||
@ -1,97 +0,0 @@
|
||||
import unittest
|
||||
import simplejson as json
|
||||
|
||||
|
||||
class ForJson(object):
|
||||
def for_json(self):
|
||||
return {'for_json': 1}
|
||||
|
||||
|
||||
class NestedForJson(object):
|
||||
def for_json(self):
|
||||
return {'nested': ForJson()}
|
||||
|
||||
|
||||
class ForJsonList(object):
|
||||
def for_json(self):
|
||||
return ['list']
|
||||
|
||||
|
||||
class DictForJson(dict):
|
||||
def for_json(self):
|
||||
return {'alpha': 1}
|
||||
|
||||
|
||||
class ListForJson(list):
|
||||
def for_json(self):
|
||||
return ['list']
|
||||
|
||||
|
||||
class TestForJson(unittest.TestCase):
|
||||
def assertRoundTrip(self, obj, other, for_json=True):
|
||||
if for_json is None:
|
||||
# None will use the default
|
||||
s = json.dumps(obj)
|
||||
else:
|
||||
s = json.dumps(obj, for_json=for_json)
|
||||
self.assertEqual(
|
||||
json.loads(s),
|
||||
other)
|
||||
|
||||
def test_for_json_encodes_stand_alone_object(self):
|
||||
self.assertRoundTrip(
|
||||
ForJson(),
|
||||
ForJson().for_json())
|
||||
|
||||
def test_for_json_encodes_object_nested_in_dict(self):
|
||||
self.assertRoundTrip(
|
||||
{'hooray': ForJson()},
|
||||
{'hooray': ForJson().for_json()})
|
||||
|
||||
def test_for_json_encodes_object_nested_in_list_within_dict(self):
|
||||
self.assertRoundTrip(
|
||||
{'list': [0, ForJson(), 2, 3]},
|
||||
{'list': [0, ForJson().for_json(), 2, 3]})
|
||||
|
||||
def test_for_json_encodes_object_nested_within_object(self):
|
||||
self.assertRoundTrip(
|
||||
NestedForJson(),
|
||||
{'nested': {'for_json': 1}})
|
||||
|
||||
def test_for_json_encodes_list(self):
|
||||
self.assertRoundTrip(
|
||||
ForJsonList(),
|
||||
ForJsonList().for_json())
|
||||
|
||||
def test_for_json_encodes_list_within_object(self):
|
||||
self.assertRoundTrip(
|
||||
{'nested': ForJsonList()},
|
||||
{'nested': ForJsonList().for_json()})
|
||||
|
||||
def test_for_json_encodes_dict_subclass(self):
|
||||
self.assertRoundTrip(
|
||||
DictForJson(a=1),
|
||||
DictForJson(a=1).for_json())
|
||||
|
||||
def test_for_json_encodes_list_subclass(self):
|
||||
self.assertRoundTrip(
|
||||
ListForJson(['l']),
|
||||
ListForJson(['l']).for_json())
|
||||
|
||||
def test_for_json_ignored_if_not_true_with_dict_subclass(self):
|
||||
for for_json in (None, False):
|
||||
self.assertRoundTrip(
|
||||
DictForJson(a=1),
|
||||
{'a': 1},
|
||||
for_json=for_json)
|
||||
|
||||
def test_for_json_ignored_if_not_true_with_list_subclass(self):
|
||||
for for_json in (None, False):
|
||||
self.assertRoundTrip(
|
||||
ListForJson(['l']),
|
||||
['l'],
|
||||
for_json=for_json)
|
||||
|
||||
def test_raises_typeerror_if_for_json_not_true_with_object(self):
|
||||
self.assertRaises(TypeError, json.dumps, ForJson())
|
||||
self.assertRaises(TypeError, json.dumps, ForJson(), for_json=False)
|
||||
@ -1,86 +0,0 @@
|
||||
from unittest import TestCase
|
||||
import textwrap
|
||||
|
||||
import simplejson as json
|
||||
from simplejson.compat import StringIO
|
||||
|
||||
class TestIndent(TestCase):
|
||||
def test_indent(self):
|
||||
h = [['blorpie'], ['whoops'], [], 'd-shtaeou', 'd-nthiouh',
|
||||
'i-vhbjkhnth',
|
||||
{'nifty': 87}, {'field': 'yes', 'morefield': False} ]
|
||||
|
||||
expect = textwrap.dedent("""\
|
||||
[
|
||||
\t[
|
||||
\t\t"blorpie"
|
||||
\t],
|
||||
\t[
|
||||
\t\t"whoops"
|
||||
\t],
|
||||
\t[],
|
||||
\t"d-shtaeou",
|
||||
\t"d-nthiouh",
|
||||
\t"i-vhbjkhnth",
|
||||
\t{
|
||||
\t\t"nifty": 87
|
||||
\t},
|
||||
\t{
|
||||
\t\t"field": "yes",
|
||||
\t\t"morefield": false
|
||||
\t}
|
||||
]""")
|
||||
|
||||
|
||||
d1 = json.dumps(h)
|
||||
d2 = json.dumps(h, indent='\t', sort_keys=True, separators=(',', ': '))
|
||||
d3 = json.dumps(h, indent=' ', sort_keys=True, separators=(',', ': '))
|
||||
d4 = json.dumps(h, indent=2, sort_keys=True, separators=(',', ': '))
|
||||
|
||||
h1 = json.loads(d1)
|
||||
h2 = json.loads(d2)
|
||||
h3 = json.loads(d3)
|
||||
h4 = json.loads(d4)
|
||||
|
||||
self.assertEqual(h1, h)
|
||||
self.assertEqual(h2, h)
|
||||
self.assertEqual(h3, h)
|
||||
self.assertEqual(h4, h)
|
||||
self.assertEqual(d3, expect.replace('\t', ' '))
|
||||
self.assertEqual(d4, expect.replace('\t', ' '))
|
||||
# NOTE: Python 2.4 textwrap.dedent converts tabs to spaces,
|
||||
# so the following is expected to fail. Python 2.4 is not a
|
||||
# supported platform in simplejson 2.1.0+.
|
||||
self.assertEqual(d2, expect)
|
||||
|
||||
def test_indent0(self):
|
||||
h = {3: 1}
|
||||
def check(indent, expected):
|
||||
d1 = json.dumps(h, indent=indent)
|
||||
self.assertEqual(d1, expected)
|
||||
|
||||
sio = StringIO()
|
||||
json.dump(h, sio, indent=indent)
|
||||
self.assertEqual(sio.getvalue(), expected)
|
||||
|
||||
# indent=0 should emit newlines
|
||||
check(0, '{\n"3": 1\n}')
|
||||
# indent=None is more compact
|
||||
check(None, '{"3": 1}')
|
||||
|
||||
def test_separators(self):
|
||||
lst = [1,2,3,4]
|
||||
expect = '[\n1,\n2,\n3,\n4\n]'
|
||||
expect_spaces = '[\n1, \n2, \n3, \n4\n]'
|
||||
# Ensure that separators still works
|
||||
self.assertEqual(
|
||||
expect_spaces,
|
||||
json.dumps(lst, indent=0, separators=(', ', ': ')))
|
||||
# Force the new defaults
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.dumps(lst, indent=0, separators=(',', ': ')))
|
||||
# Added in 2.1.4
|
||||
self.assertEqual(
|
||||
expect,
|
||||
json.dumps(lst, indent=0))
|
||||
@ -1,20 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
from operator import itemgetter
|
||||
|
||||
class TestItemSortKey(TestCase):
|
||||
def test_simple_first(self):
|
||||
a = {'a': 1, 'c': 5, 'jack': 'jill', 'pick': 'axe', 'array': [1, 5, 6, 9], 'tuple': (83, 12, 3), 'crate': 'dog', 'zeak': 'oh'}
|
||||
self.assertEqual(
|
||||
'{"a": 1, "c": 5, "crate": "dog", "jack": "jill", "pick": "axe", "zeak": "oh", "array": [1, 5, 6, 9], "tuple": [83, 12, 3]}',
|
||||
json.dumps(a, item_sort_key=json.simple_first))
|
||||
|
||||
def test_case(self):
|
||||
a = {'a': 1, 'c': 5, 'Jack': 'jill', 'pick': 'axe', 'Array': [1, 5, 6, 9], 'tuple': (83, 12, 3), 'crate': 'dog', 'zeak': 'oh'}
|
||||
self.assertEqual(
|
||||
'{"Array": [1, 5, 6, 9], "Jack": "jill", "a": 1, "c": 5, "crate": "dog", "pick": "axe", "tuple": [83, 12, 3], "zeak": "oh"}',
|
||||
json.dumps(a, item_sort_key=itemgetter(0)))
|
||||
self.assertEqual(
|
||||
'{"a": 1, "Array": [1, 5, 6, 9], "c": 5, "crate": "dog", "Jack": "jill", "pick": "axe", "tuple": [83, 12, 3], "zeak": "oh"}',
|
||||
json.dumps(a, item_sort_key=lambda kv: kv[0].lower()))
|
||||
@ -1,122 +0,0 @@
|
||||
from __future__ import absolute_import
|
||||
import unittest
|
||||
import simplejson as json
|
||||
from simplejson.compat import StringIO
|
||||
|
||||
try:
|
||||
from collections import namedtuple
|
||||
except ImportError:
|
||||
class Value(tuple):
|
||||
def __new__(cls, *args):
|
||||
return tuple.__new__(cls, args)
|
||||
|
||||
def _asdict(self):
|
||||
return {'value': self[0]}
|
||||
class Point(tuple):
|
||||
def __new__(cls, *args):
|
||||
return tuple.__new__(cls, args)
|
||||
|
||||
def _asdict(self):
|
||||
return {'x': self[0], 'y': self[1]}
|
||||
else:
|
||||
Value = namedtuple('Value', ['value'])
|
||||
Point = namedtuple('Point', ['x', 'y'])
|
||||
|
||||
class DuckValue(object):
|
||||
def __init__(self, *args):
|
||||
self.value = Value(*args)
|
||||
|
||||
def _asdict(self):
|
||||
return self.value._asdict()
|
||||
|
||||
class DuckPoint(object):
|
||||
def __init__(self, *args):
|
||||
self.point = Point(*args)
|
||||
|
||||
def _asdict(self):
|
||||
return self.point._asdict()
|
||||
|
||||
class DeadDuck(object):
|
||||
_asdict = None
|
||||
|
||||
class DeadDict(dict):
|
||||
_asdict = None
|
||||
|
||||
CONSTRUCTORS = [
|
||||
lambda v: v,
|
||||
lambda v: [v],
|
||||
lambda v: [{'key': v}],
|
||||
]
|
||||
|
||||
class TestNamedTuple(unittest.TestCase):
|
||||
def test_namedtuple_dumps(self):
|
||||
for v in [Value(1), Point(1, 2), DuckValue(1), DuckPoint(1, 2)]:
|
||||
d = v._asdict()
|
||||
self.assertEqual(d, json.loads(json.dumps(v)))
|
||||
self.assertEqual(
|
||||
d,
|
||||
json.loads(json.dumps(v, namedtuple_as_object=True)))
|
||||
self.assertEqual(d, json.loads(json.dumps(v, tuple_as_array=False)))
|
||||
self.assertEqual(
|
||||
d,
|
||||
json.loads(json.dumps(v, namedtuple_as_object=True,
|
||||
tuple_as_array=False)))
|
||||
|
||||
def test_namedtuple_dumps_false(self):
|
||||
for v in [Value(1), Point(1, 2)]:
|
||||
l = list(v)
|
||||
self.assertEqual(
|
||||
l,
|
||||
json.loads(json.dumps(v, namedtuple_as_object=False)))
|
||||
self.assertRaises(TypeError, json.dumps, v,
|
||||
tuple_as_array=False, namedtuple_as_object=False)
|
||||
|
||||
def test_namedtuple_dump(self):
|
||||
for v in [Value(1), Point(1, 2), DuckValue(1), DuckPoint(1, 2)]:
|
||||
d = v._asdict()
|
||||
sio = StringIO()
|
||||
json.dump(v, sio)
|
||||
self.assertEqual(d, json.loads(sio.getvalue()))
|
||||
sio = StringIO()
|
||||
json.dump(v, sio, namedtuple_as_object=True)
|
||||
self.assertEqual(
|
||||
d,
|
||||
json.loads(sio.getvalue()))
|
||||
sio = StringIO()
|
||||
json.dump(v, sio, tuple_as_array=False)
|
||||
self.assertEqual(d, json.loads(sio.getvalue()))
|
||||
sio = StringIO()
|
||||
json.dump(v, sio, namedtuple_as_object=True,
|
||||
tuple_as_array=False)
|
||||
self.assertEqual(
|
||||
d,
|
||||
json.loads(sio.getvalue()))
|
||||
|
||||
def test_namedtuple_dump_false(self):
|
||||
for v in [Value(1), Point(1, 2)]:
|
||||
l = list(v)
|
||||
sio = StringIO()
|
||||
json.dump(v, sio, namedtuple_as_object=False)
|
||||
self.assertEqual(
|
||||
l,
|
||||
json.loads(sio.getvalue()))
|
||||
self.assertRaises(TypeError, json.dump, v, StringIO(),
|
||||
tuple_as_array=False, namedtuple_as_object=False)
|
||||
|
||||
def test_asdict_not_callable_dump(self):
|
||||
for f in CONSTRUCTORS:
|
||||
self.assertRaises(TypeError,
|
||||
json.dump, f(DeadDuck()), StringIO(), namedtuple_as_object=True)
|
||||
sio = StringIO()
|
||||
json.dump(f(DeadDict()), sio, namedtuple_as_object=True)
|
||||
self.assertEqual(
|
||||
json.dumps(f({})),
|
||||
sio.getvalue())
|
||||
|
||||
def test_asdict_not_callable_dumps(self):
|
||||
for f in CONSTRUCTORS:
|
||||
self.assertRaises(TypeError,
|
||||
json.dumps, f(DeadDuck()), namedtuple_as_object=True)
|
||||
self.assertEqual(
|
||||
json.dumps(f({})),
|
||||
json.dumps(f(DeadDict()), namedtuple_as_object=True))
|
||||
@ -1,71 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
|
||||
# from http://json.org/JSON_checker/test/pass1.json
|
||||
JSON = r'''
|
||||
[
|
||||
"JSON Test Pattern pass1",
|
||||
{"object with 1 member":["array with 1 element"]},
|
||||
{},
|
||||
[],
|
||||
-42,
|
||||
true,
|
||||
false,
|
||||
null,
|
||||
{
|
||||
"integer": 1234567890,
|
||||
"real": -9876.543210,
|
||||
"e": 0.123456789e-12,
|
||||
"E": 1.234567890E+34,
|
||||
"": 23456789012E66,
|
||||
"zero": 0,
|
||||
"one": 1,
|
||||
"space": " ",
|
||||
"quote": "\"",
|
||||
"backslash": "\\",
|
||||
"controls": "\b\f\n\r\t",
|
||||
"slash": "/ & \/",
|
||||
"alpha": "abcdefghijklmnopqrstuvwyz",
|
||||
"ALPHA": "ABCDEFGHIJKLMNOPQRSTUVWYZ",
|
||||
"digit": "0123456789",
|
||||
"special": "`1~!@#$%^&*()_+-={':[,]}|;.</>?",
|
||||
"hex": "\u0123\u4567\u89AB\uCDEF\uabcd\uef4A",
|
||||
"true": true,
|
||||
"false": false,
|
||||
"null": null,
|
||||
"array":[ ],
|
||||
"object":{ },
|
||||
"address": "50 St. James Street",
|
||||
"url": "http://www.JSON.org/",
|
||||
"comment": "// /* <!-- --",
|
||||
"# -- --> */": " ",
|
||||
" s p a c e d " :[1,2 , 3
|
||||
|
||||
,
|
||||
|
||||
4 , 5 , 6 ,7 ],"compact": [1,2,3,4,5,6,7],
|
||||
"jsontext": "{\"object with 1 member\":[\"array with 1 element\"]}",
|
||||
"quotes": "" \u0022 %22 0x22 034 "",
|
||||
"\/\\\"\uCAFE\uBABE\uAB98\uFCDE\ubcda\uef4A\b\f\n\r\t`1~!@#$%^&*()_+-=[]{}|;:',./<>?"
|
||||
: "A key can be any string"
|
||||
},
|
||||
0.5 ,98.6
|
||||
,
|
||||
99.44
|
||||
,
|
||||
|
||||
1066,
|
||||
1e1,
|
||||
0.1e1,
|
||||
1e-1,
|
||||
1e00,2e+00,2e-00
|
||||
,"rosebud"]
|
||||
'''
|
||||
|
||||
class TestPass1(TestCase):
|
||||
def test_parse(self):
|
||||
# test in/out equivalence and parsing
|
||||
res = json.loads(JSON)
|
||||
out = json.dumps(res)
|
||||
self.assertEqual(res, json.loads(out))
|
||||
@ -1,14 +0,0 @@
|
||||
from unittest import TestCase
|
||||
import simplejson as json
|
||||
|
||||
# from http://json.org/JSON_checker/test/pass2.json
|
||||
JSON = r'''
|
||||
[[[[[[[[[[[[[[[[[[["Not too deep"]]]]]]]]]]]]]]]]]]]
|
||||
'''
|
||||
|
||||
class TestPass2(TestCase):
|
||||
def test_parse(self):
|
||||
# test in/out equivalence and parsing
|
||||
res = json.loads(JSON)
|
||||
out = json.dumps(res)
|
||||
self.assertEqual(res, json.loads(out))
|
||||
@ -1,20 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
|
||||
# from http://json.org/JSON_checker/test/pass3.json
|
||||
JSON = r'''
|
||||
{
|
||||
"JSON Test Pattern pass3": {
|
||||
"The outermost value": "must be an object or array.",
|
||||
"In this test": "It is an object."
|
||||
}
|
||||
}
|
||||
'''
|
||||
|
||||
class TestPass3(TestCase):
|
||||
def test_parse(self):
|
||||
# test in/out equivalence and parsing
|
||||
res = json.loads(JSON)
|
||||
out = json.dumps(res)
|
||||
self.assertEqual(res, json.loads(out))
|
||||
@ -1,67 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
|
||||
class JSONTestObject:
|
||||
pass
|
||||
|
||||
|
||||
class RecursiveJSONEncoder(json.JSONEncoder):
|
||||
recurse = False
|
||||
def default(self, o):
|
||||
if o is JSONTestObject:
|
||||
if self.recurse:
|
||||
return [JSONTestObject]
|
||||
else:
|
||||
return 'JSONTestObject'
|
||||
return json.JSONEncoder.default(o)
|
||||
|
||||
|
||||
class TestRecursion(TestCase):
|
||||
def test_listrecursion(self):
|
||||
x = []
|
||||
x.append(x)
|
||||
try:
|
||||
json.dumps(x)
|
||||
except ValueError:
|
||||
pass
|
||||
else:
|
||||
self.fail("didn't raise ValueError on list recursion")
|
||||
x = []
|
||||
y = [x]
|
||||
x.append(y)
|
||||
try:
|
||||
json.dumps(x)
|
||||
except ValueError:
|
||||
pass
|
||||
else:
|
||||
self.fail("didn't raise ValueError on alternating list recursion")
|
||||
y = []
|
||||
x = [y, y]
|
||||
# ensure that the marker is cleared
|
||||
json.dumps(x)
|
||||
|
||||
def test_dictrecursion(self):
|
||||
x = {}
|
||||
x["test"] = x
|
||||
try:
|
||||
json.dumps(x)
|
||||
except ValueError:
|
||||
pass
|
||||
else:
|
||||
self.fail("didn't raise ValueError on dict recursion")
|
||||
x = {}
|
||||
y = {"a": x, "b": x}
|
||||
# ensure that the marker is cleared
|
||||
json.dumps(y)
|
||||
|
||||
def test_defaultrecursion(self):
|
||||
enc = RecursiveJSONEncoder()
|
||||
self.assertEqual(enc.encode(JSONTestObject), '"JSONTestObject"')
|
||||
enc.recurse = True
|
||||
try:
|
||||
enc.encode(JSONTestObject)
|
||||
except ValueError:
|
||||
pass
|
||||
else:
|
||||
self.fail("didn't raise ValueError on default recursion")
|
||||
@ -1,194 +0,0 @@
|
||||
import sys
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
import simplejson.decoder
|
||||
from simplejson.compat import b, PY3
|
||||
|
||||
class TestScanString(TestCase):
|
||||
# The bytes type is intentionally not used in most of these tests
|
||||
# under Python 3 because the decoder immediately coerces to str before
|
||||
# calling scanstring. In Python 2 we are testing the code paths
|
||||
# for both unicode and str.
|
||||
#
|
||||
# The reason this is done is because Python 3 would require
|
||||
# entirely different code paths for parsing bytes and str.
|
||||
#
|
||||
def test_py_scanstring(self):
|
||||
self._test_scanstring(simplejson.decoder.py_scanstring)
|
||||
|
||||
def test_c_scanstring(self):
|
||||
if not simplejson.decoder.c_scanstring:
|
||||
return
|
||||
self._test_scanstring(simplejson.decoder.c_scanstring)
|
||||
|
||||
def _test_scanstring(self, scanstring):
|
||||
if sys.maxunicode == 65535:
|
||||
self.assertEqual(
|
||||
scanstring(u'"z\U0001d120x"', 1, None, True),
|
||||
(u'z\U0001d120x', 6))
|
||||
else:
|
||||
self.assertEqual(
|
||||
scanstring(u'"z\U0001d120x"', 1, None, True),
|
||||
(u'z\U0001d120x', 5))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('"\\u007b"', 1, None, True),
|
||||
(u'{', 8))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('"A JSON payload should be an object or array, not a string."', 1, None, True),
|
||||
(u'A JSON payload should be an object or array, not a string.', 60))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["Unclosed array"', 2, None, True),
|
||||
(u'Unclosed array', 17))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["extra comma",]', 2, None, True),
|
||||
(u'extra comma', 14))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["double extra comma",,]', 2, None, True),
|
||||
(u'double extra comma', 21))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["Comma after the close"],', 2, None, True),
|
||||
(u'Comma after the close', 24))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["Extra close"]]', 2, None, True),
|
||||
(u'Extra close', 14))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Extra comma": true,}', 2, None, True),
|
||||
(u'Extra comma', 14))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Extra value after close": true} "misplaced quoted value"', 2, None, True),
|
||||
(u'Extra value after close', 26))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Illegal expression": 1 + 2}', 2, None, True),
|
||||
(u'Illegal expression', 21))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Illegal invocation": alert()}', 2, None, True),
|
||||
(u'Illegal invocation', 21))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Numbers cannot have leading zeroes": 013}', 2, None, True),
|
||||
(u'Numbers cannot have leading zeroes', 37))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Numbers cannot be hex": 0x14}', 2, None, True),
|
||||
(u'Numbers cannot be hex', 24))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('[[[[[[[[[[[[[[[[[[[["Too deep"]]]]]]]]]]]]]]]]]]]]', 21, None, True),
|
||||
(u'Too deep', 30))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Missing colon" null}', 2, None, True),
|
||||
(u'Missing colon', 16))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Double colon":: null}', 2, None, True),
|
||||
(u'Double colon', 15))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('{"Comma instead of colon", null}', 2, None, True),
|
||||
(u'Comma instead of colon', 25))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["Colon instead of comma": false]', 2, None, True),
|
||||
(u'Colon instead of comma', 25))
|
||||
|
||||
self.assertEqual(
|
||||
scanstring('["Bad value", truth]', 2, None, True),
|
||||
(u'Bad value', 12))
|
||||
|
||||
for c in map(chr, range(0x00, 0x1f)):
|
||||
self.assertEqual(
|
||||
scanstring(c + '"', 0, None, False),
|
||||
(c, 2))
|
||||
self.assertRaises(
|
||||
ValueError,
|
||||
scanstring, c + '"', 0, None, True)
|
||||
|
||||
self.assertRaises(ValueError, scanstring, '', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, 'a', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, '\\', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, '\\u', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, '\\u0', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, '\\u01', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, '\\u012', 0, None, True)
|
||||
self.assertRaises(ValueError, scanstring, '\\u0123', 0, None, True)
|
||||
if sys.maxunicode > 65535:
|
||||
self.assertRaises(ValueError,
|
||||
scanstring, '\\ud834\\u"', 0, None, True)
|
||||
self.assertRaises(ValueError,
|
||||
scanstring, '\\ud834\\x0123"', 0, None, True)
|
||||
|
||||
def test_issue3623(self):
|
||||
self.assertRaises(ValueError, json.decoder.scanstring, "xxx", 1,
|
||||
"xxx")
|
||||
self.assertRaises(UnicodeDecodeError,
|
||||
json.encoder.encode_basestring_ascii, b("xx\xff"))
|
||||
|
||||
def test_overflow(self):
|
||||
# Python 2.5 does not have maxsize, Python 3 does not have maxint
|
||||
maxsize = getattr(sys, 'maxsize', getattr(sys, 'maxint', None))
|
||||
assert maxsize is not None
|
||||
self.assertRaises(OverflowError, json.decoder.scanstring, "xxx",
|
||||
maxsize + 1)
|
||||
|
||||
def test_surrogates(self):
|
||||
scanstring = json.decoder.scanstring
|
||||
|
||||
def assertScan(given, expect, test_utf8=True):
|
||||
givens = [given]
|
||||
if not PY3 and test_utf8:
|
||||
givens.append(given.encode('utf8'))
|
||||
for given in givens:
|
||||
(res, count) = scanstring(given, 1, None, True)
|
||||
self.assertEqual(len(given), count)
|
||||
self.assertEqual(res, expect)
|
||||
|
||||
assertScan(
|
||||
u'"z\\ud834\\u0079x"',
|
||||
u'z\ud834yx')
|
||||
assertScan(
|
||||
u'"z\\ud834\\udd20x"',
|
||||
u'z\U0001d120x')
|
||||
assertScan(
|
||||
u'"z\\ud834\\ud834\\udd20x"',
|
||||
u'z\ud834\U0001d120x')
|
||||
assertScan(
|
||||
u'"z\\ud834x"',
|
||||
u'z\ud834x')
|
||||
assertScan(
|
||||
u'"z\\udd20x"',
|
||||
u'z\udd20x')
|
||||
assertScan(
|
||||
u'"z\ud834x"',
|
||||
u'z\ud834x')
|
||||
# It may look strange to join strings together, but Python is drunk.
|
||||
# https://gist.github.com/etrepum/5538443
|
||||
assertScan(
|
||||
u'"z\\ud834\udd20x12345"',
|
||||
u''.join([u'z\ud834', u'\udd20x12345']))
|
||||
assertScan(
|
||||
u'"z\ud834\\udd20x"',
|
||||
u''.join([u'z\ud834', u'\udd20x']))
|
||||
# these have different behavior given UTF8 input, because the surrogate
|
||||
# pair may be joined (in maxunicode > 65535 builds)
|
||||
assertScan(
|
||||
u''.join([u'"z\ud834', u'\udd20x"']),
|
||||
u''.join([u'z\ud834', u'\udd20x']),
|
||||
test_utf8=False)
|
||||
|
||||
self.assertRaises(ValueError,
|
||||
scanstring, u'"z\\ud83x"', 1, None, True)
|
||||
self.assertRaises(ValueError,
|
||||
scanstring, u'"z\\ud834\\udd2x"', 1, None, True)
|
||||
@ -1,42 +0,0 @@
|
||||
import textwrap
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
|
||||
|
||||
class TestSeparators(TestCase):
|
||||
def test_separators(self):
|
||||
h = [['blorpie'], ['whoops'], [], 'd-shtaeou', 'd-nthiouh', 'i-vhbjkhnth',
|
||||
{'nifty': 87}, {'field': 'yes', 'morefield': False} ]
|
||||
|
||||
expect = textwrap.dedent("""\
|
||||
[
|
||||
[
|
||||
"blorpie"
|
||||
] ,
|
||||
[
|
||||
"whoops"
|
||||
] ,
|
||||
[] ,
|
||||
"d-shtaeou" ,
|
||||
"d-nthiouh" ,
|
||||
"i-vhbjkhnth" ,
|
||||
{
|
||||
"nifty" : 87
|
||||
} ,
|
||||
{
|
||||
"field" : "yes" ,
|
||||
"morefield" : false
|
||||
}
|
||||
]""")
|
||||
|
||||
|
||||
d1 = json.dumps(h)
|
||||
d2 = json.dumps(h, indent=' ', sort_keys=True, separators=(' ,', ' : '))
|
||||
|
||||
h1 = json.loads(d1)
|
||||
h2 = json.loads(d2)
|
||||
|
||||
self.assertEqual(h1, h)
|
||||
self.assertEqual(h2, h)
|
||||
self.assertEqual(d2, expect)
|
||||
@ -1,20 +0,0 @@
|
||||
from unittest import TestCase
|
||||
|
||||
from simplejson import encoder, scanner
|
||||
|
||||
def has_speedups():
|
||||
return encoder.c_make_encoder is not None
|
||||
|
||||
class TestDecode(TestCase):
|
||||
def test_make_scanner(self):
|
||||
if not has_speedups():
|
||||
return
|
||||
self.assertRaises(AttributeError, scanner.c_make_scanner, 1)
|
||||
|
||||
def test_make_encoder(self):
|
||||
if not has_speedups():
|
||||
return
|
||||
self.assertRaises(TypeError, encoder.c_make_encoder,
|
||||
None,
|
||||
"\xCD\x7D\x3D\x4E\x12\x4C\xF9\x79\xD7\x52\xBA\x82\xF2\x27\x4A\x7D\xA0\xCA\x75",
|
||||
None)
|
||||
@ -1,97 +0,0 @@
|
||||
from __future__ import with_statement
|
||||
import os
|
||||
import sys
|
||||
import textwrap
|
||||
import unittest
|
||||
import subprocess
|
||||
import tempfile
|
||||
try:
|
||||
# Python 3.x
|
||||
from test.support import strip_python_stderr
|
||||
except ImportError:
|
||||
# Python 2.6+
|
||||
try:
|
||||
from test.test_support import strip_python_stderr
|
||||
except ImportError:
|
||||
# Python 2.5
|
||||
import re
|
||||
def strip_python_stderr(stderr):
|
||||
return re.sub(
|
||||
r"\[\d+ refs\]\r?\n?$".encode(),
|
||||
"".encode(),
|
||||
stderr).strip()
|
||||
|
||||
class TestTool(unittest.TestCase):
|
||||
data = """
|
||||
|
||||
[["blorpie"],[ "whoops" ] , [
|
||||
],\t"d-shtaeou",\r"d-nthiouh",
|
||||
"i-vhbjkhnth", {"nifty":87}, {"morefield" :\tfalse,"field"
|
||||
:"yes"} ]
|
||||
"""
|
||||
|
||||
expect = textwrap.dedent("""\
|
||||
[
|
||||
[
|
||||
"blorpie"
|
||||
],
|
||||
[
|
||||
"whoops"
|
||||
],
|
||||
[],
|
||||
"d-shtaeou",
|
||||
"d-nthiouh",
|
||||
"i-vhbjkhnth",
|
||||
{
|
||||
"nifty": 87
|
||||
},
|
||||
{
|
||||
"field": "yes",
|
||||
"morefield": false
|
||||
}
|
||||
]
|
||||
""")
|
||||
|
||||
def runTool(self, args=None, data=None):
|
||||
argv = [sys.executable, '-m', 'simplejson.tool']
|
||||
if args:
|
||||
argv.extend(args)
|
||||
proc = subprocess.Popen(argv,
|
||||
stdin=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
stdout=subprocess.PIPE)
|
||||
out, err = proc.communicate(data)
|
||||
self.assertEqual(strip_python_stderr(err), ''.encode())
|
||||
self.assertEqual(proc.returncode, 0)
|
||||
return out
|
||||
|
||||
def test_stdin_stdout(self):
|
||||
self.assertEqual(
|
||||
self.runTool(data=self.data.encode()),
|
||||
self.expect.encode())
|
||||
|
||||
def test_infile_stdout(self):
|
||||
with tempfile.NamedTemporaryFile() as infile:
|
||||
infile.write(self.data.encode())
|
||||
infile.flush()
|
||||
self.assertEqual(
|
||||
self.runTool(args=[infile.name]),
|
||||
self.expect.encode())
|
||||
|
||||
def test_infile_outfile(self):
|
||||
with tempfile.NamedTemporaryFile() as infile:
|
||||
infile.write(self.data.encode())
|
||||
infile.flush()
|
||||
# outfile will get overwritten by tool, so the delete
|
||||
# may not work on some platforms. Do it manually.
|
||||
outfile = tempfile.NamedTemporaryFile()
|
||||
try:
|
||||
self.assertEqual(
|
||||
self.runTool(args=[infile.name, outfile.name]),
|
||||
''.encode())
|
||||
with open(outfile.name, 'rb') as f:
|
||||
self.assertEqual(f.read(), self.expect.encode())
|
||||
finally:
|
||||
outfile.close()
|
||||
if os.path.exists(outfile.name):
|
||||
os.unlink(outfile.name)
|
||||
@ -1,51 +0,0 @@
|
||||
import unittest
|
||||
|
||||
from simplejson.compat import StringIO
|
||||
import simplejson as json
|
||||
|
||||
class TestTuples(unittest.TestCase):
|
||||
def test_tuple_array_dumps(self):
|
||||
t = (1, 2, 3)
|
||||
expect = json.dumps(list(t))
|
||||
# Default is True
|
||||
self.assertEqual(expect, json.dumps(t))
|
||||
self.assertEqual(expect, json.dumps(t, tuple_as_array=True))
|
||||
self.assertRaises(TypeError, json.dumps, t, tuple_as_array=False)
|
||||
# Ensure that the "default" does not get called
|
||||
self.assertEqual(expect, json.dumps(t, default=repr))
|
||||
self.assertEqual(expect, json.dumps(t, tuple_as_array=True,
|
||||
default=repr))
|
||||
# Ensure that the "default" gets called
|
||||
self.assertEqual(
|
||||
json.dumps(repr(t)),
|
||||
json.dumps(t, tuple_as_array=False, default=repr))
|
||||
|
||||
def test_tuple_array_dump(self):
|
||||
t = (1, 2, 3)
|
||||
expect = json.dumps(list(t))
|
||||
# Default is True
|
||||
sio = StringIO()
|
||||
json.dump(t, sio)
|
||||
self.assertEqual(expect, sio.getvalue())
|
||||
sio = StringIO()
|
||||
json.dump(t, sio, tuple_as_array=True)
|
||||
self.assertEqual(expect, sio.getvalue())
|
||||
self.assertRaises(TypeError, json.dump, t, StringIO(),
|
||||
tuple_as_array=False)
|
||||
# Ensure that the "default" does not get called
|
||||
sio = StringIO()
|
||||
json.dump(t, sio, default=repr)
|
||||
self.assertEqual(expect, sio.getvalue())
|
||||
sio = StringIO()
|
||||
json.dump(t, sio, tuple_as_array=True, default=repr)
|
||||
self.assertEqual(expect, sio.getvalue())
|
||||
# Ensure that the "default" gets called
|
||||
sio = StringIO()
|
||||
json.dump(t, sio, tuple_as_array=False, default=repr)
|
||||
self.assertEqual(
|
||||
json.dumps(repr(t)),
|
||||
sio.getvalue())
|
||||
|
||||
class TestNamedTuple(unittest.TestCase):
|
||||
def test_namedtuple_dump(self):
|
||||
pass
|
||||
@ -1,145 +0,0 @@
|
||||
import sys
|
||||
from unittest import TestCase
|
||||
|
||||
import simplejson as json
|
||||
from simplejson.compat import unichr, text_type, b, u
|
||||
|
||||
class TestUnicode(TestCase):
|
||||
def test_encoding1(self):
|
||||
encoder = json.JSONEncoder(encoding='utf-8')
|
||||
u = u'\N{GREEK SMALL LETTER ALPHA}\N{GREEK CAPITAL LETTER OMEGA}'
|
||||
s = u.encode('utf-8')
|
||||
ju = encoder.encode(u)
|
||||
js = encoder.encode(s)
|
||||
self.assertEqual(ju, js)
|
||||
|
||||
def test_encoding2(self):
|
||||
u = u'\N{GREEK SMALL LETTER ALPHA}\N{GREEK CAPITAL LETTER OMEGA}'
|
||||
s = u.encode('utf-8')
|
||||
ju = json.dumps(u, encoding='utf-8')
|
||||
js = json.dumps(s, encoding='utf-8')
|
||||
self.assertEqual(ju, js)
|
||||
|
||||
def test_encoding3(self):
|
||||
u = u'\N{GREEK SMALL LETTER ALPHA}\N{GREEK CAPITAL LETTER OMEGA}'
|
||||
j = json.dumps(u)
|
||||
self.assertEqual(j, '"\\u03b1\\u03a9"')
|
||||
|
||||
def test_encoding4(self):
|
||||
u = u'\N{GREEK SMALL LETTER ALPHA}\N{GREEK CAPITAL LETTER OMEGA}'
|
||||
j = json.dumps([u])
|
||||
self.assertEqual(j, '["\\u03b1\\u03a9"]')
|
||||
|
||||
def test_encoding5(self):
|
||||
u = u'\N{GREEK SMALL LETTER ALPHA}\N{GREEK CAPITAL LETTER OMEGA}'
|
||||
j = json.dumps(u, ensure_ascii=False)
|
||||
self.assertEqual(j, u'"' + u + u'"')
|
||||
|
||||
def test_encoding6(self):
|
||||
u = u'\N{GREEK SMALL LETTER ALPHA}\N{GREEK CAPITAL LETTER OMEGA}'
|
||||
j = json.dumps([u], ensure_ascii=False)
|
||||
self.assertEqual(j, u'["' + u + u'"]')
|
||||
|
||||
def test_big_unicode_encode(self):
|
||||
u = u'\U0001d120'
|
||||
self.assertEqual(json.dumps(u), '"\\ud834\\udd20"')
|
||||
self.assertEqual(json.dumps(u, ensure_ascii=False), u'"\U0001d120"')
|
||||
|
||||
def test_big_unicode_decode(self):
|
||||
u = u'z\U0001d120x'
|
||||
self.assertEqual(json.loads('"' + u + '"'), u)
|
||||
self.assertEqual(json.loads('"z\\ud834\\udd20x"'), u)
|
||||
|
||||
def test_unicode_decode(self):
|
||||
for i in range(0, 0xd7ff):
|
||||
u = unichr(i)
|
||||
#s = '"\\u{0:04x}"'.format(i)
|
||||
s = '"\\u%04x"' % (i,)
|
||||
self.assertEqual(json.loads(s), u)
|
||||
|
||||
def test_object_pairs_hook_with_unicode(self):
|
||||
s = u'{"xkd":1, "kcw":2, "art":3, "hxm":4, "qrt":5, "pad":6, "hoy":7}'
|
||||
p = [(u"xkd", 1), (u"kcw", 2), (u"art", 3), (u"hxm", 4),
|
||||
(u"qrt", 5), (u"pad", 6), (u"hoy", 7)]
|
||||
self.assertEqual(json.loads(s), eval(s))
|
||||
self.assertEqual(json.loads(s, object_pairs_hook=lambda x: x), p)
|
||||
od = json.loads(s, object_pairs_hook=json.OrderedDict)
|
||||
self.assertEqual(od, json.OrderedDict(p))
|
||||
self.assertEqual(type(od), json.OrderedDict)
|
||||
# the object_pairs_hook takes priority over the object_hook
|
||||
self.assertEqual(json.loads(s,
|
||||
object_pairs_hook=json.OrderedDict,
|
||||
object_hook=lambda x: None),
|
||||
json.OrderedDict(p))
|
||||
|
||||
|
||||
def test_default_encoding(self):
|
||||
self.assertEqual(json.loads(u'{"a": "\xe9"}'.encode('utf-8')),
|
||||
{'a': u'\xe9'})
|
||||
|
||||
def test_unicode_preservation(self):
|
||||
self.assertEqual(type(json.loads(u'""')), text_type)
|
||||
self.assertEqual(type(json.loads(u'"a"')), text_type)
|
||||
self.assertEqual(type(json.loads(u'["a"]')[0]), text_type)
|
||||
|
||||
def test_ensure_ascii_false_returns_unicode(self):
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=48
|
||||
self.assertEqual(type(json.dumps([], ensure_ascii=False)), text_type)
|
||||
self.assertEqual(type(json.dumps(0, ensure_ascii=False)), text_type)
|
||||
self.assertEqual(type(json.dumps({}, ensure_ascii=False)), text_type)
|
||||
self.assertEqual(type(json.dumps("", ensure_ascii=False)), text_type)
|
||||
|
||||
def test_ensure_ascii_false_bytestring_encoding(self):
|
||||
# http://code.google.com/p/simplejson/issues/detail?id=48
|
||||
doc1 = {u'quux': b('Arr\xc3\xaat sur images')}
|
||||
doc2 = {u'quux': u('Arr\xeat sur images')}
|
||||
doc_ascii = '{"quux": "Arr\\u00eat sur images"}'
|
||||
doc_unicode = u'{"quux": "Arr\xeat sur images"}'
|
||||
self.assertEqual(json.dumps(doc1), doc_ascii)
|
||||
self.assertEqual(json.dumps(doc2), doc_ascii)
|
||||
self.assertEqual(json.dumps(doc1, ensure_ascii=False), doc_unicode)
|
||||
self.assertEqual(json.dumps(doc2, ensure_ascii=False), doc_unicode)
|
||||
|
||||
def test_ensure_ascii_linebreak_encoding(self):
|
||||
# http://timelessrepo.com/json-isnt-a-javascript-subset
|
||||
s1 = u'\u2029\u2028'
|
||||
s2 = s1.encode('utf8')
|
||||
expect = '"\\u2029\\u2028"'
|
||||
self.assertEqual(json.dumps(s1), expect)
|
||||
self.assertEqual(json.dumps(s2), expect)
|
||||
self.assertEqual(json.dumps(s1, ensure_ascii=False), expect)
|
||||
self.assertEqual(json.dumps(s2, ensure_ascii=False), expect)
|
||||
|
||||
def test_invalid_escape_sequences(self):
|
||||
# incomplete escape sequence
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u1')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u12')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u123')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u1234')
|
||||
# invalid escape sequence
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u123x"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u12x4"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\u1x34"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ux234"')
|
||||
if sys.maxunicode > 65535:
|
||||
# invalid escape sequence for low surrogate
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u0"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u00"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u000"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u000x"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u00x0"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\u0x00"')
|
||||
self.assertRaises(json.JSONDecodeError, json.loads, '"\\ud800\\ux000"')
|
||||
|
||||
def test_ensure_ascii_still_works(self):
|
||||
# in the ascii range, ensure that everything is the same
|
||||
for c in map(unichr, range(0, 127)):
|
||||
self.assertEqual(
|
||||
json.dumps(c, ensure_ascii=False),
|
||||
json.dumps(c))
|
||||
snowman = u'\N{SNOWMAN}'
|
||||
self.assertEqual(
|
||||
json.dumps(c, ensure_ascii=False),
|
||||
'"' + c + '"')
|
||||
@ -1,42 +0,0 @@
|
||||
r"""Command-line tool to validate and pretty-print JSON
|
||||
|
||||
Usage::
|
||||
|
||||
$ echo '{"json":"obj"}' | python -m simplejson.tool
|
||||
{
|
||||
"json": "obj"
|
||||
}
|
||||
$ echo '{ 1.2:3.4}' | python -m simplejson.tool
|
||||
Expecting property name: line 1 column 2 (char 2)
|
||||
|
||||
"""
|
||||
from __future__ import with_statement
|
||||
import sys
|
||||
import simplejson as json
|
||||
|
||||
def main():
|
||||
if len(sys.argv) == 1:
|
||||
infile = sys.stdin
|
||||
outfile = sys.stdout
|
||||
elif len(sys.argv) == 2:
|
||||
infile = open(sys.argv[1], 'r')
|
||||
outfile = sys.stdout
|
||||
elif len(sys.argv) == 3:
|
||||
infile = open(sys.argv[1], 'r')
|
||||
outfile = open(sys.argv[2], 'w')
|
||||
else:
|
||||
raise SystemExit(sys.argv[0] + " [infile [outfile]]")
|
||||
with infile:
|
||||
try:
|
||||
obj = json.load(infile,
|
||||
object_pairs_hook=json.OrderedDict,
|
||||
use_decimal=True)
|
||||
except ValueError:
|
||||
raise SystemExit(sys.exc_info()[1])
|
||||
with outfile:
|
||||
json.dump(obj, outfile, sort_keys=True, indent=' ', use_decimal=True)
|
||||
outfile.write('\n')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@ -1,34 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.project
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
Returns a project for the given file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
|
||||
from .projects.git import Git
|
||||
from .projects.mercurial import Mercurial
|
||||
from .projects.subversion import Subversion
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
PLUGINS = [
|
||||
Git,
|
||||
Mercurial,
|
||||
Subversion,
|
||||
]
|
||||
|
||||
|
||||
def find_project(path):
|
||||
for plugin in PLUGINS:
|
||||
project = plugin(path)
|
||||
if project.process():
|
||||
return project
|
||||
return None
|
||||
@ -1,53 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.projects.base
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Base project for use when no other project can be found.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class BaseProject(object):
|
||||
""" Parent project class only
|
||||
used when no valid project can
|
||||
be found for the current path.
|
||||
"""
|
||||
|
||||
def __init__(self, path):
|
||||
self.path = path
|
||||
|
||||
def type(self):
|
||||
""" Returns None if this is the base class.
|
||||
Returns the type of project if this is a
|
||||
valid project.
|
||||
"""
|
||||
type = self.__class__.__name__.lower()
|
||||
if type == 'baseproject':
|
||||
type = None
|
||||
return type
|
||||
|
||||
def process(self):
|
||||
""" Processes self.path into a project and
|
||||
returns True if project is valid, otherwise
|
||||
returns False.
|
||||
"""
|
||||
return False
|
||||
|
||||
def name(self):
|
||||
""" Returns the project's name.
|
||||
"""
|
||||
return None
|
||||
|
||||
def branch(self):
|
||||
""" Returns the current branch.
|
||||
"""
|
||||
return None
|
||||
@ -1,103 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.projects.git
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Information about the git project for a given file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
from subprocess import Popen, PIPE
|
||||
|
||||
from .base import BaseProject
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from ..packages.ordereddict import OrderedDict
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class Git(BaseProject):
|
||||
|
||||
def process(self):
|
||||
self.config = self._find_config(self.path)
|
||||
if self.config:
|
||||
return True
|
||||
return False
|
||||
|
||||
def name(self):
|
||||
base = self._project_base()
|
||||
if base:
|
||||
return os.path.basename(base)
|
||||
return None
|
||||
|
||||
def branch(self):
|
||||
stdout = None
|
||||
try:
|
||||
stdout, stderr = Popen([
|
||||
'git', 'branch', '--no-color'
|
||||
], stdout=PIPE, stderr=PIPE, cwd=self._project_base()
|
||||
).communicate()
|
||||
except OSError:
|
||||
pass
|
||||
if stdout:
|
||||
for line in stdout.splitlines():
|
||||
if isinstance(line, bytes):
|
||||
line = bytes.decode(line)
|
||||
line = line.split(' ', 1)
|
||||
if line[0] == '*':
|
||||
return line[1]
|
||||
return None
|
||||
|
||||
|
||||
def _project_base(self):
|
||||
if self.config:
|
||||
return os.path.dirname(os.path.dirname(self.config))
|
||||
return None
|
||||
|
||||
def _find_config(self, path):
|
||||
path = os.path.realpath(path)
|
||||
if os.path.isfile(path):
|
||||
path = os.path.split(path)[0]
|
||||
if os.path.isfile(os.path.join(path, '.git', 'config')):
|
||||
return os.path.join(path, '.git', 'config')
|
||||
split_path = os.path.split(path)
|
||||
if split_path[1] == '':
|
||||
return None
|
||||
return self._find_config(split_path[0])
|
||||
|
||||
def _parse_config(self):
|
||||
sections = {}
|
||||
try:
|
||||
f = open(self.config, 'r')
|
||||
except IOError as e:
|
||||
log.exception("Exception:")
|
||||
else:
|
||||
with f:
|
||||
section = None
|
||||
for line in f.readlines():
|
||||
line = line.lstrip()
|
||||
if len(line) > 0 and line[0] == '[':
|
||||
section = line[1:].split(']', 1)[0]
|
||||
temp = section.split(' ', 1)
|
||||
section = temp[0].lower()
|
||||
if len(temp) > 1:
|
||||
section = ' '.join([section, temp[1]])
|
||||
sections[section] = {}
|
||||
else:
|
||||
try:
|
||||
(setting, value) = line.split('=', 1)
|
||||
except ValueError:
|
||||
setting = line.split('#', 1)[0].split(';', 1)[0]
|
||||
value = 'true'
|
||||
setting = setting.strip().lower()
|
||||
value = value.split('#', 1)[0].split(';', 1)[0].strip()
|
||||
sections[section][setting] = value
|
||||
f.close()
|
||||
return sections
|
||||
@ -1,30 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.projects.mercurial
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Information about the mercurial project for a given file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
|
||||
from .base import BaseProject
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class Mercurial(BaseProject):
|
||||
|
||||
def process(self):
|
||||
return False
|
||||
|
||||
def name(self):
|
||||
return None
|
||||
|
||||
def branch(self):
|
||||
return None
|
||||
@ -1,79 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
wakatime.projects.subversion
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Information about the svn project for a given file.
|
||||
|
||||
:copyright: (c) 2013 Alan Hamlett.
|
||||
:license: BSD, see LICENSE for more details.
|
||||
"""
|
||||
|
||||
import logging
|
||||
import os
|
||||
from subprocess import Popen, PIPE
|
||||
|
||||
from .base import BaseProject
|
||||
try:
|
||||
from collections import OrderedDict
|
||||
except ImportError:
|
||||
from ..packages.ordereddict import OrderedDict
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class Subversion(BaseProject):
|
||||
|
||||
def process(self):
|
||||
return self._find_project_base(self.path)
|
||||
|
||||
def name(self):
|
||||
return self.info['Repository Root'].split('/')[-1]
|
||||
|
||||
def branch(self):
|
||||
branch = None
|
||||
if self.base:
|
||||
branch = os.path.basename(self.base)
|
||||
return branch
|
||||
|
||||
def _get_info(self, path):
|
||||
info = OrderedDict()
|
||||
stdout = None
|
||||
try:
|
||||
stdout, stderr = Popen([
|
||||
'svn', 'info', os.path.realpath(path)
|
||||
], stdout=PIPE, stderr=PIPE).communicate()
|
||||
except OSError:
|
||||
pass
|
||||
else:
|
||||
if stdout:
|
||||
interesting = [
|
||||
'Repository Root',
|
||||
'Repository UUID',
|
||||
'URL',
|
||||
]
|
||||
for line in stdout.splitlines():
|
||||
if isinstance(line, bytes):
|
||||
line = bytes.decode(line)
|
||||
line = line.split(': ', 1)
|
||||
if line[0] in interesting:
|
||||
info[line[0]] = line[1]
|
||||
return info
|
||||
|
||||
def _find_project_base(self, path, found=False):
|
||||
path = os.path.realpath(path)
|
||||
if os.path.isfile(path):
|
||||
path = os.path.split(path)[0]
|
||||
info = self._get_info(path)
|
||||
if len(info) > 0:
|
||||
found = True
|
||||
self.base = path
|
||||
self.info = info
|
||||
elif found:
|
||||
return True
|
||||
split_path = os.path.split(path)
|
||||
if split_path[1] == '':
|
||||
return found
|
||||
return self._find_project_base(split_path[0], found)
|
||||
|
||||
Reference in New Issue
Block a user